 Zhao Chen
Zhao Chen Hao Liu
Hao Liu Yao Zhang
Yao Zhang Fei Xing
Fei Xing Jiabao Jiang
Jiabao Jiang Zhou Xiang
Zhou Xiang Xin Duan
Xin Duan
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Public Health, 21 February 2025
Sec. Public Mental Health
Volume 13 - 2025 | https://doi.org/10.3389/fpubh.2025.1472050
This article is part of the Research TopicNew Insights into Social Isolation and Loneliness, Volume IIView all 9 articles
Background: It has been increasingly recognized that adults living alone have a higher likelihood of developing Major Depressive Disorder (MDD) than those living with others. However, there is still no prediction model for MDD specifically designed for adults who live alone.
Objective: This study aims to investigate the effectiveness of utilizing personal health data in combination with a stacked ensemble machine learning (SEML) technique to detect MDD among adults living alone, seeking to gain insights into the interaction between personal health data and MDD.
Methods: Our data originated from the US National Health and Nutrition Examination Survey (NHANES) spanning 2007 to 2018. We finally selected a set of 30 easily accessible variables encompassing demographic profiles, lifestyle factors, and baseline health conditions. We constructed a SEML model for MDD detection, incorporating three conventional machine learning algorithms as base models and a Neural Network (NN) as the meta-model. Furthermore, SHapley Additive exPlanations (SHAP) analysis was used to explain the impact of each predictor on MDD.
Results: The study included 2,642 adult participants who lived alone, of whom 10.6% (279 out of 2,642) had a PHQ-9 score of 10 or above, indicating the presence of MDD. The performance of our SEML model was robust, with an area under the curve (AUC) of 0.85. Further analysis using SHAP revealed positive correlations between the occurrence of MDD and factors such as sleep disorders, number of prescription medications, need for specific walking aids, leak urine during nonphysical activities, chronic bronchitis, and Healthy Eating Index (HEI) scores for sodium. Conversely, age, the Family Monthly Poverty Level Index (FMMPI), and HEI scores for added sugar showed negative correlations with MDD occurrence. Additionally, a U-shaped relationship was noted between the occurrence of MDD and both sleep duration and Body Mass Index (BMI), as well as HEI scores for dairy.
Conclusion: The study has successfully developed a predictive model for MDD, specifically tailored for adults living alone using a stacked ensemble technique, enhancing the identification of MDD and its risk factors among adults living alone.
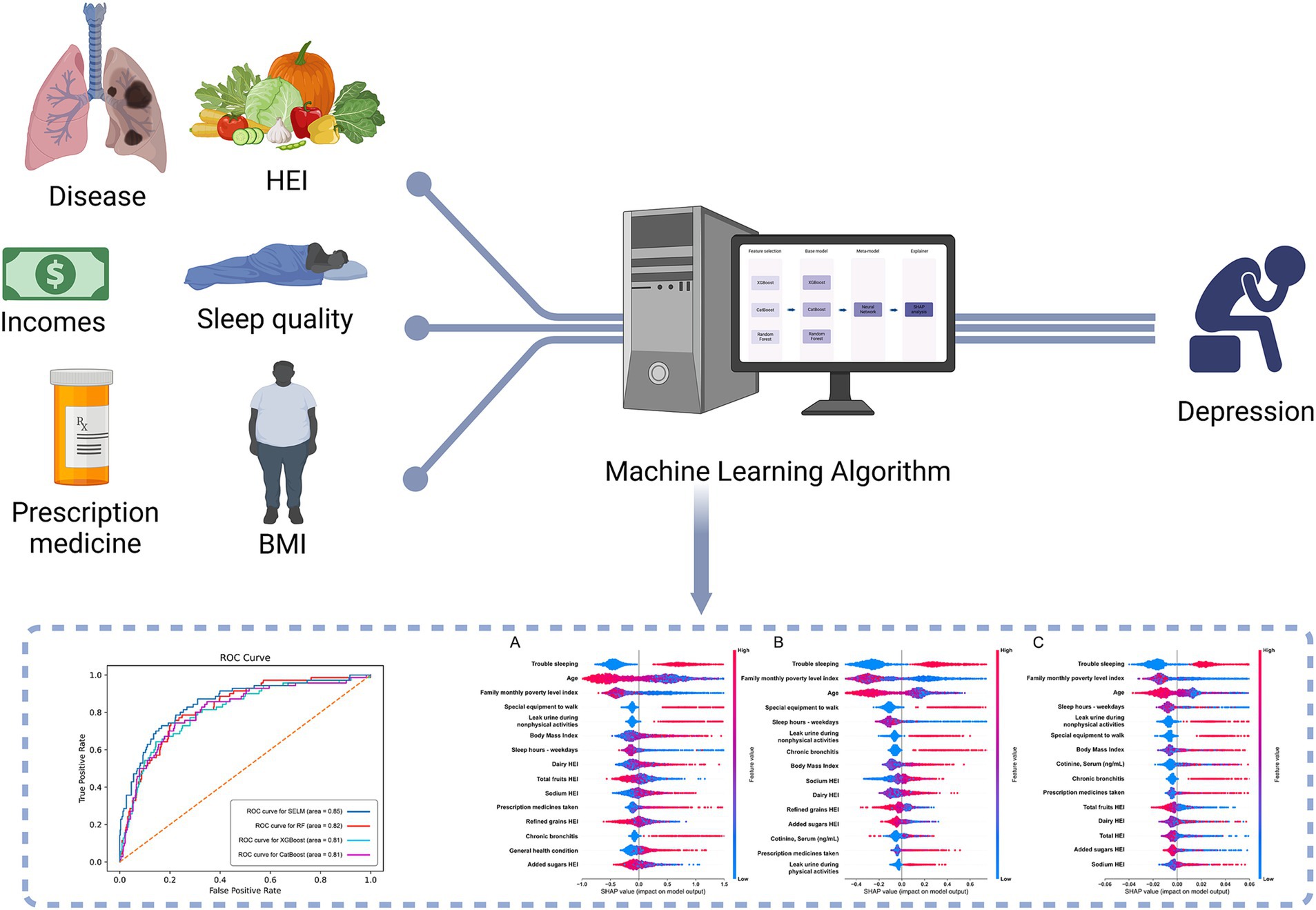
Graphic Abstract. Schematic diagram of the study on identifying major depressive disorder among adults living alone using stacked ensemble machine learning algorithms.
The past decade has witnessed a surge in the number of individuals living alone in the United States (U.S.), with a significant increase of 4.7 million to a total of 37.9 million from 2012 to 2022. This shift has garnered considerable attention due to the well-established link between living arrangements and mental health outcomes, particularly concerning Major Depressive Disorder (MDD). Recent research findings indicate a higher prevalence of MDD among adults living alone in the U.S. (6.4%) compared to those residing with others (4.1%) (1).
Major Depressive Disorder (MDD) is a prevalent mental health conditions marked by persistent mood lows, diminished interest, and a variety of affective, cognitive, somatic, and behavioral symptoms. These symptoms can profoundly impair psychosocial functioning and greatly diminish quality of life (2). The global prevalence of MDD has steadily risen over the past three decades, affecting approximately 5% of the adult population (3). It ranks as one of the leading causes of disability worldwide, contributing significantly to the overall burden of disease (4).
The therapy of MDD poses a challenge due to its heterogeneous nature (5). Key to improving patient prognosis is early detection and intervention. Unfortunately, stigma surrounding mental health assessments, inadequate mental health resources, and the common practice of concealing symptoms complicate the timely recognition and prediction of MDD (6). Although numerous studies have developed predictive models for MDD (6–10) to enhancing the likelihood of detection, there is currently a dearth of MDD predictive models specifically tailored for adults living alone.
Machine learning has demonstrated remarkable effectiveness in medical prediction (11), and is increasingly used in medical diagnostics (12). Machine learning models can adaptively learn from data to identify complex, nonlinear patterns (13). Furthermore, these models offer high interpretability, allowing researchers to understand model behavior and how decisions are made through various visualization and explanatory techniques (14, 15). Ensemble learning is a machine learning paradigm that enhances prediction accuracy by aggregating the predictions from several base models. It reduces the risk associated with individual models by combining their opinions, typically resulting in more accurate and robust predictions (16). The most common ensemble strategies include voting, averaging, stacking, and boosting. Among them, stacking has demonstrated strong predictive ability in tackling complex problems (17, 18). Nevertheless, to date, there is a dearth of research on the application of stacking in predicting the presence of MDD among adults living alone.
Therefore, we propose a stacked ensemble machine learning (SEML) model, utilizing data from the US National Health and Nutrition Examination Survey (NHANES), to predict MDD in adults living alone. We compared the performance of our SEML model with single machine learning models. Furthermore, we explored the interaction between predictors and the presence of MDD via the application of SHapley Additive exPlanations (SHAP) analysis. We aim to make a contribution to the field of MDD prediction in adults living alone and provide valuable insights for potential interventions and treatments.
This cross-sectional study utilizes publicly available data from the US NHANES, an ongoing health-related initiative conducted periodically by the National Center for Health Statistics (NCHS) at the Centers for Disease Control and Prevention (CDC). The NCHS Ethics Review Board (ERB) approved the protocol for US NHANES, and all participants provided written informed consent (19).
Our study included data from respondents surveyed between 2007 and 2018. Living arrangements were evaluated by the number of people in the household, with only one person defined as living alone. Respondents under 18 years old, living with others, or with incomplete data were excluded.
MDD was evaluated using the Patient Health Questionnaire-9 (PHQ-9), which is based on the diagnostic criteria for MDD illustrated in the Diagnostic and Statistical Manual of Mental Disorders, Fourth Edition (DSM-IV). The PHQ-9 has been widely recognized for its accuracy in screening for MDD (20), with a score of 10 or higher indicating clinically significant symptoms (21). Therefore, in this study, we utilized a PHQ-9 score of 10 as the threshold for defining MDD.
The initial phase of the study included 72 feature variables related to demographic profiles, lifestyle factors, and baseline health conditions. Subsequently, a rigorous feature selection process was conducted, resulting in the identification of a subset of 30 variables for constructing the final predictive model. Within the initial pool of 72 variables, demographic characteristics encompassed participants’ age, gender, race, marital status, citizenship status, educational level, employment status, and income level. Lifestyle factors encompassed dietary quality, physical activity level, sleep patterns, and smoking habits. Dietary quality was assessed using the Healthy Eating Index-2020 (HEI-2020) (22), following the methodology proposed by Zhan et al. (23). Physical activity level was quantified by calculating participants’ weekly metabolic equivalent task (MET) minutes, derived from multiplying the MET values of specific physical activities by their respective weekly frequency and duration. The determination of the remaining variables relied on participants’ detailed responses to interview questions. Baseline health status was assessed based on participants’ medication usage and the presence of various diseases.
In our study, the raw data from the US NHANES database was used to construct machine learning models. Continuous variables were presented as means with standard deviations (SD), while categorical variables were displayed as counts and percentages. The statistical significance of differences in continuous and categorical variables was evaluated using independent t-tests and Chi-square tests, respectively, with a significance threshold set at a two-sided p-value of less than 0.05.
In our study, a stratified sampling method was adopted to ensure an even distribution of MDD cases across different groups. The dataset was split into a training set, comprising 80% of the participants, and a test set, comprising the remaining 20%. To create the SEML model, we incorporated three algorithms as base models, including eXtreme Gradient Boosting (XGBoost), Categorical Boosting (CatBoost), and Random Forest (RF). Additionally, a Neural Network (NN) was designated as the meta-model (Figure 1). Both XGBoost and CatBoost belong to the Gradient Boosting Decision Trees (GBDT) algorithm, which employs ensemble learning to combine multiple decision trees using an additive model for predictions. RF represents another ensemble learning approach that enhances predictive power through voting or averaging the results of several decision trees. NN, a deep learning technique, process data by simulating the connections between biological neurons, making them adept at capturing complex nonlinear relationships. In this study, we integrated the aforementioned methods through SEML technique to fully leverage the strengths of each model and improve overall predictive performance.
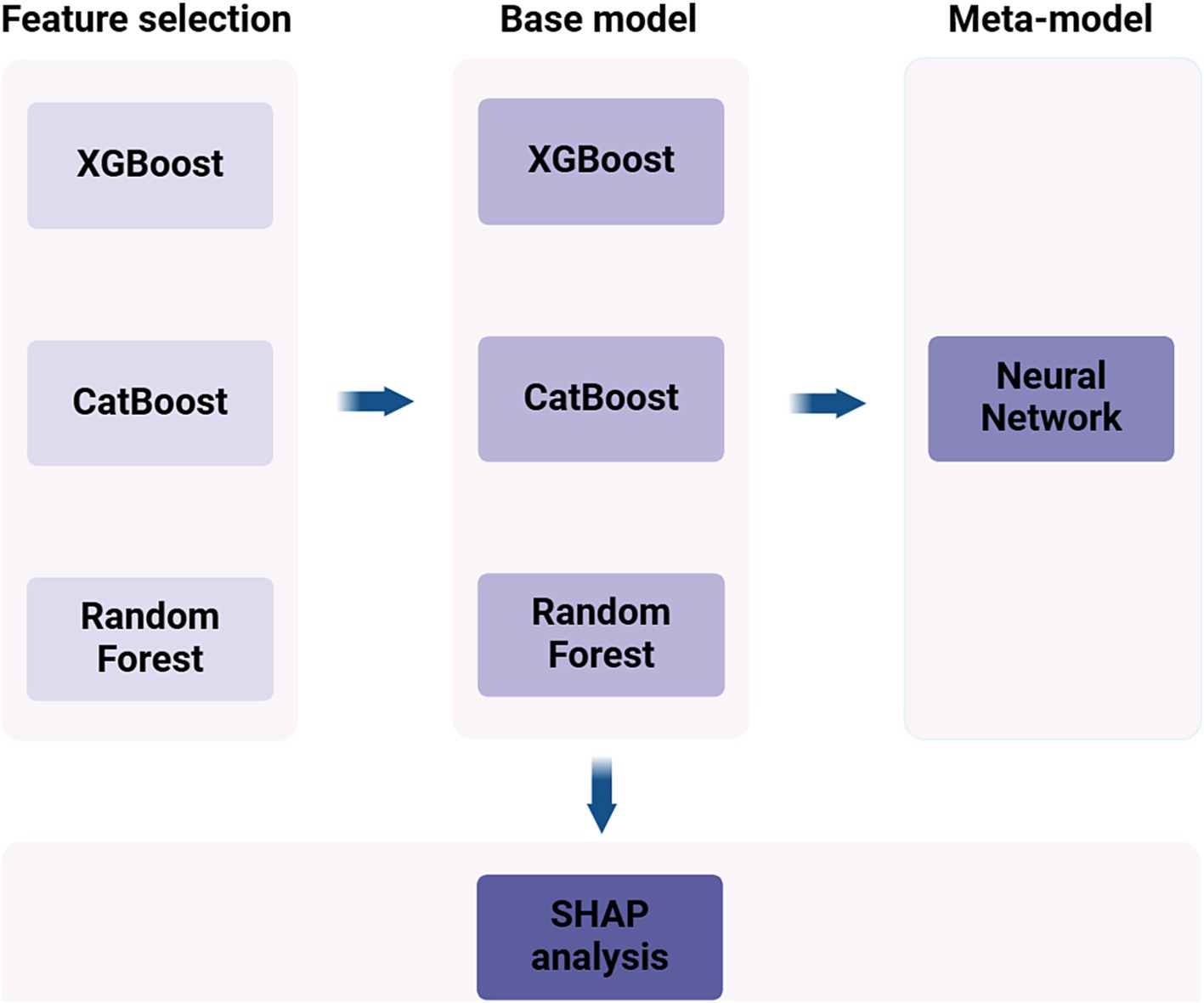
Figure 1. Flowchart of machine learning model construction.
Firstly, we employed the base models to select the top 30 variables in terms of importance out of the initial set of 72 variables. The feature importance was calculated by normalizing and summing the importance values from three different models. Both 10-fold cross-validation and Bayesian optimization were utilized by us for hyperparameter tuning and model evaluation (Details of the model hyperparameter settings are provided in the Supplementary materials). To enhance the predictive accuracy of the models, we performed normalization on the dataset. Additionally, the technique of Synthetic Minority Over-sampling Technique (SMOTE) was employed to mitigate class imbalance between MDD and non-MDD instances in the training data.
During the training phase, we utilized the predictions generated by each base model as input features for training the meta-model. When it came to the testing phase, the base models that had been trained were used to predict the test set. These predictions were then incorporated as input features to make the final prediction using the meta-model.
The assessment of model performance in this study employed the area under the Receiver Operating Characteristic (ROC) curve as the primary metric. Sensitivity, specificity, Youden index, and F1-score were also calculated at the optimal threshold to provide a comprehensive assessment. Furthermore, to elucidate the individual variables’ contributions and their importance in the model’s predictions, SHapley Additive exPlanations (SHAP) analysis was conducted.
All procedures were implemented in Python version 3.12.4.1
38,788 respondents were initially selected from the 2007–2018 US NHANES data. 9,429 participants under the age of 18 were excluded from the study. A further 26,717 participants were excluded due to incomplete data or residing with others. Finally, a total of 2,642 participants were included in the study (Figure 2).
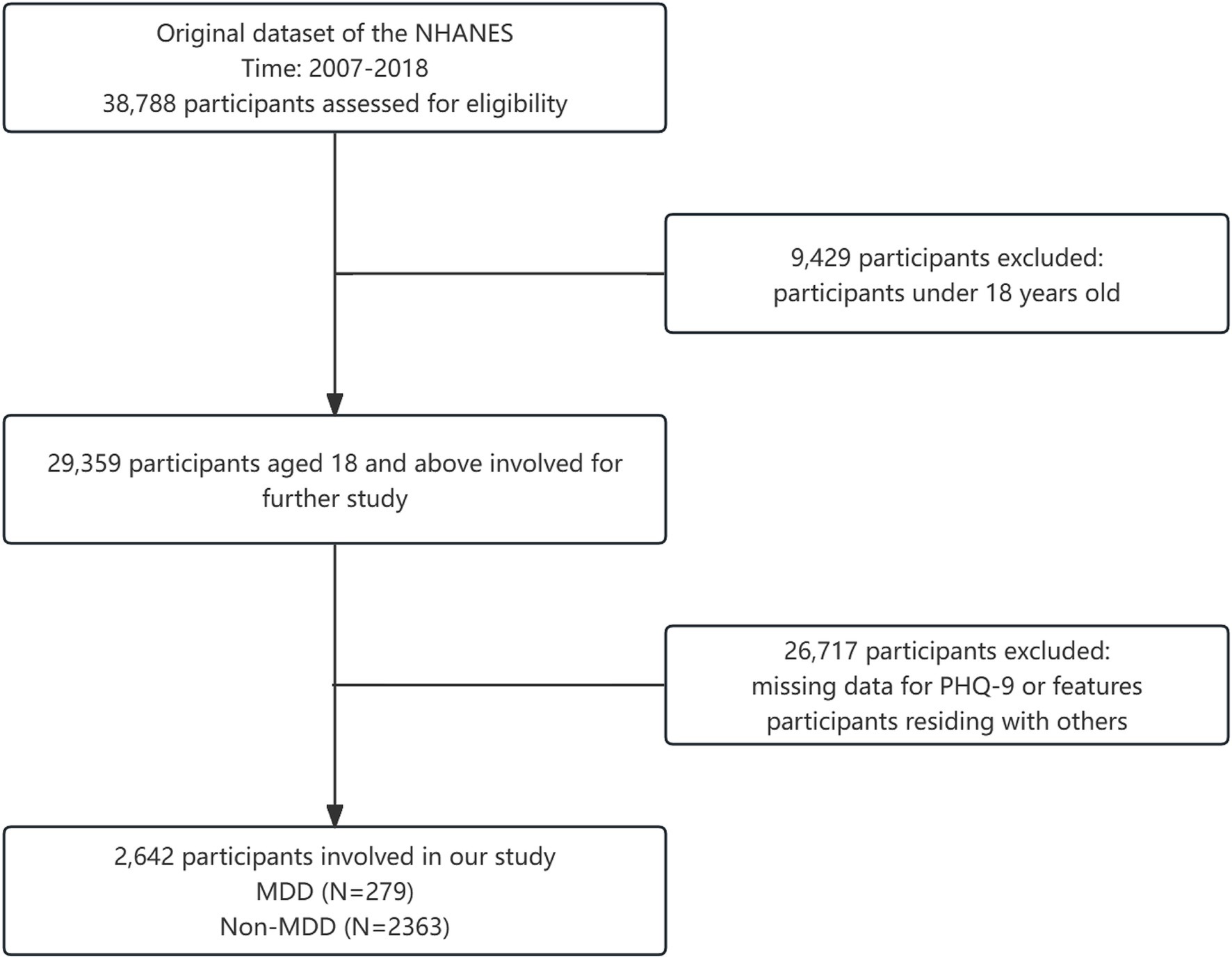
Figure 2. Flowchart of participants inclusion.
Among these participants, 10.6% (279/2,642) of them had a PHQ-9 score of 10 or higher. No significant differences were observed in age (p = 0.2), marital status (p = 0.287), race (p = 0.644) and citizenship status (p = 0.315) between participants with and without MDD. Notable differences were found in gender (p < 0.001), education level (p < 0.001), employment status (p < 0.001) and family monthly poverty level index (p < 0.001; Table 1).
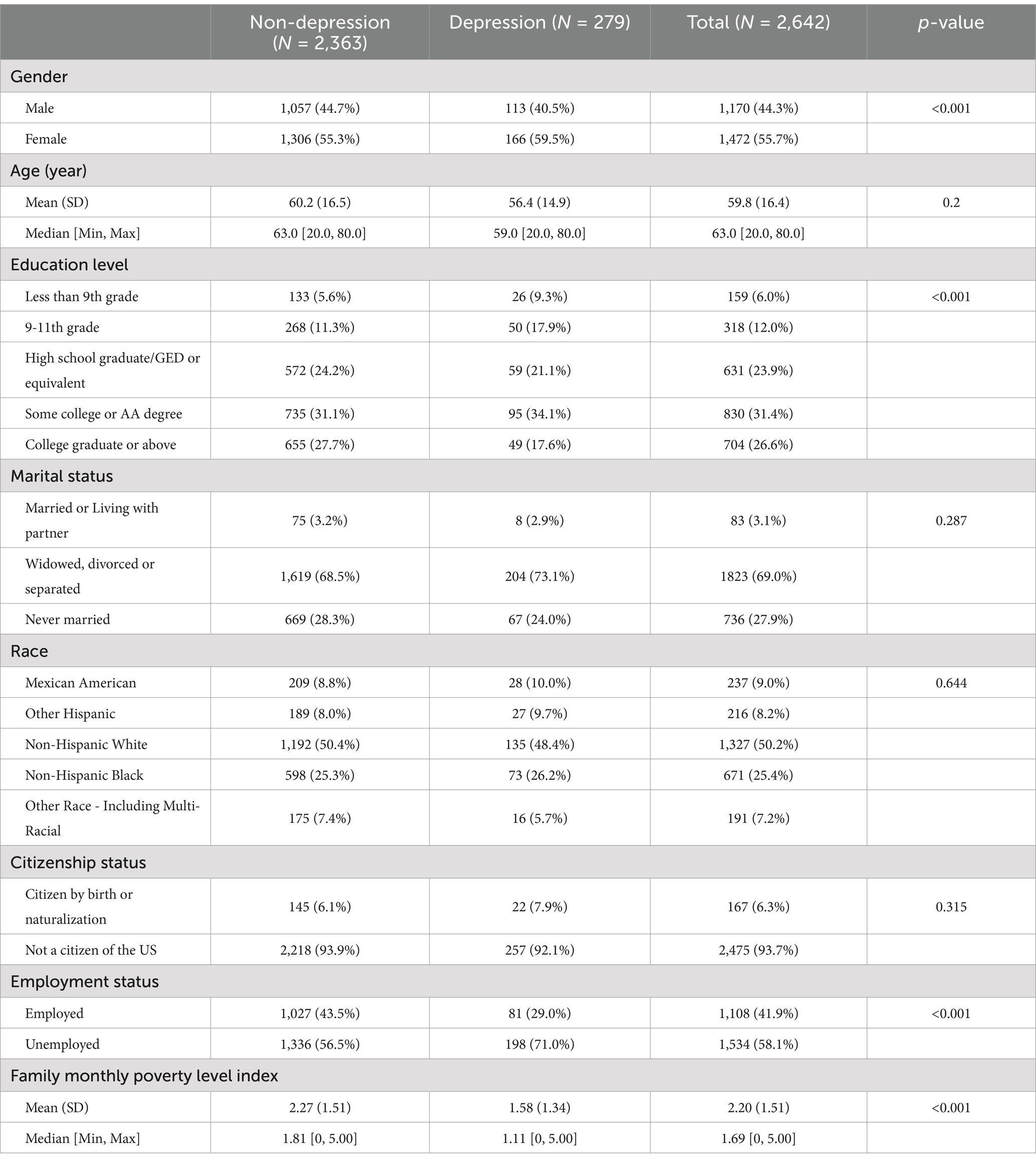
Table 1. Baseline characteristics according to depression or not.
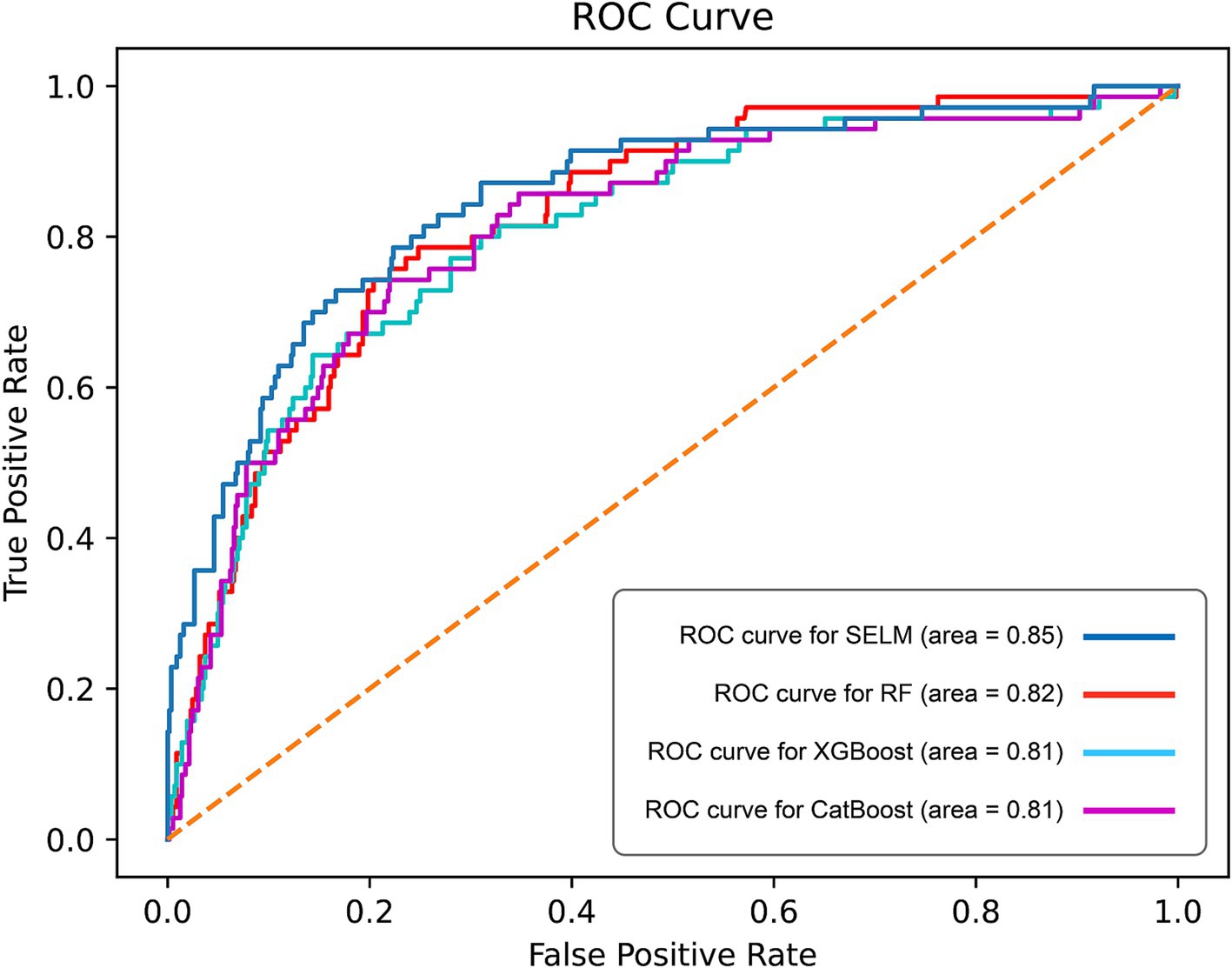
Figure 3. Curves of receiver operating characteristic (ROC) of different algorithms in test set. ROC, receiver operating characteristic; AUC, Area Under the Curve.
The final set of 30 feature variables integrated into the predictive model could be categorized as follows: demographic characteristics, including DMDMARTL, RIDAGEYR, IND235, and INDFMMPI; lifestyle factors, including HEI2020_ALL, HEI2020_DAIRY, HEI2020_ADDEDSUGAR, HEI2020_FATTYACID, HEI2020_FRT, HEI2020_GREENNBEAN, HEI2020_SODIUM, HEI2020_REFINEDGRAIN, HEI2020_SATFAT, HEI2020_SEAPLANTPRO, HEI2020_TOTALFRT, HEI2020_TOTALPRO, HEI2020_VEG and HEI2020_WHOLEGRAIN, LBXCOT, PAD680, TPA, SLD012, and SLQ050; Baseline health status, which encompassed BMXBMI, RXDDAYS, RXDCOUNT, PFQ054, MCQ160k, KIQ046, and HSD010. For more detailed information on each feature, please refer to Table 2.
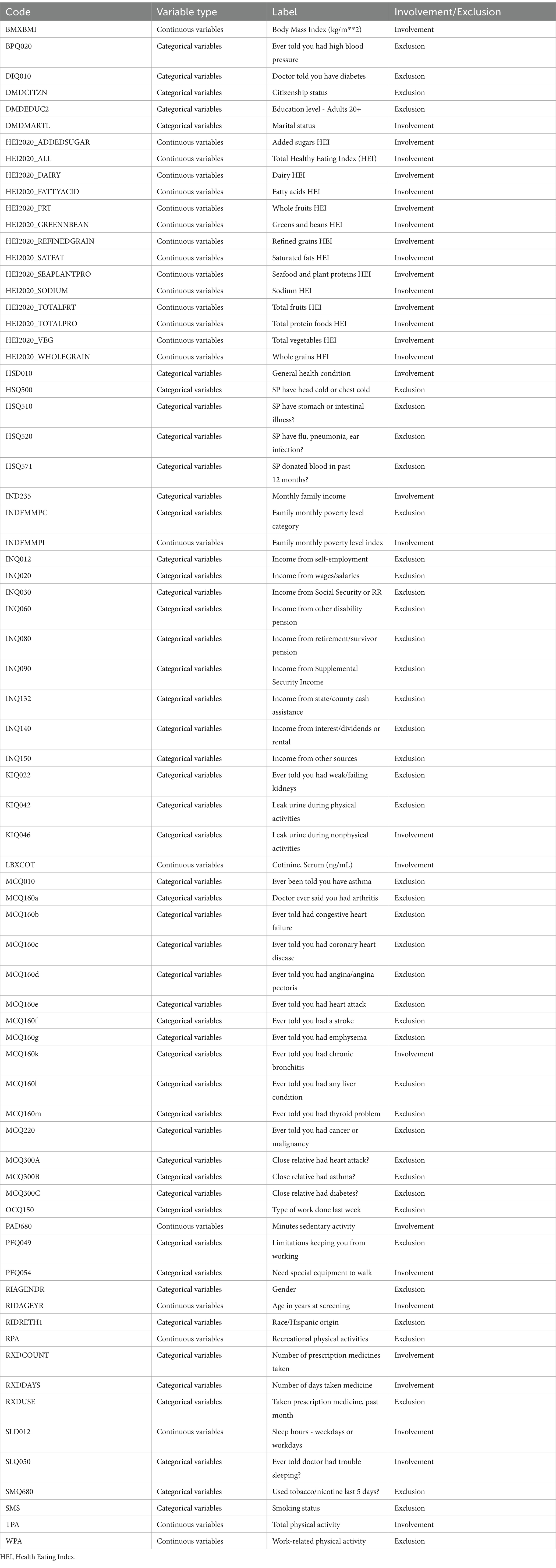
Table 2. Explanation of the predictors used in this study.
The ROC curve analysis revealed that SEML model performed the best among the evaluated models, as evidenced by an AUC value of 0.85 (95% CI 0.84–0.88), Followed by the RF model, which achieved an AUC of 0.82 (95% CI 0.80–0.83), while the AUC values for the CatBoost and XGBoost models were 0.81 (95% CI 0.78–0.84) and 0.81 (95% CI 0.77–0.85), respectively (Figure 3). Moreover, when considering the optimal threshold, the SEML model exhibited superior performance in terms of sensitivity, Youden index, and F1 score, with values of 0.79, 0.57, and 0.50, respectively. Furthermore, the SEML model demonstrated a specificity of 0.78, which was marginally lower than the specificity of the XGBoost model, recorded at 0.86. Detailed results were recorded in Table 3.

Table 3. Performance evaluation of machine learning algorithms.
In this study, we utilized SHAP analysis to determine the importance ranking of the features included in the base models. We summarized the top 15 features in terms of importance in the base models, and the detailed analysis results are presented in Figure 4. Across all three base models, the top 15 features consistently included SLQ050, SLD012, RIDAGEYR, INDFMMPI, BMXBMI, PFQ054, KIQ046, MCQ160K, HEI2020_SODIUM, HEI2020_DAIRY, and HEI2020_ADDSUGAR, amounting to a total of 12 features. Please refer to Table 3 for detailed interpretation regarding the code.
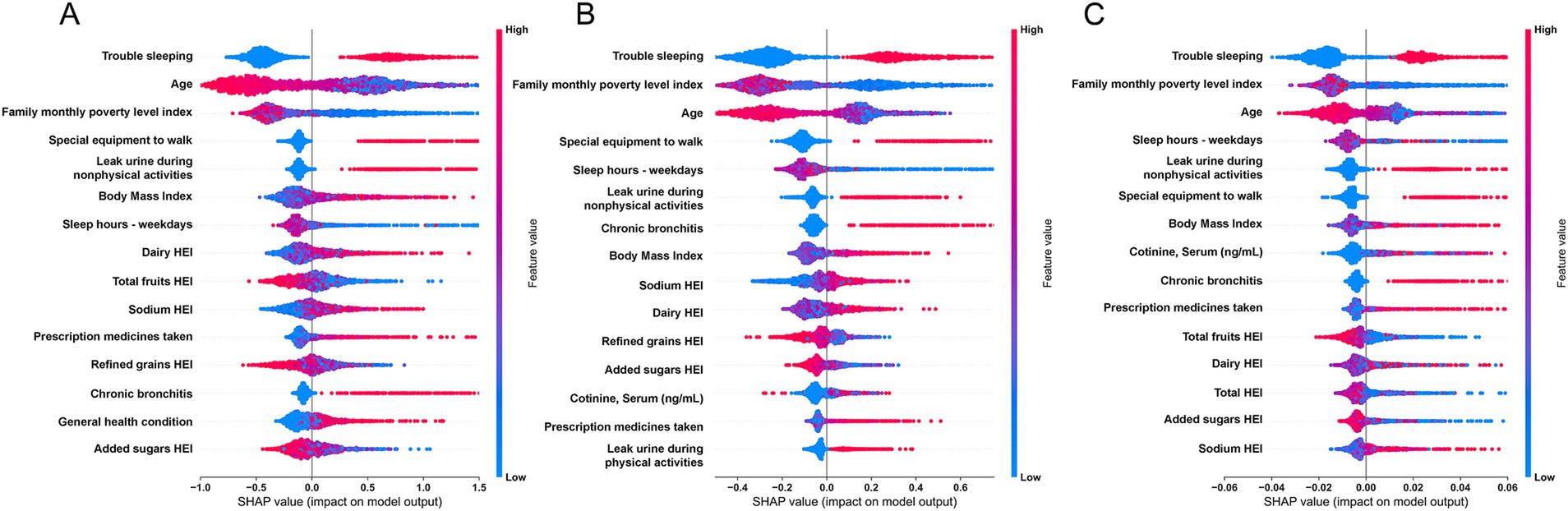
Figure 4. SHapley Additive exPlanations (SHAP) summary plot of features in the base models. (A) CatBoost; (B) XGBoost; (C) Random Forest.
By conducting SHAP analysis, we had effectively delineated the positive and negative impacts exerted by each feature on the occurrence of MDD. As illustrated in Figure 4, a set of features, namely SLQ050, PFQ054, KIQ046, BMXBMI, RXDCOUNT, HEI2020_DAIRY, HEI2020_SODIUM, MCQ160K, and HSD010 exhibited a positive correlation with the occurrence of MDD, whereas features such as RIDAGEYR, INDFMMPI, and HEI2020_ADDEDSUGAR manifested a negative correlation. Subsequent SHAP dependency analysis further corroborated these findings, as depicted in Figures 5, 6. Specifically, an augmentation in the values of features such as RXDCOUNT and HEI2020_SODIUM was concomitant with an escalated risk of developing MDD. Conversely, an escalation in the values of RIDAGEYR, INDFMMPI, and HEI2020_ADDEDSUGAR was linked to a diminished risk of MDD. Additionally, the dependence plot of SLQ012, BMXBMI, and HEI2020_DAIRY revealed a U-shaped relationship between their feature values and the occurrence of MDD. These findings aligned with the data presented in the SHAP summary plots, which depicted the influence of these features on MDD occurrence as a relatively complex interplay of both positive and negative impacts.
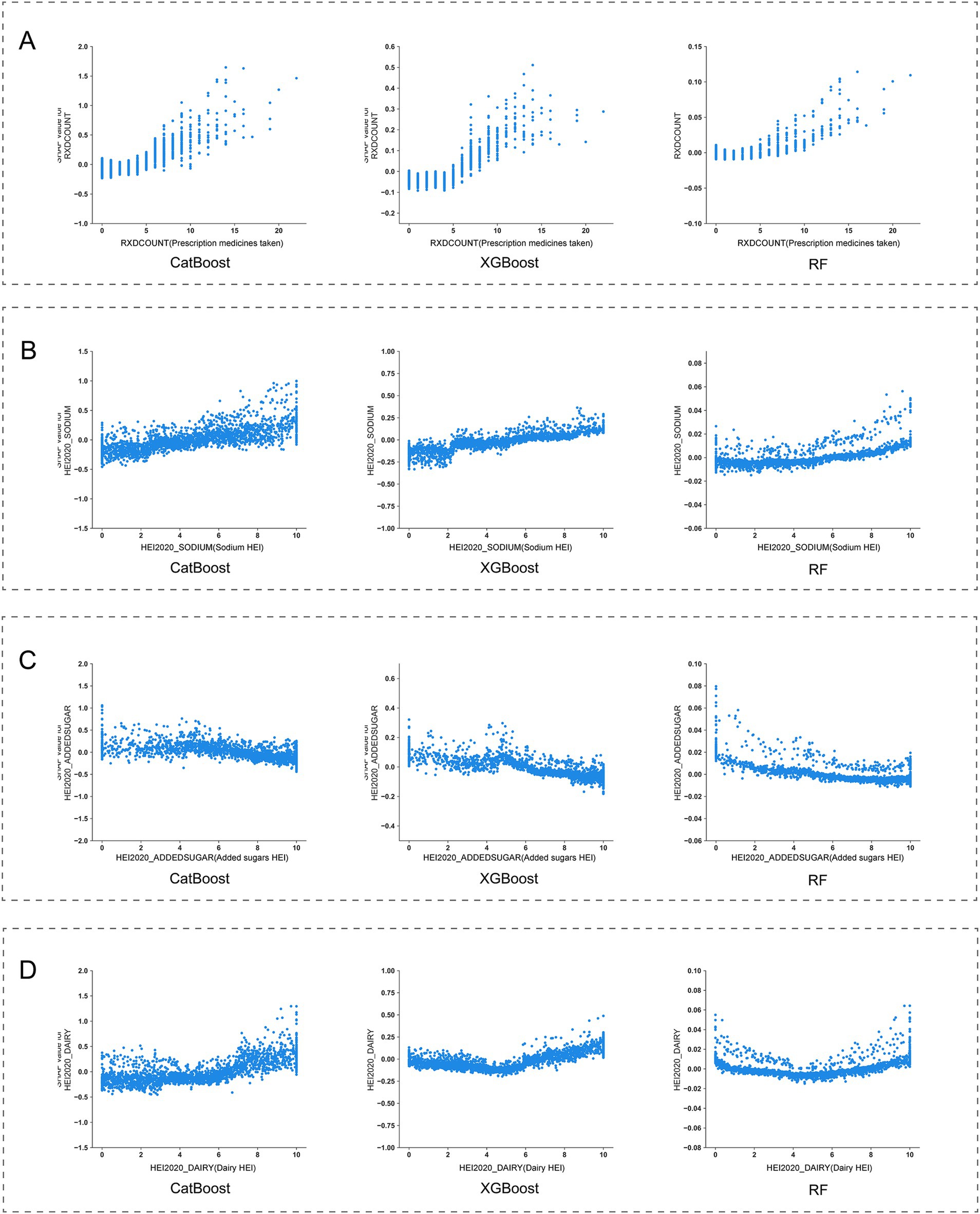
Figure 5. SHapley Additive exPlanations (SHAP) dependence plot of features in the base models. (A) RIDAGEYR; (B) BMXBMI; (C) SLD012; (D) INDFMMPI.
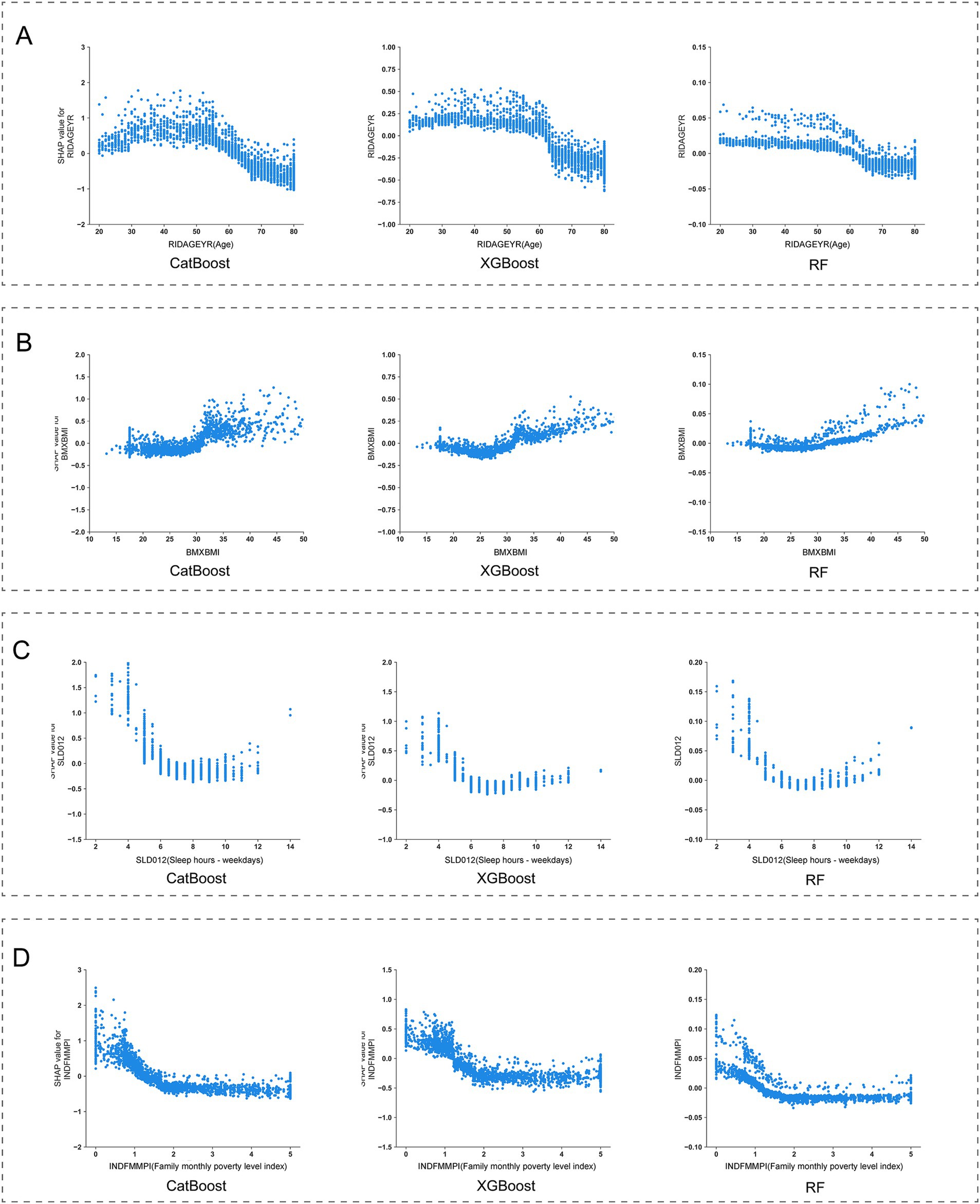
Figure 6. SHapley Additive exPlanations (SHAP) dependence plot of features in the base models. (A) RXDCOUNT; (B) HEI2020_SODIUM; (C) HEI2020_ADDEDSUGAR; (D) HEI2020_DAIRY.
Despite the existence of numerous studies utilizing machine learning methods to predict the occurrence of MDD (24–26), there remains a lack of research specifically focused on predicting MDD among adults living alone. Furthermore, many prediction models rely heavily on comprehensive clinical evaluations and laboratory data (9, 27), which limits their applicability. To address these limitations, this study is the first to focus on the population of adults living alone, utilizing easily accessible predictive variables from the US NHANES database to construct an MDD prediction model. This model incorporates 30 features related to demographic characteristics, lifestyle factors, and baseline health conditions. By employing a stacked ensemble technique, the model achieved an AUC value of 0.85, providing a new tool for predicting MDD in adults living alone.
To elucidate the contribution of each variable in the model’s predictions, we conducted SHAP analysis, a method based on game theory. The core idea is to calculate Shapley values to quantify each feature’s contribution to the prediction outcome, thereby enhancing the model’s transparency and interpretability. This helps researchers and decision-makers better understand the impact of different factors on the prediction results. Provides valuable insights for potential intervention and treatment strategies for MDD in adults living alone (28).
Compared to previous studies focused on the general adult population, our research identifies that, in addition to common influencing factors such as age, sleep, and income, daily sodium intake, added sugars, and dairy consumption are also significant factors affecting MDD in adults living alone. Furthermore, physical health factors such as mobility issues, urinary incontinence during non-physical activities, and chronic bronchitis also have important impacts on MDD (2, 27).
Firstly, within the demographic variables incorporated into our final predictive model, a significant correlation was observed between age and MDD occurrence. The SHAP dependence curve demonstrated a progressive decline in MDD risk with advancing age as participants aged 50 and above. Subsequently, as participants reached the age range of 60 to 65, we observed a shift in SHAP values from positive to negative, suggesting a potential protective effect of advanced age on the occurrence of MDD. This observation aligns with previous research by Villamil et al., who reported a significant reduction in MDD prevalence among women over 60 and men over 65 (29). Based on these findings, we can infer that individuals under 60 living alone face a higher risk of MDD compared to their older counterparts. Moreover, the Family Monthly Mean Poverty Index (FMMPI) of the participants emerged as a significant predictive feature. The SHAP dependence curve revealed a progressive decline in MDD risk as FMMPI increased within the range of 0 to 2. Previous studies have consistently demonstrated that lower income levels are typically associated with a heightened risk of MDD (30–32).Our findings further support this perspective, underscoring that adults living alone with a FMMPI below 2 are more vulnerable to MDD.
Regarding lifestyle characteristics, our findings underscore that both sleep quality and dietary quality are pivotal predictors of the occurrence of MDD. Prior study by Zhang et al. has identified sleep disorders as risk factors for secondary depression (33). Additionally, research by Baglioni et al. has shown that individuals with insomnia face a doubled risk of developing depression compared to those without sleep problems (34). Our current analysis employing SHAP reveals a positive correlation between sleep disorders and MDD occurrence, highlighting sleep disorders as significant risk factors for MDD among adults living alone. Another feature reflecting participants’ sleep status is sleep duration. In this study, the SHAP dependence curves displayed a U-shaped relationship between sleep duration and MDD occurrence. Notably, the lowest SHAP values are observed within a sleep duration of 7–8 h. This finding aligns with the conclusions drawn by Zhang et al., that individuals with an 8-h sleep duration exhibit the lowest risk of depression (35). Consequently, modifying sleep duration among adults living alone may potentially yield a substantial reduction in the risk of MDD occurrence. Regarding dietary quality, we employed the HEI scores to quantify the intake of various components. Through SHAP analysis, significant correlations were identified between the HEI scores for added sugar, dairy, and sodium components and the occurrence of MDD among adults living alone. Firstly, an inverse association was observed with the occurrence of MDD when HEI scores for added sugar exceeded 5. This finding aligns with prior research, which indicates that excessive intake of added sugars can have adverse effects on mental health and increase the risk of developing MDD (36, 37). Secondly, for sodium intake, a positive correlation was observed with the occurrence of MDD when HEI scores exceeded 2, indicating a potential link between low sodium diets and increased risk of MDD in adults living alone. This finding is consistent with findings from animal studies, which suggest that insufficient sodium intake may induce depressive symptoms, alleviated by sodium supplementation (38, 39). However, it is noteworthy that while these results from animal experiments exist, current limited human studies only support this inverse relationship between sodium intake and depression among females (40). Thus, the present findings still require further validation through larger, more rigorously designed studies. Lastly, regarding dairy intake, a U-shaped relationship was found between dairy intake and MDD occurrence. Specifically, the lowest contribution to MDD risk was observed when HEI scores reached 5, emphasizing that both excessive and insufficient dairy intake are closely associated with the occurrence of MDD in adults living alone. Given the current insufficiency of research on the relationship between dairy products and depression, particularly lacking longitudinal studies targeting the US population, we cannot yet determine a causal relationship between the two. These findings underscore the necessity for future research.
Moreover, this study has confirmed a series of baseline health conditions as key predictors for MDD. we systematically identified multiple health indicators closely associated with MDD occurrence. Firstly, body mass index (BMI), a common measure assessing whether an individual’s weight falls within a healthy range, shows a significant correlation with MDD risk. SHAP dependence curves indicate that elevated BMI (BMI > 25 kg/m2) is positively correlated with an increased risk of MDD. aligning with findings from previous epidemiological and clinical studies, which have shown that individuals who are overweight or obese have a higher risk of MDD (41–43). Conversely, a moderate BMI (18–25 kg/m2) appears to have a protective effect. This highlights the critical role of weight management in preventing MDD among adults living alone. Secondly, the number of prescription medications has also been identified as an important predictive feature. Generally, an increase in the number of prescription medications indicates potentially more complex health conditions among participants. In this study, we observed that the risk of MDD significantly rises when the number of prescription medications reaches five or more, indicating the need for special attention to mental health issues among adults living alone who require multiple medications. Additionally, the study found significant associations between the risk of MDD and the need for specific walking aids, symptoms of leak urine during nonphysical activities, and chronic bronchitis conditions. Changes in these participants’ physiological functions may indirectly increase the risk of MDD by affecting their quality of life. However, the causal relationships between these factors and MDD require further longitudinal research to be confirmed.
In summary, the findings presented above demonstrate that our model’s results are interpretable and meaningful. These outcomes not only corroborate the algorithm’s efficacy in predicting MDD but also offer a reference for the development of public health policies.
There are several limitations found in the current study. Firstly, the data utilized in this research was sourced exclusively from the US NHANES database, which contains information on the US population only. Therefore, caution ought to be applied when generalizing the predictive model to other countries. Secondly, the cross-sectional design of the study necessitates a high-quality prospective research to delve into the causal relationship between the identified predictors and the occurrence of MDD.
In conclusion, this study has successfully constructed a predictive model for MDD specifically tailored for adults living alone by applying stacked ensemble technique. Through SHAP analysis, the research thoroughly dissected the complex interplay among various predictors and MDD, providing a scientific reference for the development of personalized and effective intervention strategies.
Publicly available datasets were analyzed in this study. This data can be found at: https://www.cdc.gov/nchs/nhanes.
Ethical review and approval were not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent from the [patients/ participants OR patients/participants legal guardian/next of kin] was not required to participate in this study in accordance with the national legislation and the institutional requirements.
ZC: Conceptualization, Writing – original draft, Writing – review & editing. HL: Writing – original draft, Writing – review & editing. YZ: Methodology, Software, Writing – review & editing. FX: Formal analysis, Methodology, Writing – review & editing. JJ: Formal analysis, Methodology, Writing – review & editing. ZX: Funding acquisition, Supervision, Writing – review & editing. XD: Supervision, Writing – review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the National Natural Science Foundation of China (32371420 and 82202705), the Project of the Science and Technology Department of Sichuan Province (grant nos. 2023YFS0162 and 2023NSFSC1738), Sichuan University-Luzhou Municipal People’s Government Strategic Cooperation Project (2022CDLZ-19), Sichuan Provincial Cadre Health Research Project (2023-401), and Sanya Science and Technology Innovation Project (2022KJCX09).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2025.1472050/full#supplementary-material
1. Mykyta, L. Living alone and feelings of depression among adults age 18 and older. Natl Health Stat Report. (2024):1–11. doi: 10.15620/cdc:136451
2. Nam, SM, Peterson, TA, Seo, KY, Han, HW, and Kang, JI. Discovery of depression-associated factors from a nationwide population-based survey: epidemiological study using machine learning and network analysis. J Med Internet Res. (2021) 23:e27344. doi: 10.2196/27344
3. World Health Organization. Depressive disorder (depression). (2023). Available at: https://www.who.int/news-room/fact-sheets/detail/depression (accessed [June 1, 2024]).
4. Murray, CJ, Vos, T, Lozano, R, Naghavi, M, Flaxman, AD, Michaud, C, et al. Disability-adjusted life years (dalys) for 291 diseases and injuries in 21 regions, 1990-2010: a systematic analysis for the global burden of disease study 2010. Lancet. (2012) 380:2197–223. doi: 10.1016/S0140-6736(12)61689-4
5. Hasler, G. Pathophysiology of depression: do we have any solid evidence of interest to clinicians? World Psychiatry. (2010) 9:155–61. doi: 10.1002/j.2051-5545.2010.tb00298.x
6. Qu, Z, Wang, Y, Guo, D, He, G, Sui, C, Duan, Y, et al. Identifying depression in the United States veterans using deep learning algorithms, nhanes 2005-2018. BMC Psychiatry. (2023) 23:620. doi: 10.1186/s12888-023-05109-9
7. Oh, J, Yun, K, Maoz, U, Kim, TS, and Chae, JH. Identifying depression in the national health and nutrition examination survey data using a deep learning algorithm. J Affect Disord. (2019) 257:623–31. doi: 10.1016/j.jad.2019.06.034
8. Lee, JY, Won, D, and Lee, K. Machine learning-based identification and related features of depression in patients with diabetes mellitus based on the Korea national health and nutrition examination survey: a cross-sectional study. PLoS One. (2023) 18:e288648. doi: 10.1371/journal.pone.0288648
9. Zhang, C, Chen, X, Wang, S, Hu, J, Wang, C, and Liu, X. Using catboost algorithm to identify middle-aged and elderly depression, national health and nutrition examination survey 2011-2018. Psychiatry Res. (2021) 306:114261. doi: 10.1016/j.psychres.2021.114261
10. Gomes, S, von Schantz, M, and Leocadio-Miguel, M. Predicting depressive symptoms in middle-aged and elderly adults using sleep data and clinical health markers: a machine learning approach. Sleep Med. (2023) 102:123–31. doi: 10.1016/j.sleep.2023.01.002
11. Haug, CJ, and Drazen, JM. Artificial intelligence and machine learning in clinical medicine, 2023. N Engl J Med. (2023) 388:1201–8. doi: 10.1056/NEJMra2302038
12. Obermeyer, Z, and Emanuel, EJ. Predicting the future - big data, machine learning, and clinical medicine. N Engl J Med. (2016) 375:1216–9. doi: 10.1056/NEJMp1606181
13. Velagapudi, L, Saiegh, FA, Swaminathan, S, Mouchtouris, N, Khanna, O, Sabourin, V, et al. Machine learning for outcome prediction of neurosurgical aneurysm treatment: current methods and future directions. Clin Neurol Neurosurg. (2023) 224:107547. doi: 10.1016/j.clineuro.2022.107547
14. Tsai, SF, Yang, CT, Liu, WJ, and Lee, CL. Development and validation of an insulin resistance model for a population without diabetes mellitus and its clinical implication: a prospective cohort study. Eclinicalmedicine. (2023) 58:101934. doi: 10.1016/j.eclinm.2023.101934
15. Goodwin, NL, Nilsson, S, Choong, JJ, and Golden, SA. Toward the explainability, transparency, and universality of machine learning for behavioral classification in neuroscience. Curr Opin Neurobiol. (2022) 73:102544. doi: 10.1016/j.conb.2022.102544
16. Ensemble based systems in decision making. Ieee Circuits and Systems Magazine. (2006) 6:21–45. doi: 10.1109/MCAS.2006.1688199
17. Zhou, T, and Jiao, H. Exploration of the stacking ensemble machine learning algorithm for cheating detection in large-scale assessment. Educ Psychol Meas. (2023) 83:831–54. doi: 10.1177/00131644221117193
18. Gupta, A, Jain, V, and Singh, A. Stacking ensemble-based intelligent machine learning model for predicting post-covid-19 complications. N Gener Comput. (2022) 40:987–1007. doi: 10.1007/s00354-021-00144-0
19. About the national health and nutrition examination survey. (2024). Available at: https://www.cdc.gov/nchs/nhanes/about/erb.html (accessed [June 20, 2024]).
20. Levis, B, Benedetti, A, and Thombs, BD. Accuracy of patient health questionnaire-9 (phq-9) for screening to detect major depression: individual participant data meta-analysis. BMJ. (2019) 365:l1476. doi: 10.1136/bmj.l1476
21. Kroenke, K, Spitzer, RL, and Williams, JB. The phq-9: validity of a brief depression severity measure. J Gen Intern Med. (2001) 16:606–13. doi: 10.1046/j.1525-1497.2001.016009606.x
22. Shams-White, MM, Pannucci, TE, Lerman, JL, Herrick, KA, Zimmer, M, Meyers, MK, et al. Healthy eating index-2020: review and update process to reflect the dietary guidelines for americans,2020-2025. J Acad Nutr Diet. (2023) 123:1280–8. doi: 10.1016/j.jand.2023.05.015
23. Zhan, JJ, Hodge, RA, Dunlop, AL, Lee, MM, Bui, L, Liang, D, et al. Dietaryindex: a user-friendly and versatile r package for standardizing dietary pattern analysis in epidemiological and clinical studies. Biorxiv. (2024), 120:165–1174. doi: 10.1016/j.ajcnut.2024.08.021
24. Liang, J, Huang, S, Jiang, N, Kakaer, A, Chen, Y, Liu, M, et al. Association between joint physical activity and dietary quality and lower risk of depression symptoms in us adults: cross-sectional nhanes study. JMIR Public Health Surveill. (2023) 9:e45776. doi: 10.2196/45776
25. Nawrin, SS, Inada, H, Momma, H, and Nagatomi, R. Twenty-four-hour physical activity patterns associated with depressive symptoms: a cross-sectional study using big data-machine learning approach. BMC Public Health. (2024) 24:1254. doi: 10.1186/s12889-024-18759-5
26. Li, E, Ai, F, and Liang, C. A machine learning model to predict the risk of depression in us adults with obstructive sleep apnea hypopnea syndrome: a cross-sectional study. Front Public Health. (2023) 11:1348803. doi: 10.3389/fpubh.2023.1348803
27. Cho, SE, Geem, ZW, and Na, KS. Predicting depression in community dwellers using a machine learning algorithm. Diagnostics (Basel). (2021) 11:11. doi: 10.3390/diagnostics11081429
28. Ponce-Bobadilla, AV, Schmitt, V, Maier, CS, Mensing, S, and Stodtmann, S. Practical guide to shap analysis: explaining supervised machine learning model predictions in drug development. Clin Transl Sci. (2024) 17:e70056. doi: 10.1111/cts.70056
29. Villamil, E, Huppert, F, and Melzer, D. Low prevalence of depression and anxiety is linked to statutory retirement ages rather than personal work exit: a national survey. Psychol Med. (2006) 36:999–1009. doi: 10.1017/S0033291706007719
30. Schaakxs, R, Comijs, HC, van der Mast, RC, Schoevers, RA, Beekman, A, and Penninx, B. Risk factors for depression: differential across age? Am J Geriatr Psychiatry. (2017) 25:966–77. doi: 10.1016/j.jagp.2017.04.004
31. Liu, J, Yan, F, Ma, X, Guo, HL, Tang, YL, Rakofsky, JJ, et al. Prevalence of major depressive disorder and socio-demographic correlates: results of a representative household epidemiological survey in Beijing, China. J Affect Disord. (2015) 179:74–81. doi: 10.1016/j.jad.2015.03.009
32. Hinata, A, Kabasawa, K, Watanabe, Y, Kitamura, K, Ito, Y, Takachi, R, et al. Education, household income, and depressive symptoms in middle-aged and older japanese adults. BMC Public Health. (2021) 21:2120. doi: 10.1186/s12889-021-12168-8
33. Zhang, M, Ma, Y, Du, L, Wang, K, Li, Z, Zhu, W, et al. Sleep disorders and non-sleep circadian disorders predict depression: a systematic review and meta-analysis of longitudinal studies. Neurosci Biobehav Rev. (2022) 134:104532. doi: 10.1016/j.neubiorev.2022.104532
34. Baglioni, C, Battagliese, G, Feige, B, Spiegelhalder, K, Nissen, C, Voderholzer, U, et al. Insomnia as a predictor of depression: a meta-analytic evaluation of longitudinal epidemiological studies. J Affect Disord. (2011) 135:10–9. doi: 10.1016/j.jad.2011.01.011
35. Bulloch, AGM, Williams, JVA, Lavorato, DH, and Patten, SB. The depression and marital status relationship is modified by both age and gender. J Affect Disord. (2017) 223:65–8. doi: 10.1016/j.jad.2017.06.007
36. Knüppel, A, Shipley, MJ, Llewellyn, CH, and Brunner, EJ. Sugar intake from sweet food and beverages, common mental disorder and depression: prospective findings from the Whitehall ii study. Sci Rep. (2017) 7:6287. doi: 10.1038/s41598-017-05649-7
37. Hu, D, Cheng, L, and Jiang, W. Sugar-sweetened beverages consumption and the risk of depression: a meta-analysis of observational studies. J Affect Disord. (2019) 245:348–55. doi: 10.1016/j.jad.2018.11.015
38. Grippo, AJ, Moffitt, JA, Beltz, TG, and Johnson, AK. Reduced hedonic behavior and altered cardiovascular function induced by mild sodium depletion in rats. Behav Neurosci. (2006) 120:1133–43. doi: 10.1037/0735-7044.120.5.1133
39. Morris, MJ, Na, ES, and Johnson, AK. Mineralocorticoid receptor antagonism prevents hedonic deficits induced by a chronic sodium appetite. Behav Neurosci. (2010) 124:211–24. doi: 10.1037/a0018910
40. Goldstein, P, and Leshem, M. Dietary sodium, added salt, and serum sodium associations with growth and depression in the u.s. general population. Appetite. (2014) 79:83–90. doi: 10.1016/j.appet.2014.04.008
41. Wang, R, He, Y, Deng, Y, Wang, H, Zhang, Y, Feng, J, et al. Body weight in neurological and psychiatric disorders: a large prospective cohort study. Nature Mental Health. (2024) 2:41–51. doi: 10.1038/s44220-023-00158-1
42. He, K, Pang, T, and Huang, H. The relationship between depressive symptoms and bmi: 2005–2018 nhanes data. J Affect Disord. (2022) 313:151–7. doi: 10.1016/j.jad.2022.06.046
Keywords: major depressive disorder, adults living alone, stacked ensemble technique, machine learning, US NHANES
Citation: Chen Z, Liu H, Zhang Y, Xing F, Jiang J, Xiang Z and Duan X (2025) Identifying major depressive disorder among US adults living alone using stacked ensemble machine learning algorithms. Front. Public Health. 13:1472050. doi: 10.3389/fpubh.2025.1472050
Edited by:
Lené Levy-Storms, University of California, Los Angeles, United StatesReviewed by:
Lang Chen, Santa Clara University, United StatesCopyright © 2025 Chen, Liu, Zhang, Xing, Jiang, Xiang and Duan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhou Xiang, eGlhbmd6aG91QHNjdS5lZHUuY24=; Xin Duan, ZHhiYWFsQGhvdG1haWwuY29t
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.