 Stefano Damiano
Stefano Damiano Benjamin Cramer2
Benjamin Cramer2 Andre Guntoro
Andre Guntoro Toon van Waterschoot
Toon van Waterschoot- 1STADIUS Center for Dynamical Systems, Signal Processing and Data Analytics, Department of Electrical Engineering (ESAT), KU Leuven, Leuven, Belgium
- 2Robert Bosch GmbH, Renningen, Germany
Acoustic sensing has been widely exploited for the early detection of harmful situations in urban environments: in particular, several siren identification algorithms based on deep neural networks have been developed and have proven robust to the noisy and non-stationary urban acoustic scene. Although high classification accuracy can be achieved when training and evaluating on the same dataset, the cross-dataset performance of such models remains unexplored. To build robust models that generalize well to unseen data, large datasets that capture the diversity of the target sounds are needed, whose collection is generally expensive and time consuming. To overcome this limitation, in this work we investigate synthetic data generation techniques for training siren identification models. To obtain siren source signals, we either collect from public sources a small set of stationary, recorded siren sounds, or generate them synthetically. We then simulate source motion, acoustic propagation and Doppler effect, and finally combine the resulting signal with background noise. This way, we build two synthetic datasets used to train three different convolutional neural networks, then tested on real-world datasets unseen during training. We show that the proposed training strategy based on the use of recorded source signals and synthetic acoustic propagation performs best. In particular, this method leads to models that exhibit a better generalization ability, as compared to training and evaluating in a cross-dataset setting. Moreover, the proposed method loosens the data collection requirement and is entirely built using publicly available resources.
1 Introduction
The urban environment is characterized by a complex and dynamic acoustic scene where several agents produce overlapping sound events, some of which are artificially designed to alert humans of emergency situations that require their attention (Marchegiani and Fafoutis, 2022). The urban soundscape, therefore, contains information about the city itself. From the analysis of a recorded audio signal various details can be extracted, ranging from high level information such as a description of the recorded acoustic scene (e.g., whether it is a street, a station, a store etc.), to more fine-grained figures such as the weather condition or the time of the day when the recording was taken, and further to the identification of specific sounds appearing throughout the recording (e.g., the recognition of an alarm sound).
As smart vehicles start to populate the roads, major efforts are being devoted to enhance their perceptual abilities with the aim of improving their environmental awareness and strengthening their capacity to interact with other road agents. Autonomous cars, in fact, rely on information extracted in real time from multi-modal sensors to understand the environment, take driving decisions and interact with each other and with human drivers (Hussain and Zeadally, 2019).
In recent years, visual perception has been the primary research focus and it constitutes the main source of information for autonomous vehicles (Hussain and Zeadally, 2019). Nevertheless, the analysis of acoustic signals can provide important complementary information to enhance their environmental awareness. As a matter of fact, harmful situations are often announced by a sound event: emergency vehicles such as ambulances, police cars or fire trucks are equipped with sirens that announce their proximity and require cars to clear the way, whereas car horns can be used to quickly attract attention on an acute danger. Acoustic perception, moreover, provides specific advantages over vision: first, it is effective in situations where occlusions (e.g., caused by presence of buildings or other vehicles) or low-visibility conditions hinder the observation of visual cues. Second, it allows the detection of events that are not characterized by a corresponding visual signal, such as a car honking. Moreover, the lower dimensionality of acoustic signals enables a computationally efficient processing that best fits the deployment on embedded devices for real-time on-vehicle operation (Yin et al., 2023). Finally, in the safety-critical context of autonomous driving, the use of different sensing modalities to retrieve information serves as a mean to boost the reliability of the system. Every sensor mounted on the vehicle suffers in fact from specific limitations: visual sensors are hindered by low-visibility conditions, whereas acoustic sensors are impacted by strong background noise produced by wind, the ego-vehicle and the traffic background. For this reason, the use of multiple sensing modalities can compensate for the individual drawbacks to produce a more reliable prediction of events happening in the surrounding, making the use of audio analysis a useful resource for the overall performance of the system.
These considerations fueled the research on how to identify (and localize) emergency sounds in traffic scenarios (Tran and Tsai, 2020; Cantarini et al., 2021; Furletov et al., 2021; Sun et al., 2021; Marchegiani and Newman, 2022; Walden et al., 2022). In particular, several studies have targeted acoustic siren identification using both traditional signal processing (Meucci et al., 2008; Fazenda et al., 2009) and deep learning (Tran and Tsai, 2020; Cantarini et al., 2021; Marchegiani and Newman, 2022). The problem of siren identification is a sub-task of environmental sound classification (Piczak, 2015) (i.e., the identification of artificial or natural audio events different from speech or music) where the aim is to discriminate a siren signal from any other sound, generically labeled as background noise. This task has some application-specific challenges: first, emergency sirens have different patterns that can be grouped into two-tone, wail and yelp, each with different periodicity and time-frequency evolution (Marchegiani and Fafoutis, 2022). Not only the type of sirens varies among different countries, but within each siren type further variations can be observed in the time-frequency behavior. In other words, even between two instances of the same siren some variations may occur: in Germany, for instance, the lower fundamental frequency of the two-tone siren used can vary within the interval
Deep-learning techniques have been proven to achieve high classification accuracy in low signal-to-noise-ratio (SNR) conditions (Marchegiani and Newman, 2022). Several models based on convolutional neural networks (CNNs) have been proposed and achieve a high classification accuracy
One of the main challenges in the design of robust siren identification systems is the strong diversity of siren signals across the world, that requires algorithms to have a good generalization ability to unseen data. Although using large recorded datasets that capture the diversity of the sirens might benefit generalization capabilities, data collection is an expensive and time consuming procedure that has a limited scalability to systems that should be deployed in several different countries. Moreover, only a few datasets for siren identification are available, with a limited class diversity (Asif et al., 2022; Shah and Singh, 2023), far from representing all the existing siren variations.
Due to the strong diversity of siren sounds, in a real-world setting it is unlikely that the data seen during training is able to accurately represent all possible scenarios that might be faced by the model deployed on vehicles. For this reason, evaluating the model performance on the same dataset used for training, as is usually done in the acoustic siren identification literature, may lead to over-optimistic accuracy estimations. As a first contribution, in this work we analyze the performance of different siren identification models in a cross-dataset setting, i.e., when the dataset used for evaluation differs from the one used for training. Under the assumption that in realistic scenarios the data that will be seen at test time is unavailable (or only partially available) during the design and training phases, we then propose, as a second and main contribution, the use of synthetic data to train siren identification models: this technique, widely adopted in the image recognition domain (Jaderberg et al., 2014), obviates the need to collect real-world data for training purpose, speeding up the model design loop and cutting data recording and labeling costs. We evaluate two different data generation techniques: first, we generate synthetic siren signals (of two-tone, wail and yelp type) emitted by emergency vehicles, and simulate source motion and acoustic propagation using the pyroadacoustics simulator (Damiano and van Waterschoot, 2022). Alternatively, we collect a small amount of samples of stationary sirens (of the three types) from public databases, and feed them to pyroadacoustics to simulate acoustic propagation and Doppler effect. As a third contribution, we introduce several modifications to three state-of-the-art CNN models, in order to build an effective end-to-end siren identification system. In particular, we first enhance an existing siren classification network (Cantarini et al., 2021), by introducing batch normalization layers and dropout operations to boost generalization, and global average pooling to reduce the model complexity. We then adapt two BCResNet architectures (Kim et al., 2021), originally proposed for the acoustic scene classification task, to target siren identification. These architectures, to the best of the authors’ knowledge, are adopted for the first time in this work for the siren identification task.
We train the CNN models on the two synthetically generated datasets, and evaluate them on three real-world (unseen) datasets to assess the effectiveness of the data generation procedure. We finally show that the proposed training technique, based on the use of recorded siren signals and synthetic acoustic propagation, leads to a higher performance compared to models trained on a real-world dataset and evaluated in a cross-dataset setting.
The rest of the paper is organized as follows. In Section 2 we discuss related works on siren identification based on CNN models. In Section 3 we describe the proposed synthetic data generation strategies and training procedures, and introduce the CNN architectures adopted to solve the classification task. We then evaluate the training strategies and the different models in Section 4, and draw conclusions in Section 5.
2 Related work
2.1 Siren identification methods
In recent years the problem of identifying sirens in an urban environment has been addressed by exploiting traditional signal processing approaches (Meucci et al., 2008; Fazenda et al., 2009) as well as machine learning (Schröder et al., 2013; Nandwana and Hasan, 2016; Carmel et al., 2017) and deep learning (Beritelli et al., 2006; Tran and Tsai, 2020; Cantarini et al., 2021; Furletov et al., 2021; Sharma et al., 2021; Sun et al., 2021; Cantarini et al., 2022; Marchegiani and Newman, 2022; Walden et al., 2022) techniques. Most state-of-the-art solutions rely on deep neural networks, due to their proven robustness to strong background noise and complex non-stationary acoustic scenes (Tran and Tsai, 2020; Marchegiani and Newman, 2022). The majority of these models apply image processing techniques to a time-frequency representation of the audio signal, adopting short-time Fourier transforms (STFTs), gammatonegrams or log-mel spectrograms as input features; others, instead, use the raw audio waveform (Beritelli et al., 2006; Furletov et al., 2021), or a combination of the two approaches (Tran and Tsai, 2020; Sun et al., 2021). In more detail, in Tran and Tsai (2020) a two-branch neural network is proposed for the classification of sirens (two-tone, wail and yelp) and vehicle horns. The first branch combines mel-frequency cepstral coefficients (MFCCs) and log-mel spectrograms extracted from 1-channel audio signals in a 2D image, processed via a 2D-CNN architecture, while the second one employs a 1D-CNN to automatically extract features from the raw audio waveform. The ensemble of these two networks achieves an accuracy of
Even though these systems exploit synthetic data for training siren identification networks, the effectiveness of their use is not thoroughly assessed by evaluating the model performance on unseen, purely real-world data. A similar assessment is carried out in Cantarini et al. (2022), where a model pre-trained on synthetic data is fine-tuned in a few-shot setting to recognize the Italian two-tone ambulance siren: although this scenario represents a realistic use-case of synthetic data and shows their effectiveness in the real-world application, it is tailored to a specific target sound.
2.2 Data augmentation strategies for audio classification
The use of synthetic data to train deep learning models is a form of data augmentation that consists of artificially crafting samples, either starting from existing datasets, or by generating data from a signal model. Several data augmentation techniques have been developed both in the computer vision (Shorten and Khoshgoftaar, 2019; Man and Chahl, 2022), and audio signal processing (Wei et al., 2020) fields. Due to the different nature of image and audio signals, domain-specific augmentation strategies have been developed, notwithstanding the existence of some common methods (Wei et al., 2020). In audio applications (e.g., audio classification, speech recognition, audio signal denoising), the most common techniques involve the application of (non-)linear transformation to either the raw audio or some time-frequency representation (e.g., spectrogram) of a recorded sample. Two types of transformations can be identified: the first category includes operations on a single audio segment, like time-stretching and pitch-shifting (Wei et al., 2020), or masking operations applied to the spectrogram (Park et al., 2019). The second category is based on combining multiple signals to obtain new audio samples. Adding white (or colored) noise to an audio signal, summing or temporally juxtaposing multiple audio samples to create a synthetic mixture, and interpolating between two or more audio segments are the main techniques that belong to this category (Wei et al., 2020).
A different approach to audio data augmentation is the synthetic generation of (spatial) acoustic scenes. This approach, usually adopted in indoor scenarios, is based on placing sound sources in a virtual acoustic environment (i.e., a room) and simulating the sound received by a listener located in an arbitrary point of the acoustic scene. For this purpose, room impulse responses between the position of the source and listener are simulated (or, alternatively and in presence of real rooms, recorded) and applied to recorded, anechoic audio samples representing the signals emitted by the sound sources to create synthetic scenes. (Koyama et al., 2022). Although this method is widely adopted in room acoustics, its use in outdoor spaces is limited due the challenges posed by the accurate physical simulation of moving sources, Doppler effect and realistic sounding urban environments (Damiano and van Waterschoot, 2022; Yin et al., 2023).
Within this paper we investigate synthetic data generation techniques for training siren identification models that generalize well to multiple real-world datasets. We propose two different data generation methods: the first one is based on the synthetic generation of (stationary) siren source signals, followed by the simulation of acoustic propagation, ground reflection and Doppler effect to emulate the behavior of a moving emergency vehicle. The second one, similar to (Cantarini et al., 2021; Marchegiani and Newman, 2022), relies on the use of a small set of recorded stationary siren sounds, collected in public databases, followed by the simulation of the above mentioned acoustic propagation effects. Finally, to craft realistic acoustic scenes, we superimpose to the simulated siren real-world urban background noise taken from the SONYC dataset (Cartwright et al., 2020) and evaluate noise augmentation strategies. In the next section, we introduce the details of the proposed data generation techniques and the CNN architectures.
3 Proposed methodology
We hereby introduce two distinct data generation strategies, that will be compared and evaluated in Section 4:
1. The first one consists in defining a parametric model for the generation of synthetic stationary siren source signals, where the term source signal refers to the emitted siren sound prior to any propagation effect; the motion of the emergency vehicle is then simulated by feeding these signals to the pyroadacoustics simulator, that provides an accurate emulation of acoustic propagation, ground reflection, air absorption and Doppler effect. This method allows to generate siren sounds without requiring any real-world recording, and the parametric model allows to create infinitely many different source signals.
2. The second one relies on the use of a small set of recorded siren sounds, provided as input to pyroadacoustics to emulate source motion. The recorded signals employed in this case should be stationary and clean from background noise. Whereas the source signal diversity is reduced compared to the first method, the recorded sirens provide a higher realism than those generated synthetically.
The only difference between the two methods lies therefore in the source signals used as input to the propagation simulator. In the next subsections, we describe the two components of the synthetic data generation, namely, the generation of the siren source signals, and the definition of the acoustic scene including the simulated moving source and the underlying background noise.
3.1 Synthetic siren signal generation
The siren sound is by its nature an artificial signal produced by means of electromechanical components. In particular, it is a harmonic signal composed of a fundamental frequency, modulated over time with a certain periodicity and modulation function that depends on the specific type of siren, and of a set of higher harmonic components. Given a generic siren signal, its discrete time-dependent fundamental frequency
where
1. The two-tone siren has a fundamental frequency that jumps between two constant values every half period (although more complex duty cycles exist, they are not considered in the current model) as
where
2. The wail siren has a fundamental frequency that continuously varies between two limit values
For the falling part, we can derive similar equations by changing
3. The yelp siren behaves similarly to the wail but has a shorter period (thus resulting in a faster alternation between the low and high frequency); it can thus be simulated using the same model described in (3). We draw the signal parameters as follows:
The probability distributions from which the parameters are selected are uniform distributions on the above specified intervals. Moreover, all the mentioned parameter ranges have been picked by manual inspection of recorded real-world sirens, and randomness is used to maximize diversity and thus foster generalization.
3.2 Synthetic acoustic scene definition
Once the source signals have been either collected or generated, we create a synthetic acoustic scene resembling a real traffic environment. For the siren identification task the two relevant classes are the noise class, including all the possible sound events that contribute to the overall urban soundscape, except for sirens, and the siren class, including siren signals emitted by moving emergency vehicles, on top of the background noise. We create synthetic acoustic scenes as follows: we generate moving siren signals using the open-source1 pyroadacoustics simulator (Damiano and van Waterschoot, 2022). This tool enables to simulate sound sources moving along arbitrary trajectories, together with the Doppler effect, the sound reflection produced by the road surface and the atmospheric sound absorption. Using either the recorded or the synthetic source signals described in Section 3.1 as input to the simulator, we generate
Using this procedure and the two source signal types (synthetic or recorded) detailed above, we create two synthetic siren datasets. For the dataset based on the use of synthetic source signals (named SynSIR in the following), we generate
For the environmental noise, we rely on the SONYC dataset (Cartwright et al., 2020), a large-scale collection of urban noise recorded in different locations in New York City. The recorded audio is provided in
To create synthetic acoustic scenes using these (synthetic) siren and (recorded) noise datasets, we design a data loader, also employed to feed data to the models when training and apply noise augmentation. This component operates as follows.
This procedure is performed online each time a sample is provided as input to the model during the training stage, in order to maximize the diversity of the samples seen by the network. We manually set the size of the thus generated dataset to
3.3 Siren identification architectures
To design an end-to-end siren identification system, we propose to introduce modifications to established audio classification CNN models in order to adapt them to our specific use-case, train them using the proposed data generation strategy and evaluate their performance on real datasets unseen during training. All three models take as input log-mel spectrogram features extracted from a
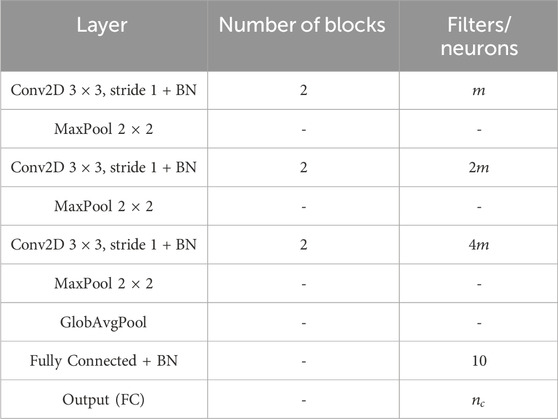
Table 1. The modified VGGSir architecture, inspired by Cantarini et al. (2021). The number
The second model is the BCResNet model, originally proposed in Kim et al. (2021) for the task of low-complexity acoustic scene classification in the DCASE 2021 challenge, Task 1 A (Martín-Morató et al., 2021), and is detailed in Table 2. This network relies on both 2D convolutions over the spectrogram features, and 1D convolutions over frequency-averaged embedded features. The processed 1D features are combined with the 2D ones by means of broadcasting operations and residual connections contained in the BC-ResBlock element (Kim et al., 2021). In our configuration, we introduce a dropout with drop probability 0.2 after each BC-ResBlock, and use

Table 2. The modified BCResNet architecture, originally proposed in Kim et al. (2021) for acoustic scene classification. The number
The third model is the BCResNorm model, a variation of the BCResNet originally introduced in Kim et al. (2021) for the same task. The difference with respect to BCResNet is the introduction of residual normalization operations for the input features and after each BC-ResBlock. The residual normalization is defined as follows. Given an input tensor
where
moreover,
where the weighting parameter
4 Experimental validation
4.1 Data description
To evaluate the performance of the architectures with real-world data, we use three datasets specifically created for siren identification.
All files have been resampled to
4.2 Implementation details
To evaluate the different CNN architectures and training strategies, we implement the models described in Section 3.3 using the Pytorch (Paszke et al., 2019) framework. We choose the log-mel spectrogram as input feature (Figure 1): to compute it, we use torchaudio (Yang et al., 2021) and set a sampling frequency
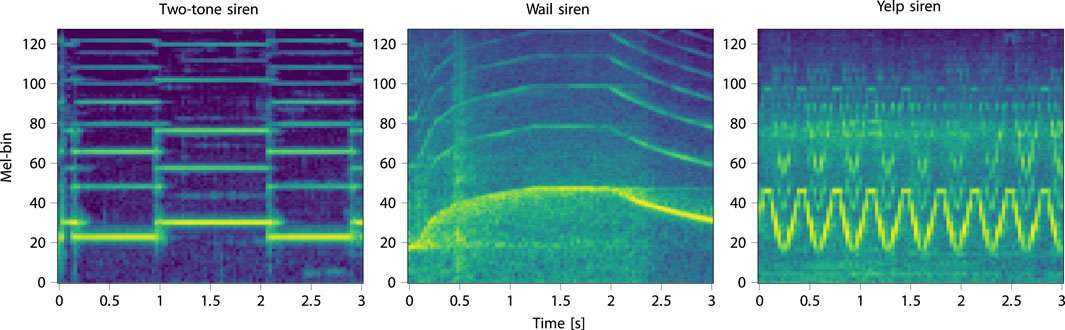
Figure 1. Log-mel spectrograms of three siren instances extracted from the LSSiren data. The log-mel spectrogram is adopted as input feature for the CNN models.
When training models using synthetic data, we use four output units in all architectures
We train all models for 15 epochs using the Adam optimizer (Kingma and Ba, 2015), the cross-entropy loss, and a batch size of 32. For each training process involving synthetic data, we split the training data into a training and validation set with ratio
4.3 Experimental evaluation
To set a reference for the evaluation of the training procedures employing synthetic data, as a first experiment we evaluate the performance of the three architectures in a cross-dataset setting. For this purpose, we only consider the three real-world datasets (BoschSiren, LSSiren, sireNNet): we train each model using one of them, and evaluate the performance on the other two. The results are reported in Figure 2, where we show, for each model and each training set, the accuracy range (min-max) on the two unseen test datasets, together with the average accuracy. Since the models are evaluated on data extracted from an unseen domain, which may have an underlying distribution different from that of the training set, the accuracy is degraded compared to models trained and evaluated on data extracted from the same dataset. This is illustrated in Table 3, where we compare the average accuracy obtained by the three architectures in the cross-dataset setting with the accuracy obtained on the test split of the same dataset used for training. We remark that, in this case, the train and test splits, though extracted from the same dataset, are disjoint. The results obtained on in-domain data (i.e., from the test split of the same dataset used for training) are comparable to those reported in the siren identification literature, where a similar evaluation setup is generally used. In the second column of this table we report the results averaged over all possible cross-dataset combinations (in total they amount to three, since we use one of the three datasets for training, and the other two for evaluation). From these two experiments we observe that the BCResNet model and its normalized variation achieve a higher accuracy compared to VGGSir, in accordance to the fact that these architectures are specifically designed to maximize the domain generalization performance. These architectures are thus promising for the task of siren identification. From Figure 2 we also observe that the BCResNorm model is characterized by narrower accuracy ranges, proving its higher robustness to data distribution shifts.
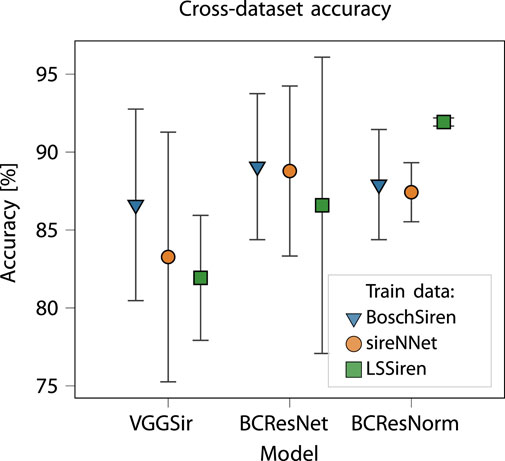
Figure 2. Baseline accuracy obtained with the three architectures (VGGSir, BCResNet, BCResNorm) evaluated in a cross-dataset setting: the models are trained using a single dataset and the accuracy score is computed on the other two. The markers show the average accuracy on the two test sets unseen during training, the whiskers denote the min-max interval.

Table 3. Comparison of the accuracy obtained when evaluating the models on in-domain data (i.e., using the test split of the same dataset used for training) and in a cross-domain setting (i.e., using the two datasets unseen during training). In the cross-domain evaluation, the results are averaged over all dataset combinations and the performance is degraded.
We then run an extensive evaluation campaign to assess the proposed training procedures based on the use of synthetic data. We thus train each model using either the SynSIR or the RecSIR datasets, and jointly evaluate the impact of applying noise augmentation. At training time, the best model is selected based on the minimum loss computed on an independent validation set generated from the same dataset used for training. In Table 4 we report, for each trained model, the accuracy obtained on the three real-world datasets, together with the average accuracy. First, we observe that training using the RecSIR data leads to a higher performance for all models: using recorded source signals represents therefore a better solution than generating synthetically, notwithstanding the limited diversity of the recorded sirens. This might be explained by the fact that the synthetic siren generation produces some artifacts that could be learned by the network, hindering its ability to generalize to real-world data, where these artifacts are not present. Second, we observe that the BCResNet and BCResNorm models achieve a higher performance than VGGSir, in line with the results of the previous experiment. Generalizing from synthetic to real-world data is in fact a different form of the same task of domain generalization tackled in the cross-dataset setting. BCResNorm shows also, once more, a narrower min-max accuracy range. Lastly, we observe that the impact of the noise augmentation strategy depends on the model and training data, and should thus be evaluated on a case-by-case basis when designing the training setup. The best-performing model is the BCResNet trained on RecSIR with noise augmentation, with an average accuracy of

Table 4. Synthetic data evaluation procedure: the three analyzed architectures (VGGSir, BCResNet, BCResNorm) are trained using the synthetic datasets SynSIR and RecSIR. Augmentation of the background noise via the introduction of stationary and moving speech and environmental noise is evaluated for all combinations. The model selection is operated on validation data extracted from the same dataset used for training; the evaluation is performed on the three real-world datasets (LSSiren, BoschSiren and sireNNet), and the average accuracy is reported in the last column. The best models (i.e., the ones that yield the highest average accuracy) trained using RecSIR data are highlighted in bold; the best ones trained using SynSIR data are highlighted in italic.
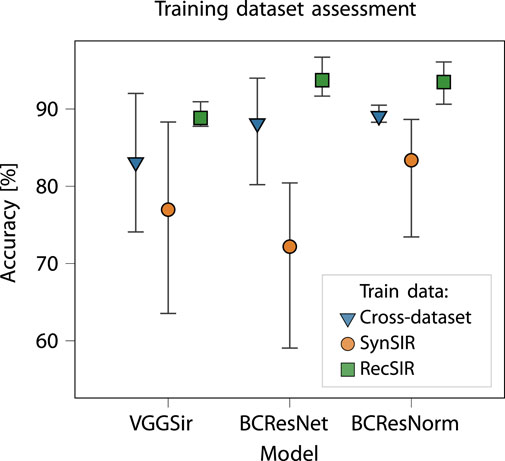
Figure 3. Performance comparison between moodels trained on the two synthetic datasets (SynSIR, RecSIR) and evaluated on the three real-world datasets: training on RecSIR always produces the highest average accuracy. The training dataset is specified in the legend, model selection is performed using validation data from the same dataset. The average accuracy on the real-world datasets is indicated by the markers, the whiskers denote the min-max interval. The average accuracy and min-max range obtained in a cross-dataset scenario are reported: in this case, the models are trained on one real-world dataset and evaluated on the remaining two.
We finally evaluate the use of real-world data for the selection of the best model when training using synthetically generated data. For this experiment we re-train from scratch the BCResNet architecture using the RecSIR data with noise augmentation (i.e., the top-performing configuration from Table 4). This time, we select four different models by minimizing the validation loss computed on the RecSIR, BoschSiren, LSSiren, sireNNet validation sets, and evaluate them on the three real-world datasets. The results are reported in Figure 4. Surprisingly, selecting the model using data from the same dataset used for evaluation leads to the highest test accuracy only for the sireNNet dataset. For the LSSiren data, the best model is selected using the same RecSIR data, while for BoschSiren the four selection strategies lead to comparable performance. We also observe that selecting the model using the RecSIR data, though leading to the best choice only for the LSSiren test set, always produces a model with a performance close to that of the best choice: for BoschSiren data the accuracy drop is
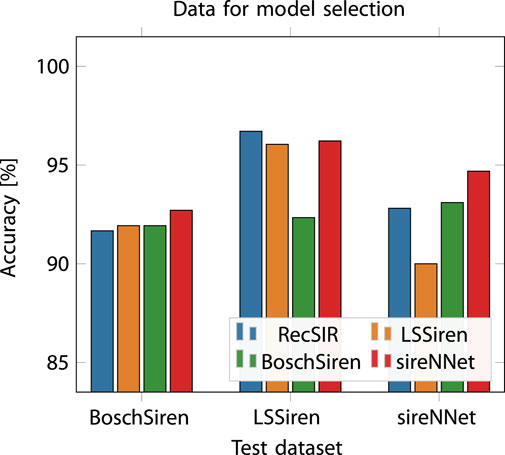
Figure 4. Performance of BCResNorm model trained on the RecSIR dataset and tested on the three real-world datasets (LSSiren, BoschSiren, sireNNet). The dataset used to select the best model during the training process is specified in the legend.
4.4 Performance investigation
In this section, we further investigate the performance of the best model selected in Table 4, namely, BCResNet trained using RecSIR data and noise augmentation (with RecSIR data used also for model selection). To this aim, we first compute, for each considered real-world dataset, the confusion matrix and evaluate the precision and recall scores. The precision metric is defined as
where
where
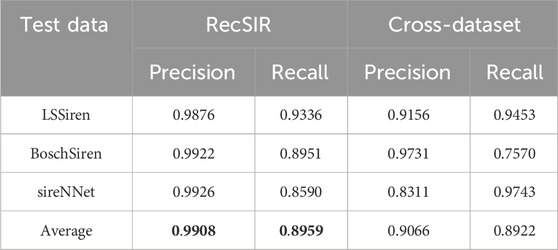
Table 5. Evaluation of precision and recall scores for the BCResNet model trained on RecSIR data with noise augmentation and evaluated on the three real-world datasets. Training on the RecSIR dataset leads to the best average scores, highlighted in bold.
We finally analyze the precision-recall (PR) curves obtained using the BCResNet model trained on RecSIR data with noise augmentation, plotted for the three datasets in Figure 5, where the area under the curve (AUC) is also reported. We highlight three operating points on the PR curve: the equal error rate point, where
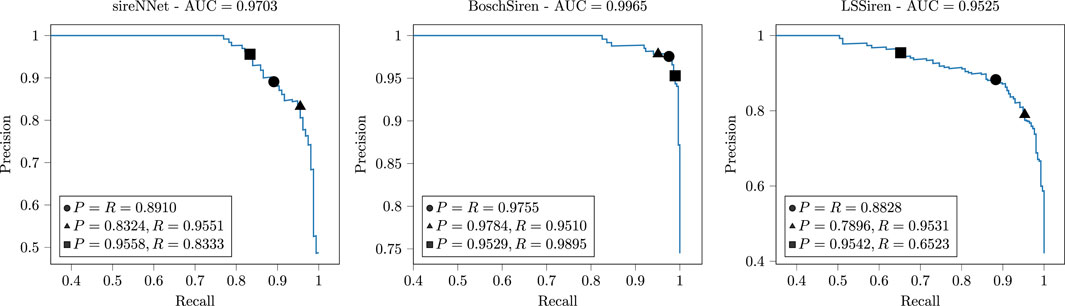
Figure 5. Precision-recall (PR) curves obtained with the BCResNet model trained on RecSIR data with noise augmentation and evaluated on the three real-world datasets. Three operating points, where
5 Conclusion
In this work we have addressed the task of emergency siren identification for automotive applications using deep learning. Though the topic is well-known in the literature, state-of-the-art models are usually trained and evaluated on data extracted from the same dataset. Due to the prominent differences that can be observed among siren sounds and background noise mixtures in different locations around the world, collecting a dataset that accurately represents all the variations is in practice unfeasible. To reduce the burden of data collection, we hence proposed to train models using synthetic data: we introduced two synthetic data generation strategies, the first one based on the synthetic generation of stationary siren signals, and the second one based on the collection of a limited number of samples of stationary sirens from public repositories. In both procedures, sound propagation and Doppler effect are then emulated using a road acoustics simulator to create synthetic datasets that can be used to train siren identification models. To evaluate the two methods, we selected state-of-the-art CNNs for siren identification and acoustic domain generalization: we introduced several modifications to enhance the performance of these models on our target task, and trained them using synthetic datasets crafted by means of the two proposed data generation strategies. Finally, we showed that using recorded stationary sirens as source signals and simulating acoustic propagation to create an augmented dataset yields the best performance using all analyzed networks. In particular, training all models using synthetic data generated using stationary recorded sirens and synthetic acoustic propagation is effective: the accuracy obtained using this proposed training method is in fact higher than the one obtained when training the models using real-world data and evaluating them in a cross-dataset setting. As an additional advantage, training using synthetic data cuts the costs of data collection. The combination of the
The proposed training strategy paves the way for future research: first, the proposed method can be extended to target the identification of additional alarm signals (e.g., car horns) in urban environments. Furthermore, the trade-off between the model complexity and performance has not been investigated: the synthetic data generation comes with the advantage of enabling to generate datasets with arbitrary sizes and to define arbitrarily complex acoustic scenes. The design of more elaborate acoustic scenes, together with the generation of larger (and more diverse) datasets, might therefore foster the generalization performance of the analyzed models or, alternatively, promote the design of larger models, at the cost of a higher complexity. Finally, the use of generative models to improve the quality of the simulated data might boost the effectiveness of the methods discussed throughout this work.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://doi.org/10.6084/m9.figshare.19291472 https://data.mendeley.com/datasets/j4ydzzv4kb/1.
Author contributions
SD: Conceptualization, Data curation, Formal Analysis, Methodology, Software, Visualization, Writing–original draft. BC: Methodology, Writing–review and editing. AG: Resources, Supervision, Writing–review and editing. TW: Conceptualization, Funding acquisition, Methodology, Supervision, Writing–review and editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 956962, from the European Union’s Horizon Europe research and innovation programme under the grant agreement No. 101070374, and from the European Research Council under the European Union’s Horizon 2020 research and innovation program/ERC Consolidator Grant: SONORA (no. 773268).
Acknowledgments
The authors wish to thank Dr. Luca Bondi (Bosch Research) for the useful discussions that helped in shaping this manuscript.
Conflict of interest
Authors BC and AG were employed by Robert Bosch GmbH.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Author disclaimer
This paper reflects only the authors’ views and the Union is not liable for any use that may be made of the contained information.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1https://github.com/steDamiano/pyroadacoustics/
References
Asif, M., Usaid, M., Rashid, M., Rajab, T., Hussain, S., and Wasi, S. (2022). Large-scale audio dataset for emergency vehicle sirens and road noises. Sci. Data 9, 599. doi:10.1038/s41597-022-01727-2
Beritelli, F., Casale, S., Russo, A., and Serrano, S. (2006). “An automatic emergency signal recognition system for the hearing impaired,” in Proc. 2006 IEEE 12th digital signal process. Workshop & 4th IEEE signal process. Education workshop (teton national park, WY, USA), 179–182. doi:10.1109/DSPWS.2006.265438
Cantarini, M., Brocanelli, A., Gabrielli, L., and Squartini, S. (2021). “Acoustic features for deep learning-based models for emergency Siren detection: an evaluation study” in Proc. 2021 12th int. Symp. Image signal process. Anal. (ISPA), zagreb, Croatia, 47–53.
Cantarini, M., Gabrielli, L., and Squartini, S. (2022). Few-shot emergency Siren detection. Sensors 22, 4338. doi:10.3390/s22124338
Carmel, D., Yeshurun, A., and Moshe, Y. (2017). “Detection of alarm sounds in noisy environments,” in Proc. 25th European signal process. Conf. (EUSIPCO) (kos, Greece), 1839–1843. doi:10.23919/EUSIPCO.2017.8081527
Cartwright, M., Cramer, J., Mendez, A. E. M., Wang, Y., Wu, H.-H., Lostanlen, V., et al. (2020). SONYC Urban Sound Tagging (SONYC-UST): a multilabel dataset from an urban acoustic sensor network. doi:10.5281/zenodo.3966543
Damiano, S., and van Waterschoot, T. (2022). “Pyroadacoustics: a road acoustics simulator based on variable length delay lines,” in Proc. 25th int. Conf. Digital audio effects (DAFx20in22) (vienna, Austria), 216–223.
DIN14610:2022-03 (2022). Sound warning devices for authorized emergency vehicles. doi:10.31030/3325071
Fazenda, B., Atmoko, H., Gu, F., Guan, L., and Ball, A. (2009). “Acoustic based safety emergency vehicle detection for intelligent transport systems,” in Proc. 2009 ICCAS-SICE (fukuoka, Japan), 4250–4255.
Furletov, Y., Willert, V., and Adamy, J. (2021). “Auditory scene understanding for autonomous driving,” in Proc. 2021 IEEE intelligent vehicles symp. (IV) (nagoya, Japan), 697–702. doi:10.1109/IV48863.2021.9575964
Hussain, R., and Zeadally, S. (2019). Autonomous cars: research results, issues, and future challenges. IEEE Commun. Surv. Tutorials 21, 1275–1313. doi:10.1109/COMST.2018.2869360
Jaderberg, M., Simonyan, K., Vedaldi, A., and Zisserman, A. (2014). Synthetic data and artificial neural networks for natural scene text recognition. arXiv preprint arXiv:1406.2227. doi:10.48550/arXiv.1406.2227
Kim, B., Yang, S., Kim, J., and Chang, S. (2021). “Domain generalization on efficient acoustic scene classification using residual normalization,” in Proc. Detection classification acoustic scenes events (DCASE2021).
Kingma, D. P., and Ba, J. (2015). “Adam: a method for stochastic optimization,” in Proc. 3rd int. Conf. Learning representations (ICLR) (san diego, USA). doi:10.48550/arXiv.1412.6980
Koyama, Y., Shigemi, K., Takahashi, M., Shimada, K., Takahashi, N., Tsunoo, E., et al. (2022). “Spatial data augmentation with simulated room impulse responses for sound event localization and detection,” in Proc. 2022 int. Conf acoust., speech and signal process. (ICASSP), 8872–8876. doi:10.1109/ICASSP43922.2022.9746754
Lin, M., Chen, Q., and Yan, S. (2014). Network in network. arXiv preprint arXiv.1312.4400. doi:10.48550/arXiv.1312.4400
Man, K., and Chahl, J. (2022). A review of synthetic image data and its use in computer vision. J. Imaging 8, 310. doi:10.3390/jimaging8110310
Marchegiani, L., and Fafoutis, X. (2022). How well can driverless vehicles hear? A gentle introduction to auditory perception for autonomous and smart vehicles. IEEE Intell. Transp. Syst. Mag. 14, 92–105. doi:10.1109/MITS.2021.3049425
Marchegiani, L., and Newman, P. (2022). Listening for sirens: locating and classifying acoustic alarms in city scenes. IEEE Trans. Intelligent Transp. Syst 23, 17087–17096. doi:10.1109/TITS.2022.3158076
Martín-Morató, I., Heittola, T., Mesaros, A., and Virtanen, T. (2021). Low-complexity acoustic scene classification for multi-device audio: analysis of DCASE 2021 challenge systems. arXiv preprint arXiv.2105.13734. doi:10.48550/arXiv.2105.13734
Meucci, F., Pierucci, L., Del Re, E., Lastrucci, L., and Desii, P. (2008). “A real-time siren detector to improve safety of guide in traffic environment,” in Proc. 16th European signal process. Conf. (Lausanne, Switzerland: EUSIPCO), 1–5.
Nandwana, M. K., and Hasan, T. (2016). “Towards smart-cars that can listen: abnormal acoustic event detection on the road,” in Proc. Interspeech 2016 (san francisco, USA), 2968–2971. doi:10.21437/Interspeech.2016-1366
Panayotov, V., Chen, G., Povey, D., and Khudanpur, S. (2015). “Librispeech: an asr corpus based on public domain audio books,” in Proc. 2015 IEEE int. Conf. Acoust. Speech signal process. (ICASSP) (south brisbane, QLD, Australia), 5206–5210. doi:10.1109/ICASSP.2015.7178964
Park, D. S., Chan, W., Zhang, Y., Chiu, C.-C., Zoph, B., Cubuk, E. D., et al. (2019). “SpecAugment: a simple data augmentation method for automatic speech recognition,” in Proc. Interspeech 2019 (graz, Austria), 2613–2617. doi:10.21437/Interspeech.2019-2680
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “Pytorch: an imperative style, high-performance deep learning library,” in Proc. 33rd int. Conf. Neural information processing syst. (red hook, NY, USA).
Piczak, K. J. (2015). “Environmental sound classification with convolutional neural networks,” in Proc. 2015 IEEE 25th int. Workshop machine learning for signal process. (MLSP) (boston, MA, USA), 1–6. doi:10.1109/MLSP.2015.7324337
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-net: convolutional networks for biomedical image segmentation,” in Proc. Medical image computing and computer-assisted intervention (MICAAI 2015) (munich, Germany), 234–241. doi:10.1007/978-3-319-24574-4_28
Salamon, J., Jacoby, C., and Bello, J. P. (2014). “A dataset and taxonomy for urban sound research,” in Proc. 22nd ACM int. Conf. Multimedia (ACM-MM’14) (orlando, FL, USA), 1041–1044. doi:10.1145/2647868.2655045
Schröder, J., Goetze, S., Grützmacher, V., and Anemüller, J. (2013). “Automatic acoustic siren detection in traffic noise by part-based models,” in Proc. 2013 IEEE int. Conf. Acoust. Speech signal process. (ICASSP) (vancouver, BC, Canada), 493–497. doi:10.1109/ICASSP.2013.6637696
Shah, A., and Singh, A. (2023). sireNNet-emergency vehicle Siren classification dataset for urban applications. doi:10.17632/j4ydzzv4kb.1
Sharma, J., Granmo, O.-C., and Goodwin, M. (2021). “Emergency detection with environment sound using deep convolutional neural networks,” in Proc. 5th int. Congr. Inf. Commun. Technol. (London, UK), 144–154. doi:10.1007/978-981-15-5859-7_14
Shorten, C., and Khoshgoftaar, T. (2019). A survey on image data augmentation for deep learning. J. Big Data 6, 60. doi:10.1186/s40537-019-0197-0
Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. doi:10.48550/arXiv.1409.1556
Sun, H., Liu, X., Xu, K., Miao, J., and Luo, Q. (2021). Emergency vehicles audio detection and localization in autonomous driving. arXiv preprint arXiv:2109.14797. doi:10.48550/arXiv.2109.14797
Tran, V.-T., and Tsai, W.-H. (2020). Acoustic-based emergency vehicle detection using convolutional neural networks. IEEE Access 8, 75702–75713. doi:10.1109/ACCESS.2020.2988986
Walden, F., Dasgupta, S., Rahman, M., and Islam, M. (2022). Improving the environmental perception of autonomous vehicles using deep learning-based audio classification. arXiv Prepr. arXiv:2209.04075. doi:10.48550/arXiv.2209.04075
Wei, S., Zou, S., Liao, F., and Lang, W. (2020). A comparison on data augmentation methods based on deep learning for audio classification. J. Phys. Conf. Ser. 1453, 012085. doi:10.1088/1742-6596/1453/1/012085
Yang, Y.-Y., Hira, M., Ni, Z., Chourdia, A., Astafurov, A., Chen, C., et al. (2021). Torchaudio: building blocks for audio and speech processing. arXiv Prepr. arXiv:2110.15018. doi:10.48550/arXiv.2110.15018
Keywords: synthetic data generation, acoustic simulation, moving sound sources, data augmentation, siren identification, convolutional neural networks
Citation: Damiano S, Cramer B, Guntoro A and van Waterschoot T (2024) Synthetic data generation techniques for training deep acoustic siren identification networks. Front. Sig. Proc. 4:1358532. doi: 10.3389/frsip.2024.1358532
Received: 19 December 2023; Accepted: 06 June 2024;
Published: 12 July 2024.
Edited by:
Ina Kodrasi, Idiap Research Institute, SwitzerlandReviewed by:
Manuel Rosa Zurera, University of Alcalá, SpainJaume Segura-Garcia, University of Valencia, Spain
Copyright © 2024 Damiano, Cramer, Guntoro and van Waterschoot. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Stefano Damiano, c3RlZmFuby5kYW1pYW5vQGVzYXQua3VsZXV2ZW4uYmU=