 Ahmed Abdelhafeez1*
Ahmed Abdelhafeez1* Ali Maher
Ali Maher
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Public Health , 17 April 2023
Sec. Digital Public Health
Volume 11 - 2023 | https://doi.org/10.3389/fpubh.2023.1123581
Variations in the size and texture of melanoma make the classification procedure more complex in a computer-aided diagnostic (CAD) system. The research proposes an innovative hybrid deep learning-based layer-fusion and neutrosophic-set technique for identifying skin lesions. The off-the-shelf networks are examined to categorize eight types of skin lesions using transfer learning on International Skin Imaging Collaboration (ISIC) 2019 skin lesion datasets. The top two networks, which are GoogleNet and DarkNet, achieved an accuracy of 77.41 and 82.42%, respectively. The proposed method works in two successive stages: first, boosting the classification accuracy of the trained networks individually. A suggested feature fusion methodology is applied to enrich the extracted features’ descriptive power, which promotes the accuracy to 79.2 and 84.5%, respectively. The second stage explores how to combine these networks for further improvement. The error-correcting output codes (ECOC) paradigm is utilized for constructing a set of well-trained true and false support vector machine (SVM) classifiers via fused DarkNet and GoogleNet feature maps, respectively. The ECOC’s coding matrices are designed to train each true classifier and its opponent in a one-versus-other fashion. Consequently, contradictions between true and false classifiers in terms of their classification scores create an ambiguity zone quantified by the indeterminacy set. Recent neutrosophic techniques resolve this ambiguity to tilt the balance toward the correct skin cancer class. As a result, the classification score is increased to 85.74%, outperforming the recent proposals by an obvious step. The trained models alongside the implementation of the proposed single-valued neutrosophic sets (SVNSs) will be publicly available for aiding relevant research fields.
Skin cancer is common throughout the world, and it is responsible for many fatalities each year (1). Because it is such an aggressive disease, early discovery is critical to preserve lives. Skin cancer cases are increasing in both developed and developing countries. Skin cancer cases increased to 1.2 million in 2020, and according to the World Health Organization (WHO), there will be approximately 2.2 million cancer cases by 2025 (2). Early tumor detection and classification of malignant and benign tumors, in contrast, have a considerable effect on survival (3). According to recent research, early diagnosis raised 5-year survival rates to 91% (4). This is exacerbated by a global shortage of radiologists and doctors capable of interpreting screening data, particularly in rural areas and developing nations (5). Humanoid resources and technologies to give quick patient care by using screening, diagnosis, and treatment are vital because time is a major factor in saving lives (6).
However, due to the presence of noise, artifacts, and complicated structures, tumor detection takes time and is often difficult for radiologists who review medical pictures. Furthermore, an increasing count of lesions adds to the radiologist’s workload, which frequently leads to tumor misdiagnosis and can lead to poor tumor detection performance. When compared to the human eye, dermoscopy is a common skin imaging technique that has been utilized for building benchmark datasets to improve melanoma diagnosis (7). Few forms of skin cancer are included in the majority of these small datasets, and there may not be many images in any class. In addition, three crucial factors reduce the accuracy of automated melanoma detection using dermoscopy images. First, while skin lesions are divided into various groups, their characteristics, such as size, texture, color, and form, are quite similar, making classification difficult. Second, melanoma and non-melanoma lesions have a significant relationship. The environment, which includes hair, veins, and illumination, is the third factor (8). When the number of images required to train a deep convolutional neural network (DCNN) is insufficient, conventional augmentation is widely used. However, publicly available skin cancer databases are severely unbalanced, with an unfair instance count for each class. For technological research, ISIC created the ISIC Archive, a global library of dermoscopy images.1
The proposed study spots the light on that unfairness to fairly augment leaked-instance classes. In the medical area, transfer learning (TL) is critical for improving diagnosis performance, particularly while dealing with the multifaceted properties of skin cancer images. Scholars have recently become interested in fine-tuned TL networks with pre-trained weights for performing complex classification tasks with substantial interpretation performance. The proposed study adopts TL to fine-tune the well-known deep networks for investigating the top ones in the skin cancer classification task. Image processing and machine learning approaches may be useful for detection and diagnosis, but they frequently result in false-positive and false-negative cases (9). There are several deep learning procedures obtainable right now, but not all of them have been tested for their effectiveness in identifying skin cancer. Such algorithms extract essential distinguishing features from images without the need for manual human intervention, allowing for fully automatic mass segmentation, discovery, and organization. When the number of images required to train a deep convolutional neural network (DCNN) is insufficient, the augmentation technique can be applied to have a sufficient number of images.
Several studies created binary or multiclass skin cancer classification models, but they were unable to determine which model was best. Individual models have been used for binary and multiclass skin cancer classification, with varying degrees of success, including CNN-PA (10), EfficentNet (11), MobileNet (12), VGGNET (13), AlexNet (14), GoogleNet (15), and LCNET (16). A model selection experiment must be carried out to fairly assess which model is preferable for the same dataset and number of classes. In the first planned experiment, five models have been examined to determine which offers a more useful option and a more reliable decision. The accuracy of each model has been independently increased by utilizing the feature fusion method to further construct the two superior models. The two best models for the second planned experiment are produced by using such models.
In the study, ensemble models outperformed individual deep learners in performance ratios, while dermatologists’ diagnosis accuracy classification outperformed both. A machine learning technique called ensemble combines the judgments of multiple individual learners to improve classification accuracy (17). It is anticipated that the ensemble model will improve classification accuracy since it draws on the diversity of the individual models to form a collective judgment. In many articles, researchers employed different ensemble models to determine which combination was best. In Ref. (18), GoogleNet, AlexNet, and VGGNet were combined to achieve the desired outcome, while in Ref. (19), GoogleNet, AlexNet, and VGGNet were combined to achieve various outcomes. It was unclear why certain combinations of models would produce outcomes with higher accuracy, and what if choosing a different combination would produce the best outcome? Depending on the outcome of the first planned experiment, the top two models, DarkNet and GoogleNet, have been fused in the second proposed experiment to obtain a suitable fusion selection rather than a random one.
Neutrosophic approaches have recently been proposed by researchers to improve classification performance. An intelligent neutrosophic diagnostic method for cardiotocography data was suggested by the authors in Ref. (20). These techniques demonstrate that some lesions can be neutrosophically categorized even when individual or combination models fail to yield the desired classification. A brand-new method for multiclass skin cancer categorization was created. According to experimental findings, adding the single-valued neutrosophic sets (SVNSs) to the combined deep learners for feature fusion methodology (FFM) results in increased skin cancer classification accuracy. The findings indicate that the suggested models perform better than the multiclass skin cancer classification models that have recently been created.
The following contributions are made to this research work:
• To deal with over-fitting difficulties, the skin lesion dataset is categorized tacitly into eight classes in terms of the number of their instances which is rich and poor clusters. Various spatial data augmentation methods are applied to the poor cluster to balance the dataset on the fly in the training phase.
• To find the superior net model for the ISIC 2019 dataset, pre-trained networks such as DarkNet, AlexNet, GoogleNet, XceptionNet, and DenseNet are examined using transfer learning.
• After extensive research, a feature fusion methodology is suggested for the top two models. The fusion is carried for enriching the feature descriptive supremacy by fusing different feature maps from various network layers.
• To exploit the individual descriptive power for each net fused feature, a set of true and false classifiers is designed and trained via the ECOC scheme.
• Each true classifier and its opponent may disagree with the classification result, which establishes an ambiguity. This ambiguity is quantified by an indeterminacy set and resolved by the SVNSs to further investigate the robustness.
Furthermore, it is worth noting that the work is made generally where it is applicable for boosting any individual classifiers and resolving their contradictions and dependably that no pre-processing of the images or lesion segmentation has been done.
The rest of this article is organized as follows: Section 2 provides the materials and methods. Section 3 describes the experimental results. A discussion is presented in Section 4. The conclusion of this article and future studies are presented in Section 5.
Figure 1 depicts the whole categorization process as a series of blocks. The original ISIC 2019 skin cancer dataset is represented by block (1). A dataset has been supplemented using data augmentation methods on a pre-processed dataset (2). Experimenting with a variety of pre-trained models and choosing the most accurate model for use with an updated dataset yields suggested GoogleNet and DarkNet models (3). After a suggested model was selected, a feature fusion method was applied based on accuracy comparison (4). The ECOC’s coding matrices are designed to train each classifier and its opponent in one-versus-another fashion (5) and (6) the final model was assessed using SVNSs to get superior accuracy.
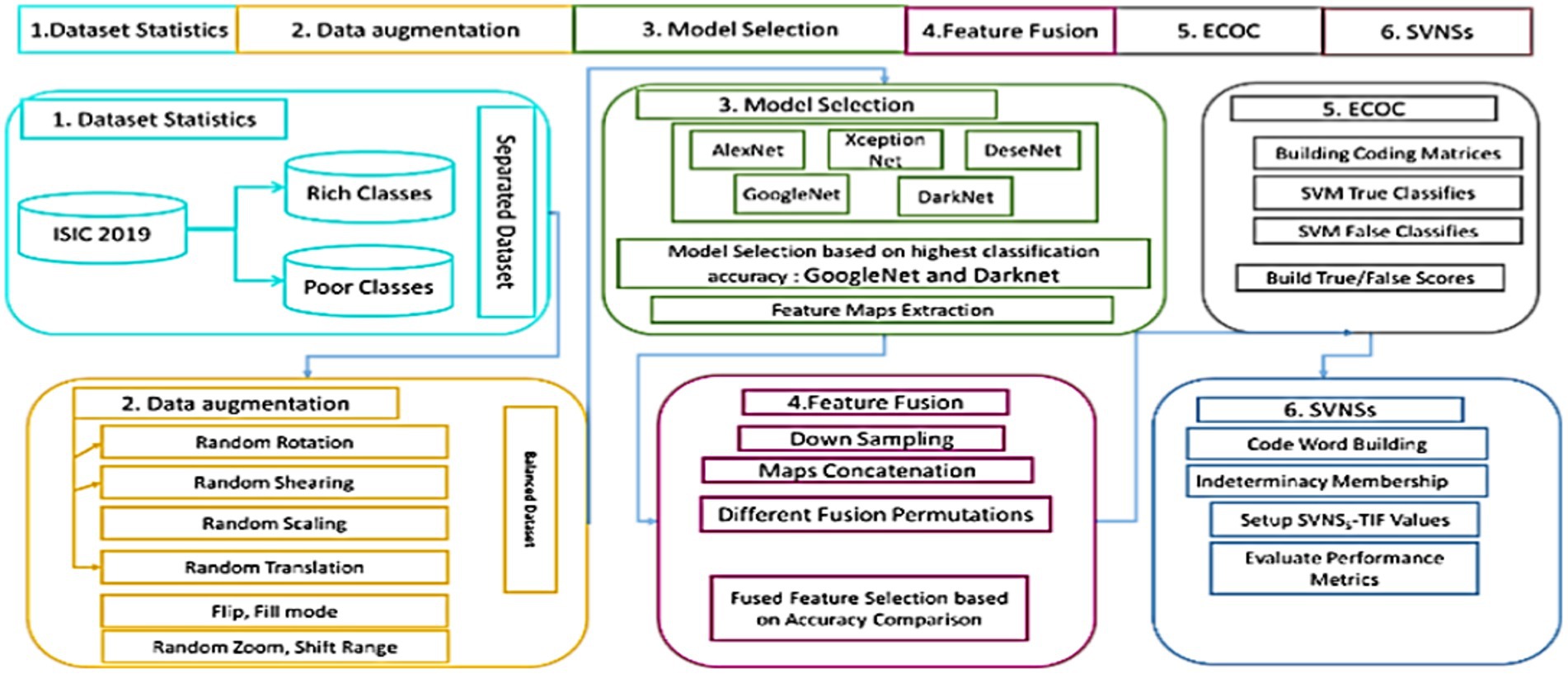
Figure 1. Full technique of skin cancer categorization described in this article.
Several artificial intelligence-based techniques have been developed to automate the classification process, which includes standard phases, such as pre-processing, feature extraction, segmentation, and classification. Many classification methods rely heavily on constructed feature sets, which have limited generalizability for dermoscopic skin pictures due to a lack of biological pattern knowledge (21). Because of their closeness in size, shape, and colors, lesions have a strong visual likeness and are highly linked, resulting in poor feature information (22). Handmade, feature-based methods are, therefore, useless for skin classification. Deep networks are more effective in calculating specific features to do precise lesion categorization than shallow networks. Convolutional neural networks (CNNs) are widely used for medical image processing and categorization. Authors in Ref. (10) made the first breakthrough in using DCNN for skin cancer. To make a binary classification between the two fatal skin tumors, malignant and nevus, the network was likened to 21 board-certified medicinal professionals. Specialists testified that the envisioned network could accurately detect skin cancer. The dataset of 1,29,450 clinical images, including 3,374 dermoscopic images, was processed using the InceptionV3 architecture pre-trained on ImageNet. The scientists demonstrated that a deep neural network-based solution outperformed clinical professionals in terms of dermoscopy picture categorization accuracy over a large dataset. It is demonstrated that artificial intelligence can diagnose skin cancer with a level of competency comparable to dermatologists by CNN, which behaves equally well on both jobs as all verified experts. Gessert et al. (11) demonstrated a multiclass classification job utilizing an ensemble model created from Efficient Nets, SENet, and ResNeXt WSL on the ISIC 2019 dataset. The authors employed a cropping method on photographs to deal with the multiple models’ input resolutions. For unbalanced datasets, a loss-balancing method was also employed. Authors in Ref. (12) suggested a new CNN architecture for skin lesion categorization that consists of several tracts. A CNN has been retrained for multi-resolution input after it had been trained on a single resolution. Transfer learning is used to train seven classes of the HAM10000 dataset using a pre-trained MobileNet model. A categorical accuracy of 83.1% is reported, as well as precision, recall, and F1 scores of 89, 83, and 83%, respectively. (13) The importance of dermoscopy skin cancer images being classified as malignant or benign to detect melanoma was emphasized. The authors evaluated the ISIC archive dataset; the proposed solution achieved an accuracy of 81.3%, a precision of 79.74%, and a recall of 78.66% using transfer learning and the VGGNet convolutional neural network. This technique, however, was limited to a binary classification of skin cancer. When classifying skin cancer into three groups, Harangi et al. (14) looked at how an ensemble of deep CNNs may be utilized to increase the accuracy of individual models. The GoogleNet, AlexNet, ResNet, and VGGNet models’ respective accuracy rates were 84.2, 84.88, 82.88, and 81.38%. The best accuracy, 83.8%, was again reached by the combination of the GoogleNet, AlexNet, and VGGNet models. In addition, the recall rates for each of their models were 59.2, 51.8, 52.0, and 43.4%, respectively. Authors in Ref. (17) conducted a comprehensive analysis of seven distinct deep learning-based approaches for skin cancer. On the ISIC-2018 challenge dataset, experiments were conducted on neural networks such as PNASNet-5-Large, InceptionResNetV2, SENet154, and InceptionV4. The PNASNet-5-Large model has the highest accuracy at 76%. The authors in Ref. (15) obtained 99.03% accuracy, 99.81% recall, 98.7% precision, and a 99.25% F-score by proposing a deep pre-trained model of unclassified skin cancer images. The authors do not mention deleting some data from the dataset. The authors retrained the last layers of the proposed model on a small number of foot skin images. Furthermore, adding a new class to the eight classes makes it nine instead of eight, which makes the results comparison not applicable. A previous study in dermoscopic computer-aided classification has not only failed to obtain improved accuracy for skin cancer classification but also lacks generality. Unfortunately, much of the earlier research did not use large datasets, which are essential for deep learning models to perform well. In this study, the suggested strategy uses extremely accurate and efficient pre-trained models trained on a large ISIC 2019 dataset to obtain an exceptionally high accuracy for skin cancer classification.
The most frequently used dataset in this field of research has been the ISIC 2019, which was employed.
The dataset is available at https://challenge.isic-archive.com/data#2016. ISIC 2019 dataset is one of the most difficult to classify into eight groups due to an uneven number of photographs in each class. The most difficult difficulty is detecting outliers or other “out of distribution” diagnosis confidence. The dataset was divided into three parts: training, validation, and testing, with the training portion comprising 80% of the dataset and the validation and testing portions each comprising 10%. The description of the dataset is summarized as follows:
The total number of images 25,331, dimension 256 × 256, color carding RGB, melanoma (MEL) 4,522, melanocytic nevus (NV) 12,875, basal cell carcinoma (BCC) 3,323, actinic keratosis (AK) 867, benign keratosis (BKL) 2,624, dermatofibroma (DF) 239, vascular lesion (VASC) 253, and squamous cell carcinoma (SCC) 628.
The validation/test set was used to validate the model on data it had never seen before, and the training set was used to train it.
Deep learning models are data-hungry and generalize effectively when fed a large amount of data. Rotation, flip, random crop, modify brightness, adjust contrast, pixel jitter, aspect ratio, random shear, zoom, vertical and horizontal shift, and flip are utilized for data augmentation. Data augmentation is a method of artificially increasing the quantity of data available by adding slightly changed copies of existing training data rather than having to obtain new data. The training dataset size is intentionally increased, or the model is protected from over-fitting from the start, by either data warping or oversampling; in addition, it is used to improve the diversity of the data by slightly modifying copies of already existing data or creating synthetic data from existing data (23).
To augment it fairly, the ISIC 2019 dataset was tacitly divided into two sets, rich and poor. The rich set comprises “BCC,” “BKL,” “MEL,” and “NV” cancer classes with 23,344 instances in total. In contrast, the poor set involves “AK,” “DF,” “SCC,” and “VASC” classes with 1987 instances in total. Thus, the rich set occupies 92.16% of the dataset compared to the poor set which occupies 7.84%. Applying augmentation parameters to poor set classes to alleviate the imbalance in the training dataset while not applying augmentation to rich set classes. The poor set augmentation process is conducted on the fly (online augmentation) for the sake of saving resources and time for labeling at the expense of increasing training time.
The proposed model has two main experiments as follows: the first experiment used the augmented data for five different models for both Dag and Series Networks. A variety of topologies, including AlexNet, XceptionNet, DarkNet, DenseNet, and GoogleNet, were assessed.
Compared to each other, GoogleNet and DarkNet fared better than the rest of them. Applying transfer learning for each net will improve the accuracy as illustrated in Section 3.1. The second experiment applied to feature fusion for both GoogleNet and DarkNet through multi-SVM using ECOC is illustrated in Section 3.2.
To employ transfer learning, an algorithm is trained on one set of data and then applied to another set of data, which is referred to as a task linked to the original job.
To enhance generalization in another situation, domain adaptation and transfer learning are terms used to describe the phenomenon. Transfer learning is an exceptionally good technique in deep networks because of the immense resources needed and the vast quantity of pictures. Due to a tiny number of pictures, these data sets cannot be used to train deep neural networks from the beginning because of their lack of variety. This issue may have been solved through transfer learning (24).
The imageNet (25) pre-trained models for classifying 1,000 objects are transferred to classify eight classes via transfer learning. There are three processes involved in achieving transfer learning. First, the last learnable layer for each net is altered one by one to classify eight skin classes. Second, it freezes the initial layers’ weights and biases to preserve their generalization extraction capability. Finally, by increasing the weights and biases learn rate factors, it speeds up the learning process for the deeper layers. Figure 2 illustrates the process of training and testing the picked-up networks to determine their classification accuracy.
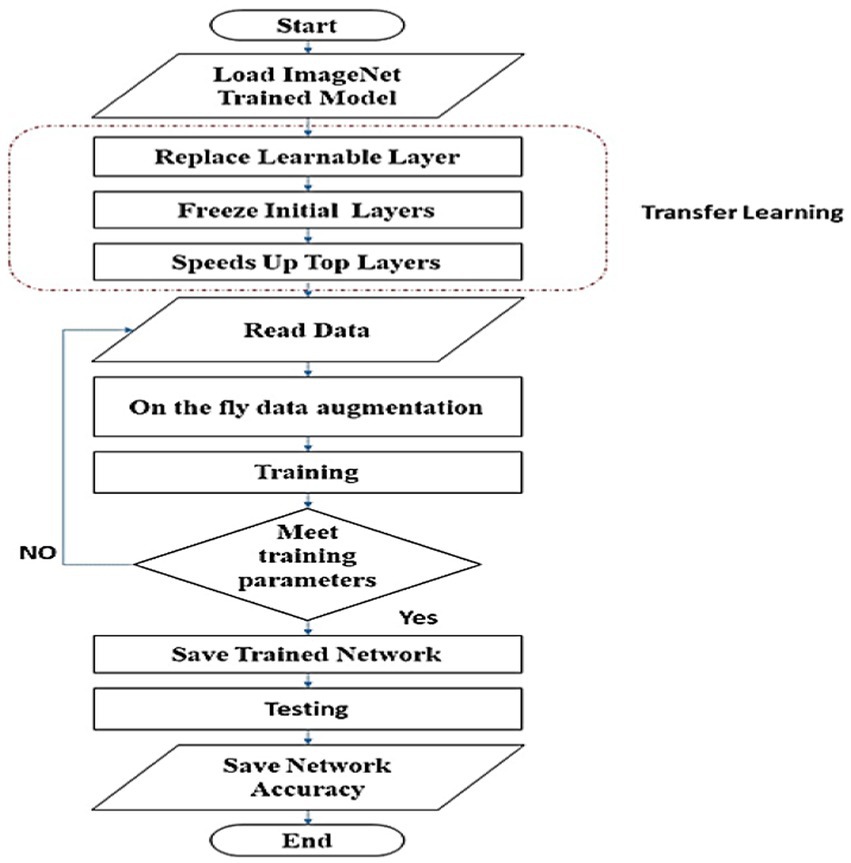
Figure 2. Flowchart of training and testing scheme to rank examined networks, according to their classification accuracy.
The deepest (top) layer feature maps have the most abstract features that describe each class more semantically and contextually. While going backward for previous layers alleviates that description, it becomes higher resolution and may represent some abstracted features better. Applying the thought for enriching the feature descriptive supremacy via fusing different feature maps from various network layers will improve the accuracy for each net. In this study, the fusion is conducted for both trained networks (GoogleNet and DarkNet) at two levels, as follows:
1. GoogleNet’s inception4e is fused with inception5a feature map activations to form the first-level fusion. Furthermore, DarkNet’s Conv17 is fused with Conv18 feature map activations to spawn its first-level fusion.
2. GoogleNet’s resultant fused features are re-fused with inception5b activations, whereas the first-level fused DarkNet features are re-fused with Conv19 activations, resulting in the second-level fused features for both networks. The activation of a layer is determined after training ends to obtain its feature maps, and the earlier feature maps are downsampled in a bilinear interpolation fashion to permit the concatenation process for fusion. The proposed feature fusion schemes are presented in Figures 3A,B for GoogleNet and DarkNet, respectively.

Figure 3. Proposed feature fusion scheme for (A) GoogleNet and (B) DarkNet.
For huge datasets, t-distributed stochastic neighbor embedding (t-SNE) has become the effective standard for visualizing high-dimensional datasets across a wide range of biomedical data.
Using this technique to have a more clear visualization for each class will provide more clearance to researchers. T-SNE includes, but is not limited to, computer security, music analysis, cancer biology, and Bioinformatics. Similar to SNE, t-SNE chooses two different similarity measures between pairs of points for the high-dimensional information and the two-dimensional embedding. The goal of this step is to create a two-dimensional embedding that minimizes the KL divergence between the vector of similarities between points in pairs over the full dataset and the similarities between points in the encoding. The nonconvex optimization issue is solved using T-SNE using gradient descent with random initialization. Figures 4A,B visualizes the extracted features for both GoogleNet and DarkNet, respectively, before and after fusion using t-SNE. The fused features have a better similarity representation for instances belonging to the same class.
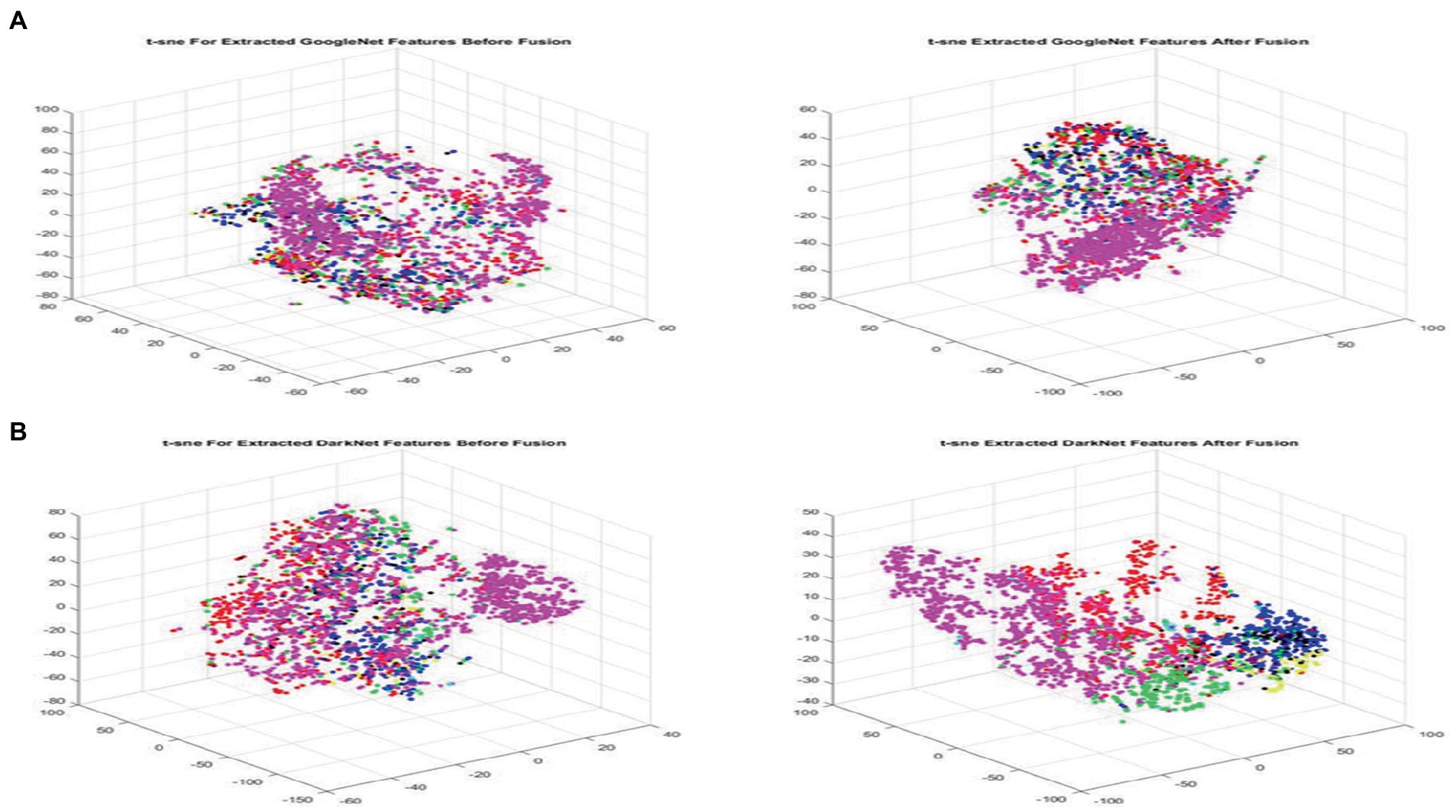
Figure 4. Visualizing extracted features before (left) and after (right) fusion using t-SNE for GoogleNet and DarkNet, respectively, best viewed in color. (A) GoogleNet and (B) DarkNet.
An error-correcting output code (26) is utilized to simplify the multiclass classification task to binary ones. The simplification is usually conducted to train each learner in one of the two coding schemes which are one-versus-all (OvA) or one-versus-one (OvO). The desired training scheme is designed in a coding matrix (CM) that formulates how binary learner L considers class C in the training process.
The rows of the designed CM represent the classes while the columns are the learners. The filled values in each (i,j) matrix cell are altered between three values 0, 1, and − 1 representing that:
• An assigned value 1 marks all jth Class instances Cj as a positive class for the training of ith binary learner Li.
• An assigned value −1 marks all jth Class instances Cj as a negative class for the training of ith binary learner Li.
• An assigned value 0 discards all jth Class instances Cj for the training of ith binary learner Li.
Table 1 shows the true and false multi-SVM learners for eight classes. The true and false SVM learners for eight classes are shown in Table 2.
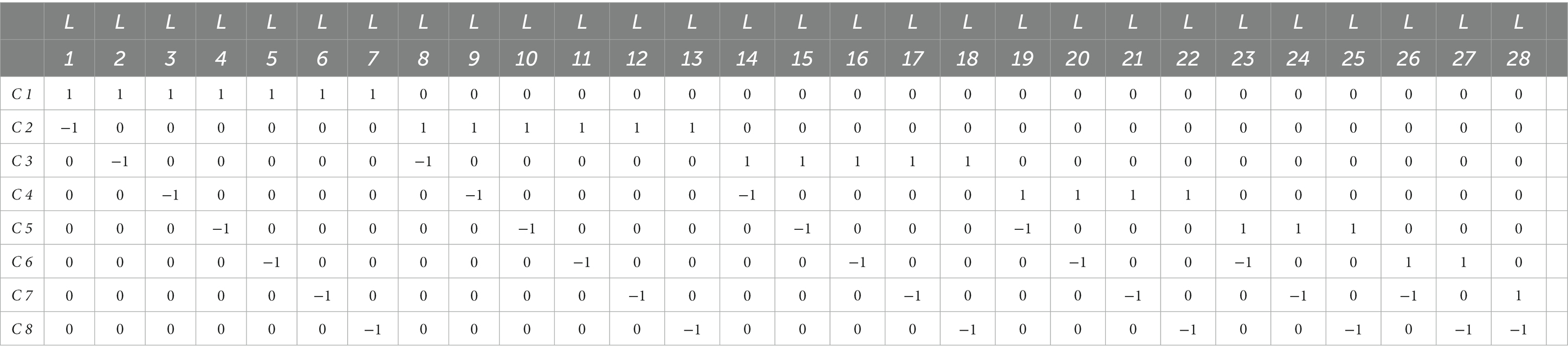
Table 1. Designed coding matrix for multi-SVM learners Li in OvO fashion for eight cancer classes Cj.
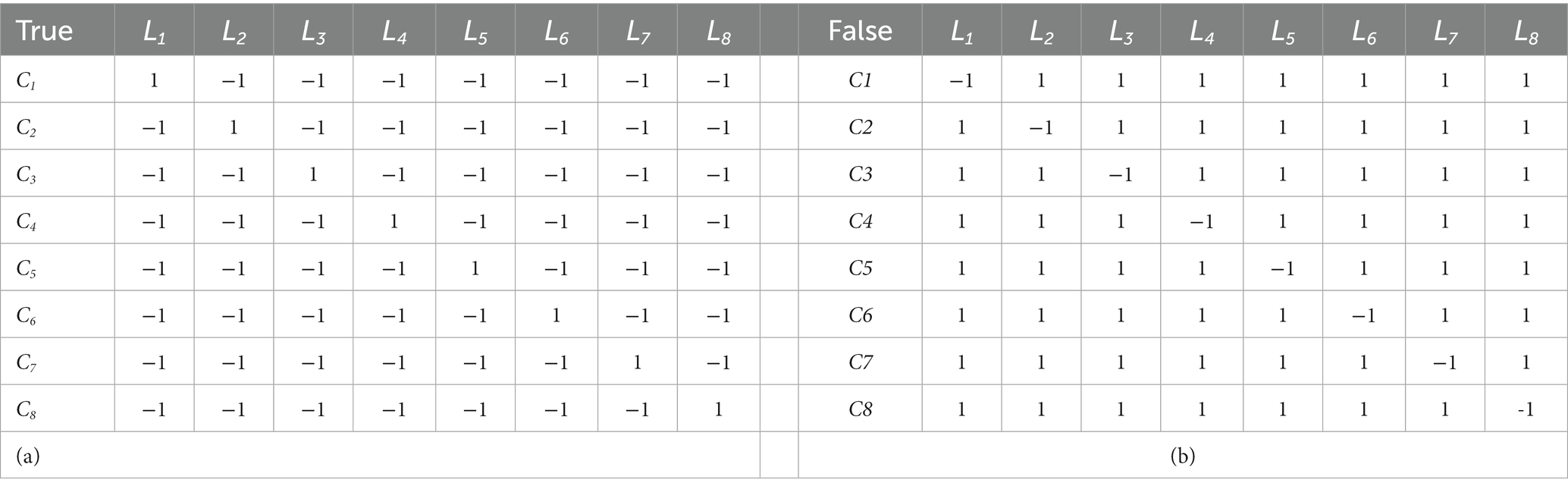
Table 2. Designed coding matrices for (a) multi-SVM true and (b) false learners. Where learner li is directed to deal with class cj as corresponding assigned values.
These characteristics were classified using the multiclass SVM. To categorize fresh photographs, the multiclass SVM that was developed during the training phase may be used (test set). The ISIC 2019 test set was classified using the stored classifier, and the similarity score was calculated for each picture with various classifications.
Figure 5 presents the feature fusion for GoogleNet and DarkNet and neutrosophic. Algorithm 1 states the main steps in the experiment as a pseudo-code.
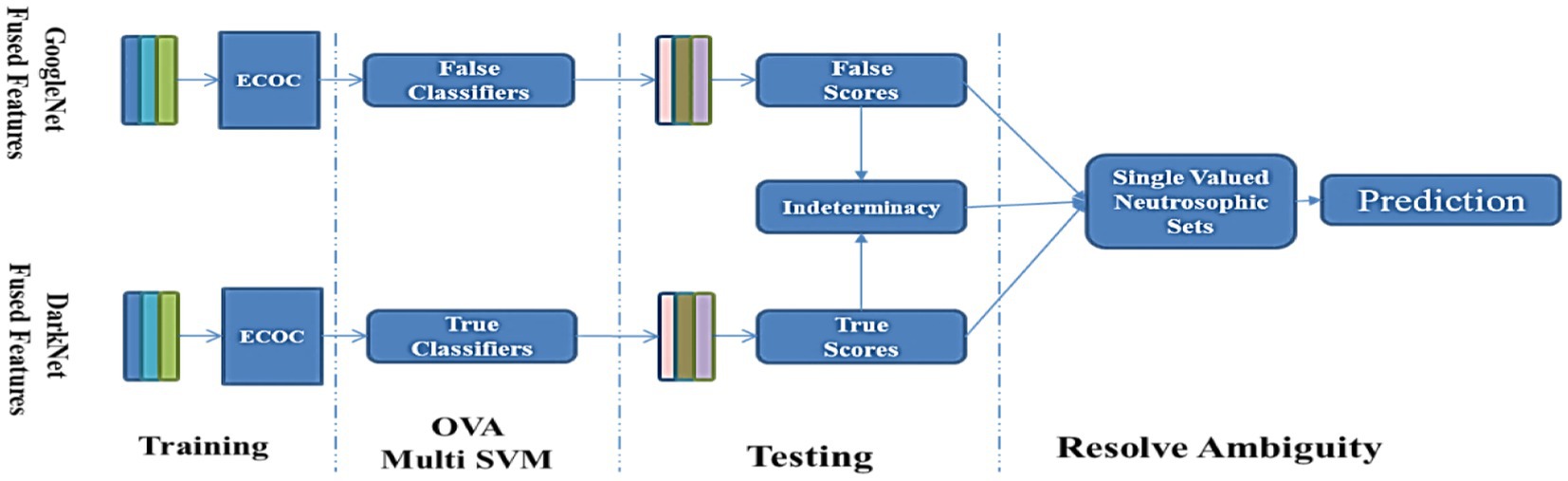
Figure 5. Proposed work’s overall scheme utilizes neutrosophic to resolve the feature fusion GoogleNet and DarkNet.
From a philosophical perspective, Ref. (27) extended the fuzzy set (28), the IFS, and the interval-valued IFS (29, 30) by introducing the neutrosophic set (31, 32). Authors in Ref. (33) used study data from Al-Bayrouni Hospital to categorize breast cancer. The used data were skewed and contains missing and anomalous numbers, so inverse Lagrangian interpolation and neutrosophic logic were used to rectify and analyze the data before formulating a two-kernel support vector machine algorithm. The proposed technique outperforms the traditional support vector machine algorithm since it is linearly orthogonal by neutrosophic logic and was trained on the data. This approach, which is based on inverse Lagrangian interpolation, correlates the inputs to determine how much each input belongs to each class. Authors in Ref. (34) include the idea of interval-valued Fermatean neutrosophic, Pythagorean neutrosophic, single-valued neutrosophic, and bipolar neutrosophic graphs. Many sorts of interval-valued Fermatean neutrosophic graphs as well as additional varieties of these graphs were described. This novel graph type was utilized in a situation involving decision-making. In addition, the interval-valued Fermatean neutrosophic number, interval-valued Fermatean triangle, and interval-valued Fermatean trapezoidal neutrosophic number were introduced. Authors in Ref. (35) analyzed interval-valued pentapartitioned neutrosophic graph features such as cut vertex, bridge, and degree, which are researched and thoroughly analyzed using relevant instances for making use of the suggested interval value. A decision-making technique called pentapartitioned neutrosophic graphs has been created and applied in a real-world scenario with numerical examples. In addition, the developed notions can be expanded to include isomorphic and regularity properties in the suggested graph topologies. Regular and irregular interval-valued pentapartitioned neutrosophic graphs, interval-valued pentapartitioned neutrosophic intersection graphs, interval-valued pentapartitioned neutrosophic hypergraphs, and other variations are all possible extensions of the interval-valued pentapartitioned neutrosophic graph. It is possible to model networks, telephony, image processing, computer networks, and expert systems using the interval-valued pentapartitioned neutrosophic graph.
Although new in principle, using neutrosophic sets in actual issues proved challenging, especially owing to the non-standard interval across which membership functions might take on values]-0,1+ [.
Three functions describe the membership of a neutrosophic set A in a universal set X: the truth function T(x), the indeterminacy function I(x), and the falsity function F(x). If X is a real standard or non-standard subset of]-0,1+ [, then T(x), I(x), and F(x) are all functions in X such that T(x):X→]-0,1+ [, I(x):X→]-0,1+ [, and F(x):X→]-0,1+ [. As a result, T(x), I(x), and F(x) may all add up to any value, therefore -0 ≤ supT(x) + supI(x) + supF(x) ≤ 3 + .
SVNSs–DarkNet–GoogleNet is a suggested framework for dealing with uncertainty in skin cancer data that combines the approximate ideas provided by DarkNet and GoogleNet with the indeterminacy ideas of SVNSs. The SVNSs–DarkNet–GoogleNet is approachable postprocessing for uncertainty in DarkNet–GoogleNet model predictions that draw on neutrosophic ideas for multiple classes. The SVNSs–DarkNet–GoogleNet framework is used to assess the performance metrics, including accuracy, sensitivity, precision, and F1 score.
Algorithm 1 The pseudo-code of the proposed SVNSs.

To forecast the scaling values of output classes, SVNSs–DarkNet–GoogleNet is constructed from two separate DarkNet–GoogleNet and they are trained using the same characteristics as input vectors. The DarkNet forecasts correct membership as true (T) decisions, whereas the GoogleNet forecasts incorrect ones as false (F). As shown in Algorithm 1, the conclusion of such classification is defined by SVNSs-TIF values, which are generated by the uncertainty border zone used to compute indeterminacy values (I).
To anticipate the opposite target value (code-word/on-hot-encoding), false GoogleNet is trained differently from true DarkNet. The number of distinct categories in the output is proportional to the length of the code-words. For example, if the true values are greater than the false values of the k^th bit of the codeword representing the k^th class is set to 1 and the rest of the bits are set to 0, then the k^th bit of the codeword representing the k^th The class will be set to 0, and the rest of the bits will be set to 1 if the false values are greater than the true values.
Binary predictions for multiple classifications in the SVNSs–DarkNet–GoogleNet model are very sensitive to the genuine membership code-word, as shown in Step 3 of the method shown in Algorithm 1. When a conflict arises between two possible outcomes, a codeword of 0 or several bits in the same codeword each equaling 1 in Step 3 (27–28) is employed to make a call.
If the expected value of the genuine DarkNet–GoogleNet is high, then the predicted value of the false membership DarkNet should be low, and vice versa. Due to their inconsistency, a zone of ambiguity has emerged. In line (1) of the SVNS definition, we see that the difference between the true and false membership values may be used as a rough approximation of the indeterminacy membership value. If there is not much of a disparity between them, then the uncertainty will be large, and vice versa.
The training phase was conducted on an i7 10th generation machine @2.6GHz using NVIDIA GeForce GTX 1060 Ti GPU. An x64-bit MATLAB 2021-b was employed to perform the program. The performance of the proposed model was evaluated using four quantitative measures, accuracy, sensitivity, precision, and F1 score (36). These measures are computed as follows:
This is referred to as true positive ( ), false positive ( ), true negative ( ), and false negative ( ).
Unlike traditional approaches to updating parameters in gradient descent, SGD requires a single record at a time. However, because of its dependence on forward and backward propagation for each record, SGD is sluggish to converge. The road to a global minimum gets cluttered with noise. For the trained models that utilized an adaptive moment estimation (ADAM) solver, the training was conducted with an initial learning rate of 0.00003 and a square gradient decay factor of 0.99. While for stochastic gradient descent with momentum (SGDM) solver, the training was conducted with an initial learning rate of 0.00100 for the initial learning rate with a 0.1 Learning rate drop factor.
Table 3 illustrates the result of the first experiment, trained DAG and Series Networks Parameters and Accuracy in individual use to show the superior for each net, respectively.
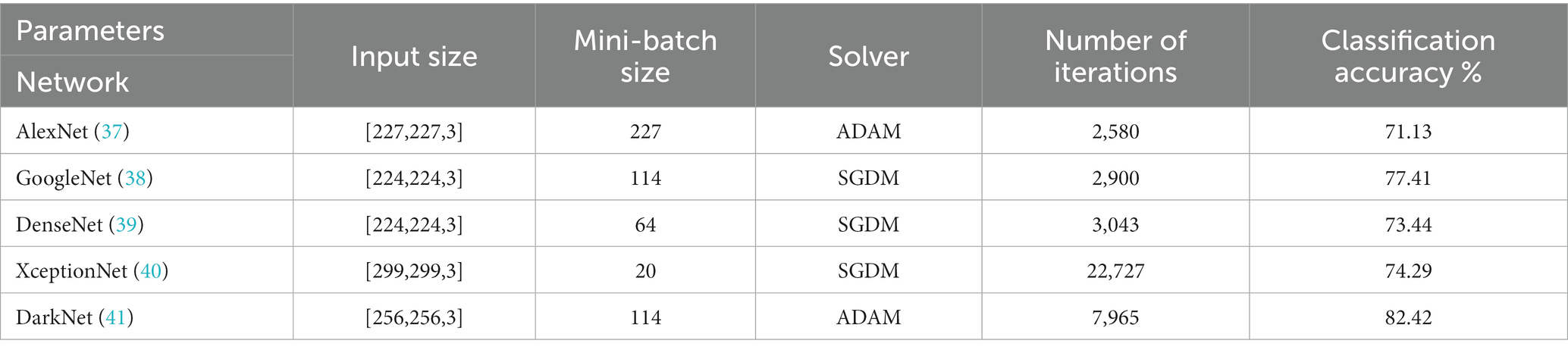
Table 3. Trained network parameters and their classification accuracy.
The easiest technique to enhance deep neural network efficiency is to increase the network capacity or depth. The depth corresponds to the number of network layers (levels). To train deeper models, a vast amount of labeled data was necessary. In this manner, there are two negatives to be considered. To begin, there are a lot of variables to consider.
When a small, labeled dataset is utilized for training, these values may lead to architectural overfitting. The second problem is that utilizing a network with several hidden layers increases the computing cost.
Figures 6A,B shows results for the second experiment, the confusion matrix (8×8) for the target class feature map for both DarkNet and GoogleNet, respectively.
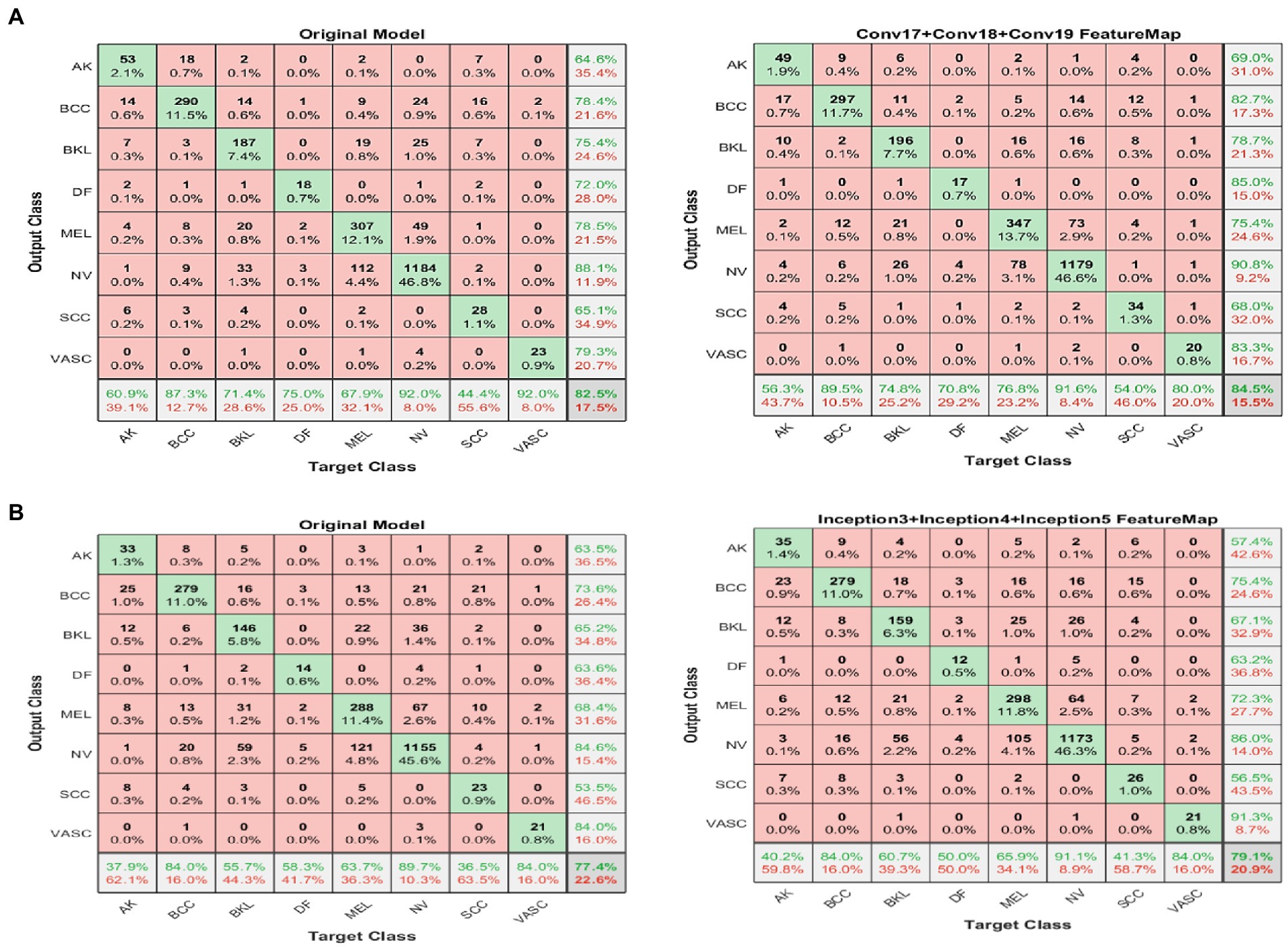
Figure 6. Confusion matrix (8 × 8) for the DarkNet and GoogleNet experiment (left) before and (right) after applying the proposed FFM. (A) GoogleNet and (B) DarkNet.
An unfamiliar picture is one with a score of less than the value required for its classification as a similar image. This experiment used 25,331 photographs in total. The proposed model was trained and validated employing 80% of the ISIC 2019 dataset, which equates to 20,256 photographs, and 10% of the dataset, which equates to 2,531 images.
Figure 7 shows the confusion matrix (8×8) for the target class feature map for combined fused and neutrosophic.
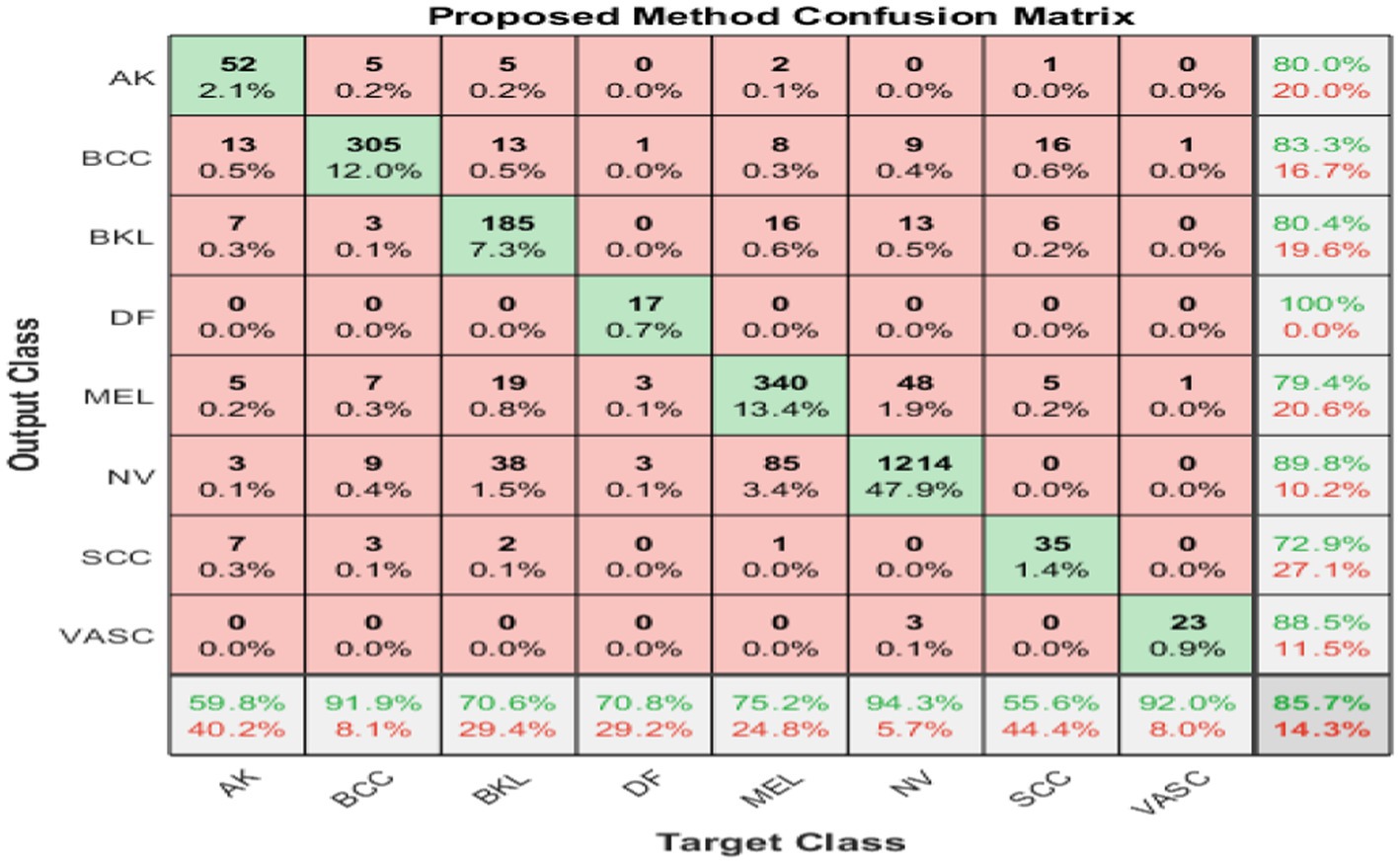
Figure 7. Resultant confusion matrix after contradiction resolving via SVNSs experiment.
DarkNet–GoogleNet is done at this stage. True values are computed from the DarkNet, and false values are computed from GoogleNet. To make better-informed judgments in the uncertainty boundary zone, the SVNS characterization procedure calculates the indeterminacy values of the projected classes based on the SVNS definition. Algorithm 1 shows how the anticipated categorization of dataset samples is evaluated based on true (T), false (F), and indeterminacy (I) membership values, shows the code-word of all classes, and the crisp values of the eight test images.
Scaled values for T, I, and F membership are shown in Table 4. Using line (18) from Step 3 in Algorithm 1, we estimate the membership values of T and F for the two classes using DarkNet and GoogleNet and the membership values of I for the eight classes. Line (19) in Step 3 uses the code-words presented in Algorithm 1 to provide a binary classification of each class in the skin cancer dataset. The new examples of first and second image binary classification results are shown in Algorithm 1, where seven code-words are equivalent to zero, and one class is equivalent to one. From images 3 and 4, we have more than one class code-word that is equivalent to one, so we apply the equation of crisp value to select the max crisp value in Step 3 in line. (20) In Algorithm 1, from images 5 and 6 in Table 4, we have all code-words equivalent to zero, so we selected the max indeterminacy value from Step 3 in. line (21) In Algorithm 1, from Table 4 for eight images, SVNSs predicted eight true classes and zero false classes, DarkNet predicted only three true classes and five false classes, and GoogleNet predicted six true classes and two false classes. Table 5 shows the SVNS classification under eight classes. Figure 6 presents the feature fusion for GoogleNet and DarkNet and neutrosophic. Algorithm 1 states the main steps in the experiment as a pseudo-code.
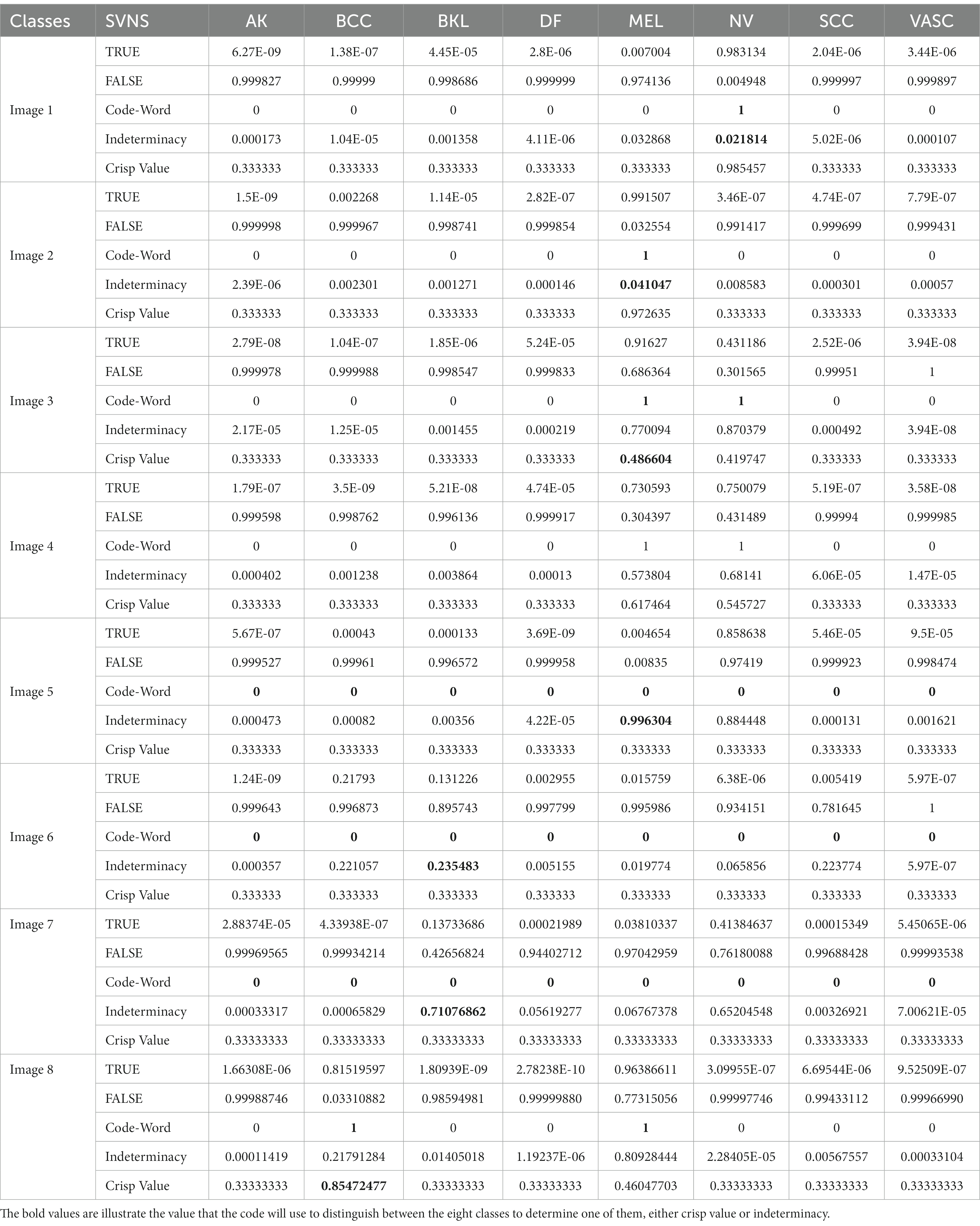
Table 4. Single-valued neutrosophic sets.
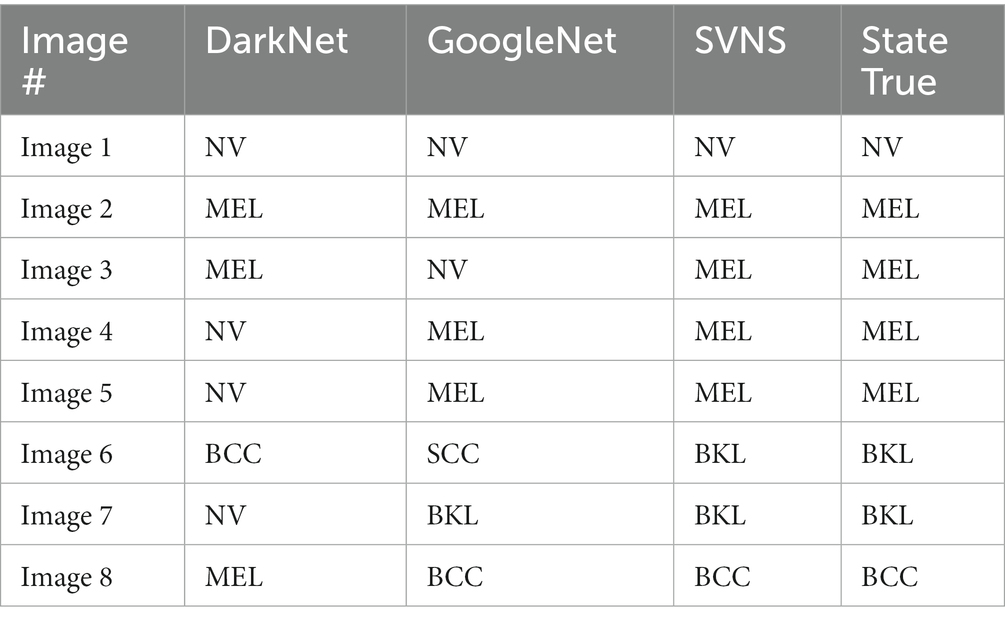
Table 5. SVNSS classification of eight classes.
Table 6 shows the overall results for (I) the original model and (II) FFM and (III) combined FFM with neutrosophic experiments. Table 7 shows the average performance to show the impact of the two experiments.
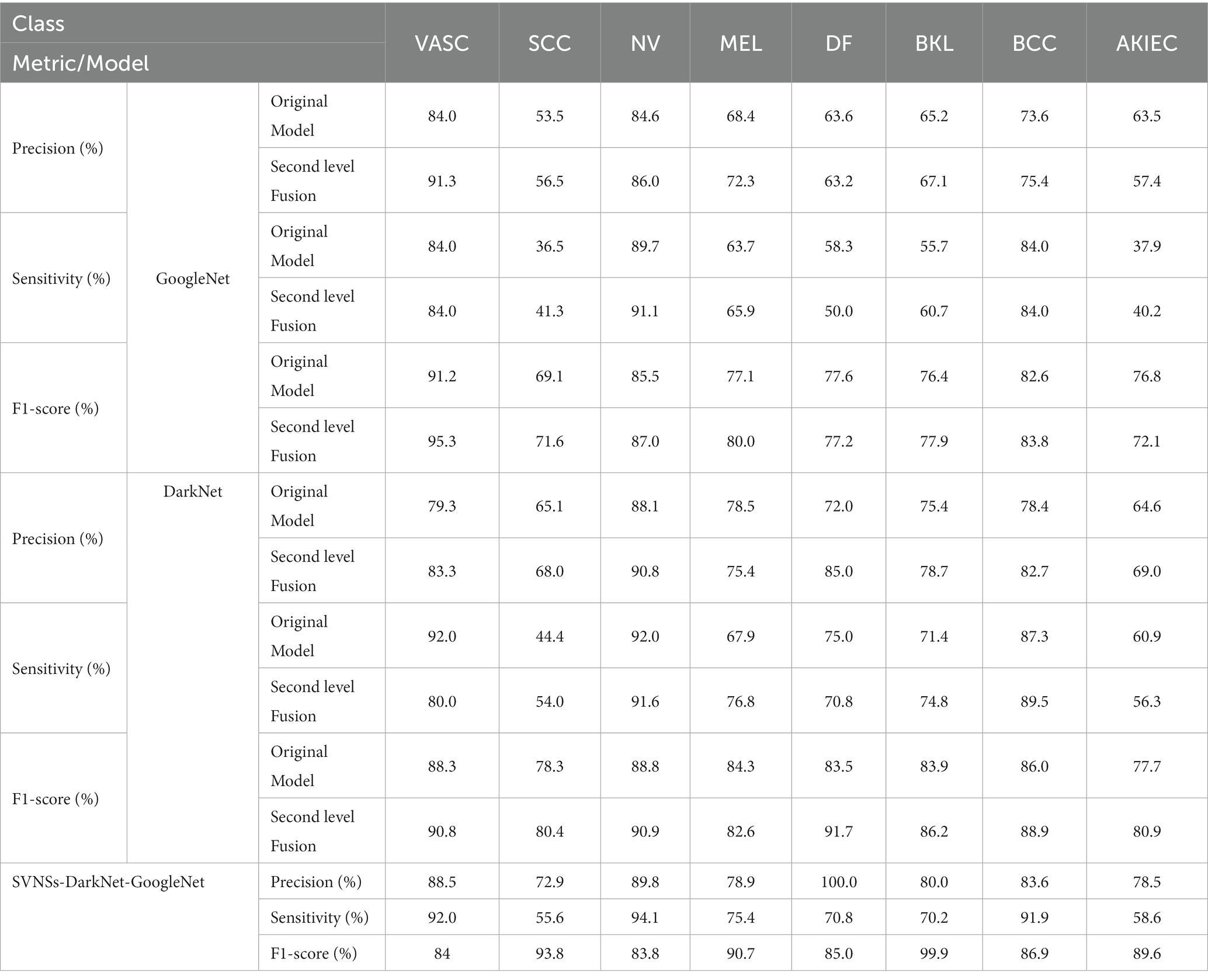
Table 6. Overall results of combined fused and neutrosophic experiments for eight classes.

Table 7. Overall average performance under the two experiments.
The purpose of this study is to create a diagnostic tool that divides skin lesion photographs into multiple classes. We rigorously evaluate a variety of DL models on the same dataset, the freely accessible ISIC 2019 database, to acquire a consistent set of measures for their performance because the training/testing dataset has an impact on the findings. The obvious imbalance in the training dataset affects how well the DL models perform; a set of spatial augmentation for the small instances classes was carried out tacitly as a remedy. The transfer learning is applied with the pre-trained GoogleNet, Xception, DarkNet, DenseNet, and AlexNet to exploit their efficient generalization and shorten training time. The trained models are ranked to pick the top two models for further improvements. A simple yet efficient feature fusion methodology is applied to boost the individual model’s performance. In addition, we show that using a neutrosophic environment to combine the boosted individuals maximizes classification performance, as evidenced by improvements in the collection of measurements (accuracy, precision, recall, and F-score).
The accuracy of the pre-trained models is listed in Table 3. We use the same procedure for each pre-trained model as shown in Figure 3. There are three processes involved in achieving transfer learning: altering the last learnable layer, freezing the initial layers, and accelerating the learning process for the deeper layers. The accuracy for the Xception, AlexNet, and DenseNet models stays the same and does not increase with the number of epochs approximately 0.74, 0.71, and 0.73 correspondingly as stated in Table 3.
After a few epochs, the loss function reaches a minimum and stays there, indicating that the model has stopped learning. Furthermore, as more epochs are added, both GoogleNet and DarkNet’s accuracy improves, yielding converged accuracy values of 0.77 and 0.82, respectively. Table 6 also includes the additional measures (precision, recall, and F-score). DarkNet, which has a value of 0.75, and GoogleNet, which has a value of 0.7, both produce the highest precision. DarkNet has the highest recall, followed by GoogleNet with values of 0.74 and 0.64, respectively. Finally, DarkNet has the greatest F-score when compared to GoogleNet, with a value of 0.84. These findings demonstrate that GoogleNet and DarkNet perform similarly on this database in terms of accuracy and F-score, with GoogleNet having a higher overall precision. As a result, DarkNet is the skin cancer detection model with the highest overall efficiency. Figure 4 is a qualitative visualization via the t-SNE to echo the proposed FMM efficiency.
The ECOC flexibility scheme eases implementing the proposed classification ensemble method as explained in Subsection 2.3.4. That flexibility appears obviously in the designed coding matrices in Table 2 which construct the true and false classifiers for DarkNet and GoogleNet, respectively. The disagreement between each true classifier and its opponent about an instance classification class creates ambiguity. The proposed scheme adopts the SVNSs to resolve that ambiguity to tilt the balance toward the correct skin class as listed in Algorithm 1. Moreover, Table 4 shows a practical application of Algorithm 1 on a sample from the test set with and without classification results agreement.
Table 8 recapitulates the comparative study between the proposed study and the recent other two related studies using the same dataset and the same number of classes.
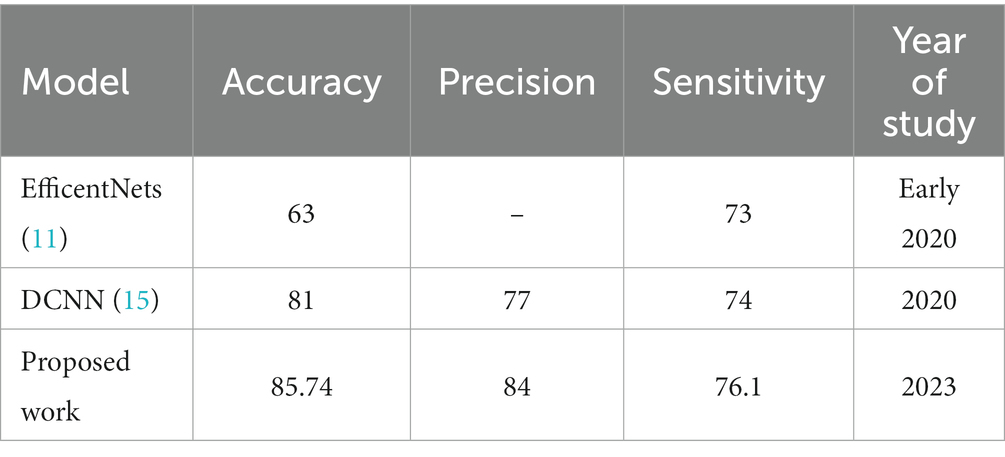
Table 8. Comparison with the recent related study.
Numerous studies have been conducted on the classification of skin cancer, but most of them were not successful in extending their research to the high-performance classification of various classes of skin cancer. The proposal investigates leveraging the classification accuracy in two successive stages: first, boosting the classification accuracy of the trained networks individually. A proposed feature fusion methodology is applied to enrich the extracted features’ descriptive power, which raises the accuracy by approximately 2%. The second stage explores how to combine the top two networks for further improvement. A set of true and false classifiers is built via the ECOC scheme, utilizing the fused features of the top two networks. Each true classifier and its opponent may disagree with the classification result, which establishes a contradiction. This contradiction is quantified by an indeterminacy set and resolved by the single-valued neutrosophic sets, which add 1.2% accuracy. The proposed study is generic and applicable to various classification tasks, and the extensive experiments conducted divulge its superiority and efficiency. In further research, the classification accuracy maybe improved using a preprocessing data purification technique to remove occlusions and hair from dataset instances.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
AA: conceptualization and writing—original draft. AA and AM: formal analysis and methodology. AA and NK: funding acquisition and resources. HM and AM: investigation. AM: software and visualization. AM, AA, and HM: validation. AA, AM, and NK: writing—review and editing. All authors have read and agreed to the published version of the manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^https://www.isic-archive.com, viewed on 6 October 2022.
1. Khazaei, Z, Ghorat, F, Jarrahi, AM, Adineh, HA, Sohrabivafa, M, and Goodarzi, E. Global incidence and mortality of skin cancer by histological subtype and its relationship with the human development index (HDI); an ecology study in 2018. WCRJ. (2019) 6:e1265. doi: 10.32113/wcrj_20194_1265
2. Narayanan, DL, Saladi, RN, and Fox, JL. Ultraviolet radiation and skin cancer. Int J Dermatol. (2010) 49:978–86. doi: 10.1111/j.1365-4632.2010.04474. x
3. American Cancer Society Survival rates for melanoma skin cancer (n.d.), Available at: https://www.cancer.org/cancer/melanoma-skin-cancer/detection-diagnosis-staging/survival-rates-for-melanoma-skin-cancer-by-stage.html
4. Ibrahim, A, Mohamed, HK, Maher, A, and Zhang, BA. Survey on human cancer categorization based on deep learning. Front Artif Intell. (2022) 5:884749. doi: 10.3389/frai.2022.884749
5. Gabriela, TM, Robert, AS, María de la Luz, C, and Flores, MHAM. Radiographers supporting radiologists in the interpretation of screening mammography. A viable strategy to meet the shortage in the number of radiologists. BMC Cancer. (2015) 15:410. doi: 10.1186/s12885-015-1399-2
6. Delivering quality health services . A global imperative for universal health coverage. International Bank for Reconstruction and Development/The World Bank: World Health Organization. OECD (2018).
7. Dascalu, A, Walker, BN, Oron, Y, and David, EO. Non-melanoma skin cancer diagnosis: a comparison between dermoscopic and smartphone images by unified visual and sonification deep learning algorithms. J Cancer Res Clin Oncol. (2022) 148:2497–505. doi: 10.1007/s00432-021-03809-x
8. Abdelwahab, R, Huang, R, Potla, S, Bhalla, S, AlQabandi, Y, Nandula, SN, et al. The relationship between vitamin D and basal cell carcinoma: a systematic review. J Clin Med. (2022) 14:e29496. doi: 10.7759/cureus.29496
9. Ramaprasad, P, Roma, R, and Amit, KM. Effect of data-augmentation on fine-tuned CNN model performance. IAES Int J Artif Intellig. (2021) 10:84–92. doi: 10.11591/ijai.v10.i1.pp84-92
10. Esteva, A, Kuprel, B, Roberto, A, Novoa, JK, Susan, M, Swetter, HM, et al. Dermatologist–level classification of skin cancer with deep neural networks. Nature. (2017) 542:115–8. doi: 10.1038/nature21056
11. Nils, G, Maximilian, N, Mohsin, S, René, W, and Alexander, S. Skin lesion classification using ensembles of multi-resolution EfficientNets with meta data. MethodsX. (2020) 7:100864. doi: 10.1016/j. Mex.00864,2020
12. Chaturvedi, SS, Gupta, K, and Prasad, PS. Skin lesion analyzer: an efficient seven-way multi-class skin cancer classification using MobileNet In: AE Hassanien, R Bhatnagar, and A Darwish, editors. Advanced machine learning technologies and applications, vol. 1141. Cairo: Springer (2021). 165–76.
13. Lopez, AR, Giro-I-Nieto, X, Burdick, J, and Marques, O. Skin lesion classification from dermoscopic images using deep learning techniques. In: IEEE 13th IASTED international conference on biomedical engineering (BioMed) Innsbruck, Austria, (2017). 49–54
14. Balazs, H . Skin lesion classification with ensembles of deep convolutional neural networks. J Biomed Inform. (2018) 86:25–32. doi: 10.1016/j.jbi.2018.08.006
15. Kassem, MA, Hosny, KM, and Fouad, MM. Skin lesions classification into eight classes for ISIC 2019 using deep convolutional neural network and transfer learning. IEEE Access. (2020) 8:114822–32. doi: 10.1109/ACCESS.2020.3003890
16. Al Masni, MA, Kim, DH, and Kim, TS. Multiple skin lesions diagnostics via integrated deep convolutional networks for segmentation and classification. Comput Methods Programs BioMed. (2020) 190:105351. doi: 10.1016/j.cmpb.2020.105351
17. Kiangala, SK, and Wang, Z. An effective adaptive customization framework for small manufacturing plants using extreme gradient boosting-XGBoost and random forest ensemble learning algorithms in an industry 4.0 environment. Mach Learn Applicat. (2021) 4:100024. doi: 10.1016/j.mlwa.2021.100024
18. Kawahara, J, and Hamarneh, G. Multi-resolution-tract CNN with hybrid pre-trained and skin-lesion trained layers In:. International workshop on machine learning in medical imaging. Cham: Springer. 164–71.
19. Majtner, T, Bajić, B, Yildirim, S, and Hardeberg, J Y J Lindblad and S. Nataša Ensemble of convolutional neural networks for dermoscopic image classification. Comput Vis Pattern Recog (2018) 1:1–5. doi:10.48550/arXiv.1808.05071
20. Amin, B, Salama, A, El-Henawy, IM, Mahfouz, K, and Gafar, MG. Intelligent neutrosophic diagnostic system for cardiotocography data. Comput Intellig Neurosci. (2021) 2021:6656770. doi: 10.1155/2021/6656770
21. Yue Iris, C, Swamisai, RSE, and Srinivasan, USK. Skin lesion classification using relative color features. Skin Res Technol. (2008) 14:53–64. doi: 10.1111/j.1600-0846.2007.00261.x
22. Milton, MAA . Automated skin lesion classification using ensemble of deep neural networks in ISIC 2018: Skin lesion analysis towards melanoma detection challenge, 2019. arXiv preprint arXiv:190110802. doi: 10.48550/arXiv.1901.10802
23. Montesinos, LA, and Crossa, J. Fundamentals of artificial neural networks and deep learning In:. Multivariate statistical machine learning methods for genomic prediction. Cham. Switzerland: Springer International Publishing (2022). 379–425.
24. Ribani, R, and Marengoni, M. A survey of transfer learning for convolutional neural networks. in 32nd SIBGRAPI conference on graphics, patterns, and images tutorials (SIBGRAPI-T). (2019). pp. 47–57
25. Ricardo, R, and Mauricio, M. ImageNet: A large-scale hierarchical image database. CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition Miami, (2009)
26. Sergio, E, David, MJT, Oriol, P, Petia, R, and Robert, PWD. Subclass problem-dependent design for error-correcting output codes. IEEE Trans Pattern Anal Mach Intell. (2008) 30:1041–54. doi: 10.1109/TPAMI.2008.38
27. Florentin, S . Neutrosophic set is a generalization of intuitionistic fuzzy set, inconsistent intuitionistic fuzzy set (picture fuzzy set, ternary fuzzy set), Pythagorean fuzzy set, spherical fuzzy set, and q-rung orthopair fuzzy set, while neutrosophication is a generalization of regret theory, grey system theory, and three-ways decision. J New Theory. (2019) Issue 29:01–31. doi: 10.48550/arXiv.1911.07333
29. Jerry, M . Type-2 fuzzy sets and systems: a retrospective. Informatik Spektrum. (2015) 38:523–32. doi: 10.1007/s00287-015-0927-4
30. Glad, D, Chris, C, and Etienne, E K. Generalized atanassov intuitionistic fuzzy sets. Proceedings of the fifth international conference on information. Process. and knowledge management. IARIA. (2013). pp. 51–56: France
31. Ibrahim, A, Mohamed, HK, Maher, A, and Abdelmonem, A. A Neutrosophic based c-means approach for improving breast cancer clustering performance. Neutros Sets Syst. (2023) 53:317–30. doi: 10.5281/zenodo.7536039
32. Ansari, AQ, Ranjit, B, and Swati, A. Extension to fuzzy logic representation: moving towards neutrosophic logic. IEEE Int Conf Fuzzy Syst. (2013). doi: 10.1109/FUZZ-IEEE.6622412
33. Mohammed, A, Maissam, J, and Said, B. A study of a support vector machine algorithm with an orthogonal Legendre kernel according to neutrosophic logic and inverse Lagrangian interpolation. J Neutros Fuzzy Syst. (2023) 5:41–51. doi: 10.54216/JNFS.050105
34. Said, B, Raman, S, Marayanagaraj, S, Giorgio, N, Mohamed, T, Assia, B, et al. Interval-valued fermatean neutrosophic graphs. Dec Mak. (2022) 5:176–200. doi: 10.31181/dmame0311072022b
35. Said, B, Ajay, D, Chellamani, P, Lathamaheswari, M, Mohamed, T, Assia, B, et al. Interval valued pentapartitioned Neutrosophic graphs with an application to MCDM. Operat Res Eng Sci. (2022). ISSN: 2620-1607) 5:68–91. doi: 10.31181/oresta031022031b
36. Das, S, Chowdhury, M, Kundu, MK, and Brain, MR. Image classification using multi-scale geometric analysis of ripplet. Prog Electromagn. (2013) 137:1–17. doi: 10.2528/PIER13010105
37. Krizhevsky, A, Sutskever, I, and Hinton, GE. Imagenet classification with deep convolutional neural networks, 84. Commun ACM. (2017) 60:–90. doi: 10.1145/3065386
38. Szegedy, C, Liu, W, Jia, Y, Sermanet, P, Reed, S, Anguelov, D, et al. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. Boston, MA (2015) pp. 1–9.
39. Huang, G, Liu, Z, Van Der Maaten, L, and Weinberger, K Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI (2017). pp. 4700–4708
40. Chollet, F. Xception: deep learning with depth-wise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu, HI (2017). pp. 1251–1258
Keywords: transfer learning, fused deep features, skin cancer classification, multi-support vector machine, error-correcting output codes, single-valued neutrosophic sets
Citation: Abdelhafeez A, Mohamed HK, Maher A and Khalil NA (2023) A novel approach toward skin cancer classification through fused deep features and neutrosophic environment. Front. Public Health. 11:1123581. doi: 10.3389/fpubh.2023.1123581
Edited by:
Surapati Pramanik, Nandalal Ghosh B. T. College, IndiaReviewed by:
Florentin Smarandache, University of New Mexico Gallup, United StatesCopyright © 2023 Abdelhafeez, Mohamed, Maher and Khalil. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ahmed Abdelhafeez, YWFoYWZlZXouc2Npc0BvNnUuZWR1LmVn
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.