 Volker Gabler
Volker Gabler Dirk Wollherr
Dirk Wollherr- All authors are with the Chair of Automatic Control Engineering, TUM School of Computation, Information and Technology, Technical University of Munich, Munich, Germany
This article focuses on learning manipulation skills from episodic reinforcement learning (RL) in unknown environments using industrial robot platforms. These platforms usually do not provide the required compliant control modalities to cope with unknown environments, e.g., force-sensitive contact tooling. This requires designing a suitable controller, while also providing the ability of adapting the controller parameters from collected evidence online. Thus, this work extends existing work on meta-learning for graphical skill-formalisms. First, we outline how a hybrid force–velocity controller can be applied to an industrial robot in order to design a graphical skill-formalism. This skill-formalism incorporates available task knowledge and allows for online episodic RL. In contrast to the existing work, we further propose to extend this skill-formalism by estimating the success probability of the task to be learned by means of factor graphs. This method allows assigning samples to individual factors, i.e., Gaussian processes (GPs) more efficiently and thus allows improving the learning performance, especially at early stages, where successful samples are usually only drawn in a sparse manner. Finally, we propose suitable constraint GP models and acquisition functions to obtain new samples in order to optimize the information gain, while also accounting for the success probability of the task. We outline a specific application example on the task of inserting the tip of a screwdriver into a screwhead with an industrial robot and evaluate our proposed extension against the state-of-the-art methods. The collected data outline that our method allows artificial agents to obtain feasible samples faster than existing approaches, while achieving a smaller regret value. This highlights the potential of our proposed work for future robotic applications.
1 Introduction
Robotic manipulators have been established as a key component within industrial assembly lines for many years. However, applications of robotic systems beyond such well-defined and usually caged environments remain challenging. Simply reversing the process, i.e., asking a robot to disassemble a product that has been assembled by a robot manipulator in the past, uncovers the shortcomings of currently available (industrial) robot manipulators: the impacts of damage, temporal wear-offs, or dirt most often diminish available model knowledge and thus do not allow an accurate perception of the environment. Rather than relying on the well-defined environment model, robot manipulators are required to account for this uncertainty and thus find a suitable control strategy to interact with the object in a compliant manner. While RL has found remarkable success in dealing with unknown environments, most of these approaches rely on a tremendous amount of data, which are usually costly to obtain, cf. Levine et al. (2015), Levine et al. (2016). In contrast, GPs allow acquiring data efficiently but suffer from poor scaling with respect to state-size and dimension. A previous work has proposed to exploit existing model and task knowledge in order to reduce the parameter space from which a robot has to extract a suitable control policy.
Nonetheless, these approaches have usually been applied on (partially) compliant robots, where constraint violations, e.g., unforeseen contact impulses, can easily be compensated and are, thus, neglected. In the context of this article instead, a non-compliant—i.e., position-controlled—industrial robot is intended to solve manipulation tasks that require compliant robot behavior, such as screwdriver insertion, given a noisy goal location. Therefore, this study outlines an episodic RL scheme that uses Bayesian optimization with unknown constraints (BOC) to account for unsafe exploration samples during learning. In order to apply the proposed scheme on an industrial robot platform that does not provide the default interfaces for compliant controllers, such as a hybrid Cartesian force–velocity controller, we outline a slightly modified version of existing controllers. The resulting controller allows enabling force/velocity profiles along selective axes, while using a high-frequency internal position controller as an alternative fallback. The hybrid nature of this controller allows the direct application of a graphical skill-formalism for meta-learning in robotic manipulation from the previous work. Thus, the state complexity can be reduced to a level where the advantages of GPs outweigh their scaling deficiency. The core contribution of this study lies in the extension and adjustment of BOC to the outlined graphical skill-formalism such that safety constraints can not only be incorporated but also directly added to the graphical skill-formalism. Specifically, we outline how the underlying graph structure can be extended to directly account for safety constraints and thus improve exploration behavior during early exploration stages, where a successful episode is unlikely.
Before sketching our contribution against the related work below, we present a brief outline of the notation and terminology used in this article. Given the mathematical problem in Section 2, we shortly sketch the methodical background of our work in Section 3 and outline the technical insights of our approach in Section 4. Eventually, we outline a specific application example in Section 5 and present our experimental results collected with an industrial robot manipulator in Section 6 before concluding this article in Section 7.
1.1 Notation
In order to outline the notation used throughout this article, we use an arbitrarily chosen placeholder variable
A temporal sequence of vectors
Expected values of a stochastic variable
If
For kinematic robot chains, we refer to the origin of the chain as base
Eventually, we summarize by shortly defining the terminology of this work. For brevity, we only highlight technical terms, which distinctly differ in their meaning across research fields.
• A (manipulation) task describes the challenge for a robot to reach a predefined goal-state, closely related to the definitions from automated planning (Nau et al., 2004). As this work focuses on episodic RL, the result of an episode is equal to the outcome of a task.
• A manipulation primitive (MP) defines a sub-step of a task. In contrast to automated planning, this work does not intend to plan a sequence of (feasible) MPs but instead focuses on the parameterization of a predefined sequence of MPs. In contrast to hierarchical planning, we omit further hierarchal decompositions—e.g., methods (Nau et al., 2004)—such that a task can only be realized as a sequence of primitives.
• Using such MPs in order to solve a manipulation task directly leads to the introduction of the term of a skill. While a (robotic or manipulation) skill denotes the ability of a robot to achieve a task, we explicitly use the term (graphical) skill-formalism to denote a specific realization of sequential MPs to solve a manipulation task.
• Our work seeks to increase the learning speed for episodic RL by limiting learning to a reduced parameter space, which we denote as meta-learning as used in the existing work (Johannsmeier et al., 2019). It still has to be noted that this terminology is different to common terminologies such as meta-RL (Frans et al., 2018).
• Within episodic RL, a robot is usually asked to find an optimal parameter sample or a policy with respect to a numeric performance metric that is obtained at the end of a multi-step episode. In the scope of this work, we specifically focus on the former, i.e., a robot is asked to sample parameter values during the learning phase. Similar to literature in Bayesian optimization, we often denote this sampling process as the acquisition of samples (Rasmussen and Williams, 2006). Eventually, the performance metric is obtained at the very end of a successful trial episode.
1.2 Related work
In the context of learning force-sensitive manipulation skills, a broad variety of research work has been presented in the last decade. Profiting from compliant controllers that were designed to mimic human motor skills (Vanderborght et al., 2013), the concept of adaptive robot skills has found an interesting way beyond an adaptive control design. Thus, this section outlines the state-of-the-art methods across multiple research fields before setting the contribution of this article in relation to these works.
1.2.1 Force-adaptive control for unknown surfaces or objects
As covering all aspects of interacting with unknown surfaces, e.g., tactile sensing (Li Q. et al., 2018), is beyond the scope of this article, we refer to existing surveys (Li et al., 2020) and specifically summarize findings on learning force-adaptive manipulation skills.
In this context, the peg-in-hole problem is one of the most covered research challenges. Early work, such as Gullapalli et al. (1992) and Gullapalli et al. (1994), proposed to apply machine learning (ML), e.g., real-valued RL, to learn a stochastic policy for the peg-in-hole task. The neural networks for the force controllers were trained by conducting a search guided by an evaluative performance feedback.
In addition to ML, many approaches have applied learning from demonstration to obtain suitable Cartesian space trajectories, cf. Nemec et al. (2013) or Kramberger et al. (2016) who adjust dynamic movement primitives conditioned on environmental characteristics using online inference. While initial attempts have focused on adjusting the position of the robot end-effector directly, recent approaches have also investigated the possibility of replicating demonstrated motor skills that also involve interaction wrenches (Cho et al., 2020) or compliant behavior (Deniša et al., 2016; Petric et al., 2018).
Alternative work proposes adaptive controllers that adjust the gains of a Cartesian impedance controller as well as the current desired trajectory based on the collected interaction dynamics. Yanan Li et al. (2018) evaluated observed error-dynamics, current pose, velocity, and excited wrenches.
Even though these works have achieved great results for modern and industrial robot manipulators in their application fields, they do not allow robots to autonomously explore and refine a task. While learning from demonstration always requires a demonstration to be given, adaptive controllers assume to have access to a desired state or trajectory. In addition, the majority of proposed controllers usually require high-frequency update rate on the robot joints, cf. Scherzinger et al. (2019b); Stolt et al. (2012); Stolt et al. (2015), which usually is only accessible for the robot manufacturer. In contrast to this, this study seeks for a setup that can be deployed on off-the-shelf industrial robot manipulators.
A few years ago, the idea of end-to-end learning via means of deep RL techniques had been studied thoroughly to combine the efforts of the former and the latter in a confined black-box system. In these studies, the concept of controlling the gains is omitted and instead replaced by a feed-forward torque policy that generates joint-torques from observed image data using a deep neural network (NN). Levine et al. (2015) and Levine et al. (2016) used a guided policy search that leverages the need for well-known models or demonstrations. Instead, the system learns contact-rich manipulation skills and trajectories through time-varying linear models that are unified into a single control policy. Devin et al. (2017) have tackled the issue of slow converging rates due to the enormous amount of required data by introducing distributed learning, where evidence is shared across robots, and the network structure allows distinguishing between task-specific and robot-specific modules. These models are then trained by means of mix-and-match modules, which can eventually solve new visual and non-visual tasks that were not included in the training data. The issue of low precision has been improved by Inoue et al. (2017), who evaluated the peg-in-hole task with a tight clearance.
Recently, the application of deep RL has reverted to use existing controllers and improve their performance by applying deep NNs in addition, e.g., Luo et al. (2019) proposed to learn the interaction forces as Pfaffian constraints via a NN. Beltran-Hernandez et al. (2020) applied an admittance controller for a stiff position-controlled robot in a joint space and applied RL via soft actor-critic (Haarnoja et al., 2018) to achieve a compliant robot behavior that successfully learns a peg-in-hole task by adjusting the gains of the admittance controller. Similarly, the feed-forward wrench for an insertion task is learnt from human demonstrations (Scherzinger et al., 2019a) using NNs and a Cartesian admittance controller tailored to industrial platforms (Scherzinger et al., 2017).
Aside from the aspect of meta-RL (Frans et al., 2018; Gupta et al., 2018), which investigates the idea of bridging data generated in simulations to physical platforms, the performance benefits and ability to learn almost arbitrarily complex tasks and existing methods for deep RL still require a tremendous amount of experimental data to be collected to achieve reliable performance.
1.2.2 Robot skill learning on reduced parameter spaces
The size of required data is directly subject to the size of the parameter space that needs to be regressed. Thus, another promising line of research is given by decreasing the search space and problem complexity.
A recent research work has proposed to use available expert knowledge rather than learning a skill from scratch. LaGrassa et al. (2020) proposed to categorize the working space into regions where model knowledge is sufficient and into unknown regions, where a policy is obtained via deep RL. Johannsmeier et al. (2019) proposed to incorporate expert knowledge in order to reduce the search space for adaptive manipulation skills by introducing MPs. On this basis, they showcased a peg-in-hole task, where a robot adjusts the stiffness and a feed-forward interaction wrenches of a Cartesian impedance controller by means of Bayesian optimization (BO) and black-box optimization.
The application of such MPs also encouraged the application of deep RL approaches. Zhang et al. (2021) proposed two RL approaches based on the principle of MPs, where the policy is represented by the feed-forward Cartesian wrench and the gains of a Cartesian impedance controller. Martín-Martín et al. (2019) similarly proposed to learn the controller selection and parameterization during a peg-in-hole task. Hamaya et al. (2020) applied a model-based RL via GP on a peg-in-hole task for an industrial position-controlled robot by attaching a compliant wrist to the robot end-effector, which compensates for perception inaccuracy. Mitsioni et al. (2021) instead proposed to learn the environment dynamics from an NN in order to apply a model predictive control, if the current state is classified as safe via a GP classifier. Alt et al. (2021) also applied NNs via differentiable shadow programs that employ the parameterization of robotic skills in the form of Cartesian poses and wrenches in order to achieve force-sensitive manipulation skills, even on industrial robots. They include the success probability in the output of the NNs, in order to minimize the failure rate.
While these approaches have shown promising results by solely collecting experimental data within reasonable time, neither of those approaches include interaction constraints—e.g., maximum contact wrenches—during the acquisition or evaluation of new data samples nor allow the application of the presented results on an industrial platform without an additional compensation unit. As for the former, the majority of research projects have applied BOC to account for safety critical or unknown system constraints during learning, and we continue with a dedicated overview of research in this field.
1.2.3 Bayesian optimization with unknown constraints for robotics
Within robotic applications, BO has shown potential in achieving online RL due to effective acquisition of new samples (Deisenroth et al., 2015; Calandra et al., 2016), that is still used within robotic research applications (Demir et al., 2021).
In the context of BOC, safe RL methods have been proposed that estimate safe or feasible regions of the parameter space into account to allow for safe exploration, cf. Berkenkamp et al. (2016a,b), Sui et al. (2015), or Baumann et al. (2021).
Similarly, Englert and Toussaint (2016) proposed the probability of improvement with a boundary uncertainty criterion (PIBU) acquisition function that encourages exploration in the boundaries of safe states. Their approach was further evaluated on generalizing small demonstration data autonomously in Englert and Toussaint (2018) as well as on force-adaptive manipulation tasks by Drieß et al. (2017). A similar acquisition function has been proposed by Rakicevic and Kormushev (2019), even though they do not approximate the success as a GP.
Approaches such as those by Wang et al. (2021), who used GPs to regress the success of an atomic planning skill from data, have further shown that BOC is well-suited to regress high level, i.e., task-planning constraints from data. While they approximated this success probability as a constraint with a predefined lower bound 0, Marco et al. (2021) outlined a constraint-aware robot learning method based on BOC that allows improving sampling even if no successful sample is available yet. Recent practical application examples of BOC are found in Khosravi et al. (2022), Stenger et al. (2022), and Yang et al. (2022).
While these approaches have achieved promising results within small-scale (robot) learning problems, they suffer from poor scaling properties as GPs require to use the covariance matrix for prediction and acquisition of new data samples, which grows exponentially in the state space of the underlying problem. While various works have focused on finding proper approximation methods to leverage this problem, we propose that within a robotic context, it is preferable to explicitly incorporate structural knowledge whenever possible. To conclude this overview of the state-of-the-art methods, we shortly summarize the contribution of this article in relation to the work stated previously.
1.3 Contribution
This study introduces a novel episodic RL-scheme for compliant manipulation tasks tailored to industrial robots. In order to allow for compliant manipulation tasks, the control interfaces of an industrial robot are adjusted to follow a Cartesian hybrid force–velocity controller (Craig and Raibert, 1979; Khatib and Burdick, 1986). By exploiting the hybrid nature of this controller and available expert knowledge, a complex manipulation task can be reformulated into graphical skill-formalisms—i.e., a sequence of simplified MPs—from existing work. Eventually, we outline an extension of these graphical skill-formalisms by taking into account parameter constraints and success-probabilities at each sub-step. This improves learning especially at early stages and allows refining the individual sub-steps of a robotic manipulation task even when no successful episode could have been observed yet. Furthermore, we define suitable BOC models to estimate the success probability of each MP as well as the overall task, as well as the outline of suitable acquisition functions that allow collecting data efficiently during learning.
2 Problem formulation
The mathematical problem tackled in this article is the optimization of an unknown objective function
specifically tailored to robotic applications. In here, the objective
as the current performance sample
approximate the objective
weighted by the success probability of ξ given as the joint probability over all constraints. Thus, (4) does not only optimize the main task-objective but also accounts for the probability of violating imposed constraints. This directly allows optimizing the performance of an unknown manipulation task for robotic systems, while accounting for constraints such as limited interaction wrenches during contact tooling.
3 Preliminaries and background
Before outlining our approach in detail, we provide a brief introduction into the graphical skill-formalisms from Johannsmeier et al. (2019) and the BOC approach from Marco et al. (2021) and Englert and Toussaint (2016), which we use as a baseline comparison in our experimental evaluation.
3.1 Meta-learning for robotic systems using graphical skill formalisms
Within robotic tasks, the hyper-parameter space is usually large due to the degrees of freedom in SE (3) or the configuration space of the robot. Therefore, Johannsmeier et al. (2019) proposed to model tasks in fine-grained Moore finite-state automaton (FSA), according to the schematic shown in Figure 1. The vertices

FIGURE 1. Schematic skill-formalism for manipulation tasks as presented in Johannsmeier et al. (2019). Each MP—i.e., node
Eventually, the manipulation skill is further defined by a set of constraints that define the start- and end-constraints, as well as any time constraints that the robot shall never violate. This provides the benefit of exploiting available object knowledge, while also providing a skill-formalism that is closely related to that of automated task planning (Nau et al., 2004). In fact, these constraints are closely related to autonomous planning and first-order logic, where planning primitives are often described by a set of pre-conditions and effects. In the context of concurrent planning, this is also extended to any time constraints that must not be violated while the task primitive is executed. This results in a skill representation as shown in Figure 1, where the task-constraints are defined as deterministic mapping functions
• Initialization constraints
• Success-constraints
• Safety and performance constraints
In the context of the graphical skill-formalism from Johannsmeier et al. (2019),
3.2 Bayesian optimization with unknown constraints
Within BO, an unknown function or system is regressed from data as a stochastic process. A common model is a GP, which is defined as a collection of random variables, namely, joint normally distributed functions over any subset of these variables. They are fully described by their second-order statistics, i.e., a prior mean and a covariance kernel function
where the probability of improvement (PI) is maximized
Here, Φ denotes the normal cumulative distribution function (CDF), whereas
that uses the PI in admissible regions of the parameter space and the variance σ of the latent GP in the boundary regions to encourage a safe exploration. They further use a constant negative mean prior for the latent GP to limit sampling to the boundary regions of the safe parameter space. In contrast to this, Marco et al. (2021) proposed to use a constraint-aware GP model that allows using EIC, which they denote as a Gaussian process for classified regression (GPCR). GPCR allows updates even if no successful constraint sample has been drawn yet, based on the environmental feedback in (2). Furthermore, Marco et al. (2021) proposed to regress the constraint thresholds cj directly from data. Thus, having
where H denotes the Heaviside function. Using a zero-mean Gaussian prior, the posterior is given as follows:
where the Gaussian distribution
where
4 Technical approach
In order to allow online RL to be applied from a handful of exploration samples, it is favorable to exploit available knowledge and thus decrease the overall meta parameter space of the observed system. As mentioned before, we thus extend the concept of modeling robotic tasks as skill-graphs from Johannsmeier et al. (2019) to allow compliant manipulation tasks to be tuned online. In contrast to preliminary work, we outline how a stiff position-controlled industrial robot platform can be controlled in order to allow for compliant robot behavior. Building upon this, we emphasize how a graphical skill-formalism can exploit the structure of the presented controller, such that the controller parameters can be adjusted online. As crash constraints are critical, if a stiff robot is asked to interact with unknown objects, we conclude our technical contributions by not only outlining how the structure of the skill-graph can be further exploited to simplify the BOC-RL algorithm but also proposing suitable BOC models and acquisition functions in order to improve the overall learning performance.
4.1 Compliant Controller design for an industrial Robot
In the context of this article, we use a COMAU robot2. While this robot prohibits the control of the motor torques or impedance-based controller interfaces, it allows controlling the position of the end-effector x of the robot via an external client in the form of a Cartesian deviation relative to the current end-effector pose, such that the controlled system simplifies to
where δx forms the control command being sent to the robot. As the robot runs at a real-time safe, constant update rate δt, the Cartesian deviation command
where
for position and force control.
Thus, a Cartesian velocity and the force-profile F can be followed along selective axes. The presented controller differs from classic hybrid force-position control by the fact that disabling the force control along an axis does not directly result in position control. If
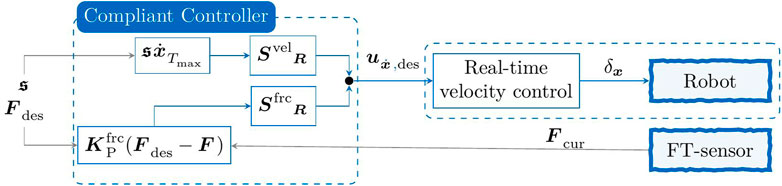
FIGURE 2. Schematic overview of a hybrid force–velocity controller (Craig and Raibert, 1979; Khatib and Burdick, 1986) using the Cartesian deviation control interface of an industrial COMAU robot. Here, the selection matrices
4.2 Applying Bayesian optimization with unknown constraints on graphical skill representations
Even though a skill graph can decrease the search space complexity, the resulting space may still suffer from the curse of dimensionality. Furthermore, collecting data from actual experiments is at risk of gathering various incomplete and, thus, useless data samples. In the context of episodic RL, one (successful) graph iteration represents a single episode. This requires all steps to succeed for a useful return value. Thus, we outline how the BOC problem from Section 2 can be reformulated to exploit available model knowledge in this skill-graph to improve sampling and learning. We assume that the feedback from (2) can be obtained at each node of the skill-graph and that each parameter in ξ is bounded. Given a graphical skill representation as in Figure 1, represented by MP nodes
Thus, (4) results in
where
4.2.1 Naive Bayes approach
In order to approximate
where
while the success probability of each intermediate node is obtained as the product of individual terms
4.2.2 Modeling the success function as a factor graph
In addition to the naive Bayes approach, it is also possible to directly impose the structural task knowledge that results from the graph structure. Namely, we propose to model the overall success probability as a factor graph representation Kschischang et al. (2001) for the task-constraints, where the scalar elements of ξ form the variables, and the constraints from (1) form the factors, cf. Figure 3.
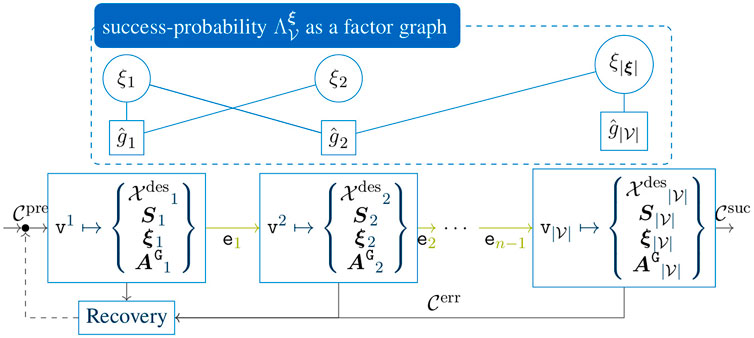
FIGURE 3. Graphical skill-formalism with an additional factor graph representation for the task success probability. The individual node parameters
Having obtained the general factor graph for a manipulation skill, this graph is fully described by an adjacency matrix
If, for example, only the active success-constraint per MP node is introduced and each constraint has the same input dimension, the naive Bayes approach is reconstructed. In contrast to the naive Bayes approach, each MP constraint can depend on arbitrary subsets of ξ. In order to fully exploit the structure of the MP-graph, we propose to embed the underlying success probability for each vertex in the skill-graph. This can be directly achieved by extending the current set-values commanded to the robot system by an MP-specific adjacency matrix
4.3 BOC model and acquisition function
Given the extended MP-graph, the objective of acquiring samples efficiently is again subject to the choice of the acquisition function and underlying GP model. Recalling Section 3.2, a key benefit of the method from Marco et al. (2021) is the ability to push the probability mass above the current threshold estimate, which allows gaining more knowledge from failed samples. Nonetheless, this model relies on approximating the posterior due to nonlinear components in (10). Instead, we propose to induce artificial data points and fit GPs on this artificial dataset instead. The algorithmic skeleton is sketched in Algorithm 1, where we again assume to have safe and failed data samples in the data buffer

Algorithm 1. Induce artificial data points to fit GP on datasets with failed samples.
We propose fitting a GP into the safe dataset first. Given this safe distribution, we propose to estimate the constraint value
and weigh the sum of acquisition functions by the overall success probability to encourage acquisition of samples that are expected to succeed in the overall task. Due to the linear structure and the conditional independence of each node,
using
4.4 Exploit conditional dependencies for collected samples

Algorithm 2. Overall BOC algorithm.
The final BOC algorithm for the proposed online RL approach is sketched in Algorithm 2. In contrast to learning the full parameterization of the task, the sequential skill-graph receives the additional feedback as to which node was explored last in Line 4. This information is crucial to assign samples correctly for the success- and constraint data buffers in Line 7 and Line 6. While the assignment for the MP node objectives is straightforward, i.e., only valid samples for explored nodes are assigned to the datasets, invalid samples may also be assigned even though the related MP or constraint factor has not yet been evaluated. The necessary condition for a sample to be added to the dedicated dataset is that at least one scalar component has to be explored or visited. Due to the sequential procedure of the skill-graph, the mapping of the last explored node
Before outlining an application example, we briefly outline the theoretical improvements of our approach, i.e., the scaling with respect to size of the meta parameter space.
4.5 Complexity analysis
In this section, we analyze the proposed method in terms of scaling with respect to size of the meta parameter space. It has to be noted that we do not emphasize improving GP scaling against big data, for which there is existing work (e.g., Ambikasaran et al. (2016)) available. For brevity, we denote the dimension of the original learning problem as nξ, i.e.,
Definition 4.1. Valid MP-Graph
An MP-graph is a valid representation for (4), if the following constraints are given.
• The graph has no absorbing nodes.
• There exists a finite path from the start-to the end-node.
• The underlying objective can be represented by a convex composition of sub-objectives.
Definition 4.2. Feasible MP-graph
An MP-graph is a feasible representation for (4), if the following constraints are given.
• The meta parameter space for each node of the MP-graph is bounded by
• The meta parameter space for all constraints is bounded by
• The number of active constraints per node is bounded by
Claim 4.1
Regressing a general robot task 1) as a stochastic representation 4) via GPs according to Definition 4.2, the resulting complexity can be reduced from
Proof. Recalling (16), the objective function of the algorithm scales linearly with the numbers of nodes within the graph. According to Definition 4.2, the meta-parameter space of each MP node is bounded; thus,
This proves claim 4.1 if there are no success-constraints active, i.e.,
Claim 4.2. Using the factor graph method and a task-representation as outlined in claim 4.1, the complexity from
Proof. In contrast to the naive Bayes approach, the system complexity grows linearly with respect to the number of constraints
Eventually, it has to be noted that adding artificial data adds data to the datasets of MP nodes or factors, which decreases scaling behavior. Nonetheless, it has to be noted that adding artificial data is not mandatory and intends to add support during early exploration when datasets are usually small. Therefore, we omitted the possibility of adding artificial data in the aforementioned complexity analysis.
5 Application example—screw insertion
In this section, we outline an application example for the proposed manipulation learning framework that uses the proposed controller from Section 4.1: the insertion of a screwdriver into a screwhead. Even though the environment suffers from high uncertainty, there exists available pre-knowledge that can be incorporated to reduce the problem size and thus use a skill-graph according to Section 4.2. While the previous sections have outlined the generic modalities of our method, this section intends to present an application example, which is eventually used to evaluate our approach. The main motivation of constructing a graphical skill-formalism is the reduction of the actual search space for the episodic RL task, i.e., the dimension of the parameter vector ξ. Therefore, we assume the following constraints to be given:
• the screw is accessible by the robot end-effector, i.e., there exists a robot configuration that does not result in a self-collision of the robot with any surrounding object when the screwdriver is inserted. Furthermore, the robot configuration is singularity-free as this would not allow using the underlying Cartesian robot controller reliably.
• In case the position of the screwhead is subject to uncertainty, the condition above needs to be guaranteed for the full range of the uncertain region.3
• The robot is equipped with a screwdriver, and the transformation from the screwdriver pin, i.e., control frame
• The type of screw matches the pin of the screwdriver of the robot.
Given these assumptions, motion planning or pose optimization against infeasible states or collisions can be omitted. Instead, the framework focuses on finding a correct parameterization of the controller presented in Section 4.1. In approaches such as end-to-end learning, the problem could be represented as an RL-problem, with sparse rewards that penalize any constraint violations and add positive feedback for a successful task. While this allows to learn such a skill from visual data on arbitrary robot platforms, first, a supervised learning method is required to classify task success or constraint violation, and infeasible amount of data needs to be collected from experimental trial and error, where a supervised learning method is required, which will violate feasible time-budgets. In contrast, directly applying a GP policy would result in extremely large datasets, which will in return affect the evaluation or acquisition calculation. Thus, we propose to exploit the available expert knowledge and construct a skill-graph formalism similar to that of Johannsmeier et al. (2019). First, the normal vector n of the surface and the screw4 is approximately known from visualization. Furthermore, we assume that an expert has set the desired contact wrench-magnitudes beforehand. Similarly, a designer has chosen a tilting angle for the robot end-effector to ease the contact tooling.
Given this, we outline the resulting skill-graph as visualized in Figure 4 from left to right. In this skill-graph, we explicitly denote the output alphabet, i.e., the desired set-values per node as well as the MP-parameters ξi. For brevity, only non-zero values are explicitly mentioned, e.g., if not explicitly noted, all values of
The second node
The success of this MP is given as an established contact with the environment, which is defined as follows:
where the variance σF denotes the approximated sensor noise and μF the filtered force–torque (FT) sensor readings over a sliding window of fixed size NFT. This node further checks against the maximum allowed contact force Fmax, as follows:
to raise a failure of the skill. The subsequent node
The success of this MP is evaluated by the accumulated force-error for a fixed window-size Ncont:
using only the force-measurement
to detect contact loss with the environment as an error constraint. During the next node
The success of this MP is evaluated via the force impulse encountered in the current motion direction, i.e.,
For the error constraint, this node applies (29) and (32) and also checks against the robot position.
where pcur denotes the translational component of the tool-tip of the robot, whereas
While the error constraint is identical to
where
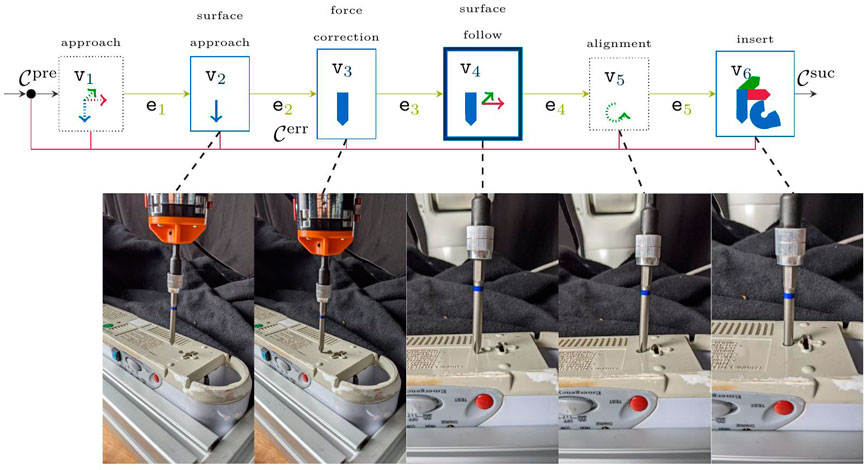
FIGURE 4. Schematic screw-insertion skill as an MP-graph. Each vertex shows the dedicated control direction, and thus the selection matrix from (14), where bold arrows represent force control and thin lines velocity control. Straight arrows in each MP denote translation with respect to
Having introduced the general MP-graph, we now outline how the success-constraint of the overall skill can be derived as a factor graph for the outlined skill graph. First, the naive Bayes approach retrieves the success-constraint as the joint probability of
This results in the factor graph from Figure 5a. For the factor graph representation, the actual parameter vector needs to be decomposed into the scalar components to obtain the underlying factors. Thus, this strongly depends on the actual parameterization of
• the search pattern on the surface of the object is restricted to a constant velocity, where the direction is set by an expert, while only the velocity needs to be adjusted to prevent the robot to miss the screw. Thus, we replace
• For the force controller, the proportional gain is set equally for all translational components x, y, and z.
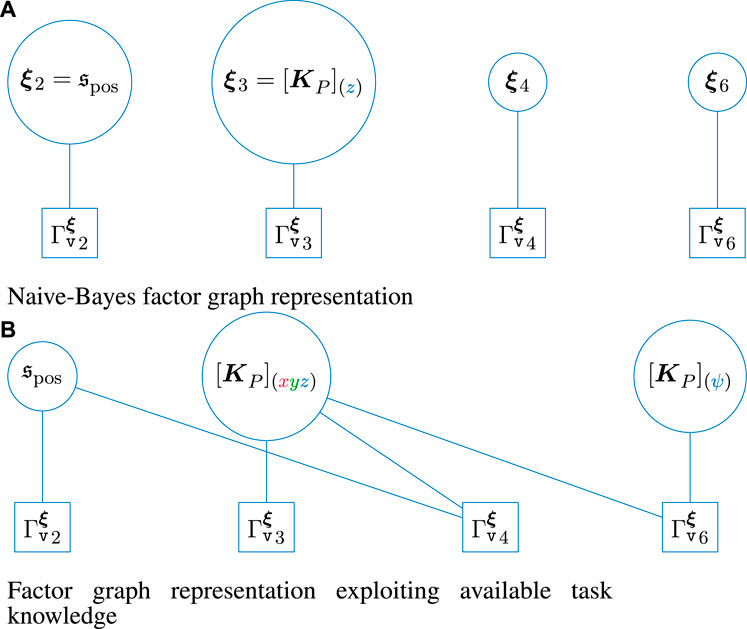
FIGURE 5. Representation of the success probability of the unscrewing skill as factor graphs. Here, the naive Bayes approach is also highlighted as a factor graph, while the actual factor graph exploits available task knowledge to introduced conditional dependence and independence in the regression problem that allows adding samples efficiently during learning.
As a result, the overall success probability results in the factor graph from Figure 5b.
The according adjacency matrices are then given as follows:
Recalling Section 4.4, the graph structure needs to be respected when assigning samples. Failed trials at

TABLE 1. This table summarizes the unknown controller parameters for the unscrewing skill given the presented controller from Section 4.1.
6 Experimental results
Given the exemplary MP-graph for the unscrewing task from Figure 4, a suitable controller parameterization is regressed from data by setting the objective

TABLE 2. Predefined parameters for the unscrewing skill. The value for
Given this, each algorithm was run 25 times using Neps = 60 iteration steps for each run. In each run new samples were added to the dedicated datasets, and the current optimum guess is stored at each step. Using the collected empirical evidence as ground-truth, the best empirical sample
The averaged regrets over 25 trials per method are plotted in Figure 6, where the shaded area highlights the CI of 70%. The presented data underline that our graphical representations allow acquiring feasible data distinctly faster than GPCR and PIBU. This improved learning performance mainly stems from the decreased meta parameter space and the ability to collect evidence of the individual factors rather than learning the full task.
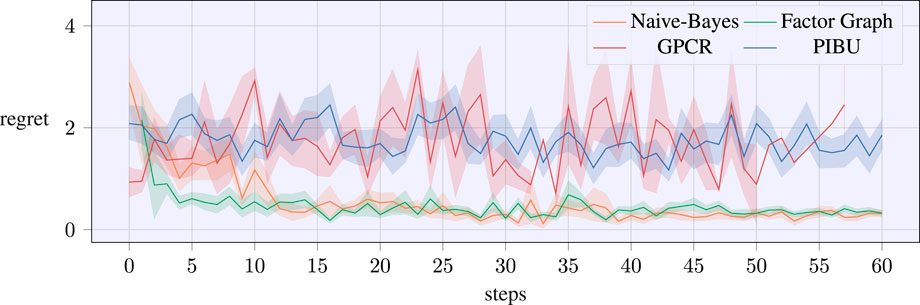
FIGURE 6. Regret evolution of the experimental screw-insertion task over the number of trials. The data are averaged over 25 runs per algorithm, with the shaded areas denoting a CI of 70 %.
This is further underlined by the evolution of successful samples that are collected by the algorithms as visualized in Figure 7. Again, a CI of 70% is added over the averaged temporal evolution of the successful samples. It also has to be noted that this number is only increased if all nodes of the proposed graphical structures receive a successful sample, i.e., the overall exploration sample returns a successful sample. In this experiment, the naive Bayes approach could collect new successful samples earlier than the factor graph version. Nonetheless, the difference diminishes by the end of the 60 trials, and the evolution of successful samples equals out for both graphical approaches. Within our experimental evaluations, the GPCR method suffered from numerical instability after latest 60 iterations, while our approaches could evaluate further trials. As samples above 60 do not allow for a fair comparison, we omit the continuation of the plots. Still, we ran extended simulations for the proposed graphical methods with 80 steps, and the evolution of the successful samples converged to similar values for the final trial-episodes. While Figure 6 denotes the performance of the evaluated methods, Figure 7 denotes how many safe samples are explored. Nonetheless, Figure 6 only contains valid evaluations of the MPs or the tasks, as even if only a single MP fails, the regret would return an infinite value. In order to compare our algorithms in terms of safety awareness, the rates of estimating a valid optimal sample are listed for each algorithm in Table 3. As it can be seen, the pure GP classification within PIBU outperforms the remaining methods distinctly.

TABLE 3. Rate of estimating a correct optimal sample. The best performing, i.e., highest success-percentage is highlighted in bold.
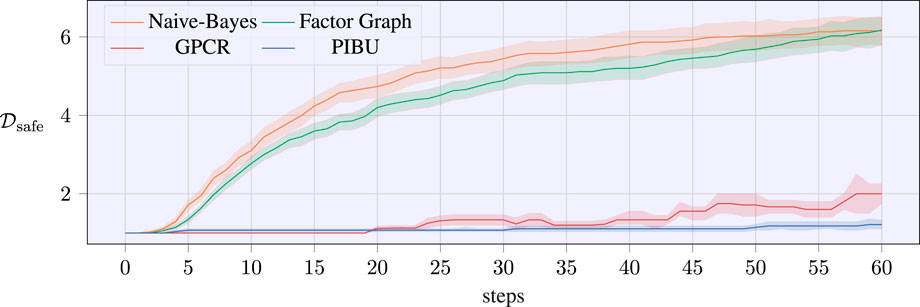
FIGURE 7. Number of safe samples for the experimental screw-insertion task over the number of trials. The data are averaged over 25 runs per algorithm, with the shaded areas denoting a CI of 70 %.
This effect mainly stems from the structure of the task, where the approaching speed scaling is linearly increasing the objective, while the constraint is given as a strict upper threshold, that also represents the optimal value. With only a handful samples, estimating the constraint rather than the classification labels remains numerically challenging.
In contrast, the application of a pure classification GP may also be overly conservative, and being only provided with a small number of successful samples, the classification may not be capable of returning a useful solution for the task to be learned. In addition to receiving a distinctly smaller regret, our approaches also converge closer to the actual optimum parameter samples. This is visualized by the temporal evolution of the estimated optimal parameter samples in Figure 8, where the shaded areas again denote a CI of 70%. In contrast to related work, our approaches quickly converge to a solution for ξ1 and ξ2, while ξ3 is only slowly converging toward the optimal value. This delay stems from ξ3 being conditionally dependent on the performance of the remaining data samples. Even though the estimation of ξ3 also suffers from higher variance than that of related work, our approaches distinctly outperform the related work in this aspect. This underlines that our approaches do not result in suitable parameter estimation by chance but due to efficient data acquisition.
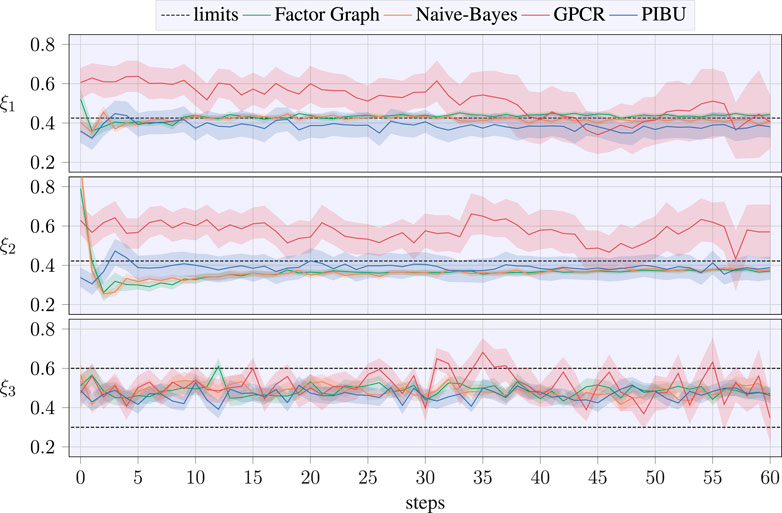
FIGURE 8. Temporal evolution of the estimated optimum parameter value, where the dashed lines denote the upper bound for the parameter, while the lower dashed line in the bottom plot denotes the dedicated lower bound. Shaded areas denote the CI of 70 %. The optimal values to be regressed from data are
6.1 Discussion
Having collected the experimental data, our approaches outperform existing work in terms of data efficiency and allow obtaining suitable results from only a handful of samples. Furthermore, our approaches apply standard GPs on smaller meta parameter spaces. Even though our regression method requires multiple parameter fits for multiple nodes, each GP is conditionally independent by definition within a factor graph. This allows for full parallelization, even though we evaluated our method in a purely sequential manner.
Nonetheless, the presented results also highlighted a particular downside of our method, which is exposed by the small chance of drawing successful samples. While our method outperformed existing work in drawing successful samples during exploration, this effect can be neglected during exploitation. If the current estimate is to be applied on safety-critical applications, the provided success rate needs to be improved. While it has to be noted that neither GPCR nor a classification GP can provide a safety guarantee when drawing success-estimate, the combination of our method with one of the former methods allows alleviating this issue. Thus, the overall graph success probability can be replaced by a product of experts, where the experts are given as the individual success-models. Another possible solution is given by using a negative prior mean similar to PIBU in the constraint GP and evaluating the constraint metric by shifting the probability of the posterior. Using this, the search of the optimal value is constrained to a tightened set of the parameter space, which automatically results in an increased probability to draw a correct sample.
Eventually, it has to be mentioned that the presented problem on regressing ξ1 is a special case, while in general cases, where the optimum value is not in the near distance of the success-constraint, our method reliably converges to the correct parameter guess. Given the overall improvements of our method that is evident in the collected experimental data and the overall framework, it can be summarized that our method improves existing methods on regressing task-parameters for autonomous robots in a constraint-aware manner. Referring to the ability of converging to correct values within a reasonable time and amount of data, this makes our application a reasonable method to be applied on future robot platforms and manipulation tasks.
Finally, the question of whether either our factor graph or the naive Bayes approach is favorable needs discussion. Referring to the overall results, the performance of both methods is comparably similar. This mainly stems from the fact that the first parameter and thus the first sample is the most critical evaluation parameter of the task to be learnt. As this node is conditionally independent of the last parameter, the benefit of generating artificial data samples can only be applied rarely. Nonetheless, the preferable major advantage of the factor graph is given by the ability to apply it to arbitrary tasks and allows regressing constraints that have a different input space than the current objective node. Given that both approaches obtained almost identical performance results, the factor graph method forms the generic representation and preferable method, whereas the naive Bayes version is distinctive by its simplicity and simple adjustment to alternative models.
7 Conclusion
In this study, we proposed an episodic RL-scheme that uses BOC to account for unsafe exploration samples during learning. In order to apply the proposed scheme online, we further outlined a suitable control architecture for an industrial robot platform that uses a Cartesian displacement control interface at a comparably low update rate. The hybrid controller interface is well-suited to apply selective control strategies along individual axes, which can then be embedded into a graphical skill-formalism from previous work to reduce the required parameter space for the task to be learned.
In contrast to existing work, we further claimed that it is beneficial to not only exploit available task knowledge to decrease the parameter- or search space for the current task but also to incorporate task knowledge on regressing the failure constraints. For this reason, we proposed a graphical skill-formalism for the overall success probability as factor graphs. Here, we proposed a pure naive Bayes method that regresses the failure of the overall task as the joint probability of each node failing for a given sample. While this method improves the overall sampling, it may hinder assigning failed samples to subsequent nodes, even though conditional dependencies are well-known beforehand. Thus, we further proposed to incorporate these relations into a graphical skill-formalism for the success probability and thus improve scaling behavior to eventually regress feasible samples. In addition, we proposed suitable acquisition functions for the individual representations and proposed a novel conservative acquisition method.
Finally, we outlined an application example for the proposed method as the screw-insertion task for an industrial robot, where the exact goal-pose is unknown and the controller parameterization of our proposed controller needs to be regressed from data.
Given the outlined screw-insertion task, we compared our approaches against existing state-of-the-art methods for BOC-based RL using an industrial robot manipulator in a laboratory environment. Given the collected experimental data, our method distinctly outperformed the state-of-the-art in performance, which we have evaluated by the collected objective regret. Furthermore, our method required distinctly smaller number of data samples and thus learning time and steps compared to existing work. These results underline that it is preferable to not only incorporate available task knowledge for the objective but also the constraints of robotic manipulation tasks during learning whenever possible in order to decrease the number of samples needed.
Future work
Building upon the data collected and the presented method, a promising path for future research projects lies in combining our method with visual feedback. This may further allow defining robust success- and error constraints, as, for example, missing the screwhead or hole remains unreliable solely from FT data, especially if a constant velocity vector results in a robot missing the screwhead completely. If such feedback is obtained, the presented method would strongly benefit in learning advanced motion policies, i.e., comparing different search patterns, e.g., spirals or straight-line patterns. Nonetheless, regressing the optimal search pattern usually is preferably solved by visual servoing. In these scenarios, the interaction does not rely on accurate FT data and feedback control. Thus, this allows collecting data within simulated environments and applying recent results from machine learning, especially meta-RL.
Eventually, future research should evaluate the possibility of self-evaluating models, i.e., artificial agents should be aware that some of the imposed model knowledge may be subject to false design. Thus, another line of research is given by designing new methods that allow not only exploiting available task knowledge but also evaluating the accuracy and discrepancy of the assumed model against the empirical evidence.
Data availability statement
The original contributions presented in this study are available at the repository https://gitlab.com/vg_tum/graph-boc. Further inquiries can be directed to the corresponding author.
Author contributions
VG proposed, implemented, and outlined the methods presented in the article, performed the experiments, and evaluated the collected evidence. VG and DW verified the approach. All authors discussed the results and contributed to the final manuscript.
Funding
The research, leading to the results presented in this work, has received funding from the Horizon 2020 research and innovation program under grant agreement №820742 of the project “HR-Recycler—Hybrid Human-Robot RECYcling plant for electriCal and eLEctRonic equipment”.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1For more information about GPs and GP classification, we refer to Rasmussen and Williams (2006).
2The extension to arbitrary robots is subject to the internal robot control and dynamics. As the methods in this article are dynamically independent, this extension is left for future work.
3This condition also includes that a Cartesian path applied within this region will not result in a collision of the robot or a singularity since the actual control input is commanded directly in task- and not in joint space.
4We set these normal vectors as constant within this evaluation, but it is possible to update the normal vectors online if needed.
References
Alt, B., Katic, D., Jäkel, R., Bozcuoglu, A. K., and Beetz, M. (2021). “Robot program parameter inference via differentiable shadow program inversion,” in IEEE international conference on robotics and automation (ICRA) (Xi’an, China: IEEE), 4672–4678. doi:10.1109/ICRA48506.2021.9561206
Ambikasaran, S., Foreman-Mackey, D., Greengard, L., Hogg, D. W., and O’Neil, M. (2016). Fast direct methods for Gaussian processes. IEEE Trans. Pattern Anal. Mach. Intell. 38, 252–265. doi:10.1109/TPAMI.2015.2448083
Bari, S., Gabler, V., and Wollherr, D. (2021). “MS2MP: A min-sum message passing algorithm for motion planning,” in IEEE international conference on robotics and automation (ICRA) (Xi’an, China: IEEE), 7887–7893. doi:10.1109/ICRA48506.2021.9561533
Baumann, D., Marco, A., Turchetta, M., and Trimpe, S. (2021). “Gosafe: Globally optimal safe robot learning,” in IEEE international conference on robotics and automation (ICRA) (Xi’an, China: IEEE), 4452–4458. doi:10.1109/ICRA48506.2021.9560738
Beltran-Hernandez, C. C., Petit, D., Ramirez-Alpizar, I. G., Nishi, T., Kikuchi, S., Matsubara, T., et al. (2020). Learning force control for contact-rich manipulation tasks with rigid position-controlled robots. IEEE Robot. Autom. Lett. 5, 5709–5716. doi:10.1109/LRA.2020.3010739
Berkenkamp, F., Krause, A., and Schoellig, A. P. (2016a). Bayesian optimization with safety constraints: Safe and automatic parameter tuning in robotics. CoRR abs/1602.04450.
Berkenkamp, F., Schoellig, A. P., and Krause, A. (2016b). “Safe controller optimization for quadrotors with Gaussian processes,” in IEEE international conference on robotics and automation (ICRA). Editors D. Kragic, A. Bicchi, and A. D. Luca (Stockholm, Sweden: IEEE), 491–496. doi:10.1109/ICRA.2016.7487170
Calandra, R., Seyfarth, A., Peters, J., and Deisenroth, M. P. (2016). Bayesian optimization for learning gaits under uncertainty - an experimental comparison on a dynamic bipedal walker. Ann. Math. Artif. Intell. 76, 5–23. doi:10.1007/s10472-015-9463-9
Cho, N. J., Lee, S. H., Kim, J. B., and Suh, I. H. (2020). Learning, improving, and generalizing motor skills for the peg-in-hole tasks based on imitation learning and self-learning. Appl. Sci. 10, 2719. doi:10.3390/app10082719
Craig, J. J., and Raibert, M. H. (1979). “A systematic method of hybrid position/force control of a manipulator,” in The IEEE Computer Society’s Third International Computer Software and Applications Conference, COMPSAC 1979, Chicago, Illinois, USA, 6-8 November, 1979 (Chicago, Illinois, United States: IEEE), 446–451. doi:10.1109/CMPSAC.1979.762539
Deisenroth, M. P., Fox, D., and Rasmussen, C. E. (2015). Gaussian processes for data-efficient learning in robotics and control. IEEE Trans. Pattern Anal. Mach. Intell. 37, 408–423. doi:10.1109/TPAMI.2013.218
Demir, S. O., Culha, U., Karacakol, A. C., Pena-Francesch, A., Trimpe, S., and Sitti, M. (2021). Task space adaptation via the learning of gait controllers of magnetic soft millirobots. Int. J. Rob. Res. 40, 1331–1351. doi:10.1177/02783649211021869
Deniša, M., Gams, A., Ude, A., and Petrič, T. (2016). Learning compliant movement primitives through demonstration and statistical generalization. Ieee. ASME. Trans. Mechatron. 21, 2581–2594. doi:10.1109/TMECH.2015.2510165
Devin, C., Gupta, A., Darrell, T., Abbeel, P., and Levine, S. (2017). “Learning modular neural network policies for multi-task and multi-robot transfer,” in IEEE international conference on robotics and automation (ICRA) (Singapore: IEEE), 2169–2176. doi:10.1109/ICRA.2017.7989250
Drieß, D., Englert, P., and Toussaint, M. (2017). “Constrained bayesian optimization of combined interaction force/task space controllers for manipulations,” in IEEE international conference on robotics and automation (ICRA) (Singapore: IEEE), 902–907. doi:10.1109/ICRA.2017.7989111
Englert, P., and Toussaint, M. (2016). “Combined optimization and reinforcement learning for manipulation skills,” in Robotics: Science and systems (RSS). Editors D. Hsu, N. M. Amato, S. Berman, and S. A. Jacobs (AnnArbor, Michigan) http://www.roboticsproceedings.org.
Englert, P., and Toussaint, M. (2018). Learning manipulation skills from a single demonstration. Int. J. Rob. Res. 37, 137–154. doi:10.1177/0278364917743795
Frans, K., Ho, J., Chen, X., Abbeel, P., and Schulman, J. (2018). “Meta learning shared hierarchies,” in International conference on learning representations (ICLR). Vancouver, BC, Canada: OpenReview.net.
Gullapalli, V., Franklin, J. A., and Benbrahim, H. (1994). Acquiring robot skills via reinforcement learning. IEEE Control Syst. Mag. 14, 13–24.
Gullapalli, V., Grupen, R. A., and Barto, A. G. (1992). “Learning reactive admittance control,” in IEEE international conference on robotics and automation (ICRA) (Nice, France: IEEE Computer Society), 1475–1480. doi:10.1109/ROBOT.1992.220143
Gupta, A., Mendonca, R., Liu, Y., Abbeel, P., and Levine, S. (2018). “Meta-reinforcement learning of structured exploration strategies,” in Annual conference on neural information processing systems (NeurIPS). Editors S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Montreal, QC, Canada: Curran Associates, Inc.), 5307–5316.
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., et al. (2018). Soft actor-critic algorithms and applications. CoRR abs/1812.05905.
Hamaya, M., Lee, R., Tanaka, K., von Drigalski, F., Nakashima, C., Shibata, Y., et al. (2020). “Learning robotic assembly tasks with lower dimensional systems by leveraging physical softness and environmental constraints,” in IEEE international conference on robotics and automation (ICRA) (Paris, France: IEEE), 7747–7753. doi:10.1109/ICRA40945.2020.9197327
Inoue, T., Magistris, G. D., Munawar, A., Yokoya, T., and Tachibana, R. (2017). “Deep reinforcement learning for high precision assembly tasks,” in IEEE international workshop on intelligent robots and systems (IROS) (Vancouver, BC, Canada: IEEE), 819–825. doi:10.1109/IROS.2017.8202244
Johannsmeier, L., Gerchow, M., and Haddadin, S. (2019). “A framework for robot manipulation: Skill-formalism, meta learning and adaptive control,” in IEEE international conference on robotics and automation (ICRA) (Montreal, QC, Canada: IEEE), 5844–5850. doi:10.1109/ICRA.2019.8793542
Khatib, O., and Burdick, J. (1986). “Motion and force control of robot manipulators,” in IEEE international conference on robotics and automation (ICRA) (San Francisco, CA, United States: IEEE), 1381–1386. doi:10.1109/ROBOT.1986.1087493
Khosravi, C., Khosravi, M., Maier, M., Smith, R. S., Rupenyan, A., and Lygeros, J. (2022). “Safety-aware cascade controller tuning using constrained bayesian optimization,” in IEEE Trans. Ind. Electron., 1. doi:10.1109/tie.2022.3158007
Kramberger, A., Gams, A., Nemec, B., Schou, C., Chrysostomou, D., Madsen, O., et al. (2016). “Transfer of contact skills to new environmental conditions,” in IEEE-RAS international workshop on humanoid robots (humanoids) (Cancun, Mexico: IEEE), 668–675. doi:10.1109/HUMANOIDS.2016.7803346
Kschischang, F. R., Frey, B. J., and Loeliger, H. (2001). Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 47, 498–519. doi:10.1109/18.910572
LaGrassa, A., Lee, S., and Kroemer, O. (2020). “Learning skills to patch plans based on inaccurate models,” in IEEE international workshop on intelligent robots and systems (IROS) (Las Vegas, NV, United States: IEEE), 9441–9448. doi:10.1109/IROS45743.2020.9341475
Levine, S., Finn, C., Darrell, T., and Abbeel, P. (2016). End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 17, 1–40.
Levine, S., Wagener, N., and Abbeel, P. (2015). “Learning contact-rich manipulation skills with guided policy search,” in IEEE international conference on robotics and automation (ICRA) (Seattle, WA, United States: IEEE), 156–163. doi:10.1109/ICRA.2015.7138994
Li, Q., Kroemer, O., Su, Z., Veiga, F., Kaboli, M., and Ritter, H. J. (2020). A review of tactile information: Perception and action through touch. IEEE Trans. Robot. 36, 1619–1634. doi:10.1109/TRO.2020.3003230
Li, Q., Natale, L., Haschke, R., Cherubini, A., Ho, A. V., and Ritter, H. J. (2018a). Tactile sensing for manipulation. Int. J. Hum. Robot. 15, 1802001. doi:10.1142/S0219843618020012
Li, Y., Gowrishankar, G., Jarrassé, N., Haddadin, S., Albu-Schäffer, A., and Burdet, E. (2018b). Force, impedance, and trajectory learning for contact tooling and haptic identification. IEEE Trans. Robot. 34, 1170–1182. doi:10.1109/TRO.2018.2830405
Luo, J., Solowjow, E., Wen, C., Ojea, J. A., Agogino, A. M., Tamar, A., et al. (2019). “Reinforcement learning on variable impedance controller for high-precision robotic assembly,” in IEEE international conference on robotics and automation (ICRA) (Montreal, QC, Canada: IEEE), 3080–3087. doi:10.1109/ICRA.2019.8793506
Marco, A., Baumann, D., Khadiv, M., Hennig, P., Righetti, L., and Trimpe, S. (2021). Robot learning with crash constraints. IEEE Robot. Autom. Lett. 6, 1439–1446. doi:10.1109/LRA.2021.3057055
Martín-Martín, R., Lee, M. A., Gardner, R., Savarese, S., Bohg, J., and Garg, A. (2019). “Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks,” in IEEE international workshop on intelligent robots and systems (IROS) (Macau, SAR, China: IEEE), 1010–1017. doi:10.1109/IROS40897.2019.8968201
Mitsioni, I., Tajvar, P., Kragic, D., Tumova, J., and Pek, C. (2021). “Safe data-driven contact-rich manipulation,” in IEEE-RAS international workshop on humanoid robots (humanoids) (Munich, Germany: IEEE), 120–127. doi:10.1109/HUMANOIDS47582.2021.9555680
Nemec, B., Abu-Dakka, F. J., Ridge, B., Ude, A., Jørgensen, J. A., Savarimuthu, T. R., et al. (2013). “Transfer of assembly operations to new workpiece poses by adaptation to the desired force profile,” in IEEE international conference onn advanced robotics (ICAR) (Montevideo, Uruguay: IEEE), 1–7. doi:10.1109/ICAR.2013.6766568
Petric, T., Gams, A., Colasanto, L., Ijspeert, A. J., and Ude, A. (2018). Accelerated sensorimotor learning of compliant movement primitives. IEEE Trans. Robot. 34, 1636–1642. doi:10.1109/TRO.2018.2861921
Rakicevic, N., and Kormushev, P. (2019). Active learning via informed search in movement parameter space for efficient robot task learning and transfer. Auton. Robots 43, 1917–1935. doi:10.1007/s10514-019-09842-7
Rasmussen, C. E., and Williams, C. K. I. (2006). Gaussian processes for machine learning. Adaptive computation and machine learning. Cambridge, United States: MIT Press.
Scherzinger, S., Roennau, A., and Dillmann, R. (2019a). “Contact skill imitation learning for robot-independent assembly programming,” in IEEE international workshop on intelligent robots and systems (IROS) (Macau, SAR, China: IEEE), 4309–4316. doi:10.1109/IROS40897.2019.8967523
Scherzinger, S., Roennau, A., and Dillmann, R. (2019b). “Inverse kinematics with forward dynamics solvers for sampled motion tracking,” in International conference on advanced robotics (ICAR) (Horizonte, Brazil: IEEE), 681–687. doi:10.1109/ICAR46387.2019.8981554
Scherzinger, S., Rönnau, A., and Dillmann, R. (2017). “Forward dynamics compliance control (FDCC): A new approach to cartesian compliance for robotic manipulators,” in IEEE international workshop on intelligent robots and systems (IROS) (Vancouver, BC, Canada: IEEE), 4568–4575. doi:10.1109/IROS.2017.8206325
Sobol’, I. M. (1967). On the distribution of points in a cube and the approximate evaluation of integrals. USSR Comput. Math. Math. Phys. 7, 86–112. doi:10.1016/0041-5553(67)90144-9
Stenger, D., Nitsch, M., and Abel, D. (2022). “Joint constrained bayesian optimization of planning, guidance, control, and state estimation of an autonomous underwater vehicle,” in 2022 European Control Conference (ECC), London, United Kingdom, 12-15 July 2022. CoRR abs/2205.14669. doi:10.48550/arXiv.2205.14669
Stolt, A., Carlson, F. B., Ardakani, M. M. G., Lundberg, I., Robertsson, A., and Johansson, R. (2015). “Sensorless friction-compensated passive lead-through programming for industrial robots,” in IEEE international workshop on intelligent robots and systems (IROS) (IEEE), 3530–3537. doi:10.1109/IROS.2015.7353870
Stolt, A., Linderoth, M., Robertsson, A., and Johansson, R. (2012). “Force controlled robotic assembly without a force sensor,” in IEEE international conference on robotics and automation (ICRA) (Hamburg, Germany: IEEE), 1538–1543. doi:10.1109/ICRA.2012.6224837
Sui, Y., Gotovos, A., Burdick, J. W., and Krause, A. (2015). “Safe exploration for optimization with Gaussian processes,” in International conference on machine learning (ICML). Editors F. R. Bach, and D. M. Blei (Lille, France: JMLR Workshop and Conference Proceedings), 997–1005.
Vanderborght, B., Albu-Schäffer, A., Bicchi, A., Burdet, E., Caldwell, D. G., Carloni, R., et al. (2013). Variable impedance actuators: A review. Robotics Aut. Syst. 61, 1601–1614. doi:10.1016/j.robot.2013.06.009
Wang, Z., Garrett, C. R., Kaelbling, L. P., and Lozano-Pérez, T. (2021). Learning compositional models of robot skills for task and motion planning. Int. J. Rob. Res. 40, 866–894. doi:10.1177/02783649211004615
Yang, L., Li, Z., Zeng, J., and Sreenath, K. (2022). “Bayesian optimization meets hybrid zero dynamics: Safe parameter learning for bipedal locomotion control,” in IEEE international conference on robotics and automation (ICRA) (Philadelphia, PA, United States: IEEE), 10456–10462. doi:10.1109/ICRA46639.2022.9812154
Zhang, X., Sun, L., Kuang, Z., and Tomizuka, M. (2021). Learning variable impedance control via inverse reinforcement learning for force-related tasks. IEEE Robot. Autom. Lett. 6, 2225–2232. doi:10.1109/LRA.2021.3061374
Nomenclature
Acronyms
BO Bayesian optimization
BOC Bayesian optimization with unknown constraints
CDF Cumulative distribution function
CI Confidence-interval
EI Expected improvement
EIC Expected improvement with constraints
EP Expectation propagation
FSA Finite-state automaton
FT Force–torque
GP Gaussian process
GPCR Gaussian process for classified regression
ML Machine learning
MP Manipulation primitive
NN Neural network
PDF Probability density function
PI Probability of improvement
PIBU Probability of improvement with a boundary uncertainty criterion
RL Reinforcement learning
List of indices
art Artificial variable
cont Contact with object or environment
cur Current value, e.g., measured state of a plant
des Desired value, e.g., a desired trajectory
dspl Displacement related variable, e.g., a maximum distance
eps Current variable is related to current or all episodes
err Error-term for current value
fail Failed trial/sample
frc Force/wrench-related variable
impls Impulse variable, e.g., force-impulse during contact
insrt Insertion related variable, e.g., time needed for a screwdriver insertion
max Maximum value of the current variable
min Minimum value of the current variable
noise Noise-related variable, may be systematic or artificially injected noise
pos Position-related variable or term
pre Pre-condition, e.g., within a planning domain
R Rotated variable Rotation matrix in SO(3), i.e., in
rot Rotation-related variable or term
safe Safe variable with respect to a constraint metric
spl Sampled version of the current variable
suc Indicating success for the current task or episode
vel Velocity-related variable
List of operators and functions
α Acquisition function to generate new data samples in
g Scalar inequality constraint in
g Scalar inequality constraint in
diag Get diagonal elements from a matrix as vector in
H Heaviside function in
k Kernel function
Notation
⊤ Boolean true Boolean true
⊥ Boolean false Boolean false
⊤ Boolean true Boolean true
⊥ Boolean false Boolean false
: = Equal by definition
κ Hyper-parameter; indexing defines actual meaning
∅ Empty set
ζ Threshold-value; indexing defines actual meaning
t Current time or temporal indexing variable
Tmax Maximum runtime (continuous) or number of time steps (discrete) in
List of symbols
δx Cartesian displacement in SE(3), i.e., in
x Cartesian pose of and object or the end-effector in SE(3) Cartesian x-coordinate in
p Cartesian position in
F Cartesian wrench as force–torque measures in SE(3)
c Scalar constraint value in
c Scalar constraint value in
u Control input signal
e SE(3) Coordinate system axis in
x Cartesian pose of and object or the end-effector in SE(3) Cartesian x-coordinate in
y Cartesian y-coordinate in
z Cartesian z-coordinate in
ex SE(3) Coordinate system x-axis in
ey SE(3) Coordinate system y-axis in
ez SE(3) Coordinate system z-axis in
Σ Covariance matrix of a multivariate probability density function (PDF)
f Force magnitude or scalar force component of translational component of F in
KP Proportional force controller gain matrix (quadratic, positive semi-definite)
K Gram matrix, where
k Kernel function
μ Mean of a PDF
Φ Normal cumulative distribution function
n Normal vector of a surface/object in Cartesian space in
Ncont Number of evaluation measurements to check against environment contact
Nspl Number of samples
Neps Number of steps, e.g., within an episode
ξ Unknown meta parameter vector in
ξ Unknown meta parameter vector in
υ Polyak-averaging weight, e.g., used to update target network
S Hybrid force/position controller selection matrix
s Diagonal element of the force/position controller selection matrix S
R Rotated variable Rotation matrix in SO(3), i.e., in
Rφ Rotation matrix around ex in
Rθ Rotation matrix around ey in
Rψ Rotation matrix around ez in
ψ Yaw angle in
gspl Episodic constraint-vector sample
sspl Episodic success sample, where each scalar evaluates gi(ξ) ≤ ci
nξ Dimension of the parameter of a regression problem
δt Update time step for discrete control processes in
τ Torque magnitude or scalar force component of rotational component of F in
T Coordinate transformation matrix using homogeneous transformation in SE(3), i.e., in
v Translational velocity in SE(3)
σ Variance of a one-dimensional PDF
NFT Size of sliding window to evaluate data obtained from a FT sensor
Keywords: Bayesian optimization, robot learning and control, episodic reinforcement learning, safe learning, compliant manipulation
Citation: Gabler V and Wollherr D (2022) Bayesian optimization with unknown constraints in graphical skill models for compliant manipulation tasks using an industrial robot. Front. Robot. AI 9:993359. doi: 10.3389/frobt.2022.993359
Received: 13 July 2022; Accepted: 08 September 2022;
Published: 14 October 2022.
Edited by:
Chao Zeng, University of Hamburg, GermanyReviewed by:
Lizhi Yang, California Institute of Technology, United StatesMarkku Suomalainen, University of Oulu, Finland
Copyright © 2022 Gabler and Wollherr. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Volker Gabler, di5nYWJsZXJAdHVtLmRl