 Alexander Scholtes
Alexander Scholtes Oktay Karakuş*
Oktay Karakuş*
- School of Computer Science and Informatics, Cardiff University, Cardiff, United Kingdom
This study employs Bayesian methodologies to explore the influence of player or positional factors in predicting the probability of a shot resulting in a goal, measured by the expected goals (xG) metric. Utilising publicly available data from StatsBomb, Bayesian hierarchical logistic regressions are constructed, analysing approximately 10,000 shots from the English Premier League (for the years of 2003 and 2015) to ascertain whether positional or player-level effects impact xG. The findings reveal positional effects in a basic model that includes only distance to goal and shot angle as predictors, highlighting that strikers and attacking midfielders exhibit a higher likelihood of scoring. However, these effects diminish when more informative predictors are introduced. Nevertheless, even with additional predictors, player-level effects persist, indicating that certain players possess notable positive or negative xG adjustments, influencing their likelihood of scoring a given chance. The study extends its analysis to data from Spain’s La Liga ( K shots from 1973 and 2004 to 2020) and Germany’s Bundesliga ( K shots from 2015), yielding comparable results. Additionally, the paper assesses the impact of prior distribution choices on outcomes, concluding that the priors employed in the models provide sound results but could be refined to enhance sampling efficiency for constructing more complex and extensive models feasibly.
1 Introduction
One of the most common advanced football analytics metrics is the idea of expected goals (xG), which estimates the probability of a given shot resulting in a goal based on several features about the shot such as distance from the shooter to the goal or the body part used by the shooter. However, none of the mainstream xG models take into account any player-specific features when estimating these values. To illustrate this, imagine that you have two players taking the same shot from the same position, with defenders in the same place and everything else being the same. Still, one player is Lionel Messi and the other is a random player from the National League (English 5th tier). Obviously, players who play in the National League are good, but it is not unreasonable to assume that Lionel Messi would be more likely to score. However, xG metrics would assign the same value for both of these changes.
The objective of this paper is to investigate if there are position or player effects on xG, meaning that certain positions or players have higher or lower goal probabilities for a given chance than others. This will be achieved using a Bayesian hierarchical model, where the hierarchies will be the position of the player or the player. The results of this method will initially be compared to a more traditional frequentist xG model to evaluate baseline results without any group effects. Then the hierarchical models will be compared to the non-hierarchical Bayesian models, to assess the impact of having hierarchies in the data on the results. If the rationale described above of the two players taking the same shot is valid, then it is expected that the xG predictions of the hierarchical models will differ significantly from the non-hierarchical models, supporting the idea that there is a position and/or player effect on the xG of a given shot.
This paper will begin with a review of the relevant literature around this topic, looking at the development of football analytics and xG, as well as any attempts to use Bayesian modelling in football analytics. Thereafter, the methodology will be described by going through the frequentist and Bayesian techniques used. Then, the data will be introduced and described with any changes made before the choice of Bayesian prior distributions for predictors is discussed. Next, the results of the modelling will be presented before validating the results of the Bayesian models on additional data. The aforementioned choice of prior distributions will then be evaluated. Finally, a discussion section will deliberate on the significance of the results before concluding the paper.
2 Related works
The use of data in football is often not fully embraced, with many decision-makers arguing the sport is too complex for data to be used effectively to improve results and performance (1). However, with its successful use in other sports, there was sufficient interest for some clubs, companies, and individuals to pursue using data to derive conclusions and make suggestions in football. With a growing demand for data, companies that specialise in sports data collection have grown too, along with their ability to track data. The result is that there is now an enormous amount of football data to use for several purposes, such as player/club performance, scouting, and player fitness and injury risk, to name a few (2).
At the heart of the idea of using data in football was the potential to gain a competitive advantage. As a result, clubs that use data tend to be secretive about their operations and procedures (2). Despite this, there is plenty of publicly available literature and sources showing how data can be used in football. Moreover, sports broadcasters have long used data when giving an overview of a match, such as possession statistics. Still, these have only recently moved away from simple counts and percentages to more complex metrics. The Bundesliga, for example, provides a goal probability value after each goal is scored, giving the chance of that given opportunity resulting in a goal (3).
This goal probability, also commonly called expected goals (xG), has been a central topic in the development of more advanced statistics using football data (1). Crucially, it moves away from the idea of things that did happen and focuses on things that could have happened. With football being such a complex and chaotic sport, outcomes often do not reflect expectations as matches are often decided by fine margins or decisions out of the players’ and coaches’ control. Nevertheless, using expectations gives decision-makers an idea of the underlying performance of their team and allows them to see if their team is over or underperforming according to expectations (4).
There have been many versions of xG models created since the idea was founded, using a variety of machine-learning techniques and data sources. Herold et al. (5) provide a summary of many applications of machine learning in football, including xG models. The most common methods of estimating xG in their paper are logistic regressions, decision trees, ensemble methods (e.g., random forest), and neural networks. Lucey et al. (6) use player and ball tracking data from the 10 s leading up to a shot to estimate goal probabilities across an entire season and found that “defender proximity, interaction of surrounding players, speed of play, coupled with shot location play an impact on determining the likelihood of a team scoring a goal”.
Furthermore, Anzer and Bauer (7) evaluate several machine-learning approaches with hand-crafted features from synchronised positional and event data of 105,627 shots in the German Bundesliga and conclude that their extreme gradient boosting-based xG model reaches the best performance. Madrero Pardo (8) uses qualitative data from the popular video game FIFA to account for player effects on xG using a logistic regression and an XGBoost model. They found that an adjusted model can better predict goals over a season for individual players and teams than an overall xG model. Fairchild et al. (9) built an xG model again using logistic regression and used it to estimate MLS teams’ offensive efficiency in scoring. They also discuss evaluation metrics for expected goals models and suggest the use of the Brier score to compare predicted probability to ground-truth binary outcomes. Cavus and Biecek (10) apply a variety of ensemble and boosting methods to calculate xG values and find that a random forest model performs best, even compared to models from other papers using other techniques and data.
The closest study to this paper to date is that of Hewitt and Karakuş (11), which investigates position and player-adjusted xG models. They find evidence of positional adjustments with forwards having a positive adjustment, midfielders having a slightly negative adjustment, and defenders having a large negative adjustment. Moreover, they also find evidence of player effects on xG by fitting their model with only data from Lionel Messi and find a large positive adjustment in this case.
One of the features a lot of these models have in common is their frequentist approach, as opposed to using Bayesian methods. Spearman (12) uses a Bayesian approach to estimate the maximum a posteriori effects of parameters in a model for predicting future scoring of teams in games. Joseph et al. (13) used Bayesian networks to predict the results of matches played by Tottenham Hotspur and compared the results to ML techniques such as Naïve Bayes, K-nearest neighbour and decision tree. They reiterate one of the benefits of Bayesian modelling which is comparably accurate predictions in the absence of a large amount of data. Zambom-Ferraresi et al. (14) use Bayesian methods to analyse team performance in Europe’s top leagues to determine which features tend to be most significant in predicting team performance. They find that the most important features include the number of assists, the number of shots conceded, saves made by the goalkeeper, passing accuracy, and number of shots on target.
One area of Bayesian modelling which is also often not considered in football analytics is using multi-level, or hierarchical, models. Tureen and Olthof (15) construct a multi-level model for player-adjusted expected goals but do not use a Bayesian approach to do so. Still, they use their model to calculate estimated player impact values on xG. On the other hand, Baio and Blangiardo (16) construct a Bayesian hierarchical model but use it to predict match results as opposed to xG directly and group their data by the team as opposed to by the player. Blanco et al. (17) in their study employ a Bayesian methodology to probabilistically estimate Chilean Premier League team positions, revealing insights into attack and defence strengths. While the model accurately predicts the top five positions, it identifies weak defensive capabilities across all teams, showcasing its competitiveness for soccer championship prediction. Still, the use of Bayesian hierarchical modelling in football is a relatively unexplored area.
By using Bayesian hierarchical modelling, group-level effects can be reliably estimated even with small group sizes. Therefore, the effect of a player’s position or even the player themselves on the chance of a given shot resulting in a goal can be reliably measured. The result is that certain players could be identified as being more likely to score than others for given chances, which is a result that can be used for player selection or scouting purposes. This idea is present in the work of Hewitt and Karakuş (11), where Messi is found to be an extremely efficient goal scorer. This conclusion may be obvious to football fans, but the fact that the efficiency can be reliably measured is extremely interesting for potentially comparing the goalscoring efficiency of footballers. Tureen and Olthof (15) construct a metric they refer to as “estimated player impact”, which is another calculation of a player’s individual effect on the probability of scoring. The estimation of a player’s impact on xG can potentially be another tool in evaluating player performance for team selection or scouting purposes.
After a general look at the literature on the xG metric and its evaluation throughout the years, in the following section, we explain the details of the methodology this paper is proposing to study positional and player-related corrections to generic xG approaches. We propose the utilisation of the Bayes formula by taking player and position information into a conditional probability formulation which is then evaluated under Bayesian hierarchical modelling.
3 Methodology
3.1 Preliminaries on xG calculation
Before showing how Bayesian methods can be applied to xG modelling, we now show how xG models are typically created. This involves using a frequentist approach and, in this case, a logistic regression appears as the natural choice to obtain goal probabilities. This paper will first attempt to build a generic xG model with comparable results to an xG model built by StatsBomb, an industry leader in data collection and analysis. To do so, we gradually increase the number of predictors (both given and engineered) used in the logistic regression that generally follows the formulation given below
where is the probability of the shot resulting in a goal, is the value of predictor for the shot . Moreover, for is the logistic model coefficients, and is the number of parameters of the logistic regression. Traditional logistic regression can be seen as a method used to model the relationship between a binary dependent variable (in this context Goal or No-Goal) and one or more independent variables (given and engineered features). It uses the logistic function in Equation (1) to transform a linear combination of features into a probability of the dependent variable being one of the two classes.
3.2 On the Bayesian predictive modelling of expected goals (xG) models
In predictive modelling of xG, accurate prediction of xG is crucial for assessing team performance and predicting match outcomes. The posterior predictive distribution plays a pivotal role in this process as it provides a probabilistic framework for estimating the likelihood of different goal-scoring scenarios given observed data and model parameters.
The posterior predictive distribution, which can be denoted as , represents the distribution of expected goals yxG for future events, conditioned on the observed features and corresponding outcomes . Mathematically, it is expressed as in Equation (2):
where is the target posterior distribution of model parameters given the observed data, and is the likelihood function representing the probability of observing expected goals given the parameters .
In simpler terms, approaching modelling from a Bayesian perspective means we can incorporate prior knowledge about model parameters, resulting in a posterior density of these parameters (). This posterior is then used in the inference process to predict future xG values by sampling from the posterior predictive distribution of . Essentially, estimating this distribution helps us measure the uncertainty in xG predictions by considering both uncertainty in parameters and variability in observed data.
3.3 Bayesian logistic regression
Bayesian logistic regression extends logistic regression by introducing a Bayesian framework for modelling. Instead of estimating fixed model parameters as in traditional logistic regression, Bayesian logistic regression defines these parameters as unknowns and treats the uncertainty around these unknowns as random variables with associated probability distributions. This means that we get the single population value as the estimate for the model parameters as well as full probability distributions, allowing us to quantify uncertainty.
In Bayesian logistic regression, we specify prior distributions for the model parameters, representing our beliefs about their values before observing any data. The likelihood function represents the probability of observing the data given the model parameters. Using Bayes’ theorem, we update the prior distribution with the likelihood distribution to obtain the posterior distribution, which reflects our updated beliefs after considering the data. To compute the posterior distribution in Bayesian logistic regression, various techniques can be used, including Markov Chain Monte Carlo (MCMC) methods and variational inference. These methods sample from the posterior distribution of the parameters to estimate their values and uncertainties.
Once we have the posterior distribution of the model parameters, we can perform various tasks such as parameter estimation, uncertainty quantification, and prediction. Bayesian logistic regression provides a natural way to make probabilistic predictions, as it generates a distribution of predicted probabilities for each class, rather than just point estimates.
For this paper, the Bayesian methods used will involve fitting Bayesian logistic regressions as both single-level models (baseline) without group-level effects, and multi-level, or hierarchical, models with group-level effects. The predictions from both models will then be compared to determine if there is evidence of group-level effects on xG. To formulate such Bayesian models, this paper specifies expressions in Equations (3) to (9) below:?>
where the likelihood distribution is
Hence, the Baseline and Hierarchical models are like
where is the index of the grouping variable in the data, refers to the probability of shot for th grouping effect resulting in a goal, and is the model coefficient for predictor and th grouping effect.
3.4 Data
The data used for this project is all freely available event data from StatsBomb, obtained using their Python package StatsBombPy (please see the Statsbomb GitHub page via https://github.com/statsbomb for details). From their database, only men’s competitions were used because it could be that there is a difference in given goal probabilities in men’s and women’s football, and we have more data from men’s competitions. Then, all open-play shots were extracted with all relevant information for each shot. Set-pieces were excluded because again goal probabilities could vary for set-pieces, and we are not interested in modelling this effect.
The resulting data has 63,309 shots from a variety of competitions and years, with 42 columns of information for each shot. Table 1 gives a breakdown of leagues and seasons that the full data consists of whilst Table 2 gives some summary statistics for the most relevant variables in the data. As well as the information given in the columns already in the data, there are several features which were not included by StatsBomb which could be useful for predicting goal probability. Many sources cite distance to goal and shot angle to be two of the most important predictors of goal probability (11, 18–20).
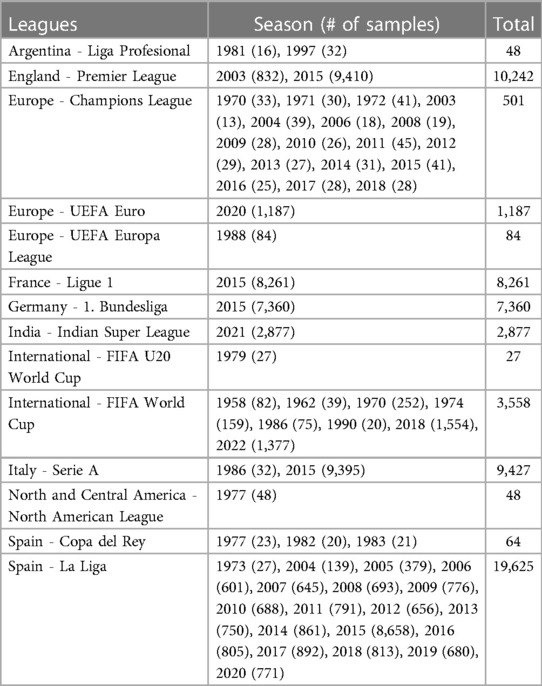
Table 1. Full dataset details including leagues and seasons where the total number of shots taken is 63,309.

Table 2. Summary statistics for most relevant features for xG in the dataset.
The data has the location of the shot, and the StatsBomb data specification (21) provides information about the coordinates of the goalposts. Distance to goal is therefore calculated as the Euclidean distance from the shot to the centre of the goal.
For shot angle, the cosine rule is used to calculate the angle from the shooter to the two goalposts. To calculate this reliably, any shots that are taken from the same x-coordinate as the goal line are excluded since this would create a straight line instead of a triangle with no shot angle.
Statsbomb’s open-access datasets offer a valuable “freeze frame” feature, providing detailed insights into specific moments within a match. This freeze frame information captures crucial events such as passes, shots, and tackles, along with the positional coordinates of players involved, enabling thorough analysis of on-field actions. By offering this level of granularity, we are able to delve deeper into detailed analysis for the shot taken and to engineer new useful features that can affect the xG predictions. Thanks to this feature, the freeze-frame feature in the data is utilised, we engineered several features: the goalkeeper’s distance to the goal, whether the goalkeeper is present in the shot triangle formed by the shot and two goalposts, the number of players present in the shot triangle, and the number of opponents within a 1m radius of the shooter. Opponents are used for the 1m radius as opposed to all players because the only time a non-opponent in the radius of a shooter would impact goal probability is when they are in the shot triangle, which is already being accounted for. Otherwise, only opponents will try to put pressure or tackle the shooter outside of the shot triangle.
The initial dataset categorises each player into 25 distinct positions, such as Left Centre Forward, Second Striker, Right Wing, and Right Centre Back. Due to players’ flexibility across positions and potential overlap in samples, clustering them into positional groups poses a challenge. To address this issue, we compute mode statistics for each player’s position, condensing them into a single positional variable. However, given the analytical focus of this study and the abundance of players in certain positions, particularly those with low sample sizes, we consolidate these positions into four main categories: strikers (ST, encompassing L/R/C Centre Forward), attacking midfielders (AM, including Secondary Striker, L/R Wing, and L/R/C Attacking Midfield), non-attacking midfielders (M, comprising L/R/C Centre Midfield, L/R Midfield, and L/R/C Defensive Midfield), and defenders (D, covering L/R/C Centre Back, L/R Back, L/R Wing Back, and Goalkeeper). This process results in the engineering of the “general_position” feature, consisting of these four positions, with an expected average decline in goal probability for each respective group.
Finally, we modify the body part used by changing “left foot” and “right foot” to “preferred foot” and “other foot” according to the player’s apparent preference. To assign these, we go back through the open data and instead look at the passes for each player, we then assign whichever foot the player made the most passes with as their preferred foot because they often have more time to choose which foot to pass with and will then tend to go safely with their preferred foot, which is less feasible when taking a shot as players tend to be under more pressure and have less time.
3.5 Reference models
As outlined in the preceding sections, the primary aims of this paper are to support the adoption of the Bayesian hierarchical modelling approach in investigating the xG metric, specifically concerning player-specific attributes and position groups of players. To fulfil these objectives, we commence by providing definitions for the benchmark and baseline models in the subsequent sections.
3.5.1 Statsbomb xG model
This model, employed for comparison in this study, relies on Statsbombpy’s open data set to provide corresponding xG calculations for each shot discussed in the dataset. The specifics of Statsbomb’s xG model remain undisclosed, and it serves as the benchmark model in this paper.
3.5.2 Baseline xG model
The initial frequentist model introduced is a fundamental model primarily utilising the distance between the shooter and the goal as a predictor, recognised as a key factor in goal probability determination. Another crucial feature considered is the angle of the shot, formed by the shooter and the two goalposts. Recognising the inherent link between distance and shot angle, an interaction term is incorporated to capture the combined influence of both features. This foundational parameterisation constitutes the formulation of the Baseline xG model under a logistic regression model as in Equation (10)
It is logical to infer that, under reasonable assumptions, the likelihood of scoring decreases, on average, as the distance to the goal increases. This implies that the coefficient is likely to be negative. Conversely, is expected to be positive, reflecting the observation that as the shot angle decreases, the shot’s position is likely to be farther away or from a wider position, both scenarios leading to a lower goal probability. Figure 1 illustrates the associations between shot angle, distance, and the proportion of goals scored to shots, providing a clearer insight into these relationships.
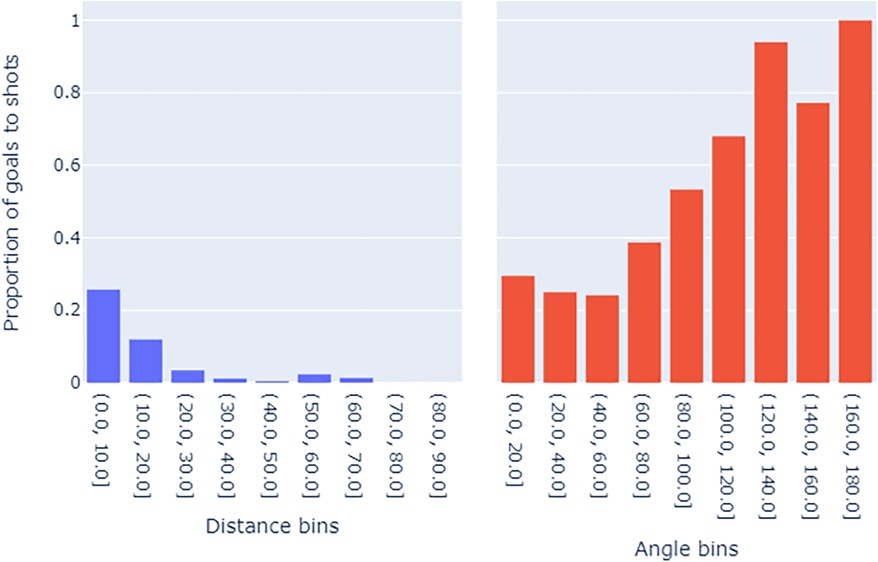
Figure 1. Bar plots showing the relationships between (left) distance to goal - binned in 10 s & (right) shot angle - binned in the 20 s and the proportion of goals from shots.
3.5.3 Extended model
While the primary factors considered for calculating the goal probability are typically assumed to be the distance and angle of the shot utilised in the Baseline Model, it is important to acknowledge that various other elements can influence the shot’s outcome as shown clearly in the literature. Section 3.4 has previously addressed each of these factors, and we now introduce our frequentist Extended model, outlined below in Equation (11)
3.6 Bayes-xG models
Bayesian logistic regression hierarchical modelling is a powerful statistical approach used to analyse and model complex relationships within data. In this context, an additional grouping parameter is employed to incorporate the hierarchical structure of the data, acknowledging potential dependencies or variations across groups. Unlike frequentist logistic regression, Bayesian hierarchical modelling allows for the inclusion of prior information, facilitating a more robust estimation of parameters and uncertainties. Below, we initiate by formulating our Bayes-xG models to account for player and position grouping effects. Subsequently, we provide a comprehensive explanation of the rationale behind selecting specific prior distributions for the model parameters.
3.6.1 Model definitions
The foundational Bayesian logistic regression model extends the traditional logistic regression equation by adding a grouping effect as in Equation (12)
where with is the number of elements in the group. It is also clear that for this formulation, we extended logistic regression model coefficients into a complex form for grouping effect as . This leads to fitting different logistic regression coefficients for each specific group where the same shot predictors will result in different xG calculations for each element in the group.
Specifically, is a group-specific intercept for th element of the group which accounts for variations in the baseline success probability across different groups. On the other hand, refer to the group-specific slopes which capture variations in the effect of the covariate across groups.
Following the technical details above, for this paper, we decided to define three versions of Bayes-xG models which can be expressed as
• Bayes-xG1 uses the Baseline model with grouping parameter of position,
• Bayes-xG1 uses the Extended model with grouping parameter of position,
• Bayes-xG1 uses the Extended model with grouping parameter of player.
3.6.2 Choice of priors
When using Bayesian modelling methods, one important consideration is the choice of prior distributions for the predictors in the model. Table 3 lists the predictors in each of the models and the prior distributions used for them.
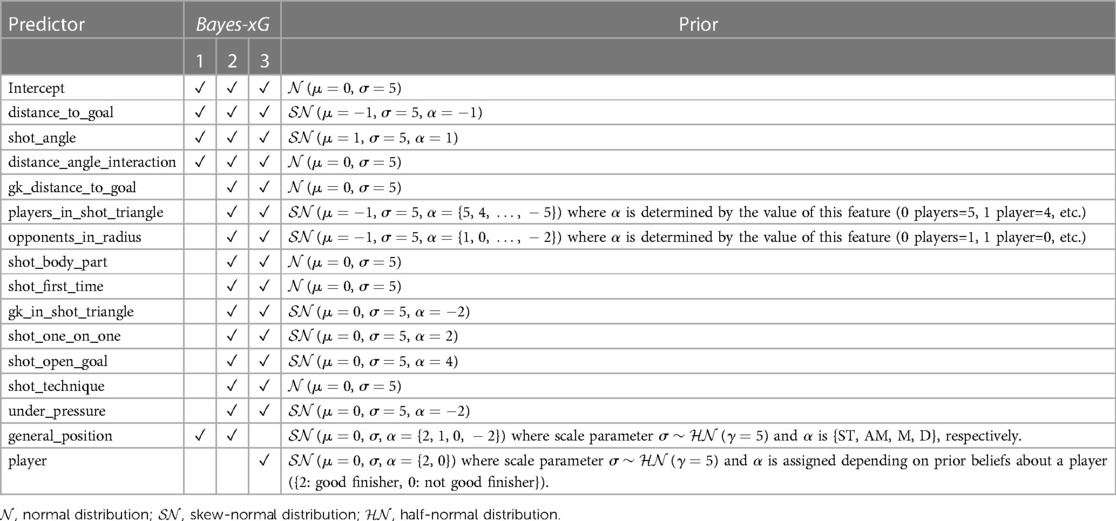
Table 3. Listing which predictors are used in each of the Bayesian models, and what prior distribution is given to the coefficient of the given predictor.
Variables lacking a clear rationale for a positive or negative value are assigned a prior distribution modelled on the normal distribution. In contrast, variables, where the direction of the effect can be reasonably predicted, are assigned a prior distribution skewed towards that direction. This choice is made to favour values in the predicted direction while still allowing for the possibility of values in the opposite direction, acknowledging the potential for an incorrect prediction. The justifications for prior distribution choices are given below:
• distance_to_goal ( and ): Scoring becomes progressively more challenging as the distance from the goal increases, primarily because the goalkeeper gains additional time to react to the shot.
• shot_angle ( and ): This is because an increase in the shot angle implies either moving closer to the goal or positioning oneself more centrally, both of which result in a higher average scoring probability.
• players_in_shot_triangle (): The presence of an increasing number of players within the shot triangle makes it increasingly challenging for a player to execute a shot in a manner that avoids hitting any of the players while still managing to score a goal.
• opponents_in_radius (): In a manner akin to the previously mentioned feature, an increase in the number of opponents within the shooter’s proximity corresponds to an increased challenge for the shooter. With more players in the vicinity, there is an augmented effort from opponents to disrupt and block the shot, consequently making it more difficult for the shooter to successfully score.
• gk_in_shot_triangle (): If the goalkeeper is positioned within the shot triangle, their chances of successfully saving a shot are higher compared to when they are located outside of the shot triangle.
• shot_one_on_one (): When a player finds themselves in a one-on-one situation with the goalkeeper, their sole task is to outplay the goalkeeper with their shot, without the need to navigate or consider other players. This circumstance makes scoring comparatively more straightforward.
• shot_open_goal (): Similar to the previous feature, in this case, there is no goalkeeper present. Consequently, the shooter’s sole objective is to direct the shot accurately towards the target, making the likelihood of scoring very high.
• under_pressure (): When a player is under pressure, their ability to concentrate on accurate and well-targeted shooting diminishes, resulting in a decreased likelihood of scoring on average.
• general_position (): The values signify the expectation that strikers will exhibit the highest proficiency in finishing, followed by attacking midfielders, other midfielders, and, finally, a decrease for defenders.
• player (): If a player is anticipated to excel in finishing skills based on their name and reputation, they are given a value of 2 for ; otherwise, a value of 0 is assigned.
• A standard value of was chosen for the priors to strike a balance, ensuring sufficient variability. This choice aims to prevent the priors from becoming overly narrow in case the underlying prior knowledge is incorrect. Simultaneously, it avoids excessive largeness that could prolong convergence and necessitate numerous rounds of sampling.
3.7 Model development
Following the exposition of technical aspects related to the models employed in this paper, we proceed to elucidate the practical details of their implementation. The entire computational implementation was carried out using the Python programming language, specifically version 3.8 and above. In non-Bayesian modelling phases, logistic regression was executed using the Python sklearn module along with its associated methods.
Bayesian modelling stages were implemented by using the bambi module which is an open-source Python package and purposefully crafted to simplify the fitting of generalised linear multilevel models (GLMMs) using a Bayesian framework. This encompasses a broad category of techniques widely employed in various research domains, including linear regression, analysis of variance (ANOVA), logistic and Poisson regression, as well as multilevel and crossed-group-specific effects models. Bambi facilitates the specification of intricate generalised linear hierarchical models through a formula notation reminiscent of R, providing a balance between user-friendly syntax for novices and direct access to internal objects for advanced users. This design allows beginners to swiftly articulate complex models with default priors, akin to popular R packages while providing seasoned users with the flexibility to directly manipulate internal objects for a more advanced and nuanced modelling approach (22).
Specifically, we employed the Python module bambi to construct Markov Chain Monte Carlo (MCMC) models, generating posterior distributions. Monitoring instantaneous parameter estimates from the chains confirmed their convergence, leading us to select 1,500 draws, with the initial 250 draws designated as the burning period. In total, 4 Markov chain sampling is developed resulting in 6,000 total samples for each Bayes-xG model. We set a target acceptance ratio of 95% in the model whilst using the prior distributions given in Table 3. Considering the target feature in the models is a binary variable of goal status, we decided to utilise a Bernoulli likelihood for all Bayes-xG models.
Furthermore, in the context of this paper, Bayesian implementation of the models was executed using data from a specific league. This decision was driven by the fact that a substantial portion of the entire dataset consisted primarily of Barcelona matches, as this information was publicly provided by StatsBomb. The concern was that including such a dominant dataset might introduce bias and influence the results. By focusing on a single league, the analysis can encompass a diverse range of players and team matchups, ensuring a more balanced and comprehensive examination.
4 Experimental analysis
The experimental analysis of this paper was studied under six cases:
(1) Frequentist model comparison to benchmark model for the whole 60 K shots data set,
(2) Bayes-xG model-based “positional” analysis and comparisons for English Premier League data set (10 K shots),
(3) Bayes-xG model-based “player-specific” analysis and comparisons for English Premier League data set (10 K shots),
(4) Extending the developed Bayes-xG model evaluations into different countries, e.g., Spain (La Liga - 19 K shots) and Germany (Bundesliga - 7.5 K shots),
(5) Investigating the choice of priors on Bayes-xG model outputs, and
(6) Uncertainty quantification via discussing some posterior predictive analysis on developed Bayesian xG models.
4.1 Frequentist/non-Bayesian models
In the initial series of experiments, we assessed the modelling performance of frequentist models based on logistic regression, namely the Baseline xG and Extended xG, utilising two distinct sets of features. The analysis involved the complete data set comprising 63,309 instances. The objective was to observe and compare how these models deviate from the predictions of the benchmark Statsbomb xG model.
The distributions of the predicted xG values for each model are shown in Figure 2, along with the StatsBomb xG values for comparison. As expected, the Extended model performs better than the Baseline model (with shot angle, distance to goal, and the interaction between the two) by also predicting much more extreme values and by decreasing the interquartile and whisker ranges. Furthermore, the extended model has a distribution very close to that of the StatsBomb model.

Figure 2. Distributions of predictions from frequentist xG models.
Concerning the evaluation criteria, Table 4 displays how each model performs compared to the Statsbomb xG model regarding , mean absolute error (MAE), and root mean square error (RMSE). As expected, the extended model outperformed the Baseline model due to its enriched data for predicting the goal likelihood. Particularly noteworthy is that the extended model achieved a Brier score significantly close to the StatsBomb model’s Brier score of 0.075, suggesting a similar performance to an industry-leading xG model. Please also note that the Brier score is a version of the DeFinetti measure (23) which is used to measure Euclidean distance between predictions and outcome probabilities of the event (24).
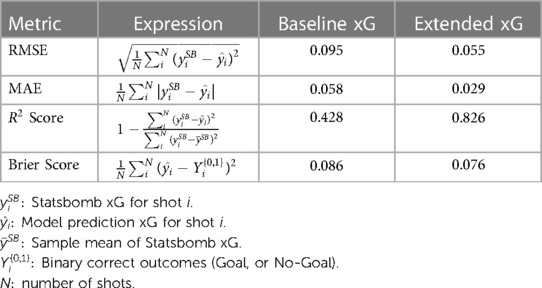
Table 4. Comparison of outcomes from non-Bayesian models, including the Baseline xG model integrating distance to the goal, shot angle, and their interaction, and the Extended xG model incorporating additional features, with reference to the StatsBomb xG model.
In the final analysis of the initial set of experiments, we explored the impact of incorporating engineered advanced features on the performance of the frequentist logistic regression model. Figure 3 illustrates the trends in performance evaluation metrics—Brier score, R2, MAE, and RMSE—relative to the number of features integrated into the model. We initiated the analysis with a single-parameter model, utilizing only the distance to the goal, and systematically added features one by one. Typically, there are 16 model parameters (as detailed in Table 3), but this count increases to a maximum of 33 after one-hot encoding categorical features. Examining Figure 3 reveals a substantial influence on model performance resulting from the introduction of these created parameters. Notably, there are certain plateaus in the trends, particularly associated with one-hot encoded parameters representing categories with a minimal number of samples in the dataset (e.g., 10 players in the shot triangle).
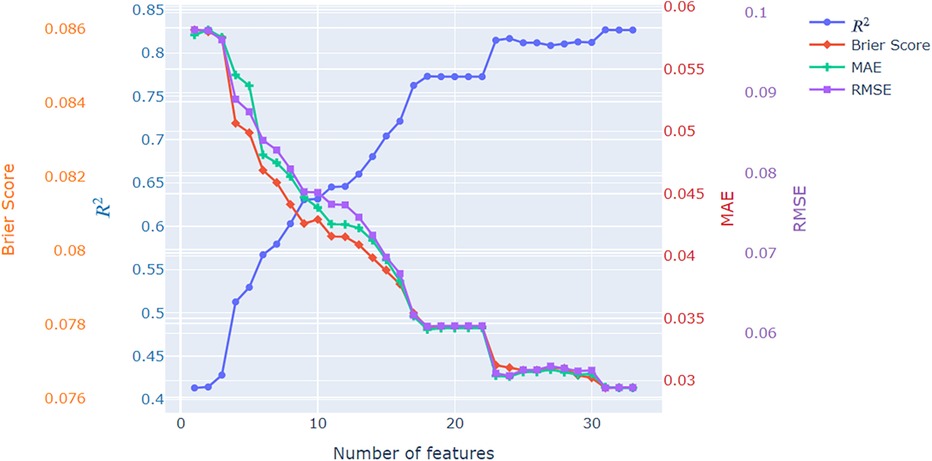
Figure 3. Fitting performance plots for the extended xG model when increasing the number of features.
4.2 Positional analysis via Bayesian models
For the second experimental case in this paper, we investigate the effects of the general player positions on the pitch to the xG values by performing a Bayesian hierarchical modelling approach. Baseline xG and Extended xG models are redeveloped by using the positional grouping effect and we obtained Bayes-xG1 and Bayes-xG2 models, respectively.
We commence with a more straightforward model that examines only a few features within the logistic regression framework. As mentioned in the above sections, the baseline xG model incorporates distance to the goal, shot angle, and their interaction as predictors. To assess the influence of the grouping variable, “general position” on xG, we calculate the differences in xG predictions between the single-level frequentist model and its hierarchical Bayesian counterpart, referred to as the Bayes-xG1 model, for each shot in the dataset.
Figure 4 illustrates the distributions of the xG adjustment, considering the general position within the hierarchical model for each position category. The observed distributions align well with the prior beliefs regarding the impact of the general position. Defenders exhibit a substantial number of negative xG adjustments in comparison to the baseline model’s xG predictions, with some adjustments reaching as low as 0.1. As anticipated, non-attacking midfielders display smaller xG adjustments, encompassing both positive and negative values. Contrary to expectations, attacking midfielders exhibit larger positive xG adjustments on average compared to strikers, who also generally have positive adjustments. This unexpected finding may stem from the fact that strikers, by shooting more frequently from high xG scoring positions, often possess sufficiently high xG values without requiring a significant positional adjustment. On the other hand, attacking midfielders frequently take shots from areas around the goal, where xG chances are lower, yet they excel in scoring due to their above-average attacking and scoring capabilities.
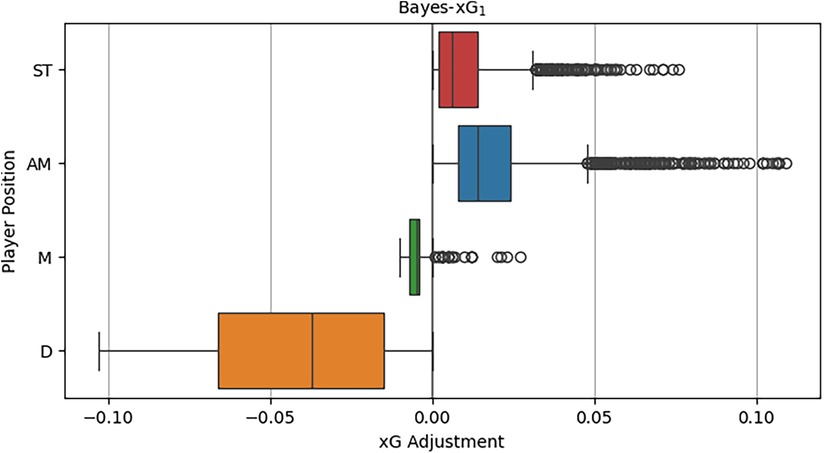
Figure 4. Distributions of xG adjustments by position of Bayes-xG1.
Figure 5 illustrates the shot locations categorised by general playing positions, normalised for each position. It highlights the notable concentration of chances for defenders positioned directly in front of the goal, providing a potential explanation for the observed reversals in Figure 4. Contrary to the theorised expectation from the analysis in Figure 4, attacking midfielders are not inclined to take shots from distant or challenging angles. In fact, on average, strikers exhibit a higher tendency for such shots. This discovery, coupled with the observation that attacking midfielders, on average, have larger positive xG adjustments than strikers, suggests that attacking midfielders may have a superior ability, on average, to convert high xG chances situated right in front of the goal compared to their striking counterparts.
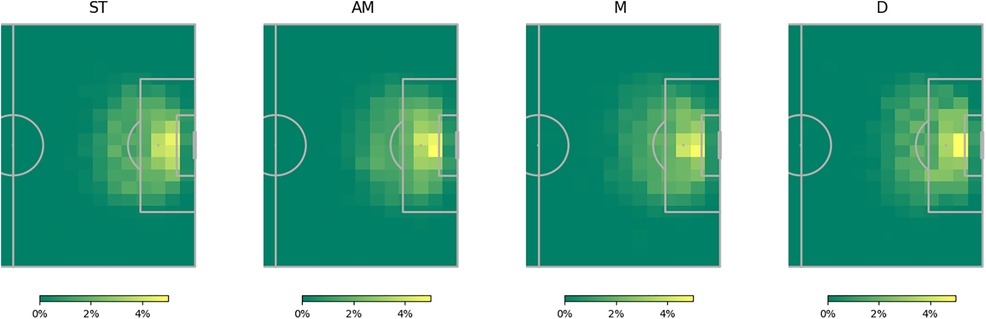
Figure 5. Normalized heatmap of shot locations by general position.
Before delving into the more intricate model analysis for Bayes-xG2, we aim to showcase a validation step to demonstrate the accuracy of the MCMC-based sampling technique employed in developing Bayesian models in this paper. To achieve this, we replicated the Bayesian analysis, this time utilising Bayes’ Formula in Equation (13)
This allowed us to conduct an analysis where the results of the baseline model could be adjusted using Bayes’ Theorem, and these adjusted outcomes were then compared to the results of the hierarchical model. The comparison aimed to assess the proximity between theoretical adjustments and model adjustments. The outcomes of this process are detailed in Table 5. Notably, the mean model adjustments closely align with the theoretical adjustments for each position, affirming that the model has effectively estimated the positional impact.
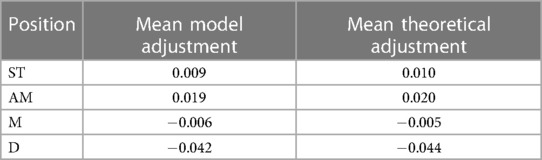
Table 5. Mean xG adjustment for each general position from Bayes-xG1 vs. theoretical adjustment of Baseline xG prediction using Bayes’ Theorem.
We proceed with our analysis by delving into the upgraded iteration of the Baseline model, referred to as the Extended model. Employing Bayes-xG2, this advanced model involves a positional analysis akin to its predecessor, Bayes-xG1. However, it incorporates numerous additional predictors, including factors such as opponents_in_radius and gk_distance_to_goal, aiming to enhance the baseline xG predictions. Upon inspecting the distributions of xG adjustments by position in Figure 6, it is evident that the values are notably smaller when compared to those derived from Bayes-xG1. Few adjustments now exceed 0.01 away from the baseline xG values. This observation implies that the supplementary predictors effectively contribute to position prediction. This indicates that xG advantages stem less from the player’s position and more from the specific play situation during shooting. For instance, while attackers generally enjoy better scoring chances on average, leading to positive xG adjustments in the basic model, the Extended model, by accounting for various features defining these improved scoring chances (e.g., one-on-ones), mitigates the impact of player position on xG adjustments.
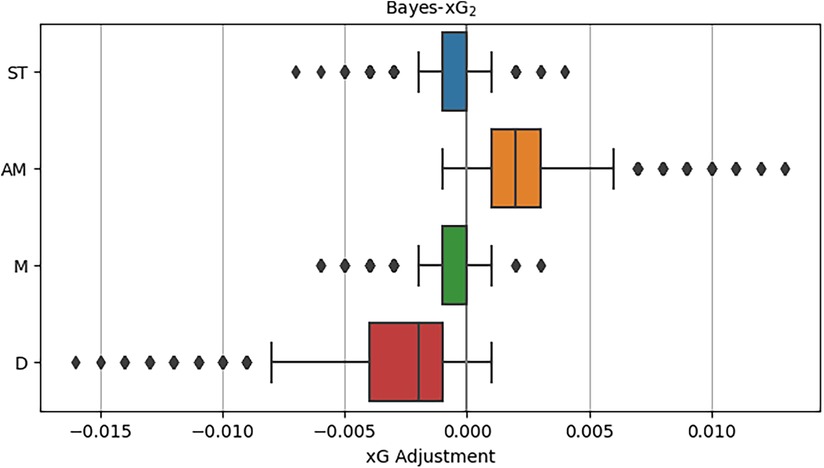
Figure 6. Distributions of xG adjustments for Bayes-xG2, where adjustment is hierarchical model prediction minus baseline model prediction - grouped by general position.
It is intriguing to examine the xG adjustments across the predictor ranges of “distance_to_goal” and “shot_angle.” Figure 7 illustrates these xG adjustments grouped by the position for both Bayes-xG models. In Figure 7A for Bayes-xG1, the convergence of each position towards an adjustment of 0 signifies that, at a certain distance, the xG value tends to be close to zero, regardless of other shot-related factors. Notably, defenders exhibit a slight dip in xG adjustments at the lowest distance before increasing. This suggests scenarios where defenders find themselves in goal-scoring positions, perhaps following set pieces or during a team’s pursuit in a match. The order of adjustments in Figure 4 aligns consistently across positions, with attacking midfielders having the highest positive adjustments, followed by strikers, and other midfielders showing minimal adjustment from the baseline model. Examining the “shot_angle” for Bayes-xG1 in Figure 7B, smaller values correspond to more challenging scoring opportunities, either due to being far from the goal or from tight angles. Defenders display gradually larger negative adjustments as the shot angle increases, reversing after a certain point for very high shot angles, likely corresponding to very close distances to the goal. Similar patterns emerge for other positions, with attacking midfielders having the largest positive xG adjustments, followed by strikers and other midfielders. For Bayes-xG2 model outputs in Figures 7C,D, the compensation of positional effects through additional predictors is evident. Despite a clear distinction in the effects of distance to the goal and shot angle for each position in Bayes-xG1, no significant differences between positions are observed in Bayes-xG2. The diminishing impact of position on xG adjustment is attributed to the diverse player abilities and roles within each position category. A distinct observation evident in both Figures 7C,D is that defenders exhibit consistent trends for all angles just below 0, whereas attacking midfielders mirror the same pattern but above the 0 line. Adjustments made to strikers’ and midfielders’ xG values are barely discernible, with values hovering around 0 across all shot angles.
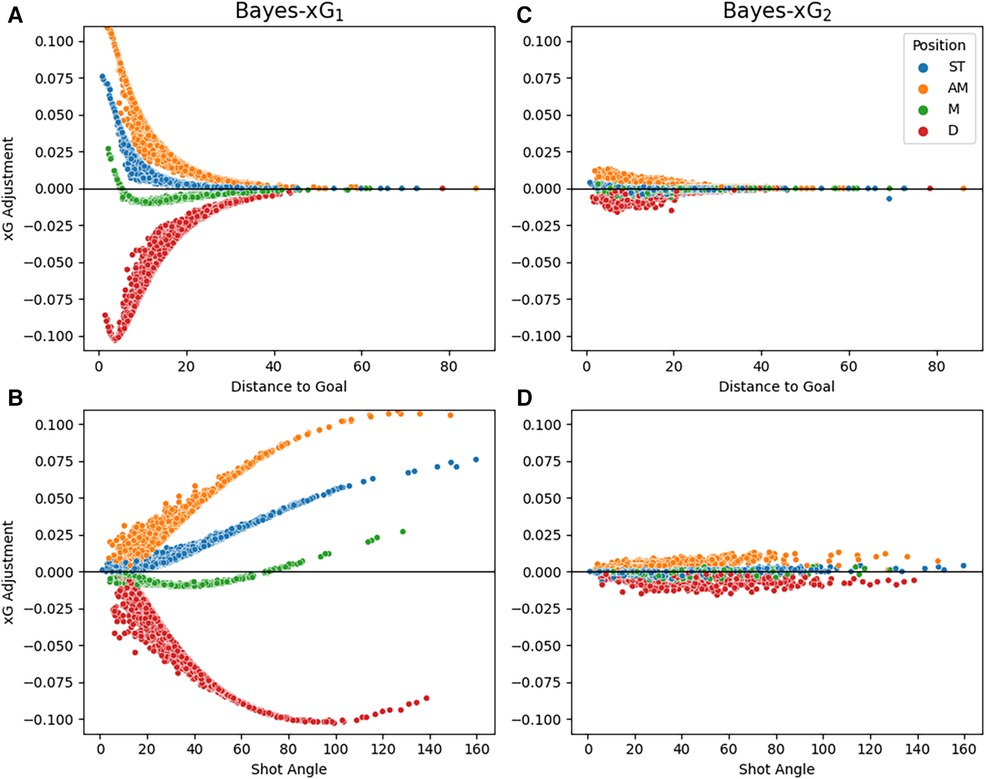
Figure 7. Comparison of point estimates for xG adjustments against distance_to_goal (A and C) and shot_angle (B and D) between Bayes-xG1 (A and B) and Bayes-xG2 (C and D), grouped by general position. Adjustments are hierarchical model prediction minus baseline model prediction.
To further explore the aforementioned phenomena, the next experimental case involves a player-specific analysis with Bayes-xG3, grouping data based on the player taking the shot rather than their general position.
4.3 Player-specific analysis via Bayesian models
In the context of the third experimental case explored in this paper, we introduced Bayes-xG3, derived from the Extended model, with players designated as the grouping variable in Bayesian hierarchical modelling. The focus here is to assess whether the models necessitate player-specific adjustments. Unlike the previous experimental case that centred on positional analysis, conducting a player-specific analysis poses increased complexity due to the considerably larger pool of candidates within the group, making the analysis more challenging and computationally intensive. Instead of individually representing each player in our group, a selective approach is employed, categorising the majority as “other” and opting for a few players with expected positive or negative xG adjustments. Player selection is based on the “conversion rate,” i.e., the percentage of shots scored. To ensure relevance, only players with a minimum of 50 shots are considered, and the chosen players, along with their statistics, are detailed in Table 6. Players like R. Pirès, S. Agüero, and J. Vardy, recognized for their prolific goal-scoring, are expected to have positive xG adjustments. Pirès, notably, exhibits an exceptional conversion rate in the data subset. Conversely, players like P. Coutinho and R. Barkley, with below-average conversion rates, might have slight negative xG adjustments, while J. Shelvey, who failed to convert any of his 51 shots in the data, is likely to have a more substantial negative xG adjustment.
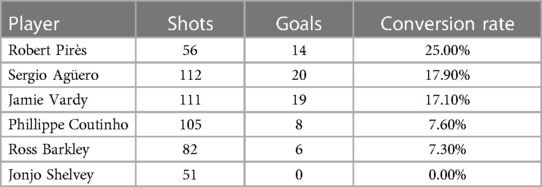
Table 6. Selected players for Bayes-xG3 and their goal-scoring statistics in the data set.
As explained in the preceding methodology section, the impact of each player will be characterised by a prior distribution, specifically a skewed normal distribution. The choice of distribution parameters is dependent upon the prior beliefs regarding a player’s proficiency as a goal scorer, with the parameter taking values of either 2 or 0. This selection is guided by qualitative beliefs about the players rather than direct utilisation of the data for informing the priors. Players such as Pirès, Agüero, Vardy, and Coutinho, acknowledged as talented attacking players, are attributed . In contrast, Barkley and Shelvey, who are not commonly associated with being top-tier attackers but possess other defining qualities in their game, are assigned .
Figure 8 illustrates the distributions of xG adjustments for individual players and the collective “other” players group. A prominent observation is the substantial positive xG adjustments for Robert Pirès, some reaching as high as 0.3 above the baseline xG. Notably, these adjustments persist even after incorporating additional predictors in Bayes-xG7 that were intended to eliminate group effects in the previous experimental analysis. Pirès also exhibits a wide spread of adjustments, ranging close to 0, indicating a diverse array of shot types. Some were high xG chances, requiring minimal adjustment, while others were more challenging but consistently converted by Pirès, resulting in significant positive adjustments. Agüero displays consistently positive xG adjustments, albeit smaller on average and with a narrower spread compared to Pirès. Intriguingly, Vardy and Coutinho exhibit minimal positive xG adjustments, not significantly greater than those of Barkley. Shelvey aligns with expectations, displaying substantial negative xG adjustments based on his conversion rate in the data. Lastly, the “other” group centres around 0 for xG adjustment, as anticipated, given its diverse player composition with no discernible group effect to capture.
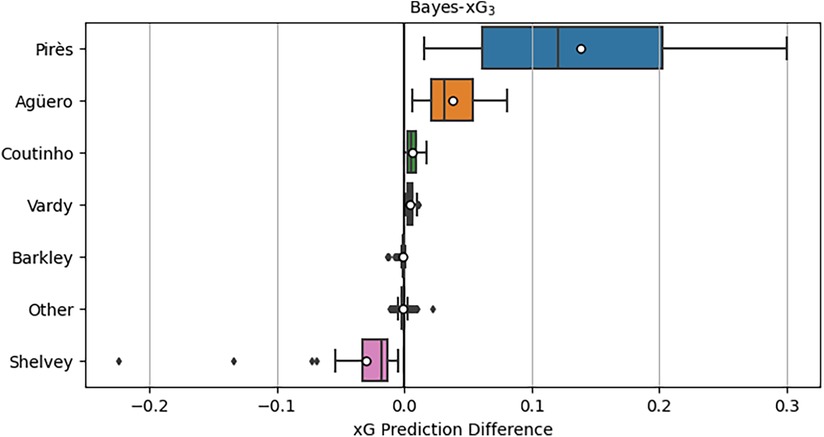
Figure 8. Distributions of xG adjustments for Bayes-xG3, where adjustment is hierarchical model prediction minus baseline model prediction - grouped by player. Mean xG for each player shown as “o” in boxplots.
Figure 9 displays the shot locations and outcomes for the selected players, offering insights into the findings presented in Figure 8. Beginning with Pirès, notable for his substantial positive xG adjustments, the observation centres on his efficiency in goal scoring despite a relatively low number of shots. His ability to score from challenging positions, such as both corners of the box and outside the area, contributes to the positive xG adjustments, indicating his prowess as a goal scorer even in demanding scenarios. Agüero and Vardy exhibit similar shot patterns, but the model assigns significantly higher positive xG adjustments to Agüero. This discrepancy may stem from the nature of Vardy’s shots being inherently high xG chances, like one-on-one opportunities, whereas Agüero manages to convert more challenging shots, resulting in larger adjustments. Comparing Vardy with Coutinho and Barkley, who exhibit similar xG adjustments in Figure 8, suggests that their goal-scoring patterns align with baseline xG values without substantial player adjustments. Lastly, Shelvey’s shot map lacks goals from various positions. While difficult-to-score shots receive minor adjustments, centrally located missed chances likely contribute to the notable negative adjustments, reflecting Shelvey’s poor conversion rates in this dataset.
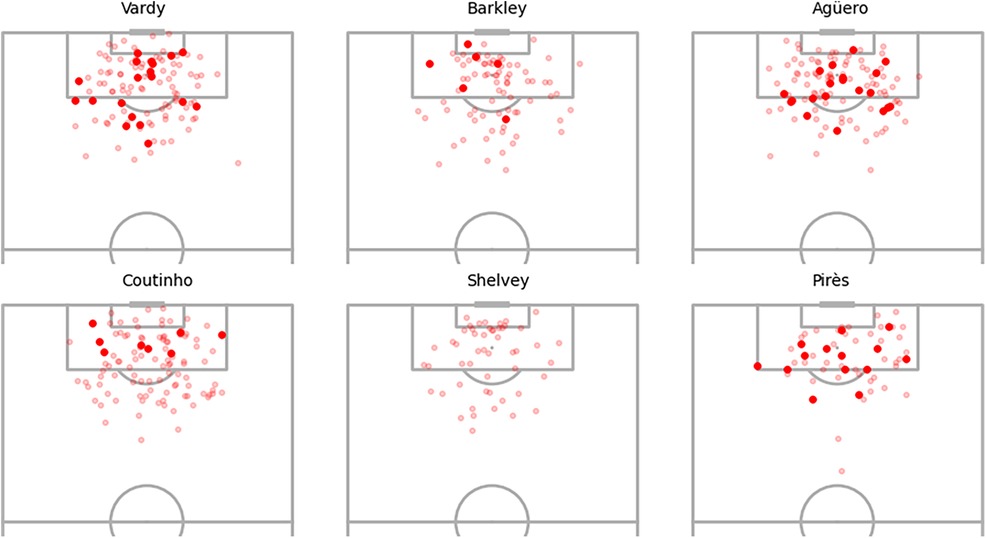
Figure 9. Selected player shot locations and goals.
Figure 10 displays the cumulative data for goals scored, baseline expected goals (xG) from the single-level model, and adjusted xG from the player-corrected model for the selected players in this analysis. The visual representation illustrates that, in comparison to the single-level model, the player-corrected model provides more accurate estimates of total goals scored by each player. Notably, players like Pirès and Agüero, who outperformed their baseline xG by scoring difficult chances, exhibit adjusted xG totals much closer to their actual goals scored. Conversely, Shelvey’s adjusted xG total is more aligned with the zero goals he scored, although it is crucial to emphasise that it is not precisely zero.
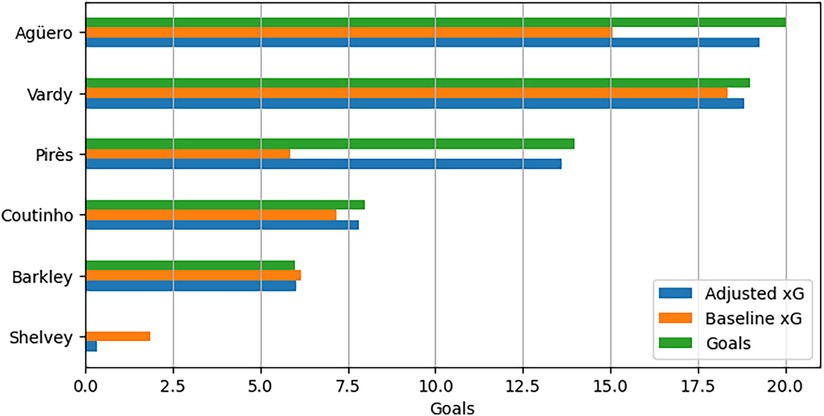
Figure 10. Comparison of baseline, Bayes-xG3 hierarchical predictions, and actual goals scored for selected players.
4.4 Extension into other leagues
To ascertain the generalizability of the conclusions drawn in this study beyond the Premier League dataset examined earlier and their applicability to football on a broader scale, as our fourth experimental case, a parallel analysis was conducted using data from Spain’s La Liga and Germany’s Bundesliga. The datasets for these leagues encompass approximately 19,000 and 7,500 shots, respectively. It is noteworthy that the La Liga dataset is notably influenced by Barcelona, primarily due to the fact that StatsBomb predominantly released data from games in which Lionel Messi, a prominent Barcelona player, participated.
Figure 11 displays the distributions of xG adjustments for the Bundesliga and La Liga, which serve as the data sets for the Bayes-xG1 and Bayes-xG2 models. The outcomes for both leagues closely resemble those of the Premier League in the Bayes-xG1 model. The average adjustments follow a consistent order across all leagues, with attacking midfielders exhibiting the most positive adjustments, followed by strikers, other midfielders, and then a substantial drop to defenders. Additionally, the magnitudes of these adjustments exhibit similar patterns. The Bayes-xG2 model reveals a noteworthy reduction in the magnitude of xG adjustments, a trend observed consistently across all leagues. Although the Bayes-xG2 model indicates slightly larger adjustment magnitudes for the additional leagues, the variation is not significant enough to alter the model results significantly when compared to those of the Premier League.
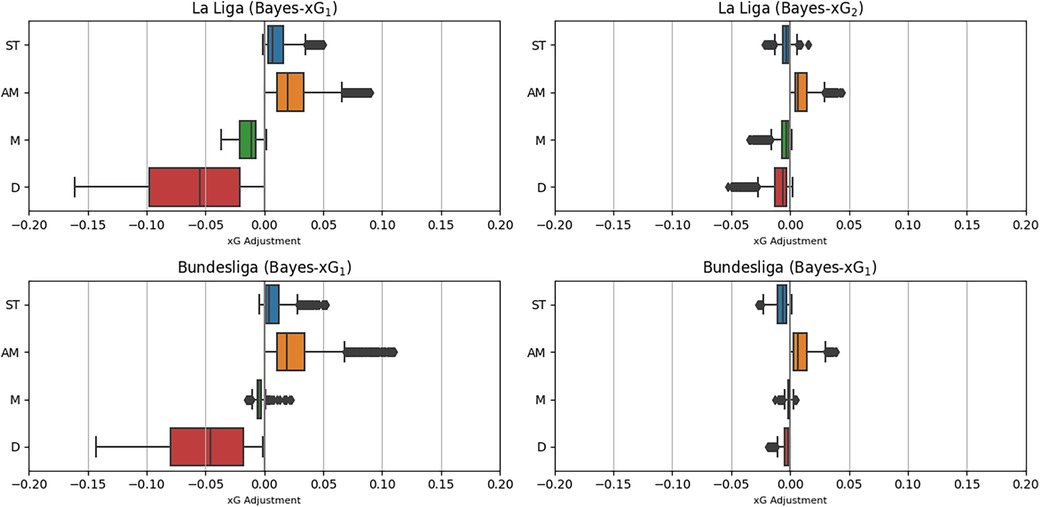
Figure 11. Distributions of xG adjustments for Bayes-xG1 and Bayes-xG2 for Spanish La-Liga and the German Bundesliga.
To conduct a player-specific examination of Bayes-xG3, the inclusion of new players from both leagues was necessary. The selection process mirrored that of the Premier League, where players were listed based on their conversion rates in the data sets, encompassing both the best and worst performers. Tables 7 and 8 display the chosen players and their respective statistics for La Liga and the Bundesliga, providing a comprehensive overview of the selected players’ performance in each league.
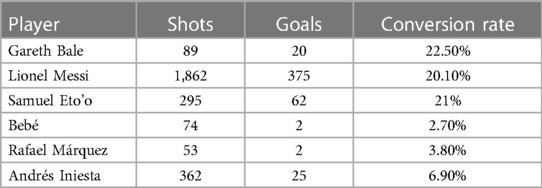
Table 7. Selected players for Bayes-xG3 and their scoring statistics from La Liga data set.
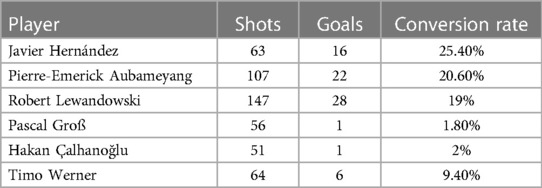
Table 8. Selected players for Bayes-xG3 and their scoring statistics from Bundesliga data set.
Given these conversion rates, it is reasonable to infer that the top three performers in each table would, on average, experience positive adjustments in expected goals (xG), while the bottom three would, on average, encounter negative or negligible xG adjustments. The visual representation in Figure 12 illustrates these adjustments for players in both the Spanish La Liga (A) and the German Bundesliga (B). As anticipated, players like Bale, Messi, and Eto’o from La Liga predominantly exhibit positive xG adjustments, aligning with expectations. Conversely, other selected players either display minimal adjustments or predominantly negative adjustments. In the Bundesliga context, Figure 12B reaffirms many anticipated outcomes. An intriguing finding is that Aubameyang, despite maintaining a high conversion rate, exhibits predominantly negative xG adjustments. This suggests that the goals he scores tend to be from chances with already high expected goals, contrary to some expectations.
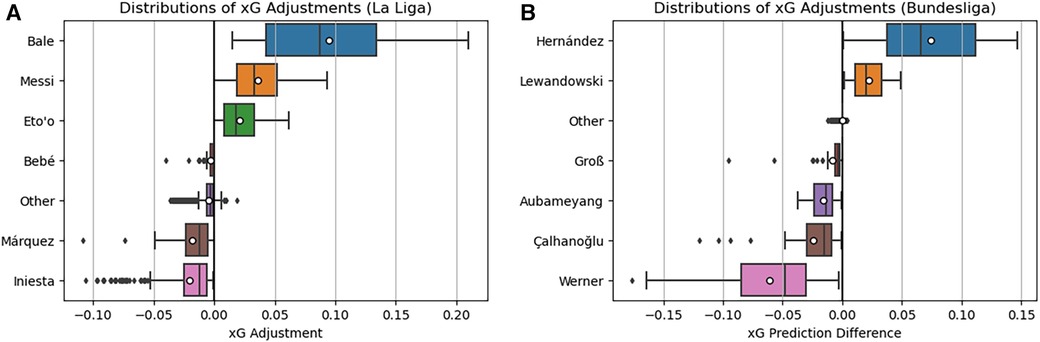
Figure 12. Distributions of xG adjustments for Bayes-xG3 for Spanish La-Lida (A) and the German Bundesliga (B). Mean xG for each player is shown as “o” in boxplots.
Figure 13 illustrates the shot locations of Bundesliga players, validating that the majority of Aubameyang’s shots originate from within the penalty area. This observation implies that these shots likely possess additional characteristics, such as one-on-one opportunities, making them high expected goals (xG) chances. In contrast, Timo Werner exhibits minimal goals despite a comparable shot map, and the substantial negative xG adjustments suggest that he should have scored more from these shot positions. On a different note, Çalhanoğlu records relatively few goals from shots that present higher difficulty due to their distance from the goal, resulting in slightly fewer negative xG adjustments.
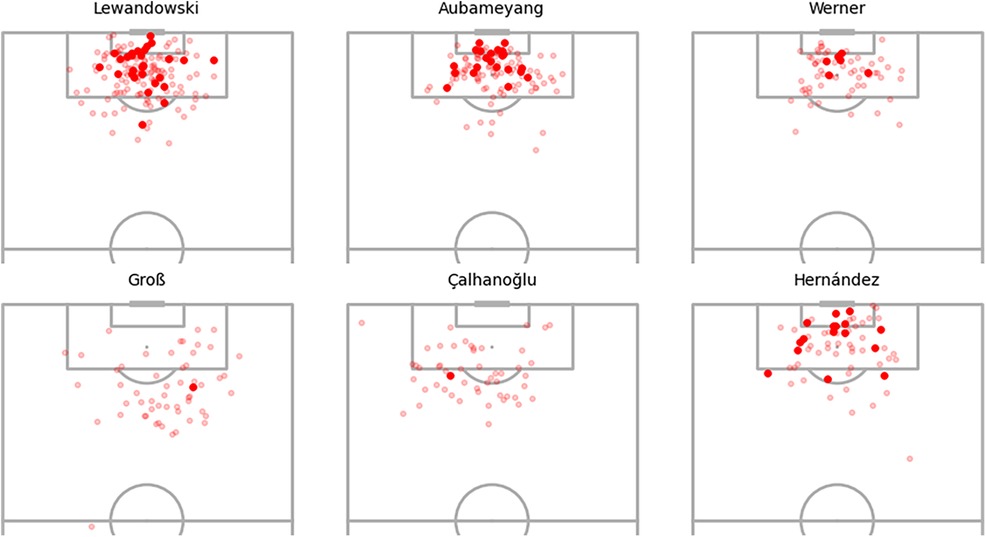
Figure 13. Selected player shot locations and goals for the German Bundesliga.
In conclusion, the findings from both La Liga and the Bundesliga verify the results obtained in the Premier League sections above. Notably, there is an indication of a positional impact on xG in a fundamental xG model (Bayes-xG1), but such effects markedly diminish with the adoption of a more intricate model (Bayes-xG2). Nevertheless, even with the extended model, there remains evidence of player-specific effects on xG, providing a quantitative measure of how certain players excel or lag behind others in scoring.
4.5 Analysing the choice of priors
The impact of prior choices is particularly evident when assessing the efficiency and accuracy of Bayesian models. Sensitivity to the choice of priors is crucial, and careful consideration is needed to strike a balance between the informativeness of priors and their impact on computational efficiency. In Bayesian hierarchical modelling, this emphasizes the need for a thoughtful approach to prior selection, ensuring that the chosen priors align with the characteristics of the data and contribute to the model’s robustness and reliability.
The selection of prior distributions holds significant importance in Bayesian hierarchical modelling for several reasons. Firstly, the choice of prior widths plays a pivotal role. Employing overly wide priors, encompassing a large range of values, may necessitate an extensive number of samples for the model to converge to the true values of the variables, leading to prolonged computation times. Conversely, if the prior distributions are excessively narrow and the true values are unlikely to be sampled, the model’s outcomes may be biased and inaccurate.
To evaluate the appropriateness of the chosen prior distributions, a reassessment will be conducted by refitting the extended baseline model (single-level) with different priors, followed by a comparison of predictions. The sets of priors under consideration include (1) the existing priors given in Table 3, (2–3) a pair of wide-tight uniform priors, (4–5) a pair of wide-tight normal priors, and (6) a deliberately ill-suited set of priors. The choices of priors for the cases of (2–6) are presented in Table 9. For the uniform priors, each variable has been given a wide and tight uniform distribution pair. Similarly, for normal priors, zero mean priors are chosen with two different values to represent a wise and tight value support. On the other hand, the ill-suited priors have been given very narrow distributions by using a small value for . Moreover, some of the skews in the distributions have been flipped such that the prior belief about the effect is the reverse of what was actually used.
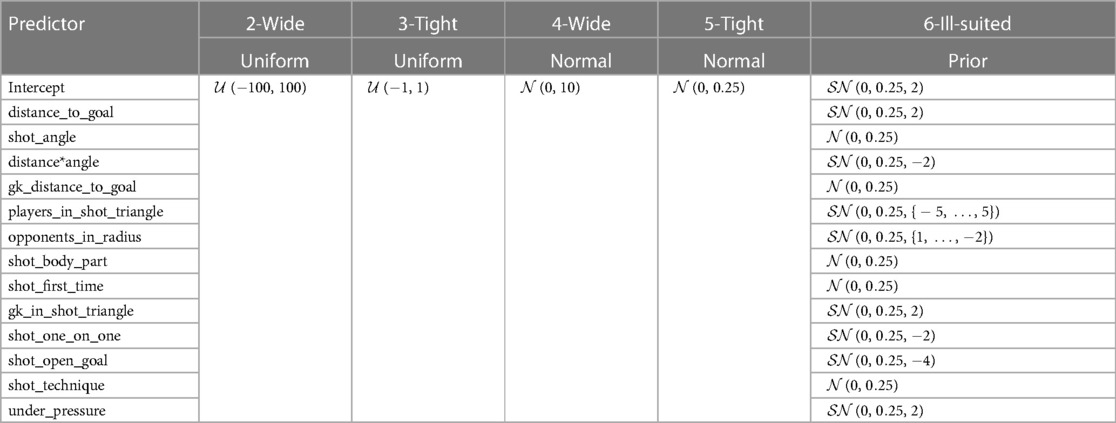
Table 9. Choices of prior distributions for analysing the impact of prior choice on results.
Furthermore, the predictions generated by these models will be juxtaposed with those of the extended non-Bayesian model on the same data, providing a baseline for assessing the efficacy of the selected priors in yielding accurate predictions.
Figure 14 illustrates the distributions of predictions generated by each of the prior models. The model utilising wide uniform prior distributions exhibits notably poor performance when compared to both the non-Bayesian baseline model and the Statsbomb benchmark, displaying a considerable spread of predictions. On the other hand, employing tight uniform priors leads to more restricted predictions, although the average expected goals (xG) predictions tend to be relatively smaller. The utilisation of a tight normal prior yields similar performance, primarily underestimating xG values, particularly with the highest xG values concentrated around 0.8. In contrast, adopting wide normal priors results in enhanced performance compared to the tight setting, with predictions following a similar trend to the existing prior configuration. It is noteworthy that the mean and interquartile ranges of both normal priors depicted in Figure 14 exhibit a favourable correspondence with the baseline and benchmark models.
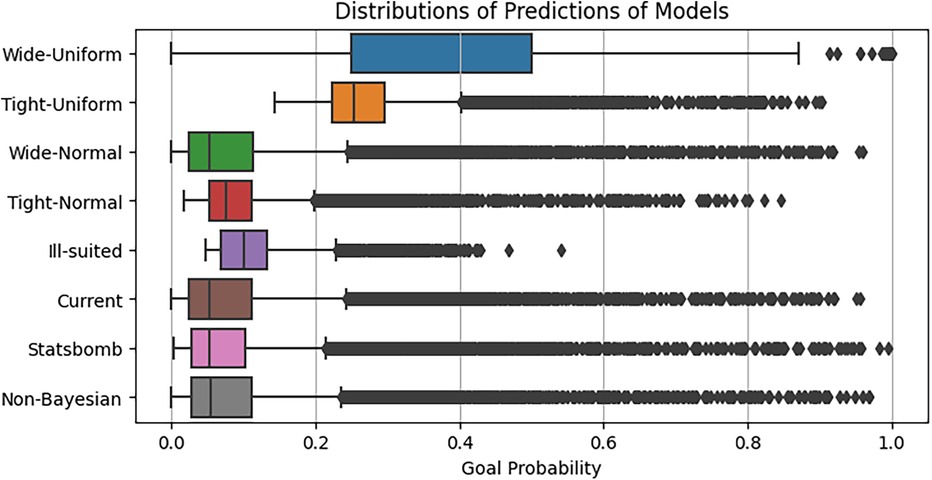
Figure 14. Distributions of xG predictions for each of the extended single-level Bayesian model, with different choices of prior distributions.
On the other hand, as depicted in Figure 14, ill-suited priors result in a notably narrow spread, with scarce xG predictions exceeding 0.5. Despite this, the ill-suited priors exhibit improved performance compared to uniform priors in terms of aligning the average with the baseline and benchmark predictions and maintaining a similar-sized interquartile range. This improved performance is likely attributed to the greater number of samples utilised for parameter estimation. In the case of the model with uniform priors, the same number of samples, however, prevented the model from converging to optimal parameter values, resulting in poor predictions. While, given more samples, this model could eventually yield accurate results, the computational time required is uncertain and could be extensive. The model with the existing prior distributions outperforms the others significantly, closely resembling the distribution of baseline and benchmark models’ predictions while also offering valuable insights based on player positions.
In the 5th experimental case’s final analysis, we explore the mean signed deviation (MSD) values between each prior case and the predictions of the Non-Bayesian extended model. The selection of MSD aims to emphasize instances of over or underprediction based on the prior choice, using the mean spread of MSD values as a performance metric. Figure 15 illustrates the distributions of MSD values for each prior group through various box plots. Notably, Figure 15 highlights the considerable performance of the Wide Normal prior choice, exhibiting results akin to the current prior approaches. Its interquartile range closely aligns with the current prior case, albeit with a few more instances of over-predicted outliers. It is crucial to observe that both uniform priors’ MSD values are distributed around zero, despite with a broader spread. In contrast, the Tight-Normal and Ill-suited prior cases exhibit notably poor performance, marked by a higher frequency of overestimated xG values compared to the Non-Bayesian extended model.
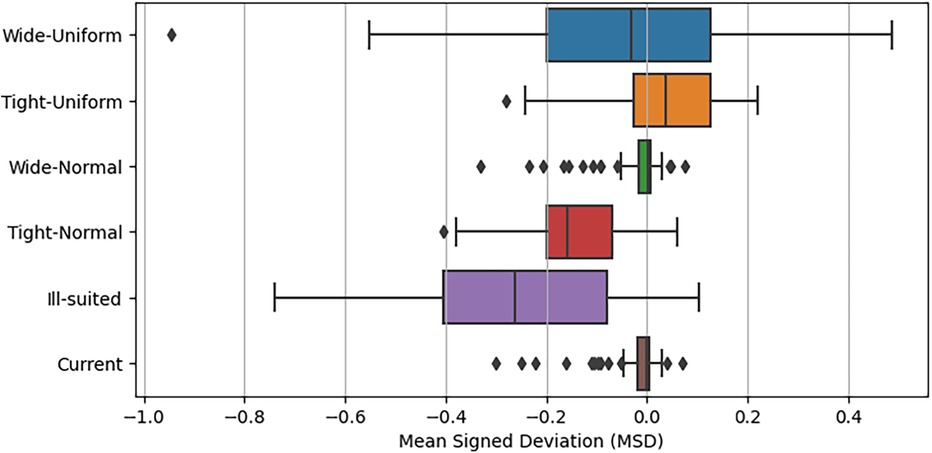
Figure 15. Mean signed deviation distributions for each analysed prior choice.
4.6 Uncertainty quantification
The final experimental case of this study involves examining and reflecting on the uncertainty inherent in the models and priors proposed and employed. While motivating for a Bayesian approach in earlier sections, we highlighted how Bayesian models treat parameters as unknowns and assign random variables to represent the uncertainty surrounding these parameters. Each of these random variables is linked to a probability distribution, ultimately yielding a posterior distribution of estimations as a result of the inference process. In this subsection, unlike the previous experimental cases, we visualize and discuss the posterior predictive densities of model outcomes to more accurately quantify the uncertainty offered by Bayesian xG models.
We initiate by examining the positional Bayesian models of Bayes-xG1 and Bayes-xG2 in this section. For each instance specific to a position in the English Premiership dataset, we selected a shot with a Statsbomb xG of approximately 0.15, resulting in a goal. Subsequently, we illustrated the posterior predictive densities of these two Bayesian positional models alongside their corresponding 95% high-density intervals (HDI) (2.5% from each tail). Figures 16A–D illustrate the outcomes of this uncertainty analysis for the D, M, AM, and ST positions, respectively. Additionally, Figure 16E presents a boxplot distributional analysis of the 95% HDI for each position obtained from both Bayesian models.
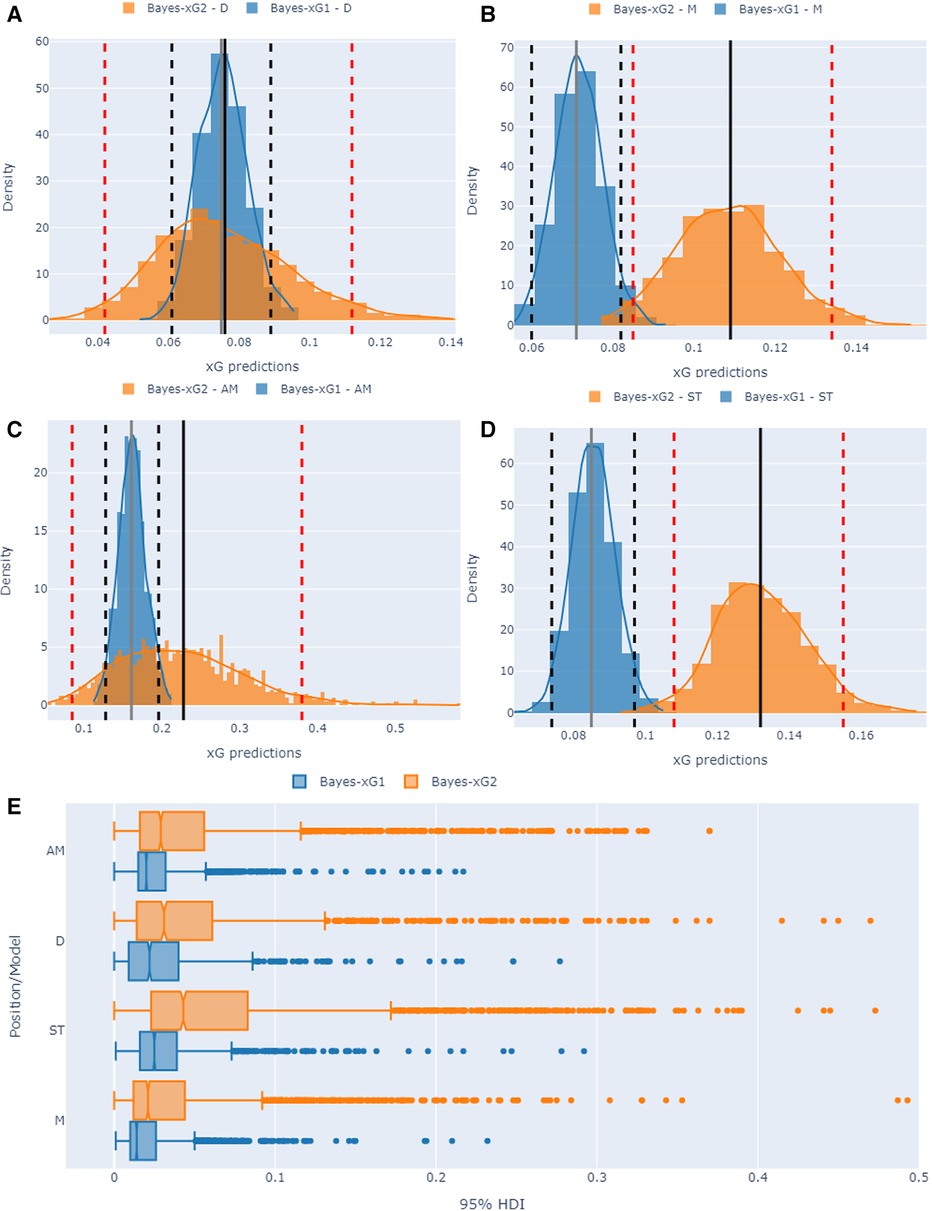
Figure 16. Uncertainty quantification visuals for positional Bayesian models (Bayes-xG1 and Bayes-xG2). Histograms in (A) to (D) refer to comparing two Bayesian models for the same shot with a Statsbomb xG of 0.15. Dashed vertical lines refer to 2.5% and 97.5% HDI whilst solid vertical lines refer to mean predicted xG values. (E) shows 95% HDI box plots for each position/model pair.
Analyzing Figures 16A–D, it becomes evident that the Bayes-xG2 model consistently exhibits higher uncertainty in its xG predictions across all positional models. This is indicated by its broader shape and lower probability peak, as observed in the analysis, where the 95% highest density interval (HDI) values consistently surpass those of the baseline positional model, Bayes-xG1. Conversely, Bayes-xG1 appears to consistently underestimate xG values compared to Bayes-xG2, despite its narrower HDI ranges. This discrepancy can be understood from a probabilistic standpoint, where the enhanced positional model of Bayes-xG2, incorporating more comprehensive engineered features, challenges the inference process with a more nuanced perspective. This is reflected in its wider 95% HDI values, which effectively account for positional effects. This observation is further supported by Figure 16E, where all Bayes-xG2 models demonstrate broader 95% HDI values across all positional parameters. Additionally, it is noteworthy that HDI intervals for defensive (D) and striker (ST) positions exhibit greater width compared to midfield (M) and attacking midfielder (AM) positions. This implies that the positional corrections applied to xG predictions are more pronounced for defensive and striker positions, encompassing both positive and negative adjustments.
The higher uncertainty outcomes of Bayes-xG2 model may initially seem concerning, but it actually signifies a more robust and adaptable model that performs well in capturing the intricacies of football dynamics. It reflects the model’s ability to account for the complexity and variability inherent in shots in football matches, where numerous factors can influence goal-scoring opportunities. The richer set of engineered features in Bayes-xG2 enables it to capture more nuanced patterns and positional effects, thus providing a more comprehensive assessment of xG probabilities with wider HDIs.
For the player-specific analysis in our study, we examined the posterior predictive results derived from the extended player model of the Bayes-xG3 model. Figure 17 illustrates a boxplot distributional analysis of the 95% HDIs for six players across three leagues. Upon reviewing the obtained 95% HDI values for our player set from the English Premier League (EPL), La Liga, and Bundesliga using the Bayes-xG3 model, several observations emerge. Notably, players with significant positive or negative xG corrections, such as Hernandes (), Werner (), Bale/Messi (), Shelvey (), and Pires (), exhibit higher HDI values. Particularly, among the top positively corrected players from each league (Hernandes, Bale, and Pires), we observe markedly low median HDIs with numerous outliers. This suggests that these players’ shooting abilities yield nuanced and detailed posterior predictive estimates, indicating their scoring capabilities differ significantly from the average player in the dataset. Consequently, this heightened uncertainty in their model outcomes serves as a meaningful indicator within the context of our study.
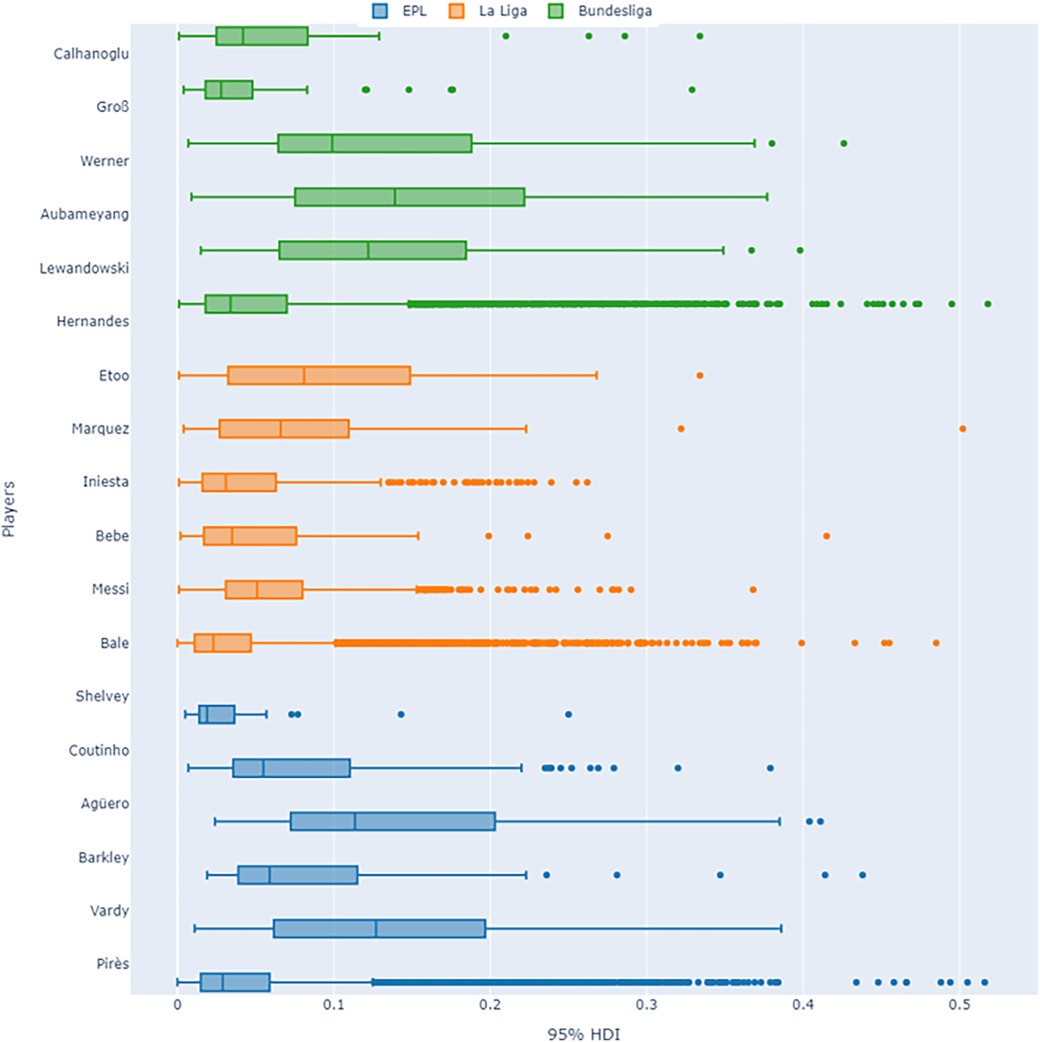
Figure 17. Uncertainty quantification visuals for player-specific Bayesian model (Bayes-xG3).
Additionally, higher uncertainty in Bayes-xG3 model outcomes provides more insightful perspectives for the performance analysis of players. When a player’s predicted outcomes exhibit greater variability, it implies that their performance is not easily characterised by conventional metrics alone. Instead, it suggests a more complex and multifaceted contribution to their team’s performance. By acknowledging and delving into this uncertainty, we believe one can uncover hidden strengths or weaknesses that may not be apparent when considering only deterministic and generalised predictions. Thus, embracing uncertainty opens avenues for a deeper understanding of player performance dynamics and facilitates more informed decision-making in player evaluation and team strategy development.
The final experimental set of this paper addresses the assessment of uncertainty arising from the selection of priors for the Bayesian models proposed. Alongside the hierarchical modelling of model parameters, the choice of priors represents a crucial aspect in the application of Bayesian models. While we previously examined the impact of various priors in the preceding subsection, our focus now shifts to evaluating the uncertainty inherent in the single-level extended Bayesian model resulting from the selection of prior distributions. Figure 18 illustrates three subplots depicting this analysis. The first subplot (A) showcases a boxplot distributional examination of the 95% HDIs for each prior. Following this, a specific shot from the EPL dataset with a Statsbomb xG value of approximately 0.5 is utilized to generate posterior predictive estimates for each prior. These estimations are displayed in the form of a distribution plot (B) and a rug plot (C).
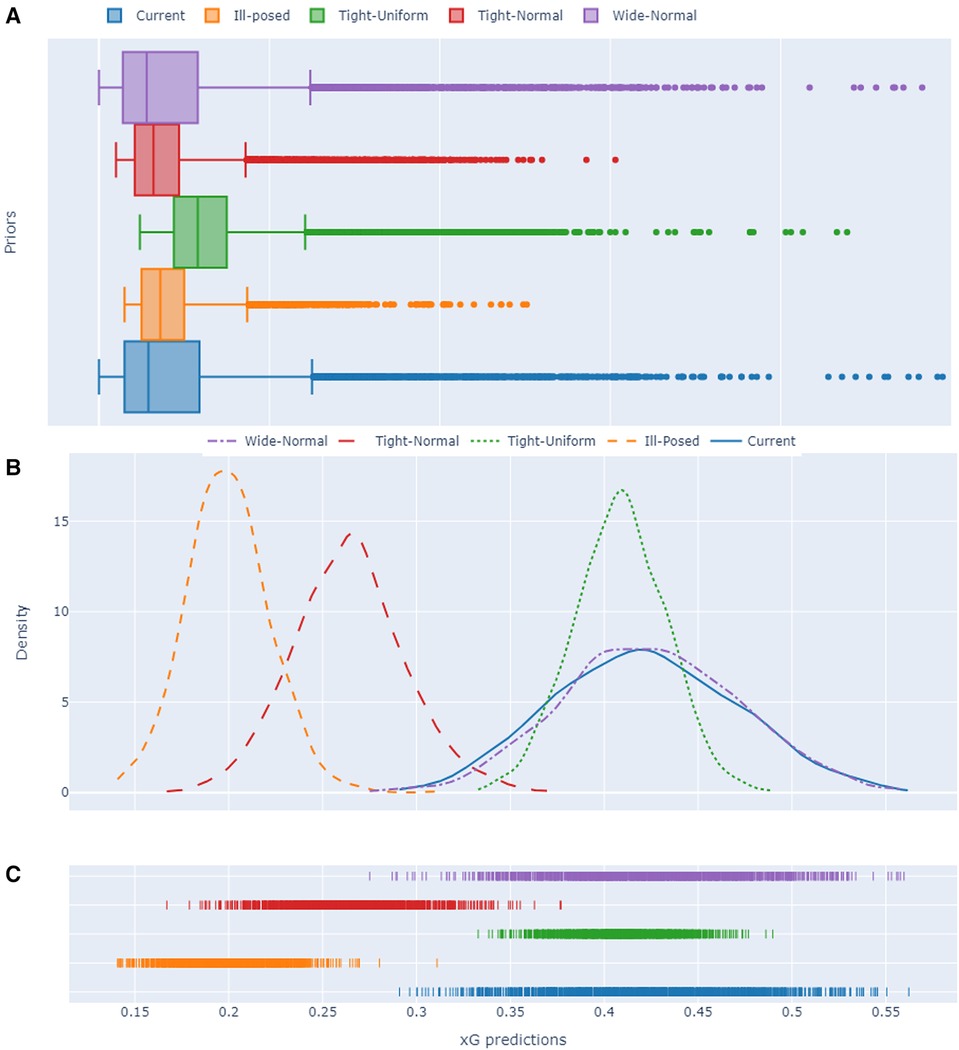
Figure 18. Uncertainty quantification visuals for different prior choices associated with the extended single-level Bayesian model. (A) 95% HDI box plots, (B) Posterior predictive estimate distribution plots and (C) rug plots for a randomly selected shot from the EPL data set with a Statsbomb xG value of approximately 0.5.
The issue of high uncertainty persists in the analysis of the best-performing models. As depicted in Figure 18A, both the proposed priors and Wide-Normal priors demonstrate comparable performance, with their HDI values notably larger than those of the less informative priors, Ill-posed and Tight Uniform. Upon examining the xG predictions under different prior selections in Figures 18B,C, it becomes evident that although less informative priors yield lower uncertainty, their xG predictions tend to be significantly underestimated, approximately around 0.2 and 0.27 for Ill-posed and Tight-Normal priors respectively. Conversely, the remaining three prior choices yield similar xG predictions, with the Tight-Normal model exhibiting less uncertainty. Notably, the proposed and Wide-Normal priors, with their posterior predictive outcomes characterised by high uncertainty, offer a broader range of variability in xG predictions.
5 Final remarks & conclusion
The objective of this study was to explore whether there exist distinct effects based on player position on expected goal (xG) values, suggesting that different positions or players may exhibit specific xG adjustments for given scoring opportunities. The hypothesis was that proficient attacking players, such as strikers, attacking midfielders, or those recognised for their offensive prowess, would demonstrate positive xG adjustments. In contrast, players less renowned for their attacking contributions, such as defenders or those with defensive roles, were expected to show negative xG adjustments.
To reach the objective mentioned above, this study has developed several Bayesian models to evaluate the influence of a player’s position and individual player effects on xG predictions. Initially, a basic xG model (Baseline xG), incorporating only distance to the goal, shot angle, and their interaction, indicated positional effects on xG (Bayes-xG1). Strikers and attacking midfielders exhibited positive xG adjustments, midfielders displayed minimal adjustments, while defenders had notably negative xG adjustments on average. However, the introduction of additional predictors in the models diminished the positional effects to the extent that they became almost insignificant (Extended xG), suggesting that player position had minimal impact on xG when considering more shot-related factors (Bayes-xG2). Subsequently, player effects were explored using the extended model employed for the second positional-effects model (Bayes-xG3), grouping the data based on the player’s shooting rather than the shooter’s position. The model was illustrated using six players from each dataset from three of the European Top 5 leagues, revealing significant player effects on xG even when controlling for various shot-related factors. These effects were diverse in direction, notably positive for R. Pirés (as well as for G. Bale and J. Hernandez) and negative for J. Shelvey (as well as for A. Iniesta and T. Werner).
The indication that there exist player-specific effects in determining goal probability could prove beneficial in football scouting and player selection. By computing adjusted xG values for various players and comparing these adjusted values to their non-adjusted counterparts, as demonstrated in this analysis, it becomes possible to distinguish players who excel at converting challenging opportunities from those who consistently find themselves in advantageous positions. Examining the results for the English Premier League dataset, particularly for J. Vardy, reveals that his total adjusted xG is not significantly different from his baseline xG (see Figure 10). This suggests that, given the quality of chances Vardy receives, he scores at a relatively average rate. On the other hand, S. Agüero demonstrates a more consistent ability to score from more challenging positions, evident in his larger adjusted xG. It is important to note that this observation does not imply that Agüero is a superior player or attacker compared to Vardy. Instead, it suggests that, on average, Agüero is more adept at converting chances with lower xG values than Vardy, indicating proficiency in scoring from less favourable situations.
It is important to acknowledge that there might also be team-related influences at play in this context. To further compare Vardy and Agüero, Vardy is part of a Leicester team known for its high-tempo and direct attacking style. This approach likely leads to shooting scenarios where the ball is played behind the defence, creating situations with fewer defenders to obstruct or impede a shot. This dynamic often results in one-on-one opportunities with the goalkeeper, contributing to Vardy consistently receiving numerous high xG chances. Conversely, Agüero played for one of the top teams in the league, causing opponents to adopt a more conservative approach. Teams facing Manchester City tend to minimise space, making chances more challenging with multiple players in the shot triangle and other complicating factors. We also recognise a potential limitation of the player-specific analysis proposed in this study concerning average-performing players. Our analysis emphasises players who either exceed their expected goals (xG) significantly or fall short, potentially overlooking consistent players who consistently score high xG but also miss smaller xG opportunities. This does not imply that these players are unworthy of analysis; rather, they represent player profiles that are less complex and easier to predict. However, effectively addressing the nuances of consistent players of this nature falls outside the scope of our current paper but remains an area for future research exploration.
Lastly, the examination of uncertainty analysis, particularly in the context of position-specific and player-specific corrections on xG, illuminates crucial insights into the intricacies of performance assessment in sports analytics. Through methodologies like Bayesian regression and posterior predictive distributions, researchers can effectively quantify and interpret the variability in xG predictions, taking into account factors such as prior knowledge, model parameters, and observed data. The observation of higher uncertainty in certain player positions or individual player corrections underscores the complexity and variability inherent in player performance dynamics. This increased uncertainty, while concerning and challenging, presents valuable opportunities for deeper insights and more precise evaluations. By acknowledging and incorporating uncertainty into the analytical framework, future studies can enhance the accuracy and reliability of xG predictions, ultimately leading to more informed decision-making processes and strategic interventions in sports management, scouting and coaching.
The Bayesian modelling results were collocated with non-Bayesian, or frequentist, modelling. Particularly in the case of player correction, Bayesian modelling offers a significant advantage by capturing uncertainty through posterior distributions rather than relying solely on point estimates. This becomes particularly advantageous when dealing with younger players with limited match experience, as Bayesian hierarchical modelling effectively addresses data groups with few observations. Regardless, Bayesian modelling is rarely used in the literature of football analytics. Beyond its applications in scouting and player selection, Bayesian hierarchical modelling holds promise for various metrics in football. For instance, the assessment of injury risk among players is a common practice in large football clubs, where certain players may have a higher overall susceptibility to injuries. Hierarchical modelling, in this context, has the potential to provide more accurate assessments of individual players’ injury risks by considering their specific injury history.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://github.com/statsbomb/open-data.
Author contributions
AS: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing; OK: Conceptualization, Methodology, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article.
Funding was provided by Cardiff University.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Smith R. Expected Goals: The Story of How Data Conquered Football and Changed the Game Forever. London: Mudlark - HarperCollins Publishers (2022).
2. Tippett J, The Expected Goals Philosophy: A Game-Changing Way of Analysing Football. London: Wydawca Nieznany (2019).
3. Aberle M, Figdor L, Mongrand L, Janetzke M. The Tech Behind the Bundesliga Match Facts Xgoals: How Machine Learning is Driving Data-Driven Insights in Soccer. AWS Machine Learning Blog (2020). Available online at: https://aws.amazon.com/blogs/machine-learning/the-tech-behind-the-bundesliga-match-facts-xgoals-how-machine-learning-is-driving-data-driven-insights-in-soccer/ (accessed September 1, 2024).
4. Brechot M, Flepp R. Dealing with randomness in match outcomes: how to rethink performance evaluation in European club football using expected goals. J Sports Econ. (2020) 21:335–62. doi: 10.1177/1527002519897962
5. Herold M, Goes F, Nopp S, Bauer P, Thompson C, Meyer T. Machine learning in men’s professional football: current applications and future directions for improving attacking play. Int J Sports Sci Coaching. (2019) 14:798–817. doi: 10.1177/1747954119879350
6. Lucey P, Bialkowski A, Monfort M, Carr P, Matthews I. Quality vs quantity: improved shot prediction in soccer using strategic features from spatiotemporal data. In 8th MIT Sloan Sports Analytics Conference; 2005 Feb 27–28; Boston Convention and Exhibition Center, Boston, MA, United States. (2015).
7. Anzer G, Bauer P. A goal scoring probability model for shots based on synchronized positional and event data in football (soccer). Front Sports Active Living. (2021) 3:1–15. doi: 10.3389/fspor.2021.624475
8. Madrero Pardo P. Creating a model for expected goals in football using qualitative player information (Master’s thesis). Universitat Politècnica de Catalunya.
9. Fairchild A, Pelechrinis K, Kokkodis M. Spatial analysis of shots in MLS: a model for expected goals and fractal dimensionality. J Sports Anal. (2018) 4:165–74. doi: 10.3233/JSA-170207
10. Cavus M, Biecek P. Explainable expected goal models for performance analysis in football analytics. In: 2022 IEEE 9th International Conference on Data Science and Advanced Analytics (DSAA). IEEE (2022). p. 1–9.
11. Hewitt JH, Karakuş O. A machine learning approach for player and position adjusted expected goals in football (soccer). Frankl Open. (2023) 4:100034. doi: 10.1016/j.fraope.2023.100034
12. Spearman W. Beyond expected goals. In: Proceedings of the 12th MIT Sloan Sports Analytics Conference (2018). p. 1–17.
13. Joseph A, Fenton NE, Neil M. Predicting football results using Bayesian nets and other machine learning techniques. Knowl Based Syst. (2006) 19:544–53. doi: 10.1016/j.knosys.2006.04.011
14. Zambom-Ferraresi F, Rios V, Lera-López F. Determinants of sport performance in European football: what can we learn from the data? Decis Support Syst. (2018) 114:18–28. doi: 10.1016/j.dss.2018.08.006
15. Tureen T, Olthof S. “Estimated Player Impact” (EPI): quantifying the effects of individual players on football (soccer) actions using hierarchical statistical models. In: StatsBomb Conference Proceedings. StatsBomb (2022).
16. Baio G, Blangiardo M. Bayesian hierarchical model for the prediction of football results. J Appl Stat. (2010) 37:253–64. doi: 10.1080/02664760802684177
17. Blanco LB, Ferreira PH, Louzada F, Nascimento DC. Is football/soccer purely stochastic, made out of luck, or maybe predictable? how does Bayesian reasoning assess sports? Axioms. (2021) 10:1–17. doi: 10.3390/axioms10040276
18. Eggels H, van Elk R, Pechenizkiy M. Expected goals in soccer: explaining match results using predictive analytics. In: The Machine Learning and Data Mining for Sports Analytics Workshop. Vol. 16 (2016).
19. Mead J, O’Hare A, McMenemy P. Expected goals in football: improving model performance and demonstrating value. PLoS One. (2023) 18:e0282295. doi: 10.1371/journal.pone.0282295
20. Umami I, Gautama DH, Hatta HR. Implementing the expected goal (xg) model to predict scores in soccer matches. Int J Inform Inf Syst. (2021) 4:38–54. 47738/ijiis.v4i1.76
22. Capretto T, Piho C, Kumar R, Westfall J, Yarkoni T, Martin OA. Bambi: a simple interface for fitting Bayesian linear models in python. J Stat Softw. (2022) 103:1–29. doi: 10.18637/jss.v103.i15
Keywords: expected goals, football, Bayesian hierarchical models, player adjustment, position adjustment, prior effects, soccer
Citation: Scholtes A and Karakuş O (2024) Bayes-xG: player and position correction on expected goals (xG) using Bayesian hierarchical approach. Front. Sports Act. Living 6:1348983. doi: 10.3389/fspor.2024.1348983
Received: 3 December 2023; Accepted: 16 May 2024;
Published: 14 June 2024.
Edited by:
Korkut Ulucan, Marmara University, TürkiyeReviewed by:
Diego Nascimento, Universidad de Atacama, ChilePaulo Henrique Ferreira, Federal University of Bahia (UFBA), Brazil
Keisuke Fujii, Nagoya University, Japan
© 2024 Scholtes and Karakuş. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Oktay Karakuş, a2FyYWt1c29AY2FyZGlmZi5hYy51aw==