 Dabao Wang1†
Dabao Wang1† Teng Miao
Teng Miao Tongyu Xu
Tongyu Xu
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Plant Sci. , 31 January 2023
Sec. Technical Advances in Plant Science
Volume 14 - 2023 | https://doi.org/10.3389/fpls.2023.1109314
This article is part of the Research Topic 3D Plant Approaches for Phenotyping, Geometric Modelling, and Visual Computing View all 7 articles
The 3D point cloud data are used to analyze plant morphological structure. Organ segmentation of a single plant can be directly used to determine the accuracy and reliability of organ-level phenotypic estimation in a point-cloud study. However, it is difficult to achieve a high-precision, automatic, and fast plant point cloud segmentation. Besides, a few methods can easily integrate the global structural features and local morphological features of point clouds relatively at a reduced cost. In this paper, a distance field-based segmentation pipeline (DFSP) which could code the global spatial structure and local connection of a plant was developed to realize rapid organ location and segmentation. The terminal point clouds of different plant organs were first extracted via DFSP during the stem-leaf segmentation, followed by the identification of the low-end point cloud of maize stem based on the local geometric features. The regional growth was then combined to obtain a stem point cloud. Finally, the instance segmentation of the leaf point cloud was realized using DFSP. The segmentation method was tested on 420 maize and compared with the manually obtained ground truth. Notably, DFSP had an average processing time of 1.52 s for about 15,000 points of maize plant data. The mean precision, recall, and micro F1 score of the DFSP segmentation algorithm were 0.905, 0.899, and 0.902, respectively. These findings suggest that DFSP can accurately, rapidly, and automatically achieve maize stem-leaf segmentation tasks and could be effective in maize phenotype research. The source code can be found at https://github.com/syau-miao/DFSP.git.
Maize is one of the most important food crops in the world. Therefore, its production is essential in ensuring global food supplies. High-throughput phenotypic measurement is crucial for future maize variety improvement. The 3D sensing technologies, such as 3D laser scanners (Rist et al., 2018), multi-view images (Wu et al., 2020), and lidar (Jin et al., 2021), have been recently used for plant phenotype parameter measurements based on 3D point clouds. The organ-level segmentation of plant point clouds is necessary if the measurements of the organ-level phenotype indicators, such as leaf length and width, are involved. Numerous studies have evaluated point cloud segmentation at the organ level.
Plant organs are mainly classified and segmented using the local geometric features of point clouds. Tensor based features are simple features formed by combining the eigenvalues of neighborhood points. However, these features can only be used for simple stem and leaf segmentation tasks (Elnashef et al., 2019). The Point Feature Histogram (Rusu and Cousins, 2011) has been widely used in the segmentation of grapes (Paulus et al., 2013; Wahabzada et al., 2015), sorghum (Vijayarangan et al., 2018), and tomato (Ziamtsov and Navlakha, 2019) through integration with machine learning, clustering, and regional growth methods. The traditional point cloud feature extraction methods should be improved to enhance the segmentation accuracy and reduce computational time in the extraction of neighborhood point cloud features for each point in the plant.
Geometric features of organs can also be used for segmentation. The stem segmentation step is crucial in organ segmentation process. Stem point cloud removal weakens the connection between the remaining organs, allowing clustering methods to achieve instant segmentation. Although early methods mostly used the cylindrical fitting strategy to identify stems (Paproki et al., 2012; Gelard et al., 2017), the methods relied on appropriate parameter selection and required high resolution and point cloud quality.
The global topological structure of plant point cloud is also widely used for organ segmentation. Currently, most studies use point cloud skeletons to describe the topology of plants and segment the stems and leaves according to the topological relationship. This method is extremely dependent on the quality of the extracted skeleton. Currently, slice-based (Xiang et al., 2019; Zermas et al., 2020) and Laplacian-based methods (Wu et al., 2019; Miao et al., 2021b) are commonly used to extract plant point cloud skeletons. However, the slice-based method requires that the point cloud is aligned with the coordinate axis, which limits its application. Meanwhile, Laplacian-based method does not need point cloud alignment, but it is often incomplete or wrong when applied to plants, resulting in reduced segmentation accuracy. As a result, certain interactive corrections are usually made to ensure the segmentation accuracy of the Laplacian-based method. Notably, the Laplacian-based method has low computational efficiency.
Numerous studies have recently used deep learning network data to abstract point cloud features for semantic and instance segmentation of the organs (Griffiths and Boehm, 2019; Jin et al., 2019; Li et al., 2022a; Li et al., 2022b; Li et al., 2022c). Deep learning can learn local geometric features and global structural features of plant point clouds from data. Although deep learning has high segmentation effectiveness and efficiency, it requires a lot of data for training. Manual labeling of these data is time-consuming, labor-intensive, and expensive. Moreover, the current deep learning technology requires a down-sampling of the point cloud to a very low resolution (4096 or less), leading to the loss of numerous potential geometric features of small organs and plants.
The success of deep learning proves that the combination of global features and local features of point clouds can improve segmentation accuracy. However, getting enough data for training models in many application scenarios is difficult. In this study, an unsupervised segmentation method, which could easily integrate the global and local features of the plant was developed to achieve fast and accurate stem and leaf segmentation of maize. Like most crops, maize plants have many branching structures. This global structure makes the end areas of organs (leaf tip and the lowest end of the stem) more dispersed in 3D space, facilitating the positioning of these areas. The local connection between maize organs is also fixed. These global and local spatial morphological structures can be used to improve the efficiency of plant point cloud segmentation. A distance field-based segmentation pipeline (DFSP) was developed to integrate these features. The Minkowski distance field of maize point cloud was constructed to code these structures. Quickshift++ can theoretically operate on the distance field to realize rapid organ location and segmentation. The maize stem and leaf segmentation method combined with DFSP obtained the following characteristics: 1) The method encoded the global morphological structure information of maize plants and the local connection relationship of organs; 2) The method could limit time-consuming geometric feature calculation to a few organ end point clouds, thus effectively integrating local features and enhancing the efficiency of organ semantic recognition; 3) This method could automatically find the organ position, thus automating the whole segmentation process; 4) The method could segment the leaves from the tip, and deal with a situation where multiple new leaves are close to each other, and larger new leaves surround smaller leaves. In summary, the method provides an effective unsupervised automatic segmentation scheme for maize stems and leaves, enhancing organ segmentation efficiency equivalent to that of a deep learning model without additional data training.
This paper is organized into three main sections: the methodology, results, and discussion, excluding the introduction and abstract. The methodology introduces the data acquisition process and preprocessing method (2.1). Section 2.2 introduces the distance field-based segmentation pipeline (DFSP). The segmentation process was conducted for the subsequent stem and leaf segmentation tasks. Section 2.3 of the methodology introduces the stem extraction method. DFSP was used to automatically extract the low-end point cloud of the stem (2.3.1), quickly estimate the growth direction (2.3.2) on this basis and perform the median normalized-vectors growth segmentation (2.3.3). Section 2.4 outlines how the DFSP was used to segment the remaining leaf point cloud instances. The results of the study are presented in section 3 and then discussed in section 4. The flowchart of the entire process is shown in Figure 1.
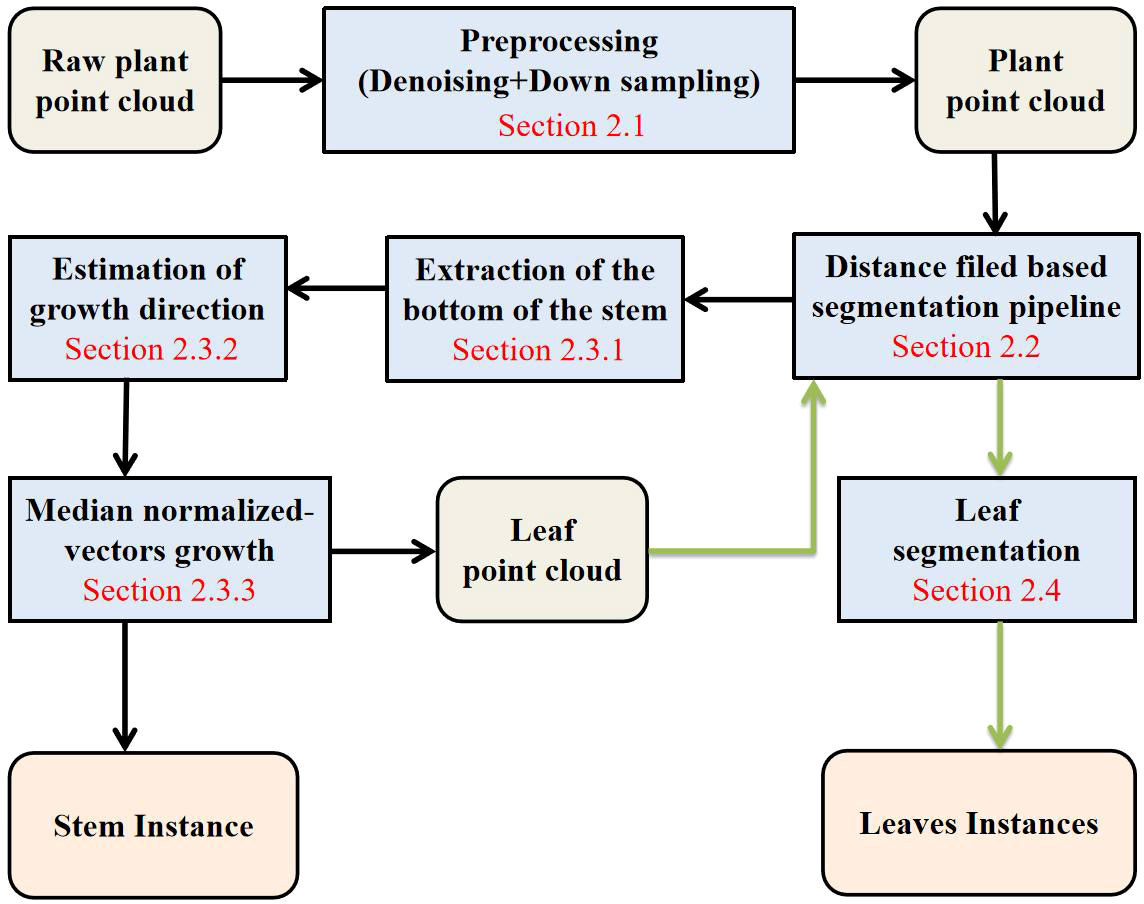
Figure 1 Flow chart of this article method.
Field experiments were conducted in the experimental maize field of Shenyang Agricultural University (41.83 N, 123.56E) between May and July of 2019, 2020, and 2021. Five maize varieties (XianYu 335, LD145, LD502, LD586, and LD 1281) were planted in plots with an area of 666 m² with a row-row and plant-plant distances of 60 cm and 25 cm, respectively. Maize samples (420) were randomly chosen and transplanted into pots in an indoor laboratory. The raw point clouds were then obtained using a 3D laser scanner (FreeScan X3, Tianyuan Inc, Beijing, China). The raw data included the pot and other surrounding object point clouds. We used the CloudCompareStereo software to manually remove these points, leaving only the plant point cloud. The number of point cloud data from the different numbers of leaves in the various maize varieties is shown in Table 1. A more detailed description of the FreeScan X3 scanner and data acquisition environment is shown in Table 2.
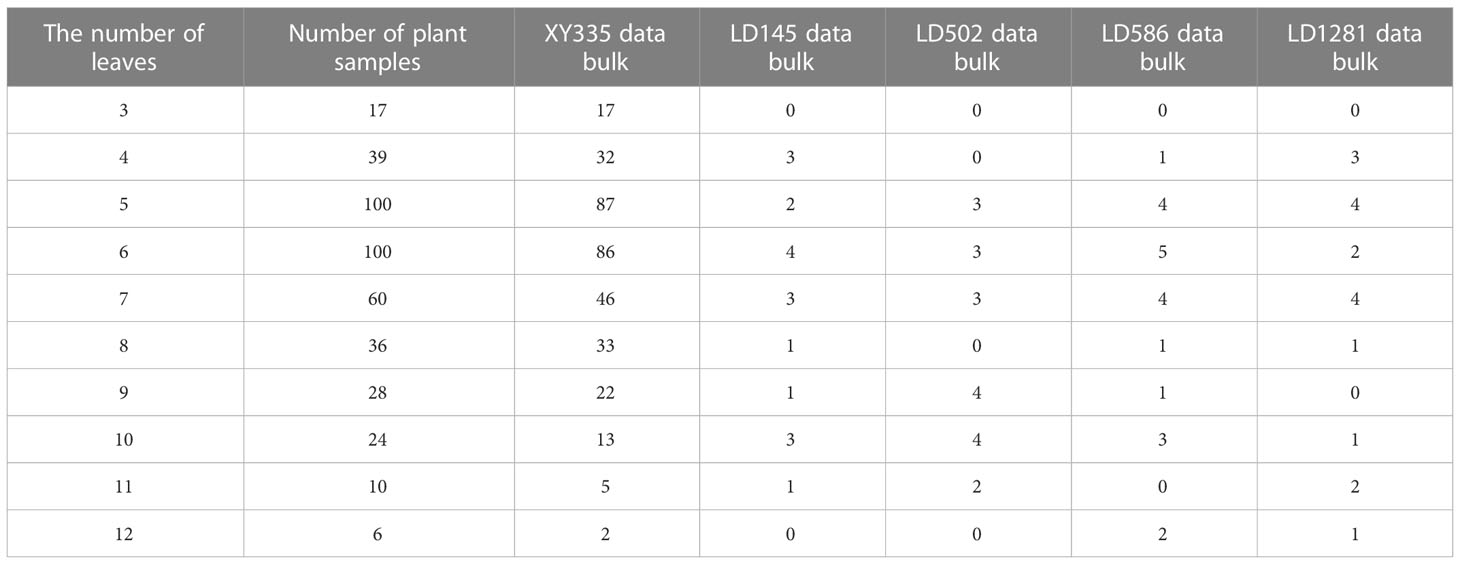
Table 1 Number of plant samples from different numbers of leaves in the various maize varieties.
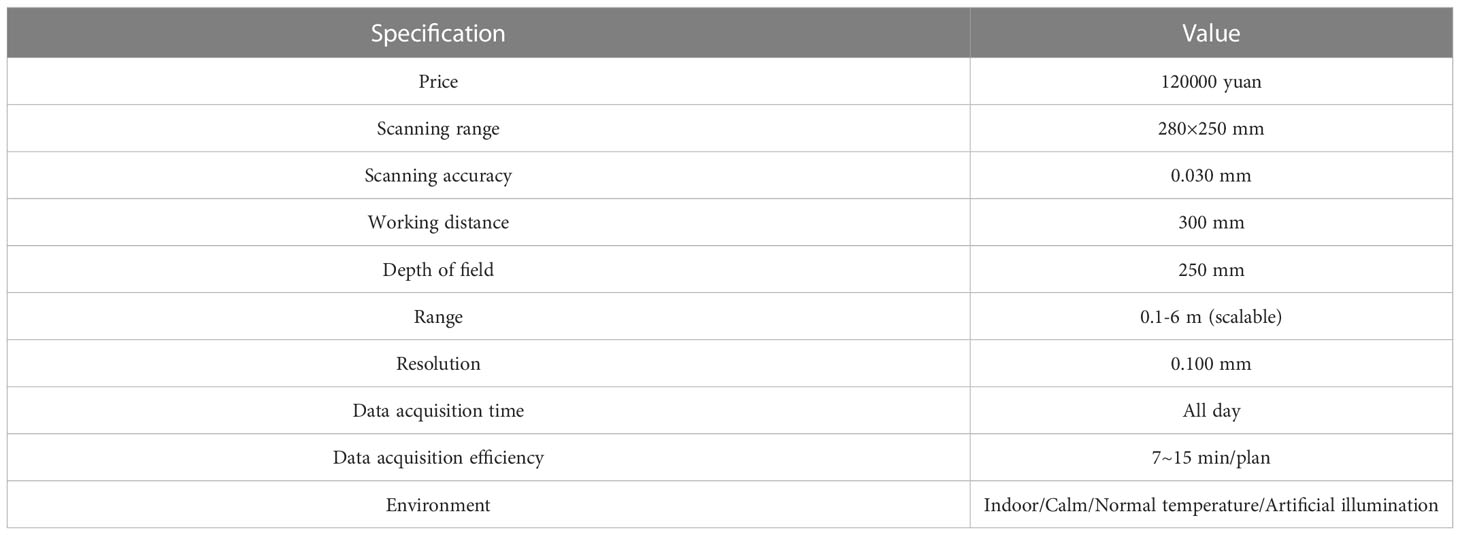
Table 2 General specification of FreeScan laser scanner.
The pass-through and statistical outlier removal filters were used to denoise the point cloud and manually segment the original point cloud to obtain the ground truth. Too much data significantly reduces the segmentation efficiency when performing point-cloud segmentation. In this study, the segmentation process was improved using the method described by Miao et al. (2021a). The number of point clouds was first down-sampled to about 15,000 points while maintaining the local geometric characteristics of maize. The sampled point clouds were then segmented. Notably, the segmentation results of the subsampled point clouds could be up-sampled to the original point clouds through the sample-based segmentation method if the segmentation results in the original point cloud were needed.
Besides maintaining the original geometry of the point cloud, the down-sampling process also reduced the number to a fixed 15,000 points. The fixed number of point clouds enables a better generalization of the parameter setting of the segmentation algorithm. Although farthest point sampling (FPS) is a suitable down-sampling method, it lasts longer because of the excessive number of original point clouds in the hundreds, thousands, and millions of levels. Moreover, the voxel-grid filter (Rusu and Cousins, 2011) was integrated with FPS to enhance efficiency. Although the voxel-grid filter is highly efficient and can maintain the original point cloud form, it does not guarantee the number of point clouds. As a result, the point clouds were down-sampled to slightly above 15,000 points using the voxel-grid filter. An excessive strategy from high sampling interval to low sampling interval was adopted because of differences in the number of point clouds for each raw data, which makes it difficult to obtain a suitable number of point clouds by sampling all the files once. A maximal sampling interval was first set to allow the point cloud to directly down-sample to fewer points. The result was used directly in the subsequent FPS and down-sampled to 15,000 points if higher. In many cases, large sampling intervals make the down-sampled point cloud have less than 15,000 points. In such cases, the sampling interval was gradually reduced until the number of point clouds was more than 15,000 points and then sampled using FPS. The down-sampling results of a plant with 1,383,494 points are shown in Figure 2. Notably, although the sampling results obtained herein (Figure 2) were similar to those obtained by directly using FPS, the operation efficiency was greatly improved.

Figure 2 A comparison plot of plant point cloud down-sampling methods.
In this study, the global morphological structure of corn plant point cloud and the connection relationship of local point cloud were used to segment organs. The end areas of organs (the tip of leaves and the bottom of stems) were sparsely distributed in space, making it easy for positioning. The number of organs on the maize plant and the general position of each organ were determined if the point clouds at the end of these organs were successfully extracted. The rest of the point clouds were divided into corresponding organs based on the connection between the point clouds.
Determining the point cloud at the end of organs is crucial for segmentation. In this study, a special base point was set in 3D space. The Minkowski distance was then calculated from each point of the plant to the base point to form a Minkowski distance field. The location of the base point should be carefully designed to ensure that the Minkowski distance between the point cloud at the end of the organ and the base point is relatively large in the local regions of the plant. Finally, some local regions with large distance values in the distance field were extracted as the end-point clouds of organs.
If P[n]={p1⋯pn} represents the set of plant point clouds to be treated, and p represents a point in the set, the Minkowski distance was defined as the function F over the Lebesgue measure on R3 as follows:
where ‖∙‖ represents L2 normal, and α represents a parameter adjusted by the user to increase the contrast of the distance value. PB represents the base point. Different base point locations should be selected for different tasks. However, it is necessary to ensure that the distance value of the point cloud at the end of the organ should be large in local areas. Herein, each point cloud was given a distance value to form the plant Minkowski distance field. The position of the point cloud at the end of the organ was determined using the distance value. Locating the end of the point cloud by extracting local maxima may obtain multiple maxima at the end of an organ due to the noise and missing of the point cloud, resulting in over-segmentation. Therefore, the locally high-distance regions in the distance field should be identified. In this study, Quickshift++ was introduced to extract the locally high-distance regions.
Quickshift++ (Jiang et al., 2018) is a new density-based clustering procedure based on the latest development in topological data analysis (Stuetzle and Nugent, 2010; Rinaldo et al., 2012). Quickshift++ consists of two algorithms (1 and 2). Algorithm 1 first works by traversing some k-NN graphs, which encode the level set of k-NN density estimation and form several cluster-cores of the density. Each cluster core represents a data set in which the data are clustered into the same category. The data have a large density value in the local range. Algorithm 2 assigns the remaining data to their appropriate cluster-cores using a hill-climbing procedure based on Quick Shift (Vedaldi and Soatto, 2008).
Quickshift++ was originally used to operate on the k-NN density estimator of data to achieve clustering.In this study, Quickshift++ operates on the Minkowski distance field. We showed that the Minkowski distance function (Formula 1) satisfies the regularity mathematical assumptions of Quickshift++ for input data to theoretically explain why Quickshift++ can perform cluster core recovery and point cloud segmentation in the Minkowski distance field of plant point cloud. The Minkowski distance function has the condition that pB∉P[n], and thus it is easy to see that it has a continuous partial derivative and to know that formula (1) is continuous and differentiable. Meanwhile, the function is continuously differentiable and lower bound since it is always greater than 01. Therefore, the function can converge to the local maximum in the gradient direction with local attraction regions2. This ensures that the function has cluster cores (locally high-value regions). The points in the attraction regions cluster to these cluster cores along the gradient direction. The corn point cloud is bounded in 3D space. As a result, formula (1) is continuous on the closed interval. Formula (1) is uniform continuity based on the cantor theorem 3. This ensures that there is no approximately flat area in the distance field and that Quickshift++ will not get stuck in such a flat area.
The effect of the entire segmentation pipeline is determined based on three parameters: the K parameter, the β parameter, and α parameter. The K and the β parameters mainly affect the QuickShift++ algorithm. The K parameter is used to construct the k-NN graph in the QuickShift++ algorithm. The larger the value of K, the fewer the number of clusters. The parameter β, where 0 < β < 1, can be used to adjust the number of cluster-cores in the QuickShift++ algorithm. The smaller the β parameter value, the more the cluster-cores are extracted, and the fewer the number of point clouds in each cluster core, causing over-segmentation in the final segmentation category. A larger value of α causes a higher sensitivity to the distance change of the local area, yielding more refined segmentation results and more segmented categories. Over-segmentation occurs in such cases. In contrast, the distance contrast of the local areas is not significant when the value of α is smaller, yielding fewer segmentation categories.
In this study, DFSP was used to locate point clouds at the end of plant organs and segment the point cloud in the leaf.
The median normalized-vectors growth segmentation (MNVG) algorithm (Jin et al., 2018b) was used to segment the stem point cloud, starting with a point at the lower end of the stem as the initial seed point. Jin et al. (2018b) obtained the point cloud through human interaction.
In this study, two strategies were used to automatically obtain the initial seed point. The initial seed point was easily obtained when the point cloud of the plant was aligned, making the growth direction consistent with a certain coordinate axis (assuming Z-axis). Several point clouds at the bottom were first selected based on the z-axis coordinates of the point cloud, followed by a calculation of their median point as the seed point. When using Kinect or lidar to obtain point clouds, we can align the obtained point clouds with the coordinate axis by adjusting the position and direction of the sensor.
It is difficult to automatically obtain initial seed points from point clouds that are not aligned. In this study, the plant point cloud obtained by a hand-held scanner was not aligned, and DFSP was used to find the initial seed point.
A base point pB was set to make the distance value of the point cloud at the end of the organ belong to the local high-distance regions as far as possible, as follows:
A small random disturbance was made to the coordinates of pB if the coordinates of pB were exactly equal to a point in P[n], to ensure that pB and the points in P[n] are not equal. The point cloud at the end of plant organs was then extracted via DFSP. In this step, DFSP only needs to find the locally high-distance regions of the distance field, indicating that it only needs to execute algorithm 1 in Quickshift++. Furthermore, the K, β, and α parameters in DFSP are represented by K1, β1 and α1 respectively, to distinguish the parameter settings when DFSP is subsequently used.
The thermodynamic diagram of the distance function is shown in Figure 3A. The terminal point clouds of each organ had higher distance values. QuickShift + + was used to extract these organ terminal point clouds, which were then clustered into several cluster cores (Figure 3B). In this step, DFSP needs to find the stem area to ensure the correct operation of the subsequent algorithm. DFSP does not need to correctly find all the leaf tip regions. As long as most of the tip regions can be found, the geometric features can be used to identify the stem region.
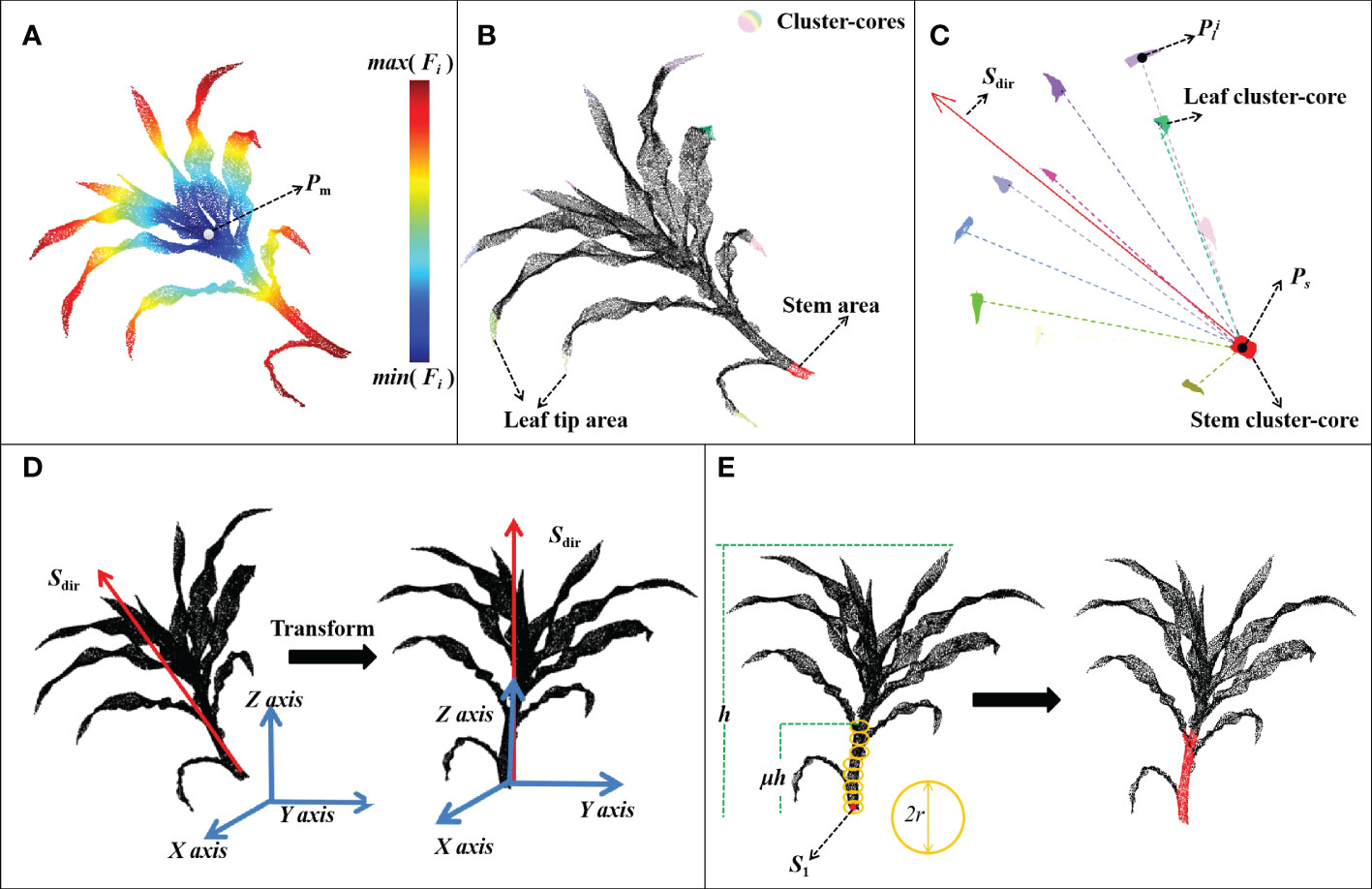
Figure 3 Flow chart of the stem segmentation process. (A) A thermodynamic diagram of distance function; (B) Stem region extraction based on DFSP; (C) Estimation of plant growth direction; (D) Plant point cloud alignment; (E) Median normalized growth segmentation of the stem point cloud.
The local geometric feature of each cluster-core was calculated to determine the stem region. The m-th cluster core was set as Am. The set of k nearest neighbors of the i-th point piAm in Am is Bi (the number of k nearest neighbors was controlled by the variable Kf). Principal component analysis (PCA) was used to calculate the first, second, and third principal component vectors of Bi set point cloud, and the corresponding eigenvalues are λ1i, λ2i, and λ3i{λ1i ≥ λ2i ≥ λ3i}. The local geometric feature of Am was then calculated using formula (3) below:
where M represents the number of point clouds in Am. λ3i is used to distinguish the planar features of local point clouds. The smaller the λ3i, the stronger the planar features. (λ1i−λ2i)/λ1i describes the linearity of the local point cloud. The larger this value, the stronger the linearity. Notably, the stem area presents a weak planarity and a strong linear shape compared with the leaf area. Herein, a cluster core with the largest f(Am) was selected as the stem area, while the rest was the leaf area. Formula validation tests suggested that 98% of the test plant data (420 plants) could correctly get the point cloud at the stem base when Kf, K1, β1, α1 were set at 64, 32, 0.85 and 5, respectively.
The growth direction of the maize plant was estimated after obtaining the stem and leaf cluster cores (Figure 3C). The plant was aligned with the coordinate axis based on the growth direction (Figure 3D). Notably, the maize plants presented certain symmetrical characteristics along the stem. The spatial distribution of cluster cores was used to estimate the plant growth direction Sdir. Supposing that the median point of stem-cluster core was ps and the median point of the i -th leaf cluster-core was pli the plant growth direction was calculated using formula (4)below:
where {∙}, ‖∙‖2 and nl represent the median operation, L2 normal, and the number of leaf cluster-cores, respectively.
The coordinates of the point cloud of the plant were transformed after obtaining the growth direction of the plant to ensure that the growth direction Sdir coincides with the Z axis and ps coincides with the original coordinate point. The z-axis was used as the normal vector to project the point cloud onto the plane. PCA assigned the first and second principal component vectors as the x- and y-axes, respectively, of the new coordinate system. The original point cloud coordinates were then transformed into a new plant coordinate system. The coordinates of their z-value were used to judge the height of points in the plant. The height of points increased with greater z-values
The MNVG algorithm was adopted to iteratively segment the stem point cloud (Figure 3E). The coordinate origin was used as the initial seed point s1 after the plants were aligned, followed by updating the seed point position through multiple iterations and dividing the point cloud around the seed point into the stem point cloud.
Assuming that the algorithm was in the j-th iteration and the seed point of this iteration was sk, the specific process of stem segmentation was as follows:
1) Taking sj as the center of the sphere, the point set A within its radius r was added to stem point cloud.
2) The growth direction vj was calculated using formula (5) below:
3) The position of the seed point sj+1 in the next iteration was calculated using formula (6) below:
4) The end condition of regional growth was then determined when the maximum coordinate of the z-axis of the plant point cloud was h. The growth stopped if the z-coordinate of sj+1 was greater than μh; otherwise, the next iteration occured, and step 1 was executed.
Notably, vj is affected by vj−1 at each iteration, playing a corrective role in ensuring that the growth direction of the stem is not significantly curved. Herein, v0 was set as zero vector, while r was an adjustable parameter, which was set as the euclidean distance between the farthest two points in the stem cluster core. μ(0 ≤ μ ≤ 1) was a user-adjusted parameter. The larger its value, the longer the segmented stem. The stem segmentation of different plant types of maize was processed by adjusting the value of μ. Herein, maize plants before the jointing stage were the main test data, and thus μ=0.30 yielded better results.
The point cloud of maize shoots was spatially divided into several relatively discrete point clouds (excluding the stem) after stem segmentation. However, the end-point clouds of the leaves (adjacent to the stem) were still mixed, making it difficult to segment each leaf. Notably, the tip regions of different leaves of maize were scattered and far away from the lower end of the stem. Therefore, different leaves were separated by extracting the tip point cloud of each leaf to determine the general position and distribution to realize the instance segmentation of the leaves. In the new plant coordinate system, the coordinate of point ps in the stem base point cloud was the origin of the coordinate system, and thus pB was set as zero vector. The leaf point cloud was segmented using DFSP. DFSP simultaneously executed algorithms 1 and 2 in Quickshift++. In this step, the K parameter in QuickShift++ was represented by K2, while the β parameter was represented by β2 during the segmentation. K2, β2, and α2 were set at 32, 0.85, and 9, respectively, through the test when processing the plant data of 15,000 points to obtain a better leaf segmentation effect. The whole process of leaf segmentation and the final visualization result of stem-leaf segmentation are shown in Figure 4. In this study, the new leaves wrapped by each other could be separated, thus enhancing segmentation from the tip.

Figure 4 The process of leaf segmentation: (A) A thermodynamic diagram of the distance function. (B) Extraction results of leaf Cluster-cores. (C) Result of leaf instance segmentation. (D) Result of stem and leaf segmentation.
The segmentation results were compared with the ground truth. The precision Po, recall ;Ro, and F1 score Fo for each organ instance were calculated using formula (7). In the formula, TP denoted the true positive points, indicating the number of points that were segmented correctly into instance A; FN represented the false negative points, which were the points originally belonging to instance A but wrongly divided into another instance; and FP represented the number of false positive points in an organ, representing the points of other instances that were wrongly assigned to instance A.
The precision Pp, recall Rp, and micro-F1 score Fp were also calculated for the individual maize using formula (8). In the formula,
No denoted the number of organ instances of individual maize.
The 420 maize plant point clouds were used to evaluate the segmentation accuracy. Visualization is the most intuitive and effective way to evaluate the accuracy of 3D digital results (Room et al., 1996). The representative segmentation results with different leaf numbers are shown in Figure 5. The segmentation results of the leaves had little difference at different leaf positions, indicating that our method was effective for both fully expanded leaves and undeveloped leaves. However, there was a false segmentation at the organ boundary. The numerical accuracy evaluation results for the plant point clouds with different leaf numbers further quantitatively evaluated the segmentation results (Table 3). The precision, recall, and F1-score values of each organ instance point cloud were calculated based on the results of the manual segmentation, which were taken as the ground truth.

Figure 5 Visualization results of stem and leaf segmentation. The top image in each figure represents the result of our method, while the bottom image represents the ground truth. (A) Three leaves; (B) Four leaves; (C) Five leaves; (D) Six leaves; (E) Seven leaves; (F) Eight leaves; (G) Nine leaves; (H) Ten leaves; (I) Eleven leaves; (J) Twelve leaves.
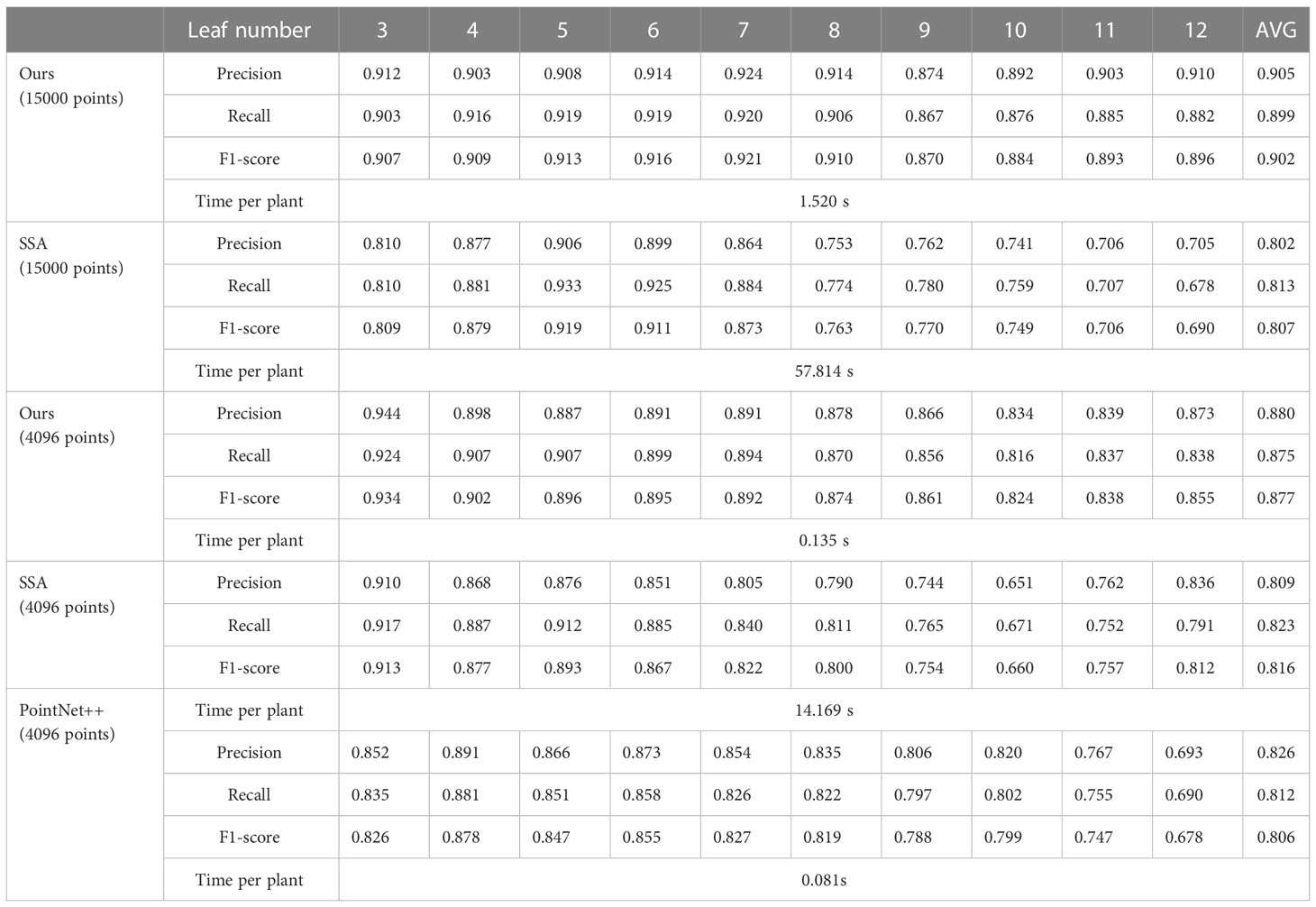
Table 3 The numerical accuracy evaluation results of plant point clouds with different leaf numbers.
The developed algorithm was compared with skeleton-based segmentation algorithm (SSA) (Miao et al., 2021a) based on plant data of 15000 point clouds and 4096 point clouds. It was also compared with PointNet++ (Qi et al., 2017) based on plant data of 4096 point clouds. When processing data of 4096 points, Kf, K1 and K2 were set at 16, 8 and 8, respectively, while the other parameters were set the same as when processing data of 15000 points. A computer with a Core i7 processor and 32 GB memory was used to test our algorithm and SSA. A computer with a Core i9 processor, 64 GB memory, and RTX 3090Ti GPU was used to train and test PointNet++.
The segmentation accuracy and the average running time of the three algorithms are shown in Table 3. The developed segmentation algorithm had good segmentation accuracy and efficiency compared with the other two algorithms. However, its accuracy (F1 score) slightly decreased when dealing with multi-leaf by less than 2%. Moreover, the average running efficiency of the algorithm reached 0.135 s when the algorithm was used to segment plants with 4096 points, which was 100 times faster than SSA and twice slower than PointNet++. However, its average segmentation speed per plant when processing 15000 points was only 1.52 s. Notably, PointNet++ had good accuracy when segmenting plants with four, five, and six leaves (more data). However, its accuracy was significantly reduced when segmenting plants with more than seven leaves. Although the PointNet++ model was limited by its weak generalization ability caused by the data imbalance, it had a good running efficiency. Furthermore, its average processing time was less than 0.1 ms, due to the parallel computing capability of GPU. Although SSA achieved good segmentation accuracy when segmenting point clouds with few leaves, its segmentation accuracy significantly decreased when segmenting plants with more leaves. Obviously, SSA was more limited to the seedling stage. Besides, SSA algorithm had poor running efficiency. Its average running times when processing 4096 points and 15000 points were 14.2 s and 57.8 s, respectively, with most time being spent on skeleton extraction. These results show that the developed segmentation algorithm is effective for maize plant segmentation, especially when there is insufficient data to train a deep-learning network.
DFSP used two algorithms (1 and 2) in Quickshift++for organ segmentation. However, it should be noted that using Quickshift++directly instead of DFSP cannot perform stem-leaf segmentation. Figure 6 shows the visualization difference in organ terminal area recognition and leaf segmentation using DFSP and Quickshift++. The reason for this difference is that their inputs were different. DFSP takes the distance field encoding the global structure information of the plant as the input, while Quickshifit++ takes the density field of the point cloud as the input. For organ segmentation tasks, point cloud density is not a useful prior knowledge. This proves that the success of DFSP is not only due to the role of Quickshifit++, but also due to the encoding of plant global features using Minkowski distance fields.
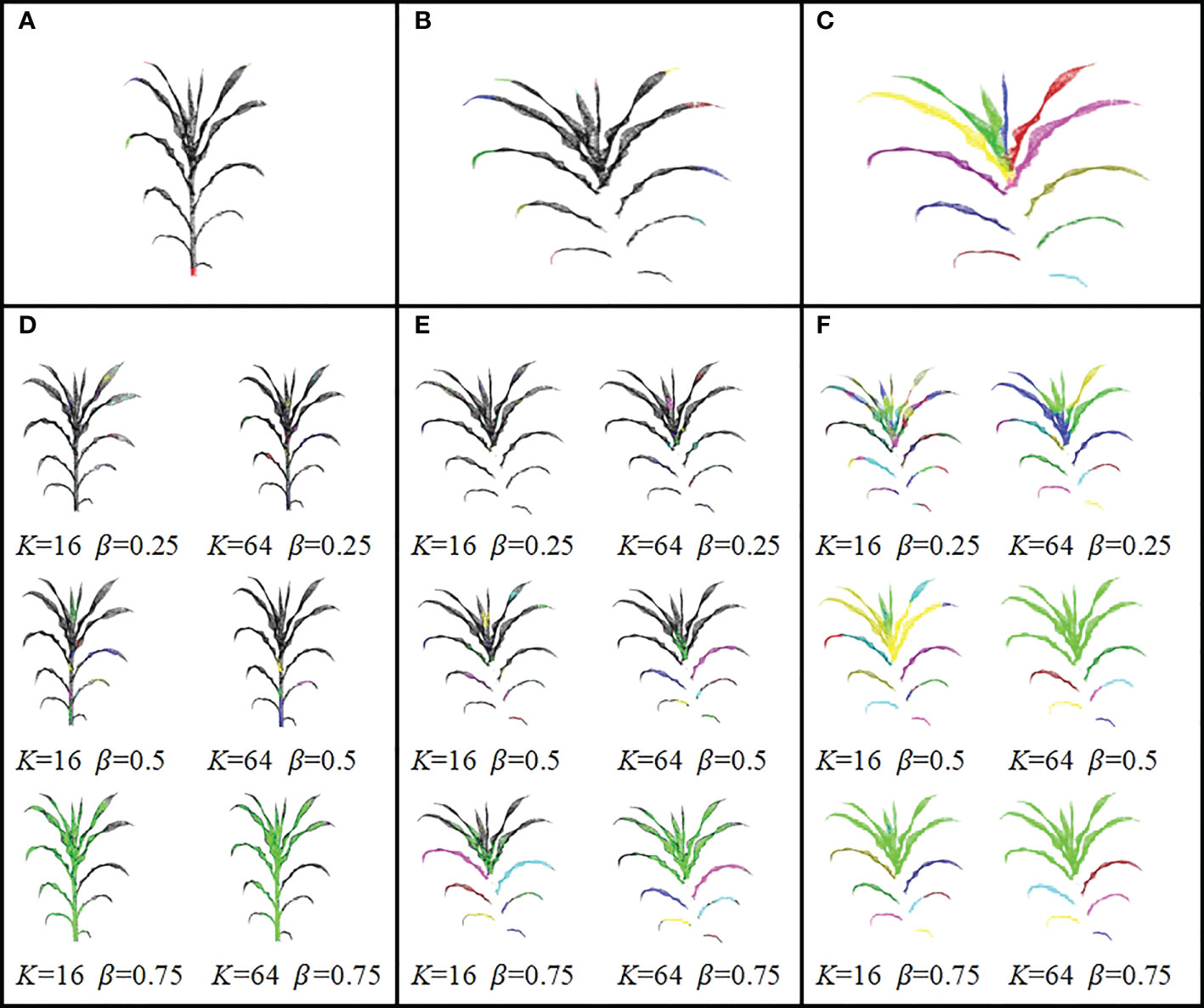
Figure 6 Visualization differences between DFSP and Quickshift++ for organ terminal region extraction and leaf segmentation. The same K and β parameters are used with DFSP and Quickshift++. (A) Organ terminal region extraction using DFSP; (B) Leaf tip region extraction using DFSP; (C) Leaf segmentation using DFSP. (D) Organ end region extraction directly with Quickshift++ under multiple sets of parameters. (E) Leaf tip region extraction directly with Quickshift++ under multiple sets of parameters. (F) Leaf segmentation directly with Quickshift++ under multiple sets of parameters.
Clustering algorithms are often used in point cloud segmentation of maize plants, such as density-based clustering algorithm (Elnashef et al., 2019) and the Eucliden distance-based clustering method (Zermas et al., 2020). We compared the results of our DFSP, two density- based clustering algorithms (DBSCAN and Quickshift++) and Eucliden distance-based clustering algorithm for leaf segmentation (as shown in Figure 7). The leaf base parts of new leaves are very close to each other, and the leaf base of a larger leaf covers that of a smaller leaf. None of the three clustering methods can segment such leaves correctly. The fully expanded leaves at the lower part of the plant are far away from each other, and the three clustering methods can successfully segment them. Compared with the three clustering methods, our DFSP is better in the segmentation of new leaves.
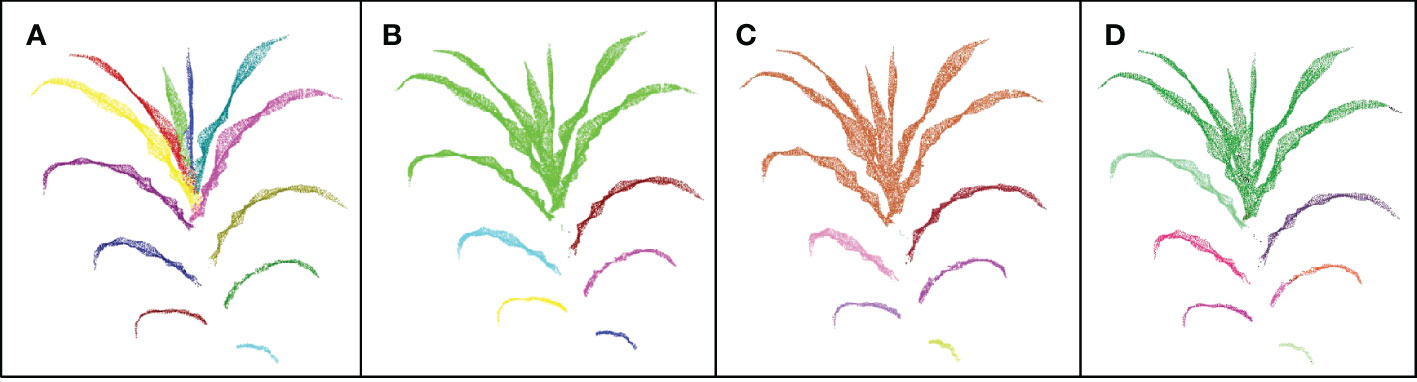
Figure 7 Comparison of leaves segmentation results of DFSP, Quickshift++,DBSCAN clustering method and Euclidean distance-based clustering method. (A–D) represents the results of segmentation using the DFSP, Quickshift++, DBSCAN and Euclidean distance-based clustering method, respectively.
In this study, all data were processed using similar parameters when validating the algorithm, leading to poor segmentation results for some plants. Notably, the segmentation algorithm was adjustable, providing flexibility for plant segmentation in different plant types and growth periods of maize. A case where the top new leaf was too small, wrapped, and almost stuck to other leaves is shown in Figure 8. The general parameters used in leaf segmentation step were invalid for such new leaves. However, small leaves can be extracted to obtain more refined results by reducing the K2 parameter.

Figure 8 The new leaf segmentation results. (A) Ground truth; (B) K2 set at 32; (C). K2 set at 8.
Plants have different heights at different stages. Herein, the data at the seedling stage accounted for the largest percentage, suggesting that the set parameters were more suitable for the point cloud at the seedling stage. Therefore, stem segmentation of higher plants can be under-segmented at μ=0.3. However, a better stem segmentation effect can be obtained if μ is increased. The effect of different μ values when processing point clouds of higher plants is shown in Figure 9. Notably, the stem length increased with increasing (μ =0.53) value, thus obtaining more refined segmentation results.

Figure 9 Segmentation results of stems with different μ values. (A) Ground truth; (B) μ=0.3; (C) μ=0.53.
Besides maize plant segmentation, DFSP has also been used to segment other plants. The segmentation results of mature maize, potted wheat, mimosa, and eggplant using DFSP are shown in Figure 10. Notably, the developed method can only apply to stem segmentation of plants with single-branch structures and not to plants with multi-branch structures because it adopts the regional growth method for stem segmentation. However, DFSP has a very good generalization ability and segmentation effect for the segmentation of non-stem organs with different geometric characteristics. For instance, it has a good segmentation effect in mimosa leaves with strong planar characteristics, maize ears with cylindrical characteristics, split tomato leaves, and slender curly wheat leaves, among other characteristics. Therefore, DFSP can be integrated into other segmentation methods and applied to other plant species.
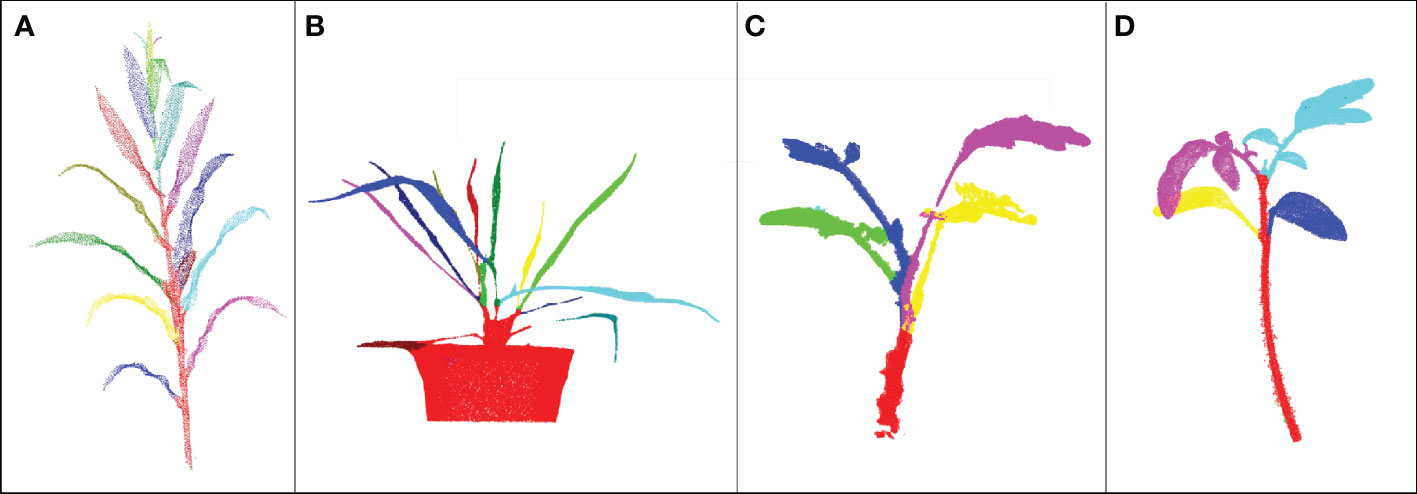
Figure 10 The segmentation effect of the median normalized growth segmentation method on different plants. (A) Mature maize (B) Potted wheat (C) Mimosa (D) Eggplant plant.
The developed method achieved great segmentation accuracy due to the integration of global structural features and local geometric features of the plant. DFSP was used as the core segmentation technology. The Minkowski distance function was used to code the global spatial structure and local connections of the plant. Herein, the sparse distribution of the end positions of various organs of maize in the 3D space was coded into Minkowski distance, which was extracted and recognized with Quickshift++. The point cloud tensor feature, a local geometric feature, in stem recognition was also used. Some few point clouds at the end of organs were first extracted through DFSP to improve the algorithm speed. The stem bottom region could be identified because of the different features on these point clouds. In general, the global and local features of the plant point cloud were integrated via DFSP to achieve good segmentation accuracy and avoid introducing complex machine learning technology.
Phenotypic parameters, such as leaf length, width, inclination, stem diameter, and other organ-level parameters, can be calculated through organ-level segmentation. In this study, The algorithm could quickly locate the lower end of the stem and the leaf tip by only one step of cluster-core extraction, thus enabling the extraction of the stem diameter and leaf number parameters without organ level segmentation. Moreover, it enables the calculation of plant height and width after point cloud alignment.
The identification of the lower end of the stem by DFSP also makes the method fully automated, which is crucial for high-throughput phenotype detection. This also ensures that the entire data processing process is non-interactive and less time-consuming. Compared with machine learning and deep learning technologies, the developed method avoids numerous manual annotation work and training processes. Compared with SSA and other methods that use skeleton extraction technology to locate stems, the method also has significant computational efficiency.
Like SSA (Miao et al., 2021b), the developed method can also segment new emerging leaves that are close and wrapped through DFSP. DFSP can be used to identify the leaf tip and segment the blade from tip to base. Jin et al. (2018b) segmented the leaf from the leaf base to leaf tip using the MNVG algorithm. However, this strategy is unsuitable for new emerging leaves (Miao et al., 2021b). Similar to the role of point cloud skeleton in SSA, DFSP can also represent the global topology information of maize plants with significantly reduced time.
A recent work developed Label3DMaize software (Miao et al., 2021a) to label maize point clouds. The software could be used to segment non-stem organs by interactively obtaining the key points of each organ. However, the process of obtaining the key points of each organ is the most time-consuming and labor-intensive step in the whole software. Notably, the developed DFSP segmentation strategy could automatically extract the key area points of each organ, reducing the operational complexity of the entire software.
This study expands the application scope of QuickShift++ in plant point cloud processing from group segmentation (Nelson and Papanikolopoulos, 2021) to single plant segmentation scale. Therefore, the two methods can be easily integrated to develop an organ-level group segmentation tool for the maize. Besides, the relevant existing technologies are mostly implemented by integrating different methods. For example, Jin et al. (2018a) first located the point cloud at the lower end of the stem through the fast RCNN (Girshick, 2015) and then used the regional growth algorithm to achieve single plant segmentation. They finally employed a 3D deep learning network (Jin et al., 2019) to segment the stem and leaf. Ao et al. (2022) first performed stem and leaf semantic recognition through PointCNN (Li et al., 2018) and then used DBSCAN clustering to cluster the stems and leaves into single plants through connection relationships for organ segmentation. DFSP enables group segmentation and organ segmentation through a unified segmentation process, thereby reducing the complexity of developing a maize point cloud segmentation tool.
The proposed method has the following limitations: First, the method used the regional growth method when extracting stems and height when judging how to stop growth, thereby introducing subjectivity despite the increased flexibility. Therefore, future studies should focus on using geometric features to accurately find the junction area between the stem and the top leaf. However, this limitation can be solved using deep learning for semantic segmentation. Second, DFSP is associated with over-segmentation in leaf segmentation (Figure 11A). However, when the tip point cloud of one leaf is mixed with another leaf, DFSP will mistakenly segment the two leaves into one instance, resulting in under segmentation (Figure 11B). Therefore, post-processing methods should be added in the subsequent works to optimize the segmentation results. Finally, the geometric features (formula 3) used in the identification of stem cluster cores are sensitive to the missing point clouds. The lowest end of the stem can be misidentified if the stem point cloud is seriously missing and its cylindrical feature disappears (Figure 11C). Therefore, future studies should introduce more robust geometric features for semantic recognition.
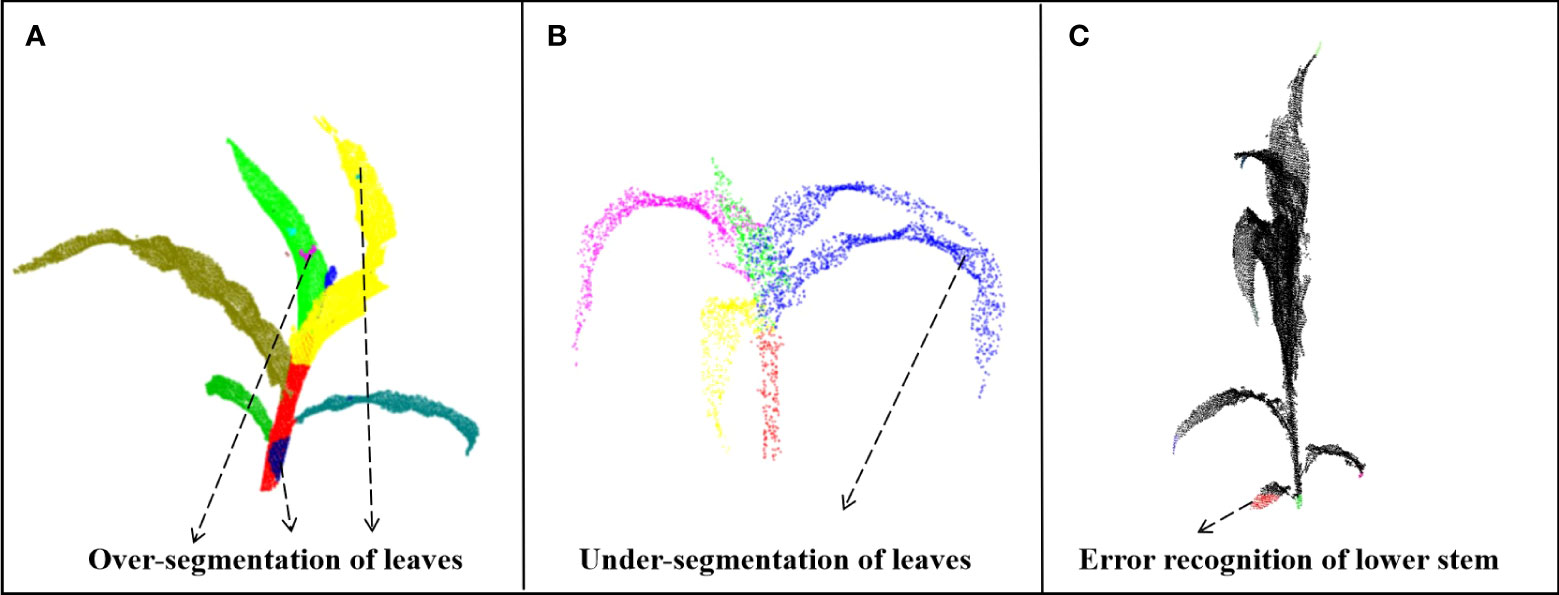
Figure 11 Limitations of the our algorithm. (A) Over segmentation of leaves. (B) Under segmentation of leaves. (C) Error recognition of lower stem.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/syau-miao/DFSP.
TM and TX conceived and designed the study. TM designed and implemented the algorithms. DW ran the pipeline on the data sets and analyzed the results. ZS theoretically proved the applicability of Quickshift++ in the distance field. TM, DW and ZS wrote the paper. CZ performed the experiments, acquired the 3D data, and produced the ground truth data. XY run the pointnet++ on the data sets. TY, YZ, and HD improved the approach in some details. All authors contributed to the article and approved the submitted version.
This work was supported by Joint Funds from the Natural Science Foundation of Liaoning [2021-NLTS-11-03], the China Postdoctoral Science Foundation [grant number 2018 M631821], General projects of Hainan Natural Science Foundation [grant number 620MS065], and the National Natural Science Foundation of China [grant number 31901399].
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ao, Z., Wu, F., Hu, S., Sun, Y., Su, Y., Guo, Q., et al. (2022). Automatic segmentation of stem and leaf components and individual maize plants in field terrestrial lidar data using convolutional neural networks. Crop J. 10, 1239–1250. doi: 10.1016/j.cj.2021.10.010
Elnashef, B., Filin, S., Lati, R. N. (2019). Tensor-based classification and segmentation of three-dimensional point clouds for organ-level plant phenotyping and growth analysis. Comput. Electron. Agric. 156, 51–61. doi: 10.1016/j.compag.2018.10.036
Gelard, W., Devy, M., Herbulot, A., Burger, P.. (2017). “Model-based segmentation of 3D point clouds for phenotyping sunflower plants,” in Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Volume 4 Setúbal, Portugal: VISAPP ,SciTePress Digital Library. doi: 10.5220/0006126404590467
Girshick, R. (2015). “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV). New Jersey, USA: IEEE Computer Society 1440–1448.
Griffiths, D., Boehm, J. (2019). A review on deep learning techniques for 3D sensed data classification. Remote Sens. 11 (12), 1499. doi: 10.3390/rs11121499
Jiang, H., Jang, J., Kpotufe, S. (2018). Quickshift++: Provably good initializations for sample-based mean shift. Proc Mach Learn Res 80, 2294–2303. doi: 10.48550/arXiv.1805.07909
Jin, S., Su, Y., Gao, S., Wu, F. F., Guo, Q. (2019). Separating the structural components of maize for field phenotyping using terrestrial LiDAR data and deep convolutional neural networks. IEEE Trans. Geosci Remote Sensing. 58, 2644–2658. doi: 10.1109/TGRS.2019.2953092
Jin, S., Su, Y., Gao, S., Wu, F. F., Hu, T. Y. (2018a). Deep learning: individual maize segmentation from terrestrial lidar data using faster RCNN and regional growth algorithms. Front. Plant Science. 9, 866. doi: 10.3389/fpls.2018.00866
Jin, S., Sun, X., Wu, F., Su, Y. J., Guo, Q. (2021). Lidar sheds new light on plant phenomics for plant breeding and management: Recent advances and future prospects. ISPRS J. Photogrammetry Remote Sensing. 171, 202–223. doi: 10.1016/j.isprsjprs.2020.11.006
Jin, S., Su, Y., Wu, F., Pang, S., Gao, S., Hu, T., et al. (2018b). Stem-leaf segmentation and phenotypic trait extraction of individual maize using terrestrial LiDAR data. IEEE Trans. Geosci. Remote Sensing. 57, 1336–1346. doi: 10.1109/TGRS.2018.2866056
Li, Y., Bu, R., Sun, M., Wu, W., Di, X., Chen, B., et al. (2018). PointCNN: convolution on x-transformed points. Adv. Neural Inf. Process. Syst. Cambridge, Massachusetts, USA: Mit Press. 31, 820–830.
Li, D., Li, J., Xiang, S., Pan, A.. (2022a). PSegNet: simultaneous semantic and instance segmentation for point clouds of plants. Plant Phenomics 3, 1–20. doi: 10.34133/2022/9787643
Li, D., Shi, G., Li, J., Chen, Y., Zhang, S., Xiang, S., et al. (2022b). PlantNet: A dual-function point cloud segmentation network for multiple plant species. ISPRS J. Photogrammetry Remote Sens. 184, 243–263.
Li, Y., Wen, W., Miao, T., Wu, S., Yu, Z., Wang, X., et al. (2022c). Automatic organ-level point cloud segmentation of maize shoots by integrating high-throughput data acquisition and deep learning. Comput. Electron. Agric. 193 (5), 106702. doi: 10.1016/j.compag.2022.106702
Miao, T., Wen, W., Li, Y., Wu, S., Zhu, C., Guo, X., et al. (2021a). Label3dmaize: toolkit for 3d point cloud data annotation of maize shoots. GigaScience 10 (5). doi: 10.1093/gigascience/giab031
Miao, T., Zhu, C., Xu, T., Yang, T., Li, N., Zhou, Y., et al. (2021b). Automatic stem-leaf segmentation of maize shoots using three-dimensional point cloud. Comput. Electron. Agriculture. 187, 106310. doi: 10.1016/j.compag.2021.106310
Nelson, H., Papanikolopoulos, N. (2021). Pre-clustering point clouds of crop fields using scalable methods. arXiv[Preprint]. doi: 10.48550/arXiv.2107.10950
Paproki, A., Sirault, X., Berry, S., Fripp, J. (2012). A novel mesh processing based technique for 3D plant analysis. BMC Plant Biol. 12 (1), 63. doi: 10.1186/1471-2229-12-63
Paulus, S., Dupuis, J., Mahlein, A. K., Kuhlmann, H. (2013). Surface feature based classification of plant organs from 3d laserscanned point clouds for plant phenotyping. BMC Bioinf. 14, 238. doi: 10.1186/1471-2105-14-238
Qi, C., Li, Y., Hao, S., Guibas, L. (2017). Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 30, 5105–5114.
Rinaldo, A., Singh, A., Nugent, R., Wasserman, L. (2012). Stability of density-based clustering. J. Mach. Learn. Res. 13 (1), 905–948. doi: 10.1109/TASE.2012.2183739
Rist, F., Herzog, K., Mack, J., Richter, R., Steinhage, V., Topfer, R. (2018). High-precision phenotyping of grape bunch architecture using fast 3D sensor and automation. Sensors 18 (3), 763. doi: 10.3390/s18030763
Room, P., Hanan, J., Prusinkiewicz, P. (1996). Virtual plants: New perspectives for ecologists, pathologists and agricultural scientists. Trends Plant Science. 1 (1), 33–38. doi: 10.1016/S1360-1385(96)80021-5
Rusu, R., Cousins, S. (2011). “3D is here: Point cloud library (PCL),” in IEEE International Conference on Robotics and Automation. New Jersey, USA: IEEE press, 1–4. doi: 10.1109/ICRA.2011.5980567
Stuetzle, W., Nugent, R. A. (2010). Generalized single linkage method for estimating the cluster tree of a density. J. Comput. Graphical Statistics. 19 (2), 397–418. doi: 10.1198/jcgs.2009.07049
Vedaldi, A., Soatto, S. (2008). “Quick shift and kernel methods for mode seeking,” in Computer Vision - ECCV. Berlin, German: Springer, 705–718. doi: 10.1007/978-3-540-88693-8_52
Vijayarangan, S., Sodhi, P., Kini, P., Bourne, J., Du, S., Sun, H., et al. (2018). “High-throughput robotic phenotyping of energy sorghum crops,” in Field and service robotics. Berlin, Germany: Springer Press 5, 99–113. doi: 10.1007/978-3-319-67361-5
Wahabzada, M., Paulus, S., Kersting, K., Mahlein, A. (2015). Automated interpretation of 3d laserscanned point clouds for plant organ segmentation. BMC Bioinf. 16, 248. doi: 10.1186/s12859-015-0665-2
Xiang, L., Bao, Y., Tang, L., Ortiz, D., G.Salas-Fernandezb, M. (2019). Automated morphological traits extraction for sorghum plants via 3D point cloud data analysis. Comput. Electron. Agric. 162, 951–961. doi: 10.1016/j.compag.2019.05.043
Wu, S., Wen, W., Xiao, B., Guo, X., Du, J., Wang, C., et al. (2019). An accurate skeleton extraction approach from 3D point clouds of maize plants. Front. Plant Sci. 10. doi: 10.3389/fpls.2019.00248
Wu, S., Wen, W., Wang, Y., Fan, J., Wang, C., Guo, W., et al. (2020). MVS-pheno: a portable and low-cost phenotyping platform for maize shoots using multiview stereo 3D reconstruction. Plant Phenomics. 2 (1), 17. doi: 10.34133/2020/1848437
Zermas, D., Morellas, V., Mulla, D., Papanikolopoulos, N. (2020). 3D model processing for high throughput phenotype extraction – the case of corn. Comp. Electron. Agric. 172, 105047. doi: 10.1016/j.compag.2019.105047
Keywords: point cloud, segmentation, maize, distance field, quickshift++
Citation: Wang D, Song Z, Miao T, Zhu C, Yang X, Yang T, Zhou Y, Den H and Xu T (2023) DFSP: A fast and automatic distance field-based stem-leaf segmentation pipeline for point cloud of maize shoot. Front. Plant Sci. 14:1109314. doi: 10.3389/fpls.2023.1109314
Received: 27 November 2022; Accepted: 10 January 2023;
Published: 31 January 2023.
Edited by:
Yuntao Ma, China Agricultural University, ChinaReviewed by:
Shenglian Lu, Guangxi Normal University, ChinaCopyright © 2023 Wang, Song, Miao, Zhu, Yang, Yang, Zhou, Den and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Teng Miao, bWlhb3RlbmdAc3lhdS5lZHUuY24=; Tongyu Xu, eHV0b25neXVAc3lhdS5lZHUuY24=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.