 Wenhao Li
Wenhao Li Ding He2†
Ding He2† Fenghe Wang
Fenghe Wang Fengliang Huang
Fengliang Huang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 21 March 2023
Sec. Technical Advances in Plant Science
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1146485
This article is part of the Research Topic Cutting Edge Microscopy and Imaging Techniques in Plant and Algal Research View all 8 articles
It is difficult for laser scanning confocal microscopy to obtain high- or ultra-high-resolution laser confocal images directly, which affects the deep mining and use of the embedded information in laser confocal images and forms a technical bottleneck in the in-depth exploration of the microscopic physiological and biochemical processes of plants. The super-resolution reconstruction model (SRGAN), which is based on a generative adversarial network and super-resolution reconstruction model (SRResNet), which is based on a residual network, was used to obtain single and secondary super-resolution reconstruction images of laser confocal images of the root cells of the hyperaccumulator Solanum nigrum. Using the peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and mean opinion score (MOS), the models were evaluated by the image effects after reconstruction and were applied to the recognition of endocytic vesicles in Solanum nigrum root cells. The results showed that the single reconstruction and the secondary reconstruction of SRGAN and SRResNet improved the resolution of laser confocal images. PSNR, SSIM, and MOS were clearly improved, with a maximum PSNR of 47.690. The maximum increment of PSNR and SSIM of the secondary reconstruction images reached 21.7% and 2.8%, respectively, and the objective evaluation of the image quality was good. However, overall MOS was less than that of the single reconstruction, the perceptual quality was weakened, and the time cost was more than 130 times greater. The reconstruction effect of SRResNet was better than that of SRGAN. When SRGAN and SRResNet were used for the recognition of endocytic vesicles in Solanum nigrum root cells, the clarity of the reconstructed images was obviously improved, the boundary of the endocytic vesicles was clearer, and the number of identified endocytic vesicles increased from 6 to 9 and 10, respectively, and the mean fluorescence intensity was enhanced by 14.4% and 7.8%, respectively. Relevant research and achievements are of great significance for promoting the application of deep learning methods and image super-resolution reconstruction technology in laser confocal image studies.
Confocal laser scanning microscopy (CLSM) has been used in cellular molecular biology (Stephens and Allan, 2003), 3D imaging of materials (Ji et al., 2021), material porosity determination (Mauko et al., 2009), and reaction process visualization (Onuma et al., 2017). It has also been used to identify the distribution of fillers in a polymer matrix (Zhong et al., 2017), including the examination of the structure of tobacco microsporocytes involved in the intercellular migration of nuclei (cytomixis), as well as to study live cell chiral molecular interactions (Mursalimov et al., 2017; Stachelek et al., 2022). For the purpose of cellular molecular biology, the high sensitivity, high spatial resolution, and super-optical sectioning ability of CLSM make it an ideal tool for studying biological systems, including membranes, tissues, and cell structures. It can be used to carry out quantitative fluorescence determination in tissues and cells, physicochemical determinations in cells, and long-term observation of cell migration and growth. It can also provide visual evidence for the study of plant growth processes and phytoremediation processes and mechanisms (Stephens and Allan, 2003; Nwaneshiudu et al., 2012; Paddock and Eliceiri, 2014; Hall et al., 2016; Khan et al., 2020; He et al., 2021; Zhang et al., 2022). One important application is the filming of plant cell endocytosis. Endocytosis plays an important role in information transfer, nutrient uptake, and pollution remediation in plants. The visualization of endocytosis in plant cells can provide important theoretical support for the elucidation of life processes in plants (Fan et al., 2015; He et al., 2023). The number of endocytosis vesicles is important information, and currently, endocytosis cell counting is mainly identified by manual visual counting with low levels of efficiency and large error. At present, high-resolution and clear images in laser scanning confocal microscopy are mostly obtained by adjusting the relevant parameters using acquisition software. Due to the diffraction limit in optical microscopy and the principle of point-by-point scanning in laser scanning confocal microscopy, and point-to-line and line-to-plane imaging, it is difficult to directly obtain higher or ultra-high-resolution laser confocal images using laser scanning confocal microscopes, which greatly hinders the deep mining and use of the embedded information in the images.
Super-resolution image reconstruction (SRIR) is a technology for obtaining high-resolution images from low-resolution images using algorithms. SRIR has great importance and value in practical applications such as medical imaging, satellite remote sensing, monitoring, and scientific research (Zhang et al., 2010; Isaac and Kulkarni, 2015; Courtrai et al., 2020). Traditional super-resolution reconstruction algorithms rely on basic digital image processing techniques for reconstruction, including interpolation-based, degradation-based, and learning-based super-resolution reconstruction (Shezaf et al., 2000; Yang et al., 2008; Yang et al., 2022). The rapidly developing technology of artificial intelligence has injected energy into scientific research and now plays an important role in life sciences, mathematics, chemistry, space science, and other disciplines (Yu, 2022). Deep learning, as a core technology in artificial intelligence, forms a new research field in machine learning. It simulates the human brain in analyzing and interpreting data to allow a computer to learn relevant features and make relevant predictions according to the learned features. It has obvious advantages over machine learning, which requires the manual extraction of relevant features (Yann et al., 2015). The application of deep learning to image super-resolution reconstruction is an emerging trend. In 2014, Dong et al. used a convolution neural network for single-image super-resolution reconstruction and proposed a super-resolution convolution neural network, which had a lightweight structure, could be used online, and was the best image reconstruction model at that time (Dong et al., 2016). Owing to the remarkable effects deep learning produced when applied to super-resolution reconstruction, a variety of neural networks in deep learning, such as deep convolutional neural networks (Kim et al., 2016) and generative adversarial networks (GAN) (Ledig et al., 2017; Yuan et al., 2022), have been applied to image super-resolution reconstruction.
The potential to obtain high-definition images through image super-resolution reconstruction technology has attracted the attention of many researchers (Lin et al., 2019; Yang et al., 2020; Dreier et al., 2021; Wei et al., 2022), but no reconstruction or application of laser confocal images has been reported in the literature. GAN and residual networks (ResNet) are two representative deep-learning networks. Applying the GAN-based Super-resolution Reconstruction Model (SRGAN) and ResNet-based Super-resolution Reconstruction Model (SRResNet) to laser confocal image reconstruction has strong overall importance for exploring the application of deep learning methods in laser confocal image research. In this study, deep learning was applied to laser scanning confocal microscopic images of the root cells of the hyperaccumulator Solanum nigrum. We compared super-resolution image reconstruction using SRGAN and SRResNet, evaluating different image quality indicators. Our results promote the intersection of artificial intelligence and botany, environmental science, ecology, and other disciplines and provide a new concept for the in-depth study of phytoremediation-related cytological characteristics.
SRGAN has the same overall structure as GAN. It is composed of a generative network and a discriminant network, and the perceived loss is used as the loss function (Ledig et al., 2017; Li and Zhang, 2022; Singla et al., 2022). The generative network of the SRGAN can take an image as an n-dimensional vector input to generate the reconstructed image output. The discriminant network determines the authenticity of the image generated by the network using a loss function. For the loss function, the perceptual loss includes content- and adversarial- loss, where the former is the mean square error (MSE) between the reconstructed high-resolution image feature map and the original image feature map, and the latter is the loss when the reconstructed high-resolution image is correctly judged by the discriminator. Perceptual loss is continuously optimized using algorithms, and the learning of the generative and discriminant models is continuously supervised. When the number of iteration rounds reaches a set value to end the training, a generative network is obtained for image reconstruction. Figure 1 shows the process of super-resolution reconstruction of an image based on SRGAN.
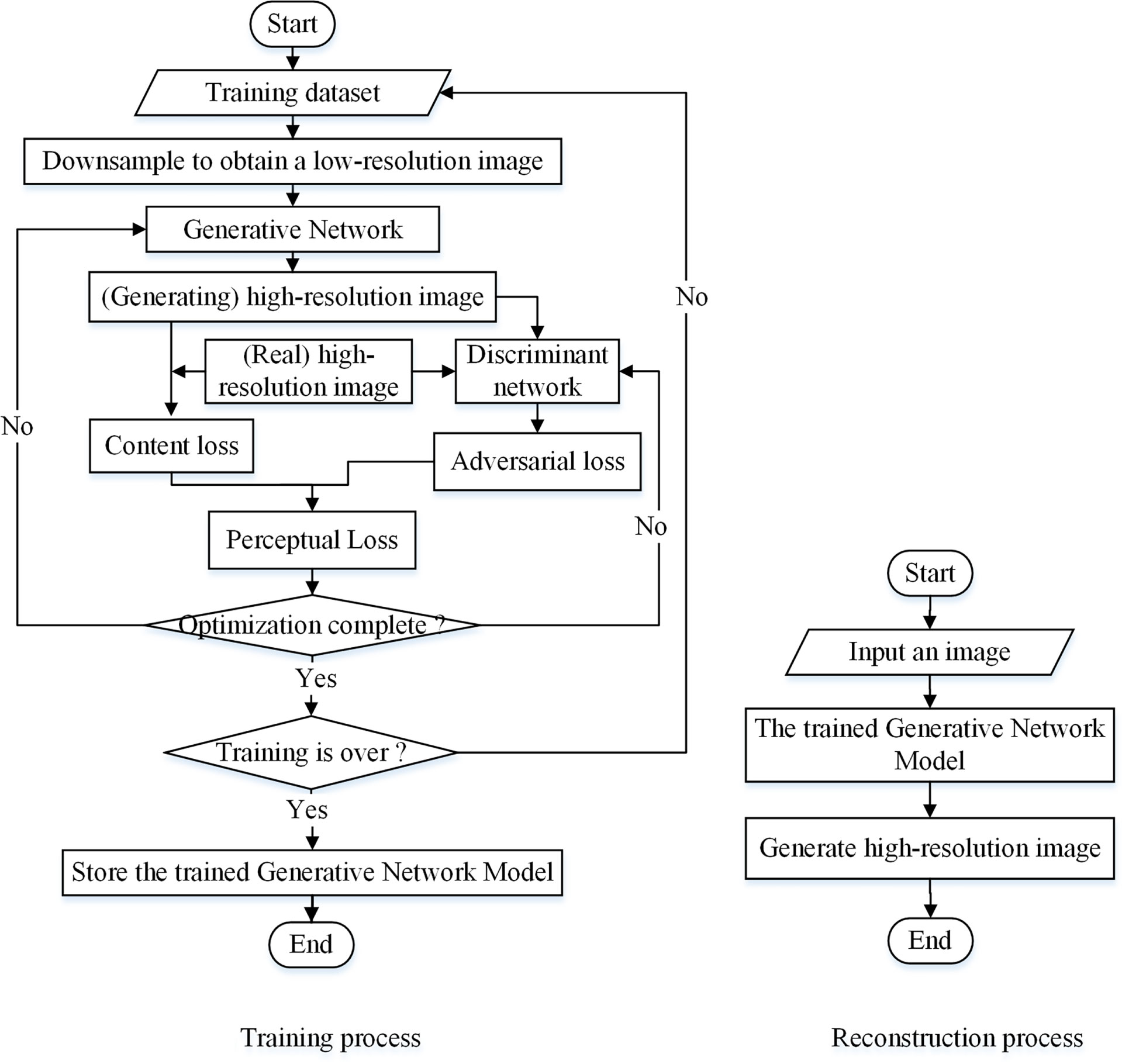
Figure 1 Image super-resolution reconstruction process for SRGAN.
SRResNet is based on a convolutional neural network added to a residual learning network structure (Ledig et al., 2017; Lu et al., 2022). The main body includes two parts: a deep residual network and a sub-pixel convolution network. It uses the MSE as the loss function. The deep residual network adds a residual learning module to the convolutional neural network, which effectively solves problems of accuracy degradation and gradient dispersion in the deep network, greatly deepens the number of network layers, and ensures precision. Thus, the depth and precision of the training is effectively improved, which aids efficient feature extraction and reduces image noise. The main function of the sub-pixel convolution model is to increase the size and the accuracy of the enlarged image through sample learning. SRResNet uses a low-resolution image as its input and outputs a reconstructed high-resolution image. Figure 2 shows the process of image super-resolution reconstruction based on SRResNet.
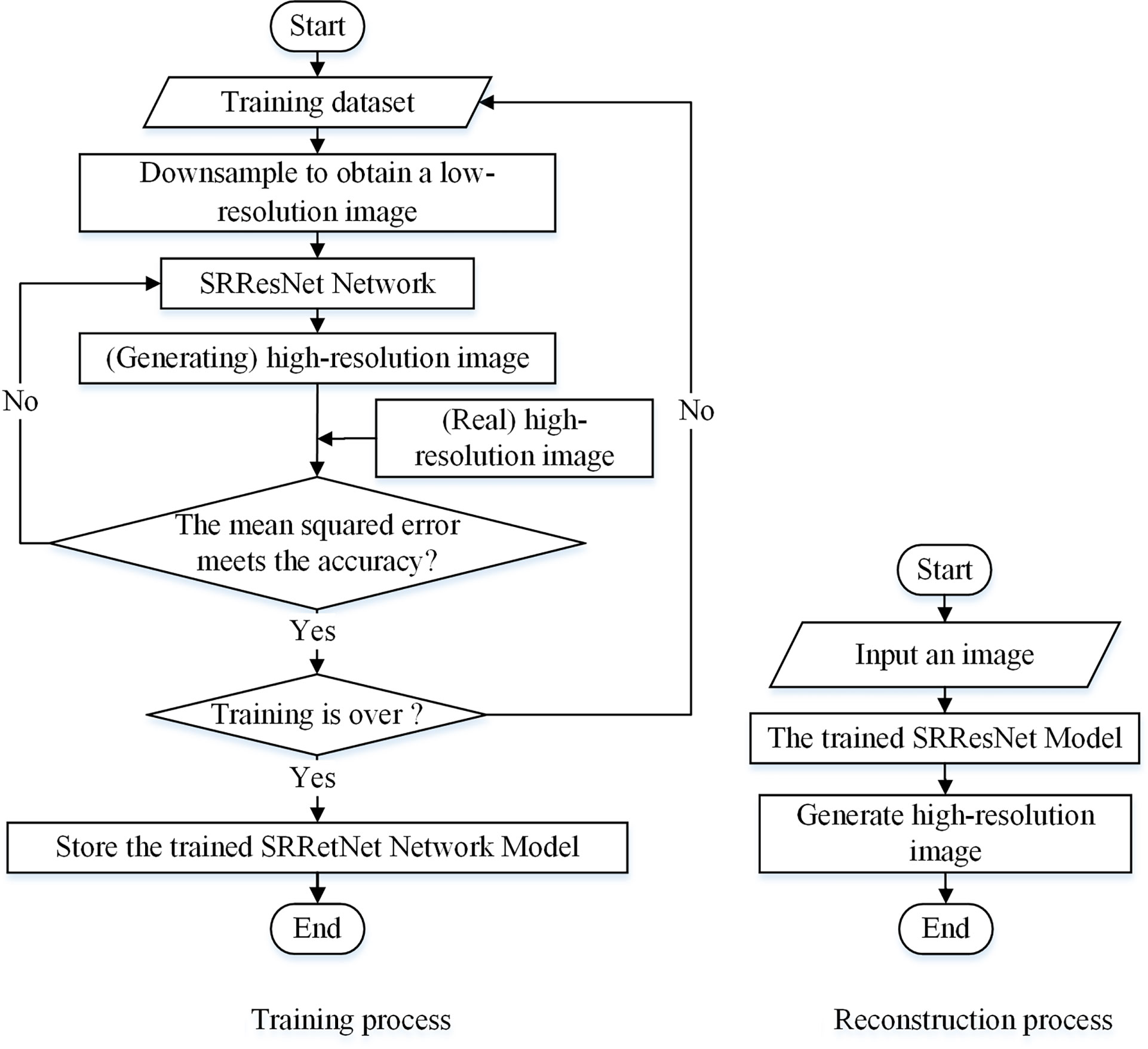
Figure 2 Image super-resolution reconstruction process for SRResNet.
In the laser confocal images reconstructed by SRGAN and SRResNet, the image quality was evaluated using three indices: peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and mean opinion score (MOS). The former two indicators are objective evaluations, based on experimental numerical calculations, and the latter is a subjective evaluation based on the system of visual perception of the human eye. Taking into account the efficiency factor of practical use, the time cost of the super-resolution reconstruction of laser confocal images using different models was also considered in this evaluation.
PSNR represents the ratio of the maximum possible power of the signal to the destructive noise that affects its representation accuracy and is defined by the maximum pixel value and the MSE of the image (Singla et al., 2022).
where represents the maximum value of the image point color, and the maximum pixel value of the image is determined by the number of binary bits. The greater the PSNR value, the better the reconstructed image quality. For PSNR values higher than 40 dB, the image quality is excellent, while PSNRs of 30–40 dB indicate that image quality is good.
SSIM is a quality-evaluation framework based on structural information, which comprehensively considers the brightness, contrast, and structural information of an image (Wang et al., 2004). It uses the image mean value as brightness estimation, standard deviation as contrast estimation, and covariance as the structural similarity extent estimation. The range of SSIM is 0–1, where higher values, indicate better reconstructed image qualities.
where represents the brightness comparison of images, represents the contrast comparison of the images, represents the structural comparison of images, μ represents the mean value, σ represents the standard deviation, represents the covariance, and is a constant.
MOS measures image quality as scored by professionals in related fields who observe images with their eyes (Singla et al., 2022). It is a comprehensive evaluation of images by observers in terms of color, clarity, noise, texture, and so on. Originally used as a criterion for evaluating the quality of a compressed voice, it came to be used to evaluate image quality. The range of MOS is 1–5 points; the larger the score, the better the image quality and the higher the clarity. Usually, several professionals are selected to score image quality, and the average score is taken as the final scoring result.
The test samples were collected from Solanum nigrum grown hydroponically for 4 weeks in a greenhouse (photoperiod: 16-h/8-h day/night, light intensity: 100 μmol/m2/s, temperature: 22°C) in 1/2 Hoagland nutrient solution. About 1 cm fresh Solanum nigrum root was cut, and than in 0.5 mL of 10 μM FM4-64 dye (4-{6-[4-(Diethylamino)phenyl]-1,3,5-hexatrien-1-yl}-1-[3-(triethylammonio)propyl]pyridinium dibromide) was stained for 30 min. Then the samples were carefully removed and washed with deionized water to clean the surface of the dye, placed on slides, and sealed with coverslips. They were observed within 1 h via CLSM (Nikon Eclipse Ti, Japan) using a complementary metal-oxide-semiconductor image sensor with an image resolution of 1024×1024. The light source is a laser with an excitation wavelength of 488 nm and an emission wavelength of 500—530 nm. After setting the parameters, use the 4× objective lens was used to find the sample under the bright field and adjust the position and lens focal length to bring the image to the middle of the field of view. Then, the 20× objective lens was applied, and the appropriate brightness of the field of view was adjusted. After this, the 60× oil lens was used, and mirror oil was dripped onto the surface of the objective lens. Next, the brightness of the field of view and the lens focal length were adjusted to clarify the image; finally, the bright field was closed, the laser was turned on, and the appropriate laser intensity was chosen to take the fluorescent image of the root hair cells.
A dataset was produced using test samples from the confocal laser scanning microscope. The 8294 images that were obtained from sampling were used to create a dataset of which the ratio of the training set to the test set was 100:45, which meets the requirements of deep learning for the training and test sets without interfering with either. We selected 200 of these images as the set for training the model in each batch. Then, 90 were used as the test set to evaluate the model reconstruction effect.
Both models were implemented using the PyTorch framework. The training and testing processes were performed on the training and test sets, respectively, using Ubuntu on an Intel E5-2678 v3 64 G 1 TB + 256 G solid-state computer that had a dual NVIDIA 2080Ti (video memory 12 G).
The training learning rate of the model was set to 2×10-4, and the backpropagation algorithm adopted was Adam (Kingma and Jimmy, 2015). First, the training set images were input into the model in batches for training: 200 images were randomly selected for training in each batch, and 200 batches of training were carried out to obtain effective weights.
The reconstruction effect of the model was evaluated based on the test set.
Combined with the dataset images and the reconstructed images during training and testing, the super-resolution reconstruction process and the post-reconstruction image quality of the SRGAN and SRResNet models were evaluated by obtaining the values for PSNR, SSIM, and MOS and the time required for the reconstruction process. The MOS was determined as the average result provided by the 26 selected professionals after scoring the reconstructed images obtained in different ways.
To obtain and analysis a high-resolution reconstructed image, 4× image reconstruction (4×, 4 times the width and height) as single reconstruction and 16× image reconstruction (16×, 16 times the width and height) as secondary reconstruction were used here.
Using a learning rate of 2×10-4 and the Adam back-propagation algorithm, 200 images were randomly selected from the training set in each batch, and the training images were input into the SRGAN and SRResNet models implemented using PyTorch. After 200 training batches were completed, effective weight parameters were obtained when the loss function was 0.0164.
In all, 90 laser confocal images of the test set were input into the trained SRGAN and SRResNet models. Figure 3 shows the results and comparison of the original image, single reconstruction image, secondary reconstruction image, and local magnification 10× maps corresponding to the two kinds of images.
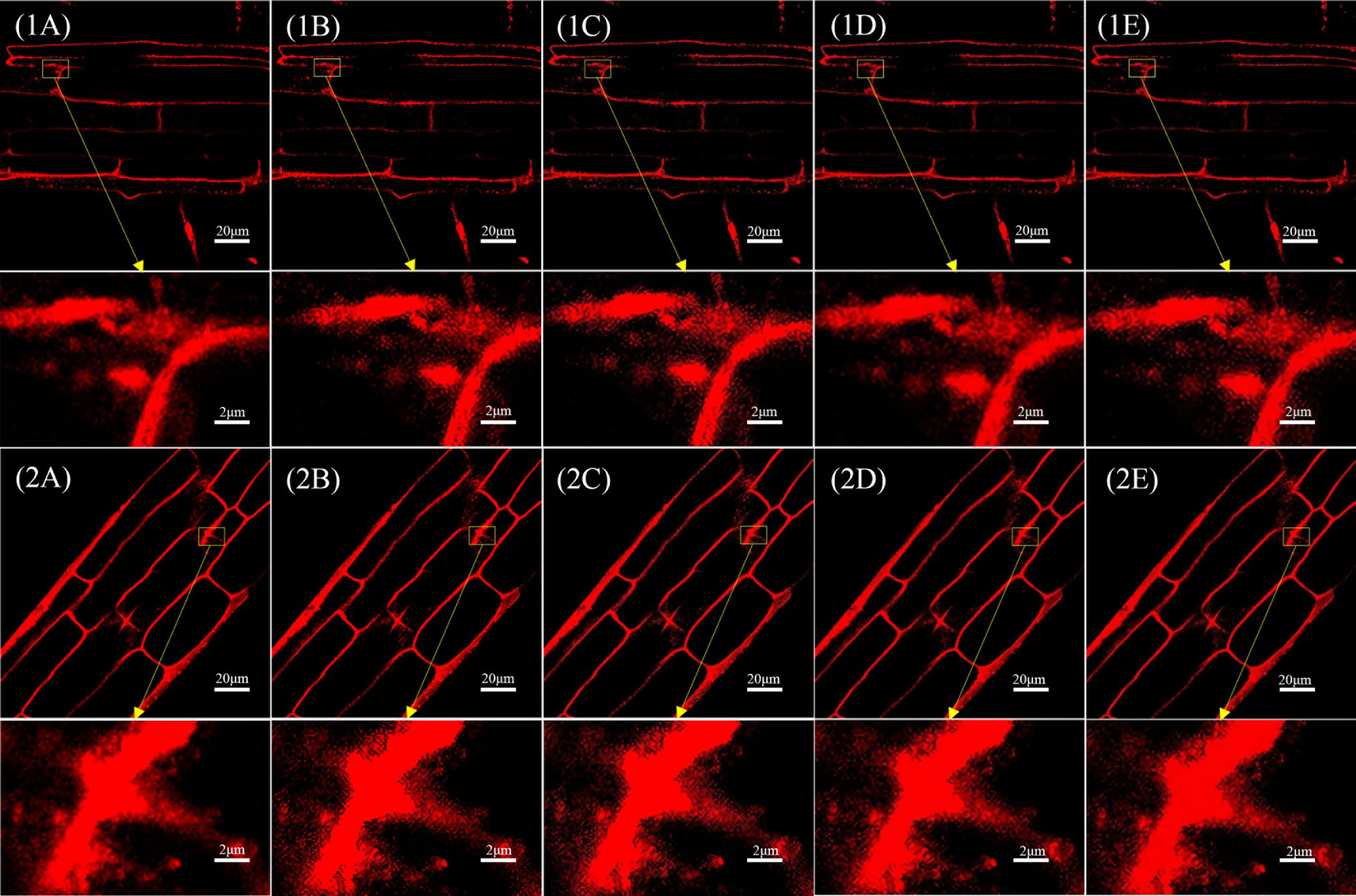
Figure 3 Comparison of single and secondary reconstruction images of different models in different images. (1A) Original image 1(pixel: 1024×1024) and local magnification map(pixel: 102×66). (1B) SRGAN single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×264). (1C) SRGAN secondary-reconstruction image(pixel: 16384×16384) and local magnification map(pixel: 1638×1056). (1D) SRResNet single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×264). (1E) SRResNet secondary-reconstruction image(pixel: 16384×16384) and local magnification map(pixel: 1638×1056). (2A) Original image 2(pixel: 1024×1024) and local magnification map(pixel: 102×66). (2B) SRGAN single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×264). (2C) SRGAN secondary-reconstruction image(pixel: 16384×16384) and local magnification map(pixel: 1638×1056). (2D) SRResNet single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×264). (2E) SRResNet secondary-reconstruction image(pixel: 16384×16384) and local magnification map(pixel: 1638×1056).
Table 1 compares the quality evaluation indicators (PSNR, SSIM, MOS) and time required for those reconstruction of different models (see Appendix for MOS evaluation) for the images in Figure 3. The MOS values of the images reconstructed by SRGAN and SRResNet were larger than those of the original image, with a maximum increase of 15.6%. The PSNR values were at a minimum of 37.268 and a maximum of 47.690, and the image quality was greatly improved. The PSNR and SSIM of the images following the secondary reconstruction of the same model were higher than those following the single reconstruction, with maximum increases of 21.7% and 2.8% for PSNR and SSIM, respectively, following secondary reconstruction. The MOS values of the secondary reconstruction images of different models were lower than those of the single reconstruction, and the time cost of the secondary reconstruction process was far higher than that of the single reconstruction. The time-consuming ratio of secondary and single reconstructions was greater than 130:1, and the maximums for SRGAN and SRResNet were 139.1 and 130.8, respectively. These results indicate that the reconstructions significantly improved image quality, signal-to-noise ratio, and image contrast; however, multiple reconstructions could reduce perceived quality to a certain extent, and result in a very large time cost.
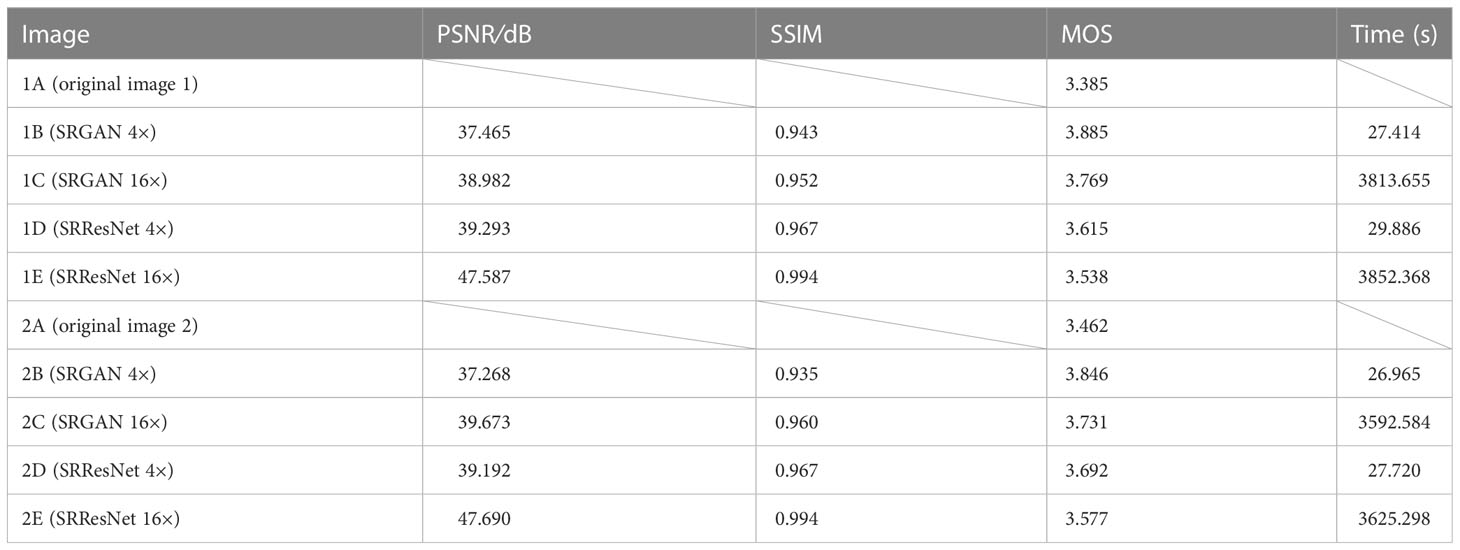
Table 1 Comparison of the quality evaluation indicators and time required for different reconstruction.
For the same reconstruction times, the PSNR and SSIM values were higher in SRResNet than in SRGAN, the MOS values were lower in SRResNet than in SRAGN, and the time costs were similar between the two. This indicates that SRResNet had superior performance in improving the signal-to-noise ratio and image contrast, but had inferior perceived quality to that of SRGAN.
Figure 4 shows a comparison of the original laser confocal image, SRGAN reconstruction image, and SRResNet reconstruction image of Solanum nigrum root cells containing endocytic vesicles and the 10× local magnification maps of endocytic vesicles. The image qualities of the SRGAN and SRResNet reconstructions were better than that of the original image. Further, the boundary clarities of endocytic vesicles were significantly better than those in the original image.
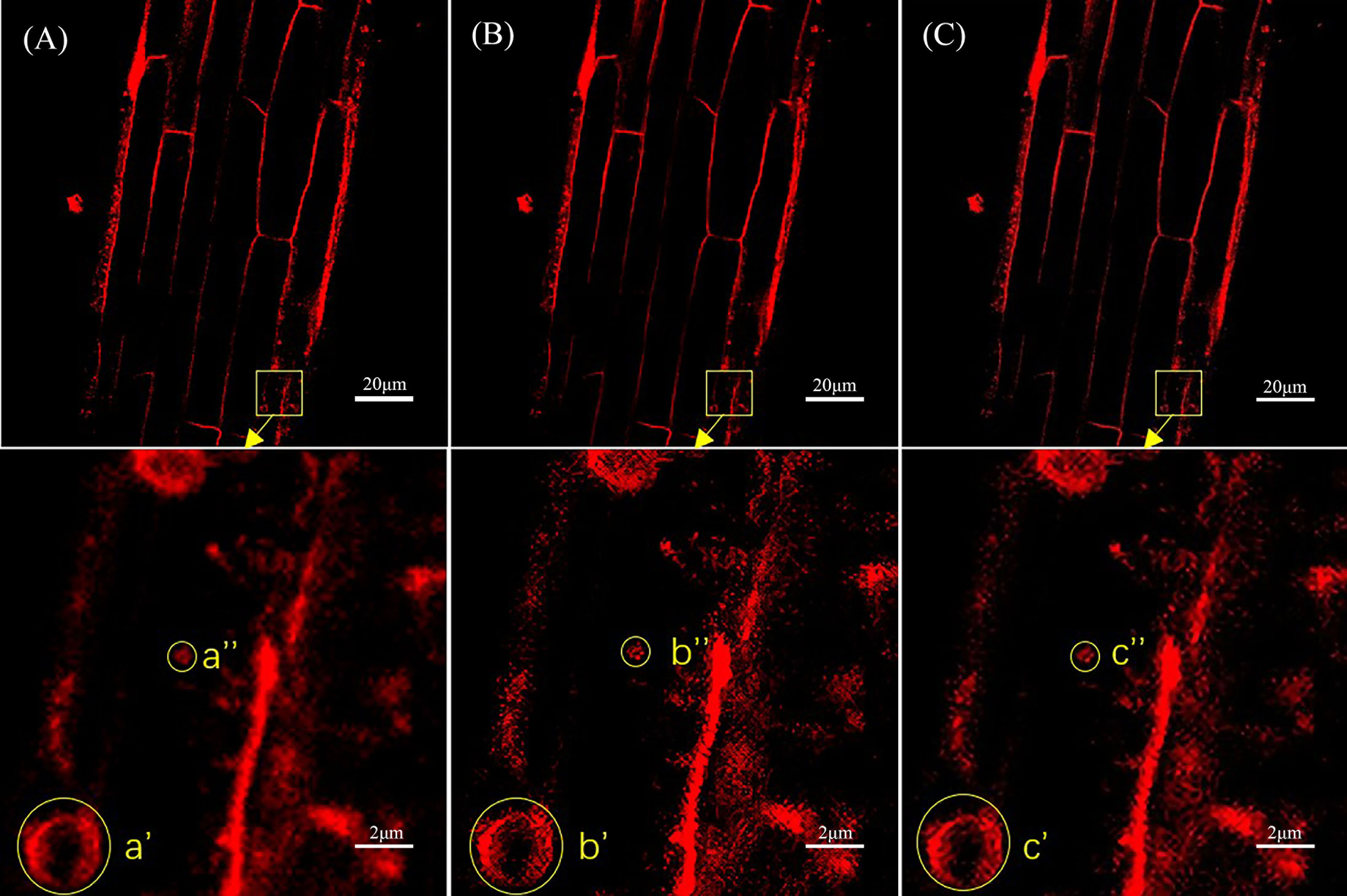
Figure 4 Comparison of the three types of images of Solanum nigrum root cells containing endocytic vesicles. (A) Original image(pixel: 1024×1024) and local magnification map(pixel: 102×102). (B) SRGAN single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×410). (C) SRResNet single-reconstruction image(pixel: 4096×4096) and local magnification map(pixel: 410×410).
Next, the reconstructed images were automatically identified using YOLOv5 for endocytic vesicles using the same model parameters and weights. Figure 5 shows the quantitative recognition effect corresponding to the original image, the SRGAN single reconstruction image, and the SRResNet single reconstruction image. Endocytic vesicles are marked with yellow boxes and the regions where the extra vesicles were identified by the two models are marked with blue boxes.

Figure 5 Comparison of recognition of endocytic vesicles in laser confocal images of Solanum nigrum root cells. (A) Recognition of endocytic vesicles in original image(pixel: 1024×1024). (B) Recognition of endocytic vesicles in SRGAN single-reconstruction image(pixel: 4096×4096). (C) Recognition of endocytic vesicles in SRResNet single-reconstruction image(pixel: 4096×4096).
Six, nine, and ten endocytic vesicles were identified in the three images, respectively. These results indicate that the reconstruction effectively improved the quantitative recognition effect, confirming the improvement of image quality. The image details were richer, which would aid the mining of the deep-level information contained in the image. The recognition effect of the SRResNet-reconstructed image was better than that of the SRGAN-reconstructed image.
Finally, the mean fluorescence intensity of each image shown in Figure 5 was analyzed using ImageJ. The intensities were 175.654, 200.981, and 189.387 for the original image, the SRGAN reconstruction image, and the SRResNet reconstruction image, respectively, enhanced by 14.4% and 7.8% by the two models,respectively.
Super-resolution reconstruction technology based on deep learning can be used in the study of laser confocal images. Single reconstruction (4×) and secondary reconstruction (16×) using the SRGAN and SRResNet models significantly improved the evaluation indicators PSNR, SSIM, and MOS of the image as well as the resolution. The maximum PSNR was 47.690, indicating that the quality of reconstructed image was significantly improved. The PSNR and SSIM of the secondary reconstruction image were obviously better than those of the single reconstruction, with maximum increases of 21.7% and 2.8%, respectively. Additionally, the objective evaluation of the image quality was good, but the MOS was generally lower than that of the single reconstruction, and the perceptual quality was weakened. The reconstruction effect using SRResNet was better than that obtained using SRGAN. The images reconstructed by SRGAN and SRResNet also clarified the boundaries of endocytic vesicles in Solanum nigrum root cells. They also revealed more vesicles (9 and 10, respectively, versus only 6 in the original image). Finally, the mean fluorescence intensity was enhanced by 14.4% and 7.8%, which indicates the feasibility of deep mining of the embedded information in laser confocal images.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
FH and FW conceived and designed the research, and guided the preparation and writing of the manuscript. WL searched for relevant literature, carried out super-resolution reconstruction of images based on laser confocal images, and wrote the manuscript. DH and YL sampled and collected those laser confocal images of hyperaccumulator Solanum nigrum endocytosis vesicles. All authors contributed to the article and approved the submitted version.
This work was supported by The National Key Research and Development Program of China (2020YFF0218300).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1146485/full#supplementary-material
Courtrai, L., Pham, M. T., Lefevre, S. (2020). Small object detection in remote sensing images based on super-resolution with auxiliary generative adversarial networks. Remote Sens 12 (19), 1–19. doi: 10.3390/rs12193152
Dong, C., Loy, C. C., He, K., Tang, X. (2016). Image super-resolution using deep conventional networks. In IEEE Trans. Pattern Anal. Mach. Intell. 38 (2), 295–307. doi: 10.1109/TPAMI.2015.2439281
Dreier, T., Peruzzi, N., Lundström, U., Bech, M. (2021). Improved resolution in x-ray tomography by super-resolution. Appl. Opt 60 (20), 5783–5794. doi: 10.1364/AO.427934
Fan, L. S., Li, R. L., Pan, J. W., Ding, Z., Lin, J. X. (2015). Endocytosis and its regulation in plants. Trends Plant Sci. 20 (6), 388–397. doi: 10.1016/j.tplants
Hall, H. C., Fakhrzadeh, A., Luengo Hendriks, C. L., Fischer, U. (2016). Precision automation of cell type classification and Sub-cellular fluorescence quantification from laser scanning confocal images. Front. Plant Sci. 7. doi: 10.3389/fpls.2016.00119
He, D., Guo, T., Peng, C. Q., Li, J. N., Wang, F. H. (2023). Foliar application of lanthanum promotes growth and phytoremediation potential Solanum nigrum l. J. Environ. Manage. 334, 117259. doi: 10.1016/j.jenvman.2023.117259
He, Y., Pan, L., Yang, T., Wang, W., Li, C., Chen, B., et al. (2021). Metabolomic and confocal laser scanning microscopy (CLSM) analyses reveal the important function of flavonoids in amygdalus pedunculata pall leaves with temporal Changes.Front. Plant Sci. 12. doi: 10.3389/fpls.2021.648277
Isaac, J. S., Kulkarni, R. (2015). “Super resolution techniques for medical image processing,” in 2015 International Conference on Technologies for Sustainable Development (ICTSD). 1–6. doi: 10.1109/ICTSD.2015.7095900
Ji, X. P., Chen, Y., Hou, Y. Q., Dai, C., Chen, B., Zou, H. W. (2021). Surface microscopic properties of various aggregates using laser scanning confocal microscope. Constr Build Mater. 290, 123222. doi: 10.1016/j.conbuildmat.2021.123222
Khan, F. A., Voß, U., Pound, M. P., French, A. P. (2020). Volume segmentation of cell cycle markers in confocal images using machine learning and deep learning. Front. Plant Sci. 11. doi: 10.3389/fpls.2020.01275
Kim, J., Lee, J. K., Le, K. M. (2016). “Accurate image super-resolution using very deep constructive networks,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1646–1654. doi: 10.1109/CVPR.2016.182
Kingma, D. P., Jimmy, L. B. (2015). “Adam: A method for stochastic optimization,” in International Conference on Learning Representations. 1–15. doi: 10.48550/arXiv.1412.6980
Ledig, C., Theis, L., Huszar, F., Caballero, J., Cunningham, A., Acosta, A., et al. (2017). “Photo-realistic single image super-resolution using a generative adversarial network,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vol. 2017. 105–114. doi: 10.1109/CVPR.2017.19
Li, P. Y., Zhang, Y. L. (2022). Research on face image super-resolution construction based on improved SRGAN model. Comput. Eng. 48 (11), 1–9. doi: 10.19678/j.issn.1000-3428.0064174
Lin, L., Li, J., Yuan, Q., Shen, H. (2019). “Polarimetric SAR image super-resolution VIA deep constructive neural network,” in 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). 3205–3208. doi: 10.1109/IGARSS.2019.8898160
Lu, B., Li, C. L., Feng, X. L., Song, S., Wang, H. (2022). Super-resolution reconstruction method for low illumination images based on improved SRResNet deep learning network [J]. Sci. Technol. Eng. 22 (27), 12045–12052.
Mauko, A., Muck, T., Mirtic, B., Mladenovic, A., Kreft, M. (2009). Use of confocal laser scanning microscopy (CLSM) for the characterization of porosity in marble. Mat Charact. 60, 603–609. doi: 10.1016/j.matchar.2009.01.008
Mursalimov, S., Sidorchuk, Y., Deineko, E. (2017). Analysis of cytomixis in tobacco microsporocytes with confocal laser scanning microscopy. Protoplasma 254, 539–545. doi: 10.1007/s00709-016-0973-z
Nwaneshiudu, A., Kuschal, C., Sakamoto, F. H., Anderson, R. R., Schwarzenberger, K., Young, R. C. (2012). Introduction to confocal microscope. J. Invest. Dermatol. 132 (12), 1–5. doi: 10.1038/jid.2012.429
Onuma, A., Maruyama, S., Komatsu, N., Mitani, T., Kato, T., Okumura, H., et al. (2017). Quantitative analysis of nanoscale step dynamics in high-temperature solution-grown single crystal 4H-SiC via in situ confocal laser scanning microscope. Cryst Growth Des. 17, 2844–2851. doi: 10.1021/acs.cgd.7b00325
Paddock, S. W., Eliceiri, K. W. (2014). Laser scanning confocal microscope: history, applications, and related optical sectioning techniques. Methods Mol. Biol. 1075, 9–47. doi: 10.1007/978-1-60761-847-8_2
Shezaf, N., Abramov-Segal, H., Sutskover, I., Bar-Sella, R. (2000). “Adaptive low complexity algorithm for image zooming at fractional scaling ratio,” in 21st IEEE Convention of the Electrical and Electronic Engineers in Israel. 253–256. doi: 10.1109/EEEI.2000.924383
Singla, K., Pandey, R., Ghanekar, U. (2022). A review on single image super resolution techniques using generative advertising network. Optik-Internat. J. Light Electron Optics 266, 169607. doi: 10.1016/j.ijleo.2022.169607
Stachelek, P., MacKenzie, L., Parker, D., Pal, R. (2022). Circularly polarised luminescence laser scanning confocal microscopy to study live cell chiral molecular interactions. Nat. Commun. 13, 553. doi: 10.1038/s41467-022-28220-z
Stephens, D. J., Allan, V. J. (2003). Light microscope techniques for live cell imaging. Science 300 (5616), 82–86.D. doi: 10.1126/science.1082160
Wang, Z., Bovik, A. C., Sheikh, H. R., Simoncelli, E. P. (2004). Image quality assessment: from error visibility to structural similarity. In IEEE Trans. Imag. Process. 13 (4), 600–612. doi: 10.1109/TIP.2003.819861
Wei, R., Xie, Z., Liu, J., Liu, H. J. (2022). Spatial resolution improvement of spectrum sensing data of LEO satellite based on image super-resolution. J. Univ. Chin. Acad. Sci. 39 (3), 386–391.
Yang, T., Jia, S., Ma, H. (2020). Research on the application of super resolution reconstruction algorithm for underwater image. Comput. Mat. Continua 62 (3), 1249–1258. doi: 10.32604/cmc.2020.05777
Yang, C. D., Li, C. Y., Li, Z. B., Xie, Y. Q., Sun, F. W., SUN, J. Q. (2022). Review of image super-resolution reconstruction algorithms based on deep learning. J. Front. Comput. Sci. Technol. 16 (09), 1900–2010. doi: 10.3778/j.issn.1673-9418.2202063
Yang, J., Wright, J., Huang, T., Ma, Y. (2008). “Image super-resolution as sparse presentation of raw image patches,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition. 1–8. doi: 10.1109/CVPR.2008.4587647
Yann, L. C., Yoshua, B., Groffrey, H. (2015). Deep learning. Nature 521 (7553), 436–444. doi: 10.1038/nature14539
Yu, S. N. (2022). Artistic intelligence injections intelligent kinetic energy into scientific research. People's Daily 10-20, (14).
Yuan, C., Deng, K. D., Li, C., Zhang, X. T., Li, Y. Q. (2022). Improved image super-resolution based on multiscale generative adversarial networks. Entropy 24, 1030. doi: 10.3390/e24081030
Zhang, Y. L., Liu, B. Y., Chen, Y. L., Wang, J. Y., Cao, H. Z. (2022). Optimization of live cell imaging with laser scanning confocal microscopy. Prog. Mod. Biomed. 22 (01), 196–200. doi: 10.13241/j.cnki.pmb.2022.01.038
Zhang, L. P., Zhang, H. Y., Shen, H. F., Li, P. X. (2010). A super-resolution reconstruction algorithm for survival images. Signal Processing. 90 (3), 848–859. doi: 10.1016/j.sigpro.2009.09.002
Keywords: laser confocal, deep learning, plant cell, endocytic vesicle, super-resolution reconstruction, SRGAN, SRResNet
Citation: Li W, He D, Liu Y, Wang F and Huang F (2023) Super-resolution reconstruction, recognition, and evaluation of laser confocal images of hyperaccumulator Solanum nigrum endocytosis vesicles based on deep learning: Comparative study of SRGAN and SRResNet. Front. Plant Sci. 14:1146485. doi: 10.3389/fpls.2023.1146485
Received: 17 January 2023; Accepted: 09 March 2023;
Published: 21 March 2023.
Edited by:
Allison van De Meene, The University of Melbourne, AustraliaReviewed by:
Tao Lan, China National Institute of Standardization, ChinaCopyright © 2023 Li, He, Liu, Wang and Huang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fengliang Huang, aHVhbmdmZW5nbGlhbmdAbmpudS5lZHUuY24=; Fenghe Wang, d2FuZ2ZlbmdoZUBuam51LmVkdS5jbg==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.