 Shuzhen Luo
Shuzhen Luo Ghaith Androwis
Ghaith Androwis Sergei Adamovich
Sergei Adamovich Hao Su3
Hao Su3 Xianlian Zhou
Xianlian Zhou- 1Department of Biomedical Engineering, New Jersey Institute of Technology, Newark, NJ, United States
- 2Kessler Foundation, West Orange, Newark, NJ, United States
- 3Department of Mechanical Engineering, The City University of New York, Newark, NY, United States
A significant challenge for the control of a robotic lower extremity rehabilitation exoskeleton is to ensure stability and robustness during programmed tasks or motions, which is crucial for the safety of the mobility-impaired user. Due to various levels of the user’s disability, the human-exoskeleton interaction forces and external perturbations are unpredictable and could vary substantially and cause conventional motion controllers to behave unreliably or the robot to fall down. In this work, we propose a new, reinforcement learning-based, motion controller for a lower extremity rehabilitation exoskeleton, aiming to perform collaborative squatting exercises with efficiency, stability, and strong robustness. Unlike most existing rehabilitation exoskeletons, our exoskeleton has ankle actuation on both sagittal and front planes and is equipped with multiple foot force sensors to estimate center of pressure (CoP), an important indicator of system balance. This proposed motion controller takes advantage of the CoP information by incorporating it in the state input of the control policy network and adding it to the reward during the learning to maintain a well balanced system state during motions. In addition, we use dynamics randomization and adversary force perturbations including large human interaction forces during the training to further improve control robustness. To evaluate the effectiveness of the learning controller, we conduct numerical experiments with different settings to demonstrate its remarkable ability on controlling the exoskeleton to repetitively perform well balanced and robust squatting motions under strong perturbations and realistic human interaction forces.
1 Introduction
Due to the aging population and other factors, an increasing number of people are suffering from neurological disorders, such as stroke, central nervous system disorder, and spinal cord injury (SCI) that affect the patient’s mobility. Emerging from the field of robotics, robotic exoskeletons have become a promising solution to enable mobility impaired people to perform the activities of daily living (ADLs) (Mergner and Lippi, 2018; Vouga et al., 2017; Zhang et al., 2018). Lower-limb rehabilitation exoskeletons are wearable bionic devices that are equipped with powerful actuators to assist people to regain their lower leg function and mobility. With a built-in multi-sensor system, an exoskeleton can recognise the wearer’s motion intentions and assist the wearer’s motion accordingly (Chen et al., 2016). Compared to traditional physical therapy, rehabilitation exoskeleton robots have the advantages of providing more intensive patient repetitive training, better quantitative feedback, and improved life quality for patients (Chen et al., 2016).
A degradation or loss of balance as a result of neuromusculoskeletal disorders or impairments is a common symptom, for instance, in patients with SCI or stroke. Balance training in the presence of external perturbations (Horak et al., 1997) is considered as one of the more important factors in evaluating patients’ rehabilitation performance. A rehabilitation exoskeleton can be employed for balance training to achieve static stability (quiet standing) or dynamic stability (squatting, sit-to-stand, and walking) (Bayon et al., 2020; Mungai and Grizzle, 2020; Rajasekaran et al., 2015). Squatting exercises are very common for resistance-training programs because their multiple-joint movements are a characteristic of most sports and daily living activities. In rehabilitation, squatting is commonly performed as an important exercise for patients during the recovery of various lower extremity injuries (McGinty et al., 2000; Salem and Powers, 2001; Crossley et al., 2011; Yu et al., 2019). Squatting, which is symmetric by nature, can help coordinate bilateral muscle activities and strengthen weaker muscles on one side (e.g., among hemiplegia patients) or both sides. Compared to walking, squatting is often perceived to be safer for patients who are unable to perform these activities independently. In addition, the range of motion and the joint torques required for squatting are often greater than walking (Yu et al., 2019). With a reliable lower extremity rehabilitation exoskeleton, performing squatting exercises without external help (e.g., from a clinician) will be a confidence boost for patients to use the exoskeleton independently. However, in order for the exoskeletons to cooperate with the human without causing risks of harm, advanced balance controllers to robustly perform squatting motion that can deal with a broad range of environment conditions and external perturbations need to be developed.
Most existing lower extremity rehabilitation exoskeletons require the human operator to use canes for additional support or having a clinician or helper to provide balance assistance to avoid falling down. They often offer assistance via pre-planned trajectories of gait and provide limited control to perform diverse human motions. Some well known exoskeletons include the ReWalk (ReWalk Robotics), Ekso (Ekso bionics), Indego (Parker Hannifin), TWIICE (Vouga et al., 2017) and VariLeg (Schrade et al., 2018). When holding the crutches, the patient’s interactions with the environment is also limited (Baud et al., 2019). One example is that the patient is unlikely to perform squatting with long canes or crutches. Very few exoskeletons are able to assist human motions such as walking without the need of crutches or helpers with the exception of a few well known ones: the Rex (Rex Bionics) (Bionics, 2020) and the Atalante (Wandercraft) (Wandercraft, 2020). These exoskeletons free the user’s hands, but come at the cost of an very low walking speed and an increased overall weight (38 kg for the Rex, 60 kg for the Atalante) and are very expensive (Vouga et al., 2017). In this paper, we introduce a relatively light weight lower extremity exoskeleton that includes a sufficient number of degrees of freedom (DoF) with strong actuation. On each side, this skeleton system has a one DoF hip flexion/extension joint, a one DoF knee flexion/extension joint, and a 2-DoF ankle joint, which can perform ankle dorsi/plantar flexion as well as inversion/eversion that can swing the center of mass laterally in the frontal plane. Moreover, four force sensors are equipped on each foot for accurate measurement of ground reaction forces (GRFs) to estimate the center of pressure (CoP) so as to build automatic balance control without external crutches assistance.
Designing a robust balance control policy for a lower extremity exoskeleton is particularly important and represents a crucial challenge due to the balance requirement and safety concerns for the user (Chen et al., 2016; Kumar et al., 2020). First, the control policy needs to run in real-time with limited sensing and capabilities dictated by the exoskeletons. Second, due to various levels of patients’ disability, the human-exoskeleton interaction forces are unpredictable and could vary substantially and cause conventional motion controllers to behave unreliably or the robot to fall down. Virtual testing of a controller with realistic human interactions in simulations is very challenging and the risk of testing on real humans is even greater. To the best of our knowledge, investigations presenting robust controllers against large and uncertain perturbation forces (e.g., due to human interactions) have rarely been carried out as biped balance control without perturbation itself is a challenging task. Most existing balance controller designs for such lower extremity rehabilitation exoskeletons focused mostly on the trajectory tracking method, conventional control like Proportional–Integral–Derivative (PID) (Xiong, 2014), model-based predictive control (Shi et al., 2019), fuzzy control (Ayas and Altas, 2017), impedance control (Hu et al., 2012; Karunakaran et al., 2020), and momentum-based control for standing (Bayon et al., 2020). Although the trajectory tracking approaches can be easily applied to regular motions, its robustness against unexpected large perturbations is not great. On the other hand, model-based predictive control could be ineffective or even unstable due to inaccurate dynamics modeling, and it typically requires a laborious task-specific parameters tuning. The momentum-based control strategies have also been applied to impose standing balancing on the exoskeleton (Bayon et al., 2020; Emmens et al., 2018), which was first applied in humanoid robotics to impose standing and walking balance (Lee and Goswami, 2012; Koolen et al., 2016). This method aimed to simultaneously regulate both the linear and angular component of the whole body momentum for balance maintenance with desired GRF and CoP at each support foot. The movement of system CoP is an important indicator of system balance (Lee and Goswami, 2012). When the CoP leaves or is about to leave the support base, a possible toppling of a foot or loss of balance is imminent and the control goal is to bring the CoP back inside the support base to keep balance and stability. Although the CoP information can sometimes be estimated from robot dynamics (Lee and Goswami, 2012), the reliability of such estimation highly depends on the accuracy of the robot model and sensing of joint states. When a human user is involved, it is almost impossible to estimate the CoP accurately due to the difficulty to estimate the user’s dynamic properties or real-time joint motions. Therefore, it is highly desired to obtain the foot CoP information directly and accurately. In most existing lower extremity rehabilitation exoskeletons, the mechanical structures of the foot are either relatively simple with no force or pressure sensors or with sensors but no capability to process the GRF and CoP information for real-time fall detection or balance control. In this work, a lower extremity rehabilitation exoskeleton with force sensors equipped on each foot for accurate estimation of CoP is presented. Inspired by the CoP-associated balance and stability (Lee and Goswami, 2012), this paper aims to explore a robust motion controller to encourage the system CoP to stay inside a stable region when subjected to the uncertainty of human interaction and perturbations.
Recently, model-free control methods, like reinforcement learning (RL), promise to overcome the limitations of prior model-based approaches that require an accurate dynamic model. It has gained considerable attention in multi-legged robots control for their capability to produce controllers that can perform a wide range of complicated tasks (Peng et al., 2016; Peng and van de Panne, 2017; Peng et al., 2018; Hwangbo et al., 2019; Peng et al., 2020). The RL-based balance control approach for lower extremity rehabilitation exoskeletons to perform squatting motion have not been investigated before, especially when balancing with a human strapped inside is considered. Since the coupling between the human and exoskeleton could leads to unexpected perturbation forces, it is highly desired to develop a robust controller to learn collaborative human-robot squatting skills. In this paper, we propose a novel robust control framework based on RL to train a robust control policy that operates on the exoskeleton in real-time so as to overcome the external perturbations and unpredictable varying human-exoskeleton force.
The central contributions of this work are summarized in the following:
• We build a novel RL-based motion control framework for a lower extremity rehabilitation exoskeleton to imitate realistic human squatting motion under random adversary perturbations or large uncertain human-exoskeleton interaction forces.
• We take advantage of the foot CoP information by incorporating it into the state input of the control policy as well as the reward function to produce a balance controller that is robust against various perturbations.
• We demonstrate that the lightweight exoskeleton can carry a human to perform robust and well-balanced squatting motions in a virtual environment with an integrated exoskeleton and full-body human musculoskeletal model.
To demonstrate the effectiveness and robustness of the proposed control framework, a set of numerical experiments under external random perturbations and varying human-exoskeleton interactions are conducted. Dynamics randomization is incorporated into the training to minimize the effects of model inaccuracy and prepare for sim-to-real transfer.
2 Exoskeleton and Interaction Modeling
2.1 Mechanical Design of a Lower Extremity Robotic Exoskeleton
A lower extremity robotic exoskeleton device (Androwis et al., 2017) is currently under development by the authors to assist patients with ADL, such as balance, ambulation and gait rehabilitation. In Figure 1A, the physical prototype of this exoskeleton is shown. The total mass of the exoskeleton is
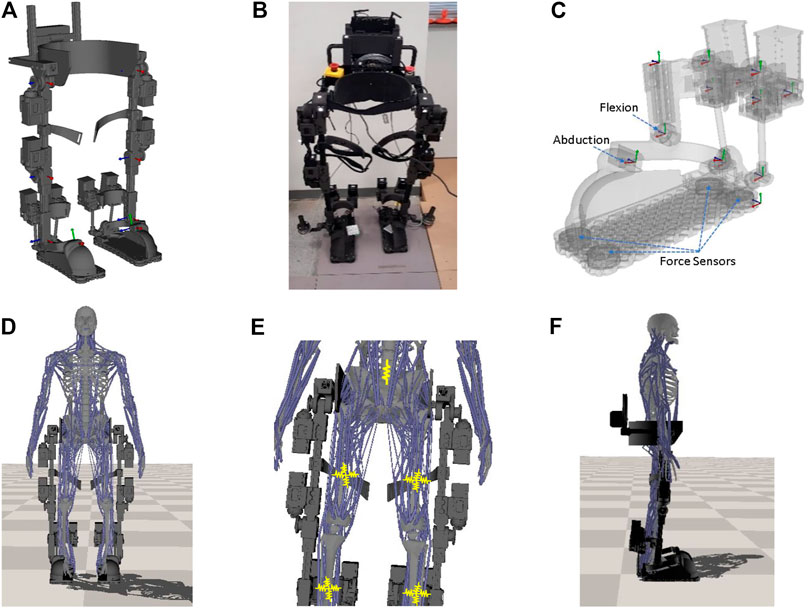
FIGURE 1. The lower extremity exoskeleton and integrated human-exoskeleton model. (A) The multibody dynamics model of the exoskeleton with joint frames (red/green/blue axes) rendered in place. (B) The physical prototype of the exoskeleton. (C) The foot model with force sensors locations and the two independent ankle DoFs indicated. The joint axes of the model are displayed as well. (D) Integrated human and lower extremity exoskeleton model. (E) Spring (yellow) connections between the human and the strap on the robot. (F) Side view.
Both hip and knee joints are driven by bevel gears for compact design. The ankle is actuated by two parallel motors that are attached to the posterior side the shank support and operate simultaneously in a closed-loop to flex or abduct the ankle. Figure 1C shows the foot model of our exoskeleton system. At the bottom of each foot plate, four 2000N 3-axis force transducers (OptoForce Kft, Hungary) are installed to measure GRFs. These measured forces can be used to determine the CoP in real-time. The CoP is the point on the ground where the tipping moment acting on the foot equals zero (Sardain and Bessonnet, 2004), with the tipping moment defined as the moment component that is tangential to the foot support surface. Let
from which
2.2 Exoskeleton Modeling
A multibody dynamics model of the exoskeleton, shown in Figure 1A, is created with mass and inertia properties estimated from each part’s 3D geometry and density or measured mass. Simple revolute joints are used for the hips and knees. Each ankle has two independent rotational DoFs but their rotation axes are located at different positions (Figure 1C). These two DoFs are physically driven by the closed-loop of two ankle motors together with linkage of universal joints and screw joints. When extending or flexing the ankle, both motors work in sync to move the two long screws up or down simultaneously. When adducting or abducting the ankle, the motors move the screws in opposite directions. The motors can generate up to 160
2.3 Modeling of Human Exoskeleton Interactions
2.3.1 Human Musculoskeletal Model
To simulate realistic human exoskeleton interactions, the exoskeleton is integrated with a full body human musculoskeletal model (Lee et al., 2019) that has a total mass of
where
where
2.3.2 Human-Exoskeleton Interactions
To integrate the human musculoskeletal model with the exoskeleton, the root of the human model (pelvis) is attached to the exoskeleton hip through a prismatic joint that only allows relative movement along the vertical (up and down) direction (all rotations and the translations along the lateral and fore-and-aft directions are fixed). The assembled exoskeleton, as shown in Figure 1D, has straps around the hip, femur and tibia to constraint the human motion. Here we utilize the spring models to simulate the strap forces. Figure 1E shows the spring connections between the human and exoskeleton at the strap locations with the yellow zigzag lines illustrating the springs. From Figure 1E, an elastic spring with stiffness
3 Learning Controller for Balanced Motion
In this section, we propose a robust motion control training and testing framework based on RL that enables the exoskeleton to learn squatting skill with strong balance and robustness. Figure 2 shows the overall learning process of the motion controller. The details of the motion controller learning process will be introduced in the following sections.
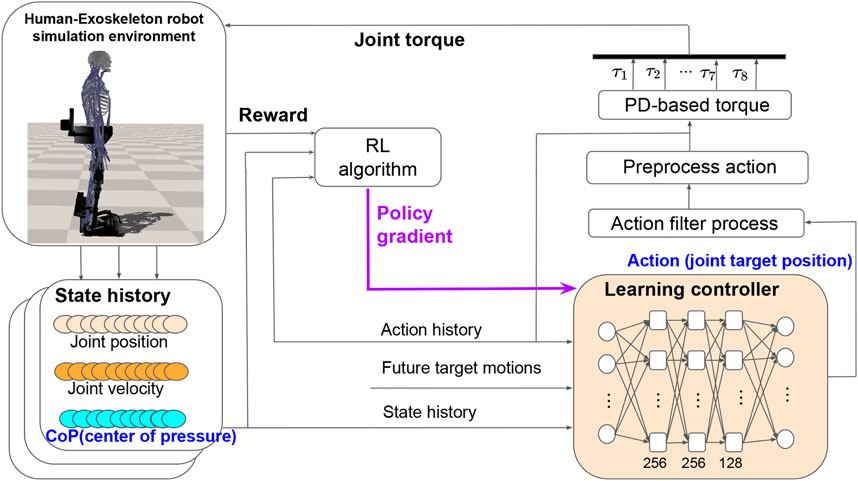
FIGURE 2. The overall learning process of the integrated robust motion controller. We construct the learning controller as a Multi-Layer Perception (MLP) neural network that consists of three hidden layers. The neural network parameters are updated using the policy gradient method. The network produces joint target positions, which are translated into torque-level commands by PD (Proportional Derivative) control.
3.1 Reinforcement Learning With Motion Imitation
The controller (or control policy) is learned through a continuous RL process. We design the control policy through a neural network with parameters θ, denoting the weights and bias in the neural network. The control policy can be expressed as
The action
where
The control policy is task- or motion-specific and starts with motion imitation. Within the learning process (Figure 2), the input of the control policy network is defined by
3.2 Learning With Proximal Policy Optimization
To train the control policy network, we use a model-free RL algorithm known as Proximal Policy Optimization (PPO). An effective solution to many RL problems is the family of policy gradient algorithms, in which the gradient of the expected return with respect to the policy parameters is computed and used to update the parameters θ through gradient ascent. PPO is a model-free policy gradient algorithm that samples data through interaction with the environment and optimizes a “surrogate” objective function (Schulman et al., 2017). It utilizes a trust region constraint to force the control policy update to ensure that the new policy is not too far away from the old policy. The probability ratio
This probability ratio is a measure of how different the current policy is from the old policy
where ϵ is a small positive constant which constrain the probability ratio
3.3 Proportional-Derivative-Based Torque
It has been reported that the performance of RL for continuous control depends on the choice of action types (Peng and van de Panne, 2017). It works better when the control policy outputs PD position targets rather than joint torque directly. In this study, we also let the learning controller output the joint target positions as actions (shown in Figure 2). To obtain smooth motions, actions from the control policy network are first processed by a second low-pass filter before being applied to the robot. Our learning process allows the control policy network and the environment to operate at different frequencies since the environment often requires a small time step for integration. During each time integration step, we apply preprocessed actions that are linear interpolated from two consecutive filtered actions. Then the preprocessed actions are specified as PD targets and the final PD-based torques applied to each joint are calculated as
where
3.4 Reward Function
We design the reward function to encourage the control policy to imitate a target joint motion
where
where j is the index of joints,
where i is the index of the end-effector. Let
We also design the root reward function
The overall center of mass reward
The movement of system CoP is an important indicator of system balance as set forth in the introduction. When the CoP leaves or is about to leave the foot support polygon, a possible toppling of the foot or loss of balance is imminent. During squatting (or walking), there are always one or two feet on the ground and the support polygon on the touching foot persists, and thus the CoP criterion is highly relevant for characterizing the tipping equilibrium of a bipedal robot (Sardain and Bessonnet, 2004). When the CoP point lies within the foot support polygon, it can be assumed that the biped robot can keep balance during squatting. Considering the importance of CoP, we incorporate the CoP positions in the state input as a feedback from the controller and also add a CoP reward function to encourage the current CoP (
where
At last, we design the torque reward to reduce energy consumption or improve efficiency and to prevent damaging joint actuators during the deployment.
where i is the index of joints.
3.5 Dynamics Randomization
Due to the model discrepancy between the physics simulation and the real-world environment, well-known as reality or sim-to-real gap (Yu et al., 2018), the trained control policy usually performs poorly in the real environment. In order to improve the robustness of the controller against model inaccuracy and bridge the sim-to-real gap, we need to develop a robust control policy capable of handling various environments with different dynamics characteristics. To this end, we adopt dynamics randomization (Sadeghi and Levine, 2016; Tobin et al., 2017) in our training strategy, in which dynamics parameters of the simulation environment are randomly sampled from an uniform distribution for each episode. The objective in Eq. 5 is then modified to maximize the expected reward across a distribution of dynamics characteristics
where μ represents the values of the dynamics parameters that are randomized during training. By training policies to adapt to variability in environment dynamics, the resulting policy will be more robust when transferred to the real world.
4 Numerical Experiment Results and Discussion
We design a set of numerical experiments aiming to answer the following questions: 1) Can the learning process generate feasible control policies to control the exoskeleton to perform well-balanced squatting motions? 2) Will the learned control policies be robust enough under large random external perturbation? 3) Will the learned control policies be robust enough to sustain stable motions when subjected to uncertain human-exoskeleton interaction forces from a disabled human operator?
4.1 Simulation and Reinforcement Learning Settings
To demonstrate the effectiveness of our RL-based robust controller, we train the lower extremity exoskeleton to imitate a 4s reference squatting motion that is manually created based on human squatting motion. The reference squatting motion can provide guidance for motion mimicking but needs not to be generated precisely. The exoskeleton contains eight joint DoFs actuated with motors, all of which are controlled by the RL controller. On each leg, there are has four actuators, including one actuator for hip flexion/extension, one actuator for knee flexion/extension, two actuators for ankle dorsiflexion/plantarflexion and ankle inversion/eversion, respectively. The open source library DART (Lee et al., 2018) is utilized to simulate the exoskeleton dynamics. The GRFs are computed by a Dantzig LCP (linear complementary problem) solver (Baraff, 1994). We utilize PyTorch (Paszke et al., 2019) to implement the neural network and the PPO method for the learning process. The networks are initialized by the Xavier uniform method (Glorot and Bengio, 2010). We use a desktop computer with an Intel® Xeon(R) CPU E5-1660 v3 at 3.00 GHz

TABLE 1. Hyper-parameters settings for training.
To verify the robustness of the trained controller, we test the control policies in out-of-distribution simulated environments, where the dynamic parameters of the exoskeleton are sampled randomly from a larger range of values than those during training. Table 2 shows the dynamics parameters details of the exoskeleton and their range during training and testing. Note that the observation latency denotes the observation time delay in the real physical system due to sensor noise and time delay during information transfer. Considering the observation latency improves the reality of the simulations and further increases the difficulty of policy training. The simulation frequency (time step for the environment simulation) and control policy output frequency are set to 900 and 30Hz, respectively. According to the PD torque Eq. 8, the parameters about the proportional gain

TABLE 2. Dynamic parameters and their respective range of values used during training and testing. A larger range of values are used during testing to evaluate the generalization ability of control policies in dynamics uncertainties.
4.2 Learned Squatting Skill
4.2.1 Case 1–Feasibility Demonstration
In the first case, a squatting motion controller is learned from the 4s reference squatting motion without considering external perturbation. It is worth noting that, compared with the training, we use the larger-range dynamics randomization of the exoskeleton model to demonstrate the generalization ability of our learned controller (as shown in Table 2). A series of snapshots of the squatting behavior of the lower extremity exoskeleton under the learned control policy are shown in Figure 3A. The lower extremity exoskeleton can perform the squatting and stand-up cycle with a nearly symmetric motion. We test the learned controller in 200 out-of-distribution simulated environments, where the dynamics parameters are sampled from a larger range of values than those used during training (as shown in Table 2). Figure 4A displays the statistical results of the hip flexion/extension, knee flexion/extension, ankle dorsiflexion/plantarflexion and ankle inversion/eversion joint angles in the first squatting cycle. Joint torques statistics are depicted in Figure 4B and the peak torque at the knee joint for the squatting is around

FIGURE 3. Snapshots of the squatting motion of the exoskeleton. This RL-based controller enables the lower extremity exoskeleton to perform the squatting skill under different types of external perturbations with various intensities. (A) Performing the squatting skill without perturbation forces. (B) Performing the squatting skill with large random perturbation forces. (Red, cyan and blue arrows show the random perturbation force applied on the hip, femur and tibia, respectively). (C) Performing the squatting skill with human interaction.
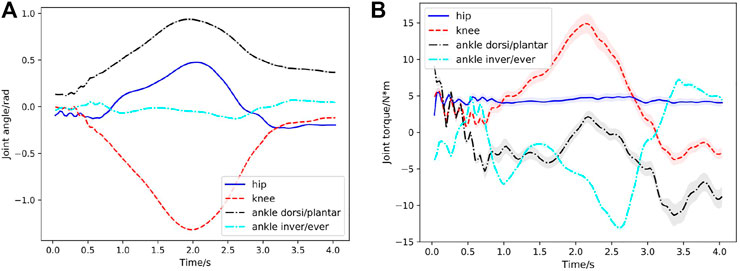
FIGURE 4. Case1: Joint behavior statistics in the first squatting cycle (curve: mean; shade: STD) with respect to time for 200 simulated environments. (A) Hip, knee, ankle dorsiflexion/plantarflexion, ankle inversion/eversion joint angles with respect to time during the first squatting cycle. Since the learned STDs
Figure 5 show the best obtained result of foot CoP trajectories (left and right feet) in the lateral and forward directions, which are calculated in real-time using the ground contact force information. As it can be seen, the exoskeleton controller can keep the foot CoP well inside the stable region for both lateral and forward directions in a complete squatting cycle. Noted at the beginning the CoP is close to the back edge (due to its initial state) but gradually it is bought to near the center. This indicates that the exoskeleton controller is able to recognize the current state of CoP and capable of bring it to a more stable state. And the balance in the lateral direction is better than that in the forward direction due to the symmetric nature of the squatting motion. The right foot CoP trajectories have very similar patterns with those of the left foot CoP.
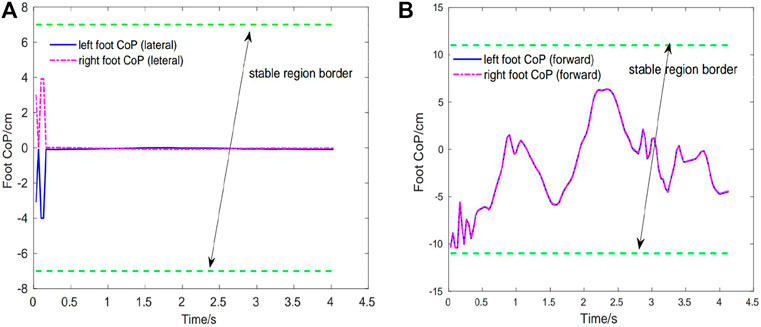
FIGURE 5. Case1: Foot CoP trajectories during the first squatting cycle. Green dotted line depicts the stable region border of CoP. (A) Left foot CoP and right foot CoP trajectories (lateral direction). (B) Left foot CoP and right foot CoP trajectories (forward direction).
Figure 6 presents the performance of the learned controller while performing multiple squatting cycles. We can clearly observe the high CoP rewards, indicating good system balance when the exoskeleton performs the squatting motion. The relatively high joint position tracking and end-effector tracking rewards illustrate strong tracking performance of the control system. The second figure shows the torques for the hip, knee, and ankle joints. The last figure demonstrates the predicted actions (PD target positions) for these joints. It is clear from these plots that the actions predicted from the policy network are smooth and exhibit clear cyclic patterns.
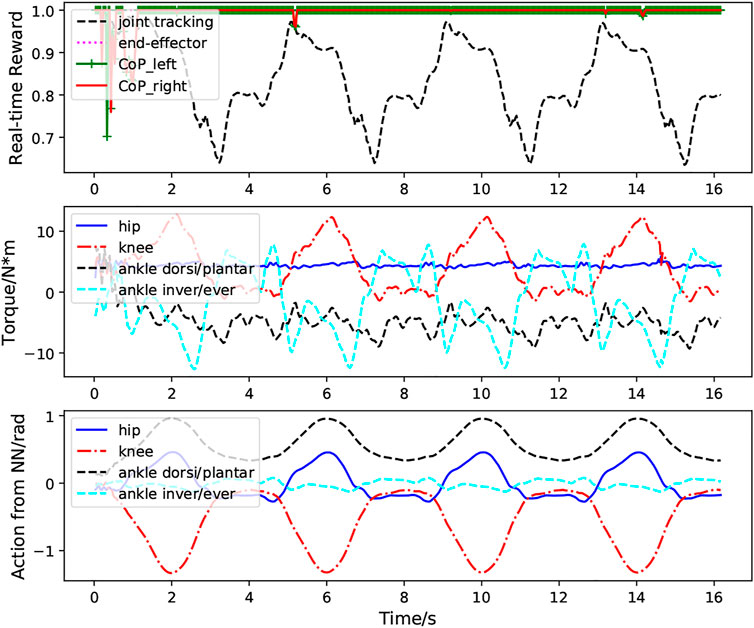
FIGURE 6. Case1: Performance of the RL based controller without external perturbation during multiple squatting cycles. The first figure demonstrates the foot CoP reward (green and red lines), end-effector tracking reward (magenta line) and joint position tracking reward (black line) calculated according to Eqs 10–15. The bottom figure depicts the actions for the hip, knee ankle joint predicted from the neural network.
4.2.2 Case 2–Robustness Against Random Perturbation Forces
In the second case, we aim to verify the robustness of the controller under random external perturbation forces. From our tests, the learned control policy from case 1, trained without any perturbation forces, could perform well with random perturbation forces up to
Figure 3B shows a series of snapshots of the lower extremity exoskeleton behavior with the newly trained controller when tested with random, large perturbation forces during squatting motion. Statistical results of the Joint angles and torques at the hip, knee and ankle joint in the first squatting cycle under 200 simulated environments are shown in Figure 7. We can clearly observe that the motion is still relative smooth and the torques calculated from Eq. 8 have more ripples in response to the random perturbation forces. Figure 7C shows randomly varying perturbation forces applied on the hip, femur and tibia. Compared to the joint angles and torques without external perturbation (Case 1, Figure 4), the joint torques under random perturbation forces are almost doubled but the joint angles are relatively close. Under the large, random perturbation forces, the controller can achieve the target squatting motion with a low average joint angle tracking error (about
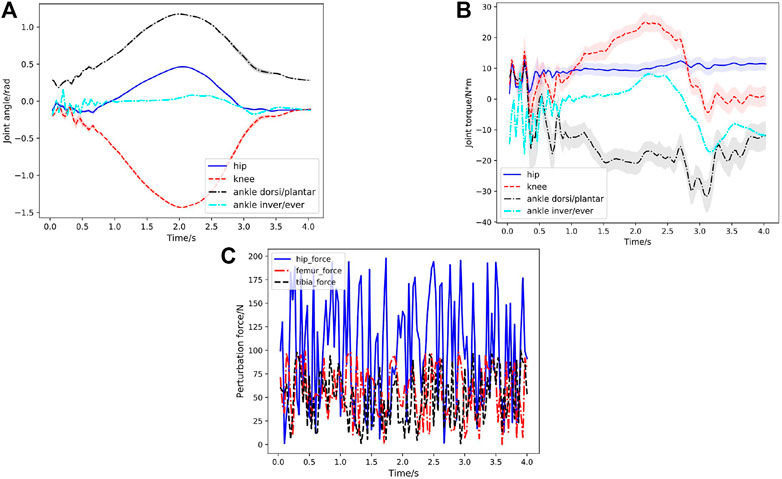
FIGURE 7. Case2: Joint behavior statistics (curve: mean; shade: STD) under random perturbation forces in the first squatting cycle with respect to time for 200 simulated environments. (A) Hip, knee, ankle dorsiflexion/plantarflexion, ankle inversion/eversion joint angles with respect to time in the first squatting cycle. The learned STDs
Figure 8 shows the CoP trajectories of the left and right feet in both lateral and forward directions in the first squatting cycle. As shown in this figure, the foot CoP trajectories have oscillation under the random perturbation forces compared with Case1. But the robot can still keep the CoP inside the safe region of the support foot to guarantee stability and balance. It further validates that this controller enables the robot to perform squatting motion with strong stability and robustness. To further demonstrate the robustness of the learning controller, we increase the random perturbation forces up to
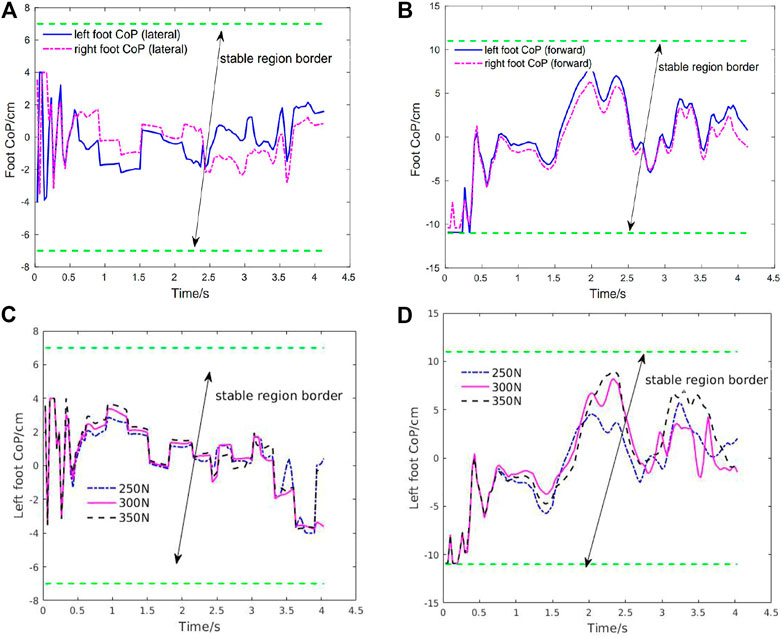
FIGURE 8. Case2: Foot CoP trajectories under random external perturbations in the first squatting cycle and robustness test on the foot CoP stability under 75% greater perturbation forces compared with the training setting. (A) Left and right foot CoP trajectories (lateral direction). (B) Left and right foot CoP trajectories (forward direction). (C) Left foot CoP trajectory (lateral direction) under 75% greater perturbation forces compared with the training setting. (D) Left foot CoP trajectory (forward direction) under greater perturbation forces compared with the training setting.
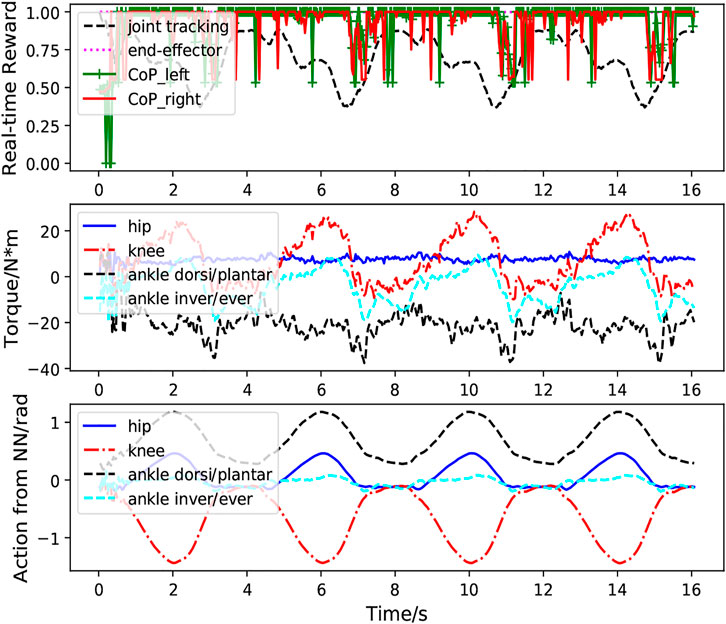
FIGURE 9. Case2: Real-time performance of the reinforcement-learning based controller with large, random external perturbation during multiple squatting cycles. The first figure demonstrates the real-time foot CoP reward (green and red lines), end-effector tracking reward (magenta line) and joint position tracking reward (black line) calculated according to Eqs 10–15. The bottom figure depicts the actions for the hip, knee ankle joint predicted from the neural network.
4.2.3 Case3–Robustness Under Human-Exoskeleton Interaction
In the third case, the human musculoskeletal model is integrated with the exoskeleton to simulate more realistic perturbation forces. As described in section 2.3, the springs at the strap locations can generate the varying interaction forces between the human and exoskeleton robot during the motion, which are applied on both human and exoskeleton. We first train the network with the integrated human-exoskeleton model to account for the interaction forces. Here we do not consider the active muscle contraction of the human operator or actuation torques on the human joints, considering the operator could be a patient suffering from spinal cord injury or stroke, with very limited or no control of his or her own body. Nonetheless, the passive muscle forces as described in Eq. 3 during movement are incorporated. The squatting skill learned by the exoskeleton and performance of the motion controller are shown in Figure 3C and Figures 10–13.
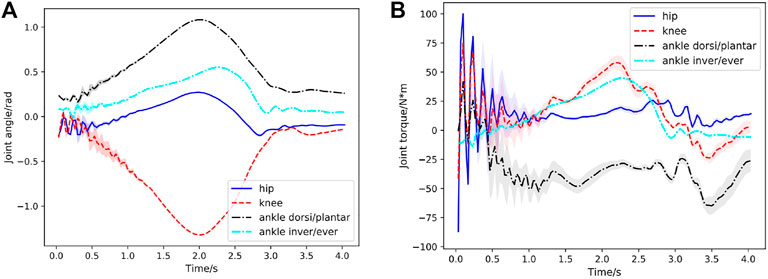
FIGURE 10. Case3: Joint behavior statistics under human-exoskeleton interactions during the first squatting cycle with respect to time for 200 simulated environments. (A) Hip, knee, ankle dorsiflexion/plantarflexion, ankle inversion/eversion joint angles in the first squatting cycle. The learned STDs
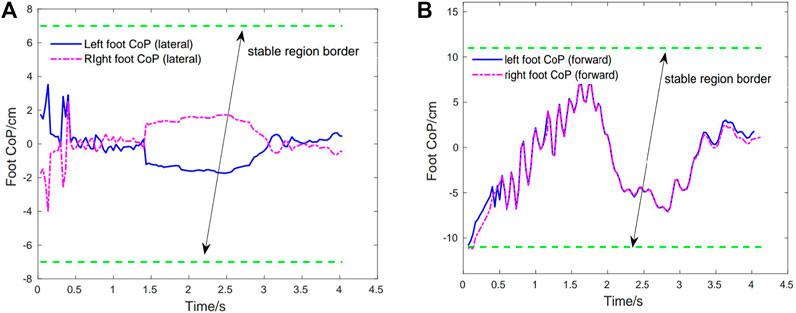
FIGURE 11. Case3: Foot CoP trajectories under human-exoskeleton interactions in the first squatting cycle. The stable region border is marked with green dotted lines. (A) Left foot CoP and right foot CoP trajectories (lateral direction). (B) Left foot CoP and right foot CoP trajectories (forward direction).
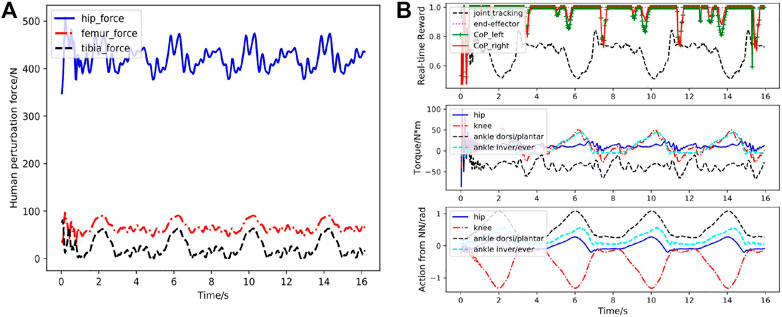
FIGURE 12. Case3: Performance of the RL based controller under human-exoskeleton interactions during more squatting cycles. (A) Human-exoskeleton interaction (strap) forces during multiple squatting cycles. hip

FIGURE 13. Performance of learned controller under human-exoskeleton interactions in 200 simulated environments with different dynamics. The dynamic model of the exoskeleton is randomly initialized. (A) Rewards statistics (curve: mean; shade: STD) with respect to time for 200 simulated environments. (B) Average reward of a complete squatting cycle for each simulated environment.
As shown in Figure 3C, the rehabilitation exoskeleton is able to assist the human to perform the squatting motion without external assistance. Statistical results of angles and torques at the hip, knee and ankle joint of the left leg in the first cycle under 200 simulated environments are shown in Figures 10A, B. The torques at the hip, knee and ankle joint are greater than those without the human interaction while still below the maximum torques. The controller can still maintain low joint angle average tracking error (about
Figure 13 visualizes the performance of the learned controller in 200 simulated environments with different dynamics. Figure 13A depicts the rewards statistics (mean and STD) with respect to time calculated from Eqs 10–15 under 200 simulated environments. The end-effector reward indicating the foot tracking performance consistently maintains a high value, revealing the exoskeleton robot has no falling condition in 200 simulated environments with unfamiliar dynamics and it can stand on the ground with stationary feet when performing the complete squatting motion. The joint position tracking and foot CoP also achieve a high reward with less variance under more diverse dynamics of the exoskeleton robot. Figure 13B shows the average reward of a complete squatting cycle for each simulated environment. These results suggest that the learned controller is able to effortlessly generalize to environments that differ from those encountered during training and achieve good control performance under very diverse dynamics. The extensive testing performed with the integrated human-exoskeleton demonstrate that the RL controller is robust enough to sustain stable motions when subjected to uncertain human-exoskeleton interaction forces.
5 Discussion
Through these designed numerical tests, we verified that our learning framework can produce effective neural network-based control policies for the lower extremity exoskeleton to perform well-balanced squatting motions. By incorporate adverse perturbations in training, the learned control policies are robust against large random external perturbations during testing. And it can sustain stable motions when subjected to uncertain human-exoskeleton interaction forces from a disabled human user. From all numerical tests performed, the effectiveness and robustness of the learned balance controller are demonstrated by its capability to maintain CoP inside the foot stable region along both lateral and forward directions.
In this study, we evaluated the controllers in a specific case for which the human musculoskeletal model has only passive muscle response (i.e., without active muscle contraction). In reality, the human-exoskeleton interaction forces might vary substantially for different users with different weights and levels of disability. One may assume that a user with good body or muscle control tends to minimize the interaction forces on the straps. On the other hand, a passive human musculoskeletal model tends to generate larger interaction forces. Therefore, using a passive musculoskeletal model can be considered a more difficult task for the exoskeleton. Further investigations with an active human musculoskeletal model are possible but will likely to need additional information on the health condition of the user.
Through dynamics randomization, our learned controller is robust against modeling inaccuracy and differences between the training and testing environments (Tan et al., 2018). Nonetheless, it is still beneficial to validate and further improve the dynamic exoskeleton model. This can be done through a model identification process, for which we can conveniently rely on the real-time measurement of GRFs and derived CoP information from the foot force sensors during programmed motions. Experiments can be conducted to correlate the CoP position with the exoskeleton posture and the CoP movement with motion. Stable squatting motions of different velocities can be used to record the dynamic responses of the exoskeleton and the collected data then can be used to further identify or optimize the model’s parameters (such as inertia properties and joint friction coefficients).
By incorporating motion imitation into the learning process, the proposed robust control framework has the potential to learn a diverse array of human behaviors without the need to design sophisticated skill-specific control structure and reward functions. Common rehabilitation motions such as sit-to-stand, walking on flat or inclined ground can be learned by feeding proper target motions. Since we incorporate the reference motion as the input of the control policy network, it requires a reference motion trajectory for each new activity. The use of reference motion data (as the input of the control policy network) can alleviate the need to design sophisticated task-specific reward functions and thereby facilitates a general framework to learn a diverse array of behaviors. Note the reference motion provides guidance and needs not to be precise or even physically feasible. In this paper, the reference motion is manually generated by mimicking a human squatting, and we use it to guide the exoskeleton squatting, knowing the motion maybe not be feasible for the exoskeleton to follow exactly due to the differences in mass and inertia properties. Nonetheless, during training, the dynamic simulation environment automatically generates dynamically consistent (thus physically feasible) motions while trying to maximize the tracking reward. For other rehabilitation motions such as walking on flat or inclined ground, sit-to-stand, reference motions can be generated similarly without too much effort (unlike conventional motion or trajectory prediction or optimization methods). In addition, due to the nature of imitation learning and CoP based balance control, we foresee minimal changes to the learning framework with the exception of crafting different target motions for imitation. The learning process will automatically create specific controllers that can produce physically feasible and stable target motions (even when the target motion is coarsely generated and may not be physically feasible).
Transferring or adapting RL control policies trained in the simulations to the real hardware remains a challenge in spite of some demonstrated successes. To bridge the so-called “sim-to-real” gap, we have adopted dynamics randomization during training that is often used to prepare for sim-to-real transfer (Tan et al., 2018). In a recent work by Exarchos et al. (2020), it is shown kinematic domain randomization can also be effective for policy transfer. Additionally, efficient adaptation techniques such as latent space (Clavera et al., 2019; Yu et al., 2019) or meta-learning (Yu et al., 2020) can also be applied to further improve the performance of pre-trained policies in the real environment. We plan to construct an adaptation strategy to realize the sim-to-real control policy transfer for the lower extremity exoskeleton robot in the near future.
6 Conclusion
In this work, we have presented a robust, RL-based controller for exoskeleton squatting assistance with human interaction. A relatively lightweight lower extremity exoskeleton is presented and used to build a human-exoskeleton interaction model in the simulation environment for learning the robust controller. The exoskeleton foot CoP information collected from the force sensors is leveraged as a feedback for balance control and adversary perturbations and uncertain human interaction forces are used to train the controller. We have successfully demonstrated the lower extremity exoskeleton’s capability to carry a human to perform squatting motions with a moderate torque requirement and provided evidence of its effectiveness and robustness. With the actuation of the ankle inversion/eversion joint, the learned controllers are also capable of maintaining the balance within the frontal plane under large perturbation or interaction forces. The success demonstrated in this study has implications for those seeking to apply reinforcement learning to control robots to imitate diverse human behaviors with strong balance and increased robustness even when subjected to the larger perturbations. Most recently, we have extended the proposed controller to perform flat ground walking with additional rewards and improved training methods and obtained stable interactive human-exoskeleton walking motions, which demonstrates the versatility of the method that will be presented in a future work. In the near future, we plan to further extend this framework to learn a family of controllers that can perform a variety of human skills like sit-to-stand, inclined ground walking and stair climbing. Lastly, these learned controllers will be deployed to the hardware through a sim-to-real transfer method and experimental tests will be performed to validate the controllers’ performance.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
In this work, XZ first proposed the research idea and approach of the paper and provided the project guidance. The code implementation, development and data analysis were done by SL and XZ. The CAD design, development and fabrication of the robotic exoskeleton were done by GJA and EN and its multibody model was created by XZ with support from GJA, EN, and SA. The first draft of the manuscript was written by SL and XZ. SA, GJA, and HS provided valuable suggestions and feedback on the draft, and HS also made some important revisions to the final paper. All authors contributed to the article and approved the submitted version.
Funding
This work was partially supported by the National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR) funded Rehabilitation Engineering Research Center Grant 90RE5021-01-00, and by National Science Foundation (NSF) Major Research Instrumentation grant 1625644). HS was partially supported by the NIDILRR grant 90DPGE0011.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2021.702845/full#supplementary-material
References
Androwis, G. J., Karunakaran, K., Nunez, E., Michael, P., Yue, G., and Foulds, R. A. (2017). Research and Development of New Generation Robotic Exoskeleton for over Ground Walking in Individuals with Mobility Disorders (Novel Design and Control). In 2017 International Symposium on Wearable Robotics and Rehabilitation (WeRob). IEEE, 1–2.
Ayas, M. S., and Altas, I. H. (2017). Fuzzy Logic Based Adaptive Admittance Control of a Redundantly Actuated Ankle Rehabilitation Robot. Control. Eng. Pract. 59, 44–54. doi:10.1016/j.conengprac.2016.11.015
Baraff, D. (1994). Fast Contact Force Computation for Nonpenetrating Rigid Bodies. In Proceedings of the 21st annual conference on Computer graphics and interactive techniques. 23–34.
Baud, R., Fasola, J., Vouga, T., Ijspeert, A., and Bouri, M. (2019). Bio-inspired Standing Balance Controller for a Full-Mobilization Exoskeleton. In 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR). IEEE, 849–854. doi:10.1109/ICORR.2019.8779440
Bayon, C., Emmens, A. R., Afschrift, M., Van Wouwe, T., Keemink, A. Q. L., Van Der Kooij, H., et al. (2020). Can Momentum-Based Control Predict Human Balance Recovery Strategies? IEEE Trans. Neural Syst. Rehabil. Eng. 28, 2015–2024. doi:10.1109/tnsre.2020.3005455
Bionics, R. (2020). Rex Technology. Available at: https://www.rexbionics.com/us/product-information/(Accessed April, 2020).
Chen, B., Ma, H., Qin, L.-Y., Gao, F., Chan, K.-M., Law, S.-W., et al. (2016). Recent Developments and Challenges of Lower Extremity Exoskeletons. J. Orthopaedic Translation 5, 26–37. doi:10.1016/j.jot.2015.09.007
Clavera, I., Nagabandi, A., Liu, S., Fearing, R. S., Abbeel, P., Levine, S., et al. (2019). Learning to Adapt in Dynamic, Real-World Environments through Meta-Reinforcement Learning. In International Conference on Learning Representations.
Crossley, K. M., Zhang, W.-J., Schache, A. G., Bryant, A., and Cowan, S. M. (2011). Performance on the Single-Leg Squat Task Indicates Hip Abductor Muscle Function. Am. J. Sports Med. 39, 866–873. doi:10.1177/0363546510395456
Delp, S. L., Anderson, F. C., Arnold, A. S., Loan, P., Habib, A., John, C. T., et al. (2007). Opensim: Open-Source Software to Create and Analyze Dynamic Simulations of Movement. IEEE Trans. Biomed. Eng. 54, 1940–1950. doi:10.1109/tbme.2007.901024
Emmens, A., van Asseldonk, E., Masciullo, M., Arquilla, M., Pisotta, I., Tagliamonte, N. L., et al. (2018). Improving the Standing Balance of Paraplegics through the Use of a Wearable Exoskeleton. In 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob). 707–712. doi:10.1109/BIOROB.2018.8488066
Exarchos, I., Jiang, Y., Yu, W., and Liu, C. K. (2020). Policy Transfer via Kinematic Domain Randomization and Adaptation. arXiv preprint arXiv:2011.01891
Glorot, X., and Bengio, Y. (2010). Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics. 249–256.
Horak, F. B., Henry, S. M., and Shumway-Cook, A. (1997). Postural Perturbations: New Insights for Treatment of Balance Disorders. Phys. Ther. 77, 517–533. doi:10.1093/ptj/77.5.517
Hu, J., Hou, Z., Zhang, F., Chen, Y., and Li, P. (2012). Training Strategies for a Lower Limb Rehabilitation Robot Based on Impedance Control. In 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2012. IEEE, 6032–6035. doi:10.1109/EMBC.2012.6347369
Hwangbo, J., Lee, J., Dosovitskiy, A., Bellicoso, D., Tsounis, V., Koltun, V., et al. (2019). Learning Agile and Dynamic Motor Skills for Legged Robots. Sci. Robot 4. doi:10.1126/scirobotics.aau5872
Karunakaran, K. K., Abbruzzese, K., Androwis, G., and Foulds, R. A. (2020). A Novel User Control for Lower Extremity Rehabilitation Exoskeletons. Front. Robot. AI 7, 108. doi:10.3389/frobt.2020.00108
Koolen, T., Bertrand, S., Thomas, G., De Boer, T., Wu, T., Smith, J., et al. (2016). Design of a Momentum-Based Control Framework and Application to the Humanoid Robot Atlas. Int. J. Hum. Robot. 13, 1650007. doi:10.1142/s0219843616500079
Kumar, V. C., Ha, S., Sawicki, G., and Liu, C. K. (2020). Learning a Control Policy for Fall Prevention on an Assistive Walking Device. In 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 4833–4840.
Lee, J., X. Grey, M., Ha, S., Kunz, T., Jain, S., Ye, Y., et al. (2018). Dart: Dynamic Animation and Robotics Toolkit. Joss 3 (22), 500. doi:10.21105/joss.00500
Lee, S.-H., and Goswami, A. (2012). A Momentum-Based Balance Controller for Humanoid Robots on Non-level and Non-stationary Ground. Auton. Robot 33, 399–414. doi:10.1007/s10514-012-9294-z
Lee, S., Park, M., Lee, K., and Lee, J. (2019). Scalable Muscle-Actuated Human Simulation and Control. ACM Trans. Graph. 38, 1–13. doi:10.1145/3306346.3322972
McGinty, G., Irrgang, J. J., and Pezzullo, D. (2000). Biomechanical Considerations for Rehabilitation of the Knee. Clin. Biomech. 15, 160–166. doi:10.1016/s0268-0033(99)00061-3
Mergner, T., and Lippi, V. (2018). Posture Control-Human-Inspired Approaches for Humanoid Robot Benchmarking: Conceptualizing Tests, Protocols and Analyses. Front. Neurorobot. 12, 21. doi:10.3389/fnbot.2018.00021
Mungai, M. E., and Grizzle, J. (2020). Feedback Control Design for Robust Comfortable Sit-To-Stand Motions of 3d Lower-Limb Exoskeletons. IEEE Access.
Nunez, E. H., Michael, P. A., and Foulds, R. (2017). 2-dof Ankle-Foot System: Implementation of Balance for Lower Extremity Exoskeletons. In 2017 International Symposium on Wearable Robotics and Rehabilitation (WeRob). IEEE, 1–2.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). Pytorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 8024–8035.
Peng, X. B., Abbeel, P., Levine, S., and van de Panne, M. (2018). DeepMimic. ACM Trans. Graph. 37, 1–14. doi:10.1145/3197517.3201311
Peng, X. B., Berseth, G., and Van de Panne, M. (2016). Terrain-adaptive Locomotion Skills Using Deep Reinforcement Learning. ACM Trans. Graph. 35, 1–12. doi:10.1145/2897824.2925881
Peng, X. B., Berseth, G., Yin, K., and Van De Panne, M. (2017). DeepLoco. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, 1–13. doi:10.1145/3072959.3073602
Peng, X. B., Coumans, E., Zhang, T., Lee, T.-W., Tan, J., and Levine, S. (2020). Learning Agile Robotic Locomotion Skills by Imitating Animals. arXiv preprint arXiv:2004.00784.
Rajasekaran, V., Aranda, J., Casals, A., and Pons, J. L. (2015). An Adaptive Control Strategy for Postural Stability Using a Wearable Robot. Robotics Autonomous Syst. 73, 16–23. doi:10.1016/j.robot.2014.11.014
Sadeghi, F., and Levine, S. (2016). Cad2rl: Real Single-Image Flight without a Single Real Image. arXiv preprint arXiv:1611.04201.
Salem, G. J., and Powers, C. M. (2001). Patellofemoral Joint Kinetics during Squatting in Collegiate Women Athletes. Clin. Biomech. 16, 424–430. doi:10.1016/s0268-0033(01)00017-1
Sardain, P., and Bessonnet, G. (2004). Forces Acting on a Biped Robot. center of Pressure-Zero Moment point. In IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans 34, 630–637. doi:10.1109/tsmca.2004.832811
Schrade, S. O., Dätwyler, K., Stücheli, M., Studer, K., Türk, D. A., Meboldt, M., et al. (2018). Development of Varileg, an Exoskeleton with Variable Stiffness Actuation: First Results and User Evaluation from the Cybathlon 2016. J. Neuroeng Rehabil. 15, 18. doi:10.1186/s12984-018-0360-4
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347.
Shi, D., Zhang, W., Zhang, W., and Ding, X. (2019). A Review on Lower Limb Rehabilitation Exoskeleton Robots. Chin. J. Mech. Eng. 32, 74. doi:10.1186/s10033-019-0389-8
Tan, J., Zhang, T., Coumans, E., Iscen, A., Bai, Y., Hafner, D., et al. (2018). Sim-to-real: Learning Agile Locomotion for Quadruped Robots. arXiv preprint arXiv:1804.10332.
Thelen, D. G. (2003). Adjustment of Muscle Mechanics Model Parameters to Simulate Dynamic Contractions in Older Adults. J. Biomech. Eng. 125, 70–77. doi:10.1115/1.1531112
Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., and Abbeel, P. (2017). Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 23–30.
Vouga, T., Baud, R., Fasola, J., Bouri, M., and Bleuler, H. (2017). TWIICE - A Lightweight Lower-Limb Exoskeleton for Complete Paraplegics. In 2017 International Conference on Rehabilitation Robotics (ICORR). IEEE, 1639–1645. doi:10.1109/ICORR.2017.8009483
Wandercraft (2020). Atalante. Available at: https://www.wandercraft.eu/en/exo/(Accessed April, 2020).
Xiong, M. (2014). Research on the Control System of the Lower Limb Rehabilitation Robot under the Single Degree of freedom. In Applied Mechanics and Materials. Switzerland: Trans Tech Publ, 15–20. doi:10.4028/www.scientific.net/amm.643.15
Yu, S., Huang, T.-H., Wang, D., Lynn, B., Sayd, D., Silivanov, V., et al. (2019). “Sim-to-Real Transfer For Biped Locomotion,” In IEEE/RSJ International Conference on Intelligent Robots and Systems IROS, Macau, China, 4, 4579–4586. doi:10.1109/lra.2019.2931427
Yu, W., Kumar, V. C., Turk, G., and Liu, C. K. (2019). Sim-to-real Transfer for Biped Locomotion. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. IROS, 3503–3510.
Yu, W., Liu, C. K., and Turk, G. (2018). Policy Transfer with Strategy Optimization. arXiv preprint arXiv:1810.05751.
Yu, W., Tan, J., Bai, Y., Coumans, E., and Ha, S. (2020). Learning Fast Adaptation with Meta Strategy Optimization. IEEE Robot. Autom. Lett. 5, 2950–2957. doi:10.1109/lra.2020.2974685
Keywords: lower extremity rehabilitation exoskeleton, reinforcement learning, center of pressure, balanced squatting control, human-exoskeleton interaction
Citation: Luo S, Androwis G, Adamovich S, Su H, Nunez E and Zhou X (2021) Reinforcement Learning and Control of a Lower Extremity Exoskeleton for Squat Assistance. Front. Robot. AI 8:702845. doi: 10.3389/frobt.2021.702845
Received: 30 April 2021; Accepted: 29 June 2021;
Published: 19 July 2021.
Edited by:
Nitin Sharma, North Carolina State University, United StatesReviewed by:
Yue Chen, University of Arkansas, United StatesXiao Xiao, Southern University of Science and Technology, China
Copyright © 2021 Luo, Androwis, Adamovich, Su, Nunez and Zhou. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xianlian Zhou, YWxleHpob3VAbmppdC5lZHU=