 Su-Yen Chen
Su-Yen Chen H. Y. Kuo
H. Y. Kuo Shu-Hao Chang
Shu-Hao Chang- 1Institute of Learning Sciences and Technologies, National Tsing Hua University, Hsinchu, Taiwan
- 2Department of Sport Management, College of Health and Human Performance, University of Florida, Gainesville, FL, United States
Introduction: This study explores the perceptions of ChatGPT in healthcare settings in Taiwan, focusing on its usefulness, trust, and associated risks. As AI technologies like ChatGPT increasingly influence various sectors, their potential in public health education, promotion, medical education, and clinical practice is significant but not without challenges. The study aims to assess how individuals with and without healthcare-related education perceive and adopt ChatGPT, contributing to a deeper understanding of AI’s role in enhancing public health outcomes.
Methods: An online survey was conducted among 659 university and graduate students, all of whom had prior experience using ChatGPT. The survey measured perceptions of ChatGPT’s ease of use, novelty, usefulness, trust, and risk, particularly within clinical practice, medical education, and research settings. Multiple linear regression models were used to analyze how these factors influence perception in healthcare applications, comparing responses between healthcare majors and non-healthcare majors.
Results: The study revealed that both healthcare and non-healthcare majors find ChatGPT more useful in medical education and research than in clinical practice. Regression analysis revealed that for healthcare majors, general trust is crucial for ChatGPT’s adoption in clinical practice and influences its use in medical education and research. For non-healthcare majors, novelty, perceived general usefulness, and trust are key predictors. Interestingly, while healthcare majors were cautious about ease of use, fearing it might increase risk, non-healthcare majors associated increased complexity with greater trust.
Conclusion: This study highlights the varying expectations between healthcare and non-healthcare majors regarding ChatGPT’s role in healthcare. The findings suggest the need for AI applications to be tailored to address specific user needs, particularly in clinical practice, where trust and reliability are paramount. Additionally, the potential of AI tools like ChatGPT to contribute to public health education and promotion is significant, as these technologies can enhance health literacy and encourage behavior change. These insights can inform future healthcare practices and policies by guiding the thoughtful and effective integration of AI tools like ChatGPT, ensuring they complement clinical judgment, enhance educational outcomes, support research integrity, and ultimately contribute to improved public health outcomes.
Introduction
ChatGPT, developed by OpenAI, is a chatbot powered by a large language model (LLM) that utilizes deep learning and natural language processing (NLP) techniques. Since its launch on November 30, 2022, ChatGPT has rapidly gained widespread popularity, amassing over 100 million users within two months. This remarkable growth underscores the significant interest in and potential applications of ChatGPT across various sectors. Consequently, its ability to generate coherent and varied text responses, a key feature of generative AI, positions it as a valuable tool for healthcare, supporting clinical, educational, and research activities (1, 2). Understanding how different user groups, particularly those in healthcare and non-healthcare fields, perceive this technology is crucial for its effective adoption and integration into healthcare environments. This study aims to contribute to the strategic development of AI technologies and support broader public health objectives by enhancing the quality and accessibility of healthcare through technological advancements.
The potential of ChatGPT to reshape healthcare has been extensively explored in academic literature, highlighting its significant impact in various fields. Scholars have emphasized ChatGPT’s potential and challenges in clinical, teaching, and research applications, stressing the importance of addressing issues of accuracy, transparency, and ethics (1). This multifaceted impact suggests a significant future role for ChatGPT in enhancing medical education and patient care, provided it operates within a responsible and ethical framework (1–11).
In clinical applications, ChatGPT has shown promise in diagnosis and decision-making. Studies have explored ChatGPT’s capabilities in clinical diagnostics, highlighting both its potential and constraints in handling diverse clinical issues. Evaluations by major medical institutions suggest that while ChatGPT can enhance decision-making and efficiency, medical professionals must be aware of its capabilities and limitations, advocating for cautious use in clinical settings (5, 7). Additionally, another study illustrates how ChatGPT could be effectively integrated into medical consultations, particularly when used alongside other multiagent models, to enhance clinic practices (11).
Similarly, in medical education, ChatGPT has shown potential in developing curricula, enhancing teaching methodologies, creating personalized study plans, and improving teaching efficiency (3, 6). Scholars also note its impact on enhancing student learning and clinical reasoning skills. Research illustrates ChatGPT’s effectiveness in preparing students for exams like the USMLE and various Chinese medical licensing examinations, suggesting its potential for students’ self-directed leaning in test preparation, and for transforming educational and assessment materials (12, 13). However, these advancements also bring challenges such as potential for academic dishonesty, and the need for a multicultural approach in teaching methodologies.
In medical research, ChatGPT’s influence is growing as it assists with medical writing, literature summary, and research review (3). It can support the advancement of the academic community in medical research by reducing the burden of critical appraisal and research reporting, facilitating knowledge dissemination, and generating novel research idea for knowledge creation (1, 2). Despite these benefits, challenges related to misinformation, inconsistency, and the risk of overdependence on technology must be addressed through careful management and continuous oversight to fully leverage the benefits of AI in medical research while mitigating associated risks (2–4).
The discussion on key ethical principles for using AI in healthcare is essential, particularly in ensuring that AI tools like ChatGPT are aligned with human values and acknowledging that AI cannot replace the moral reasoning and critical reflection provided by human professionals (6). It is also vital to focus on fairness and the prevention of exacerbating existing biases in healthcare (1). The deployment of generative AI in healthcare must prioritize accountability and transparency in clinical decision-making (9), while also addressing the risks of misinformation (8).
AI has significant potential in clinical settings, especially in decision-making and workflow integration; however, notable limitations exist. While AI tools like ChatGPT demonstrate impressive accuracy, they require continuous information input and careful interpretation to avoid errors in differential diagnosis and clinical management (7). Additionally, concerns about the reliability and comprehensiveness of AI-generated responses, the inability to interpret images, and the challenges of maintaining up-to-date and accurate information underscore the need for further validation and transparency in AI applications (1, 2, 5). The use of AI in healthcare, particularly with tools like ChatGPT, presents significant risks, including the potential for generating inaccurate or biased information. These risks are heightened with free versions of AI models, which may lack necessary updates, real-time data access, and security measures, increasing the likelihood of misinformation.
Literature on ChatGPT usage behaviors predominantly employs two main theoretical frameworks: technology acceptance model (TAM) and Uses and Gratifications Theory. TAM is instrumental in investigating how users come to accept and utilize new technologies, focusing on factors such as perceived usefulness, ease of use, trust, and perceived risk. On the other hand, the Uses and Gratifications Theory explores how individuals engage with new technologies, with a particular focus on user experience, motivations, and gratifications derived from the technology.
Several studies have examined perceptions and acceptance of ChatGPT across diverse user groups, offering insights into the factors that influence its adoption. For example, a survey of healthcare and non-healthcare professionals in India revealed that healthcare professionals generally had a more positive outlook on ChatGPT, despite lower usage rates compared to non-healthcare professionals (14). In the Middle East, a modified TAM for ChatGPT identified that perceived risk and attitudes toward technology significantly influence user acceptance among healthcare students, with ease of use and positive attitudes being crucial for fostering favorable views (15, 16). Similarly, research involving university students in Oman found that while ChatGPT’s perceived usefulness drove adoption for educational purposes, ease of use was not a significant factor in their intentions (17).
The Uses and Gratifications Theory further elucidates user engagement with ChatGPT. A study from Norway identified productivity and novelty as key motivations within this framework, highlighting ChatGPT’s potential as a reliable educational and collaborative tool (18). Research on American users, which applied measurement items from existing Uses and Gratifications literature, found that personalization reduced perceived creepiness and increased trust, enhancing user confidence and intentions to continue using the technology (19). Additionally, a survey involving Chinese users adapted TAM into an AI Device Use Acceptance (AIDUA) model, incorporating Cognitive Appraisal Theory (CAT). This study revealed that social influence, novelty value, and perceived humanness positively influenced performance expectancy (perceived usefulness), while these factors, along with hedonic motivation, negatively impacted effort expectancy (ease of use) (20).
Furthermore, specific applications of ChatGPT in healthcare have been explored in recent studies, examining perceptions from both the general public and healthcare professionals. In the United States, a survey found a positive relationship between general trust in ChatGPT and both the intention to use and actual use of the AI, particularly for health-related queries (21). Another study highlighted a significant willingness among users to rely on ChatGPT for self-diagnosis, pointing to the need for safe AI integration in healthcare (22). American healthcare stakeholders have shown higher acceptance of ChatGPT in medical research compared to its use in healthcare and education (23), while healthcare workers in Saudi Arabia have recognized its utility but expressed concerns about its accuracy and reliability (24). An assessment of ChatGPT’s feasibility in patient-provider communication in the United States discovered moderate trust levels, which decreased with the complexity of the questions (25). Additionally, an experimental study in the UK found that while most participants preferred doctors for consultations, chatbots were favored for handling embarrassing symptoms, suggesting a nuanced role for AI in patient interactions (26).
These findings collectively highlight the complex landscape of generative AI acceptance, marked by differing perceptions across user demographics and professional backgrounds. They underscore the need for tailored approaches to effectively integrate ChatGPT into various settings, particularly in healthcare, where developing trustworthy AI tools that complement traditional services is crucial.
While frameworks like the Technology Acceptance Model (TAM) and Uses and Gratifications Theory have significantly advanced our understanding of user acceptance and engagement with AI technologies such as ChatGPT, challenges persist in effectively applying these insights to healthcare settings. TAM, originating from Davis, focuses on understanding how users accept and utilize new technologies, with core concepts including perceived ease of use and perceived usefulness (27). This model has been widely applied in many technology adoption studies, such as those involving ChatGPT (16, 17, 20), including in healthcare (15). On the other hand, Uses and Gratifications Theory explores the motivations and gratifications of individuals when using new technologies. Initially proposed by Katz et al. (28), this theoretical framework has been extensively used in media and technology studies, including those on ChatGPT (18, 19). These theoretical frameworks provide valuable perspectives for analyzing user behavior, trust levels, and risk perceptions regarding ChatGPT. However, existing research predominantly focuses on general user populations or specific educational contexts, often overlooking the nuanced needs and perceptions of healthcare professionals and patients. Additionally, the varying factors influencing AI adoption across different demographics and cultural backgrounds remain underexplored, particularly in healthcare, where the stakes are higher due to the direct impact on patient outcomes.
This study aims to bridge these gaps by investigating how general perceptions of ChatGPT as a generative AI influence its adoption and integration into healthcare, with a particular focus on differences between individuals with and without healthcare-related education. By examining attributes such as ease of use, novelty, perceived usefulness, trust, and risk, derived from both empirical studies and theoretical frameworks like TAM and Uses and Gratifications Theory, we seek to provide a comprehensive understanding of the factors driving AI acceptance in healthcare. This investigation will contribute to the development of more effective and tailored AI solutions that meet the unique needs of this critical sector.
Table 1 provides a summary of key factors from studies that explored ChatGPT’s general and healthcare-specific applications. It highlights how ease of use, novelty, and perceived usefulness significantly influence general adoption, while usefulness, trust and risk perceptions play a critical role in healthcare-specific applications. While general studies often rely on existing or modified question sets, the domain-specific question sets used in healthcare contexts were compiled in this study, drawing from a variety of review and survey research.
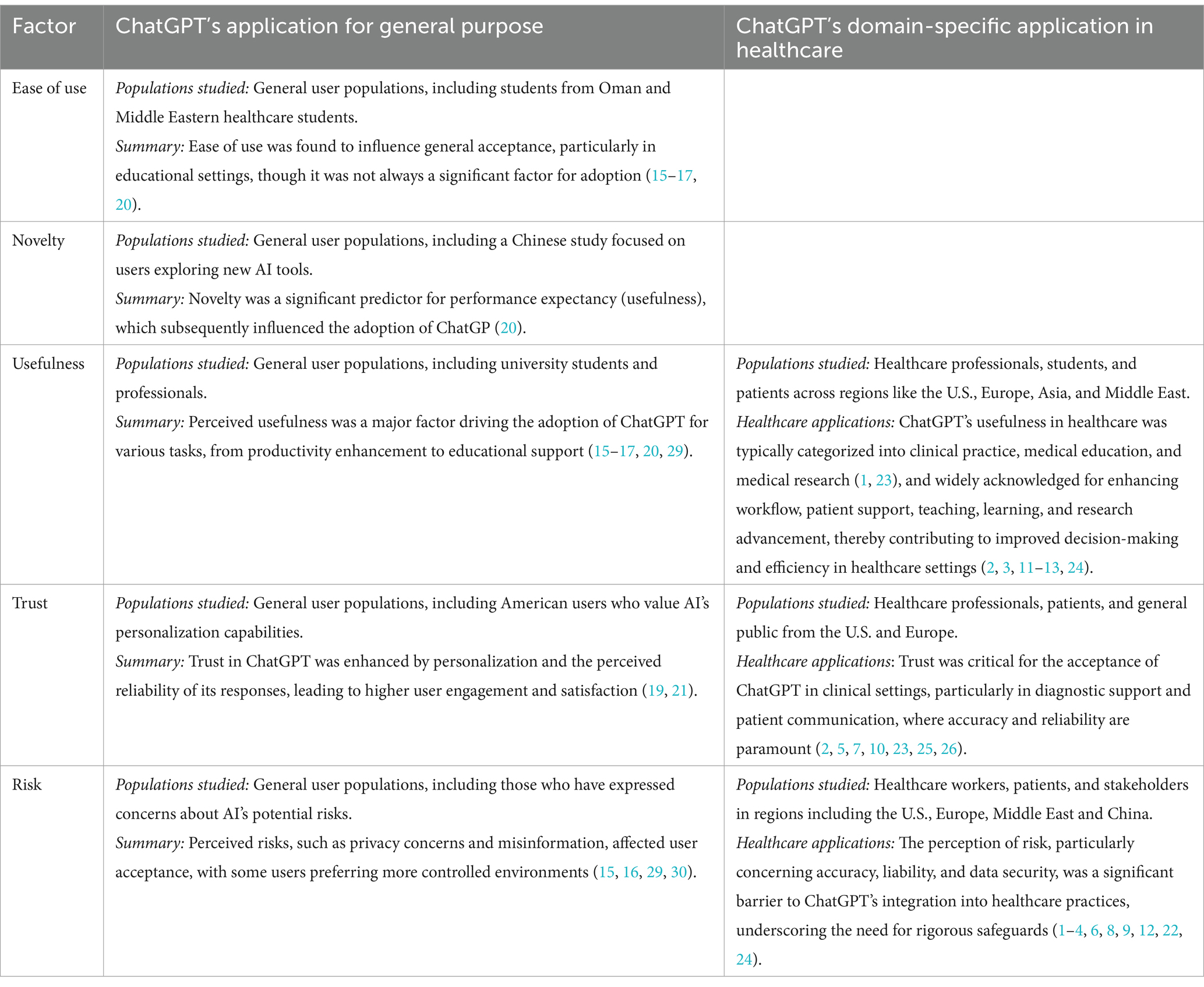
Table 1. Key factors in studies investigating ChatGPT’s general and healthcare-specific applications.
In conclusion, comprehensive research on ChatGPT has underscored its strengths and limitations across clinical, educational, and research contexts, focusing on crucial issues like accuracy, transparency, and ethical standards. Theoretical frameworks such as TAM and Uses and Gratifications Theory offer valuable perspectives for analyzing user behavior, trust levels, and risk perceptions. However, a gap remains in understanding how general user perceptions translate into practical healthcare applications, emphasizing the need for further research.
Building on this foundation, our primary research objective is to explore the relationship between general perceptions of ChatGPT and its specific applications in healthcare, particularly in clinical practice, medical education, and research. We aim to assess how attributes such as perceived usefulness, trust, risk, ease of use, and novelty impact the perception of ChatGPT’s implementation in these areas. Additionally, this study will examine how these perceptions differ between individuals with and without healthcare-related education, providing insights into how educational background influences technology adoption in healthcare contexts.
Main research question:
How do general perceptions of ChatGPT (ease of use, novelty, perceived usefulness, trust, and risk) influence its perceived usefulness, trust, and risk in specific healthcare applications among different user groups (healthcare majors and non-healthcare majors)?
Sub-questions:
How do these perceptions influence the perceived usefulness, trust, and risk of ChatGPT in healthcare applications among healthcare majors?
How do these perceptions influence the perceived usefulness, trust, and risk of ChatGPT in healthcare applications among non-healthcare majors?
Materials and methods
Participants
Participants for this study were recruited through an online survey, with eligibility limited to those who had prior experience using ChatGPT. Recruitment was conducted using a convenience-based approach, targeting current students through email invitations distributed via university mailing lists, social media platforms, and online forums focused on healthcare and technology. While convenience sampling was chosen for its practicality and cost-effectiveness, we acknowledge its potential biases and limited generalizability. To mitigate these biases, efforts were made to recruit a diverse group of students across various disciplines and demographics, and the sample size was sufficiently large to enhance the robustness of the findings. The survey, hosted on a secure platform, was accessible for 4 weeks in March 2024. Participants were informed about the study’s objectives and the voluntary nature of their participation at the beginning of the survey, and they were required to provide informed consent electronically before proceeding. To ensure high data quality and reduce dropout rates, follow-up reminders were sent, and the survey was designed to be completed in approximately 20 min.
The inclusion criteria for this study encompassed current students who had experience using ChatGPT. The exclusion criteria included records from students in fields with smaller sample sizes, such as art, law, and agriculture, as well as those from individuals who were unwilling to disclose their gender or who had already graduated. An initial sample of 808 records was collected, and based on these criteria, 149 records were excluded. The final sample comprised 659 university and graduate students from Taiwan, with an average age of 22.72 years (SD = 2.50). This included 488 university students and 171 graduate students. Among the participants, 266 were enrolled in healthcare-related majors and 393 in non-healthcare fields, with 455 identifying as female and 204 as male. This study was approved by the Ethics Committee of National Tsing Hua University (approval number: 11212HT159).
Instrument
The survey consists of three parts: background information; ChatGPT usage frequency and contexts (such as information gathering, problem-solving, idea generation, and health-related queries); perceptions of ChatGPT’s applications for general purposes; and perceptions of ChatGPT’s domain-specific applications in healthcare. While the question sets for general purpose perceptions primarily utilize existing or modified instruments, the domain-specific question sets were specifically developed for this study. These were based on a diverse range of review and survey research conducted by the research team, which includes a professor from the Graduate Institute of Learning Sciences and Technologies as the first author and her PhD student as the second author. The team, with multiple years of experience executing projects funded by the Taiwan National Science and Technology Council in the field of medical education, refined the instrument following a small-scale pilot study. This pilot study involved discussions with students from healthcare backgrounds to revise the survey topics and a trial run of the survey to ensure its effectiveness in Taiwan’s context. SH-C first-year PhD student in Health and Human Performance at the University of Florida, contributed to the conceptualization of this manuscript and the analysis of the research findings’ implications. In this study, some questionnaire items were specifically developed based on concepts from the literature, while others were adapted from existing instruments. Exploratory factor analysis (EFA) and reliability analysis confirmed the validity and reliability of the questionnaire, identifying distinct factors related to perceptions of ChatGPT’s general-purpose and healthcare-specific applications, thus demonstrating the instrument’s suitability for further research. The complete instrument is shown in Table 2.
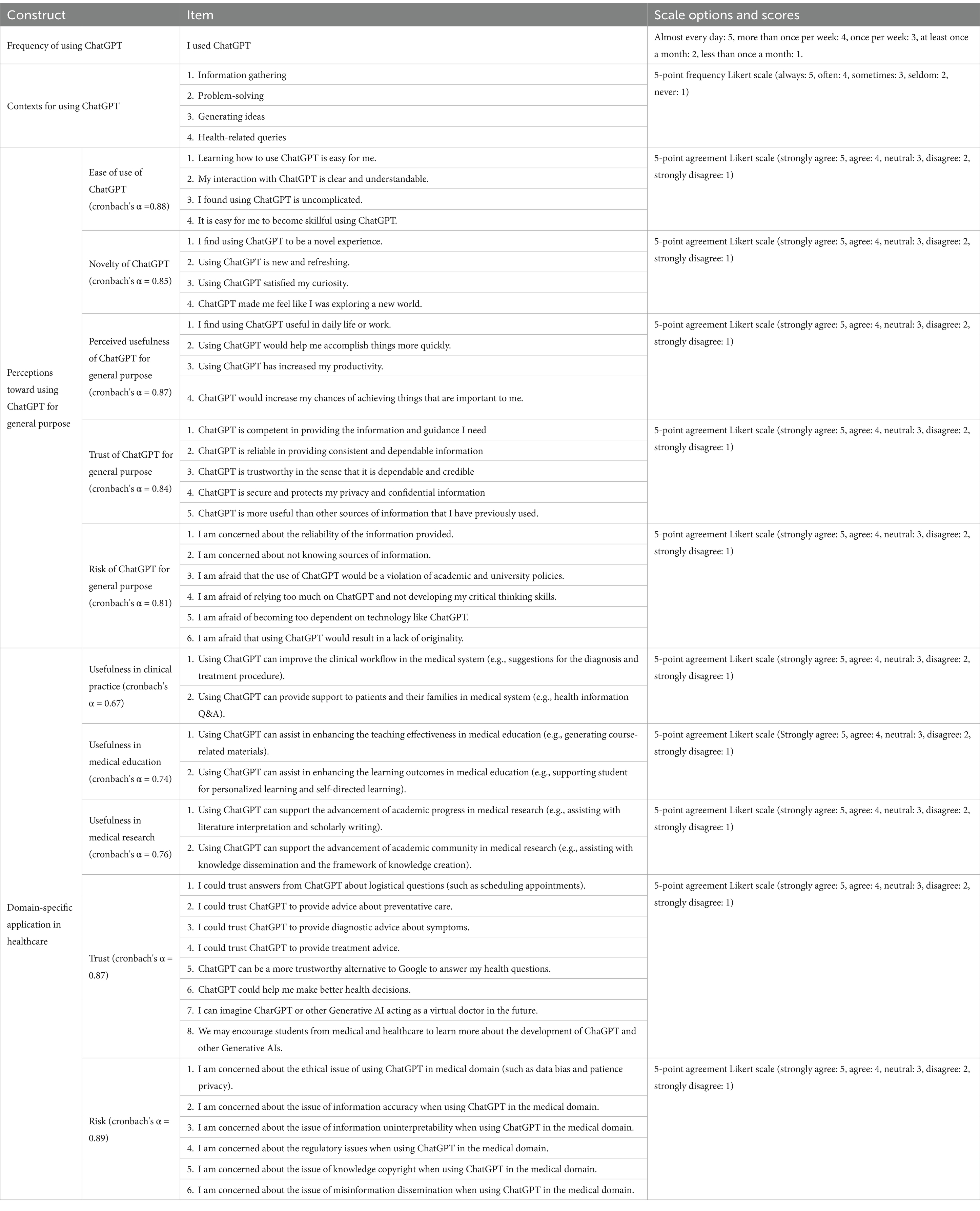
Table 2. Survey questions.
For perceptions of ChatGPT’s general-purpose applications, there are five subscales:
Ease of use was assessed with four items (Cronbach’s α = 0.88), exemplified by “Learning how to use ChatGPT is easy for me.” Ease of use was assessed with four items (Cronbach’s α = 0.88), exemplified by “Learning how to use ChatGPT is easy for me,” with items adapted from (17, 20).
Novelty was assessed with four items (Cronbach’s α = 0.85), including “I find using ChatGPT to be a novel experience,” with items adapted from (20).
Perceived usefulness was measured by four items (Cronbach’s α = 0.87), featuring “I find using ChatGPT useful in daily life or work,” with items adapted from (20).
Trust was evaluated with five items (Cronbach’s α = 0.84), including “ChatGPT is reliable in providing consistent and dependable information,” and “ChatGPT is more useful than other sources of information that I have previously used,” with items adapted from (21).
Risk was assessed with six items (Cronbach’s α = 0.81), featuring “I am afraid of relying too much on ChatGPT and not developing my critical thinking skills,” and “I am afraid that the use of ChatGPT would be a violation of academic and university policies,” with items developed based on concepts discussed in (15, 29, 30).
For perceptions of ChatGPT’s domain-specific applications in healthcare, there are three main themes: Perceived Usefulness, Trust, and Risk. These are further divided into five subscales, with Perceived Usefulness broken down into its applications in clinical practice, medical education, and medical research, following the tripartite division outlined in (1, 23).
Perceived usefulness in clinical practice was assessed by two items (Cronbach’s α = 0.67), including “Using ChatGPT can improve the clinical workflow in the medical system (e.g., suggestions for diagnosis and treatment procedures)” and “Using ChatGPT can provide support to patients and their families in the medical system (e.g., health information Q&A),” with items developed based on concepts discussed in (2, 11, 24).
Perceived usefulness in medical education was assessed by two items (Cronbach’s α = 0.74), including “Using ChatGPT can assist in enhancing teaching effectiveness in medical education (e.g., generating course-related materials)” and “Using ChatGPT can assist in enhancing learning outcomes in medical education (e.g., supporting personalized and self-directed learning),” with items developed based on concepts discussed in (1, 3, 12).
Perceived usefulness in medical research was assessed by two items (Cronbach’s α = 0.76), including “Using ChatGPT can support the advancement of academic progress in medical research (e.g., assisting with literature interpretation and scholarly writing)” and “Using ChatGPT can support the academic community in medical research (e.g., assisting with knowledge dissemination and knowledge creation),” with items developed based on concepts discussed in (1, 3, 13).
Trust was measured by eight items (Cronbach’s α = 0.87), including “I could trust ChatGPT to provide advice about preventative care,” “to provide diagnostic advice about symptoms,” “to provide treatment advice,” and “to help me make better health decisions.” These eight items were primarily derived from Nov et al. (25) survey. In Nov et al. (25) study, participants were asked about their trust in chatbots for patient-provider communication. They evaluated their trust in chatbots to provide different types of services, including logistical information, preventative care advice, diagnostic advice, and treatment advice. Additionally, participants compared their trust in AI chatbots for answering health questions to that of a Google search and assessed their overall trust in AI chatbots to assist them in making better health decisions.
Risk was measured by six items (Cronbach’s α = 0.89), including “I am concerned about the ethical issues of using ChatGPT in the medical domain (such as data bias and patient privacy),” and “the issue of information accuracy when using ChatGPT in the medical domain,” with items developed based on concepts discussed and findings informed by the non-survey research papers in (1, 3, 6).
Statistical analysis
For the purpose of this study, mean, SD, T-tests, and ANOVA were performed, and multiple linear regression models were conducted using 5 subscales on perceptions of ChatGPT’s domain-specific applications in healthcare as dependent variables: Perceived usefulness in clinical practice, Perceived usefulness in medical education, Perceived usefulness in medical research, Trust in healthcare applications, and Risk in healthcare applications. The independent variables are the 5 subscales on perceptions of ChatGPT’s general-purpose applications: Ease of use, Novelty, Perceived usefulness, Trust, and Risk. The regressions were performed separately for healthcare majors and non-healthcare majors, resulting in a total of 10 regression models.
Results
Descriptive analysis
The final sample comprised 659 university and graduate students from Taiwan, including 266 enrolled in healthcare-related majors and 393 in non-healthcare fields. Specifically, healthcare majors included 13.8% from the Medical Department, 13.1% from the Nursing Department, 7.9% from various health-related departments, and 5.6% from the Pharmacy Department. Non-healthcare majors were distributed across a range of fields: 10.8% from the College of Engineering, 9.9% from the College of Management, 9.4% from the College of Education, 9.3% from the College of Humanities and Social Sciences, 7.3% from the College of Electrical Engineering and Computer Science, 7.1% from the College of Science and Life Sciences, and 5.9% from the College of Information Management and Communication.
To explore ChatGPT usage patterns, we examined both the frequency and contexts of its use. Healthcare majors reported an average usage frequency of 2.20 (SD = 1.17) on a scale where 5 indicated almost every day, 4 more than once per week, 3 once per week, 2 at least once a month, and 1 less than once a month. In terms of usage contexts, they reported average scores of 3.48 (SD = 1.05) for problem-solving, 3.42 (SD = 1.07) for information gathering, 3.13 (SD = 1.13) for generating ideas, and 2.35 (SD = 1.18) for health-related queries, using a 5-point frequency Likert scale where 5 indicated always, 4 often, 3 sometimes, 2 seldom, and 1 never. In contrast, non-healthcare majors had an average usage frequency of 2.80 (SD = 1.20) and reported scores of 3.70 (SD = 0.96) for problem-solving, 3.64 (SD = 0.99) for information gathering, 3.43 (SD = 1.07) for generating ideas, and 1.98 (SD = 1.00) for health-related queries. T-test results revealed that non-healthcare majors use ChatGPT significantly more often than healthcare majors [t(657) = 6.40, p < 0.001], with significant group differences in all four contexts: non-healthcare majors use ChatGPT more frequently for problem-solving [t(532.479) = 2.722, p = 0.007], information gathering [t(657) = 2.747, p = 0.006], and idea generation [t(657) = 3.426, p < 0.001], while healthcare majors use it significantly more for health-related queries [t(503.317) = −4.162, p < 0.001]. These findings suggest that the field of study influences how students engage with AI tools like ChatGPT, potentially reflecting differing academic and professional needs.
For the research variables, healthcare majors reported average scores of 4.02 (SD = 0.74) for ease of use, 4.19 (SD = 0.64) for novelty, 4.11 (SD = 0.69) for usefulness, 3.51 (SD = 0.77) for trust, and 3.76 (SD = 0.77) for risk in their perceptions of using ChatGPT for general purposes, based on a 5-point agreement Likert scale where 5 indicated strongly agree, 4 agree, 3 neutral, 2 disagree, and 1 strongly disagree. In terms of ChatGPT’s domain-specific applications in healthcare, they reported average scores of 3.70 (SD = 0.81) for usefulness in clinical practice, 3.85 (SD = 0.78) for usefulness in medical education, 3.84 (SD = 0.80) for usefulness in medical research, 3.24 (SD = 0.73) for trust, and 3.84 (SD = 0.74) for risk. Conversely, non-healthcare majors reported average scores of 4.06 (SD = 0.66) for ease of use, 4.10 (SD = 0.65) for novelty, 4.17 (SD = 0.60) for usefulness, 3.51 (SD = 0.65) for trust, and 3.77 (SD = 0.67) for risk. They also reported scores of 3.79 (SD = 0.68) for usefulness in clinical practice, 3.93 (SD = 0.67) for usefulness in medical education, 3.89 (SD = 0.68) for usefulness in medical research, 3.33 (SD = 0.65) for trust, and 3.84 (SD = 0.64) for risk. Although non-healthcare majors had slightly higher average scores than healthcare majors across almost all items, these differences were not statistically significant: in ChatGPT’s general-purpose applications: for ease of use, t(657) = 0.812, p = 0.417; for novelty, t(519.553) = 1.216, p = 0.225; for usefulness, t(657) = 1.246, p = 0.213; for risk, t(657) = −0.164, p = 0.87; for trust, t(501.654) = 0.011, p = 0.991. In domain-specific healthcare applications: for usefulness in clinical practice, t(500.608) = 1.607, p = 0.109; for usefulness in medical education, t(511.026) = 1.305, p = 0.192; for usefulness in medical research, t(506.845) = 0.808, p = 0.419; for trust, t(657) = 1.76, p = 0.079; for risk, t(514.05) = −0.06, p = 0.952.
Additionally, a one-way repeated measures ANOVA was conducted to compare the perceived usefulness of ChatGPT in clinical practice, medical education, and medical research among healthcare majors. The results revealed significant differences [F(1.933, 512.287) = 6.276, p = 0.002, = 0.023]. Then, post-hoc tests were performed using pairwise comparisons. Clinical practice receiving significantly lower scores compared to medical education (MD = −0.152, p = 0.002) and research (MD = -141, p = 0.007). However, there was no significant difference between the scores of medical education and research (MD = 0.011, p = 0.798). This pattern was similarly observed among non-healthcare majors [F(1.912, 749.581) = 8.721, p < 0.001, = 0.022]. Post-hoc tests showed that clinical practice scored significantly lower than both medical education (MD = −0.132, p < 0.001) and research (MD = −0.093, p = 0.009), with no significant difference between the latter two (MD = 0.039, p = 0.183). These findings suggest that while ChatGPT is valued for its educational and research potential, its application in clinical practice may face greater scrutiny and require more rigorous validation to gain similar levels of acceptance.
In summary, both healthcare and non-healthcare majors showed positive perceptions of ChatGPT, although non-healthcare majors rated it slightly higher across all aspects. The application of ChatGPT in healthcare settings indicated particular strengths in education and research over clinical practice.
Regressions
Furthermore, this study explores how healthcare majors’ and non-healthcare majors’ overall impressions of ChatGPT (such as ease of use, novelty, usefulness, trustworthiness, and perceived risks) influence its perceived utility in healthcare settings, including clinics, medical schools, and research environments. Regression model results indicate that for healthcare majors, general trust in ChatGPT emerges as the only significant predictor of its application in clinical practice, as detailed in Table 3. In the areas of medical education and medical research, both perceived general usefulness and trust in ChatGPT serve as significant predictors, highlighting the importance of trust and perceived usefulness for healthcare majors. Conversely, for non-healthcare majors, the primary significant predictor for the application of ChatGPT in clinical practice is the novelty of the technology, as indicated in Table 4. Meanwhile, in the domains of medical education and medical research, the novelty of ChatGPT, along with perceived general usefulness and trust, are significant predictors.
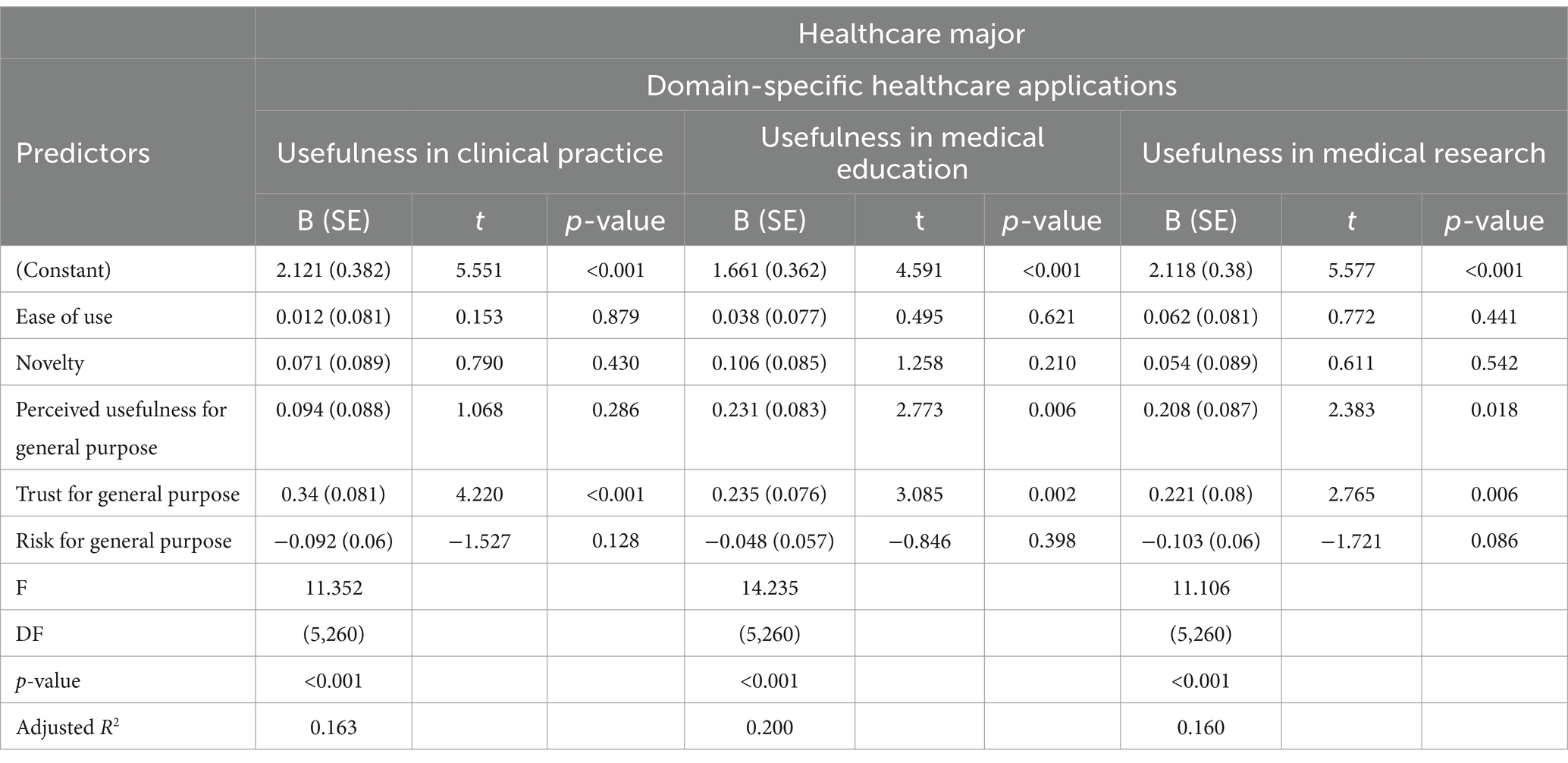
Table 3. Multiple linear regression for predicting usefulness in domain-specific healthcare applications of healthcare major students.
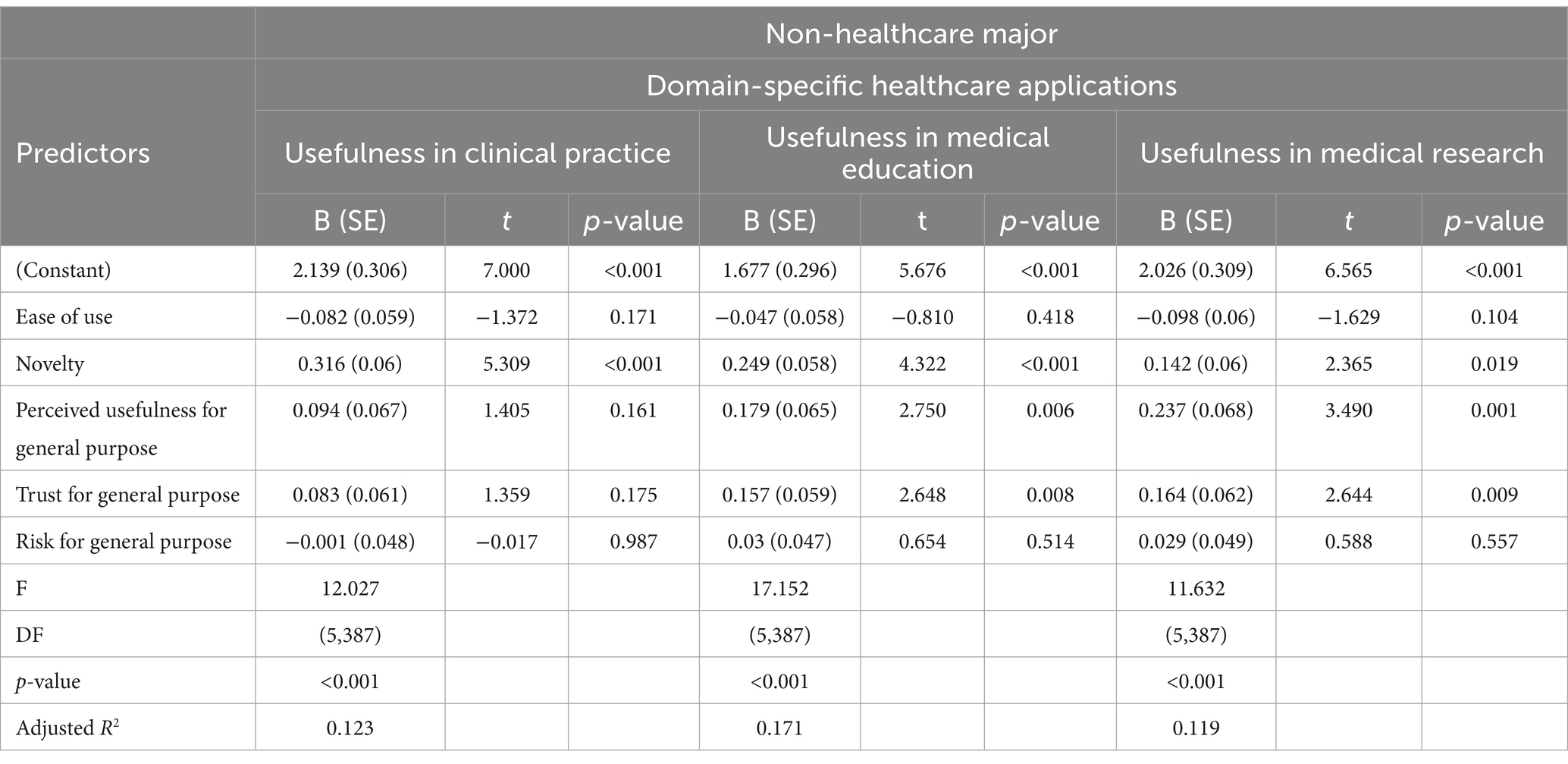
Table 4. Multiple linear regression for predicting usefulness in domain-specific healthcare applications of non-healthcare major students.
On the other hand, healthcare majors’ overall impressions of ChatGPT substantially influence their trust and perceived risk when deploying the technology in specific healthcare settings, accounting for 29.5 and 35.3% of variance, respectively, as shown in Table 5. Notably, general trust in ChatGPT emerges as the sole significant predictor of their trust in its application within healthcare domains. In contrast, the assessment of risk associated with using ChatGPT in healthcare is determined by three principal factors: general trust, perceived general risks, and the ease of use of the technology. Specifically, a lower general trust and higher perceived general risks correlate with increased perceived risks in healthcare applications. Additionally, a notable observation is that greater ease of use is associated with higher perceived risks in healthcare-specific applications, suggesting that while ease of use generally promotes adoption, in healthcare, it may raise concerns about potential overreliance and the adequacy of critical oversight. This understanding of how ease of use influences perceived risk highlights the complex considerations healthcare professionals make when integrating new technologies into their practice.
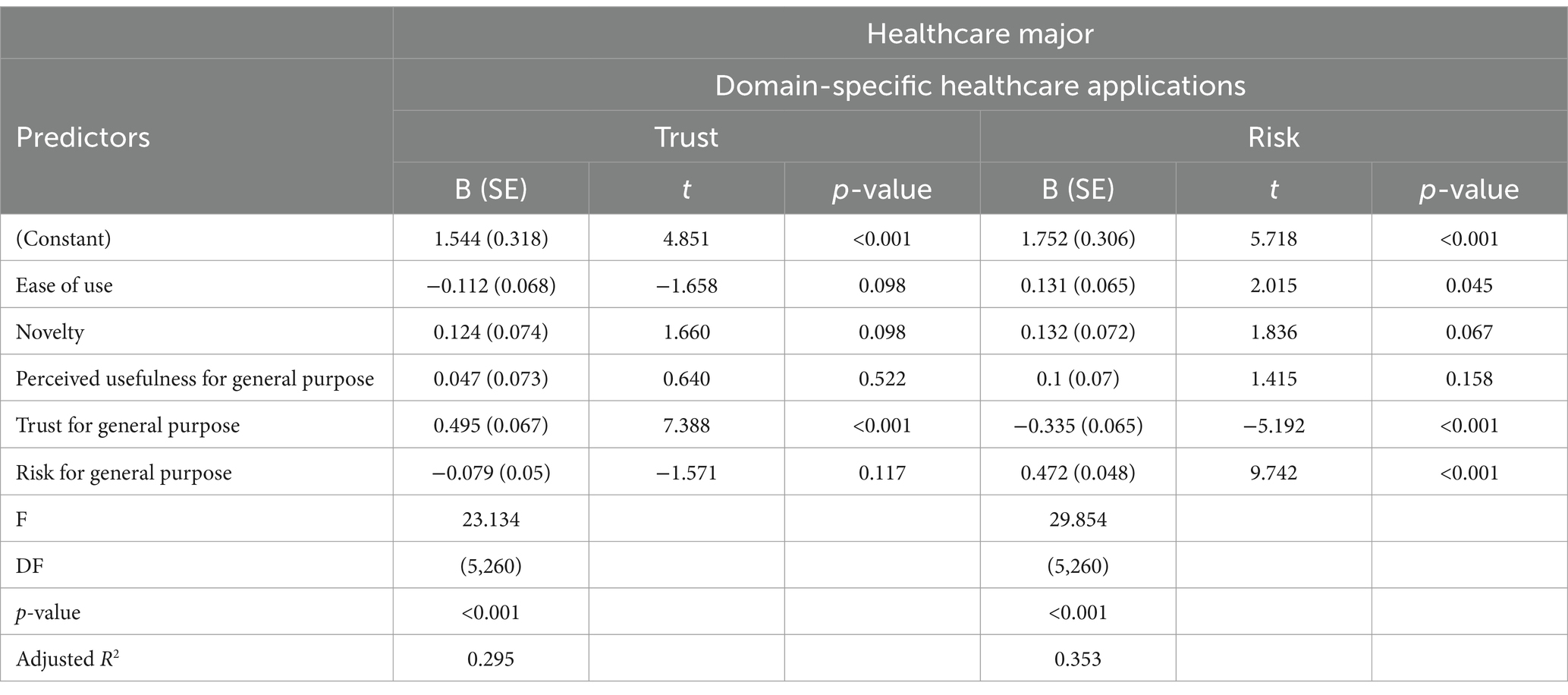
Table 5. Multiple linear regression for predicting trust and risks in domain-specific healthcare applications of healthcare major students.
Transitioning to non-healthcare majors, the factors influencing their trust in using ChatGPT for specific applications in healthcare are rather different, as detailed in Table 6. Here, general trust, novelty, and ease of use significantly affect their trust, where an increase in general trust and perceived novelty, coupled with a decrease in ease of use, correlates with greater trust in ChatGPT’s application in healthcare. Paradoxically, while less ease of use increases trust, it also highlights a critical perspective: that a technology requiring more effort to use may be perceived as more robust or serious, enhancing trust among non-healthcare professionals. Conversely, their assessment of risk is heavily swayed by perceived general risks and diminished general trust, resulting in greater perceived risks in healthcare applications. This illustrates that non-healthcare majors, although drawn to the innovative aspects of technology, remain cautious, reflecting a complex approach to adopting AI tools in sensitive fields similar to their healthcare counterparts.
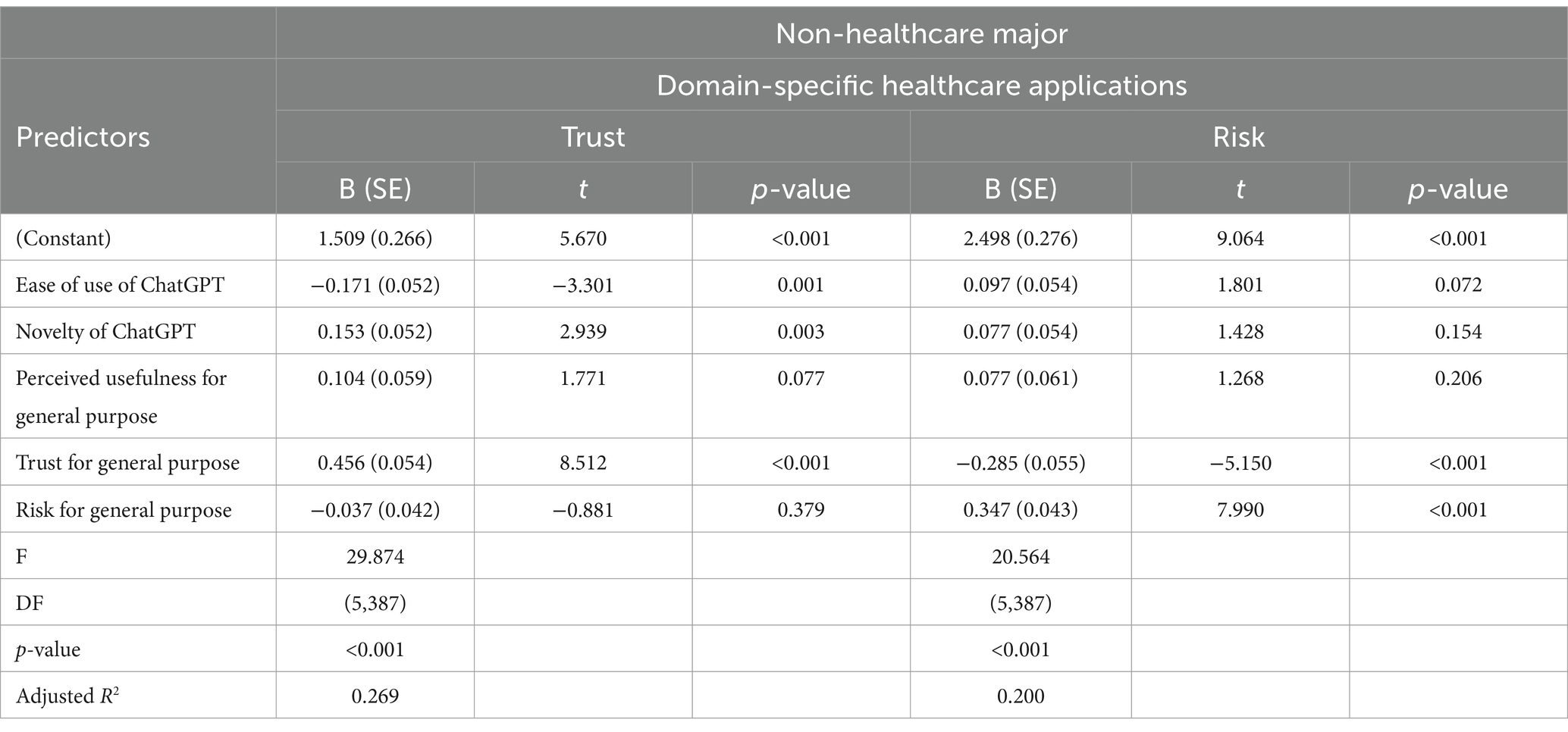
Table 6. Multiple linear regression for predicting trust and risks in domain-specific healthcare applications of non-healthcare major students.
Discussion
Main findings
Our study revealed that both healthcare and non-healthcare majors consider ChatGPT more useful in medical education and research than in clinical practice. Although there were no significant differences in perceived usefulness between education and research, healthcare majors rated its application in clinical practice lower, indicating concerns about the reliability and applicability of AI in direct patient care. Additionally, our study identified distinct patterns in how these two groups perceive and adopt ChatGPT in medical contexts. Healthcare majors emphasize trust as a crucial factor in adopting ChatGPT across clinical practice, education, and research, showing a strong preference for AI tools that are reliable and credible. In contrast, non-healthcare majors are more influenced by ChatGPT’s novelty, especially in clinical practice, viewing it as an innovative tool. They also value the general usefulness and trustworthiness of ChatGPT, particularly in educational and research settings. These findings highlight the differing priorities between the two groups: healthcare majors prioritize trust and reliability, while non-healthcare majors are attracted to innovation and novelty.
These differing perceptions have significant implications for the practical integration of AI in healthcare settings. The lower confidence healthcare majors place in ChatGPT for clinical practice suggests that the integration of AI tools like ChatGPT in patient care may face resistance unless these tools can demonstrably meet the high standards of accuracy and reliability required in clinical settings. This highlights the need for ongoing validation and improvement of AI technologies to build trust among healthcare professionals. On the other hand, the enthusiasm for innovation among non-healthcare majors suggests that AI adoption in less critical areas such as education and research may be more straightforward, with fewer barriers to acceptance. However, this enthusiasm must be tempered with a critical understanding of AI’s limitations to ensure that its application is both responsible and effective. The contrast in perceptions underscores the importance of tailoring AI implementation strategies to address the specific concerns and priorities of different user groups within the healthcare ecosystem.
Contrasting with existing literature
Results from the descriptive statistics revealed that, while prior research showed American healthcare stakeholders are more open to using ChatGPT in medical research than in clinical practice or educational applications (23), our findings indicate that both healthcare and non-healthcare groups in Taiwan rate clinical practice lower than medical education and research, with no significant differences observed between the latter two categories.
Our findings align with previous research that emphasizes the importance of general trust in the adoption of AI technologies like ChatGPT (19, 21), especially in healthcare settings where patient outcomes and ethical considerations are paramount. For healthcare majors, trust in ChatGPT emerges as the primary determinant of its adoption, consistent with earlier studies that underscore the need for AI tools to demonstrate reliability and credibility in high-stakes environments (25). This reliance on trust suggests that healthcare professionals are cautious about adopting new technologies that could impact patient care, highlighting the critical need for AI tools that complement human judgment rather than replace it.
Conversely, the novelty of ChatGPT plays a more significant role for non-healthcare majors, who are attracted to its innovative features. This extends earlier findings on the importance of novelty in AI adoption (18, 20), suggesting that non-healthcare majors are more open to exploring new technologies, particularly when they perceive them as useful and trustworthy.
Interestingly, our study also reveals a paradox where non-healthcare majors associate increased complexity with greater trust, viewing more complex interfaces as indicators of thoroughness and reliability. This contrasts with healthcare majors, who view ease of use with caution, fearing that overly simplistic systems might undermine the rigorous analytical processes required in clinical practice. While extant literature has inconsistent findings on the role of ease of use on ChatGPT’s adoption (16, 17), our results suggest a subtle influence, where professional background significantly shapes perceptions in technology.
Implications for clinical practice
In the domain of clinical practice, the findings underscore the necessity for AI tools like ChatGPT to build trust among healthcare professionals by demonstrating reliability and ethical integrity. The lower ratings for clinical applications suggest that future developments should focus on integrating AI in ways that complement human judgment, ensuring that the technology supports clinical rigor rather than undermines it. This approach could help alleviate concerns and foster greater acceptance of AI in clinical settings. By fostering a collaborative relationship between AI and healthcare professionals, where AI serves as a supportive tool rather than a substitute for human expertise, the healthcare sector can move toward a future where AI enhances the quality of care. This approach will not only increase the acceptance of AI in clinical settings but also ensure that these tools contribute meaningfully to patient outcomes and the overall integrity of medical practice.
Implications for medical education
In the domain of medical education, the high ratings for ChatGPT’s usefulness suggest a strong acceptance of AI as a transformative tool capable of revolutionizing the training of healthcare professionals. This recognition highlights the potential of ChatGPT to offer personalized learning experiences, tailor educational content to individual needs, and enhance the overall process of knowledge acquisition. By integrating AI into educational frameworks, institutions can develop innovative teaching methodologies that not only improve educational outcomes but also prepare students to navigate the complexities of modern healthcare environments. However, AI should serve as a tool to augment the learning process, enabling students to explore new ideas and approaches while maintaining the rigor and depth of traditional education. This collaboration will not only improve the quality of training for healthcare professionals but also ensure that graduates are well-prepared to leverage AI in their future clinical and research endeavors.
Implications for medical research
In the domain of medical research, the favorable perceptions of ChatGPT’s utility reflect a growing acceptance of AI as a critical tool for advancing research practices. This acceptance underscores ChatGPT’s potential to enhance various aspects of academic work, including medical writing, literature interpretation, and scholarly communication. By supporting the advancement of academic progress and fostering the development of the academic community, ChatGPT aligns with the needs of researchers who seek efficient and innovative solutions to complex problems. However, just as in clinical practice and medical education, the adoption of AI in research must be approached with caution. Challenges such as the risks of misinformation, content inconsistency, and potential overdependence on AI highlight the need for careful management and oversight. Ensuring that AI tools like ChatGPT are used responsibly will be essential to maximizing their benefits while safeguarding the integrity of medical research.
Implications for public health: responsible and ethical use of AI in healthcare
The integration of AI tools like ChatGPT into healthcare presents significant opportunities for improving public health, but it also raises critical ethical and operational challenges. To harness the benefits of AI while mitigating risks, healthcare professionals must prioritize transparency and trust in AI operations, ensuring that AI tools complement, rather than replace, clinical judgment. Continuous oversight and regulation are essential to prevent misuse and overdependence on technology, with a focus on understanding AI’s limitations, particularly in the patient care. Addressing risks such as misinformation and content inconsistency is crucial, requiring robust validation processes and regular updates to keep AI tools accurate and reliable. Additionally, equity and accessibility must guide AI adoption in healthcare, ensuring that all patients benefit from these advancements regardless of socioeconomic status or location. Ultimately, responsible and ethical use of AI in healthcare can enhance public health outcomes while maintaining the integrity and trust that are fundamental to patient care.
Conclusion
The findings of this study emphasize the critical importance of designing AI tools that meet the distinct needs of healthcare and non-healthcare majors. For healthcare professionals, trust in AI technologies is paramount, particularly in clinical settings where the stakes are high. AI developers should focus on creating systems that are not only reliable and accurate but also transparent. By integrating explainable AI (XAI) features into tools like ChatGPT, developers can enhance credibility by providing clear, interactive explanations of how decisions are made. This transparency, which includes clear decision-making processes, the ability to customize based on context, and the capacity for auditability, is crucial for building trust and ensuring that AI tools are viewed as valuable supports for clinical judgment, rather than as replacements.
For non-healthcare majors, the appeal of innovation and novelty in AI tools suggests that developers should also focus on user-friendly interfaces and the integration of cutting-edge features that encourage exploration and engagement, especially in educational and research contexts. However, it is crucial that this enthusiasm is balanced with a clear understanding of AI’s limitations to prevent over-reliance or misuse.
Future research directions
Future research should investigate the long-term impacts of AI adoption in healthcare, focusing on how sustained use affects clinical outcomes, patient trust, and the educational development of healthcare professionals. Qualitative studies, such as interviews and focus groups, are needed to explore the nuanced ways in which trust in AI is built and maintained across different user groups. Additionally, research should address the ethical implications of AI in healthcare, including issues related to patient privacy, data security, and the equitable distribution of AI benefits across different populations. Understanding these factors will be key to developing AI tools that are not only effective but also ethically sound and widely accepted.
Limitations and contributions
This study acknowledges several limitations that could impact the generalizability of its findings. The use of convenience sampling and reliance on self-reported data may introduce biases and limit the depth of understanding of participants’ perceptions. Additionally, the focus on a specific demographic—students from Taiwan—means that the findings may not be fully applicable to other cultural or healthcare contexts. These limitations suggest that caution should be exercised when interpreting the results, particularly regarding their applicability to different populations.
To address these limitations, future research should incorporate more diverse sampling methods, including participants from multiple countries with varying cultural, socioeconomic, and educational backgrounds. Incorporating qualitative approaches, such as interviews or focus groups, would also provide richer insights into how trust in AI is built and maintained, allowing for a more nuanced understanding of user perceptions and behaviors.
Despite these limitations, this study offers valuable insights into the differing perceptions of AI among healthcare and non-healthcare students. The findings provide essential guidance for the development of AI tools that cater to the specific needs and concerns of these distinct groups. By addressing both the practical and ethical challenges of AI integration, this research contributes to the ongoing conversation about the role of AI in transforming healthcare and education.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
This study was approved by the Ethics Committee of National Tsing Hua University (approval number: 11212HT159). The participants provided their written informed consent to participate in this study.
Author contributions
S-YC: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Writing – original draft. HK: Data curation, Formal analysis, Methodology, Writing – review & editing. S-HC: Conceptualization, Resources, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Science and Technology Council in Taiwan (Grant no. NSTC 113-2410-H-007-066). The authors expressed their gratitude.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Thirunavukarasu, AJ, Ting, DSJ, Elangovan, K, Gutierrez, L, Tan, TF, and Ting, DSW. Large language models in medicine. Nat Med. (2023) 29:1930–40. doi: 10.1038/s41591-023-02448-8
2. Li, J, Dada, A, Kleesiek, J, and Egger, J. ChatGPT in healthcare: a taxonomy and systematic review. Comput Methods Prog Biomed. (2024) 245:108013. doi: 10.1101/2023.03.30.23287899
3. Abd-Alrazaq, A, AlSaad, R, Alhuwail, D, Ahmed, A, Healy, PM, Latifi, S, et al. Large language models in medical education: opportunities, challenges and future directions. JMIR Med Educ. (2023) 9:e48291. doi: 10.2196/48291
4. De Angelis, L, Baglivo, F, Arzilli, G, Privitera, GP, Ferragina, P, Tozzi, AE, et al. ChatGPT and the rise of large language models: the new AI-driven infodemic threat in public health. Front Public Health. (2023) 11:1166120. doi: 10.3389/fpubh.2023.1166120
5. Johnson, D, Goodman, R, Patrinely, J, Stone, C, and Zimmerman, E. Assessing the accuracy and reliability of AI-generated medical responses: an evaluation of the chat-GPT model. Res Square. [Preprint]. (2023):rs.3.rs-2566942. doi: 10.21203/rs.3.rs-2566942/v1
6. Rahimzadeh, V, Kostick-Quenet, K, Blumenthal-Barby, J, and McGuire, AL. Ethics education for healthcare professionals in the era of ChatGPT and other large language models: do we still need it? Am J Bioeth. (2023) 23:17–27. doi: 10.1080/15265161.2023.2233358
7. Rao, AS, Pang, M, Kim, J, Kamineni, M, Lie, W, Prasad, AK, et al. Assessing the utility of ChatGPT throughout the entire clinical workflow. J Med Internet Res. (2023) 25:e48659. doi: 10.2196/48659
8. Sallam, M . ChatGPT utility in healthcare, education, research and practice: a systematic review on the promising perspectives and valid concerns. Healthcare. (2023) 11:887. doi: 10.3390/healthcare11060887
9. Tustumi, F, Andreollo, NA, and Aguilar-Nascimento, JED. Future of the language models in healthcare: the role of chatGPT. ABCD Arquivos Brasileiros Cirurgia Digestiva. (2023) 36:e1727. doi: 10.1590/0102-672020230002e1727
10. Van Bulck, L, and Moons, P. What if your patient switches from Dr. Google to Dr. ChatGPT? A vignette-based survey of the trustworthiness, value, and danger of ChatGPT-generated responses to health questions. Eur J Cardiovasc Nurs. (2023) 23:95–8. doi: 10.1093/eurjcn/zvad038
11. Wang, DQ, Feng, LY, Ye, JG, Zou, JG, and Zheng, YF. Accelerating the integration of ChatGPT and other large-scale AI models into biomedical research and healthcare. MedComm-Future Med. (2023) 2:e43. doi: 10.1002/mef2.43
12. Kung, TH, Cheatham, M, Medenilla, A, Sillos, C, De Leon, L, Elepaño, C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLoS Digit Health. (2023) 2:e0000198. doi: 10.1371/journal.pdig.0000198
13. Wang, H, Wu, W, Dou, Z, He, L, and Yang, L. Performance and exploration of ChatGPT in medical examination records and education in Chinese: pave the way for medical AI. Int J Med Inform. (2023) 177:105173. doi: 10.1016/j.ijmedinf.2023.105173
14. Parikh, PM, Talwar, V, and Goyal, M. ChatGPT: an online cross-sectional descriptive survey comparing perceptions of healthcare workers to those of other professionals. Cancer Res Stat Treat. (2023) 6:32–6. doi: 10.4103/crst.crst_40_23
15. Sallam, M, Salim, NA, Barakat, M, Al-Mahzoum, K, Ala'a, B, Malaeb, D, et al. Assessing health students' attitudes and usage of ChatGPT in Jordan: a validation study. JMIR Med Educ. (2023) 9:e48254. doi: 10.2196/48254
16. Abdaljaleel, M, Barakat, M, Alsanafi, M, Salim, NA, Abazid, H, Malaeb, D, et al. A multinational study on the factors influencing university students’ attitudes and usage of ChatGPT. Sci Rep. (2024) 14:1983. doi: 10.1038/s41598-024-52549-8
17. Tiwari, CK, Bhat, MA, Khan, ST, Subramaniam, R, and Khan, MAI. What drives students toward ChatGPT? An investigation of the factors influencing adoption and usage of ChatGPT. Interact Technol Smart Educ. (2023) 21:333–55. doi: 10.1108/ITSE-04-2023-0061
19. Baek, THT, and Kim, M. Is ChatGPT scary good? How user motivations affect creepiness and trust in generative artificial intelligence. Telematics Inform. (2023) 83:102030. doi: 10.1016/j.tele.2023.102030
20. Ma, X, and Huo, Y. Are users willing to embrace ChatGPT? Exploring the factors on the acceptance of chatbots from the perspective of AIDUA framework. Technol Soc. (2023) 75:102362. doi: 10.1016/j.techsoc.2023.102362
21. Choudhury, A, and Shamszare, H. Investigating the impact of user trust on the adoption and use of ChatGPT: survey analysis. J Med Internet Res. (2023) 25:e47184. doi: 10.2196/47184
22. Shahsavar, Y, and Choudhury, A. User intentions to use ChatGPT for self-diagnosis and health-related purposes: cross-sectional survey study. JMIR Hum Factors. (2023) 10:e47564. doi: 10.2196/47564
23. Hosseini, M, Gao, CA, Liebovitz, DM, Carvalho, AM, Ahmad, FS, Luo, Y, et al. An exploratory survey about using ChatGPT in education, healthcare, and research. PLoS One. (2023) 18:e0292216. doi: 10.1371/journal.pone.0292216
24. Temsah, MH, Aljamaan, F, Malki, KH, Alhasan, K, Altamimi, I, Aljarbou, R, et al. Chatgpt and the future of digital health: a study on healthcare workers’ perceptions and expectations. Healthcare. (2023) 11:1812. doi: 10.3390/healthcare11131812
25. Nov, O, Singh, N, and Mann, D. Putting ChatGPT’s medical advice to the (Turing) test: survey study. JMIR Med Educ. (2023) 9:e46939. doi: 10.2196/46939
26. Branley-Bell, D, Brown, R, Coventry, L, and Sillence, E. Chatbots for embarrassing and stigmatizing conditions: could chatbots encourage users to seek medical advice? Front Commun. (2023) 8:1275127. doi: 10.3389/fcomm.2023.1275127
27. Davis, FD . Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. (1989) 13:319–40. doi: 10.2307/249008
28. Katz, E, Blumler, JG, and Gurevitch, M. Uses and gratifications research. Public Opin Q. (1973) 37:509–23.
29. de Winter, J, Dodou, D, and Eisma, YB. Personality and acceptance as predictors of ChatGPT use. Discov Psychol. (2024) 4:57. doi: 10.1007/s44202-024-00161-2
Keywords: healthcare, clinical practice, medical education, medical research, technology acceptance model, ChatGPT, uses and gratifications theory, Taiwan
Citation: Chen S-Y, Kuo HY and Chang S-H (2024) Perceptions of ChatGPT in healthcare: usefulness, trust, and risk. Front. Public Health. 12:1457131. doi: 10.3389/fpubh.2024.1457131
Edited by:
Francisco Tustumi, University of São Paulo, BrazilReviewed by:
Davi Rumel, Retired, São Paulo, BrazilCharles F. Harrington, University of South Carolina Upstate, United States
Isabel Rada, Universidad del Desarrollo, Chile
Carlos Alberto Pereira De Oliveira, Rio de Janeiro State University, Brazil
Copyright © 2024 Chen, Kuo and Chang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Su-Yen Chen, c3V5Y2hlbkBteC5udGh1LmVkdS50dw==