 Xinke Li
Xinke Li Wenyan Jia2
Wenyan Jia2
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychiatry, 04 September 2018
Sec. Psychopathology
Volume 9 - 2018 | https://doi.org/10.3389/fpsyt.2018.00415
This article is part of the Research TopicOvereating and Decision Making VulnerabilitiesView all 11 articles
Currently, there has been a new trend in applying modern robotics, information technology, and artificial intelligence to restaurants for improvements of food service, cost-effectiveness, and customer satisfaction. As robots replace humans to serve food, there is a clear need for robotic servers to help consumers select foods from a menu that satisfies their preferences such as taste and nutrition. However, currently, little is known about how eating behaviors drive food choices, and it is often difficult for consumers to make choices from a variety of foods offered by the typical restaurant, even with the assistance from a human server. In this paper, we conduct an exploratory study on an intelligent food choice method that recommends dishes by predicting individual's dietary preference, including ingredients, types of spices, price, etc. A multi-attribute relation matrix tri-factorization (MARMTF) technique is developed for a relation-driven food recommendation system. First, the user's ordering history and their rating scores of the foods in the menu are gathered and represented by a user-dish rating matrix. Next, the attribute relations of the ingredients, spicy level, and price of each food choice are extracted to construct a group of the relation matrices. Then, these matrices are integrated into a large block matrix. In the next step, a matrix tri-factorization algorithm is employed to decompose the block matrix and fuse the complex relationships into matrix factors. Further, a set of approximation block matrices are constructed and the predicted food rating matrix is generated. Finally, the foods (dishes) with sufficiently high preference scores are recommended to the consumers. Our experiments demonstrate that the MARMTF technique can provide effective dish recommendation for customers. Our system significantly simplifies the daunting task of making food choices and has a great potential in providing intelligent and professionally trained non-human waiters and waitresses for employment by future restaurants.
In recent years, there has been an interesting new trend to apply modern robotics, information technology and artificial intelligence (AI) to restaurants. Tablet computers for food ordering have been widely utilized in many countries (1–3). Robotic restaurants without human waiters and waitresses have been in operation, such as those in Canada (4), Japan (5), and Singapore (6). Although these trends have great potential in improving restaurant service, reducing cost, and enhancing customer satisfaction, the reduction or elimination of human interaction with customers on food choices significantly increases the problem in selecting a dish from a long restaurant menu. Although food flavor and appearance have been important features for consumers choosing their favorite foods (7–10), for meal ordering service in restaurants, it is also very important to understand what drives consumers' food choices and give recommendations through computational analysis of the variables collected both historically and at the tableside. Personalized recommendation systems using information and communication technologies (ICT) have been reported (11, 12). At present, these systems mainly satisfy specific needs expressed by consumers (13), such as healthy diet (14), balanced nutrition (15), and food taste (16). With the recent developments of machine learning, artificial intelligence, and cloud computing technologies, the development of smart food recommender systems for the general customers has been reported. For instance, a cloud-based smart restaurant management system (17) can provide easy-to-use interfaces to its users for food menu recommendation. Using advanced algorithms and Amazon Web Services (AWS), not only consumers can easily find their favorite food, but also restaurants can improve service, productivity and profits. Therefore, developing an intelligent menu recommender engine is an important task with promising applications to the enormous food service industry.
Beyond the field of dietary recommendation, many systems have been developed to predict people's interests (18). Personalized recommender engines play an increasingly important role in helping people make selections from overwhelming numbers of choices. For example, online stores such as Amazon, Netflix, and Pandora can recommend books, digital products, and other commodities. There have also been considerable recommenders in the academic field for students to choose schools, majors and classes (19–21). Regardless applications, existing recommender systems can typically be classified into three categories (22): (1) content-based, (2) collaborative, and (3) hybrid systems. The first category makes recommendations by matching item features; the second category makes predictions by analyzing rating data; and the last category possesses both content-based and collaborative features. Among different recommendation algorithms, the collaborative filtering (CF) algorithm and its variants have been used most widely (23). The CF-based algorithms can be further divided into memory-based and model-based algorithms (22, 24). It has been reported that, using a hybrid content-based collaborative filtering (CCF), the recommendation performance can be improved (25, 26). Recently, there has been a new progress in using matrix-factorization (MF)-based methods with high performance and scalability (27). The earliest version of the MF approach was based on singular value decomposition (SVD) (28). Lately, MF-based methods employed customer rating data to extract features and train a recommender based on predicted user preferences (29). There have also been cross integrations of CF recommender systems with regularized MF which have appeared at the Netflix prize competition (30). CF and MF based methods, along with their variations, have found various industrial applications (31–37). Relative to other fields, restaurant menu recommenders are less developed but some works have been reported. A real-time system was developed to monitor dining activity by videos (38). The system recommends additional dishes when the customers finish the existing ones and want more. Tan et al. (13) utilized the radio frequency identification (RFID) technology to improve food service. Elahi et al. (39) used tags and latent factors to design an interactive food recommendation system. Shaikh et al. (40) described a mobile recommendation system using context and user-profile information.
Some dietary recommendation systems pay special attention to the needs of customers who are patients. A system was developed to recommend foods based on user's illness and demographic information (41). Achieving a balanced nutrition was the focus of the recommender established using consumers' dietary records (42). Similarly, a recipe recommendation system was developed to help customers achieve fitness goals (43).
There were other recommender studies focusing on ingredients. Freyne et al. (44) and Feng et al. (45) extracted ingredients, which were individually rated by users, from menus. Recommendations were produced by weighting each ingredient. He et al. (46) used tastes (sour, sweet, bitter, spicy, and salty) to compose a vector of flavors for each dish. Then, customers' food ordering records and the established flavor vectors were used to make recommendations.
Incorporating other content information from recipes, MF-based recommenders generally achieved better preference prediction for users. Forbes and Zhu (47) proposed an algorithm incorporating the ingredient information into the MF method and improved the recipe recommendation performance. Lin et al. (48) employed main ingredients, courses, cuisines, etc. to obtain a recommender model. Although these food recommendation systems enhanced prediction accuracy, they directly incorporated the content information into item vectors for matrix factorization without revealing the hidden associations among these factors. As a result, these systems can only exploit explicit information about users' preferences. In order to reveal associations of food components, consumers' needs, and other related factors to produce better recommendations, we present a multi-attribute relation matrix tri-factorization (MARMTF) technique in this work. We first represent heterogeneous information as multi-type relation matrices. In addition to including users' ordering record and ratings for the dishes, we construct a set of relationship matrices, which reflects ingredients, spicy level, and price and integrate it into the recommendation framework. The multi-variant matrices are then integrated by data fusion using an advanced MF algorithm (49).
This paper is organized as follows. We introduce the recommendation strategies and methods in section Recommendation Strategies and Methods, where attribute relations for the food recommendation system are described. In section Experimental Studies, our experimental studies are presented which employ the multi-attribute relation matrix tri-factorization (MARMTF) framework to produce menu recommendation. Then, the performance of our recommendation system is discussed in section Results and Discussion. Finally, we draw conclusions in section Conclusion.
It has been proven that Matrix factorization (MF) is both accurate and scalable for recommendation systems (27, 29). In this framework, a user-rating matrix is initially filled with the input data representing the collected information. Let the numbers of users and the pieces of information be n and d, respectively. Let R be a relation matrix describing the usefulness of the information items to the users. Thus, n×d→ R. Normally, this matrix R is sparse. Next, the rating matrix is factorized into two low-rank factor matrices. Finally, we estimate the unknown entries using the inner products of the matrices and the entries with the highest values are used to produce recommendations.
During the MF process, the non-negativity matrix factorization (NMF) is critically important. NMF aims to find two non-negative matrix factors U and V from a non-negative matrix X, i.e.,
where and [are all d-by-c matrices whose entries are non-negative. The rank c usually satisfiesc ≪ min(n, d)].
Ding et al. (50) provided a systematic analysis of the NMF. It was shown that the NMF performs spectral clustering and the orthogonal NMF is equivalent to K-means clustering. Furthermore, Ding et al. (51) proposed a bi-orthogonal 3-factor NMF:
where and . Equation (2) can be called orthogonal non-negative matrix tri-factorization (ONMTF) which has a better capability in simultaneously clustering rows and columns of the data matrix. As an effective co-clustering tool, ONMTF was applied to collaborative filtering with improved performance (52).
Wang et al. (53) presented a novel symmetric penalized matrix tri-factorization (tri-PMF) framework which employs penalized terms for dyadic constrained co-clustering.
where V1 and V2 denote the cluster indicator matrices of χ1 and χ2, respectively, and P(χ1) and P(χ2) correspond to the penalties on χ1 and χ2. Here the tri-PMF is extended to symmetric penalized matrix tri-factorization in order to cluster multi-type data objects simultaneously. Wang et al. (54) also proposed a symmetric non-negative matrix tri-factorization (S-NMTF) method to co-cluster multiple types of relational data.
Besides the user-dish rating data, our dish recommendation system also combines other relational data including dish-ingredients, dish-spices, and dish-price. Additional food-choice related factors, such as consumer's age, physical/medical condition, native region, meal time, season of the year, etc., may also be included. Based on the matrix tri-factorization techniques, we present a multi-attribute relational information fusion scheme which integrates available data sources to predict consumers' preferences.
In our recommendation model, the input data are relation matrices. If the i-th and j-th object types constitute a relation matrix Rij, then all relation matrices can be integrated to a block matrix R, given by
where the relation matrices between the same type of objects are denoted by the asterisk (“*”). For our recommendation system, if some relation matrices, such as user-ingredient, and ingredient-price, are not directly modeled, we let the corresponding locations be blank. Obviously, the relation matrices may not be symmetric, i.e., .
Let us consider constraints of the relation between the same types of objects. Suppose that there are r data sources represented by a set of constraint matrices Pi for i ∈ {1, 2, ⋯ , r}. Constraints are collectively encoded in a set of constraint block diagonal matrices P
where Diag(·) denote the diagonalization for the block diagonal matrix P. In order to use all modeled relation matrices to obtain a fused block matrix, we first use matrix tri-factorization to decompose the original block matrix R into integrant block matrix factors V and B:
Block matrix B has the same structure as R in Equation (4). From Equations (6, 7), we can reconstruct the block structure as VBVT:
The objective function aims at the closest approximation of the input data by the following minimization:
where ||·|| and tr(·) denote the Frobenius norm and trace, respectively, and ℜ is the set of all relations included in our model. We can compute the factorization to obtain the latent factors V and B by solving the minimization problem with Equation (9). The factorization algorithm can be simply described as follows. Firstly, the matrix factors V and B are initialized (section Initialization of Decomposition Factors). Next, alternating between fixing V and updating B, and then fixing B and updating V, until the results achieve convergence to iteratively refine the latent matric factors. The update functions of B and V can be derived by multiplicative updating rules (49). For convergence criterion, run for a fixed number of iterations (section The Number of Iterations) is adopted in this study. Finally, we can use the convergent B and V to compute the approximation of input block matrix VBVT.
To predict users' preference ratings of different dishes, we reconstruct the rating matrix from the observed relation matrices. The whole processing procedure can be represented in Figure 1. In the step of matrix tri-factorization and fusion, we can use the multi-type relation matrices to obtain matrix factors V and B. Finally, the predicted rating matrix can be extracted from the reconstructed block matrix .

Figure 1. Flowchart of the recommendation system.
After the new user-dish rating matrix is generated, each dish is assigned with a predicted value. Then, the system will make the recommendation for users according to the ranking of dishes with adequate scores (determined empirically).
Our experimental study was performed using Chinese foods which are renowned for their wide choices and varieties. First, we generated a list of Chinese foods commonly found in Chongqing, a major mid-west city of over 10 million, well-known for its spicy Sichuan cooking style. The foods selected were mostly in the low or moderate price range. Therefore, they have a large customer base. We recruited 37 adult evaluators (22 males and 15 females) who were all ethnic Chinese but were from different regions in China, not limited in Chongqing. They were healthy (based on their own evaluation), and their ages were between 20 and 60, for a better generalizability of our study. Each evaluator was presented with a list of 289 foods (dishes). He/she gave a rating for each dish according to his/her preference. The rating grades were integers within the range of 1–5, representing “hate,” “dislike,” “neutral,” “like,” and “love,” respectively. If the evaluator has no experience about a particular dish or was not sure because of a poor memory recall or other reasons, he/she simply left a blank for the dish. After all lists were collected, we integrate them to form the initial user-dish rating matrix exemplified in Table 1. For compactness of the table, we represent each dish with a sequential number. It can be seen that the matrix is, as it is normally, quite sparse.
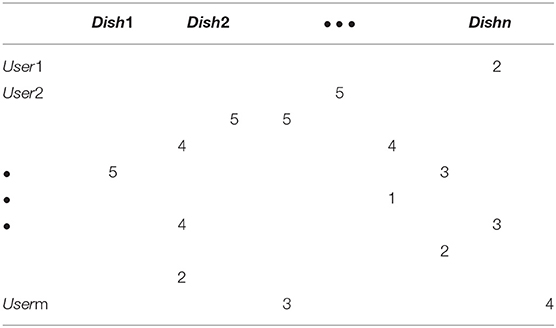
Table 1. The user-dish rating matrix.
As stated previously, food ingredients represent an important attribute for dishes. It is also one of the key factors driving consumers to choose their preferred dishes (55, 56). Therefore, we incorporated the ingredient-dish information, as exemplified in Table 2 where the dishes were classified into six main food ingredients: meat, poultry, vegetables, aquatic products, soybean products, and cereals. We used Boolean values to indicate whether a dish contains the particular ingredient (“1”) or not (“0”).
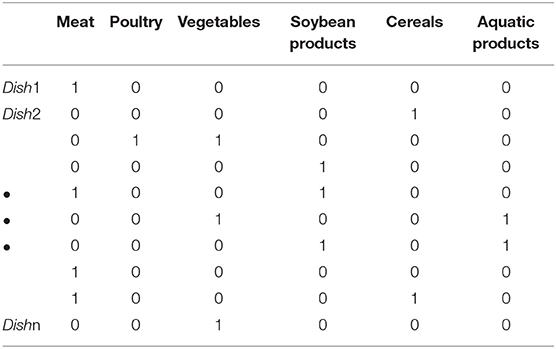
Table 2. The relationship matrix between the dishes and the food ingredients.
For the Sichuan and many other Chinese cuisine systems, the degree of spiciness is important for people to make food choices (57). Some studies have been conducted on the factors that influence consumers' behavior of eating spicy food (58–60). Therefore, we also utilized spiciness as an important factor for consumers' food choices. The spicy level of each dish is commonly available in restaurants' menus (e.g., indicated by the number of hot pepper symbols). Using this information, the dishes were classified in four levels: “not spicy,” “slightly spicy,” “medium spicy,” and “very spicy.” Table 3 describes the relationship matrix of the dishes and their spiciness.
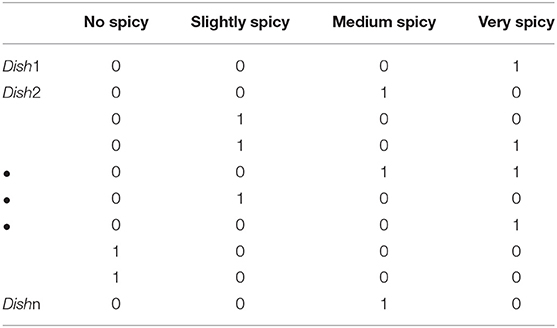
Table 3. Relationship matrix of the dishes and their spicy levels.
Additionally, price is an undeniable factor influencing food choices, especially for low- and middle-income consumers (61, 62). For people dining away from home, food consumption is largely responsive to price change (63). Therefore, we incorporated food price into our recommendation system, as shown the dish-price relation matrix in Table 4 where three price levels were extracted from the restaurant menu: “low price,” “medium price,” and “high price.”
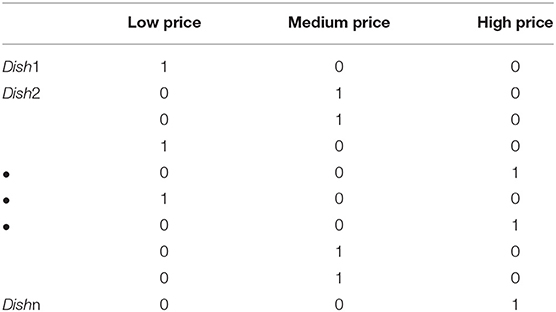
Table 4. Relationship matrix between the dishes and the price levels.
In terms of mathematical modeling, we have formed 5 object types, ε1 through ε5, corresponding to “dish,” “user,” “food ingredient,” “price level,” and “spicy level.” For convenience in implementation, each relationship matrix was represented in the Comma Separated Value (CSV) format. From these data sources, we integrated them into a relation graph as shown in Figure 2. The attribute relations of user-dish, dish-ingredient, dish-price, and dish-spicy were represented by R21, R13, R14, and R15, respectively. We used these relation matrices as input data for the matrix tri-factorization model.
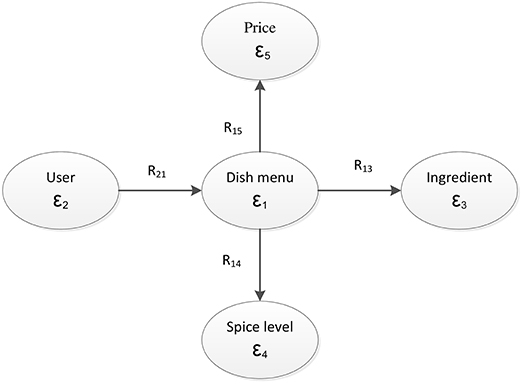
Figure 2. Relation fusion graph of the system.
We collected input data from 37 evaluators for 289 dishes (described in section Materials and Datasets), along with the preparation of the relation matrices described above. The user-dish rating dataset was then divided into two sets, training set (83.3% of data) and test set (16.7% of data).
The root mean-squared error (RMSE) and mean absolute error (MAE) were utilized to evaluate the performance of our recommendation systems (18), given by
where rui and denote the ratings given by the user u and the recommendation system for item i, respectively, and |T| denotes the number of elements in rating set T.
The initialization of factor matrix V in Equation (1) is important because system performance is sensitive to V. The initialization also influences the convergence of the algorithm. We adopt the random Acol method (64) to initialize V in which the initialization of each column of V is formed by averaging random columns of R. Our algorithm derives factors B in Equation (2) from V, as described in section Objective Function and Data Processing Procedure. In addition to the initialization, there are two important parameters, the factorization rank and the number of iterations, to be discussed below.
In matrix tri-factorization formula , the dimensions of and are ni × nj and ki × kj, respectively. ki and kj are factorization ranks which are smaller than ni and nj. Therefore, the matrix factor Bij can be considered as a compressed version of the original matrix Rij (65). The factorization ranks determine the degree of dimension reduction for the object types. In our study, we use the dimension compression ratios and to denote the degree of dimension reduction determined by the selected factorization ranks ki and kj. The ratios affect the performance of our data fusion model. For each ratio, if it is too large, the clustering becomes overly fine. On the other hand, if it is too small, the clustering tends to be rough. In order to simplify parameter tuning, we let for all i and j. To find the dimension compression ratio that optimizes the quality of the system, we fixed the number of iterations at 200, varied the unified compression ratio between 0 and 1, and utilized the RMSE and MAE defined in (10) and (11) to measure performance. Our result is shown in Figure 3. It can be observed that the optimal value of the compression ratio is ~0.4 which was selected.
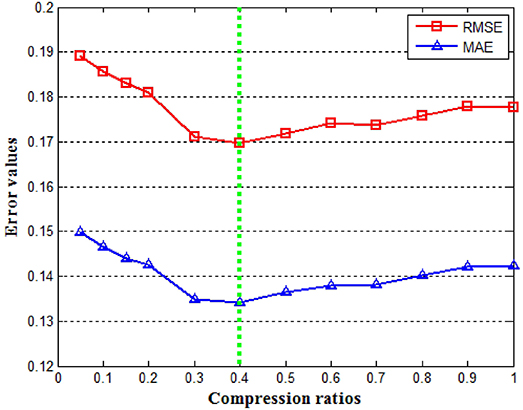
Figure 3. Effect of the different factorization ranks. Both the RMSE and MAE are minimized at a compression ratio near 0.4.
The objective function J(V;B) given by Equation (9) can be minimized by multiplicative updating for V and B. Since it is an iterative process, the number of iterations must be determined. We determined it experimentally by observing the convergence of our system. It can be seen from Figure 4 that both RMSE and MAE decrease as the number of iterations increases. However, when it reaches 100, the error reduction becomes insignificant. We therefore selected the number of iterations to be 200 with a sufficient safety margin.
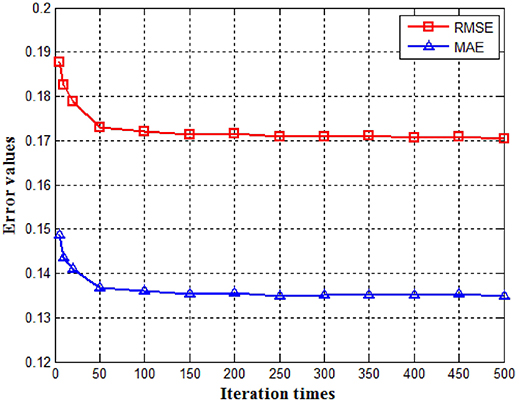
Figure 4. RMSE (top curve) and MAE (bottom curve) vs. the number of iterations.
We implemented our 3-factor matrix factorization algorithm (unoptimized) in Python 3.5 edition on a laptop with an i5 core. The execution time was ~15 s. Despite the relative slowness in this implementation, we believe that the computational efficiency can be reduced significantly by optimizing the algorithm and utilizing a parallel processor, such as a GPU.
Using the optimally determined parameters, we constructed our recommendation system using the training set, which was composed of 83.3% of the total data. Once constructed, we utilized the test set, composed of the rest of collected data, to evaluate performance based on the RMSE and MAE metrics. For reliability of the output, the test procedure was repeated 10 times, and we took the average of the evaluation results.
Additionally, we compared our method with several commonly used methods, including projected gradient NMF (pgNMF) (66), classical matrix factorization (MF) (29), and SVD++ (67). Furthermore, we compared our current use of 3-factor matrix factorization (MARMTF) with an alternative of using 2-factor matrix factorization based on the same multi-type relation dataset. Finally, in order to validate our approach of using multi-type relation data, we performed the matrix tri-factorization using only the user-dish rating matrix. The comparison results can be observed in Figure 5. The MARMTF model achieve the best prediction rating accuracy.
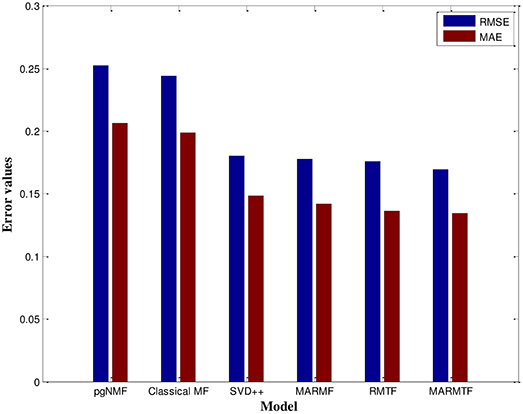
Figure 5. RMSE and MAE for different models.
For more details, our results are listed in Table 5. It can be observed that the RMSE and MAE have the minimum values at 0.1693 and 0.1342, respectively, indicating that the MARMTF method outperformed other algorithms. The next performers are the rating matrix tri-factorization (RMTF) and multi-attribute relation matrix factorization (MARMF) methods which are better than the traditional methods, including SVD++, classical MF, and pgNMF.
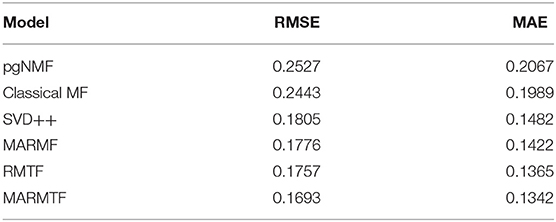
Table 5. Accuracy comparison of recommenders.
In this comparison, the recommendation models utilize different amounts of information and/or treated the information differently. For example, the projected gradient NMF model assumes that an absence of rating implies an unfavored item, and the classical MF model only utilizes the rating matrix (68). In contrast, the SVD++ is a matrix factorization model that can combine mean rating, user-item bias, and implicit feedback information (69). As a result, the prediction accuracies of the SVD++ and other multi-attribute methods are higher than those of the projected gradient NMF and Classical MF. Thus, our results agree with a previous report that a recommendation model generally achieves a better performance if it incorporates more background information (67). However, it is difficult for the existing techniques to fuse a large number of attributes from a wide variety of resources.
With regard to making dish recommendations for consumers in restaurants, the relation matrices must be constructed with multiple attributes. Therefore, it is important to integrate and fuse the information from different sources. Our MARMTF model decomposes all the relation matrices systematically for the reconstruction of the rating prediction matrix. In addition, this model achieves a better clustering accuracy by simultaneously co-clustering multiple attributes simultaneously. Due to these valuable properties, the prediction accuracy of the MARMTF overperforms the MARMF which adopts 2-factor matrix decomposition. Overall, the MARMTF can better “understand” complex underlying relationships from different sources to produce more relevant recommendations for consumers.
Despite the advantages, we point out that the current version of the MARMTF has certain limitations. The evaluation was performed in a particular region (Chongqing) where foods tend to be spicy. As a result, there is a tendency that our food choice preferences are biased toward spicy foods and our results are subject to regional limitations. Additionally, we adopted only food ingredients, spicy levels, and price levels as the factors to help consumers choose food. Therefore, the attributes utilized are limited. In future studies, we plan to enhance our recommendation model by considering additional attributes, such as time of meal, season of the year, native region of the consumer, etc., under the MARMTF framework. Finally, food recommendations for healthy diet and balanced nutrition are of great interests for people with chronic diseases or being overweight. In order to produce health-awareness recommendations, we plan to use both food preference and demographic/medical data [e.g., age, body mass index (BMI), existing chronic conditions, etc.] and apply the MARMTF model to make dietary recommendations.
With improvements in food production and services, consumers are facing with increased food products and diverse eating environments which make food-choice decisions more complex (70). In order to provide an effective meal selection tool for consumers in restaurants, we have developed a food recommendation system incorporating the information about eating behaviors and food attributes. A multi-attribute relation matrix tri-factorization framework has been presented. Based on the user-dish rating matrix, our relation-driven recommendation model utilizes other dish attribute relation matrices, including dish-ingredients, dish-spices, and dish-price, as the input data to predict consumers' food choices. Experimental results using real-world data have shown that the MARMTF model achieved better performance than existing recommendation methods. In the future work, we will incorporate more information and attributes, not only for choosing favorable food, but also for healthy eating and balanced nutrition.
All of the authors contributed to the study conception and design, data collection, and interpretation of findings. XL conducted the statistical analyses and drafted the manuscript. MS performed the study design, interpretation of findings, and revised the manuscript. WJ advised on the statistical analysis and reviewed drafts of the manuscript.
This work was financially supported in part by the National Institutes of Health Grants (No. R01CA165255 and R21CA172864), and Bill and Melinda Gates Foundation Grant (No. OPP117395) of the United States, and the Fundamental Research Funds for the Central Universities (No. 106112015CDJXY160003), the Basic and Advanced Research Project in Chongqing (No. cstc2018jcyjAX0440), and the State's Key Project of Research and Development Plan (No. 2016YFE0108100) of China.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
1. Hartwell H, Johns N, Edwards J. E-menus—Managing choice options in hospital foodservice. Int J Hosp Manag. (2016) 56:12–6. doi: 10.1016/j.ijhm.2015.11.007
2. Ali A, Mahdi H. Tablet PC in restaurant. In: IEEE Student Conference on Research and Development. Putrajaya (2013). p. 311–14.
3. Shafei R, Rastad S, Kamangar A. Effecting of electronic-tablet-based menu and its impact on consumer choice behavior (An Empirical Study in Iranian Restaurant). In: 10th International Conference on E-Commerce in Developing Countries: With focus on e-Tourism. Isfahan (2016). p. 1–8.
4. Meeden L, Maxwell B, Addo NS, Brown L, Dickson P, Ng J, et al. Alfred: the robot waiter who remembers you. In: AAAI Workshop on Robotics. Orlando, FL (1999). p. 12–9.
5. Tzou JH, Su KL. The development of the restaurant service mobile robot with a laser positioning system. In: Proceedings of 27th Chinese Control Conference. Kunming (2008). p. 981–7.
6. Ang B. Robot Lucy at Your Service at Newly Opened Rong Heng Seafood, The Strait Times Lifestyle (2016) Available online at: http://www.straitstimes.com/lifestyle/food/robot-lucy-at-your-service
7. Rosa A, Leone F, Cheli F, Chiofalo V. Fusion of electronic nose, electronic tongue and computer vision for animal source food authentication and quality assessment—A review. J Food Eng. (2017) 210:62–75. doi: 10.1016/j.jfoodeng.2017.04.024
8. Jantathai S, Danner L, Joechl M, Dürrschmid K. Gazing behavior, choice and color of food: Does gazing behavior predict choice? Food Res Int. (2013) 54:1621–6. doi: 10.1016/j.foodres.2013.09.050
9. Lee S, Lee K, Lee S, Song J. Origin of human colour preference for food. J Food Eng. (2013) 119:508–15. doi: 10.1016/j.jfoodeng.2013.06.021
10. Zhang J, Zhang X, Dediu L, Victor C. (2011). Review of the current application of fingerprinting allowing detection of food adulteration and fraud in China. Food Control, 22:1126–35. doi: 10.1016/j.foodcont.2011.01.019
11. Bobadilla J, Ortega F, Hernando A, Gutiérrez A. Recommender systems survey. Knowledge Based Syst. (2013) 46:109–32. doi: 10.1016/j.knosys.2013.03.012
12. Lu J, Wu D, Mao M, Wang W, Zhang G. Recommender system application developments: a survey. Decis Support Syst. (2015) 74:12–32. doi: 10.1016/j.dss.2015.03.008
13. Tan T, Chang C, Chen Y. Developing an intelligent e-Restaurant with a menu recommender for customer-Centric service. IEEE Trans Syst Man Cybernet C Appl Rev. (2012) 42:775–87. doi: 10.1109/TSMCC.2011.2168560
14. Ge M, Ricci F, Massimo D. Health-aware food recommender system. In: Proceedings of the 9th ACM Conference on Recommender Systems. New York, NY: ACM (2015). p. 333–334.
15. Yang L, Hsieh C, Yang H, Pollak J, Dell N, Belongie S, et al. Yum-me: personalized healthy meal recommender system. ACM Trans Inform Syst. (2017) 36:7. doi: 10.1145/3072614
16. Ge M, Elahi M, Fernaández-Tobías I, Ricci F, Massimo D. Using tags and latent factors in a food recommender system. In: Proceedings of the 5th International Conference on Digital Health 2015. New York, NY: ACM (2015). p. 105–12.
17. Hassain S, Ali S, Mais E, Mostafa S, Shikharesh M, Chung HL. Near-field communication sensors and cloud-based smart restaurant management system. In: IEEE 3rd World Forum on Internet of Things (WF-IOT). Reston, VA (2016). p. 686–91.
18. Lü L, Medo M, Yeung CH, Zhang YC, Zhang ZK, Zhou T. Recommender systems. Phys Rep. (2012) 519:1–49. doi: 10.1016/j.physrep.2012.02.006
19. Aditya P, Petros V, Hector G. Recommendation systems with complex constraints: a course recommendation perspective. ACM Trans Inform Syst. (2011) 29:20. doi: 10.1145/2037661.2037665
20. Taha K. CRS: A Course Recommender System, Technology Platform Innovations and Forthcoming Trends in Ubiquitous Learning. Hershey, PA: IGI Global (2014). p. 177–93.
21. Patel B, Kakuste V, Eirinaki M. CaPaR: a career path recommendation framework. In: 3rd IEEE International Conference on Big Data Computing Service and Applications. San Francisco, CA (2017). p. 23–30.
22. Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans Knowledge Data Eng. (2005) 17:734–49. doi: 10.1109/TKDE.2005.99
23. Adomavicius G, Zhang J. Improving stability of recommender systems: a meta-algorithmic approach. IEEE Trans Knowledge Data Eng. (2015) 27:1573–87. doi: 10.1109/TKDE.2014.2384502
24. Nilashi M, Ibrahim O, Bagherifard K. A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques. Expert Syst Appl. (2018) 92:507–20. doi: 10.1016/j.eswa.2017.09.058
25. Melville P, Mooney RJ, Nagarajan R. Content-boosted collaborative filtering for improved recommendations. In: Association for the Advancement of Artificial Intelligence. Menlo Park, CA (2002). p. 187–92.
26. Lu Z, Dou Z, Lian J, Xie X, Yang Q. Content-based collaborative filtering for news topic recommendation. In: AAAI'15 Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin, TX (2015).
27. Luo X, Zhou M, Xia Y, Zhu Q. An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems. IEEE Trans Industr Inform. (2014) 10:1273–84. doi: 10.1109/T.I.I.2014.2308433
28. Sarwar B, Karypis G, Konstan J, Reidl J. Application of dimensionality reduction in recommender systems—a case study. In: Proceedings ACM WebKDD. Boston, MA (2000). p. 285–95.
29. Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer (2009) 42:42–9. doi: 10.1109/MC.2009.263
30. Gorrell G. Generalized Hebbian algorithm for incremental singular value decomposition in natural language processing. In: Proceedings 11th Conference Europeon Chapter of the Association for Computational Linguistics. Stroudsburg, PA (2006). p. 97–104.
31. Paterek A. Improving regularized singular value decomposition for collaborative filtering. In: Proceedings 13th ACM SIGKDD International Conference Knowledge Discovery Data Mining. San Jose, CA (2007). p. 39–42.
32. Takács G, Pilászy I, Németh B, Tikky D. Scalable collaborative filtering approaches for large recommender systems. J Mach Learn Res. (2009) 10:623–56. doi: 10.1145/1577069.1577091
33. Salakhutdinov R, Mnih A. Probabilistic matrix-factorization. Adv Neural Inform Process Syst. (2008) 20:1257–1264. doi: 10.1145/1390156.1390267
34. Ning Z, Cheung WK, Guoping Q, Xiangyang X. A hybrid probabilistic model for unified collaborative and content-based image tagging. IEEE Trans Pattern Anal Mach Intell. (2011) 33:1281–94. doi: 10.1109/TPAMI.2010.204
35. Wu J, Chen L, Feng YP, Zheng ZB, Zhou MC, Wu Z. Predicting quality of service for selection by neighborhood-based collaborative-filtering. IEEE Trans Syst Man Cybernet Syst. (2013) 43:428–39. doi: 10.1109/TSMCA.2012.2210409
36. Weng MF, Chuang YY. Collaborative video reindexing via matrix factorization. ACM Trans Multimedia Comput Commun Appl. (2008) 8:1–20. doi: 10.1145/2168996.2169003
37. Pan JJ, Pan SJ, Jie Y, Ni LM, Qiang Y. Tracking mobile users in wireless networks via semi-supervised colocalization. IEEE Trans Pattern Anal Mach Intell. (2012) 34:587–600. doi: 10.1109/TPAMI.2011.165
38. Inoue T, Matsusaka Y. A system to recommend dishes by the real time recognition of dining activity. In: IEEE International Conference on Systems, Man, and Cybernetics. Istanbul (2008). p. 2448–52.
39. Elahi M, Ge M, Ricci F, Fernández-Tobías I, Berkovsky S, Massimo D. Interaction design in a mobile food recommender system. In: Proceedings of the Joint Workshop on Interfaces and Human Decision Making for Recommender Systems. Vienna (2015). p. 49–52.
40. Shaikh I, Samarsen M, Vyas P. Food dishes recommendation system based on mobile context-aware services. Int J Sci Res Sci Eng Technol. (2016) 2:465–8.
41. Kim J, Lee J, Park J, Lee Y, Rim K. Design of diet recommendation system for healthcare service based on user information. In: IEEE Fourth International Conference on Computer Sciences and Convergence Information Technology. Seoul (2009). p. 516–518.
42. Li X, Liu X, Zhang Z, Xia Y, Qian S. Design of health eating system based on web data mining. In: IEEE International Conference on Information Engineering. Beidaihe (2010). p. 346–49.
43. Mino Y, Kobayashi I. Recipe recommendation for a diet considering a user's schedule and the balance of nourishment. In: IEEE International Conference on Intelligent Computing and Intelligent Systems. Shanghai (2009) p. 383–7.
44. Freyne J, Berkovsky S, Smith G. Recipe recommendation: accuracy and reasoning. In: International Conference on User Modeling, Adaptation, and Personalization. Berlin; Heidelberg: Springer. (2011). p. 99–110.
45. Feng Z, Wu L, Jing Y, Wang D, Zhang H, Zhang C. A recommendation scheme by user preference to components. In: IET International Radar Conference. Hangzhou (2015). p. 1–5.
46. He N, Liu M, Zhao F. A chinese dishes recommendation algorithm based on personal taste. In: IEEE 2nd International Conference on Cybernetics. Gdynia (2015). p. 277–80.
47. Forbes P, Zhu M. Content-boosted matrix factorization for recommender systems: experiments with recipe recommendation. In: Proceedings of the Fifth ACM Conference on Recommender Systems. Chicago, IL (2011). p. 261–64.
48. Lin CJ, Kuo TT, Lin SD. A content-based matrix factorization model for recipe recommendation. In: 18th Pacific-Asia Conference, Advances in Knowledge Discovery and Data Mining, PAKDD 2014. Tainan (2014). p. 560–71.
49. Zitnik M, Zupan B. Data fusion by matrix factorization. IEEE Trans Pattern Anal. Mach Intell. (2015) 37:41–53. doi: 10.1109/TPAMI.2014.2343973
50. Ding C, He X, Simon H. On the equivalence of nonnegative matrix factorization and spectral clustering. In: Proceedings of the Fifth SIAM International Conference on Data Mining. Newport Beach, CA (2005). p. 606–10.
51. Ding C, Li T, Peng W, Park H. Orthogonal nonnegative matrix tri-factorizations for clustering. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Philadelphia, PA (2006). p. 126–35.
52. Chen G, Wang F, Zhang C. Collaborative filtering using orthogonal nonnegative matrix tri-factorization. Inform Process Manage. (2009) 45:368–79. doi: 10.1016/j.ipm.2008.12.004
53. Wang F, Li T, Zhang C. Semi-supervised clustering via matrix factorization. In SDM. San Diego, CA (2008). p. 1–12.
54. Wang H, Huang H, Ding C. Simultaneous clustering of multi-type relational data via symmetric nonnegative matrix tri-factorization. In: Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York, NY: ACM (2011) p. 279–84.
55. Jacob C, Boulbry G, Gueguen N. Does the information regarding the ingredients composing a dish influence consumers' decisions? Eval Restaurant J Hospital Market Manage. (2016) 26:207–14. doi: 10.1080/19368623.2016.1194796
56. De Pelsmaeker S, Schouteten J, Lagast S, Dewettinck K, Gellynck X. Is taste the key driver for consumer preference? A conjoint analysis study. Food Qual Prefer. (2017) 62:323–31. doi: 10.1016/j.foodqual.2017.02.018
57. Nolden A, Hayes J. Perceptual and affective responses to sampled capsaicin differ by reported intake. Food Qual Prefer. (2017) 55:26–34. doi: 10.1016/j.foodqual.2016.08.003
58. Byrnes N, Hayes J. Behavioral measures of risk tasking, sensation seeking and sensitivity to reward may reflect different motivations for spicy food liking and consumption. Appetite (2016) 103:411–422. doi: 10.1016/j.appet.2016.04.037
59. Bègue L, Bricout V, Boudesseul J, Shankland R, Duke A. Some like it hot: Testosterone predicts laboratory eating behavior of spicy food. Physiol Behav. (2015) 139:375–7. doi: 10.1016/j.physbeh.2014.11.061
60. Törnwall O, Silventoinen K, Kaprio J, Tuorila H. Why do some like it hot? Genetic Environmental contributions to the pleasantness of oral pungency. Physiol Behav. (2012) 107:381–9. doi: 10.1016/j.physbeh.2012.09.010
61. French S. Pricing effects on food choices. J Nutr. (2003) 133:841s–3s. doi: 10.1093/jn/133.3.841S
62. Vilaro M, Barnett T, Mathews A, Jamie P. Income differences in social control of eating behaviors and food choice priorities among southern rural women in the US: a qualitative study. Appetite (2016) 107:604–12. doi: 10.1016/j.appet.2016.09.003
63. Tatiana A, Michael L, Kelly B. The impact of food prices on consumption: a systematic review of research on the price elasticity of demand for food. Am J Public Health (2010) 100:216–22. doi: 10.2105/AJPH.2008.151415
64. Langville AN, Meyer CD, Albright R, Cox J, Duling D. Algorithms, Initializations, and Convergence for the Nonnegative Matrix Factorization. Cary, NC: SAS Institute, Inc. (2014).
65. Zitnik M, Zupan B. Discovering disease-disease associations by fusing systems-level molecular data. Sci Rep. (2013) 3:3202. doi: 10.1038/srep03202
66. Lin CJ. Projected gradient methods for nonnegative matrix factorization. Neural Comput. (2007) 19:2756–79. doi: 10.1162/neco.2007.19.10.2756
67. Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model. In: KDD2008 Conference Proceedings. New York, NY (2008). p. 426–34. doi: 10.1145/1401890.1401944
68. Hernando A, Bobadilla J, Ortega F. A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowledge Based Syst. (2016) 97:188–202. doi: 10.1016/j.knosys.2015.12.018
69. Kannan R, Ishteva M, Park H. Bounded matrix factorization for recommender system. Knowledge Inform Syst. (2014) 39:491–511. doi: 10.1007/s10115-013-0710-2
Keywords: food choice, consumer preference, eating behaviors, food's attributes, matrix tri-factorization, food recommendation system, robotic restaurant, non-human waiter/waitress
Citation: Li X, Jia W, Yang Z, Li Y, Yuan D, Zhang H and Sun M (2018) Application of Intelligent Recommendation Techniques for Consumers' Food Choices in Restaurants. Front. Psychiatry 9:415. doi: 10.3389/fpsyt.2018.00415
Received: 15 April 2018; Accepted: 14 August 2018;
Published: 04 September 2018.
Edited by:
Yonghui Li, University of Chinese Academy of Sciences (UCAS), ChinaReviewed by:
Xin Zheng, Beijing Normal University, ChinaCopyright © 2018 Li, Jia, Yang, Li, Yuan, Zhang and Sun. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xinke Li, bHhrQGNxdS5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.