 Claudio M. Verdun1,2†
Claudio M. Verdun1,2† Tim Fuchs1†
Tim Fuchs1† Pavol Harar3,4‡
Pavol Harar3,4‡ Dennis Elbrächter5‡
Dennis Elbrächter5‡ David S. Fischer6
David S. Fischer6 Julius Berner5‡Philipp Grohs3,5,7
Julius Berner5‡Philipp Grohs3,5,7 Fabian J. Theis1,6
Fabian J. Theis1,6 Felix Krahmer1,8*
Felix Krahmer1,8*- 1Department of Mathematics, Technical University of Munich, Garching, Germany
- 2Department of Electrical and Computer Engineering, Technical University of Munich, Munich, Germany
- 3Research Network Data Science, University of Vienna, Vienna, Austria
- 4Department of Telecommunications, Brno University of Technology, Brno, Czechia
- 5Faculty of Mathematics, University of Vienna, Vienna, Austria
- 6Institute of Computational Biology, Helmholtz Zentrum München, Munich, Germany
- 7Johann Radon Institute for Computational and Applied Mathematics, Austrian Academy of Sciences, Linz, Austria
- 8Munich Data Science Institute, Technical University of Munich, Garching, Germany
Background: Due to the ongoing COVID-19 pandemic, demand for diagnostic testing has increased drastically, resulting in shortages of necessary materials to conduct the tests and overwhelming the capacity of testing laboratories. The supply scarcity and capacity limits affect test administration: priority must be given to hospitalized patients and symptomatic individuals, which can prevent the identification of asymptomatic and presymptomatic individuals and hence effective tracking and tracing policies. We describe optimized group testing strategies applicable to SARS-CoV-2 tests in scenarios tailored to the current COVID-19 pandemic and assess significant gains compared to individual testing.
Methods: We account for biochemically realistic scenarios in the context of dilution effects on SARS-CoV-2 samples and consider evidence on specificity and sensitivity of PCR-based tests for the novel coronavirus. Because of the current uncertainty and the temporal and spatial changes in the prevalence regime, we provide analysis for several realistic scenarios and propose fast and reliable strategies for massive testing procedures.
Key Findings: We find significant efficiency gaps between different group testing strategies in realistic scenarios for SARS-CoV-2 testing, highlighting the need for an informed decision of the pooling protocol depending on estimated prevalence, target specificity, and high- vs. low-risk population. For example, using one of the presented methods, all 1.47 million inhabitants of Munich, Germany, could be tested using only around 141 thousand tests if the infection rate is below 0.4% is assumed. Using 1 million tests, the 6.69 million inhabitants from the city of Rio de Janeiro, Brazil, could be tested as long as the infection rate does not exceed 1%. Moreover, we provide an interactive web application, available at www.group-testing.com, for visualizing the different strategies and designing pooling schemes according to specific prevalence scenarios and test configurations.
Interpretation: Altogether, this work may help provide a basis for an efficient upscaling of current testing procedures, which takes the population heterogeneity into account and is fine-grained towards the desired study populations, e.g., mild/asymptomatic individuals vs. symptomatic ones but also mixtures thereof.
Funding: German Science Foundation (DFG), German Federal Ministry of Education and Research (BMBF), Chan Zuckerberg Initiative DAF, and Austrian Science Fund (FWF).
1. Introduction
The current spreading state of the COVID-19 pandemic urges authorities around the world to take measures in order to contain the disease or, at least, to reduce its propagation speed, as commonly referred to by the term “curve flattening1.” At the time of writing, the World Health Organization (WHO) reported 12,552,765 cases and 561,617 deaths with 230,370 new cases in the last 24 hours2. In particular, more than 50 countries experiencing larger outbreaks of local transmission and severe depletion of the workforce, for example, among healthcare workers (HCWs), had been reported to the WHO. Also, given the current number of tests described by several government agencies, this number likely underrepresents the total number of SARS-CoV-2 infections globally.
Even though a lot of research is currently being performed toward a cure of this infectious disease, to date, the most effective reasonable measure against its spread is the tracking and subsequent isolation of positive cases via an intensive test procedure on a large part of the population or at least important risk groups (1). A pilot study conducted by the University of Padua and the Italian Red Cross in Vò, Italy, showed encouraging results in this direction3.
At present, the standard tests for the detection of SARS-CoV-2, are nucleic acid amplification tests (NAAT), such as the quantitative reverse transcription-polymerase chain reaction (qRT-PCR). These biochemical tests are based on samples from the lower respiratory or upper respiratory tract of tested individuals4. The former is too delicate of an operation to be widely applicable and usually only feasible for hospitalized patients. In the routine laboratory diagnosis, however, sampling the upper respiratory tract with nasopharyngeal and oropharyngeal swabs is much less invasive and usually the method of choice.
The demand for this type of SARS-CoV-2 testing, however, is drastically increasing in many healthcare systems, resulting in shortages of necessary materials to conduct the test or capacity limits of the testing laboratories5.
The concept of group testing (also called pooled testing or pooling) is a promising way to make better use of the available capacities by mixing the samples of different individuals before testing, and to first perform the test on these mixtures, the so-called pools, as if it were only one sample. This idea goes back to mathematical ideas developed in the 1940s and has since been used for tests based on various biospecimens such as swab, urine, and blood (2–4). In particular, group tests are employed when testing for sexually transmitted diseases such as HIV, chlamydia, and gonorrhea, and were recently used in viral epidemics such as influenza, e.g. (5, 6) and references therein.
Very recently, there have also been successful proofs of concept for experimental pooling strategies in SARS-CoV-2 testing. An Israeli research team demonstrated the feasibility of pooling up to 32 samples; they encountered false negative rates of around 10% (7). Subsequently, a German initiative filed a patent for a new approach that allows for so-called minipools combining 5–10 samples with a significantly reduced false negative rate (8). Similarly, a US American research group performed a test with 12 pools of 5 specimens, each from individuals at risk, and were able to correctly identify the two infected individuals out of the 60 with only 22 tests (9).
The main goal of these works is to demonstrate the feasibility of the experimental design; they propose to use the original group testing design by Dorfman of including each specimen into exactly one pool then testing every specimen of the pool again individually in case of a positive outcome of the group test (2). Other works over the last weeks have suggested refined approaches, typically based on examples or, from a more theoretical viewpoint, with a simplified model (10–16).
In this manuscript, we will demonstrate and systematically explore that even within the limitations of the initial experimental designs for COVID-19 testing, more sophisticated pooling strategies can lead to a significantly reduced number of tests. Thus connecting the recent SARS-CoV-2 pool tests to the rich literature on group testing developed over the last decades may be a key ingredient for effectual national responses to the current pandemic. Such connections have been established by Abdalhamid, Bilder and McCutchen by incorporating a decision step regarding how to optimize the number of samples within each pool based on the estimated infection rate—this led to the choice of 5 for the pool size (9). The problem of choosing the right pool size had previously been analyzed in many works (17–19). And we argue that a massive testing program based on pooled tests can have significant positive effects on the physical and mental health of the general population, given that it can allow for partial reopenings or the use of less restrictive social distancing measures, hence allaying social deprivation and isolation with its strong negative effects (20, 21).
The theoretical and practical understanding of group testing developed since the first results of Dorfman (2), however, goes far beyond merely optimizing the pool sizes (22, 23). For example, it is also possible to study group testing in the case of responses involving three categories or more (24), and to use pooling for the more involved problem of estimating the prevalence of a disease in a population (17).
The main message of this paper is that in realistic prevalence regimes for the current COVID-19 pandemic, concepts like array testing and informative testing, explained in detail in section 2, may help to improve the testing efficiency even significantly beyond the gain achieved by the simple pooling strategies implemented in the first approaches. By no means we claim statistical originality; our goal is rather to explore and numerically compare classical methods for a variety of realistic parameter choices, demonstrating their efficiency for large-scale SARS-CoV-2 testing. This paper is accompanied by a repository of source code that allows for parallel computation and comparative visualizations6.
2. Group Testing
As described in section 1, group testing (GT) is the procedure of performing joint tests on mixtures of specimens, so-called pools, as a whole, instead of administering individual tests, thereby requiring significantly fewer tests than the number of specimens to be tested. Ideally, this joint test will produce a positive outcome if any one of the specimens in the pool is infected and a negative outcome otherwise. Because of the limited information contained in a positive outcome, it is required to test certain specimens multiple times—either in parallel for all the specimens or sequentially with additional testing only for those specimens with positive test results.
Sequential test designs in which the grouping of samples into pools in each stage depends on the results of the former stages are called adaptive. For non-adaptive methods, in contrast, all the sample groupings are specified in advance, which translates into a one-stage procedure in which all pool tests can be performed in parallel.
A special class of adaptive test designs is hierarchical tests, where in the first stage, each specimen is included in exactly one pool, and, in every subsequent stage, groups with positive results are divided into smaller non-overlapping groups and retested, while all specimens contained in groups with negative results are discarded. The original Dorfman test, for example, is a two-stage hierarchical group test.
The left part of Figure 1 illustrates the hierarchical structure of the Dorfman test with a 10 × 10 illustrative microplate. Each circle in the plate represents specimens from separate individuals and the red circles are the infected ones that need to be identified. The specimens are then amalgamated row by row to perform a group test for each row. A positive test result indicates that some individual in the corresponding row is infected. Once the results from the group tests are available, they can be used for the next stage, so only the specimens sharing a pool with an infected specimen will need to be retested.
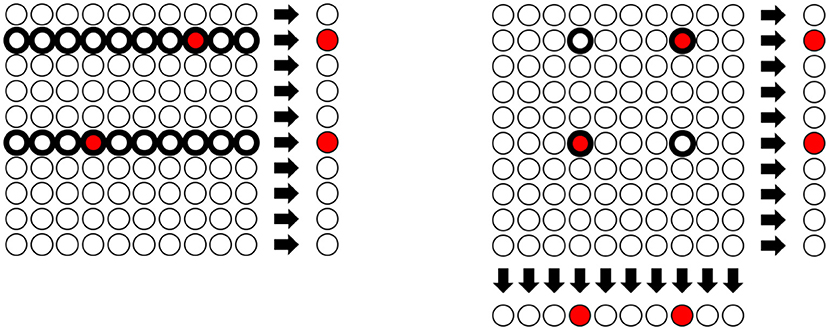
Figure 1. Hierarchical Testing as proposed by Dorfman vs. array testing: In the left figure, 100 specimens are randomly sorted in groups/rows of size 10. As indicated on the right-hand side, the row-wise group test correctly identifies the groups which contain a positive sample (indicated by the red color). Every sample of a positive group will be flagged as possibly positive (indicated by the bold circle) and used for the next stage of tests. In the right figure, we illustrate array testing where, in addition to testing the row groups, column group tests are performed simultaneously. Only specimens which were tested positive in both group tests will be flagged as possibly positive. While this is an example with two simultaneous pool tests, also a higher amount of simultaneous tests can be performed.
Entirely non-adaptive group testing procedures have been designed and analyzed using techniques at the interface of coding theory (25), information theory (23), and compressive sensing (26–28). The symbiosis among those fields leads to developments such as the establishment of optimal theoretical bounds for the best expected group testing strategies (29). However, some of the developments lead to algorithms that may not be practically efficient to implement and, consequently, are not suited for many medical applications including SARS-CoV-2 testing.
Nevertheless, the idea of including every specimen in multiple pools to be tested in parallel is an integral part of many medical testing procedures, as the implementation of hierarchical tests with many stages can be rather complex and hard to automatize. Often, the test proceeds by arranging the specimens in a two-dimensional array and assembling all the specimens of each column in a pool. Then, the same procedure is done with all the specimens of each row (30). This testing strategy is a special instance of the so-called array testing, already mentioned in section 1. In this way, every specimen is included in exactly two pools. All the specimens in the intersection of two pools with positive test results have to be retested in a second stage, but the number of these individual tests can be considerably smaller than for the Dorfman design. Figure 1 illustrates the array testing procedure for a 10 × 10 microplate with two infected individuals; here only four of the 100 specimens need to be retested.
Sometimes, for array tests, an initial master pool consisting of all specimens in a certain array is formed and all the k2 individuals are tested together. This allows for a rejection of a large group in case it exhibits a negative result. Otherwise one proceeds with the array strategy described above. It is important to note, however, that master pooling should be used when there are no clear restrictions on the pool size, e.g., given by dilution effects. In case that such effects are not present, as claimed recently at least for small pool sizes (8), master pooling strategies could be explored.
Another important methodological advancement in group testing is the design of informative tests, i.e., testing strategies that are not based on the assumption of a uniform infection rate, but rather incorporate different estimates for the infection rate of subgroups of the population. We expect that such strategies will be of particular relevance for SARS-CoV-2 testing; for example, the infection rate among healthcare professionals or elderly care workers is expected to be higher than for citizens working from home due to different levels of exposure and, similarly, a stratification based on the level of symptoms also seems reasonable. A first attempt to make use of such a stratification for SARS-CoV-2 testing has recently been made with two subpopulations (13). This paper, however, only assembles homogeneous pools within the two subpopulations and hence does not make use of the full power of informative testing. Namely, the testing efficiency can be significantly improved by smartly assembling combined pools with members of both subpopulations.
Indeed our simulations confirm that this approach, when available, can help improve testing efficiency for realistic choices of parameters. At the same time, we expect that for best performance, one will have to employ a combination of different approaches.
As for many other applications, the design of the GT strategy needs to be driven by the following challenges (31).
i. What practical considerations restrict the pooling strategies available to the laboratory?
ii. How do the pool size and the choice of the assay for NAAT affect the ability of a pooling algorithm to detect infected individuals in a testing population?
iii. Given the assay and maximum pool size, what efficiencies can be expected for different pooling strategies in testing populations with different prevalences of the disease or well-defined subgroups of varying prevalence?
iv. How can pooling strategies be expected to impact the accuracy of the results?
Especially the fourth point has not received much attention in the literature on GT approaches for SARS-CoV-2 testing yet. Like most other testing procedures, qRT-PCR for COVID-19 misclassifies some negative specimens as positive and vice versa, as quantified by the sensitivity and the specificity of the test (the precise definitions are recalled in section 3).
Causes of these inaccuracies that have been documented include low viral load in some patients, difficulty to collect samples from COVID-19 patients, insufficient sample loading during qRT-PCR tests, and RNA degradation during the sample handling process (32). Some of these effects are to be amplified in group testing procedures, so it becomes even more important to take errors into account.
At the same time, the accuracy of a test is difficult to assess. Namely, as described above, NAAT is used to quantify the abundance of SARS-CoV-2 genetic material in a sample similarly to tests for other viral infections (33). In the specific case of qRT-PCR, the abundance measurement is on a continuous scale, the cycle (Ct) at which the readout, given by a fluorescence trace, surpasses a threshold. A decision boundary for a positive observation, i.e., infected, has to be established based on negative samples, i.e., biological control. Accordingly, the estimates on false negative and false positive rates of NAAT tests (and group tests in particular) for the SARS-CoV-2 infection depend on the strength of the classifier induced by this decision boundary. The accuracy of this classifier is influenced by several factors such as the following.
1. The ability of the test to selectively amplify virus genetic material depends on primer design. Multiple primers for qRT-PCR testing on COVID-19 samples were recently compared and found to be similarly strong, with a few exceptions of published weaker primers (34).
2. A large worry about group testing is that the pooling of few positive samples with many negative samples could push the virus concentration in the pooled sample below the detection limit, increasing the false negative rate. This effect has been investigated by studying the test accuracy for dilutions containing virus samples, and false negatives rates were found to be below 10% at a wide range of dilutions, suggesting that the qRT-PCR stage of the testing pipeline introduces small error rates only (7). Still, it is of fundamental importance to accurately estimate the errors introduced by dilution effects since a good understanding of the error is crucial to allow for any reliable inference in a disease study (35).
3. Thirdly, sample extraction methods may have varying yield in virus material: This yield depends on the tissue or fluid that is sampled and on the processing of the sample, such as the time between sampling and qRT-PCR or the temperature at which the sample is held. One would expect this sample extraction to mostly have a destructive effect and to inflate negative rates rather than inflate positive rates.
4. The establishment of gold standard disease labels on samples that were also tested with NAAT is of fundamental importance to assess the overall accuracy of the classifier. There is little such data for COVID-19 testing right now. To this end, a recent study analyzed the positive test result rate of qRT-PCR tests on COVID-19 patients identified based on symptoms, where the symptom-based diagnosis served as ground truth (36). They found false negative rates of individual tests of around 11–25% on sputum samples. At the same time, false positive rates are hard to estimate in the current situation in which non-symptomatic infections occur at an unknown frequency and because of the lack of reference gold-standard labels for positive observations that are non-symptomatic. However, as sample collection does likely contribute little to false positive rates, the overall false positive rate of a group test would largely depend on the qRT-PCR stage in which there is reason to believe that it should be small. Some previous studies on the use of PCR for similar infectious diseases such as SARS-like viruses as well as for SARS-CoV-2 reported high sensitivity for PCR (34, 37). Indeed, in the absence of cell culture methods, qRT-PCR tests are considered to be the gold standard for the identification and diagnosis of most pathogens.
The importance of such estimates described above lead to a recent collaborative effort between FIND, a Swiss foundation for diagnostics, and the World Health Organization for the COVID-19 pandemic in order to evaluate the qRT-PCR tests and to assess their accuracy (38). FIND is currently evaluating a list of more than 300 SARS-CoV-2 commercially available tests and establishing accurate estimates for sensitivity and specificity with their respective confidence intervals7. Based on the preliminary findings, in this work we will assume that the specificity of a single PCR test is 99%. For the sensitivity, we will mostly assume the value of 99% as well but also explore the impact of lower values to account for potential dilution effects along the several tables presented in the Appendix.
A common thread in the various aspects discussed in this section seems to be the large variety of relevant parameters due to differences between testing scenarios and uncertainty as a consequence of infected individuals without symptoms. In this note, we aim to illustrate that the test design of choice should very much depend on these parameters to make the best use of the testing capacities. We will provide a numerical comparison between different designs for large classes of parameters, such as the sensitivity, specificity, and the expected number of tests per person, so the design can be constantly adapted to what is the best fit to the current best estimate of, e.g., the infection rate and the sensitivity.
Before discussing our numerical results, we will precisely introduce the relevant design parameters and testing strategies in the next section.
3. Methods
3.1. Terminology
We start by introducing some terminology.
• Prevalence p: This is the assumed infection rate of the population that is going to be tested, that is, the fraction of the population that is infected. Hence it also is the probability of infection for a randomly selected individual. For simplicity of notation, we will write q = 1 − p for the probability that a randomly selected individual is negative. When the test subjects can be divided into groups with different fractions of infected subjects, we also speak of the prevalences of these subgroups. Without further specification, however, the term refers to the full population to be tested.
• Number of stages: This denotes how many steps the method performs sequentially and these steps are characterized by the fact that each stage requires the results from the previous one. In this paper, we will study adaptive methods with up to three stages, even though more stages, usually up to four in the case of infectious diseases, can be used (30).
• Divisibility: This refers to the maximal number of tests that can be performed on a given specimen. This number provides a limitation on how many group tests can be performed, in parallel or in different stages, that include the corresponding test subject.
• Group size k: This is the size of the groups that are used in a pooling scheme. For a testing strategy to be feasible, one needs to ensure that the maximal group size k still allows for reliable detection of a single positive in a pool of size k.
• Sensitivity Se: This is the probability that an individual test correctly returns a positive result when applied to a positive specimen or pool. A priori, this probability can be different depending on the number of positives included, for example, due to dilution effects (35, 39, 40), but we will neglect this important distinction for the mathematical description below and assume that a PCR test has a fixed sensitivity independent of pool size. Analogously, for a pooling strategy X, Se(X) is the probability of the whole method X returning a positive result for a positive specimen.
• Specificity Sp: This is the probability that an individual test correctly returns a negative result when applied to a negative specimen or pool. Again we assume that a PCR test has a fixed specificity independent of pool size. In case dilution effects are taken into account and more specific information on how the sensitivity/specificity changes with the pool size k is added, one should write Se and Sp with a dependency on k. Analogously, for a pooling strategy X, Sp(X) is the probability of the method X returning a negative result when a negative specimen is tested.
• Expected number of tests per person E: We consider the expected number of tests per person as a measure of efficiency. Naturally, the expected number of tests per person of a method depends on the prevalence p as well as Se and Sp, but also on the design parameters, such as the group size k and the number of stages. We will write E(X) to denote the expected number of tests per person for a method X, without explicitly indicating its dependence on these parameters for the sake of notational simplicity. There exist recent discussion in the literature about alternative objective functions which take directly into account the effects on specificity and sensitivity. The findings, however, show that such an alternative choice most often does not affect the optimal group testing configuration (41).
The optimal choice of design will depend on the aforementioned parameters. In section 4, we will explore these dependencies numerically.There is also some theory on the optimal design choice and the necessary amount of tests. An argument given by Sobel and Groll (42), which is based on the seminal works by Shannon and Huffman (43, 44), shows the theoretical lower bound for the expected number of tests per individual of any given group testing method. More precisely, they showed that E(X) ≥ − plogp − qlogq must hold for any method X with Se(X) = Sp(X) = 1. In addition to its theoretical interest, it pragmatically indicates how much further improvement might still be possible. Note that it is only a bound, which may very well not be achievable with practically feasible methods. Figures 5, 6 illustrate how the methods discussed here compare to this bound and how much gain one could expect for any large-scale group testing strategy.
Regarding the influence of the infection rate, it has been established by Ungar that for infection rates , the optimal pool size is 1, so there does not exist a group testing scheme that is better than individual testing (45). Also, on an intuitive level, one may think that the higher the prevalence, the higher the expected number of tests should be. In fact, Yao and Hwang proved that the minimum of the expected number of tests with respect to all possible test strategies should be non-decreasing with respect to p, if (46).
Therefore, in the COVID-19 pandemic where the prevalence in most countries, both among the tested individuals and the entire population is clearly believed to be smaller than the threshold provided by Ungar's theorem, one can expect a significant reduction in the average number of tests by employing suitable group testing methods. In the following subsection, we will discuss some of these methods and their mathematical formulation.
3.2. Standard Group Testing Methods
In this subsection, we will recall some standard methods for group testing that we will numerically explore in the following section. An overview of these methods and their mathematical formulation can be found in the book by Kim and colleagues while their mathematical derivation was published by Johnson et al. (47, 48).
3.2.1. 2-Stage Hierarchical Testing (D2)
Dorfman's method is an adaptive method, which tests, in a first stage, each individual as part of a group of size k (2). Then, in the groups that tested positive, all the individuals are tested again individually in a second stage. Consequently, the test requires divisibility of 2. The probability of a pool of size k, here denoted by ℙk, drawn at random from the population to test positive is
the expected number of tests per person of the method is given by
and its sensitivity and specificity are
A slight improvement of Dorfman's method is possible by omitting one of the individual tests per pool in the second stage and only performing it in a third stage when at least one of the other second-stage tests of that pool has a positive result—exploiting that if all test results in the second stage are negative, the last specimen must be infected for the group test to be valid (42).
A more significant modification was proposed by Sterrett (3). In his method, the second stage is modified by performing individual tests until the first positive is found. Then a pooling procedure similar to the first stage is performed for the remaining, still unlabeled, specimens, and this scheme is repeated until all specimens are labeled. While requiring a smaller number of tests per individual on average, especially for small infection rates (19), the number of stages that need to be performed sequentially is not known a priori and may be very high. As such Sterrett's method is more involved in practice, while D2 is a simple and straightforward procedure. Thus the latter is often preferred in applications, which is also why we will perform the simulations for the original form of D2 in this paper.
3.2.2. 3-Stage Hierarchical Testing (D3)
In this method, each individual is tested as part of a pool of size k in the first stage. Every pool that tests positive is then split into subgroups, which are tested in a second stage. Every member of a subgroup with a positive result in the second stage is tested individually in a third stage. Consequently, this method requires divisibility 3. In this paper, we will focus on the case that all subgroups are of size s. Expected number of tests per person, sensitivity, and specificity of this method are given by
A schematic comparison between the hierarchical tests with two and three stages, D2 and D3, is given in Figure 2.
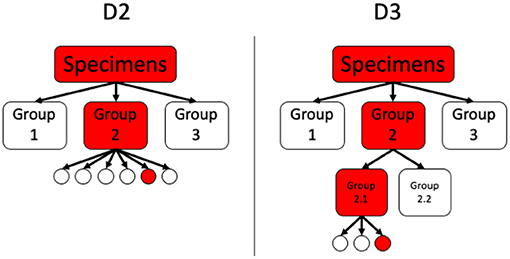
Figure 2. Comparison between D2 and D3.
3.2.3. Array Testing (A2)
This is a 2-stage method, originally proposed by Phatarfod and Sudbury and later explored by Kim et al. (47, 49, 50), that tests every individual twice in a first stage as a part of two different groups of size k. In a second stage all the individuals, for which both group test results are positive, are tested individually. Consequently, this method requires divisibility 3. A schematic overview of array testing for different scenarios is given in Figures 3, 4.
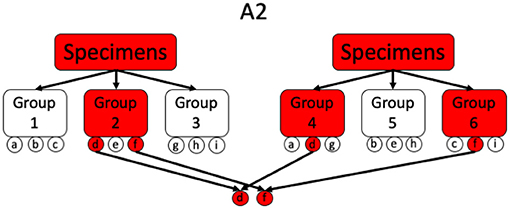
Figure 3. Illustration of a simple A2 procedure where the positive individuals are uniquely determinable after the first stage. Every individual a, b, c, …, i gets pooled exactly twice.
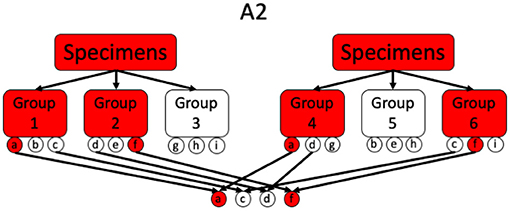
Figure 4. Illustration of a simple A2 procedure where also two negative samples got flagged the first stage.
Precisely determining the optimal way to assemble the pools is rather non-trivial, see, e.g., the publication by Kim et al. (47), but the following configuration provides a good trade-off between simplicity and the expected number of tests. At first, k2 specimens are arranged in a k× k array, then every row and every column is pooled and subjected to a group test. This ensures that each specimen is tested exactly twice as part of a group of size k and constitutes the unique intersection of these two pools. For Sp = Se = 1 it is sufficient to only test a person individually if both its row and column tests return positive results. In this case one obtains the following formula for the expected number of tests
If Se or Sp differ from 100%, the first stage may yield positive rows without any positive columns or vice versa. In this case, it makes sense to test every member of such a row or column individually (47, 51). This results in a slight increase in sensitivity at the expense of a slight increase in the expected number of tests per person. As this change makes the formulas much more involved, we omit them here and refer to the corresponding literature (47).
A2 can be generalized to procedures with three or more simultaneous pools. In this case, the pools could be assembled, for example, by creating pools along the diagonals and/or the anti-diagonals8 of an array, in addition to rows and columns (51). An advantage of such approaches is that the group tests for all these pools can be performed in parallel, which can lead to faster test results, but one has to take into account that the sensitivity is decreasing with the number of pool tests per individual.
The method above can be extended to higher-dimensional procedures, i.e., j > 3, and a connection to optimally efficient two-stage methods can be established. Note that these arrays have size kj rendering this approach practically infeasible very quickly as j and k increase. More concretely, Berger et al. (52) showed that if the prevalence is p = 0.01, then an (almost) optimally efficient two-stage method can be achieved by j = 6 and k = 74, i.e., a 6-dimensional array with side length 74. However, the population, in this case, would need to contain 746 ≈ 164 billion individuals to be screened, which is impractical to be applied in any real-world problem. Thus, the quest for methods that use the same principles but are effective for a realistic population size still remains.
3.2.4. Non-adaptive Array Testing (A1)
All the group testing methods discussed so far terminate with an individual test for all specimens with positive test results in all previous stages to avoid false positives only based on the choice of the pools. In a situation with a shortage of test components, there may be scenarios where one is willing to accept a significant number of additional false positives as a means to reduce the expected number of tests and simplify the test design—in particular, it is desirable to perform all different tests necessary for a testing procedure in parallel.
Toward this goal, one may consider replacing the last stage of individual tests in an adaptive procedure by an additional pooling dimension to be performed in parallel, hence transforming the adaptive into a non-adaptive method.
When this adaption is applied to the Dorfman method, one obtains a procedure A12 that is identical to the first stage of A2. When applied to A2, this yields a method A13 of three parallel pool tests per specimen, again without a decisive individual test at the end. By design, the resulting methods have a significantly lower specificity, but lead to a reduction in necessary tests. An additional advantage is that the resulting methods are fully non-adaptive and can be performed in a single testing stage, allowing for faster test results. At the same time, the adaptation from the methods D2 and A2 does not affect the divisibility required nor the sensitivity of the resulting procedure as adding another additional pooling dimension is accompanied by omitting the last stage—one is really just trading specificity for a lower number of tests and non-adaptivity.
Hence a suitable decision parameter is the minimal acceptable specificity. By the trade-off just mentioned, this also implicitly determines the group size and hence the expected number of tests per person via the relations
where j = 2, 3. It is important to note that such tests can only be used when a certain false positive rate can be accepted. If a non-adaptive method with perfect detection of positive individuals, i.e., assuming perfectly accurate RT-PCR, is required, a theoretical result by Aldridge shows that no testing strategy is better than individual testing (53). Also, in contrast to the adaptive tests discussed above, the minimal number of expected tests per person alone is not a viable measure for the optimal choice of the group size k—it would yield a strong bias toward tests with many false positives. For the remainder of this work, the threshold for the minimal acceptable specificity is set to 95%. Nevertheless, we will give a short comparison with a preset of 90 and 97% in section 4.
3.3. Extension to the Informative Case
As described in section 2, it is possible to incorporate prior information such as demographic, clinical, spatial, or temporal knowledge into refined estimates for the prevalence and to stratify the population accordingly, reflecting the heterogeneous distribution of the infected individuals. This heterogeneity, first explored by Nebenzahl and Sobel (54), and Hwang (55), can be exploited for refined GT strategies.
From a mathematical point of view, informative tests are somewhat more challenging to analyze (56–59). To illustrate the findings of the analysis of the informative tests and demonstrate its relevance for SARS-CoV-2 testing, we will work with a scenario where two distinct subpopulations, one with a high prevalence phigh (e.g., HCWs) and another, larger, subpopulation of individuals with low prevalence plow (e.g., representative samples of the general population) are to be tested. As shown for example by Bilder and Tebbs (60), informative testing reduces the expected number of tests per individual even further when compared with their corresponding non-informative counterparts. As argued by them, it is crucial to exploit this heterogeneity and employ an efficient mixing strategy of individuals from both subpopulations to form the pools. Our goal here has a different perspective on how to exploit such strategies as will be discussed in the next section. It sheds light on testing methodologies where as much individuals as possible should be tested with the available tests while subject to the constraint of constantly testing high-risk individuals such as HCWs.
4. Numerical Results
In this section, we will numerically explore different design choices in group testing for SARS-CoV-2. A key tool is the R-package binGroup for identification and estimation using group testing, that features the computation of optimal parameter choices for standard group testing algorithms9 (61). We have complemented this package with a repository of source code for parallel computation and comparative visualization that has been used to create all the graphics in this section and is available for the reader to produce visualizations adapted to different prevalence ranges of interest10.
As indicated in the previous section, the choices of the correct method and the optimal group size k heavily depend on several constraints, most importantly the underlying prevalence p (or the subpopulation prevalences for a refined model). In this work, instead of attempting to find the optimal method, we evaluate the properties of a group testing design for a single fixed group size. We will investigate different infection scenarios with the different group testing methods described above. We apply the tests D2, D3, A2, and A1j with overall prevalence varying from 0.25 to 15%. The results for D2, D3, and A2 have been simulated using binGroup2 while A1j has been implemented separately11.
An important aspect to take into account when putting the number of individuals tested per available test into perspective is that methods based on multiple pools or stages will typically have a smaller overall sensitivity than individual tests, cf. section 3.2. It is crucial to integrate the sensitivity considerations into any pooling strategy (40). In Tables A2–A4, we will illustrate (potential) efficiency increase assuming a sensitivity of 99 and 90%, respectively, for the qRT-PCR test. As mentioned before, extensive tests are currently being performed to confirm the high accuracy of qRT-PCR for SARS-CoV-2 testing. Indeed, they indicate that many available PCR procedures for SARS-CoV-2 testing show a sensitivity of or close to 100% (62). Nevertheless, an appropriate quantitative understanding of pooling effects and viral load progression on the sensitivity is still an active discussion (63).
For a PCR sensitivity of 99%, we observe that the reduction caused by the use of a pooling method is very small (97% for D3, A2, and A13; 98% for D2 and A12). Only a single PCR procedure showed low sensitivity of 90% when choosing a specific gene target (compared to 100% when choosing another target) (62). In that case, we find a sensitivity of 73% for D3, A2, and A13 and 81% for D2 and A12. While the specificity of PCR already appears to be close to 100%, the tables indicate that D2, D3, and A2 improve the specificity even further while A12 and A13 fulfill the preset threshold Sp(.) ≥ 95%. Due to the specificity constraint, A12 can not be recommended for very high infection rates of at least 12% as there is no reduction of necessary tests over individual testing. A13 is more robust but shows the same behavior at p > 15%.
Se(.) and Sp(.) depend mostly on the method and underlying sensitivity Se of the qRT-PCR test and barely change for increasing p. Therefore, Table A5 shows the change of Se(.) and Sp(.) for p = 3% and varying Se. It should be noted that the sensitivity Se(.) virtually does not depend on the specificity Sp of PCR. Only a slight change in initial group size can be detected. As explained in section 3, the sensitivity can be computed as and .
To reflect practical considerations such as dilution effects (7), we constrain the group size to at most sixteen12. We observe that all the methods yield a significantly reduced expected number of tests per person as compared to individual testing. This improvement decays with the growing infection rate, in line with our discussion above. For prevalence values below 4%, and hence including the estimated range of current infection rates for SARS-CoV-2 in different countries13, all adaptive methods (D2, D3, A2) allow to test at least 3 times as many individuals with the same amount of tests. Around a prevalence of 3% both non-adaptive methods allow testing around 5 individuals per test if a false positive rate up to 5% can be accepted.
Compared to individual testing where only a single individual can be tested per available test, Figures 5, 6 demonstrate the average amount of individuals who can be tested per available test when applying different group testing methods. For infection rates as high as 2%, up to 5 times as many individuals compared to the amount of available tests can be tested using adaptive methods. For a low prevalence below 0.5% this number varies between a 7- and 15-fold efficiency increase.
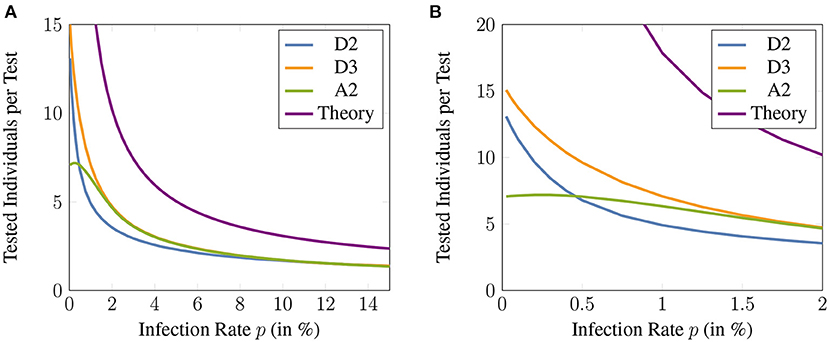
Figure 5. (A) The number of individuals that can be tested per test available for the different adaptive methods. Here, the sensitivity and specificity are assumed to be 99%. The theoretical bound given by (42) is also shown for comparison and the maximum group size is assumed to be 16. (B) zoomed version of (A) that illustrates the low prevalence regime of infection rates up to 2%.
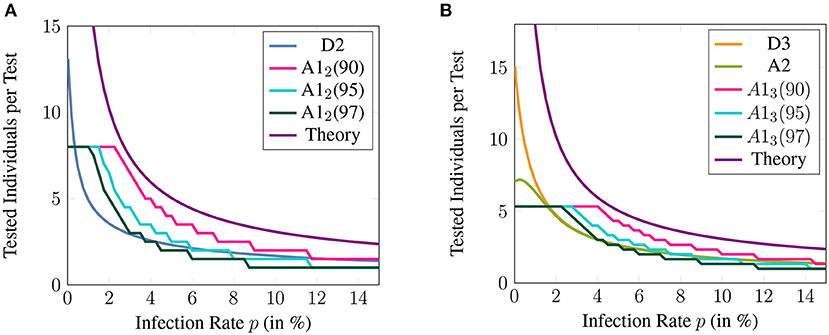
Figure 6. The number of individuals that can be tested per test available for different non-adaptive and their corresponding adaptive methods. A1j (9X) denotes the non-adaptive method A1j with a specificity threshold 9X%. Here, the sensitivity and specificity of qRT-PCR are assumed to be 99%. The theoretical bound given by (42) is also shown for comparison and the maximum group size is assumed to be 16.
Figure 6 shows the efficiency improvement of A1j compared to the corresponding adaptive method. The specificity reduction, the biggest drawback of the proposed non-adaptive methods, is controlled by setting the threshold to 90, 95, and 97%. Naturally, the methods relying on the lowest threshold show the biggest improvement. The suggested threshold of 95% leads to a significant improvement of A12 compared to D2 for an infection rate between 0.4 and 5%. A13 significantly exceeds A2 and D3 for a prevalence between 2.5 and 5%.
This is exemplified by some numerical examples in Table A1; for example, this entails that for an infection rate of 0.4%, the city of Munich with 1.47 million inhabitants could be tested with only 141 thousand tests using D3, the 6.69 million inhabitants of Rio de Janeiro could be tested using around 1 million tests if the infection rate does not exceed 1% and the adaptive methods D3 or A2 are performed. If a false positive rate up to 5% is considered acceptable, the non-adaptive method A12 would only require 836,000 tests and at the same time allow for higher prevalence values of up to 1.5%.
To summarize, below 1% infection rate, any of the presented group testing procedures will constitute an extreme improvement over individual testing while D3 shows the best performance. For 1% ≤ p < 6%, A2 and D3 show a comparable performance which is superior to D2. For p ≥ 10% all adaptive methods show a similar performance.
Considering the non-adaptive methods, A12 requires a significantly reduced expected amount of tests for an infection rate between 1 and 4%. For a prevalence between 3 and 8%, A13 shows the highest reduction in the number of tests of all methods. However, the trade-off between the lowest amount of tests and a false positive rate of up to 5% has to be considered when choosing the testing method.
Next, we numerically explore the average number of tests of different approaches for informative testing, with the goal of finding the best way to incorporate refined knowledge about different prevalences for distinct subpopulations. Each plot of Figure A1 compares the expected number of tests per person of two informative testing methods, namely the approach of choosing pools separately for the subpopulations, and the approach of assembling the pools with members of all subpopulations. We study a model with two subpopulations of different prevalence, and consider prevalence values between 5 and 25% for the high-risk and between 0.1 and 5% for the low-risk group. As far as we are aware, this assumption regarding different prevalence values for two groups, in line with the two subpopulations we mention, was first mentioned in the context of SARS-CoV-2 by Deckert et al. (13), where they speak of homogeneous pools and use non-informative D2 for their analysis. However, the question of whether and how to adjust the testing procedure based on subpopulation knowledge did not arise in this work.
We find that for A2 and D3, the advantage of assembling combined pools from both subpopulations gets larger when the prevalence of the low-risk group decreases. How it depends on the prevalence of the high-risk group differs depending on the methods and also the constraints imposed on the group size. For D2, however, the same phenomenon was not observed. More experiments of the same type but with different group sizes as well as different sensitivities and specificities can be visualized at our web application14.
5. Discussion
In this manuscript, we provide a comparison of general strategies for group testing in view of their application to medical diagnosis in the current COVID-19 pandemic.
Our numerical study confirms the recent observation that even under practical constraints for pooled SARS-CoV-2 tests, such as restrictions on the pool size, and for prevalence values in the estimated range of current infection rates in many regions13, group testing is typically more efficient than individual testing and it allows for an efficiency increase of up to a factor 10 across realistic scenarios and testing strategies. We also find significant efficiency gaps between different group testing strategies in realistic scenarios for SARS-CoV-2 testing, highlighting the need for an informed decision of the pooling protocol. The repository for parallel computation and comparative visualization accompanying this manuscript allows the reader to visualize the performance of the different approaches similarly to the tables and graphics contained in this paper for different sets of parameters12.
For every scenario and method, an optimal pool size can be determined. However, the pool size is constrained biochemically by dilution effects and by sensitivity considerations. For a low prevalence, this can prevent choosing the optimal pool size. We find that within pooling protocols, sophisticated methods that employ multiple stages or multiple pools per sample, or exploit prevalence estimates for subpopulations have the strongest advantages at low prevalences.
Such low prevalence values are realistic assumptions especially for large-scale tests of representative parts of the population, so these methods are particularly suited for full population screens or representative sub-population screens with the goal of reducing transmission and flattening the infection curve. This is of fundamental importance since transmission before the onset of symptoms has been commonly reported and asymptomatic cases seem to be very common (65). For example, 328 of the 634 positive cases on board of the formerly quarantined Diamond Princess cruise ship were asymptomatic at the time of testing, which corresponds to 52% of the cases. Another study conducted in a homeless shelter in Boston, MA, USA, confirmed that standard COVID-19 symptoms like cough, shortness of breath, and fever were uncommon among individuals who tested positive and strongly argues for universal PCR testing on that basis (66). Also, besides enhancing the tests of mild/asymptomatic cases, some disease control centers, such as the ECDC, recommend that group testing should potentially be applied to prevalence studies15.
The pooling schemes suggested here can also include routine tests of cohesive subpopulations with high prevalence, such as healthcare workers, and therefore propose a sensible way to include commonly available information about risk groups into the setup (67). For certain scenarios, our numerical experiments show a reduced expected number of tests when employing combined pools consisting of high-risk and low-risk individuals provided some estimates for the prevalence in these two parts of the test population are available.
One could also envision separate pooled tests with different requirements on specificity and population coverage in sub-populations with different prevalence, again highlighting the importance of proper stratification: High specificity is for example likely desirable among healthcare workers whereas specificity may be partially traded for coverage during contact tracing. At the heart of these trade-offs lie considerations about the societal cost of false positives in comparison to the cost of missed diagnosis because of a lack of available tests.
The improved test efficiency of group testing is, however, only one aspect of test design. Carefully tracing every single specimen throughout the whole process is of utmost importance. As this already is the case for individual tests, the additional requirements for tracing pooled probes are therefore rather minor and typically covered by the specimen registration into the laboratory information systems (LIS). Moreover, the FDA has published an amendment for pooling protocols which includes guidelines for the appropriate traceability/registration of the samples pooled16. From the IT point of view, sample tracing can be implemented for example via a hash file, which has proven successful for large-scale implementations of group testing, see (68).
Nevertheless, practitioners have to take several factors into account when deciding if group testing can provide a feasible solution for massive tests procedures (40). Some important practical considerations are time constraints, specimen conservation for multi-stage testing, and resource availability, as well as the actual execution of the test in the labs, such as variations in pipetting and sample collection. In particular, the decision at which stage the pooling is taking place (pre-pre analytical, pre-analytical, or analytical) is crucial for the expected turnaround time (69). All of these aspects need to be carefully considered before the establishment of massive pooled test policies.
qRT-PCR-based tests are currently widely deployed for COVID-19 diagnosis and, more generally, to identify current infections (37, 70). As for any nucleic acid amplification tests, one can only identify cases where virus particles can still be detected. Thus for long-term disease monitoring, NAATs will have to be complemented by serological tests, as these can be used to infer the immunity state of a patient and hence identify past asymptomatic infections through detection of disease-specific antibodies. Such tests have already been deployed in a few cases (71, 72). In contrast to the PCR testing procedures mainly discussed in this paper, the main intention of serological testing is to obtain accurate estimations of the number of unidentified previous infections as a measure for the progress toward herd immunity. Group testing can also be expected to yield accuracy gains for this problem. Namely, group testing for prevalence estimation is an active area of research with many recent advancements. Also, in settings like a hospital, nursing homes, or similar, the employment of rapid and massive testing may be superior for overall infection control compared to less frequent, highly sensitive tests with prolonged turnaround times. Therefore, pooling strategies for antigen tests or other point-of-care tests should also be considered in this scenario and we are confident that some of these results can be employed once pooled tests become available (17, 73). In any case, there are still many well-established methodological tools available in the literature that have not yet been explored for SARS-CoV-2 testing, so we advocate for a continued exchange between theory, simulation and visualization, and practice.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: Source code is available on Gitlab: https://gitlab.com/hararticles/group-testing-simulations.
Author Contributions
CV: conceptualization (manuscript), methodology, validation, formal analysis, investigation, writing—original draft, review and editing, and visualization. TF: conceptualization (manuscript), methodology, software, validation, formal analysis, investigation, writing—original draft, review and editing, and visualization. PH, DE, and JB: methodology, software, validation, formal analysis, investigation, data curation, writing—review and editing, and visualization. DF: validation, investigation, writing—original draft, and review and editing. PG: conceptualization (project), supervision, and project administration. FT: supervision and project administration. FK: conceptualization (project and manuscript), supervision, and project administration. All authors contributed to the article and approved the submitted version.
Funding
CV gratefully acknowledge support by German Science Foundation (DFG) within the Gottfried Wilhelm Leibniz Prize under Grant BO 1734/20-1, under contract number PO-1347/3-2 and within Germany's Excellence Strategy EXC-2111 390814868. CV and FK gratefully acknowledge support by German Science Foundation in the context of the Emmy Noether junior research group KR 4512/1-1. TF and FK gratefully support funding by German Science Foundation (project KR 4512/2-2). FT gratefully acknowledges support by the BMBF (grant# 01IS18036A and grant# 01IS18053A) and by the Chan Zuckerberg Initiative DAF (advised fund of Silicon Valley Community Foundation, 182835). JB and DE gratefully acknowledge support by Austrian Science Fund (FWF) under grants I3403-N32 and P 30148. PG and PH declare that no external funding was received and DF acknowledges support from a German Research Foundation (DFG) fellowship through the Graduate School of Quantitative Biosciences Munich (QBM) [GSC 1006 to DF] and by the Joachim Herz Stiftung. All data are publicly available. FK had the final responsibility for the decision to submit for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors are grateful to Luciana Jesus da Costa, from the Virology Department at the Federal University of Rio de Janeiro, for insightful discussions about SARS-CoV-2. This manuscript has been released as a pre-print at medRxiv (74).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2021.583377/full#supplementary-material
Footnotes
1. ^Why outbreaks like coronavirus spread exponentially, and how to “flatten the curve,” The Washington Post. Available online at: https://wapo.st/2wLMbzI (accessed July 10, 2020).
2. ^Coronavirus disease 2019 (COVID-19), Situation Report—174, World Health Organization Webpage. Available online at: https://bit.ly/2ZoN8JJ (accessed July 13, 2020).
3. ^In one Italian town, we showed mass testing could eradicate the coronavirus, The Guardian. Available online at: https://bit.ly/2VBsmDM (accessed July 10, 2020).
4. ^Laboratory testing for 2019 novel coronavirus (2019-nCoV) in suspected human cases, World Health Organization Webpage. Available online at: https://bit.ly/38SLDH1 (accessed July 10, 2020).
5. ^Why Widespread Coronavirus Testing Isn't Coming Anytime Soon, The New Yorker. Available online at: https://bit.ly/3dCAHz9 (accessed July 10, 2020).
6. ^Harar P, Berner J, Elbrächter D, et al. Group Testing Simulations (2020). Available online at: https://gitlab.com/hararticles/group-testing-simulations.
7. ^FIND Evaluation Update: SARS-CoV-2 Molecular Diagnostics, Foundation for Innovative New Diagnostics. Available online at: https://www.finddx.org/covid-19/sarscov2-eval-molecular/ (accessed July 10, 2020).
8. ^By combining different diagonals resp. anti-diagonals in a suitable way, such that one gets groups of size k obeying the unique intersection property.
9. ^While working on this manuscript, the updated package binGroup2 with improved and unified functionalities was released. Even though some of our calculations were performed with it, since the repository makes use of the previous version, we kept it here for consistency.
10. ^Harar P, Berner J, Elbrächter D, et al. Group Testing Simulations (2020). Available online at: https://gitlab.com/hararticles/group-testing-simulations.
11. ^Bilder CR, Zahng B, Schaarschmidt F, M Tebbs J, et al. binGroup2: A Package For Grouptesting (2020). Available online at https://cran.r-project.org/web/packages/binGroup2/binGroup2.pdf, Version 1.0.2.
12. ^Since writing the article, further publications demonstrate the feasibility of pooling specimens for even larger pool sizes of up to 30 (64).
13. ^Infection rates of viruses involved in outbreaks worldwide as of 2020. Statista. Available online at: https://bit.ly/2wOmuyo (accessed April 28, 2020).
14. ^Harar P, Berner J, Elbrächter D, et al. Group Testing Simulations (2020). Available online at: https://gitlab.com/hararticles/group-testing-simulations.
15. ^Laboratory support for COVID-19 in the EU/EEA, European Center for Disease Prevention and Control. Available online at: https://www.ecdc.europa.eu/en/novel-coronavirus/laboratory-support (accessed April 28, 2020).
16. ^In Vitro Diagnostics EUAs - Molecular Diagnostic Tests for SARS-CoV-2, US Food and Drug Administration. Available online at: https://bit.ly/2QCxCIQ (accessed April 30, 2021).
References
1. Fraser C, Riley S, Ferguson NM. Factors that make an infectious disease outbreak controllable. Proc Natl Acad Sci USA. (2004) 101:6146–51. doi: 10.1073/pnas.0307506101
2. Dorfman R. The detection of defective members of large populations. Ann Math Statist. (1943) 14:436–40. doi: 10.1214/aoms/1177731363
3. Sterrett A. On the detection of defective members of large populations. Ann Math Statist. (1957) 28:1033–6. doi: 10.1214/aoms/1177706807
4. Sobel M, Groll PA. Binomial group-testing with an unknown proportion of defectives. Technometrics. (1966) 8:631–56. doi: 10.2307/1266636
5. Tebbs JM, McMahan CS, Bilder CR. Two-stage hierarchical group testing for multiple infections with application to the Infertility Prevention Project. Biometrics. (2013) 69:1064–73. doi: 10.1111/biom.12080
6. Hourfar MK, Themann A, Eickmann M, Puthavathana P, Laue T, Seifried E, et al. Blood screening for influenza. Emerg Infect Dis. (2007) 13:1081–3. doi: 10.3201/eid1307.060861
7. Yelin I, Aharony N, Tamar ES, Argoetti A, Messer E, Berenbaum D, et al. Evaluation of COVID-19 RT-qPCR test in multi-sample pools. Clin Infect Dis. (2020) 71:2073–78. doi: 10.1093/cid/ciaa531
8. Schmidt M, Hoehl S, Berger A, Zeichhardt H, Hourfar K, Ciesek S, et al. FACT-Frankfurt adjusted COVID-19 testing- a novel method enables high-throughput SARS-CoV-2 screening without loss of sensitivity. medRxiv [Preprint]. (2020). doi: 10.1101/2020.04.28.20074187
9. Abdalhamid B, Bilder CR, McCutchen EL, Hinrichs SH, Koepsell SA, Iwen PC. Assessment of specimen pooling to conserve SARS CoV-2 testing resources. Am J Clin Pathol. (2020) 153:715–8. doi: 10.1101/2020.04.03.20050195
10. Shani-Narkiss H, David Gilday O, Yayon N, Daniel Landau I. Efficient and practical sample pooling for high-throughput PCR diagnosis of COVID-19. medRxiv [Preprint]. (2020). doi: 10.1101/2020.04.06.20052159
11. Mentus C, Romeo M, DiPaola C. Analysis and applications of non-adaptive and adaptive group testing methods for COVID-19. medRxiv [Preprint]. (2020). doi: 10.1101/2020.04.05.20050245
12. Sinnott-Armstrong N, Klein D, Hickey B. Evaluation of group testing for SARS-CoV-2 RNA. medRxiv [Preprint]. (2020). doi: 10.1101/2020.03.27.20043968
13. Deckert A, Barnighausen T, Kyei N. Pooled-sample analysis strategies for COVID-19 mass testing: a simulation study. Bull World Health Organ. (2020) 98:590. doi: 10.2471/BLT.20.257188
14. Theagarajan LN. Group testing for COVID-19: how to stop worrying and test more. arXiv [Preprint]. arXiv:2004.06306. (2020).
15. de Wolff T, Pfluger D, Rehme M, Heuer J, Bittner MI. Evaluation of pool-based testing approaches to enable population-wide screening for COVID-19. PLoS ONE. (2020) 15:e0243692. doi: 10.1371/journal.pone.0243692
16. Shental N, Levy S, Skorniakov S, Wuvshet V, Shemer-Avni Y, Porgador A, et al. Efficient high throughput SARS-CoV-2 testing to detect asymptomatic carriers. medRxiv [Preprint]. (2020). doi: 10.1101/2020.04.14.20064618
17. Bilder CR. Group testing for estimation. In: Balakrishnan N, Colton T, Everitt B, Piegorsch W, Ruggeri F, and Teugels JL, editor. Wiley StatsRef: Statistics Reference Online. John Wiley & Sons (2019). p. 1–11. doi: 10.1002/9781118445112.stat08231
18. Hughes-Oliver JM. Pooling experiments for bloodscreening and drug discovery. In: Dean A, Lewis S, editor. Screening. New York, NY: Springer (2006) 48–68. doi: 10.1007/0-387-28014-6_3
19. Malinovsky Y, Albert PS. Revisiting nested group testing procedures: new results, comparisons, and robustness. Am Stat. (2019) 73:117–25. doi: 10.1080/00031305.2017.1366367
20. Orben A, Tomova L, Blakemore SJ. The effects of social deprivation on adolescent development and mental health. Lancet Child AdolescHealth. (2020) 4:634–40. doi: 10.1016/S2352-4642(20)30186-3
21. Lyng GD, Sheils NE, Kennedy CJ, Griffin DO, Berke EM. Identifying optimal COVID-19 testing strategies for schools and businesses: balancing testing frequency, individual test technology, and cost. PLoS ONE. (2021) 16:e0248783. doi: 10.1371/journal.pone.0248783
22. Du DZ, Hwang FK. Combinatorial Group Testing and Its Applications. 2nd ed. Singapore: World Scientific (2000). doi: 10.1142/4252
23. Aldridge M, Johnson O, Scarlett J. Group testing: an information theory perspective. Found Trends Commun Inform Theory. (2019) 15:196–392. doi: 10.1561/0100000099
25. Atia KG, Saligrama V. Boolean compressed sensing and noisy group testing. IEEE Trans Inf Theory. (2012) 58:1880–901. doi: 10.1109/TIT.2011.2178156
26. Bryan K, Leise T. Making do with less: an introduction to compressed sensing. SIAM Rev. (2013) 55:547–66. doi: 10.1137/110837681
27. Gilbert AC, Iwen MA, Strauss MJ. Group testing and sparse signal recovery. In: 42nd Asilomar Conference on Signals, Systems and Computers. Pacific Grove, CA (2009). p. 1059–62. doi: 10.1109/ACSSC.2008.5074574
28. Chan CL, Jaggi S, Saligrama V, Agnihotri S. Non-adaptive group testing: explicit bounds and novel algorithms. IEEE Trans Inf Theory. (2014) 60:3019–35. doi: 10.1109/TIT.2014.2310477
29. Zaman N, Pippenger N. Asymptotic analysis of optimal nested group-testing procedures. Prob Eng Inform Sci. (2016) 30:547–52. doi: 10.1017/S0269964816000267
30. Bilder CR. Group testing for identification. In: Wiley StatsRef: Statistics Reference Online. (2019). p. 1–11. doi: 10.1002/9781118445112.stat08227
31. Westreich DJ, Hudgens MG, Fiscus SA, Pilcher CD. Optimizing screening for acute human immunodeficiency virus infection with pooled nucleic acid amplification test. J Clin Microbiol. (2008) 46:1785–92. doi: 10.1128/JCM.00787-07
32. Lu R, Wang J, Li M, Wang Y, Dong J, Cai W. SARS-CoV-2 detection using digital PCR for COVID-19 diagnosis, treatment monitoring and criteria for discharge. medRxiv [Preprint]. (2020). doi: 10.1101/2020.03.24.20042689
33. Sheridan C. Coronavirus and the race to distribute reliable diagnostics. Nat Biotechnol. (2019) 38:382–4. doi: 10.1038/d41587-020-00002-2
34. Vogels CBF, Brito AF, Wyllie AL, Fauveret JR, Ott IM, Kalinich CC, et al. Analytical sensitivity and efficiency comparisons of SARS-COV-2 qRT-PCR assays. Nat Microbiol. (2020) 5:1299–305. doi: 10.1038/s41564-020-0761-6
35. Wein LM, Zenios S. Pooled testing for HIV screening: capturing the dilution effect. Operat Res. (1996) 44:543–69. doi: 10.1287/opre.44.4.543
36. Yang Y, Yang M, Shen C, Wang F, Li J, Zhang M, et al. Evaluating the accuracy of different respiratory specimens in the laboratory diagnosis and monitoring the viral shedding of 2019-nCoV infections. Innov. (2020) 1:100061. doi: 10.1101/2020.02.11.20021493
37. Corman VM, Landt O, Kaiser M, Molenkamp R, Meijer A, Chu DKW. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Euro Surveill. (2020) 25:1–8. doi: 10.2807/1560-7917.ES.2020.25.3.2000045
39. Ransohoff DF, Feinstein AR. Problems of spectrum and bias in evaluating the efficacy of diagnostic tests. N Engl J Med. (1978) 299:926–30. doi: 10.1056/NEJM197810262991705
40. Haber G, Malinovsky Y, Albert PS. Is group testing ready for prime-time in disease identification? arXiv [Preprint]. arXiv:2004.04837. (2020).
41. Hitt BD, Bilder CR, Tebbs JM, McMahan CS. The objective function controversy for group testing: much ado about nothing? Stat Med. (2019) 38:4912–23. doi: 10.1002/sim.8341
42. Sobel M, Groll PA. Group testing to eliminate efficiently all defectives in a binomial sample. J Bell System Tech. (1959) 38:1179–252. doi: 10.1002/j.1538-7305.1959.tb03914.x
43. Shannon CE. A mathematical theory of communication. Bell Syst Tech J. (1948) 27:379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x
44. Huffman DA. A method for the construction of minimum redundancy codes. Proc IRE. (1952) 40:1098–103. doi: 10.1109/JRPROC.1952.273898
45. Ungar P. The cutoff point for group testing. Commun Pure Appl Math. (1960) 13:49–54. doi: 10.1002/cpa.3160130105
46. Yao YC, Hwang FK. A fundamental monotonicity in group testing. SIAM J Discrete Math. (1988) 1:256–9. doi: 10.1137/0401026
47. Kim HY, Hudgens MG, Dreyfuss JM, Westreich DJ, Pilcher CD. Comparison of group testing algorithms for case identification in the presence of test error. Biometrics. (2007) 63:1152–63. doi: 10.1111/j.1541-0420.2007.00817.x
48. Johnson NL, Kotz S, Wu XZ. Inspection Errors for Attributes in Quality Control. London: Chapman and Hall Ltd (1991).
49. Phatarfod RM, Sudbury A. The use of a square array scheme in blood testing. Stat Med. (1994) 13:2337–43. doi: 10.1002/sim.4780132205
50. Kim HY, Hudgens MG. Three-dimensional array-based group testing algorithms. Biometrics. (2009) 65:903–10. doi: 10.1111/j.1541-0420.2008.01158.x
51. Woodbury CP, Fitzloff JF, Vincent SS. Sample multiplexing for greater throughput in HPLC and related methods. Anal Chem. (1995) 67:885–90. doi: 10.1021/ac00101a015
52. Berger T, Mandell JW, Subrahmanya P. Maximally efficient two-stage screening. Biometrics. (2000) 56:833–40. doi: 10.1111/j.0006-341X.2000.00833.x
53. Aldridge M. Individual testing is optimal for nonadaptive group testing in the linear regime. IEEE Trans Inform Theory. (2019) 65:1059–62. doi: 10.1109/TIT.2018.2873136
54. Nebenzahl E, Sobel M. Finite and infinite models for generalized group-testing with unequal probabilities of success for each item. In: Cacoullos T, editor. Discriminant Analysis and Applications. New York, NY: Academic Press Inc. (1973). p. 239–84.
55. Hwang FK. A generalized binomial group testing problem. J Am Stat Assoc. (1975) 70:923–6. doi: 10.1080/01621459.1975.10480324
56. Bilder CR, Tebbs J, Chen P. Informative retesting. J Am Stat Assoc. (2010) 105:942–55. doi: 10.1198/jasa.2010.ap09231
57. McMahan C, Tebbs J, Bilder CR. Informative Dorfman screening. Biometrics. (2012) 68:287–96. doi: 10.1111/j.1541-0420.2011.01644.x
58. McMahan C, Tebbs J, Bilder CR. Two-dimensional informative array testing. Biometrics. (2012) 68:793–804. doi: 10.1111/j.1541-0420.2011.01726.x
59. Black MS, Bilder CR, Tebbs JM. Optimal retesting configurations for hierarchical group testing. J R Stat Soc Ser C. (2015) 64:693–710. doi: 10.1111/rssc.12097
60. Bilder CR, Tebbs JM. Pooled-testing procedures for screening high volume clinical specimens in heterogeneous populations. Stat Med. (2012) 31:3261–8. doi: 10.1002/sim.5334
61. Bilder CR, Zahng B, Schaarschmidt F, Tebbs JM. binGroup: a package for group testing. R J. (2010) 2:56–60. doi: 10.32614/RJ-2010-016
62. FIND Evaluaion Update: SARS-CoV-2 Molecular Diagnostics, Foundation for Innovative New Diagnostics. Available online at: https://www.finddx.org/covid-19/sarscov2-eval-molecular/ (accessed April 28, 2020).
63. Nguyen NT, Aprahamian H, Bish EK, Bish DR. A methodology for deriving the sensitivity of pooled testing, based on viral load progression and pooling dilution. J Transl Med. (2019) 17:49–54. doi: 10.1186/s12967-019-1992-2
64. Lohse S, Pfuhl T, Berkó-Göttel B, Rissland J, Geißler T, Gärtner B, et al. Pooling of samples for testing for SARS-CoV-2 in asymptomatic people. Lancet Infect Dis. (2020) 20:1231–2. doi: 10.1016/S1473-3099(20)30362-5
65. Zhang J, Litvinova M, Wang W, Wang Y, Deng X, Chen X, et al. Evolving epidemiology and transmission dynamics of coronavirus disease 2019 outside Hubei province, China: a descriptive and modelling study. Lancet Infect Dis. (2020) 20:793–802. doi: 10.1016/S1473-3099(20)30230-9
66. Baggett TP, Keyes H, Sporn N M, Gaeta J. COVID-19 outbreak at a large homeless shelter in Boston: Implications for universal testing. medRxiv [Preprint]. (2020) doi: 10.1101/2020.04.12.20059618
67. Black JRM, Bailey C, Przewrocka J, Dijkstra KK, Swanton C. COVID-19: the case for health-care worker screening to prevent hospital transmission. Lancet. (2020) 395:1418–20. doi: 10.1016/S0140-6736(20)30917-X
68. Barak N, Ben-Ami R, Sido T, Perri A, Shtoyer A, Rivkin M, et al. Lessons from applied large-scale pooling of 133,816 SARS-CoV-2 RT-PCR tests. Sci. Transl. Med. (2021) 13. doi: 10.1101/2020.10.16.20213405
69. Tan JG, Omar A, Lee WB, Wong MS. Considerations for group testing: a practical approach for the clinical laboratory. Clin Biochem Rev. (2020) 41:79. doi: 10.33176/AACB-20-00007
70. Chu DKW, Pan Y, Cheng SMS, P Y, Hui K, Krishnan P, Liu Y, et al. Molecular diagnosis of a novel coronavirus (2019-nCoV) causing an outbreak of pneumonia. Clin Chem. (2020) 66:549–55. doi: 10.1093/clinchem/hvaa029
71. Kontou PI, Braliou GG, Dimou NL, Nikolopoulos G, Bagos PG. Antibody tests in detecting SARS-CoV-2 infection: a meta-analysis. Diagnostics. (2020) 10:319. doi: 10.3390/diagnostics10050319
72. GeurtsvanKessel CH, Okba NMA, Igloi Z, Bogers S, Embregts CWE, Laksono BM, et al. An evaluation of COVID-19 serological assays informs future diagnostics and exposure assessment. Nat Commun. (2020). 11:3436. doi: 10.1038/s41467-020-17317-y
73. Malinovsky Y, Zacks S. Proportional closeness estimation of probability of contamination under group testing. Sequential Anal. (2018) 37:145–57. doi: 10.1080/07474946.2018.1466518
Keywords: group testing, SARS-CoV-2, pooling, COVID-19, informative testing, RT-PCR
Citation: Verdun CM, Fuchs T, Harar P, Elbrächter D, Fischer DS, Berner J, Grohs P, Theis FJ and Krahmer F (2021) Group Testing for SARS-CoV-2 Allows for Up to 10-Fold Efficiency Increase Across Realistic Scenarios and Testing Strategies. Front. Public Health 9:583377. doi: 10.3389/fpubh.2021.583377
Received: 14 July 2020; Accepted: 26 July 2021;
Published: 18 August 2021.
Edited by:
Olivier Vandenberg, Laboratoire Hospitalier Universitaire de Bruxelles (LHUB-ULB), BelgiumReviewed by:
Elizaveta Padalko, Ghent University Hospital, BelgiumMohamed Gomaa Kamel, Minia University, Egypt
Copyright © 2021 Verdun, Fuchs, Harar, Elbrächter, Fischer, Berner, Grohs, Theis and Krahmer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Felix Krahmer, ZmVsaXgua3JhaG1lckB0dW0uZGU=
†These authors have contributed equally to this work
‡These authors have contributed equally to the repository and the web application