
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
TECHNOLOGY AND CODE article
Front. Transplant. , 03 April 2024
Sec. Organ and Tissue Preservation
Volume 3 - 2024 | https://doi.org/10.3389/frtra.2024.1305468
 Ka Ho Tam1*
Ka Ho Tam1* Maria F. Soares2
Maria F. Soares2 Jesper Kers3,4,5
Jesper Kers3,4,5 Edward J. Sharples6
Edward J. Sharples6 Rutger J. Ploeg6,7
Rutger J. Ploeg6,7 Maria Kaisar6,7
Maria Kaisar6,7 Jens Rittscher1
Jens Rittscher1
Two common obstacles limiting the performance of data-driven algorithms in digital histopathology classification tasks are the lack of expert annotations and the narrow diversity of datasets. Multi-instance learning (MIL) can address the former challenge for the analysis of whole slide images (WSI), but performance is often inferior to full supervision. We show that the inclusion of weak annotations can significantly enhance the effectiveness of MIL while keeping the approach scalable. An analysis framework was developed to process periodic acid-Schiff (PAS) and Sirius Red (SR) slides of renal biopsies. The workflow segments tissues into coarse tissue classes. Handcrafted and deep features were extracted from these tissues and combined using a soft attention model to predict several slide-level labels: delayed graft function (DGF), acute tubular injury (ATI), and Remuzzi grade components. A tissue segmentation quality metric was also developed to reduce the adverse impact of poorly segmented instances. The soft attention model was trained using 5-fold cross-validation on a mixed dataset and tested on the QUOD dataset containing PAS and SR biopsies. The average ROC-AUC over different prediction tasks was found to be , significantly higher than using only ResNet50 (), only handcrafted features (), and the baseline () of state-of-the-art performance. In conjunction with soft attention, weighting tissues by segmentation quality has led to further improvement . Using an intuitive visualisation scheme, we show that our approach may also be used to support clinical decision making as it allows pinpointing individual tissues relevant to the predictions.
Computational pathology can assist pathologists by providing an automated second opinion on their assessment. Moreover, it may help us to better understand the mechanisms of organ injury by detecting and quantifying subtle histological changes in biopsies. While these models can help us improve the discriminative power of assessment tasks with performance unrivalled by classical image processing algorithms, several challenges are limiting their applicability. Firstly, training neural networks often requires large amounts of labelled data. However, most datasets contain no more than several hundred slides. In our setting, samples with known outcomes are biased due to pre-transplantation screening (either based on the patient’s clinical information or histology). The only available data are “hard examples” that have either been missed by pathologists or are plagued by factors not guaranteed to be visible in biopsies. There is also a “bootstrap” problem - while a severe shortage of pathologists is a primary motivation to expedite the development of an automated tool, this shortage limits the speed and scale in which labelled data can be procured.
To date, most deep-learning-based computational pathology platforms are designed to predict or assess only a bespoke set of narrowly defined clinical outcomes or visual changes (collectively known as slide-level labels). Most existing work (1–5) is limited to fully-supervised learning, which requires labelling large number of tissue compartments or rectangular tiles as either normal or diseased. To adapt these platforms for a different diagnosis would require additional time from pathologists to go through the entire dataset, adding further to the project’s investment. Regrettably, the expert-time cost of fully-supervised learning is prohibitive and has been a major reason for the limited number of publications applied to renal histology.
To address the lack of local expert annotations, a number of multi-instance learning approaches (6–9) have been developed to train classification tasks using only slide-level labels. However, available multi-instance learning models typically need to be trained on large datasets or slides with plenty of tissue area with good diagnostic quality. In our setting, where many slides contain sub-optimal tissue areas, existing approaches fail to deliver acceptable classification performance.
Furthermore, models trained under multi-instance learning tend to have limited diagnostic transparency - features are often extracted from rectangular tiles which are inconsistent with the anatomical, irregular tissue compartments within the biopsies. It is common for different functional tissue structures to vary in size by several orders of magnitude (e.g., cell nuclei vs. arteries). This may be partially addressed by using tiles from several magnifications (8), but this solution could make visualisation considerably more challenging.
Any histology analysis framework also needs to be robust to artefacts. This is particularly true in our application for two reasons. Firstly, in needle biopsies, a large proportion of tissue resides close to the edge and is often distorted or truncated. Exclusion of these tissues is not always possible as biopsies are often narrow and have limited material available. Secondly, transplantation decisions are time-sensitive; hence, the long-term aim is to eventually read histology from frozen biopsies that are often plagued with artefacts. There is a lack of definitive attempts to reduce the impact of artefacts. Treatment of artefacts is often either not mentioned or is excluded manually in most experiments. To our knowledge, the most common approach to tackle artefacts includes explicitly labelling artefacts and aggressive data augmentation (1, 4). However, these approaches would only work on objects that resemble the training data.
This pilot study aims to show the feasibility of a flexible yet scalable platform for providing quantitative insight into visual associations to transplant dysfunction using renal biopsies stained with periodic acid-Schiff (PAS) and Sirius Red (SR) while addressing the aforementioned issues. Our workflow extracted a number of histologically relevant visual features from tissues and was developed with minimal laborious labelling by expert pathologists. We used these visual features in combination with convolutional neural network (CNN) features to predict several slide-level labels such as Delayed Graft Function (DGF) - defined as patients who need dialysis within the first week after transplantation (10), Acute Tubular Injury (ATI), and Remuzzi Scores (11). We compared the predictive performance of our framework with features based on tissue compartments with a standard workflow that relied only on CNN-derived features and on rectangular tiles and showed that the proposed workflow produces consistently higher area-under-the-curve (AUC) in the models’ receiver operator characteristics (ROC) and Precision-Recall (PR) curves.
Furthermore, we developed a visualisation scheme that works specifically for our proposed workflow. Compared to prior work (6, 7, 9), using tissue-derived features enabled us to pinpoint a diagnosis of specific tissues irrespective of their size and shape, enabling the potential for transparent diagnosis and visualisation.
Finally, through our experiments, we also find that tissue quality and quantity may play a significant role in the predictability of a slide. By incorporating a metric derived from Bayesian Neural Networks (BNN) describing tissue quality similar to Tam et al. (12) derived from an ensemble of CNN models, we can improve the quality of predictions measured by AUC consistently.
We propose a computational framework to extract visual histopathological features from different functional components of the biopsy. A schematic of the workflow is shown in Figure 1. In the first step, we identify specific tissue compartments (Figure 1A). Details of the segmentation algorithm are discussed in Section 2.2. Subsequently, we extract a set of tissue compartment-specific features (Figure 1B) which are described in Section 2.3.
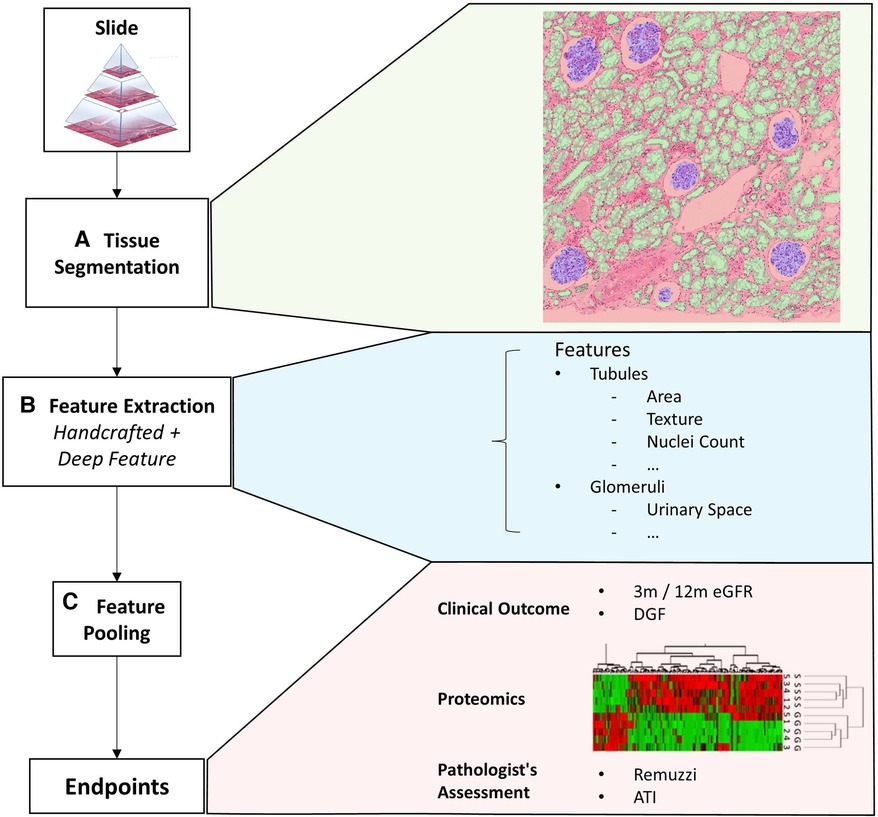
Figure 1. Overview of the framework. This figure shows an overview of the proposed quantitative analysis framework. (A) Tissue segmentation returns the instance outline of three different tissue types and cell nuclei. (B) Feature extraction returns a mixture of handcrafted and deep features iterated over each tissue. (C) Finally, features from a variable number of tissues are pooled together with soft attention to form a single vectorial description of a slide to predict the slide’s label. The slide label could either be clinical endpoints, assessment results given by pathologists, or other biomarkers.
Finally, we combine instance level features into a fixed-length description of the whole slide (Figure 1C). We evaluate different approaches to combining these features. The most trivial method is to simply perform an average/max pooling from the feature values of all the tissues. However, if the segmented tissues were only coarsely categorised, a large portion may be irrelevant for diagnosis. Pooling features from different tissues irrespective of their histopathological importance could lead to erroneous predictions that lack transparency.
Multi-instance learning (MIL) (6, 13, 14) is another approach commonly applied to histology analysis for making slide level (bag) predictions from a variable number of instances. A slide is classified as positive if at least one positive instance is detected. Implementation of the original MIL algorithm involves predicting a probability value for each instance and then converting these instance probabilities into a bag-level value using max-pooling. However, this approach has several limitations that make it unsuitable for predicting kidney function. Firstly, the use of max-pooling means that the method is particularly sensitive to noise. Our slides often have artefacts or tissues with morphology not previously seen during training. There is an inherent risk that the presence of these artefacts could sway the predictions as the classifiers have not been trained on embeddings beyond the original data. Secondly, although we are formulating our problem as a classification task, kidney function and the grading of slides have an inherent progressive nature. Standard MIL is not well adapted to handling multi-class classification problems, and it gives predictions that lack symmetry between the positives and negatives.
To partially mitigate the aforementioned limitations, we implement a soft attention mechanism. As a result, we can use attention-weighted averages of the instances to make predictions, as shown in the schematic in Figure 2. The model consists of multiple stages: Firstly, it converts each instance’s features into a permutation-invariant embedding. From these embeddings, a gated attention mechanism (13) assigns weights to each instance depending on their relative importance for the bag-level predictions. A gated mechanism is used to enhance the non-linearity of when the function’s input values are small. Because soft attention is learned, theoretically, it should be capable of rejecting instances not relevant for the assigned bag-level prediction task. The fractional contribution of an instance k to the final prediction is given in Equation 1:
Where is an embedding derived from the feature vector of one instance, are learnable weights in our neural network.
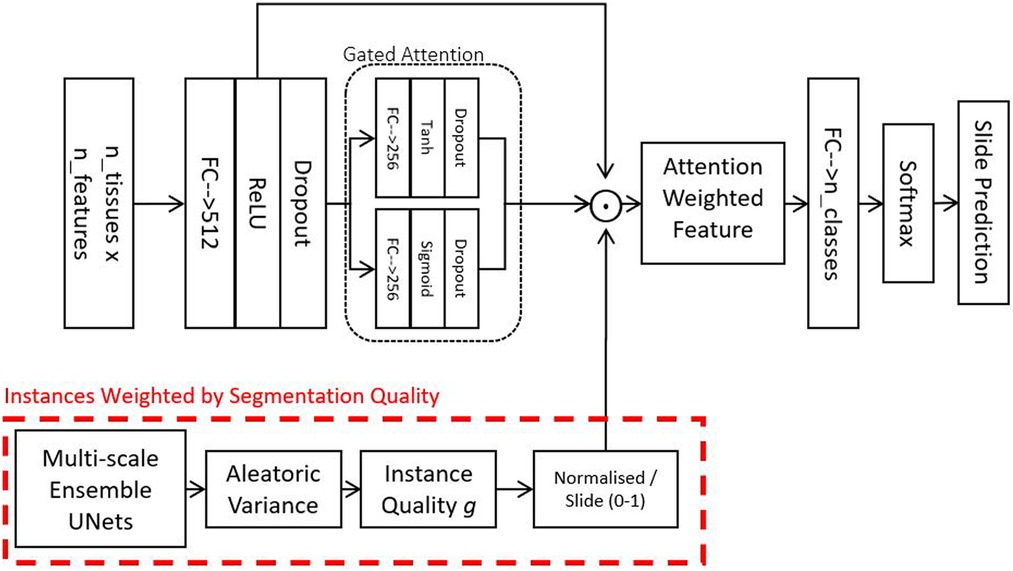
Figure 2. Attention model - this model is used for combining feature vectors from a variable number of tissues into a single vector describing a slide. The gate attention module learns which instances are relevant for the bag-level prediction tasks. Optionally, in addition to the learned attention, we also weight instances by their segmentation quality and how much the instances resemble our locally-delineated training examples.
In practice, however, in many biomedical datasets, the number of instances in each bag could be greater than the number of bags, making it very difficult to train a reliable attention mechanism. The attention network may also fail to assign a meaningful score for instances that do not resemble any of those from the training examples. To address this challenge, we propose to include an additional factor into the weighted average. The weight over an instance can be described as a confidence score of the neural network on an instance indicative of its resemblance to the training data. Such a score can be derived using probabilistic predictions from BNNs (15–17). As we have a plethora of delineated tissues, we decided to obtain using our UNet ensemble (described in Section 2.2). To account for the Bayesian uncertainty of different instances, we simply incorporate into the attention as follows:
Two main datasets are used in this study. A breakdown of the datasets is summarised in Table 1. The datasets contain slides stained using PAS and SR. While PAS is a routine stain for renal biopsy assessment, SR could be promising for the computational quantification of fibrotic tissues. SR is normally viewed under polarised light (18) for maximum signal-to-noise ratio, but attempts to quantify the extent of fibrosis under unpolarised light have also been shown to be highly reproducible (19).

Table 1. Datasets.
The QUOD Dataset consists of paraffin-embedded 22mm pre-implantation half-core needle biopsies from the Quality in Organ Donor Biobank,1 a national multi-centre UK-wide bioresource of deceased donor clinical samples procured during donor management and organ procurement. These biopsies were from a larger cohort of cases where both kidneys from the donor have been transplanted and yielded similar outcomes (12-month eGFR) in both recipients. This cohort selection criteria allow us to reduce the importance of recipient-related factors amongst other variables influencing transplant outcomes. Clinical parameters of the QUOD dataset are listed in the Supplementary Table S6. We have received biopsies from donors from this dataset. Histology slides prepared from pre-implantation biopsies from donors (373 recipients) were stained in PAS, and donors (174 recipients) were stained in SR. 180 donors had biopsy sections that were only stained with PAS but not SR, and 6 donors were stained vice versa.
A characteristic of these QUOD biopsies is that they are very small for two reasons. Firstly, a small needle is used to minimise bleeding complications after the transplant. Secondly, biopsies were halved in length as the other halves were used for other assays. The majority of slides do not contain enough tissues for full assessment according to the Banff criteria (20), which state that glomeruli and artery is necessary for assessment. (Distributions of glomeruli and arteries are available in Supplementary Figures S3 and S4.) Slides that contain no arteries or glomeruli are only partially assessed. Hence only 90 PAS slides had received a full Remuzzi score. Several slides containing only fractions of an artery also received a Remuzzi artery score. A large proportion of tissues also suffer from artefacts such as forceps compression, folding, or duplication of serial sections.
The NMP dataset2 originated from an organ normothermic perfusion experiment (21, 22) from 35 donors. The slides were 18 gauge 33mm core needle biopsies obtained from deceased donor kidneys that were discarded as deemed unsuitable as transplants for mechanical reasons. These kidneys were placed into a normothermic machine perfusion (NMP) system. Biopsies were obtained at different time points during NMP; hence most samples suffered notable ischemic damage. Most of the slides () were stained with Haemotoxylin and Eosin (H&E) but had been computationally converted to PAS stain using a CycleGAN (23) with image quality largely indiscernible by our collaborating pathologist. From the same dataset, we also have a smaller number of slides stained directly with PAS and SR ( from 4 donors for each stain).
Apart from the two main datasets, we have also included additional slides from native biopsies3 in PAS (Supplementary Section S5) and slides from The Cancer Genome Atlas (24) stained in H&E. These slides were solely used for strengthening the segmentation algorithms (Section 2.2) to ensure it would generalise well to unseen data.
From each dataset, we manually marked out a number of rectangular tiles to delineate different tissue compartments - tubules, glomeruli, vessels, and cell nuclei. The number of delineated tissues for each dataset is shown in Table 2. Delineating the outline of tissues is a laborious task. To make the task scalable, initial annotations were performed by an engineer with limited training in pathology. Thus, we only have the coarse classification of these tissues. For instance, proximal tubules are relevant for assessment, but a notable portion of objects marked as “tubules” were actually distal tubules or the collecting duct. Objects marked as “vessels” consist of a mixture of arteries, arteriole, and veins; some casts might be misidentified as sclerosed glomeruli. The boundaries of glomeruli were inconsistent regarding the inclusion of the urinary space. Owing to the small size of many biopsies, tissues that were truncated near the edge of the biopsies were also delineated as long as they were human-recognisable. A subset of these tissues was cross-checked by our pathologist (Details in the Supplementary Tables S2 and S3).
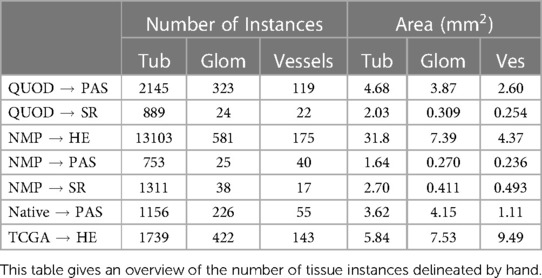
Table 2. Overview of tissue instances delineated.
The tiles selected for tissue delineation may contain a mixture of tissue-containing and blank areas and are of different sizes and aspect ratios such that it covers a diverse range of tissue morphology. As the number of tubules is far greater than the number of glomeruli and vessels, in 165 out of 425 tiles (967 out of 1210 mm in terms of area) listed in Table 1 we only delineated the glomeruli and vessels but not tubules.
Segmenting tissues according to functional compartments allows us to incorporate known visual features into histology analysis and maximises the interpretability of predictions made by algorithms. Tissue segmentation was performed using an ensemble of UNets (25). As we have a varying number of annotations available, we chose to use a different number of UNets for PAS and SR-stained slides.
For segmenting tissues in PAS-stained slides, we used a total of 13 models as follows: 2 models to segment cell nuclei at 0.44 microns-per-pixel (mpp); 2 models to segment tubules, glomeruli, and vessels at 0.44mpp; 3 models to segment tubules and glomeruli at 0.44mpp; 3 models to segment glomeruli and vessels at 0.88mpp; 3 models to segment glomeruli and vessels at 1.76mpp. Models that process identical tissue classes at the same magnification were trained on a different train:validation (4:1) split. These UNets were trained and validated using tissues delineated from the NMP, TCGA, and native biopsy slides.
For SR-stained tissues, we used 4 models as follows: 2 models to segment tubules, glomeruli, and vessels at 0.44mpp; 2 models to segment the same tissues at 0.88mpp. Cell nuclei are not segmented as they are not visible under SR.
We implemented the ensemble of UNets with dropout to simulate Bayesian Neural Networks (16, 26) to process the test data with the same hyperparameters as Tam et al. (12). The motivation for using BNNs is that they generally output predictions where the soft values are more representative of the probability of a correct prediction. However, in cases where uncertainties are data-limited (aleatoric uncertainties) rather than model-limited (epistemic uncertainties), there could still be notable discrepancies between the predictions and the actual probabilities. In particular, if the relevant class is rare or looks very different in the test data, it could lead to under/over-confident predictions. Thus, we propose to correct the predictions using a data-driven approach as shown in Equation 3:
Where is the mean output from the neural network ensemble; is the standard deviations from the ensemble over a single pixel; is a constant to be empirically determined from the training data; is the corrected probabilistic output from the network ensembles, which is clamped to a value above zero. we shall see in Section 3.1, this serves to remove overconfident pixels and would help suppress false-positive pixels caused by artefacts.
From the ensemble-averaged (Equation 3) segmentation maps, we obtain tissue instances using the max-flow-min-cut (27) algorithm. Individual tissues are cropped from the original slide with padding on each side. In order to perform localised diagnostics based on individual tissues, areas outside of the tissues are blurred. This helps prevent extra-tissue regions from contributing to visual features at later steps.
In our case, we have chosen to derive from the UNet ensemble. For a slide with tissue instances, the weight assigned to the instance is given as:
is the mean value of over the segmentation mask for instance . If all UNets from the ensemble predict similar values for the pixels within instance , would have a value close to 1. Otherwise, high discordance between different UNets would result in close to 0.
More details regarding the implementation of tissue segmentation are detailed in Section S3 under Supplementary Materials.
We aim to demonstrate (i) the benefits of using handcrafted features to augment deep features and (ii) how extracting features from functional tissue structures can boost performance and interpretability in multi-instance learning settings. As there are currently very few studies that quantitatively assess how individual histological features correlate with physiologically relevant measurements, we tested a wide range of features in our study, including both handcrafted and deep features. Using the aforementioned workflow, we extracted a number of histological features from our slides from tissues. We designed handcrafted features that comprise tissue morphological descriptors, colour, texture, and second-order features such as how colour/texture are distributed with respect to the tissue compartment. The majority of handcrafted features were designed with one tissue type in mind but implemented across all tissue classes such that the feature vector is the same length for all tissue types.
Some of these features are designed to reflect visual changes in tubules that have undergone chronic or acute injuries. For PAS-stained slides, cell nuclei are typically visible within each tissue, so their colour and distribution may also shed light on the state of the biopsy. In proximal tubules, darker nuclei in epithelial cells may be a feature of mitosis and cellular repair; whereas cell nuclei located far away from the boundary of proximal tubules may signify cell dropout or cytoplasm expansion which is a feature of acute tubular injury (28, 29). As the number of nuclei in each tissue is variable, the values are pooled together at every tenth percentile. This has an advantage over max-pooling of being less sensitive to artefacts/falsely detected cell nuclei.
The complete list of handcrafted features used in this study is shown in Supplementary Table S7. Several features are derived from the distribution and colour of segmented cell nuclei. However, we recognise that some tissue compartments may not have any nuclei, leading to missing feature values. To prepare our data for machine processing, missing values are imputed with the mean value from the rest of the datasets. Some slide-level information, such as the total area of the biopsy, is appended to the feature vector of each individual tissue. In total, this resulted in 98 unique handcrafted features for the PAS-stained slides and 40 features for the SR slides.
Figures 3 and 4 show a selection of tissue examples with close to minimum/maximum feature values from the QUOD/PAS slides.
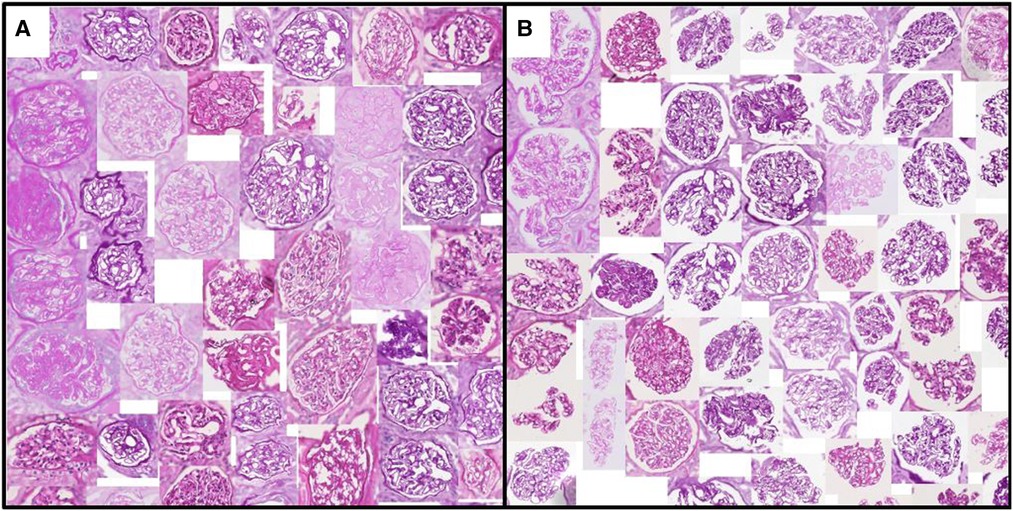
Figure 3. Glomeruli with (A) minimum/(B) maximum urinary space area. Examples are algorithmically selected from the entire QUOD dataset. Visual differences of individual handcrafted features can be easily interpreted by inspecting the collection of tissues with low vs. high values. Note that regions outside the tissue are blurred.
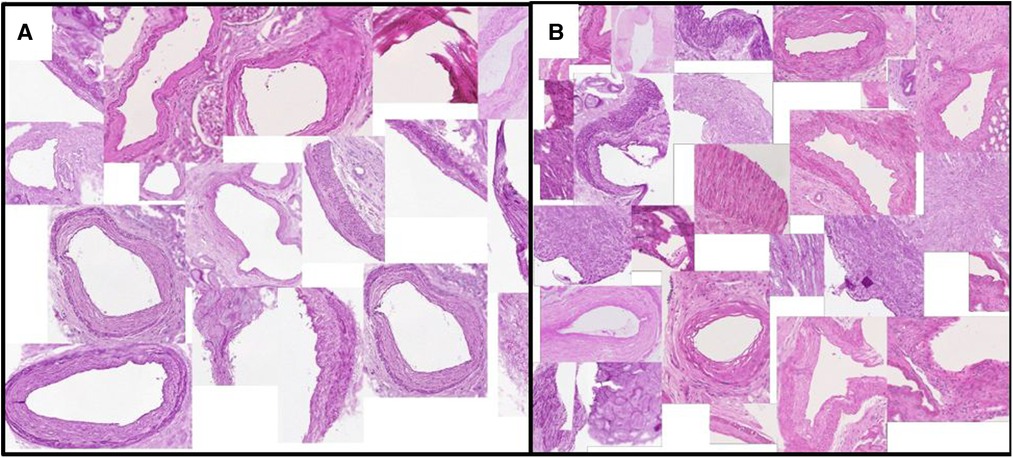
Figure 4. Vessels with (A) minimum/(B) maximum ratio between the lumen area to total vessel area. This exemplary feature corresponds to one of the Remuzzi Score criteria. Examples are algorithmically selected from the entire QUOD dataset. We choose to calculate the ratio of areas instead of diameters to avoid geometric template fitting, as most vessel sections are not round.
In addition to handcrafted features, we also experimented with features from several established deep neural networks. Deep features are obtained from the same patch (with surroundings blurred) as the handcrafted features at 0.44mpp. The crops were not resized before we fed them into neural networks as we want objects of the same physical size to elicit the same filter responses. Fully-connected layers of neural networks were replaced by adaptive average pooling, resulting in a single 1D feature vector for each tissue. Each feature is normalised to unit variance with zero mean over our datasets to speed up convergence during training.
Several different physiologically relevant measurements are available for our datasets.
A subset of PAS-stained slides has been assessed by an experienced pathologist (blinded to the donor characteristics and outcome) to determine the extent of histological changes. Slides are graded according to the Remuzzi criteria (11) based on the severity of Tubule Atrophy (Remuzzi TA), arterial and arteriolar narrowing (Remuzzi A), glomerular global sclerosis (Remuzzi G), and interstitial fibrosis (Remuzzi IF). In addition, as part of the assessment routine, biopsies are also graded for Acute Tubular Injury (ATI). The distribution of the assessed grades can be found in the Supplementary Figure S1.
For labels with insufficient cases for training or testing, we regrouped the most severe cases until there were enough donors for cross-validation to reduce class imbalance. As a result, Remuzzi G, TA, and IF become a binary classification task, whereas labels for ATI are regrouped to either two or three (0–2) grades instead of four grades from the original assessment.
Apart from eGFR, the QUOD dataset also contains binary labels regarding whether the recipient has suffered from DGF. DGF may have origins in a variety of diagnoses. While ATI is one of the known leading culprits there are other causes such as T cell-mediated rejection, antibody-mediated rejection, and acute calcineurin toxicity (30, 31). While it may not be possible to detect some recipient-related factors (such as rejection) or surgical causes (such as anastomosis) from histology, subtle or localised acute lesions may be within small regions of some biopsies. A method based on multi-instance learning may have a chance of detecting these localised changes missed by human inspectors or not meeting histological thresholds of established grading criteria.
Combinations of handcrafted histological features and deep features are used as input for our multi-instance soft attention model (Figure 2). The length of training is determined using the validation AUC at 40 epochs after the metric becomes stagnant. A weighted sampling approach was used to increase the frequency of sampling the rarer classes.
Our attention model’s hyperparameters are tuned based on a trivial task to reduce bias. Slides are labelled by whether they contain enough glomeruli for assessment. Slides with , , and unique glomeruli are separated into three classes. Hyperparameters are searched using HyperOpt (32) and remain fixed for other tasks in order to be able to compare different featuresets fairly. Examples of hyperparameters explored include the choice of gated/un-gated attention network, size of network layers, and regularisation weight.
Because the QUOD slides were obtained from real transplant settings, there were several challenges to developing an algorithmic workflow based on these slides. Firstly, these slides consist mostly of kidneys with little chronic damage - the dataset is biased due to pre-transplant donor screening, and the distribution of biopsies with pathological changes is highly imbalanced. Secondly, the majority of biopsies are inadequately small in that they do not meet the Banff criteria (20). For predicting assessment grades given by pathologists, we only included slides with enough tissues for each grade. As for the prediction of DGF, we found that it was necessary to include slides of all sizes in order to achieve at least one donor per label per cross-validation. Cross-validation splits are subjected to the constraint where all slides from each donor remain in the same training/validation/test set.
Experimental results are presented in four sections. Section 3.1 briefly describes the segmentation results on the QUOD dataset. In Section 3.2, features are extracted based on segmented tissue instances and are used to predict slide labels. We also compare classification performance between different featuresets across several tasks. Section 3.3 shows a pilot visualisation scheme of the proposed workflow. Finally, Section 3.4 presents results showing that segmentation uncertainty can be used to improve prediction performance.
As per earlier experiments, we found that UNets that were trained on the same magnification tend to produce false-positive segments in the same areas of the test data regardless of how dataset splits, weight parameters, input tile size, and regularisation are initialised. These false positives were likely caused by tissues with morphology not present in the training data. Combining multiple magnifications according to Equation 3 has helped to remove most of these false positives. Figure 5 shows the segmentation examples from individual models and the combined soft prediction. It can be seen that most artefacts from individual UNets (b-e) are no longer visible once combined (f). Although it may be sufficient to use fewer UNets in the ensemble to reduce the amount of computational work, for this experiment, we are interested in the rest of the workflow where segmentation is not a limiting factor. More details on tissue segmentation are described in Supplementary Section S3.
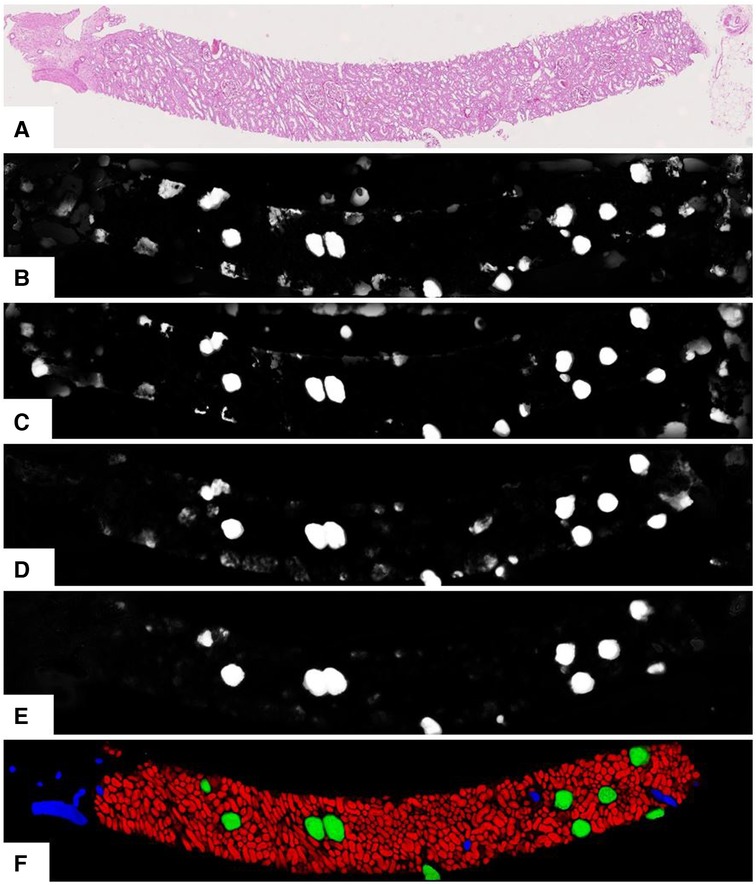
Figure 5. Output from the UNet ensemble. (A) Original PAS-stained slide; (B)–(E) Softmax predictions of glomeruli from single UNets at different magnifications segmenting specific tissue classes. (B) 0.44mpp, all tissue classes; (C) 0.44mpp, tubules glomeruli; (D) 0.88mpp, glomeruli vessels; (E) 1.76mpp, glomeruli+vessels; (F) Ensemble-combined predictions showing tubules, glomeruli, and vessels in red, green, and blue respectively.
In this section, the soft attention models are implemented directly without accounting for the segmentation quality (Figure 2) of the tissues.
We compared predictive performance using a variety of featuresets as the input to the soft attention models. In order to avoid the need to set up an arbitrary threshold, we reported results in the form of ROC and PR curves. Curves are weighted by the number of tissues/patches in each slide to reduce the noisy impact from biopsies that do not meet the Banff criteria.
To conclude the optimal methodology, we have calculated not just AUCs but also their variability. Reported ROC-AUC values of the soft attention model in all tables in this paper averaged across 5 fold cross-validation test set (3:1:1 training/validation/testing) and 5 different seeded weight initialisation (total 25 models). Multi-class models are macro-class-averaged. We reported the unbiased standard error of the mean AUC to ensure that comparisons are meaningful and to account for data and model noise. Standard errors are calculated as if the different prediction tasks are independent. In addition, because the training was performed on mixed datasets, neural networks may have learned to look for “shortcuts” (e.g., classification based on staining protocol rather than pathological changes) instead of performing the main task. Thus, all AUC values are evaluated based on only the QUOD slides.
Deep features are extracted from a number of neural networks, including several networks pre-trained with ImageNet (ResNet50 (33), VGG16 (34), InceptionV3 (35)), two networks trained using cropped image patches (ResNet50 and a Variational AutoEncoder (36)), and ScatterNet (37). Details of these features are summarised in Table 3 with further description in the Supplementary Table S8. Features extracted from the segmented tissues are given the prefix “Tissue”. We have also extracted features using fixed-sized rectangular tiles - these are given the prefix “Tiles” in the table. While handcrafted features can be calculated for individual tissues, there is no intuitive way to do so for rectangular tiles as they may contain a varying number of tissues. A breakdown of the predictive performance of some of these featuresets for different tasks is shown in Table 4.
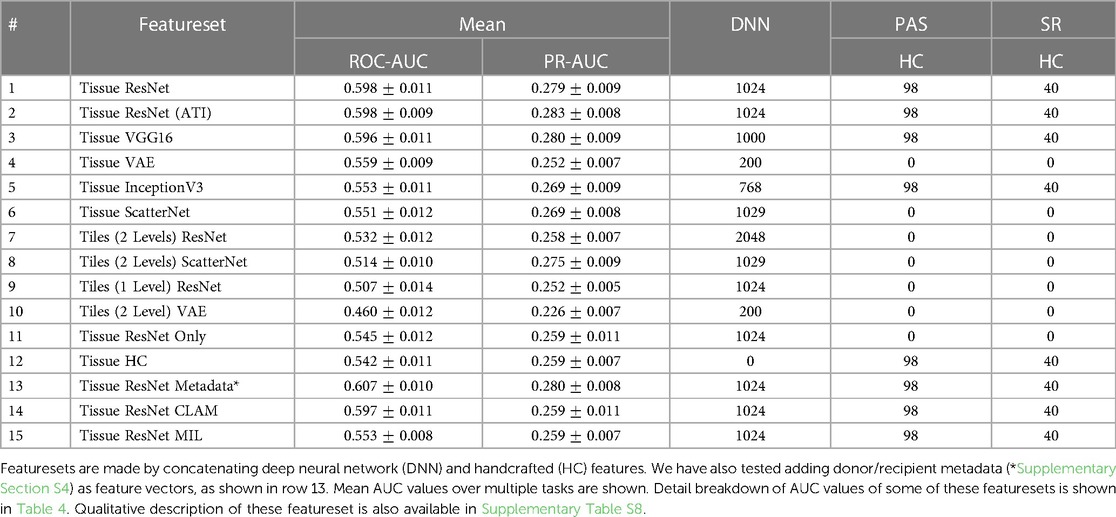
Table 3. Overview of featuresets.
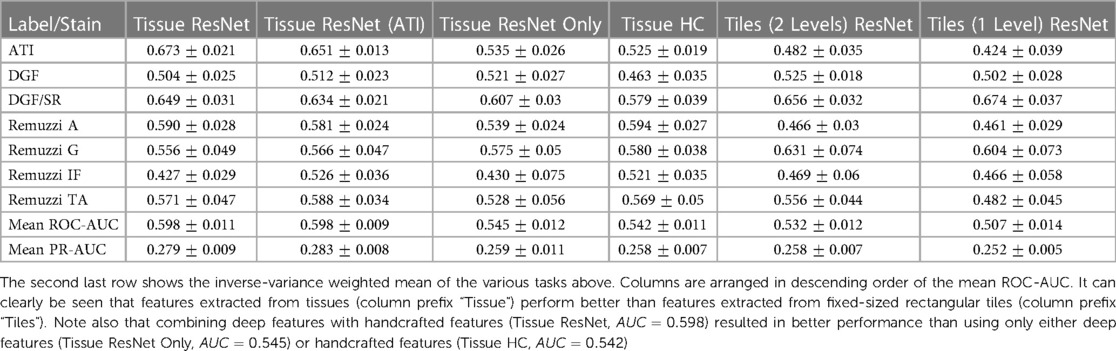
Table 4. Overview of AUC values of predictions based on different featuresets (columns) and prediction tasks (rows).
To compare the general utility of the different methodologies, we averaged the AUCs from different tasks. ROC-AUCs are averaged with inverse variance weighting, so tasks with higher prediction consistencies are weighted more. Precision-Recall (PR) curve AUCs are also given in the results (Table 3) as a complementary metric to ROC-AUCs. PRs could be insightful for tasks with highly imbalanced labels. However, variances of PR-AUCs tend to be small for the more challenging tasks, so we only reported the arithmetic mean rather than the inverse variance weighted mean in the table.
The mean ROC-AUC values in Table 3 demonstrate the progress towards improving performance by using features extracted from tissue compartments vs. the simplistic model that uses only features from rectangular tiles. For example, when comparing the ResNet50 featuresets (rows 1 and 7) we get and for features extracted from tissues and rectangular tiles, respectively. These results show that our proposed approach is superior in most cases. If we look at the results at a more granular level, we will find some tasks where tile features may have the potential to outperform tissue features. From the prediction task breakdown for these two featuresets (corresponding columns in Table 4), we see that tiles perform better for Remuzzi G ( vs. ), DGF/PAS ( vs. ), and DGF/SR ( vs. ). However, the differences for these individual tasks have not yet reached statistical significance so this could be down to noise in the data.
A second observation to note is that performance is better when deep and handcrafted features are combined compared to using only deep features or only handcrafted features (, , and in respective order as seen from rows 1, 11, and 12 in Table 3). While the overall AUC values for “Tissue ResNet50 Only” and “Tissue HC” are not significantly different, from the task breakdown in Table 4 we can see that AUCs are more variable for the predictions based on handcrafted features. This could be because handcrafted features are specialised in specific tasks. For example, in our dataset, most slides that have been graded for Remuzzi A had only the minimum number of one artery, many of which are partially truncated. So it may be hard for our attention model to learn to predict Remuzzi A grades based on only deep features. Handcrafted features can help to supply complementary information based on domain knowledge. These results suggest that both types of features may have their respective advantages. Thus, implementing a hybrid approach in the workflow may be optimal for general tasks.
Furthermore, we have also attempted to compare our soft attention model with other multi-instance methods such as CLAM (9) and MIL (6, 14), as shown in rows 14 and 15 in Table 3. While soft attention has consistently outperformed MIL, a comparison is more challenging for CLAM due to the extra hyperparameters. An extensive search over several hyperparameters using HyperOpt’s Bayesian optimisation algorithm (32) with the Ray Tune platform (38) has shown that the extra clustering step in CLAM has not led to any benefits to our prediction tasks.
In additional to neural networks pre-trained with ImageNet, we have modified a ResNet50 architecture to predict ATI scores (0–3) based on localised tissue patches (Image patches with ATI distribution are shown in Supplementary Figure S7). This modified ResNet was trained and validated on 731 images of proximal tubules with a 4:1 split. The purpose of this model is to test whether convolution filters would better capture histopathological changes if it has prior exposure to such images. The results ( from rows 1 and 2 in Table 3) show there is no significant difference in performance regarding how the networks were trained, suggesting the convolution filters learned from ImageNet may already be adequate for capturing diversity in renal histology.
Multi-instance learning on whole slide images is not commonly trained end-to-end due to their large size. Features are usually saved onto the disk before being processed by the MIL model. Gradients from neural network feature extractors could take up an enormous amount of space, so they are discarded during the feature extraction process in real-life implementations. As a result, the most straightforward parameters that could be directly visualised are the attention values attributed to the different instances. However, visualisation of attention parameters could often be ambiguous. In the case where rectangular tiles are chosen, the resolution of the attention map is limited by the size of the tile. Localisation of the diagnostic will be poor if the tile size is too large. If the tile size is too small, there would be limited a receptive field, and we may risk truncating meaningful tissue structures; a hybrid approach that uses tiles at multiple scales may be complicated to visualise as interpolations may be required to fuse them.
On the other hand, soft attention mechanism based on individual tissues allows for improved diagnostic interpretability strictly confined to the anatomical boundaries of these tissues. Figure 6 shows how our visualisation scheme (left) compares to the standard approach (right), which uses deep features from rectangular tiles. The models producing these exemplary overlay images were both trained to predict Remuzzi G grade. Both overlays show that the networks have learned to attend to the Glomeruli. In the standard approach, we see that the tiles around most glomeruli are highlighted in red, but in many cases, it may not be clear to an inexperienced observer which tissues within the tiles triggered the prediction. Conversely, our approach clearly pinpoints the tissues of interest as the glomeruli are mostly highlighted in red whereas irrelevant tissues, including those adjacent to the glomeruli, are shaded in blue.
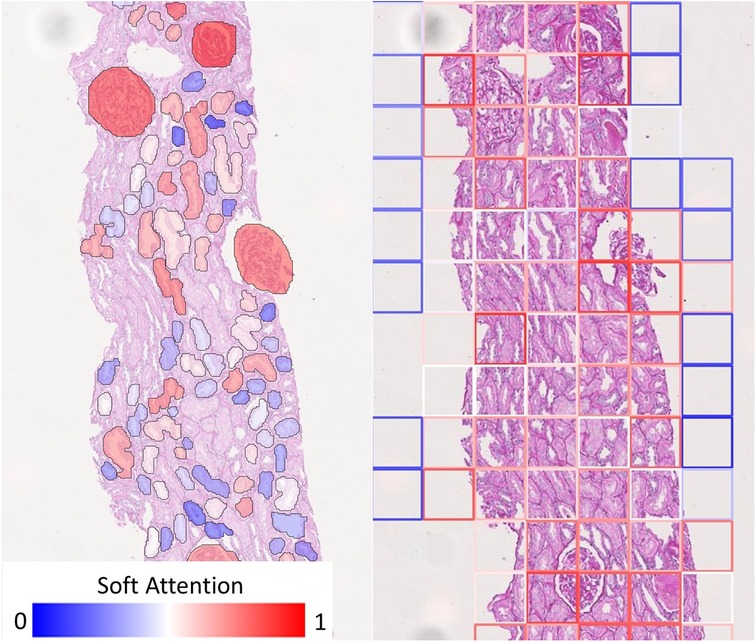
Figure 6. Comparison of visualisation of attention map. (Left) Our visualisation scheme highlights individual tissue instances relevant to the prediction. (Right) If rectangular tiles are used, diagnostic could be ambiguous as the tile boundaries do not generally convey any diagnostic meaning. This makes it hard to pinpoint the offending tissue if they are much larger or smaller than the tile. While it may be possible to produce a smoother heatmap by using overlapping tiles, this will merely be a visual gimmick - the resolution of the attention map cannot be improved because the information would have already been lost.
Saliency maps within individual instances can be produced if greater clarity is desired at the cost of processing time. In implementations where only deep features are used, it may be possible to produce saliency maps directly by chaining up feature extractors with the soft attention model while keeping track of gradients in only a small number of instances. However, if handcrafted features are included, direct localisation to the image space would not be possible using the original network. In these cases, heatmaps can be produced with an ad-hoc network trained using only the relevant tissues (as given by the soft attention model) to predict slide-level labels.
We demonstrate the overlay of the saliency map based on a soft attention model trained on ResNet50+handcrafted features to predict binary ATI grades as this is a case with high AUC (corresponding model in Figure 9). Using the attention values and slide labels, we trained a ResNet18 model to predict ATI slide labels using individual tissues as inputs. The network is trained using L2 loss, where different instances are scaled by outputs from an attention model which learns the same task. All instances are used for training this ResNet18 model but instances with low attention scores contribute to smaller loss. Figure 7 shows the result of this attempt - saliency map within each tissue is produced using an occlusion-based approach (39) using the Python package Captum (40); whereas the outline of the tissues is colour-coded by the instance-level attention. We can see that the attention model has learned to focus on the proximal tubules in the cortical regions of the biopsy (outlined in red). Within these tissues, there is some evidence that the saliency maps highlight areas close to the epithelial cells’ boundaries. Apart from the occlusion-based approach, we also attempted to use Integrated Gradients (41) and Noise Tunnel (42), but visualisation was found to be less intuitive as the saliency maps generated were too rough for the magnification we worked on.
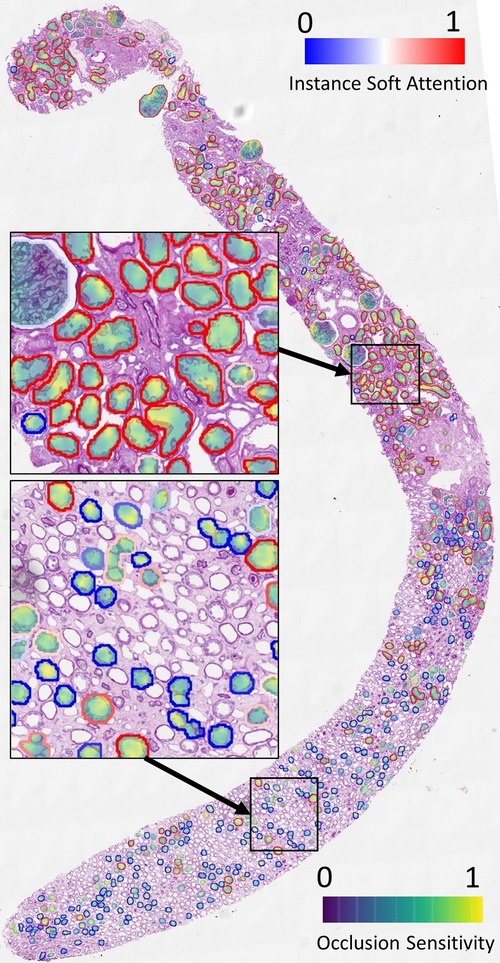
Figure 7. Visualisation of instance-level attention combined with saliency maps from individual tissues. Tissue boundaries are coloured by the learned instance-level soft attention value, indicating its relevance to the slide-level prediction. In this example, the slide-level label is ATI. The image clearly shows our network is able to attend to proximal tubules (mostly outlined in red). The saliency maps are produced from an occlusion-based approach using an additional network trained on individual tissues to predict the slide label.
In the previous sections, we presented results whereby tissue features were combined using soft attention models without accounting for the quality of the segmentation. We argue that the soft attention vectors learned by the models may not always be meaningful. This will happen if the instances do not resemble those in the training data, in which case the presence of the instance would only contribute to noise. We propose a scheme to consider the quality of the instances in the form of Equations 2 and 4. Under the proposed scheme, is added as a feature to the original featureset and each instance is weighted by during both training and testing time.
Figures 8, 9, and 10 show examples of ROC/PR curves on three different tasks, all of which were weighted by segmentation quality in the models. The solid plot lines show the median values, and the shaded regions show the range of five bootstraps. Figure 8 plots the “Trivial” task where models are trained using only ResNet50 features to classify whether a slide contains an adequate number of glomeruli. This task differs from counting glomeruli as there are duplicated tissue sections in 268 out of 612 slides (some slides contain multiple cut-throughs of the same biopsy). A naive model that only counts glomeruli would overestimate the number. We tuned our model based on this task as all slides are labelled, so the dataset-induced noise would be minimal.
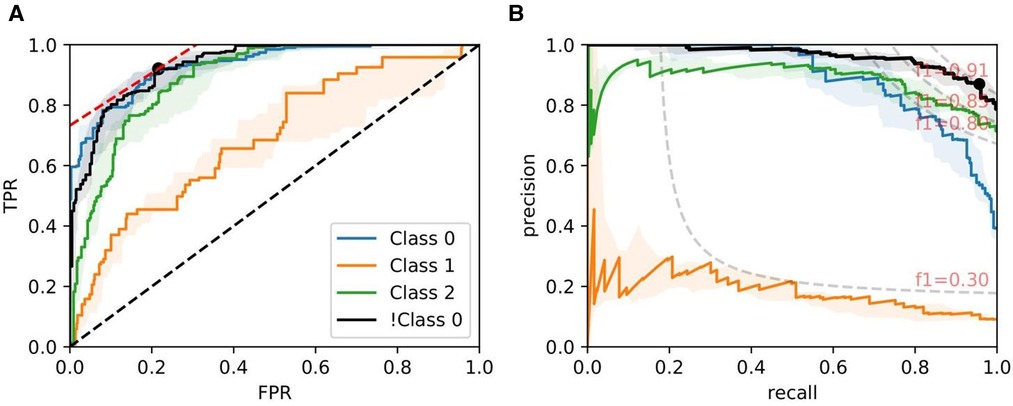
Figure 8. ROC/PR plots from tissue quality-weighted models predicting whether a PAS-stained slide has an adequate number of unique glomeruli for assessment (3 classes). Class 0: ; Class 1: ; Class 2: ; !Class 0: glomeruli. The curves with the median AUC from 5 bootstraps are shown as solid lines. There are duplicated tissue sections in approximately 268 of the slides, so models are likely to overestimate the number of unique glomeruli. The marker on the plots shows the optimal operating threshold for the respective class. ROC/PR curves for !Class 0 represent the performance when Class 1–2 are grouped as a single class. (A) !Class 0: Median ROC-AUC = 0.934; (B) !Class 0: Median PR-AUC = 0.963.
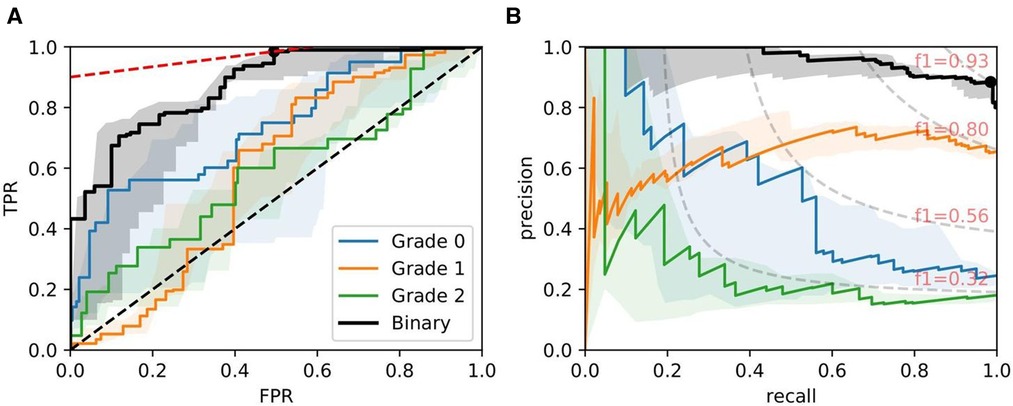
Figure 9. ROC/PR plots from tissue quality-weighted models predicting ATI grades based on PAS slides. Models are trained using ResNet50 and handcrafted features. Curves with the median AUC from five bootstraps are shown as solid lines. (Grade 0–2): Models trained to predict ATI grades , , and ; Binary: ROC/PR curves from models specifically trained to predict only two grades: (, ). (A) Binary: Median ROC-AUC = 0.873; (B) Binary: Median PR-AUC = 0.963.
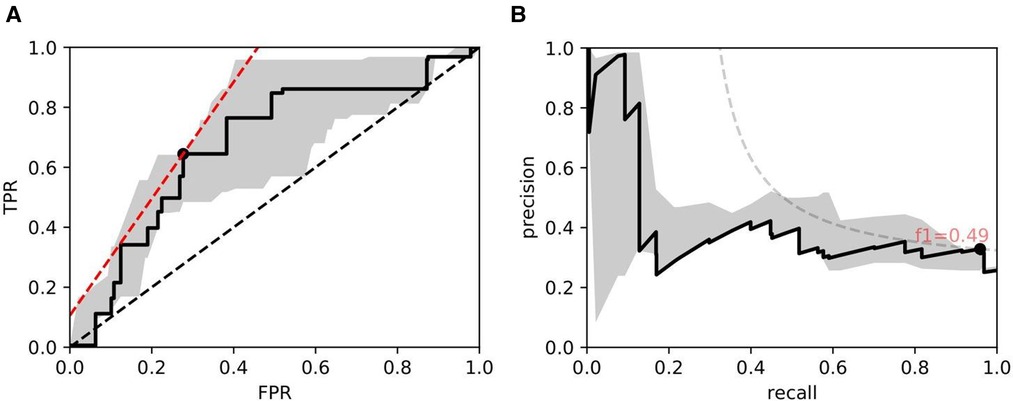
Figure 10. ROC/PR plots from tissue quality-weighted models predicting the presence of DGF after transplant based on SR slides. 37 out of 143 cases exhibited DGF. Models are trained using ResNet50 and handcrafted features. Curves with the median AUC from 5 bootstraps are shown as solid lines. (A) ROC: Median AUC = 0.676; (B) PR: Median AUC = 0.406.
Figure 9 shows ROC/PR curves for ATI grades where each solid line (Grade 0-2) represents the trade-offs from one-vs.-other classification with models trained using ResNet50 combined with handcrafted features. If the grading is instead re-formulated as a binary task (labelled “Binary” in the plot), grouping all grades together and re-training the models, we get a mean . The optimal operating threshold can be found using the curve’s intercept with the maximum iso-accuracy line. At this threshold, we report a performance of and .
As for DGF, we find that performances are generally higher in SR slides. Figure 10 shows the performance of the models trained on ResNet50 and handcrafted features. Based on the optimal threshold from the ROC curve, we get and .
Table 5 shows the mean AUCs for different tasks with the proposed addition where instances are weighted by segmentation quality. Entries in this table correspond to those in Table 4. Again, a comparison of individual predictive tasks is not always possible due to the limited size of the labelled data, but an improvement can clearly be seen when we average over different tasks. For example, when we use ResNet50 and handcrafted features (column “Tissue ResNet”), implementation of has led to an increase in ROC-AUC and PR-AUC from () to ().
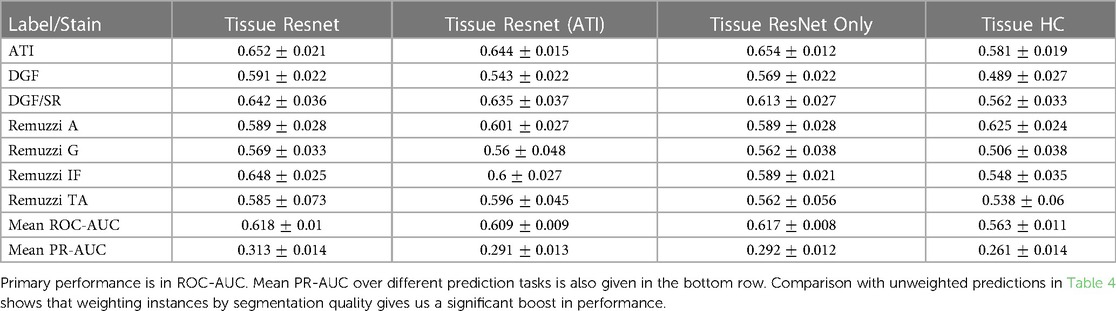
Table 5. Segmentation quality-weighted performance.
While weighting tissues by segmentation quality has provided a performance boost for most prediction tasks, the boost is largest for the prediction of Remuzzi IF (average ROC-AUC improvement: ). One possible explanation is that interstitial fibrosis is a histological change not so well captured by our featuresets as the changes reside between, rather than within, the segmented tissues. Fibrosis also correlates strongly with tubular atrophy, which is characterised by changes in the basement membrane near tissue boundaries. Neither of these will be visible if objects are under-segmented. In our case, most instances with poor segmentation quality are also the ones that are under-segmented due to how the segmentation results were combined (Equation 3). Consequently, these tissues also become less relevant to the prediction task.
There may be a second reason why the proposed weighting improves predictions. As biopsies tend to contain many tissues, it is often not possible to delineate every tissue within a slide. The annotator may have the tendency to choose regions where tissues are legible and create training sets based on these examples. Even though the delineation task was not performed by an expert, the choice of tissues on its own may still contain information indicative of what constitutes as “good quality” or what counts as “relevant”.
We propose a scheme to improve the performance of multi-instance prediction tasks based on soft attention models by incorporating weak labels at the local level. This approach could make projects that are currently bottle-necked by expert annotations more scalable. In our case, the weak labels are the tissues’ outlines delineated into coarse classes. These delineated tissue instances provided several advantages over featuresets extracted from rectangular tiles. Firstly, having features extracted from tissues allow us to design handcrafted features inspired by domain knowledge. We show that the generalised performance improves significantly when handcrafted features are combined with deep features compared to models trained using only deep or handcrafted features. Secondly, features from rectangular tiles do not generally conform to the functional boundaries of tissue compartments. Using features based on tissues in soft attention models allows an intuitive visualisation scheme pinpointing relevant tissues for transparent diagnostics. Thirdly, we argue that the attention values predicted could only be meaningful if the images resemble the training data. Instances significantly different from the training set could contribute to noise at the bag-level prediction, so we propose incorporating a tissue quality metric derived from an ensemble of BNNs to reduce their impact.
Some limitations need to be addressed in our experiments. Firstly, it is not clear whether the advantage of combining handcrafted features with deep features will still hold for larger datasets. Secondly, when there are multiple relevant instances in a slide, soft attention would only focus on a small number of instances in most cases. Many relevant instances are predicted low values. Therefore, it remains challenging to quantify the number of relevant tissue compartments in a slide - this will be needed to quantify the uncertainties of slide-level predictions. We will need to investigate whether it can be solved using an ensemble of models.
Thirdly, we find that there are currently insufficient diseased cases in our dataset. For example, there are currently only several dozens of sclerosed glomeruli from all datasets combined. Hence the segmentation performance may not generalise well to diseased instances. In many cases, if the segmentation of diseased instances is suboptimal, soft attention may focus on tissues with confounding visual changes. This would result in correct slide-level prediction but a wrong focus of attention. Isolating highly correlated pathological changes may be possible through arithmetic operations with soft attention maps, but this may require a sufficiently large training dataset.
In some cases, we recognise that performance of multi-instance learning may still not match models trained by fully-supervised approaches. If full supervision is needed, our proposed platform can be used as a guide for a human-in-a-loop labelling scheme to bootstrap a project. For example, we can choose to label specifically only tissue compartments with high attention values from slides that have been given a wrong prediction. The soft attention model can then be repeatedly re-trained with labelled instances excluded from the slide in each iteration. This may help to reduce the time needed for pathologists to go through the entire dataset when we want to add a new diagnosis.
The data analyzed in this study is subject to the following licenses/restrictions: Permission from QUOD is required to access dataset. Requests to access these datasets should be directed to a2Foby50YW0ucGhAZ21haWwuY29t.
The studies involving humans were approved by QUOD (NW/18/0187). National Ethics Review Committee of the United Kingdom (12/EE/0273). Research Ethics Committee of Oxford University Hospital NHS Foundation Trust Research and Governance (19/WM/0215). The studies were conducted in accordance with the local legislation and institutional requirements. The human samples used in this study were acquired from Collection of QUOD samples and the research ethics approval was provided by QUOD (NW/18/0187). Research ethics approved by the National Ethics Review Committee of the United Kingdom (12/EE/0273). Ethics approved by the Research Ethics Committee of Oxford University Hospital NHS Foundation Trust Research and Governance (19/WM/0215). Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
KT: Conceptualization, Software, Writing – original draft, Writing – review & editing, Formal Analysis, Methodology, Visualization. MS: Data curation, Validation, Writing – review & editing. JK: Validation, Writing – review & editing. ES: Data curation, Writing – review & editing. RP: Funding acquisition, Investigation, Project administration, Resources, Supervision, Writing – review & editing. MK: Data curation, Funding acquisition, Investigation, Project administration, Resources, Supervision, Writing – review & editing. JR: Conceptualization, Funding acquisition, Methodology, Project administration, Resources, Supervision, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article.
KT is funded by the EPSRC and MRC grant number EP/L016052/1. JR is supported by the Oxford NIHR Biomedical Research Centre and the PathLAKE consortium (Innovate UK App. Nr. 18181). JK is supported by the Dutch Kidney Foundation (Grant No. 17OKG23) and the Human(e) AI Research Priority Area by the University of Amsterdam. MK is supported by NHS Blood and Transplant and QUOD sample analysis funded by Kidney Research UK funding KS_RP_002_20210111 awarded to MK.
The authors thank the UK QUOD Consortium and NHS Blood and Transplant UK Registry for the clinical samples and metadata analysed in this study.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frtra.2024.1305468/full#supplementary-material
1Collection of QUOD samples and the research ethics approval was provided by QUOD (NW/18/0187).
2Research ethics approved by the National Ethics Review Committee of the United Kingdom (12/EE/0273).
3Ethics approved by the Research Ethics Committee of Oxford University Hospital NHS Foundation Trust Research and Governance (19/WM/0215).
1. Davis RC, Li X, Xu Y, Wang Z, Souma N, Sotolongo G, et al. Deep learning segmentation of glomeruli on kidney donor frozen sections. medRxiv (2021). doi: 10.1101/2021.09.16.21263707
2. Hermsen M, de Bel T, Den Boer M, Steenbergen EJ, Kers J, Florquin S, et al. Deep learning–based histopathologic assessment of kidney tissue. J Am Soc Nephrol. (2019) 30:1968–79. doi: 10.1681/ASN.2019020144
3. Kers J, Bülow RD, Klinkhammer BM, Breimer GE, Fontana F, Abiola AA, et al. Deep learning-based classification of kidney transplant pathology: a retrospective, multicentre, proof-of-concept study. Lancet Digit Health. (2022) 4:e18–26. doi: 10.1016/S2589-7500(21)00211-9
4. Marsh JN, Matlock MK, Kudose S, Liu TC, Stappenbeck TS, Gaut JP, et al. Deep learning global glomerulosclerosis in transplant kidney frozen sections. IEEE Trans Med Imaging. (2018) 37:2718–28. doi: 10.1109/TMI.2018.2851150
5. Yi Z, Salem F, Menon MC, Keung K, Xi C, Hultin S, et al. Deep learning identified pathological abnormalities predictive of graft loss in kidney transplant biopsies. Kidney Int. (2022) 101:288–98. doi: 10.1016/j.kint.2021.09.028
6. Campanella G, Hanna MG, Geneslaw L, Miraflor A, Silva VWK, Busam KJ, et al. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nat Med. (2019) 25:1301–9. doi: 10.1038/s41591-019-0508-1
7. Iizuka O, Kanavati F, Kato K, Rambeau M, Arihiro K, Tsuneki M. Deep learning models for histopathological classification of gastric, colonic epithelial tumours. Sci Rep. (2020) 10:1–11. doi: 10.1038/s41598-020-58467-9
8. Li B, Li Y, Eliceiri KW. Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision, Pattern Recognition (2021). p. 14318–28. doi: 10.48550/arXiv.2011.08939.
9. Lu MY, Williamson DF, Chen TY, Chen RJ, Barbieri M, Mahmood F. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat Biomed Eng. (2021) 5:555–70. doi: 10.1038/s41551-020-00682-w
10. Yarlagadda SG, Coca SG, Garg AX, Doshi M, Poggio E, Marcus RJ, et al. Marked variation in the definition and diagnosis of delayed graft function: a systematic review. Nephrol Dial Transpl. (2008) 23:2995–3003. doi: 10.1093/ndt/gfn158
11. Remuzzi G, Cravedi P, Perna A, Dimitrov BD, Turturro M, Locatelli G, et al. Long-term outcome of renal transplantation from older donors. N Engl J Med. (2006) 354:343–52. doi: 10.1056/NEJMoa052891
12. Tam KH, Sirinukunwattana K, Soares MF, Kaisar M, Ploeg R, Rittscher J. Improving pathological distribution measurements with Bayesian uncertainty. In: Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, and Graphs in Biomedical Image Analysis. Springer (2020). p. 61–70. doi: 10.1007/978-3-030-60365-6_7
13. Ilse M, Tomczak J, Welling M. Attention-based deep multiple instance learning. In: International Conference on Machine Learning. PMLR (2018). p. 2127–36. doi: 10.48550/arXiv.1802.04712
14. Maron O, Lozano-Pérez T. A framework for multiple-instance learning. Adv Neural Inf Process Syst. (1998) 10: 570–6.
15. Blundell C, Cornebise J, Kavukcuoglu K, Wierstra D. Weight uncertainty in neural networks. arXiv [Preprint]. arXiv:1505.05424 (2015). Available online at: https://doi.org/10.48550/arXiv.1505.05424.
16. Gal Y, Ghahramani Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning. In: International Conference on Machine Learning (2016). p. 1050–9. doi: 10.48550/arXiv.1506.02142
17. Kendall A, Gal Y. What uncertainties do we need in Bayesian deep learning for computer vision? In: Advances in Neural Information Processing Systems (2017). p. 5574–84. doi: 10.48550/arXiv.1505.05424
18. Grimm PC, Nickerson P, Gough J, McKenna R, Stern E, Jeffery J, et al. Computerized image analysis of sirius red–stained renal allograft biopsies as a surrogate marker to predict long-term allograft function. J Am Soc Nephrol. (2003) 14:1662–8. doi: 10.1097/01.ASN.0000066143.02832.5E
19. Farris AB, Adams CD, Brousaides N, Della Pelle PA, Collins AB, Moradi E, et al. Morphometric, visual evaluation of fibrosis in renal biopsies. J Am Soc Nephrol. (2011) 22:176–86. doi: 10.1681/ASN.2009091005
20. Racusen LC, Solez K, Colvin RB, Bonsib SM, Castro MC, Cavallo T, et al. The Banff 97 working classification of renal allograft pathology. Kidney Int. (1999) 55:713–23. doi: 10.1046/j.1523-1755.1999.00299.x
22. Weissenbacher A, Lo Faro L, Boubriak O, Soares MF, Roberts IS, Hunter JP, et al. Twenty-four–hour normothermic perfusion of discarded human kidneys with urine recirculation. Am J Transplant. (2019) 19:178–92. doi: 10.1111/ajt.14932
23. Zhu JY, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision (2017). p. 2223–32. doi: 10.48550/arXiv.1703.10593
24. TCGA. The cancer genome atlas program. Available online at: https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga.
25. Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing, Computer-Assisted Intervention. Springer (2015). p. 234–41. doi: 10.48550/arXiv.1505.04597.
26. Kendall A, Badrinarayanan V, Cipolla R. Bayesian segnet: model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv [Preprint]. arXiv:1511.02680 (2015). Available online at: https://doi.org/10.48550/arXiv.1506.02142.
27. Boykov Y, Funka-Lea G. Graph cuts and efficient nd image segmentation. Int J Comput Vis. (2006) 70:109–31. doi: 10.1007/s11263-006-7934-5
28. Pieters TT, Falke LL, Nguyen TQ, Verhaar MC, Florquin S, Bemelman FJ, et al. Histological characteristics of acute tubular injury during delayed graft function predict renal function after renal transplantation. Physiol Rep. (2019) 7:e14000. doi: 10.14814/phy2.14000
29. Solez K, Axelsen RA, Benediktsson H, Burdick JF, Cohen AH, Colvin RB, et al. International standardization of criteria for the histologic diagnosis of renal allograft rejection: the Banff working classification of kidney transplant pathology. Kidney Int. (1993) 44:411–22. doi: 10.1038/ki.1993.259
30. Kers J, Peters-Sengers H, Heemskerk MB, Berger SP, Betjes MG, Van Zuilen AD, et al. Prediction models for delayed graft function: external validation on the Dutch prospective renal transplantation registry. Nephrol Dial Transpl. (2018) 33:1259–68. doi: 10.1093/ndt/gfy019
31. Rolak S, Djamali A, Mandelbrot DA, Muth BL, Jorgenson MR, Zhong W, et al. Outcomes of delayed graft function in kidney transplant recipients stratified by histologic biopsy findings. In: Transplantation Proceedings. Elsevier (2021). p. 1462–9. doi: 10.1016/j.transproceed.2021.01.012.
32. Bergstra J, Yamins D, Cox DD. Hyperopt: a python library for optimizing the hyperparameters of machine learning algorithms. In: Proceedings of the 12th Python in Science Conference. Citeseer (2013). p. 20. doi: 10.25080/Majora-8b375195-003
33. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016). p. 770–8. doi: 10.1109/CVPR.2016.90
34. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv [Preprint]. arXiv:1409.1556 (2014). Available online at: https://doi.org/10.48550/arXiv.1409.1556.
35. Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016). p. 2818–26. doi: 10.1109/CVPR.2016.308
36. Kingma DP, Welling M. Auto-encoding variational bayes. arXiv [Preprint]. arXiv:1312.6114 (2013). Available online at: https://doi.org/10.48550/arXiv.1312.6114.
37. Bruna J, Mallat S. Invariant scattering convolution networks. IEEE Trans Pattern Anal Mach Intell. (2013) 35:1872–86. doi: 10.1109/TPAMI.2012.230
38. Liaw R, Liang E, Nishihara R, Moritz P, Gonzalez JE, Stoica I. Tune: a research platform for distributed model selection and training. arXiv [Preprint]. arXiv:1807.05118 (2018). Available online at: https://doi.org/10.48550/arXiv.1807.05118.
39. Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. In: European Conference on Computer Vision. Springer (2014) p. 818–33. doi: 10.48550/arXiv.1311.2901
40. Kokhlikyan N, Miglani V, Martin M, Wang E, Alsallakh B, Reynolds J, et al. Captum: a unified and generic model interpretability library for pytorch (2020). doi: 10.48550/arXiv.2009.07896.
41. Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks. In: International Conference on Machine Learning. PMLR (2017). p. 3319–28. doi: 10.48550/arXiv.1807.05118
42. Adebayo J, Gilmer J, Muelly M, Goodfellow I, Hardt M, Kim B. Sanity checks for saliency maps. arXiv [Preprint]. arXiv:1810.03292 (2018). Available online at: https://arxiv.org/abs/1810.03292.
Keywords: digital histopathology, kidney transplant, multi-instance learning, Bayesian Neural Network (BNN), computer vision
Citation: Tam KH, Soares MF, Kers J, Sharples EJ, Ploeg RJ, Kaisar M and Rittscher J (2024) Predicting clinical endpoints and visual changes with quality-weighted tissue-based renal histological features. Front. Transplant. 3:1305468. doi: 10.3389/frtra.2024.1305468
Received: 1 October 2023; Accepted: 15 March 2024;
Published: 3 April 2024.
Edited by:
Hirofumi Hirao, Kyoto University, JapanReviewed by:
Krzysztof Pabisiak, Regional Hospital, Poland© 2024 Tam, Soares, Kers, Sharples, Ploeg, Kaisar and Rittscher. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ka Ho Tam a2Foby50YW0ucGhAZ21haWwuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.