
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Robot. AI, 11 September 2020
Sec. Soft Robotics
Volume 7 - 2020 | https://doi.org/10.3389/frobt.2020.00117
This article is part of the Research TopicAdvances in Modelling and Control of Soft RobotsView all 13 articles
 Franco Angelini1,2,3*
Franco Angelini1,2,3* Cosimo Della Santina4,5,6
Cosimo Della Santina4,5,6 Manolo Garabini1,3
Manolo Garabini1,3 Matteo Bianchi1,3
Matteo Bianchi1,3 Antonio Bicchi1,2,3
Antonio Bicchi1,2,3Human beings can achieve a high level of motor performance that is still unmatched in robotic systems. These capabilities can be ascribed to two main enabling factors: (i) the physical proprieties of human musculoskeletal system, and (ii) the effectiveness of the control operated by the central nervous system. Regarding point (i), the introduction of compliant elements in the robotic structure can be regarded as an attempt to bridge the gap between the animal body and the robot one. Soft articulated robots aim at replicating the musculoskeletal characteristics of vertebrates. Yet, substantial advancements are still needed under a control point of view, to fully exploit the new possibilities provided by soft robotic bodies. This paper introduces a control framework that ensures natural movements in articulated soft robots, implementing specific functionalities of the human central nervous system, i.e., learning by repetition, after-effect on known and unknown trajectories, anticipatory behavior, its reactive re-planning, and state covariation in precise task execution. The control architecture we propose has a hierarchical structure composed of two levels. The low level deals with dynamic inversion and focuses on trajectory tracking problems. The high level manages the degree of freedom redundancy, and it allows to control the system through a reduced set of variables. The building blocks of this novel control architecture are well-rooted in the control theory, which can furnish an established vocabulary to describe the functional mechanisms underlying the motor control system. The proposed control architecture is validated through simulations and experiments on a bio-mimetic articulated soft robot.
Daily activities of human beings are a clear example of the exceptional versatility of their motor control system. Tasks that are still challenging for robots are indeed easily executed by people. Responsible for such a high level of performance are the musculoskeletal system and the Central Nervous System (CNS). The musculoskeletal system allows to exert forces and to percept the external world through a multitude of receptors. One of the main characteristics of this system is its compliant nature. Indeed, body flexibility provided by muscles and tendons enables features like energy efficiency, power amplification and shock absorption (Roberts and Azizi, 2011).
The same feature are usually hard to be achieved by traditional rigid robots. Inspired by the effectiveness of the biological example, researchers developed robots with compliant elements to mimic the animal body. This novel generation of systems, namely soft robots, can be categorized as invertebrate-inspired or vertebrate-inspired (Della Santina et al., 2020). The latter class includes articulated soft robots, which are systems with rigid links and elasticity lumped at the joints (Albu-Schaffer et al., 2008). In this paper, we focus on the latter category, i.e., robots actuated by series elastic actuators (SEA) (Pratt and Williamson, 1995) or variable stiffness actuators (VSA) (Vanderborght et al., 2013). The musculoskeletal system of vertebrates allows to adjust its dynamics, for instance, it allows to vary joint stiffness via co-contraction of antagonistic muscles. Agonistic-antagonist VSAs mimic this mechanism as described in Garabini et al. (2017), thus they try to replicate the working principle of the human musculoskeletal system.
Several works in literature describe how the features of a flexible body can be conferred also to a robot through different solutions (Landkammer et al., 2016; Zhang et al., 2019; Pfeil et al., 2020). Particularly relevant are the solutions that completely replicate the whole structure of the human musculoskeletal system. For examples, Kenshiro (Asano et al., 2016) is a humanoid robot reproducing the human skeleton and muscle arrangement. Marques et al. (2010) presents ECCE, an anthropomimetic humanoid upper torso. Jäntsch et al. (2013) proposes Anthrob, a robot mimicking a human upper limb.
Yet, controlling soft robots still remains a very challenging task. The reason is that articulated soft robots have highly non-linear dynamics, presenting also hysteresis, bandwidth limitation and delays. Therefore, obtaining an accurate and reliable dynamic model is not a trivial task that could directly affect the performance of model-based control techniques. Moreover, articulates soft robots present anatomical degrees of freedom (DoFs) redundancy, because they typically have more than one motor per joint, and they may have kinematic DoFs redundancy, depending on the platform. The majority of existing model-based control approaches has the strong drawback of requiring an accurate model identification process, which is hard to be accomplished and time-consuming. In Buondonno and De Luca (2016) feedback linearization of VSA is faced. In Zhakatayev et al. (2017) an optimization framework to minimize time performance is proposed. In Keppler et al. (2018) the Authors propose a controller to achieve motion tracking while preserving the elastic structure of the system and reducing the link oscillations. On the other hand, model-free algorithms are promising, but usually require long-lasting learning procedures and face generality issues (Angelini et al., 2018; Hofer et al., 2019).
However, the complexity of the articulated soft robot body is analogous to that of their source of inspiration. Indeed, the human body is a complex system that presents an unknown non-linear dynamics and redundancy of degrees of freedom (DoFs). Despite that, the CNS is able to cope with these issues, fully exploiting the potential of the musculoskeletal system. For this reason, in this work, we analyze the effectiveness of a bio-inspired algorithm to control bio-mimetic robots.
To the authors best knowledge, despite the variety of approaches in the motor control field, an architecture based on control theory able to present at the same time various CNS behavior is still lacking for articulated soft robots (Cao et al., 2018; Ansari et al., 2019). The study of the human CNS has been already exploited to enhance robot capability. For instance, in Medina et al. (2019) the Authors propose a method for modeling human motor behavior in physical and non-physical human-robot interactions. Based on previous observations, the developed model is able to predict the force exerted during the interaction. Capolei et al. (2019) presents a cerebellar-inspired controller for humanoid robot moving in unstructured environment. The controller is based on machine learning, artificial neural network, and computational neuroscience. In Kuppuswamy et al. (2012) the Authors propose a motor primitive inspired architecture for redundant and compliant robots. Lee et al. (2018) proposes a model of human balancing with the goal of designing a controller for exoskeleton.
In this work, our goal is to make a step further toward the development of human-inspired controllers for articulated soft robots: taking inspiration from motor control theories, we implemented a hierarchical control architecture exhibiting well-known characteristics of human motor control system (i.e., learning by repetition, anticipatory behavior, synergistic behavior). Such a control framework is a proper combination of feedback control, feedforward, Iterative Learning Control, and Model Predictive Control. The goal is to design a bio-mimetic control architecture for bio-inspired robots, focusing on trajectory planning and tracking tasks.
A major contribution of this work is to show how well-established paradigms belonging to the control theory can be used to approach the motor control problem. Finally, the authors want to clearly state that is beyond the scope of this work to infer possible neurophysiological implications based on the presented control framework.
Our belief is that a control system able to work like the CNS, such the one proposed here, can successfully manage a soft robotic system. We test here this hypothesis, among with the human-like behaviors, both in simulation and in experiments, using as testbed robots actuated by VSAs.
The unparalleled performance of the animal CNS are an ambitious goal for the robotic community, especially because the issues faced by the CNS are very similar to the ones occurring in robots, i.e., unknown non-linear dynamics and redundancy of degrees of freedom. These are (Latash, 2012):
• Unknown non-linear dynamics. The human body is a complex system, with strong non-linearities at every level. Moreover, environmental force fields can not be known a priori.
• Degree of freedom (DoF) redundancy. The human body presents three types of redundancy. Anatomical—human body is characterized by a complex highly redundant structure. The number of joints is greater than the number of DoFs necessary to accomplish a generic task, and the number of muscles is greater than the number of joints. Kinematic—infinite joints trajectories can achieve the same task, or simply perform the same end effector point to point movement. Neurophysiological—each muscle consists of hundreds of motor units, and they are activated by moto-neurons that can spike with different frequency (hundreds of variables).
For this reason, we use the motor control theory as a source of inspiration for our controller.
There are several evidences that the Central Nervous System can cope with the incredible complexity of the musculoskeletal apparatus by relying on a hierarchical organization of subsequent simplifications of the control problem (Swanson, 2012; Hordacre and McCambridge, 2018). For example, the Bernstein classification (Bemstein, 1967) categorizes the construction of movement in six levels, from symbolic reasoning to muscle tone activation. Level A is called rubro-spinal level or paleokinetic level, and it provides reflex function and manages muscle tone. Level B, i.e., thalamo-pallidal level, is the level of synergies and patterns and produces coordinate movement patterns. Finally, level C1, is the striatal or extrapyramidal level. This is one of the two levels of the spatial field level, and it specifies a way to reach performance defined by higher levels. The other three levels, C2, D, and E, describe higher level of abstractions, as meaningful actions and information transmission. Therefore, they will not be treated in by the proposed control architecture.
In this section we list a few of salient characteristics of the neural control architecture that we consider of paramount importance for the human motion performance, and that we aim at replicating on the considered bio-mimetic robots. In the remainder of the article we will often refer to them as (i)–(v). These peculiar characteristics of the CNS are:
(i) Learning by repetition (Shadmehr and Mussa-Ivaldi, 1994): CNS inverts an unknown dynamic over a trajectory, repeating it several times. Figure 1A represents a classical experiment. It is possible to notice that the subject is asked to reach some points in the workspace. Then a force field is introduced. Initially, trajectories are strongly deformed. After repetitions of the same movements, performances obtained before the introduction of the force field are achieved again. The same behavior can be found in the development, where the CNS needs to adapt to its own dynamics.
(ii) Anticipatory behavior (Hoffmann, 2003): ability of CNS to usually anticipate the necessary control action relying on sensory-motor memory. The acquired previous experiences cause a shift in the control action from closed loop to open loop. Anticipatory behavior is fundamental in many human activities, such as manipulation (Fu et al., 2010), coordinated (Flanagan and Wing, 1993), and fast movements (Haith et al., 1988).
(iii) Aftereffect over a learned trajectory (Lackner and Dizio, 1998) and aftereffect over unknown trajectories (Gandolfo et al., 1996). After recovering the performance loss due to the introduction of the external force field, by removing the force field, subjects exhibit deformations of the trajectory specular to the initial deformation due to the force field introduction. This behavior is called mirror-image aftereffect Figure 1B. This effect arises also in novel trajectories as depicted in Figure 1C.
(iv) Synergistic behavior (Latash, 2010): synergy can be defined as “[…] a hypothetical neural mechanism that ensures task-specific co-variation of elemental variables providing for desired stability properties of an important output (performance) variable.” Given an “important output variable” we can define two variables Vgood and Vbad. Vgood is the variance through the directions where output is constant and the constraints are verified (named uncontrolled manifold), while Vbad is the variance in the other directions (Scholz and Schöner, 1999). The system presents a synergistic behavior when Vgood > Vbad. Figure 2 visually explains this point.
(v) Re-plan of anticipatory action: CNS modifies the anticipatory motor actions on-line if the goal changes (e.g., Soechting and Lacquaniti, 1983), or if the sensory outcome is different from the expected one (e.g., Engel et al., 1997). Note that this is fundamentally different from feedback. Indeed, feedback actions are proportional to the instantaneous error, while re-plan of anticipatory action depends on the outcome of the task.
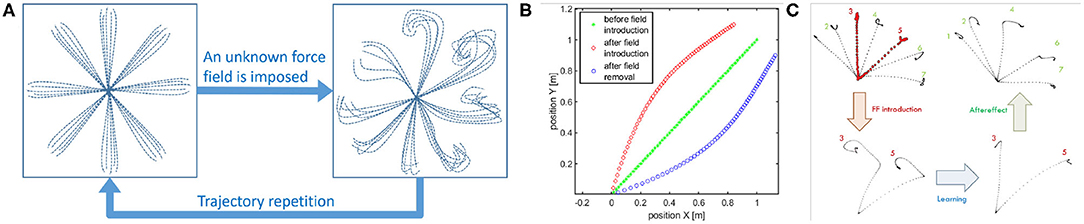
Figure 1. Representation of some human behaviors considered in this work. Learning by repetition (A): a subject is able to reach a series of point in space with its end effector, when a force field is imposed the trajectories result deformed, repeating the reaching trials many times the subject results able to restore the initial behavior. Aftereffect in known trajectories: (B) Hand trajectories of a typical point to point movement. The typical movement is a strict line. If a force field is introduced the trajectory is firstly deformed. After some repetitions the strict movement is recovered. If the force field is then removed the hand trajectory is deformed in a way specular to the first deformation. This is called aftereffect. Aftereffect in unknown trajectories: (C) Hand trajectories of typical point to point movements. When the force field is introduced the subject make experience through learning by repetition of just trajectories 3 and 5. When the force field is removed aftereffect is present on trajectories not experienced closer to trajectories 3 and 5: trajectory 4 presents maximum aftereffect, trajectories 1 and 7 presents negligible aftereffect (image obtained from an elaboration of images in Gandolfo et al., 1996).
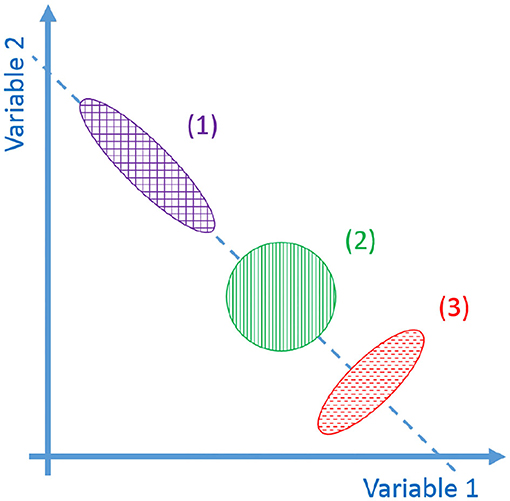
Figure 2. Representations of the synergistic behavior. In the figure there are different possible distributions of task configuration in task space. The dashed line is locus of configurations that meets the task. Vgood is the variance of the distribution along the dashed line, Vbad is the variance in the orthogonal directions. The fact that Vgood > Vbad indicates that a task synergy exists (1). If Vgood ≃ Vbad no synergy exists (2). If Vgood << Vbad a destabilizing synergy exists (3).
Inspired by the biological example, we design the control architecture with a hierarchic structure similar to the one of CNS. In particular we reproduce the first three levels of the Bernstein classification (Bemstein, 1967) (briefly summarized in section 2.1) with the goal of executing a task reference ν generated by the three higher abstraction levels. Furthermore, the controller has to reproduce the peculiar behaviors of the human CNS described in section 2.2.
We refer to a generic dynamic system, which may represent both articulated soft robots and biological models (Figures 3A,B), i.e., ẋ(t) = f(x(t), u(t)), y(t) = h(x(t)), where f is the dynamic function, is the state vector, q ∈ ℝn are the Lagrangian variables, y ∈ ℝl is the output variable, and h(x) is the output function. It is worth mentioning here that human muscles and agonistic antagonistic variable stiffness actuators share similar characteristics as depicted in Figures 3C,D (Garabini et al., 2017). We propose a bio-mimetic control architecture for bio-inspired robots. The architecture is divided into two layers and summarized in Figure 4. The whole controlled system is organized in four building blocks: the two control levels, the dynamic system, and the output function h(x) selecting the portion of the state from which depends the task to be accomplished.
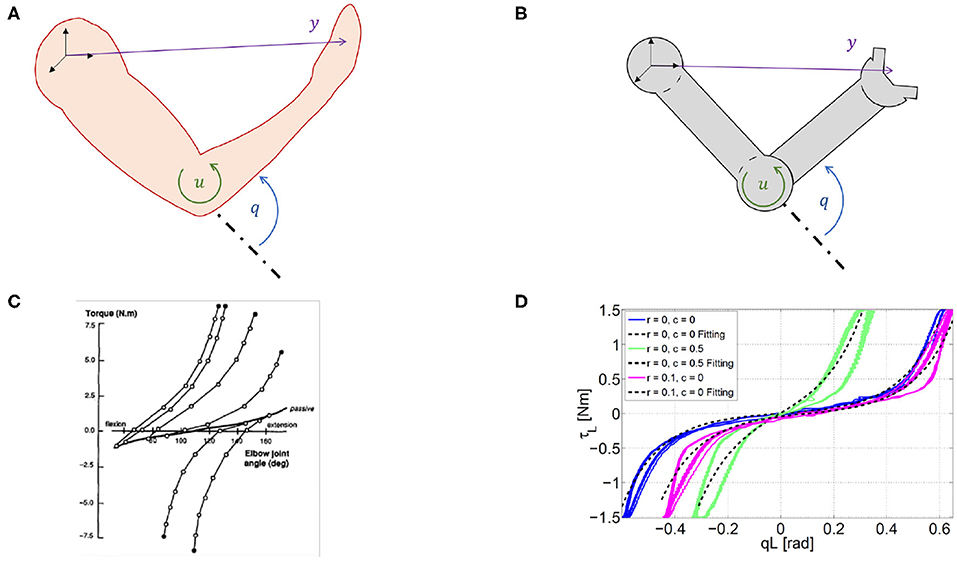
Figure 3. Similarity between humans and robots. Variable definitions in humans (A) and robots (B). q ∈ ℝn are the Lagrangian variables, is the state vector, u ∈ ℝm is the input and y ∈ ℝl is the output. These variables are valid both for biological systems and articulated soft robots. Experimentally measured force–length characteristics in natural (C) and robotic (D) system. (C) Elastic characteristic of agonist and antagonist muscles acting on the elbow joint in the human, taken from Gribble et al. (1998). (D) Elastic characteristic of a agonist and antagonist variable stiffness actuator (Garabini et al., 2017).
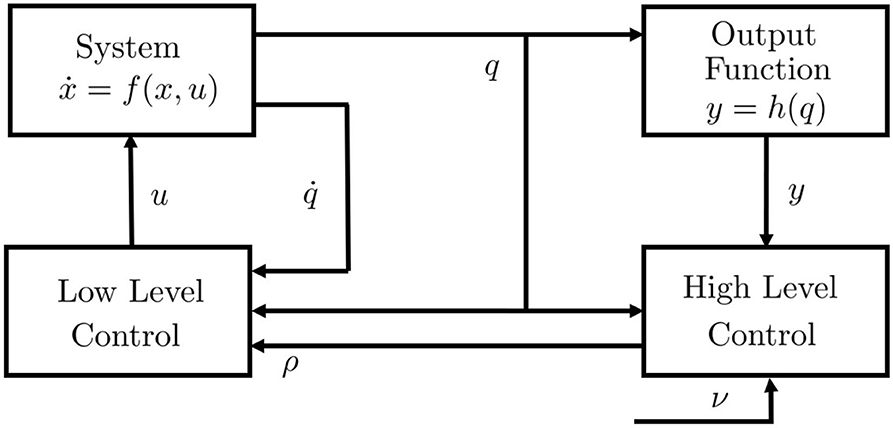
Figure 4. Control structure. u is the low level control variable or efferent action, ρ is the high level control variable, ν is the reference in the task space, q is the position vector, is the speed vector, is the state vector, y is the output vector, h(·) is the output function. The control system is supposed equipped by a complete proprioception.
The low level features characteristics similar to level A of the Bernstein classification, i.e., it provides low level feedback and dynamic inversion. Thus, it generates as output the efferent action u depending on afferent proprioceptive inputs, i.e., , and higher level reference ρ ∈ ℝp, generated by the high level control, relying on q and y. Thus, given a desired output trajectory , where tf is the terminal time, the low level control is an appropriate controller able to track that trajectory. On the other hand, the high level control is inspired by level B and level C1 and provides task management.
The low level controller has to present three behaviors: learning by repetition (i), anticipatory behavior (ii), and aftereffect over known and unknown trajectories (iii). The high level control will present synergistic behavior (iv) and ability of re-plan the anticipatory action (v).
To design the control architecture we assume the desired robot impedance behavior as given. Future extension of this work will also consider a direct learning of the optimal impedance depending on the task.
In this section we describe the proposed control architecture and its components. To obtain learning by repetition (i) we will employ a learning algorithm able to cope with the non-linear dynamics of the studied class of robots. In particular, we rely on the Iterative Learning Control (ILC) framework (Bristow et al., 2006). The employed ILC method merges a low gain feedback with a feedforward action. Through repetitions the feedforward action will prevail over the feedback action leading to the desired anticipatory behavior (ii). It is worth mentioning that ILC is a local method and requires a new learning phase for every novel desired trajectory. Conversely, humans are able to generalize the motion learned through repetitions (Sternad, 2018). To obtain the same feature, we employ Gaussian Process Regression (GPR) (Williams and Rasmussen, 2006) to create a map of learned trajectories. We aim at obtaining also aftereffect, i.e., behavior (iii)—to test the level of bio-mimecity of the proposed architecture. We base the high level controller on an optimization problem to define the desired task and to solve the redundancy issue. From this optimization problem a synergistic behavior (iv) results. Finally, to re-plan an anticipatory action (v) we propose two different approaches, one based on proportional control and the other one based on Model Predictive Control (MPC). Both methods will be tested and compared. We also focus on a trade off between problem dimensionality and accuracy.
Let us define the error signal as , where x is the measured state vector, while is the desired evolution, given by higher levels of the architecture. In addition, let us define the inverse functional , mapping a desired state trajectory into the input û able to track that trajectory. The purpose of the low level controller is to perform dynamic inversion of the system given any desired trajectory , thus to find a map approximating W. In addition, we aim at replicating the CNS features 1, 2 and 3. To this end, we propose a new algorithm combining Iterative Learning Control (ILC) and Gaussian Process Regression (GPR).
The learning by repetition behavior 1 can be achieved using a learning technique. Emken et al. (2007) presents a model of learning by repetition process, derived from a statistic model of error evolution over iterations
where α, β ∈ ℝ+ are two positive constants, while ui and ei are the control action and the error at the i-th iteration, respectively. In this way an input sequence is iteratively computed such that the output of the system is as close as possible to the desired output. Iterative Learning Control (ILC) (Bristow et al., 2006) permits to embed this rule in a general theory, and already achieved good results when applied to VSA robots (Angelini et al., 2018). ILC exploits the whole previous iteration error evolution to update a feedforward command, according to the law
where the function z(ei) identifies the iterative update, while L(ui) is a function1 mapping the control action of the previous iteration ui into the current one.
While in works, such as Tseng et al. (2007) is described the pure contribution of error signals, there are evidence, such as Kawato (1996), that feedback motor correction plays a crucial role in motor learning. Hence, a more general algorithm able to merge all of these contribution is needed. Thanks to the described inclusion we can design an ILC controller merging both feedback and feedforward, applying a control law, such as
where the presence of the error of the current iteration ei+1 leads to the feedback action. The combination of feedback and feedforward actions, allows to profitably collect sensory-motor memory implementing also the described anticipatory behavior (ii). Furthermore, relying mostly on a feedforward action, ILC allows a limited stiffening of the robot (Della Santina et al., 2017a).
Among all the ILC algorithms, in order to opportunely generalize (1) maintaining its intrinsic model-free structure, in this work we use an PD-ILC law in the form of the ones proposed (e.g., in Shou et al., 2003; Ruan et al., 2007), to obtain a minimal dependence on a model of the system dynamics. The proposed approach has been already preliminarily introduced in Angelini et al. (2020a). The adopted iterative update is
where, ei is the error evolution at the i-th iteration, and are the PD control gains of the iterative update while and are the PD feedback gains. We choose a decentralized structure for the ILC controller, hence, the gain matrices are block diagonal. The gains of the control algorithm can be chosen through several methods. Trial and error approaches could be adopted, but they are usually time consuming and the final performance depends on the experience of the human operator. The ILC framework proposes several techniques to guarantee the convergence of the iterative process depending on the control gains. Thus, other tuning approaches rely on these convergence condition to choose the gains. Some relevant examples of convergence conditions can be found in Arimoto et al. (1984), Ahn et al. (1993), Moore (1999), Bristow et al. (2006), and Wang et al. (2009). In Angelini et al. (2018) an algorithm to automatically tune the control gains is proposed. Finally, it is worth mentioning that the feedback gains should be set low to avoid alteration of the softness of the controlled system (Della Santina et al., 2017a; Angelini et al., 2018).
The adopted solution achieves aftereffect over known trajectories (iii). Indeed, the method is able to compensate also unmodeled potential external force field, because it is model-free and learning based. This means that the learned action depends on the external force disturbances that were present during the learning phase. Furthermore, since the method is mostly feedforward, when the external force field is removed, the system presents the desired aftereffect (iii).
Given a desired trajectory , ILC returns an input û such that , thus it returns a pair (,). However, the method lacks of generality. Indeed, ILC is a local method, and it requires a novel learning phase for each novel desired trajectory . Conversely, humans are capable of effectively performing novel tasks exploiting and generalizing the previously acquired experiences (Sternad, 2018). Angelini et al. (2020b) proposes a method to generalize the control actions w.r.t. to time execution given a limited set of pairs (,). Given a desired trajectory , the method allows to track with any desired velocity, without any knowledge of the robot model. In this paper, we are interested in generalizing the learning control action w.r.t. the joint evolution, replicating the feature of human beings. To this end, we apply GPR on a set of learned pairs , in order to regress a map—approximating W—able to track any novel desired trajectory . Then, the system will present also the desired behavior aftereffect over unknown trajectories (iii). This is achieved because the regressed map will be based on the learned feedforward control actions.
Several approaches can be applied to compute the inverse functional W. Some methods contemplate the independent estimation of a complete model of the system (e.g., Arif et al., 2001; Purwin and D'Andrea, 2009). The limitations of complete model estimation (Nguyen-Tuong et al., 2008) approaches are well-known (e.g., computational onerous). Conversely, in our approach we will focus on a reduced space of control actions and trajectories, in order to limit the computational burden.
W is the functional mapping the functional space of the state trajectories into the functional space of the input signals. Computing the regressor of a functional is not a trivial task. For this reason, we reduce the problem complexity limiting our analysis to an approximated solution. In particular we transform the functional W into a function through the introduction of two parameterization functions. Then, we focus on the regressor of this approximated solution.
Let us define:
• a parameterization B of a subspace of the trajectories space , with dimension p, B:ℝp → F.
• a parameterization S of a subspace of the input space , with dimension d, S:ℝd → V.
The trajectory parameterization B constraints low level controller to manage only a sub-set F of the possible evolutions. The parameterization S defines an approximation of control actions, reducing them to the ones included in V. Hence, with an abuse of notation, we indicate with S−1 the application that, given a control action u, returns the set of parameters that identifies its approximation, and such that S−1(S(μ)) = μ ∀μ ∈ ℝd. Hence M(ρ):ℝp → ℝd is so defined
M(·) is the map we are interested for (Figure 5). ρ is the array of parameters defining the desired trajectory. The map can then be approximated using a non-linear regression technique. We can then use the approximated map to estimate the control action needed to track a new trajectory. We employ here Gaussian Process Regression (GPR), because it achieves good performance, while maintaining low the computational cost. In particular, in the GPR algorithm implementation, we employ the squared exponential as covariance function (Williams and Rasmussen, 2006) described as where δ(·) is the Kronecker delta, and σf, σn, and γ are free parameters.
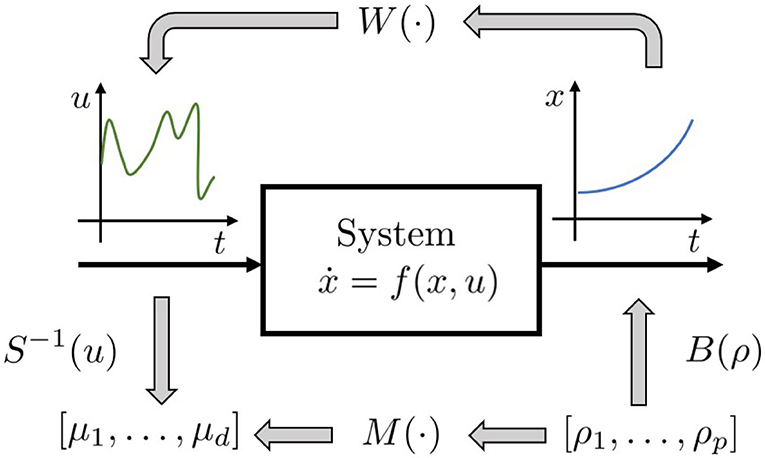
Figure 5. Proposed regression approach: instead of trying to regress the whole inverse functional W(·), the idea is to regress the function M(·), which provides an approximation [defined by S(·)] of control action needed to induce a reduced set of evolution [defined by B(·)].
Each novel control action will update the map used for generalization. However, to further limit the number of regressed points, for each pair , we remove all the stored points from the map which are in a sphere of radius δerr, centered in .
The parametrization of the sub-spaces F and V can be chosen freely, with the primary goal of keeping low the method complexity without compromising its generality. Several solutions could be implemented and tested. For instance, F can be set as a space of polynomial with a fixed order, or as a space of sums of sinusoidal signals. On the other hand, V can be approximated as a Gaussian space, or simply a discretization of the signal (Herreros et al., 2016).
Regarding the choice of the sub-space F, we would like to adopt trajectories that mimic the human motions. Which are the main characteristics of a motion that make it human-like is still an ongoing debate in literature. In Mombaur et al. (2010), the Authors apply inverse optimal control to define a model of human locomotion path and to exploit it for humanoid robot motion generation. In Tomić et al. (2018) it is studied the problem of human dual-arm motion in presence of contacts with the environment, and it is proposed an algorithm merging inverse optimal control and inverse kinematics to map human motion to humanoid robot motion. An additional method to characterize the human-likeness of robot motion is the adoption of functional synergies directly extracted from human examples as base space (Averta et al., 2017). Without any claim about the solution of this debate, in this work, we adopt the hypothesis formulated in Flash and Hogan (1985) and Friedman and Flash (2009), which states that human movements minimize the jerk. Minimum jerk trajectories are fifth order polynomial (Flash and Hogan, 1985), thus—without any claim of exhaustiveness—we set the vector ρ as the coefficients of the polynomial.
For what concerns the input space parametrization, in this work we focus on piece-wise constant functions with a fixed number d of constant length segments, and we implement S−1 as a time discretization, since it is one of the more natural signal approximation in control. Future work will analyze different choices of parametrization of the input and output spaces.
In Figure 6 we report the resulting low level control scheme. The input ρ is used in the form of B(ρ) as efferent copy for feedback compensation, and through as estimated anticipatory action. Then, this action can be refined through the learning algorithm. It is worth to be noticed that the proposed low level controller combines learned anticipatory actions and feedback control, working mainly in feedforward when the map reaches the convergence.
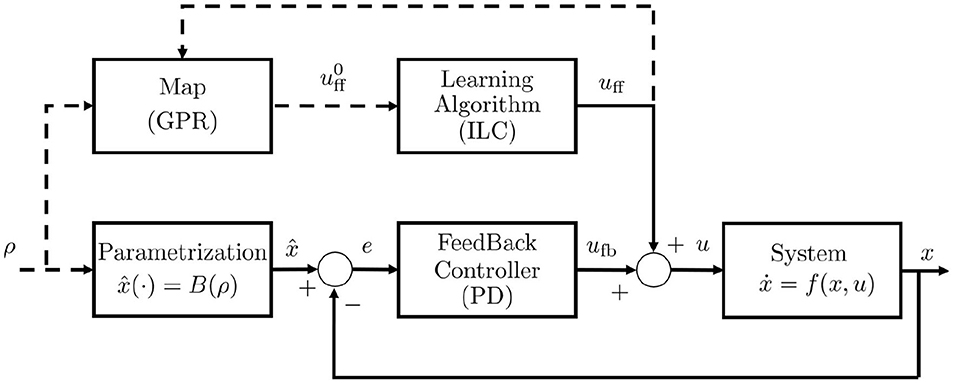
Figure 6. Low level control scheme. u = ufb+uff is the resulting afferent action, and ufb and uff are respectively the closed loop and the open loop control components, is the a-priori feedforward estimation returned by the map S−1(W(B(·))), ρ is the parameter array, x is the configuration vector. The Feedback Controller is a PD controller, the Learning Algorithm is the ILC algorithm, the block Parametrization implements the B(·) function. Dashed lines indicates flux of information.
It is worth remarking that the adopted solution achieves aftereffect over unknown trajectories (iii). Indeed, the regressed map depends on the learned actions. These actions depend on the external force disturbances that were present during the learning phase. Therefore, when the external force field is removed, the system presents the desired aftereffect (iii).
The acquired control inputs and, more in general, the regressed map depends on the impedance behavior. This was assumed as provided by an higher level of control in this article (section 3). However, future extension of this work will aim at learning the optimal impedance behavior too, imitating the human capabilities (Burdet et al., 2001). In Mengacci et al. (2020) it is presented a method to decouple the control input to track a trajectory and the control input to regulate the robot impedance, removing the dependency between learned control input and desired stiffness profile. This, in combination with GPR, could be used to generalize the acquired control input w.r.t. the desired stiffness profile and the desired task.
The role of the high level controller is to perform DoFs management in task execution. In particular we are interested in reproducing two of the characteristics of the CNS: synergistic behavior (iv) [i.e., given the desired output h(x), Vgood > Vbad in the configuration space] and re-plan of anticipatory action (v).
The degrees of freedom redundancy in humans is classified as anatomical, kinematic or neurophysiological (section 2). Here we focus on the kinematic redundancy, and the proposed high level control produces a synergistic behavior for this class of synergies. However, we believe that it could be extended also to the anatomical redundancy. Future work will focus on this point. The neurophysiological redundancy does not have a counterpart in robotics, so it is the Authors' opinion that it is not required to deal with it.
Several works report evidences of the discrete nature of the higher levels of the neural control of movements (e.g., Morasso and Ivaldi, 1982; Loram et al., 2011). In particular, in Neilson et al. (1988) is postulated that the CNS does not plan a new movement until the previous one is finished. This happens because the CNS plan a new motion after receiving the desired perceptual consequences of a movement in a finite interval of time. In order to replicate this behavior we choose a time-discrete control approach. Hereinafter we will use the superscript [k], k ∈ ℝ to indicate the k-th planned movement. Each interval will have the same fixed duration tf.
Low level controller abstracts the largely unknown and non-linear system into a discrete one which depends on the choice of the subspace. As a trade-off between complexity and accuracy, we heuristically chose a smaller subspace: fifth order monic polynomial with two constraints, which reduces space dimension to 3, while ensuring that subspace elements juxtaposition is of class C2. In particular we will focus on trajectories fulling these constraints
where qs and qf are the starting and final values of the polynomials, respectively. Following this choice, we find that . Given this definition of ρ, the resulting curve is a polynomial spline, and the abstracted dynamics is a discrete integrator
where is the third element of ρ[k]. Note that and are constrained by the initial conditions, thus they do not appear in (7).
Hence, the high level controller uses ρ as control variable, and its role is to choose the sequence of , generating a polynomial spline reference.
Level C2 in Bernstein classification (Bemstein, 1967) specifies the task to be accomplished. Analogously, we aim at replicating the same behavior in the proposed high level controller. We define as task a cost function and a set of constraints. Thus, the high level controller is defined by a solver and an optimization problem formulated as
where J is the cost function. h(·) is the output function selecting the variables of interest for the task. Δρ3 is the difference between two consecutive control commands, i.e., at the k-th interval we have . gq and gρ are generic constraint functions, while λq ∈ ℝ and λρ ∈ ℝ are the values of the upper bounds. It is worth noting that ||Δρ3||R assumes the role of actuation cost, while the difference between the desired and the actual output ||ŷ−h(q)||Q is a metric for performance.
We test two different solvers for the high level control:
• Proportional Control (P): it consists in pre-solving the problem and controlling the system over xopt through a proportional controller, which is a dead beat controller for the discrete integrator if , with the identity matrix.
• Model Predictive Control (MPC): it consists in recalculating the optimum on-line at each time interval, using the first element of the resulting control sequence (Köhler et al., 2020). Conventionally, MPC is hardly applicable to mechanical systems due to their high bandwidths, but the architecture here presented allows MPC application because it is sufficient to apply it only each tf seconds.
P control and MPC usually present much different performance and implementation complexity. For this reason, we decided to test both of them to check if a simpler P solver is effective enough, or if the difference in performances can justify the use of a more demanding method, such as MPC.
The high level feedback loop consists in a periodical re-plan of the control sequence, if the actual sensory outcomes are different from the expected ones.
To obtain the desired synergistic behavior (iv), we rely on the uncontrolled manifold theory (Scholz and Schöner, 1999). As briefly described in section 2.2, the uncontrolled manifold is the variance through the directions where output is constant and the constraints are verified. This means that the uncontrolled manifold can be identified as the manifold such that h(q)−ŷ = 0. Focusing on the regulation of the output, rather than on the joint error, is sufficient to obtain the desired synergistic behavior (iv).
It is worth noting that the quality of the task execution is strongly affected by the accuracy of the learned low level map. A pre-learning of the map is time consuming and generally not required. So, we will use an online approach to generate the map: if a new task is not properly executed (i.e., its error is greater than a certain threshold ηth) then the accuracy of the map should be improved through the introduction of a new point, obtained through an ILC execution along the failed trajectory. This approach results in a task-oriented learned map: most of the points will be collected in the portions of the subspace F that are more useful for the tasks, obtaining a very good trade-off between map dimension and accuracy.
In this section, we test the effectiveness of the proposed control architecture through simulations and experiments. In both cases, we employ as testbed a two degrees of freedom robotic arm, actuated by VSAs (Figure 7). Specifically, we employ two qbmoves Maker Pro (Della Santina et al., 2017b), which are bio-metitic variable stiffness actuators presenting characteristics similar to human muscles (Garabini et al., 2017). In both validations we consider the following gains for the algorithm ΓFFp is blkdiag([1, 0.1], [1.25, 0.0375]), ΓFFd is blkdiag([0.1, 0.001], [0.0375, 0.001]), ΓFBp is blkdiag([0.25, 0.025], [0.25, 0.025]), and ΓFBd is blkdiag([0.025, 0.001], [0.025, 0.001]). The parameters of the squared exponential as covariance function in GPR algorithm are σf = 1, σn = 0.05, γ = 2, and δerr = π/20.
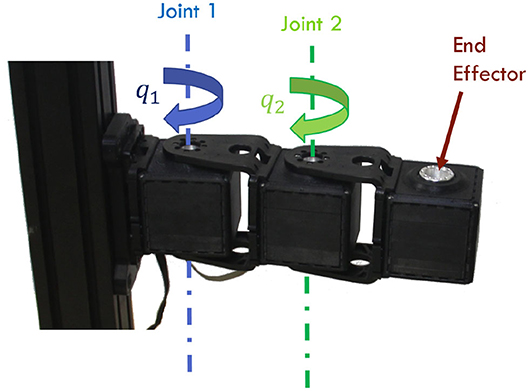
Figure 7. Two degrees of freedom robotic arm used as validation setup. The manipulator is actuated by two qbmoves Maker Pro, which are bio-metitic VSAs.
For performance evaluation we use the error norm 1 of the tracking error evolution, i.e., the integral over time of the norm of the error, mean error hereinafter. Furthermore, we refer as total error evolution the sum of the absolute tracking error of each joint at a given time.
In section 5.1 we present simulations proving that the proposed control architecture presents the desired behaviors (i)–(v) separately. In section 5.2 we present experiments testing the complete control architecture.
The employed model is a two degrees of freedom arm. Each link wights 0.5kg and is 0.5m long. Viscous friction equal to 1.2Ns on output shaft is considered. Joints limits are . The model of the actuators takes into account hardware parameters, such as measure noise, communication delays, saturations, motors dynamics2. In the following the test separately the low level and the high level controllers.
In this section, we verify that the proposed low level control achieves the human-like behaviors described in (i)–(iii). We present a set of three simulations to test each behavior. First, we validate the presence of learning by repetition (i) and anticipatory action 2. Then, we test the effectiveness of the learned map. Finally, we verify that the system presents aftereffect over know and unknown trajectories (iii).
First, we perform trajectory tracking over 50 trajectories randomly selected in F through a uniform distribution. Results are shown in Figure 8. Figure 8A shows that the system profitably implements learning by repetition [behavior (i)], reducing the error by repeating the same movement. Figure 8B shows that the controller is able to capitalize the sensory-motor memory over a trajectory increasing the role of anticipatory action [behavior (ii)].
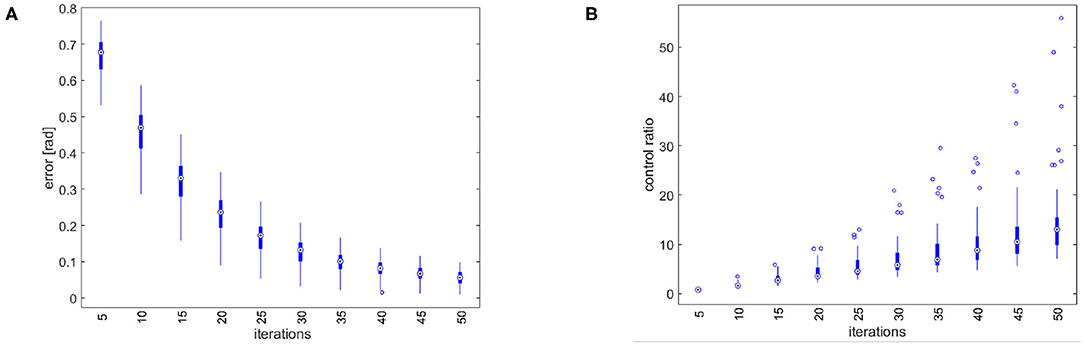
Figure 8. Simulation results of the tracking performance of 50 trajectories randomly selected from F. (A) Total error over iterations. The control architecture presents the learning by repetitions behavior. (B) Ratio between the feedforward and the feedback action. The control architecture presents the anticipatory behavior.
Then, we validate the effectiveness of the map. To this end, we test two scenarios: trajectory tracking without any map and trajectory tracking with a pre-trained map. In the latter case the map is trained on the 50 learning phases performed in the previous simulation. Given the two scenarios, we simulate 2 · 103 trajectories randomly selected in F through a uniform distribution. The results are reported in Figure 9. Results show that the performance using the map learned with only 50 random repetitions are more than one order of magnitude better than the ones without the map, and with a sensibly lower variance.
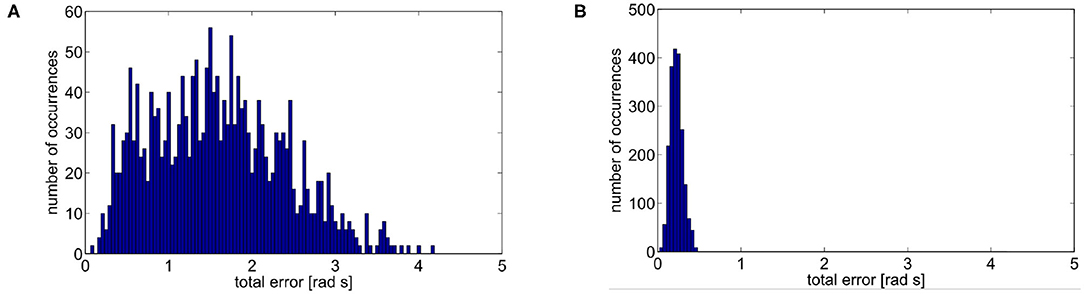
Figure 9. Mean error of 2 · 103 simulations. (A) No map is used. The mean error is 1.5929rads with a variance of 0.6272rad2s2. (B) A learned map is used. The mean error is 0.226rads with a variance of 0.0055rad2s2.
Finally, we verify the presence of the aftereffect, i.e., behavior (iii). Results are shown in Figure 10, specifically we show aftereffect over known trajectories in Figure 10A, and aftereffect over unknown trajectories in Figure 10B. In the first case, the green asterisk line represents the motion of the robot at the end of the learning phase. Then, we introduce an external force field, which acts on the joints as an external torque described by and , for the first and second joint, respectively. The trajectory is deformed as a consequence of the force field introduction (diamond red line). We repeat the learning process to recover from performance loss, and the system is again able to follow the initial trajectory (again, green asterisk line). Finally, the field is removed, and the end-effector presents the mirror-image aftereffect, i.e., the trajectory (circle blue line) is specular to the red one.
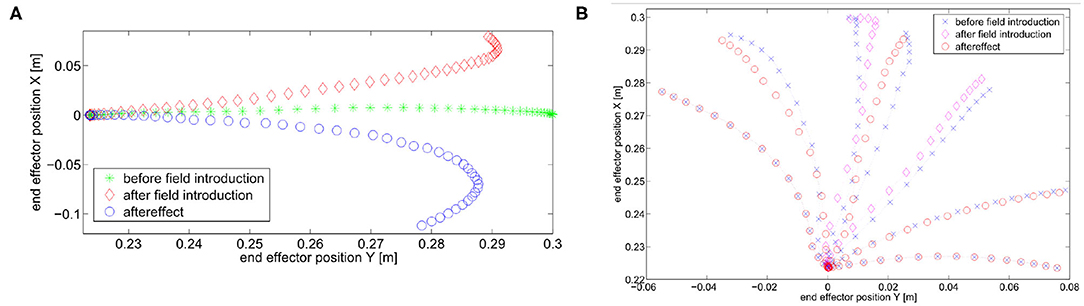
Figure 10. Simulations present aftereffect over known and unknown trajectories. Before field introduction are the tracking performance before the introduction of the external force field. The reference trajectory can be considered overlapped. After field introduction is the trajectory deformed by the external force field. Aftereffect is the trajectory after the field removal. (A) Known trajectory. (B) Two known trajectories and five unknown trajectories.
In the second case we test presence of the aftereffect on unknown trajectories. To this end, we simulate a motor control experiment accounted in Gandolfo et al. (1996). The controller experiences the unknown force field only on two trajectories. In this simulation the external torque is described by and . After field removal, we track five additional trajectories. Each one presents aftereffect. Moreover, its effect is more evident near in the trajectories close to the experienced ones. This result proves that the proposed control architecture presents a typical behavior of the CNS, validating its human resemblance.
In this section, we verify that the proposed high level control achieves the human-like behaviors described in (iv)–(v). We present a set of two simulations to test each behavior. First, we validate the ability to re-plan an anticipatory action (v) and we compare the two approaches (P and MPC). Then, we verify that the system presents a synergistic behavior (iv).
We evaluate the iterative procedure through 20 tasks. As output we employ the task position of the end-effector along the x axis, i.e., h(x) = a cos(q1) + a cos(q1 + q2), where a is the length of both links. Each task consists in moving the arm such that ||h(x)−ȳj|| is minimized, where ȳj is the desired evolution of task j. The map is regressed online with a threshold . This means that there is no pre-learned map and a new learning process is executed each time the tracking error is greater than ηth. Figure 11 shows the result. Figure 11A reports the average number of sub-tasks that presents error greater than ηth at each iteration. It is worth noting that the map converges to a complete representation of the inverse system, i.e., no more learning is needed, after ~8 tasks, with both P and MPC algorithms. Figure 11B shows that the MPC performance are better than the P one. This occurs thanks to the re-optimization at each iteration that permits to fully exploit task redundancies. In other terms, if the system moves to a state different from the desired one , but such that , then the P controller reacts trying to regulate the two states to be the same, while the MPC recognizes that the task is accomplished and does not generate any further control action.
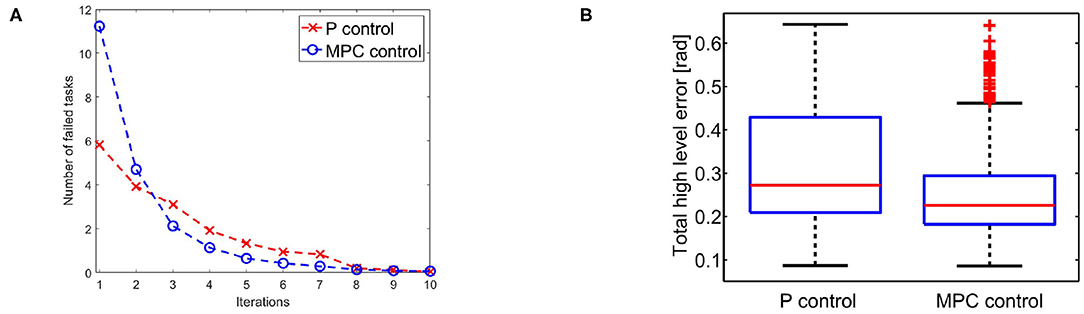
Figure 11. (A) Average number of low level evolution tracking which fails the error test at each iteration. (B) Error distributions with the two approaches at the first step of the learning process: the MPC approach presents lower error than P approach exploiting the task redundancy.
In terms of tracking, the P controller presents good performance but worse than MPC. Therefore, due to the greater complexity of the latter method it would be possible to opt for the P controller. However, we are also interested in obtaining a synergistic behavior (iv). To this end, the MPC approach is preferable. To verify the presence of the synergistic behavior (iv), we track a reference trajectory with different initial conditions. In particular, we randomly select 250 initial conditions using a normal distribution with standard deviation equal to 0.03 and mean value equal to the correct initial condition value. Figure 12A shows high variability in joints evolution, while Figure 12B highlights that the task performance are preserved. Considering the definition of synergy reported in section 4.1, this simulation shows the presence of a synergistic behavior of the controlled system, presenting Vgood >> Vbad in the configuration space (Figure 12C).
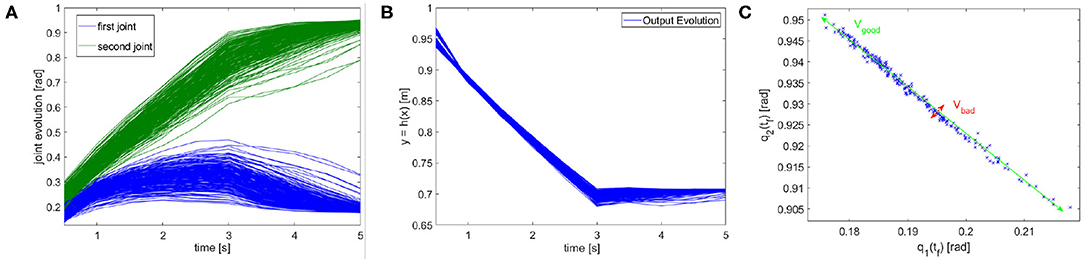
Figure 12. Synergistic behavior. The same task is executed 250 times with randomly selected initial conditions using a normal distribution with standard deviation equal to 0.03 and mean value equal to the correct initial condition value. (A) The evolution of the joint present high variability. (B) The evolution in the task space presents an analogous behavior, thus the performance are unvaried. (C) The distribution in configuration space highlights the synergy-like behavior of the high level controller.
In this section we test the complete control architecture, and we verify that it presents the desired behavior (i)–(v). Three experiments are presented, one testing the learning by repetition (i) and anticipatory behavior (ii), one testing the aftereffect (iii), and one testing the performance of the online map learning. It is worth noting that the reference trajectory is provided by the high level control, validating the complete architecture.
The robotic platform is the two degrees of freedom planar arm depicted in Figure 7. The output function h(x) is the end-effector position given by h(x) = [b cos(q1) + b cos(q1 + q2), b sin(q1) + b sin(q1 + q2)], where b = 0.1m is the length of the links. Given a desired position ȳ, and a discrete time interval , the experimental task is to maximize the velocity of the end effector in the desired position ȳ at the desired time step . This task can be modeled as the optimization problem
where and are the joint limits. R, Qp and Qv are the weight matrices of the input, the final position cost, and the final velocity, respectively, and their value is set as R = 0.1I20×20, Qp = 20I2×2, and Qv = 10I2×2.
Figure 13A shows the solution of the optimization problem (9) with parameters tf = 0.5s, and , , ȳ = [0.20]T. This is the reference trajectory of the fist experiment, and it is equal for both joints.
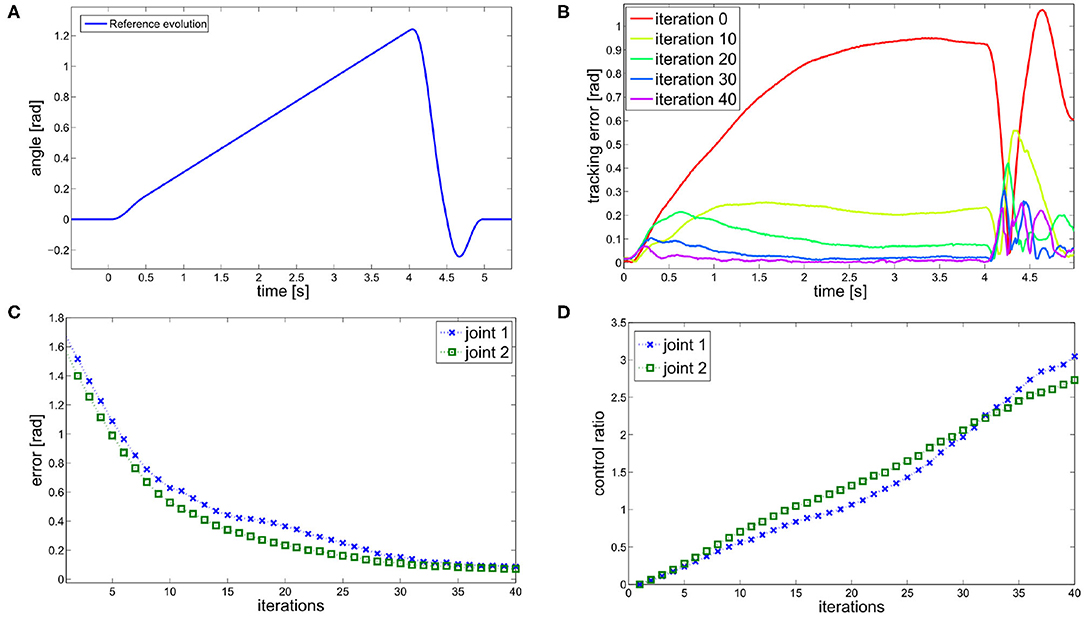
Figure 13. ILC experiment. (A) Reference trajectory resulting from the optimization problem (9). The trajectory is equal for both joints. (B) Tracking error evolution for different meaningful iteration of the ILC algorithm. (C) The evolution of the error over iterations shows the learning by repetitions behavior. (D) The ratio between feedforward and feedback actions shows an anticipatory behavior.
The results are shown in Figure 13. The proposed algorithm learns the task through repetitions: in 40 iterations the achieved performance are satisfying. Figure 13B shows the tracking error evolution over time, for a few meaningful iterations. Figure 13C proves that the system implements learning by repetition [behavior (i)], reducing the error exponentially by repeating the same movement. The mean error decreases approximately about 63.7% w.r.t. its initial value in 10 iterations, and of the 95% in 40 iterations. Finally, Figure 13D depicts the ratio between total feedforward and feedback action, over learning iterations. This shows the predominance of anticipatory action at the growth of sensory-motor memory [behavior (ii)]. It is worth to be noticed that feedback it is not completely replaced by feedforward, which is coherent with many physiological evidences (e.g., Shadmehr et al., 2010).
The second experiment has two goals. First, it tests the ability of the control algorithm to cope with aggressive external disturbances as springs in a parallel configuration (Figure 14A). Then, it validates the presence of mirror-image aftereffect [behavior (iii)]. The robotic arm learns to move its end-effector following the movement depicted in Figure 14B (green asterisk line). After the learning process we introduced an external force field. The unknown external force field is generated by a couple of springs of elastic constant 0.05Nm−1, connected as in Figure 14A. Due to the spring introduction, the robot end-effector evolution is altered as depicted in Figure 14B (red diamond line). At this point, the algorithm recovers the original performance after few iterations, proving its ability to cope with external disturbances (learning process not shown for the sake of clarity). Finally the springs are removed, and the end-effector follows a trajectory (blue circle line in Figure 14B), which is the mirror w.r.t. the nominal one, of the one obtained after field introduction, therefore proving the ability of the proposed algorithm to reproduce mirror-image aftereffect [behavior (iii)].
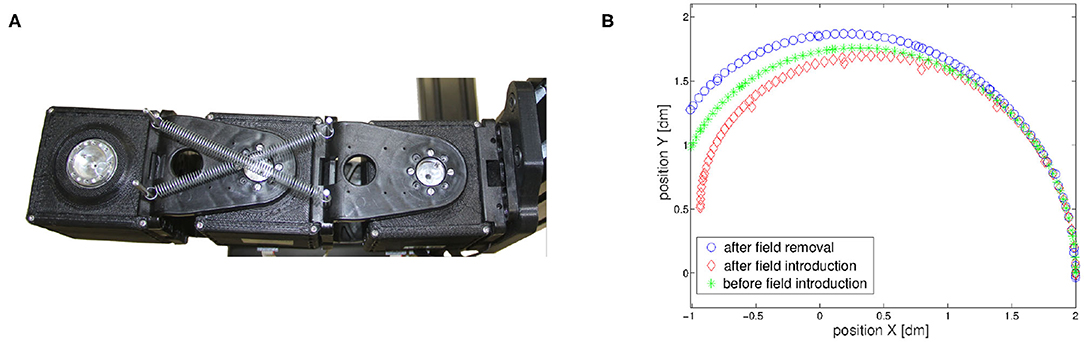
Figure 14. The designed control architecture presents aftereffect on known trajectories. (A) An unknown external force field is applied to the robotic arm through the addition of springs. (B) The introduction of the force field deforms the trajectory (red line) After some repetitions the strict movement is recovered. If the force field is then removed the trajectory (blue line) is deformed in a way specular to the first deformation.
To conclude we test the map in the complete control architecture. The idea is to repeatedly perform similar tasks, and to quantify the map performance. In particular, we are interested in verifying that the map capitalizes upon the information of the previous task executions in the new trials. In this experiment, we sequentially perform 10 tasks. The task parameters are tf = 0.5s, and , and ȳ = [0.20]T. In this experiment, is chosen randomly with a uniform distribution in the interval {2, …, 10} for each task. This means that each task aims to maximize the link velocity at a different time step. The resulting trajectory has a form similar to the one depicted in Figure 13A, eventually scaled on the abscissa axis respect to the value of , and on the ordinate respect to the values of and : the system moves as slow as possible (i.e., in steps) in the configuration that is most distant from the starting point (i.e., ), then in a time step it moves at the maximal possible speed to the initial position, finally it remains stationary.
For each task we performed a learning process lasting for 40 iterations. The resulting low level control is used for map regression. This process is repeated 20 times. Hereinafter each of these repetition is referred as trial. To analyze the results we define two error metrics E and Ii. For every i-th task in the j-th trial we evaluate (i) , i.e., the tracking error without the use of the map, and (ii) , i.e., the tracking error with the map learned with previous trajectories.
It is worth to be noticed that both error values and are not correlated with index j. However, while is neither correlated with index i, appears to be correlated with task i, due to the presence of the map.
What we are interested in evaluating is how much the error decreases respect to the performance without map . Hence we define the metric
where T = 10tf is the task duration, Ni = 10 is the number of tasks in a sequence of learning, Nj = 20 is the number of trials. Hence E is the mean value of error without map, and it will be used for normalization purpose.
Therefore the considered error index for the i-th task is defined as
Ii represents the normalized mean controlled system behavior over trials at the i-th task. Ii > 1 indicates that the map degrades the performance of the system, Ii = 1 indicates that the map does not modify the system behavior, Ii ∈ [0, 1) indicates that the map increases the system performance.
However, it is worth noticing that the regressed map has the goal of improving the performance also of trajectories that differ from the ones stored in the map itself. In particular, the regressed map aims at improving the performance of dynamically similar tasks, while maintaining unaltered the performance of dynamically different tasks. To analyze this point, we test it in presence of a novel different trajectory w. represent index (11) for the novel reference. Specifically, the employed trajectories are: s, i.e., dynamically similar, and r, i.e., dynamically different
The two trajectories are presented in Figures 15A,B, respectively. It is worth noticing that the s motion is more similar to the task trajectories than the r motion since both joint evolution are concordant.
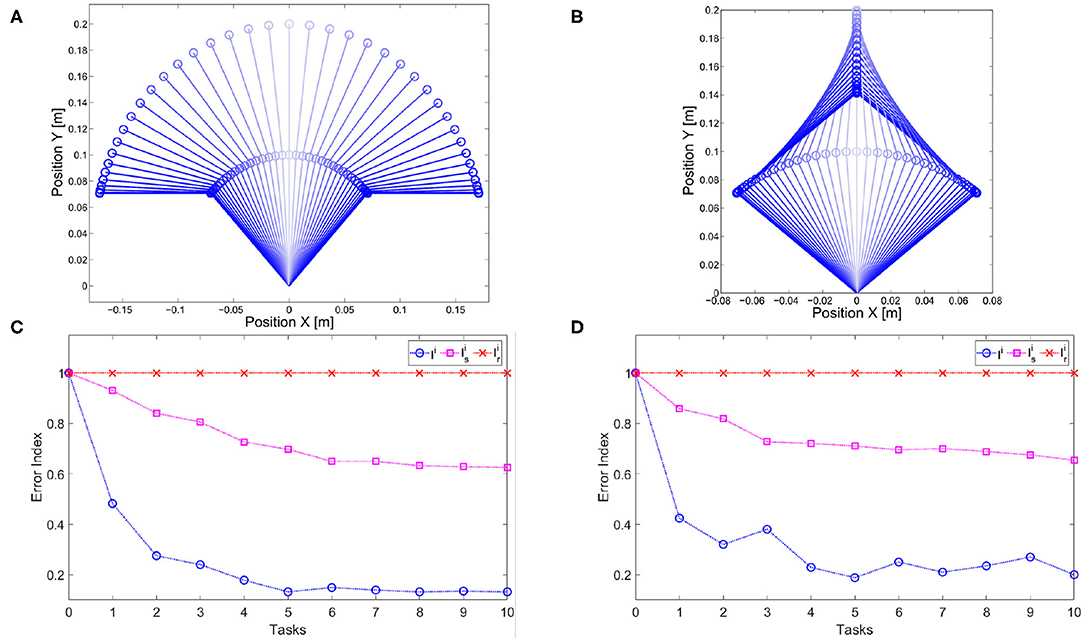
Figure 15. Experimental map evaluation. (A) Dynamically similar trajectory. (B) Dynamically different trajectory. Evolution of the error index (11) used for map evaluation in soft (C) and stiff (D) scenario. The error index Ii on the set of tasks of interest converges to the best reachable performance after ~5 tasks in both cases. Then, two different trajectories are tested: s which is dynamically similar and r which is dynamically different. The map reduces the error on the dynamically similar trajectory (), and it leaves unadulterated the performance on the dynamically different trajectory ().
This experiment has been performed with two different scenarios: low and high stiffness. The results are reported in Figures 15C,D, respectively. Both figures show that the map converges to a complete inversion of the system in the set of tasks of interest in ~5 iterations, i.e., when five tasks are included in the map there is no more improvement and the best performance are achieved. Furthermore, the method is able to reduce the error on the trajectory dynamically similar, without degrading the performance of the trajectory dynamically different. This result is achieved both in the low stiffness case and in the high one.
In this work a novel control architecture that simultaneously shows the main characteristics of human motor control system (learning by repetition, anticipatory behavior, aftereffect, synergies) has been stated. The effectiveness of the proposed control framework has been validated in simulations and via experimental tests. The experiments have been conducted on a robotic platform, the qbmoves, closely resembling the muscular system and in which the control inputs, namely reference position and stiffness preset, have their biological counterpart in the reciprocal and co-activation, as per Equilibrium Point Hypothesis. The proposed control architecture translates elements of the main motor control theories in well-stated mechanisms belonging to control theory. Control Engineering could provide a useful framework for theory falsification in motor control, and it could give an already well-formed global language for problem definition. Furthermore, human behavior can be used to ensure human-like performance in robotic systems, and hence be used as a starting point for novel control models. We will further analyze this point in future work.
Future work will also aim at increasing the human-likeness of the proposed control architecture. First we will focus on merging the generalization method proposed in Angelini et al. (2020b) and the generalization method based on GPR that was presented in this paper. The union of the two approaches will grant to the robot the ability to track any desired trajectory, with any desired velocity, considerably limiting the amount of required learning procedures. This solution will further close the gap between robot and human capability in terms of previous experience exploitation. Then, we will aim at replicating the impedance behavior learning that is typical of human beings, and it is generally related to the performed task. Indeed, thanks to our control architecture the robot compliance is not altered, meaning that it can be freely exploited. Additionally, we will exploit functional synergies extracted from recorded human motions to increase the human-likeness of the robot movements (Averta et al., 2020). Finally, this work focused on robot powered by mono-articular actuators, i.e., platforms where each motor separately drives each link. However, some systems, e.g., human musculoskeletal system, present a poly-articular structure. In Mengacci et al. (2020), a few preliminary insights about the application of ILC to poly-articular systems have been discussed. Starting from these results, future work will also study the application of the proposed control architecture to poly-articular robots, achieving also a anatomical synergistic behavior.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
FA and CD developed the method and equally contributed to the paper. CD performed the experiments. All authors conceived the idea together and contributed to writing the manuscript.
This project has been supported by European Union's Horizon 2020 research and innovation programme under grant agreement 780883 (THING) and 871237 (Sophia), by ERC Synergy Grant 810346 (Natural BionicS) and by the Italian Ministry of Education and Research (MIUR) in the framework of the CrossLab project (Departments of Excellence).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. ^L(ui) is typically a smoothing function.
2. ^The simulink model is available online at www.naturalmachinemotioninitiative.com.
Ahn, H.-S., Choi, C.-H., and Kim, K.-B. (1993). Iterative learning control for a class of nonlinear systems. Automatica 29, 1575–1578. doi: 10.1016/0005-1098(93)90024-N
Albu-Schaffer, A., Eiberger, O., Grebenstein, M., Haddadin, S., Ott, C., Wimbock, T., et al. (2008). Soft robotics. IEEE Robot. Autom. Mag. 15, 20–30. doi: 10.1109/MRA.2008.927979
Angelini, F., Bianchi, M., Garabini, M., Bicchi, A., and Della Santina, C. (2020a). “Iterative learning control as a framework for human-inspired control with bio-mimetic actuators,” in Biomimetic and Biohybrid Systems. Living Machines 2020. Lecture Notes in Computer Science (Cham: Springer).
Angelini, F., Della Santina, C., Garabini, M., Bianchi, M., Gasparri, G. M., Grioli, G., et al. (2018). Decentralized trajectory tracking control for soft robots interacting with the environment. IEEE Trans. Robot. 34, 924–935. doi: 10.1109/TRO.2018.2830351
Angelini, F., Mengacci, R., Della Santina, C., Catalano, M. G., Garabini, M., Bicchi, A., et al. (2020b). Time generalization of trajectories learned on articulated soft robots. IEEE Robot. Autom. Lett. 5, 3493–3500. doi: 10.1109/LRA.2020.2977268
Ansari, Y., Laschi, C., and Falotico, E. (2019). “Structured motor exploration for adaptive learning-based tracking in soft robotic manipulators,” in 2019 2nd IEEE International Conference on Soft Robotics (RoboSoft) (Seoul: IEEE), 534–539. doi: 10.1109/ROBOSOFT.2019.8722767
Arif, M., Ishihara, T., and Inooka, H. (2001). Incorporation of experience in iterative learning controllers using locally weighted learning. Automatica 37, 881–888. doi: 10.1016/S0005-1098(01)00030-9
Arimoto, S., Kawamura, S., and Miyazaki, F. (1984). Bettering operation of robots by learning. J. Robot. Syst. 1, 123–140. doi: 10.1002/rob.4620010203
Asano, Y., Kozuki, T., Ookubo, S., Kawamura, M., Nakashima, S., Katayama, T., et al. (2016). “Human mimetic musculoskeletal humanoid kengoro toward real world physically interactive actions,” in 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids) (Cancun: IEEE), 876–883. doi: 10.1109/HUMANOIDS.2016.7803376
Averta, G., Della Santina, C., Battaglia, E., Felici, F., Bianchi, M., and Bicchi, A. (2017). Unvealing the principal modes of human upper limb movements through functional analysis. Front. Robot. AI 4:37. doi: 10.3389/frobt.2017.00037
Averta, G., Della Santina, C., Valenza, G., Bicchi, A., and Bianchi, M. (2020). Exploiting upper-limb functional principal components for human-like motion generation of anthropomorphic robots. J. Neuroeng. Rehabil. 17, 1–15. doi: 10.1186/s12984-020-00680-8
Bristow, D. A., Tharayil, M., and Alleyne, A. G. (2006). A survey of iterative learning control. IEEE Control Syst. 26, 96–114. doi: 10.1109/MCS.2006.1636313
Buondonno, G., and De Luca, A. (2016). Efficient computation of inverse dynamics and feedback linearization for vsa-based robots. IEEE Robot. Autom. Lett. 1, 908–915. doi: 10.1109/LRA.2016.2526072
Burdet, E., Osu, R., Franklin, D. W., Milner, T. E., and Kawato, M. (2001). The central nervous system stabilizes unstable dynamics by learning optimal impedance. Nature 414, 446–449. doi: 10.1038/35106566
Cao, J., Liang, W., Zhu, J., and Ren, Q. (2018). Control of a muscle-like soft actuator via a bioinspired approach. Bioinspir. Biomimet. 13:066005. doi: 10.1088/1748-3190/aae1be
Capolei, M. C., Andersen, N. A., Lund, H. H., Falotico, E., and Tolu, S. (2019). A cerebellar internal models control architecture for online sensorimotor adaptation of a humanoid robot acting in a dynamic environment. IEEE Robot. Autom. Lett. 5, 80–87. doi: 10.1109/LRA.2019.2943818
Della Santina, C., Bianchi, M., Grioli, G., Angelini, F., Catalano, M., Garabini, M., et al. (2017a). Controlling soft robots: balancing feedback and feedforward elements. IEEE Robot. Autom. Mag. 24, 75–83. doi: 10.1109/MRA.2016.2636360
Della Santina, C., Catalano, M. G., and Bicchi, A. (2020). Soft Robots. Berlin; Heidelberg: Springer Berlin Heidelberg. Available online at: https://tinyurl.com/tbdw3g6
Della Santina, C., Piazza, C., Gasparri, G. M., Bonilla, M., Catalano, M. G., Grioli, G., et al. (2017b). The quest for natural machine motion: an open platform to fast-prototyping articulated soft robots. IEEE Robot. Autom. Mag. 24, 48–56. doi: 10.1109/MRA.2016.2636366
Emken, J. L., Benitez, R., Sideris, A., Bobrow, J. E., and Reinkensmeyer, D. J. (2007). Motor adaptation as a greedy optimization of error and effort. J. Neurophysiol. 97, 3997–4006. doi: 10.1152/jn.01095.2006
Engel, K. C., Flanders, M., and Soechting, J. F. (1997). Anticipatory and sequential motor control in piano playing. Exp. Brain Res. 113, 189–199. doi: 10.1007/BF02450317
Flanagan, J. R., and Wing, A. M. (1993). Modulation of grip force with load force during point-to-point arm movements. Exp. Brain Res. 95, 131–143. doi: 10.1007/BF00229662
Flash, T., and Hogan, N. (1985). The coordination of arm movements: an experimentally confirmed mathematical model. J Neurosci. 5, 1688–1703. doi: 10.1523/JNEUROSCI.05-07-01688.1985
Friedman, J., and Flash, T. (2009). Trajectory of the index finger during grasping. Exp. Brain Res. 196, 497–509. doi: 10.1007/s00221-009-1878-2
Fu, Q., Zhang, W., and Santello, M. (2010). Anticipatory planning and control of grasp positions and forces for dexterous two-digit manipulation. J. Neurosci. 30, 9117–9126. doi: 10.1523/JNEUROSCI.4159-09.2010
Gandolfo, F., Mussa-Ivaldi, F., and Bizzi, E. (1996). Motor learning by field approximation. Proc. Natl. Acad. Sci. U.S.A. 93, 3843–3846. doi: 10.1073/pnas.93.9.3843
Garabini, M., Santina, C. D., Bianchi, M., Catalano, M., Grioli, G., and Bicchi, A. (2017). “Soft robots that mimic the neuromusculoskeletal system,” in Converging Clinical and Engineering Research on Neurorehabilitation II. Biosystems & Biorobotics, Vol. 15, eds J. Ibáñez, J. González-Vargas, J. Azorín, M. Akay and J. Pons (Cham: Springer). doi: 10.1007/978-3-319-46669-9_45
Gribble, P. L., Ostry, D. J., Sanguineti, V., and Laboissière, R. (1998). Are complex control signals required for human arm movement? J. Neurophysiol. 79, 1409–1424. doi: 10.1152/jn.1998.79.3.1409
Haith, M. M., Hazan, C., and Goodman, G. S. (1988). Expectation and anticipation of dynamic visual events by 3.5-month-old babies. Child Dev. 59, 467–479. doi: 10.2307/1130325
Herreros, I., Arsiwalla, X., and Verschure, P. (2016). “A forward model at Purkinje cell synapses facilitates cerebellar anticipatory control,” in Advances in Neural Information Processing Systems 29, eds D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon and R. Garnett (Curran Associates, Inc.), 3828–3836. Available online at: http://papers.nips.cc/paper/6151-a-forward-model-at-purkinje-cell-synapses-facilitates-cerebellar-anticipatory-control.pdf
Hofer, M., Spannagl, L., and D'Andrea, R. (2019). “Iterative learning control for fast and accurate position tracking with an articulated soft robotic arm,” in Conference: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Macau), 6602–6607. doi: 10.1109/IROS40897.2019.8967636
Hoffmann, J. (2003). “Anticipatory behavioral control,” in Anticipatory Behavior in Adaptive Learning Systems. Lecture Notes in Computer Science, Vol. 2684, eds M. V. Butz, O. Sigaud, and P. Gérard (Berlin, Heidelberg: Springer). doi: 10.1007/978-3-540-45002-3_4
Hordacre, B., and McCambridge, A. (2018). “Motor control: structure and function of the nervous system,” in Neurological Physiotherapy Pocketbook E-Book, eds S. Lennon, G. Ramdharry, and G. Verheydenlug (Elsevier Health Sciences), 21.
Jäntsch, M., Wittmeier, S., Dalamagkidis, K., Panos, A., Volkart, F., and Knoll, A. (2013). “Anthrob–a printed anthropomimetic robot,” in 2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids) (Atlanta, GA), 342–347. doi: 10.1109/HUMANOIDS.2013.7029997
Kawato, M. (1996). “2 f\ learning internal models of the motor apparatus,” in The Acquisition of Motor Behavior in Vertebrates (A Bradford Book), eds J. R. Bloedel, T. J. Ebner and S. P. Wise (The MIT Press), 409.
Keppler, M., Lakatos, D., Ott, C., and Albu-Schäffer, A. (2018). Elastic structure preserving (esp) control for compliantly actuated robots. IEEE Trans. Robot. 34, 317–335. doi: 10.1109/TRO.2017.2776314
Köhler, J., Soloperto, R., Muller, M. A., and Allgower, F. (2020). A computationally efficient robust model predictive control framework for uncertain nonlinear systems. IEEE Trans. Autom. Control. doi: 10.1109/TAC.2020.2982585
Kuppuswamy, N., Marques, H. G., and Hauser, H. (2012). “Synthesising a motor-primitive inspired control architecture for redundant compliant robots,” in From Animals to Animats 12. SAB 2012. Lecture Notes in Computer Science, Vol. 7426, eds T. Ziemke, C. Balkenius, J. Hallam (Berlin; Heidelberg: Springer). doi: 10.1007/978-3-642-33093-3_10
Lackner, J. R., and Dizio, P. (1998). Gravitoinertial force background level affects adaptation to coriolis force perturbations of reaching movements. J. Neurophysiol. 80, 546–553. doi: 10.1152/jn.1998.80.2.546
Landkammer, S., Winter, F., Schneider, D., and Hornfeck, R. (2016). Biomimetic spider leg joints: a review from biomechanical research to compliant robotic actuators. Robotics 5:15. doi: 10.3390/robotics5030015
Latash, M. L. (2010). Motor synergies and the equilibrium-point hypothesis. Motor Control 14:294. doi: 10.1123/mcj.14.3.294
Lee, J., Huber, M. E., Stemad, D., and Hogan, N. (2018). “Robot controllers compatible with human beam balancing behavior,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Madrid: IEEE), 3335–3341. doi: 10.1109/IROS.2018.8593549
Loram, I. D., Gollee, H., Lakie, M., and Gawthrop, P. J. (2011). Human control of an inverted pendulum: is continuous control necessary? Is intermittent control effective? Is intermittent control physiological? J. Physiol. 589, 307–324. doi: 10.1113/jphysiol.2010.194712
Marques, H. G., Jäntsch, M., Wittmeier, S., Holland, O., Alessandro, C., Diamond, A., et al. (2010). “Ecce1: the first of a series of anthropomimetic musculoskeletal upper torsos,” in 2010 10th IEEE-RAS International Conference on Humanoid Robots (Nashville: IEEE), 391–396. doi: 10.1109/ICHR.2010.5686344
Medina, J. R., Börner, H., Endo, S., and Hirche, S. (2019). Impedance-based gaussian processes for modeling human motor behavior in physical and non-physical interaction. IEEE Trans. Biomed. Eng. 66, 2499–2511. doi: 10.1109/TBME.2018.2890710
Mengacci, R., Angelini, F., Catalano, M. G, Grioli, G., Bicchi, A., et al. (2020). On the motion/stiffness decoupling property of articulated soft robots with application to model-free torque iterative learning control. Int. J. Robot. Res.
Mombaur, K., Truong, A., and Laumond, J.-P. (2010). From human to humanoid locomotion—an inverse optimal control approach. Auton. Robots 28, 369–383. doi: 10.1007/s10514-009-9170-7
Moore, K. L. (1999). “Iterative learning control: an expository overview,” in Applied and Computational Control, Signals, and Circuits, editor B. N. Datta (Boston, MA: Birkhäuser). doi: 10.1007/978-1-4612-0571-5_4
Morasso, P., and Ivaldi, F. M. (1982). Trajectory formation and handwriting: a computational model. Biol. Cybernet. 45, 131–142. doi: 10.1007/BF00335240
Neilson, P., Neilson, M., and O'dwyer, N. (1988). Internal models and intermittency: a theoretical account of human tracking behavior. Biol. Cybernet. 58, 101–112. doi: 10.1007/BF00364156
Nguyen-Tuong, D., Peters, J., Seeger, M., and Schölkopf, B. (2008). “Learning inverse dynamics: a comparison,” in European Symposium on Artificial Neural Networks (Belgium).
Pfeil, S., Henke, M., Katzer, K., Zimmermann, M., and Gerlach, G. (2020). A worm-like biomimetic crawling robot based on cylindrical dielectric elastomer actuators. Front. Robot. AI 7:9. doi: 10.3389/frobt.2020.00009
Pratt, G. A., and Williamson, M. M. (1995). “Series elastic actuators,” in Proceedings 1995 IEEE/RSJ International Conference on Intelligent Robots and Systems. Human Robot Interaction and Cooperative Robots, Vol. 1 (Pittsburgh, PA: IEEE), 399–406. doi: 10.1109/IROS.1995.525827
Purwin, O., and D'Andrea, R. (2009). “Performing aggressive maneuvers using iterative learning control,” in ICRA'09. IEEE International Conference on Robotics and Automation, 2009 (Kobe: IEEE), 1731–1736. doi: 10.1109/ROBOT.2009.5152599
Roberts, T. J., and Azizi, E. (2011). Flexible mechanisms: the diverse roles of biological springs in vertebrate movement. J. Exp. Biol. 214, 353–361. doi: 10.1242/jeb.038588
Ruan, X., Bien, Z. Z., and Park, K.-H. (2007). Decentralized iterative learning control to large-scale industrial processes for nonrepetitive trajectory tracking. IEEE Trans. Syst. Man Cybernet. A Syst. Hum. 38, 238–252. doi: 10.1109/TSMCA.2007.909549
Scholz, J. P., and Schöner, G. (1999). The uncontrolled manifold concept: identifying control variables for a functional task. Exp. Brain Res. 126, 289–306. doi: 10.1007/s002210050738
Shadmehr, R., and Mussa-Ivaldi, F. A. (1994). Adaptive representation of dynamics during learning of a motor task. J. Neurosci. 14, 3208–3224. doi: 10.1523/JNEUROSCI.14-05-03208.1994
Shadmehr, R., Smith, M. A., and Krakauer, J. W. (2010). Error correction, sensory prediction, and adaptation in motor control. Annu. Rev. Neurosci. 33, 89–108. doi: 10.1146/annurev-neuro-060909-153135
Shou, J., Pi, D., and Wang, W. (2003). “Sufficient conditions for the convergence of open-closed-loop pid-type iterative learning control for nonlinear time-varying systems,” in IEEE International Conference on Systems, Man and Cybernetics, 2003, Vol. 3 (Washington, DC: IEEE), 2557–2562.
Soechting, J., and Lacquaniti, F. (1983). Modification of trajectory of a pointing movement in response to a change in target location. J. Neurophysiol. 49, 548–564. doi: 10.1152/jn.1983.49.2.548
Sternad, D. (2018). It's not (only) the mean that matters: variability, noise and exploration in skill learning. Curr. Opin. Behav. Sci. 20, 183–195. doi: 10.1016/j.cobeha.2018.01.004
Swanson, L. W. (2012). Brain Architecture: Understanding the Basic Plan. Oxford: Oxford University Press.
Tomić, M., Jovanović, K., Chevallereau, C., Potkonjak, V., and Rodić, A. (2018). Toward optimal mapping of human dual-arm motion to humanoid motion for tasks involving contact with the environment. Int. J. Adv. Robot. Syst. 15:1729881418757377. doi: 10.1177/1729881418757377
Tseng, Y., Diedrichsen, J., Krakauer, J. W., Shadmehr, R., and Bastian, A. J. (2007). Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J. Neurophysiol. 98, 54–62. doi: 10.1152/jn.00266.2007
Vanderborght, B., Albu-Schäffer, A., Bicchi, A., Burdet, E., Caldwell, D. G., Carloni, R., et al. (2013). Variable impedance actuators: a review. Robot. Auton. Syst. 61, 1601–1614. doi: 10.1016/j.robot.2013.06.009
Wang, Y., Gao, F., and Doyle, III, F. J. (2009). Survey on iterative learning control, repetitive control, and run-to-run control. J. Process Control 19, 1589–1600. doi: 10.1016/j.jprocont.2009.09.006
Williams, C. K. I., and Rasmussen, C. E. (2006). Gaussian Processes for Machine Learning. Cambridge, MA: MIT press.
Zhakatayev, A., Rubagotti, M., and Varol, H. A. (2017). Time-optimal control of variable-stiffness-actuated systems. IEEE/ASME Trans. Mechatron. 22, 1247–1258. doi: 10.1109/TMECH.2017.2671371
Keywords: motion control algorithm, motor control, natural machine motion, articulated soft robots, human-inspired control, compliant actuation
Citation: Angelini F, Della Santina C, Garabini M, Bianchi M and Bicchi A (2020) Control Architecture for Human-Like Motion With Applications to Articulated Soft Robots. Front. Robot. AI 7:117. doi: 10.3389/frobt.2020.00117
Received: 30 April 2020; Accepted: 28 July 2020;
Published: 11 September 2020.
Edited by:
Concepción A. Monje, Universidad Carlos III de Madrid, SpainReviewed by:
Barkan Ugurlu, Özyeğin University, TurkeyCopyright © 2020 Angelini, Della Santina, Garabini, Bianchi and Bicchi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Franco Angelini, ZnJuY2FuZ2VsaW5pQGdtYWlsLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.