 Claudio Zito
Claudio Zito Eliseo Ferrante
Eliseo Ferrante- 1Autonomous Robotics Research Centre, Technology Innovation Institute, Masdar City, United Arab Emirates
- 2Department of Computer Science, Vrije Universiteit Amsterdam, Amsterdam, Netherlands
This paper is concerned with learning transferable contact models for aerial manipulation tasks. We investigate a contact-based approach for enabling unmanned aerial vehicles with cable-suspended passive grippers to compute the attach points on novel payloads for aerial transportation. This is the first time that the problem of autonomously generating contact points for such tasks has been investigated. Our approach builds on the underpinning idea that we can learn a probability density of contacts over objects’ surfaces from a single demonstration. We enhance this formulation for encoding aerial transportation tasks while maintaining the one-shot learning paradigm without handcrafting task-dependent features or employing ad-hoc heuristics; the only prior is extrapolated directly from a single demonstration. Our models only rely on the geometrical properties of the payloads computed from a point cloud, and they are robust to partial views. The effectiveness of our approach is evaluated in simulation, in which one or three quadcopters are requested to transport previously unseen payloads along a desired trajectory. The contact points and the quadcopters configurations are computed on-the-fly for each test by our approach and compared with a baseline method, a modified grasp learning algorithm from the literature. Empirical experiments show that the contacts generated by our approach yield a better controllability of the payload for a transportation task. We conclude this paper with a discussion on the strengths and limitations of the presented idea, and our suggested future research directions.
1 Introduction
There is evidence that humans possess an internal model of physical interactions that enables us to grasp, lift, pull, or push objects of diverse nature in various contexts (Mehta and Schaal, 2002). It is also evident that such internal models are constructed over time as an accumulation of experience as opposed to an inherent comprehension of physics. In this paper, we investigate an internal model for enabling autonomous quadrotors equipped with cable-suspended passive grippers to generate contacts with unknown payloads for aerial transportation. By unknown payloads, we mean that our approach does not require a full CAD model of the object or information relative to its physical properties, such as its centre of mass (CoM) or friction coefficients. We only rely on geometric features extrapolated from vision. As the human’s internal model, our solution is not failure-free but provides a way to generate candidate grasps even when no information is available.
The hype for aerial manipulation has reached a high-fever pitch. Unmanned aerial vehicles (UAVs), such as quadrotors, have been recently at the centre of attention of the scientific community as the next means of autonomy. Their dynamic simplicity, manoeuvrability and high performance make them ideal for many applications ranging from surveillance to emergency response. More recently, such systems have been investigated for aerial transportation of payloads by towed cables. Small-size single and multiple quadrotors have been employed for load transportation and deployment by designing control laws for minimum swing and oscillation of the payload (Sreenath et al., 2013; Li et al., 2021a; Li et al., 2021b). Although in their dawn, current approaches disregard the generation of the contact points. Single drones assume point-mass loads to simplify the effects of the dynamics, and multiple drones are manually attached nearby the vertices or edges of the load, following the intuition of maximising the moments exercised on the object. No aerial system is capable of generating on-the-fly contacts, and it is not clear how the proposed controllers can cope with different payloads or contact configurations.
On the other hand, we have witnessed a growing interest in robot grasping and manipulation tasks in the last decade (Bohg et al., 2014; Stüber et al., 2020). Although we are still far from robots freely manipulating arbitrary objects, several promising solutions have been proposed over the years (Brahmbhatt et al., 2019; Sun et al., 2022). Google employed a dozen robots interacting in parallel with their own environment to learn how to predict what happens when they move objects around (Levine et al., 2018). However, collecting such a large amount of data for any task is very hard, and many researchers have focussed on more practical solutions. Additionally, the task of aerial manipulation presents another significant challenge–failed attempts may irreparably damage the payload and the AUVs. A more appealing approach is to learn models in a one-shot or a few-shot fashion when possible. Such approaches typically employ generative models which learn probability densities from demonstrations. We substantially reduce the searching effort when facing novel contexts by providing one or a few examples of a good solution. Furthermore, when the learning space is constructed over local features, the models tend to have a good generalisation capability within and across object categories (Kopicki et al., 2016).
In (Kopicki et al., 2016; Arruda et al., 2019), the authors formulate dexterous grasps for a humanoid robot as contacts between the robot’s manipulative links and the object’s surface. Only local surface properties of the object’s geometrics are required to learn the model, such as curvatures on the (local) contact patches. The model learns grasp types but does not encode task-dependent features or physical properties of the objects, and it has only been demonstrated for pick-and-place tasks. For different tasks beyond pick-and-place, the authors enable the possibility of encoding handcrafted loss functions, which requires (a rarely available) insight knowledge by the user on the specific task. In (Stüber et al., 2018; Howard and Zito, 2021), this approach has been extended to enable a robot to make predictions over push operations for novel objects. One-shot learning is utilised for identifying the contacts between the pusher and the object, and between the object and the environment, but an extra motion model needs to be learned from real or simulated experience in order to make the predictions. In practice, the motion models encode the task. Given the initial contact models, motion models are designed as conditional probabilities, following the general idea that making predictions on familiar initial conditions will yield more robust solutions. A few dozens examples are sufficient to learn a motion model for planar push operations since the environment constrains the motion. Such luxury is not available for aerial manipulation, and it would require us to approximate the drone-payload system dynamics to make any prediction.
In contrast, this paper proposes one-shot learning for aerial manipulation in which contacts are not solely learned from local features but also encode intrinsic task-dependent knowledge without needing handcrafted features, as visible in Figure 1. The underpinning idea is simple. Imagine having to connect a load to a single drone. If the load is a box with uniform mass distribution, probably the best thing we could do is attach the drone in the middle of the top-facing surface, just above the payload’s CoM. In order to find the desired spot, we do not need to have a perfect model of the object or see it in its completeness. A view of its entireness of the top-facing surface would be sufficient for estimating its centre. Nevertheless, counterexamples come to mind where merely teaching the robot to attach the payload above its CoM may not be a robust strategy; a package with overlapping ridges makes the desired contact area irregular and unsuitable for reliable contact. If we have taught the robot to connect over flat surfaces, we desire to maintain this property on novel objects. Hence, our approach weights the contact’s local shape versus its relative location over the visible payload’s surface. The latter is implemented as a probability distribution over the distances between the taught contact regions and sampled patches that describe the general shape of the visible geometry of the payload, e.g., flat surfaces, edges and corners. The main drawback of this approach is that we will need to learn a new contact model for each desired task and contact type. In robot manipulation, a grasp encodes the desired contacts with the object to be grasped, such as a pinch or power grasp. These grasp models generalise well over object categories, but the grasp model has no knowledge of the task. Further (context-dependent) information is needed to decide when a pinch grasp is more suitable than a power grasp. By including the task information in the model, e.g., transporting a load with uniform mass distribution, we lose this decoupling and new models need to be learned.
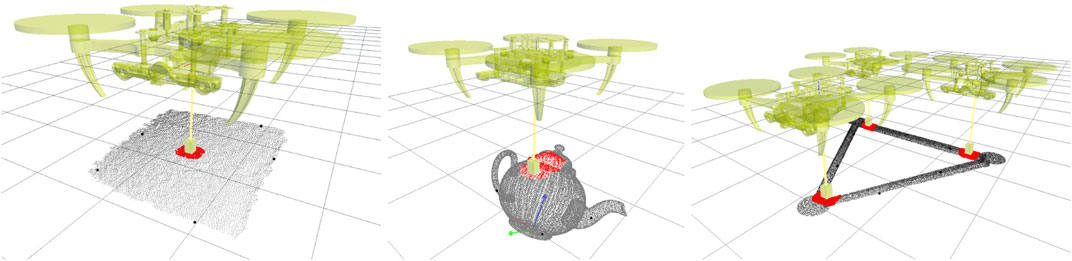
FIGURE 1. Learned contact models. (left) shows a central contact with a flat surface, i.e. top face of the Fedex box, (middle) shows a curved contact on a teapot, and (right) a triangular configuration for three drones. The red points represent the sub-sampled local area of the surface used to learn the contact model. Black points represent the five highest local features used to learn the task. The global reference frame of the object, e.g. at the base of the teapot (middle), is not considered in the learning.
We evaluate our proposed approach in a set of empirical experiments and compare the results against a baseline method. Our aim is to demonstrate that our approach successfully captures the task from the training sample while a more conventional contact-based approach would fail. First, we have modified the approach in (Kopicki et al., 2016) to cope with a single or multiple UAVs equipped with cable-suspended passive grippers in lieu of a dexterous manipulator. From the same training data, we learned contact models for the baseline and our approach. Then, we use the learned models to generate candidate contact points for four test payloads. The contacts have been evaluated in a simulated transportation task, where the UAVs need to lift the payload and transport it along a desired trajectory, showing that our inferred contacts are more suitable for the given task.
In summary, our main contribution is the investigation of a contact-based grasp synthesis approach for dynamic tasks. Without physical knowledge of the payload optimal solutions cannot be guaranteed, but our simulated experiments demonstrate that our approach leads to more reliable contacts. The full pipeline of our approach is presented in Figure 2. For clarity’s sake, we identify the same 4 stages as presented in the original work of our modified baseline (Kopicki et al., 2016). While the baseline only learns a contact and configuration models from the training, we extend this formulation with the task model. Further details are available in the caption.
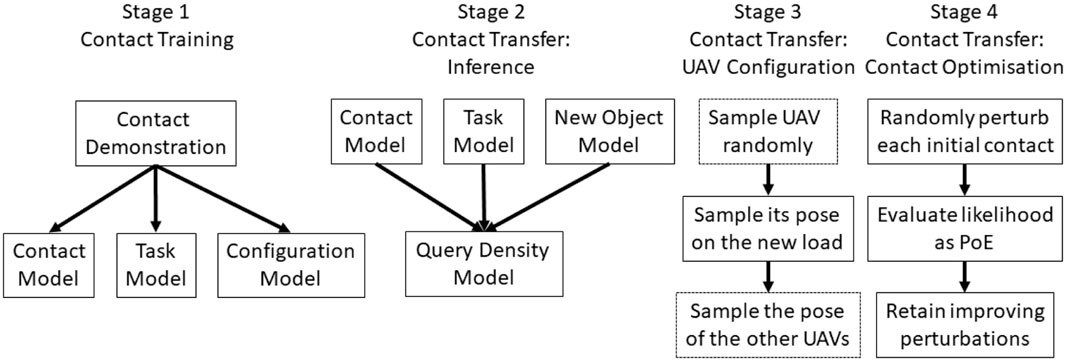
FIGURE 2. Full pipeline of our method. Stage 1 represents the training of the models. From one single example we extrapolate the three models as probability density functions. Inferring the contact on a new load is decomposed in the three phases: Stage 2 samples similar local contacts on the new object; Stage 3 samples a feasible configuration for the UAV(s); and Stage 4 optimises the contacts and configurations for a better solution, if any. The baseline approach uses the same pipeline but without the task model. For a single UAV Stage 3’s dotted blocks are disregarded.
The rest of the paper is structured as follows. In Sec. 2, we introduce the problem formulation in terms of object-centric representation of the contacts and the robot mechanics. Section 3 describes how we learn the models needed for aerial manipulation. Section 4 presents how we infer contacts on novel shapes. The experimental evaluation is presented in Section 5 and our results are discussed in Section 6. We conclude with our final remarks about the strengths and limitations of this work and future research directions.
2 Problem formulation
Let us begin from defining our notation. Vectors will be consider column vectors and written in bold letters. Matrix will be written as capital letters. We also denote by
2.1 Mechanics
We consider a set of Nq ≥ 1 quadrotors with cable-suspended magnetic grippers. The inertia frame
The pose bn = (pn, qn) ∈ SE (3) describes the location of the CoM of the n-th quadrotor,
Each quadrotor is equipped with a cable of length ln and let
2.2 Surface features
Surface features encode the geometrical properties of an object and are derived from a 3D point cloud, as shown in Figure 3. We represent a surface feature as a pair
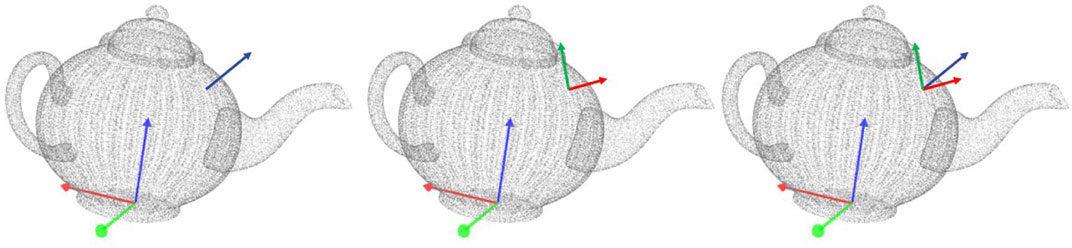
FIGURE 3. Computation of a surface feature on a teapot. (left) the full point cloud of the teapot with its reference frame. The normal of the sampled point is shown as a blue arrow (middle) the principal curvature directions are drawn for the same point as red and green arrows (right) the associated reference frame for the surface feature with respect to the object’s reference frame.
To compute the pose v ∈ SE (3), we first estimate the surface normal at point p using a PCA-based method (Kanatani, 2005). Surface descriptors correspond to the local principal curvatures around point p (Spivak, 1999), which lie on the tangential plane to the object’s surface and perpendicular to the surface normal at p. Let
2.3 Kernel density estimator
In this work, probability density functions are approximated via kernel density estimation (KDE) (Silverman, 1986), which are built around surface features (see Section 2.2). A kernel can be described by its mean point μs = (μp, μq, μr) and bandwidth σs = (σp, σq, σr):
where s = (v, r) = (p, q, r) is the surface feature being compared against the kernel,
Given a set of Ns surface features, the probability density in a region of space is computed as the local density of features in that region, as
where si corresponds to the i-th surface feature acting as a kernel, wi corresponds to its weighting with the constraint
3 Learning contacts
We learn contacts from a single demonstration. We require a point cloud of the payload and the configuration of the quadrotors and their passive grippers. Partial views of the objects are sufficient for learning reliable models under the assumption that the surface in contact is fully visible. Figure 1 (left) shows the case in which only the top face of a box is visible at training time. Although learning contacts is computational efficient, as demonstrated in (Kopicki et al., 2016), the time computation grows linearly with the number of links in contact, the number of triangles in the mesh representing the links, and the surface points considered. Furthermore, a new model needs to be learned for different drone configurations, contact types or tasks.
3.1 Object and task model
The object model describes the composition of a point cloud in terms of its surface features distribution. In the literature, this approach is used to learn the features distribution only nearby the contact area, e.g., (Kopicki et al., 2016; Stüber et al., 2018; Arruda et al., 2019), while in (Howard and Zito, 2021) the CoM of the object to be pushed is also estimated as a distribution from visible surface features. In contrast, we decouple the object model into two densities. The first describes the surface features distribution nearby the contacts, while the second encodes the location of these near-the-contact features with respect to other features in the visible point cloud, e.g., its corners and edges.
At training time, we observe a set of contacts between the quadrotors’ manipulative links and an object point cloud. Before learning a contact model (see Section 3 2), we collect a set of NO features,
further referred as the object model as in (Kopicki et al., 2016), where the weight wi = 1/NO. Figure 1 shows in red the local area considered for extrapolating the features for two different contact types: a) flat contact and b) curved contact.
From the same point cloud, we collect a second set of NT features by uniformly sampling the visible point cloud to compute a second joint probability as
further referred as the task model, where
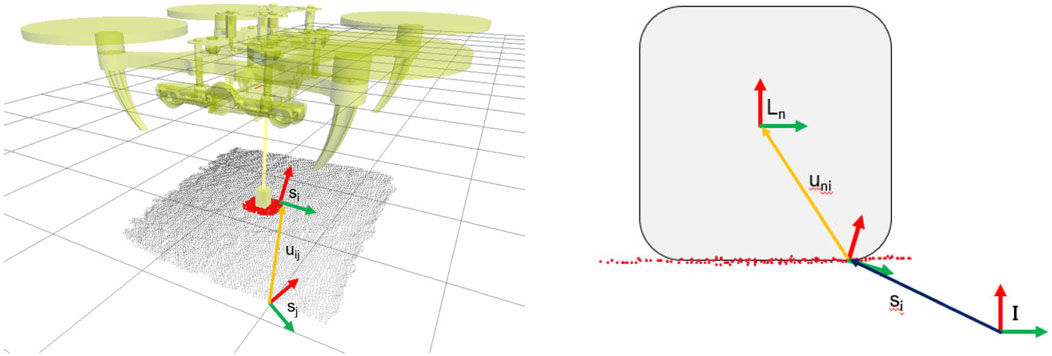
FIGURE 4. Graphical representation of the task model (left) and the link pose (right) used in the contact model. The task model is constructed as a rigid body transformation uij in SE (3) from a task feature sj to a surface feature si in the contact region. The link pose is computed as a rigid body transformation uni in SE (3) from a surface feature si in the contact region to the reference frame of the robot’s link. All the SE (3) poses sj, si, Ln are computed with respect to the inertia frame
3.2 Contact models
The contact model describes the relation between the robot’s end-effector and the object surface. It is trained in a one-shot fashion from a demonstration. A teacher presents to the robot the desired contact, either in simulation or in reality, then the local surface in contact with the robot’s link is sampled, and a probability density function is learned.
We denote by uni = (pni, qni) ∈ SE (3) the pose Ln of the n-th link relative to the pose vi of the i-th surface feature from (3). We compute this as
where ◦ denotes the pose composition operator, and
The contact density Mn (u, r) closely resembles the surface feature kernel function in (1), and is defined as follows:
where Nc ≤ NO is a user defined parameter to allow downsampling to save computational time and wni corresponds to the kernel’s weighting such that
3.3 Quadrotor configuration model
The configuration model encodes the poses of the quadrotors and their grippers as demonstrated during training. For a single drone, the configuration model merely describes the kinematic relation between the quadrotor and its gripper. However, when n > 1, this model enables us to reduce the configuration space when transferring the contacts to another surface by focusing only on those configurations that resemble the one in the training example, e.g., a triangular formation. The configuration model is not capable of choosing the correct number of UAVs. It reinforces the learned formation onto a novel payload. The SA optimisation can locally optimise the pose of the single UAV in order to generate a higher-scoring contact while simultaneously avoiding collisions or kinematically impossible configurations. The room for the local improvements is bounded by a user-provided standard deviation on the expected placement of the gripper for the desired formation. This enables us to cope with different sized and shaped payloads.
The poses of the Nb ≥ 1 quadrotors are represented as hn = (bn, Ln) with bn = (pn, qn) ∈ SE (3) the pose of the n-th drone and
where
4 Transferring to novel surfaces
Once the models are learned, we can transfer the contacts on novel payloads. The aim is to find local features on the new object that are similar to those presented in training and to place the robot’s manipulative links accordingly. For evaluating the approach, we learn several contact models for different tasks and contact types–we call them testing conditions as introduced in Section 5. However, when presented with a new point cloud, we manually select the appropriate contact model for each testing condition. Automatic model selection can be formulated as an optimisation problem (Pozzi et al., 2022) or a learning one (Kober et al., 2013), but we kept it as out of scope for this work.
4.1 Query density
The query density represents the distribution of link poses over a novel point cloud. By searching for local similarities in the query point cloud’s surface features, we can estimate the relative link pose u, which transfers the learned contact onto the new surface. This process is designed to be transferable such that a model trained upon a single object can be applied to a variety of previously unseen objects. Figure 5 shows a graphical representation of the method: starting from a sampled task feature, we identify a potential area on the visible surface where to seek for a good contact.
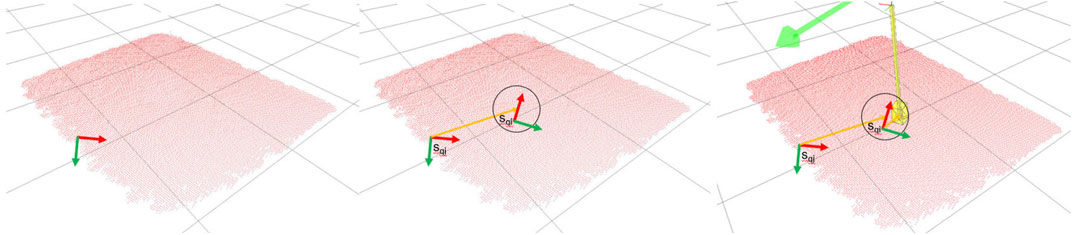
FIGURE 5. Graphical representation of inferring a candidate link pose for a novel surface. First, from the task model we sample a feature sqj on the novel point cloud. We then apply the transformation uij observed when learning the model to identify a feasible contact region. From that region (circled area in the middle image), we sample a surface feature from the object model O (v, r). Finally we apply the transformation uni observed at training time to place the link Ln.
We define the query density as Q (Ln, u, v, r) where v ∈ SE (3) denotes a point on the object’s surface expressed in the inertial frame,
For each link, its pose distribution over a new point cloud is given by marginalising Q (Ln, u, v, r) with respect to u, v, and r. Since Ln = v◦u is described in terms of v and u, and by assuming that the density in the inertia frame of the surface point, v, and the distribution of link poses relative to a surface point, u, are conditionally independent given the curvature on a point, r, we factorise the query density as follows
where, by following (Kopicki et al., 2016), we implement p (Ln|u, v) as a Dirac function, and p (u|r) as Mn (u|r), the conditional probability that the n-th link will be placed at pose u with respect to the surface feature, given that this surface feature has curvature r. p (v|r) is implemented as O (v|r), the probability of the observed curvature r. Finally, p(r) = Mn(r)O(r) is chosen to reinforce that the contact model M and the object model O are observing the same surface feature. Mn(r) is the distribution of features in the contact model, and O(r) is the distribution of feature r in the new point cloud.
We extend this formulation with another random variable uij = (vij, qij) to encode the desired pose of the selected i-th surface feature of the contact model relative to the task model’s features defined in (4). Thus,
where (pk, qk) ∈ SE (3) describes the k-th kernel. The variable
weights the query density according to the contact model and the task model. To compute the weighting, we randomly sample from the new point cloud Ni surface features from the estimated contact surface and Nj features according to the task model so that sj ∼ T (vj|rj) is the observed feature rj on the new point cloud. Again, we implement p (uij|ri, rj) as a Dirac function and T (vj|rj)T (rj) represents the probability of the observed curvature on the new point cloud. The value Z is a normaliser, and the value Ni and Nj are maintained constant across all the experiments.
4.2 Contact optimisation and selection
Let us denote by
where
5 Results
In this section we present our empirical results aiming to demonstrate that task-dependent features can be encoded in the contact models without the need of heuristics or prior knowledge. The proposed approach has been evaluated in a set of simulated experiments on several conditions. For a single UAV, we learn two types of contacts: (i) a contact placed at the centre of the visible upper surface of a box, and (ii) a contact on a curved surface. For multiple drones, we learn a triangular formation for three UAVs for a transportation task.
In all conditions, we learn each contact model in one single demonstration. Each training object was loaded in the simulation as full or partial point cloud, as presented in Figure 1. We do not retrieve global information about the object, such as its CoM. The UAVs were manually placed to generate the desired contacts with their passive gripper over the visible point cloud. For all conditions, we sampled NO = 500 local features to represent the contacts in both our approach and baseline method and NT = 50 for the task model (present only in our approach). Once a contact model was learned, it was stored and labelled for future reference. Only kinematic and geometrical information was used to learn the models; forces and dynamics are not needed for learning.
Once the contact models are learned, a new full or partial point cloud is presented to the system. In Figure 6 we show the point clouds belonging to four objects used for testing: a) 68cm x 61 cm x 28cm FedEx box (top two rows); b) the Stanford bunny (third and fourth rows); the hollowed triangular shape used to learn the three drones’ contact models (fifth and seventh rows); and a 68cm x 68 cm x 28cm FedEx box (sixth and eighth rows). We then compare the best five solutions generated for each condition with those computed by an adapted version of the grasping algorithm presented in (Kopicki et al., 2016). Since (Kopicki et al., 2016) considers a robot manipulator equipped with a hand, we modify it to consider the quadrotor configuration model. Therefore, the main difference between the two approaches remains the task model.

FIGURE 6. Contact inference on a new shape for aerial manipulation. The first column shows the training examples used for learning the contact models. The first, third, fifth and sixth rows show the transferring of the contacts for our approach. The other rows show the baseline method (Kopicki et al., 2016). The first column shows the UAVs configuration, the surface used for learning and the contact features. Red points are the local features of the contacts; black points are the task features. The other columns demonstrate the link pose computed on a new surface. The associated drone’s pose is shown with a frame using the conventional RGB colour map for x-, y-, and z-axes, respectively.
5.1 Contact inference: a qualitative analysis
Our first experiment aims to compare how our model infers contacts on a novel surface against the baseline method. Figure 6 presents the results. For the purpose of qualitative analysis, we can identify the following four conditions: C1) single UAV with a flat contact (row 1 and 2 in Figure 6), C2) single UAV with a curved contact (row 3 and 4), C3) three UAVs with no generalisation (row 5 and 7), and C4) three UAVs with generalisation to a novel shape (row 6 and 8). The rows in Figure 6 for each condition are directly comparable, showing our method’s solutions against the baseline’s ones, respectively.
In condition C1, we learn a flat surface contact on a squared box and test on a rectangular-shaped box. The taught contact lays in the middle of the upper face of the box, ideal for transportation of payloads with uniform mass distribution. Under the assumption that no more information is available on the physical properties of the load but that of uniform mass distribution, it is safe to assume that even a human operator would attempt to generate contacts in the middle of the upper face of the rectangular box. We encode this strategy in the training example. Nonetheless, a more conventional contact-based algorithm such as the baseline is not capable of extrapolating this subtlety. The load presents a large number of possible solutions in which the gripper is in contact with a flat surface. All these candidates are evaluated according to local surface features extrapolated from the point cloud, as shown in Eq. 8, and feature-rich areas would uncontroversially score higher values. Hence, flat surfaces nearby corners or edges look more promising for such methods. In contrast, our task model forces the contacts away from such areas, giving the method a sort of global, task-dependent understanding of the payload’s geometry. Yet, thanks to the soft probabilistic representation of the task model, our approach can deal with the different shape of the test payload, adapting the learned contact on a squared surface onto a rectangular one. The first and second rows in Figure 6 show that the five best candidates for our method are clustered towards the middle of the rectangular face, while the baseline’s solutions span the entire surface.
Condition C2 presents a less intuitive example in which a clear optimal solution may not be identifiable on a bunny-shaped payload. The contact model trained in C1 would not be helpful in this case–and it should not be expected to–since it would seek flat contacts on a mostly curved surface. We, therefore, demonstrate to the system how to generate contacts on a curved surface using a teapot as a payload. The contacts we demonstrated take advantage of the teapot’s symmetry and lay in the centre to have its handle and beak on opposite sides. Because of the irregular shape of its lid, we placed the contacts on its body’s smoother surface just below the lid’s edge. Without the need to encode this strategy into the model explicitly, our approach seems to capture the essence. The solutions presented in the third row of Figure 6 are clustered in the mid-section of the bunny taking advantage of its symmetry but avoiding the more irregular areas on its tail and snout. In contrast, the baseline solutions shown in the fourth row only maximise the similarity in the local surfaces between the taught contact points and the new point cloud. In fact, its best solution is placed on the edge of the bunny’s chest; a large, smooth surface area with a similar curvature to the one on the teapot. Nevertheless, as demonstrated in the transportation task, contacts in this area lead to high swings when the payload is lifted. Its next three solutions are also far from the bunny’s mid-section: two on the edge of the ears and one on the face, making the payload difficult to be controlled along the desired trajectory.
In conditions C3 and C4, we test the ability of the algorithms to deal with multiple contact points simultaneously. We demonstrate a tripodal grasp with three UAVs in a triangular formation on a hollowed triangle shape. We represent the robot configurations as a virtual robot hand’s three kinematic chains or fingers. Similarly to any other contact-based grasping algorithm in the literature, different finger configurations and contacts characterise each grasp type; thus, the tripodal contact model must be used with three UAVs and cannot scale up or down. Another model would need to be learned for a different number of drones or configurations (e.g. three drones in a straight line). However, each UAV’s pose can be adjusted to adapt the grasp to a different payload thanks to the soft probability representation of the configuration model presented in Section 3.3.
Condition C3 does not attempt to generalise to a novel shape. Three contacts must be found on the triangle’s surface, and the query distribution treats that as an optimisation problem. It randomly selects one UAV and finds a suitable contact, with the same procedure used for the single UAV case. It then places the other drones according to the formation presented in the training data. The optimisation allows local modifications of all three UAV configurations to maximise the sum of each contact’s score. Similarly to the single UAV case, many local patches on the triangle provide flat contacts to initialise the procedure, but not all lead to a reliable tripodal grasp. This yields to local minima observable in the baseline, which often cannot find a three-contact placement on the challenging surface. In contrast, our task model helps the optimisation procedure identify better initial guesses and yields more reliable solutions. We extrapolate the same conclusion from the last condition in which the tripodal grasp is generalised on a squared flat surface. In this condition, it is even more observable how the baseline chooses its initial guess nearby feature-rich areas of the test objects, i.e. corners and edges, whilst our approach is not biased by it.
5.2 Transportation task: a quantitative analysis
Each solution from Figure 6 is also evaluated in a simulated environment for a transportation task. The simulator is initialised with the computed optimised contacts. The UAVs will need to transport the payload along a pre-planned circular trajectory with a 1 m radius performed for 12 seconds. The trajectory is computed such that the UAVs need to lift the payload to the starting position of the trajectory, perform the circle twice and then hover above the ground, maintaining the payload in the same position as the last waypoint of the trajectory. The simulation uses the PCMPC controller as in (Li et al., 2021b), also adapted by us to control a single UAV with a payload that is not a point mass object. Additional, Gaussian noise with 1cm standard deviation was applied to the perceived position of the payload, and each transportation task for each contact was repeated ten times. The results were averaged across each object and trial and presented in Figure 7.
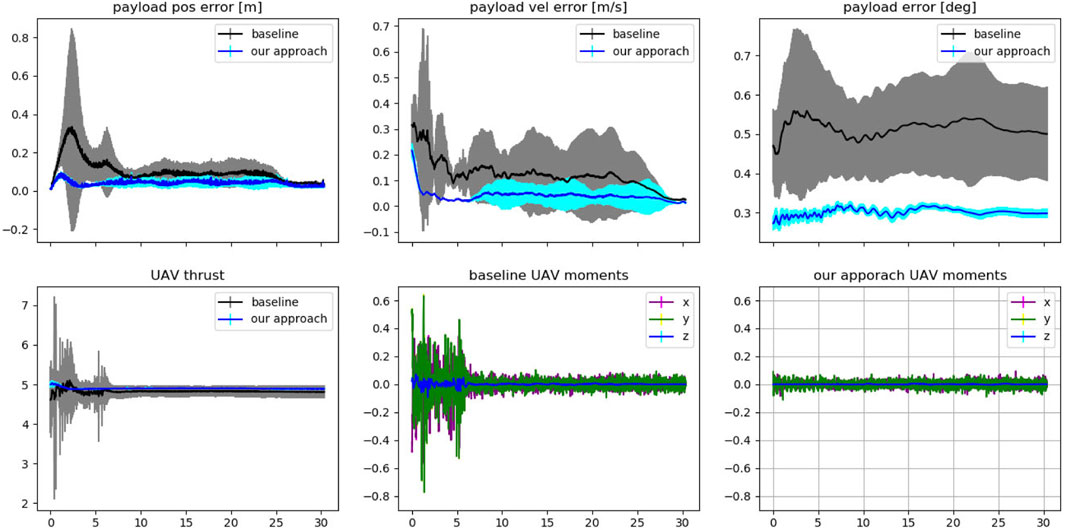
FIGURE 7. The results summarise the transportation experiments. Each solution from Figure 6 is used for ten trials in a simulated environment in which the single or multiple UAVs lift the payload, transport it along a circular trajectory twice, and then hover the payload above ground for at least 5 seconds. The x-axis represents the time in seconds for all plots. The top row shows the averaged position and velocity error w.r.t. the desired payload’s trajectory (baseline and proposed method separately), and both averaged rotational errors in the last plot. The bottom row shows the UAV’s thrust (together) and moments (separately). For the three UAVs condition, the values in the bottom row have been averaged for each UAV.
The solutions for the hollowed triangular shape are from the complete point cloud of the object, for which solution 3 for our approach and solution 4 for the baseline suggested an upside-down contact. We discarded these solutions from the transportation task since we could not achieve the required kinematic of the contact. All the other solutions from the baseline methods that do not provide contacts for each UAV have been modified to connect the gripper to the closest point on the payload. Considering the kinematically infeasible solutions for the three drones condition, we had a total of 147 runs (3 contact models x 5 solutions x 10 trials −3 infeasible solutions) for the proposed model and 147 for the baseline. In all conditions, we use a set of fixed parameters as shown in Table 1.
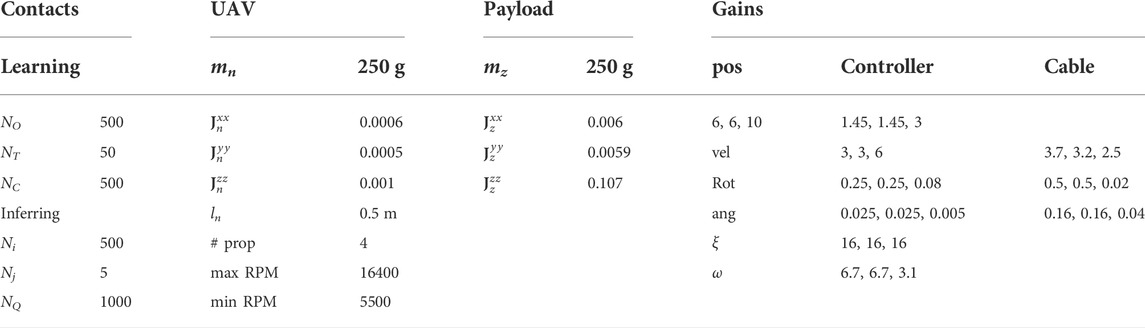
TABLE 1. Experimental parameters. All of the parameters are kept constant over the experiments. We use diagonal inertia matrices for both the UAVs and payloads. The gains values are for the x −, y −and z −components, respectively. UAV and gains parameters are taken from (Li et al., 2021b).
In Figure 7 we observe the averaged difference in transporting the payloads given the choice of the contacts. Our approach outperforms the baseline in terms of accuracy in following the pre-planned payload trajectory and by minimising the effort computed by the UAVs as thrust and moments. Interestingly, in all conditions, our approach enables the UAV to control the orientation of the payload in a more agile way. This is due to the relative position of the contact points with respect to the payload’s shape, which minimises oscillations during the transportation. This is clearly visible by the lower standard deviation from the desired position and orientation of the payload associated with our approach. Furthermore, the velocity profile of the payload and the output to the controller (thrust and moments) show that our contact points simplify the work of the controller in following the desired path.
The next section will present our final remarks.
6 Conclusion
This paper proposed a framework for learning task-dependent contacts for aerial manipulation. Our models are learned in a one-shot fashion and do not require a complete CAD model of the payload or dynamic modelling. We build on a contact-based formulation. Typically, such methods rely only on local information, and task-dependent features must be handcrafted. In contrast, thanks to the task model presented in Section 3.1, we capture meta-information regarding the task by merely looking at the geometrical features of the point cloud, without the need for user-specific insight about the task.
Although performed in simulation, the empirical evaluation shows the potential of the proposed idea. Without physical and dynamic information about the system, a full convergence to an optimal solution is impossible to achieve. Nonetheless, such information is rarely available in reality, and this work is the first step toward autonomous contact selection for aerial manipulation.
7 Strengths, limitations and future work
The presented work extends a (static) contact-based formulation of grasp synthesis to a dynamic task. While previous efforts have focused on integrating an approximation of such dynamics in the models, we investigate how much knowledge about the task we can capture by disregarding the dynamics altogether.
The probabilistic formulation could be considered as a soft simultaneous optimisation of multiple experts. Each expert learns some of the characteristics of the contacts within the feature space, e.g. the task model, and weighs their opinion in the choice of the candidate contact at query time. Any soft simultaneous optimisation of multiple criteria would work in principle. However, the probabilistic representation allows us to draw contact points from a continuous representation of the payload’s surface. Nevertheless, the experts only weight geometrical properties, which do not play a key role in defining the dynamic behaviour of the payload. We assume that the demonstration encodes the contact type (e.g., flat contact), the task (e.g., contact above the payload’s CoM for a transportation task) and the visible surface of the object provides enough salient features to learn a good task model. Although there is no need for handcrafting task features into the model, the training data choice becomes crucial.
Furthermore, our approach assumes that the contact types and tasks are conditionally independent in our model. However, this is generally not true, as seen in the transportation of a FedEx box and the teapot examples. Applying the model learned on the FedEx over the Stanford bunny will lead to a poor choice of contacts since flat surfaces are quite limited in the chosen payload. Therefore, generalisation across contact types and tasks becomes harder to achieve. This also limits the use of the same contact model for a different task (e.g., flat contact next to the edge for dragging the payload) which will require learning a new model.
With many models that need to be learned, we also need to solve the model selection problem when facing a novel payload. Our empirical evaluation disregards this problem by manually providing the correct model at testing time. Reinforcement learning techniques can be used for model selection, but the task would need to be encoded a more informative way for this technique to converge to a good reward function.
The choice of the principal curvatures as surface features is also limiting. It is a baseline for determining the contact points and the general shape of the payload. However, other features may provide better information about the intrinsic dynamic properties of the payload or the encoding task, such as surface roughness or intensity features–or more likely a combination of multiple features.
In order to achieve a fully autonomous aerial manipulation, all these problems will need to be addressed. This work pioneers the problem of grasp synthesis for aerial transportation, but with the increasing interest in aerial manipulation and the technological maturity that we are witnessing, we would suggest that it will become central to many applications. In future work, we will focus on evaluating this framework on a real platform with payloads with different dynamical properties, e.g., mass distribution. Since our approach is a generative model, multiple candidate contacts will be provided for each payload. Primitive dynamic motions could be used to evaluate the selected contacts according to the observed behaviour of the payload.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author contributions
CZ is the main author of this work. CZ has designed and implemented the idea, evaluated the framework and written the manuscript. EF has supervised this project and revised the manuscript and data.
Acknowledgments
We thank Giuseppe Loianno and Marek Kopicki for the support in developing this work.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2022.960571/full#supplementary-material
References
[Dataset] Arruda, E., Zito, C., Sridharan, M., Kopicki, M., and Wyatt, J. L. (2019). Generative grasp synthesis from demonstration using parametric mixtures. arXiv. doi:10.48550/ARXIV.1906.11548
Bohg, J., Morales, A., Asfour, T., and Kragic, D. (2014). Data-driven grasp synthesis—A survey. IEEE Trans. Robot. 30, 289–309. doi:10.1109/TRO.2013.2289018
Brahmbhatt, S., Handa, A., Hays, J., and Fox, D. (2019). “ContactGrasp: Functional multi-finger grasp synthesis from contact,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).
Fisher, R. A. (1953). Dispersion on a sphere. Proc. R. Soc. A Math. Phys. Eng. Sci. 217, 295–305. doi:10.1098/rspa.1953.0064
Howard, R., and Zito, C. (2021). Learning transferable push manipulation skills in novel contexts. Front. Neurorobot. 15, 671775. doi:10.3389/fnbot.2021.671775
Kanatani, K. (2005). Statistical optimization for geometric computation: Theory and practice. Dover, New York: Courier Corporation.
Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P. (1983). Optimization by simulated annealing. Science 220, 671–680. doi:10.1126/science.220.4598.671
Kober, J., Bagnell, J. A., and Peters, J. (2013). Reinforcement learning in robotics: A survey. Int. J. Rob. Res. 32, 1238–1274. doi:10.1177/0278364913495721
Kopicki, M., Detry, R., Adjigble, M., Stolkin, R., Leonardis, A., and Wyatt, J. L. (2016). One-shot learning and generation of dexterous grasps for novel objects. Int. J. Robotics Res. 35, 959–976. doi:10.1177/0278364915594244
Levine, S., Pastor, P., Krizhevsky, A., Ibarz, J., and Quillen, D. (2018). Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robotics Res. 37, 421–436. doi:10.1177/0278364917710318
Li, G., Ge, R., and Loianno, G. (2021a). Cooperative transportation of cable suspended payloads with mavs using monocular vision and inertial sensing. IEEE Robot. Autom. Lett. 6, 5316–5323. doi:10.1109/LRA.2021.3065286
Li, G., Tunchez, A., and Loianno, G. (2021b). “Pcmpc: Perception-constrained model predictive control for quadrotors with suspended loads using a single camera and imu,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). doi:10.1109/ICRA48506.2021.9561449
Mehta, B., and Schaal, S. (2002). Forward models in visuomotor control. J. Neurophysiology 88, 942–953. doi:10.1152/jn.2002.88.2.942
Pozzi, L., Gandolla, M., Maccarini, M., Pedrocchi, A., Braghin, F., Piga, D., et al. (2022). Grasping learning, optimization, and knowledge transfer in the robotics field. Sci. Rep. 12, 4481–4680. doi:10.1038/s41598-022-08276-z
Spivak, M. (1999). A comprehensive introduction to differential geometry, 1. Houston, TX: Publish or Perish, Incorporated.
Sreenath, K., Michael, N., and Kumar, V. (2013). Trajectory generation and control of a quadrotor with a cable-suspended load - a differentially-flat hybrid system. IEEE International Conference on Robotics and Automation, 4888–4895. doi:10.1109/ICRA.2013.6631275
Stüber, J., Kopicki, M., and Zito, C. (2018). “Feature-based transfer learning for robotic push manipulation,” in 2018 IEEE International Conference on Robotics and Automation (ICRA), 5643–5650. doi:10.1109/ICRA.2018.8460989
Stüber, J., Zito, C., and Stolkin, R. (2020). Let’s push things forward: A survey on robot pushing. Front. Robot. AI 7, 8. doi:10.3389/frobt.2020.00008
Keywords: robotics, one-shot learning, aerial manipulation, single and collaborative transportation, aerial grasping
Citation: Zito C and Ferrante E (2022) One-shot learning for autonomous aerial manipulation. Front. Robot. AI 9:960571. doi: 10.3389/frobt.2022.960571
Received: 03 June 2022; Accepted: 29 August 2022;
Published: 05 October 2022.
Edited by:
Chenguang Yang, University of the West of England, United KingdomReviewed by:
Xiao Liang, Nankai University, ChinaWeiyong Si, University of the West of England, United Kingdom
Copyright © 2022 Zito and Ferrante. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Claudio Zito, Q2xhdWRpby5aaXRvQHRpaS5hZQ==