 Xueze Gao
Xueze Gao Quan Feng
Quan Feng Shuzhi Wang2
Shuzhi Wang2- 1School of Mechanical and Electrical Engineering, Gansu Agricultural University, Lanzhou, China
- 2School of Electrical Engineering, Northwest University for Nationalities, Lanzhou, China
- 3Agricultural Information Institute, Chinese Academy of Agricultural Sciences, Beijing, China
- 4National Nanfan Research Institute, Chinese Academy of Agricultural Sciences, Sanya, China
Accurate identification of potato diseases is crucial for reducing yield losses. To address the issue of low recognition accuracy caused by the mismatch between target domain and source domain due to insufficient samples, the effectiveness of Multi-Source Unsupervised Domain Adaptation (MUDA) method in disease identification is explored. A Multi-Source Domain Feature Adaptation Network (MDFAN) is proposed, employing a two-stage alignment strategy. This method first aligns the distribution of each source-target domain pair within multiple specific feature spaces. In this process, multi-representation extraction and subdomain alignment techniques are utilized to further improve alignment performance. Secondly, classifier outputs are aligned by leveraging decision boundaries within specific domains. Taking into account variations in lighting during image acquisition, a dataset comprising field potato disease images with five distinct disease types is created, followed by comprehensive transfer experiments. In the corresponding transfer tasks, MDFAN achieves an average classification accuracy of 92.11% with two source domains and 93.02% with three source domains, outperforming all other methods. These results not only demonstrate the effectiveness of MUDA but also highlight the robustness of MDFAN to changes in lighting conditions.
1 Introduction
Potato is one of the main food crops in many countries. However, various factors make them susceptible to different diseases, which can adversely affect their yield (Arshaghi et al., 2023). Early detection and warning are crucial for effective disease prevention and control, playing a pivotal role in management and decision-making (Fang and Ramasamy, 2015). In reality, it is an extremely time-consuming and unreliable way to detect and diagnose disease types by visual inspection of a farmer. Although the accuracy of laboratory-based identification method is very high, it is not suitable for the current situation of large-scale planting while the cost is high (Verma et al., 2020). This highlights the need for automated methods such as machine learning to improve the efficiency of disease recognition in agricultural environments. Given these challenges, machine learning techniques have gained increasing attention in recent years. Early machine learning methods primarily relied on manual feature extraction (Liaghat et al., 2014; Hlaing and Zaw, 2018; Deng et al., 2019; Basavaiah and Arlene Anthony, 2020). These features typically include salient structures such as texture, edges, color, and corners in the image (Sahu and Minz, 2023). Implementing such methods requires substantial engineering skills and specialized domain knowledge. Moreover, these methods are often tailored to specific problems, lacking generality.
In recent years, deep learning methods have been widely applied in crop disease recognition, achieving better performance than approaches based on manual feature extraction (Bevers et al., 2022). Atila et al. (2021) employed data augmentation techniques to augment the PlantVillage dataset to 61,486 images, evaluating the classification performance of various deep learning models. The experimental findings highlighted that the B4 and B5 models of the EfficientNet architecture achieved the highest performance in both the original and augmented datasets. Hassan and Maji (2022) introduced a novel deep learning model incorporating Inception layers and residual connectivity, achieving high classification accuracies of 99.39% on the PlantVillage dataset, 99.66% on the rice disease dataset, and 76.59% on the cassava dataset. Gu et al. (2022) proposed an enhanced deep learning-based multi-plant disease identification method, conducting experiments on 14,304 field images of six diseases in apples and pears. The results demonstrated a 14.98% improvement in accuracy compared to the baseline method.
However, deep learning, being a data-driven algorithm, heavily relies on large-scale labeled data for success. Establishing such datasets for a specific task incurs significant financial and time costs. In agricultural environments, various interfering factors pose challenges to data annotation. In addition, traditional machine learning assumes that the training data (source domain) and test data (target domain) of the model obey the independent identical distribution. However, this assumption is often invalidated in agriculture due to variables like lighting conditions, crop variety, planting environment, disease progression stages, and the tools used for data collection. The resultant disparity in distribution between the source and target domain data, known as domain shift, refers to the significant differences in data distribution encountered in transfer learning or domain adaptation (Tanabe et al., 2021). This phenomenon degrades the model’s performance, as the knowledge learned from the source domain may not generalize well to the target domain (Zhang et al., 2022).
Essentially, domain shift arises when training samples are insufficient to cover the testing ones. However, in reality, obtaining a large number of samples is prohibitively expensive, making addressing domain shift with limited samples a crucial area for exploration. Unsupervised Domain Adaptation (UDA) is one such solution. As a pivotal component of transfer learning (Pan and Yang, 2009), UDA methods aim to learn generalizable features across domains. These methods involve training a predictive function on labelled data in source domain and minimizing the prediction error on unlabelled data in target domain. UDA methods can be broadly categorized into two types (Wang et al., 2023): the first type is metric-based methods (Tzeng et al., 2014; Sun and Saenko, 2016; Zhu et al., 2020; Zhang et al., 2022), which aim to adopt a certain metric to minimize the distribution difference between the source and target domain data. The second type is adversarial-based methods (Long et al., 2015; Yu et al., 2019), which involve applying a MinMax adversarial training between a feature extractor and a discriminator to learn domain-invariant features and align the two domains.
Recently, researchers have applied UDA methods to the field of agriculture. Fuentes et al. (2021) proposed a system specifically designed for open-set learning problems, capable of performing open-set domain adaptation and cross-domain adaptation tasks. Yan et al. (2021) proposed a UDA method for cross-species plant disease recognition based on mixed subdomain alignment, building upon the Deep Subdomain Adaptation Network (DSAN), particularly addressing situations with poor correlation between the source and target domains. Extensive experiments have demonstrated that this method exhibits excellent recognition performance for subdomains with low correlation. Wu et al. (2023) used data captured in the laboratory as the source domain and field environment data as the target domain. They employed the DSAN method to align the data of each class in the two domains, achieving better classification accuracy than other UDA methods on several crop datasets.
Although these studies have made progress in applying UDA to agricultural tasks, they primarily focus on learning crop disease features from a single source domain (Single-Source Unsupervised Domain Adaptation, SUDA), overlooking the fact that real-world agricultural datasets often originate from multiple domains with diverse characteristics. This necessitates more advanced methods, such as Multi-Source Unsupervised Domain Adaptation (MUDA), to better handle such complex data. These research works, although to a certain extent, alleviates the above problems. However, they focus solely on learning the disease characteristics of crops from a single source domain (Single-Source Unsupervised Domain Adaptation, SUDA), neglecting the fact that the labelled data available in real-world scenarios originate from multiple domains. Taking potato diseases in field environment as an example, due to the constraints of capturing and labelling costs, there are very few labelled data samples conforming to the same distribution. Furthermore, the interferences of multiple factors such as capture equipment, potato varieties, planting regions, and light conditions lead to significant distribution differences among data captured under different conditions. Although images captured under different conditions contain a wealth of disease feature information, SUDA only has one source domain and cannot simultaneously utilize data from multiple sources. To prevent ‘negative transfer’, which occurs when significant differences or weak correlations between the source and target domains cause the transferred knowledge to degrade the target domain’s model performance (Wang et al., 2019), it is necessary to restrict SUDA’s selection of data, thereby exacerbating the issue of data scarcity. To effectively utilize multiple potato disease datasets characterized by significant distributional disparities, the Multi-Source Unsupervised Domain Adaptation (MUDA) method emerges as a preferred choice. The simplest way to implement MUDA is by merging all source domains into a single domain (referred to as Source Combine), followed by aligning data distributions using the SUDA approach. This approach may improve the predictive capabilities of SUDA models due to data expansion (Zhu et al., 2019a). However, it may exacerbate the mismatch problem when aligning the multiple source domains with the target domain, resulting in unsatisfactory performance of the model on the target domain (Csurka, 2017). Thus, MUDA methods have been proposed to more effectively utilize multi-source data.
Early MUDA mainly uses a shallow model combination classifier to use data from multiple source domains. Xu et al. (2018) proposed a Deep Cocktail Network (DCN) to address issues related to domain and category shifts among multiple sources. Peng et al. (2019) introduced the M3SDA method, which dynamically adjusts the moments of feature distribution to transfer knowledge learned from multiple source domains to an unlabelled target domain. The aforementioned methods can be categorized into two groups: the first involves mapping multiple source domains and the target domain into a common feature space, where their distribution differences are minimized; the second involves combining classifiers trained separately on multiple source domains to obtain the final classifier for the target domain.
Zhu et al. (2019a) pointed out that both of these types of methods focus on extracting a common domain invariant representation for all domains, but this goal is challenging to achieve and can easily lead to significant mismatches. Even for a single source and target domain, learning their domain-invariant representations is not easy, as shown in Figure 1A. When attempting to align multiple source and target domains, the degree of mismatch increases and can lead to poor performance. Figure 1B is a schematic diagram of this process. The common domain invariant representation of the source (from source1 to source3) and target domains are their overlap. It can also be intuitively seen from the schematic diagram that when there are multiple source domains, it is very difficult to obtain their common domain-invariant representation with the target domain. Furthermore, these methods do not consider the relationship between target samples and the decision boundaries of domain-specific when matching distributions. Therefore, they proposed MFSAN to solve the above problems. While this method has shown promising results on public datasets, it still has limitations in two aspects. Firstly, when aligning each source-target domain pair, they adopted a global alignment approach, as shown in Figure 2A. This may lead to the failure to capture fine-grained information due to the neglect of relationships between subdomains of the same category in different domains, thereby affecting the model’s performance (Zhu et al., 2020). Secondly, the above method employed a single network structure in the feature extraction process, limiting the information that could be obtained.
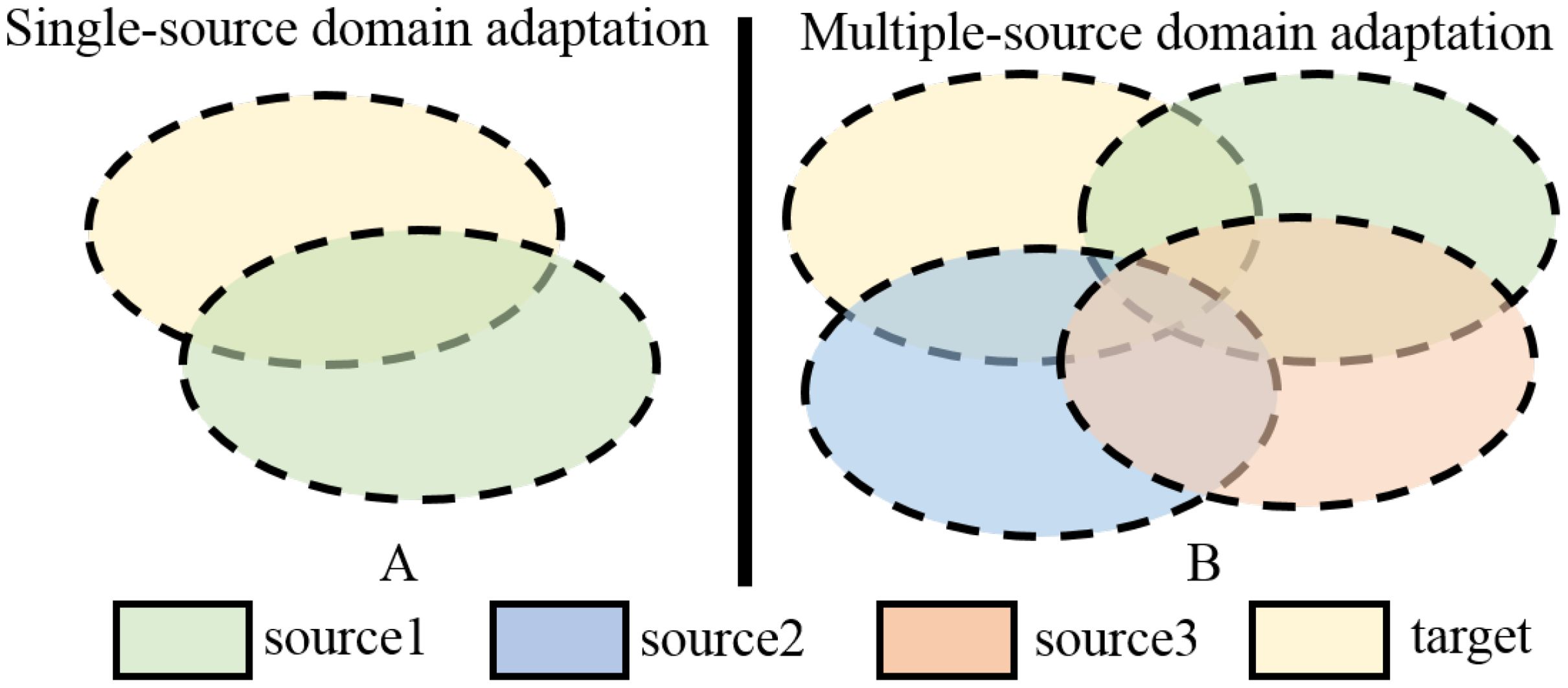
Figure 1. Schematic of SUDA and MUDA Methods. (A) Single-source domain adaptation. (B) Multiple-source domain adaptation.
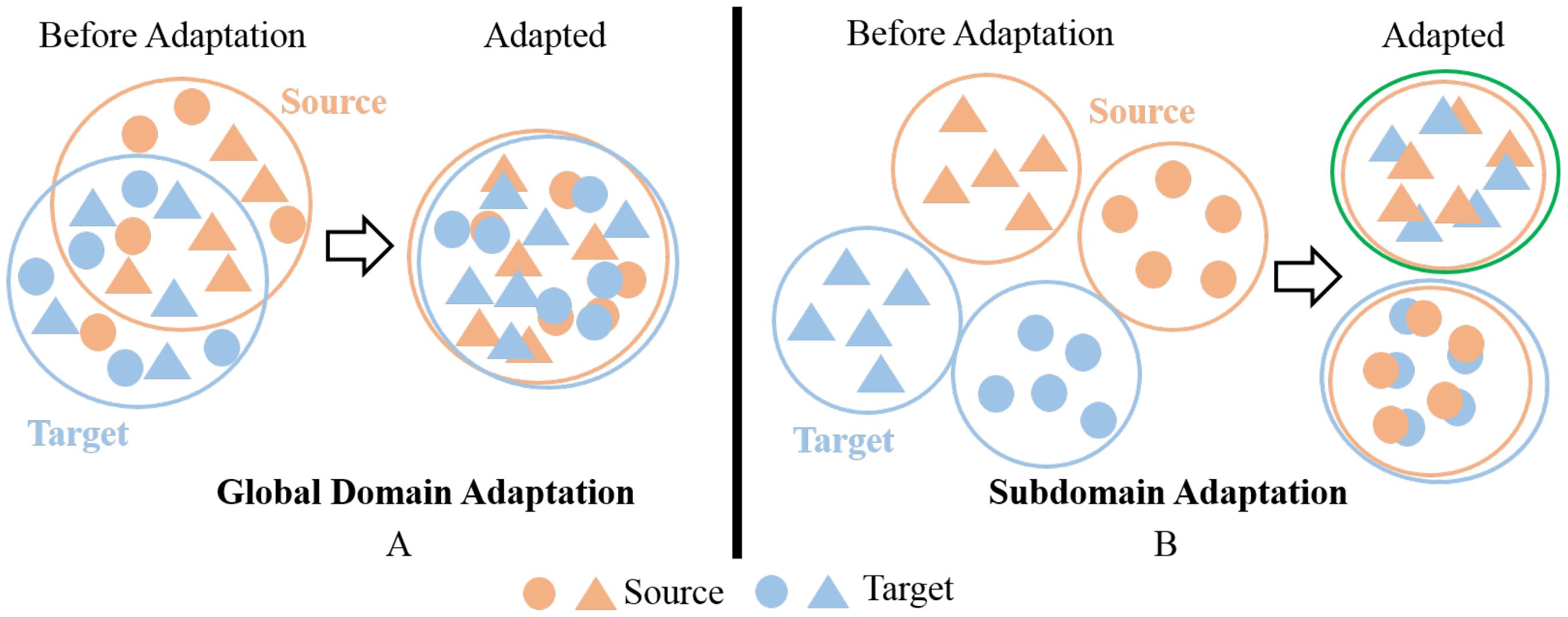
Figure 2. (A) Global Domain Adaptation (B) Subdomain Adaptation.
While MUDA methods have demonstrated promising results in various fields such as fault diagnosis (Wen et al., 2021; Wang et al., 2022a), visual emotion classification (Lin et al., 2020), healthcare (Deng et al., 2021; Abbet et al., 2022), gait detection (Guo et al., 2021) and text sentiment analysis (Peng et al., 2023), its effectiveness in the agricultural domain has not been widely researched and validated. Wang et al. (2022b) applied the MUDA method to unsupervised crop mapping and achieved good results. Ma et al. (2023) proposed an UDA method using a multisource maximum predictor discrepancy (MMPD) neural network for county-level corn yield prediction. Case studies in the U.S. Corn Belt and Argentina demonstrate that the MMPD model effectively reduces domain differences and outperforms several other advanced deep learning and UDA methods in terms of performance. There have been no reported studies related to MUDA in the field of crop disease recognition. To address the reduction in recognition accuracy caused by complex backgrounds and significant illumination changes in potato disease recognition within field environments, we propose the Multi-Source Domain Feature Adaptation Network (MDFAN), which introduces a two-stage alignment strategy. MDFAN leverages multi-feature extraction and subdomain alignment techniques to achieve better domain alignment and feature extraction across multiple domains, resulting in more accurate potato disease recognition.
The main contributions of this paper can be summarized as follows:
1. Changes in lighting can significantly affect the RGB pixel values of images captured in field environments, causing substantial differences in image features obtained under various lighting conditions. To maximize the use of data from different lighting conditions to train disease recognition models and enhance their generalization ability and avoid negative transfer, using the MUDA method is a feasible option. This paper proposes a disease recognition model named MDFAN to achieve this goal.
2. MDFAN includes two alignment stages. The first stage is domain-specific distribution alignment, primarily aimed at achieving distribution alignment for each source-target domain pair within a specific domain. The second alignment stage is called classifier alignment. In this stage, the predictions of various classifiers are aligned through decision boundaries specific to the domain, mitigating prediction discrepancies between different classifiers and enhancing prediction consistency.
3. In the domain-specific distribution alignment stage, a multi-representation extraction module and a subdomain alignment module (as illustrated in Figure 2B) are employed to learn multiple representations of domain variables for source-target domain pairs. These techniques help capture finer-grained information between subdomains of the same category across different domains and achieve more effective alignment.
4. Based on the lighting conditions during image capture, the dataset is divided into four domains, each encompassing five disease types. Extensive experiments were conducted on this dataset using 2 and 3 source domains to evaluate the performance of MDFAN. The experimental results demonstrate the robust generalization capability of MDFAN under this interference.
The rest of this paper is organized as follows. Section 2 provides a detailed introduction to the experimental data and MDFAN. Section 3 validates the effectiveness of MDFAN through experiments conducted on the dataset. Finally, some conclusions are drawn in Section 4.
2 Materials and methods
2.1 Database
The study by (Suh et al., 2018) indicates that changes in illumination are a significant factor causing differences in data distribution. Therefore, to evaluate the efficacy of MDFAN under conditions where illumination is the primary variable, a potato disease dataset, named DIF_light_intensities, was constructed, with all images captured in the field. Based on the time periods of image capture and the weather conditions (sunny or cloudy), we partition the data into four domains: Morning (Mo), Midday (Mi), Afternoon (A), and Cloudy (C). Among them, the pictures in the Mo, Mi and A domains are all captured on sunny days, which makes the contrast between light and shade caused by occlusion prevalent in the pictures, and there are still some overexposed pictures in the Mi domain. In the C domain, the image is generally dark due to insufficient lighting. In Figure 3, we present two images each from the insufficient lighting (Domain: C) and the sufficient lighting (Domain: Mi), providing a visual comparison to highlight the lighting differences in field environments.

Figure 3. Lighting Conditions Comparison.
Each domain contains images of Potato Cercospora Leaf Spot (PCLS), Potato Early Blight (PEB), Potato Late Blight (PLB), Potato Macrophomia Blight (PMB), Potato Powdery Mildew (PPW). Each disease type corresponds to a subdomain in its own domain. Taking the Mo domain as an example, it contains five subdomains: PCLS, PEB, PLB, PMB, and PPW. Therefore, the subdomain labels in these four domains are consistent.
The domains and corresponding subdomains of disease images in this dataset are illustrated in Figure 4.

Figure 4. Disease Illustration in DIF_light_intensities Dataset.
Table 1 provides relevant information about the dataset, including the capture time of images in each domain, the number of images for each disease type, and other pertinent information. Taking Mo as an example, the image capture time is 7: 00-11: 00, and there are 86 PEB images.
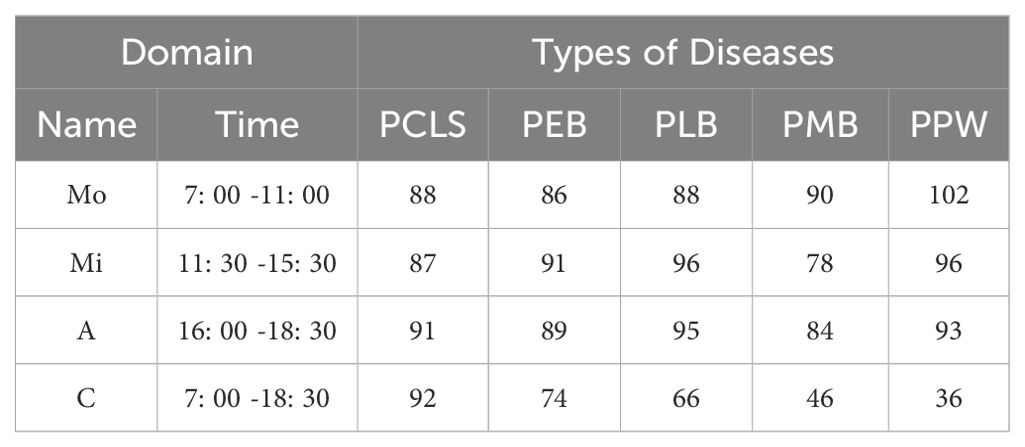
Table 1. Composition of DIF_light_intensities dataset.
To comprehensively assess the effectiveness of MDFAN, the investigation focuses on the transfer tasks associated with both the 2-source and 3-source domains of the dataset. Among them, there are twelve transfer tasks corresponding to 2-source domains, abbreviated as: Mo, Mi →A; Mo, Mi →C; Mo, A →Mi; Mo, A→C; Mi, A →Mo; Mi, A→C; Mo, C →Mi; Mo, C→A; Mi, C →Mo; Mi, C→A; A, C →Mo; A, C →Mi. Additionally, there are four transfer tasks corresponding to the 3-source domains, abbreviated as: Mo, Mi, A→C; Mo, Mi, C→A; Mo, A, C →Mi; Mi, A, C →Mo. In the case of Mo, Mi → A, where Mo, Mi represent two available source domains and A represents the target domain, the arrow “→” denotes the transfer process, and the 3-source domains follow a similar pattern.
We have devoted significant effort to obtaining potato disease data under varying lighting conditions in field environments and have developed the DIF_light_intensities dataset. This is because changes in lighting directly affect image brightness, contrast, and shadows, making it challenging for models to effectively extract features. This dataset offers a practical and challenging platform for evaluating the robustness of our method. The following section provides a detailed introduction to the MDFAN method, which is designed to mitigate the impact of lighting variations through a carefully crafted two-stage alignment strategy.
2.2 Methods
2.2.1 Problem definition
This section introduces the proposed potato disease recognition method, MDFAN, designed for use in field environments. First, we make some basic assumptions:
1. The data in the source domain are labelled, and an effective source classifier can be constructed.
2. The target domain data is unlabelled.
3. The feature space and label space of each domain are the same, but the probability distributions differ.
In MUDA, N different source domains are considered, with their data distributions represented as , where sj denotes the j-th source domain. The labelled data from the source domain is denoted as , where refers to the samples from source domain j, and refers to the corresponding labels. The distribution of the target domain is represented as . Sampling from this distribution results in the target domain data, denoted as , where is unlabelled. Our aim is to establish an effective prediction model using data from multiple source domains to achieve accurate classification of target domain samples.
2.2.2 Overview of network framework
The structure of the proposed MDFAN is depicted in Figure 5. It consists of three parts: common feature extractor, domain-specific distribution alignment, and classifier alignment. The domain-specific distribution alignment is the first alignment stage. In this stage, the distribution alignment in the specific domain is achieved for each source-target domain pair by using multiple domain-invariant representations of the source-target domain pair. The method for extracting multiple domain-invariant representations for each source-target domain pair is to map each domain-invariant representation to a specific feature space and match their distributions. Generally speaking, the simplest way to map each source-target domain pair to a specific feature space is by training multiple networks, but this approach is extremely time-consuming. In MDFAN, this objective is achieved through the use of two subnetworks. The first part is a shared subnetwork used to learn common features across all domains, which is the common feature extractor in the MDFAN structure. The second part consists of N subnetworks corresponding to specific domains, also referred to as non-shared subnetworks. As shown in Figure 5, Hj (j=1,…,N) represents a non-shared subnetwork, which belongs to the Source j -target pair, and its obtained weights are not shared. In each non-shared subnetwork, a multi-representation extraction module, referred to as the Inception Module (Szegedy et al., 2015), is used to capture more fine-grained information. In addition, in conjunction with the LMMD metric method in the subdomain alignment module, to minimize intra-class variance as much as possible. After each non-shared subnetwork, there is a corresponding domain-specific classifier Cj. Due to the potential inconsistencies in the predictions of Cj for target domain data near different domain decision boundaries, a classifier alignment module was designed as the second alignment stage. This module aligns the outputs of domain-specific classifiers for target samples to enhance prediction consistency.
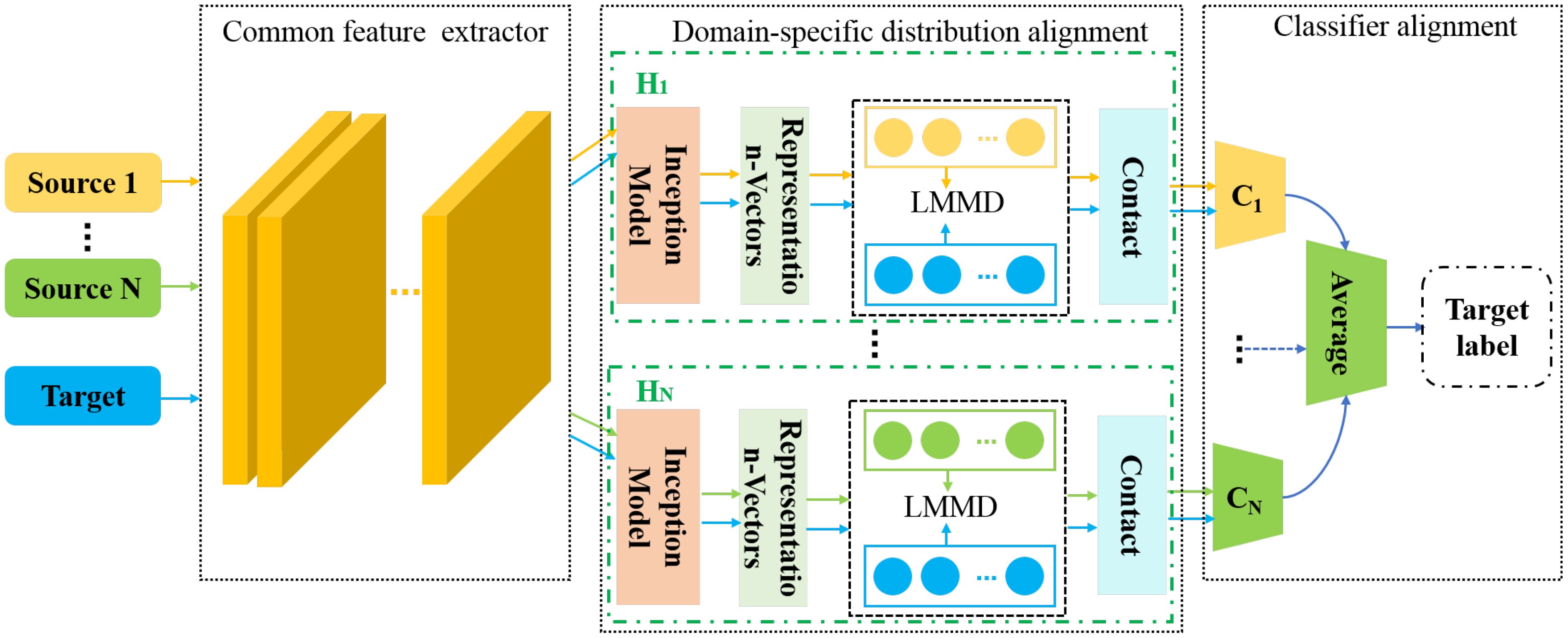
Figure 5. Structure of the MDFAN.
2.2.3 Common feature extractor
ResNet50 (He et al., 2016) is a classic feature extraction network architecture widely used across various tasks. In MDFAN, ResNet50 is utilized as the common feature extractor to extract shared features from all domains. Upon sequentially inputting data from Source 1 to Source N and the target domain sequentially, it maps images from the original feature space of each domain to a common feature space.
Let denote the ResNet50 network. Then, for a batch of images from the source domain and a batch of images from the target domain , the common feature extraction process can be represented as follows:
Here, represents the features learned from the j-th source domain, and represents the learned features from the target domain.
2.2.4 Domain-specific distribution alignment
This part is used to implement the first alignment stage, consisting of N independent non-shared subnetworks . Each corresponds to a source-target domain pair, where N equals the number of source domains. contains an Inception module that learns multiple domain-invariant representations of source-target domain pairs in a specific domain. It is also called a domain-specific feature extractor. It also includes a subdomain alignment module that implements domain-specific distribution alignment. The details are introduced as follows.
(1) Domain-specific feature extraction.
To minimize the differences in data distribution between the source and target domains during subsequent processes, multiple domain-invariant representations of each source-target domain pair are mapped to a specific feature space. The domain-specific feature extractor is designed to achieve this goal. First, the common features and are obtained from the shared feature extractor. Then, the common features of each source-target domain pair will be mapped to a specific feature space by their corresponding non-shared subnetwork . The complete structure of the Inception module is illustrated in Figure 6, consisting of a total of four branch structures: A1 - A4. This structure increases the width of the network, with each branch complementing the others, effectively capturing the overall information of the leaves in the image. In addition to acquiring overall features, it maintains the relationship between the leaves and the background environment. Taking Source1-target as an example, the features of Source1 and the target obtained from the shared feature extractor are sequentially inputted into the Inception module. The Inception module processes input data through four parallel paths, allowing different paths to independently extract features. The resulting representation vector is the specific domain feature representation corresponding to the Source1-target domain pair. The vector representations obtained from each branch are outputted to the corresponding specific domain predictor C1 after being processed by the corresponding specific domain distribution alignment module.
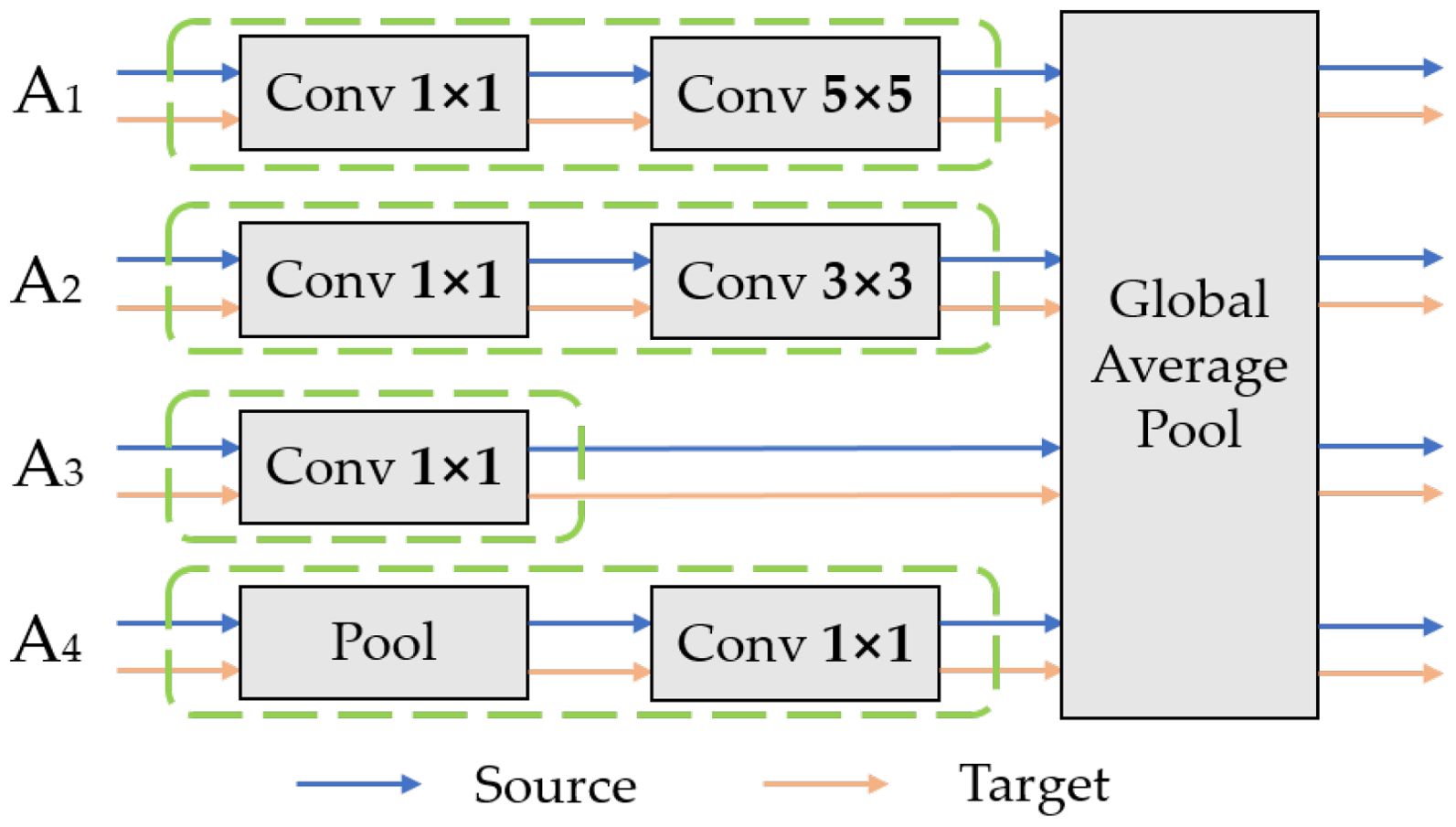
Figure 6. Architecture of the Inception Module.
(2) Domain-specific distribution alignment.
To achieve better alignment in the first stage, the conventional Maximum Mean Discrepancy (MMD) (Gretton et al., 2012) is not chosen. This is because the MMD method focuses on the global distribution alignment between the source and target domains at the domain level. Its drawback is that even if the distributions of the source domain and the target domain are well aligned, errors in aligning the same subdomains in these two domains may occur. This can lead to the loss of fine-grained information, thereby affecting the model’s performance. The LMMD (Local Maximum Mean Discrepancy) method proposed by (Zhu et al., 2020) is employed, which achieves effective domain-level alignment by accurately aligning the distributions of relevant subdomains across different domains.
To achieve subdomain alignment, the source domain and the target domain are divided into k subdomains, and , respectively, based on the number of categories K. Here, k takes on values from the set to represent category labels. In the DIF_light_intensities dataset, when the Mi domain serves as the source domain, it is split into five subdomains: PCLS, PEB, PLB, PMB, and PPW. In the case of the Mo domain as the target domain, it is also split into five subdomains.
In formal terms, LMMD defines the following divergence metric:
Here, represents the mathematical expectation of category k. and are instances of the source domain and the target domain , respectively. and are the distributions of and , respectively. denotes the Reproducing Kernel Hilbert Space (RKHS) equipped with the characteristic kernel . is the mapping function that transforms the original sample into one of the RKHS feature maps. The kernel can be defined as , where denotes the inner product of vectors. By minimizing Equation 2, the gap between the distribution of the corresponding subdomains can be narrowed.
It is assumed that each sample is associated with a category according to the weight . Therefore, the unbiased estimate of Equation 2 can be expressed as:
Where and represent the weights of and belonging to category k, respectively. Both and sum to 1, and is the weighted sum over category k. The weight for the sample is calculated using the following equation:
Where is the kth value of the vector . For samples in the source domain, the true labels are used to calculate the weight for each sample. However, since the target domain lacks available labels, the probability distribution predicted by the neural network is used instead. Since the output is a probability distribution, it can effectively assign to each category K.
After applying LMMD to the representation vectors obtained from the multi-representation module, Equation 3 can be rewritten as:
As cannot be directly computed, it is replaced by Equation 6, resulting in the LMMD loss being redefined as:
Among them, and represent the activations of the source and target subdomains samples after the multi-feature extraction, respectively, and and represent the weights of and belonging to class K.
Equation 6 can be briefly expressed as:
2.2.5 Classifier alignment
During the domain-specific distribution alignment process, the results obtained from each non-shared subnetwork are fed into their corresponding predictor Cj in the classifier alignment section. This predictor is referred to as the domain-specific predictor. Because predictors are trained independently on various source domains, they often exhibit discrepancies in their predictions for target samples. This limitation easily leads to misclassification of samples near category boundaries in the target domain. To address this issue, we propose the second alignment stage, referred to as classifier alignment. It consists of two parts: domain-specific classifiers and prediction alignment. They are introduced separately as follows.
(1) Domain-specific classifiers
The domain-specific classifier C is a multi-output network consisting of N specific domain predictors . Each predictor is a softmax classifier and receives domain-invariant features after the specific feature extractor of the j-th source domain. represents the common feature extractor introduced in Section 2.2.3, while is the domain-specific feature extractor introduced in Section 2.2.4. Each classifier uses a cross-entropy loss, formulated as follows:
(2) Prediction alignment
This stage is used to minimize the differences of the decisions among all classifiers. Specifically, by utilizing the absolute differences between the probability outputs of all predictors for target domain data as the difference loss, the calculation process is as shown in Equation 9:
In which denotes mathematical expectation, minimizing Equation 9 ensures that the probability outputs of all classifiers are similar. Finally, the average value of classifiers C1 -CN (i.e., the ‘Average’ portion in Figure 4) is calculated and used as the predicted output for the target sample.
2.2.6 Optimization objectives and training strategies
MDFAN includes a classifier loss , an LMMD loss , and a classifier discrepancy loss . Among them, by minimizing the classifier loss, the network can accurately classify the source domain data; minimizing the loss captures more fine-grained information, and minimizing the classifier discrepancy loss reduces differences between classifiers. Finally, the total loss is calculated as:
Where and are balancing parameters that compromise the roles of various functional modules. The optimization objective (10) can be easily trained and implemented using standard mini-batch stochastic gradient descent. The whole process is summarized in Algorithm 1.

Algorithm 1. Multi-source domain feature adaptation network.
3 Experiment
3.1 Baseline and comparison
At present, the commonly used method in plant disease identification is pre-training-fine-tuning. Therefore, the pre-training-fine-tuning model based on ResNet50 is used as the Baseline. Other methods participating in the comparison are summarized as follows:
(1) DDC, DAN, and DeepCoral: These three methods are commonly used metric-based approaches and are widely employed in SUDA methods. DDC (Tzeng et al., 2014) reduces domain shift between the source and target domains through the MMD, while DAN (Long et al., 2015) achieves this by using an enhanced version of MMD called MK-MMD. DeepCoral (Sun and Saenko, 2016) aligns the second-order statistics of the distributions between the source and target domains through a linear transformation.
(2) DANN, DAAN: Both of these methods are based on adversarial UDA approaches. DANN (Ganin et al., 2016) employs an adversarial learning strategy to achieve cross-domain feature fusion, while DAAN (Yu et al., 2019) shares a similar base network with DANN. The core of DAAN lies in the introduction of a conditional domain discriminator block and integrated dynamic adjustment factors, enabling dynamic adjustment of the relationship between marginal and conditional distributions.
(3) MRAN: The method (Zhu et al., 2019b) introduced a domain adaptation algorithm based on multiple representations, utilizing a hybrid structure for the extraction and alignment of multiple representations.
(4) MFSAN: Zhu et al. (2019a) integrated the technical approaches of two previous MUDA methods, achieving both the minimization of feature space differences between multiple source and target domains, and the optimization of multiple classifier outputs.
Since most of the previously mentioned methods are specifically designed for SUDA, for convenient comparison, we devise three MUDA evaluation criteria tailored for different purposes. Each criterion is introduced separately below:
(1) Single-Best: This criterion assesses the performance of a single source domain in transferring to the target domain and reports the highest accuracy achieved in the transfer task. For example, in the transfer tasks Mo, Mi → A, this criterion lists the highest accuracy results from the two transfer tasks Mo → A and Mi → A.
(2) Source-Combine: In this criterion, multiple source domains are merged, and the accuracy of each method is reported on the corresponding transfer tasks for the merged dataset. This approach can be viewed as a form of data augmentation for a single-source domain. Similarly, taking Mo, Mi →A as an example, under this criterion, it refers to merging the source domains Mo and Mi into a single source domain based on the same categories, and then listing the classification accuracy of their transfer to the target domain D.
(3) Multi-Source: This criterion is used to report the results of the MUDA method in each task. Still taking Mo, Mi →A as an example, under this criterion, the Mo and Mi domains are keep independent as source domains, and the classification accuracy of their transfer to the target domain A is listed.
The first criterion functions as a benchmark to assess whether the introduction of data from additional source domains can lead to improved accuracy in various transfer tasks, irrespective of whether it involves source domain merging or multiple source domains. The second criterion aims to demonstrate the research value of MUDA methods by evaluating their effectiveness through the merging of multiple source domains and assessing performance on corresponding transfer tasks. The third criterion is to demonstrate the effectiveness of MFSAN and MDFAN.
3.2 Implementation details
All experiments in this paper are conducted on the server with the following configuration: Ubuntu 18.04 system, i7-10000 processor, NVIDIA GeForce GTX 3070Ti, 8GB RAM, and PyTorch1.7 as the deep learning framework. During data loading, images are initially resized to 256x256 and subsequently randomly cropped to 224x224 before being fed into the network.
The initial learning rate is set to 0.01, batch size to 32, and the training runs for 100 epochs. Stochastic Gradient Descent (SGD) with a momentum of 0.9 is employed as the optimizer. The learning rate is adjusted during SGD using a decay strategy with the following formula: , where linearly changes from 0 to 1 over the course of training. The initial value is set to 0.01, and are set to 10 and 0.75, respectively. In the early stages of the training process, to suppress noisy activations, and are set as dynamic adjustment factors, gradually transitioning from 0 to 1 through the following formula: is fixed at 10 throughout the entire experiment.
3.3 Experimental results and analysis
3.3.1 Performance comparison
As described in Section 2.1, significant differences exist in the distribution of images captured under varying illumination intensities. Considering this variability, the DIF_light_intensities dataset is created, which accounts for changes in illumination during image capture. This dataset encompasses four domains: Mo, Mid, A, and C, each representing five distinct types of potato diseases. To evaluate the resilience of the MDFAN method against lighting variations, a comprehensive series of transfer experiments is conducted using this dataset across 2-source and 3-source domains. Each experiment is assessed using three indicators: Single-Best, Source-Combine, and Multi-Source. Detailed descriptions of these experiments are provided in the following section.
(1) 2-source domain
Table 2 presents the classification accuracy of various algorithms on individual transfer tasks and the average accuracy across all tasks, denoted as Avg1, when using 2-source domains. The highest accuracy for each transfer task is highlighted in bold, and the second is underlined. Analyzing these values reveals several patterns. For the same SUDA method, the accuracy in the Source-Combine scenario surpasses that in the Single-Best scenario. Additionally, the Multi-Source scenario outperforms Source-Combine. These improvements can be attributed to different factors. The enhancement in Source-Combine performance results from the increased data volume after merging the source domains. In contrast, Multi-Source not only benefits from the increased available data but also effectively mitigates domain shift between different source domains and between the source and target domains.
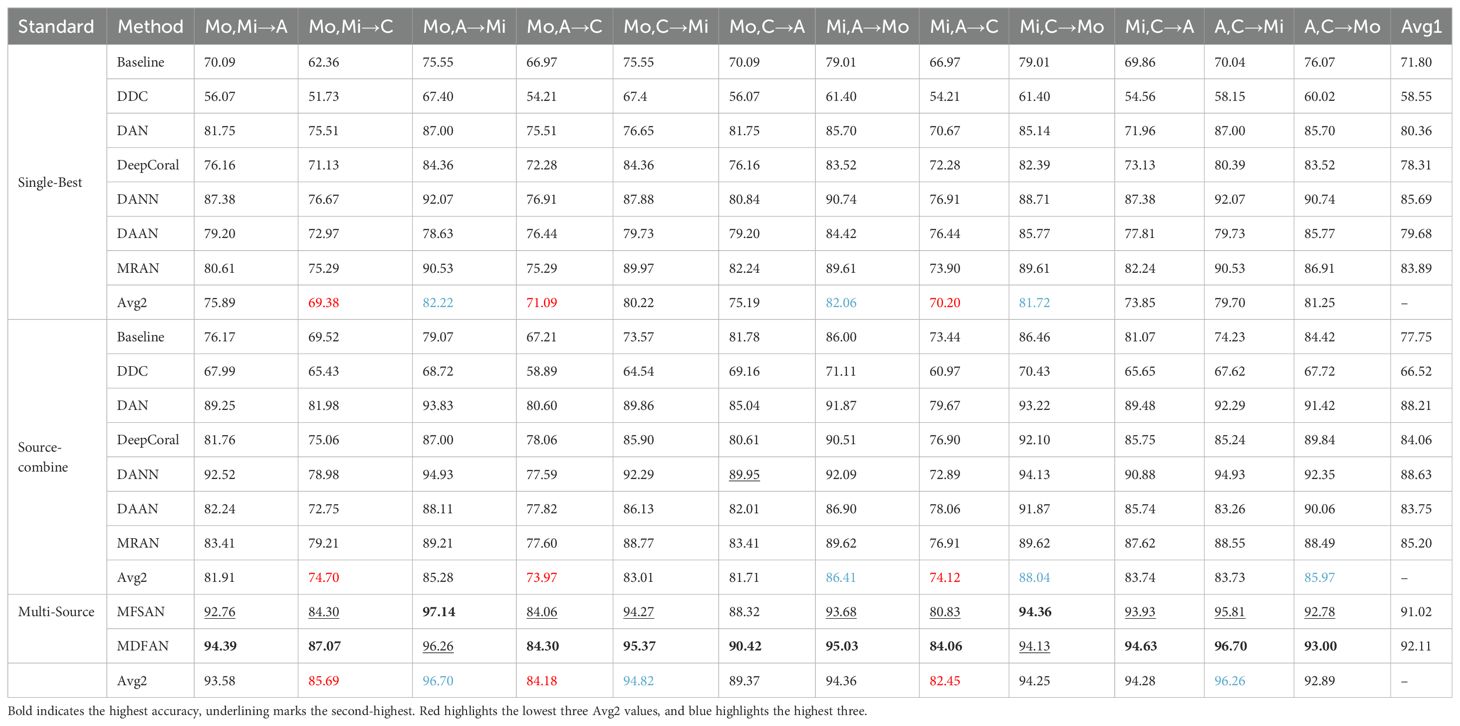
Table 2. Classification accuracies (%) with 2-source domain.
All UDA methods, except for DDC, outperform Baseline in both individual task accuracy and average accuracy Avg1. Source-Combine demonstrates a notable improvement of 1.31%-7.97% in average accuracy compared to Single-Best. Multi-Source exhibits an even more substantial increase of 2.39%-8.36% over Source-Combine and achieves a remarkable 5.33%-13.8% improvement over Single-Best in terms of average accuracy. Based on these results, the following conclusions can be drawn: (1) Since images captured under different illumination intensities exhibit significant differences, commonly used pre-training-fine-tuning method have poor generalization ability on such experimental configuration. This results in the Baseline model having low classification accuracy. (2) The UDA method can effectively improve the accuracy of disease classification on such condition. (3) Compared to the “rudely” approach of source domain combination, Multi-Source further enhances network performance by more “sophisticatedly” leveraging data from multiple source domains.
DDC exhibits the lowest performance, and analysis suggests that this is primarily due to the characteristics of DDC’s own network structure. DDC fixes the first 7 layers of AlexNet and incorporates MMD as an adaptive metric on the 8th layer. However, AlexNet tends to overfit on small datasets, and its limited depth hinders effective extraction of abstract features.
Across twelve transfer tasks, MDFAN achieves the highest accuracy in ten of them. For individual task accuracy, it outperforms MFSAN by 0.22%-3.23%, with an average accuracy improvement of 1.09%. This demonstrates that MDFAN addresses the issue of domain shift caused by illumination changes more effectively than MFSAN. The improvement in accuracy indicates that MDFAN’s two-stage alignment strategy offers greater deployment advantages in field environments with significant lighting variations.
To analyze how the Mo, Mi, A, and C domains, and their corresponding illumination conditions, affect model performance, Avg2 is introduced, representing the average accuracy of various methods in the same transfer task. As shown in Table 2, Avg2 is calculated under three criteria: Single-Best, Source-Combine, and Multi-Source. The three transfer tasks with the bottom Avg2 values are marked in red, while the three with the top values are marked in blue. Under the three criteria, the bottom 3 transfer tasks of Avg2 consistently have C domain as the target domain regardless of changes in their source domains. For the top 3 tasks of Avg2, under Single-Best criterion, the target domain is consistently Mo; under Source-Combine criterion, two have Mo as the target domain and one has Mi. Under Multi-Source criterion, two have Mi as the target domain and one has Mo. Analyzing Avg2 across different modes reveals that for Source-Combine, even the worst performance is improved by 4.59% compared to Single-Best, and the best performance is enhanced by 5.82%. In contrast, Multi-Source demonstrates improvements of 13.07% and 14.48% for the worst and best Avg2 values respectively, compared to Single-Best, and 8.48% and 8.66% compared to Source-Combine. It is MDFAN that achieves this level of accuracy, further highlighting its strong robustness to illumination changes.
Based on the above results, the following conclusions can be drawn: (1) Insufficient lighting conditions, such as overcast days, can limit the model’s ability to extract features from images captured under such conditions. (2) Images captured during the morning and noon on sunny days are beneficial for improving the model’s performance. (3) Compared to single-source domain and source combine, MUDA methods demonstrate stronger robustness to varying lighting conditions.
The confusion matrix is a commonly used tool to assess classification task performance. It allows for further evaluation of the recognition accuracy of a classification model for different diseases. Each disease type corresponds to a subdomain within its respective domain. Thus, by examining the classification accuracy of each method for each disease type in the confusion matrix of a given transfer task, the strengths and weaknesses of each method can be clearly identified.
Figure 7 illustrates the confusion matrices for DAN, DeepCoral, DANN and MFSAN under three criteria for the Mo, Mi → A tasks. From this figure, it can be observed that the different UDA algorithms exhibit distinct error sources when identifying potato diseases. ‘Single-’, ‘Combine-’, and ‘Multi-’ in Figure 7 indicate that the method belongs to ‘Single-Best’, ‘Source-Combine’, and ‘Multi-Source’, respectively. The same is true in other figures. For example, the recognition rate of Single-DAN for PCLS is very low only 55% and the test samples are misidentified as PLB. The other methods in Source-Combine and Multi-Source greatly improve the accuracy of the disease. The accuracy of Combine-DANN and Multi-MDFAN is the highest, reaching 100%. The classification of the other four disease types by each method also conforms to this trend, so it is no longer repeated.

Figure 7. Confusion matrices of transfer task Mo, Mi → A. (A) Single-DAN, (B) Single-DeepCoral, (C) Single-DANN, (D) Combine-DAN, (E) Combine-DeepCoral, (F) Combine-DANN, (G) Multi-MFSAN, (H) Multi-MDFAN.
(2) 3-source domain
The results for the 3-source domains are presented in Table 3, from which conclusions similar to those for the 2-source domains scenario can be drawn. However, there are some differences between the experimental results of the 3-source domains and the 2-source domains, which are described below: (1) Due to the further increase in available data, the classification accuracy on individual tasks and average accuracy of each method in Single-Best, Source-Combine, and Multi-Source have improved compared to the 2-source domains scenario. (2) Under the Source-Combine criterion, the adversarial-based DANN method achieves the highest accuracy among all methods in two transfer tasks. This implies that an increase in the dataset size to a certain extent (in this experiment, the number of images for each disease type ranges from 200 to 300) is beneficial for the performance improvement of the DANN method.
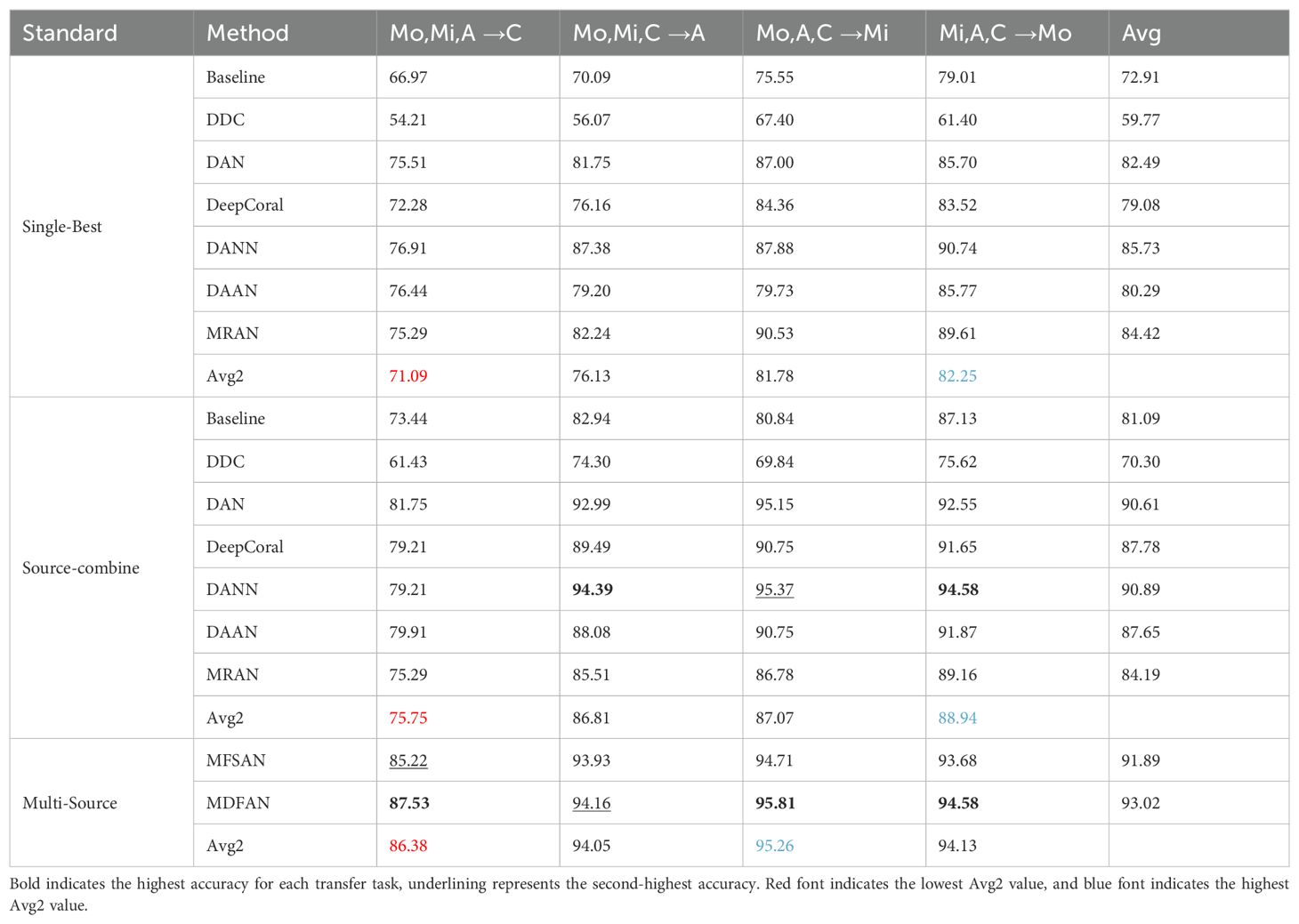
Table 3. Classification accuracies (%) with 3-source domain.
When 3-source domain datasets are available, a similar analysis is conducted to assess the impact of the Mo, Mi, A, and C domains on the model’s performance, following the same analysis as with the 2-source domain scenario. The difference is that only the lowest value in Avg2 is marked in red, and only the best is marked in blue. From Table 3, it can be observed that when the target domain is C, the Avg2 is the lowest, while it is the highest when the target domain is Mi. This leads to the conclusion that insufficient lighting can affect model performance, while abundant lighting contributes to the improvement of model performance.
Although insufficient illumination adversely affects the model’s performance, the Multi-Source method can better solve this problem and improve the accuracy of the corresponding tasks. In this scenario, MFSAN achieves an accuracy of 85.22% in the task Mo, Mi, A→C, while MDFAN further improves the accuracy to 87.53%. Compared to the three transfer tasks Mo, Mi → C, Mo, A → C, and Mi, A → C with C as the target domain under the condition of 2 source domains, MDFAN achieves higher accuracies of 0.46%, 3.23%, and 3.47% respectively for the transfer task Mo, Mi, A → C. In summary, it is evident that by incorporating a third source domain, MDFAN further enhances accuracy. This demonstrates its ability to more effectively leverage diverse data sources, thereby improving the model’s generalization capability.
To analyze the classification of each disease by typical methods under three criteria when the target domain is C, we present their confusion matrices in Figure 8 for the transfer task Mo, Mi, A→C.
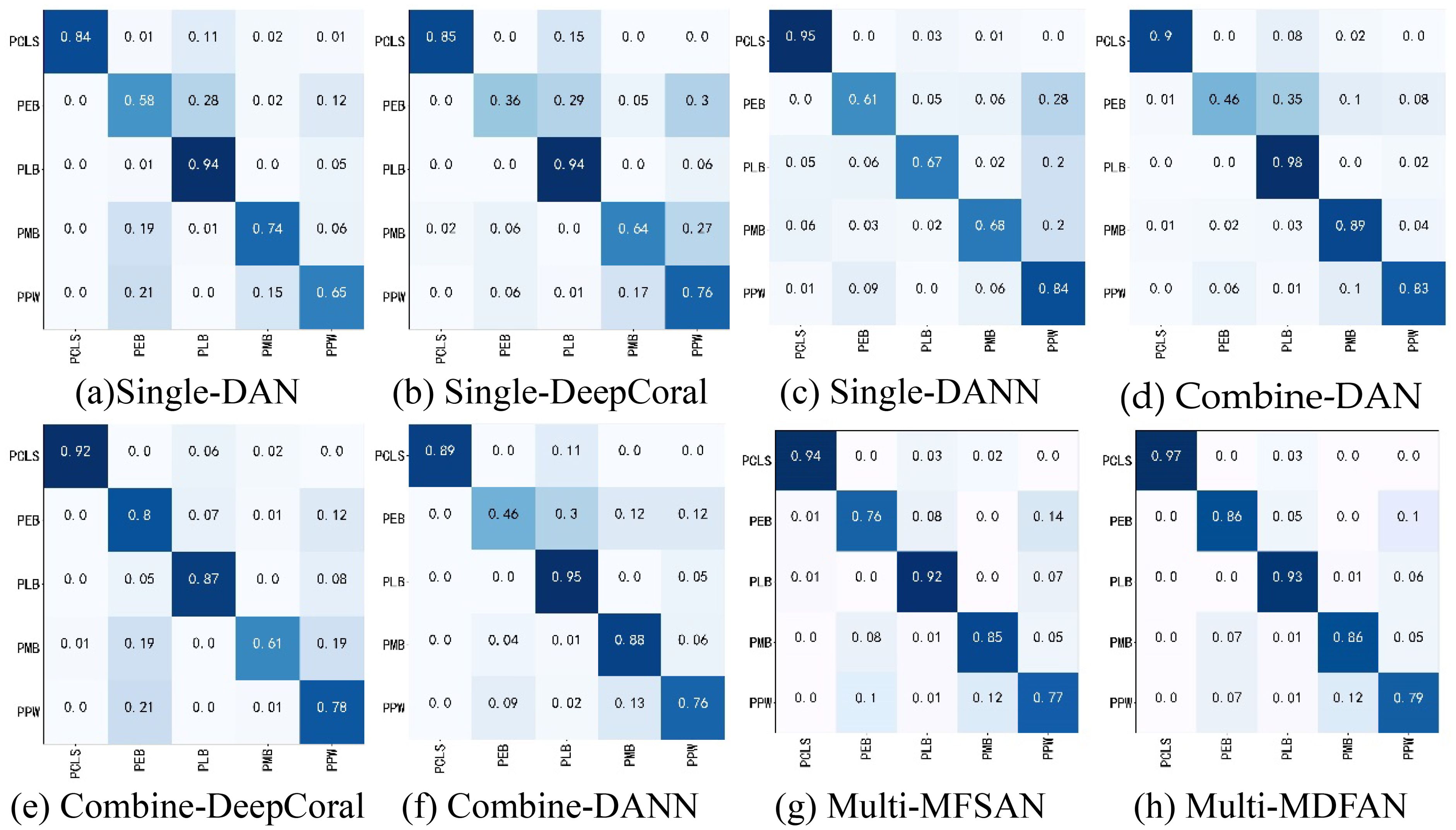
Figure 8. Confusion matrices of transfer task Mo, Mi, A → C. (A) Single-DAN, (B) Single-DeepCoral, (C) Single-DANN, (D) Combine-DAN, (E) Combine-DeepCoral, (F) Combine-DANN, (G) Multi-MFSAN, (H) Multi-MDFAN.
For example, the recognition rates of Single-DAN for PEB, PMB, and PPW are 58%, 74%, and 65%, respectively. In comparison, the classification results of various methods in Combine-Source for these items show both improvements and declines in accuracy. However, the methods in Multi-Source have greatly improved the accuracies for these three diseases. The situation for the other two disease types is similar and will no longer be repeated. Overall, Multi-Source is better adapted to insufficient lighting conditions compared to Combine-Source.
3.3.2 Feature visualization
To visualize the differences in the performance of UDA methods, t-distributed stochastic neighbor embedding (t-SNE) and gradient-weighted class activation mapping (Grad-CAM) are used to display the relevant results. Firstly, t-SNE is used to visualize the latent feature space representation of the source domains and the target domain, and their categories for the transfer task Mi, A →Mo in the methods DAN and DANN from Single-Best and Source-Combine, as well as MFSAN and MDFAN from Multi-Source. Since Single-Best and Source-Combine both belong to SUDA methods, and the final result of Multi-Source is obtained based on classifiers for multiple source domain-target domain pairs, the Multi-Source are further divided into single source domains for visualization. In other words, within the MUDA method, Mi, Mo → A is separately visualized by breaking it down into Mi → A and Mo → A.
Figure 9 displays the feature alignment performance of the mentioned methods on this transfer task. It is evident that MDFAN has the best performance, followed by MFSAN, and DAN performs the worst. This aligns with the quantitative analysis results in Table 2. Figure 10 shows the t-SNE visualization effect of the above method on the classification objects in the target domain. Different disease types are represented by various shapes and colors. It is easy to see that MDFAN has better category discrimination ability than MFSAN, DANN, and DAN. This indicates that the comprehensive use of two-stage alignment strategy, multi-representation extraction module and subdomain alignment method can make the model have better generalization ability for datasets with domain shift caused by light variation.
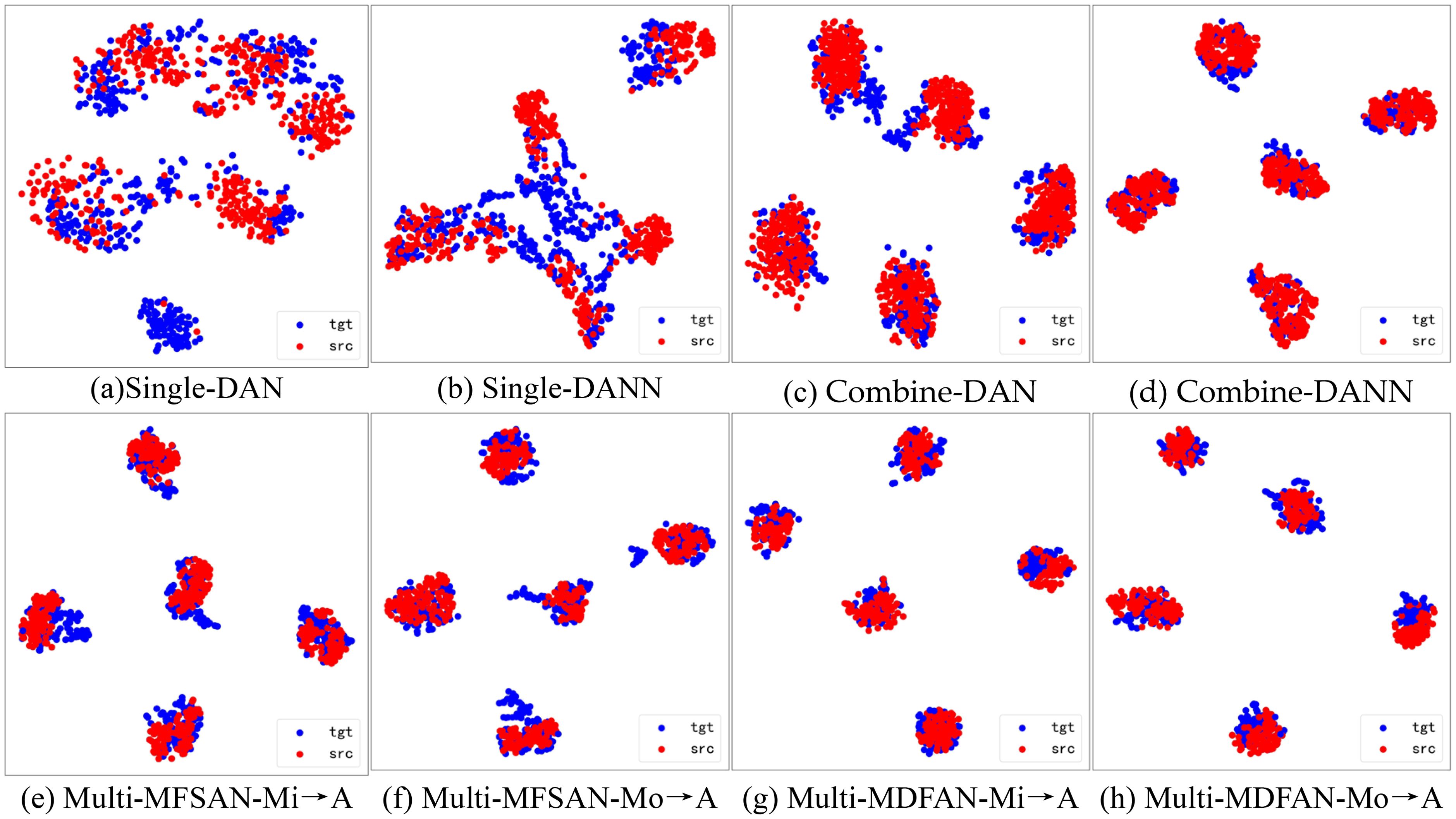
Figure 9. Visualization of potential spatial representations for Mi, A → Mo task using t-SNE(• is source domain, • is target domain). (A) Single-DAN, (B) Single-DANN, (C) Combine-DAN, (D) Combine-DANN, (E) Multi-MFSAN-Mi→A, (F) Multi-MFSAN-Mo→A, (G) Multi-MDFAN-Mi→A, (H) Multi-MDFAN-Mo→A.
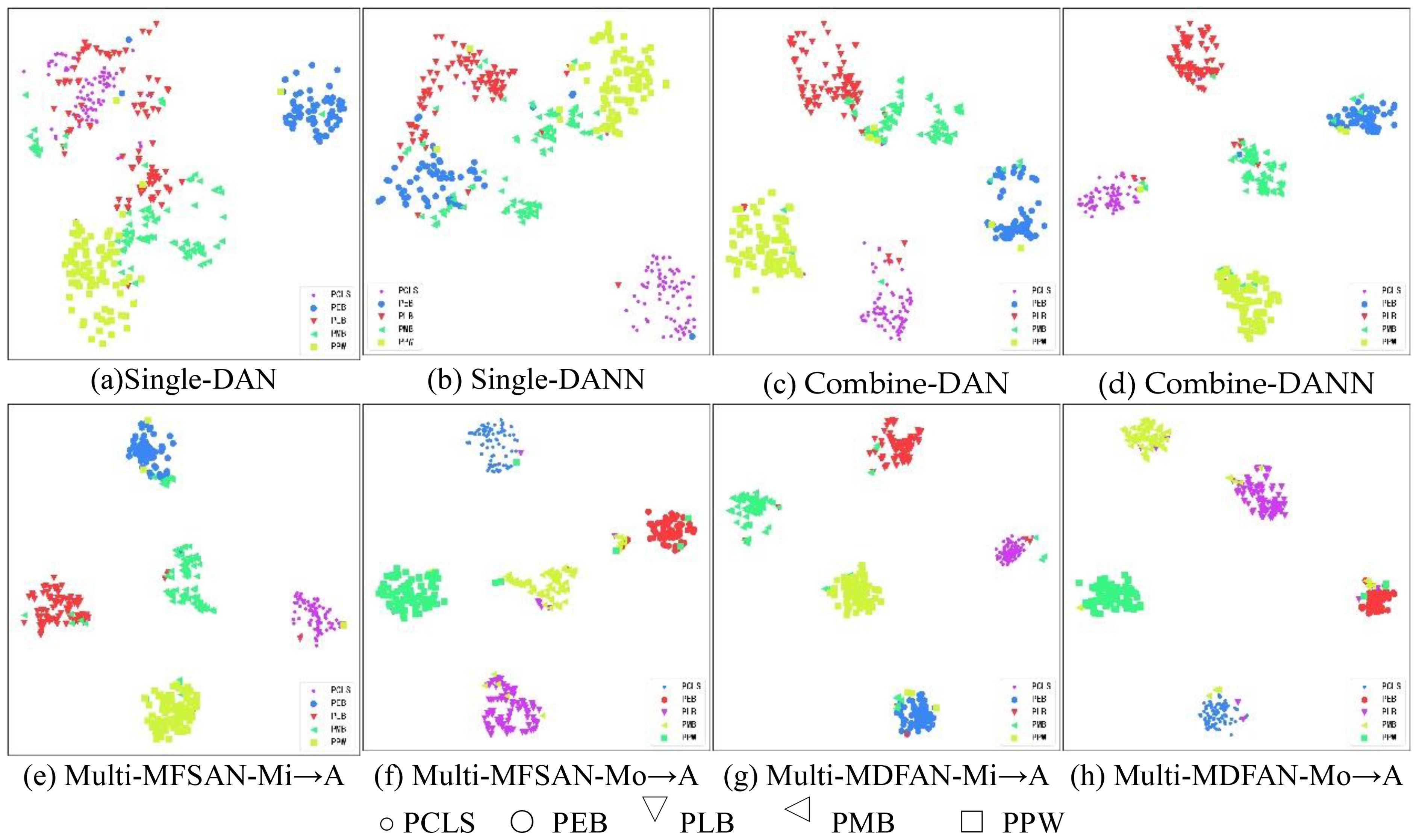
Figure 10. Visualization for Mi, Mo → A task using t-SNE. (A) Single-DAN, (B) Single-DANN, (C) Combine-DAN, (D) Combine-DANN, (E) Multi-MFSAN-Mi→A, (F) Multi-MFSAN-Mo→A, (G) Multi-MDFAN-Mi→A, (H) Multi-MDFAN-Mo→A.
In Figure 11, the Grad-CAM maps of several methods on the target domain A are presented. From these Grad-CAM maps, the regions of interest for each method in the images of each disease type are clearly visible. The performance of each method can be assessed based on the degree of agreement between the regions of interest and the lesion regions. The first row shows the disease images, and others display the Grad-CAM maps, produced by DAN(Single-Best), DAN(Source-Combine), MFSAN and MDFAN, respectively. It is evident that MDFAN can pinpoint the location of the potato disease more accurately than other methods.

Figure 11. Grad-CAM visualization for Mi, Mo →A task.
3.3.3 Ablation experiment
Ablation experiments are crucial for understanding the contribution of each component within MDFAN. By isolating the multi-representation extraction module and the subdomain alignment module, we can assess the impact of each part. In the following experiments and analyses, we will explore the significance of these components. Ablation experiments are conducted on transfer tasks corresponding to both 2-source domain and 3-source domain scenarios. Table 4 presents the experimental results corresponding to the 2-source domain scenario. The compared methods include MFSAN, MDFANInception, MDFANlmmd, and MDFAN. Among them, MDFANInception retains the multi-representation extraction structure, with the subdomain alignment module replaced by MMD; MDFANlmmd, on the other hand, retains the subdomain alignment module but does not have the multi-representation extraction structure.
By examining Table 4, it is observed that in 50% of the transfer tasks (Mo,Mi →A; Mo,A →C; Mo,C → A; Mi, A →Mo; Mi,A → C; A,C →Mi), the accuracy of MDFANInception and MDFANlmmd methods is lower than when they are combined, i.e., the accuracy of the MDFAN. This trend is also reflected in the average accuracy metric. It indicates that the combination of multi-representation extraction and subdomain alignment techniques effectively enhances model performance. Moreover, in the remaining 50% of the transfer tasks, the accuracy of MDFANlmmd is either greater than or equal to the accuracy of MDFAN. Regarding average accuracy, MDFANlmmd surpasses MDFANInception but falls short of MDFAN. This suggests that while subdomain alignment contributes more to the final method’s performance than the multi-representation extraction network, it cannot entirely replace the role of the multi-representation extraction module.

Table 4. Classification accuracy (%) of ablation experiments with 2-source domain.
Table 5 shows the results of the ablation experiments for the 3-source domain scenarios. In 75% of the transfer tasks (Mo,Mi,A→C; Mo,Mi,C→A; Mo,A,C→Mi), the accuracy of MDFANlmmd is superior to MDFANInception and MDFAN, with MDFAN being the best only in 25% of the tasks. The situation is consistent with average accuracy, where the average accuracy of MDFANlmmd is higher than that of MDFANInception and MDFAN. This indicates that the contribution of the subdomain alignment module is greater than that of the multi-representation extraction module. However, despite this, the average accuracy of the worst-performing method, MDFANInception, in MDFAN is still better than that of MFSAN.

Table 5. Classification accuracy (%) of ablation experiments with 3-source domain.
The results of the ablation experiments indicate that both multi-representation extraction and subdomain alignment techniques contribute to improving model accuracy. Specifically, subdomain alignment demonstrated superior effectiveness, suggesting that this technique is more efficient in reducing data distribution differences caused by illumination variations in real field environments. Therefore, compared to other models, MDFAN offers a more effective solution for disease recognition in real agricultural settings.
4 Conclusion
This paper proposes a Multi-Source Domain Feature Adaptation Network (MDFAN) based on a two-stage alignment strategy to address the issue of data distribution differences caused by illumination changes in field environments, which negatively impact model performance. In the recognition tasks for five types of potato diseases, MDFAN effectively reduces distribution differences between source and target domains through multi-representation extraction and subdomain alignment techniques, while enhancing prediction consistency. The experimental results demonstrate that MDFAN achieves average accuracies of 92.11% and 93.02% in 2-source and 3-source domain transfer tasks, respectively, significantly outperforming other methods. Furthermore, ablation experiments indicate that the subdomain alignment module contributes more to improving model performance than the multi-representation extraction module, though the combination of both yields the best results.
In our study, the following limitations exist: Although MDFAN demonstrates strong generalization ability under varying lighting conditions, its performance under other differing factors, such as soil conditions, camera types, and crop varieties, as well as its generalization to other crops, still requires further validation. Additionally, the model assumes access to multiple labelled source domain data; however, in practical agricultural environments, collecting and annotating such data may pose significant challenges, particularly under varying field conditions.
Based on the findings and limitations of this study, the following future research directions are proposed: Further exploration of MDFAN’s performance under various environmental factors beyond lighting, such as different soil conditions, crop type variations, and its applicability to other crops, is necessary. Developing a generalized model that can be widely applied across different plant species and disease types will greatly enhance its practical value in agriculture.
Overcoming these limitations will facilitate the deployment of MDFAN in practical applications and further enhance the automation of crop disease recognition.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
XG: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Writing – original draft, Writing – review & editing. QF: Conceptualization, Funding acquisition, Methodology, Project administration, Resources, Supervision, Validation, Visualization, Writing – review & editing. SW: Funding acquisition, Project administration, Resources, Supervision, Visualization, Writing – review & editing. JZ: Methodology, Writing – review & editing. SY: Data curation, Project administration, Resources, Supervision, Visualization, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work is supported by the National Natural Science Foundation of China (Grant No.32160421, No.32201663), the Industrialization Support Project from Education Department of Gansu Province (Grant No.2021CYZC-57).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abbet, C., Studer, L., Fischer, A., Dawson, H., Zlobec, I., Bozorgtabar, B., et al. (2022). Self-rule to multi-adapt: Generalized multi-source feature learning using unsupervised domain adaptation for colorectal cancer tissue detection. Med. image Anal. 79, 102473. doi: 10.1016/j.media.2022.102473
Arshaghi, A., Ashourian, M., Ghabeli, L. (2023). Potato diseases detection and classification using deep learning methods. Multimed. Tools Appl. 82, 5725–5742. doi: 10.1007/s11042-022-13390-1
Atila, Ü., Uçar, M., Akyol, K., Uçar, E. (2021). Plant leaf disease classification using EfficientNet deep learning model. Ecol. Inf. 61, 101182. doi: 10.1016/j.ecoinf.2020.101182
Basavaiah, J., Arlene Anthony, A. (2020). Tomato leaf disease classification using multiple feature extraction techniques. Wireless Pers. Commun. 115, 633–651. doi: 10.1007/s11277-020-07590-x
Bevers, N., Sikora, E. J., Hardy, N. B. (2022). Soybean disease identification using original field images and transfer learning with convolutional neural networks. Comput. Electron. Agric. 203, 107449. doi: 10.1016/j.compag.2022.107449
Csurka, G. (Ed.). (2017). Domain adaptation in computer vision applications (Springer). doi: 10.1007/978-3-319-58347-1
Deng, X., Huang, Z., Zheng, Z., Lan, Y., Dai, F. (2019). Field detection and classification of citrus Huanglongbing based on hyperspectral reflectance. Comput. Electron. Agric. 167, 105006. doi: 10.1016/j.compag.2019.105006
Deng, F., Tu, S., Xu, L. (2021). “Multi-source unsupervised domain adaptation for ECG classification,” in 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 854–859 (Houston, TX, USA: IEEE).
Fang, Y., Ramasamy, R. P. (2015). Current and prospective methods for plant disease detection. Biosensors 5, 537–561. doi: 10.3390/bios5030537
Fuentes, A., Yoon, S., Kim, T., Park, D. S. (2021). Open set self and across domain adaptation for tomato disease recognition with deep learning techniques. Front. Plant Sci. 12, 758027. doi: 10.3389/fpls.2021.758027
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., et al. (2016). Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17, 1–35. doi: 10.1007/978-3-319-58347-1_10
Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., Smola, A. (2012). A kernel two-sample test. J. Mach. Learn. Res. 13, 723–773. doi: 10.1142/S0219622012400135
Gu, Y. H., Yin, H., Jin, D., Zheng, R., Yoo, S. J. (2022). Improved multi-plant disease recognition method using deep convolutional neural networks in six diseases of apples and pears. Agriculture 12, 300. doi: 10.3390/agriculture12020300
Guo, Y., Gu, X., Yang, G.-Z. (2021). MCDCD: Multi-source unsupervised domain adaptation for abnormal human gait detection. IEEE J. Biomed. Health Inf. 25, 4017–4028. doi: 10.1109/JBHI.2021.3080502
Hassan, S. M., Maji, A. K. (2022). Plant disease identification using a novel convolutional neural network. IEEE Access 10, 5390–5401. doi: 10.1109/ACCESS.2022.3141371
He, K., Zhang, X., Ren, S., Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, pp. 770–778.
Hlaing, C. S., Zaw, S. M. M. (2018). “Tomato plant diseases classification using statistical texture feature and color feature,” in 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS). 439–444 (Singapore: IEEE).
Liaghat, S., Mansor, S., Ehsani, R., Shafri, H. Z. M., Meon, S., Sankaran, S. (2014). Mid-infrared spectroscopy for early detection of basal stem rot disease in oil palm. Comput. Electron. Agric. 101, 48–54. doi: 10.1016/j.compag.2013.12.012
Lin, C., Zhao, S., Meng, L., Chua, T.-S. (2020). “[amp]]ldquo;Multi-source domain adaptation for visual sentiment classification,” in Proceedings of the AAAI Conference on Artificial Intelligence. 2661–2668.
Long, M., Cao, Y., Wang, J., Jordan, M. (2015). “Learning transferable features with deep adaptation networks,” in International conference on machine learning: PMLR. 97–105.
Ma, Y., Yang, Z., Zhang, Z. (2023). Multisource maximum predictor discrepancy for unsupervised domain adaptation on corn yield prediction. IEEE Trans. Geosci. Remote Sens. 61, 1–15. doi: 10.1109/TGRS.2023.3247343
Pan, S. J., Yang, Q. (2009). A survey on transfer learning. IEEE Trans. knowledge Data Eng. 22, 1345–1359. doi: 10.1109/TKDE.2009.191
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., Wang, B. (2019). “Moment matching for multi-source domain adaptation,” in Proceedings of the IEEE/CVF international conference on computer vision. 1406–1415.
Peng, S., Zeng, R., Cao, L., Yang, A., Niu, J., Zong, C., et al. (2023). Multi-source domain adaptation method for textual emotion classification using deep and broad learning. Knowledge-Based Syst. 260, 110173. doi: 10.1016/j.knosys.2022.110173
Sahu, K., Minz, S. (2023). Adaptive fusion of K-means region growing with optimized deep features for enhanced LSTM-based multi-disease classification of plant leaves. Geocarto Int. 38, 2178520. doi: 10.1080/10106049.2023.2178520
Suh, H. K., Hofstee, J. W., IJsselmuiden, J., van Henten, E. J. (2018). Sugar beet and volunteer potato classification using Bag-of-Visual-Words model, Scale-Invariant Feature Transform, or Speeded Up Robust Feature descriptors and crop row information. Biosyst. Eng. 166, 210–226. doi: 10.1016/j.biosystemseng.2017.11.015
Sun, B., Saenko, K. (2016). “Deep coral: Correlation alignment for deep domain adaptation,” in Computer Vision–ECCV 2016 Workshops, Hua, G., Jégou, H., Amsterdam, The Netherlands (Eds.), October 8-10 and 15-16, 2016. 443–450 (The Netherlands: Springer International Publishing, Cham, Amsterdam), pp. 443–450.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition. Boston, MA, USA. 1–9.
Tanabe, R., Purohit, H., Dohi, K., Endo, T., Nikaido, Y., Nakamura, T., et al. (2021). “MIMII DUE: Sound dataset for malfunctioning industrial machine investigation and inspection with domain shifts due to changes in operational and environmental conditions,” in 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). 21–25 (New Paltz, NY, USA: IEEE).
Tzeng, E., Hoffman, J., Zhang, N., Saenko, K., Darrell, T. (2014). Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474. doi: 10.48550/arXiv.1412.3474
Verma, S., Chug, A., Singh, A. P. (2020). Exploring capsule networks for disease classification in plants. J. Stat Manage. Syst. 23, 307–315. doi: 10.1080/09720510.2020.1724628
Wang, Z., Dai, Z., Póczos, B., Carbonell, J. (2019). “Characterizing and avoiding negative transfer,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11293–11302.
Wang, Y., Feng, L., Sun, W., Zhang, Z., Zhang, H., Yang, G., et al. (2022b). Exploring the potential of multi-source unsupervised domain adaptation in crop mapping using Sentinel-2 images. GIScience Remote Sens. 59, 2247–2265. doi: 10.1080/15481603.2022.2156123
Wang, R., Huang, W., Wang, J., Shen, C., Zhu, Z. (2022a). Multisource domain feature adaptation network for bearing fault diagnosis under time-varying working conditions. IEEE Trans. Instrument. Measure. 71, 1–10. doi: 10.1109/TIM.2022.3168903
Wang, S., Wang, B., Zhang, Z., Heidari, A. A., Chen, H. (2023). Class-aware sample reweighting optimal transport for multi-source domain adaptation. Neurocomputing 523, 213–223. doi: 10.1016/j.neucom.2022.12.048
Wen, T., Chen, R., Tang, L. (2021). Fault diagnosis of rolling bearings of different working conditions based on multi-feature spatial domain adaptation. IEEE Access 9, 52404–52413. doi: 10.1109/ACCESS.2021.3069884
Wu, X., Fan, X., Luo, P., Choudhury, S. D., Tjahjadi, T., Hu, C. (2023). From laboratory to field: Unsupervised domain adaptation for plant disease recognition in the wild. Plant Phenom. 5, 0038. doi: 10.34133/plantphenomics.0038
Xu, R., Chen, Z., Zuo, W., Yan, J., Lin, L. (2018). “Deep cocktail network: Multi-source unsupervised domain adaptation with category shift,” in Proceedings of the IEEE conference on computer vision and pattern recognition. 3964–3973.
Yan, K., Guo, X., Ji, Z., Zhou, X. (2021). Deep transfer learning for cross-species plant disease diagnosis adapting mixed subdomains. IEEE/ACM Trans. Comput. Biol. Bioinf. 20, 2555–2564. doi: 10.1109/tcbb.2021.3135882
Yu, C., Wang, J., Chen, Y., Huang, M. (2019). “Transfer learning with dynamic adversarial adaptation network,” in 2019 IEEE international conference on data mining (ICDM), 778–786 (Beijing, China: IEEE).
Zhang, Y., Wang, Y., Jiang, Z., Zheng, L., Chen, J., Lu, J. (2022). Subdomain adaptation network with category isolation strategy for tire defect detection. Measurement 204, 112046. doi: 10.1016/j.measurement.2022.112046
Zhu, Y., Zhuang, F., Wang, D. (2019a). “Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources,” in Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA. 5989–5996.
Zhu, Y., Zhuang, F., Wang, J., Chen, J., Shi, Z., Wu, W., et al. (2019b). Multi-representation adaptation network for cross-domain image classification. Neural Networks 119, 214–221. doi: 10.1016/j.neunet.2019.07.010
Keywords: field environment, potato disease recognition, multi-source unsupervised domain adaptation, multi-representation extraction, subdomain alignment
Citation: Gao X, Feng Q, Wang S, Zhang J and Yang S (2024) A multi-source domain feature adaptation network for potato disease recognition in field environment. Front. Plant Sci. 15:1471085. doi: 10.3389/fpls.2024.1471085
Received: 26 July 2024; Accepted: 19 September 2024;
Published: 10 October 2024.
Edited by:
Lorena Parra, Universitat Politècnica de València, SpainReviewed by:
Francisco Javier Diaz, Universitat Politècnica de València, SpainKelly Lais Wiggers, Federal Technological University of Paraná, Brazil
Copyright © 2024 Gao, Feng, Wang, Zhang and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Quan Feng, ZnF1YW5AZ3NhdS5lZHUuY24=