 Samer A. Kharroubi
Samer A. Kharroubi Dan Kelleher
Dan Kelleher
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Public Health, 23 June 2022
Sec. Health Economics
Volume 10 - 2022 | https://doi.org/10.3389/fpubh.2022.917728
This article is part of the Research TopicHealth-Related Quality of Life in Health CareView all 9 articles
Valuations of preference-based measures for health are conducted in different countries. There is scope to use results from existing countries' valuations to generate better valuation estimates than analyzing the data from each country separately. We analyse data from two smaller design EQ-5D-5L valuation studies where a sample of 119 Polish migrants and 123 native Irish valued 30 common health states using similar composite time trade-off protocols. We apply a non-parametric Bayesian method to provide better predictions of the Polish (Irish) population utility function when the existing Irish (Polish) results were used as informative priors. The resultant new estimates were then compared to those obtained by analyzing the data from each country by itself via different prediction criterions. The results suggest that existing countries' valuations could be used as potential informative priors to produce better valuation estimates under all prediction criterions used. The implications of these results will be hugely important in countries where valuation studies are expensive and hard to conduct. Future application to other countries and to other preference-based health measures are encouraged.
Several preference-based measures of health-related quality of life (HRQoL) are currently available. Such generic measures include the EuroQol five-dimensional (EQ-5D) questionnaire (1), health utilities index 2 (HUI2) and 3 (2, 3), assessment of quality of life (4), Quality of Well-being scale (QWB) (5), and the six-dimensional health state short form (SF-6D) (6) along with disease-specific measures (7, 8). All of these measures produce derived health-state utilities that can be used for computing quality-adjusted life-years (QALYs) for use in cost-effectiveness analyses (9).
The EQ-5D is the most commonly used preference-based measure of HRQoL. It describes five multi-level dimensions of health: mobility, self-care, usual activities, pain/discomfort and anxiety/depression. Two versions of the instrument are available: the three level EQ-5D (EQ-5D-3L) allowing the determination of 35 = 243 health states and the five level EQ-5D (EQ-5D-5L) allowing the determination of 55 = 3,125 health states (10, 11). The EQ-5D-5L, though, improves the sensitivity and discriminatory potential of the EQ-5D (12, 13). The EQ-5D-5L has been valued in more countries than any of the other generic measures, thereby there are many different value sets from different countries and subgroups available (14–22).
In the context when plenty of data on each country is available, good utility estimates for each country can be produced by analyzing its data separately. However, in the case when limited quantity of data on some (or all) countries is available, it is argued that combined analysis may generate better estimation of every country's utility estimates than analyzing its data by itself. This sort of analysis (adopting strength from existing countries) will be greatly important in countries where large-scale evaluation exercises are very expensive and hard to conduct, especially for countries with smaller populations or low- and middle-income countries (LMIC).
Advancement in statistical modeling techniques, such as Bayesian inference methods (23), offers the potential for borrowing strength from existing countries. In particular, it offers the potential for using the existing results of country 1 to improve those in country 2 by using the results in country 1 as informative priors. As such, the resultant utility estimates of country 2 could be more precise than modeling its own data separately. A number of researchers have investigated the use of such approach. For example, Chan et al. (24) found that EQ-5D-3L health state utilities obtained from shrinkage estimation allow valuation studies with very low sample size to adopt strength from another valuation studies to help improve precision in the estimated mean health utilities and reduce uncertainty. Kharroubi (25) developed a non-parametric Bayesian method that allows the already existing results from one country to be employed as a potential prior information in another country, and applied this method for analyzing the US EQ-5D-3L valuation dataset alongside the available UK dataset (26). In (27–32), Kharroubi et al. extended this work further to handle the SF-6D Hong Kong, Japan and Lebanon alongside the already available UK dataset, respectively.
Our primary purpose in the present paper is to investigate the use of aforementioned method for countries with smaller design valuation studies and different population compositions, type of work, cultures and languages, all of which could have an impact, suggesting that analyzing its own data separately may not always generate precise valuation estimates. This is investigated using a case study for Polish migrants and native Irish data modeling Irish (Polish) data alongside small Polish (Irish) samples to generate Polish (Irish) estimates. Despite the present paper not offering new methodological advances as the model presented here is a replication of that already reported in Kharroubi et al. (25–32) papers, it further tells a reassuring story regarding the superiority and flexibility of the non-parametric Bayesian approach in using existing preference data, thereby generating accurate estimates.
The Polish and Irish EQ-5D-5L valuation surveys and study methods alongside the corresponding datasets are summarized in Section 2. In the next section, the Bayesian non-parametric model is described whereas the results are reported in Section 3. In the last section, the results are discussed and some limitations and suggestions for further research are set out.
The EQ-5D-5L describes five multi-level dimensions of health: mobility, self-care, usual activities, pain/discomfort and anxiety/depression. Each dimension is assigned to five levels of health-related problems: no problems “1,” slight problems “2,” moderate problems “3,” severe problems “4,” and extreme problems “5” (11). Different combinations allow the determination of 3,125 distinct health states, each of which is associated with a five-digit identifier, beginning from 11,111 for best health state (perfect health) and ending with 55,555 for the worst health state, referred to as “the pits.”
Data from two smaller design EQ-5D-5L valuation studies where, using similar composite time trade-off protocols (cTTO), valuations for 30 common health states were elicited from Polish migrants and native Irish, both living in Ireland. Since they represent the largest non-Irish community residing in Ireland, the Polish migrants were chosen to be included in this valuation study. Detailed description of the survey design and sampling strategy has been reported elsewhere (33). In brief, a sample of 240 (120 Polish migrants and 120 native Irish) respondents was recruited to value six practice states each in addition to one block of 11 cTTO states. The valuation study was conducted between June 2018 and September 2019 and the orthogonal design of the health states was provided by the EuroQol Research Foundation. All interview sessions were conducted using the EuroQol Portable Valuation Technology (EQ-PVT), which is a computer assisted personal interview software and protocol (34, 35). The valuation study has been ethically approved by the NUI Galway's Research Ethics Committee. Further details on the valuation study is provided elsewhere (33).
The orthogonal design was analogous to the one applied in Yang et al. (34). A sample of 30 EQ-5D-5L health states was chosen for valuation. The sample contained 25 health states, including the ‘pits' state. A further five mild health states were selected, resulting a total of 30 EQ-5D-5L health states for valuation. A key advantage of using an orthogonal design is that it allows for a small number of health states to be valued and a small sample size to be used in comparison to that of a full national valuation study, which includes 86 EQ-5D-5L health states and a minimum sample size of 1,000 respondents (17). A comparative study between estimates of a smaller design EQ-5D-5L valuation study and that of the full national valuation study has been conducted in Yang et al. (34, 36). Results revealed that the smaller design EQ-5D-5L valuation study performed well in comparison to the larger design and that no significant changes in prediction errors have been obtained when modeling EQ-5D-5L cTTO data.
Using the blocking algorithm that is readily available in the “AlgDesign” package in the software package R, the 30 EQ-5D-5L health states were split up into three blocks of 11 health states. The rationale for this is to make sure that within-block variance is maximized, thereby observations on the full health–dead scale are attained [see Kelleher et al. (33) for an overview].
The EQ-5D-5L cTTO data were extracted from Polish migrants and native Irish, both living whole-time in Ireland. Full details on the valuation study is provided in Kelleher et al. (33). Prior to the survey, respondents were asked to state their country of birth and whether they reside in Ireland whole-time. The interviews were conducted by a group of seven interviewers plus one study coordinator. Respondents were contacted through a Facebook page, by email through the study coordinator, or through friends and family using snowball sampling. Respondents were also asked to provide written consent to be included in the study.
More detailed explanation on the extended experimental design, survey design and sampling strategy is provided in Kelleher et al. (33).
Kharroubi (25) developed a non-parametric Bayesian model that allows the already existing results from one country to be employed as a potential prior information in another country. Here we make use of this model to investigate whether the use of Polish (Irish) alongside the existing Irish (Polish) dataset generates more accurate utility estimates than modeling the data from each country alone. These resultant estimates are then compared in terms of different prediction criterions, including predicted against actual mean utility estimates, mean predicted error and root mean square error (RMSE).
Following Kharroubi (25), the non-parametric Bayesian model is defined as
where for i = 1, 2, …, Ij and j = 1, 2, …, J, xij is the ith health state evaluated by respondent j and the dependent variable yij is the respondent j's cTTO valuation for that health state, αj is a random effect of respondent j and εij is the usual random error.
Assume that tj is a vector of covariates for respondent j e.g., age, gender, socio-economic status or level of education. Kharroubi (25) then used the following distributions:
where γ is the vector of unknown coefficients and τ2 and v2 are further unknown variance parameters to be estimated. That is, the distribution of the respondent effect αj is then independent log-normal, resulting in a skewness that is also typically observed in valuation data, and εij are independent normally distributed errors,
Note that, because of the way that the respondent effects have been modeled in distribution (2), the utility function u(x) turns out to be the median utility of health state x. Given it is an unknown function, it becomes a random variable in the Bayesian model, which in turn needs a prior belief. Kharroubi (25) formally assigned a multivariate normal distribution for u(x) with mean
and variance–covariance matrix
where E (u0(x)|y) represents the average utility value for state x and denotes the variance–covariance matrix between the two utility functions u0(x) and for two distinct health states x and x′, both of which are computed directly from modeling the existing countries' data. More details on this are given in Kharroubi (25).
Given equations (3) and (4), it is noteworthy that x = (x1, x2, …, x5) denotes a vector comprising discrete levels on each EQ-5D-5L dimensions and γ, β, and σ2 are unknown parameters. Note also that the regression parameters γ and β represent, respectively, the intercept term and the slopes as each of the 5 dimensions (mobility, self-care, usual activities, pain/discomfort and anxiety/depression) increases, whereas the term c (x, x′), defined below, represents the correlation between the two utility functions u (x) and u (x′) for two distinct health states x and x′ in the new country's data. As for equation (3), the prior mean E (u (x)|β) represents a prior belief about the utility function that it is approximately linear and additive in the different dimensions. In addition, the actual utility function is allowed to vary around this mean in accordance with to its multivariate normal distribution, and so it takes any form at all. With regards to equation (4), the correlation c(x, x′) decreases when the distance between x and x′ gets bigger. Kharroubi (25) defined c(x, x′) as
where for d = 1, 2, …, 5, xd and - represents, respectively, the levels of dimension d in x and x′. The term bd denotes a roughness parameter which by definition controls how close the actual utility function to a linear form in dimension d. For more explanation of this specific point, see Kharroubi (25).
In order to complete the Bayesian model, we need to assign prior distributions for hyperparameters γ, τ2, v2, β and σ2. Vague priors are usually specified unless specific prior information is available. Formally, we assign
Note that a flat prior was specified for σ, hence p(σ2) ∝ σ−1 (37). Note also that no prior distributions were assigned to the roughness hyper-parameters bds. It is noted in Kharroubi et al. (23) that inference about bds in Gaussian models is generally problematic, thus it is recommended to give them fixed values. We shall discuss one method to demonstrate this in section results.
We now formulate the posterior distribution of interest. Letting be the vector of utilities for the health states in the sample. Equations (3) and (4) give rise for the prior distribution of u
where
and
Note that u0 and C0 are obtained from modeling the existing countries' data. Now let be the vector of respondent effects, then the posterior distribution of θ = (u, α, γ, τ2, v2, β, σ2) is
We now compute p(u|y) to predict utility estimates for all health states in the sample. This is obtained by integrating out equation (7) with respect to α and the hyperparameters γ, τ2, v2, β, and σ2. It follows from equation (7) that the posterior distribution of θ is not in the closed form. This implies that the Markov Chain Monte Carlo (MCMC) methods are then needed. Full conditional posterior distributions for all parameters u, α, γ, τ2, v2, β, and σ2 using MCMC methods are all set out in Kharroubi (25).
To this end, it is important to correct utility to the population mean. Note that the distribution of the individual respondent effect αj in (2) is defined as independent log-normal. This implies that the utility function u(x) in model (1) represents the population median utility for a health state x and not the required population mean utility which, using model (1), is defined as
where E(α) represents the expected value of α over the total population. When E(α) = 1, then will be the same as u(x).
In the context when no covariates are used, the distribution (2) of the respondent effects becomes . This results in E(α)=exp(τ2/2). However, when there are covariates, it follows from (2) that
all of which are obtained directly from the MCMC simulation. Therefore, the calculation of E (α) is straightforward
All theoretical and technical details of the non-parametric Bayesian model are reported in Kharroubi et al. (23, 25). Matlab source code for implementing the Bayesian approach is available online in the Supplementary Material. Note that the codes are not generic and need to be modified as per users' specific purposes.
The Bayesian model (1) was first implemented to predict an Irish value set, where the Polish results were employed as informative priors (which we will refer to as combined analysis from now on). The resultant utility estimates were then compared to those obtained from analyzing the Irish data alone (which from now on we will refer to as single analysis).
Here, the vector of individual-specific covariates is set as (Age, Age2, Sex). Also the roughness parameters bd in formula (5) is set to be , where ld denotes the number of levels in dimension d (23). This value of bd is chosen because exprepresents the correlation between the utility values for two health states differing only in that one is at level 1 and the other at level ld in dimension d (23).
The MCMC sampler was allowed to iterate for 3,000 runs, with an initial run of 1,000 iterations as “burn-in” (these runs were discarded). Figures 1A,B presents the estimated (line in pink) and actual (line in blue) mean utilities for the 30 EQ-5D-5L health states valued in the Irish survey as well as the full health obtained from the combined and single analyses, respectively. The errors in both plots are displayed by the line in yellow and are obtained by calculating the difference between the two utilities. In both figures, the health states were ordered in terms of estimated mean utilities and were then plotted accordingly. The single analysis in Figure 1A exhibits a clear variation of the actual mean utilities around the estimated ones, particularly for the mild and worse health states, whereas Figure 1B clearly shows that the combined analysis predicts the mean utilities quite well across the full board.
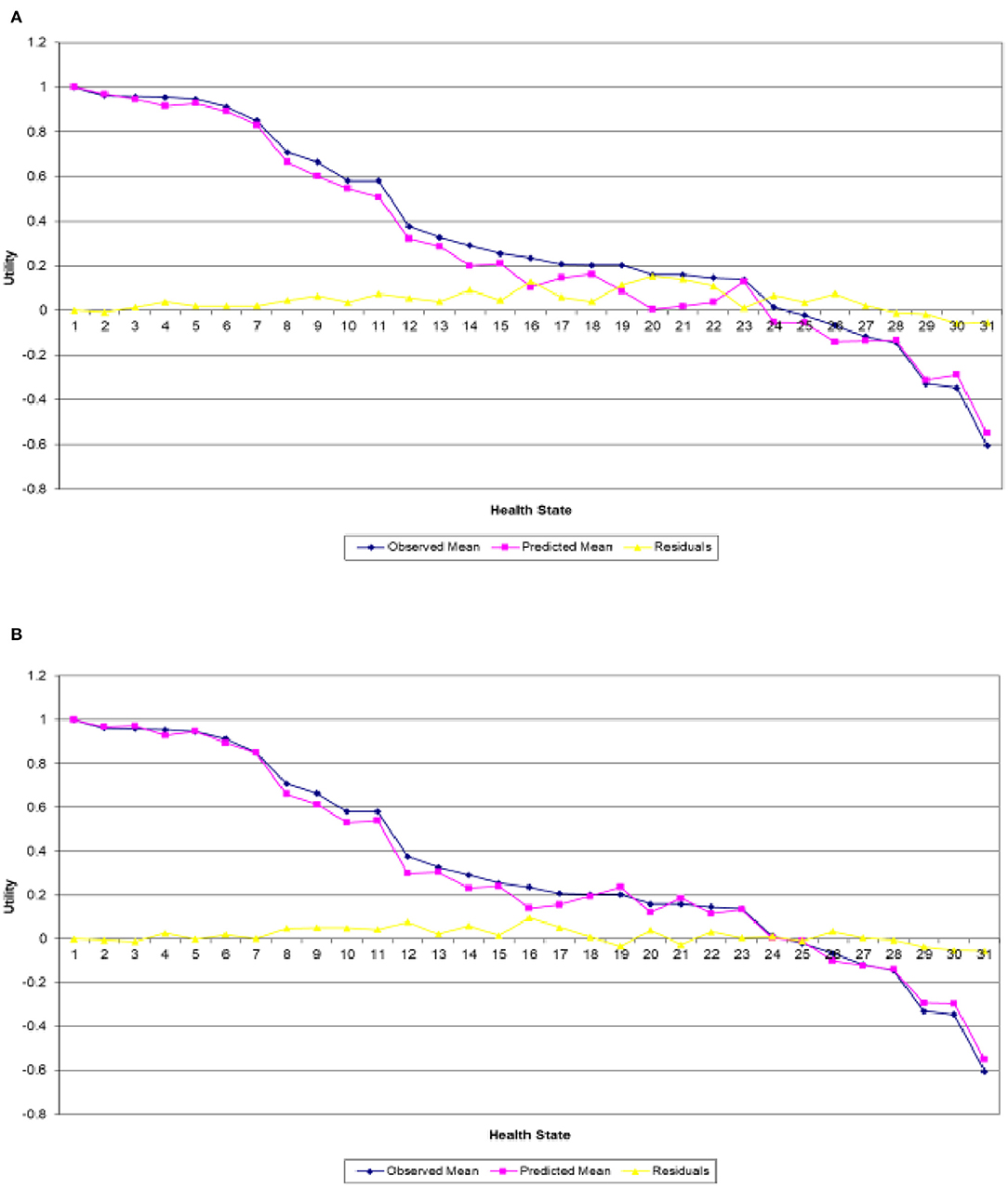
Figure 1. Actual and predicted mean health states valuations generated from analyzing. (A) Irish data only and (B) Irish data with Polish results as informative priors.
Another way to check the adequacy of the assumed models is to quantify the gains in terms of bias and/or precision. This is achieved by the Bland–Altman agreement plot that displays the difference values between predicted and actual mean utilities against the average bias (38). Figures 2A,B present the Bland–Altman agreement plot obtained from the combined and single analyses, respectively. The solid line in each plot represents the average bias, whereas the dotted lines are the 95% limits-of-agreement. It can be clearly seen that the combined analysis shows a much greater agreement than the single one. The rationale for this is based on the following three observations. Firstly, shorter width of the 95% limits of agreement, with values of 0.1402 for the combined analysis vs. 0.2030 for the single one. Secondly, smaller difference in average bias, with values of 0.0144 for the combined analysis and 0.0441. Thirdly, the standard deviation of the differences obtained from the combined analysis is also smaller than from the single analysis, with values of 0.0357 and 0.0518, respectively.
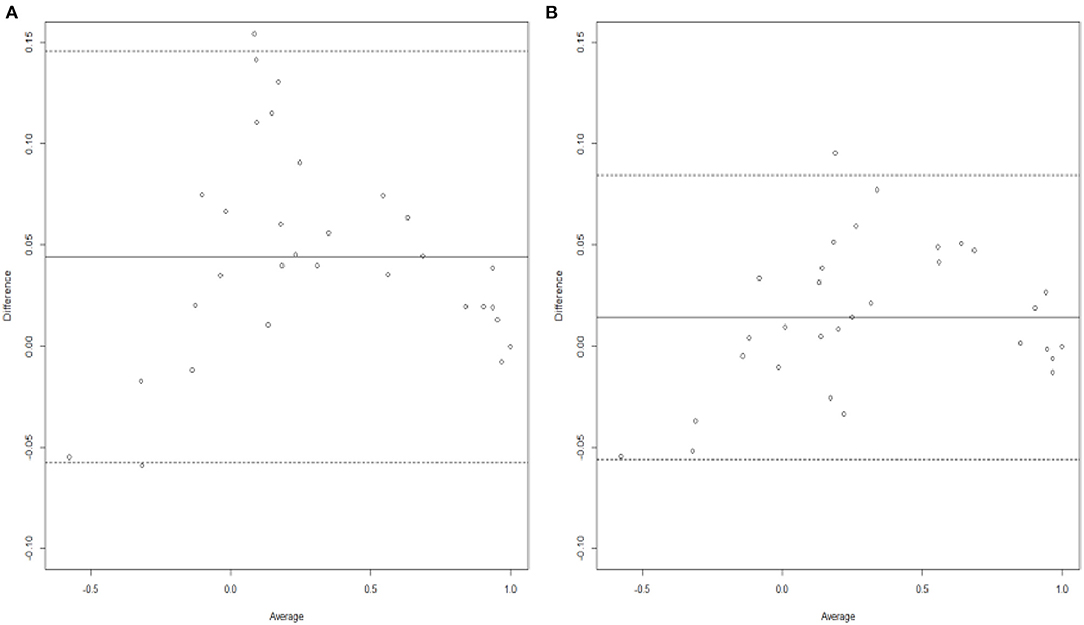
Figure 2. Bland-Altman plots generated from analyzing (A) Irish data only and (B) Irish data with Polish results as informative priors.
The overall impact of this can be seen from Table 1 which displays the inferences for the utilities of the 30 EQ-5D-3L states evaluated in the study as well as the perfect health. For each health state, Columns 2 and 3 present, respectively, the number of valuations together with the observed mean utility of the Irish data only, while Columns 4 and 5 show the Polish estimated mean utility and standard deviation that were used as informative priors in the combined analysis. Moreover, Columns 6 and 7 exhibit the predicted mean utility and standard deviation obtained from the single analysis, respectively, whereas Columns 8 and 9 show the corresponding estimates obtained from the combined analysis. As clearly seen throughout this comprehensive table, the combined analysis provides much better predictions compared to the single analysis overall, with RMSE of 0.038 vs. 0.068, respectively. Furthermore, it can also be seen that the posterior standard deviations of the utility estimates are larger for the single analysis. The posterior standard deviations for the combined analysis are smaller is due to the fact that it is a model that employs the Polish results as prior beliefs, hence producing better estimates.
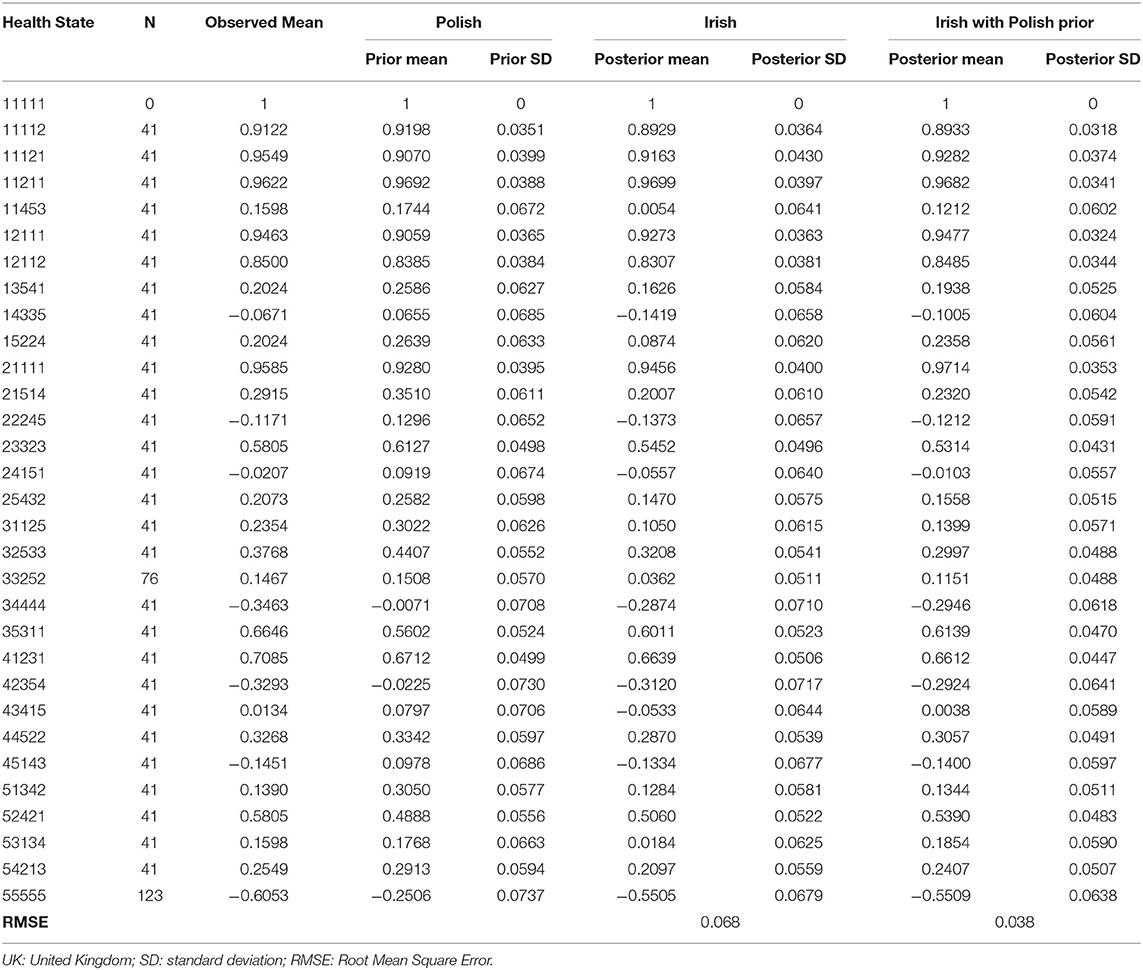
Table 1. Estimates for utilities of the 30 EQ-5D-5L health states valued in the survey in addition to the full health.
We now apply model (1) to predict a Polish value set, where the Irish results were now employed as informative priors (combined analysis), and the resultant utility estimates were then compared to those obtained from analyzing the Polish data alone (single analysis).
In a similar way to section Irish With Polish Prior, Figures 3A,B present the predicted and actual mean utility estimates for the 30 EQ-5D-5L health states valued in the Polish survey along with their differences obtained from the combined and single analyses, respectively. As is the case in section Irish With Polish Prior, Figure 3A exhibits a clear variability of the actual values around the estimated mean utilities, particularly for the mild and worse health states, while Figure 3B clearly shows that that the combined analysis predicts the mean utilities quite well for almost all heath states in the study.
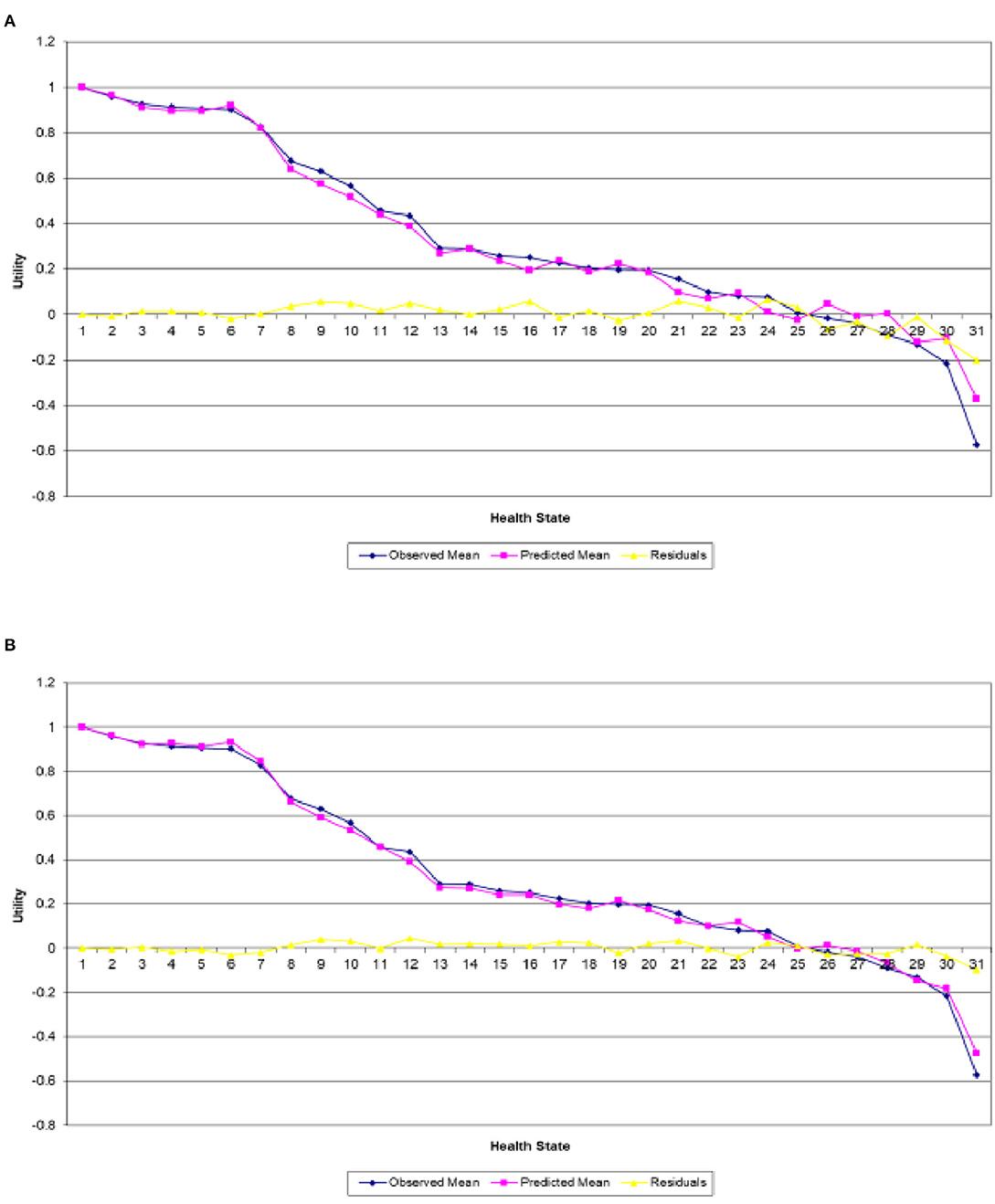
Figure 3. Actual and predicted mean health states valuations generated from analyzing (A) Polish data only and (B) Polish data with Irish results as informative priors.
When comparing the two analyses using the Bland–Altman agreement plots (Figures 4A,B), we can also see clearly that the combined analysis has performed better in terms of a greater agreement. As in section Irish With Polish Prior, this is also due to (1) shorter width of the 95% limits of agreement, with values of 0.1205 for the combined analysis compared to a value of 0.2186 for the single one, (2) smaller difference in mean bias, with values of −0.0006 for the combined analysis and −0.0011, and (3) smaller standard deviation of the differences, with values of 0.0307 for the combined analysis vs. 0.0557 for the single analysis. Finally, and in a similar pattern to Table 1, it can be clearly seen throughout the comprehensive Table 2 that the combined analysis provides much better predictive performance when compared to the single analysis overall, with a value of 0.030 for RMSE against 0.055 from the single analysis. The posterior standard deviations of the utility estimates are also smaller for the combined analysis.
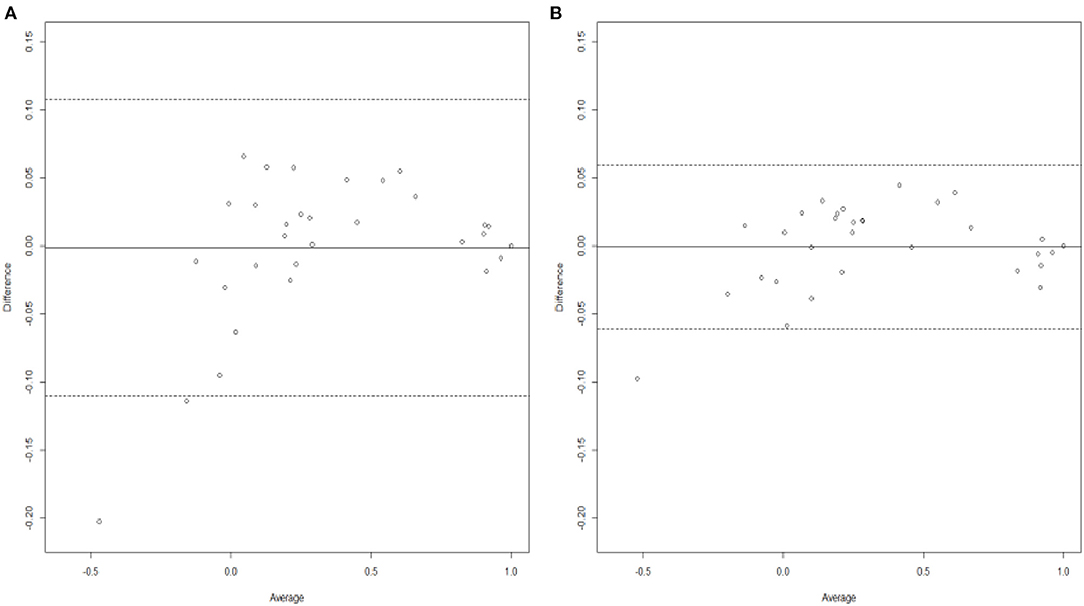
Figure 4. Bland-Altman plots generated from analyzing (A) Polish data only and (B) Polish data with Irish results as informative priors.

Table 2. Estimates for utilities of the 30 EQ-5D-5L health states valued in the survey in addition to the full health.
Kharroubi (25) built a non-parametric Bayesian model that allows the already existing results from one country to be employed as a potential prior information in another country. Here, we explored the use of this method for Polish migrants and native Irish data modeling Irish (Polish) data alongside small Polish (Irish) samples to generate Polish (Irish) estimates. The resultant new estimates were then compared to those obtained modeling the data from each country alone. The findings proved that existing countries' valuations could be used as informative priors to produce better utility estimates under all criterions used, including estimated against actual mean utilities, mean predicted error and RMSE. This sort of analysis (adopting strength from existing countries) will be greatly important in countries where large-scale evaluation exercises are hard to conduct, especially for countries with small population size or LMICs.
Despite the present paper not offering new methodological advances, the novelty here was to investigate the use of non-parametric Bayesian model for countries with smaller design valuation studies and different population compositions, type of work, cultures and languages. All of these could have an impact on the relative valuations of the dimensions of health (such as, self-care and anxiety/depression) and on where-about each health state lies on the [0–1] dead-perfect health scale. This suggests that the approach presented here may not generate precise utility estimates all the time. Further, the analysis presented here also provided a re-assuring story regarding the superiority and flexibility of the non-parametric Bayesian approach in using existing preference data, thereby generating accurate utility estimates.
It is true from the two analysis presented here that the improvement in the utility estimates in general and in the mean-squared error in particular is moderate. However, there are other crucial benefits especially those related to health and quality of life gains. As lots of reimbursement agencies worldwide need cost-effectiveness assessments, effectiveness analysis would become more international with combination of data across different countries. The valuation of health states for calculating QALYs would be a key component of this process which, in turn, requires accurate utility estimates. For example, results from Table 1 revealed that the combined analysis provides much better predictive performance when compared to the single analysis overall, with values for RMSE of 0.038 and 0.068, respectively. Therefore, the difference in utility estimates is, on average, equal to 0.03, which leads to an increase in QALYs from 0.5 to 0.53 for a treatment that extends life by an extra year. This in turn leads to a decrease in the cost per QALY from £20,000 to £18, 867 for a treatment costing £10,000, and so puts it under the cost-effectiveness threshold employed by the National Institute for Health and Clinical Excellence (NICE) in the UK. As a result, this could potentially influence the probability of whether a new treatment or health care scheme is deemed cost-effective and funded. It could also impact on the validity of the resource allocation decisions being made. Heijink et al. (39) drew similar conclusion from their analysis on the impact of different valuation functions on QALYs.
A key benefit of the non-parametric Bayesian model presented here is that it allows for multi-countries to be analyzed rather than two. Further, equations (3) and (4) may be generalized further to handle n (n > 2) countries. Thus, we formally assign a multivariate normal distribution for u(x) with mean:
and variance–covariance matrix
where is the overall expected utility of state x and is the overall variance–covariance matrix between the two utility functions uk(x) and for two distinct health states x and x', both of which are computed directly from modeling the existing datasets in n different countries. Work is in progress on demonstrating this idea for SF-6D in the UK, Hong Kong and Japan has introductory results that are particularly promising.
As already mentioned, generic measures of HRQoL, such as the EQ-5D and SF-6D, have been valued in different countries and so there are many different value sets from different countries and subgroups available. Such valuation studies are very expensive and are potentially wasteful. The analysis presented here demonstrates how existing countries' valuations could be used as informative priors to produce better utility estimates. This offers the potential to reduce the need for conducting large surveys in every country which in turn will reduce the cost of cross-country valuation. The approach presented here (borrowing strength from existing countries) could be particularly promising for countries where large-scale evaluation exercises are hard to conduct, especially for countries with small population size or LMICs. For instance, it is worth noting that large-scale national EQ-5D-5L valuations studies are significant undertakings of research that require substantial resources and logistics to be completed. These studies require a minimum of 1,000 respondents to value 86 health states, as mentioned above. As such, using the methods employed in this paper and a similar smaller design EQ-5D-5L valuation study to Kelleher et al. (33), future national valuation studies could be conducted more efficiently by having less respondents to value less health states compared to current large-scale national valuation studies. Examining this could be particularly promising and would form a key research agenda for further research. In addition, further analysis could be conducted more efficiently using simulated data. The thing is that, if through simulated data we know how the value sets differ, then we can explore the relationship between how different the countries are and how useful the use of priors are. However, although the empirical example is helpful and a worthwhile addition to the literature in its own right, it does not allow exploration of the full range of distances between national value sets (24). Further research is encouraged to examine this.
The present study has certain limitations that ought to be considered. First, the study sample size was small which may in some sense limit the generalizability of the utility values obtained. Second, snowball sampling has been used, thus a good representative sample of Polish migrants and/or native Irish was not selected, let alone there was some difficulties associated with obtaining a good representative sample [see Kelleher et al. (33) for an overview]. This implies that the results of this study ought not to be considered as good representative of Polish migrants and/or native Irish in Ireland. Third, the small number of health states (i.e., 30 EQ-5D-5L health states) valued in this study could have an impact on the precision of econometric modeling, suggesting that the presented EQ-5D-5L utility estimates may not be considered as representative of the general Polish migrants or native Irish population. Future research with more representative samples is then encouraged to produce the Polish migrants or native Irish specific EQ-5D-5L value set. However, because of the way the non-parametric Bayesian model is defined, this should not in theory impact on the resulting utility estimates from this paper, though this could be further examined in future work.
In conclusion, the promising results suggest that existing countries' valuations could be used as informative priors to generate better utility estimates than modeling the data from each country separately. This kind of analysis could be particularly promising in terms of reducing the need for conducting large surveys in every country which in turn would reduce the cost of cross-country valuation. This will be greatly important for countries where large-scale evaluation exercises are expensive and hard to conduct. Similar approach could be used to other descriptive measures like HUI-II (40), in addition to other condition-specific measures (41). Ongoing research is underway to examine this
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by NUI Galway's Research Ethics Committee (application number 18-Mar-13). The patients/participants provided their written informed consent to participate in this study.
SK participated in the conceptualization of the idea, the design of the methodology, software, data analysis, data interpretation, manuscript drafting, and the final review of the manuscript. DK reviewed and finalized the manuscript and participated in the conceptualization of the study. All authors have read and approved the final manuscript.
This research was funded by the University Research Board (URB) at the American University of Beirut (AUB) awarded to SK (Grant No. 104110). The original study was funded by the Hardiman Research Scholarship 2017 awarded by NUI Galway to DK.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The leading author would like to thank the URB at AUB for funding this study. DK would like to thank NUI Galway for funding the original study through the Hardiman Research Scholarship 2017. The authors would also like to acknowledge the support and advice from the EuroQol Research Foundation who made the survey possible, especially from Dr. Kristina Ludwig and Dr. Elly Stolk.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2022.917728/full#supplementary-material
1. Brooks R. EuroQol: the current state of play. Health Policy. (1996) 37:53–72. doi: 10.1016/0168-8510(96)00822-6
2. Torrance GW, Feeny DH, Furlong WJ, Barr RD, Zhang Y, Wang QA. Multi-attribute utility function for a comprehensive health status classification system: Health Utilities Index Mark 2. Med Care. (1996) 34:702–22. doi: 10.1097/00005650-199607000-00004
3. Feeny DH, Furlong WJ, Torrance GW, Goldsmith CH, Zenglong Z, Depauw S, et al. Multi-attribute and single-attribute utility function for the Health Utility Index Mark 3 system. Med Care. (2002) 40:113–28. doi: 10.1097/00005650-200202000-00006
4. Hawthorne G, Richardson G, Day NA. A comparison of the Assessment of Quality of Life (AQoL) with four other generic utility instruments. Ann Med. (2001) 33:358–70. doi: 10.3109/07853890109002090
5. Kaplan RM, Anderson JP. A general health policy model: update and application. Health Serv Res. (1988) 23:203–35.
6. Brazier JE, Roberts J, Deverill M. The estimation of a preference-based measure of health from the SF-36. J Health Econ. (2002) 21:271–92. doi: 10.1016/S0167-6296(01)00130-8
7. Revicki DA, Leidy NK, Brennan-Diemer F, Sorenson S, Togias A. Integrating patients' preferences into health outcomes assessment: the multiattribute asthma symptom utility index. Chest. (1998) 114:998–1007. doi: 10.1378/chest.114.4.998
8. Brazier JE, Czoski-Murray C, Roberts J, Brown M, Symonds T, Kelleher C. Estimation of a preference-based index from a condition specific measure: the King's Health Questionnaire. Med Decis Making. (2008) 28:113–26. doi: 10.1177/0272989X07301820
9. Drummond MF, Sculpher M, O'Brien B, Stoddart GL, Torrance GW. Methods for the Economic Evaluation of Health Care Programmes, Oxford Medical Publications. Oxford (2005).
10. TE-Group. EuroQol-a new facility for the measurement of health-related quality of life. Health Policy. (1990) 16:199–208. doi: 10.1016/0168-8510(90)90421-9
11. Herdman M, Gudex C, Lloyd A, Janssen M, Kind P, Parkin D, et al. Development and preliminary testing of thenew five-level version of EQ-5D (EQ-5D-5L). Qual Life Res. (2011) 20:1727–36. doi: 10.1007/s11136-011-9903-x
12. Buchholz I, Janssen MF, Kohlmann T, Feng Y-S. A systematic review of studies comparing the measurement properties of the three level and five-level versions of the EQ-5D. Pharmacoeconomics. (2018) 36:645–61. doi: 10.1007/s40273-018-0642-5
13. Janssen M, Pickard AS, Golicki D, Gudex C, Niewada M, Scalone L, et al. Measurement properties of the EQ-5D-5L compared to the EQ-5D-3L across eight patient groups: a multicountry study. Qual Life Res. (2013) 22:1717–27. doi: 10.1007/s11136-012-0322-4
14. Devlin NJ, Shah KK, Feng Y, Mulhern B, van Hout, B. Valuing health-related quality of life: an EQ-5D-5L value set for England. Health Econ. (2018) 27:7–22. doi: 10.1002/hec.3564
15. Gasper D, Truong TD. Movements of the ‘we': international and transnational migration and the capabilities approach. J Hum Dev Capabilities. (2010) 11:339–57. doi: 10.1080/19452821003677319
16. Golicki D, Jakubczyk M, Graczyk K, Niewada M. Valuation of EQ-5D-5L health states in Poland: the first EQ-VT-based study in central and Eastern Europe. PharmacoEconomics. (2019) 37:1165–76. doi: 10.1007/s40273-019-00811-7
17. Hobbins A, Barry L, Kelleher D, Shah K, Devlin N, Goni JMR, et al. Utility values for health states in Ireland: a value set for the EQ-5D-5L. Pharmacoeconomics. (2018) 36:1345–53. doi: 10.1007/s40273-018-0690-x
18. Ludwig K, Graf von der Schulenburg JM, Greiner W. German value set for the EQ-5D-5L. Pharmacoeconomics. (2018) 36:663–74. doi: 10.1007/s40273-018-0615-8
19. Purba FD, Hunfeld JAM, Iskandarsyah A, Fitriana TS, Sadarjoen SS, RamosGoni JM, et al. The Indonesian EQ-5D-5L value set. Pharmacoeconomics. (2017) 35:1153–65. doi: 10.1007/s40273-017-0538-9
20. Versteegh M, Vermeulen K, M A A Evers S, de Wit GA, Prenger R, A Stolk, et al. Dutch tariff for the five-level version of EQ-5D. Value Health. (2016) 19:343–52. doi: 10.1016/j.jval.2016.01.003
21. Xie F, Pullenayegum E, Gaebel K, Bansback N, Bryan S, Ohinmaa A, et al. A time trade-off-derived value set of the EQ-5D-5L for Canada. Med Care. (2016) 54:98–105. doi: 10.1097/MLR.0000000000000447
22. Kelleher D, Barry L, Hobbins A, O'Neill S, Doherty E O'Neill C. Examining the transnational health preferences of a group of Eastern European migrants relative to a European host population using the EQ-5D-5L. Soc Sci Med. (2020) 246:112801. doi: 10.1016/j.socscimed.2020.112801
23. Kharroubi SA, O'Hagan A, Brazier JE. Estimating utilities from individual health preference data: a non-parametric Bayesian method. J Roy Stat Soc Ser C. (2005) 54:879–95. doi: 10.1111/j.1467-9876.2005.00511.x
24. Chan KKW, Xie F, Willan AR, Pullenayegum EM. Conducting EQ-5D valuation studies in resource-constrained countries: the potential use of shrinkage estimators to reduce sample size. Med Decis Making. (2018). 38:26–33. doi: 10.1177/0272989X17725748
25. Kharroubi SA. Valuations of EQ-5D health states: could United Kingdom results be used as informative priors for United States. J Appl Stat. (2018) 45:1579–94. doi: 10.1080/02664763.2017.1386770
26. Kharroubi SA. Bayesian non-parametric estimation of EQ-5D utilities for United States using the existing United Kingdom data. Health Qual Life Outcomes. (2017) 15:195. doi: 10.1186/s12955-017-0770-1
27. Kharroubi SA. Valuation of preference-based measures: Can existing preference data be used to generate better estimates? Health Qual Life Outcomes. (2018) 16:116. doi: 10.1186/s12955-018-0945-4
28. Kharroubi SA, Brazier J, McGhee S. A comparison of Hong Kong and United Kingdom SF-6D health states valuations using a non-parametric Bayesian method. Value Health. (2014) 17:397–405. doi: 10.1016/j.jval.2014.02.011
29. Kharroubi SA, Beyh Y. Bayesian modeling of health state preferences: could borrowing strength from existing countries' valuations produce better estimates. Eur J Health Econ. (2021) 22:773–88. doi: 10.1007/s10198-021-01289-x
30. Kharroubi SA. A comparison of Japan and United Kingdom SF-6D health states valuations using a non-parametric Bayesian method. Appl Health Econ Health Policy. (2015) 13:409–20. doi: 10.1007/s40258-015-0171-8
31. Kharroubi SA. Modeling SF-6D health utilities: is Bayesian approach appropriate? Int J Environ Res Public Health. (2021) 18:8409. doi: 10.3390/ijerph18168409
32. Kharroubi SA, Beyh Y, El Harake MD, Dawoud D, Rowen D, Brazier J, et al. Examining the feasibility and acceptability of valuing the Arabic version of SF-6D in a Lebanese population. Int J Environ Res Public Health. (2020) 17:1037. doi: 10.3390/ijerph17031037
33. Kelleher D, Kharroubi S, Doherty E, Baio G, O'Neill C. Examining the association between Polish migrant status and health preferences using a novel application of a smaller design EQ-5D-5L valuation study. Pharmacoecon Open. (2022) 6:425–35. doi: 10.1007/s41669-021-00314-2
34. Yang Z. Toward a smaller design for EQ-5D-5L valuation studies. Value Health. (2019) 22:1295–1302. doi: 10.1016/j.jval.2019.06.008
35. Welie AG. Valuing health state: an EQ-5D-5L value set for Ethiopians. Value Health Reg Issues. (2020) 22:7–14. doi: 10.1016/j.vhri.2019.08.475
36. Yang Z. Effect of health state sampling methods on model predictions of EQ-5D-5L values: small designs can suffice. Value Health. (2019) 22:38–44. doi: 10.1016/j.jval.2018.06.015
37. Gelman A. Prior Distributions for Variance Parameters in Hierarchical Models. Technical Report. Department of Statistics Department of Political Science, Columbia University, New York (2004). Available online at: http://www.stat.columbia.edu/gelman/research/unpublished.
38. Bland JM, Altman D. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet. (1986) 327:307–10. doi: 10.1016/S0140-6736(86)90837-8
39. Heijink R, van Baal P, Opp M, Koolman X, Westert G. Decomposing cross country differences in quality adjusted life expectancy: the impact of value sets. Popul Health Metrics. (2011) 9:17. doi: 10.1186/1478-7954-9-17
40. Kharroubi SA, McCabe C. Modeling HUI 2 health state preference data using a non-parametric Bayesian method. Med Decis Making. (2008) 28:875–87. doi: 10.1177/0272989X08317000
Keywords: non-parametric Bayesian methods, preference-based health measures, EQ-5D-5L, composite time trade-off, health-related quality of life
Citation: Kharroubi SA and Kelleher D (2022) Use of a Non-parametric Bayesian Method to Model Health State Preferences: An Application to Polish and Irish EQ-5D-5L Valuations. Front. Public Health 10:917728. doi: 10.3389/fpubh.2022.917728
Received: 11 April 2022; Accepted: 31 May 2022;
Published: 23 June 2022.
Edited by:
Ronny Westerman, Bundesinstitut für Bevölkerungsforschung, GermanyReviewed by:
Fatemah Alqallaf, Kuwait University, KuwaitCopyright © 2022 Kharroubi and Kelleher. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Samer A. Kharroubi, c2sxNTdAYXViLmVkdS5sYg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.