
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Public Health , 19 February 2025
Sec. Public Mental Health
Volume 13 - 2025 | https://doi.org/10.3389/fpubh.2025.1512537
This article is part of the Research Topic Empowering Suicide Prevention Efforts with Generative AI Technology View all 4 articles
 Elias Balt1,2*†
Elias Balt1,2*† Salim Salmi1†
Salim Salmi1† Sandjai Bhulai3Stefan Vrinzen1Merijn Eikelenboom1,2
Sandjai Bhulai3Stefan Vrinzen1Merijn Eikelenboom1,2 Renske Gilissen1,4
Renske Gilissen1,4 Daan Creemers5,6
Daan Creemers5,6 Arne Popma2
Arne Popma2 Saskia Mérelle1,7
Saskia Mérelle1,7Background: Psychosocial autopsy is a retrospective study of suicide, aimed to identify emerging themes and psychosocial risk factors. It typically relies heavily on qualitative data from interviews or medical documentation. However, qualitative research has often been scrutinized for being prone to bias and is notoriously time- and cost-intensive. Therefore, the current study aimed to investigate if a Large Language Model (LLM) can be feasibly integrated with qualitative research procedures, by evaluating the performance of the model in deductively coding and coherently summarizing interview data obtained in a psychosocial autopsy.
Methods: Data from 38 semi-structured interviews conducted with individuals bereaved by the suicide of a loved one was deductively coded by qualitative researchers and a server-installed LLAMA3 large language model. The model performance was evaluated in three tasks: (1) binary classification of coded segments, (2) independent classification using a sliding window approach, and (3) summarization of coded data. Intercoder agreement scores were calculated using Cohen’s Kappa, and the LLM’s summaries were qualitatively assessed using the Constant Comparative Method.
Results: The results showed that the LLM achieved substantial agreement with the researchers for the binary classification (accuracy: 0.84) and the sliding window task (accuracy: 0.67). The performance had large variability across codes. LLM summaries were typically rich enough for subsequent analysis by the researcher, with around 80% of the summaries being rated independently by two researchers as ‘adequate’ or ‘good.’ Emerging themes in the qualitative assessment of the summaries included unsolicited elaboration and hallucination.
Conclusion: State-of-the-art LLMs show great potential to support researchers in deductively coding complex interview data, which would alleviate the investment of time and resources. Integrating models with qualitative research procedures can facilitate near real-time monitoring. Based on the findings, we recommend a collaborative model, whereby the LLM’s deductive coding is complemented by review, inductive coding and further interpretation by a researcher. Future research may aim to replicate the findings in different contexts and evaluate models with a larger context size.
Qualitative research is essential for suicide prevention to establish new theories, explore trends and identify previously unexplored psychosocial risk factors (1). Aspers and Corte (2) broadly define qualitative research as: “an iterative process in which improved understanding to the scientific community is achieved by making new significant distinctions resulting from getting closer to the phenomenon studied.” More specifically, Tenny and colleagues (3) note that, instead of collecting numeric data points, qualitative research aims to gather participants’ perceptions, experiences or behavior. Notwithstanding its importance, qualitative research has received criticism for being prone to interpretation bias, problems with accuracy, and challenges to reproducibility (4). Moreover, there are various labor-intensive tasks involved with qualitative research, particularly when interviews are involved. These range from generating full-word transcriptions to coding the data, which entails that the text is labeled along certain concepts to provide structure and facilitate subsequent analysis (1). While quantitative analyses have been largely automated (e.g., statistical tests), many processes in qualitative research remain tediously archaic.
Automating part of qualitative analyses by means of artificial intelligence may reduce interpretation bias, enhance the reproducibility of findings from qualitative research, and reduce the researchers’ time investment. In 2011, Yu and colleagues (5) already noted that text processing tools can “capitalize on the epistemological compatibility between text mining and qualitative research,” and this is echoed by a recent editorial (6). Over the last years, large language models (LLM) have been recognized for their ability to generate general-purpose language. LLMs are transformer models (7) that were trained with an exceptionally large corpus of linguistic data and can interpret text, respond to queries, and generate textual content in a human-like fashion within the reasonable limitations of the training data (8). Several benchmarks for zero-shot questions (meaning the LLM had no prior knowledge of the question) show that LLMs can perform at high levels of accuracy. LLMs may therefore have the potential to analyze large amounts of textual data in- and outside of scientific research, for example in sentiment analysis (9), summarization of content, e.g., medical records in clinical settings (10), and structuring textual data (11).
Several recent studies concluded that integrating LLMs with qualitative analysis could have merit to make qualitative research more efficient and replicable, particularly in the coding process (11–13). In a recent study, Xiao and colleagues (11) used a pretrained Chat-GPT based language model to deductively code qualitative data from interviews with children. Their model achieved fair to substantial agreement with the coding work of an independent researcher. There are other examples of successfully integrating an LLM in qualitative analyses (12, 14). However, Christou and colleagues (15) provide important critical reflections on the pitfalls of using language models to support qualitative analysis, including hallucination, which entails that the model provides output that is incorrect or nonexistent, as well as bias (models can consistently fail to address a particular theme due to deficient training and performance in that topic). Consequently, the authors suggest that an LLM cannot perform independently of researchers yet. Moreover, experts of qualitative research warn that LLMs should be used cautiously and that ethical and intellectually challenging tasks are still beyond their potential (16). This conceivably includes inductive coding, whereby the model must recognize, prioritize and label themes in a text body without receiving a priori definitions. A collaborative approach may, however, be feasible, whereby the model performs deductive coding, which is scrutinized by a research team (11). This could support public health surveillance in novel ways, as noted by Olawade and colleagues in a recent narrative review (17).
Psychosocial autopsy is a research methodology aimed at investigating suicide cases, which generally combines interviews with bereaved informants and available records (18), facilitating mixed methods analyses with a large qualitative component. Internationally, psychosocial autopsy is an acclaimed method to obtain insights into risk factors for suicide, in particular in a case–control design (19, 20). Additionally, psychosocial autopsy interviews can be used to obtain a better understanding of proximal stressors for suicide (21). In the Netherlands, psychosocial autopsy studies have been formerly conducted to investigate suicides of young people (22) and railway suicides (23). Recently, a psychosocial autopsy has been implemented to monitor and investigate suicides routinely on a national scale. This resulted in a cross-sectional, retrospective, dynamic cohort where quantitative and qualitative data are added constantly. This data envelops dichotomous and categorical variables such as psychiatric diagnoses or education level, but also data from many interviews with next-of-kin of suicide decedents. Through this information, we can obtain real-time insights into psychosocial characteristics associated with suicides, investigate trends, and provide recommendations for prevention.
LLMs may be integrated with research procedures to standardize the qualitative analysis of psychosocial autopsy data, to increase efficiency and possibly enhance reproducibility. To the best of our knowledge, state-of-the-art language models have not been evaluated for their ability to process complex interview data from a psychosocial autopsy. We can understand the possibilities of LLMs in this field better based on empirical data in addition to expert authority and theoretical knowledge. The current study aimed to investigate if an LLM achieves sufficient agreement with a researcher in the deductive coding of interview data obtained in a psychosocial autopsy and can summarize data of adequate quality to be feasibly integrated with qualitative research procedures.
The corpus for this study consisted of 38 full-word interview transcripts obtained in a psychosocial autopsy study of railway suicides, collected between October 2021 and May 2022 (MREC of the Amsterdam University Medical Centre, NL76295.029.21). Respondents were people who lost a loved one to suicide. The instrument for the two-hour semi-structured interviews was based on international examples and covered topics ranging from school- and work problems to social media use and mental health problems, using instruments based on international examples (19, 20, 24) and national health monitors (25). Instead of training a model to recognize codes, we employed a few-shot learning approach (26). This approach included a labeled example of each class in the prompt. This methodology was guided by advancements in the field which suggest that LLMs can recognize topics without specific training due to their extensive knowledge of contextual semantics (8). For our study, we used the 70B instruct version of Llama3. Llama3 is an open-source, large language model which was developed by Meta (27). The model uses generative artificial intelligence for language prediction. Version 3 of the model had high benchmark scores in various language processing tasks and an increased context size compared to earlier versions of the model. Most importantly, the model could be installed onto a server for offline use, which ensured safety of the data, and this was a prerequisite for this study. The model was sourced and implemented using the Huggingface Transformers library (28). We opted for this model over other open-source models as it had the best performance in language understanding at the time of development (April 2024), as is reflected by benchmarks in Table 1.
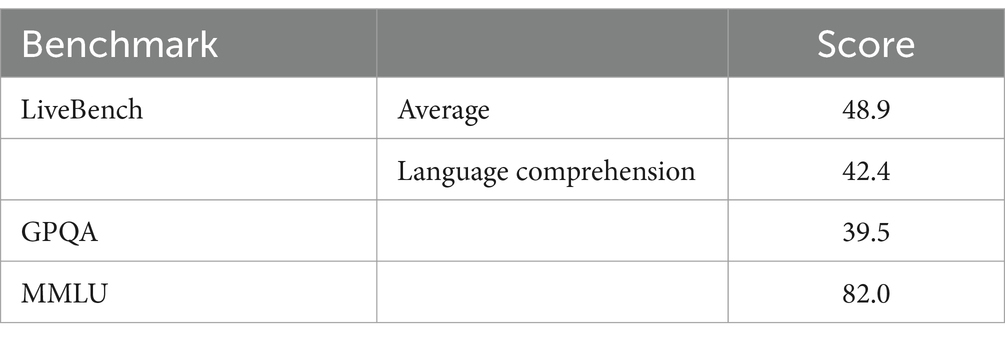
Table 1. List of language understanding benchmarks for Llama 3 70b instruct.
The topics the model extracted were segments of text associated with predefined labels, or codes, which are commonly used in qualitative analyses. The dataset contained 2,666 coded transcript fragments averaging 207.62 (SD 190.57) words. The transcripts had been coded by researchers using a coding sheet. Manual coding of the interviews was performed in the context of the psychosocial autopsy study and took place from May 2022 to September 2022. Coding was performed independently by two individual researchers and received the consensus of a third researcher. This represented the ‘gold standard.’ Both deductive coding, which means that codes were formulated a priori, and inductive coding, which entails that new codes were created for emerging themes, were performed by the researchers. However, for the model’s evaluation we focused on deductive codes, formulated directly from questions in the interview instrument with fixed definitions. The code list with corresponding definitions has been supplemented with this manuscript (Supplementary File 1).
Before the formal evaluation, we ran several preliminary iterations to optimize prompts and prevent logical errors. We first used synthetic interview data, after which we dedicated a single transcript of the corpus to engineer the prompt. Furthermore, one positive and one negative example were selected from the coded transcript fragments for each code. These examples were used to create the few-shot learning prompt and excluded from the evaluation dataset. We started the evaluation once the research team agreed that the prompts were satisfactory.
To implement the few-shot classification approach, the following prompts were utilized:
System Prompt: This prompt defines the intended behavior of the LLM and sets the context for its responses. The system prompt used was:
"You are a helpful assistant. Your task is to determine whether a given topic is explicitly mentioned in segments of interview transcripts between interviewers and relatives of suicide victims. Respond with 'True' or 'False,' initially assuming 'False' unless the text explicitly proves otherwise."
User Prompt: This prompt specifies the classification question. The prompt used was:
"Could you please tell me if the topic '{label_definition}' is mentioned in the interview transcript: '{interview_text}'?"
To create a few-shot learning prompt, correct responses from the LLM were artificially included for the first two examples in the prompt. These examples served as demonstrations of the desired input–output behavior. The LLM was then asked to generate the response for a third, unseen example based on the context provided. The final prompt for the few-shot setting was constructed as follows:
System: “You are a helpful assistant. Your task is to determine whether a given topic is explicitly mentioned.”
User: “Could you please tell me if the topic ‘{label_definition}’ is mentioned in the interview transcript: ‘{positive_interview_text}’?”
Assistant: “True.”
User: “Could you please tell me if the topic ‘{label_definition}’ is mentioned in the interview transcript: ‘{negative_interview_text}’?”
Assistant: “False.”
User: “Could you please tell me if the topic ‘{label_definition}’ is mentioned in the interview transcript: ‘{unseen_interview_text}’?”
The evaluation foremostly concerned the model’s capability. Still, the research team also discussed the model’s utility, transparency and accountability of the LLM in the context of psychosocial autopsy research (29).
We evaluated the model’s capability on three levels, moving toward increasingly specialized tasks. Aligning the pioneering work of Xiao and colleagues (11), we aimed to assess the ability of the model to:
1. Correctly identify a code in a segment.
2. Identify segments in the transcript that match a specific code.
3. Summarize relevant information from identified segments with respect to a specific code.
In the first level we introduced a binary classification problem. The model was prompted to determine whether a specific code was found in a text segment. The code in this context is the detailed description of a topic. There was agreement if both the researcher and the model determined that a code was (TP), or was not (TN), found in the text. We calculated accuracy and intercoder agreement (Cohens Kappa). Landis and Koch (30) propose criteria for agreement between qualitative researchers, with a Cohens Kappa of less than 0 as indicating no agreement, between 0 and 0.20 as slight, 0.21 and 0.40 as fair, 0.41 and 0.60 as moderate, 0.61 and 0.80 as substantial, and 0.81 and 1 as nearly perfect agreement.
For the second step, the model was presented with the same prompt, i.e., classify text based on a topic definition, but applied to the entire transcript using a sliding window approach. The windows were subsequent sentences in the transcript that did not exceed 300 words. The starting sentence of the next window was at least 75 words after the starting sentence of the current window. Motivations for this approach were that (1) the corpus was too long to integrally load into the model, (2) the interviews lacked logical markers to segment the text, and (3) there was a high variance in the length of fragments coded by the researchers. During pretests, we confirmed that segment length did not affect model performance, except when segments were either very short or very long. A length of 300 words was deemed appropriate, accounting for model performance and computational limits.
After the sliding window operation, peak detection was performed to filter any text relevant to a code from the interview. Peak detection was done by taking the number of times a sentence appeared in a positively classified window, smoothing this number using a moving average, and selecting all sentences where the result was above a threshold. The threshold was initially set at 51% of the maximum window overlap, rounded up to the next whole number. In the case of our parameters, this was a maximum of four, thus the threshold was set at three. Selected sentences that formed contiguous blocks of text were grouped. Each group obtained in this way is one detected segment. However, if a particular code resulted in large segments that exceeded the capacity of the model, the threshold was incrementally increased, until the largest segment for that code was 3,000 words at maximum. This was a prerequisite for the summarization task (Figure 1).
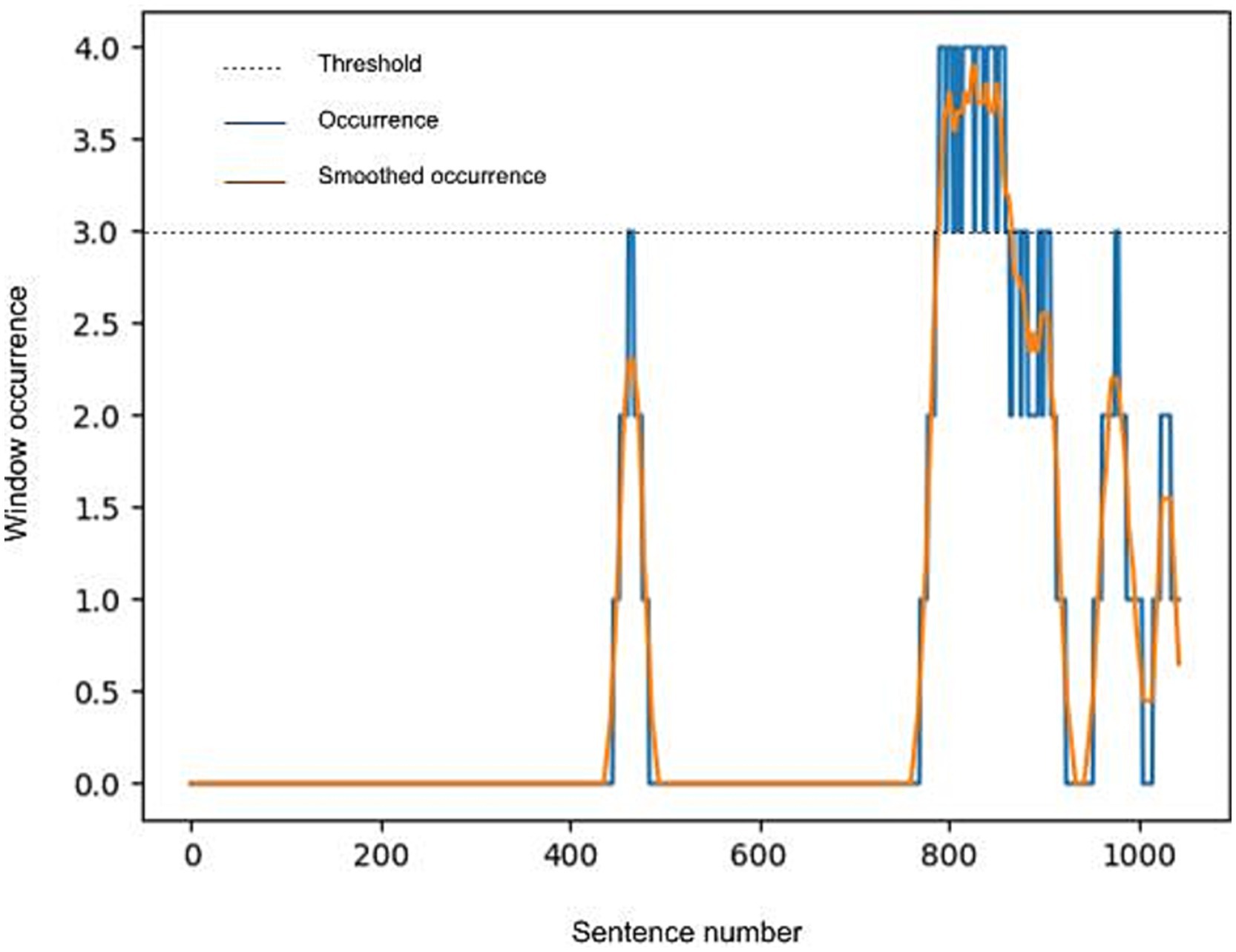
Figure 1. Example peak detection and smoothing procedure.
We evaluated this task based on two metrics. The relative code frequency of the LLM (i.e., how many segments were detected) was compared to that of the researcher. Because of the sliding window, we did not expect the frequency of codes labeled by the model and the researcher to be similar. Instead, we report the relative frequency. This measure indicates how likely the model was to identify a code compared to the researcher and thus illustrates the model’s tendency to emphasize particular codes. Second, we compared the binary occurrence of codes in the matrices of the researcher and the model and calculated accuracy.
Finally, we evaluated a summarization task. The model was prompted to summarize all identified segments per code. If too much text was identified for a single prompt, the segments were equally divided into two or more prompts. As part of the qualitative analysis method ‘Constant Comparative Method’ (31), researchers created a matrix with interview cases in rows, and codes in columns, facilitating axial comparison of key themes between cases. Data coded by the researcher was summarized into this matrix. A duplicate matrix was developed with the data coded by the model. Two researchers independently assessed the content of the model’s summaries compared to the researchers’ summaries. The researchers scored the LLM summaries with ‘good,’ ‘adequate,’ or ‘poor.’ Additionally, notable qualitative findings were recorded and discussed with the research team.
For the binary classification task, we calculated the sensitivity, specificity, accuracy and Cohens Kappa. For the code frequencies obtained using the sliding window method we report the code frequency of the LLM, of the researcher, and a ratio of the code frequency of the LLM compared to that of the researcher (Factor). Finally, we report the classification score of the sliding window in terms of accuracy.
The model had a mean accuracy of 0.84 (SD: 0.09) in binary classification. There was substantial agreement with the researcher (Cohens Kappa: 0.68). The highest accuracy scores were found for codes detailing a specific topic, including details about the location and circumstances of the suicide, transportation to the location, the suicide method and preparation of the suicide. We found a lower performance for codes that aimed to capture (changes in) behaviors, communication and interpersonal problems. Specifically, we identified a high number of false positives compared to a low number of false negatives. This means the model labeled data with a code that the researcher did not use. Table 2 reports the model’s performance in the binary classification task, with sensitivity, specificity, accuracy (ACC) and intercoder agreement (Cohens Kappa, CK).
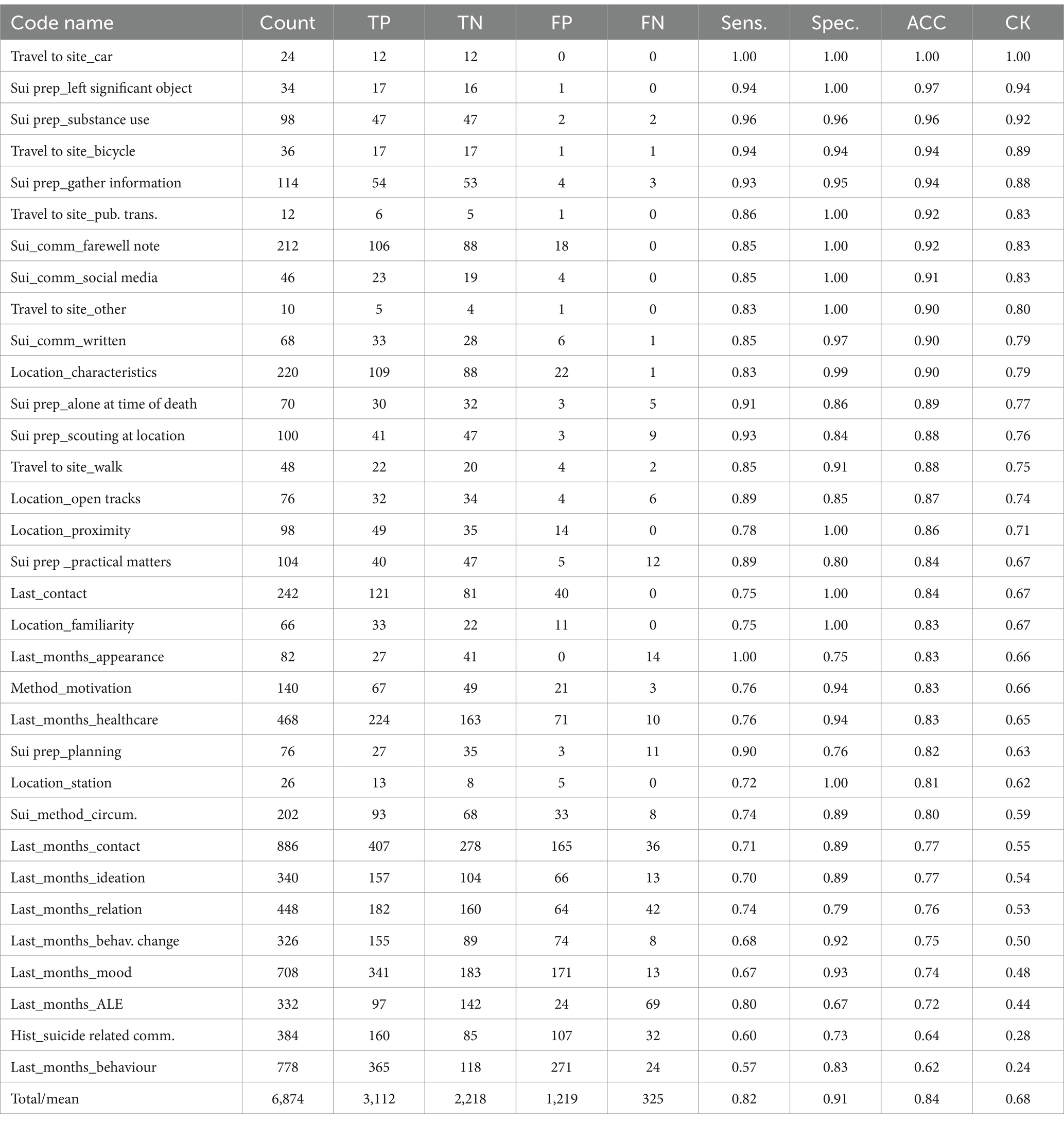
Table 2. Binary classification task.
Table 3 shows the relative frequency of codes labeled by the LLM compared to the researchers. The LLM was more likely to determine a code in a corpus by a factor 1.6. Seemingly paradoxical, the absolute code frequency was higher among the researchers. Codes that the LLM was disproportionally inclined to use were often codes with overall low occurrence, leading to a high relative frequency but a small difference in the absolute number of classified segments. These included multiple codes relating to the mode of transportation used by the decedent to travel to the location of the suicide. The median factor was 0.8.
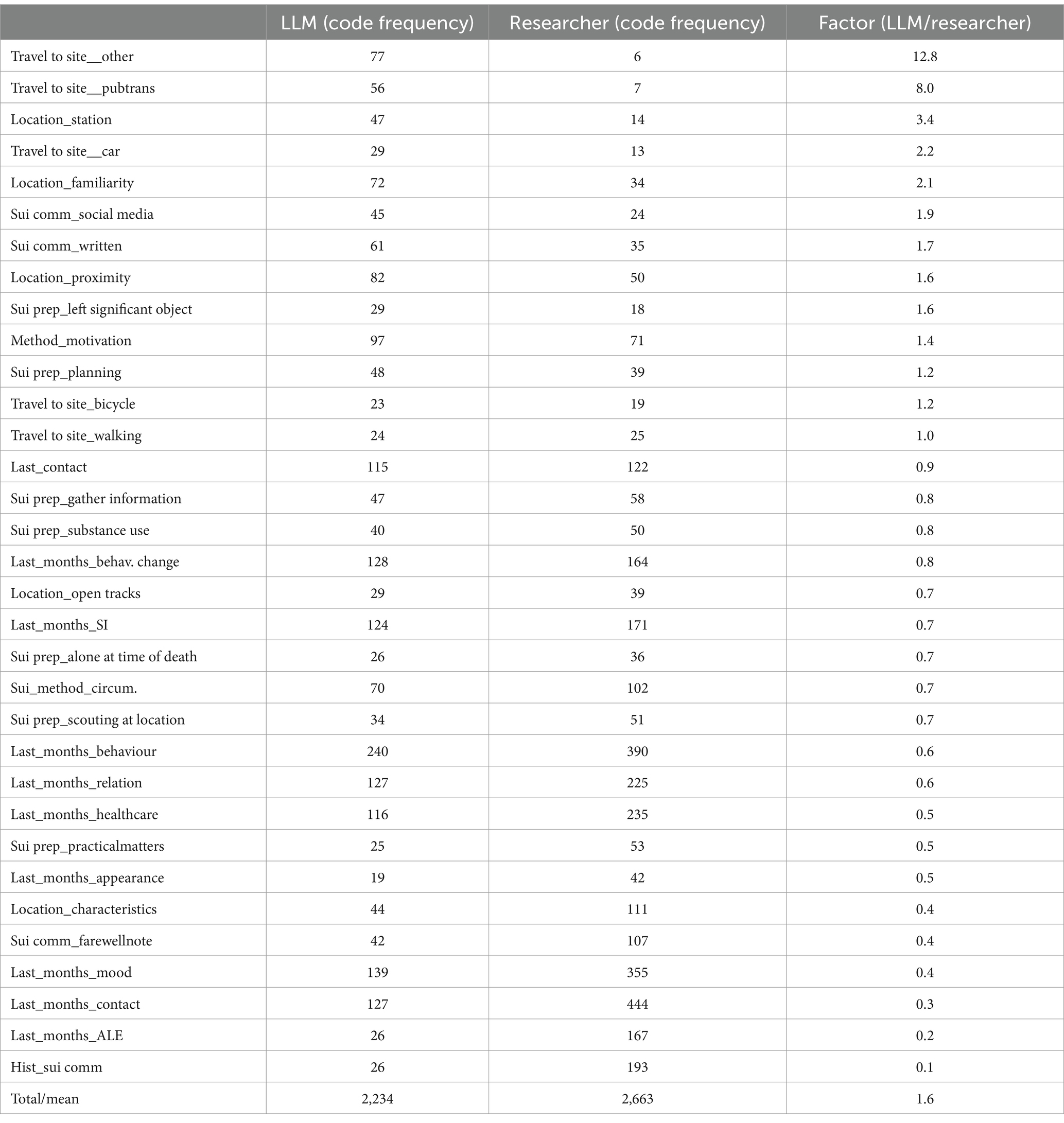
Table 3. Sliding window classification (frequencies).
We plotted the dichotomous occurrence of codes identified by the LLM with the sliding window approach. This was compared to the work of the researcher (Table 4). The model’s accuracy in this task was 0.67. It performed well for most codes, with several outliers that strongly influenced overall performance, including the mode of transportation to the location of the suicide. Some performance scores contrasted those found in the binary classification, which we address in the discussion.
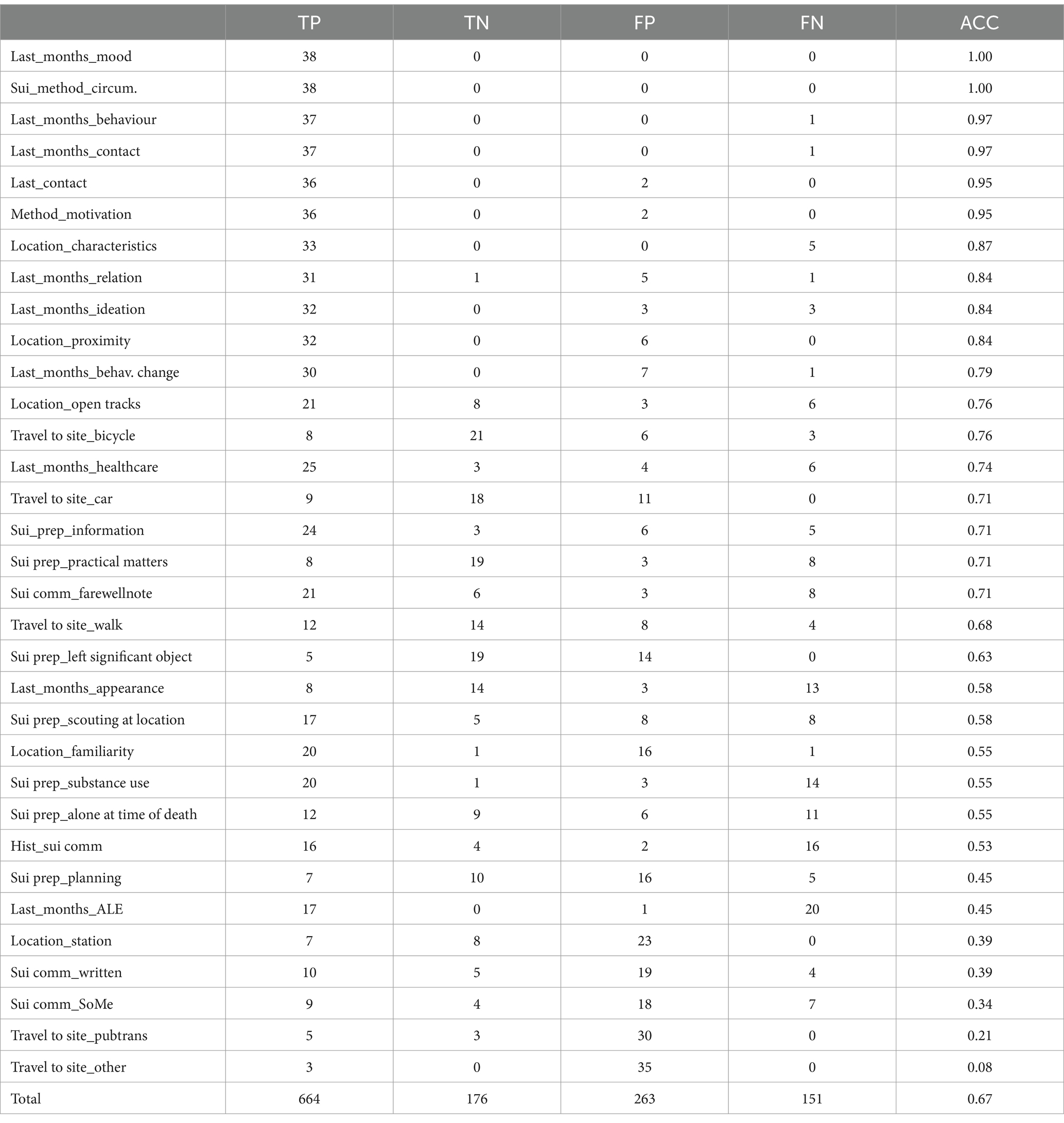
Table 4. Sliding window classification (binary).
Table 5 presents the scores for the LLM’s summaries of the data. Eighty percent of the summaries were rated as ‘adequate’ or ‘good.’ and sufficiently rich for subsequent qualitative analyses. It repeatedly referenced the original text, without having been specifically prompted, which facilitated review. Illustrative (anonymized) examples of a good, adequate and poor summary have been added as Supplementary File 2.
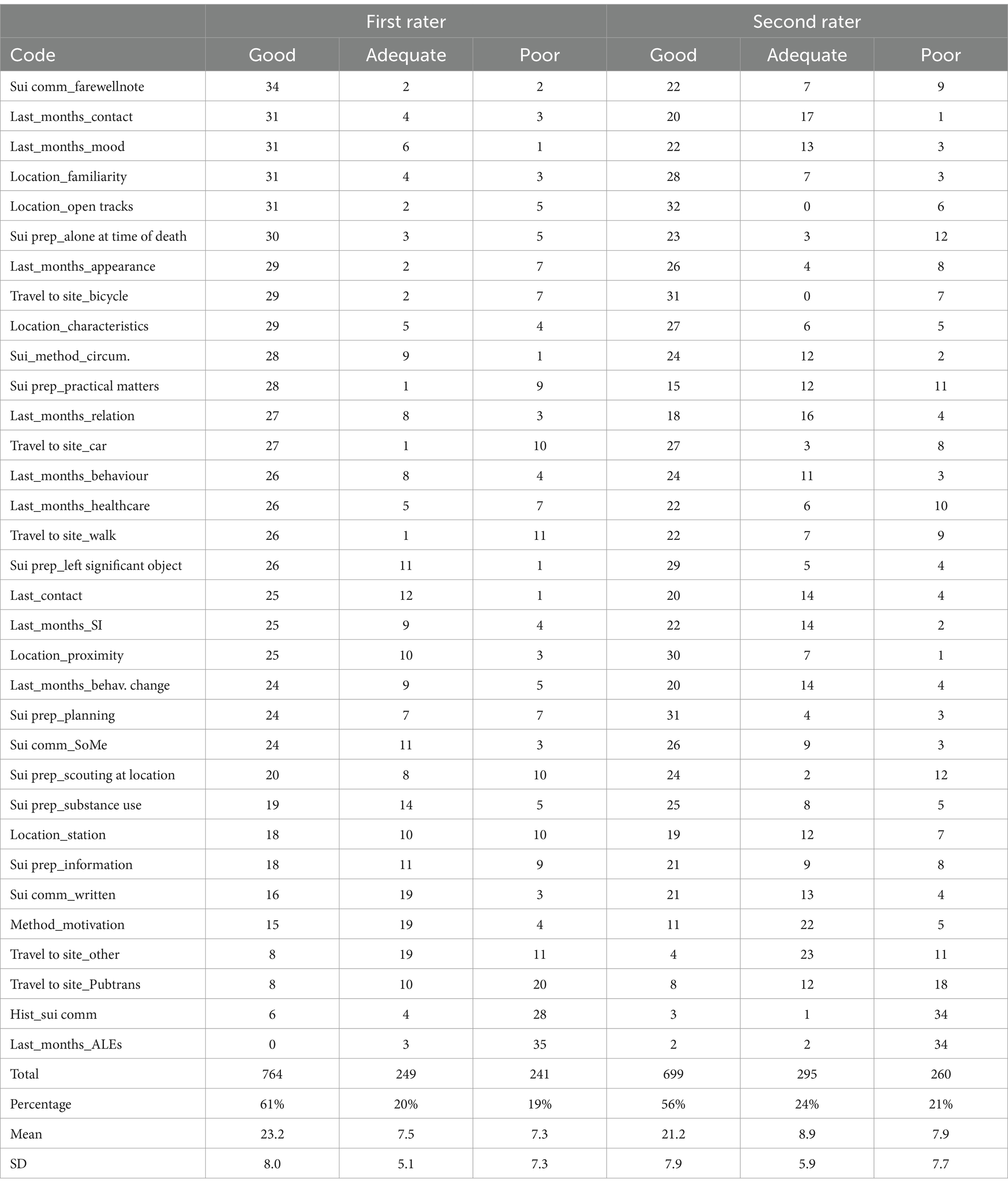
Table 5. Summarization task rated.
The researchers qualitatively analyzed the summaries and marked key themes that constituted adequate and poor summaries.
For all codes, including those with narrow definitions, the LLM was inclined to return summaries that were far more elaborate than the code definition would stipulate. This occurred in at least 247 of the coded segments (19.7%) As opposed to hallucination (theme 4), unsolicited elaboration referred to data that was both correct and relevant output, but not for a given code. This produced duplicate data under multiple codes. Segments typically included information to which various codes could be applied, but the model should remove abundant information in the summary when given a focal point.
The model did not consistently recognize the subject of a sentence, which compromised the credibility of some details in the summaries. The model may have been confused by different demonstrative pronouns used by the interviewer and the respondent. The fact that transcripts were anonymized during transcription may have also affected this.
The model failed to summarize crucial information under the correct code in at least 38 instances across the 1,254 fragments (3.0%). For example, in one case, the model did not recognize that a young man had lied about having to go to school on the day he took his own life. In fact, the model mentioned that the boy had to attend school on the day of his suicide, seemingly oblivious to semantic cues referring to this as a lie. However, it stood out that the LLM sometimes reported the required information under an overlapping code. In the case example, the model reported the decedent lying about his school assignment under another code. Overlapping codes (and definitions) appeared to have acted as a failsafe at the cost of accuracy.
In at least sixteen summarized segments (1.3%), the model fabricated a summary that was factually wrong or based on non-existent data. Notably, it stood out that the hallucinated data was clearly not in line with the quality of the other output, which made it easy to recognize. Nevertheless, this finding indicates a need to consistently check the LLM’s work, which has obvious implications for the feasibility of independent LLM data classification.
The LLM performed poorly at summarizing codes relying on a non-specific time indicator. An example was the code ‘Last_contact’ which refers to the last time the respondent saw or spoke to the decedent. The LLM wrongly summarized an interaction as ‘last contact’ in several cases, apparently influenced by syntactic cues in that window (e.g., “last time I saw her at work…”) without understanding its actual meaning. Later in the interview (outside the window), the respondent discussed an event more proximal to the suicide.
This study investigated if a large language model can achieve sufficient agreement with qualitative researchers to be integrated with qualitative research procedures in a psychosocial autopsy study. The model performed well in the binary classification task (accuracy: 0.84), proving itself capable of recognizing predefined codes in shorter segments. There was substantial agreement with a researcher (Cohens Kappa: 0.68). Performance was lower with the sliding window technique (accuracy: 0.67). We noted that most errors were false positives in the binary classification and the sliding window tasks. This might be explained by research that suggests LLMs can hallucinate data to conform with a task (16), which results in false positives rather than false negatives. Interestingly, a recent publication instead warns of the propensity of LLMs to generate false negatives more often than false positives (32). We believe that, in a collaborative approach, false positives are preferable to false negatives, because it is less time-consuming to confirm findings from the model compared to identifying what the model missed. An alternative and more optimistic perspective is that the LLM may have labeled data independently, while researchers implicitly weighed the relative compatibility of different codes. For example, if a text segment referred to the preparation for the suicide, researchers often exclusively used a code describing preparation. Meanwhile, the LLM selected any codes relating to behavior and suicide preparation.
The discrepancy in performance between binary classification and data labeling through a sliding window approach stood out. In the latter, we dichotomized the occurrence of a code in a transcript, which obviously favors codes that are salient in the corpus. Codes scoring well in both the binary classification and the sliding window task were characterized by (1) a specific definition, (2) semantic exclusivity (as little overlap with other codes as possible) and (3) moderate occurrence throughout the corpus. An LLM particularly struggles with “other” categories based on negation and does not adequately classify this type of data. Codes and coherent definitions are critical for performance. Codes purposed to identify a specific topic should be split into a list of subcodes, preferably with mutually exclusive definitions to improve accuracy, and they should not be formulated with a negation structure. Although accuracy was lower for the broader codes in binary classification due to the large number of false positives, the summaries were exhaustive. Researchers could consider a stepped summarization procedure to further condense LLM output, but this requires additional scrutiny.
On an hourly scale, the model was not optimized for performance. The model took approximately 5 h per interview (maximum n = 30,000 words), which was 1 h longer than a researcher typically needed to code the average interview. One avenue to achieve large reductions in computing time is to use sequential segments instead of a sliding window approach. Properly segmenting an interview beforehand result in roughly four times fewer operations, for segments equal to the window size. This would mean the model could code an interview in slightly over an hour. Another possible time increase could be gained with improvements to the capability of the LLM and its context window, allowing for interviews to be coded in their entirety without segmentation. Moreover, we believe that it is in the broader time schedule of a qualitative research project that Large Language Models will make the difference. The researchers in our project took roughly 4 months to code 38 interviews, as they obviously did not work continuously and needed to balance other work, while the model completed the deductive coding task of all 38 interviews in 8 days.
Qualitative research entails more than coding the data alone. A comparison of the steps after coding—reviewing, interpreting, and processing the findings for a report— was outside the scope of this study. The time investment of these intellectual tasks is conceivably affected by familiarity with the data (which manual coding might foster), how the output is structured, the quality of the output, and many other factors. We believe it would require more rigorous research to properly compare the efficiency of an LLM research assistant to a human researcher, in a design that includes accurate measures of all subprocesses of qualitative analysis but also appreciates the broader time schedule of a study (33).
The contents summarized by the LLM were mostly rated as ‘good’ by researchers. The model provided summaries suitable for subsequent qualitative analysis by a researcher, referring to the original data. The reference to the original data increases transparency, as it indicates how a model came to its output despite operating as a black box and allowing researchers to double check any conclusions made by the LLM. Approximately one fifth of the summaries were rated as ‘poor.’ There was a large discrepancy in quality between different codes. The LLM sometimes summarized inaccurately, using data unrelated to the code definition. These findings align with recent research by Zhang, Jijo and colleagues (34), and are conceivably affected by text structure. Interviewers can additionally be instructed to more strictly adhere to an interview protocol, if required, to improve the interview structure, and ensure that all topics from the instrument are touched. An infrequent but serious error was hallucination. This may have been caused by incomplete or noisy data, unspecific definitions, or semantic gaps. In our qualitative assessment, we noticed that the content of hallucinated data often mirrored syntactic structures in the few-shot examples in our prompts. Future research may determine if prompts combined with few-shot examples can induce hallucinations. High-quality data, specific prompts and techniques such as ‘self-familiarity’ (35) may prevent hallucination to some extent. Finally, the summaries appeared consistent across demographically diverse cases. Our model was not provided with demographic information about the decedent. A different methodology could be more appropriate to rigorously investigate bias of language models in coding tasks. Researchers could, for example, prompt the model with a duplicate interview segment, but provide a different -fabricated- demographic background with each segment to compare and assess the model outputs for structural bias.
The current study has been among the first to investigate the potential of an LLM to deductively code and summarize complex qualitative data. Performance was high for a first attempt without training and these findings are promising in a reasonably young field of research. There are several limitations of our research. Firstly, the corpus was not large enough to create a dataset with enough training and test examples. A trained model may improve outcomes. Secondly, although state-of-the-art LLMs have increasingly large context lengths [8,192 tokens for LLAMA3 (27)], this is not yet enough to capture an interview of up to 30,000 words. Therefore, our model used a sliding window. This obstructed chronological annotation. For example, capturing the nuances of (changes in) behavior in chronological order in the period preceding suicide was hampered by the windows’ brevity. Chronological classification may become possible as the context size of LLMs increases, and feasible with improved computing power. Lastly, the dataset used in this research was Dutch. Our findings may not directly translate to other languages.
State-of-the-art language models can support researchers in deductively coding complex interview data. We found some evidence that it improved efficiency, but more research is needed to investigate if large language models can systematically alleviate the investment of time and resources in qualitative research. Additionally, these models may facilitate unprecedented, near real-time monitoring based on qualitative data which can improve the timeliness of public health prevention efforts. Qualitative researchers can thus reinvent their workflow by integrating language models, but they should explicitly retain responsibility for the quality of the output. Based on our findings, we recommend a collaborative approach to strike a balance between efficiency and oversight, whereby the LLM performs initial deductive coding using key indicators and the researchers review the output, interpret the data, and perform additional inductive coding. Ideally, an active learning loop is incorporated into the design, through which researchers can provide feedback to the model about appropriately and inappropriately coded segments. Future research should aim to include a variety of qualitative data, concerning both data structure and subjects, to investigate functionality in diverse contexts.
The datasets presented in this article are not readily available because interview data used to evaluate the model cannot be shared publicly because of ethical restrictions: the dataset contains potentially identifying and sensitive information, and the Medical Research Ethics Committee (MREC) of Amsterdam UMC has imposed this restriction (registration number: NL76295.029.21). Contact: bWV0Y0B2dW1jLm5s, https://metc.amsterdamumc.org/. Data may be made available upon reasonable request if the researcher adheres to the criteria formulated by the MREC. Contact the corresponding author (EB) for inquiries. Requests to access the datasets should be directed to ZS5iYWx0QDExMy5ubA==.
The studies involving humans were approved by the corpus for this study consisted of 38 full-word interview transcripts obtained in a psychosocial autopsy study of railway suicides, collected between October 2021 and May 2022 (MREC of the Amsterdam University Medical Centre, NL76295.029.21). The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
EB: Conceptualization, Data curation, Formal analysis, Methodology, Writing – original draft, Writing – review & editing, Investigation, Project administration. SS: Conceptualization, Formal analysis, Methodology, Software, Visualization, Writing – original draft, Writing – review & editing, Investigation. SB: Conceptualization, Methodology, Supervision, Writing – review & editing. SV: Writing – review & editing, Data curation, Formal analysis, Investigation, Writing – original draft. ME: Supervision, Writing – review & editing. RG: Supervision, Writing – review & editing, Conceptualization. DC: Investigation, Supervision, Writing – review & editing. AP: Conceptualization, Supervision, Writing – review & editing. SM: Conceptualization, Investigation, Methodology, Supervision, Validation, Writing – review & editing.
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2025.1512537/full#supplementary-material
Supplementary File 1 | Codes and definitions.
Supplementary File 2 | LLM summarization scores illustration.
Supplementary File 3 | Server specifications.
2. Aspers, P, and Corte, U. What is qualitative in qualitative research. Qual Sociol. (2019) 42:139–60. doi: 10.1007/s11133-019-9413-7
3. Tenny, S, Brannan, JM, and Brannan, GD. Qualitative study. StatPearls. (2022). Available at: https://www.ncbi.nlm.nih.gov/books/NBK470395/
4. André, Q, Daniel, F, and Fernando, A. Strengths and limitations of qualitative and quantitative research methods. Eur J Educ Stud. (2017) 3:370. doi: 10.5281/zenodo.887088
5. Yu, C, Jannasch-Pennell, A, and DiGangi, S. Compatibility between text mining and qualitative research in the perspectives of grounded theory, content analysis, and reliability. Qual Rep. (2014) 16:730–44. doi: 10.46743/2160-3715/2011.1085
6. Kantor, J. Best practices for implementing ChatGPT, large language models, and artificial intelligence in qualitative and survey-based research. JAAD Int. (2024) 14:22–3. doi: 10.1016/j.jdin.2023.10.001
7. Vaswani, A, Shazeer, N, Parmar, N, Uszkoreit, J, Jones, L, Gomez, AN, et al. Attention is all you need. In: advances in neural information processing systems. (2017). Available at: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
8. Jason, W, Wang, X, Dale, S, Maarten, B, Brian, I, Fei, X, et al. Chain-of-thought prompting elicits reasoning in large language models In: Advances in neural information processing systems Eds. S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh. Curran Associates, Inc. (2022). 24824–37.
9. Zhang, W, Deng, Y, Liu, B, Pan, SJ, and Bing, L. Sentiment analysis in the era of large language models: a reality check. arXiv [Preprint]. (2023). doi: 10.18653/v1/2024.findings-naacl.246
10. van, D, van, C, Blankemeier, L, Delbrouck, JB, Aali, A, Bluethgen, C, et al. Adapted large language models can outperform medical experts in clinical text summarization. Nat Med. (2024) 30:1134–42. doi: 10.1038/s41591-024-02855-5
11. Xiao, Z, Yuan, X, Liao, QV, Abdelghani, R, and Oudeyer, PY. Supporting qualitative analysis with large language models: combining codebook with GPT-3 for deductive coding In: In: 28th international conference on intelligent user interfaces. New York, NY, USA: ACM (2023). 75–8.
12. Zhao, F, Yu, F, Trull, T, and Shang, Y. A new method using LLMs for Keypoints generation in qualitative data analysis In: In: 2023 IEEE conference on artificial intelligence (CAI). Santa Clara, CA, USA IEEE (2023). 333–334. doi: 10.1109/CAI54212.2023.00147
13. Hitch, D. Artificial intelligence augmented qualitative analysis: the way of the future? Qual Health Res. (2024) 34:595–606. doi: 10.1177/10497323231217392
14. Gebreegziabher, SA, Zhang, Z, Tang, X, Meng, Y, Glassman, EL, and Li, TJJ. PaTAT: human-AI collaborative qualitative coding with explainable interactive rule synthesis In: Proceedings of the 2023 CHI conference on human factors in computing systems. New York, NY, USA: ACM (2023). Eds. A. Schmidt, K. Väänänen, T. Goyal, P. O. Kristensson, A. Peters, S. Mueller. 1–19.
15. Christou, PA. The use of artificial intelligence (AI) in qualitative research for theory development. Qual Rep. (2023) 28, 2739–2755. doi: 10.46743/2160-3715/2023.6536
16. Roberts, J, Baker, M, and Andrew, J. Artificial intelligence and qualitative research: the promise and perils of large language model (LLM) ‘assistance’. Crit Perspect Account. (2024) 99:102722. doi: 10.1016/j.cpa.2024.102722
17. Olawade, DB, Wada, OJ, David-Olawade, AC, Kunonga, E, Abaire, O, and Ling, J. Using artificial intelligence to improve public health: a narrative review. Front. Public Health. (2023) 11:11. doi: 10.3389/fpubh.2023.1196397
18. Pouliot, L, and De Leo, D. Critical issues in psychological autopsy studies. Suicide Life Threat Behav. (2006) 36:491–510. doi: 10.1521/suli.2006.36.5.491
19. Portzky, G, Audenaert, K, and van Heeringen, K. Psychosocial and psychiatric factors associated with adolescent suicide: a case-control psychological autopsy study. J Adolesc. (2009) 32:849–62. doi: 10.1016/j.adolescence.2008.10.007
20. Arensman, E, Bennardi, M, Larkin, C, Wall, A, McAuliffe, C, McCarthy, J, et al. Suicide among young people and adults in Ireland: method characteristics, toxicological analysis and substance abuse histories compared. PLoS One. (2016) 11:e0166881. doi: 10.1371/journal.pone.0166881
21. van Landschoot, R, De Jaegere, E, Rotsaert, I, and Witvrouwen, B. INSIGHT study - Een case-control onderzoek bij 45–60 jarige suïcideslachtoffers in Vlaanderen. (2018). doi: 10.1111/sltb.13163
22. Mérelle, S, van Bergen, D, Looijmans, M, Balt, E, Rasing, S, van Domburgh, L, et al. A multi-method psychological autopsy study on youth suicides in the Netherlands in 2017: feasibility, main outcomes, and recommendations. PLoS One. (2020) 15:e0238031. doi: 10.1371/journal.pone.0238031
23. Balt, E, Mérelle, S, Popma, A, Creemers, D, Heesen, K, van Eijk, N, et al. Sociodemographic and psychosocial risk factors of railway suicide: a mixed-methods study combining data of all suicide decedents in the Netherlands with data from a psychosocial autopsy study. BMC Public Health. (2024) 24:607. doi: 10.1186/s12889-024-18120-w
24. Houston, K, Hawton, K, and Shepperd, R. Suicide in young people aged 15–24: a psychological autopsy study. J Affect Disord. (2001) 63:159–70. doi: 10.1016/S0165-0327(00)00175-0
25. GGD/GHOR. Kaarten Corona Gezondheidsmonitor Volwassen en Ouderen 2022. (2022). Available at: https://www.vzinfo.nl/atlas-vzinfo/kaarten-gezondheidsmonitor-volwassenen-en-ouderen#:~:text=Met%20de%20resultaten%20van%20het,Gezondheidsmonitor%20Volwassenen%20en%20Ouderen%202022.
26. Kojima, T, SShane, G, Machel, R, Yutaka, M, and Iwasawa, Y. Large language models are zero-shot reasoners In: Conference on neural information processing systems (NeurIPS) Eds. S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh. Curran Associates, Inc. (2022)
27. Meta. Introducing Meta Llama 3. (2024). Available at: https://ai.meta.com/blog/meta-llama-3/
28. Meta. Meta-Llama-3-70B-Instruct. (2024). Available at: https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
29. Reddy, S. Evaluating large language models for use in healthcare: a framework for translational value assessment. Inform Med Unlocked. (2023) 41:101304. doi: 10.1016/j.imu.2023.101304
30. Landis, JR, and Koch, GG. The measurement of observer agreement for categorical data. Biometrics. (1977) 33:159. doi: 10.2307/2529310
31. Boeije, H. A purposeful approach to the constant comparative method in the analysis of qualitative interviews. Qual Quant. (2002) 36:391–409. doi: 10.1023/A:1020909529486
32. Song Jongyoon, Y, and Sangwon, YS. Large language models are skeptics: false negative problem of input-conflicting hallucination. arXiv [Preprint]. (2024). doi: 10.48550/arXiv.2406.13929
33. Tai, RH, Bentley, LR, Xia, X, Sitt, JM, Fankhauser, SC, Chicas-Mosier, AM, et al. An examination of the use of large language models to aid analysis of textual data. Int J Qual Methods. (2024) 23:23. doi: 10.1177/16094069241231168
34. Liang, Z, Katherine, J, Spurthi, S, Eden, C, Fatima, J, Natan, V, et al. Enhancing large language model performance to answer questions and extract information more accurately. arXiv [Preprint]. (2024). doi: 10.48550/arXiv.2402.01722
Keywords: qualitative research, psychosocial autopsy, large language model (LLM), suicide prevention, public health
Citation: Balt E, Salmi S, Bhulai S, Vrinzen S, Eikelenboom M, Gilissen R, Creemers D, Popma A and Mérelle S (2025) Deductively coding psychosocial autopsy interview data using a few-shot learning large language model. Front. Public Health. 13:1512537. doi: 10.3389/fpubh.2025.1512537
Edited by:
Gunther Meinlschmidt, University of Basel, SwitzerlandReviewed by:
Saurabh Raj, Babasaheb Bhimrao Ambedkar Bihar University, IndiaCopyright © 2025 Balt, Salmi, Bhulai, Vrinzen, Eikelenboom, Gilissen, Creemers, Popma and Mérelle. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Elias Balt, ZS5iYWx0QDExMy5ubA==
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.