 Dipanwita Guhathakurta
Dipanwita Guhathakurta Fatemeh Rastgar
Fatemeh Rastgar  M. Aditya Sharma
M. Aditya Sharma  K. Madhava Krishna
K. Madhava Krishna  Arun Kumar Singh
Arun Kumar Singh 
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI, 08 July 2022
Sec. Robotic Control Systems
Volume 9 - 2022 | https://doi.org/10.3389/frobt.2022.890385
We present a joint multi-robot trajectory optimizer that can compute trajectories for tens of robots in aerial swarms within a small fraction of a second. The computational efficiency of our approach is built on breaking the per-iteration computation of the joint optimization into smaller, decoupled sub-problems and solving them in parallel through a custom batch optimizer. We show that each of the sub-problems can be reformulated to have a special Quadratic Programming structure, wherein the matrices are shared across all the problems and only the associated vector varies. As result, the batch solution update rule reduces to computing just large matrix vector products which can be trivially accelerated using GPUs. We validate our optimizer’s performance in difficult benchmark scenarios and compare it against existing state-of-the-art approaches. We demonstrate remarkable improvements in computation time its scaling with respect to the number of robots. Moreover, we also perform better in trajectory quality as measured by smoothness and arc-length metrics.
Deployment of multiple aerial vehicles such as quadrotors is critical for applications like search and rescue and exploration and mapping of large areas (Schranz et al., 2020). Over the last decade, robot fleets have also become ubiquitous in applications like ware-house automation that have a substantial economic impact on society (Li et al., 2020; Bolu and Korçak, 2021). Furthermore, with the advent of connected autonomous cars, it becomes imperative also to view urban mobility as a multi-robot system (Zhou et al., 2017). A fundamental component of any multi-robot system is the coordination planning that guides individual robots between their start and goal locations while avoiding collisions with the environment and other robots. In this paper, we adopt the optimization perspective for multi-robot motion planning (Rastgar et al., 2021). In this context, the existing approaches broadly fall into two spectra. On one end, we have the centralized approaches wherein the trajectory of all the robots are computed together. The centralized approach can be further subdivided into sequential (Chen et al., 2015), Park et al. (2020) and joint optimization (Augugliaro et al., 2012; Rastgar et al., 2021) respectively depending on whether the trajectories of the robots are computed one at a time or simultaneously. On the other end of the spectrum, we have online distributed model predictive control (DMPC) (Luis et al., 2020; Soria et al., 2021) based approaches wherein each individual robot computes its trajectories in a decoupled manner based on the trajectory prediction of the other robots in the environment. In some works, the prediction module is replaced by robots communicating their current trajectory with each other (Luis and Schoellig, 2019).
Centralized approaches, especially the joint optimization variants, provide a rigorous treatment of the collision avoidance constraints and access a larger feasible space formed by all trajectory variables of all the robots. However, joint optimization quickly becomes intractable as the number of robots increases (Chen et al., 2015). In contrast, the distributed MPC approaches can run in real-time but can lead to oscillatory behaviors, and consequently, low success rates of collision avoidance (Luis and Schoellig, 2019; Luis et al., 2020). This is because the trajectories computed at each control cycle by any robot are only collision-free with respect to the predicted (or prior communicated) trajectories of other robots and not the actual trajectories followed by them.
Our main motivation in this paper is to improve the computational tractability of multi-robot trajectory planning using a distributed optimization approach to the extent that it becomes possible to compute trajectories for tens of robots in densely cluttered environments in a few tens of milliseconds. To put in context, the said timing is several orders of magnitude faster than some of the existing approaches for joint multi-robot trajectory optimization (Augugliaro et al., 2012; Bento et al., 2013). Such improvements in computation time would ensure the applicability of our approach for even online re-planning besides the standard use case of computing offline global trajectories for the robots. For example, consider a scenario wherein each robot uses local real-time planners such as Dynamic Window Approach (Fox et al., 1997) or DMPC (Luis et al., 2020) to avoid collisions with other robots in a distributive manner. Our approach could provide global re-planning for the local planners at more 5 Hz. or more.
On the application side, our main focus is on coordination of multiple quadrotors, typically for applications like search and rescue and coordinated exploration. These applications require point-to-point, collision-free navigation and forms the main benchmark in our experiments. However, our algorithm can be useful for coordination of multiple wheeled mobile robots and even autonomous cars.Contributions: The computational efficiency of our approach is built on several layers of reformulation of the underlying numerical aspects of the joint multi-robot trajectory optimization. We summarize the key points and the benefits that it leads to below.Algorithmic: Our main idea is to break the per-iteration computation of the joint multi-robot trajectory optimization into smaller, distributed sub-problems by leveraging the solution computed in the previous iterations. Although similar ideas have appeared in many existing works (Bento et al., 2013; Luis and Schoellig, 2019), a core challenge remains: how to efficiently solve the decoupled problem arising at each iteration in parallel. The basic assumption is that the decoupled optimizations can be parallelized across separate CPU threads (Bento et al., 2013). However, our recent works have shown that such a parallelization approach does not scale well with an increase in the number of problems (Adajania et al., 2022). The inherent limitation stems from the available CPU cores and thread synchronization issues.
Thus our main algorithmic contribution in this paper lies in deriving a novel optimizer that can be efficiently run in a batch setting. In other words, our optimizer can take a set of decoupled optimization problems and vectorize the underlying numerical computations across multiple problem instances. Consider an optimizer that solves a given problem by adding two vectors as a hypothetical example. We can trivially vectorize the computation over different problem instances by stacking each problem’s vectors together in the form of a matrix and adding them together. Moreover, this matrix addition can be easily parallelized over GPUs for many problem instances. Our proposed optimizer achieves similar vectorization but for a set of difficult non-convex sub-problems, resulting in each iteration of joint multi-robot trajectory optimization. Specifically, we show that solving the decoupled sub-problems predominantly reduces to solving novel equality constrained quadratic programming (QP) problems under certain collision constraint reformulations. The novelty of the QPs stems from the fact that they all share the same matrices (e.g., Hessian), and only the vectors associated with the QPs vary across the sub-problems. We show that solving all the QP sub-problems in one shot reduces to computing one large matrix-vector product that can be trivially parallelized over GPUs using off-the-shelf linear algebra solvers.Applied: We release our entire implementation for review and to promote further research on this problem. We also release the benchmark data sets used in our simulations.State-of-the-art Performance We compare our GPU accelerated optimizer with two strong baselines (Park et al., 2020; Rastgar et al., 2021) and show massive improvement in computation time while being competitive in trajectory quality as measured by metrics like arc-length and smoothness. Our first comparison is with (Park et al., 2020) that uses a sequential approach for multi-robot trajectory optimization. Our computation time is at least 76.48% lower than that of (Park et al., 2020) for a smaller problem size involving 16 robots. Moreover, the performance gap increases substantially in our favor as we increase the number of robots and make the environment more cluttered by introducing more static obstacles. We observe similar trends in trajectory arc-length and smoothness comparison between the two approaches. Our second comparison is with (Rastgar et al., 2021) that searches directly in the feasible joint space formed by all the pair-wise collision avoidance constraints. Our proposed optimizer shows improved scalability over (Rastgar et al., 2021) for a larger number of robots while being also superior in trajectory arc length and smoothness.
This section introduces the general problem formulation for multi-robot trajectory optimization. We subsequently use the problem set-up to review existing works and contrast our optimizer with them. We begin by summarizing the main symbols and notations used throughout the paper.
In this paper, the lower normal and bold letters denote the scalars and vectors, respectively, while the upper bold case variants represent matrices. The left and right super-scripts denoted by k and T will be used to denote the iteration index of the optimizer and transpose of the vectors and matrices. The time-stamp of any variable will be denoted by t. The symbol

TABLE 1. Important symbols.
Our optimizer is designed for robots with holonomic motion models. That is, the motion along each axis is decoupled from each other. This is a common assumption made in quadrotor motion planning. Many commercially available wheeled mobile robots also have similar kinematic model. Under certain conditions, even motion planning for car-like vehicles also adopt similar kinematic model and thus our optimizer is suitable for those as well Werling et al. (2010).
For holonomic robots modeled as series of integrators, the joint trajectory optimization can be formulated in the following manner.
The cost function Eq. 1a minimizes the squared norm of the acceleration at each time instant for all the robots. The equality constraints Eqs. 1b and 1c enforces the initial and final boundary conditions on positions, velocity, and accelerations on each robot trajectory. The pair-wise collision avoidance constraints are modeled by inequalities Eq. 1d, wherein we have assumed that the robots are shaped as axis-aligned spheroids with axis dimensions (a, a, b). For the ease of exposition, we consider all robots to have the same shape. Extension to a more general setting is trivial. The constraints Eq. 1d are typically enforced at pre-selected discrete time-stamps, and thus a fine resolution of discretization is necessary for accurately satisfying the constraints. For now, we do not consider any static obstacles in the environment in the formulation above. The extension is trivial as static obstacles can be considered robots with zero velocity and whose trajectories are not updated within the optimizer’s iteration.
Let the trajectory of each robot along each motion axis x, y, z be parameterized through nv number of variables. For example, these variables could be time-stamped way-points representing the trajectory or the coefficients of their polynomial representation (see Eq. 8). Then, for a set-up with nr number of robots and a planning horizon of np, optimization Eqs. 1a–1d involves nr∗nv variables, and 18∗nr equality constraints. The number of pair-wise collision constraints would be
The number of decision variables in optimization Eqs. 1a–1d scales linearly with the number of robots. Although this increase poses a computational challenge, the main difficulty in solving the optimization stems from the non-convex pair-wise collision avoidance constraints Eq. 1d as the rest of the cost and constraint functions are convex. Moreover, the number of collision avoidance constraints increases exponentially with the number of robots. Existing works (Augugliaro et al., 2012; Chen et al., 2015; Li et al., 2020; Park et al., 2020; Rastgar et al., 2021) have adopted different simplifications on the collision avoidance constraints to make multi-robot trajectory optimization more tractable. We thus next present a categorization of these works based on the exact methodology used.
The most conceptually simple approach is to solve Eqs. 1a–1d as one large optimization problem, wherein the trajectory of every robot is computed in one shot. Authors in (Augugliaro et al., 2012) simplified the joint optimization by deriving a conservative affine approximation of the collision avoidance constraints Eq. 1d and consequently reducing Eqs. 1a–1d to a sequence of QPs. As a result, their solution process becomes somewhat tractable for a moderate number of robots
Sequential planners plan for only one robot at a time. At any given planning cycle, the previously computed robot trajectories are considered dynamic obstacles for the currently planned robot. As a result, these approaches ensure that the number of decision variables does not increase with robots. Moreover, the number of collision avoidance constraints increases linearly as the planning cycle progresses. However, note that the linear increase in the number of constraints does not translate to similar scaling in computation time. Even state-of-the-art interior-point solvers have cubic complexity with respect to the number of constraints.
A critical disadvantage of sequential planners is that each subsequent robot has access to less feasible space to maneuver. As a result, optimization problems become progressively constrained as the planning cycle progresses, leading to potential infeasibility. Authors in (Chen et al., 2015a) tackle this problem by developing an incremental constraint tightening approach. The authors integrate a subset of collision avoidance constraints into the optimization problem, and the size of this set is gradually increased based on the actual collision residuals.
Sequential planners naturally have the notion of priority, and these can be chosen carefully for improved performance. For example (Li et al., 2020), adopts a priority-based optimization method in which the robots are divided into groups/batches with pre-determined priorities, and the trajectory optimization problem is solved from the highest to the lowest priority group. Similar approach was adopted in (Park et al., 2020). Performing sequential planning over a small batch of robots reduces its conservativeness. On the other hand, it introduces an additional challenge of ensuring collision amongst the robots in a given batch. Authors in (Park et al., 2020) tackle this bottleneck by leveraging graph-based Multi-robot Path Finding (MAPF) methods.
Distributed optimizers at each iteration, break Eqs. 1a–1d into decoupled smaller problems. For example, see (Bento et al., 2013; Halsted et al., 2021). The key insight upon which all existing works build is that the only coupling between different robots stem from the pair-wise collision constraints Eq. 1d (Halsted et al., 2021). Thus, we if we discard this coupling, Eqs. 1a–1d can be easily reduced to nr number of decoupled optimizations. One way to achieve the said decoupling is to let each robot make prediction of how the trajectories of other robots are going to look in the immediate next iterations and use that to simplify the collision avoidance constraints. More formally, let
Note that
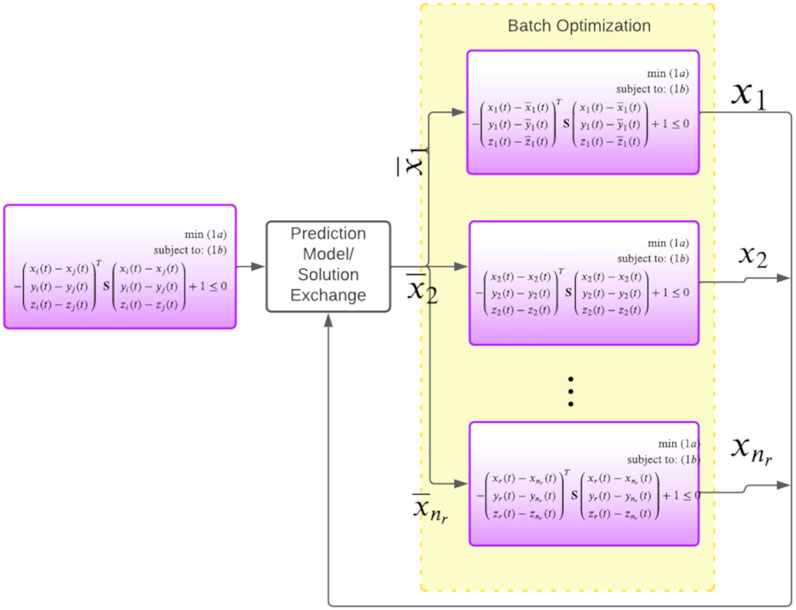
FIGURE 1. Figure shows our approach for breaking the joint optimization (first block) at each iteration into decoupled sub-problems (third group of blocks). Each robot exchanges their current computed trajectories with each other. For the next iteration, robots will use the communicated trajectories to frame their collision avoidance constraints. Thus, in this manner, we can avoid the inter-robot coupling in collision constraints. Our core novelty in this paper is a batch optimizer that can solve all the decoupled problems in parallel over GPUs. It is also possible to replace the trajectory exchange set-up with a model that predicts the nature of the robot trajectories in the immediate next iteration. Note that we only show the x component of the trajectory purely to maintain clarity in the figure.
DMPC approaches are the online variants of the distributed optimization approach. In other words, if we run one iteration of distributed optimization and let each robot move with the computed trajectory, we recover the DMPC works such as (Luis et al., 2020), Luis and Schoellig (2019). This insight also points to the main issue of DMPC. At each control cycle, imagine a robot i receiving information (directly through communications or indirectly through prediction) about the trajectory that the other robot j computed. Then it uses this information to construct collision avoidance constraints in its trajectory optimization set-up. However, robot j will follow the same process and update its trajectory as well. Thus, essentially both robot i and j compute their motion based on outdated information about each other’s behavior.
Parallelization of a batch of optimization problems across CPUs and GPUs operates fundamentally differently, and both classes of approaches have been tried in existing works to speed up multi-robot trajectory optimization. Each CPU core is efficient at handling arbitrary numerical computations, and thus solving a batch of optimizations problems in parallel is conceptually simple. We can solve each problem in a separate thread without needing to make any change in the underlying numerical algebra of the optimizer (Adajania et al., 2022), (Bento et al., 2013). As mentioned earlier, the scalability of CPU parallelization is limited by the number of cores (typical 6 in a standard laptop). On the other hand, GPUs have many cores, but these are primarily efficient at parallelizing primitive operations such as matrix-vector and matrix-matrix multiplication. Moreover, GPUs excel in performing the same primitive operations over many data points. Thus, to fully leverage the compute power of GPUs, it is necessary to modify the underlying numerical aspect of an optimizer to fit the strengths of GPUs. For example, GPU acceleration of Newton’s method requires adopting indirect matrix factorization over the more common direct approaches (Kylasa et al., 2019). One optimization technique that trivially accelerates over GPUs is Gradient Descent (GD) since it boils down to just matrix-vector multiplication. Authors in (Hamer et al., 2018) leverage this insight for developing a fast multi-robot trajectory optimization algorithm. One critical issue of (Hamer et al., 2018) is that the proposed GD is very sensitive to hyper-parameters like weights of the different cost function, learning rate, etc.
GPUs are designed using threads grouped into blocks, which are themselves organized as grids to parallelize computations for computational efficiency (Li et al., 2012). The GPU first tiles an n × n matrix using p × q tiles indexed with a 2-dimensional index to multiply large matrices. The output of each tile in the result matrix is independent of other tiles, which allows for parallelization. The parallelized CUDA code uses a block of threads to compute each tile of the result matrix, and to compute the entire result matrix; it uses a
Similar to (Bento et al., 2013), we break the joint multi-robot trajectory optimization Eqs. 1a–1d into decoupled smaller sub-problems at each iteration. This is illustrated in Figure 1. At a conceptual level, this decoupling process can be interpreted in the following manner: the robots communicate among themselves the trajectories they obtained in the previous iteration of the optimizer. Each robot then uses them to independently formulate their collision avoidance constraints. Our work differs from existing works in the way the decoupled problems illustrated in Figure 1 is solved. As mentioned before, a trivial approach to solving the sub-problems in parallel CPU threads is not scalable for tens of robots. In contrast, our main idea in this paper is to develop a GPU accelerated optimizer that can solve a batch of optimization problems in one shot.
In this sub-section, we aim to provide a succinct mathematical abstraction of our main idea. We discuss a special class of problems that are simple to solve in batch fashion. To this end, consider the following batch of equality constrained QPs, i ∈ {1, 2, …, nr}.
In total, there are nr QPs to be solved, each defined over variable ξi. The QPs defined in Eq. 3 have a unique structure. The Hessian
where μi are the dual optimization variables. Now, it can be observed that the matrix on the left-hand side of Eq. 4 is independent of the batch index i, and thus, the solutions for the entire batch can be computed in one shot through Eq. 5.
where | represents that the columns are stacked horizontally. The batch solution Eq. 5 amounts to multiplying one single matrix with a batch of vectors. Furthermore, the matrix is constant, and its dimension is independent of the number of problems in the batch. Thus, operation Eq. 5 can be trivially parallelized over GPUs using off-the-shelf libraries like JAX (Bradbury et al., 2020).How it all fits: In the next few sub-sections, we will show how the distributed sub-problems of Eqs. 1a–1d, shown in Figure 1 can be solved efficiently in a batch setting. Specifically, we reformulate these problems in such a way that the most intensive part of their solution process reduces to solving a batch of QPs with the special structure presented in Eq. 3.
An important building block of our approach is rephrasing the collision avoidance constraints into the following polar representation from (Rastgar et al., 2021; Rastgar et al., 2020).
where αij(t), βij(t), dij(t) are unknown variables that will be computed by the optimizer along with each robot’s trajectory. Physically, αij(t) and βij(t) represent the 3D solid angle of the line-of-sight connecting robot i and j based on the predicted motion of the latter. The variable dij(t) is the ratio of the length of the line-of-sight vector with minimum safe distance
Using Eq. 6, we can reformulate the distributed sub-problems presented in Figure 1 for the ith robot in the following manner. We reiterate that
Optimization Eqs. 7a–7e is expressed in terms of functions and thus has the so called infinite dimensional representaton. To obtain a finite-dimensional form, we assume some parametric form for this functions. For different
Similar expressions as Eq. 8 can be written for the y, z component of the trajectory as well. The matrix P is formed with time dependent polynomial basis functions. Using Eq. 8, we can re-write Eqs. 7a–7e in the following matrix form.
where, ξ1,i = (cx,i, cy,i, cz,i), ξ2,i = αij, ξ3,i = βij and ξ4,i = dij. Note that αij is formed by stacking αij(t) at different time instants. Similar construction is followed for other elements in ξ2, ξ3. The matrix Q is block diagonal matrix with
where,
Matrix F and vector gi defining constraints Eq. 7e are constructed as
where,
and Fo is formed by vertically stacking P, nr − 1 times. The vectors
REMARK 1. The subscript i signifies that Eqs. 9a–9c is constructed for the ith agent.
REMARK 2. All the non-convexity in optimization Eqs. 9a–9d is rolled into the equality constraint Eq. 9c.
REMARK 3. The matrices Aeq, F in optimization Eqs. 9a–9d is independent of the robot index. In other words, these matrices remain the same irrespective of the which sub-problems shown in Figure 1 we are solving.
Remark 3 sheds light behind our motivation of presenting the elaborate reformulations of the collision avoidance constraints. In fact, on the surface, our chosen representation Eq. 6 seems substantially more complicated than the conventional form Eq. 1d based on the Euclidean norm. In the next sub-section, we present an optimizer that can leverage the insights presented in Remark 3. More precisely, we will show that the due to the matrices Aeq, F being independent of the robot index i, the most intensive part of solving Eqs. 9a–9d reduces to the batch QP structure presented in Section 3.1.
Our proposed optimizer for Eqs. 9a–9d relies on relaxing the non-convex equality constraints Eq. 9c as l2 penalties and incorporating them into the cost function in the following manner.
As the residual of the constraint term is driven to zero, we recover the solution to the original problem. To this end, the parameter λi, known as the Lagrange multiplier, plays an important part. Its role is to appropriately weaken the effect of the primary cost function so that the optimizer can focus on minimizing the constraint residual (Taylor et al., 2016). The parameter ρ is a scalar and is typically constant. However, it is possible to increase or decrease it depending on the magnitude of the constraint residual at each iteration of the optimizer.
The relaxation of non-convex equality constraints, as augmented Lagrangian (AL) cost, is extensively used in non-convex optimization (Ferranti and Keviczky, 2017; Ferranti et al., 2018). However, what differentiates our use of AL from existing works is how we minimize Eq. 13. Typical approaches towards non-convex optimization are based on first (and sometimes second) order Taylor Series expansion of the non-convex costs or constraints. In contrast, we adopt an Alternating Minimization (AM) based approach, wherein at each iteration, we minimize only one of the variable blocks amongst ξ1,i, ξ2,i, ξ3,i, ξ4,i while others are held constant at specific values. In the next section, we present the various steps of our AM optimizer and highlight how it never requires any linearization of cost or constraints. Moreover, we show how the AM steps naturally lead to a simple yet efficient batch update rule using which we can solve Eqs. 9a–9d for all the robots in one shot.
Algorithm 1. Alternating Minimization Based Solution for the Ith Sub-Problem

Our AM based optimizer for minimizing Eq. 13 subject to Eqs. 9b–9d is presented in Algorithm 1. Here, the left superscript k is used to track the values of the variable across iteration. For example, kξ2,i denotes the value of this respective variable at iteration k.
The Algorithm begins (line 1) by providing the initial guesses for ξ2,i, ξ3,i, ξ4,i. The main optimizer iterations run within the while loop for the specified max iteration limit or till the constraint residuals are a below specified threshold. Each step within the while loop involves solving a convex optimization over just one variable block. We present a more detailed analysis of each of the steps next.
Step (14): This optimization is a convex QP with a similar structure as Eq. 3 with
Thus, we can easily solve Eq. 14 for all the robots in parallel to obtain
For a constant ρ, the inverse of
The dimension of F, gi and G is ((nr − 1)∗np) × 3nv, ((nr − 1)*np) × 1, and ((nr − 1)*np) × nr respectively. For convenience, we recall that nr, np, nv represents the number of robots, planning steps and coefficients of the trajectory polynomial (along each axis) respectively. Thus, the row-dimension of F and G increases linearly with nr.
Step (15): The variable k+1ξ1,i computed in the previous step and Eq. 8 can be used to fix the position trajectory k+1xi, k+1yi, k+1zi at the (k + 1)th iteration. Thus, optimization Eq. 15 reduces the following form
where
Although Eq. 21 is a seemingly non-convex problem but it has a few favorable computational structures. First, for a fixed position trajectory k+1xi, k+1yi, k+1zi, we can treat each element of αij as independent from each other. Thus, Eq. 21 reduces to (nr − 1)*np decoupled problems. Second, the solution can be obtained by purely geometrical intuition; αij is simply one part of the 3D solid-angle of the line-of-sight connecting the ith robot and the predicted trajectory of jth agent. The exact solution update is given by the following.
Step (16): Following the exact same reasoning as the previous step (15), we have the following solution update rule for ξ3,i:
Step k+1ξ4,i: Similar to the last two steps, each element of ξ4,i = dij once the position trajectory k+1xi, k+1yi, k+1zi is fixed. Thus, Eq. 17 can be broken down into (nr − 1)*np parallel problems of the following form.
Each optimization in Eq. 24 is a single variable QP with simple bound constraints. We first obtain the symbolic formulae for the unconstrained version and then clip the resulting solution to [0 1].
REMARK 4. Evaluating Eqs. 22 and 23 and the solution of Eq. 24 requires no matrix factorization/inverse or even matrix-matrix products. We just need element-wise operation that can obtained for all the sub-problems in one shot. In other words, we obtain
The objective of this section is twofold. First, to validate that a distributed approach augmented with our custom batch optimizer can indeed generate collision-free trajectories for tens of robots in highly cluttered environments. Second, to compare our approach with the existing state-of-the-art (SOTA) multi-robot trajectory optimizer in terms of solutions quality and computation time.
Implementation Details: We built our optimizer in Python using JAX (Bradbury et al., 2020) as our GPU accelerated linear algebra back-end. We considered static obstacles as robots with fixed zero velocity. We modeled each robot by a sphere and each obstacle by its circumscribing sphere. We experiment with a diverse range of radii of both robots and obstacles. Simulations were run on a desktop computer with 32 GB RAM and RTX 2080 NVIDIA GPU.
Our optimizer is tested using the following benchmarks.
• The robots’ start and goal positions are sampled along the circumference of a circle.
• The robots are initially located on a grid and are tasked to converge to a line formation.
By changing the number and positions of robots and static obstacles, we created several variations of the mentioned benchmarks and utilized them to validate our optimizer. Figures 2A–I presents a few qualitative results in a diverse set of environments. Figures 2A–C shows an environment with 32 robots and 20 obstacles. Interestingly, we observe a circular pattern formation among the robots while passing through narrow passages between static obstacles. In Figures 2D–F, 36 robots initially arranged in a grid are given the task to navigate to a line formation while avoiding collisions with each other and with the four static obstacles in the environment. Figure 3 shows the execution of the computed trajectories in a high-fidelity physics engine called Gazebo available in Robot Operation System (Koenig and Howard, 2004).
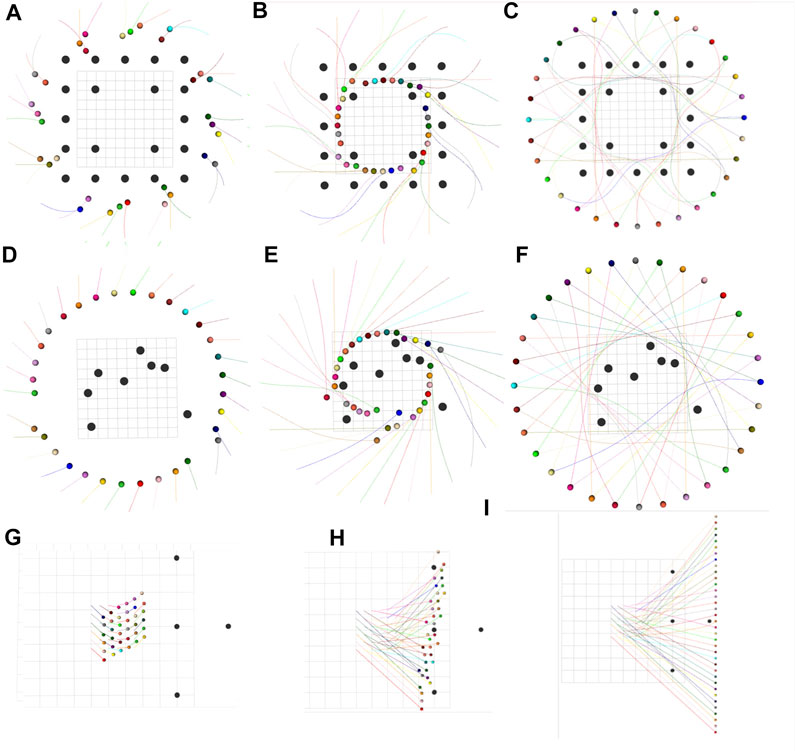
FIGURE 2. Trajectory snapshots for (A–C) 32 robots, each of radius 0.3 m arranged in a circle and 20 obstacles of radius 0.4 m (D–F) 32 robots, each of radius 0.3 m arranged in a circle and 8 randomly placed obstacles of radius 0.4 m (G–I) 36 robots, each of radius 0.1 m arranged in a grid configuration are required to move to a line formation. Also, the environment has 4 static obstacles, each of radius 0.15 m.

FIGURE 3. Simulation snapshots for (A–F) 16 drones and 8 static obstacles of radius 0.3 m, and (G–L) 8 drones and 2 static obstacles of radius 0.3 m (A–C, G–I) are screenshots of simulations on Gazebo. In (A–C), the gray static hovering drones represent static obstacles while in (G–I) white hovering drones represent static obstacles. (D–F, J–L) are screenshots of RViz simulations with the brown hovering drones representing static obstacles. For the full simulation videos, please refer to the following link: https://www.dropbox.com/scl/fo/xnostapkvf72uudyb840t/h?dl=0&rlkey=02gjjllohbomzi0kcifbqezt9.
A conceptually simple way of validating the convergence of the proposed optimizer is to observe the trends in residual of constraints Eq. 9c over iterations. If the residuals converge to zero, the computed trajectories are guaranteed to be collision-free. Figure 4 empirically provides this validation. It presents ‖Fξ1,i − gi‖ averaged over all i. Furthermore, we average the residuals over different trials in various benchmarks. We can observe from Figure 4 that, on average, 100 iterations are sufficient to obtain residuals around 0.01. A further increase in residuals can be obtained by increasing the number of iterations but at the expense of increasing the computation time. In our implementation, we adopt a heuristic wherein we inflate the size of the robots with four times the typical residual observed after 100 iterations.
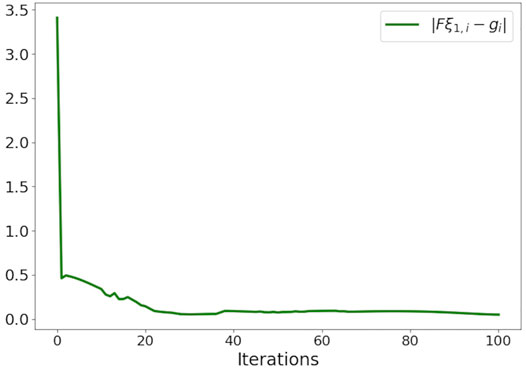
FIGURE 4. Empirical validation of convergence of our optimizer. The figure shows the residual of ‖Fξ1,i − gi‖ averaged over all i (agent index) and across different benchmarks.
For a further sanity check, we check for inter-robot and robot-obstacle distances at each point along the computed trajectories (Figure 5). Collisions are considered to have happened if the distances are less than sum of the robots’ (blue line in Figure 5) or robot-obstacles’ (yellow line in Figure 5) radii. Figure 5 summarizes the average behavior observed across several trials, which validates the satisfaction of the collision avoidance requirement.
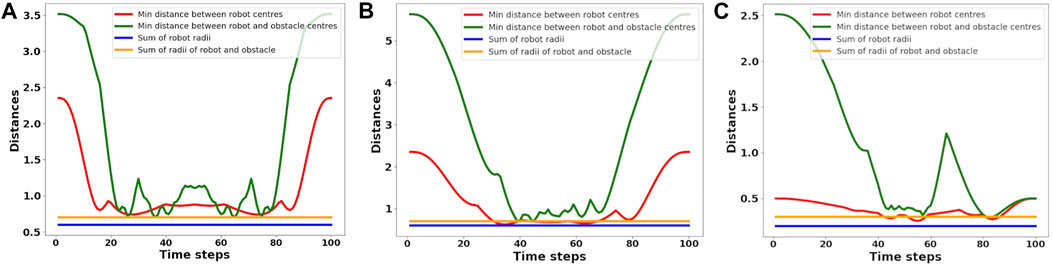
FIGURE 5. Figure showing the minimum of the pair-wise distances between the robots averaged across different benchmarks, some of which are shown in Figure 2. The pair-wise distance is always greater than the lower bound shown in blue. Similarly, we also show the average minimum distance between the robots’ and obstacles’ centers. The corresponding lower bound is shown in yellow which is always respected by the computed trajectories. (A) denotes the pairwise-distance plot for the scenario in Figures 2A–C, (B) for Figures 2D–F and (C) for Figures 2G–I.
This subsection compares our optimizer with existing state-of-the-art approaches (Rastgar et al., 2021) and (Park et al., 2020). We use the following metrics for bench-marking.
• Smoothness cost: It is computed as the norm of the second-order finite-difference of the robot position at different time instances.
• Arc-length: It is computed as the norm of the first-order finite-difference of the robot positions at different time instances.
• Computation Time: The time taken for each approach to return a smooth and collision-free solution.
Figure 6 presents a qualitative comparison between the trajectories obtained by our optimizer and (Park et al., 2020) in two different benchmarks. Both approaches are successful; however, ours results in shorter trajectories. This trend is further confirmed by Figure 7. Our optimizer achieves an average reduction of 3.90 and 13.72% in arc-length in 16 and 32 robots benchmarks, respectively. Furthermore, the performance gap between our optimizer and (Park et al., 2020) increases as the environment becomes more cluttered with static obstacles. We also observe similar trends in the smoothness metric, with the performance gap being even starker. Our optimizer achieves an average reduction of 35.86 and 59.06% in smoothness cost in 16 and 32 robots benchmark, respectively.
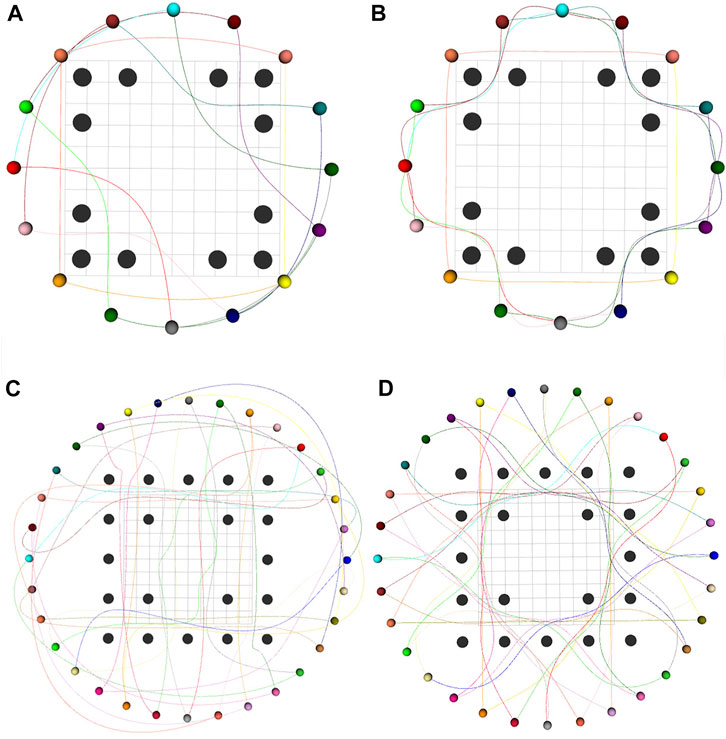
FIGURE 6. Comparison of trajectories generated by (Park et al., 2020) (A,C) and our optimizer (B,D) for 16 robots-12 obstacles (upper row) and 32 robots-20 obstacles (bottom row) benchmarks. Black spheres denote static obstacles and colored spheres denote robots. Our optimizer generates trajectories with smaller arc-length than (Park et al., 2020).
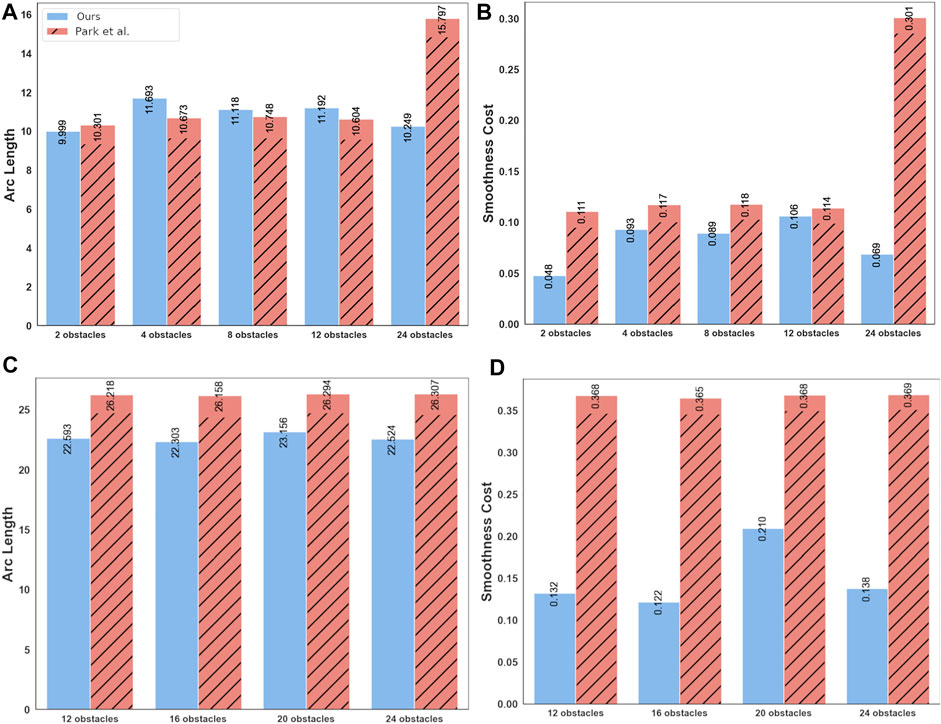
FIGURE 7. Comparison of our optimizer with (Park et al., 2020) in terms of arc-length and smoothness of obtained trajectories in 16 robots (A,B) and 32 robots (C,D) benchmarks. Our optimizer generates trajectories with not only better smoothness, but also with shorter arc-lengths. Moreover, the performance gap between our approach and (Park et al., 2020) increases as the environment becomes more cluttered.
Table 2 compares the computation time of our optimizer and (Park et al., 2020). Our optimizer shows better scaling with the number of robots and obstacles in the environment. On the considered benchmark, our optimizer shows a worst and best case improvement of 74.28 and 98.48% respectively. The trends in computation time can be understood in the following manner. The approach of (Park et al., 2020) uses sampling-based multi-agent pathfinding algorithms to compute initial guesses for the robot trajectories. As the environment becomes more cluttered, the computational cost of computing the initial trajectories increases dramatically. Moreover, their sequential optimization also becomes increasingly more computationally intensive as the number of robots and obstacle increase.

TABLE 2. Comparison with current state-of-the-art (Park et al., 2020) in terms of computation time.
In contrast, our optimizer only requires matrix-matrix products, and the dimension of these matrices increases linearly with the number of robots and obstacles. This linear scaling along with GPU parallelization explains our computation time.
Table 3 compares the performance of our optimizer with (Rastgar et al., 2021). Our core difference with (Rastgar et al., 2021) stems from the fact that we break a large optimization problem into smaller distributed sub-problems. In contrast, (Rastgar et al., 2021), retains the original larger problem itself. However, both our optimizer and (Rastgar et al., 2021) use GPUs to accelerate the underlying numerical computations. Thus, unsurprisingly, (Rastgar et al., 2021), shows a decent scaling with the number of robots and obstacles. Nevertheless, our approach still outperforms (Rastgar et al., 2021). Specifically, in 16 robot benchmarks, our optimizer shows a worst-case improvement of 2 times over (Rastgar et al., 2021) in computation time. As the environment becomes more cluttered, this factor increases to almost 10. In 32 robot benchmarks, the difference between our optimizer and (Rastgar et al., 2021)’s computation time is around nine times.
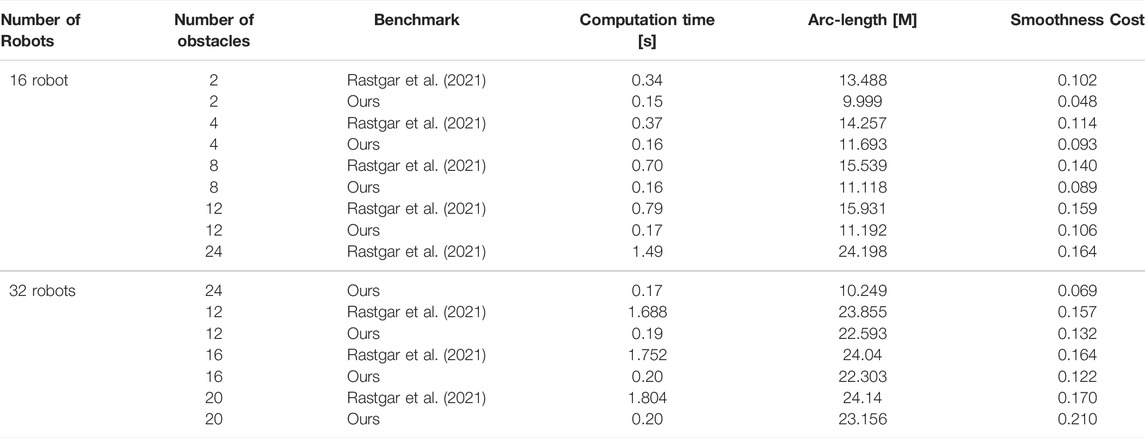
TABLE 3. Comparison with (Rastgar et al., 2021) in terms of computation time, arc-length and smoothness cost.
In terms of the arc-length and the smoothness metrics, our optimizer shows an improvement of around 57 and 58% respectively over (Rastgar et al., 2021). However, both approaches provide comparable results in the more challenging 32 robot benchmarks. The arc-length and smoothness cost difference decreases the environment becomes more cluttered.
Joint multi-robot trajectory optimizations are generally considered intractable beyond a small number of robots. This is because the number of pair-wise collision avoidance constraints increases exponentially with the number of robots. Moreover, even the best optimization (QP) solvers show polynomial scaling with the number of constraints. In this paper, we fundamentally altered this notion. By employing a clever set of reformulations and parallelism offered by modern computing devices such as GPUs, we managed to compute trajectories for tens of robots in highly cluttered environments in a fraction of a second. Our formulation is simple to implement and involves computing just matrix-matrix products. Such computations can be trivially accelerated or parallelized on GPUs using off-the-shelf libraries like JAX (Bradbury et al. (2020)). We benchmarked our approach against two strong baselines and showed substantial improvement over them in terms of computation time and trajectory quality.
Our work has potential beyond multi-robot coordination. For example, currently, we are looking to use the proposed multi-robot trajectory optimization for interaction-aware trajectory prediction. Our optimizer’s current form is suited for only holonomic robots. In future works, we are looking to integrate non-holonomic constraints to make our optimizer applicable for coordination of car-like vehicles.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/susiejojo/distributed_GPU_multiagent_trajopt/.
DG and AS worked on the literature review. DG, FR, and AS presented problem formulation and code implementation. DG, FR, and MS conducted experiments for the validation and results section. DG, FR and AS wrote the original manuscript. Also, all authors edited and reviewed the manuscript. AS and MK supervised the study and managed the funding resources. Finally, all authors engaged in providing the study conceptualization.
The work was supported in part by the European Social Fund through IT Academy program in Estonia and grant PSG753 from Estonian Research Council.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2022.890385/full#supplementary-material
Adajania, V. K., Sharma, A., Gupta, A., Masnavi, H., Krishna, K. M., and Singh, A. K. (2022). Multi-modal Model Predictive Control through Batch Non-holonomic Trajectory Optimization: Application to Highway Driving. IEEE Robot. Autom. Lett. 7, 4220–4227. doi:10.1109/LRA.2022.3148460
Augugliaro, F., Schoellig, A. P., and D’Andrea, R. (2012). “Generation of Collision-free Trajectories for a Quadrocopter Fleet: A Sequential Convex Programming Approach,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (Vilamoura-Algarve, Portugal: IEEE), 1917–1922. doi:10.1109/iros.2012.6385823
Bento, J., Derbinsky, N., Alonso-Mora, J., and Yedidia, J. S. (2013). “A Message-Passing Algorithm for Multi-Agent Trajectory Planning,” in Advances in Neural Information Processing Systems (Lake Tahoe, NV), 26.
Bolu, A., and Korçak, O. (2021). Adaptive Task Planning for Multi-Robot Smart Warehouse. IEEE Access 9, 27346–27358. doi:10.1109/access.2021.3058190
Bradbury, J., Frostig, R., Hawkins, P., Johnson, M. J., Leary, C., Maclaurin, D., et al. (2020). Jax: Composable Transformations of python+ Numpy Programs, 2018. URLhttp://github.com/google/jax 4, 16.
Chen, Y., Cutler, M., and How, J. P. (2015). “Decoupled Multiagent Path Planning via Incremental Sequential Convex Programming,” in 2015 IEEE International Conference on Robotics and Automation (ICRA) (Seattle, WA: IEEE), 5954–5961. doi:10.1109/icra.2015.7140034
Ferranti, L., and Keviczky, T. (2017). Operator-splitting and Gradient Methods for Real-Time Predictive Flight Control Design. J. Guid. Control, Dyn. 40, 265–277. doi:10.2514/1.g000288
Ferranti, L., Negenborn, R. R., Keviczky, T., and Alonso-Mora, J. (2018). “Coordination of Multiple Vessels via Distributed Nonlinear Model Predictive Control,” in 2018 European Control Conference (ECC) (Limassol, Cyprus: IEEE), 2523–2528. doi:10.23919/ecc.2018.8550178
Fox, D., Burgard, W., and Thrun, S. (1997). The Dynamic Window Approach to Collision Avoidance. IEEE Robot. Autom. Mag. 4, 23–33. doi:10.1109/100.580977
Halsted, T., Shorinwa, O., Yu, J., and Schwager, M. (2021). A Survey of Distributed Optimization Methods for Multi-Robot Systems. arXiv preprint arXiv:2103.12840.
Hamer, M., Widmer, L., and D’andrea, R. (2018). Fast Generation of Collision-free Trajectories for Robot Swarms Using Gpu Acceleration. IEEE Access 7, 6679–6690. doi:10.1109/ACCESS.2018.2889533
Koenig, N., and Howard, A. (2004). “Design and Use Paradigms for Gazebo, an Open-Source Multi-Robot Simulator,” in 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Sendai, Japan), 3, 2149–2154. doi:10.1109/IROS.2004.1389727
Kylasa, S., Roosta, F., Mahoney, M. W., and Grama, A. (2019). “GPU Accelerated Sub-sampled Newton's Method for Convex Classification Problems,” in Proceedings of the 2019 SIAM International Conference on Data Mining (Calgary, AB: SIAM), 702–710. doi:10.1137/1.9781611975673.79
Li, J., Ran, M., and Xie, L. (2021). Efficient Trajectory Planning for Multiple Non-holonomic Mobile Robots via Prioritized Trajectory Optimization. IEEE Robot. Autom. Lett. 6, 405–412. doi:10.1109/LRA.2020.3044834
Luis, C. E., and Schoellig, A. P. (2019). Trajectory Generation for Multiagent Point-to-point Transitions via Distributed Model Predictive Control. IEEE Robot. Autom. Lett. 4, 375–382. doi:10.1109/lra.2018.2890572
Luis, C. E., Vukosavljev, M., and Schoellig, A. P. (2020). Online Trajectory Generation with Distributed Model Predictive Control for Multi-Robot Motion Planning. IEEE Robot. Autom. Lett. 5, 604–611. doi:10.1109/lra.2020.2964159
[Dataset] Park, J., Kim, J., Jang, I., and Kim, H. J. (2020). “Efficient Multi-Agent Trajectory Planning with Feasibility Guarantee Using Relative Bernstein Polynomial,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). doi:10.1109/icra40945.2020.9197162
Rastgar, F., Masnavi, H., Shrestha, J., Kruusamäe, K., Aabloo, A., and Singh, A. K. (2021). Gpu Accelerated Convex Approximations for Fast Multi-Agent Trajectory Optimization. IEEE Robot. Autom. Lett. 6, 3303–3310. doi:10.1109/lra.2021.3061398
Rastgar, F., Singh, A. K., Masnavi, H., Kruusamae, K., and Aabloo, A. (2020). “A Novel Trajectory Optimization for Affine Systems: Beyond Convex-Concave Procedure,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Las Vegas, NV: IEEE), 1308–1315. doi:10.1109/iros45743.2020.9341566
Schranz, M., Umlauft, M., Sende, M., and Elmenreich, W. (2020). Swarm Robotic Behaviors and Current Applications. Front. Robot. AI 7, 36. doi:10.3389/frobt.2020.00036
Soria, E., Schiano, F., and Floreano, D. (2021). Predictive Control of Aerial Swarms in Cluttered Environments. Nat. Mach. Intell. 3, 545–554. doi:10.1038/s42256-021-00341-y
Taylor, G., Burmeister, R., Xu, Z., Singh, B., Patel, A., and Goldstein, T. (2016). “Training Neural Networks without Gradients: A Scalable Admm Approach,” in International Conference on Machine Learning (New York, NY: PMLR), 2722–2731.
Werling, M., Ziegler, J., Kammel, S., and Thrun, S. (2010). “Optimal Trajectory Generation for Dynamic Street Scenarios in a Frenet Frame,” in 2010 IEEE International Conference on Robotics and Automation (Anchorage, AK: IEEE), 987–993.
Keywords: multi-robot trajectory optimization, batch optimization, convex, collision avoidance, obstacle avoidance, GPU accelerated optimizer
Citation: Guhathakurta D, Rastgar F, Sharma MA, Krishna KM and Singh AK (2022) Fast Joint Multi-Robot Trajectory Optimization by GPU Accelerated Batch Solution of Distributed Sub-Problems. Front. Robot. AI 9:890385. doi: 10.3389/frobt.2022.890385
Received: 05 March 2022; Accepted: 30 May 2022;
Published: 08 July 2022.
Edited by:
Maria Guinaldo, National University of Distance Education (UNED), SpainReviewed by:
Zhi Feng, Nanyang Technological University, SingaporeCopyright © 2022 Guhathakurta, Rastgar , Sharma , Krishna and Singh . This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dipanwita Guhathakurta, ZGlwYW53aXRhLmdAcmVzZWFyY2guaWlpdC5hYy5pbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.