 Christian R. Werner
Christian R. Werner Dorcus C. Gemenet
Dorcus C. Gemenet Daniel J. Tolhurst
Daniel J. Tolhurst
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci., 04 April 2024
Sec. Plant Breeding
Volume 15 - 2024 | https://doi.org/10.3389/fpls.2024.1330574
This paper presents a general framework for simulating plot data in multi-environment field trials with one or more traits. The framework is embedded within the R package FieldSimR, whose core function generates plot errors that capture global field trend, local plot variation, and extraneous variation at a user-defined ratio. FieldSimR’s capacity to simulate realistic plot data makes it a flexible and powerful tool for a wide range of improvement processes in plant breeding, such as the optimisation of experimental designs and statistical analyses of multi-environment field trials. FieldSimR provides crucial functionality that is currently missing in other software for simulating plant breeding programmes and is available on CRAN. The paper includes an example simulation of field trials that evaluate 100 maize hybrids for two traits in three environments. To demonstrate FieldSimR’s value as an optimisation tool, the simulated data set is then used to compare several popular spatial models for their ability to accurately predict the hybrids’ genetic values and reliably estimate the variance parameters of interest. FieldSimR has broader applications to simulating data in other agricultural trials, such as glasshouse experiments.
This paper presents a general framework for simulating plot data in multi-environment field trials with one or more traits. The framework is embedded within the R package FieldSimR, whose core function generates plot errors that capture global field trend, local plot variation, and extraneous variation. FieldSimR’s capacity to simulate realistic plot data makes it well-suited to a wide range of improvement processes in plant breeding, such as the optimisation of experimental designs and statistical analyses of multi-environment field trials. It is also well-suited to a range of education purposes, such as teaching the principals of spatial modelling and multi-environment trial analysis.
Plant breeding programmes continuously evaluate, select, and release improved genotypes in order to meet the complex and dynamic requirements of different customer groups, including farmers, processors, and end-users (Covarrubias-Pazaran et al., 2022). The resources required to compare different improvement strategies in the field, however, can quickly exceed the practical possibilities of a plant breeding programme. Often, multiple factors must be evaluated simultaneously over several years or even decades to identify an optimised breeding strategy. This requires a pragmatic approach to identify profitable long-term strategies in plant breeding programmes.
Simulation is a fast and cost-efficient tool for comparing different breeding strategies over time (Gaynor et al., 2021). Interestingly, this is not a new concept. Simulations have been utilised by plant and animal breeders for almost a century, beginning with the application of the Breeder’s equation (Lush, 1937), a form of deterministic simulation to predict genetic gain based on selection intensity, selection accuracy, genetic variance, and generation interval. However, only recently, with the availability of modern computers and flexible software have breeders and researchers been granted access to more powerful stochastic simulations for optimising entire breeding programmes across multiple generations. Currently available software includes QU-GENE (Podlich and Cooper, 1998), ADAM-plant (Liu et al., 2019), and ChromaX (Younis et al., 2023), as well as the R packages Selection Tools (Frisch, 2023) and AlphaSimR (Gaynor et al., 2021). These software applications can be used, for example, to compare different crossing and selection strategies over time. They lack, however, the functionality to simulate realistic plot data in multi-environment field trials. This capacity is necessary to evaluate the impact of different experimental designs, multi-environment testing strategies, and statistical analyses on the performance of a breeding programme.
The motivation to simulate realistic plot data has stemmed from the importance of spatial variation in plant breeding field trials (see, for example, Wilkinson et al., 1983; Besag and Kempton, 1986; Cullis and Gleeson, 1991; Rodríguez-Álvarez et al., 2018; Piepho et al., 2022). Spatial variation occurs naturally in field trials laid out as a two-dimensional lattice of plots (Gogel et al., 2023), and can account for more than 50% of the total phenotypic variation. Spatial variation can be broadly categorised as either global trend, local variation, or extraneous variation (Gilmour et al., 1997). Global trend occurs on a large scale across the field, such as large scale moisture and fertility gradients (Green et al., 1985). Local variation occurs on a small scale between neighbouring plots. It may reflect small scale changes in soil composition (trend) or random error (noise), such as measurement error and within-plot variability (Besag, 1977). Conversely, extraneous variation is predominately induced during the conduct of the trial, and as a result is often aligned with the column and row dimensions. It may reflect management practices, such as serpentine harvesting and spraying, multi-plot seeders that sow multiple plots simultaneously, or inaccurate trimming resulting in unequal plot lengths (Stefanova et al., 2009). The complexity and importance of spatial variation dictate the need for a general framework to simulate realistic plot errors that capture the main components described above.
FieldSimR is an R package for simulating plot errors in multi-environment field trials that capture global and local trend, random error, and extraneous variation. It also provides compatibility with AlphaSimR to generate plot phenotypes, by combining the simulated plot errors with genetic values. This makes FieldSimR a powerful tool for a wide range of improvement processes, such as:
● Comparing spatial modelling approaches, e.g., separable autoregressive processes, tensor-product penalised splines, and nearest neighbour adjustments.
● Comparing experimental designs for single- and multi-environment studies, e.g., complete and incomplete block designs, including various p-rep and sparse testing designs.
● Comparing approaches for analysing multi-environment trial data, e.g., reaction norms, random regressions, and factor analytic models.
The paper is arranged as follows. The “Methods” section presents the theoretical framework for simulating plot errors, which are generated by combining spatial, random, and extraneous error components at a user-defined ratio. The “Results and discussion” section introduces an example simulation of field trials that evaluate 100 maize hybrids for two traits in three environments. To demonstrate FieldSimR’s value as an optimisation tool, the simulated data set is then used to compare several popular spatial models for their ability to accurately predict the hybrids’ genetic values and reliably estimate the variance parameters of interest.
This section presents the framework in FieldSimR for simulating plot errors in multi-environment field trials. FieldSimR generates plot errors by combining spatial, random, and extraneous error components at a user-defined ratio. The simulation framework is initially developed for a single trait and then extended for multiple traits.
Assume a single-trait multi-environment trial data set comprises p environments with n plots in total, where and is the number of plots in environment j. Also assume that each environment is laid out as a two-dimensional lattice of plots such that nj = cj × rj, where cj and rj are the number of columns and rows, respectively. The n-vector of plot errors is then given by , where εj is the nj-vector of plot errors for environment j (ordered as rows within columns). The vector εj captures the main components of spatial variation, i.e., global and local trend, random error, and extraneous variation.
FieldSimR generates the vector of plot errors for each environment as the sum of three terms:
where sj is a vector of errors that capture global and local spatial trend, rj is a vector of random errors, and ej is a vector of errors that capture extraneous variation. The errors in sj and ej are hereafter referred to as the spatial and extraneous errors, respectively. All terms are simulated as mutually independent with zero means and variance components given by , , and , respectively. The total plot error variance is then given by .
The errors in sj capture both global and local trend, such as large scale fertility gradients (Green et al., 1985) and small scale changes in soil composition (Gilmour et al., 1997). FieldSimR has the capacity to generate spatial errors based on either bivariate interpolation (Akima, 1978) or an autoregressive process (Box and Jenkins, 1970). The key difference is that bivariate interpolation applies a (non-stochastic) smoothing function to the errors, while autoregressive processes assume correlated errors based on a stochastic variance matrix (Gogel et al., 2023). Both approaches have been widely and successfully adopted for the empirical analysis of field trial data, and hence their implementation within FieldSimR.
Bivariate interpolation is implemented through the interp() function in the R package interp (Gebhardt et al., 2023), which applies piece-wise linear interpolation across the two-dimensional lattice of plots. An example field array with spatial trend generated using bivariate interpolation is presented in Figure 1. The field array comprises cj = 10 columns and rj = 20 rows for nj = 200 plots in total. The field spans 80 m long in the column direction and 40 m wide in the row direction, with rectangular plots 8 m long by 2 m wide (Figure 1A). There are two square blocks aligned in the column direction (side-by-side), with 100 plots in each block. Four interpolation (knot) points are placed outside the four corners of the field, which prevents continuity issues that occur at the interpolation boundary. The z-values at these points were sampled from a standard normal distribution, with z = 2.56, 1.08, 0.43, and −2.56 for the example (clockwise from top left). The continuous array between the knot points is then interpolated, which produces a smooth continuous surface across the lattice of plots (Figure 1B). A single error value is assigned to each plot by averaging over the continuous surface within each plot (Figure 1C). The error values are then scaled to the defined spatial error variance for each environment, . This produces the vector of spatial errors, sj.
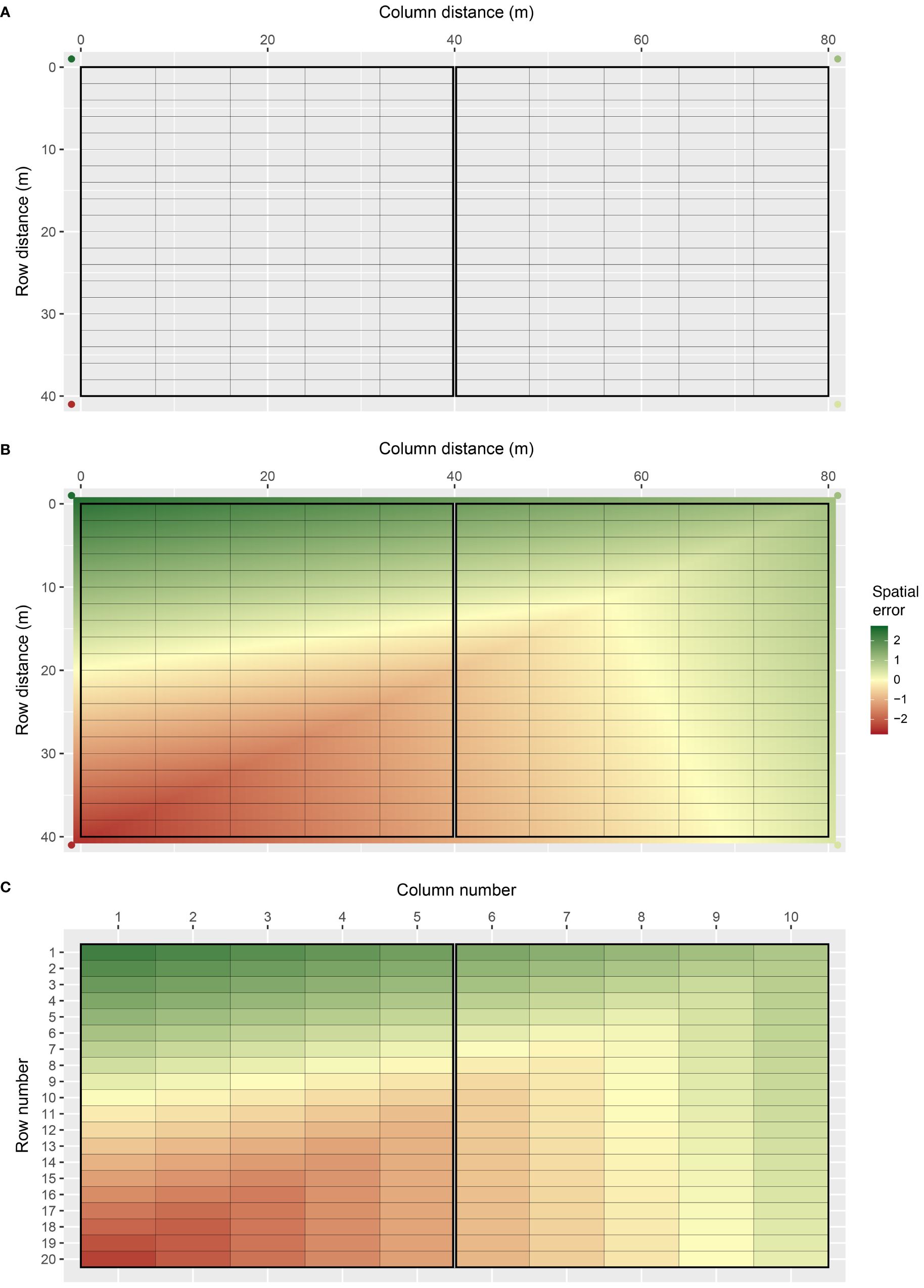
Figure 1 Demonstration of how FieldSimR generates spatial errors using bivariate interpolation: (A) the two-dimensional lattice of plots is constructed with four knot points placed outside the four corners, (B) the continuous array between the knot points is interpolated which produces a smooth continuous surface, and (C) a single error value is assigned to each plot by averaging over the continuous surface within each plot.
The complexity of spatial trend can be controlled in FieldSimR by setting the number of additional knot points sampled inside the field array. By altering the complexity, users can explicitly change the ratio of global to local trend. The example in Figure 1 has no additional knot points besides those at the four corners, so the simulated spatial error predominately captures global trend with minimal or no local trend. Three additional examples are presented in Figure 2, which have 5, 10, and 50 knot points, respectively. The knot points are sampled from a continuous uniform distribution defined by all points in the continuous array. This means that more than one knot point can be sampled for each plot. The position of the knot points and corresponding z-values are presented in Supplementary Figure S1, which displays the smooth continuous surface for the examples in Figure 2.
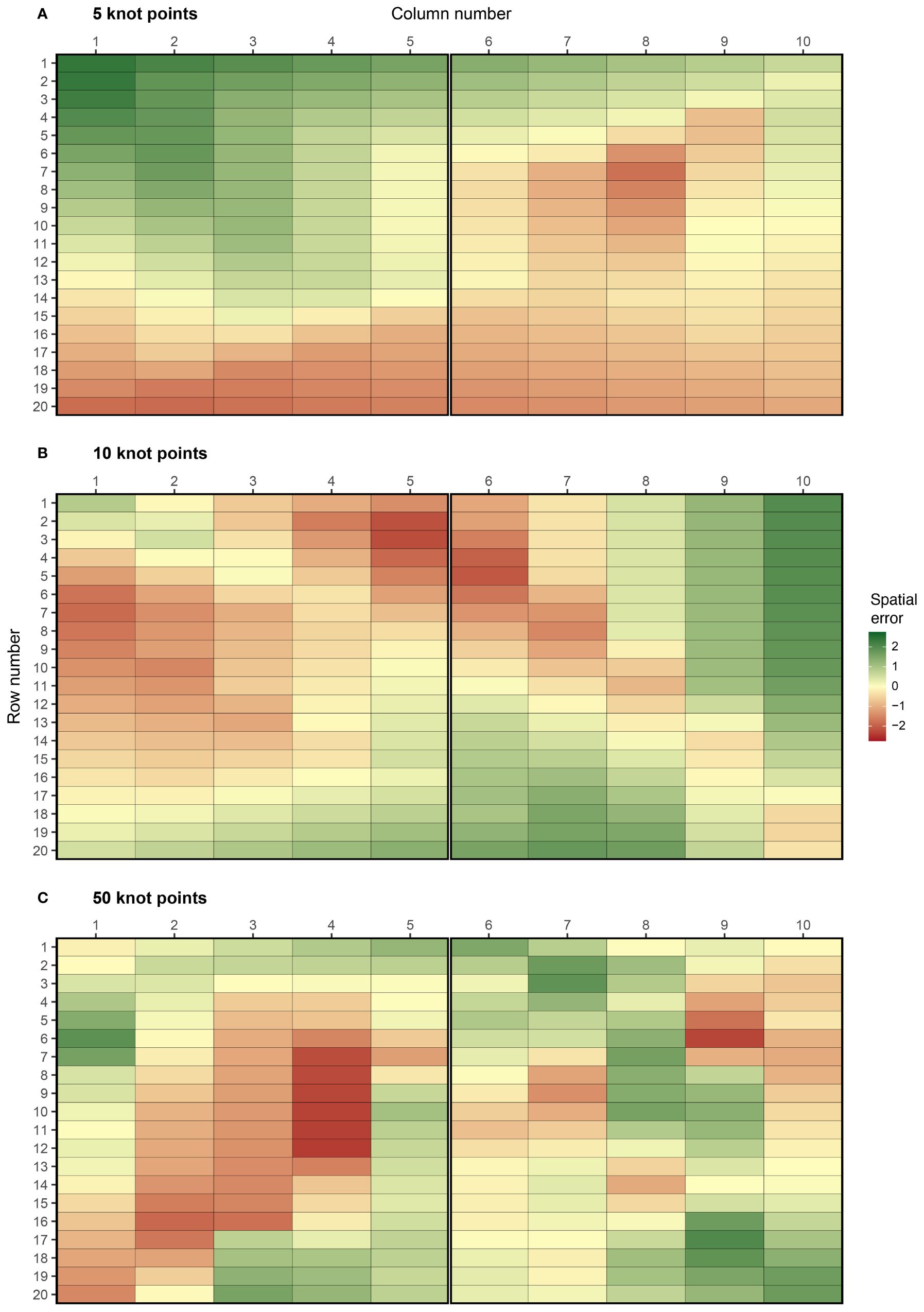
Figure 2 Examples of spatial errors generated using bivariate interpolation with (A) 5, (B) 10, and (C) 50 knot points. These options are set using complexity = 5, 10, and 50. The coordinates of the knot points are presented in Supplementary Figure S2. The graphics were produced with the plot_effects() function in FieldSimR.
The examples demonstrate FieldSimR’s capacity to simulate global and local trend, as well as within-plot variability. Increasing the complexity will generate more local trend relative to global trend, up to a point where the errors capture minimal or no trend (i.e., only noise). At this point, numerous knot points may be sampled for each plot which further increases the amount of within-plot variability. By default, FieldSimR sets the number of knot points to half the maximum of the number of columns and rows. For example, the default complexity for a field trial with 10 columns and 20 rows is given by max(10, 20)/2 = 10 knot points (see, for example, Figure 2B). This generally provides a good ratio of global to local trend, but users are encouraged to alter the complexity as required.
Trellis plots for the three examples are presented in Supplementary Figure S2. These graphics also demonstrate that various ratios of global to local trend can be generated by altering the complexity. For example, the first graphic demonstrates a gradual decrease in spatial error as the row number increases, which is a classical sign of global trend in field trials. Conversely, the last graphic demonstrates more small-scale fluctuations between neighbouring columns and rows, which is a sign of local trend. Note that since bivariate interpolation is a smoothing function, rather than a stochastic process, the spatial errors are not simulated as random variables.
Alternatively, the spatial errors can be generated as random variables in FieldSimR based on a separable first order autoregressive (AR1) process. Separable AR1 processes explicitly model spatial dependence (correlation) between neighbouring plots in the column and row dimensions, rather than interpolating a smooth continuous surface across the field array. In this case, FieldSimR simulates the vector of spatial errors:
where is the spatial error variance and Sj is the nj×nj separable correlation matrix, which is constructed as:
where is the column autocorrelation parameter with cj× cj correlation matrix and is the row autocorrelation parameter with rj × rj correlation matrix . Note that, in contrast to bivariate interpolation, the separable AR1 process does not require plot dimensions, since they are implicitly modelled through and (see Gilmour et al., 1997). This approach allows users to implement estimates of and previously obtained from empirical analyses of field trial data.
The ratio of global to local trend can be controlled by altering the column and row autocorrelation parameters. Decreasing the autocorrelation parameters will effectively increase the complexity of the spatial trend, in the sense that more local trend will be generated relative to global trend, up to a point where the errors capture minimal or no trend (i.e., only noise). This occurs when the autocorrelation parameters are set to zero. Three examples are presented in Supplementary Figure S3, which show spatial trend generated using a separable AR1 process with (a) = 0.7 and = 0.9, (b) = 0.5 and = 0.7, and (c) = 0.3 and = 0.5. The theoretical and sample variograms for these examples are presented in Supplementary Figure S4. The examples demonstrate the stochastic nature of the spatial errors generated based on the separable AR1 process.
The methods above for generating global and local trend will be well-suited to most applications. However, some users may desire to explicitly set the amount of global and local trend without fine-tuning the complexity or the autocorrelation parameters. In this case, users may simulate spatial trend as the sum of two components, i.e., global trend (with no/low complexity) and local trend (with moderate/high complexity or low/moderate autocorrelations). This is left to the discretion of the user.
The errors in rj capture local variation that is not trend, such as noise, measurement error, and intrinsic variability within the plots (Besag, 1977; Wilkinson et al., 1983). FieldSimR simulates the vector of random errors as:
where is the random error variance and is an identity matrix of order nj.
The errors in ej capture extraneous variation predominately induced during the conduct of the trial, such as serpentine harvesting or spraying and unequal plot dimensions (Gilmour et al., 1997; Stefanova et al., 2009). This type of variation is assumed to be aligned with the columns and rows of the trial. FieldSimR generates the vector of extraneous errors as the sum of two terms as:
where is a vector of column errors with nj × cj design matrix and is a vector of row errors with nj × rj design matrix . The design matrices are given by .
The column and row errors are simulated as:
where is the column error variance and is the row error variance, which are set according to whether column and/or row errors are desired. The total extraneous error variance is then given by .
FieldSimR has the capacity to simulate extraneous errors based on zig-zag or random ordering between neighbouring columns and/or rows. The zig-zag ordering is achieved by alternating the positive and negative simulated values between neighbouring columns and rows. The two examples in Figure 3 demonstrate the two types of extraneous variation. The first example demonstrates a zig-zag pattern where the errors in odd row numbers are always positive (mean of +0.37), while those in even row numbers are always negative (mean of -0.37). This type of non-stationarity is a classical sign of extraneous variation attributed to systematic management practices, such as serpentine harvesting and spraying. The second example demonstrates a more stochastic pattern in which the errors may be attributed to random processes, such as inaccurate plot trimming resulting in unequal plot dimensions. Interested users may also manipulate the above functionality to simulate interplot competition, typically observed as a negative correlation between neighbouring rows (Durban et al., 2001; Stringer et al., 2011).
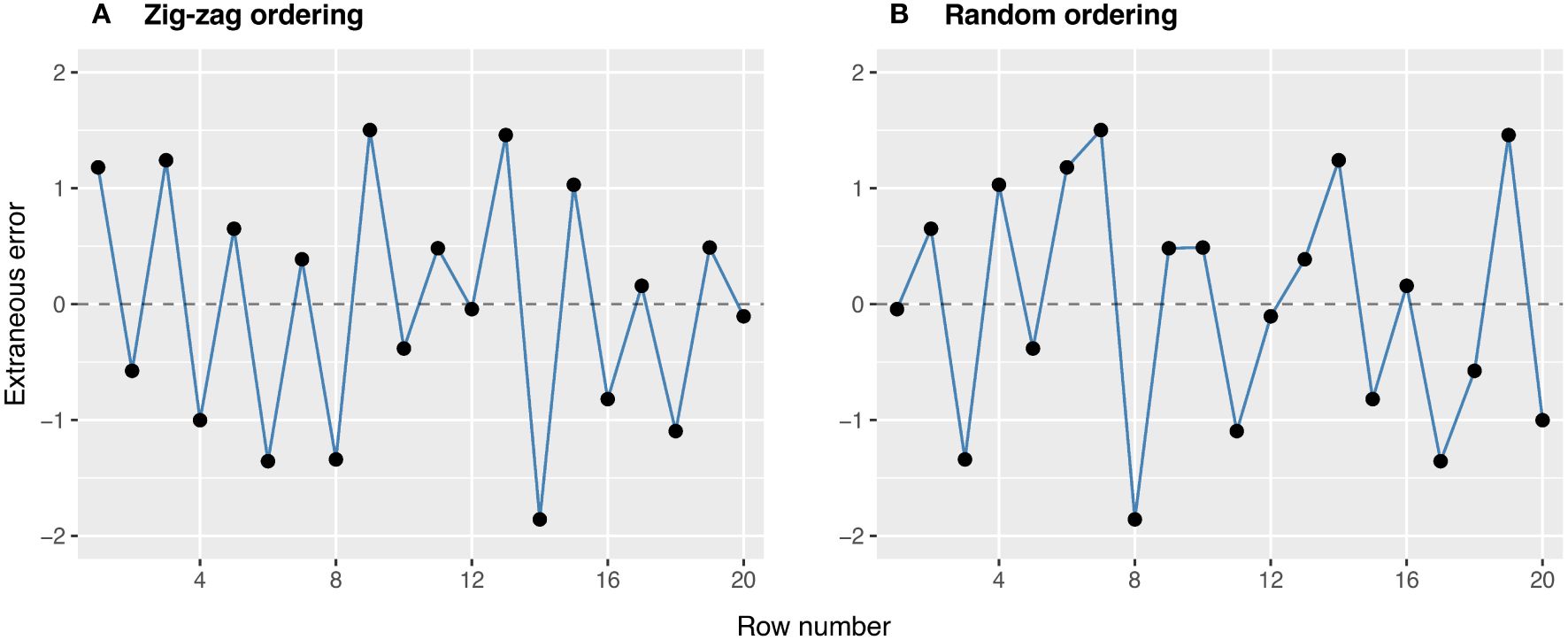
Figure 3 Examples of extraneous errors generated using (A) zig-zag and (B) random ordering. These options are set using ext.ord = “zig-zag” and “random”.
FieldSimR generates the total plot errors in Equation 1 by combining the spatial errors with the random and extraneous errors according to a user-defined ratio. The desired ratio is applied by setting the proportions of spatial and extraneous error variance, with the remaining proportion assigned to random error. By default, FieldSimR sets the proportion of spatial error to 0.5 and extraneous error to 0, resulting in a proportion of random error variance of 0.5.
FieldSimR has the capacity to simulate correlated plot errors for multiple traits. The correlation matrix between traits can be set for the spatial, random, and extraneous errors terms separately. By default, FieldSimR fits a separable correlation structure between traits and environments (Bančič et al., 2023), but note that different error variances can be set for different environment-within-trait combinations. It is also important to note that when bivariate interpolation is used, the correlation matrix for the spatial errors is applied to the z-values at the knot points, not the spatial errors themselves. This is because the spatial errors generated using bivariate interpolation do not have an assumed stochastic variance matrix, and the z-values are treated as the random variables.
FieldSimR is an R package for simulating plot errors that comprise global and local trend, random error, and extraneous variation. This functionality makes FieldSimR a powerful tool for a wide range of improvement processes, such as the comparison of different spatial modelling approaches. This section demonstrates the simulation and analysis of field trials that evaluate 100 maize hybrids for two traits in three environments. In the first part, FieldSimR is used to simulate plot errors, genetic values, and phenotypes for the 100 maize hybrids in the three field trials. In the second part, eight spatial models are compared for their ability to accurately predict the true genetic values of the maize hybrids and to reliably estimate the true variance parameters of interest.
Consider a scenario in which 100 maize hybrid genotypes are evaluated for grain yield (t/ha) and plant height (cm) in field trials across three environments. The simulation of plot phenotypes with FieldSimR involves three steps:
1. Simulation of plot errors.
2. Simulation of genetic values.
3. Generation of phenotypes by combining the plot errors with the genetic values.
Plot errors for grain yield and plant height were simulated with FieldSimR’s core function field_trial_error(), assuming independence between traits and between environments. Environments 1 and 2 comprised two blocks each, while Environment 3 comprised three blocks. The blocks were aligned in the column direction (side-by-side) and comprised 5 columns and 20 rows for 100 plots in each block. The plots were 8 m long in the column direction by 2 m wide in the row direction.
To obtain plot-level heritabilities of h2 = 0.3 for grain yield and h2 = 0.5 for plant height in all three environments, the total error variances for the two traits were defined relative to their genetic variances, as demonstrated in Supplementary Script S10. The simulated plot errors comprised spatial, random, and extraneous error terms. The spatial errors were simulated using bivariate interpolation with complexity set to 10 and proportion of spatial error variance set to 0.4 in all three environments. The extraneous errors were simulated using zig-zag ordering across neighbouring rows. The proportion of extraneous error variance was set to 0.2 in all three environments. This resulted in a proportion of random error variance of 1 − (0.4 + 0.2) = 0.4.

.
The simulated plot errors can also be accessed through the example data frame error_df_bivar, which will be used below to generate phenotypes. The spatial errors, extraneous errors, random errors, and total plot errors are presented in Figure 4 for gain yield in Environment 1.
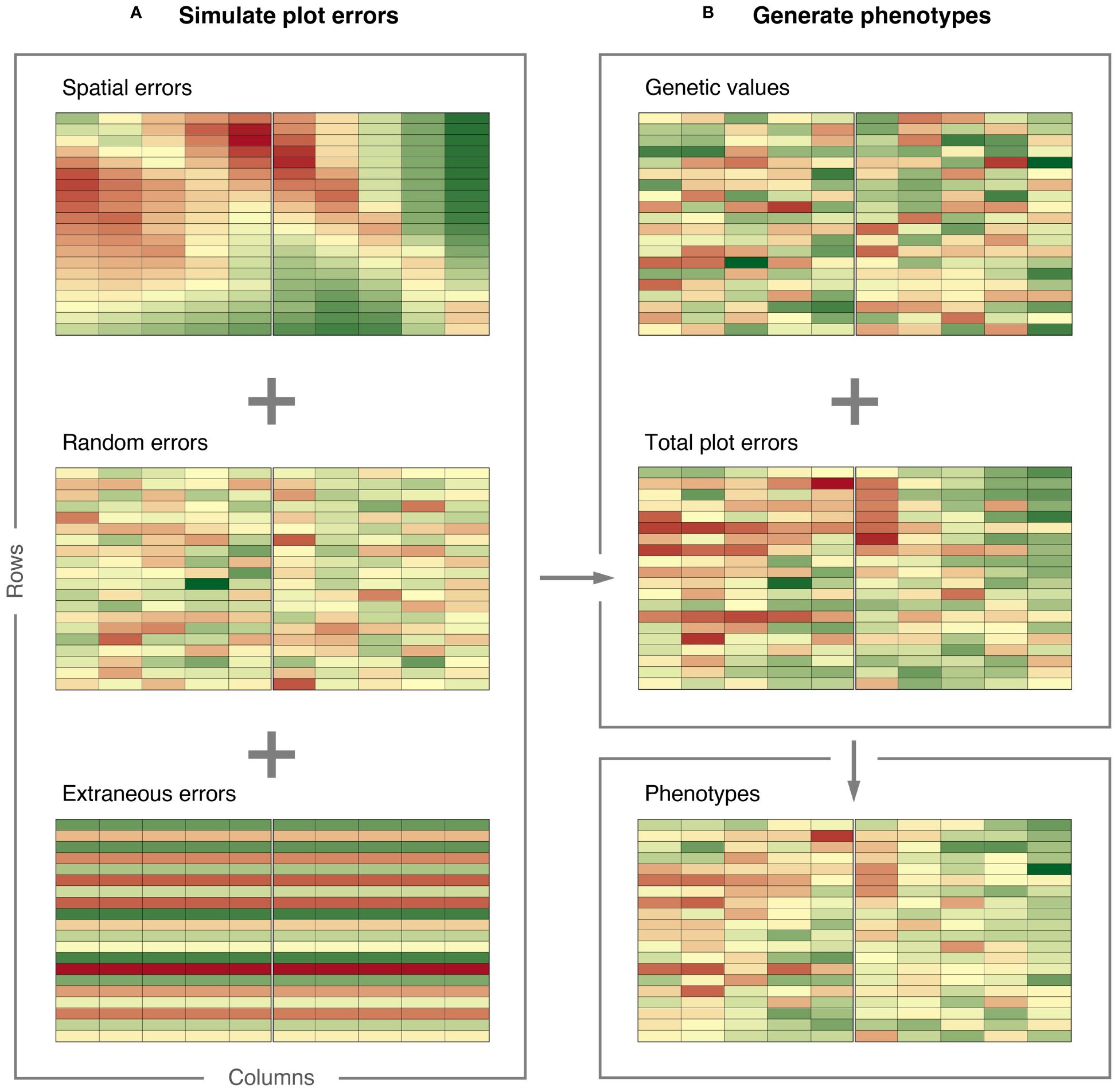
Figure 4 Demonstration of how FieldSimR generates phenotypes: (A) plot errors are simulated by combining the spatial errors with the random and extraneous errors at a user-defined ratio, and (B) phenotypes are generated by combining the total plot errors with the true genetic values simulated with AlphaSimR. The graphics were produced with the plot_effects() function in FieldSimR.
Genetic values for grain yield and plant height in the three environments were simulated based on an unstructured model for genotype-by-environment (GxE) interaction. The simulation was done in AlphaSimR (Gaynor et al., 2021), using FieldSimR’s wrapper functions unstr_asr_input() and unstr_asr_output(), as demonstrated in Supplementary Script S10. The simulated genetic values can be accessed through the example data frame gv_df_unstr. The genetic values for grain yield in Environment 1 are presented in Figure 4.
In addition to the unstructured model, FieldSimR provides wrapper functions for simulating genetic values based on compound symmetry and multiplicative models for GxE interaction. Alternatively, users can provide their own set of genetic values, e.g., through simulation or previously obtained from empirical analyses.
Phenotypes for grain yield and plant height were generated by combining the simulated plot errors with the genetic values stored in FieldSimR’s example data frame gv_df_unstr. The maize hybrids were randomly allocated to plots according to a randomised complete block design (RCBD).

.
The phenotypes are presented together with the plot errors and genetic values in Figure 4 for grain yield in Environment 1. The graphics in Figure 4 were produced with FieldSimR’s plot function plot_effects().

.
FieldSimR currently provides functionality to generate an RCBD, but note that other (incomplete) designs are being implemented. Users will also have the ability to apply experimental designs generated externally, e.g., with R packages such as agricolae (de Mendiburu, 2023), odw (Butler, 2021), and DiGGer (Coombes, 2020).
The comparison of spatial models is demonstrated for the simulated grain yield data in Environment 1 (Figure 4). A sequential approach was adopted for model fitting following Gilmour et al. (1997), with global trend and extraneous variation diagnosed using the sample variogram and accounted for using fixed and random model terms. This resulted in eight spatial models, including a baseline model, three models with a separable first order autoregressive (AR1) process, two models with a tensor-product penalised spline (TPS), and two models implementing nearest neighbour (NN) adjustments (Table 1). All models were fitted with ASReml-R (Butler et al., 2018), as demonstrated in Supplementary Script S11.
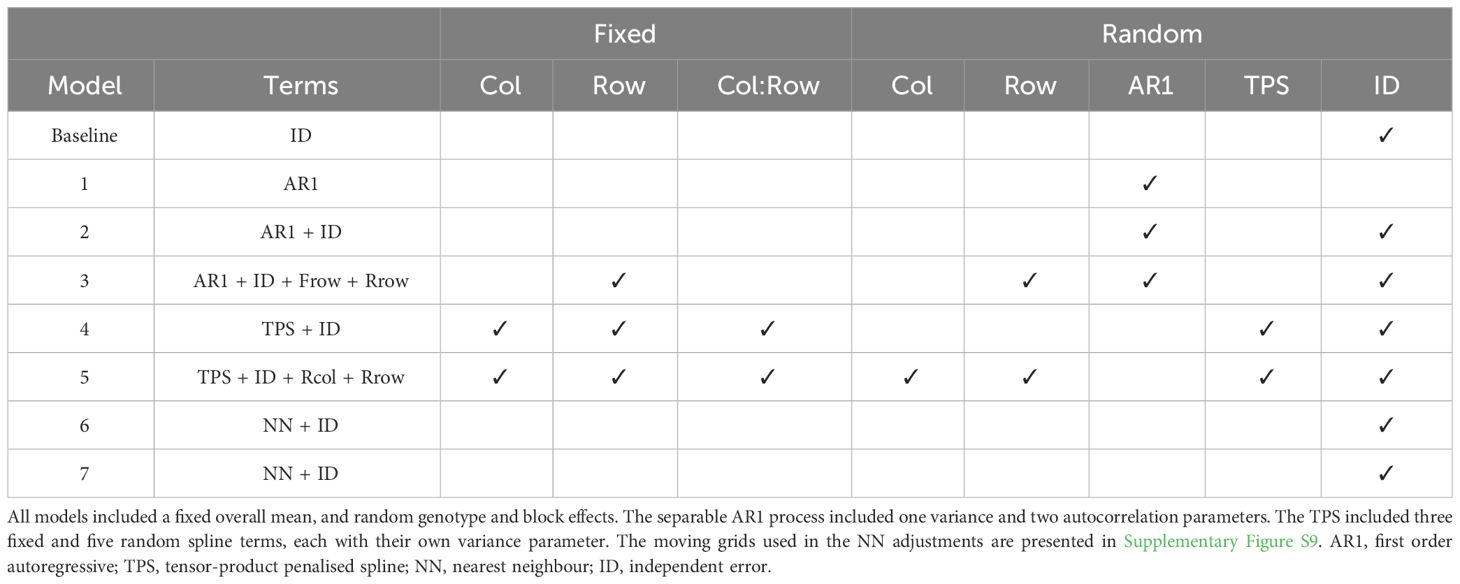
Table 1 Linear mixed models fitted to the simulated grain yield data in Figure 4, Part 1: Summary of non-genetic model terms.
The spatial models were evaluated in three ways (Table 2):
1. The model fit was assessed using the residual maximum likelihood ratio test (REMLRT) and the Akaike information criterion (AIC).
2. The prediction accuracy was calculated as Pearson’s correlation coefficient (r) between the true genetic values from the simulation and the predicted genetic values from the analysis.
3. The bias was calculated as the difference between the true and estimated genetic variance parameters.
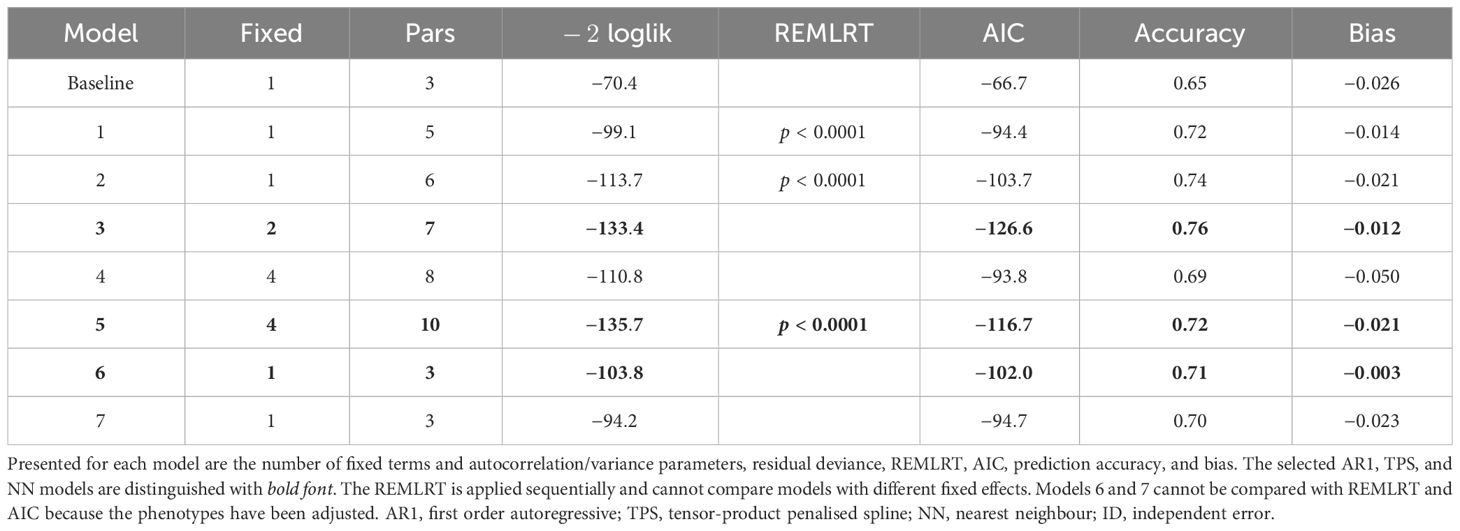
Table 2 Linear mixed models fitted to the simulated grain yield data in Figure 4, Part 2: Model fit criteria, prediction accuracy, and bias.
Note that the expected prediction accuracy for the data set is 0.68, based on the simulation parameters. Also note that the REMLRT is based on the non-zero variance approach of Stram and Lee (1994) and the AIC is based on the full log-likelihood approach of Verbyla (2019), which can compare models with different fixed effects. Typical experimental design and data checks were performed prior to model fitting (Supplementary Figure S5).
The analyses commenced by fitting a baseline linear mixed model, which included random genotype and block effects, and an independent (ID) error term (Table 1). This model reflects a classical complete block analysis that assumes independent genotypes, blocks, and residuals. The prediction accuracy of the baseline model was lower than the expected accuracy (r = 0.65 compared to 0.68; Table 2). The estimated genetic variance was , which was lower than the true value of 0.087 (bias = −0.026; Tables 2, 3).
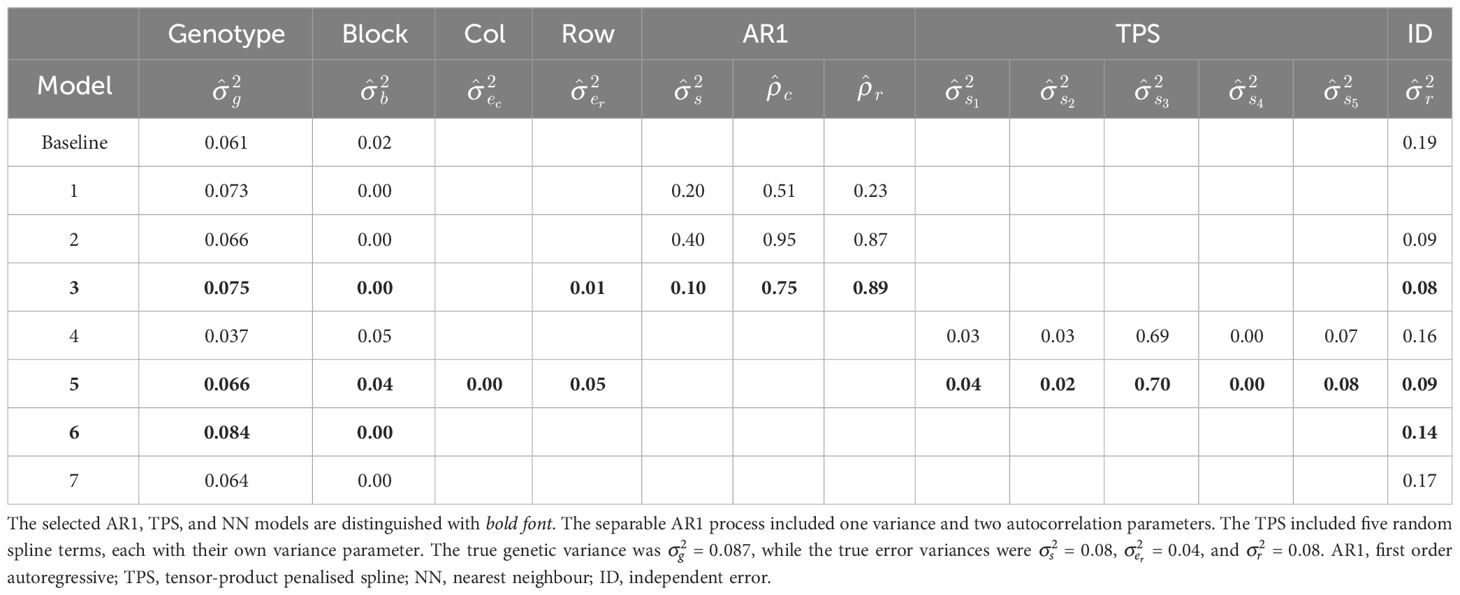
Table 3 Linear mixed models fitted to the simulated grain yield data in Figure 4, Part 3: REML estimates of autocorrelation and variance parameters.
Models 1, 2, and 3 included random genotype and block effects, and a separable AR1 process. The separable AR1 process represents a stochastic process which assumes correlated residuals in the column and row dimensions (Martin, 1990; Cullis and Gleeson, 1991). It comprised one variance and two autocorrelation parameters (Table 1).
Model 1 provided a significantly better fit than the baseline model in terms of REMLRT (p < 0.0001) and AIC (−94.4 compared to −66.7), and produced a higher prediction accuracy (r = 0.72 compared to 0.65; Table 2). The estimated genetic variance was , which provided a better estimate than the baseline model (bias = –0.014; Tables 2, 3). The estimated column and row autocorrelations were and .
Model 2 was an extension of Model 1 that included an additional ID error term (Besag, 1977; Wilkinson et al., 1983). Model 2 provided a significantly better fit than Model 1 and produced a higher prediction accuracy (Table 2). The estimated genetic variance was , which was slightly lower than Model 1 (Table 3). The estimated column and row autocorrelations were and , which were substantially higher than for Model 1. This indicated that the AR1 process captured (highly correlated) spatial trend, while the ID term captured the remaining random error. The sample variogram in Figure 5A shows a zig-zag pattern between neighbouring rows, with consistently higher semivariances for odd displacements compared to even displacements (also see Supplementary Figure S6). The row face of the variogram shows that the semivariances do not fall within the coverage intervals (see Stefanova et al., 2009). This is a classical sign of extraneous variation attributed to systematic practices aligned with the rows, which matches the extraneous error simulated in this data set.
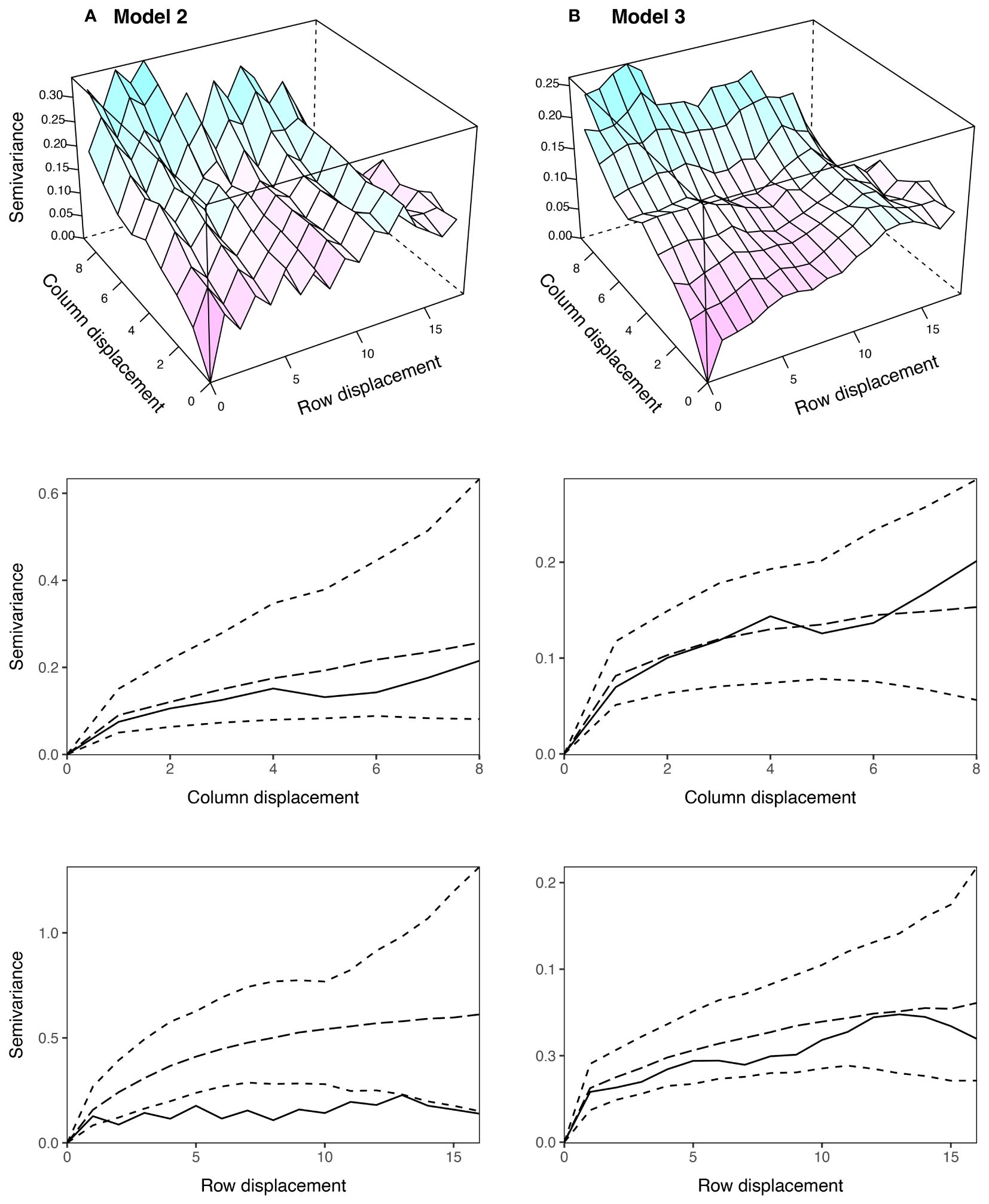
Figure 5 Sample variograms for the AR1 spatial models fitted to the simulated grain yield data in Figure 4: (A) Model 2: AR1 + ID and (B) Model 3: AR1 + ID + Frow + Rrow. The column and row faces of each variogram were constructed following Stefanova et al. (2009), and are supplemented with approximate 95% coverage intervals. Only semivariances based on more than 30 pairs are shown. AR1, first order autoregressive process, ID, independent error, Frow, fixed row, Rrow, random row.
Model 3 was an extension of Model 2 that included additional fixed and random row terms. The fixed term was coded as a factor with 1 for odd row numbers and 2 for even row numbers, while the random term was coded as a factor with levels equivalent to row number (Stefanova et al., 2009). The significance of the fixed term was assessed using a Wald F-test with denominator degrees of freedom (p < 0.001; Kenward and Roger, 1997). Model 3 provided a better fit than Model 2 in terms of AIC and produced a higher prediction accuracy (Table 2). The estimated genetic variance was , which was the second best estimate of all models (Table 3). The estimated column autocorrelation was much lower than for Model 2 ( compared to 0.95). The sample variogram in Figure 5B no longer shows a zig-zag pattern between neighbouring rows (also see the row face of the variogram). Instead, a discontinuity is shown at 0 displacement, reflecting the random error variance, followed by a gradual incline in the column direction. This type of non-stationarity is a sign of global trend in the column direction, which matches the spatial error simulated in this data set. However, the column face of the variogram shows that the semivariances fall within the coverage intervals. The observed non-stationarity is, therefore, an artefact of the correlated AR1 process, rather than global trend requiring further remediation. Model 3 was selected as the final AR1 spatial model based on the model fit criteria.
Models 4 and 5 included random genotype and block effects, a TPS, and an ID error term. The TPS represents a smoothing function which is applied to the two-dimensional continuous array (Rodríguez-Álvarez et al., 2018; Piepho et al., 2022). Both models were fitted with the SpATS package (Rodríguez-Álvarez et al., 2018) and also with ASReml-R using the TPSbits helper functions (Welham, 2019). A cubic B-spline basis was used with 6 knots in the column direction and 12 knots in the row direction (Velazco et al., 2017). The TPS included three fixed and five random spline terms, each with their own variance parameter (Table 1).
Model 4 provided a better fit than the baseline model in terms of AIC (−93.8 compared to −66.7), and produced a higher prediction accuracy (r = 0.69 compared to 0.65; Table 2). However, Model 4 provided a poorer fit and lower prediction accuracy than any of the AR1 spatial models. The estimated genetic variance was , which provided the worst estimate of all models (bias = −0.050; Tables 2, 3). Like for Model 2, the sample variogram in Supplementary Figure S7 shows a zig-zag pattern between neighbouring rows, suggesting the presence of extraneous variation.
Model 5 was an extension of Model 4 that included additional random column and row terms. This model is equivalent to the SpATS approach of Rodríguez-Álvarez et al. (2018). Model 5 provided a significantly better fit than Model 4 and a higher prediction accuracy (Table 2). However, it still provided a poorer fit and lower prediction accuracy than the final AR1 spatial model, despite having five additional model parameters (Table 1). The sample variogram in Supplementary Figure S8 no longer shows a zig-zag pattern, suggesting that the prescribed extraneous variation was sufficiently remediated. Model 5 was selected as the final TPS spatial model based on the model fit criteria.
Models 6 and 7 implemented NN adjustments to the grain yield phenotypes (Papadakis, 1937; Bartlett, 1978). The NN adjustments were obtained by averaging over neighbouring plots with the mvngGrAd package (Technow, 2015). The moving grids for Models 6 and 7 are presented in Supplementary Figure S9. Both models were fitted with ASReml-R, with model terms equivalent to the baseline model (Table 1).
Models 6 and 7 produced higher prediction accuracies than the baseline model (r = 0.71 and 0.70 compared to 0.65; Table 2). However, both models produced lower prediction accuracies than the final AR1 and TPS spatial models (r = 0.71 and 0.70 compared to 0.76 and 0.72, respectively). The estimated genetic variance for Model 7 was , which was the best estimate of all models (bias = −0.003; Table 3). Model 7 was selected as the final NN adjusted model based on the ratio of genetic to total phenotypic variance.
FieldSimR’s capacity to simulate realistic plot errors that capture global and local trend, random error, and extraneous variation makes it a flexible and powerful tool for various improvement processes in plant breeding. It’s general framework for simulating spatial variation exploits two widely adopted approaches for analysing real-world field trial data: bivariate interpolation and autoregressive processes. In contrast to real-world data, however, FieldSimR enables the efficient and comprehensive assessment of experimental designs and statistical analyses on a large scale, across an extensive array of scenarios. It also provides a platform for obtaining unbiased comparisons of statistical approaches for their ability to accurately predict the genetic values and to reliably estimate the variance parameters of interest, as the true values are defined by the user and, therefore, are known.
FieldSimR is available on CRAN, and has been extensively deployed as part of the Excellence in Breeding (EiB) initiative to provide guidance on the improvement of field trial design and analysis strategies across numerous CGIAR breeding programmes.
The R scripts generated for this study are available in the Supplementary Material. FieldSimR is available to download from CRAN https://cran.rproject.org/web/packages/FieldSimR/index.html and the GitHub repository https://github.com/crWerner/fieldsimr, which also contains vignettes for simulating plot errors, genetic values, and phenotypes.
CW: Conceptualization, Formal analysis, Methodology, Software, Writing – original draft, Writing – review & editing. DG: Writing – review & editing. DT: Conceptualization, Formal analysis, Methodology, Software, Writing – original draft, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Bill and Melinda Gates Foundation Grant No. OPP1177070.
The authors thank Chris Gaynor, Giovanny Covarrubias, and Lorena Batista for their initial feedback on the FieldSimR package.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2024.1330574/full#supplementary-material
Akima, H. (1978). A method of bivariate interpolation and smooth surface fitting for irregularly distributed data points. ACM Trans. Math. Softw. 4, 148–159. doi: 10.1145/355780.355786
Bančič, J., Ovenden, B., Gorjanc, G., Tolhurst, D. J. (2023). Genomic selection for genotype performance and stability using information on multiple traits and multiple environments. Theor. Appl. Genet. 136, 104. doi: 10.1007/s00122-023-04305-1
Bartlett, M. S. (1978). Nearest neighbour models in the analysis of field experiments. J. R. Stat. Soc. Ser. B (Methodological) 40, 147–158. doi: 10.1111/j.2517-6161.1978.tb01657.x
Besag, J. (1977). Errors-in-variables estimation for gaussian lattice schemes. J. R. Stat. Soc. Ser. B (Methodological) 39, 73–78. doi: 10.1111/j.2517-6161.1977.tb01607.x
Besag, J., Kempton, R. A. (1986). Statistical analysis of field experiments using neighbouring plots. Biometrics 42, 231–251. doi: 10.2307/2531047
Box, G., Jenkins, G. (1970). Time Series Analysis: Forecasting and Control (Holden-Day, San Francisco).
Butler, D. G. (2021) odw: Generate optimal experimental designs. Available online at: https://mmade.org/optimaldesign/.
Butler, D. G., Cullis, B. R., Gilmour, A. R., Gogel, B. J., Thompson, R. (2018) ASReml-R reference manual version 4. Available online at: https://vsni.co.uk/software/asreml-r.
Coombes, N. (2020) DiGGer: DiGGer design generator under correlation and blocking. Available online at: http://nswdpibiom.org/austatgen/software.
Covarrubias-Pazaran, G., Gebeyehu, Z., Gemenet, D., Werner, C., Labroo, M., Sirak, S., et al. (2022). Breeding schemes: what are they, how to formalize them, and how to improve them? Front. Plant Sci. 12. doi: 10.3389/fpls.2021.791859
Cullis, B. R., Gleeson, G. N. (1991). Spatial analysis of field experiments - an extension to two dimensions. Biometrics 47, 1449–1460. doi: 10.2307/2532398
de Mendiburu, F. (2023) agricolae: Statistical Procedures for Agricultural Research. Available online at: https://CRAN.R-project.org/package=agricolae.
Durban, M., Currie, I. D., Kempton, R. A. (2001). Adjusting for fertility and competition in variety trials. J. Agric. Sci. 136, 129–140. doi: 10.1017/S0021859601008541
Frisch, M. (2023) Selection Tools. Available online at: http://population-genetics.uni-giessen.de/~software/.
Gaynor, R. C., Gorjanc, G., Hickey, J. M. (2021). AlphaSimR: an R package for breeding program simulations. G3: Genes Genomes Genet. 11, jkaa017. doi: 10.1093/g3journal/jkaa017
Gebhardt, A., Bivand, R., Sinclair, D. (2023) interp: Interpolation Methods. Available online at: https://CRAN.R-project.org/package=interp.
Gilmour, A. R., Cullis, B. R., Verbyla, A. P. (1997). Accounting for natural and extraneous variation in the analysis of field experiments. J. Agricult. Biol. Environ. Stat 2, 269–293. doi: 10.2307/1400446
Gogel, B., Welham, S., Cullis, B. R. (2023). Empirical comparison of time series models and tensor product penalised splines for modelling spatial dependence in plant breeding field trials. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.1021143
Green, P., Jennison, C., Seheult, A. (1985). Analysis of field experiments by least squares smoothing. J. R. Stat. Soc. Ser. B (Methodological) 47, 299–315. doi: 10.1111/j.2517-6161.1985.tb01358.x
Kenward, M. G., Roger, J. H. (1997). Small sample inference for fixed effects from restricted maximum likelihood. Biometrics 53, 983–997. doi: 10.2307/2533558
Liu, H., Tessema, B. B., Jensen, J., Cericola, F., Andersen, J. R., Sørensen, A. C. (2019). ADAM-plant: A software for stochastic simulations of plant breeding from molecular to phenotypic level and from simple selection to complex speed breeding programs. Front. Plant Sci. 9. doi: 10.3389/fpls.2018.01926
Martin, R. J. (1990). The use of time-series models and methods in the analysis of agricultural field trials. Commun. Stat - Theory Methods 19, 55–81. doi: 10.1080/03610929008830187
Papadakis, J. S. (1937). Methode statistique pour des experiences sur champ. Bull. scientifique Instit. d’Amelioration Des. Plantes Thessaloniki 23, 13–29.
Piepho, H. P., Boer, M. P., Williams, E. R. (2022). Two-dimensional P-spline smoothing for spatial analysis of plant breeding trials. Biometric. J. 64, 835–857. doi: 10.1002/bimj.202100212
Podlich, D. W., Cooper, M. (1998). QU-GENE: a simulation platform for quantitative analysis of genetic models. Bioinformatics 14, 632–653. doi: 10.1093/bioinformatics/14.7.632
Rodríguez-Álvarez, M. X., Boer, M. P., van Eeuwijk, F. A., Eilers, P. H. C. (2018). Correcting for spatial heterogeneity in plant breeding experiments with P-splines. Spatial Stat 23, 52–71. doi: 10.1016/j.spasta.2017.10.003
Stefanova, K. T., Smith, A. B., Cullis, B. R. (2009). Enhanced diagnostics for the spatial analysis of field trials. J. Agricult. Biol. Environ. Stat 14, 392–410. doi: 10.1198/jabes.2009.07098
Stram, D. O., Lee, J. W. (1994). Variance components testing in the longitudinal mixed effects model. Biometrics 50, 1171–1177. doi: 10.2307/2533455
Stringer, J. K., Cullis, B. R., Thompson, R. (2011). Joint modeling of spatial variability and within-row interplot competition to increase the efficiency of plant improvement. J. Agricult. Biol. Environ. Stat 16, 269–281. doi: 10.1007/s13253-010-0051-5
Technow, F. (2015) mvngGrAd: moving grid adjustment in plant breeding field trials. Available online at: https://cran.r-project.org/web/packages/mvngGrAd/index.html.
Velazco, J. G., Rodríguez-Álvarez, M. X., Boer, M. P., Jordan, D. R., Eilers, P. H. C., Malosetti, M., et al. (2017). Modelling spatial trends in sorghum breeding field trials using a two-dimensional P-spline mixed model. Theor. Appl. Genet. 130, 1375–1392. doi: 10.1007/s00122-017-2894-4
Verbyla, A. P. (2019). A note on model selection using information criteria for general linear models estimated using REML. Aust. New Z. J. Stat 61, 39–50. doi: 10.1111/anzs.12254
Welham, S. J. (2019) TPSbits. Available online at: https://https://mmade.org/tpsbits.
Wilkinson, G. N., Eckert, S. R., Hancock, T. W., Mayo, O. (1983). Nearest neighbour (NN) analysis of field experiments. J. R. Stat. Soc. Ser. B (Methodological) 45, 151–211. doi: 10.1111/j.2517-6161.1983.tb01240.x
Keywords: simulation, spatial variation, plot error, multi-environment field trials, linear mixed models
Citation: Werner CR, Gemenet DC and Tolhurst DJ (2024) FieldSimR: an R package for simulating plot data in multi-environment field trials. Front. Plant Sci. 15:1330574. doi: 10.3389/fpls.2024.1330574
Received: 31 October 2023; Accepted: 01 February 2024;
Published: 04 April 2024.
Edited by:
Patrick Vincourt, Institut National de recherche pour l’agriculture, l’alimentation et l’environnement (INRAE), FranceReviewed by:
Rodrigo S. Alves, Universidade Federal de Viçosa, BrazilCopyright © 2024 Werner, Gemenet and Tolhurst. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Christian R. Werner, Yy53ZXJuZXJAY2dpYXIub3Jn; Daniel J. Tolhurst, ZHRvbGh1cnNAZWQuYWMudWs=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.