 Alex van den Berg1*
Alex van den Berg1* Bart de Vries1
Bart de Vries1 Zoë Breedveld1
Zoë Breedveld1 Annelouk van Mierlo1
Annelouk van Mierlo1 Marnix Tijhuis1
Marnix Tijhuis1 Laura Marchal-Crespo1,2
Laura Marchal-Crespo1,2- 1Motor Learning and Neurorehabilitation Lab, Cognitive Robotics Department, Delft University of Technology, Delft, Netherlands
- 2Department of Rehabilitation Medicine, Erasmus Medical Center, Rotterdam, Netherlands
Immersive Virtual Reality (IVR) has gained popularity in neurorehabilitation for its potential to increase patients’ motivation and engagement. A crucial yet relatively unexplored aspect of IVR interfaces is the patients’ representation in the virtual world, such as with an avatar. A higher level of embodiment over avatars has been shown to enhance motor performance during upper limb training and has the potential to be employed to enhance neurorehabilitation. However, the relationship between avatar embodiment and gait performance remains unexplored. In this work, we present the results of a pilot study with 12 healthy young participants that evaluates the effect of different virtual lower limb representations on foot placement accuracy while stepping over a trail of 16 virtual targets. We compared three levels of virtual representation: i) a full-body avatar, ii) only feet, and iii) no representation. Full-body tracking is computed using standard VR trackers to synchronize the avatar with the participants’ motions. Foot placement accuracy is measured as the distance between the foot’s center of mass and the center of the selected virtual target. Additionally, we evaluated the level of embodiment over each virtual representation through a questionnaire. Our findings indicate that foot placement accuracy increases with some form of virtual representation, either full-body or foot, compared to having no virtual representation. However, the foot and full-body representations do not show significant differences in accuracy. Importantly, we found a negative correlation between the level of embodiment of the foot representation and the distance between the placed foot and the target. However, no such correlation was found for the full-body representation. Our results highlight the importance of embodying a virtual representation of the foot when performing a task that requires accurate foot placement. However, showing a full-body avatar does not appear to further enhance accuracy. Moreover, our results suggest that the level of embodiment of the virtual feet might modulate motor performance in this stepping task. This work motivates future research on the effect of embodiment over virtual representations on motor control to be exploited for IVR gait rehabilitation.
1 Introduction
During VE-based motor training, movements in Virtual Environments (VEs) can simulate different real or imaginary activities of daily living, which can be adapted to the patient’s needs while providing a motivating environment Lee et al. (2003). In conventional VE-based neurorehabilitation, a flat-screen displays the VE, and patients interact via a symbolic virtual representation of their limbs (e.g., a cursor). VE-based training is associated with several benefits for rehabilitation, such as improved engagement and participation, enhanced feedback, and tracking of the rehabilitation process. VEs also allow the opportunity to provide very flexible and customizable stimuli and interactions to enhance motor learning Massetti et al. (2018); Ferreira and Menezes (2020). Moreover, VE-based training is an effective tool in improving the outcome of balance and gait rehabilitation Kashif et al. (2022); Porras et al. (2018), with skills acquired during such training can be transferable to real-world locomotion Kim et al. (2019).
Recently, there has been an increase in the use of Immersive Virtual Reality (IVR) for rehabilitation employing low-cost, widely available commercial Head-Mounted Displays (HMDs). HMDs enable a more realistic virtual representation of the patient’s limbs (avatar) from a first-person perspective. The avatar part/entire body can be animated following the patient’s movements, using the already incorporated hardware and software in some off-the-shelf HMD systems. These commercial solutions are relatively cheap and easy to use Flueratoru et al. (2020), opening the door to more widespread use in clinical and at-home rehabilitation settings.
Showing avatars in IVR might bring several benefits to locomotion training. For example, using a full-body virtual avatar in IVR has been shown to improve the egocentric distance estimation in a blind walking test, i.e., navigating to a position indicated on the floor with eyes closed after seeing a static avatar positioned within the virtual environment Ries et al. (2008). Animating the avatar before performing a blind-walking test further improves the distance estimation compared to visualizing a static avatar Mohler et al. (2010). A later study investigated this effect on distance estimation while also evaluating embodiment Gonzalez-Franco et al. (2019). They concluded that the degree to which this distance perception during blind walking is improved with animated avatars might be related to the degree of embodiment of the virtual avatar. The sense of embodiment describes the phenomenon in which the avatar’s limbs are processed like the users’ own limbs Kilteni et al. (2012). Body ownership (a subpart of embodiment) is the cognition that body parts belong to oneself Blanke (2012) and results from the integration of multimodal sensory information in the brain Botvinick and Cohen (1998); Ehrsson et al. (2004). Brain areas involved in body ownership are shared with those linked to motor performance and learning, namely, multimodal areas associated with motor control (i.e., frontal premotor cortices, temporal, parietal junction, and insula Ehrsson et al. (2004; 2005); Tsakiris et al. (2007)). Several studies have suggested that this anatomical coupling could be functional Ehrsson et al. (2004), Ehrsson et al. (2005), Tsakiris et al. (2007) and thus by enhancing body ownership, e.g., using congruent multimodal information, might result in better motor performance. Recent research has suggested that this anatomical couple might indeed be functional; for example, it has been shown that reaction times are modulated by the sense of body ownership over virtual hands Grechuta et al. (2017).
It has also been observed that participants perform tasks more accurately and quickly with the implementation of an animated virtual avatar. Adding an (animated) avatar was found to improve the stepping accuracy when walking on stones McManus et al. (2011). In a more recent study, participants who were asked to solve a jigsaw puzzle task while trying to prevent collisions with virtual objects completed the task faster when visualizing an avatar compared to having no virtual representation Pan and Steed (2019). Furthermore, it has been shown that visualizing an animated self-avatar can reduce the time taken to walk over a beam in IVR Pastel et al. (2020). However, the virtual representation of the feet in the IVR environment did not significantly affect this metric. The importance of visualizing and animating the feet to enhance motor performance in IVR has also been investigated in sports tasks, such as kicking a football into a goal Bonfert et al. (2022) and climbing Kosmalla et al. (2020). These studies indicate that foot tracking and the virtual representation of the feet are critical for motor performance. However, these previous studies have not investigated a potential correlation between the embodiment of virtual representations and motor performance. We hypothesize that this enhanced performance observed in previous work may be correlated with the sense of embodiment provided by the virtual representation, which may allow participants to better incorporate the sensory feedback and adapt their movements to the virtual environment.
In this study, we aimed to extend previous work by investigating the relationship between the level of embodiment over avatars in IVR and motor performance in a target stepping task. We conducted a within-subject human factors pilot study with 12 healthy young participants comprising a target stepping task, where we evaluated motor performance in terms of foot placement accuracy. We employed two different virtual representations, a full-body avatar and only visualizing the feet. We investigated whether the level of embodiment differs between virtual representations and, importantly, whether the potential relationship between embodiment and performance is specific to each type of virtual representation. For completeness, we added a third condition without any virtual representation of the participants’ limbs, as this condition is usually employed during gait training. We compared the accuracy in the target stepping task between the three conditions, i.e., full-body avatar, only feet, and no virtual representation. This pilot investigation aims to provide insight into how to design virtual representations for future applications in IVR gait rehabilitation by answering the following two research questions:
• What is the effect of different virtual representations on embodiment and foot placement accuracy in an IVR target-stepping task?
• What is the relationship between the embodiment of different virtual representations on foot placement accuracy in an IVR target-stepping task?
First, we speculate that the full-body representation would result in a greater embodiment and foot placement accuracy (reduced distance to target) as compared to the feet representation (H1). Second, we hypothesize that the feet and full-body representations would result in higher foot placement accuracy than having no virtual representation (H2). Finally, we expect to find a negative correlation between the embodiment of both virtual representations and the average distance from the foot to the target (H3).
2 Materials and methods
2.1 Participants
We involved twelve healthy participants (two female) aged from 21 to 27 (μ = 23.75, σ = 4.43), with a median height of 186.5 cm (μ = 186.5 cm, σ = 8.48 cm), who provided their informed written consent to participate in the study. The local ethics committee approved the study. Of the participants, four had previous experience with IVR and three indicated they had motion sickness problems in the past. None of them had prior knowledge of the experiment.
2.2 The virtual stepping task
The experiment consisted of stepping over a trail of 16 circular targets (radius r = 0.3 m), as shown in Figure 1. Participants were asked to complete the trail, stepping with alternating feet on each target while aiming to place the center of their foot as close to the center of the targets as possible. The targets are represented as circled on poles in order to make the task intuitive and motivate participants not to rush the task and to place their feet carefully. A confirmation sound plays when successfully stepping on a target, and a scoreboard showing their points is updated. The maximum amount of points for each step is 30, where one point is subtracted per centimeter of distance to the target center. To ensure participants took approximately the same amount of time, we informed them of a time limit of 30 seconds for the entire course. Time started once the participants entered the area directly in front of the first target. No trials surpassed the time limit.

FIGURE 1. The virtual environment showing the full-body avatar representation. The avatar is standing next to the practice target. To the avatar’s right are the 16 targets that make up the trail for the stepping task. The scoreboard can be seen in the back, showing the score for the current condition. Created with Unity Game Engine®. Unity is a trademark or registered trademark of Unity Technologies.
At the start of the experiment, participants received a general explanation of the whole experiment. After signing a consent agreement form, they answered questions to collect demographic data. We then attached two HTC-Vive 3.0 trackers (HTC Corporation, Taiwan) to their feet and one to their waist using a belt (Figure 2). Then, participants wore the HMD (HTC Vive Pro Eye, HTC Corporation, Taiwan) and held two controllers (HTC Vive Pro Controller 2.0, HTC Corporation, Taiwan). After this, the experimenter executed a short (one-time) calibration procedure during which the avatar was uniformly scaled to match each participant’s height. Additionally, offsets between the trackers and the tracked positions on the avatar were calculated to match the avatar’s body to that of the participant. The same offsets were used across all conditions. Figure 2 presents a picture illustrating the complete setup.

FIGURE 2. The first image on the left shows a participant with the trackers they wore during the whole experiment, consisting of 1) the head-mounted display, 2) the tracker on the waist, 3) the Vive controllers tracking the hand positions, and 4) the trackers on the feet. The three images on the right show the three different virtual representations. Created with Unity Game Engine®.
Each participant walked around the trail three times (trials), each trial with a different experimental condition relating to three different virtual representations (shown in Figure 2).
• Avatar: Full-body avatar is shown
• Feet: Only the feet of the avatar are shown
• None: No representation of the body is shown
Participants were asked to remove the HMD and answer a questionnaire after each condition (see Section 2.4). The execution order of the three conditions was counterbalanced between the participants to limit potential learning and exposure effects. The whole experiment, including the questionnaires, had an approximate duration of 20 min. Participants were asked to experiment with a practice target before each condition to understand the score calculation, where again 30 points were received for placing the center of their foot precisely in the center of the target, and one point was subtracted from the score for each centimeter of distance from this center. During this time, they could also observe their virtual representation (if any) in a mirror. Then, participants completed the trail, stepping over all the virtual targets. Upon completing the trial for the full-body avatar and feet conditions, we measured the level of embodiment using a questionnaire (see Section 2.4) relating to that condition. After completing all three conditions, the participants were asked which was their preferred condition and during which condition they felt they performed the best.
2.3 Virtual environment
We built the environment using the Unity Game Engine, release 2020.3.21f (Unity Technologies, U.S.A.). To ensure a smooth and immersive experience for the participants, the virtual environment was set to run at a minimum of 90 Hz, which matched the refresh rate of the HMD utilized in the study. The experiment was executed within the Unity Editor on a Windows 10 PC (Microsoft, USA), equipped with 32 GB of DIMM DDR4 working memory, an NVIDIA GeForce RTX 3080 GPU, and an AMD Ryzen 5,900 × 3.70 GHz 12-Core processor (AMD, USA). The full-body animation was achieved through a custom package (written by the authors for the purpose of this experiment) using inverse kinematics built into the Unity animation component.
The avatar was created using Ready Player Me (https://readyplayer.me/, 2022) and uniformly scaled to match the height of the current participant. Calibration of the full body tracking was performed by asking participants to stand on a defined spot with their arms straight down while holding the controllers and calculating the offsets between the trackers and the tracked positions on the avatar. The avatar’s location was tracked with the hip position as the root, which was estimated from the tracker attached to the waist. In this way, we could ensure the most accurate representation of the legs, which was the main focus of the full-body representation for this experiment. This calibration was done once at the start of the experiment and the same offsets were used for all conditions, including the condition with no virtual representation. All participants had the same full-body and feet representations, regardless of their sex, as shown in Figure 2.
2.4 Questionnaire
Seven statements were adopted from the avatar embodiment standardized questionnaire from Peck and Gonzalez-Franco (2021), covering different aspects of embodiment, namely, body ownership, appearance, agency, and response. We picked questions that we judged were most relevant to this pilot study and that cover the different aspects of embodiment. The employed questionnaire for the embodiment of the virtual feet and the full-body avatar can be found in Table 2. We opted to shorten the questionnaire as this was a within-subject experiment and we did not want participants to reduce their engagement as a result of multiple, longer questionnaires. The questions were modified, i.e., using feet or body terms, based on the virtual representation that the participants had just experienced. Participants rated these statements on a seven-point Likert scale (strongly disagree, disagree, slightly disagree, neutral, slightly agree, agree, strongly agree) relating to a score from 1 to 7. The final embodiment score for each questionnaire was calculated by taking the average score of all seven questions.
Finally, after completing the entire experiment, participants were asked which was their favorite virtual representation and with which representation they felt they performed the best.
2.5 Data analysis
Position and orientation data of the trackers were recorded at a frame rate varying from 90 to 100 Hz within the Unity environment, using the Unity Experimental Framework Brookes et al. (2019). A step was registered when a collider in the position and shape on the virtual foot intersected with one of the targets. The positions and shapes of these colliders relative to the trackers on the feet were the same for all conditions. The step accuracy was calculated as the distance to target (m), i.e., for each step taken, the distance between the center of the target and the center of the foot was recorded. After completion of the target trail in the full-body and feet conditions, the level of embodiment (−) was measured using a questionnaire (see Section 2.4). Questionnaire data were collected in handwriting and later digitized.
We observed that, for some participants, steps were detected before the real foot hit the ground due to a tilt in the virtual play space Niehorster et al. (2017). These steps resulted in an inaccurate measurement of the distance between the foot and the target center. These foot-target contact positions were manually corrected during post-processing by selecting the contact position at the position where the foot was stationary and at its lowest height (placed on the floor). Furthermore, in five out of the 240 steps performed, the foot tracker lost tracking when the participant placed their foot on the target, making the detection of the step unreliable. Consequently, these steps were removed from the data analysis. This resulted in some participants missing one step for one or two of the conditions.
Due to the unequal sample size (caused by the removal of unreliably detected steps), we analyzed the distance to the target (of the individual steps) using a repeated measures linear mixed model with the condition (feet, avatar, or none) and trial order (first, second, or third trial) as fixed effects and the participant as a random effect. Although the order of the conditions was counterbalanced across participants, we included the trial order in the model to assess any potential exposure effects. Statistical analysis was performed in R (The R Foundation, Austria), using the lme4 package Bates et al. (2015). The complete model had the form:
For post-hoc analysis, we used the Kenward–Roger method to approximate the degrees of freedom. The results and effect sizes were adjusted for multiple comparisons using the Tukey correction. For the effect sizes of the pairwise comparisons, we report the Cohen’s d. The threshold for statistical significance was set at α = 0.05.
Embodiment scores between the feet and full-body representations were compared using a Wilcoxon signed-rank test. Pearson’s correlation coefficients were calculated to investigate the relationships between the embodiment scores and the distance to the target (accuracy). Additionally, Spearman’s correlation coefficients were calculated when data were found to be skewed. Note that we have chosen to report both values, as the Pearson (unranked) correlation relates more closely to our hypothesis but should be interpreted with caution in the case of non-parametric data.
3 Results
The distribution of foot placement positions relative to the center of the target for each condition is plotted in Figure 3. The distances between foot placement and target center for each combination of condition and trial order are presented in Figure 4.
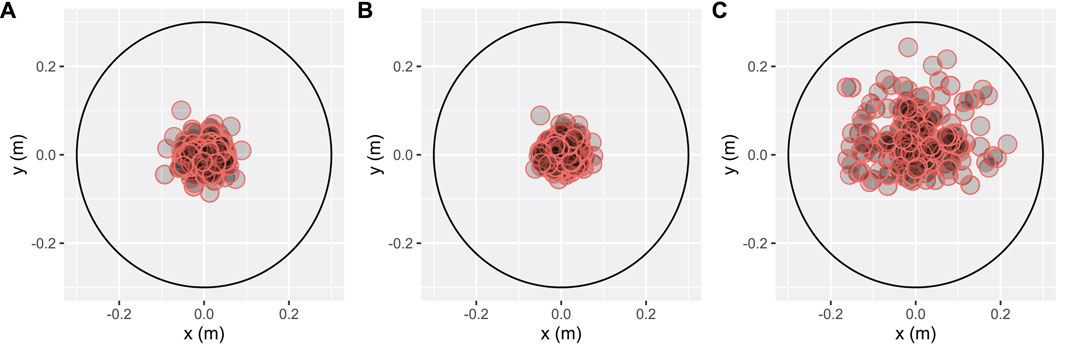
FIGURE 3. The foot placement locations relative to the center of the target for (A) the full-body condition, (B) the feet condition, and (C) the none condition. The large black circle represents the target’s outer perimeter. The red circles within this perimeter represent the foot placement locations of the steps of all participants for that condition.
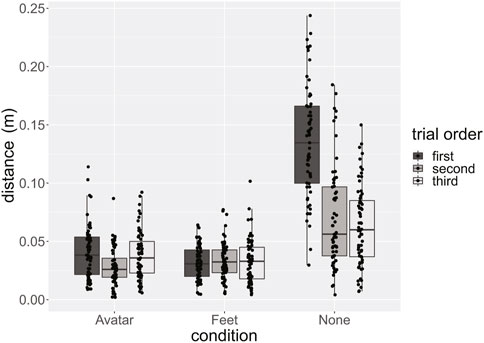
FIGURE 4. Boxplot of the distance to target, grouped for condition (i.e., Avatar, Feet, None) and trial order (first, second, third; in different grey shades).
We found a significant main effect of the virtual representation (i.e., condition; F (2, 557.96) = 284.72, p < 0.0001,
Post-hoc comparisons revealed that the distance to the target was higher when there was no representation compared to the Avatar (p < 0.0001, d = −2.05) and the Feet (p < 0.0001, d = −2.18) representations. However, we did not find a significant difference between the Avatar and Feet conditions (p = 0.47, d = 0.12). Additionally, the distance to the target was higher for the first trial, compared to the second trial (p < 0.0001, d = 0.96) and the third trial (p < 0.0001, d = 0.93), while no significant difference was found between the second and third trials (p = 0.95, d = −0.032). We also found a significant interaction effect between the virtual representation and the trial order. This seems to be driven by the None representation, as observed in Figure 4; Table 1. In particular, the distance to the target appeared to be especially high in the None condition when this was the first condition presented to the participants, while this distance was smaller (although overall higher compared to other conditions) when another condition with some sort of virtual representation was performed before the None condition. The results from the multiple post-hoc comparisons of the interaction between condition and trial order are reported in Table 1. However, it is important to note that the statistical power of the multiple post-hoc comparisons for the interaction effect is limited, as each group contained the steps of only four participants.
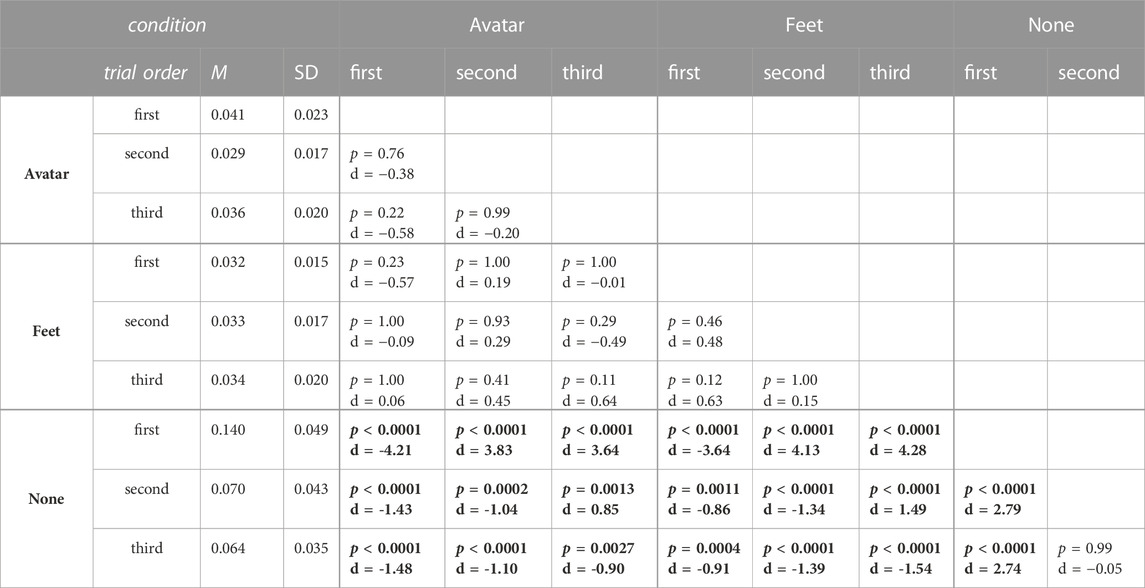
TABLE 1. Results from the post-hoc analysis of the interaction between condition (i.e., Avatar, Feet, None) and trial order (i.e., first, second, third). Values where p < 0.05 are printed in bold, to indicate a statistically significant difference for that comparison. We also included the means (M) and standard deviations (SD) for each group.
We did not find significant differences between the level of embodiment during the full-body (μ = 5.18, σ = 0.97) and feet (μ = 5.36, σ = 0.89) conditions (z = 20, p = 0.813). All the means and standard deviations for each question and the final embodiment score can be found in Table 2. For the feet representation, we found a significant negative correlation between distance to target and embodiment (Figure 5B, rPearson(10) = −0.65, p = 0.02; CI95% = −.89 to −0.12). When visually inspecting the histograms of the feet embodiment scores and the average distance to the target, we found that the distribution is slightly skewed (as seen in the histograms in Figure 5B). Consequently, we additionally investigated the (non-parametric) Spearman correlation. Here, although we still find a relatively strong effect, the correlation was no longer significant (rSpearman(10) = −0.53 p = 0.08; CI95% = −0.85 to −0.08). No such correlation was found for the full-body representation (Figure 5A, rPearson(10) = −0.19 p = 0.55; CI95% = −0.69 to 0.43).
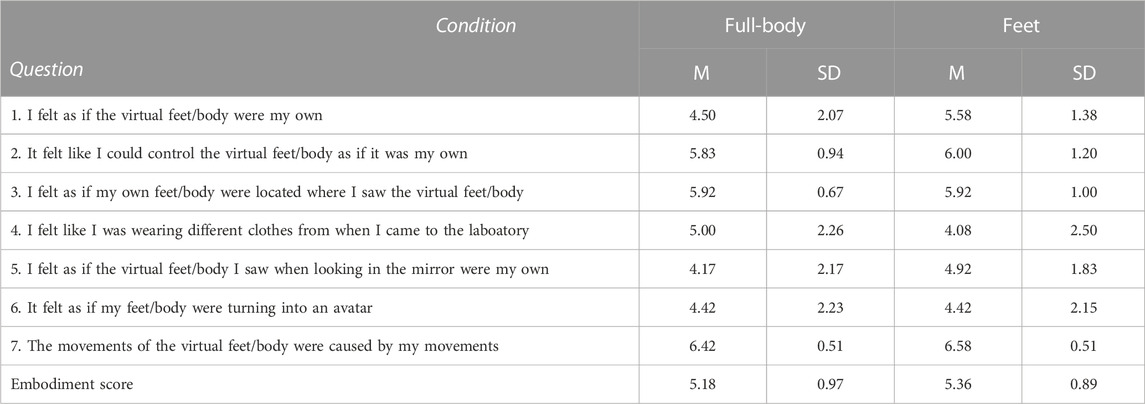
TABLE 2. Means (M) and standard deviations (SD) for the embodiment questionnaires. The embodiment score is the average of all questions for that participant.
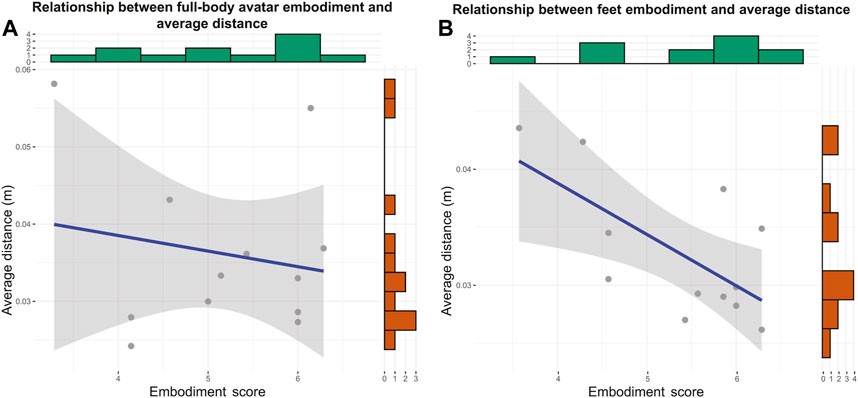
FIGURE 5. Linear fit of the relation between the embodiment scores and the average distance to target for (A) the full-body condition and (B) the feet condition. Here, the blue line shows the best linear fit, and the grey area shows the 95% confidence interval. Additionally, both subfigures include a histogram above, showing the distribution of the embodiment scores, and a histogram to its right, showing the distribution of the average distance to the target.
Of the twelve participants, nine preferred the full-body representation, while the other three preferred the feet representation. In contrast, only two participants felt they performed best with the full-body representation, while nine participants felt they performed best with the feet representation.
4 Discussion
In this study, we aimed to investigate the effect of the virtual representation of the lower limbs and the embodiment of that representation on motor performance during a target-stepping task in IVR. The level of embodiment was evaluated through questionnaires, whereas we evaluated the motor performance by measuring the foot placement accuracy as the distance to the target. We evaluated and compared these metrics for three levels of virtual representation: i) a full-body avatar, ii) only feet, and iii) no representation.
4.1 Providing a virtual representation of the participant’s body parts in the virtual environment enhances step accuracy
As expected, having a virtual representation of the participant in the virtual environment is essential to allow accurate foot placement (reducing the distance to the target), confirming our second hypothesis (H2). For the condition without a virtual representation, steps were distributed mainly in the upper half of the targets (see Figure 4C). This suggests that participants tended to step too far ahead without a visual representation, as this was the direction the trail was heading.
The improved performance with the virtual representations aligns with previous literature that showed improved stepping accuracy with the implementation of an animated avatar McManus et al. (2011). Furthermore, this result aligns with previous work that has shown that providing visual and/or haptic feedback during motor task execution may result in improved performance Sigrist et al. (2013). The visual feedback provided by the position of the virtual representation with respect to the target provides extra sensory information to the central nervous system (CNS) to correct movements and improve motor performance. Therefore, using virtual representations, either full body or feet, could be crucial in future gait training applications.
Interestingly, we observed that when participants experienced a condition with some sort of representation before the None condition, their foot placement accuracy in the None condition improved compared to performing the None condition during the first trial. This suggests that the advantages of providing visual feedback through virtual representations of the feet or the entire body might extend beyond enhancing motor performance while the visualization is present. These virtual representations could potentially have carry-over effects on the foot placement accuracy even after their removal. This finding, although limited by the relatively low statistical power, could be exploited in clinical applications such as the training of proprioception in people suffering from sensory impairments, such as people with acquired brain injury Cho et al. (2014); Kim et al. (2013).
4.2 Providing a full-body virtual representation does not increase the foot placement accuracy or embodiment when compared to the only feet representation
In contrast to our first hypothesis (H1), having a full-body representation instead of only the feet representation does not increase the foot placement accuracy or the embodiment level. Here, it is important to note that for the condition with the full-body avatar, the questionnaire queried participants about the embodiment of the whole body instead of just the feet.
One potential reason we do not observe the hypothesized increase in embodiment is that, in contrast to the representation of the feet, the legs were not fully tracked, i.e., the position of the knees was estimated using inverse kinematics. Thus, a mismatch between the knees’ real and virtually represented position might introduce a visual-proprioception sensory incongruency. Such a mismatch of sensory information has been shown to hamper motor performance in highly embodied virtual reality Odermatt et al. (2021). The absence of an increase in performance could also have been hindered because the legs would sometimes obstruct the vision of the targets, making the task slightly more challenging, as noted by several participants. More research is needed to evaluate whether adding trackers to accurately determine and visualize the position of the avatar’s knees might provide additional benefits to embodiment and motor performance. Finally, it is worth noting that we worked with a relatively small sample size, which may not allow us to observe the hypothesized difference in the level of embodiment.
4.3 Stepping accuracy is associated with the level of embodiment of only the feet representation
Finally, our third hypothesis (H3) was only partially confirmed. A (negative) correlation was found between the embodiment of the feet and the foot’s distance to the target. This aligns with previous research that found a similar relationship between body ownership and performance in the upper extremities Grechuta et al. (2017).
However, this correlation was not found for the embodiment of the full-body avatar. One possible explanation for this difference between the two conditions could be that, for this specific task, the full-body avatar’s embodiment is irrelevant to the relationship between embodiment and motor performance. Instead, for this experiment, it was enough for the participants to focus only on the feet, and they did not need to pay attention to the whole body. An interesting future direction for this research would be to conduct a similar experiment in which participants are questioned about the embodiment of the feet of the full-body avatar specifically. Through such an experiment, we could investigate the effect of adding the full-body avatar on the embodiment of the different distal body parts and how this may correlate with motor performance.
4.4 Study limitations
We have identified several limitations that are important to consider when interpreting the results of this work. First, due to a tilt in the virtual play space, steps would sometimes be detected before the participant reached the floor with their foot (see Section 2.5). For these steps, the score the participants saw was different from their actual distance to the target. This might have negatively affected the agency and motivation of the participants. Further, we would like to point out that we used a relatively small sample size for this pilot study, consisting mostly of male students living in Delft in the Netherlands. From this experiment, it is unclear whether the results we found would be consistent across larger or more diverse populations. Additionally, the relatively small sample size limits the statistical power to establish robust relationships between the variables of interest. Therefore, the correlations presented in this pilot study should be interpreted with caution and viewed as exploratory. Finally, our full-body avatar was the same for all participants. As a result, the two female participants saw a virtual representation that did not match their sex, which has been found to result in a decreased level of embodiment Schwind et al. (2017). The effect of this mismatch could have influenced the results regarding the relationship between embodiment and motor performance. Regardless, while the embodiment scores of the female participants are below average, being 4.14 and 3.29, their removal still does not result in a significant difference between the embodiment scores of the feet and full-body conditions. Nonetheless, we acknowledge the importance of adding gender-matched avatars, as there is a significant under-representation of female participants in virtual reality research Peck et al. (2020). Future studies should address this issue and include a more diverse range of avatars to ensure the findings apply to a wider population.
4.5 Future work
This particular task required participants to pay close attention to the position of their feet. It would be interesting to see how the (lack of) correlation between the embodiment of the feet or full-body avatar may change when participants face a task requiring a more external focus of attention, such as kicking a ball toward a goal. In a recent publication, such a task has been investigated Bonfert et al. (2022). However, no full-body avatar was included in the study, and the relationship between embodiment and accuracy was not specifically investigated. Furthermore, in this pilot study, we did not ask about the embodiment of just the feet of the full-body avatar but the embodiment of the whole body. In a future study, it could be interesting to investigate if the relationship between the embodiment of only the feet and the motor performance may change depending on the presence or appearance of the rest of the body in the virtual environment. Finally, different techniques can be investigated to influence the level of embodiment. For example, the embodiment can be enhanced by accurately matching the dimensions and appearance of the avatar or virtual feet to the participant Fribourg et al. (2020); Waltemate et al. (2018) or by modulating the fidelity of the tracking of body parts Eubanks et al. (2020). Applying these additional methods to modulate the level of embodiment could provide additional insight into the relationship between embodiment and motor performance for the lower extremities.
5 Conclusion
In IVR, the possibilities of how this reality looks and reacts are nearly infinite. With the increasing use of IVR in rehabilitation, it is crucial to consider the design of these interfaces. In this work, we have investigated a stepping task for the purpose of gait rehabilitation in IVR. We have shown that a virtual representation of the feet is essential for accurate foot placement. Additionally, we have found a correlation between the embodiment of the virtual feet and the accuracy of the foot placement, suggesting that the level of embodiment of the feet could play a role in modulating motor performance. Future work should aim to investigate different tasks related to gait rehabilitation, as well as a broader range of virtual representations. Deepening the understanding of the underlying mechanisms behind this correlation could enable leveraging this effect for gait rehabilitation interfaces, which could lead to more effective gait rehabilitation training.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://zenodo.org/record/7927396.
Ethics statement
The studies involving human participants were reviewed and approved by The Human Research Ethics Committee, TU Delft. The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any identifiable images or data included in this article.
Author contributions
This project was led by AB and LM-C and developed and conducted by BV, ZB, AM, and MT. AB and BV collaborated on the statistical analysis. The writing was performed by AB and LM-C. The whole project was supervised by LM-C and AB. All authors contributed to the article and approved the submitted version.
Funding
This work was partially supported by the Dutch Research Council (NWO) under the VIDI 2020 grant 18934, titled “Hyper-Realistic Personalized Multisensory Robotic Neurorehabilitation”.
Acknowledgments
We want to thank our colleagues from the VR Zone at TU Delft for their support. The authors also thank Dr. Karin Buetler for the valuable discussions during the document drafting, as well as Alexis Derumigny for advice on statistical methodology. Finally, sincere gratitude goes to our participants.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Finding patients before they crash: The next major opportunity to improve patient safety. J. Stat. Softw. 67, 1–3. doi:10.1136/bmjqs-2014-003499
Blanke, O. (2012). Multisensory brain mechanisms of bodily self-consciousness. Nat. Rev. Neurosci. 13, 556–571. doi:10.1038/nrn3292
Bonfert, M., Lemke, S., Porzel, R., and Malaka, R. (2022). “Kicking in virtual reality: The influence of foot visibility on the shooting experience and accuracy,” in Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Christchurch, New Zealand, 12-16 March 2022 (IEEE), 711–718.
Botvinick, M., and Cohen, J. (1998). Rubber hands ‘feel’touch that eyes see. Nature 391, 756. doi:10.1038/35784
Brookes, J., Warburton, M., Alghadier, M., Mon-Williams, M., and Mushtaq, F. (2019). Studying human behavior with virtual reality: The Unity Experiment Framework. Behav. Res. Methods 52, 455–463. doi:10.3758/s13428-019-01242-0
Cho, S., Ku, J., Cho, Y. K., Kim, I. Y., Kang, Y. J., Jang, D. P., et al. (2014). Development of virtual reality proprioceptive rehabilitation system for stroke patients. Comput. methods programs Biomed. 113, 258–265. doi:10.1016/j.cmpb.2013.09.006
Ehrsson, H. H., Holmes, N. P., and Passingham, R. E. (2005). Touching a rubber hand: Feeling of body ownership is associated with activity in multisensory brain areas. J. Neurosci. 25, 10564–10573. doi:10.1523/jneurosci.0800-05.2005
Ehrsson, H. H., Spence, C., and Passingham, R. E. (2004). That’s my hand! activity in premotor cortex reflects feeling of ownership of a limb. Science 305, 875–877. doi:10.1126/science.1097011
Eubanks, J. C., Moore, A. G., Fishwick, P. A., and McMahan, R. P. (2020). The effects of body tracking fidelity on embodiment of an inverse-kinematic avatar for male participants, 2020 IEEE international symposium on mixed and augmented reality, 54–63.
Ferreira, B., and Menezes, P. (2020). Gamifying motor rehabilitation therapies: Challenges and opportunities of immersive technologies. Information 11, 88. doi:10.3390/info11020088
Flueratoru, L., Simona Lohan, E., Nurmi, J., and Niculescu, D. (2020). “Htc vive as a ground-truth system for anchor-based indoor localization,” in Proceedings of the 2020 12th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops, Brno, Czech Republic, 05-07 October 2020 (ICUMT), 214–221. doi:10.1109/ICUMT51630.2020.9222439
Fribourg, R., Argelaguet, F., Lécuyer, A., and Hoyet, L. (2020). Avatar and sense of embodiment: Studying the relative preference between appearance, control and point of view. IEEE Trans. Vis. Comput. Graph. 26, 2062–2072. doi:10.1109/tvcg.2020.2973077
Gonzalez-Franco, M., Abtahi, P., and Steed, A. (2019). “Individual differences in embodied distance estimation in virtual reality,” in Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23-27 March 2019 (IEEE), 941–943.
Grechuta, K., Guga, J., Maffei, G., Rubio Ballester, B., and Verschure, P. F. (2017). Visuotactile integration modulates motor performance in a perceptual decision-making task. Sci. Rep. 7, 3333–3413. doi:10.1038/s41598-017-03488-0
Kashif, M., Ahmad, A., Bandpei, M. A. M., Farooq, M., Iram, H., and e Fatima, R. (2022). Systematic review of the application of virtual reality to improve balance, gait and motor function in patients with Parkinson’s disease. Medicine 101, e29212. doi:10.1097/md.0000000000029212
Kilteni, K., Groten, R., and Slater, M. (2012). The sense of embodiment in virtual reality. Presence Teleoperators Virtual Environ. 21, 373–387. doi:10.1162/pres_a_00124
Kim, A., Schweighofer, N., and Finley, J. M. (2019). Locomotor skill acquisition in virtual reality shows sustained transfer to the real world. J. neuroengineering rehabilitation 16, 113–210. doi:10.1186/s12984-019-0584-y
Kim, S. I., Song, I.-H., Cho, S., young Kim, I., Ku, J., Kang, Y. J., et al. (2013). “Proprioception rehabilitation training system for stroke patients using virtual reality technology,” in Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 03-07 July 2013 (IEEE), 4621–4624.
Kosmalla, F., Zenner, A., Tasch, C., Daiber, F., and Krüger, A. (2020). “The importance of virtual hands and feet for virtual reality climbing,” in Extended abstracts of the 2020 CHI conference on human factors in computing systems (New York, United States: Association Computing Machinery), 1–8.
Lee, J. H., Ku, J., Cho, W., Hahn, W. Y., Kim, I. Y., Lee, S.-M., et al. (2003). A virtual reality system for the assessment and rehabilitation of the activities of daily living. CyberPsychology Behav. 6, 383–388. doi:10.1089/109493103322278763
Massetti, T., Da Silva, T. D., Crocetta, T. B., Guarnieri, R., De Freitas, B. L., Bianchi Lopes, P., et al. (2018). The clinical utility of virtual reality in neurorehabilitation: A systematic review. J. central Nerv. Syst. Dis. 10, 117957351881354. doi:10.1177/1179573518813541
McManus, E. A., Bodenheimer, B., Streuber, S., De La Rosa, S., Bülthoff, H. H., and Mohler, B. J. (2011). The influence of avatar (self and character) animations on distance estimation, object interaction and locomotion in immersive virtual environments. Proc. ACM SIGGRAPH Symposium Appl. Percept. Graph. Vis., 37–44.
Mohler, B. J., Creem-Regehr, S. H., Thompson, W. B., and Bülthoff, H. H. (2010). The effect of viewing a self-avatar on distance judgments in an hmd-based virtual environment. Presence 19, 230–242. doi:10.1162/pres.19.3.230
Niehorster, D. C., Li, L., and Lappe, M. (2017). The accuracy and precision of position and orientation tracking in the htc vive virtual reality system for scientific research. i-Perception 8, 204166951770820. doi:10.1177/2041669517708205
Odermatt, I. A., Buetler, K. A., Wenk, N., Özen, Ö., Penalver-Andres, J., Nef, T., et al. (2021). Congruency of information rather than body ownership enhances motor performance in highly embodied virtual reality. Front. Neurosci. 15, 678909. doi:10.3389/fnins.2021.678909
Pan, Y., and Steed, A. (2019). How foot tracking matters: The impact of an animated self-avatar on interaction, embodiment and presence in shared virtual environments. Front. Robotics AI 6, 104. doi:10.3389/frobt.2019.00104
Pastel, S., Chen, C.-H., Petri, K., and Witte, K. (2020). Effects of body visualization on performance in head-mounted display virtual reality. PLoS One 15, e0239226. doi:10.1371/journal.pone.0239226
Peck, T. C., and Gonzalez-Franco, M. (2021). Avatar embodiment. a standardized questionnaire. Front. Virtual Real. 1, 575943. doi:10.3389/frvir.2020.575943
Peck, T. C., Sockol, L. E., and Hancock, S. M. (2020). Mind the gap: The underrepresentation of female participants and authors in virtual reality research. IEEE Trans. Vis. Comput. Graph. 26, 1945–1954. doi:10.1109/tvcg.2020.2973498
Porras, D. C., Siemonsma, P., Inzelberg, R., Zeilig, G., and Plotnik, M. (2018). Advantages of virtual reality in the rehabilitation of balance and gait: Systematic review. Neurology 90, 1017–1025. doi:10.1212/wnl.0000000000005603
Ries, B., Interrante, V., Kaeding, M., and Anderson, L. (2008). “The effect of self-embodiment on distance perception in immersive virtual environments,” in Proceedings of the 2008 ACM symposium on Virtual reality software and technology (New York, United States: Association Computing Machinery), 167–170.
Schwind, V., Knierim, P., Tasci, C., Franczak, P., Haas, N., and Henze, N. (2017). “These are not my hands! effect of gender on the perception of avatar hands in virtual reality,” in Proceedings of the 2017 CHI conference on human factors in computing systems (New York, United States: Association Computing Machinery), 1577–1582.
Sigrist, R., Rauter, G., Riener, R., and Wolf, P. (2013). Augmented visual, auditory, haptic, and multimodal feedback in motor learning: A review. Psychonomic Bull. Rev. 20, 21–53. doi:10.3758/s13423-012-0333-8
Tsakiris, M., Hesse, M. D., Boy, C., Haggard, P., and Fink, G. R. (2007). Neural signatures of body ownership: A sensory network for bodily self-consciousness. Cereb. cortex 17, 2235–2244. doi:10.1093/cercor/bhl131
Keywords: embodiment, gait training, virtual reality, avatar, locomotion, motor perfomance, rehabilitation
Citation: Berg Avd, Vries Bd, Breedveld Z, Mierlo Av, Tijhuis M and Marchal-Crespo L (2023) Embodiment of virtual feet correlates with motor performance in a target-stepping task: a pilot study. Front. Virtual Real. 4:1104638. doi: 10.3389/frvir.2023.1104638
Received: 21 November 2022; Accepted: 26 May 2023;
Published: 18 July 2023.
Edited by:
Daniel Thalmann, Swiss Federal Institute of Technology Lausanne, SwitzerlandReviewed by:
David Harris, University of Exeter, United KingdomAnthony Steed, University College London, United Kingdom
Copyright © 2023 Berg, Vries, Breedveld, Mierlo, Tijhuis and Marchal-Crespo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alex van den Berg, YS52YW5kZW5iZXJnLTJAdHVkZWxmdC5ubA==