 Maria I. Artigas
Maria I. Artigas Rômulo T. Rodrigues
Rômulo T. Rodrigues Lars Vanderseypen
Lars Vanderseypen Herman Bruyninckx
Herman Bruyninckx- 1Department of Mechanical Engineering, KU Leuven, Leuven, Belgium
- 2Flanders Make, Leuven, Belgium
- 3Department of Mechanical Engineering, TU Eindhoven, Eindhoven, Netherlands
This paper introduces software patterns (registration, acquire-release, and cache awareness) and data structures (Petri net, finite state machine, and protocol flag array) to support the coordinated execution of software activities (also called “components” or “agents”). Moreover, it presents and tests an implementation for Petri nets that supports real-time execution in shared memory for deployment inside one individual robot and separates event firing and handling, enabling distributed deployment between multiple robots. Experimental validation of the introduced patterns and data structures is performed within the context of activities for task execution, control and perception, and decision making for an application on coordinated navigation.
1 Introduction
Society expects “smarter” robotics technology and “higher performance” of the applications and systems that are built with it. A major contribution toward realizing these expectations is improving the capabilities and the predictability of the composition of robotic components into systems. Coordination plays a major role in achieving this predictability: a system has several concurrently active components that require access to “resources” that cannot be shared trivially, such as locations in space or tools and sensors. Application developers must translate user requirements into concrete coordination specifications: when and why each of the components in the system must start or stop a particular “behavior.” Coordination is triggered by “events” generated by the software component in the system that has the authority to make such decisions, and it is provided with the necessary information by all the components that rely on its coordination. A good (but not necessarily unique) separation of concerns (Dijkstra, 1982) approach to ensure coordinated resource sharing with predictable performance and acceptable access policies is to introduce a dedicated coordination software component for each shared resource. The contributions of this paper are focused on this coordination design concern.
The left-hand side of Figure 1 shows a simple example of the role of coordination in multi-robot systems (Section 1.3 provides an overview of more archetypical coordination-use cases).
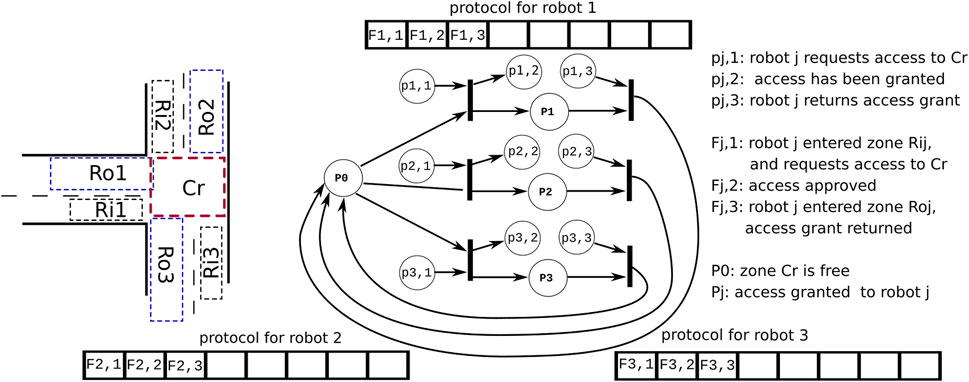
Figure 1. Coordination between concurrently active “agents” in traffic situations, particularly a T-junction. Left: only one “robot” coming from one of the three roads shall be allowed to access the crossing Cr. Right: our design introduces a mediator software component to realize such coordination problems. It relies on i) a Petri net as a declarative model of the coordination’s decision making and ii) a protocol between the mediator and each of the coordinated robots, via which the latter’s own internal decision making is decoupled from that of all other robots.
The figure’s right-hand side sketches our software design (which is described in detail in the later sections of this paper).
The map is also a shared resource in itself, but its software design presents a different set of coordination challenges, which are beyond the scope of this paper; for further details, refer to Van Baelen et al. (2022).
The following sub-sections introduce and define all the concepts needed in this paper. Section 2 discusses the previous work on which this paper is based and other related work. Section 3 describes the coordination mechanisms introduced in this paper and the complementary communication and configuration mechanisms for its integration. Section 4 introduces the implementation and evaluation of the Petri nets for runtime coordination. Section 5 explains the application of the previously described patterns in a coordinated navigation case. A secondary demonstration is also provided. Section 6 concludes the paper with a discussion of the presented and future work. Supplementary Appendix SA explains the connection between the coordinating and coordinated activities via events.
1.1 Component
The terminology “(software) components” has been interpreted several times over the past decades (Brugali and Scandurra, 2009; Brugali and Shakhimardanov, 2010), referring to the software primitive that provides “computational behavior” to a system. The terminology used in this paper to represent complementary types of computational behavior is as follows:
One could have given the name software component to what is called activity above. Because activities are designed to be executed concurrently, an appropriate set of asynchronous data exchange mechanisms is needed; these mechanisms should be shared between the activities within the same process memory or use one or more inter-process communication technologies. The challenges of data consistency between concurrently running activities are to be solved at the activity level but not at the thread or algorithm levels. The thread level in a software component design is responsible for scheduling by the operating system. The process level is responsible for managing resources shared between all activities within all process’s threads, such as file descriptors, signal handling, and thread priorities.
1.2 Coordination
Coordination is all decision making shared between concurrently executing activities about which of their algorithms (“behaviors”) must become “(in)active” at each moment in time in each of the robot components and about how to keep other robot components informed about which behavior(s) are currently “(in)active.” A key message of this paper is that all forms of inter-activity coordination can be realized with the following primitives, whose “separation of concerns” roles (Dijkstra, 1982) are illustrated in Figure 1.
This description of the mechanism of an FSM corresponds to that of a Mealy machine (Mealy, 1955), which is formally represented as a tuple
In the actual execution of an FSM, the policy must be added to select one of the states as the initial state
This mechanismof a Petri net is formally represented as a tuple
In the actual execution of a Petri net, the policy must be added to define an initial marking
For example, the protocols in Figure 1 show that for each robot, the sequence of execution is as follows: 1) the robot requests access, 2) the access is approved, and 3) the robot can enter the area.
Note that the “array” used in Figure 1 to represent a protocol is always finite, and flag entries are entered always from the first entry on the left. In other words, it is not an endlessly growing “stream” of flag entries. When the protocol ends, for one reason or another, all entries are removed so that the next execution of the protocol starts with an empty array again.
In the simple workspace sharing example in Figure 1, the labeled circles (called “places”) represent conditions that can be true or false, and the solid lines (called “transitions”) represent decision making: if all the input conditions are true, the transition is “fired.” The result is that the conditions in the input places are put to false again, and those in the output places become true. The truth values of the “source” places (i.e., those without input transition) are determined by the flags in the protocol arrays. Similarly, the truth values of the “sink” places (i.e., without output transition) determine the value of the corresponding flags in the protocol.
The ideal lifetime of an event is “zero”: as soon as an event is fired by an activity, all the activities that need to react to the event (that is, “to handle” it) will consume the event during their reaction. The software architecture of such coordinated components must foresee the communication of events between the firing activity and each of the handling activities, which is (one of the reasons) why asynchronous data exchange is needed between these activities.
Figure 1 uses the simplest form of a protocol sequence, namely, an array; in general, protocols consist of compositions of more than one such array, representing different allowable “paths” in the coordination. Note the important difference between the very narrow and lean semantics of a “protocol” as needed in this paper and the much wider semantics of “protocol stacks” as used in inter-process communication (Delanote et al., 2008).
1.3 Archetypical use cases
The following example set of multi-robot applications, with multi-tasking functionalities for each robot, is representative of the scope of this paper’s coordination design contributions:
1.4 Scope
This paper focuses on the software design of the coordination of runtime decision making, including data structures, policies, decision-making functionalities, software patterns, and best practices. An implementation using Petri nets, with the purpose of being used within these coordination patterns, is explained and evaluated. As the final validation, the previous patterns are applied to two coordinated navigation cases.
Subjects outside the scope of this study are the functional algorithms that define the behavior inside activities, the creation of maps and Petri nets, the policies behind the reasons why the application takes these decisions, and the communication functionalities via which activities exchange the data they need from each other to realize their functional behavior.
1.5 Contributions
The contributions of the paper are
2 Related work
The coordination of components is only one of the necessary “concerns” that large-scale “cyber–physical” systems must deal with. It fits into the broader context of the “5Cs” approach of making systems-of-systems software architecture (Bruyninckx, 2023; Klotzbücher et al., 2012; Radestock and Eisenbach, 1996; Vanthienen et al., 2014). The five parts of the 5Cs meta model are
Each of the first four “Cs” can, in itself, be a full or partial sub-system of the “5Cs”. A very established pattern within the coordination “C” is that of the life cycle state machine (LCSM), responsible for the “top-level” coordination inside one single activity: to create, to start up, to execute, to pause, to reconfigure, and to shut down activities (and the resources they manage) in predictable and composable ways. One single robot will have many activities (sensing, control, world modeling, task execution, etc.), each with its own LCSM, and the focus of this paper is to explain how to maintain the coordination between all these LCSMs, which is where the Petri nets come into play.
Petri nets have been widely used for modeling concurrent activities/processes (e.g., to analyze the concurrency behavior of several activities with respect to deadlock analysis or reachability analysis), and their implementations come in various forms depending on the use case context in which they are deployed. The implementation proposed by Davidrajuh (2010) has been widely used with MATLAB integration for Petri net modeling, simulation, and performance analysis. In the case of generalized stochastic Petri nets, the implementation proposed by Dingle et al. (2009) provides an open-source tool for design and analysis. The TINA toolbox (Berthomieu et al., 2004) offers a broad set of tools for the construction and analysis of Petri nets and timed Petri nets, which has been extensively used in academia. IOPT-Tools (Pereira et al., 2022; Gomes et al., 2010) provide a framework for the automatic generation of controller code from a modeled Petri net. Developments toward the implementation of Petri nets for microcontrollers have been researched by Kučera et al. (2020), providing a framework to model timed interpreted Petri nets to be used in Arduino devices.
While these implementations provide frameworks to work with Petri nets for different purposes, they are not focused on optimization for low-latency execution. This focus is a primary motivator for the research presented in this paper because modern robotic applications must coordinate several activities such as control, perception, world modeling, and task monitoring, many of which expect real-time determinism (Abdellatif et al., 2013). Piedrafita and Villarroel (2011) analyzed the execution dynamics of four different Petri net software implementation techniques, whose performance is evaluated with the same Petri net models as in this paper.
For robotics applications, Ziparo et al. (2011) used Petri nets as models for multi-body and multi-robot execution and planning. Their modeling within a multi-robot context is analyzed by Costelha and Lima (2007), investigating deadlocks and reachability. Figat et al. (2017) and Figat and Zieliński (2022) focused on, respectively, hierarchical finite state machines and Petri nets. Zhou et al. (2017) used a hierarchical FSM for the control of a navigation base with a manipulator, where one FSM is embedded into a higher FSM. Lacerda and Lima (2019) generated Petri nets for the coordination of a fleet of robots according to the time logic constraints of the coordinated execution.
3 Methodology
The focus of this paper is on three of the “5Cs” software concerns:
In addition to the separation of concerns (Dijkstra, 1982) that already come with the “5Cs” approach, this paper adds other separations of concerns pertaining to the design of the inside of the relevant “5Cs” components. More concretely, the design of the data structures and operators needed to implement the envisaged coordination mechanisms.
3.1 Coordination mechanisms
The mechanisms needed for the coordination of activities are conceptually very simple: flags, events, Petri nets, and finite state machines (Section 1.2).
A finite state machine (Hrúz and Zhou, 2007; Mealy, 1955) models the discrete behaviors of one single activity. Its four data structures are the sets of 1) states that the activity can be in, 2) transitions that are allowed between states, 3) events that can trigger transitions, and 4) flags whose status is linked with (a subset of) the events. The latter is added to the mathematical representation of an FSM in Section 1.2 to allow the interaction between an FSM and a Petri net. Its functions are 1) to process the list of available events, 2) to compute which transition each of those events will trigger (when processed in order of arrival), and 3) to adapt the above-mentioned data structures accordingly.
From a software implementation point of view (but not from a semantics point of view), finite state machines are just a boundary case of Petri nets: the former has a constraint on the number of “tokens,” namely, exactly one in the whole set of “states.” Figure 2 shows an example of the mapping of an FSM to an equivalent Petri net.
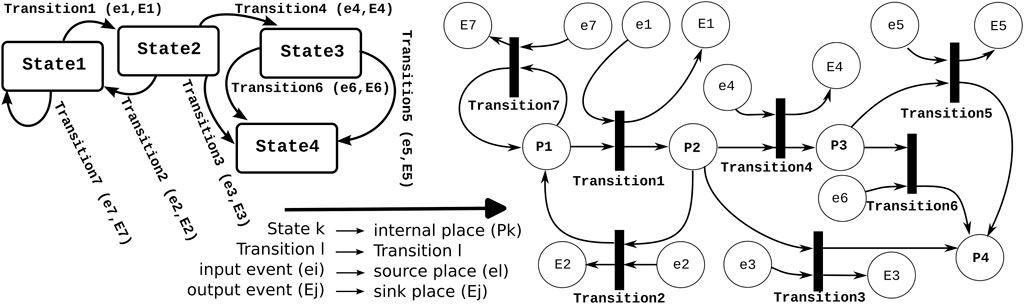
Figure 2. A finite state machine and the mapping to its equivalent Petri net. This mapping constrains the Petri net to have only one connector between any internal place and the transitions connected to that place. All other places map to “sink” or “source” events; the “source” places are denoted with small letters, and the “sink” places are denoted with capital letters. A similar typographical convention is used for input and output events in the finite state machine.
So, this paper focuses on the software design of Petri nets because that of finite state machines differs only in the configuration of the resulting library and the naming of the implementation primitives. A Petri net model shares the four above-mentioned building blocks with a finite state machine model, but it uses the following specific terminology: a place that can contain zero or one token as a marking, a transition, and a directed arc between them. The constraint on an arc is that its start and end must be either a place or a transition; in other words, places are only connected to transitions and vice versa. The constraint of a maximum of one token per place is what Murata (1989) referred to as “finite capacity nets of capacity one for all places”; other works of literature call it “safe Petri nets” (Barylska et al., 2017). A transition represents a coordination point in the Petri net: its input places represent the conditions to be fulfilled for that synchronization to take place; and its output places represent the status changes triggered by the coordination.
In addition to the above-described data structures, the Petri net mechanism also has some operators (“behavior”) on these data structures. If each input place of a particular transition has a token, that transition is enabled, and firing a transition implies that the tokens in its input places are removed and the tokens in its output places are filled. The token in the source places is to be filled by the processing of an event that comes from “somewhere.” Similarly, removing a token from a sink place gives rise to sending an event “somewhere.” The links with that “somewhere” are discussed in the following section on “communication.”
Notably, in Figure 2, the FSM and Petri net represent the same process; however, throughout the paper, this is not the case. FSMs are used for the discrete behaviors of single activities, while the Petri nets are used for the coordination across activities. This means there is a match among the FSM states of the coordinated activities and Petri net places of the coordinator; however, they do not present the same process. The latest is illustrated in Figure 3.
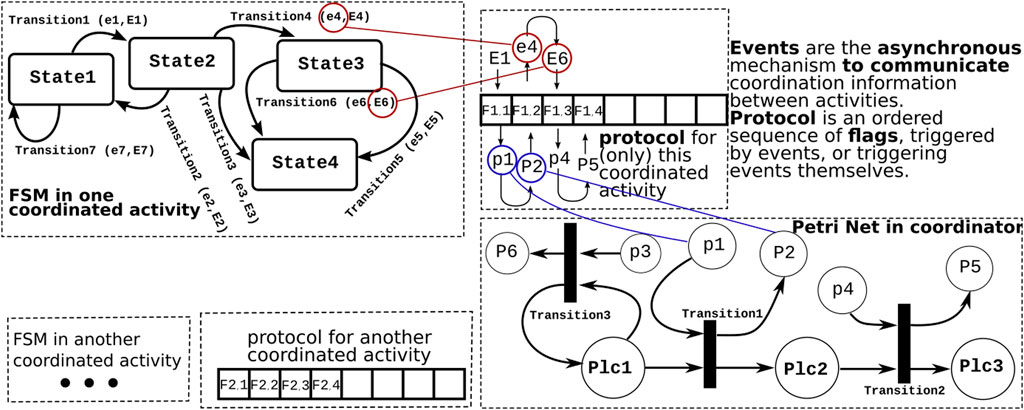
Figure 3. Examples of the three software mechanisms needed in interactivity coordination: A Petri net inside a coordinating activity, a finite state machine inside each of the coordinated activities, and (an array of) flags for the bookkeeping of which coordination “events” have been communicated between both. Capital letters are used for output events in the finite state machine and for sink places in the Petri net. The colored lines link events and places to locations in the protocol array. The “snake-like” trajectory through the array represents the temporal order in which the “communication” takes place between finite state machine events and the marking of places in the Petri net.
3.2 Communication mechanisms
The finite state machine in each of the coordinated activities exchanges events with the coordinating mediator’s Petri net (Figure 3). This is reflected in the structure of the Petri net as follows:
Source and sink places are the locations where the Petri net is connected to events from and to the “outside world.” Internal places are all other places.
The contribution of this paper with respect to communication pertains to the introduction of the protocol data structure: it decouples the internals of the finite state machines and Petri nets from the communication of the information they need for their coordination.
The protocol contains information regarding which of the two activities involved in the coordination is expected to set the next flag in the protocol. This document uses arrays as protocol data structures since they are the simplest approach needed to realize the following goal:
A flag can be set directly by an activity, or it is the result of processing an event received from that activity. Because of the strict order brought by the protocol, there is no risk that this asynchronous access to the data introduces inconsistency.
3.3 Configuration mechanisms
This section introduces three software patterns that provide the mechanisms needed to configure the coordination between activities. The patterns themselves are not explained in detail because that part of the authors’ research is beyond the scope of this document. However, they are in use in the experimental demonstration in Section 5. Each of these patterns works at a different time scale in the coordination interaction:
The registration puts the semantic ID into a table (or a “map”) with (at least) the following columns:
Table 1 shows an example of such a symbol table. The semantic ID itself has two fields, datatype and model. There can be multiple semantic IDs with the same model label, but the tuple (datatype, model) must be unique. Multiple activities can access the same variables, and coordination is done via mutexes.
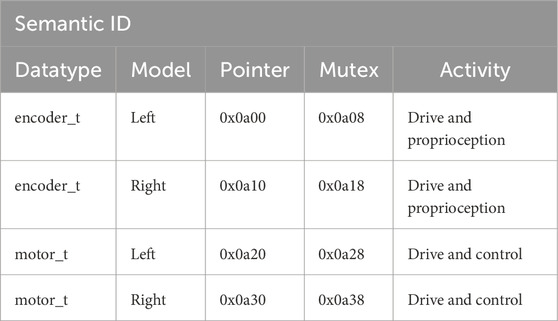
Table 1. Example of a table for registering the access of activities to shared resources. This particular example uses a mutex to coordinate the access to data structures encoder_t and motor_t, shared by three activities in a robot, control, proprioception, and drive.
The above-mentioned mechanisms are needed for the following reasons:
This paper focuses on this short-term time scale, hence, on a low-latency implementation of the acquire–release protocol. The “objects” in this paper are coordination objects, specifically Petri nets, and the scope of the presented research calls for Petri nets to be created at runtime. For example, in manufacturing or logistics cases, dozens of shared resources occur, to which, at any time, two, three, or more robots want access, and those robots can be different ones every time.
4 Implementation
The focus of the paper is on the software mechanisms that are used to realize coordination between a (possibly large) set of concurrently executing activities. The Petri net model plays a central role within the coordination mechanisms presented in the last section. Therefore, an implementation with the purpose of multi activity coordination is presented.
This paper’s design drivers of the implementation of the design discussed in Section 3 are typical for embedded systems: low-latency and asynchronicity within a shared memory deployment. The presented design is not claimed to be efficient for other use cases, such as the offline analysis of Petri nets in search of deadlocks, livelocks, starvation, etc.
One implementation decision is easy to make: while finite state machines and Petri nets are two complementary coordination mechanisms at the conceptual level, their implementations are extremely similar; both need “states” and “transitions,” with incoming “events” as triggers of the evaluation of the mechanism, as well as the evaluation’s possible outcomes. Figure 2 explains the direct mapping of a finite state machine into the equivalent Petri net, so this section restricts itself to the implementation of Petri nets only.
This summary from previous sections is behind the other implementation decisions:
4.1 Data structures
Figure 4 shows the data structures to represent and execute Petri nets. The data structures above will always be accessed synchronously within only the Petri net executor activity. The efficiency is designed for the following execution use case:
This section uses teletype font, like this, to represent data structures and operations that are used in the software implementation of this paper’s concepts. The following data structures represent the structure of a Petri net (Figure 4, left):
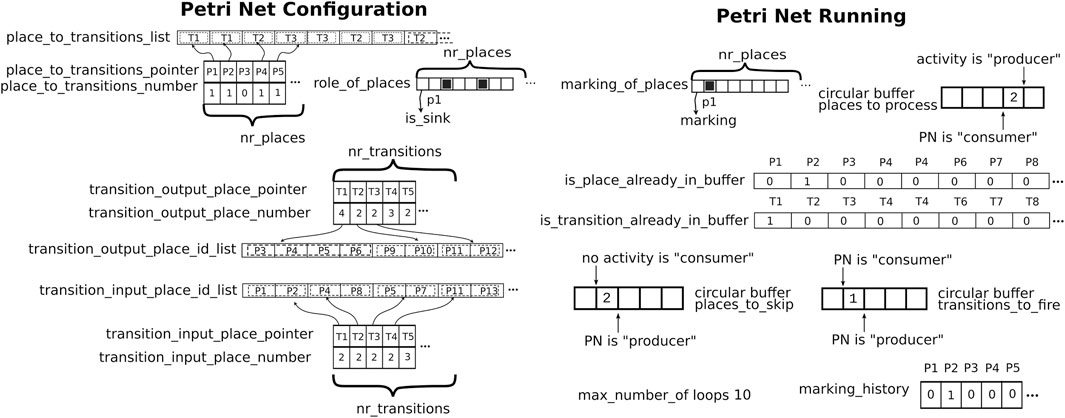
Figure 4. Overview of the data structures used in this paper’s implementation of Petri nets. Left: to represent a Petri net. Right: to execute a Petri net. Both sets can be (re)configured at compilation time or runtime.
The following data structures represent the synchronous execution status of a Petri net (Figure 4, right):
In order to reduce the cache missing latency when accessing all these data structures, they should be aligned on cache lines, including padding the last needed cache line with empty bytes.
4.2 Discussion
The presented design aims to improve execution latency at the cost of some extra memory in the data structures:
Installation instructions, examples, and the code for the implementation of Petri nets explained in this paper are available in1.
4.3 Results for generation and execution performance
To evaluate the execution time of the previous Petri net implementation, five Petri net models presented by Piedrafita and Villarroel (2011) have been built in the library. The range for scaling the size of the Petri nets is taken from the same reference. The Petri net models built were as follows:
Within this context, two tests were performed: 1) performance test with immediate firing of one transition; in this case, the execution time of 2,000 triggered transitions is measured. 2) Test with immediate firing of all transitions in the net; this type of test is expected as it marks the maximum reaction time for the complete evaluation of the Petri net. In the latest test, all the transitions of the Petri net will be enabled and triggered in each loop as the Petri net is saturated. The execution time is measured for 2,000 loops for each Petri net. The tests have been run on an HP ZBook Firefly 14 G7 Mobile Workstation.
The X-axis in Figures 5, 6 marks the computation time, while the Y-axis is the scaling parameter, which denotes the number of sub nets in the Petri net [as described by Piedrafita and Villarroel (2011)]. Figure 5 (left) presents the generation time for the Petri nets. The generation time comprises both memory allocation for the data structures in Figure 4 and its initialization. For the Petri net models SEQ, PR1, PH, and P1R, the allocation time is dominant over the initialization time, making the generation time stable within the order of nets tested. In the case of SQUARE, as the size of the net scales quadratically, the initialization time dominates.
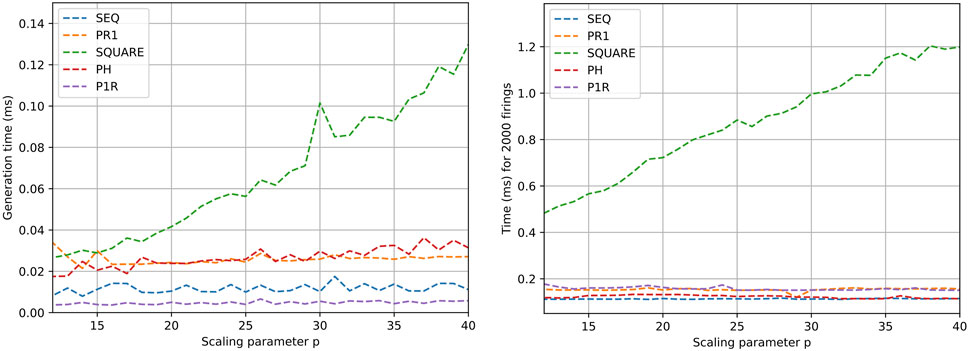
Figure 5. Generation (left) and execution (right) time results for different Petri net models. Execution time refers to transition triggering in the net 2,000 times.
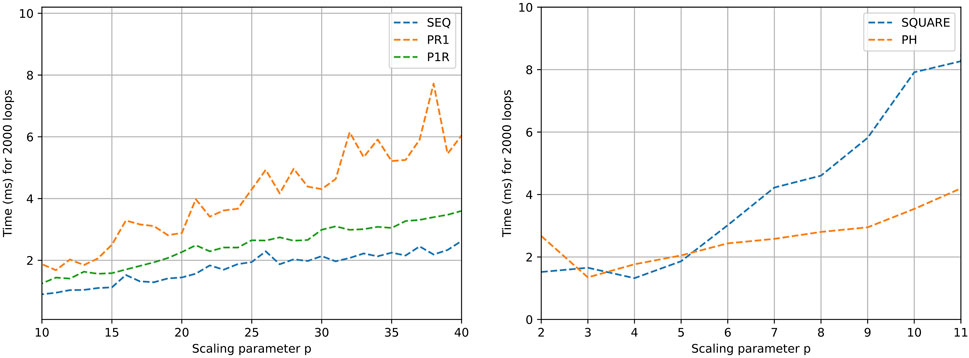
Figure 6. Time results for different Petri net design executions. Execution of all transitions enabled in the net 2,000 times.
Figure 5 (right) shows the performance of the execution of firing one transition per Petri net evaluation. In the case of SEQ, PR1, PH, and P1R, the execution time does not escalate with size, as the number of filled outgoing places from transitions is constant. In the case of SQUARE Petri nets, as the scale factor increases, the number of places to be filled after triggering a transition increases proportionally. Figure 6 shows the execution of saturated Petri nets. The execution time grows linearly for the Petri net models SEQ, PR1, PH, and P1R. This is expected because the number of evaluations is proportional to the number of places in the net. With the same logic, the time for the SQUARE Petri nets grows quadratically with respect to the scale parameter.
As the Petri nets are saturated in the second set of tests (Figure 6), the time in the graphs is taken as an upper bound for the processing time of the Petri net. For instance, a sequential Petri net with 20 processes can take up to 722 ns (1.44 ms/2,000) in the case of all processes coordinated from a mediator.
5 Experimental validation
The design and best practices proposed in this article were applied in an experimental setup with two autonomous mobile robots (AMRs) operating in an area with a pre-defined traffic layout. The demonstration case is an artificial scenario of an emergency AMR entering an area with an AMR operating at a lower speed. According to the situation, the slower robot has to reconfigure its execution at discrete and continuous levels in order to let the emergency AMR overtake. Moreover, for the coordination in the shared area, a mediator is introduced to ensure the execution of the synchronization of the AMRs.
5.1 Robot setup
Figure 7 shows one of the identical mobile platforms and the 5C activity components running on the onboard computer. Each platform is equipped with an active KELO drive 100, a Hokuyo URG-04LX LiDAR Sensor, and an ODROID XU4 Embedded Computer. In each robot, the following activities are running:
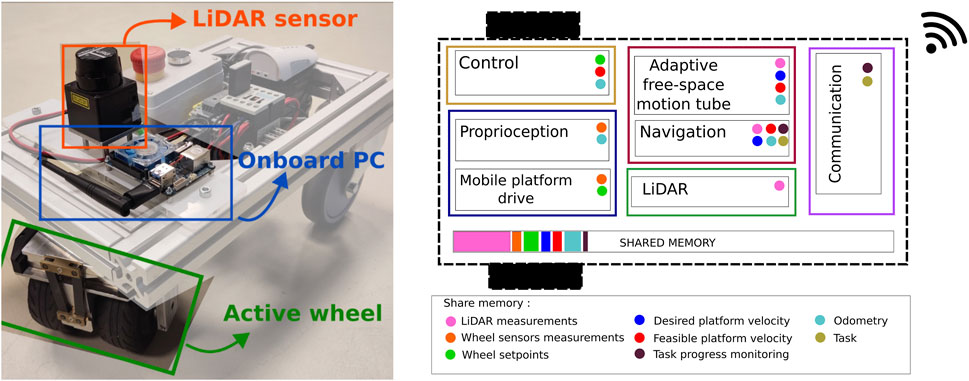
Figure 7. Mobile platform, hardware view (left), and thread and activities running on the onboard computer (right). Activities running in the same process exchange data via shared memory. Some of the data chunks accessed via shared memory are illustrated in small colored circles.
These seven activities are registered in five threads (represented in different colors in Figure 7) running at different frequencies. The five threads run in a single multi-threaded process, which allows for efficient in-memory data exchange among the different components. Figure 7 shows some examples of data shared between the activities in colored circles. For that, the variables (objects) need to be first registered in the symbol table with a semantic ID (name and datatype) by the activity owning the resource, e.g., “LiDAR measurements,” range_scan_t is registered by the LiDAR activity. For access to a shared variable, first, an activity requests the data pointers corresponding to a particular semantic ID (configuration) from the symbol table. After that, it can read the values (using acquire/release) directly from the memory without going through the symbol table (communication).
The traffic layout consists of semantic areas that are anchored in environmental features perceived by the robot (corridor and dead-ends). Figure 8 shows the control and perception layers of the semantic map. A solid black box around the map indicates solid walls detected by the LiDAR, while dashed black lines limit semantic areas in each of the layers. The control layer indicates the maneuver that a robot is expected to perform: move forward, make a U-turn, or stop. It also encodes constraints such as limits for driving velocity and deviation from the lane. The perception layer shows the feature that the robot has to track in different colored rectangles labeled as “A,” “B,” and “C.” For example, in area “A” (green), the robot resorts to a corridor detection and tracking algorithm for estimating its relative orientation and lateral position with respect to the corridor. In area “C” (yellow), the robot also tracks its relative longitudinal position with respect to the end of the solid wall at the end of the lane. The reason for the different perception behaviors is due to the finite range of the sensor, which is limited by
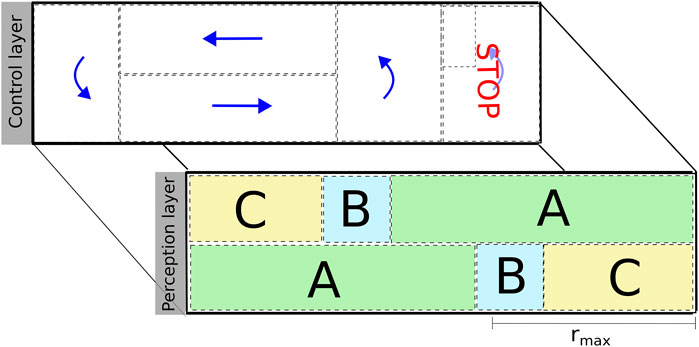
Figure 8. Illustration of the control and perception layers of the semantic map designed for the experimental validation. These layers encode the expected control and perception behaviors of the robot within a particular area. Both layers have several monitors associated with them for triggering the coordination mechanism and reconfiguring the schedule of the navigation activity of the platforms.
The schedule of the navigation activity links together perception, control, and monitoring algorithms in the form of a skill. The schedule of the activity changes at runtime according to the situation due to coordination and (re)configuration. For example, the robot starts in a known location of area “A” and moves around the circuit. A monitor that uses the information provided by dead-reckoning detects that the robot has reached area “B.” The schedule of the navigation activity changes: the algorithm for detecting the end of the lane is added to the schedule, along with a monitor that checks whether the quality of the estimation is stable. When the estimation is stable, the schedule of the navigation activity changes once again by adding (end-of-lane controller) and removing (corridor controller) algorithms accordingly.
5.2 Coordinator setup
For coordination purposes in the semantic area, an area manager is introduced for registering robots in an area and sending events to the robots when necessary. These events will trigger the (re)configuration of the schedule of the robots. The area manager is a multi-threaded process running on a different computer. It has two activities composed according to the 5C paradigm:
In this experiment, the execution of commands from both robots is not coupled, meaning that the autonomous execution of each robot does not implicitly change according to other robots in the area. Instead, the area manager works as a mediator between the two robots, coordinating them.
There are two acquire–release protocols between the area manager and AMRs. One of which is from the robot to the area manager to access the area. When the robot is navigating toward a local area, it has to request access to the area manager. When access is granted, the semantic ID of the robot and its role (normal or emergency robot) are registered in the list of robots coordinated by the area manager. This list contains the robots that “own” the area (as a passive resource) at a given time.
The area management activity coordinates the interaction of the robots in the area via the following components:
When coordination is needed among the robots in a given area, a second acquire–release interaction is established. The area management activity “acquires” the discrete control of the AMRs and releases it when the coordination is over. This means that, while the robot normally coordinates itself by executing the skills in its FSM depicted in Figure 9, when coordination happens, this is not the case anymore. When coordinated, the management activity takes control of the AMR at the discrete level via the coordination Petri net (Figure 10), with its connected protocols that trigger the sending of events to the AMRs. While the FSM in the robot is still tracking the execution of the robot, it does not trigger the maneuvers. When the coordinated execution is finished, the area management activity releases the AMR execution with a last shared event and deletes the coordination.
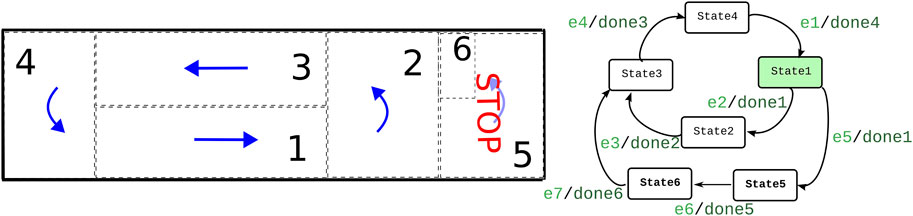
Figure 9. Finite state machine of AMRs and navigation map. The states in the finite state machine denote the traversal of the numbered areas according to directional arrows in the map. For example, state 1 would be the navigation in area 1. The input events (light green, at the left-hand side of the slash) among states come from either the navigation or communication activity (from the area manager). The output events (dark green, at the right-hand side of the slash) are triggered by the navigation activity.
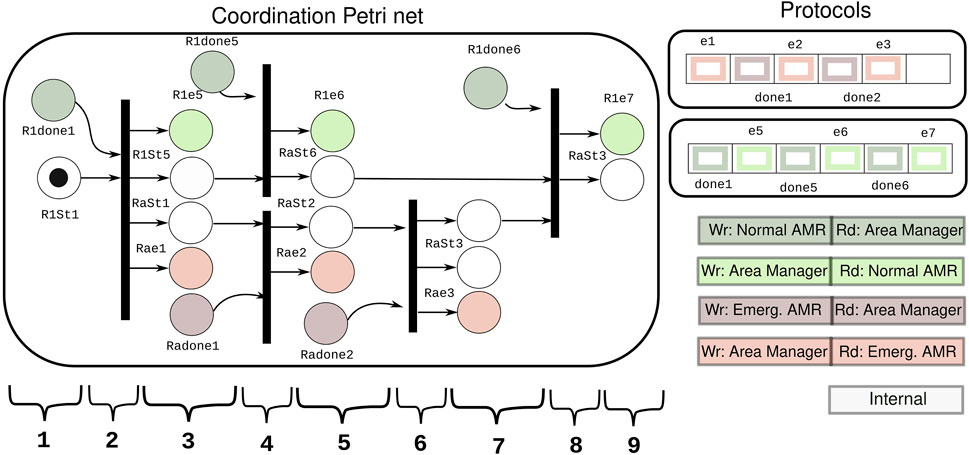
Figure 10. Petri net and protocols used for coordinating the normal AMR and the emergency AMR in the demonstration. The color legend shows the reading and writing “rights” for the flags in the protocols. The execution of the coordination at the discrete level according to the coordination in the Petri net: 1) normal AMR crosses area 1. 2) Wait until normal AMR crosses. 3) Emergency AMR is allowed to start its execution in area 1, while normal AMR gets the signal to go to the padding area with higher speed. 4) Wait for normal AMR to be out in area 5 and emergency AMR finishes in area 1. 5) Normal AMR is in padding area while emergency AMR crosses area 2. 6) Wait for emergency to be done in area 2. 7) Emergency AMR can start crossing area 3, and it is released from the coordination. 8) Wait for the normal AMR to go out of the padding area. 9) Normal AMR can start crossing area 3, and it is released from the coordination.
The Petri net used in the demonstration is depicted in Figure 10. The color legend of the image explains the ownership of the places, meaning which activity has control over the events to set the marking in the place. The white places are internal places of the Petri net, which denote the state of the AMRs in the execution. The dark places are source places, which are filled in by the coordinating activity once the corresponding event arrives from the AMRs. The light places are sink places to be filled in by the Petri net execution, triggering the sending of events to the AMRs.
For example, Figure 10 shows a case of the sink place “Rae1,” to which only the area manager has writing access. Its marking is filled in by the triggering of the Petri net. When the place “Rae1” gets a token, the connected flag “e1” in the protocol with the communication activity is raised. When the flag “e1” is raised, an event is sent to the emergency AMR, which indicates it may enter “Area 1.”
A case of the source place is “Radone1.” The communication with the emergency AMR has writing access right to the flag “done1” in the protocol, and the area manager activity reads this flag. When the event arrives from the communication activity connected to the emergency AMR, the flag “done1” is raised. Once the flag “done1” is read by the area manager activity, the place “Radone1” gets a token, and the outgoing transitions can be evaluated to continue with the coordinated execution.
The processing of incoming and outgoing events according to the sources and sinks in the coordination structure of the Petri net in Figure 10 allows the execution of the coordinated motions of the robots without disruption. Moreover, apart from the sink and source places, the internal places are added to denote the concurrent state of different activities in the coordination.
5.3 Execution of experimental demonstration
The management activity remains idle after initialization until two robots are passed to it (along with a communication channel to them). The robots are passed according to their roles in the coordination: normal robot or emergency robot. The emergency robot has priority over the normal robot. The initial state of each robot is informed to the Petri net, which translates to the initial marking.
Once the coordination is properly configured, the event loop of the management activity starts. In the event loop, the management activity processes the messages coming from the AMRs, updating them on the execution progress with respect to the skill they are performing. The activity updates the marking of the coordination Petri net when the events of finished skills are received. After the marking of the Petri net is updated from all robots, the Petri net is triggered. In the case that all the places of a transition have a token, the marking of the Petri net is updated. The updated marking is then passed to the communication modules to send the events coming from the Petri net to the robots.
The area manager is the only activity aware of the coordinated execution but is not responsible for configuring the schedule being executed in the coordinated robots. The change in configuration (e.g., of the normal robot when the emergency AMR is behind) is achieved via events that are sent from the area manager to the robots via the communication channel. These events lead to a change in the configuration of the robots, e.g., emergency AMR needs to slow down because the normal robot is still ahead or the normal robot has to drive to area 5 and wait there.
Once the coordination has finished (the emergency has overtaken the normal robot), the area manager gives back control to the AMRs because there is no need for mediation. Both robots continue their autonomous execution with their initial configuration.
5.4 Secondary demonstration: area manager for heterogeneous AMRs
The same area manager as in the previous experiment was deployed in a setup with three heterogeneous AMRs. The demonstration case is the access area to docking stations in a warehouse. In this application, coordination is needed to mediate the access to an area that can be used as two lanes by two small AMRs or one lane for a big AMR. The execution of the coordinated robots and the Petri net used can be seen in one of the videos in the multimedia part of this paper.
6 Discussion
The paper’s focus is on the efficient implementation of runtime coordination needs in multi-robot applications. Most of the efficiency comes from knowing in advance (the sizes and types) of all data structures because that knowledge allows making the most cache-efficient and data locality-driven implementations: (almost) linear-time indexing of data pointers, optimal cache alignment, known maximum usage in both time and space, etc. These efficiencies are typically only possible and useful in embedded and/or real-time software systems. Single producer, single consumer event queues, and to-do lists are common practices in this context because it is normal “to know everything” about such systems.
This section discusses implementation decisions that system developers have to be aware of to make the best use of the presented design:
For example, a robot might attempt to enter an area to which it has not yet been granted access to, or it might try to enter another area. System designs can be made more robust by introducing extra monitor activities to detect deadlocks or livelocks when the coordinated activities have not foreseen this monitoring themselves.
One reason for introducing such “non-flat” coordination is to address the coordination logic errors of the previous item. In addition to the deadlock/livelock monitors mentioned above, system designs can be made more robust by introducing pre-emption: the Petri net and/or finite state machines are extended with places/states that represent a phase in the coordination where that coordination can be pre-empted. In any case, such pre-emption needs coordination itself because all coordinated activities must somehow be brought back into a known and consistent interaction state.
This “hierarchical coordination” topic is beyond the scope of this paper.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
MA: conceptualization, investigation, methodology, software, validation, writing–original draft, and writing–review and editing. RR: conceptualization, methodology, software, validation, writing–original draft, and writing–review and editing. LV: software, writing–original draft, and writing–review and editing. HB: conceptualization, methodology, writing–original draft, and writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Flanders Make projects AssemblyRecon (“Decision Framework for Assembly System Reconfiguration”), HySLAM (“A Hybrid SLAM approach for autonomous mobile systems”), and CTO action on Cooperative motions and by the European Horizon 2020 project RobMoSys (“Composable Models and Software for Robotic Systems”) under grant agreement No. 732410.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2024.1363041/full#supplementary-material
Footnotes
1https://gitlab.kuleuven.be/u0141779/coordination_library.git
References
Abdellatif, T., Combaz, J., and Sifakis, J. (2013). Rigorous implementation of real-time systems—from theory to application. Math. Struct. Comput. Sci. 23, 882–914. doi:10.1017/s096012951200028x
Barylska, K., Best, E., Schlachter, U., and Spreckels, V. (2017). Properties of plain, pure, and safe Petri nets. Trans. Petri Nets Other Models concurrecncy. Vol 10470 Lect. notes Comput. Sci., 1–18. doi:10.1007/978-3-662-55862-1_1
Berthomieu, B., Ribet, P.-O., and Vernadat, F. (2004). The tool tina–construction of abstract state spaces for Petri nets and time Petri nets. Int. J. Prod. Res. 42, 2741–2756. doi:10.1080/00207540412331312688
Brugali, D., and Scandurra, P. (2009). Component-based robotic engineering (Part I) [Tutorial]. IEEE Robotics Automation Mag. 16, 84–96. doi:10.1109/MRA.2009.934837
Brugali, D., and Shakhimardanov, A. (2010). Component-based robotic engineering (Part II). IEEE Robotics Automation Mag. 17, 100–112. doi:10.1109/MRA.2010.935798
Bruyninckx, H. (2023). Building blocks for complicated and situational aware robotic and cyber-physical systems. KU Leuven: Department of Mechanical Engineering.
Costelha, H., and Lima, P. (2007). “Modelling, analysis and execution of robotic tasks using petri nets,” in 2007 IEEE/RSJ international conference on intelligent robots and systems, San Diego, CA, October 29–Novamber 02, 2007 (IEEE), 1449–1454.
Delanote, D., Van Baelen, S., Joosen, W., and Berbers, Y. (2008). “Using AADL to model a protocol stack,” in IEEE international conference on engineering of complex computer systems, 277–281.
Desnoyers, M., and Dagenais, M. R. (2012). Lockless multi-core high-throughput buffering scheme for kernel tracing. ACM SIGOPS Oper. Syst. Rev. 46, 65–81. doi:10.1145/2421648.2421659
Dijkstra, E. W. (1982). “On the role of scientific thought,” in Selected writings on computing: a personal perspective (Springer-Verlag), 60–66.
Dingle, N. J., Knottenbelt, W. J., and Suto, T. (2009). Pipe2: a tool for the performance evaluation of generalised stochastic Petri nets. SIGMETRICS Perform. Eval. Rev. 36, 34–39. doi:10.1145/1530873.1530881
Figat, M., and Zieliński, C. (2022). Parameterised robotic system meta-model expressed by hierarchical Petri nets. Robotics Aut. Syst. 150, 103987. doi:10.1016/j.robot.2021.103987
Figat, M., Zieliński, C., and Hexel, R. (2017). “FSM based specification of robot control system activities,” in 2017 11th international workshop on robot motion and control RoMoCo (IEEE), 193–198.
Gamma, E., Helm, R., Johnson, R., and Vlissides, J. (1995). Design patterns: elements of reusable object-oriented software
Gomes, L., Rebelo, R., Barros, J. P., Costa, A., and Pais, R. (2010). “From Petri net models to C implementation of digital controllers,” in 2010 IEEE international Symposium on industrial electronics (IEEE), 3057–3062.
Hrúz, B., and Zhou, M. (2007). Modeling and control of discrete-event dynamic systems: with Petri Nets and other tools. Springer.
Klotzbücher, M., Biggs, G., and Bruyninckx, H. (2012). “Pure coordination using the Coordinator–Configurator pattern,” in Proceedings of the 3rd international workshop on domain-specific languages and models for robotic systems, 1–4.
Kučera, E., Haffner, O., Drahoš, P., Leskovskỳ, R., and Cigánek, J. (2020). PetriNet editor+ PetriNet engine: new software tool for modelling and control of discrete event systems using Petri nets and code generation. Appl. Sci. 10, 7662. doi:10.3390/app10217662
Lacerda, B., and Lima, P. U. (2019). Petri net based multi-robot task coordination from temporal logic specifications. Robotics Aut. Syst. 122, 1–13. doi:10.1016/j.robot.2019.103289
Mealy, G. H. (1955). A method for synthesizing sequential circuits. Bell Syst. Tech. J. 34, 1045–1079. doi:10.1002/j.1538-7305.1955.tb03788.x
Murata, T. (1989). Petri nets: properties, analysis and applications. Proc. IEEE 77, 541–580. doi:10.1109/5.24143
Pereira, F., Moutinho, F., Costa, A., Barros, J.-P., Campos-Rebelo, R., and Gomes, L. (2022). “Iopt-tools–from executable models to automatic code generation for embedded controllers development,” in International conference on applications and theory of Petri nets and concurrency (Springer), 127–138.
Piedrafita, R., and Villarroel, J. L. (2011). Performance evaluation of Petri nets centralized implementation. the execution time controller. Discrete Event Dyn. Syst. 21, 139–169. doi:10.1007/s10626-010-0090-7
Radestock, M., and Eisenbach, S. (1996). “Coordination in evolving systems,” in Trends in distributed systems. CORBA and beyond (Springer-Verlag), 162–176.
Van Baelen, S., Peeters, G., Bruyninckx, H., Pilozzi, P., and Slaets, P. (2022). Dynamic semantic world models and increased situational awareness for highly automated inland waterway transport. Front. Robotics AI 8, 739062–739071. doi:10.3389/frobt.2021.739062
Vanthienen, D., Klotzbücher, M., and Bruyninckx, H. (2014). The 5C-based architectural Composition Pattern: lessons learned from re-developing the iTaSC framework for constraint-based robot programming. J. Softw. Eng. Robotics 5, 17–35. doi:10.6092/JOSER_2014_05_01_p17
Varghese, G., and Lauck, A. (1987). “Hashed and hierarchical timing wheels: data structures for the efficient implementation of a timer facility,” in Proceedings of the eleventh ACM symposium on operating systems principles, 25–38.
Zhou, H., Min, H., Lin, Y., and Zhang, S. (2017). “A robot architecture of hierarchical finite state machine for autonomous mobile manipulator,” in Intelligent robotics and applications: 10th international conference, ICIRA 2017, wuhan, China, august 16–18, 2017, proceedings, Part III 10 (Springer), 425–436.
Keywords: multi-robot, coordination, Petri net, finite state machine, real-time, shared memory
Citation: Artigas MI, Rodrigues RT, Vanderseypen L and Bruyninckx H (2024) Software patterns and data structures for the runtime coordination of robots, with a focus on real-time execution performance. Front. Robot. AI 11:1363041. doi: 10.3389/frobt.2024.1363041
Received: 29 December 2023; Accepted: 12 August 2024;
Published: 04 September 2024.
Edited by:
Federico Ciccozzi, Mälardalen University, SwedenReviewed by:
Cezary Zielinski, Warsaw University of Technology, PolandAntonio Cicchetti, Mälardalen University, Sweden
Muhammad Waseem Anwar, Mälardalen University, Sweden
Copyright © 2024 Artigas, Rodrigues, Vanderseypen and Bruyninckx. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Maria I. Artigas, bWFyaWFpc2FiZWwuYXJ0aWdhc2FsZm9uc29Aa3VsZXV2ZW4uYmU=