Editorial
06 October 2022
Erwan Renaudo
, Philipp Zech
, Raja Chatila
and
Mehdi Khamassi


Agents that need to act on their surroundings can significantly benefit from the perception of their interaction possibilities or affordances. In this paper we combine the benefits of the Interaction Tensor, a straight-forward geometrical representation that captures multiple object-scene interactions, with deep learning saliency for fast parsing of affordances in the environment. Our approach works with visually perceived 3D pointclouds and enables to query a 3D scene for locations that support affordances such as sitting or riding, as well as interactions for everyday objects like the where to hang an umbrella or place a mug. Crucially, the nature of the interaction description exhibits one-shot generalization. Experiments with numerous synthetic and real RGB-D scenes and validated by human subjects, show that the representation enables the prediction of affordance candidate locations in novel environments from a single training example. The approach also allows for a highly parallelizable, multiple-affordance representation, and works at fast rates. The combination of the deep neural network that learns to estimate scene saliency with the one-shot geometric representation aligns well with the expectation that computational models for affordance estimation should be perceptually direct and economical.
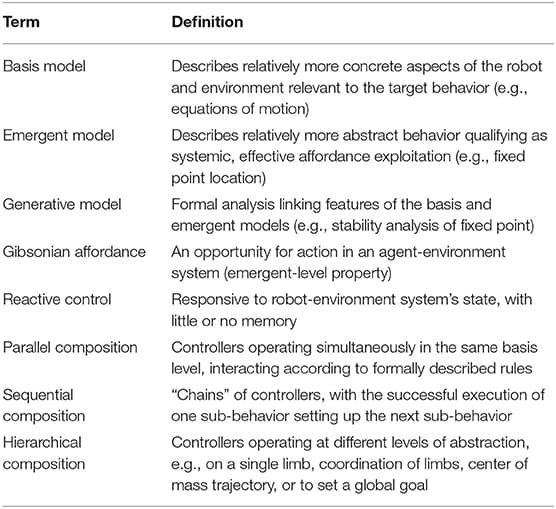
Evidence from empirical literature suggests that explainable complex behaviors can be built from structured compositions of explainable component behaviors with known properties. Such component behaviors can be built to directly perceive and exploit affordances. Using six examples of recent research in legged robot locomotion, we suggest that robots can be programmed to effectively exploit affordances without developing explicit internal models of them. We use a generative framework to discuss the examples, because it helps us to separate—and thus clarify the relationship between—description of affordance exploitation from description of the internal representations used by the robot in that exploitation. Under this framework, details of the architecture and environment are related to the emergent behavior of the system via a generative explanation. For example, the specific method of information processing a robot uses might be related to the affordance the robot is designed to exploit via a formal analysis of its control policy. By considering the mutuality of the agent-environment system during robot behavior design, roboticists can thus develop robust architectures which implicitly exploit affordances. The manner of this exploitation is made explicit by a well constructed generative explanation.

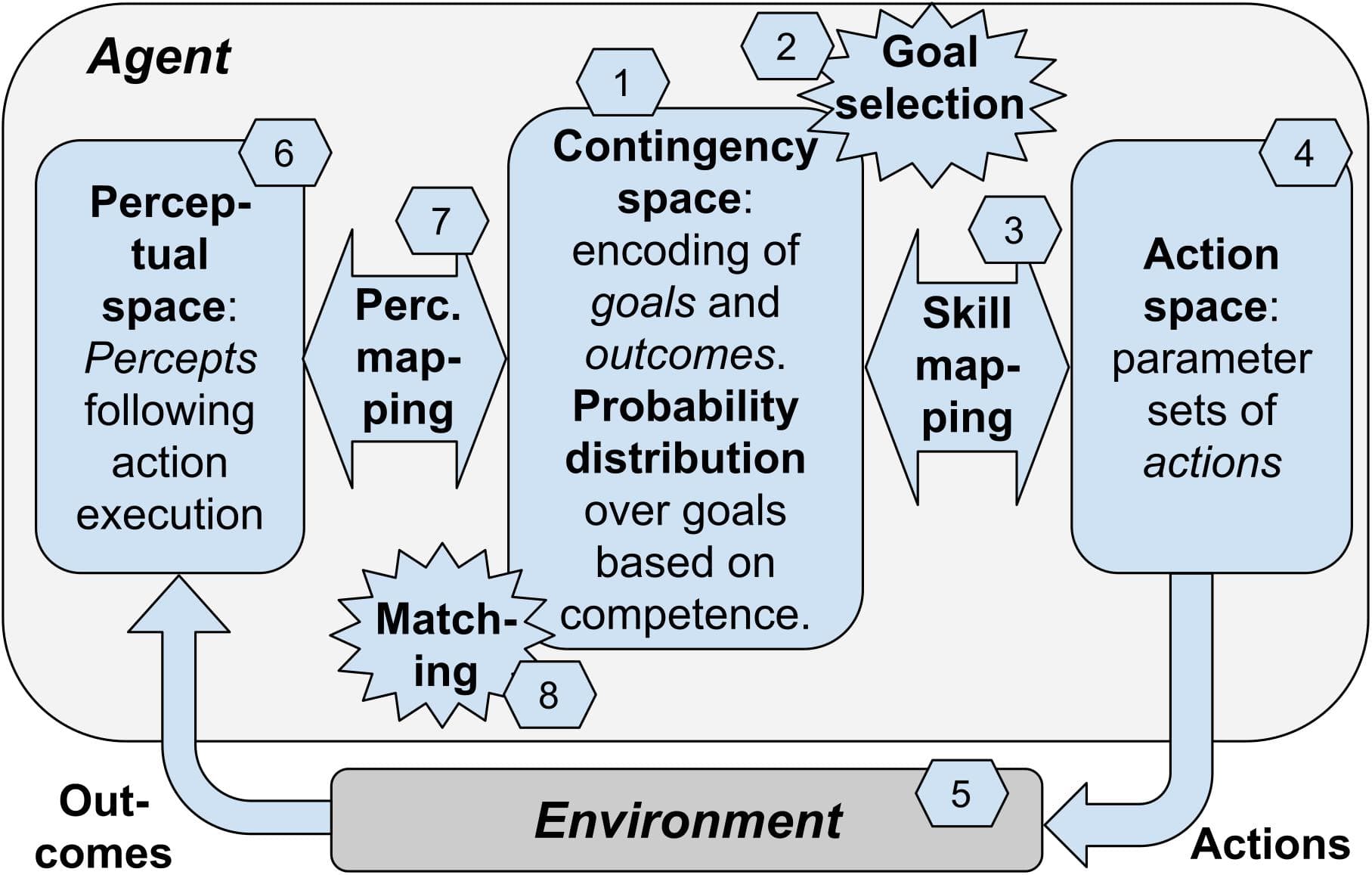
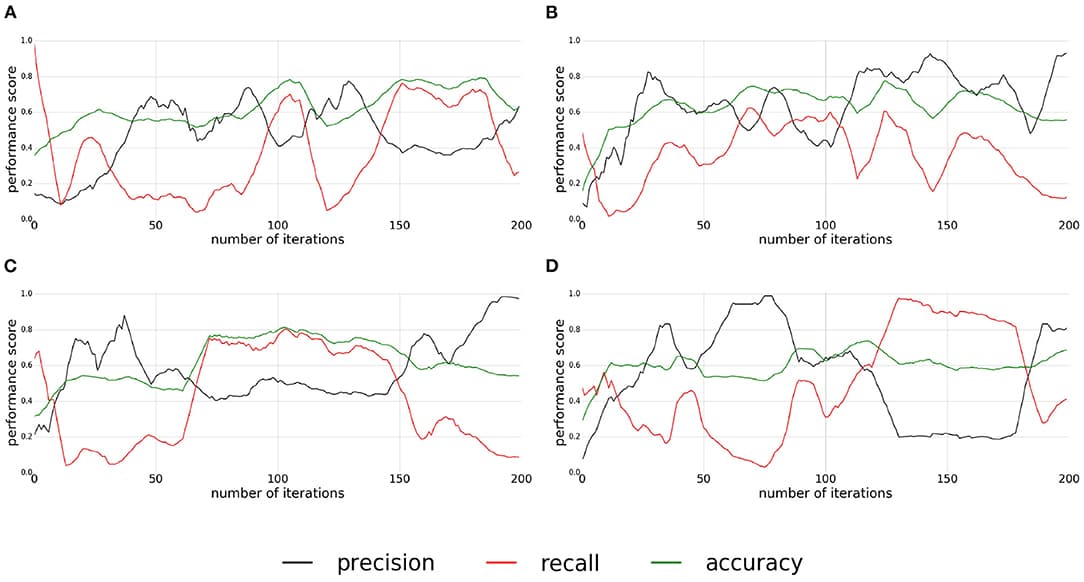
Much current work in robotics focuses on the development of robots capable of autonomous unsupervised learning. An essential prerequisite for such learning to be possible is that the agent should be sensitive to the link between its actions and the consequences of its actions, called sensorimotor contingencies. This sensitivity, and more particularly its role as a key drive of development, has been widely studied by developmental psychologists. However, the results of these studies may not necessarily be accessible or intelligible to roboticians. In this paper, we review the main experimental data demonstrating the role of sensitivity to sensorimotor contingencies in infants’ acquisition of four fundamental motor and cognitive abilities: body knowledge, memory, generalization, and goal-directedness. We relate this data from developmental psychology to work in robotics, highlighting the links between these two domains of research. In the last part of the article we present a blueprint architecture demonstrating how exploitation of sensitivity to sensorimotor contingencies, combined with the notion of “goal,” allows an agent to develop new sensorimotor skills. This architecture can be used to guide the design of specific computational models, and also to possibly envisage new empirical experiments.