 Darragh Higgins
Darragh Higgins Rebecca Fribourg
Rebecca Fribourg Rachel McDonnell
Rachel McDonnell
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Virtual Real. , 31 May 2021
Sec. Technologies for VR
Volume 2 - 2021 | https://doi.org/10.3389/frvir.2021.668499
This article is part of the Research Topic Meeting Remotely – The Challenges of Optimal Avatar Interaction in VR View all 8 articles
Avatar use on video-conference platforms has found dual purpose in recent times as a potential method for ensuring privacy and improving subjective engagement with remote meeting, provided one can also ensure a minimal loss in the quality of social interaction and sense of personal presence. This work focuses on interactions of this sort through real-time motion captured 3D personalized virtual avatars in a 2D video-conferencing context. Our experiments were designed with the intention of exploring previously defined perceptual illusions that occur with avatar-use in Virtual and Augmented Reality settings, outside of the immersive technological domains where they are normally measured. The research described here was aimed at empirically evaluating three separate dimensions of human-avatar interaction. The first was humans-as-avatars, with experimental conditions that were designed to measure changes to subjective perceptions of self-face ownership and self-concept. The second focus was other-perception, with the unique design of the studies outlined below among the first to measure social presence in a video-call between two human-driven avatars. The third emphasis was on the experiential content involved in avatar use, as there were measurements for emotion induction, fatigue and behavior change included in the data collection. The results describe some evidence for face and body ownership, while participants also reported high levels of social presence with the other avatar, indicating that avatar cameras could be a favorable alternative to non-camera feeds in video conferencing. There were also some useful insights gained regarding emotion elicitation in non-video vs. avatar conditions, as well as avatar-induced behavior change.
Virtual, mixed reality and screen-based applications for avatar use have developed considerably in terms of the technical challenges that have been documented around producing realistic virtual characters. Personalized self-representational avatars, in particular, have been increasingly common as objects of application development, given that avatar self-congruity has been associated with affective improvement in human-avatar interactions (Suh et al., 2011), while there is evidence that virtual avatar faces are recognized in the same way as human faces (Gonzalez-Franco et al., 2016).
Avatar studies in Virtual Environments (VEs) have empirically validated self-avatar influences on cognitive load (Steed et al., 2016), pain modulation (Romano et al., 2014) and perceptions of self-concept (Yee and Bailenson, 2007a; Heide et al., 2013). These specific applications of avatar-interaction science have been developed from a volume of work which has attempted to define the qualitative feeling of being a virtual self-representation of oneself; the Sense of Embodiment (SoE). SoE is an experience of a virtual body such that one processes information about it as if it were one’s own biological body (Kilteni et al., 2012; Fribourg et al., 2020).
Virtual collaboration methods have drawn widespread attention in the current era of remote working. As it stands, Immersive VR technologies have not generally been a popular choice for educational or business purposes. Remote collaboration has instead been more widely conducted through video-conferencing media, which have proven to be useful for conducting research and gathering qualitative data (Archibald et al., 2019).
Although interactions on such platforms can be considered taxing on human attention processes (Kuzminykh and Rintel, 2020) their accessibility and ease of use have seen them preferred to Social VR by the majority of industries. The use of personalized avatars in conjunction with these modes of virtual interaction has not been broadly explored or defined thus far. This research presents a novel approach to examining human-avatar perception in video-conferencing contexts. Applying modern high fidelity face-tracking avatar technologies to these situations evokes many of the same issues as their use in immersive VEs. There are unanswered questions around their impact on the self-identification mechanisms that are associated with personalized avatar use. Additionally, potential influences on perceptions of other individuals, and on communicative social processes in general, remain to be fully explicated.
The malleability of self-identification has emerged as a key issue for addressing such questions. While SoE serves as a general term for the illusion of bodily representation in avatar use, it can be described in terms of several sub-components; agency, body ownership and self-location (Kilteni et al., 2012). Modulation of these dimensions has been the motivation of work focusing specifically on agency (Jeunet et al., 2018) and ownership (Kokkinara and Slater, 2014; Dewez et al., 2019). These studies seem to implicate appearance, control and point of view (Fribourg et al., 2020) as salient factors influential in subjective SoE.
Senses of body ownership can be understood as a fusion of place and plausibility illusions (Slater, 2009) where a user attributes their body to themselves as if the body were the source of experienced sensations (Kilteni et al., 2012). Social presence may be defined as a user in a virtual environment experiencing the presence of another person (Biocca, 1997). While previous studies investigating Social Presence with avatars have failed to define a relationship to either agency or body ownership (Nowak and Biocca, 2003; C.S. Oh et al., 2018) recent work has implicated personalization of avatars as a potential modulator of experiential presence and virtual body ownership (Waltemate et al., 2018). Similarly, Embodied Social Presence theory posits SoE as a necessary precondition to experiencing any categories of presence in virtual worlds, with bodily experience considered as the primary bottom-up sensory modality for the physical and social actions contingent on presence (Mennecke et al., 2010).
The term “enfacement” has also been coined as a means of defining the plasticity of subjective senses of face ownership, which can be adapted according to features of virtual faces (Sforza et al., 2010; Porciello et al., 2018). In an analogous way of the SoE, the enfacement illusion can be considered as a model instance of self-identification and involve the same kind of multisensory integration applied to the face (Tajadura-Jiménez et al., 2012). The notion of enfacement is especially relevant to the present study, as the avatar applications used in our experiments depict the face, head and shoulders view that is traditionally used for video-conferences. The animation quality of our avatars is considerably high, which has been a factor documented to influence levels of reported enfacement with avatars (Gonzalez-Franco et al., 2020), while there has also been previous research linking facial mimicry of others to strong senses of face-ownership (Minio-Paluello et al., 2020).
Another primary topic of consideration has been the use of avatars in emotive virtual contexts. Mood inductions, mediated by PC monitors, have been associated with higher senses of immersion and presence in virtual environments compared with neutral non-emotive conditions (Baños et al., 2004). Emotion has also been prescribed as crucial for achieving core self-presence in interactions with virtual-self representations (Ratan, 2012). Emotion recognition between avatar user studies in video-conferencing contexts (Bailenson et al., 2006), have described the effects of behavioral realism on valence induction, and encourage future work to use more realistic avatar representations to further explore this domain.
However, previous works on enfacement and avatars in 2D dyadic video-conferencing contexts did not seem to involve personalized avatars but generic ones, and would not explore their use in the context of dyadic conversation in which participants would see their avatar as well as the conversation partner’s avatar. To our knowledge, the study of enfacement toward a personalized self-avatar, social presence and the impact of valence on such aspects remained therefore unexplored in the context of dyadic video-conferencing, motivating this study.
The phenomena outlined here informed the development of our research goals. The aim of this work was to address three key factors in the domain of human-avatar connections: avatar embodiment and self perception, social contexts with other avatars, and the experiential perception of avatar-avatar interaction.
1) Can senses of ownership be experienced with embodied self-avatars in video-conferences?
2) Do avatar-avatar conversations produce senses of social presence?
3) How will cartoon avatar use impact emotional content of conversation?
4) Can cartoon avatars induce perceived behavior and self-concept change in a video-call context?
The novel experimental designs posited below were developed to explore these questions. The first experiment served as a pilot. It was intended to develop evidence for the legitimacy of these research questions, and inform iterations on our hypotheses using personalized avatars for dyadic conversation.
The exploratory method provided us with some preliminary data and design notes, to inform the construction and focuses of the second experiment, which had additional emphases on personalization, as well as subjective perceptions of self-avatar and other-avatar interactions. Both experiments used video-conferencing to evaluate the qualitative aspects of avatar-avatar conversation under varying conditions of emotional valence. The novelty of these designs can be described by the experimenter-as-avatar factors, as each dyadic conversation was conducted in an interview style format via zoom video-conference.
It is expected that there will be a proliferation of work in the fields of video-conferencing and social VR. Given the unique challenges posed by the last year, such methods for remote collaboration threaten to replace many in-person meetings that were previously considered essential. Avatars can provide a functional alternative to a “camera off” option in these situations. The questions asked by the present research revolve around the non-veridical self-identification with embodied avatars, the perception of presence from other human-driven avatars in social conversation, and the experiential aspects of avatar use in video-conferencing.
One of the topics that our study sought to address was the interaction between individuals in remote conversation. While many of the phenomena measured by this study are common occurrences in Immersive VR contexts, the novelty of bringing virtual characters to video-conferencing gave us an opportunity to blend emphases for the purpose of advancing scientific understanding of generalized avatar effects with an “in the wild” avatar-interaction experiment. As a platform for collecting qualitative data, Zoom has been used effectively, as facilitated by its ease of use and distribution qualities (Archibald et al., 2019).
Perceptual research, which comprises the focus of the work outlined here, can benefit from the use of such a platform, particularly because the experience of remote presence (Minsky, 1980) may be explored in the context of computer-mediated social exchanges, with the virtual environmental factors reduced to a simple dyadic conversational format (Shahid et al., 2018).
Video-conferencing platforms have been used for purposes similar to ours to measure perception of self-representational avatars, which yields a neural reaction that originally processes the animated face as an object other than a face, before assimilating it into face and self-face recognition over time (Gonzalez-Franco et al., 2016).
Studies on aspects of emotion recognition and presence in dyadic conversations (Bailenson et al., 2006) have produced findings on the effects of animation realism from screen-mediated avatar interaction. Comparable emotion induction and measurement research has been conducted with avatar interactions in screen-based and collaborative VEs examining different aspects of presence (Ratan, 2012) as well as Immersive VR contexts, using Mood Induction Procedures (MIP’s) that have been employed widely in psychological research (Gerrards-Hesse et al., 1994; Baños et al., 2004).
Studies using realistic virtual avatars to represent individuals in both immersive and screen-mediated virtual spaces have benefited from advancements in face tracking technology. The use of real-time facial mapping has been shown to induce SoE with avatars under the control of individuals (Kokkinara and McDonnell, 2015).
This effect can be directly related to the realistic detail of avatar faces, given that a reduction in facial detail and real-time responsiveness has an antithetical effect on subjective reports of these psychological dimensions of avatar control (Kokkinara and McDonnell, 2015). The ownership dimension of SoE in particular has been demonstrated to benefit from improved realism in avatar interactions (Gorisse et al., 2019).
There is some evidence to suggest that the use of avatars for collaboration purposes can be improved with embodied realism in Immersive VR. Some studies have implicated full-body avatars as the most useful for generating senses of social presence between users in Social VR settings (Heidicker et al., 2017; Wang et al., 2019) and highlighted their impact in enhancing engagement of users while doing a virtual task (Fribourg et al., 2018). However, similar results have been achieved with head-and-shoulder style avatars (Yoon et al., 2019) provided they can represent a users bodily movements to a sufficient degree. These styles of avatars needed testing under novel conditions, to develop our understanding of their relationship to traditional avatar effects. These effects can even be observed without representing an individual as their avatar in realistically detailed appearance (González-Franco et al., 2020).
Driving avatars in social VEs can induce perceptual effects of comparable significance. SoE in virtual characters has been influencial in studies of social presence (Mennecke et al., 2010), the perception of a “real” other in a virtual environment (Biocca et al., 2001; C.S.; Oh et al., 2018).
Collaborative avatar use in shared VEs is regarded as a fruitful platform for social neuroscience research (Parsons et al., 2017), facilitated by the dirigible qualities of virtual environments, which enable researchers to control the audio-visual and tactile scene data that experimental subjects experience, to the most minute of details. Studies utilizing these advantages have been able to examine non-verbal social behaviors and cues (Roth et al., 2018) as well as task-coordination, joint attention and eye gaze in digitalized social scenarios (Roth et al., 2018; Wienrich et al., 2018). Work in this domain has also sought to quantify the effects of smile enhancements (Bailenson et al., 2016) and pro-social intentions (Roth et al., 2019).
Animations which seek to mimic facial movement, in conjunction with lip-syncing motions, have been shown to be sufficient for induction of a self-identification process between an individual and an avatar. Studies have verified such effects, even when a face is not directly mimicking those of the user (González-Franco et al., 2020), which can be used in virtual environments where head mounted displays prevent accurate facial mapping.
The effect of enfacement, perceiving an avatar’s face to be one’s own, can be shown even if the animations are pre-generated. However, measures for self-identifying with an avatar do scale up once lip-syncing is enabled and facial motion is mapped to the user. In carrying out this experimental work, we sought correlations between this assimilation and the notion of enfacement (Gonzalez-Franco et al., 2020).
This notion, by extension, allowed us to measure SoE, given the similarities in the processing mechanisms for both concepts (Tajadura-Jiménez et al., 2012) and the fact that both terms are employed to measure the pliability of self-identity (Porciello et al., 2018), with an emphasis on enfacement in particular proving empirically fruitful in dyadic interactions such as those measured in our study (Minio-Paluello et al., 2020).
Cartoon avatars depicted in a positive light through the enhancement or exaggeration of a user’s smile have been shown to improve subjective measures of social presence in an avatar interaction setting (Bailenson et al., 2016). This manufactured positivity is also mirrored in the conversational dynamics between avatars, as objective measures have shown it is more likely to influence conversations toward more upbeat and lively interactions, even if the subjects are unaware of the subtle changes in the expressions of an avatar. It follows that the exaggerated positive appearance of the avatars could potentially affect the behavior of participants in this experiment.
Studies in immersive virtual environments have indicated that there are correlations in avatar attractiveness and reported friendliness (Yee and Bailenson, 2009) which informed our exploration in this domain. Similar research has demonstrated the antithetical effect of negative valence and aggressive reaction (Peña et al., 2009), while our approach was also justified by evidence for manifest behavior changes following avatar based self-concept alteration (Heide et al., 2013), also termed the Proteus Effect (Yee and Rickertsen, 2007).
The work outlined here contextualizes the experimental designs elucidated below. Personalization of avatars has been investigated in Immersive VR environments as a potential factor influencing levels of perceived SoE (Waltemate et al., 2018), which have built upon related monitor-based experiments that have yielded similar results (Kokkinara and McDonnell, 2015). There has been similar research conducted on enfacement with avatars, although without the element of dyadic conversation (Gonzalez-Franco et al., 2020). Conversely, research that does not highlight aspects of SoE such as enfacement, has investigated avatar-avatar conversations with manipulated affect conditions such as ours (Bailenson et al., 2016), although without participants being able to see both themselves and each other. The present study combines these emphases. Personalized avatars have not been examined in 2D video-conferencing scenarios as included in the work outline below. Similarly, the cited experimental studies on SoE and the role of valence in dyadic conversation have also been consolidated here in a way which helped us to measure their mutual influences.
This range of screen-based and immersive VR studies, measuring such perceptual factors, give scope for an avatar-based experimental design using video conferencing software. The experimental designs outlined below imbue characteristics of these studies, to focus on a combination of the same measured factors, in dyadic, avatar-mediated, screen-based conversations.
For the preliminary version of this study, one experimenter interviewed individual participants who were embodied in self-representational avatars. It was designed to test our hypotheses around whether participants could experience senses of ownership and social presence, and how mood induction and self-concept varied between conditions.
Fourteen participants were recruited to take part in this experiment. They were provided with information and consent forms prior to the experiment. The participants were recruited using university mailing lists, and comprised of undergraduate students, postgraduate students and research staff. The mean age was 26.6 years, and there was a reasonably representative spread of seven males, six females and one non-binary participant. Ethical approval was provided by the university in advance of this recruitment and all participants signed a consent form prior to the experiment. They were each entered into a draw for a €50 voucher for their efforts.
Zoom platform was used to run the conference call, chosen for its ease of use and free distribution qualities. The participants used a modern avatar application with accurate tracking of 198 facial landmarks and moderately rich facial animation of 51 expression blendshapes1 which included a Zoom camera plugin. The application was chosen as for allowing the virtual face to directly map the visual and kinesthetic actions of each participants face and head as in the study by Kokkinara et al. (Kokkinara and McDonnell, 2015). The faces of the respective avatars were displayed side-by-side in gallery view on the video call Figure 1.

FIGURE 1. Pilot Experiment: Video call between participant (left) and experimenter (right), both embodied in virtual avatars and viewed side-by-side on-screen.
Both the experimenter and participant embodied their chosen avatars from the beginning of the call. The cartoon-like appearance of individual avatars (Figure 2) was predicted to modulate how the participants perceived themselves and the experimenter. Specifically, it seemed relevant that the avatars possessed larger eyes and also expressed enhanced smiling features compared to real human faces. Such smile-enhancement features have been implicated in improving positive affect induction (Bailenson et al., 2016). The experimenter embodied the same generic avatar for each experiment with a view to consistency within conditions. One of the limitations inflicted on this study by the COVID era was the necessity for participants to use their own personal computers, webcams and internet connections to complete the experiment tasks. However this drawback was tolerable, given that, since our participants would have been experiencing multiple Zoom calls a day, it was more appropriate to try and measure these effects from the place where they usually conducted the same activity. So there was also a positive influence on the integrity of the study conducted.

FIGURE 2. Pilot Experiment: Some examples of the customized avatars created by the participants.
Prior to the experiment, the participants personally designed their avatars to represent themselves. There were a variety of detailed parameters to change in the character design, with functions for shaping face parts and shading tones which the participants adjusted to closely represent themselves (see Supplementary Video S1).
Each participant was individually trained on operating the avatar software. It helped to gauge how effectively the face-tracking software was able to integrate into the individual operating systems that the participants were using. There was no way to control for this extraneous factor given the circumstances, but a sufficient standard of interaction quality was attained for all subjects prior to the main experimental task phase.
The metrics used have been derived from a body of similar research, using methods adapted from established evaluations of social presence, enfacement and embodiment in avatar interaction settings.
Participants were individually welcomed into a pre-arrange Zoom conference call and asked to engage in a video-conversation using a personalized avatar in their likeness for the entire experiment.
The conversations took place in two separate blocks following two separate Mood Induction Procedures (MIPs) (Gerrards-Hesse et al., 1994), the use of which has been commonplace in avatar-interaction experiments in immersive VR (Baños et al., 2004). In the context of our experiment, deploying this technique meant using stimuli in the form of positive and negative newsreel clips with appropriately valenced audio backing in each of the two videos.
The first video2 was chosen to elicit positive emotional content such as joy, amusement, respect and charm. This contrasted with the second video3, which is presented in a negative light and intended to put the participants in a state of unease and discomfort. See Supplemental movie for an example of the experiment. After each of the two videos, the participant and experimenter engaged in 4 min of conversation, in order to encourage the participant to fully engage in the social use of their avatar using pre-specified neutrally worded dialogue prompts. It was predicted that the cartoon-like appearance of the avatars was likely to make interactions difficult during the negatively valenced conversation. Previous work with avatars has described difficulties in attempting to interpret wide-eyed expressions of negative valence (Koda and Ishida, 2006), while previous work which outlines the effects of positive enhancements of avatar features (Bailenson et al., 2016) also motivated this prediction.
Following the two videos and two conversations, the participants were asked to report on a subjective questionnaire on the topics outlined below (see Table 1). The responses included a commentary section which we analyzed separately to the rest of the questionnaire data. The structure of this experiment was adapted from previous efforts to standardize data gathering methods in emotional elicitation experiments (Kossaifi et al., 2019). The experiment was conducted with participants and the same male experimenter for all fourteen recorded versions.

TABLE 1. Pilot experiment: Questions arranged by group and variable name. Each question could be answered on a scale from 1–“Not at all” to 7–“Extremely”.
We were constrained somewhat in our valence examination, given that we chose to distribute only one questionnaire at the end of the experiment, instead of one after each valence stimulus. We decided that the data we sought to derive from the questionnaire could be confounded in the second instance. If a participant was asked, for example, whether the videos affected their mood, they might be more cognizant of that information for the second video and questionnaire. The main Experiment (Section 4) was designed to account for such demand characteristics.
Another measurement constraint impacted attempts to control for animation and face-tracking accuracy. In order to ensure a fair comparison across the board, this quality was post-rated following each experiment recording. Subjective scores for an objective quality such as face-tracking accuracy was considered to be a potential confound, so a post-experiment analysis rated the quality as either high or low.
The subjective questionnaire we used to obtain data from this experiment was constructed using a body of literature in the area of human-avatar interaction. The questions we used which sought to elucidate subjective senses of enfacement (see Table 1), are adapted from previous research which attempted to standardize the categories of information-seeking queries that should be included in these kinds of experiments. We also used the Linguistic Inquiry and Word Count to analyze data from an open-ended comment section at the end of the questionnaire.
The valence items were extracted from studies that made efforts to standardize emotional appraisal questions (Roseman, 1996) and their use in avatar experiments similar to ours (Bailenson et al., 2006), and were adapted to suit this investigation. The questionnaire items used to measure enfacement have been extracted from questionnaires used in research into self-face recognition and the SoE (Sforza et al., 2010; Panagiotopoulou et al., 2017; Gonzalez-Franco and Peck, 2018). These items have been used for subjective reports of face ownership and have been considered suitable for avatar-interaction studies (Suh et al., 2011).
The question items for Proteus measurements were composed based on the self-perception theory (Yee and Bailenson, 2007a) which underpins the occurrence of transformed self-representation, and work which has linked avatar appearances to properties of extroversion (Koda and Oguri, 2019).
Specifically (Yee and Bailenson, 2007a), posits the example of measuring friendliness after inhabiting an attractive avatar. Our item Proteus two in Table 1 reflect the converse inquiry, with perceived attractiveness measured based on the friendly avatar facial details described in Section 3.2. Item Proteus one is similarly composed to capture a self-reported change in behavior. Talkativeness has been described as a Proteus measure for inhabiting animated avatars of improved appearance (Koda and Oguri, 2019).
The social presence items were extracted from previous study (Nowak and Biocca, 2003) and adapted for the purpose of investigations such as ours. The realism and social presence determinants are derived from more exploratory research in the area. Social presence is a topic that has received much attention from the VR research community, as it is a strong indicator of a user’s level of immersion in a social VR or AR platform, and has been used to measure the degree of “success” of a virtual social interaction (C.S. Oh et al., 2018). Presence is also considered to be bound inexorably to perceived SoE (Mennecke et al., 2010). As such, there has been an extensive effort to standardize the acquisition of information from subjective questioning on the topic.
The Linguistic Inquiry and Word Count (LIWC) provided us with the means to compare comment data to the questionnaire data in an attempt to quantify the data we were looking for. As described below, the LIWC was used to analyze participants open ended responses to the content. Specifically, they were asked ‘‘please describe, in at least five sentences, your experience of using the avatar for conversation. Focus on how you felt during the interaction. Please be as detailed as possible” (C.S. Oh et al., 2018).
The intended purpose was to extract implicit and explicit cues that consolidated evidence for the effects that the questionnaire data would provide. While we were interested to see if our embodiment and social presence questions could potentially be reflected in this data, the LIWC is considered a valid indicator for the content of emotional expression (Kahn et al., 2007), and we hoped that it would shed light on the effect of the valence conditions on avatar interactions.
We anticipated that participants using personalized avatars for dyadic video conversations would feel ownership of their embodied self-avatar (Ha), report social presence with an other-avatar (Hb), find it easier to discuss positive content than negative content during the experiments (Hc) and experience some alteration of perceived self-concept (Hd).
Each item from the subjective questionnaires was first analyzed separately in order to seek which variables seemed to have more effect for participants. Since most of the participant questionnaire data was collected via a 7-Point Likert-Scale, an analysis for these results was conducted using a t-test of means against the constant of 4. This numeric value represented the mid-point of the scale, and given the range of “Extremely” to “Not at all” there was appropriate scope on either end of the scale to capture nuanced responses against the constant.
We also conducted a Spearman’s Rank Order Correlation test to compare the results of some of the questions. The comment data collected at the end of the experiment, also analyzed individually, was processed using the Linguistic Inquiry and Word Count, in order to provide evidence for the effects that we sought to explicate in conjunction with the variance analysis. The data from the LIWC was taken at face value, although we used a repeated measures Analysis Of Variance (ANOVA) to analyze the linguistic affect data.
In order to explore the impact of internet quality on our dependent variables, we also conducted a one-way ANOVA with between–subject factor Quality (low, high) for the dependent variable (subjective responses).
The participants also did not interact with each other and as such we felt that the independence assumption was appropriately preserved despite the relatively small population tested. Before conducting our analysis, the normality assumption was tested using Shapiro-Wilk test. When not verified, the Kruskal-Wallis test was used instead of the ANOVA.
As the yellow bars in Figure 3 depict, the impact of positive valence seems more prevalent in the results than the effect of negative valence. Indeed, Positive Expression scores were high (significantly higher than 4:
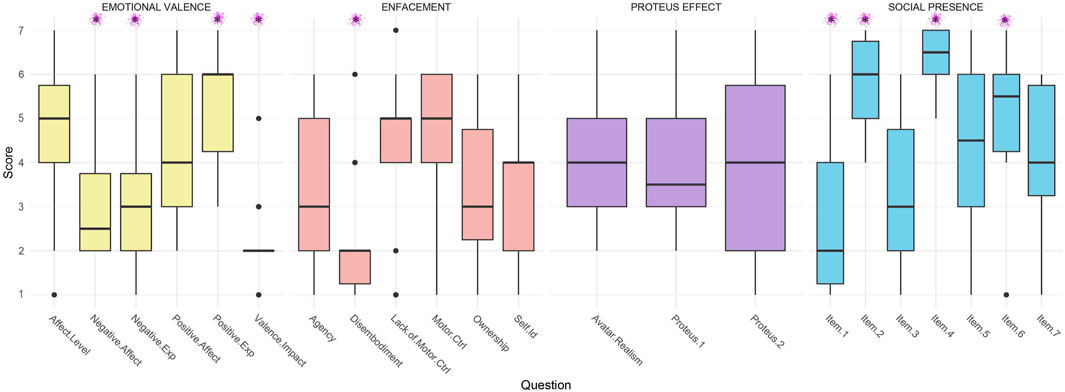
FIGURE 3. Pilot Experiment: Results for questions Emotional Valence, Enfacement, Proteus Effect and Social Presence. X-Axis labels are the variable names from Table 1. Star indicates statistical significance
However, Negative Expression scores were low (significantly lower than 4:
Face Ownership and Self Identification ratings were relatively low, suggesting that participants did not experience senses of enfacement and embodiment toward the avatar (see Figure 3, pink). While not significantly higher than 4, the highest means in the data gathered on enfacement come from the Motor Control (
This is as well consistent with agency ratings that remained relatively low. While these results depict that participants did not feel a sense of embodiment or enfacement toward the avatar, disembodiment scores were nonetheless very low showing that participants did not find it difficult to talk while using the avatar.
None of the scores from Proteus one and Proteus two were significantly different than 4, showing that participants did not feel more talkative or attractive with their avatar (see purple bars in Figure 2). Interestingly, a correlation was found between Avatar Realism scores and Proteus one scores (r = 0.66, p = 0.01), showing that the more participants felt that the avatar was similar in appearance to them, the more they felt more talkative than usual using the avatar. Both Proteus one and Proteus two scores were correlated with Ownership scores (respectively r = 0.55, p = 0.04 and r = 0.67, p
The questions where social presence was most visible were for Item 2
Quality ratings for experiments were included in order to ascertain whether poor face-tracking and latency had an effect on the perception of avatar use that we intended to measure. Quality was determined after all of the experiments had been completed, based on judgments made around frame rate and internet connection standards. A between-groups ANOVA was conducted to determine the effect of quality of facial tracking (Eight High Quality v six Low Quality). We found a main effect of quality on Proteus 2, on Table 1, in terms of attractiveness ratings
This result is consistent with other work in the field, particularly a study by Kokkinara et al. (Kokkinara and McDonnell, 2015) which found that lower quality facial tracking reduced the perceived appeal of the avatar in their reduced animation realism condition.
It is also consistent with our finding that face animation quality did not impact agency or ownership under these conditions, although our study did not deliberately manipulate this factor. Kruskal-Wallis test highlighted another main effect of quality on the Valence Impact variable, where participants found it more awkward using the avatar after the negative video when the facial tracking was poor
In particular, we predicted that the agency aspect of embodiment might have been impeded by poor function. However, this lack of effect may be explained by typical interaction quality with video calls, which often contains varying levels of latency quality without avatars. Also interesting to note is that animation quality had no effect on Ownership in the enfacement study by Kokkinara et al. (Kokkinara and McDonnell, 2015).
The LIWC allowed us to compare the questionnaire data with language use in the open ended comment format, with a word count of 1,606 across the fourteen participants.
Implications for our ownership scores can be supplemented by the LIWC analysis. This measured an average of 2.74 “body” related words between subjects open ended comment sections, making up around 2% of the total word-count. Having not included bodies or the topic of embodiment in priming the participants, these results can be indicative of a low level of SoE being achieved across the board, although significantly distant from a fully immersive embodied experience. A useful observation can also be derived from the LIWC results on social presence. A total of 7% of the total word count were identified as “social” in content; relating to others via the self. This is a significantly larger proportion of the word count than the embodiment scores, and this difference is reflected in the questionnaire data as well.
These results revealed numerous implications for Hypotheses Ha-d.
Ratings for self-face recognition, ownership and agency were not high (Ha) in our Pilot, at least at the level we had predicted based on other studies on ownership and enfacement (Kokkinara and McDonnell, 2015; Porciello et al., 2018). The most interesting results, for Motor Control and Lack of Motor Control measures (See Table 1), seemed to suggest a limited range of motion felt by participants, despite the fact that they felt that their own movements were depicted by the avatar. An explanation for this result could be derived from the fact that the avatar’s movements did not represent the full range of human motion. The participants saw their own movements represented by the avatar’s movement, but felt as if their avatar could not fully represent all of their implicit motor representations.
The Quality analysis also revealed no difference in these ratings for low or high quality, which indicated that the avatar use in this context was not sufficient to achieve levels of embodiment or enfacement, regardless of video quality.
The social presence scores were much more pronounced than the Enfacement or Proteus scores. The conversational aspect of the design meant that each participant had to engage with using their avatar in a social context. This is reflected by the results of the social presence questions (see blue bars in Figure 3). Evidence for social presence was observed on these measurements (Hb). The perceived stimulation and attentiveness of the other avatar could be due to the nonthreatening and engaging visage offered by the cartoon characters. In particular the evaluation of trustworthiness in the Pilot matches previous work related to avatar appearance (Ferstl and McDonnell, 2018). At the very least, the use of the avatars was not measured to detract from the social presence you would expect in a regular face-to-face meeting.
We had predicted that the effect of the negative stimulus would be observable in the responses to the questionnaire items about the negative video. We expected that the avatar effect scores would not generally be high for post-negative conversation, based on previous experiments on lighting manipulation and emotional expression (Wisessing et al., 2020). However, the positive affect scores suggest that the use of avatars for post-positive conversation displayed stronger mood induction efficacy (Hc), and that participants were more likely to feel “friendly”. This result is consistent with similar studies (C.S. Oh et al., 2018).
We conducted a non–parametric Spearman’s Rank Test to examine correlations between the results on enhanced feelings of attractiveness, friendliness, awkwardness, and talkative ratings, as a way of measuring self-concept change (Hd) and by extension a means to identify evidence for the Proteus Effect. There were no findings in the Spearman’s results to indicate evidence for self-concept change. Interestingly, previous studies that attempt to quantify this effect in computer-mediated dyadic avatar interaction have also failed to demonstrate this effect, and so our evidence seems indicative of an upper boundary or a necessary condition that is missed in between immersive VR and dyadic remote conversation.
This experiment was designed to test our developed hypotheses around the effects of dyadic conversation with personalized avatars, under different conditions of valence and video-feed content.
More precisely, two conditions were defined for the purpose of this experiment. Positive and negative emotion elicitation procedures were conducted for conditions of avatar-avatar conversation and avatar-voice conversation, where the experimenter did not engage using an avatar. This addition was made to use Avatar-Voice conversations as a benchmark to measure the impact of another avatar in Avatar-Avatar conversations, and whether the difference could cause variation in our measurements. The order was evenly split between experiments, with half of participants experiencing non-avatar condition before the avatar-avatar condition. The display of the participant’s on-screen self-representation remained consistently sized throughout all conversations.
There were a number of other changes between this format and the Pilot. Our data collection methods had greater depth, as the participants were asked to fill out four separate questionnaires. The question items were modified for application in the altered conditions, and there was no comment section included in the collection. Our hypotheses were similarly modified to reflect the results above.
Twenty participants were recruited separately via college mailing lists and international online distribution channels. Each participant provided consent forms, and were given information sheets prior to the experiment. One of the participants was a returning volunteer involved in the pilot study. This was considered permissible given the differences in the study design on terms of structure, measurements, task performance and avatar software, as well as the long period of time separating experiments, and the recruitment restraints imposed by multiple national lockdowns. Two experimenters (one Male, one Female) tested this group of participants. The participants were split evenly on gender between experimenters, as there were 10 Male and 10 Female volunteers with a mean age of 25.6 years.
The participants for this experiment used a different avatar application to those in the Pilot Experiment. The developers of the previous avatar application chose to close their Hypermeet venture, and so we took the opportunity to use similar software Figure 4, with the added capability of a self-representational avatar generated from a photo, which saved requiring the participants to construct their own from scratch4.

FIGURE 4. Main Experiment: Some examples of the customized avatars created by the participants using the photo avatar creator tool.
The software was slightly more significant in terms of system load, so only participants with higher quality machines, webcams and internet connections could take part. This coincidentally improved the experimental conditions and removed our need for grouping participants on the factor of quality. The experimenters used self-representational cartoon avatars, as the generic ones provided were qualitatively different in general appearance to the self-representational characters generated by a photograph. We wanted to avoid character-based confounds.
For consistency, each participant was asked to pick from one of four neutral office backgrounds in the avatar application. One of the participants used a blank background, as technical difficulties prevented full background loading. However, the avatar itself was fully functional for this instance.
Prior to the experiment, participants were also asked to configure several settings on Loomie software, such as activating Video Mode (allowing avatars to follow head movements of participants), activating Eye Tracking, importantly allowing the avatars to simulate elements of direct gaze (de Hamilton, 2016) and setting “Gesture Strength” at minimum as the Loomie avatars would otherwise perform hand gestures on their own.
The participants were welcomed individually into a conference call over Zoom with an experimenter. The experiment started with a training phase, in which participants were asked to explore the full movement parameters of their avatar head, and present two emotional expressions that can be displayed on the face.
More precisely, participants were trained on the expressive use of the avatar; they were directed to make a happy face and a sad face using particular instructions (e.g. pull your outer lips down to make a frown). This helped in ensuring that the use of avatar for conversation would be conducive to emotion elicitation procedures.
After training, each participant engaged in two emotion induction tasks for two separate conditions. The emotion induction task used a modified MCI technique. This process involves music exposition and participant ideation of thoughts relating to the intended emotional measures.
This method is widely considered as an effective means of emotion elicitation (Eich et al., 2007), and the musical stimuli were not as widely pre-consumed compared to each of the clips used in the Pilot Experiment. The pieces were chosen from a wide range of verified elicitation pieces (Eich et al., 2007): Mozart Eine kleine Nachtmusik Allegro and Vivaldi Four Seasons: Spring III Allegro for positive mood induction, Schumann Träumerei and Chopin Prelude in E-Minor (op.28 no. 4) for negative mood induction. While not sufficient to elicit positive or negative emotions in isolation, these pieces have been shown to be effective valence stimuli when combined with experiential ideation; participants were asked to imagine a positive or negative scenario as the piece played softly in the background (Eich et al., 2007).
The task requirements also provided the opportunity for a more structured conversation post-stimulus, and less room for subjective interpretation than video clips. The experimenter asked questions after each elicitation task to assess the effect of valence and engage the participant in using the avatar conversationally. For either valence stimulus, the faces of the respective avatars were displayed side-by-side in gallery view on the video call.
The individual stimuli duration was the same in this experiment as in the Pilot Experiment (90 s) and the total time spent in conversation with the avatar was 8 min in both experiments, only it was split into four segments for this version, as opposed to two conversation segments in the Pilot, due to the addition of two conditions in this experiment. Each emotion induction task was followed directly by a subjective questionnaire that participants had to fill in.
A within-subject design was adopted for the experiment, considering two independent variables: Partner Representation with two levels: Avatar (with experimenters represented by a personalized avatar) and Voice (with experimenters’ representation hidden and therefore only their voice provided to the participants), and Emotion with two levels Positive and Negative corresponding respectively to the positive or negative emotion supposed to be induced by the pieces of music. Note that the participant always used an avatar representation regardless of the experimenter representation. Moreover, when the avatar of the experimenter would be hidden, the size-on-screen of the participants’ avatar would remain the same.
The Voice condition was chosen as a means to compare the Avatar conversation to a more recognizable form of tele-communication. The aim was to see whether the participant engaged more or less with their own avatar depending on the condition, and also to assess whether emotional content was more salient in the presence of an avatar conversational partner on the screen. It was also predicted that there would be observable changes in participant feelings of Ownership as a result of increased self-avatar focus on screen.
There were two mood induction and conversation tasks for either Partner Representation condition, making for a total of four tasks comprising of 90 s stimulus exposure and 120 s conversation periods for a total of 8 min of avatar social interaction. These tasks were consistently performed in the same order, with the positive valence preceding the negative stimulus for each condition.
However, the Partner Representation conditions were counterbalanced to eliminate any potential statistical biases that could arise from a strict task order hierarchy. Similarly, the musical pieces used for positive and negative valence were used at different task times and each video condition, evenly distributed between participants.
Subjective data was gathered from a questionnaire at the end of each emotion induction task. Many of the question items represented in Table 1 were used for this second experiment’s questionnaire.
The items aimed at measuring Enfacement, Social Presence and Emotion Elicitation. We included some questions attempting to measure the Proteus Effect and also questions for determining levels of fatigue post-task. They are summarized in Table 2, which also provides the abbreviations used in the results section. Due to the quantitative increase in collection of data gathering via questionnaires for this experiment, no comment section was this time added to the forms. The questions were presented in different orderes dependent on the condition, to control for question order related biases. The participants also completed the Ten-Item Personality Inventory (TIPI) (Gosling et al., 2003), prior to taking part in the experiment. This was done as an extra data gathering measure, so that we could investigate whether individual personality traits could have any observable impact on the effect scores.

TABLE 2. Main experiment: Questions for the main experiment by variable name. Each question could be answered on a scale from 1–“Strongly Disagree” to 5–“Strongly Agree”. Question with * were only asked in the Avatar condition.
Our Likert-scale data was reduced from seven point to five point, to accommodate the larger volume of Likert data but also to ease cognitive load on participants, given they were being asked to report much more data than the previous experiments. The more defined path of the five point Strongly Disagree-Strongly Agree scale was chosen to standardize our data collection scores, given it is the same structure as the accepted TIPI assessment method (Gosling et al., 2003), and this method was also considered to be less taxing for participants to consider than the seven point Not at all-Extremely scale used in the Pilot.
In this experiment, we were first interested in investigating participants sense of enfacement toward an avatar in the context of dyadic video-conferences, and we expected participants to experience such senses toward their avatar while conversing with another person.
Because the scores of enfacement were relatively low for the avatar in the Pilot, we hypothesized that removing the avatar representation of the conversation partner (factor Partner Representation) would encourage participants in engaging more with their avatar and therefore increase their sense of enfacement toward it. Because Proteus Effect is commonly associated with the sense of embodiment (Heide et al., 2013; Ratan et al., 2020), we also expected Proteus scores to be impacted by the representation of the conversation partner.
Furthermore, we aimed at exploring the impact of positive and negative valence (factor Emotion) on participants senses of Social Presence, and other qualia related to these concepts. Work in this area has revealed that positive valence can be associated with higher levels of reported social presence (Bailenson et al., 2016). We hypothesized that participants sense of Social Presence would be higher after the positive mood induction compared to the negative mood induction, and that having the partner representation removed would decrease this subjective feeling.
In addition, Valence question was introduced to ensure that the mood induction was effective, and we therefore hypothesized that when describing positive or negative events, participants would respectively feel happy or sad.
To summarize, our hypotheses for the experiment were the following:
• (H1) Participants will experience sense of enfacement toward their avatar during the dyadic video-conference.
• (H2) Participants’ sense of enfacement will be higher in the Voice condition than in the Avatar condition.
• (H3) Proteus scores will be higher in the Voice condition than in the Avatar condition.
• (H4) Social Presence scores will be higher in the Positive condition than in the Negative condition.
• (H5) Social Presence scores will be lower in the Voice condition than in the Avatar condition.
• (H6) Valence scores will show evidence of mood induction efficiency.
• (H7) Positive mood induction will be more fully achieved with avatar representation of the partner compared to negative mood.
Two-way ANOVA analyze were conducted, considering the within-group factor Partner Representation (2 levels: Avatar and Voice) and Emotion (2 levels: Negative, Positive). The normality assumption was tested using Shapiro-Wilk test and when not verified, an Aligned Rank Transformation (ART) was applied on the data. Tukey’s post-hoc tests
To ease readibility, all significant main effects and interactions, as well as their effect sizes, are reported in Table 3 instead of directly inside the text.
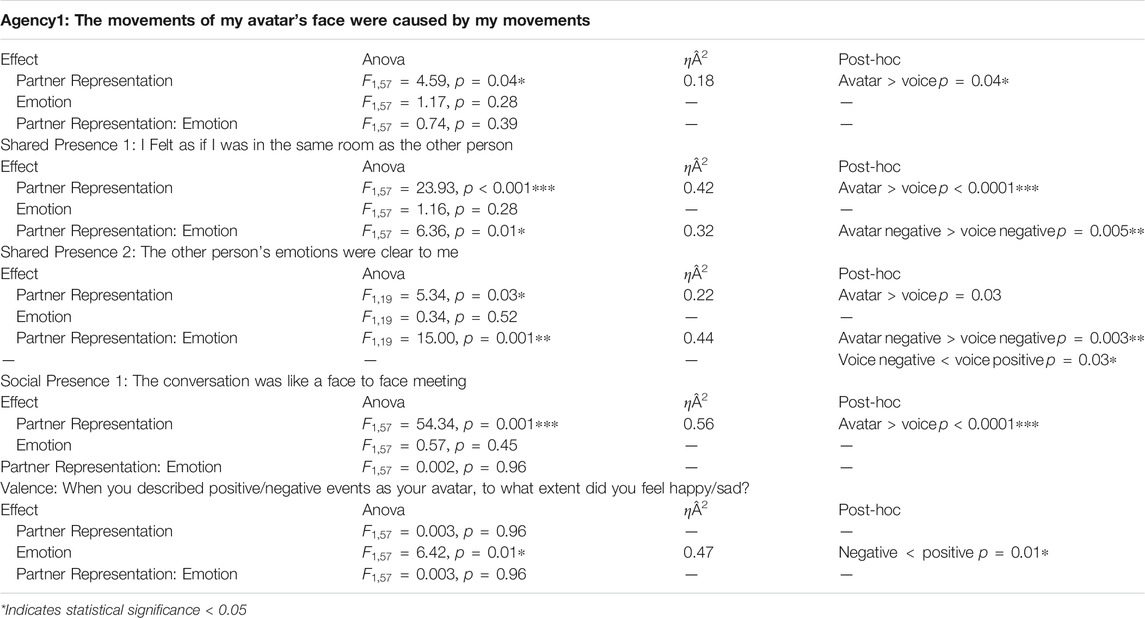
TABLE 3. Main experiment: Summary of main effects on subjective scores.
Enfacement toward the avatar was assessed through items related to face-ownership and face-agency. Variables labeled Ownership 1–3 (Table 2) focus on face-ownership. There was no main effect observed within participants, showing that Ownership toward the avatar did not seem to be impacted either by the emotion induced or the representation of the conversation partner (see Figure 5).
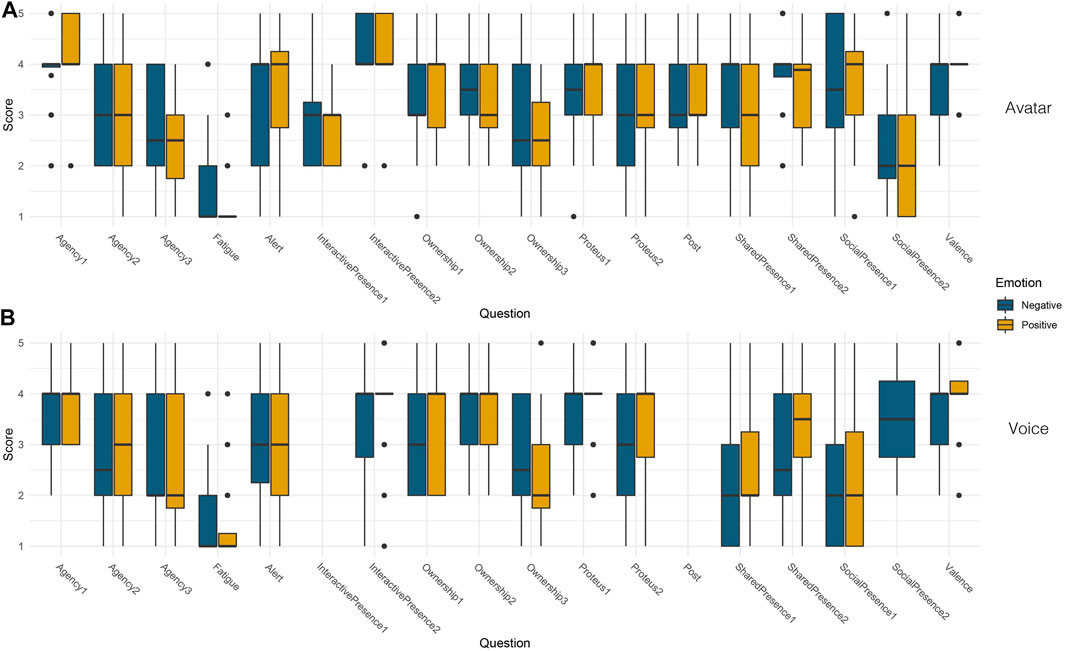
FIGURE 5. Main Experiment: Boxplots of all the dependent variables depending on factor Emotion for Avatar condition (A) and Voice condition (B).
A main effect of Partner Representation was found on agency question Agency1 (see Table 3. Post-hoc tests highlighted that Agency1 scores were higher in Avatar condition compared to Voice condition, independently of the emotion induced
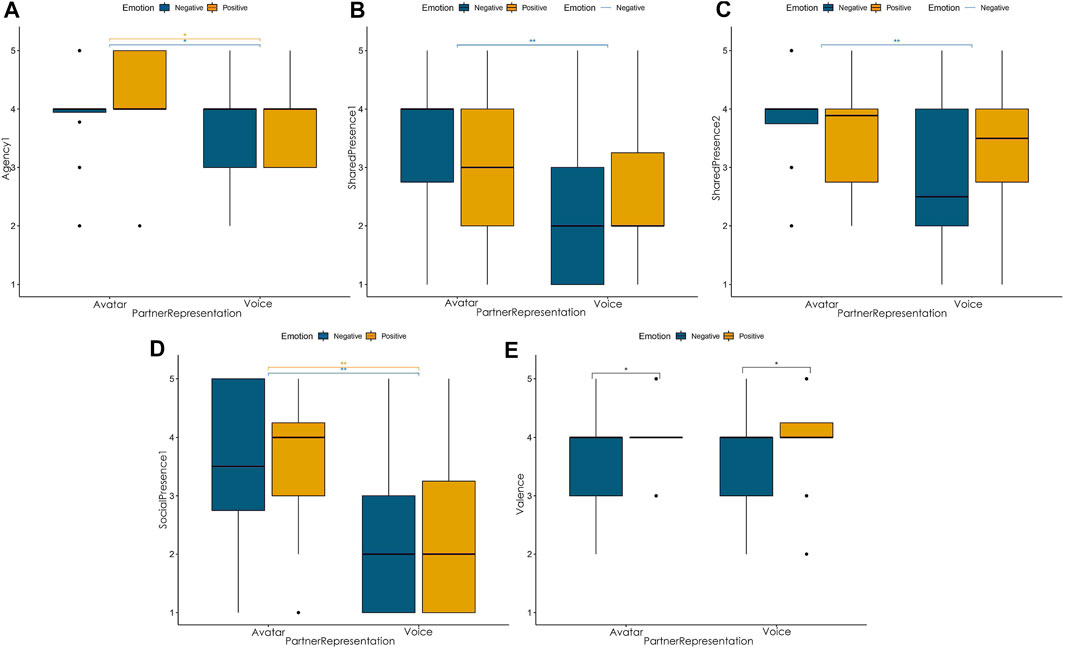
FIGURE 6. Main Experiment: Summary of significant effects of Emotion and Partner Representation on Agency 1 (A), Shared Presence 1 (B), Shared Presence 2 (C), Social Presence 1 (D) and Valence (E).
This means that participants tended to feel more that the movements of their avatar’s face were caused by their movements when they would have the possibility to see the partner’s avatar compared to when they would not. Interestingly, it seems like the presence of the other’s avatar has a positive influence on the agency of participants toward their avatar, which is the opposite of our (H2) assumption that enfacement would be stronger when not seeing the other’s avatar. Overall, Agency1 being the only item influenced by Partner Representation, and in the opposite way we had expected, our results do not support (H2).
Global Ownership and Agency scores were as well computed by combining scores of all the respective items. While the two-way ANOVA did not highlight any effect on those, their mean scores (Ownership:
Results on responses to item Proteus one and Proteus two in Table 3 showed an absence of main effect of our main conditions for improved self-concept alteration. Global Proteus1
Social Presence was assessed through several items as “interactive presence”, “shared presence”, and “social presence” items, as presented in Table 2.
A main effect of Partner Representation was found on the variable SocialPresence1 (see Table 4), confirmed by post-hoc tests

TABLE 4. Main experiment: Spearman correlations between personality scores and questionnaire items.
Interestingly, the scores of Shared Presence1 and Shared Presence2 were also influenced by the Partner Representation factor, but an interaction effect was found showing an impact of Emotion on these results (see Table 3). For Shared Presence1, post-hoc tests showed that the influence of Partner Representation was only present when factor Emotion was Negative
For Shared Presence2, post-hoc tests also showed that the influence of Partner Representation was only present when factor Emotion was Negative
This finding might be explained by the other post-hoc result, revealing an influence of Emotion when only considering the Voice condition
Valence scores for all conditions included were relatively high
In addition, a main affect of Emotion was found on Valence scores (see Table 3) and confirmed by post-hoc tests
Fatigue scores were assessed in order to evaluate the impact of our different conditions on participants fatigue, which is a common aspect when using video-conferences platforms (Yee and Bailenson, 2007a).
While our analysis did not shown any effect of our conditions on participants fatigue, it seems like participants overall did not experience strong fatigue after the experiment
It has been discussed in previous work that personality traits could influence users’s sense of presence (Wallach et al., 2010) and sense of embodiment toward an avatar (McCreery et al., 2012; Dewez et al., 2019) in virtual reality.
For this reason, we were interested in looking for possible correlations between the personality scores obtained with the TIPI questionnaire and subjective scores from the experiment. Table 4 outlines the observed results from the Spearman’s test conducted, showing correlations of different strength depending on the variables.
The most striking significance recorded came from participants who scored highly on Agreeableness. There was a positive correlation observed between Agreeableness ratings and Ownership 1
There was also a positive correlation between Extraversion and item Ownership 3
Conscientiousness scores were also significantly correlated with several Enfacement items, such as Ownership 3
Finally, Openness scores were negatively correlated with Agency 3
In order to explore the impact of gender on our result, two other independent variables were defined: Gender (whether participant was male or female) and Gender Match (whether the gender of the participant and experimenter were the same or different). A mixed three way ANOVA was performed twice with Emotion and Avatar as within factors and either Gender (Male or Female) or Gender match (Same Gender or Different Gender) as a between factor.
A main effect of Gender Match was found on Social Presence 1 variable
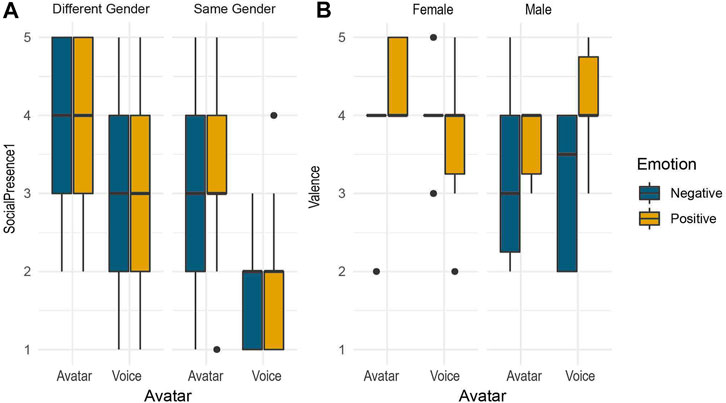
FIGURE 7. Main Experiment: Boxplots showing the influence of being of the same gender as the experimenter on Social Presence 1 (A) and the influence of participants’ gender on Valence (B).
Compiled results emphasized complex consequences for our outlined Hypotheses H1-7. There were relatively high scores for our agency measures, which indicated participants felt more in control of their avatar during this experiment than in the Pilot. There was a measured interaction between PartnerRepresentation and Agency1, Table 2. This means that participants tended to feel more that the movements of their avatar’s face were caused by their movements when they would have the possibility to see the partner’s avatar compared to when they would not, and is a direct contradiction to our second hypothesis (H2). Implications for this are discussed below. There were no other effects for enfacement between conditions, but scores were also not reported as consistently low (H1).
However, there was evidence from our Spearman’s Correlation that participants who scored highly on Agreeableness tended to return higher results for face-ownership and agency. This is important for future work in this area, which might investigate further the interaction between individual personality traits and the reports of SoE.
Our results show that people who scored highly on Agreeableness were more likely to have a strong sense of ownership and agency toward their avatar, and therefore an enhanced enfacement feeling. They were also more likely to experience a strong sense of being in the same room as the other person and find resemblance with a face to face meeting, leading to a higher sense of social presence. Agreeableness has been implicated in previous studies of social presence, which have been comparably measured here (Dewez et al., 2019).
Social presence was reported strongly in our results, suggesting that avatar-use can attain some of the social characteristics of in-person video-conferencing. The analysis revealed a measurable effect of social presence in the avatar use. While we confirmed that social presence was higher with avatar-avatar conversations (H5) we were surprised at observed results implicating negative valence interacting with the measured presence, more than positive valence (H4). It appeared that Partner Representation was an influential factor in negative conditions. This may be explained by volunteers reports of clearer emotion recognition for positive conditions.
We had to confirm the null hypothesis from our observations on Proteus effect measures (H3). The results did not display evidence for self-concept or behavior change on our measurements, despite global Proteus results showing a consistently average scoring, rather than low scoring. There was an interesting relationship observed between TIPI and Proteus measurements, with high Conscientiousness scores negatively correlated with friendliness ratings post avatar condition.
With regards to valence conditions, the results for positive inductions were reported stronger than the negative ones. This is some confirmation of our hypothesis around mood induction (H6). Evidence also suggested that the cartoon avatars were more conducive to conditions of positive valence (H7).
Regarding the influence of gender, there was some evidence to suggest that non matching pairs (e.g. Experimenter F, Participant M) were likely to consider the conversations more like face to face meetings that matching pairs. Moreover, valence scores tended to be lower in the group of male participants rather that in the group of female participants. While those results are difficult to interpret, they are not the first one suggesting differences between gender in subjective feelings of virtual experience, as previous works already highlighted the influence of such aspect on the sense of Ownership toward a virtual avatar (Dewez et al., 2019) or on proxemics (Zibrek et al., 2020), which reinvigorates the need to further investigate that effect.
Furthermore, while there is not to our knowledge previous research exploring the impact of gender match between two individuals on virtual social presence, there seem to be an impact of gender matching in the process of learning in virtual platforms (Makransky et al., 2019), suggesting that further work exploring the impact of gender matching in social virtual contexts would be valuable for the community.
The experimental evidence described above shows a variation in observations on measured items. In general, it has been explicated that avatar-interaction studies for screen-based applications can provide actionable data around the quality of avatar experiences (Heide et al., 2013).
Observations from presence measurements seem to be the biggest contribution of the current research. Social presence results for both the Pilot and Main Experiment determinants implicate human use of an avatar can provide elements of the percepts underlying senses of presence.
The use of personalized avatars for remote collaboration has not been shown to detract from social presence in the main experiment, when we compared their use to non-video call conditions. The results shown here are consistent with previous work on presence and avatar personalization (Waltemate et al., 2018).
Additionally, in cases where negative emotional content was induced, avatars were an improvement on voice condition. Emotion recognition in the Voice condition was comparably difficult for negative valence scenarios. Without the presence of the other avatar, it was more difficult for participants to recognize negative emotions rather than positive ones.
There was no decrease in presence measurements on the basis of emotional valence, compared to Avatar conditions. Affected avatar studies such as ours have seen similar associations between positive affect and presence (Bailenson et al., 2016) which has important implications for future development of avatar software for video-conferencing requirements. Recording behavioral measures of social presence, such as mimicry of physical movements, through analysis of animation data and movement data correlations could be a useful point of future convergence for this kind of work.
While scores for face or body ownership observed in the Pilot were not particularly high, our re-formulated experiment saw a significant increase on measurements for agency, and slight increase for ownership. Tracking quality did not have an impact on agency in the Pilot.
The avatar condition in the main experimental design elicited higher scores for an Agency 1, as participants felt more control over the movements of their avatar. This is a useful finding, as viewing one’s own self avatar in a dyadic interaction with a voice agent could be implicated as having a potentially negative influence on feelings of agency compared to avatar-avatar conversations.
However, given that the participants could see both themselves and the other avatar (Avatar condition) or else their empty gallery (Voice condition) for the conversations that were measured, it is also likely that the view of mirror representation of the self-avatar was more strongly attended for Voice conditions. This mirror effect has been proposed to increase focus on animation details and hence decrease agency (Fribourg et al., 2018), which could explain our results.
The self-similarity of the virtual avatars for both experiences was not sufficient for producing high levels of enfacement, even though similarity and self-identity are considered key components to the experience of enfacement (Tajadura-Jiménez et al., 2012).
Furthermore, differences emerged for enfacement results between the Pilot and Main Experiment. Previous work has suggested enfacement measurements are not influenced by animation realism, which makes the absence of observed impact from our Quality measure in the Pilot experiment consistent with previous findings (Kokkinara and McDonnell, 2015).
While there was some self-concept changes observed on friendliness for the Pilot, Proteus effects were not measured strongly in either the Pilot or the Main Experiment. The results of the second study produced unconvincing measures of Proteus, but not a complete absence of ratings. It is interesting that enfacement measurements also yielded comparably underwhelming reports. The coextensive absence of effects in both ownership and self-concept results adds empirical credence to the notion that they must necessarily co-arise.
This implies some element of contingency between SoE and self-concept alteration, with embodiment implicated as a necessary precondition to perceived behavior change which has been described by meta-analyses of Proteus effect and its interaction with other factors (Ratan et al., 2020). The body is cognitively represented and volitionally experienced as an object mediated by perceptual content (Riva, 2018). Changes in bodily percepts can result in changes to manifesting bodily behavior. While the range of evidence varies between our experimental conditions, it has been explicated that behavior change post self-identity change is a more complex phenomena in computer mediated avatar interactions than previously defined by research in Immersive VR (Heide et al., 2013).
In general the results displayed for valence measurements were informative, with efficacy observed in positive and negative mood inductions during avatar use. The valence results from our studies specifically emphasize an influence of positive affect and also indicate a relative weakness of affect from the negative stimuli in comparison. Personalized avatars have been recorded to influence with emotional responses (Waltemate et al., 2018), while positively affected avatars also have documented effects on dyadic conversations (Bailenson et al., 2016).
Our results suggest an interplay between these two measured phenomena, as the use of personalized cartoon avatars has indicated a strong positive valence induction here. Despite previous research claiming that negative inductions can be more easily achieved than positive ones (Ito et al., 1998), there is further useful work on remote mood induction procedures, that makes claims about the equitable efficacy for both positive and negative emotion elicitation via internet based methods (Ferrer et al., 2015). Our results sit between these claims, and that of other avatar affect studies (Bailenson et al., 2016), as an example of mood induction efficacy that proposes to augment contemporary methods for remote valence induction.
Previous research on the influence of personality traits in immersive environments (McCreery et al., 2012) motivated our inclusion of the TIPI measurements for the second iteration of these experiments. It proved to be informative. Our results on the correlation between Agreeableness and Agency, Ownership and Presence scores suggest some interaction occurred here, while Extraversion was correlated with Ownership Item 3, Table 2.
These results are promising, particularly because Agreeableness and Extraversion have been implicated in previous work on character realism in immersive settings (Zibrek et al., 2018), while Extraversion has also been correlated with immersive tendencies in such environments (Weibel et al., 2010). Ownership has also previously been linked to the trait for Openness in a larger study (Dewez et al., 2019). Our results in tandem with the work outlined here indicate that the role of personality traits in virtual experiences can be a focus for researchers interested in quantifying subjective differences in effect quality for immersive experiences.
The period of time in which this research was conducted allowed us to employ the methods described above, as there has been an pervasive necessity for use of home-based video-conferencing systems. However, there are constraints imposed by the COVID era on this study. We could not consolidate our subjective reports with physiological evidence and the volatility of the avatar application industry also forced shifts in our emphases throughout.
Any claims made around the results of this study must have such caveats in mind. This work aimed to investigate whether the types of perceptual illusions that are normally measured with human-avatar interaction studies in Immersive VR settings could be observed in a video-conferencing avatar experiment. The conditions we used for testing these effects are a novel method for approaching them.
There are constraints on the conclusions we can draw from the data, given the sample size and potential for confounds inherent in the design of non-laboratory experiments and the compounding pandemic factor. Both experiments used cartoon avatars, but the main experiment used more realistic personalized digital characters. This may have introduced elements of realism-induced eeriness in participants, also known as the Uncanny Valley effect (Nagayama, 2007), although there is no evidence for this in the negative valence results.
Future work in this area can address a narrower range of subject matter, given the evidence that this format for an experiment can yield interesting and useful results. Immersive VR experiments with a similar focus could begin by comparing personalized-avatar and generic avatar conditions to understand and fully explicate the effects of realistic self-avatars on experience quality, relative to generic, cartoon-like or deliberately dissimilar avatars. Moreover, such work would be augmented further by investigating differences between avatar conditions and regular video-feed conditions, which already started to be explored in a pilot study comparing virtual group meetings using videoconferencing systems or immersive VR (Steinicke et al., 2020).
Similarly, such studies could also investigate real-time facial rigs with a greater depth of expressive features, as the software in this study involves the standard 51 expressions (i.e. Apple’s ARKit face tracking which is the current standard for real-time). Other future work to be considered as implications of this study would be a more natural conversational structure between participants who are known or anonymous to each other. This work could shed a new light on interactional processes in video-calls.
The face tracking capabilities of these avatar applications can be claimed, based on the results of the analyses, to have achieved some measure of emotional expression. However, this aspect of avatar use has proven difficult to optimize (Aseeri et al., 2020). Recent advancements have been made for high fidelity real-time facial animation in VR (Olszewski et al., 2016). Future work consolidating this work can incorporate a catalog of human expressions into the face of an avatar (Kossaifi et al., 2019) that could serve to advance the social use of avatars in Immersive VR and Video-Conferencing systems.
The evidence from our results on presence suggests that avatars can be effective for remote collaboration. Furthermore, our scores on fatigue were generally low, suggesting that the conversational aspect with the experimenter did not appear over taxing and is likely to be a good choice in video-conference scenarios, which is also promising for the use of such avatars in this context.
Nevertheless, we believe further research should focus on comparing avatar conditions with regular video feed conditions and interactions with levels of fatigue. Subsequent research should also seek to consolidate our results with investigations into visual effects on valence outcomes. Work from Wisessing et al. (Wisessing et al., 2020) has suggested that positive and negative affect conditions can be enhanced by bright and dark key-light illumination respectively. Lighting conditions studied in conjunction with manipulated avatar appearance could expand on these results, and could have wide-reaching implications for any research or clinical setting that would benefit from mood enhancement, such as video conferences or clinical treatments.
Self-face recognition is presented here as a target for further experimentation. The illusion of self-identity in another face (Sforza et al., 2010) has been tested in interpersonal interactions in the past as well (Bufalari et al., 2014), but could benefit from inquiry using more specific behavioral measures. While our study focused on visuo-motor synchrony, there is important work to be done on visuo-tactile perception and face-ownership, considering behavioral measurements such as threat induction have already proved fruitful on this topic in body-ownership research (Ma and Hommel, 2013).
Previous work in computer based avatar interactions (Heide et al., 2013), as well as work evaluating the difficulties of computer based remote meeting (Yee and Bailenson, 2007a; Kuzminykh and Rintel, 2020), consolidated with the results of the research described by our study, can point toward an expansion of video-conferencing tools to include avatar platforms which substitute appropriately in terms of virtual telepresence. Direct research on this topic will help elucidate the range of remote collaboration methods that can be considered functional for contemporary professional practices.
In the current era, social applications such as Snapchat are very popular in the young generations, allowing to alter self-representation with filters going from subtle modifications to full replacement of the user by what could be called an avatar. Such application can be used as well in the context of video-conferences, motivating further studies to explore the impact of self-representation and alteration in the context of dyadic video-calls.
These investigations shed light on the qualitative details of avatar-interaction. Questions motivating this study centered around the variation in subjective qualia that are used to measure ownership, presence and self-concept change in given valence conditions for avatar-mediated virtual experiences.
The systematic inquiry of these proposed avenues provided valuable insight into perceptual and emotional aspects of such experiences. Results highlighted subjective reports of social presence to be higher in avatar conversation compared to non-video conditions, while some dimensions of SoE were also observed, and were measured to interact with personality measures of participants. There is also evidence for a role of avatars in scenarios of both positive affect. There is also evidence that avatar conditions were better for negative affect conditions than voice conditions.
This evidence contrives to further scientific endeavor in this domain. This work underlines character personalization development as a future avenue of inquiry for avatar-avatar conversation research. Moreover, there is sufficient justification outlined here for further investigations into the interplay between personal characteristics and the emergence of subjectively non-veridical perceptions in virtual or screen-mediated environments that involve digital characters with varying levels of realistic detail.
The datasets presented in this article are not readily available because it contains information related to the potential identification of participants. To protect this information, requests to access the datasets should be directed to corresponding author, DH, aGlnZ2luZDNAdGNkLmll.
The studies involving human participants were reviewed and approved by the Research Ethics Committee (REC) Trinity College Dublin. The patients/participants provided their written informed consent to participate in this study.
DH, RB and RM designed and planned these experiments. RB and DH recruited participants and ran the experiments. RB and RM analyzed the data. DH, RB and RM wrote the manuscript.
This work was funded by the Science Foundation Ireland (grant number 18/CRT/6224), and Trinity College Dublin’s RADICal Project (grant number 19/FFP/6409).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frvir.2021.668499/full#supplementary-material
1https://www.hyprsense.com/hyprface.
2https://youtu.be/WFWQbTf40Ik.
3https://youtu.be/z7d4P3ybcXc.
Archibald, M. M., Ambagtsheer, R. C., Casey, M. G., and Lawless, M. (2019). Using Zoom Videoconferencing for Qualitative Data Collection: Perceptions and Experiences of Researchers and Participants. Int. J. Qual. Methods 18. doi:10.1177/1609406919874596
Aseeri, S., Marin, S., Landers, R. N., Interrante, V., and Rosenberg, E. S. (2020). Embodied Realistic Avatar System with Body Motions and Facial Expressions for Communication in Virtual Reality Applications. doi:10.1109/VRW50115.2020.0-134
Bailenson, J. N., Yee, N., Merget, D., and Schroeder, R. (2006). The Effect of Behavioral Realism and Form Realism of Real-Time Avatar Faces on Verbal Disclosure, Nonverbal Disclosure, Emotion Recognition. and copresence in dyadic interaction 15, 359–372.
Bailenson, S. Y. O. J., Krämer, N., and Li, B. (2016). Let the Avatar Brighten Your Smile: Effects of Enhancing Facial Expressions in Virtual Environments. PLoS ONE 11, e0161794. doi:10.1371/journal.pone.0161794
Baños, R. M., Botella, C., Alcañiz, M., Liaño, V., Guerrero, B., and Rey, B. (2004). Immersion and Emotion: Their Impact on the Sense of Presence. CYBERPSYCHOLOGY BEHAVIOR 7, 734–741. doi:10.1089/cpb.2004.7.734
Biocca, F., Burgoon, J. K., and Stoner, G. M. (2001). Criteria and Scope Conditions for a Theory and Measure of Social Presence See Profile.
Biocca, F. (1997). The Cyborg’s Dilemma: Progressive Embodiment in Virtual Environments [1]. J. Computer-Mediated Commun. 3, 12–26. doi:10.1111/j.1083-6101.1997.tb00070.x
Bufalari, I., Lenggenhager, B., Porciello, G., Serra Holmes, B., and Aglioti, S. (2014). Enfacing Others but Only if They Are Nice to You. Front. Behav. Neurosci. 8, 102. doi:10.3389/fnbeh.2014.00102
de Hamilton, A. F. (2016). Gazing at Me: The Importance of Social Meaning in Understanding Direct-Gaze Cues. Phil. Trans. R. Soc. B: Biol. Sci. 371. doi:10.1098/rstb.2015.0080
Dewez, D., Fribourg, R., Sanz, F. A., Hoyet, L., Mestre, D., Slater, M., et al. (2019). “Influence of Personality Traits and Body Awareness on the Sense of Embodiment in Virtual Reality,” in ISMAR 2019-18th IEEE International Symposium on Mixed and Augmented Reality, Beijin, China, October 2019. 1–12.
Eich, E., Ng, J. T. W., Macaulay, D., and Grebneva, A. D. P. (2007). Combining Music with Thought to Change Mood. Series in Affective Science. USA): Oxford University Press.
Ferrer, R. A., Grenen, E. G., and Taber, J. M. (2015). Effectiveness of Internet-Based Affect Induction Procedures: A Systematic Review and Meta-Analysis. Emotion 15, 752–762. doi:10.1037/emo0000035
Ferstl, Y., and McDonnell, R. (2018). A Perceptual Study on the Manipulation of Facial Features for Trait Portrayal in Virtual Agents. Dublin, Ireland: Association for Computing Machinery (ACM)), 281–288. doi:10.1145/3267851.3267891
Fribourg, R., Argelaguet, F., Hoyet, L., and Lécuyer, A. (2018). “Studying the Sense of Embodiment in Vr Shared Experiences,” in IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Tuebingen/Reutlingen, Germany, March 18–22, 2018, 273–280. doi:10.1109/VR.2018.8448293
Fribourg, R., Argelaguet, F., Lécuyer, A., and Hoyet, L. (2020). Avatar and Sense of Embodiment: Studying the Relative Preference between Appearance, Control and point of View. Inria, France: IEEE Trans. Visualization Comp. Graphics 26, 2062–2072. doi:10.1109/TVCG.2020.2973077
Gerrards-Hesse, A., Spies, K., and Hesse, F. (1994). Experimental Inductions of Emotional States and Their Effectiveness: A Review. Br. J. Psychol. 85, 55–78.
Gonzalez-Franco, M., Bellido, A. I., Blom, K. J., Slater, M., and Rodriguez-Fornells, A. (2016). The Neurological Traces of Look-Alike Avatars. Front. Hum. Neurosci. 10, 10. doi:10.3389/fnhum.2016.00392
Gonzalez-Franco, M., and Peck, T. C. (2018). Avatar Embodiment. Towards a Standardized Questionnaire. Front. Robotics AI 5, 74.
Gonzalez-Franco, M., Steed, A., Hoogendyk, S., and Ofek, E. (2020). Using Facial Animation to Increase the Enfacement Illusion and Avatar Self-Identification. IEEE Trans. Visualization Comp. Graphics 26, 2023–2029. doi:10.1109/TVCG.2020.2973075
González-Franco, M., Steed, A., Hoogendyk, S., and Ofek, E. (2020). Using Facial Animation to Increase the Enfacement Illusion and Avatar Self-Identification. IEEE Trans. Visualization Comp. Graphics 26, 2023–2029.
Gorisse, G., Christmann, O., Houzangbe, S., and Richir, S. (2019). From Robot to Virtual Doppelganger: Impact of Visual Fidelity of Avatars Controlled in Third-Person Perspective on Embodiment and Behavior in Immersive Virtual Environments. Front. Robotics AI 6, 8. doi:10.3389/frobt.2019.00008
Gosling, S. D., Rentfrow, P. J., and Swann, W. B. (2003). A Very Brief Measure of the Big-Five Personality Domains. J. Res. Personal. 37, 504–528. doi:10.1016/S0092-6566(03)00046-1
Heide, B. V. D., Schumaker, E. M., Peterson, A. M., and Jones, E. B. (2013). The proteus Effect in Dyadic Communication: Examining the Effect of Avatar Appearance in Computer-Mediated Dyadic Interaction. Commun. Res. 40, 838–860. doi:10.1177/0093650212438097
Heidicker, P., Langbehn, E., and Steinicke, F. (2017). Influence of Avatar Appearance on Presence in Social Vr. In IEEE Symposium on 3D User Interfaces (3DUI). Los Alamitos, CA, USA: IEEE Computer Society), 233–234. doi:10.1109/3DUI.2017.7893357
Ito, T. A., Larsen, J. T., Smith, N. K., and Cacioppo, J. T. (1998). Negative Information Weighs More Heavily on the Brain: the Negativity Bias in Evaluative Categorizations. J. Personal. Soc. Psychol. 75, 887–900. doi:10.1037/0022-3514.75.4.887
Jeunet, C., Albert, L., Sanz, F. A., Lécuyer, A., and Argelaguet, F. (2018). “Do You Feel in Control?”: Towards Novel Approaches to Characterise, Manipulate and Measure the Sense of agency in Virtual Environments. IEEE Trans. Visualization Comp. Graphics, Inst. Electr. Elect. Eng. 24, 1486–1495. doi:10.1109/TVCG.2018.2794598
Kahn, J. H., Tobin, R. M., Massey, A. E., and Anderson, J. A. (2007). Measuring Emotional Expression with the Linguistic Inquiry and Word Count. Am. J. Psychol. 120, 263–286.
Kilteni, K., Groten, R., and Slater, M. (2012). The Sense of Embodiment in Virtual Reality. Presence Teleoperators and Virtual Environments 21, 373–387. doi:10.1162/PRES_a_00124
Koda, T., and Ishida, T. (2006). Cross-cultural Study of Avatar Expression Interpretations. Int. Symp. Appl. Internet, 7–136. doi:10.1109/SAINT.2006.19
Koda, T., and Oguri, R. (2019). Analysis of the Effects of Appearances of Avatars on User’s Self-Evaluation of Extroversion. SciTePress) 1, 232–237. doi:10.5220/0007483502320237
Kokkinara, E., and McDonnell, R. (2015). “Animation Realism Affects Perceived Character Appeal of a Self-Virtual Face,” in Proceedings of the 8th ACM SIGGRAPH Conference on Motion in Games MIG ’15, Dublin, Ireland, 221–226.
Kokkinara, E., and Slater, M. (2014). Measuring the Effects through Time of the Influence of Visuomotor and Visuotactile Synchronous Stimulation on a Virtual Body Ownership Illusion. Perception 43, 43–58. doi:10.1068/p7545
Kossaifi, J., Walecki, R., Panagakis, Y., Shen, J., Schmitt, M., Ringeval, F., et al. (2019). Sewa Db: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild doi:10.1109/TPAMI.2019.2944808
Kuzminykh, A., and Rintel, S. (2020). “Classification of Functional Attention in Video Meetings,” in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20), Honolulu, HI, April 2020 (New York, NY: Association for Computing Machinery), 1–13. doi:10.1145/3313831.3376546
Ma, K., and Hommel, B. (2013). The Virtual-Hand Illusion: Effects of Impact and Threat on Perceived Ownership and Affective Resonance. Front. Psychol. 4, 604. doi:10.3389/fpsyg.2013.00604
Makransky, G., Wismer, P., and Mayer, R. E. (2019). A Gender Matching Effect in Learning with Pedagogical Agents in an Immersive Virtual Reality Science Simulation. J. Comp. Assist. Learn. 35, 349–358. doi:10.1111/jcal.12335
McCreery, M. P., Krach, S. K., Schrader, P. G., and Boone, R. (2012). Defining the Virtual Self: Personality, Behavior, and the Psychology of Embodiment. Comput. Hum. Behav. 28, 976–983. doi:10.1016/j.chb.2011.12.019
Mennecke, B. E., Triplett, J. L., Hassall, L. M., and Conde, Z. J. (2010). Embodied Social Presence Theory. doi:10.1109/HICSS.2010.179
Minio-Paluello, I., Porciello, G., Gandolfo, M., Boukarras, S., and Aglioti, S. M. (2020). The Enfacement Illusion Boosts Facial Mimicry. Cortex 123, 113–123. doi:10.1016/j.cortex.2019.10.001
Minsky, M. (1980). Telepresence. Omni Mag., Available at: https://philpapers.org/rec/MINT (Last accessed. September 17, 2020), 44–52.
Nagayama, J. S. R. S. (2007). The Uncanny valley: Effect of Realism on the Impression of Artificial Human Faces. Presence 16, 337–351.
Nowak, K. L., and Biocca, F. (2003). The Effect of the agency and Anthropomorphism on Users’ Sense of Telepresence, Copresence, and Social Presence in Virtual Environments. Presence 12, 481–494.
Oh, C. S., Bailenson, J. N., and Welch, G. F. (2018). A Systematic Review of Social Presence: Definition, Antecedents, and Implications. Front. Robotics AI 5. doi:10.3389/frobt.2018.00114
Olszewski, K., Lim, J. J., Saito, S., and Li, H. (2016). High-fidelity Facial and Speech Animation for Vr Hmds. ACM Trans. Graphics 35. doi:10.1145/2980179.2980252
Panagiotopoulou, E., Filippetti, M. L., Tsakiris, M., and Fotopoulou, A. (2017). Affective Touch Enhances Self-Face Recognition during Multisensory Integration. Scientific Rep. 7. doi:10.1038/s41598-017-13345-9
Parsons, T. D., Gaggioli, A., and Riva, G. (2017). Virtual Reality for Research in Social Neuroscience. Brain Sci. 7. doi:10.3390/brainsci7040042
Peña, J., Hancock, J. T., and Merola, N. A. (2009). The Priming Effects of Avatars in Virtual Settings. Commun. Res. 36, 838–856. doi:10.1177/0093650209346802
Porciello, G., Bufalari, I., Minio-Paluello, I., Di Pace, E., and Aglioti, S. M. (2018). The ‘enfacement’ Illusion: A Window on the Plasticity of the Self. Cortex 104, 261 – 275. doi:10.1016/j.cortex.2018.01.007Special Section: The body and cognition: the relation between body representations and higher level cognitive and social processes
Ratan, R., Beyea, D., Li, B. J., and Graciano, L. (2020). Avatar Characteristics Induce Users’ Behavioral Conformity with Small-To-Medium Effect Sizes: a Meta-Analysis of the proteus Effect. Media Psychol. 23, 651–675. doi:10.1080/15213269.2019.1623698
Ratan, R. (2012). Self-presence, Explicated: Body, Emotion, and Identity Extension into the Virtual Self. doi:10.4018/978-1-4666-2211-1.ch018
Riva, G. (2018). The Neuroscience of Body Memory: From the Self through the Space to the Others. Cortex 104, 241–260. doi:10.1016/j.cortex.2017.07.013
Romano, D., Pfeiffer, C., Maravita, A., and Blanke, O. (2014). Illusory Self-Identification with an Avatar Reduces Arousal Responses to Painful Stimuli. Behav. Brain Res. 261, 275–281. doi:10.1016/j.bbr.2013.12.049
Roseman, I. J. (1996). Appraisal Determinants of Emotions: Constructing a More Accurate and Comprehensive Theory. Cogn. Emot. 10, 241–278. doi:10.1080/026999396380240
Roth, D., Bloch, C., Schmitt, J., Frischlich, L., Latoschik, M. E., and Bente, G. (2019). Perceived Authenticity, Empathy, and Pro-social Intentions Evoked through Avatar-Mediated Self-Disclosures. New York, NY: Association for Computing Machinery, 21–30. doi:10.1145/3340764.3340797
Roth, D., Klelnbeck, C., and Feigl, T. (2018). “Beyond Replication: Augmenting Social Behaviors in Multi-User Virtual Realities,” In IEEE Conference on Virtual Reality and 3D User Interfaces. VR, Tuebingen/Reutlingen, Germany, March 18–22, 2018, 215–222. doi:10.1109/VR.2018.8447550
Sforza, A., Bufalari, I., Haggard, P., and Aglioti, S. M. (2010). My Face in Yours: Visuo-Tactile Facial Stimulation Influences Sense of Identity. Soc. Neurosci. 5, 148–162. doi:10.1080/17470910903205503
Shahid, M., Abebe, M. A., and Hardeberg, J. Y. (2018). Assessing the Quality of Videoconferencing: From Quality of Service to Quality of Communication. San Francisco, CA: Society for Imaging Science and Technology. doi:10.2352/ISSN.2470-1173.2018.12.IQSP-235
Slater, M. (2009). Place Illusion and Plausibility Can lead to Realistic Behaviour in Immersive Virtual Environments. Phil. Trans. R. Soc. B: Biol. Sci. 364, 3549–3557. doi:10.1098/rstb.2009.0138
Steed, A., Pan, Y., Zisch, F., and Steptoe, W. (2016). The Impact of a Self-Avatar on Cognitive Load in Immersive Virtual Reality , 67–76. doi:10.1109/VR.2016.7504689
Steinicke, F., Lehmann-Willenbrock, N., and Meinecke, A. (2020). A First Pilot Study to Compare Virtual Group Meetings Using Video Conferences and (Immersive) Virtual Reality. 1–2. doi:10.1145/3385959.3422699
Suh, K.-S., Kim, H., and Suh, E. K. (2011). What if Your Avatar Looks like You? Dual-Congruity Perspectives for Avatar Use. Source: MIS Q. 35, 711–729. doi:10.2307/23042805
Tajadura-Jiménez, A., Longo, M. R., Coleman, R., and Tsakiris, M. (2012). The Person in the Mirror: Using the Enfacement Illusion to Investigate the Experiential Structure of Self-Identification. Conscious. Cogn. 21, 1725–1738. doi:10.1016/j.concog.2012.10.004
Wallach, H. S., Safir, M. P., and Samana, R. (2010). Personality Variables and Presence. Virtual Reality 14, 3–13. doi:10.1007/s10055-009-0124-3
Waltemate, T., Gall, D., Roth, D., Botsch, M., and Latoschik, M. E. (2018). The Impact of Avatar Personalization and Immersion on Virtual Body Ownership, Presence, and Emotional Response. IEEE Trans. Visualization Comp. Graphics 24, 1643–1652. doi:10.1109/TVCG.2018.2794629
Wang, T., Sato, Y., Otsuki, M., Kuzuoka, H., and Suzuki, Y. (2019). Effect of Full Body Avatar in Augmented Reality Remote Collaboration. In IEEE Conference on Virtual Reality and 3D User Interfaces (VR). Los Alamitos, CA, USA: IEEE Computer Society), 1221–1222. doi:10.1109/VR.2019.8798044
Weibel, D., Wissmath, B. U., and Mast, F. W. (2010). Immersion in Mediated Environments: The Role of Personality Traits. CYBERPSYCHOLOGY, BEHAVIOR, SOCIAL NETWORKING 13. doi:10.1089/cyber.2009.0171
Wienrich, C., Schindler, K., Döllinqer, N., Kock, S., and Traupe, O. (2018). “Social Presence and Cooperation in Large-Scale Multi-User Virtual Reality - the Relevance of Social Interdependence for Location-Based Environments,” in IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Tuebingen/Reutlingen, Germany, March 18–22, 2018, 207–214. doi:10.1109/VR.2018.8446575
Wisessing, P., Zibrek, K., Cunningham, D. W., Dingliana, J., and McDonnell, R. (2020). Enlighten Me: Importance of Brightness and Shadow for Character Emotion and Appeal. ACM Trans. Graphics 39.
Yee, J. N., Bailenson, N., and Rickertsen, K. (2007). “A Meta-Analysis of the Impact of the Inclusion and Realism of Human-like Faces on User Experiences in Interfaces,” in Proc. of the SIGCHI Conference on Human Factors in Computing Systems. CHI ’07, New York, NY, April, 2007, 1–10. doi:10.1145/1240624.1240626
Yee, N., and Bailenson, J. N. (2009). The Difference between Being and Seeing: The Relative Contribution of Self-Perception and Priming to Behavioral Changes via Digital Self-Representation. Media Psychol. 12, 195–209. doi:10.1080/15213260902849943
Yee, N., and Bailenson, J. (2007a). The proteus Effect: The Effect of Transformed Self-Representation on Behavior. Hum. Commun. Res. 33, 271–290. doi:10.1111/j.1468-2958.2007.00299.x
Yoon, B., Kim, H., Lee, G. A., Billinghurst, M., and Woo, W. (2019). “The Effect of Avatar Appearance on Social Presence in an Augmented Reality Remote Collaboration,” in IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, March 23–27, 2019, 547–556. doi:10.1109/VR.2019.8797719
Zibrek, K., Kokkinara, E., and McDonnell, R. (2018). The Effect of Realistic Appearance of Virtual Characters in Immersive Environments - Does the Character’s Personality Play a Role? IEEE Trans. Visualization Comp. Graphics 24, 1681–1690. doi:10.1109/TVCG.2018.2794638
Keywords: virtual reality, virtual characters, perception, remote working, facial tracking, embodiment, face ownership, motion capture
Citation: Higgins D, Fribourg R and McDonnell R (2021) Remotely Perceived: Investigating the Influence of Valence on Self-Perception and Social Experience for Dyadic Video-Conferencing With Personalized Avatars. Front. Virtual Real. 2:668499. doi: 10.3389/frvir.2021.668499
Received: 16 February 2021; Accepted: 06 May 2021;
Published: 31 May 2021.
Edited by:
Xueni Pan, Goldsmiths University of London, United KingdomReviewed by:
Frank Steinicke, University of Hamburg, GermanyCopyright © 2021 Higgins, Fribourg and McDonnell. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Darragh Higgins, aGlnZ2luZDNAdGNkLmll
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.