 Yuxie Xiao1,2
Yuxie Xiao1,2 Lulu Lin
Lulu Lin Yi Yang
Yi Yang Zhongzhi Xu
Zhongzhi Xu
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Public Health , 05 January 2024
Sec. Injury Prevention and Control
Volume 11 - 2023 | https://doi.org/10.3389/fpubh.2023.1294338
This article is part of the Research Topic Road Traffic Injury Prevention and Control View all 12 articles
Objective: Fatal road accidents are statistically rare, posing challenges for accurate estimation through the classic logit model (LM). This study seeks to validate the efficacy of a rare events logistic model (RELM) in enhancing the precision of fatal crash estimations.
Methods: Both LM and RELM were employed to examine the relationship between pertinent risk factors and the incidence of fatal crashes. Crash-injury datasets sourced from Hillsborough County, Florida served as the empirical basis for evaluating the performance metrics of both LM and RELM.
Results: The analysis revealed that RELM yielded more accurate predictions of fatal crashes compared to LM. Receiver operating characteristic (ROC) curves were constructed, and the area under the curve (AUC) for each model was computed to offer a comparative performance assessment. The empirical evidence notably favored RELM over LM as substantiated by superior AUC values.
Conclusion: The study offers empirical validation that RELM is demonstrably more proficient in predicting fatal crashes than the LM, thereby recommending its application for nuanced traffic safety analytics.
The persistently high mortality rates from traffic crashes have intensified their classification as a significant global public health issue (1, 2). According to the World Health Organization (3), fatalities attributed to traffic crashes witnessed a 25% increase, rising from 1.08 million in 1990 to 1.35 million in 2016. This uptick not only represents a societal tragedy but also imposes considerable economic strain on communities and families.
Numerous studies have been undertaken to explore the relationships between various risk factors—such as sex, age, educational attainment, weather conditions, and alcohol consumption—and the outcomes of traffic crashes (4–10). Given that crash severity is generally categorized by levels, discrete outcome models have been instrumental in investigating the correlations between fatal crashes and contributory factors (11–16).
Among the models utilized, the binary logit model (LM) is predominant. However, this approach has limitations when dealing with rare events, such as fatal crashes. For instance, the Hong Kong Transport Department's statistics from 2015 reveal that, of 16,170 injury-related crashes, only 117 were fatal, representing a meager 0.72% of the total dataset (17). Extant literature corroborates that LM tends to significantly underestimate the occurrence of such rare events (18).
Against this empirical backdrop, the present study deploys a rare events logistic model (RELM) to enhance the precision of fatal crash estimations. The RELM has been successfully applied in other domains such as geomorphology, social science, and epidemiology (19–21). To the authors' best knowledge, this study involves the inaugural application of RELM in the specific field of fatal crash estimation.
Logistic regression is the most used method in crash injury severity analyses. To model the relationship between fatal crashes and the risk factors, the outcome variable yi in the ith crash was set to be one of the two values: yi = 1 representing fatal crashes and yi = 0 representing non-fatal crashes. The probability of yi = 1 is denoted by Pr(yi = 1), which is calculated using the following equation:
Logistic regression is the predominant method employed in the analyses of crash injury severities. To elucidate the relationship between fatal crashes and associated risk factors, we define the outcome variable yi for the ith crash as binary: yi = 1 signifies a fatal crash, while yi = 0 indicates a non-fatal crash. The probability that yi = 1, denoted as Pr(yi = 1), is calculated using the logistic function:
In Equation (1), encapsulates the linear combination of predictor variables, known as the utility function, which is expressed as:
Here, xki represents the value of the kth variable for the ith observation and βk is the corresponding coefficient.
There is another way to formulate the aforementioned question. Let us assume an unobserved continuous variable , which represents the propensity of where a fatal crash occurred. follows a logistic distribution, which is close to normal (mathematically, the difference exists but is trivial). If we want to know the effects of xi, the standard approach is to run a regression with xi as the dependent variable. To determine whether the crash is fatal or not, we observed whether this propensity is greater than a specific threshold. As documented by King and Zeng (19), this mechanism turns out to be the chief troublemaker in bias induced by rare events. The coefficients of β are estimated using the maximum-likelihood method with the following equation over a dataset of n observations:
In Equation (3), is the multiple linear combinations of explanatory variables, which are also known as the utility function, and can be represented as:
where xki denotes the value of variable k for sample i and βk is the coefficient of variable k.
Alternatively, one may conceptualize the problem using a latent variable , which signifies the propensity for a crash to be fatal. This latent variable follows a logistic distribution, which, despite its mathematical distinctiveness, is practically akin to a normal distribution. The impact of the predictors xi is typically assessed by regressing them against this unobserved variable. The determination of the crash outcome—fatal or otherwise—is contingent upon whether the propensity surpasses a specified threshold. As highlighted by King and Zeng (19), this threshold mechanism introduces a primary source of bias in the presence of rare events. The logistic regression coefficients β are estimated by employing the maximum-likelihood estimation method applied across a dataset comprising n observations:
It is imperative to acknowledge that, in the analysis of rare events data, additional occurrences of the event of interest (coded as “1”) provide greater informational value than non-occurrences (coded as “0”). During the estimation phase, the standard error of the estimated coefficient β is derived from the variance:
In Equation (6), the summation is notably influenced by the rarity of the event under study. The term πi(1−πi) attains its maximum when πi = 0.5 and approaches zero as πi converges to either extremity of the probability spectrum. Given that rare events data typically yield minuscule estimates of πi for all observations, it is crucial to consider that these estimates will be substantially smaller than 0.5. Nonetheless, if the logit model possesses explanatory significance, the estimated probabilities πi corresponding to the occurrences of “1” will be markedly higher than those associated with “0”. These estimates will also lie nearer to the apex of informational value at 0.5. Consequently, this results in the additional occurrences of “1” being more informative for the model than the additional occurrences of “0”.
To ameliorate the bias in estimation attributed to the use of LM in rare events data, King and Zeng (18) introduced the RELM. RELM not only mitigates underestimation bias but also enhances the efficiency of data collection and reduces the requirements for data storage space during the sample selection phase.
As highlighted in the preceding discussion, the LM exhibits suboptimal performance when instances of yi = 1 are infrequent within the dataset. To address this limitation, a strategic alteration in data collection is proposed. By archiving all observations where a fatal crash occurred (yi = 1) and a random subset of non-fatal crash observations (yi = 0), we can refine the accuracy of the standard logit model's estimations.
To correct for selection bias inherent in choice-based sampling, two primary methods are employed: the prior correction and the weighting correction. The subsequent sections will elucidate these approaches in detail.
Research by King and Zeng (18) demonstrates that the logit model coefficients remain statistically consistent between population estimates and those derived from selected data. The objective of the prior correction method is to adjust the intercept in the logit model using the following formula:
where τ represents the proportion of yi = 1 within the population, while y signifies the proportion of yi = 1 within the sampled dataset. The calculation of the probability of rare events occurrence is contingent upon accurate estimations of both β0 and βk, as indicated in Equation (1).
It is essential to note that the prior correction method necessitates the knowledge of τ, the population proportion of yi = 1. In the context of this study, τ can be directly ascertained from the initial dataset of crash data. A principal benefit of the prior correction method lies in its user-friendliness; it can be readily implemented with any statistical software capable of fitting standard logistic models. For instance, the study by Ren et al. (22) leveraged this method to adjust estimates concerning the influence of various factors on red-light running behavior. Next, we will delineate an alternative approach that can augment the efficacy of the logistic model (LM) when used in conjunction with prior correction.
The weighting correction involves assigning weights to the data to balance the discrepancies in the proportions of yi = 1 between the sample and the population, which arise from choice-based sampling. This method entails optimizing a weighted log-likelihood function rather than the conventional log-likelihood function:
In this context, the weights ω1 and ω0 are defined as and , respectively, where ωi = ω1yi+ω0(1−yi). The parameters τ and y retain their definitions from the “prior correction” section.
Although this method may appear more complex than the prior correction technique, Equation 6 is formulated to enable researchers to apply it using any standard logit software package.
Xie and Manski (23) posited that weighting correction could surpass prior correction in effectiveness when the available sample is substantial, and there is a mis-specification of the functional form. Conversely, Amemiya and Vuong (24) indicated that, while weighting correction may be marginally less efficient than prior correction, the difference in efficiency is typically negligible.
Subsequent to implementing the prior correction and weighting methods, we adapt modifications suitable for both cohort and choice-based sampling designs in rare events logistic models. The bias in the estimated coefficients is appraised using the weighted least-squares method, formulated as:
where symbolizes an adjustment factor, where Qii are the diagonal constituents of the matrix Q = X(X′WX)−1X′ and is a diagonal matrix with elements . Consequently, the adjusted coefficients are calculated as follows:
The final corrected probability Pi can be approximated by the following expression:
where the correction term Ci is delineated as follows:
Within this equation, denotes the estimated variance-covariance matrix of the adjusted coefficients . Xi = (1, xi) represents the vector of predictors, including the intercept for the ith observation, and is its transpose. Collectively, these amendments constitute the methodology of the RELM. To the authors' knowledge, this is the first instance of applying RELM within the domain of fatal crash estimation.
Data on crash-related injuries that occurred in the year 2006 in Florida were procured from the Florida Department of Highway Safety and Motor Vehicles (DHSMV). The dataset encompasses 107,464 driver-vehicle units implicated in 53,732 traffic incidents. A meager 0.34% of these incidents resulted in fatalities, highlighting their infrequency. The variables under scrutiny encompass critical attributes, such as those associated with the driver, the vehicle, the roadway, and the environmental context, as delineated in prior research (25–28). Table 1 delineates the variables and their corresponding characteristics as encapsulated within the Florida dataset.
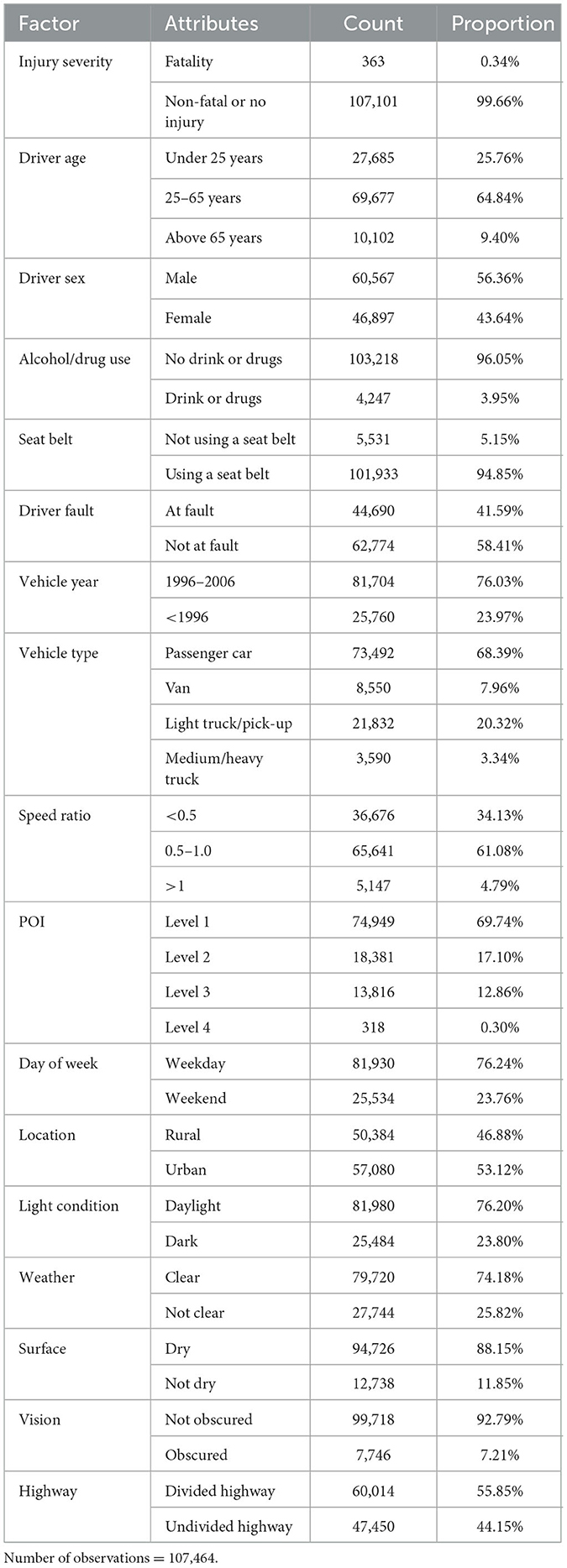
Table 1. Variables contained in the dataset.
Notably, the “speed ratio”—defined as the quotient of the estimated speed prior to the collision and the statutory speed limit post-collision—is posited to correlate positively with injury severity (25). Furthermore, the analysis includes “points of impact” (POIs) on the vehicle, enumerated in the Florida crash reports and illustrated in Figure 1. These POIs are categorized in alignment with the schema proposed by Huang et al. (29), where Level 1 encompasses nine POIs (nos. 1–2, 5–7, 9–10, 14, and 21) located peripherally relative to the driver's seat, such as the front and rear passenger sides. Level 2 consists of five POIs (nos. 3, 8, 11, 15, and 17) situated in closer proximity to the driver than those in Level 1. Level 3 includes POIs (nos. 4, 12–13, 18, and 20), which are nearest to the driver, comprising the windshield and the front passenger and driver sides. The final category, Level 4, is assigned to two POIs (nos. 16 and 19).
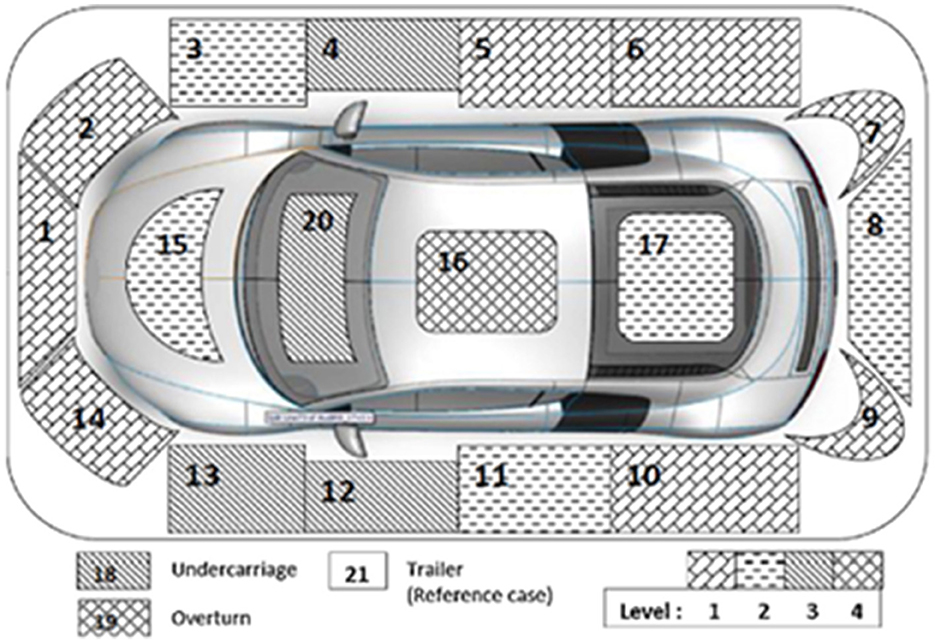
Figure 1. An illustration of the points of impact.
In the evaluation of our models, namely, RELM and the LM, we quantify the predictive performance using the area under the receiver operating characteristic curve (AUC-ROC). The AUC is a widely accepted metric for model performance evaluation, particularly in binary classification problems. It provides an aggregate measure of performance across all possible classification thresholds. The calculation of the AUC involves plotting the true positive rate (sensitivity) against the false positive rate (1-specificity) at various threshold settings (30). The AUC value ranges from 0 to 1, where an AUC of 1 indicates perfect predictive accuracy and an AUC of 0.5 suggests performance no better than random chance.
To estimate the AUC accurately, we employ the trapezoidal rule for numerical integration as this method is well-suited for the discrete data points that characterize an empirical ROC curve (31). Furthermore, we validate the robustness of our AUC estimates through K-fold cross-validation, which mitigates the potential for overfitting by ensuring that each observation is used for both training and validation. This process involves partitioning the data into K equal-sized segments, training the model on K−1 segments, and validating it on the remaining segment. This is repeated K times, with each segment used exactly once for validation. The average AUC across all K iterations provides a reliable estimate of the predictive performance of the models. In this study, K was set to 5.
As previously mentioned, the initial step involves the partial extraction of the complete dataset for regression analysis. This entails retaining all instances of fatal crashes while selectively including a subset of non-fatal crashes. To ascertain the optimal proportion of “1” events in the newly constituted dataset, this study computes the coefficients employing both the prior correction and weighting correction methods, incrementally adjusting by 1% within a range from 0.05 to 0.95. The variation in classification accuracy is further assessed using two metrics: the accurate classification rate (ACR), defined as the quotient of correctly identified fatal accidents to the total number of actual fatal accidents; and the false classification rate (FCR), computed as the quotient of erroneously classified incidents to the total number of events.
Figure 2 delineates the interplay between the three aforementioned variables: ACR, FCR, and the ascending fraction of “1” events in the sampled data. The depiction includes red dots representing outcomes via the prior correction method and blue stars indicating results from the weighting method. A 3D subgraph within Figure 2A visualizes the pairwise interactions among these factors, with the remaining panels (Figures 2B–D) presenting projections along different axes.
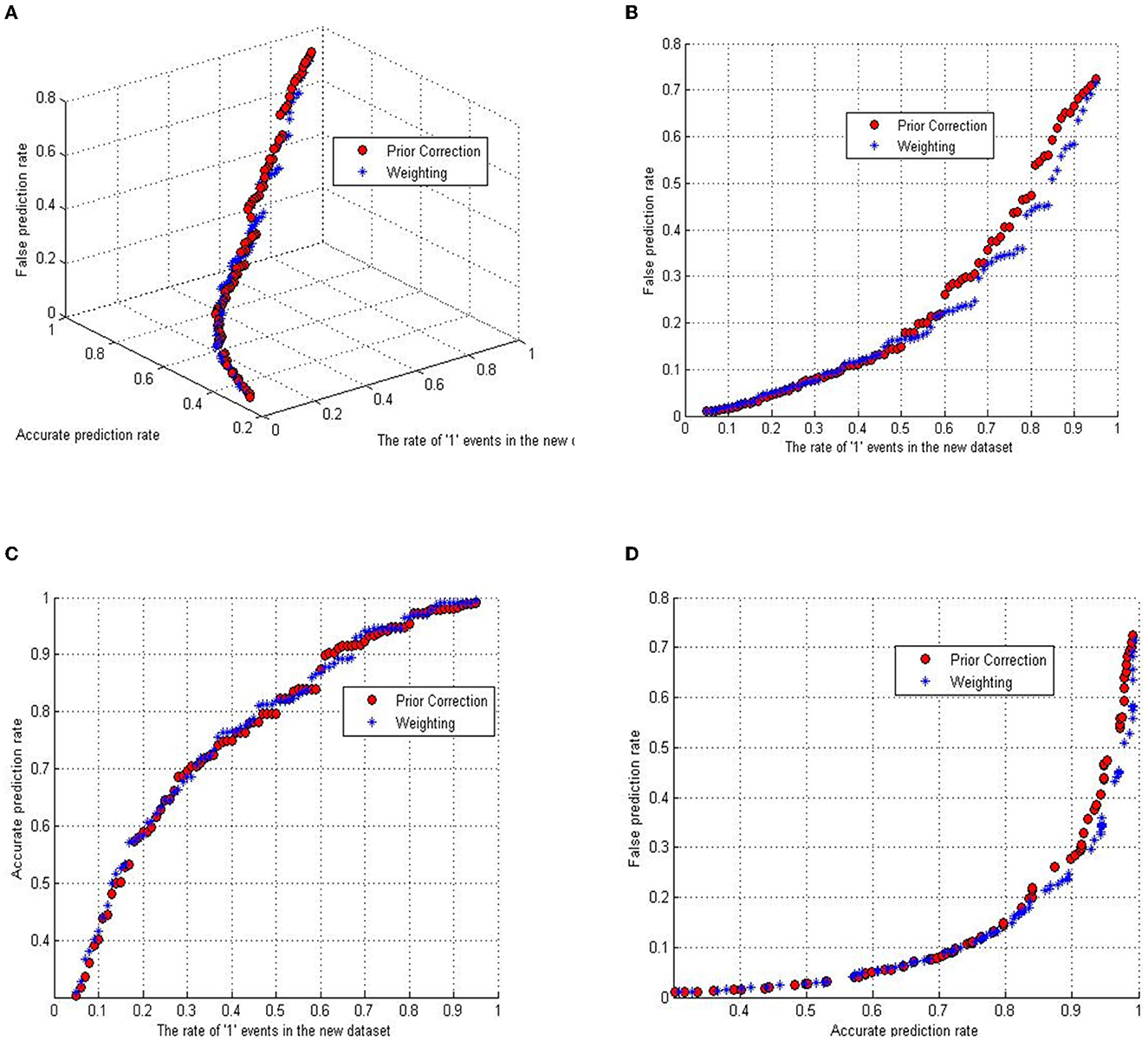
Figure 2. The relationship between measurements and the ratio of rare events. (A) The relationship between accurate classified rate, false classified rate, and the fatal event ratio. (B) The relationship between false classified rate and the fatal event ratio. (C) The relationship of accurate classified rate versus the fatal event ratio. (D) The relationship between accurate classified rate and false classified rate.
Analysis of Figure 2 reveals a close alignment between the trajectories of ACR and FCR across both correction methodologies. A trend emerges where an elevated ACR correlates with a heightened FCR. Notably, the ACR ascends more precipitously than the FCR within the “1” event ratio spectrum from 0.05 to 0.5, while this growth rate inverts for ratios between 0.5 and 0.95.
Figure 3 presents the AUC for both methods across varying proportions of fatal to non-fatal crashes. The diagram indicates that the AUC for the prior correction method remains unaffected by the percentage of “1” event post-selection. In contrast, the weighting method demonstrates superior predictive performance at most “1” event ratios. Green stars mark the coordinates with the maximum AUC values, which inform the selection of rates for the weighting method in the rare events logistic model—specifically, 43% in the corrected dataset. For the implementation of the rare events logistic model, the Stata statistical software package was employed.
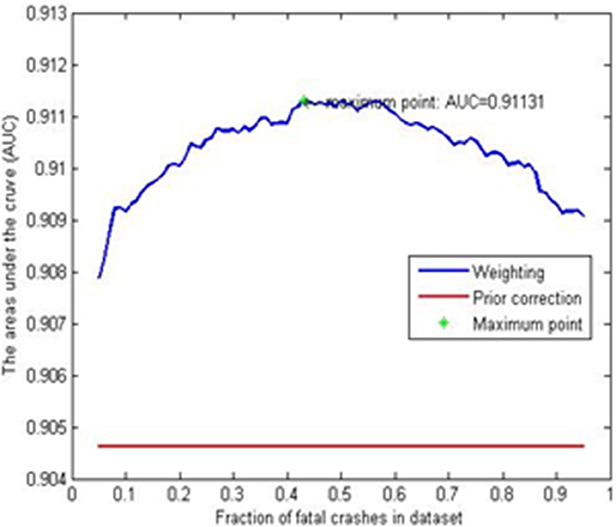
Figure 3. AUC values for the weighting method and the prior correction method.
The parameter estimates for the RELM and the LM are consolidated in Tables 2, 3, respectively. These tables encapsulate the significant parameters deduced from the empirical analysis, illustrating that the magnitude and direction of the coefficients for both models are largely consistent. The significance and impact of the variables, with the salient exception of the POI, are in concordance with the injury severities reported in antecedent research, notably by Zeng and Huang (26).
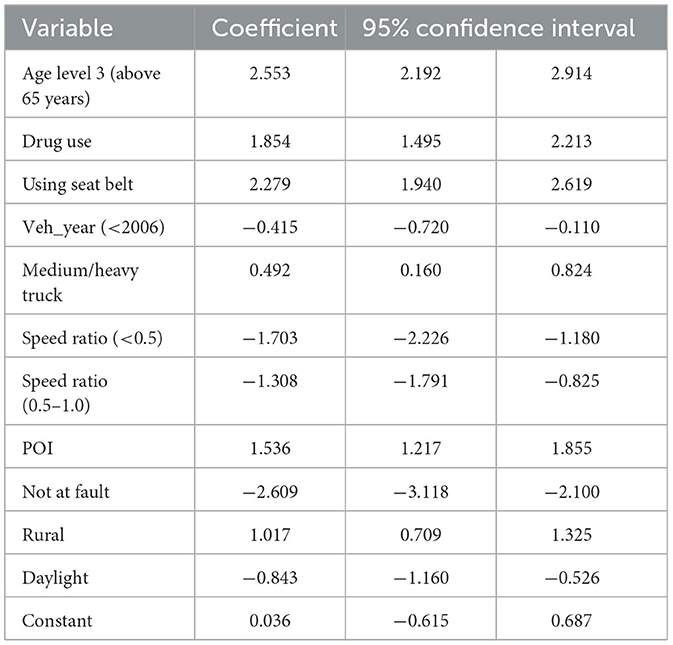
Table 2. Model parameters of RELM.
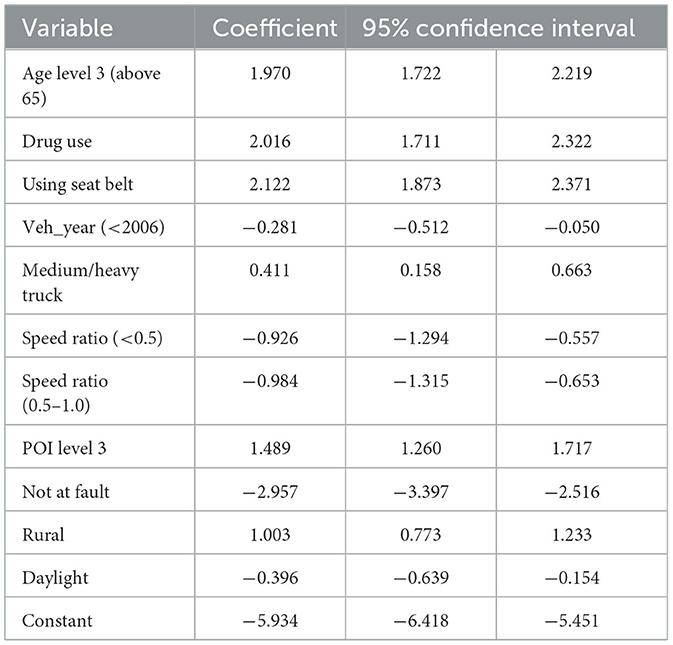
Table 3. Model parameters of LM.
Our analysis of driver demographics indicates a heightened risk of fatality for older drivers following a collision, corroborating the findings from existing literature that underscores age as a critical determinant in traffic injury severity. In relation to vehicular and environmental factors, the data suggest that more recent vehicle models correlate with a reduction in injury severity, supporting the premise that advancements in vehicular safety technologies have ameliorated crash outcomes. In clear contrast, while operators of medium/heavy trucks exhibit a lower fatality likelihood, drivers of passenger cars show an increased fatal outcome propensity. This disparity may be attributable to inherent variations in vehicle safety features, structural mass, and design specifications.
Table 4 delineates the predicted outcomes derived from both the RELM and the LM, incorporating statistically significant variables at the 0.05 level into the classification procedure. The predictive classifications of the models are juxtaposed against the actual incident outcomes, with Table 4 providing a comprehensive summary of these predictions. The data articulated in Table 4 highlights the superior performance of RELM in comparison with LM. A notable deficiency of LM is its significant underestimation of fatal accident risk, failing to identify any incident as fatal. In contrast, RELM achieves an accurate classification rate of 77.7%. Despite an increase in the false alarm rate by 12.8%, RELM is deemed tolerable when juxtaposed against the grave implications of underestimating fatal accidents; for instance, Aguero-Valverde (32) equates the impact of 1 fatal crash to that of 20 property-damage-only (PDO) crashes.

Table 4. The prediction results of LM and RELM.
An extended evaluation of the performance of the two models was conducted through the ROC curves, as exhibited in Figure 4. The predictive accuracy for fatal and non-fatal cases is contingent upon a predetermined probability threshold. An observation is designated as a fatal accident if its predicted probability transcends this threshold; otherwise, it is categorized as non-fatal. The ROC curves graphically represent the tradeoff between the true positive rate and the false positive rate as the threshold varies from 0 to 1. The AUC for each model is computed, revealing that the ROC curve for the RELM generally resides above that of the LM for thresholds below 0.8, indicative of enhanced predictive accuracy of RELM. Moreover, a juxtaposition of the AUC values in Figure 4 confirms the integrated predictive superiority of the RELM model over the LM.
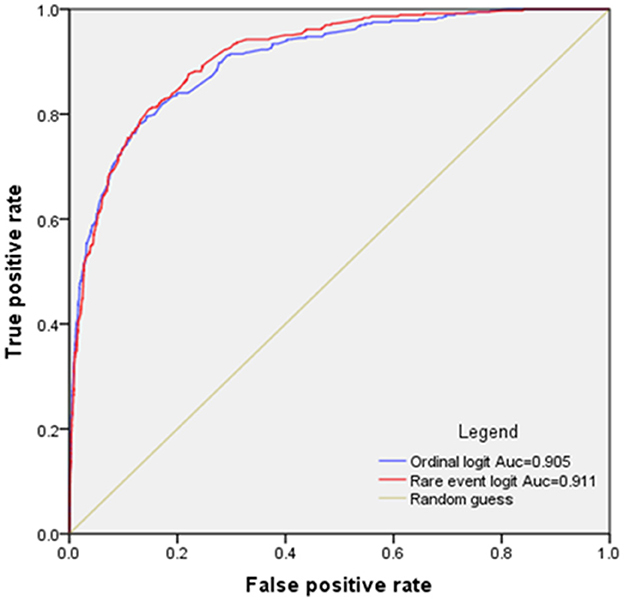
Figure 4. ROC curves for RELM and LM methods.
This study employs the rare events logistic model to scrutinize the relationship between various risk factors and the incidence of fatal road accidents in Florida. The analysis identifies six variables—older adult casualties, substance abuse, non-usage of safety equipment, passenger car, POI at level 3, and rural accidents—as positively correlated with driver fatalities. Conversely, five variables—vehicle age, speed ratios 1 and 2, driver at fault, and daylight incidents—exhibited a negative correlation with accident risk.
The findings unequivocally show that RELM supersedes LM in estimating fatal crash risks. As hypothesized, LM systematically underestimates these risks, a shortfall that RELM substantially rectifies, achieving an accuracy rate of ~80%. While a slight increase in false classification is noted, this tradeoff is deemed acceptable given the enormity of losses associated with each fatal accident. The AUC values further corroborate the superior performance of RELM over LM in this context.
The findings of this study have several implications for stakeholders involved in road safety. It is recognized that annual inspections cannot alter the fundamental crashworthiness of older vehicles; however, ensuring that aging vehicles are maintained can help mitigate risks where possible. Nevertheless, the intrinsic limitations in safety offered by older vehicle designs compared to their modern counterparts must be acknowledged. Thus, stakeholders should focus on enhancing public awareness regarding the potentially increased risks associated with older vehicles and should advocate for policies that encourage the use of vehicles with advanced safety features. For demographic groups such as older adult drivers and men who are statistically at a greater risk, targeted safety campaigns and driving aids could be beneficial. This could involve educational initiatives that promote defensive driving techniques and raise awareness about the increased risk factors these demographics face. Furthermore, urban planners and transportation authorities should take into account the findings regarding speed limits. While not the sole factor, the data suggest that higher speed limits can contribute to the severity of crashes. Therefore, a holistic approach to road design that incorporates traffic calming measures and considers the impact of speed on traffic incident severity is warranted. These measures could help in reducing the likelihood of fatal outcomes in crashes.
This study is subject to certain constraints that warrant acknowledgment. The classification of POIs into predefined levels, a method predicated on established literature, may not capture the entirety of POIs that may significantly influence crash severity. The dataset utilized provided a finite array of POIs, thereby omitting potentially crucial impact points not recorded within it. This omission could lead to a partial portrayal of crash dynamics. Moreover, spatial correlation, a factor that could yield valuable insights into the patterns and causes of fatal crashes, was not incorporated into the RELM used in this analysis. Other influential variables, such as law enforcement strategies and traffic volume data, were also not included in our dataset. The absence of these variables limits the breadth of our analysis, potentially affecting the robustness of our findings. Acknowledging these limitations, future investigative efforts in this field should endeavor to integrate a more detailed classification of POIs, alongside variables capturing spatial correlation, law enforcement efforts, and traffic metrics. Such enhancements in data collection and model sophistication would provide a more holistic understanding of the factors contributing to fatal crash outcomes.
The data is not available to the public due to data privacy policy. Requests to access these datasets should be directed to ZX, eHV6aHpoMjZAbWFpbC5zeXN1LmVkdS5jbg==.
YX: Writing—original draft. LL: Writing—original draft. HZ: Writing—original draft. QT: Writing—review & editing. JW: Writing—original draft. YY: Writing—original draft. ZX: Writing—original draft, Conceptualization, Formal analysis.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Sun Yat-sen University Basic Start-up Funding (51000-12230014).
YX and QT were employed by Changsha Planning and Design Institute Co., LTD.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. DeNicola E, Aburizaize OS, Siddique A, Khwaja H, Carpenter DO. Road traffic injury as a major public health issue in the Kingdom of Saudi Arabia: a review. Front Publ Health. (2016) 4:215. doi: 10.3389/FPUBH.2016.00215
2. Tsai JH, Yang YH, Ho PS, Wu TN, Guo YL, Chen PC, et al. Incidence and risk of fatal vehicle crashes among professional drivers: a population-based study in Taiwan. Front Publ Health. (2022) 10:1–9. doi: 10.3389/fpubh.2022.849547
3. World Health Organization. Global Status Report on Road Safety. (2018). Available online at: https://www.who.int/publications/i/item/9789241565684 (accessed June 17, 2018).
4. Lee C, Abdel-Aty M. Comprehensive analysis of vehicle-pedestrian crashes at intersections in Florida. Accid Anal Prev. (2005) 37:775–86. doi: 10.1016/j.aap.2005.03.019
5. Tay R, Rifaat SM. Factors contributing to the severity of intersection crashes. J Adv Transport. (2007) 41:245–65. doi: 10.1002/atr.5670410303
6. Song TJ, So J, Lee J, Williams BM. Exploring vehicle–pedestrian crash severity factors on the basis of in-car black box recording data. Transp Res Rec. (2017) 2659:148–54. doi: 10.3141/2659-16
7. Klaitman SS.„, Solomonov E, Yaloz A, Biswas S. The incidence of road traffic crashes among young people aged 15–20 years: differences in behavior, lifestyle and sociodemographic indices in the Galilee and the Golan. Front Publ Health. (2018) 6:202. doi: 10.3389/fpubh.2018.00202
8. Fanai S, Mohammadnezhad M, Salusalu M. Perception of law enforcement officers on preventing road traffic injury in Vanuatu: a qualitative study. Front Publ Health. (2021) 9:1–11. doi: 10.3389/fpubh.2021.759654
9. Pervez A, Lee J, Huang H. Identifying factors contributing to the motorcycle crash severity in Pakistan. J Adv Transport. (2021) 2021:6636130. doi: 10.1155/2021/6636130
10. Preuss UW, Huestis MA, Schneider M, Hermann D, Lutz B, Hasan A, et al. Cannabis use and car crashes: a review. Front Psychiatry. (2021) 12:1–11. doi: 10.3389/fpsyt.2021.643315
11. Chang HL, Yeh TH. Risk factors to driver fatalities in single-vehicle crashes: comparisons between non-motorcycle drivers and motorcyclists. J Transport Eng. (2006) 132:227–36. doi: 10.1061/(ASCE)0733-947X(2006)132:3(227)
12. Robertson LS. Prevention of motor-vehicle deaths by changing vehicle factors. Inj Prev. (2007) 13:307–10. doi: 10.1136/ip.2007.016204
13. Jou RC, Yeh TH, Chen RS. Risk factors in motorcyclist fatalities in Taiwan. Traffic Inj Prev. (2012) 13:155–62. doi: 10.1080/15389588.2011.641166
14. Lee C, Li X. Analysis of injury severity of drivers involved in single- and two-vehicle crashes on highways in Ontario. Accid Anal Prev. (2014) 71:286–95. doi: 10.1016/j.aap.2014.06.008
15. Torres P, Romano E, Voas RB, De La Rosa M, Lacey JH. The relative risk of involvement in fatal crashes as a function of race/ethnicity and blood alcohol concentration. J Saf Res. (2014) 48:95–101. doi: 10.1016/j.jsr.2013.12.005
16. Park S, Park J. Multilevel mixed-effects models to identify contributing factors on freight vehicle crash severity. Sustainability. (2022) 14:1–19. doi: 10.3390/su141911804
17. Hong Kong Transport Department. Road Traffic Accident Statistics. (2021). Available online at: https://www.td.gov.hk/en/road_safety/road_traffic_accident_statistics/index.html (accessed July 31, 2021).
18. King G, Zeng L. Logistic regression in rare events data. J Stat Softw. (2001) 8:137–63. doi: 10.18637/jss.v008.i02
19. King G, Zeng L. Explaining rare events in international relations. Int Organ. (2001) 55:693–715. doi: 10.1162/00208180152507597
20. Beguería S. Changes in land cover and shallow landslide activity: a case study in the Spanish Pyrenees. Geomorphology. (2006) 74:196–206. doi: 10.1016/j.geomorph.2005.07.018
21. Zhao J, Luo T, Fan Y. The application of rare event logistic regression in medical research. Chin J Health Stat. (2011) 28:641–4. doi: 10.1360/012010-187
22. Ren Y, Wang Y, Wu X, Yu G, Ding C. Influential factors of red-light running at signalized intersection and prediction using a rare events logistic regression model. Accid Anal Prev. (2016) 95:266–73. doi: 10.1016/j.aap.2016.07.017
23. Xie Y, Manski CF. The logit model and response-based samples. Sociol Methods Res. (1989) 17:283–302. doi: 10.1177/0049124189017003003
24. Amemiya T, Vuong QH. A comparison of two consistent estimators in the choice-based sampling qualitative response model. Econometrica. (1987) 55:699. doi: 10.2307/1913609
25. Abdelwahab HT, Abdel-Aty MA. Development of artificial neural network models to predict driver injury severity in traffic accidents at signalized intersections. Transp Res Rec. (2001) 1746:6–13. doi: 10.3141/1746-02
26. Zeng Q, Huang H. A stable and optimized neural network model for crash injury severity prediction. Accid Anal Prev. (2014) 73:351–8. doi: 10.1016/j.aap.2014.09.006
27. Huang H, Li C, Zeng Q. Crash protectiveness to occupant injury and vehicle damage: an investigation on major car brands. Accid Anal Prev. (2016) 86:129–36. doi: 10.1016/j.aap.2015.10.008
28. Huang H, Zhou H, Wang J, Chang F, Ma M. A multivariate spatial model of crash frequency by transportation modes for urban intersections. Analyt Methods Accid Res. (2017) 14:10–21. doi: 10.1016/j.amar.2017.01.001
29. Huang H, Siddiqui C, Abdel-Aty M. Indexing crash worthiness and crash aggressivity by vehicle type. Accid Anal Prev. (2011) 43:1364–70. doi: 10.1016/j.aap.2011.02.010
30. Fawcett T. An introduction to ROC analysis. Pat Recognit Lett. (2006) 27:861–74. doi: 10.1016/j.patrec.2005.10.010
31. Hand DJ, Till RJ. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach Learn. (2001) 45:171–86. doi: 10.1023/A:1010920819831
Keywords: traffic safety, fatal crashes, rare events, logit model, binary classification
Citation: Xiao Y, Lin L, Zhou H, Tan Q, Wang J, Yang Y and Xu Z (2024) Fatal crashes and rare events logistic regression: an exploratory empirical study. Front. Public Health 11:1294338. doi: 10.3389/fpubh.2023.1294338
Received: 14 September 2023; Accepted: 27 November 2023;
Published: 05 January 2024.
Edited by:
Jingwen Hu, University of Michigan, United StatesReviewed by:
You Peng, Eindhoven University of Technology, NetherlandsCopyright © 2024 Xiao, Lin, Zhou, Tan, Wang, Yang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yi Yang, eWl5YW5nQG15LnN3anR1LmVkdS5jbg==; Zhongzhi Xu, eHV6aHpoMjZAbWFpbC5zeXN1LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.