 Rubi Quiñones
Rubi Quiñones Ashok Samal1
Ashok Samal1 Sruti Das Choudhury
Sruti Das Choudhury- 1School of Computing, University of Nebraska-Lincoln, Lincoln, NE, United States
- 2Computer Science Department, Southern Illinois University Edwardsville, Edwardsville, IL, United States
- 3School of Natural Resources, University of Nebraska-Lincoln, Lincoln, NE, United States
- 4Department of Biological Systems Engineering, University of Nebraska-Lincoln, Lincoln, NE, United States
Cosegmentation and coattention are extensions of traditional segmentation methods aimed at detecting a common object (or objects) in a group of images. Current cosegmentation and coattention methods are ineffective for objects, such as plants, that change their morphological state while being captured in different modalities and views. The Object State Change using Coattention-Cosegmentation (OSC-CO2) is an end-to-end unsupervised deep-learning framework that enhances traditional segmentation techniques, processing, analyzing, selecting, and combining suitable segmentation results that may contain most of our target object’s pixels, and then displaying a final segmented image. The framework leverages coattention-based convolutional neural networks (CNNs) and cosegmentation-based dense Conditional Random Fields (CRFs) to address segmentation accuracy in high-dimensional plant imagery with evolving plant objects. The efficacy of OSC-CO2 is demonstrated using plant growth sequences imaged with infrared, visible, and fluorescence cameras in multiple views using a remote sensing, high-throughput phenotyping platform, and is evaluated using Jaccard index and precision measures. We also introduce CosegPP+, a dataset that is structured and can provide quantitative information on the efficacy of our framework. Results show that OSC-CO2 out performed state-of-the art segmentation and cosegmentation methods by improving segementation accuracy by 3% to 45%.
1 Introduction
Segmentation is a widely used technique to extract the foreground object from the background before information extraction (Langan et al., 1998; Rezaee et al., 2000; Patz and Preusser, 2012; Fan et al., 2018; Liu et al., 2021). Image segmentation has been used in many application domains, including medicine (Das and Kundu, 2013; Lian et al., 2019; Zhou et al., 2019), traffic safety (Alessandretti et al., 2007; Chang et al., 2019; Chen et al., 2020), and earth system diagnostics (Hoerser and Kuenzer, 2020). However, the success of segmentation algorithms has been limited by the complexity and diversity of the imagery. Cosegmentation is a technique developed to address the problem of segmenting an object in a set of images (Rother et al., 2006; Tao et al., 2015; Ren et al., 2018; Tao et al., 2019). Since its introduction, it has been used in many domains, including plant imagery (Quiñones et al., 2021), PET-CT images (Zhong et al., 2019), and video-based person re-identification (Subramaniam et al., 2019).
Current cosegmentation methods have been developed for RGB images (Chen et al., 2014a; Lin et al., 2014; Subramaniam et al., 2019) for objects with no defined quantitative or qualitative features (e.g., environmental conditions, perspectives, temporality, among others.) (Quiñones et al., 2021). Currently, datasets lack specific labeling for cosegmentation, limiting the success and application of these visualization methods. Furthermore, some methods are dependent on training data which make them tedious to generate and time consuming for training (Chen et al., 2014b; Meng et al., 2016; Hsu et al., 2019).
Although engineered features, such as Scale-Invariant Feature Transform (Lowe, 2004) and Histogram of Oriented Gradients (Dalal and Triggs, 2005), have been widely used in conventional cosegmentation methods, they are no longer optimal cosegmentation analytics due to their pre-designed network features. Convolutional neural networks (CNNs), on the other hand, have demonstrated their effectiveness in producing feature extraction in image pairs (Krizhevsky et al., 2012). Yuan et al (Yuan et al., 2017). proposed a CNN-based supervised method for object cosegmentation that would produce the masks for an object in a pair of images. However, their method requires additional training data for the CNN model in the form of object masking.
With the explosion in variety, velocity, and volume of plant imagery datasets, traditional segmentation algorithms grapple with processing images and achieving high accuracy due to challenges, including occlusion and overlap. Cosegmentation algorithms have the potential to overcome these issues, but they only achieve high accuracy for the dataset with which they were trained.
This paper presents Object State Change using Coattention-Cosegmentation (OSC-CO2), an end-to-end trainable unsupervised coattention- and cosegmentation-based framework for the increased segmentation of multiple feature objects that undergo state changes in high-throughput datasets. The state is referred to the object’s (plant’s) shape, orientation, and size at a specific point in time. OSC-CO2 is designed to process datasets that contain a variety of features, such as perspective (V), species (S), temporality (T), environmental conditions (E) and modality (M) (VSTEM) (Figure 1). The code for OSC-CO2 is publicly available at: https://github.com/rubiquinones/OSC-CO2.
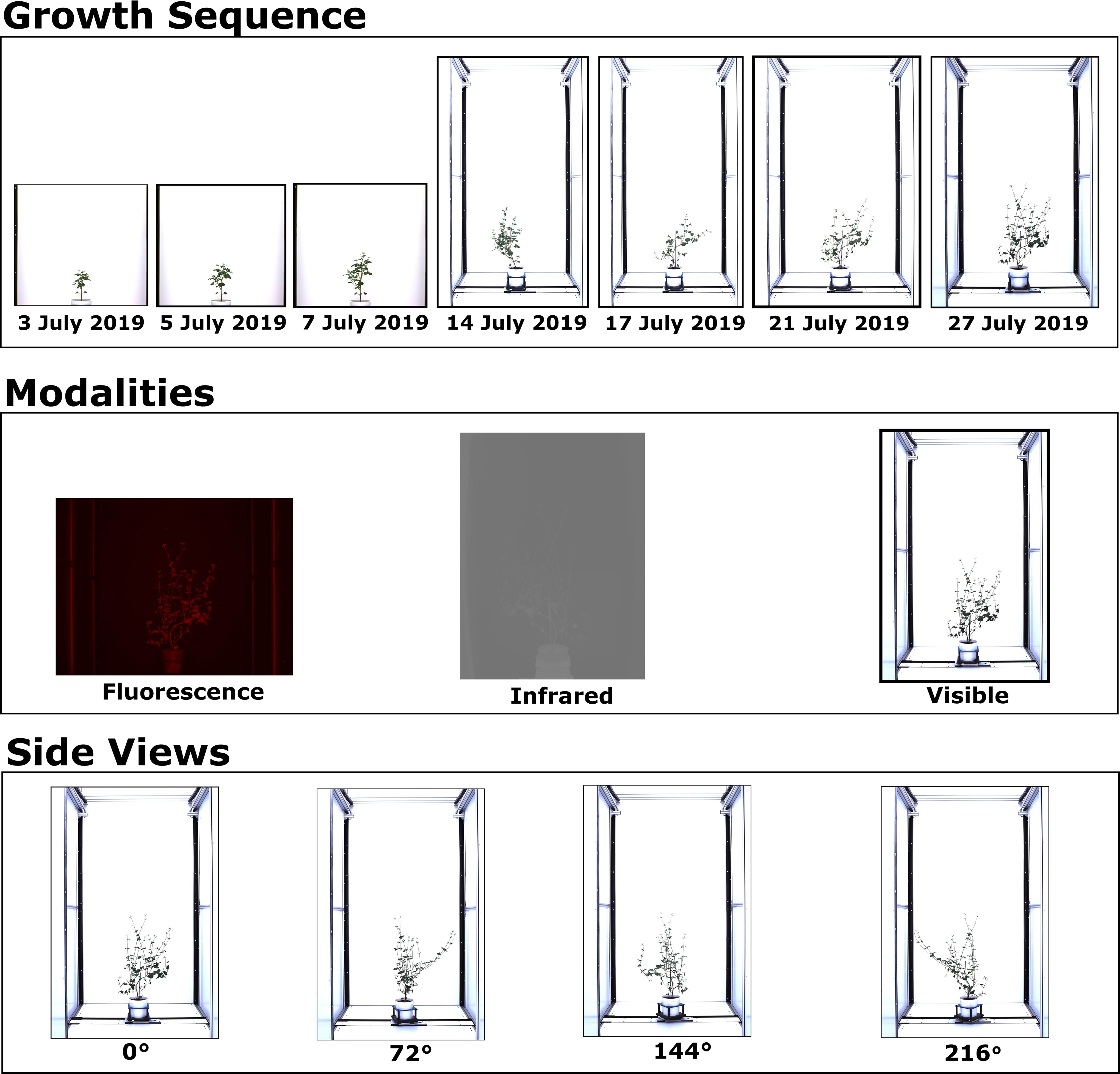
Figure 1 A preview of a VSTEM Dataset. This work will use the CosegPP dataset (Quiñones et al., 2021) and modify it as CosegPP+ and categorize it as a VSTEM dataset for our problem definition. The first row shows the growth sequence of a Buckwheat plant from 3rd July 2019 to 27th July 2019. The second row shows the three modality types of a Buckwheat plant on 27th July 2019. The third row shows the four different side views of a Buckwheat plant on 27th July 2019.
OSC-CO2 is systematically evaluated using a VSTEM dataset retrieved from a high throughput plant phenotyping facility at the University of Nebraska-Lincoln, USA. This paper will use CosegPP+ [an extension of CosegPP (Quiñones et al., 2021)], which consists of growth sequences of multiple plants in their early growth period during which the plant grows, changes shape and appearance, develops new organs (leaves), and sometimes even rotates about a vertical axis for optimal light interception. The plants are grown in a greenhouse and are imaged daily in a high-throughput imaging platform using infrared, fluorescence, and RGB cameras with multiple views. Thus, the dataset exemplifies the VSTEM imagery and is manifestly more challenging than any dataset used in cosegmentation research because it categorizes the many features that pertain to the object while other datasets are random in their object selection with undefined features. The CosegPP+ dataset is available at: https://doi.org/10.5281/zenodo.6863013.
The specific contributions of this research include:
• An end-to-end unsupervised deep learning algorithm, OSC-CO2, to cosegment VSTEM imagery,
• Novel cosegmentation and temporal loss functions to adapt to the challenges of a high volume and variety VSTEM dataset,
• The demonstration of the efficacy of OSC-CO2 in a complex application domain – plant phenotyping. What makes plant phenotyping a complex domain is the dynamic growth and environmental interaction of an object (plant).
The literature is summarized in the next section, with a discussion on open problems, dataset biases, and how OSC-CO2 addresses these research gaps. The metrics used to evaluate the efficacy of the cosegmentation algorithms are also briefly described. Section 3 presents the problem definition, introduces our overall framework, and provides details of the different parts of the framework. Section 4 discusses the quantitative and qualitative results based on our evaluation using the precision and Jaccard index measures. Section 5 provides a final discussion, our conclusions, and potential directions for future work.
2 Literature review
This section summarizes the traditional and learning-based approaches for segmentation and cosegmentation algorithms and the datasets used for their evaluation. We also identify the research gaps and how our work addresses some of them.
2.1 Traditional segmentation algorithms
Traditional segmentation algorithms use a sequence of common image-processing steps to obtain a semantic and instant region of interest in an image. One technique is called frame differencing and is most used in high-throughput plant phenotyping systems since it is capable of imaging plants in a constant fixed camera, and lighting. It has been used by researchers (Woebbecke et al., 1992; Das Choudhury et al., 2017; Choudhury et al., 2018; Das Choudhury et al., 2020) by subtracting a fixed background image that only includes an empty pot, from an image that includes the plant while ensuring the background is constant. Although the segmentation technique is quick and low in computational demands, it does require images to come from a high-throughput system and is susceptible to residual noise around the plant region.
Color-based segmentation can address the issue of residual noise in imagery while having the flexibility to be used without a high-throughput system. This technique partitions parts of the image into different color regions based on its color features while assuming the color features are homogenous. Different color-based segmentations algorithms use either RGB (red, green, and blue), Lab (where L represents lightness, a indicates the red (positive) or green (negative), and b represents the yellow (positive) and blue (negative), or HSV (hue, saturation, and value) depending on the color space application. It was first inspired by Woebbecke et al. (1992), which used the green and red channels to derive the normalized difference index. Then, other researchers leveraged this idea by utilizing the red channel to derive the excess red index (Meyer and Neto, 2008), red, green, and blue channels to derive the color index of vegetation (Kataoka et al., 2003), and others (Hunt et al., 2005; Meyer and Neto, 2008; Zheng et al., 2009). It is a common technique to use for semantic analysis since a majority of a plant can be green compared to the background, but it does not handle multiple-colored objects (common in stress-induced plants) or when the background color is like the object.
Shape modeling-based segmentation is commonly used for leaf or stem semantic analysis (Yin et al., 2014; Agapito et al., 2015; Thorp et al., 2016; Chen et al., 2017; Li et al., 2017; Chen et al., 2019; Roggiolani et al., 2023; Williams et al., 2023), flower instant analysis (Thorp et al., 2016; Zhang et al., 2022; Mahajan et al., 2023), and fruits (Grift et al., 2017; Fu et al., 2019). Chen et al. (2017) had RGB images as an input to their framework, where it transformed the images into a polar coordinate system by using a plant’s density center as the origin. Thorp et al. (2016) used RGB images as input and transformed them into an HSI (hue, saturation, intensity) color space and then segmented the flowers using a Monte Carlo approach. Pape and Klukas (2015) attempted to reduce the impacts of illumination variability by modeling 3D histograms of LAB color space to aid in the segmentation process for rosette plants. Scharr et al. (2016) applied a super pixel-based unsupervised approach that can extract various regions of interests by implementing a seeded region growing algorithm. These techniques usually do not produce a high segmentation accuracy with varying accuracies of 40% to 80% (with superficial image edits, such as cropping, to improve the segmentation).
In addition to color being an obstacle for segmenting the region of interest from the background, the irregular physical characteristics of a plant and inconsistencies in lighting during data acquisition limit the effectiveness of simple, traditional segmentation methods. Therefore, approaches based on thresholding (Otsu, 1979; Sezgin and Sankur, 2004; Meng et al., 2019), frame differencing (Choudhury et al., 2018), color-based (Woebbecke et al., 1992; Zheng et al., 2009), and morphological operations (Zhou et al., 2021) have, in general, proven to be ineffective for segmentation in high-throughput plant imaging datasets. These techniques are unable to overcome image acquisition inconsistencies, including lighting variation, shadows, and plant positions, and more significantly, do not consider or leverage the dynamic nature of the plants’ evolving physical characteristics (Choudhury et al., 2018; Choudhury, 2020).
2.2 Learning-based segmentation algorithms
Learning-based segmentation algorithms are the preferred method especially since traditional segmentation algorithms often yield unsatisfactory results due to the plant being a complex object (Yin et al., 2014). Traditional segmentation algorithms also have issues overcoming common computer vision problems such as occlusion and large-scale lighting variations.
Clustering-based segmentation is a classification technique that attempts to find relational information among pixels in an image and classify them based on a similarity measure. These algorithms are the prerequisite for pursuing further complex phenotypic traits. They can eliminate noisy spots (Lee et al., 2018; Guo et al., 2021) and obtain homogenous regions (Ojeda-Magaña et al., 2010; Liu et al., 2018). Some segmentation algorithms target the semantic segmentation of plants, while others target the instant segmentation of plant parts, such as leaves, flowers, and fruit. Liu et al (Liu et al., 2018). utilized a 3D point cloud and spectral clustering to semantically segment Ixora, Brassica, Wheat, and Basic plants. Then, they further segmented down to each of the plant part’s leaves and stem. Their technique was unique, and their framework was capable of segmenting a variety of plant species. Valliammal et al (Valliammal and Geethalakshmi, 2012). proposed a study where they applied wavelet transformation and fuzzy clustering to segment leaves. They was able to provide good segmentation results while achieving high identification of the leaf’s edges. Another study (Wang et al., 2018) proposed a framework that combined the Sobel operator and the Chan-Vese model to segment cucumber leaves with complex background and occlusion issues. A downside to these algorithms is that they are sensitive to high levels of noise and gray inhomogeneity and are difficult to determine the initial parameters (Li et al., 2020).
Researchers have begun using Convolutional Neural Networks (CNNs) in their applications since 2012 due to their promising performance in semantic and instance segmentation (Jiang and Li, 2020) by utilizing the foreground object’s features. Most applications combine CNNs with deep learning libraries such as Caffe (Pound et al., 2017), TensorFlow (Koh et al., 2021), PyTorch (Zhou et al., 2021), and Keras (Gong et al., 2021) for their analysis. Researchers have attempted to utilize neural network-based segmentation algorithms to count plant organs that have replaced some traditional-based and clustering-based algorithms. Most of these neural network-based algorithms (Bolya et al., 2019; Chen et al., 2020; Kirillov et al., 2020) require plenty of images with pixel-level annotation and available training data. Neural network-based algorithms are also used for data augmentation strategies for plant organ identification, segmentation, and counting (Das Choudhury et al., 2017; Das Choudhury et al., 2020; Mazis et al., 2020). Studies that have used CNNs have shown to have achieved accuracies from 87% to 99% for stress-based application and classification (Mohanty et al., 2016; Cruz et al., 2017; DeChant et al., 2017; Fuentes et al., 2017; Lu et al., 2017; Wang et al., 2017; Barbedo, 2018; Barbedo, 2018; Ferentinos, 2018; Liu et al., 2018; Suh et al., 2018; Nazki et al., 2020) but with manual or naïve modifications of the binary masks after processing.
2.3 Cosegmentation algorithms
Merdassi et al. (Merdassi et al., 2020), categorized cosegmentation algorithms into eight categories: Markov Random Fields-based Cosegmentation (MRF-Coseg), Co-Saliency-based Cosegmentation (CoS-Coseg), Image Decomposition-based Cosegmentation (ID-Coseg), Random Walker-based Cosegmentation (RW-Coseg), Maps-based Cosegmentation (M-Coseg), Active Contours-based Cosegmentation (AC-Coseg), Clustering-based Cosegmentation (Cl-Coseg), and Deep Learning-based Cosegmentation (DL-Coseg). They quantified that almost all algorithms in these categories used only color and texture features. This presents an issue because if the algorithms are intended to only recognize color and features, then the algorithm cannot detect a heterogeneous object that may consist of multiple distinctive regions. Complex, objects, such as plants, are heterogenous and can vary in color and texture as time progresses.
Several DL-Coseg studies (Hsu et al., 2018; Li et al., 2018; Meng et al., 2019) have found that using a CNN-based framework is optimal for detecting, extracting, and map-generating an object’s features for a set of images. Hsu (Hsu et al., 2019) used CNNs to detect co-peaks for an image pair and its features to determine segmentation masks. Li (Li et al., 2018) utilized a CNN-based Siamese encoder-decoder architecture to extract semantic features of the objects in a set of images. Hsu (Hsu et al., 2018) generated heat maps for each image and transformed the results for cosegmentation via dense CRFs. These algorithms require a large-scale set of images to achieve results, but that is extremely time-consuming. Although some algorithms tackle this problem, they end up being semi-serviced learning-based methods (Kim et al., 2011; Wang and Liu, 2013).
Recent cosegmentation algorithms have tackled important issues such as occlusion (Jerripothula et al., 2021; Meng and Zhao, 2022) by leveraging a combination of techniques to aid in object detection. Also, the literature supports incipient cosegmentation applications in pancreas research (Liu et al., 2022). Other sources of imagery, such as UAV-based high throughput platforms (Rico et al., 2020; Rico et al., 2021) or applications to improve the predictability of phenotypes (Sarzaeim et al., 2022; Sarzaeim et al., 2023), illustrate the potential of the use of cosegmentation algorithms and datasets for a variety of object types.
2.4 Cosegmentation datasets
Several datasets to demonstrate the efficacy of cosegmentation algorithms have been proposed in the literature, including iCoseg (Batra et al., 2010), MSRC (Winn et al., 2005), Internet (Rubinstein et al., 2013), Flickr-MFC (Kim and Xing, 2012), and PASCAL-VOC (Everingham et al., 2010). However, these datasets do not reflect the complexity in many application domains where the shape of the objects change over time (temporality), the objects are imaged in different imaging sensors (modality), and under different environmental conditions. These datasets are extremely big in image count that it is difficult to parse or even provide ground truth data for them. Furthermore, most of the objects in the datasets are random and have yet to be used in domain-specific research. The datasets are also limited in their ability to be used in current problems that require temporality, object state change, and multiple modalities for a diverse set of data points. CosegPP (Quiñones et al., 2021), on the other hand, contains many features that could be leveraged to aid current problems to advance cosegmentation research in general and in application-specific work–plant phenotyping.
Traditional and learning-based algorithms are not advanced enough to handle a VSTEM dataset since they currently rely on naïve modifications or are unable to leverage the necessary information for deeper plant analysis. Cosegmentation algorithms tend to overcome the issues with traditional and feature-based algorithms and address complex challenges, such as occlusion, but are only efficient for a specific type of dataset. An overview of cosegmentation datasets suggests that they may not be useful for domain-specific applications and motivates the need for domain-specific datasets. Our work introduces an end-to-end unsupervised deep learning framework and a VSTEM dataset that is 1) high dimensional, and 2) contains a small number of (7 to 14) images. Furthermore, it is the first cosegmentation-based algorithm proposed and tested for plant phenotyping.
3 Methods
OSC-CO2 uses an information fusion approach by leveraging the outputs from multiple segmentation and cosegmentation methods to learn and refine the segmentation of VSTEM images. Specifically, for the images in a VSTEM image dataset, the object of interest will exhibit a variety of state changes over time (but captured at specific temporal points) and is captured in multiple imaging modalities at multiple views. All the available information can be leveraged to aid segmentation. Iteratively, the whole VSTEM dataset is segmented by OSC-CO2 by determining the object using coattention and then cosegmenting the object with one pair of images. A novelty in OSC-CO2 is that, unlike traditional CNNs, it is completely unsupervised, which suggests that no additional data annotations are needed. OSC-CO2 is implemented in three stages: Object Mask Generation (OMG), Object Mask Refinement (OMR), and Final Joint Mask Generation (FJMG). Figure 2 shows the three stages and how they are processing the dataset input and sending information across stages to generate the metric output.
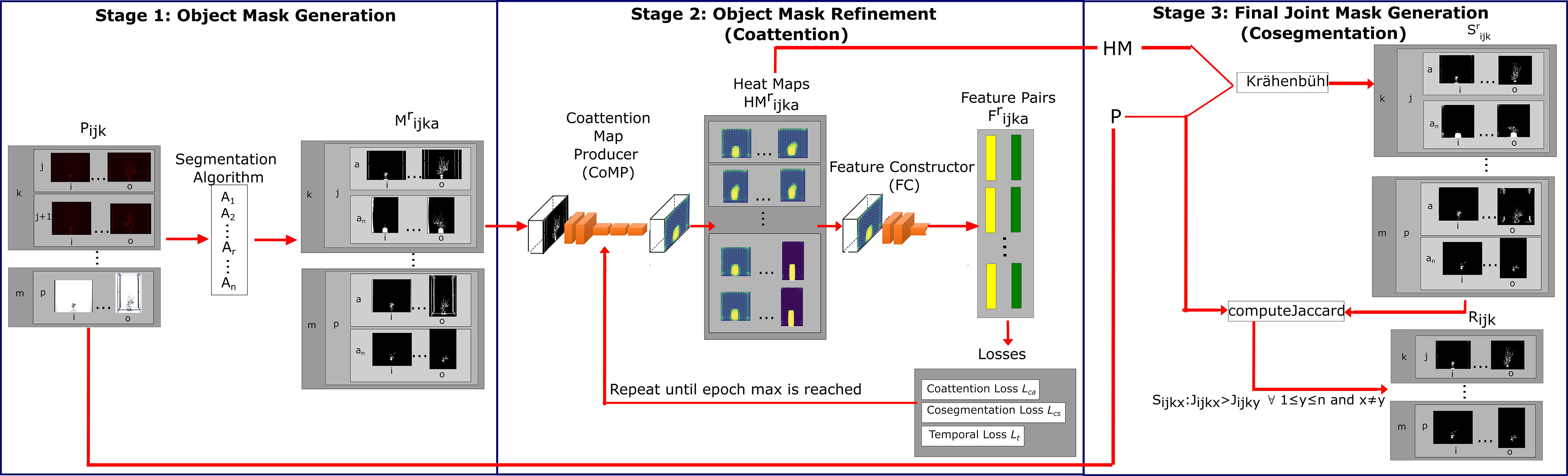
Figure 2 Block diagram of OSC-CO2. This method contains three stages. The Object Mask Generation stage takes imagery, P, and produces binary imagery, M. The Object Mask Refinement stage takes the imagery, M, and processes it through the Coattention Map Producer, CoMP, generating an HM set of heat maps. Then, the maps go through the Feature Constructor, FC, to produces a two-column tensor of feature information of the background and object. The two-column tensor is used as input to the coattention loss () (Hsu et al., 2018), and our novel cosegmentation (lcs) and temporal () loss. This stage stops after the epoch max is reached. For the Final Joint Mask Generation stage, we adopted dense conditional random fields (CRFs) as our refinement taking HM and P as input for Krähenbühl’s algorithm, then giving a final dataset, R, after computing Jaccard index similarity between S and P.
3.1 Problem definition
The problem including VSTEM imagery can be formally defined as follows:
Given a plant P, imaged at time points, modalities, and in side views, i.e., , where is the image of plant at time , view , and modality , determine , where is the final segmented mask for the plant .
The proposed OSC-CO2 algorithm incorporates a dynamic and expandable approach using coattention and cosegmentation analytics. It consists of three stages: (1) Object Mask Generation, (2) Object Mask Refinement, and (3) Final Joint Mask Generation. This model is designed to handle high-throughput image datasets to generate accurate separation of dynamic and evolving objects using a deep learning framework. This approach generates an ensemble of binary masks for a VSTEM image set and addresses some common challenges in segmentation, including background noise and the evolution of the object’s morphology. The proposed OSC-CO2 framework is summarized in Algorithm 1 below.

Algorithm 1. Proposed OSC-CO2 framework
3.2 Overview
Given a set of images of a single plant P in different modalities and views at different time points, we start with a set of basic segmentation algorithms to generate initial masks. Segmented images in the temporal sequence are reconciled in order using deep neural networks with novel loss functions. The final segmentation results are derived by analyzing the refined segmentation results from different algorithms. Figure 2 shows an overview of the OSC-CO2 framework. As shown in the figure, OSC-CO2 consists of three key stages: initial mask generation, mask refinement, and final mask creation.
3.3 Object mask generation
The goal of the OMG stage is to generate the initial segmentations for all the images of the plant, including all modalities, views, and time points. The masks are generated for each segmentation algorithm and are used in Stage 2 to refine them. In the OMG stage, the input images, P, are processed through a set of algorithms selected by the user defines to produce a set of binary images, M, for all the algorithms. This stage has no limit to the number of algorithms and images that it can handle, but it could be limited by a computer’s processing power.
3.4 Object mask refinement
The OMR stage takes the binary imagery, M, through a neural network called the Coattention Map Producer, (CoMP), to create heat maps for each image. Our definition of a heat map is shown in Figure 3. The heat maps are passed through another network called the Feature Constructor (FC) that computes the features of the estimated objects and the background. The Coattention Map Producer CoMP learns by optimizing multiple loss functions designed to address the challenges in cosegmenting a VSTEM dataset with evolving objects. The three functions are temporal, cosegmentation, and coattention loss. Temporal loss measures the inter-image object difference defined by the distance between the feature pairs of the current image and that of the previously computed image. The cosegmentation loss measures the foreground-background discrepancy within each image. The third is coattention loss adapted from (Hsu et al., 2018), which enhances inter-image object similarity and intra-image figure-ground distinctness per image. Finally, the P and HM imagery are inputs to the FJMG stage to the dense conditional random fields (CRFs) cosegmentation algorithm to produce our framework’s final joint masks, R.
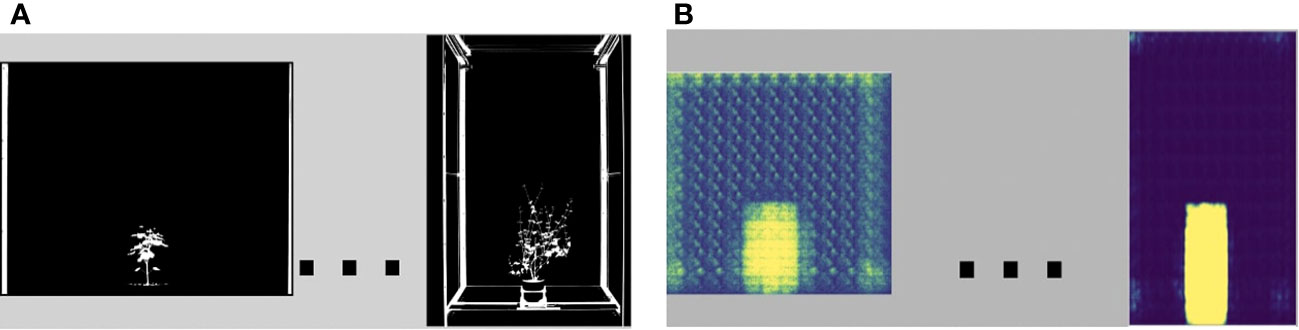
Figure 3 Our heat maps follow the standard color definition where purple and blue is the “coldest” (weak object prediction), and red and yellow is the “hottest” (strong object prediction). (A) Shows some binary imagery with its heat maps (B).
As shown in Figure 4, the OMR module is composed of two collaborative CNN modules to produce the heat maps (heat maps that differentiate between the object and background) and feature pairs (descriptive correlation between an image’s foreground and background). They are described below.
• Coattention Map Producer (CoMP): This module produces heat maps.
• Feature Constructor (FC): Generates feature information for the object and background in each image that can be used by the loss functions for optimization.
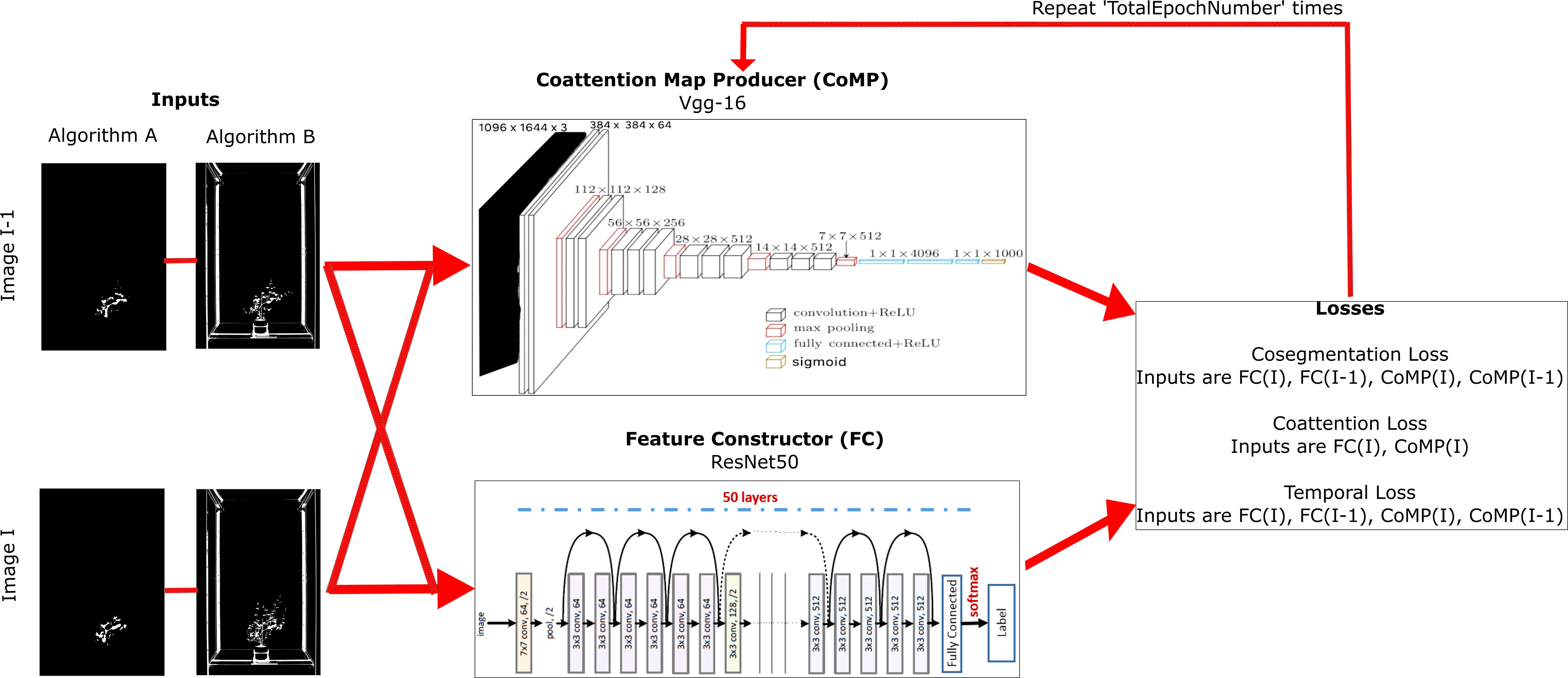
Figure 4 A detailed block diagram of Stage 2: Object Mask Refinement using Coattention. The inputs are simplified in this block diagram to show only the previous and current image with its corresponding imagery for the selected algorithms. These images are inputs to the CoMP and the FC. The generated heat maps from CoMP, and the numerical pairs from FC are used to compute the three losses. These losses are propagated back into CoMP, and this process repeats the number of epochs that is defined in the architecture.
The details of the modules and their architecture are described in detail below.
3.4.1 Coattention map producer
The is a fully convolutional network (FCN) (Long, 2015) that has a modified ReLu layer to avoid modifying the data directly and avoid allocating any additional memory. An FCN was used since the architecture does not contain any dense layers, meaning the FCN can handle a wide range of image sizes since all connections are local. This is useful for VSTEM datasets that contain hundreds of images due to the temporal resolution. For each input image to , it estimates its heat map, i.e., . We used the VGG-16 (Simonyan and Zisserman, 2015) setting of the FCN (Long et al., 2020) to create . Following (Hsu et al., 2018) we replaced the last activation function softmax layer with a sigmoid function layer which provides the heat maps as output. We also kept the learning rate set to and fixed it during the optimization process following (Hsu et al., 2018).
3.4.2 Feature constructor
is a Resnet50 (He et al., 2016) that takes in a segmented image, and computes the semantic features object () and background () using Equations 2 and 3. A Resnet50 architecture was used since it has many layers that can be trained easily without increasing the training error while overcoming the vanishing gradient problem in the VGG-16 architecture in . This approach is useful for our imagery since our evolving objects contain many parts, textures, shadows, and colors. These features are from the last fully connected layer of (Hsu et al., 2018) since VGG-16 (Simonyan and Zisserman, 2015) sometimes suffers from the vanishing gradient problem. Our method recognizes that early heat maps are too unstable and compensates with resilient adjustments. Furthermore, is an off-the-shelf model pre-trained with ImageNet (Deng et al., 2009). We have set the features extracted in as inputs to the last fully connected layer.
3.4.3 Loss functions
A novel contribution of OSC-CO2 is a loss function developed to address the unique properties of the VSTEM datasets. The overall loss function is defined as
where is the coattention loss, is the cosegmentation loss, and is the temporal loss.
The coattention loss is designed to enhance both inter-image object similarity and intra-image figure-ground distinctness in each image, aiding in extracting our object type. Our novel cosegmentation loss optimizes the images by using the object and background’s features for a high foreground object similarity across the output masks and a high foreground-background dissimilarity within each image. This loss will aid in extracting information across the different views and modalities. Our novel temporal loss optimizes the similarity of the foreground objects across two sequential images. This loss will help in providing information about a specific object’s type for each environmental condition. All these losses target all the aspects of a VSTEM dataset.
3.4.3.1 Coattention Loss
The coattention loss is defined by Hsu et al. (2018) and is meant to guide ’s training of optimal coattention masks by referring to the current object and background features that are computed by . The loss function is defined below:
3.4.3.2 Cosegmentation Loss
One assumption we made about the VSTEM dataset is that the object relatively stays in the same position but grows outwards. We exploit this advantage to aid in object alignment. The proposed cosegmentation loss is designed to guide to generate a high foreground object similarity across the images and high foreground-background dissimilarity within each image. Given the current and previously computed image pairs with the current and previously computed generated mask pairs from , we produce the object and background features. We generate the object and background features by
where denotes the pixel-wise multiplication between the two operands. The cosegmentation loss is defined by
where and defined as
The margin enlarges the difference between classes to enhance classification ability. If the margin is too large, the probabilities become unreliable, leading to a large loss for almost all samples (Zhang et al., 2019). For our framework, it is set to 2 as the cutoff threshold. Eq. (5) aims to minimize inter-image foreground object distinctiveness, and Eq. (6) maximizes the intra-image foreground-background discrepancy. Even though the cosegmentation loss is like the loss described in (Chen et al., 2020), there is a significant difference. Our cosegmentation loss measures the mean squared error (MSE) (squared L2 norm) between each element in the input and target (the variable definition used by PyTorch) instead of using the dimension of the features as the constant . In addition, since MSE penalizes prediction that is far away from the previously computed by applying a squared operator, we used that as our criterion to stop the computation of our losses when near convergence. To the best of our knowledge, computing a loss with results from previous iterations to model the temporal effect has not been explored.
3.4.3.3 Temporal Loss
This loss assumes that there exists an object that changes in shape due to environmental conditions, thus, insinuating a discrepancy between the foreground and background as time progresses. The temporal loss is designed to measure the inter-image object distance between the current and previously computed image feature pairs of . We generate the object and background features based on Eq. (2) and (3). The temporal loss is defined by
where is defined as
generates heat maps to optimize low inter-image object distances for both current and previously computed feature pairs using Eq. (9) and (10). Our temporal loss is motivated by Hsu’s (Hsu et al., 2018) coattention loss, but the difference is that ours ignores the intra-image figure-ground dissimilarity and computes the inter-image object distance with the current and previously computed image feature pairs.
3.5 Final joint mask generation
This stage uses the dense CRF approach proposed in (Krähenbühl and Koltun, 2011), where the unary and the pairwise terms are set to the two heat maps generated from the results of two segmentation algorithms and bilateral filtering, respectively. For each pixel in the heat maps, we define a probability that the pixel belongs to undefined classes. The hyperparameters for the network are summarized in Table 1. This stage outputs the final binary masks, R, by computing and selecting the mask with the highest Jaccard index similarity between the plant imagery dataset, P, and the segmented masks dataset, (S), using the dense CRF approach (Krähenbühl and Koltun, 2011).
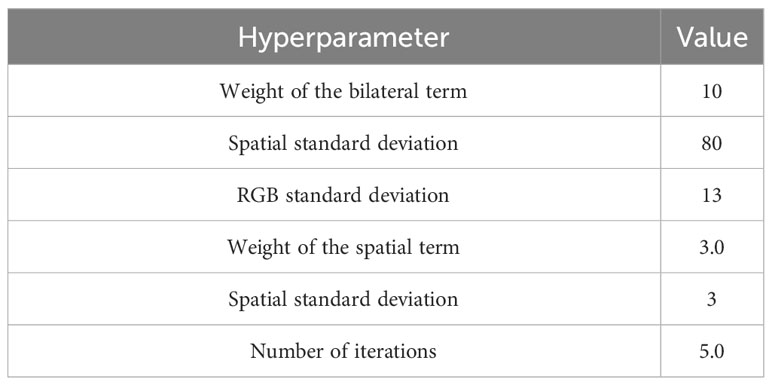
Table 1 Hyperparameter values of the dense CR network approach (Gong et al., 2021).
3.6 Optimization process
OSC-CO2 uses the ADAM optimizer to derive its hyperparameters due to its widespread use and its rapid convergence (Hsu et al., 2018; Mehta et al., 2019; Melinte and Vladareanu, 2020) properties. The final parameters determined by ADAM include a 0.01 learning rate and a 0.0005 weight decay for s parameters. At the start of processing each one-pair of images, the optimizer sets all the gradients to zero.
3.7 The data repository creation
The VSTEM imagery used to evaluate the performance of OSC-CO2 is based on the CosegPP data repository (Quiñones et al., 2021). The data repository has plant images with a large inter-class variation and background noise. The images were captured using the LemnaTec Scanalyzer at the University of Nebraska-Lincoln, USA. It contains two buckwheat plants, where one underwent drought stress, and the other remained the control, and two sunflower plants, where one underwent drought stress, and the other remained the control. Each plant represents a dataset that has four side views (0°, 72°, 144°, 216°), and three modalities (fluorescence, infrared, and visible) with 7 to 14 time points.
We created an extension of CosegPP’s datasets, which we will refer to as CosegPP+, by processing all four plant datasets through segmentation using Otsu’s method (Otsu, 1979) and cosegmentation using Subdiscover (Meng et al., 2016). These two methods were chosen since (Quiñones et al., 2021) defined these as the top methods for being able to segment some of the challenging features of computer vision. CosegPP+ is publicly available at https://doi.org/10.5281/zenodo.6863013.
We replaced the original images with the outputs generated by Otsu’s method and Subdiscover. Meaning that each time point will have at most binary images where is the number of algorithms (i.e., Otsu’s method and Subdiscover) used. Some groups do not contain Subdiscover binary masks due to the method’s limitation in not being able to segment the original images.
3.8 Implementation
OSC-CO2 allows for the dynamic input of epoch runs, but we used 10 epoch runs for CosegPP+. It is worth noting that CosegPP began overfitting after 7 epochs. OSC-CO2 also requires a minimum 2 epochs to allow for the heat maps to generate stable proposals and generate the coattention loss based on pixel-wise averaging of the masks. The cosegmentation loss and temporal loss activates at the final epoch. The batch size is set to (the number of algorithms used as input with their binary masks). Also, all input images are resized to pixel resolution prior to subsequent processing because can only be applied to images of the same size while using kernels with a stride of 3 and 3 for height and width, respectively, and with an initial learning rate of 0.001. After the cosegmentation, we resized the images back to their original sizes for performance evaluation.
4 Results and discussion
In this section, we describe the dataset, performance metrics, experimental design, and evaluation results for OSC-CO2. The results are compared with several existing methods to demonstrate the efficacy of OSC-CO2.
4.1 Evaluation metrics
Our experiment uses two widely used metrics, Precision and Jaccard index’s similarity (also known as IoU) to evaluate the final estimated masks for each time point. Precision is the measurement that identifies the percentage of correctly segmented pixels. Jaccard index is the measurement for the intersection area ratio between the detected object and ground truth. Both metrics will range from 0 to 1 where 1 is the ideal value. We chose these two metrics due to their continuous use in coattention and cosegmentation analytics (Dong et al., 2015; Meng et al., 2016; Wang and Shen, 2016; Li et al., 2018; Merdassi et al., 2020).
4.2 Quantitative results
Table 2 summarizes the performance of OSC-CO2 on the CosegPP+ data repository. The precision and Jaccard index similarity scores for the four plants are presented for each of the three modalities (visible, fluorescence, and infrared). For each modality, the scores for each of the four views are also reported. Finally, the average scores for each plant over all the views and for all the modalities are presented. OSC-CO2 produces the highest precision and Jaccard index similarity scores for the fluorescence and visible modality for the buckwheat species and high scores for the infrared modality for the sunflower species.
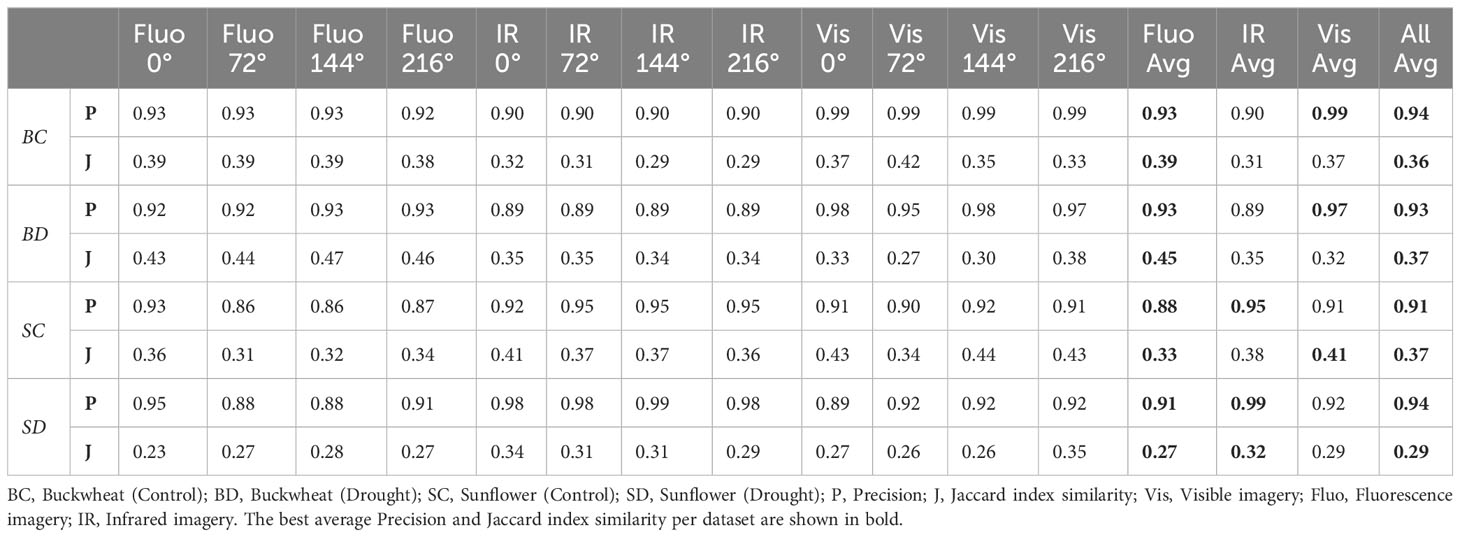
Table 2 The performance of our OSC-CO2 on the CosegPP+ data repository.
Table 3 compares the performance of OSC-CO2 against Otsu’s method, a widely used algorithm in the plant phenotyping domain, and Subdiscover, a leading cosegmentation method. The performance results for Otsu’s algorithm and Subdiscover are derived from our previous research (Quiñones et al., 2021). Table 3A summarizes the effectiveness of our method, OSC-CO2, under normal growth conditions and under drought for buckwheat images. Table 3A shows that the performance of OSC-CO2 is comparable to other algorithms based on the precision score; it is slightly lower in fluorescence and infrared modality but the same or higher for visible imagery. However, the Jaccard index similarity measures for OSC-CO2 are significantly superior to other algorithms. This implies that OSC-CO2 can properly detect the object’s pixels, but at the expense of a very slight reduction in precision.
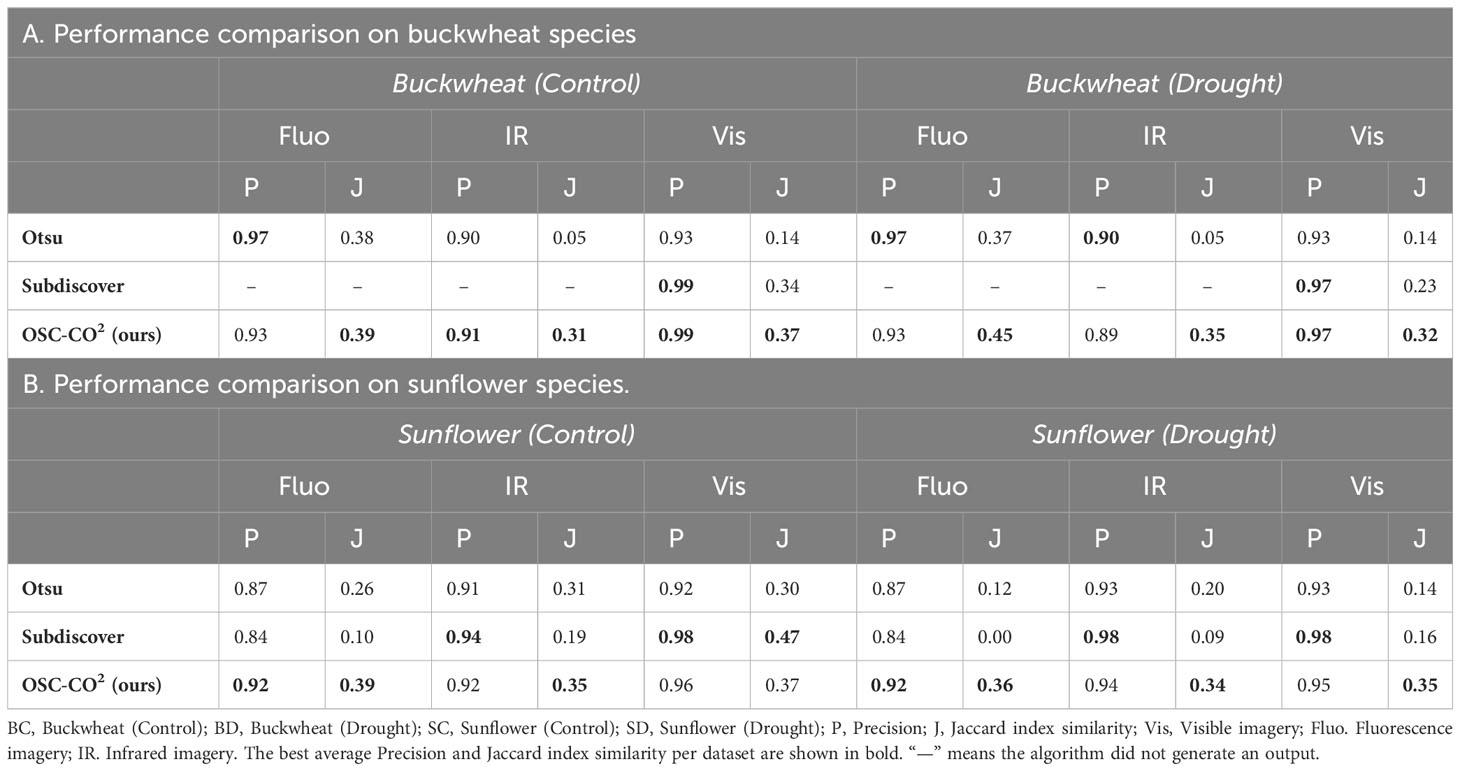
Table 3 The comparative evaluation of OSC-CO2 with Otsu’s algorithm and Subdiscover.
Table 3B compares the performance of OSC-CO2 for the sunflower species. The results are like those for the buckwheat species. The performance for the fluorescence and infrared modality is slightly lower for precision, but significantly better overall for Jaccard index similarity. However, Subdiscover clearly outperformed OSC-CO2 in the visible modality. This may be due to the inconsistent appearance of sunflower images due to the presence of flowers (yellow) with green stems and leaves.
4.3 Qualitative results
Figure 5 shows some sample images from the CosegPP+ data repository and their corresponding segmentations generated by OSC-CO2. For the buckwheat images, OSC-CO2 removes most of the background imaging chamber (background noise in plant phenotyping) while leaving the object (plant) intact. However, the infrared modality was not as accurate in this case. Sunflower images show similar patterns. However, it is noticeable with the Visible light modality that it came at a cost by removing most of the plant itself from the object since those temporal points began to include the flowers. Furthermore, the sunflower displays an empty result for the drought environmental conditions on the last temporal point leading to the assumption that it overfitted too soon. Thus, suggesting the future work of a dynamic epoch cutoff.

Figure 5 Illustration of qualitative performance of OSC-CO2 on the CosegPP data repository. This preview shows only three temporal points (start, middle, end), and one side view for all modalities.
As evident from Figure 5, the sunflower plants tend to have thicker stems and hence, generate more discernable infrared imagery, resulting in better segmentation accuracy than buckwheat. Furthermore, since buckwheat plants were imaged during the vegetative state only, they were green throughout the imaging period. In contrast, sunflower plants have yellow flowers, sometimes several, during the later stages of growth. Therefore, visible images for buckwheat were more consistent, leading to the highest accuracy. Similarly, the green organs in buckwheat in fluorescence imagery, which serves as a proxy for chlorophyll level, have higher segmentation accuracy in this modality.
5 Conclusion and future work
In this paper, we achieve our first contribution of designing an unsupervised method for cosegmenting binary plant imagery by using CNNs that outperformed previous works (Otsu, 1979; Meng et al., 2016) by improving segmentation accuracy by 3% to 45%. The model has three stages. The first stage is the Object Mask Generation which produces the necessary binary imagery from a set of user-defined algorithms. The second stage is the Object Mask Refinement which uses FCN32, VGGNet, and ResNet50. We also achieved our second contribution by designing two novel unsupervised cosegmentation and temporal loss for stage two with one unsupervised coattention loss from literature. The third stage is Final Joint Mask Generation which refines the binary image output by using the heat maps. The experimental results demonstrate a promising new technique that can learn and enhance binary masks, without training data, to refine the masks leading to higher segmentation accuracy for further object analysis.
Using CNNs for evolving objects at different temporal stages shows promising development in increasing accuracy that it may replace some traditional methods for plant phenotyping. This paper creates an unsupervised coattention and cosegmentation method for high-throughput datasets with defined quantitative and qualitative features that leverage the information from multiple algorithms’ binary output. Within this framework, we have proposed two novel loss functions: cosegmentation and temporal loss that aids the coattention loss by helping the discovery of the foreground object while removing background noise.
For our third contribution, experimental evaluations of OSC-CO2 on CosegPP+ demonstrate the method’s great capabilities of being able to recognize the evolving, moving object. This also introduces a base analysis for different types of modalities that are being used more in plant phenotyping analytics. Our method was able to leverage these object features to produce and demonstrate its optimal performance among different modalities and environmental conditions.
This paper is a critical contribution to image segmentation to high-throughput multi-modal image segmentation because it eliminates the need for researchers to perform naïve image pre-processing, such as image cropping that may skew an algorithm’s performance by eliminating the complex aspect of an image that may challenge, and push future algorithmic development.
Future work includes implementing a dynamic epoch cutoff algorithm tailored to dataset varieties in terms of environmental conditions and species. An adjustment of the coattention framework can be made to include the selection of flowers and merge it with the object. This could significantly improve segmentation accuracy. Finally, hyperparameter weights can be implemented for the different dimensions in the dataset so that the algorithm can leverage more of the appropriate dimension for higher segmentation accuracy.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author contributions
RQ contributed as the first author in constructing and analysing the framework, led the experimental analysis, and writing the manuscript. AS, FMA and SDC contributed in supervising, writing and reviewing the original draft. All authors contributed to the article and approved the submitted version.
Funding
This material is based upon work supported by the National Science Foundation under Grant No. DGE-1735362. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Also, the authors acknowledge the support provided by the Agriculture and Food Research Initiative Grant number NEB-21-176 and NEB-21-166 from the USDA National Institute of Food and Agriculture, Plant Health and Production and Plant Products: Plant Breeding for Agricultural Production.
Acknowledgments
This work was completed utilizing the Holland Computing Center of the University of Nebraska, which receives support from the Nebraska Research Initiative. I acknowledge the Agricultural Research Division, Institute of Agriculture and Natural Resources, University of Nebraska-Lincoln for providing the images from the LemnaTec
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Agapito, L., Bronstein, M. M., Rother, C. (2015). “Computer vision— ECCV 2014 workshops,” in 2014 Proceedings, Part IV. Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), (Zurich, Switzerland: Springer), September 6-7 and 12, Vol. 8928. 61–74. doi: 10.1007/978-3-319-16220-1
Alessandretti, G., Broggi, A., Cerri, P. (2007). Vehicle and guard rail detection using radar and vision data fusion. IEEE Trans. Intell. transportation Syst. 8 (1), 95–105. doi: 10.1109/TITS.2006.888597
Barbedo, J. G. A. (2018). Factors influencing the use of deep learning for plant disease recognition. Biosyst. enginee ing 172, 84–91. doi: 10.1016/j.biosystemseng.2018.05.013
Barbedo, J. G. A. (2018). Impact of dataset size and variety on the effectiveness of deep learning and transfer learning for plant disease classification. Comput. electron- ics Agric. 153, 46–53. doi: 10.1016/j.compag.2018.08.013
Batra, D., Kowdle, A., Parikh, D., Luo, J., Chen, T. (2010). “Icoseg: Interactive co-segmentation with in- telligent scribble guidance,” in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 3169–3176, (San Francisco, California: IEEE).
Bolya, D., Zhou, C., Xiao, F., Lee, Y. J. (2019). “YOLACT: Real-time instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis (Seoul, South Korea: IEEE), 2019-Octob. 9156–9165. doi: 10.1109/ICCV.2019.00925
Chang, D., Chirakkal, V., Goswami, S., Hasan, M., Jung, T., Kang, J., et al. (2019). “Multi-lane detection using instance segmentation and attentive voting,” in 2019 19th International Conference on Control, Automation and Systems (ICCAS) (Jeju, South Korea: IEEE), 1538–1542.
Chen, Y., Baireddy, S., Cai, E., Yang, C., Delp, E. J. (2019). “Leaf segmentation by functional modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (Long Beach, California: IEEE), 0–0.
Chen, Y.-C., Lin, Y.-Y., Yang, M.-H., Huang, J.-B. (2020). “Show, match and segment: joint weakly supervised learning of semantic matching and object co-segmentation,” in IEEE transactions on pattern analysis and machine intelligence (IEEE).
Chen, Y., Ribera, J., Boomsma, C., Delp, E. J. (2017). “Plant leaf segmentation for estimating phenotypic traits,” in 2017 IEEE International Conference on Image Processing (ICIP) (Beijing, China: IEEE), 3884–3888.
Chen, X., Shrivastava, A., Gupta, A. (2014a). “Eniching visual knowledge bases via object discovery and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition (Columbus, Ohio: IEEE), 2027–2034.
Chen, X., Shrivastava, A., Gupta, A. (2014b). “Enriching visual knowledge bases via object discovery and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition.
Chen, H., Sun, K., Tian, Z., Shen, C., Huang, Y., Yan, Y. (2020). “BlendMask: Top-down meets bottom-up for instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE). 8573–8581.
Chen, W., Wang, W., Wang, K., Li, Z., Li, H., Liu, S. (2020). Lane departure warning systems and lane line detection methods based on image processing and semantic segmentation: A review. J. Traffic Transportation Eng. (English Edition) 7 (6), 748–774. doi: 10.1016/j.jtte.2020.10.002
Choudhury, S. D. (2020). “Segmentation techniques and challenges in plant phenotyping,” in Intelligent Image Analysis for Plant Phenotyping (Frontiers Media SA: CRC Press), 69–92.
Choudhury, S. D., Bashyam, S., Qiu, Y., Samal, A., Awada, T. (2018). Holistic and component plant phenotyping using temporal image sequence. Plant Methods 14 (1), 35. doi: 10.1186/s13007-018-0303-x
Cruz, A. C., Luvisi, A., De Bellis, L., Ampatzidis, Y. (2017). X-fido: An effective application for detecting olive quick decline syndrome with deep learning and data fusion. Front. Plant Sci. 8, 1741. doi: 10.3389/fpls.2017.01741
Dalal, N., Triggs, B. (2005). Histograms of oriented gradients for human detection. CVPR 1, 886–893. doi: 10.1109/CVPR.2005.177
Das, S., Kundu, M. K. (2013). A neuro-fuzzy approach for meeical image fusion. IEEE Transaction Biomed. Eng. 60 (12), 3347–3353. doi: 10.1109/TBME.2013.2282461
Das Choudhury, S., Goswami, S., Bashyam, S., Samal, A., Awada, T. (2017). “Automated stem angle determination for temporal plant phenotyping analysis,” in Proceedings of the IEEE International Conference on Computer Vision Workshops (Venice, Italy: IEEE). 2022–2029.
Das Choudhury, S., Maturu, S., Samal, A., Stoerger, V., Awada, T. (2020). Leveraging image analysis to compute 3D plant phenotypes based on voxel-grid plant reconstruction. Front. Plant Sci. 11, 521431. doi: 10.3389/fpls.2020.521431
DeChant, C., Wiesner-Hanks, T., Chen, S., Stewart, E. L., Yosinski, J., Gore, M. A., et al. (2017). Automated identification of northern leaf blight-infected maize plants from field imagery using deep learning. Phytopathology 107 (11), 1426–1432. doi: 10.1094/PHYTO-11-16-0417-R
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L. (2009). “ImageNet: A preview of a large- scale hierarchical database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition (Miami, Florida: IEEE).
Dong, X., Shen, J., L., Yang, M.-H. (2015). Interactive cosegmentation using global and local energy optimization. IEEE Trans. Image Process. 24.11, 3966–3977. doi: 10.1109/TIP.2015.2456636
Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., Zisserman, A. (2010). The pascal visual object classes (voc) challenge. Int. J. Comput. Vision 88 (2), 303–338. doi: 10.1007/s11263-009-0275-4
Fan, Z., Lu, J., Wei, C., Huang, H., Cai, X., Chen, X. (2018). A hierarchical image matting model for blood vessel segmentation in fundus images. IEEE Trans. Image Process. 28 (5), 2367–2377. doi: 10.1109/TIP.2018.2885495
Ferentinos, K. P. (2018). Deep learning models for plant disease detection and diagnosis. Comput. Electron. Agric. 145, 311–318. doi: 10.1016/j.compag.2018.01.009
Fu, L., Tola, E., Al-Mallahi, A., Li, R., Cui, Y. (2019). A novel image processing algorithm to separate linearly clustered kiwifruits. Biosyst. Eng. 183, 184–195. doi: 10.1016/j.biosystemseng.2019.04.024
Fuentes, A., Yoon, S., Kim, S. C., Park, D. S. (2017). A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors 17 (9), 2022. doi: 10.3390/s17092022
Gong, L., Du, X., Zhu, K., Lin, C., Lin, K., Wang, T., et al. (2021). Pixel level segmentation of early-stage in bag rice root for its architecture analysis. Comput. Electron. Agric. 186, 106197. doi: 10.1016/j.compag.2021.106197
Grift, T. E., Zhao, W., Momin, M. A., Zhang, Y., Bohn, M. O. (2017). Semi-automated, ma- chine vision based maize kernel counting on the ear. Biosyst. Eng. 164, 171–180. doi: 10.1016/j.biosystemseng.2017.10.010
Guo, X., Qiu, Y., Nettleton, D., Yeh, C. T., Zheng, Z., Hey, S., et al. (2021). KAT4IA: K-means assisted training for image analysis of field-grown plant phenotypes. Plant Phenomics 2021. doi: 10.34133/2021/9805489
He, K., Zhang, X., Ren, S., Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Las Vegas, Nevada: IEEE).
Hoerser, T., Kuenzer, C. (2020). Object detection and image segmentation with deep learning on earth observation data: A review part i: Evolution and recent trends. Remote Sens. 12 (10), 1667. doi: 10.3390/rs12101667
Hsu, K.-J., Lin, Y.-Y., Chuang, Y.-Y. (2018). Co-attention CNNs for unsupervised object co-segmentation. IJCAI 1, 2. doi: 10.24963/ijcai.2018/104
Hsu, K.-J., Lin, Y.-Y., Chuang, Y.-Y. (2019). “Deepco3: Deep instance co-segmentation by co-peak search and co-saliency detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Long Beach, California: IEEE).
Hunt, E. R., Cavigelli, M., Daughtry, C. S., Mcmurtrey, J. E., Walthall, C. L. (2005). Evaluation of digital photography from model aircraft for remote sensing of crop biomass and nitrogen status. Precis. Agric. 6, 359–378. doi: 10.1007/s11119-005-2324-5
Jerripothula, K. R., Cai, J., Lu, J., Yuan, J. (2021). Image co-skeletonization via co-segmentation. IEEE Trans. Image Process. 30, 2784–2797. doi: 10.1109/TIP.2021.3054464
Jiang, Y., Li, C. (2020). Convolutional neural networks for image-based high-throughput plant phenotyping: a re- view. Plant Phenomics. doi: 10.34133/2020/4152816
Kataoka, T., Kaneko, T., Okamoto, H., Hata, S. (2003). “Crop growth estimation system using machine vision,” in Proceedings 2003 IEEE/ASME international conference on advanced intelligent mechatronics (AIM 2003) (Port Island, Japan: IEEE), Vol. 2. b1079–b1083
Kim, G., Xing, E. P. (2012). “On multiple foreground cosegmentation,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition (Providence, Rhode Island: IEEE). 837–844.
Kim, G., Xing, E. P., Li, F.-F., Kanade, T. (2011). “Distributed cosegmentation via submodular optimization on anisotropic diffusion,” in 2011 International Conference on Computer Vision (Barcelona, Spain: IEEE).
Kirillov, A., Wu, Y., He, K., Girshick, R. (2020). “Pointrend: Image segmentation as ren- dering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE). 9799–9808.
Koh, J. C. O., Spangenberg, G., Kant, S. (2021). Automated machine learning for high-throughput image-based plant phenotyping. Remote Sens. 13 (5), 858. doi: 10.3390/rs13050858
Krähenbühl, P., Koltun, V. (2011). “Efficient inference in fully connected crfs with gaussian edge potentials,” in Advances in neural information processing systems (Curran Associates).
Krizhevsky, A., Sutskever, I., Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems (Curran Associates), 25.
Langan, D. A., Modestino, J. W., Zhang, J. (1998). Cluster validation for unsupervised stochastic model-based image segmentation. IEEE Trans. Image Process. 7 (2), 180–195. doi: 10.1109/83.660995
Lee, U., Chang, S., Putra, G. A., Kim, H., Kim, D. H. (2018). An automated, high-throughput plant phenotyping system using machine learning-based plant segmentation and image analysis. PloS One 13 (4), e0196615. doi: 10.1371/journal.pone.0196615
Li, S., Dai, L., Wang, H., Wang, Y., He, Z., Lin, S. (2017). Estimating leaf area density of individual trees using the point cloud segmentation of terrestrial LiDAR data and a voxel-based model. Remote Sens. 9 (11), 1202. doi: 10.3390/rs9111202
Li, Z., Guo, R., Li, M., Chen, Y., Li, G. (2020). A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 176, 105672. doi: 10.1016/j.compag.2020.105672
Li, W., Jafari, O. H., Rother, C. (2018). “Deep object co-segmentation,” in Computer Vision--ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2--6, 2018, Revised Selected Papers, Part III 14 (Cham: Springer) 638–653.
Lian, C., Ruan, S., Denœux, T., Li, H., Vera, P. (2019). Joint tumor segmentation in pet-ct images using co-clustering and fusion based on belief functions. IEEE Trans. Image Process. 28 (2), 755–766. doi: 10.1109/TIP.2018.2872908
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., et al. (2014). Microsoft coco: Common objects in context. Eur. Conf. Comput. Vision 13, 740–755. Springer. doi: 10.1007/978-3-319-10602-1_48
Liu, Z., Su, J., Wang, R., Jiang, R., Song, Y.-Q., Zhang, D., et al. (2022). Pancreas Co-segmentation based on dynamic ROI extraction and VGGU-Net. Expert Syst. Appl. 192, 116444. doi: 10.1016/j.eswa.2021.116444
Liu, J., Liu, Y., Doonan, J. (2018). “Point cloud based iterative segmentation technique for 3d plant phenotyping,” in Symmetry (MDPI), 1072–1077.
Liu, B., Zhang, Y., He, D., Li, Y. (2018). Identification of apple leaf diseases based on deep convolutional neural networks. Symmetry 10 (1), 11. doi: 10.1109/ICInfA.2018.8812589
Liu, D., Zhang, D., Song, Y., Huang, H., Cai, W. (2021). Panoptic feature fusion net: a novel instance segmentation paradigm for biomedical and biological images. IEEE Trans. Image Process. 30, 2045–2059. doi: 10.1109/TIP.2021.3050668
Long, E. (2015). “Shelhamer and T. Darrell. Fully convolutional models for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Boston, Massachusette: IEEE).
Long, J., Shelhamer, E., Darrell, T. (2015). “Fully convolutional networks for semantic seg- mentation”. In: Proceedings of the IEEE conference on computer vision and pattern recognition 2015.
Lowe, D. (2004). Distinctive image features from scale-invariant keypoints. IJCV 60, 91–110. doi: 10.1023/B:VISI.0000029664.99615.94
Lu, Y., Yi, S., Zeng, N., Liu, Y., Zhang, Y. (2017). Identification of rice diseases using deep convo- lutional neural networks. Neurocomputing 267, 378–384. doi: 10.1016/j.neucom.2017.06.023
Mahajan, S., Mittal, N., Pandit, A. K. (2023). Image segmentation approach based on adaptive flower pollination algorithm and type II fuzzy entropy. Multimedia Tools Appl. 82 (6), 8537–8559. doi: 10.1007/s11042-022-13551-2
Mazis, A., Choudhury, S. D., Morgan, P. B., Stoerger, V., Hiller, J., Ge, Y., et al. (2020). Application of high-throughput plant phenotyping for assessing biophysical traits and drought response in two oak species under controlled environment. For. Ecol. Manage. 465, 118101. doi: 10.1016/j.foreco.2020.118101
Mehta, S., Paunwala, C., Vaidya, B. (2019). “CNN based traffic sign classification using adam optimizer,” in 2019 International Conference on Intelligent Computing and Control Systems (ICCS) (Madurai, India: IEEE).
Melinte, D. O., Vladareanu, L. (2020). Facial expressions recognition for human–robot interaction using deep convolutional neural networks with rectified adam optimizer. Sensors 20.8, 2393. doi: 10.3390/s20082393
Meng, F., Cai, J., Li, H. (2016). Cosegmentation of multiple image groups. Comput. Vision Image Understanding 146, 67–76. doi: 10.1016/j.cviu.2016.02.004
Meng, F., Luo, K., Li, H., Wu, Q., Xu, X. (2019). “Weakly supervised semantic segmentation by a class-level multiple group cosegmentation and fore- ground fusion strategy,” in IEEE Transactions on Circuits and Systems for Video Technology (IEEE), Vol. 30. 4823–4836.
Meng, H., Zhao, Q. (2022). “A lightweight model based on co-segmentation attention for occluded person re-identification,” in Proceedings of 2021 Chinese Intelligent Automation Conference (Singapore: Springer).
Merdassi, H., Barhoumi, W., Zagrouba, E. (2020). A comprehensive overview of relevant methods of image cosegmentation. Expert Syst. Appl. 140, 112901. doi: 10.1016/j.eswa.2019.112901
Meyer, G. E., Neto, J. C. (2008). Verification of color vegetation indices for automated crop imaging applications. Comput. Electron. Agric. 63 (2), 282–293. doi: 10.1016/j.compag.2008.03.009
Mohanty, S. P., Hughes, D. P., Salathe, M. (2016). Using deep learning for image-based plant disease detection. Front. Plant Sci. 7, 1419. doi: 10.3389/fpls.2016.01419
Nazki, H., Yoon, S., Fuentes, A., Park, D. S. (2020). Unsupervised image translation using adversarial networks for improved plant disease recognition. Comput. Electron. Agric. 168, 105117. doi: 10.1016/j.compag.2019.105117
Ojeda-Magaña, B., Ruelas, R., Quintanilla-Dominguez, J., Andina, D. (2010). “Color image segmentation by partitional clustering algorithms,” in IECON 2010-36th Annual Conference on IEEE Industrial Electronics Society (Glendale, Arizona: IEEE), 2828–2833.
Otsu, N. (1979). “A threshold selection method from gray- level histograms,” in IEEE transactions on systems, man, and cybernetics (IEEE), Vol. 9. 62–66.
Pape, J.-M., Klukas, C. (2015). Utilizing machine learning approaches to improve the prediction of leaf counts and individual leaf segmentation of rosette plant images. Proc. Comput. Vis. Probl. Plant Phenotyping 3, 1–12. doi: 10.5244/C.29.CVPPP.3
Patz, T., Preusser, T. (2012). Segmentation of stochastic images with a stochastic random walker method. IEEE Trans. Image Process. 21 (5), 2424–2433. doi: 10.1109/TIP.2012.2187531
Pound, M. P., Atkinson, J. A., Townsend, A. J., Wilson, M. H., Griffiths, M., Jackson, A. S., et al. (2017). Deep machine learning pro- vides state-of-the-art performance in image-based plant phe- notyping. Gigascience 6 (10), gix083. doi: 10.1093/gigascience/gix083
Quiñones, R., Munoz-Arriola, F., Choudhury, S. D., Samal, A. (2021). Multi-feature data repository development and analytics for image cosegmentation in high-hroughput plant phenotyping. PLoS One 16 (9), 1–21. doi: 10.1371/journal.pone.0257001
Ren, Y., Jiao, L., Yang, S., Wang, S. (2018). Mutual learning between saliency and similarity: Image cosegmentation via tree structured sparsity and tree graph matching. IEEE Trans. Image Process. 27 (9), 4690–4704. doi: 10.1109/TIP.2018.2842207
Rezaee, M. R., van der Zwet, P. M., Lelieveldt, B. P. E., van der Geest, R. J., Reiber, J. H. (2000). A multiresolution image segmentation technique based on pyramidal segmentation and fuzzy clustering. IEEE Trans. image Process. 9 (7), 1238–1248. doi: 10.1109/83.847836
Rico, D. A., Detweiler, C., Muñoz-Arriola, F. (2020). “Power-over-tether UAS leveraged for nearly-indefinite meteorological data acquisition,” in 2020 ASABE Annual International Meeting, Paper No. 1345 (American Society of Agricultural and Biological Engineers). doi: 10.13031/aim.202001345
Rico, D. A., Muñoz-Arriola, F., Detweiler, C. (2021). Trajectory selection for power-over-tether atmospheric sensing UAS. 2021 IEEE/RSJ Int. Conf. Intelligent Robots Syst. (IROS), 2021 2321–2328. doi: 10.1109/IROS51168.2021.9636364
Roggiolani, G., Sodano, M., Guadagnino, T., Magistri, F., Behley, J., Stachniss, C. (2023). “Hierarchical approach for joint semantic, plant instance, and leaf instance segmentation in the agricultural domain,” in 2023 IEEE International Conference on Robotics and Automation (ICRA) (London, United Kingdom: IEEE), 9601–9607.
Rother, C., Kolmogorov, V., Minka, T., Blake, A. (2006). “Cosegmentation of image pairs by histogram matching-incorporating a global constraint into mrfs,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (New York, New York: IEEE), 993–1000.
Rubinstein, M., Joulin, A., Kopf, J., Liu, C. (2013). “Unsupervised joint object discovery and segmentation in internet images,” in Proceedings of the IEEE conference on computer vision and pattern recognition (Portland, Oregon: IEEE), 1939–1946.
Sarzaeim, P., Muñoz-Arriola, F., Jarquin, D. (2022). Climate and genetic data enhancement using deep learning analytics to improve maize yield predictability. J. Exp. Bot vol. 73 (15), 5336–5354. doi: 10.1093/jxb/erac146
Sarzaeim, P., Munoz-Arriola, F., Jarquin, D., Aslam, H., De Leon Gatti, N. (2023). CLIM4OMICS: a geospatially comprehensive climate and multi-OMICS database for Maize phenotype predictability in the U.S. and Canada. Earth Syst. Sci. Data 15 (9), 3963-3990. doi: 10.5194/essd-2023-11
Scharr, H., Minervini, M., French, A. P., Klukas, C., Kramer, D. M., Liu, X., et al. (2016). Leaf segmentation in plant phenotyping: a collation study. Mach. Vis. Appl. 27, 585–606. doi: 10.1007/s00138-015-0737-3
Sezgin, M., Sankur, B. (2004). Survey over image hresholding techniques and quantitative performance evaluation. J. Electronic Imaging 13 (1), 146–166. doi: 10.1117/1.1631315
Simonyan, K., Zisserman, A. (2015). “Very deep convolutional networks for large-scale image recognition,” in arXiv preprint arXiv:1409.1556 (Cornell University).
Subramaniam, A., Nambiar, A., Mittal, A. (2019). “Co-segmentation inspired attention networks for video-based person re-identification,” in Proceedings of theIEEE/CVF International Conference on Computer Vision (Seoul, South Korea: IEEE), 562–572.
Suh, H. K., Ijsselmuiden, J., Hofstee, J. W., van Henten, E. J. (2018). Transfer learning for the classification of sugar beet and volunteer potato under field conditions. Biosyst. Eng. 174, 50–65. doi: 10.1016/j.biosystemseng.2018.06.017
Tao, W., Li, K., Sun, K. (2015). SaCoseg: Object cosegmentation by shape conformability. IEEE Trans. Image Process. 24 (3), 943–955. doi: 10.1109/TIP.2014.2387384
Tao, Z., Liu, H., Fu, H., Fu, Y. (2019). Multi-view saliency-guided clustering for image cosegmentation. IEEE Trans. Image Process. 28 (9), 4634–4645. doi: 10.1109/TIP.2019.2913555
Thorp, K. R., Wang, G., Badaruddin, M., Bronson, K. F. (2016). Lesquerella seed yield estimation using color image segmentation to track flowering dynamics in response to variable water and nitrogen management. Ind. Crops Products 86, 186–195. doi: 10.1016/j.indcrop.2016.03.035
Valliammal, N., Geethalakshmi, S. N. (2012). A novel approach for plant leaf image segmentation using fuzzy clustering. Int. J. Comput. Appl. 44 (3), 10–20. doi: 10.5120/6322-8669
Wang, Z., Liu, R. (2013). “Semi-supervised learning for large scale image cosegmentation,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Sydney, Australia: IEEE).
Wang, G., Sun, Y., Wang, J. (2017). Automatic image-based plant disease severity estimation using deep learning. Comput. Intell. Neurosci. doi: 10.1155/2017/2917536
Wang, Z., Wang, K., Yang, F., Pan, S., Han, Y. (2018). Image segmentation of overlapping leaves based on Chan–Vese model and Sobel operator. Inf. Process. Agric. 5 (1), 1–10. doi: 10.1016/j.inpa.2017.09.005
Wang, W., Shen, J. (2016). Higher-order image co-segmentation. IEEE Trans. Multimedia 18.6, 1011–1021. doi: 10.1109/TMM.2016.2545409
Williams, D., MacFarlane, F., Britten, A. (2023). Leaf only SAM: A segment anything pipeline for zero-shot automated leaf segmentation. arXiv preprint arXiv 2305, 09418. doi: 10.48550/arXiv.2305.09418
Winn, J., Criminisi, A., Minka, T. (2005). “Object categorization by learned universal visual dictionary,” in Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1 (Beijing, China: IEEE), Vol. 2. 1800–1807.
Woebbecke, D. M., Meyer, G. E., Von Bargen, K., Mortensen, D. A. (1992). “Plant species identification, size, and enumeration using machine vision techniques on near-binary images [1836-20],” in Optics in Agriculture and Forestry (SPIE). 208–208.
Yin, X., Liu, X., Chen, J., Kramer, D. M. (2014). “Multi-leaf alignment from fluorescence plant images,” in IEEE Winter Conference on Applications of Computer Vision (Steamboat Springs, Colorado: IEEE), Vol. 2014. 437–444. doi: 10.1109/WACV.2014.6836067
Yuan, Z., Lu, T., Wu, Y. (2017). “Deep-Dense Conditional Random Fields for Object Co-segmentation,” in IJCAI.
Zhang, X., Zhao, R., Qiao, Y., Wang, X., Li, H. (2019). “Adacos: Adaptively scaling cosine logits for effectively learning deep face representations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Long Beach, California: IEEE).
Zhang, C., Mouton, C., Valente, J., Kooistra, L., van Ooteghem, R., de Hoog, D., et al. (2022). Automatic flower cluster estimation in apple orchards using aerial and ground based point clouds. Biosyst. Eng. 221, 164–180. doi: 10.1016/j.biosystemseng.2022.05.004
Zheng, L., Zhang, J., Wang, Q. (2009). Mean-shift-based color segmentation of images containing green vegetation. Comput. Electron. Agric. 65 (1), 93–98. doi: 10.1016/j.compag.2008.08.002
Zhong, Z., Kim, Y., Plichta, K., Allen, B. G., Zhou, L., Buatti, J., et al. (2019). Simultaneous cosegmentation of tumors in pet-ct images using deep fully convolutional networks. Med. Phys. 46 (2), 619–633. doi: 10.1002/mp.13331
Zhou, S., Chai, X., Yang, Z., Wang, H., Yang, C., Sun, T. (2021). Maize-ias: a maize image analysis software using deep learning for high-throughput plant phenotyping. Plant Methods 17 (1), 1–17. doi: 10.1186/s13007-021-00747-0
Keywords: segmentation, cosegmentation, image analysis, high-throughput plant phenotyping, image sequences, object state change, multiple features, multiple dimensions
Citation: Quiñones R, Samal A, Das Choudhury S and Muñoz-Arriola F (2023) OSC-CO2: coattention and cosegmentation framework for plant state change with multiple features. Front. Plant Sci. 14:1211409. doi: 10.3389/fpls.2023.1211409
Received: 24 April 2023; Accepted: 06 October 2023;
Published: 31 October 2023.
Edited by:
Sonia Negrao, University College Dublin, IrelandReviewed by:
Nisha Pillai, Mississippi State University, United StatesParvathaneni Naga Srinivasu, Prasad V. Potluri Siddhartha Institute of Technology, India
Copyright © 2023 Quiñones, Samal, Das Choudhury and Muñoz-Arriola. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rubi Quiñones, cnF1aW5vbkBzaXVlLmVkdQ==