
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Plant Sci. , 16 September 2022
Sec. Plant Breeding
Volume 13 - 2022 | https://doi.org/10.3389/fpls.2022.972164
This article is part of the Research Topic Marker-Assisted Selection (MAS) in Crop Plants View all 45 articles
 Rubab Zahra Naqvi†
Rubab Zahra Naqvi† Hamid Anees Siddiqui†
Hamid Anees Siddiqui† Muhammad Arslan Mahmood†
Muhammad Arslan Mahmood† Syed Najeebullah
Syed Najeebullah Aiman Ehsan
Aiman Ehsan Maryam Azhar
Maryam Azhar Muhammad Farooq
Muhammad Farooq Imran Amin
Imran Amin Shaheen Asad
Shaheen Asad Zahid Mukhtar
Zahid Mukhtar Shahid Mansoor
Shahid Mansoor Muhammad Asif*
Muhammad Asif*Improving the crop traits is highly required for the development of superior crop varieties to deal with climate change and the associated abiotic and biotic stress challenges. Climate change-driven global warming can trigger higher insect pest pressures and plant diseases thus affecting crop production sternly. The traits controlling genes for stress or disease tolerance are economically imperative in crop plants. In this scenario, the extensive exploration of available wild, resistant or susceptible germplasms and unraveling the genetic diversity remains vital for breeding programs. The dawn of next-generation sequencing technologies and omics approaches has accelerated plant breeding by providing the genome sequences and transcriptomes of several plants. The availability of decoded plant genomes offers an opportunity at a glance to identify candidate genes, quantitative trait loci (QTLs), molecular markers, and genome-wide association studies that can potentially aid in high throughput marker-assisted breeding. In recent years genomics is coupled with marker-assisted breeding to unravel the mechanisms to harness better better crop yield and quality. In this review, we discuss the aspects of marker-assisted breeding and recent perspectives of breeding approaches in the era of genomics, bioinformatics, high-tech phonemics, genome editing, and new plant breeding technologies for crop improvement. In nutshell, the smart breeding toolkit in the post-genomics era can steadily help in developing climate-smart future food crops.
The world’s population is gradually up-surging and the biggest challenge is food security. The other challenges include climate change and population growth (Abberton et al., 2016). The increasing population demands more food and exerts an extra burden on agricultural resources (Ray et al., 2013). Climate change is one of the biggest challenges in the sustainable production of agricultural crops. It is defined as “the significant changes in the different elements of metrology such as temperature and precipitation, for which averages have been computed over a long period” (Malhi et al., 2021). For the past few decades, the major cause of devastating climate change is the human activities that altered the global atmospheric composition. In the troposphere where life exists, the atmospheric greenhouse effect occurs. Other causes involve rapid industrialization, urbanization, scorching of farming wastes, deforestation, and use of non-degradable merchandises, which pose a serious threat to the sustainable environment. Climate change has evoked variations in temperature, rainfall, and atmospheric conditions that adversely affect the developmental, morphological, cellular, and molecular mechanisms in plants. It can affect the crop production by direct, indirect, and socio-economic means. For example, direct effects such as morphological, physiological, and phenotypic changes in the plant productivity. Indirect effects include soil fertility, rise in the sea level, pest pressure, and availability of irrigation whereas the socio-economic effects consist of food demand, costs, trading, and unequal distribution. These factors can severely influence the agricultural production.
Since 1750, the concentration of greenhouse gases such as nitrous oxide (N2O), carbon dioxide (CO2), and methane (CH4) have been significantly increased by 20, 40, and 150%, respectively. The mainly contributing greenhouse gas is CO2 which has a positive effect on the plant growth through CO2 fertilization (Wang S. et al., 2020). Enhanced CO2 directly influences the photosynthesis, exchange of gases, and numerous other developmental processes in plants (Gray and Brady, 2016). Simultaneously, the nutritional value, as well as the quality of food decreases in response to sharp CO2 in the atmosphere that is caused by various other environmental factors. However, long-term exposure of plants to elevated CO2 can decrease the photosynthesis because of photosynthetic acclimation, ultimately affecting the vegetable quality in plants (Dong et al., 2018). Recently, Parvin et al. (2019) identified the reduced concentration of Fe, Zn, S, and P in lentil and faba bean crops upon high CO2 conditions. It has been observed that over the past 30 years, there is a decline in CO2 fertilization due to the lower availability of water and shifting nutrient concentrations (Wang S. et al., 2020).
Several biotic and abiotic stresses hit the crops’ productivity (Figure 1), which are becoming severe due to climate change. Due to extreme temperature, wheat production is heavily affected in various countries and may reduce the crop yield by 6% for every °C rise in temperature. In cereal crops like wheat, drought and high temperature are the key factors with a high impact on yield and Rubisco, the main photosynthetic enzyme. If the temperature increases from 35°C, it stops the photosynthetic process (Barnabás et al., 2008).
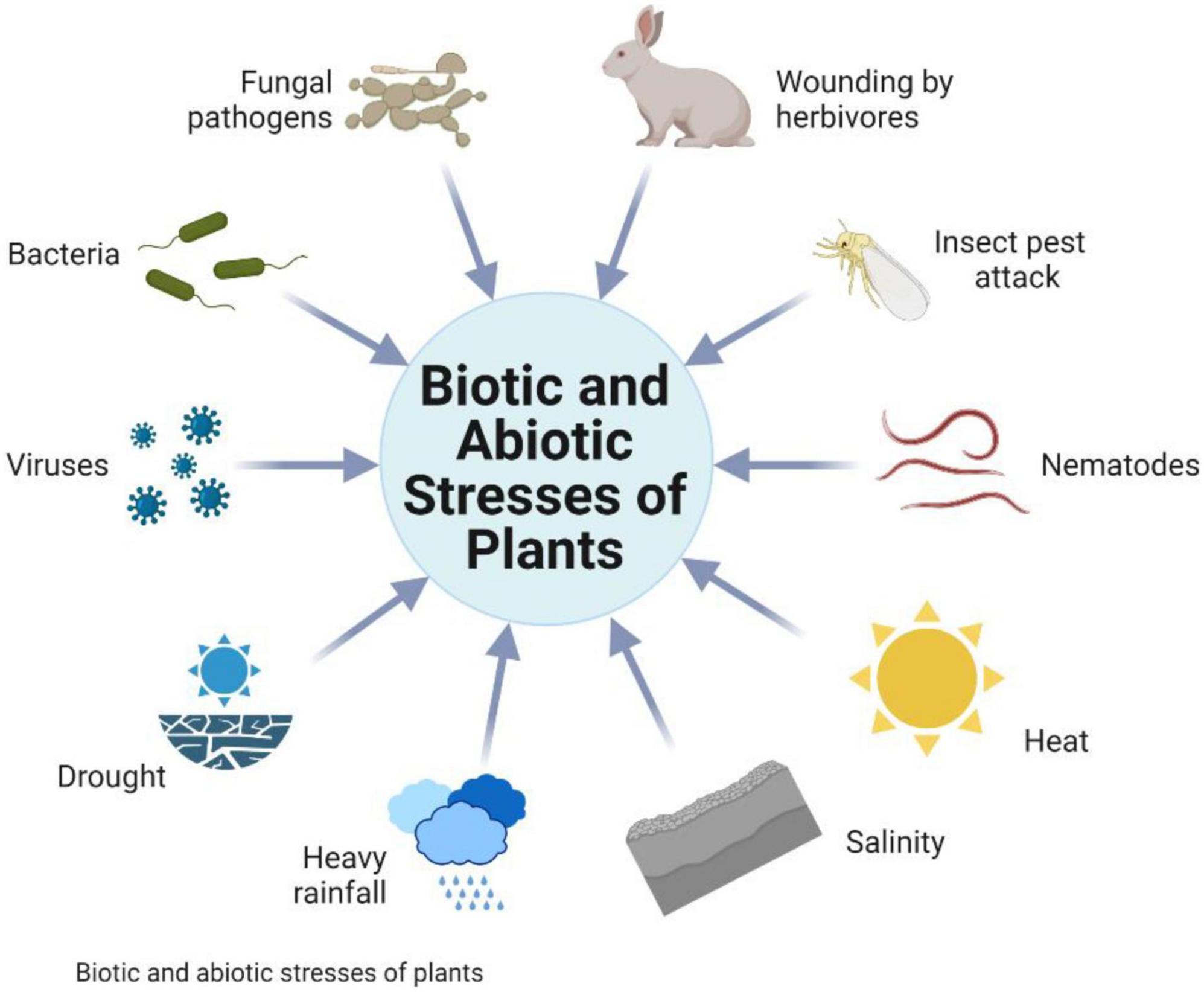
Figure 1. Different types of various stresses in crop plants.
The combined impact of drought and high temperature has been observed to result in more damaging outcomes as compared to the individual stress (Wang and Huang, 2004). The global yield of important crops like wheat and maize has been decreased from 1981 to 2010 relative to the prior years (Iizumi et al., 2018). It is estimated that atmospheric CO2 will increase up to ∼730–1000 ppm by the end of 21st century which is allied with the peaked mean global temperature that will ultimately bring the significant changes in global climate (Balasooriya et al., 2018). Elevation of temperature accelerates the metabolic activities of insect pests and enhances their crop damage frequency. Besides it, the preeminent levels of CO2 make the food crops vulnerable to insects and different pathogens. Overall, the effect of climate change on crops remains detrimental. The dilemma becomes worse because of the fluctuations in annual rainfall, temperature, and various environmental factors which are directly associated with climate change.
Humans have used an artificial selection of plants for the past 10,000 years to select the crop plants for desired traits via breeding. Conventional agricultural procedures are intended to improve the plants yield and their nutritional composition but recent modern methods offer a vast choice of options and innovations in the breeding methods. These newly developed methods can be used to cope with the devastating plant biotic as well as abiotic stresses and to combat the growing demand for food commodities (Supplementary Table 1).
Crop breeding revolutionized when Mendelian laws were announced. With the invention of new cutting-edge genomics tools, crop development is modified greatly. In this decade, novel techniques, e.g., genomic selection, modern speed breeding, and high-throughput crop phenotyping (HTTP) have been shown to speed up the plant breeding mechanism. Biotechnological interventions for instance genetic engineering tools (gene transformation) have also played an important role in the development of crops having desirable traits. Besides this, other techniques such as whole genome sequencing (WGS), genomics, gene identification, gene isolation, and fast molecular markers are opted to be a good strategy for improving cisgenesis, intragenesis, mutation, and polyploidy breeding (Muth et al., 2008; Murovec et al., 2017).
Crop breeding is a decision-making process at all its stages of breeding program such as testing, mapping, and introgression of traits, where breeders select the individual plants from large segregating populations harboring the best traits (Kaiser et al., 2020). But these conventional breeding practices mostly remain very slow and inadequate to enhance the development of crop varieties. Conventionally once the crosses are made among two parent plants, the successive generations are achieved for the identification of superior individual. The whole process involves the plants multi-years testing in replicated field trials at multiple locations for the detection of genetic potentional of candidate genotype across a wide range of conditions (Voss-Fels et al., 2019).
For ease in breeding, since the 1990s, molecular markers are used to identify and for the selection of hybrid lines (Dreher et al., 2000; Gupta et al., 2010). Artificial selection can be done by a plant breeder for refining plant’s phenotype for a precise looked-for trait. Breeders also focus on crops that achieve multiple generations within a year which ultimately leads to gaining the desired phenotype faster (Van Bueren et al., 2011; Kandemir and Saygili, 2015). Molecular markers were employed to identify seven Yr genes for stripe rust resistance in synthetic wheat (Farrakh et al., 2016). Several markers including RFLP, AFLP, SSR, and SNP have been used to identify QTLs in rice and other crops (Oladosu et al., 2019). Single nucleotide polymorphism (SNP), a DNA marker of choice is ubiquitously present in the crop genome and is quite easy and cost-efficient (Liakos et al., 2018).
The rate of annual yield improvement for major crops ranges between 0.8 and 1.2% which must be doubled to meet the exceedingly augmented future call of plant-based goods (Li et al., 2018). With the use of new approaches, we can help boosting up the staple food crops production by improving the genetics of the crops otherwise global food security will be severely compromised in the coming two to three decades. One of the major bottlenecks in plant breeding is the time it takes to develop an improved crop variety. Molecular breeding with advanced genomic studies increases the efficiency of breeding practices and also saves time. Equated with other kingdoms, the plants are straightforwardly manipulated with a desirable trait by crossbreeding, selfing, or both because of their short-generation time and larger population size that is available for studies (Stetter et al., 2016). Recently, Lee Hickey and colleagues described the idea of “speed breeding,” which is a non-GMO approach enabling the scientists and researchers to turn over many generations in a single year and select plants with desirable traits between thousands of variations (Watson et al., 2018; Voss-Fels et al., 2019). In speed breeding technique, controlled environmental settings and extended photoperiods are achieved leading to four to six generations of crops, i.e., wheat, canola, barley, etc., in a year.
Advances in DNA sequencing platforms and high throughput phenotyping have revolutionized the crop breeding and research opening up the genomics era of crop improvement. It has given the concept of new generation genotyping and phenotyping for crop breeding (Figures 2A,B). With the rapid advancement of next-generation sequencing (NGS) platforms, the complex genomes of many important crop species such as sorghum (730 Mbp) (Paterson et al., 2009), soybean (1115 Mbp) (Schmutz et al., 2010), barley (5100 Mbp) (Mayer et al., 2012), potato (850 Mbp) (Xu et al., 2011), and rapeseed (1200 Mbp) (Chalhoub et al., 2014) have been sequenced. Even the huge hexaploid genome of bread wheat (17000 Mbp) has been mapped with the combination of flow cytometry and synthetic mapping and next-generation sequencing technologies by enabling the chromosome-based draft genome sequence available (Mayer et al., 2014).
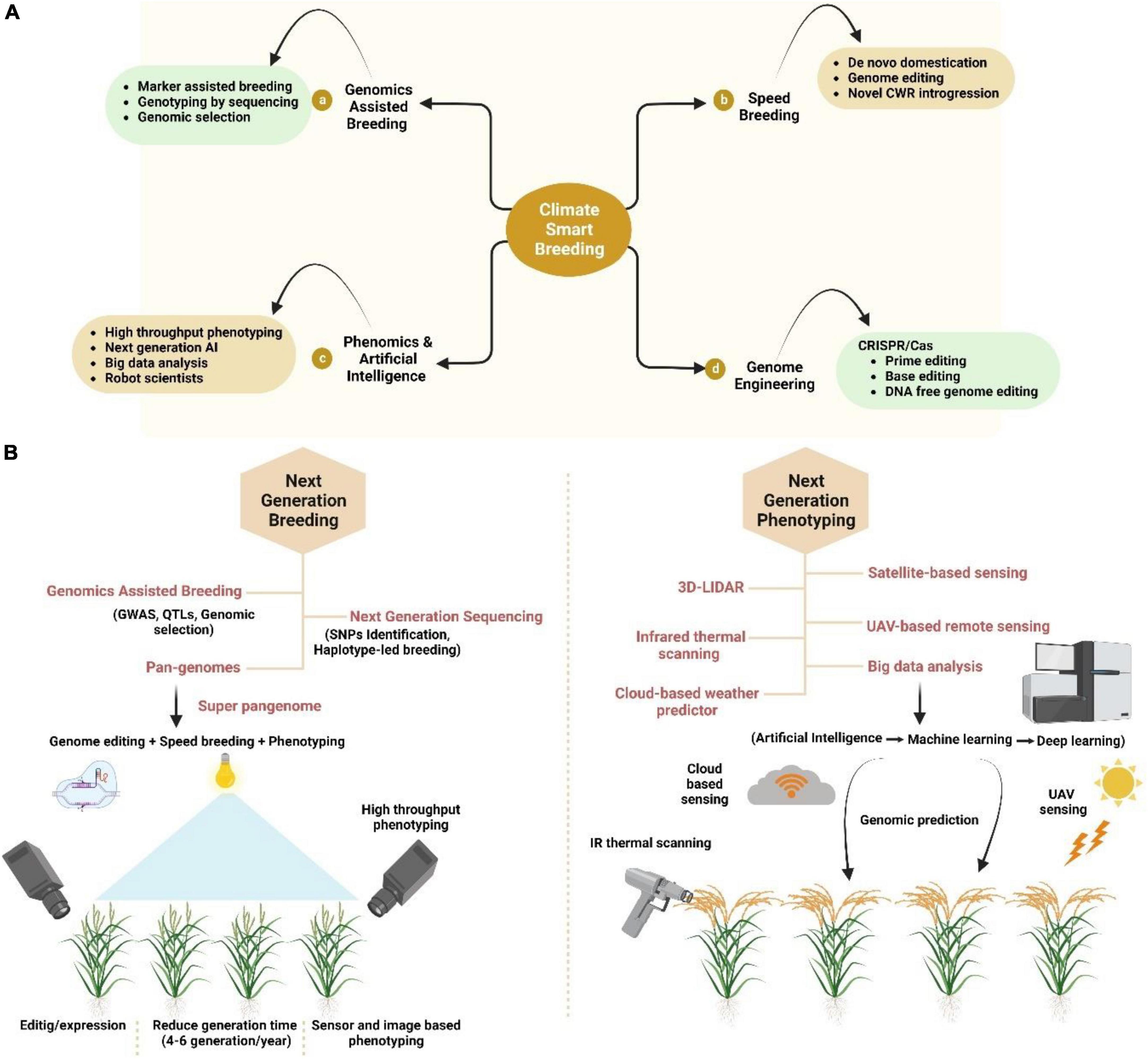
Figure 2. Modern breeding for crop improvement under climate change scenario. (A) Climate-smart breeding is the combination of (a) genomics assisted breeding, (b) speed breeding, (c) phenomics and artificial intelligence (AI), and (d) genome editing. (B) Next generation breeding and phenotyping tools including breeding with genomics, next-generation sequencing (NGS) and Pan genomics while phenotyping includes 3D LIDAR, satellite-based sensing, UAV-based remote sensing, cloud-based sensing, and Infrared thermal prediction. All these breeding techniques and tools help in the sustainable production of crops as well as the selecting the high yield crops.
Wild crop relatives (CWRs) related to the agricultural crops can enhance the adaptive capacity of the agricultural systems worldwide. They represent a pool of genetic diversity that can be used to draw new allelic variations required in breeding programs. These crop wild relatives have been extremely valuable in adapting crop varieties to changing farming practices, disease pressures, market demands, and climate conditions. The annual contribution of CWRs to the world economy is estimated to be approximately 186.3 billion USD (Tyack et al., 2020). For instance, the genes from the wild tomato increased the content of soluble solids with a worth of approximately 250 million USD.1 Over the past few decades, the number has significantly increased in introducing traits from the wild species into the cultivated crops mainly for overcoming the biotic and abiotic stresses. For instance, the introduction of late blight (fungal disease caused by Phytophthora infestans) resistance from the wild potato Solanum demissum and stem rust (fungal disease caused by Puccinia graminis ssp. graminis) resistance from the wild wheat Aegilops tauschii (Kilian et al., 2010). Generally, the primary strategy for crop improvement is a recurrent selection of wild species as a source of novel material to broaden the genetic bases of crops (Cooper et al., 2001; Moore, 2015). Wild relatives’ diversity can be classified into two major avenues; (a) “Choose first”-In this class wild species, based on phenotype and genotype for a particular trait is selected and used for crosses, while in the second class (b) “Cross first”-wide range of crosses are performed with wild species and progeny is screened for desired traits in domesticated background (Thormann et al., 2014). So, once the trait of interest has been identified in the wild genotype or individual, they need to be transferred into the crop backgrounds. Alternatively, crosses between wild and cultivated taxa are made first and their progeny, either F1 or later generation are screened for desired traits.
The subsequent genetic improvement led to the development of high-yielding crop varieties, many with resistance to abiotic stresses as well as pests and disease stress. The FAO estimates that approximately 75% of the genetic diversity harbored in traditional agricultural crop varieties has been lost over the past century.2 This important genetic loss caused by the migration of crops from their origins or modern breeding should be known as post-domestication or breeding bottlenecks (Abbo et al., 2014). There are some crucial challenges in the expansion of cultivated gene pool by using CWRs and ancestral landraces that include biological barriers to compatibility and crossability, F1 generation and backcross (BC1) sterility, reduced recombination between elite and CWR genomes, and infertility of offspring (Zamir, 2001). Careful consideration of these obstacles has opened the novel opportunities for managing the male and female sterility in the production of hybrid crops. For instance, male sterility due to the disharmony of cytoplasmic (wild) and nuclear (cultivated) genomes in interspecific crosses of vast crop species has proved to be a boon for the hybrid industry worldwide (Bohra et al., 2021).
Wild crop relatives generally express poor adaptation beyond their natural distribution range such as photoperiod sensitivity, phenological differences, and asynchronous flowering can all contribute to maladaptation to the artificial agricultural environments (Cowling, 2013; Wang et al., 2017). One of the examples here is chickpea CWRs that are collected from temperate regions show poor adaptability in tropical and subtropical regions owing to large phenological differences (Warschefsky et al., 2014). However, the perception of agronomic potential may be deceptive because an agronomically inferior CWR may contain valuable alleles for a specific trait(s). Using appropriate screening procedures, these beneficial alleles can be readily discovered in segregating population derived from wild × elite crosses (Dempewolf et al., 2017).
Genetic diversity in landraces provides a great opportunity for sustainable and improved crops. Different germplasm banks in the world play a crucial role in maintaining and sustaining the accessions of crops gathered over centuries that could be helpful in conserving the genetic resources. For instance, International Maize and Wheat Improvement Center (CIMMYT) established in 1966 runs a genetic resource program that conserves the global maize and wheat germplasm. CIMMYT holds around 150,000 wheat seeds sampled from almost 100 countries and 28,000 samples are present in the maize bank. CIMMYT launched its wheat breeding program for biofortification in 2006 and crosses among goat grass, a wild relative and wheat achieved improved disease resistance, agronomic traits, and higher zinc in wheat grains. This biofortification program is underway in different countries and hopefully will play a major role in releasing biofortified wheat that could fulfill the demand for nutrient-rich wheat in southeast Asia and other parts of the world (Singh et al., 2017). Pearl millet and its wild relative accessions have also been collected and conserved in ten gene banks in eight different countries (Sharma et al., 2021).
The Sequencing of more complex genomes required more effort. High content of repetitive element and ploidy level in complex genomes are the key challenges for plant sequencing projects. The availability of reference genome enables identification of large number of genes involved in biotic and abiotic stresses and also molecular markers. Re-sequencing projects are more appropriate to pre-breeding activities to identifying genomic variations and gathering information about useful polymorphisms. Various important plant species have been sequenced and their draft genomes have become available (Mosa et al., 2017). NGS based techniques have provided with the opportunity for enhanced resolution of QTLs and identification of genetic variations. High-throughput NGS in different formats have been used for crop population mapping. Some such studies have been highlighted in Table 1. With the advent of modern NGS technologies, following techniques are efficiently used for gene and QTLs discovery in crop plants.
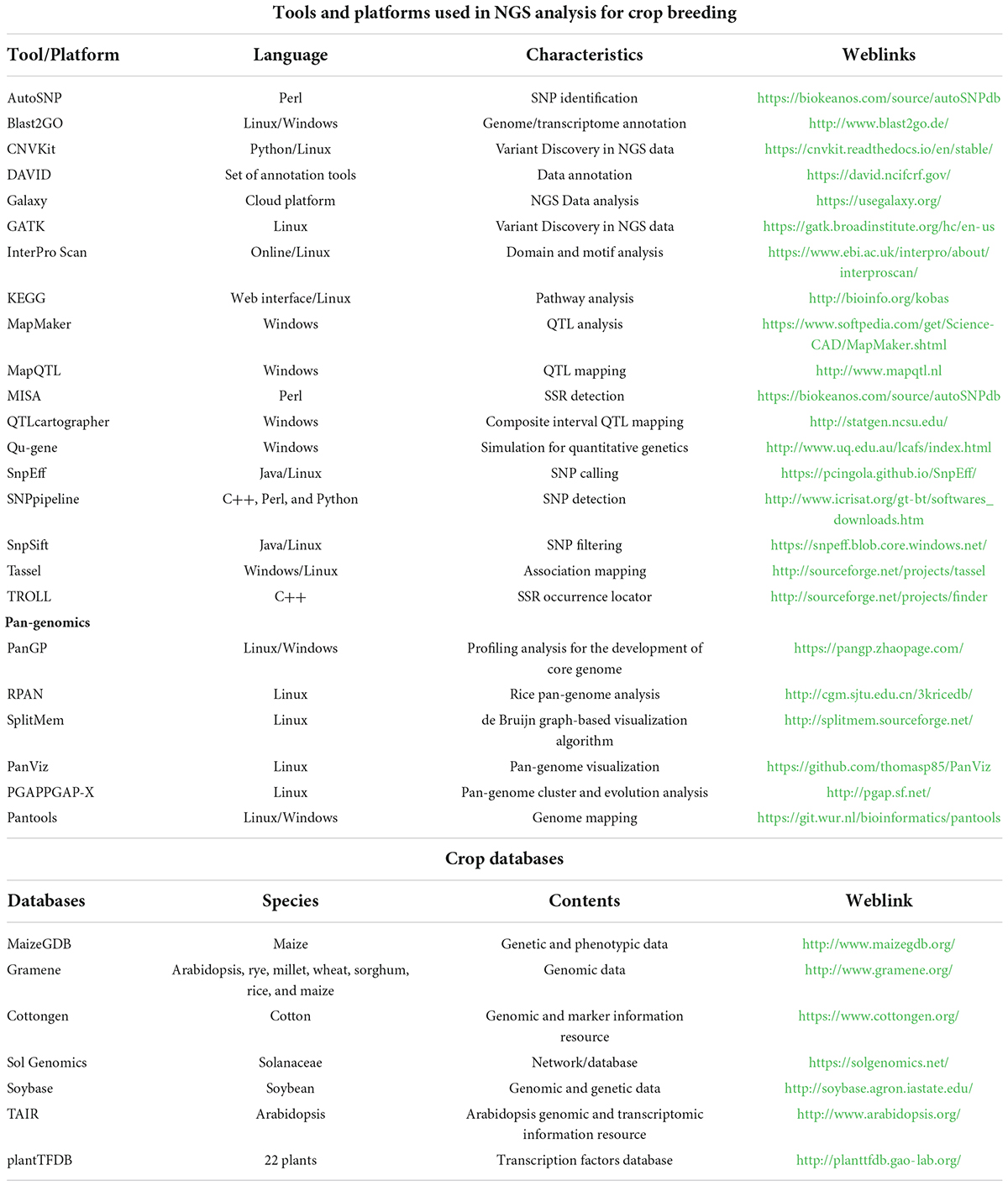
Table 1. Bioinformatics tools utilized in modern crop breeding.
Genome-wide association studies (GWAS) lead to high resolution mapping in a larger population by offering the detection of statistically significant phenotype-genotype association based on linkage disequilibrium (LD).
Restriction site-associated DNA sequencing (RADSeq) employs NGS to scoring of several genetic markers from individuals of a population. Its more advanced and cost-effective method is GBS.
Genotyping-by-sequencing (GBS) is an efficient, cost-effective, and robust tool for implementing GWAS in crops. It also allows breeders to study genetic linage, marker detection, genomic diversity, and genomic selection in different crop breeding programs.
Bulk-segregant analysis sequencing (BSA-Seq) provides the modern combination of Bulk-segregant analysis with NGS that helps in precise identification of markers for a particular trait within a breeding population.
TILLING by Sequencing harbors both Tilling and Eco tilling approaches where NGS aids to fast discovery of induced or natural genetic variation, respectively. This technique helps in the identification of rare and novel mutations.
Mutmap exploits whole genome resequencing of different DNA pools in the segregating populations for SNP genotyping in the mutant population.
The trend to utilize robust genomics assisted breeding with the help of NGS approaches for crop breeding has been amplified over the last few decades (Table 2) and will continue with dropping costs of sequencing and increased efficiency of sequencing platforms.
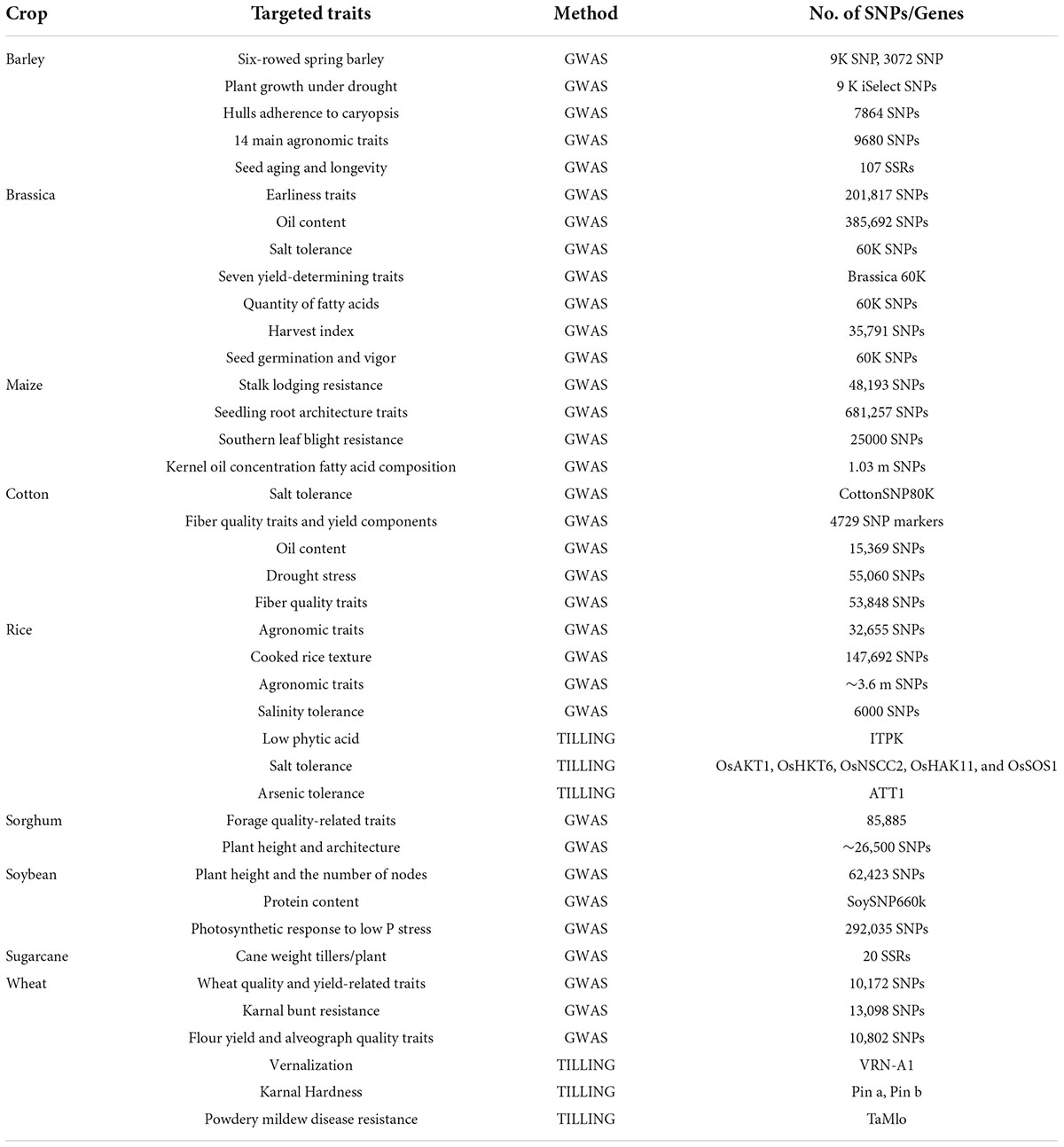
Table 2. SNP and marker gene identification in crop plants by utilizing NGS (Khalid et al., 2021; Khan et al., 2021).
Next-generation sequencing produces loads of data from a breeding population that can be through GWAS or GBS, etc.; therefore, after sequencing the data is analyzed using big-data handling of bioinformatics. Moreover, bioinformatics offer the tools both for forward and reverse genetics (Das, 2019).
The available user-friendly bioinformatics databases for nucleotide sequences are GenBank at NCBI, DNA Databank of Japan (DDBJ) and European Nucleotide Archive (ENA). For plants the database with genomics information is Ensemble Plants. Important tools of the data analysis for gene ontology and similarity searches are NCBI, GOA, BLAST, UniProtKB, GO, and KEGG. Data acquired from NGS sequencing platforms is handled by different bioinformatics tools which help in inferring information from the sequencing data. This information leads to establish a connection with plant phenotype and genotype for gene or marker identification (Kersey, 2019).
The tools, platforms, databases, and software often used in the data analysis in crop breeding are listed in Table 1.
Since the dawn of civilization agriculture has always remained one of the topmost priorities of humans for the sustained growth and to meet the financial needs. Throughout this time different techniques have been in practice to improve the quality of food crops (Mendel, 1865; Stadler, 1928; Crabb, 1947; Welsh and McClelland, 1990; Xu, 2010; Jinek et al., 2012; Figure 3). Sustained production of crops is liable to many environmental factors; be it the biotic or abiotic stresses both negatively impact on the yield in multiple ways and is a major predicament to meet the challenge of feeding world’s increasing population which is estimated to reach at ten billion over the next three decades (Hickey et al., 2019; Varshney et al., 2021). Increasing world population combined with climate change has put scientists in a challenging position and there is a pressing need to come up with new technologies for developing climate resilient crop varieties for a sustained food production (Hickey et al., 2019). Over the last 10–15 years significant progress has been made to improve crop plants including high-throughput phenotyping system enabling us to screen large number of populations (Araus et al., 2018) and advancement of sequencing technologies made the job much easier to discover new genes for particular traits and simplified the selection criteria and to design new selection markers apart from the traditional ones (Bassi et al., 2016). One of the major quandaries in developing new crop varieties is the slow process of trait fixing and generation enhancement due to the long generation time but with the advent of “speed breeding” this problem has been alleviated by following specialized protocols and has successfully been applied on the number of crop specie including wheat barley Hordeum vulgare, canola (Brassica napus), chick pea (Cicer arietinum) (Ghosh et al., 2018; Watson et al., 2018).
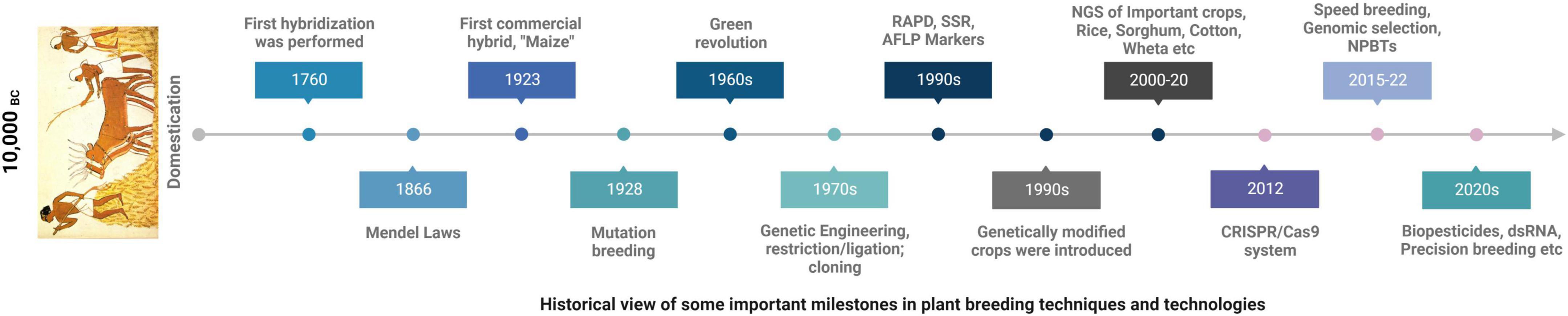
Figure 3. A timeline of major plant breeding discoveries for crop improvement over the years.
Genomic assisted breeding (GAB) assisted breeders in successfully identifying allelic variation in large number of plants including the orphan and wild species followed by successful characterization and integration in the breeding programs for the crop improvement. The importance and effectiveness of genomics can be gauged from the fact that the last few years have seen a tremendous increase in its use (Varshney et al., 2021; Figure 4). This technology has been used to create countless products that not only provide protection against the biotic and abiotic factors but have also been instrumental in improving quality traits. For example, rice products including “Improved Sambha Mashuri ISM,” “Pusa Basmati” “Pusa Basmati 1121,” “Pusa Basmati 6” against bacterial blight disease (Xanthomonas oryzae pv. oryzae), “Swarna” against abiotic stress including drought and salinity (Sundaram et al., 2008; Khanna et al., 2015; Ratna Madhavi et al., 2016); Wheat products “Overlay” and “Jagger” (Kuraparthy et al., 2009); In pearl millet, “HHB 67 improved” against downy mildew disease (Rai et al., 2008); Pulse product “Pusa 10216” having drought tolerant traits. “Farnum Somerse VR 1128” were developed in United States, Canada, and Australia respectively using GAB for “grain protein content” (Mitrofanova and Khakimova, 2017).
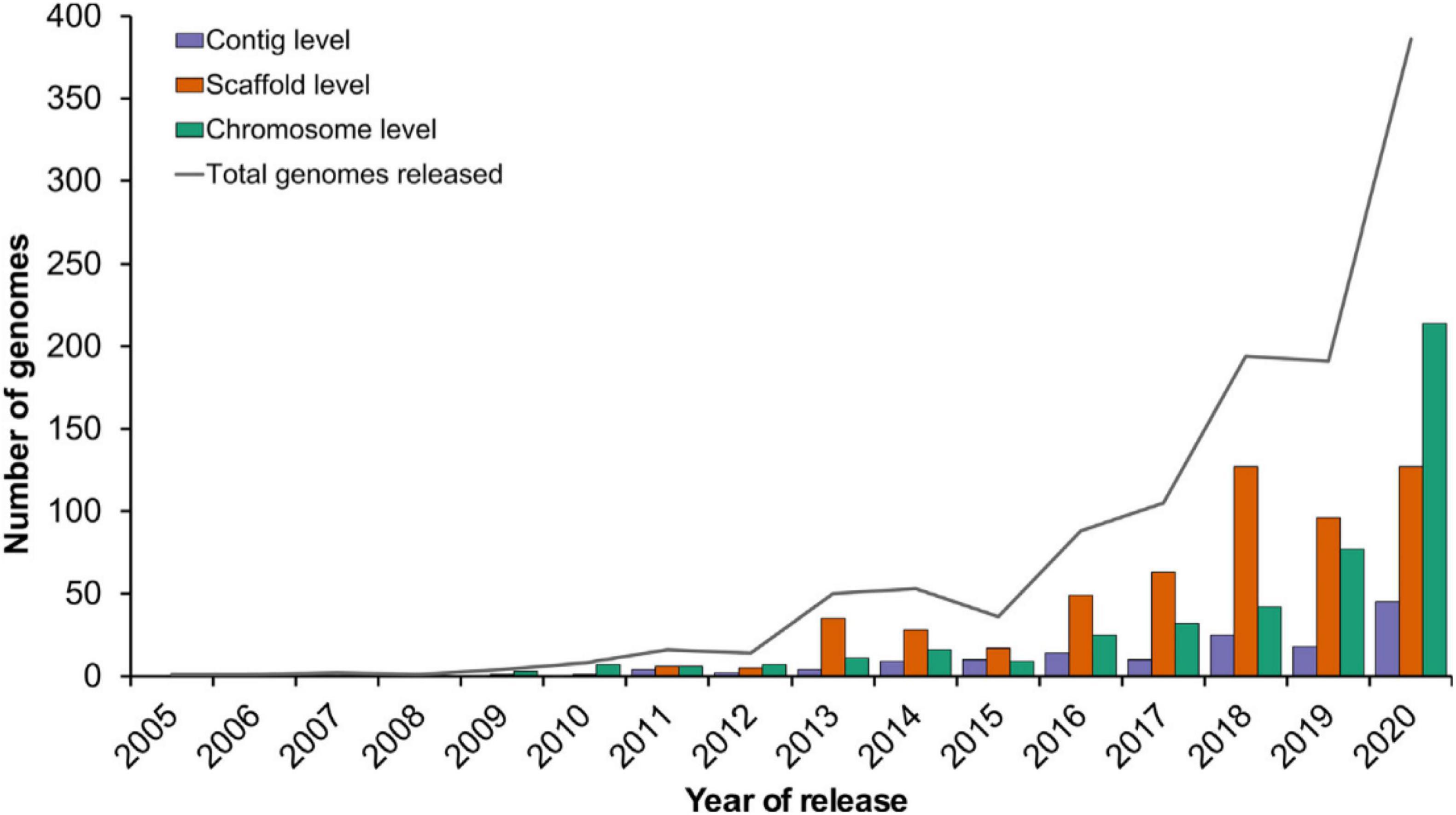
Figure 4. Recent trends in plant genome sequencing (Varshney et al., 2021).
Improving agronomic traits/quantitative traits is a difficult process because they are under control of multiple quantitative trait nucleotides (QTNs). Efficient breeding methods are required for the improvement of quantitative traits. With the advancement of genome sequencing and editing technologies the discovery and accumulation of these traits in a single genotype can now be done more easily. Due to multiple reason including climate change, insect pests resistance, a continuous surge in population, crop scientists/breeders may face serious challenges. Innovative technologies such as genome sequencing, pangenomes, genome engineering would be instrumental for the better understanding of genome structures and underlying trait architectures for precise improvement.
Haploid plants are produced naturally through parthenogenesis or elimination of the unstable genome from sperm. For the evolution of plants mixing of the genome is a key component during sexual reproduction for the success of breeding. Once the desirable genetic combination is obtained to retain this, embryos are allowed to develop from one parent followed by a doubling of chromosomes this phenomenon is called double haploid induction leads to the production of homozygous plant lines (Jacquier et al., 2020). Haploid induction in crops practically stops genetic combinations in embryos. So, when a certain genetic combination for a desirable trait is obtained it can be propagated in the next generations by producing homozygous plants. Haploid induction is done in this regard by crossing a haploid inducer line with a plant whose genetic combination is required. The genome sequence of the inducer line is not transferred to homozygous embryos. The double Haploid approach can be utilized for climate-resilient crop breeding. The induction of double haploidy in crops with favorable characters eases the passage of these characters to offspring because of the absence of dominant trait effects and new pleiotropic or gene epistasis (Prasanna et al., 2013). Various studies have been done on the incorporation of desirable genes and genetic combinations for the production of homozygous lines through the double haploid approach. In a recent study for the development of eyespot resistant lines, double haploid induction was utilized in wheat. Two wheat varieties that were highly resistant to eyespot due to the presence of the Pch1 gene were crossed with elite wheat genotypes. Wheat varieties were crossed with maize for haploid induction and treated with colchicine solution to double the chromosome number. A total of 604 haploid plants were developed from cross combinations while 458 double haploid lines were developed after chromosome doubling. Homozygous plants were analyzed for the presence of the Pch1 gene along with some markers associated with that gene. The eyespot resistance gene Pch1 was detected in 65 doubled haploid lines of winter wheat, in the second year of the study field trials also confirmed the incorporation of the gene (Wiśniewska et al., 2019). In another study, DH lines of winter barley developed through androgenesis showed enhanced tolerance to drought and cold stress than their parental genotypes. Also, the transcriptomic and proteomic study of these homozygous tolerant lines showed a better picture of ongoing indigenous molecular mechanisms. The genes which were not previously associated with the drought and cold stress were identified for their function. Based on this approach breeding for drought and cold resilient barley will be easy (Wójcik-Jagła et al., 2020). Double haploid lines also helped in mapping of QTLs better than heterozygous lines. While evaluation DH wheat lines against strip rust resistance seven new QTLs associated with APR genes were identified. APR genes are linked to pathogen identification and triggering immune response, identification of these associated QTLs can be helpful in determining better gene stacking (Tehseen et al., 2022). International Rice Research Institute developed rice DH line, AC-1 for the salinity tolerance that is commercialized in the Philippines and Bangladesh. Some other examples of DH rice with higher yield, commercialized in different countries are Dama (Hungry), Tanghuo 2, Tanfeng 1, Shanhua 7706 (China), Hirohikari, Kibinohana (Japan), Phalguni, Satyakrishna (India) (Samantaray et al., 2021). Also, in DH wheat lines under salinity stress QTL mapping was done and novel QTLs regarding potassium and sodium ions accumulation were detected. For the first time a novel shoot ion-independent tolerance QTL was also detected (Asif et al., 2018). In another study in Africa double haploid maize varieties were derived from commercially available hybrid maize varieties. The double haploid varieties showed remarkable improvement in yield and various other agronomically important traits. The DH hybrids also performed well under drought stress. One DH maize hybrid line showed 44.2% improved yield under drought stress and 23% improved yield under optimal water conditions as compared to best performing commercial hybrids. This superior performance of DH offspring can be marked with fixation and additive effects of favorable genes due to homozygosity of offspring (Sserumaga et al., 2018). The homozygosity in double haploid lines not only give a better picture about trait to gene function but it also enhances the action of desirable genes. Double Haploid approach along with the utilization of modern tools like speed breeding can be a key component for the development of better and sustainable agriculture.
Radical breakthroughs in high-throughput sequencing technology have unfolded new possibilities for studying genome diversity and evolution over the last two decades. Previously limited to a few reference genomes, modern technologies now allow for the analysis as well as sequencing of multiple genomes from closely related species. Undoubtedly, for many years, genomic studies were primarily based on the expensive and low-throughput Sanger sequencing, which limited large-scale population studies to a few markers and loci like simple sequence repeats (SSRs) (Zhang and Hewitt, 2003; Schmid et al., 2005). Researchers’ focus has shifted from single-genome analysis to multiple-genome analysis and population studies since the emergence of next-generation sequencing (NGS) technologies (Redon et al., 2006). As more genome sequence data become available, it becomes clear that the genomic information from a single plant species does not properly reflect the species’ diversity [4]. Since the publication of the first plant genome sequence (Kaul et al., 2000), comparative genomic studies have primarily concentrated on single nucleotide polymorphisms (SNPs) in various plant species (Zuckerkandl and Pauling, 1965; McNally et al., 2009; Lai et al., 2015). Plants have a dynamic genome as a result of various duplications for instance gene tandem duplications, rearrangement of genome, transposons activity, deletions, and recombination within populations (McClintock, 1956; Bennetzen, 2000; Yu et al., 2014; Chen et al., 2015; Gabur et al., 2019). While SNPs are frequently the focus of genomic diversity analysis, structural variation in the genome is increasingly being viewed as an essential element of genomic diversity (Zhao et al., 2018). Significant structural variations such as presence-absence variants (PAV) and copy number variants (CNV) are common in crops and play key roles in the genetic characterization of agronomical traits (Springer et al., 2009; Li et al., 2014; Lu et al., 2015).
A pan-genome is the whole set of genes found in a biological clade, as in a species. The pan-genome is further subdivided into the core genome and the variable genome (Tettelin et al., 2005). The core genome is a set of sequences or genes found in all organisms within a species, and it is the minimum genome that an individual requires for survival and basic functions (Segerman, 2012; Gordon et al., 2017; Wang et al., 2018) whereas the dispensable/variable genome is a set of dispensable genes that are either partially shared or unique to each individual (Tettelin et al., 2005). The dispensable genome, in particular, has been discovered to contain genes involved in crop growth and survival against a variety of biotic and abiotic environments such as phosphorus deficiency in rice (Gamuyao et al., 2012), head smut resistance in maize (Zuo et al., 2015), and temperature extremes (Tao et al., 2019). As a result, pangenome studies will aid in dissecting the genetics of these important agronomic traits for crop improvement (Zhao et al., 2018; Danilevicz et al., 2020).
To date, pangenomes in crop species have been generated using a variety of methodologies, such as a comparative de novo approach (Li et al., 2014; Schatz et al., 2014; Gordon et al., 2017; Zhao et al., 2018), an iterative assembly approach (Golicz et al., 2016b; Montenegro et al., 2017; Hurgobin et al., 2018), and the “map-to-pan” approach (Wang et al., 2018). In recent years, crop pangenomes for soybean (Li et al., 2014), maize (Hirsch et al., 2014), Brassica (Lin et al., 2014), and rice (Schatz et al., 2014) have been published. The trend toward crop pangenomes for molecular breeding instead of single sample reference genomes, will lessen sampling errors and allow for a better diversity representation (Golicz et al., 2016a). The dispensable genome of crops is found to be linked with agronomic traits, i.e., disease resistance, flowering time (Golicz et al., 2016a; Bayer et al., 2019), and environmental stress response (Hardigan et al., 2016; Hoopes et al., 2019). Graph-based pangenome was exploited to detect the missing heritability in different tomato accessions which helped it recovering 24% increase in the previously measured heritability, thus making graph-based pangenome as a suitable technique to elucidate heritability of complex traits in crop breeding (Zhou et al., 2022). CRISPR-Cas (Cong et al., 2013) technology has revolutionized plant breeding approaches by integrating them with genome editing (Scheben and Edwards, 2017, 2018; Scheben et al., 2017).
All in all, a better knowledge of the genetic diversity of the gene pool can enable trait dissection to pinpoint beneficial genetic mutations, allowing breeding programs to acquire a wide range of genetic resources to develop best breeding strategies, and eventually strengthening crop improvement to cultivate varieties with stable high yield under stressful conditions.
Recent technological advancements and high throughput techniques made it possible to have ample data on plant genotypes and phenotypes which demands an extra effort to obtain meaning from these measurements and incorporate different data sets. Concurrently, machine learning has advanced rapidly and is now extensively employed in plant genotyping as well as phenotyping (van Dijk et al., 2021). More importantly, genomics does not only involve the acquisition of molecular phenotypes, but also the use of effective data mining tools to predict and describe them (Wang H. et al., 2020). Machine learning, an evolving multidisciplinary field that proposes computational and analytical elucidation for the integrative analysis of heterogeneous, large, and unstructured datasets on a Big Data scale, is becoming an important tool in biology (Ma et al., 2014; Jordan and Mitchell, 2015). Machine Learning refers to a class of computerized modeling approaches that imitate patterns from the data and make automated decisions without programming explicit rules. The chief idea behind ML is to efficiently use experiences to find core structures, similarities and dissimilarities in data to describe or categorize a new experience accurately (Singh et al., 2016). Machine learning–based algorithms are effective enough to manage enormous data sets that display high amounts of noise, dimensionality, and/or incompleteness (Liu et al., 2020; Mahood et al., 2020).
Machine learning reads the algorithms that computers use to execute tasks by learning from data rather than trailing explicit instructions (Liu et al., 2020). There are three basic approaches: supervised learning, unsupervised learning, and semi-supervised learning. The most frequently used machine learning is supervised learning, in which each example in the data set is categorized (Liu et al., 2020). Its goal is to develop a model that maps its predictors (such as DNA sequences) to target variables (such as histone marks). Some examples of supervised learning applications are: prediction of regulatory and non-regulatory regions in the maize genome (Mejía-Guerra and Buckler, 2019), predicting level of mRNA expression (Washburn et al., 2019), sequence tagging in rice (Do et al., 2018), plant stress phenotyping, prediction of polyadenylation site in Arabidopsis (Gao et al., 2018), and prediction of macronutrient deficiencies in tomato (Tran et al., 2019). Whereas, unsupervised Machine learning is based on an algorithm that does not need tags, as in case of a clustering algorithm (Libbrecht and Noble, 2015). And a semi-supervised machine-learning approach needs labels but also uses unlabeled examples (Libbrecht and Noble, 2015). Furthermore, ML based digital image have been successfully employed for assessment of diseases in crop plants. Such examples include the detection of bacterial blight disease incidence in rice (Lu et al., 2017), maize (Dechant et al., 2017), soybean (Ghosal et al., 2018), and tomato (Prabhakar et al., 2020). Similarly, digital imaging with python based ML programs was employed to assess the mosaic, spots, brown streak, mites, and nutrient deficiency in cassava (Ramcharan et al., 2019). Hyperspectral imaging technique was utilized for the detection of yellow rust in wheat (Zhang et al., 2019) and potato Y virus in potato (Polder et al., 2019).
In reality, gene-finding systems are frequently trained by utilizing a semi-supervised approach with a set of annotated genes and an unlabeled whole-genome sequence as an input. The kind of algorithm chosen by data scientists relies upon what sort of data they desire to predict. Deep learning has been employed to solve complicated biological problems in metabolomics, genomics, proteomics, transcriptomics, and systems biology, among other areas of large-scale data analysis (Xu and Jackson, 2019). One of the chief advantages of employing ML methodologies by physiologists, plant breeders, biologists, and pathologists, is the capacity to search large datasets for patterns and govern discovery by simultaneously looking at a combination of factors rather than evaluating each feature individually. ML will accelerate the development of resilient crops by identifying crucial associations that regulate biological process (Esposito et al., 2019). Deep learning is being applied in genomics at DNA, RNA, and protein level. At the DNA level, research associated with the promoter, enhancer, non-coding DNA, methylation states, TSS position, replication, cis-regulatory, and interaction is possible through Deep learning. At the RNA level, deep learning has been utilized to explore alternative splicing, IncRNA, microRNA, messenger RNA, and expression. Deep learning also studies DNA binding proteins, transcription factors, RNA binding proteins, and generation of protein sequence at the protein level. A Generative Adversarial Network has also been used for clarifying biological queries at various molecular levels, as discussed in Liu et al. (2020). Machine learning can be used to gain new biological insights by predicting gene function and interactions among various cellular components (Mahood et al., 2020). ML provides well-defined benefits to analyze the complicated role of gene activity in response to environmental fluctuation and in determining plant phenotypes.
Several strategies have been introduced to identify essential genes for agronomically important characters, for example, utilizing gene functions (Bargsten et al., 2014), exploiting protein interactions (Liu et al., 2017), or employing gene annotation, and sequence variation (Lin et al., 2019). Furthermore, machine learning approaches will gain more popularity for predicting crop yield, high-throughput crop stress phenotyping, and assessment of the impact of climate change (Singh et al., 2016; Crane-Droesch, 2018; Esposito et al., 2019; Tong and Nikoloski, 2021).
In the present day, tackling total climate change, meeting human nutritional requirements, and ensuring adequate energy supplies remain resilient problems for humanity (Bevan and Waugh, 2007; Scheben et al., 2016; Hendre et al., 2019; Hunter et al., 2019). Plant breeding has always been important in human history, revolutionizing agriculture to feed the world’s continuously increasing population (Hill and Mackay, 2004). The key purpose of plant breeding is to create a genetically superior genotype that is suitable for both specific and general cultivation for increased production. In conventional breeding, farmers and crop breeders used to develop crop varieties by means of basic procedures, i.e., the presence of desired traits in plants for selection to propagate. Plant breeding evolved as an important approach for plant domestication and crop improvement around 10,000 years ago, utilizing the selection of desirable characteristics through a consistent selection process in many generations (Purugganan and Fuller, 2009).
However, crop production was inadequate to satisfy future demand, so a novel agricultural model is required, which includes cohesive systems of modern molecular breeding, various agronomic practices, and analysis of plant-microbiome interaction. As a result, climate-smart agriculture is getting prominence for developing climate-resilient crop varieties through the use of next-generation breeding strategies that can resist multidimensional stresses. And these climate-resilient crops are a crucial component concerning food and nutritional security.
Recognizing the significance of genomic resources in plant breeding programs, a massive amount of genetic data related to genes and QTLs (Quantitative Trait Loci) is obtained after the emergence of molecular biology and biotechnology (Wang and Pfeiffer, 2007). Genomics provides tools to tackle the challenges regarding food yield, quality and stability of production via advanced breeding techniques. Innovations in plant genomics enhance the knowledge of crop diversity at gene and species level, and an understanding of DNA markers for genetic improvement (Muthamilarasan et al., 2013, 2014).
These are some of the next-generation breeding tools that can be employed in marker-assisted selection to develop climate-resilient superior traits, combating problems of global food security.
The use of genomics tools to improve the efficacy of plant breeding is known as GAB (Varshney et al., 2005). The GAB strategies include Marker-Assisted Backcrossing (MABC); backcrossing for beneficial alleles within elite germplasm, Marker-Assisted Recurrent Selection (MARS), and Genomic Selection (GS) that are being used in breeding programs. MABC is the most commonly used technique for improving elite varieties by introducing a few loci or Major QTLs. GAB has accelerated breeding progress across a wide range of crop species over the last 15 years, developing more than 130 publicly bred cultivars of various crops (Vogel, 2014).
Genetic mapping and QTL analysis using bi-parental or Association Mapping (AM) populations have advanced the analysis of genetic control of agricultural traits, potentially permitting MAS, QTL, and AM studies, as well as direct calculation and GS of high value genotypes for breeding programs (Kole et al., 2015). NGS combined with GWAS improves mapping resolution for accurate gene/allele/QTL location (Liu et al., 2013; Varshney et al., 2014; Kole et al., 2015). Next-generation breeding can be driven by the integration of advanced genomic technologies such as NGS and comprehensive phenotyping (Varshney et al., 2005). Genomic selection (GS) is another powerful tool for facilitating the selection of superior genotypes, speeding up the breeding cycle, and lowering the budget of breeding line development (Crossa et al., 2017). Genome-Wide Association Studies explore marker-trait build upon the large nucleotide variation found in association mapping populations.
Plant breeding strategies can be revitalized by genome editing. Evidently, genome editing is creating new opportunities for accurate and faster crop modification to increase yields and guard them against diseases, pests, and abiotic stresses. The great promise of genome editing techniques is making crop breeding faster, more effective, and at a reduced cost. CRISPR genome-editing technology opens new opportunities to engineer disease resistance traits. CRISPR is expected to solve major crop improvement challenges through precise genome engineering and transgene-free applications. The introduction of next-generation CRISPR-associated (CRISPR/Cas) systems for example base editing, prime editing and de novo domestication, consumes the notion towards the potential of genome editing as repurposed for the improvement in crops.
Genome editing employs site-specific nucleases (SSNs) that are premeditated to bind and create a break in a particular nucleic acid site, generating double-stranded breaks (DSBs) at or close to the target site (Pickar-Oliver and Gersbach, 2019). The DNA DSBs are then repaired naturally either through homologous recombination (HR) or error-prone non-homologous end joining (NHEJ) (Miglani, 2017; Wright et al., 2018; Jun et al., 2019). These DSBs repair can be governed to obtain the ideal modifications in a sequence for instance insertions or deletions of large transgene arrays [160]. These SSNs have substantial plant breeding potential, as they present multidimensional approaches for modulating genome structure as well as function of host, such as targeted mutagenesis, gene knock-out, stacking, knock-in, and translation modulation. Browning-resistant mushrooms (Waltz, 2016b), high-amylopectin waxy corn (Zea mays) (Waltz, 2016a), and false flax (Camelina sativa) with enhanced omega-3 oil (Waltz, 2018) are recent examples of such products which were created utilizing CRISPR and authorized by the US Department of Agriculture (USDA) in quick time. As a result, CRISPR-Cas9 technology has been broadly utilized to create nutrition-improved as well as climate-resilient cereal crop cultivars (Xu et al., 2016; Shi et al., 2017; Kim et al., 2018; Razzaq et al., 2019; Raza et al., 2021). Potato is an important food crop in different countries of the world and faces challenges like drought, heat, nitrogen deficiency, bacterial diseases, insect pests, and their mediated viruses (Tiwari et al., 2022b). Solanum genus harboring genetic diversity has been explored through conventional potato breeding and can be further enriched with latest NGS based transcriptomics studies (Tiwari et al., 2020a,b,c) that would ultimately lead to the specific gene target identification for CRISPR-based genome editing (Tiwari et al., 2022a,c) providing new insights in crop improvement.
Crop pan genomics focuses on distinct genetic factors such as SNPs, mutations, and genes comprising structural variants (SVs) that govern crucial traits of interest within population. Crop pan-genome studies allow us to recover genes vanished in the reference genomes through the course of crop domestication. The accessibility of a crop’s pan-genome, which includes its CWRs, cultivated varieties and landraces, provides a well-defined scheme for collecting all information round the variations present at genotypic and phenotypic levels which allows the detection of missing, common and unique genes in the reference crop genomes (Danilevicz et al., 2020). The information of dispensable genome aids in selection of the elite crop cultivars against stresses possessing stress-responsive gene regulation (Bayer et al., 2019).
Crop improvement for food security relies upon the capability to detect advantageous agricultural traits in a timely and cost-effective manner. Traditional phenotyping techniques are expensive and time consuming, so the use of high-throughput plant phenotyping (HTTP) has increased in recent years. Machine learning is basically a budding application of Artificial Intelligence, which can be characterized as cutting-edge computer-based systems which enables the machine to learn automatically and enhance its potential without being rigorously computed (Singh et al., 2016). Genomic selection allows for rapid screening of elite germplasm and accelerates crop breeding cycles (Crossa et al., 2017). Presently, genomic selection relies on advances in machine learning tools and the recovering of huge genotyping data sets associated with agronomically important phenotypic characteristics (Tong and Nikoloski, 2021).
The most intriguing technology, called as speed breeding has captured the attention of the entire world. NASA prompted a scientist from the University of Queensland to grow wheat plants in space. Speed breeding is an effective tactic for reducing crop-generation time and accelerating breeding programs for crop improvement. Speed breeding has been a revolutionary technology in agriculture and could be used to speed up crop breeding tasks for example swift gene identification, crossing, mapping populations, backcrossing, and trait pyramiding (Bhatta et al., 2021). Off-season nursery/shuttle breeding, in vitro/embryo culture, and double haploid technology have all been used to decrease generational interval time in various crops. Speed breeding enables speedy generation advancement by manipulating the major parameters required by the plants including, temperature, day length, and light intensity, which leads to the reduction in generation time from 2.5 to 5 as compared to the normal greenhouse and field conditions. In case of barely, chickpea, canola, and wheat 2–3 generations are usually achieved in a controlled greenhouse, however, speed breeding allows you to achieve 4–6 crop generations within a year, providing a great opportunity to develop varieties in a short duration. Other crops where speed breeding has been successfully employed are rice, soybean, sorghum, millets, rapeseed, sugarcane, tomato, and potato which is encouraging to deal with challenging food security (Hickey et al., 2019).
Expanding population around the globe poses a great challenge to mankind by challenging food security issues. The major factor that is affecting the global food supply from field to product remains climate change. It throws multiple stresses on the crops including drought, salinity, pests, diseases, and other yield-related pressures. Furthermore, the inflation in food prices in recent years with the threatening economic upshot of the COVID-19 pandemic and the man-intended wars have led to disrupting the food supply chain and magnifying poverty, malnutrition, and hunger, entailing sustainable food security globally. In this scenario, Improved agriculture is the key to mitigating these concerns; therefore; biotechnology offers modern smart breeding tools for producing future smart crops. These tools have been successfully employed to run successful breeding programs; however; there is a dire need to utilize smart breeding approaches on underutilized, complex, and orphan food crops.
Crop wild relatives, already available germplasm, and landraces are potential candidates for the transfer of disease or stress-related gene pools to cultivated crops. Yield stagnancy and increased use of fertilizers in the crops might also be overcome by utilizing the CWRs, and germplasm available across the world. However, the identification of target trait genes and transferring them to cultivated crops could be very time-consuming if conventional breeding is employed alone, therefore latest gadgets of MAS, NGS, bioinformatics data processing, speed breeding, and high throughput phenomics will aid in accelerating this overall process. For instance, among cereals, Pearl millet is one of the resilient and hardiest crops that is cultivated in warm climatic regions of the world, thus has the features of climate resilience, adaptation to different ecological conditions, high nutritional value, better growth rate, and less utilization of fertilizers and irrigation. Therefore, millets can be crops of choice to transfer these beneficial attributes to other crop relatives. Moreover, the wild relatives of the millets are Pennisetum, which also has great potential to provide genetic diversity for millet and other cultivated cereals. With the advent of high throughput genomics and phenomics, now it would be possible to explore such genetic resources extensively and identify syntenic genes/QTLs in millets which can help in producing climate-smart crops to overcome food security challenges in the future.
High throughput phenomics-based smart agriculture enables the increased quantity and quality of crops with the help of artificial intelligence, machine learning algorithms, and remote sensing to explore and record the cultivation area in terms of salt, moisture levels, pH, soil quality, disease, pest or stress, and yield-related metadata. This could be very helpful in identifying the wild relatives or germplasm with target traits grown in large areas as well as for the precise selection of phenotypes among the crossed population. Genomic-assisted breeding combined with high throughput phenomics is the need of the hour for GS in less time. If a CWR or germplasm, is found harboring several good traits like disease resistance and well-adapted to hot weather, but its yield is stagnant or vice versa, then CRISPR offers the best opportunity to silence the unwanted genes in the crops.
Malnutrition is another challenge being faced by humanity, particularly in low-income countries where people are living below-standard life. Biofortified food crops could be the finest source of enriched Zn, Iron, nutrients, and vitamins. Efforts are underway to develop and commercialize biofortified wheat through breeding and it has been executed in a few countries. Nonetheless, breeding takes a long time so, as an alternative, genetically modified crops, called GMOs have been launched for crop improvement, which is not very much adored worldwide in the case of food crops because of the presence of foreign genes in plant DNA. One of the very famous illustrations is vitamin A-enriched golden rice produced in 1999 and remained under debate for two decades. It passed a rigorous process of risk assessment and got approval in the Philippines as safe rice in 2019. In this era, the new plant breeding technology tool CRISPR can aid in the deletion or insertion of the target gene for enhancing the nutritional value of staple food crops. However, the issues of complex regulatory processing, risk assessment, and public acceptance must timely be resolved, so that they could not hinder the timely crop availability to the farmers. Automated ML software and artificial intelligence programs with data analysis could potentially provide support in reducing the complicated and repeated risk assessments of the food crops.
Next-generation sequencing plays a crucial role to identify important genes and markers involved in a trait, for that, training of the manpower is very imperative because biological data is expanding extremely day by day. Likewise, the availability of pan-genomes of crops will aid in running improved breeding schemes, particularly in complex genome crops to elucidate the common or unique gene combinations for different traits. Nevertheless, all these technologies demand efficient computing machines and parallelization for keeping pace with growing data. The deployment of genome editing with speed breeding and phenomics can help in fast-track crop breeding. Overall, NGS-based multi-omics, genotyping techniques, genome editing, QTLome of the crop, SNP detection, plant-microbe engineering, epigenetic analysis, precision breeding, generation turnaround tools, and directed evolution are the innovative technologies as shown in Figure 5 will potentially keep helping us in designing future climate-smart food crops.
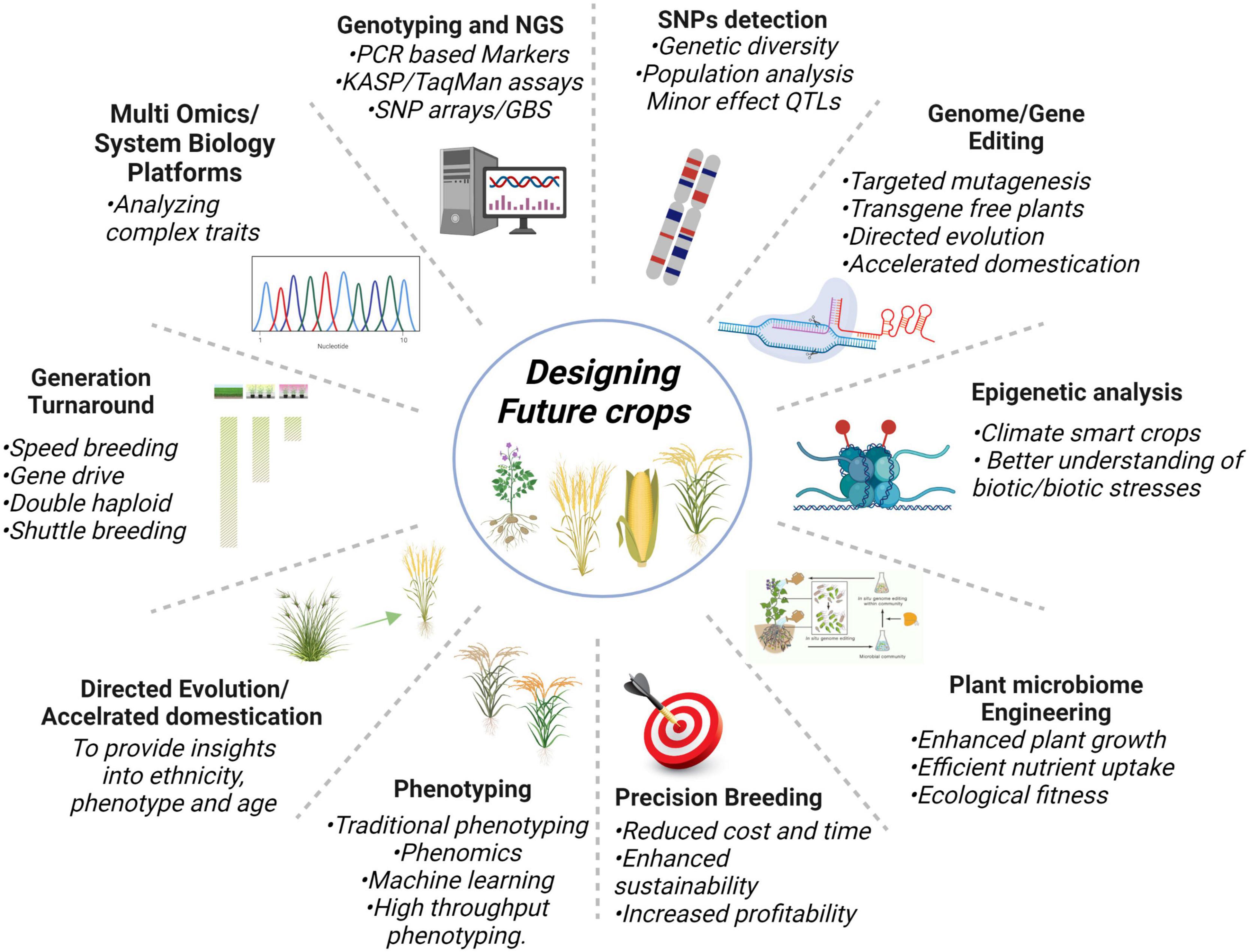
Figure 5. Cutting edge new plant breeding innovative technologies having the potential to turnaround the problems of food security.
MAs, SM, and RN conceived the idea. RN, HS, MM, SN, AE, and MAz wrote the first draft of this manuscript. HS and MM sketched the figures for this review. RN led the revisions and edits with the help of MF, IA, ZM, SA, MAs, and SM. All authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2022.972164/full#supplementary-material
Abberton, M., Batley, J., Bentley, A., Bryant, J., Cai, H., Cockram, J., et al. (2016). Global agricultural intensification during climate change: a role for genomics. Plant Biotechnol. J. 14, 1095–1098. doi: 10.1111/pbi.12467
Abbo, S., Van-Oss, R. P., Gopher, A., Saranga, Y., Ofner, I., and Peleg, Z. (2014). Plant domestication versus crop evolution: a conceptual framework for cereals and grain legumes. Trends Plant Sci. 19, 351–360. doi: 10.1016/j.tplants.2013.12.002
Araus, J. L., Kefauver, S. C., Zaman-Allah, M., Olsen, M. S., and Cairns, J. E. (2018). Translating high-throughput phenotyping into genetic gain. Trends Plant Sci. 23, 451–466. doi: 10.1016/j.tplants.2018.02.001
Asif, M. A., Schilling, R. K., Tilbrook, J., Brien, C., Dowling, K., Rabie, H., et al. (2018). Mapping of novel salt tolerance QTL in an Excalibur × Kukri doubled haploid wheat population. Theor. Appl. Genet. 131, 2179–2196. doi: 10.1007/s00122-018-3146-y
Balasooriya, H. N., Dassanayake, K. B., Seneweera, S., and Ajlouni, S. (2018). Interaction of elevated carbon dioxide and temperature on strawberry (Fragaria× ananassa) growth and fruit yield. Int. J. Biol. Biomol. Agric. Food Biotechnol. Eng. World Acad. Sci. Eng. Technol. Int. Sci. Index 12, 279–287.
Bargsten, J. W., Nap, J.-P., Sanchez-Perez, G. F., and Van Dijk, A. D. (2014). Prioritization of candidate genes in QTL regions based on associations between traits and biological processes. BMC Plant Biol. 14:330. doi: 10.1186/s12870-014-0330-3
Barnabás, B., Jäger, K., and Fehér, A. (2008). The effect of drought and heat stress on reproductive processes in cereals. Plant Cell Environ. 31, 11–38.
Bassi, F. M., Bentley, A. R., Charmet, G., Ortiz, R., and Crossa, J. (2016). Breeding schemes for the implementation of genomic selection in wheat (Triticum spp.). Plant Sci. 242, 23–36. doi: 10.1016/j.plantsci.2015.08.021
Bayer, P. E., Golicz, A. A., Tirnaz, S., Chan, C. K., Edwards, D., and Batley, J. (2019). Variation in abundance of predicted resistance genes in the Brassica oleracea pangenome. Plant Biotechnol. J. 17, 789–800. doi: 10.1111/pbi.13015
Bennetzen, J. L. (2000). Transposable element contributions to plant gene and genome evolution. Plant Mol. Biol. 42, 251–269. doi: 10.1023/A:1006344508454
Bevan, M., and Waugh, R. (2007). Applying plant genomics to crop improvement. Genome Biol. 8:302. doi: 10.1186/gb-2007-8-2-302
Bhatta, M., Sandro, P., Smith, M. R., Delaney, O., Voss-Fels, K. P., Gutierrez, L., et al. (2021). Need for speed: manipulating plant growth to accelerate breeding cycles. Curr. Opin. Plant Biol. 60:101986. doi: 10.1016/j.pbi.2020.101986
Bohra, A., Kilian, B., Sivasankar, S., Caccamo, M., Mba, C., Mccouch, S. R., et al. (2021). Reap the crop wild relatives for breeding future crops. Trends Biotechnol. 40, 412–431. doi: 10.1016/j.tibtech.2021.08.009
Chalhoub, B., Denoeud, F., Liu, S., Parkin, I. A., Tang, H., Wang, X., et al. (2014). Early allopolyploid evolution in the post-Neolithic Brassica napus oilseed genome. Science 345, 950–953. doi: 10.1126/science.1253435
Chen, J.-Y., Huang, J.-Q., Li, N.-Y., Ma, X.-F., Wang, J.-L., Liu, C., et al. (2015). Genome-wide analysis of the gene families of resistance gene analogues in cotton and their response to Verticillium wilt. BMC Plant Biol. 15:148. doi: 10.1186/s12870-015-0508-3
Cong, L., Ran, F. A., Cox, D., Lin, S., Barretto, R., Habib, N., et al. (2013). Multiplex genome engineering using Crispr/Cas systems. Science 339, 819–823. doi: 10.1126/science.1231143
Cooper, H. D., Spillane, C., and Hodgkin, T. (2001). Broadening the Genetic Base of Crop Production. Wallingford: Cabi. doi: 10.1079/9780851994116.0000
Crane-Droesch, A. (2018). Machine learning methods for crop yield prediction and climate change impact assessment in agriculture. Environ. Res. Lett. 13:114003. doi: 10.1088/1748-9326/aae159
Crossa, J., Pérez-Rodríguez, P., Cuevas, J., Montesinos-López, O., Jarquín, D., De Los Campos, G., et al. (2017). Genomic selection in plant breeding: methods, models, and perspectives. Trends Plant Sci. 22, 961–975. doi: 10.1016/j.tplants.2017.08.011
Danilevicz, M. F., Tay Fernandez, C. G., Marsh, J. I., Bayer, P. E., and Edwards, D. (2020). Plant pangenomics: approaches, applications and advancements. Curr. Opin. Plant Biol. 54, 18–25. doi: 10.1016/j.pbi.2019.12.005
Das, N. N. (2019). Relevance of poly-omics in system biology studies of industrial crops. Omics Based Approach. Plant Biotechnol. 167:167. doi: 10.1002/9781119509967.ch9
Dechant, C., Wiesner-Hanks, T., Chen, S., Stewart, E. L., Yosinski, J., Gore, M. A., et al. (2017). Automated identification of northern leaf blight-infected maize plants from field imagery using deep learning. Phytopathology 107, 1426–1432. doi: 10.1094/PHYTO-11-16-0417-R
Dempewolf, H., Baute, G., Anderson, J., Kilian, B., Smith, C., and Guarino, L. (2017). Past and future use of wild relatives in crop breeding. Crop Sci. 57, 1070–1082. doi: 10.2135/cropsci2016.10.0885
Do, H., Than, K., and Larmande, P. (2018). “Evaluating named-entity recognition approaches in plant molecular biology,” in Proceedings of the International Conference on Multi-disciplinary Trends in Artificial Intelligence, (Berlin: Springer), 219–225. doi: 10.1007/978-3-030-03014-8_19
Dong, J., Gruda, N., Lam, S. K., Li, X., and Duan, Z. (2018). Effects of elevated Co2 on nutritional quality of vegetables: a review. Front. plant Sci. 9:924. doi: 10.3389/fpls.2018.00924
Dreher, K., Morris, M., Khairallah, M., Ribaut, J.-M., Pandey, S., and Srinivasan, G. (2000). “Is marker-assisted selection cost-effective compared to conventional plant breeding methods? The case of quality protein maize,” in Proceedings of the 4th Annual Conference of the International Consortium on Agricultural Biotechnology Research (Icabr’00), Ravello, 203–236. doi: 10.1079/9780851996189.0203
Esposito, S., Carputo, D., Cardi, T., and Tripodi, P. (2019). Applications and trends of machine learning in genomics and phenomics for next-generation breeding. Plants 9:34. doi: 10.3390/plants9010034
Farrakh, S., Khalid, S., Rafique, A., Riaz, N., and Mujeeb-Kazi, A. (2016). Identification of stripe rust resistant genes in resistant synthetic hexaploid wheat accessions using linked markers. Plant Genetic Resour. 14, 219–225. doi: 10.1017/S1479262115000283
Gabur, I., Chawla, H. S., Snowdon, R. J., and Parkin, I. A. (2019). Connecting genome structural variation with complex traits in crop plants. Theor. Appl. Genet. 132, 733–750. doi: 10.1007/s00122-018-3233-0
Gamuyao, R., Chin, J. H., Pariasca-Tanaka, J., Pesaresi, P., Catausan, S., Dalid, C., et al. (2012). The protein kinase Pstol1 from traditional rice confers tolerance of phosphorus deficiency. Nature 488, 535–539. doi: 10.1038/nature11346
Gao, X., Zhang, J., Wei, Z., and Hakonarson, H. (2018). DeepPolyA: a convolutional neural network approach for polyadenylation site prediction. IEEE Access 6, 24340–24349. doi: 10.1109/ACCESS.2018.2825996
Ghosal, S., Blystone, D., Singh, A. K., Ganapathysubramanian, B., Singh, A., and Sarkar, S. (2018). An explainable deep machine vision framework for plant stress phenotyping. Proc. Natl. Acad. Sci. 115, 4613–4618. doi: 10.1073/pnas.1716999115
Ghosh, S., Watson, A., Gonzalez-Navarro, O. E., Ramirez-Gonzalez, R. H., Yanes, L., Mendoza-Suárez, M., et al. (2018). Speed breeding in growth chambers and glasshouses for crop breeding and model plant research. Nat. Protocols 13, 2944–2963. doi: 10.1038/s41596-018-0072-z
Golicz, A. A., Bayer, P. E., Barker, G. C., Edger, P. P., Kim, H., Martinez, P. A., et al. (2016b). The pangenome of an agronomically important crop plant Brassica oleracea. Nat. Commun. 7:13390. doi: 10.1038/ncomms13390
Golicz, A. A., Batley, J., and Edwards, D. (2016a). Towards plant pangenomics. Plant Biotechnol. J. 14, 1099–1105. doi: 10.1111/pbi.12499
Gordon, S. P., Contreras-Moreira, B., Woods, D. P., Des Marais, D. L., Burgess, D., Shu, S., et al. (2017). Extensive gene content variation in the Brachypodium distachyon pan-genome correlates with population structure. Nat. Commun. 8:2184. doi: 10.1038/s41467-017-02292-8
Gray, S. B., and Brady, S. M. (2016). Plant developmental responses to climate change. Dev. Biol. 419, 64–77. doi: 10.1016/j.ydbio.2016.07.023
Gupta, P., Kumar, J., Mir, R., and Kumar, A. (2010). 4 Marker-assisted selection as a component of conventional plant breeding. Plant Breed. Rev. 33:145. doi: 10.1002/9780470535486.ch4
Hardigan, M. A., Crisovan, E., Hamilton, J. P., Kim, J., Laimbeer, P., Leisner, C. P., et al. (2016). Genome reduction uncovers a large dispensable genome and adaptive role for copy number variation in asexually propagated Solanum tuberosum. Plant Cell 28, 388–405. doi: 10.1105/tpc.15.00538
Hendre, P. S., Muthemba, S., Kariba, R., Muchugi, A., Fu, Y., Chang, Y., et al. (2019). African Orphan Crops Consortium (Aocc): status of developing genomic resources for African orphan crops. Planta 250, 989–1003. doi: 10.1007/s00425-019-03156-9
Hickey, L. T., Hafeez, N., Robinson, H., Jackson, S. A., Leal-Bertioli, S., Tester, M., et al. (2019). Breeding crops to feed 10 billion. Nat. Biotechnol. 37, 744–754. doi: 10.1038/s41587-019-0152-9
Hill, W. G., and Mackay, T. F. C. (2004). D. S. Falconer and Introduction to quantitative genetics. Genetics 167, 1529–1536. doi: 10.1093/genetics/167.4.1529
Hirsch, C. N., Foerster, J. M., Johnson, J. M., Sekhon, R. S., Muttoni, G., Vaillancourt, B., et al. (2014). Insights into the maize pan-genome and pan-transcriptome. Plant Cell 26, 121–135. doi: 10.1105/tpc.113.119982
Hoopes, G. M., Hamilton, J. P., Wood, J. C., Esteban, E., Pasha, A., Vaillancourt, B., et al. (2019). An updated gene atlas for maize reveals organ-specific and stress-induced genes. Plant J. 97, 1154–1167. doi: 10.1111/tpj.14184
Hunter, D., Borelli, T., Beltrame, D. M. O., Oliveira, C. N. S., Coradin, L., Wasike, V. W., et al. (2019). The potential of neglected and underutilized species for improving diets and nutrition. Planta 250, 709–729. doi: 10.1007/s00425-019-03169-4
Hurgobin, B., Golicz, A. A., Bayer, P. E., Chan, C. K., Tirnaz, S., Dolatabadian, A., et al. (2018). Homoeologous exchange is a major cause of gene presence/absence variation in the amphidiploid Brassica napus. Plant Biotechnol. J. 16, 1265–1274. doi: 10.1111/pbi.12867
Iizumi, T., Shiogama, H., Imada, Y., Hanasaki, N., Takikawa, H., and Nishimori, M. (2018). Crop production losses associated with anthropogenic climate change for 1981–2010 compared with preindustrial levels. Int. J. Climatol. 38, 5405–5417. doi: 10.1002/joc.5818
Jacquier, N. M. A., Gilles, L. M., Pyott, D. E., Martinant, J.-P., Rogowsky, P. M., and Widiez, T. (2020). Puzzling out plant reproduction by haploid induction for innovations in plant breeding. Nat. Plants 6, 610–619. doi: 10.1038/s41477-020-0664-9
Jinek, M., Chylinski, K., Fonfara, I., Hauer, M., Doudna, J. A., and Charpentier, E. (2012). A programmable dual-RNA–guided DNA endonuclease in adaptive bacterial immunity. Science 337, 816–821. doi: 10.1126/science.1225829
Jordan, M. I., and Mitchell, T. M. (2015). Machine learning: trends, perspectives, and prospects. Science 349, 255–260. doi: 10.1126/science.aaa8415
Jun, R., Xixun, H., Kejian, W., and Chun, W. (2019). Development and application of CRISPR/Cas system in rice. Rice Sci. 26, 69–76. doi: 10.1016/j.rsci.2019.01.001
Kaiser, N., Douches, D., Dhingra, A., Glenn, K. C., Herzig, P. R., Stowe, E. C., et al. (2020). The role of conventional plant breeding in ensuring safe levels of naturally occurring toxins in food crops. Trends Food Sci. Technol. 100, 51–66. doi: 10.1016/j.tifs.2020.03.042
Kandemir, N., and Saygili, I. (2015). Apomixis: new horizons in plant breeding. Turk. J. Agric. For. 39, 549–556. doi: 10.3906/tar-1409-74
Kaul, S., Koo, H. L., Jenkins, J., Rizzo, M., Rooney, T., Tallon, L. J., et al. (2000). Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 408, 796–815. doi: 10.1038/35048692
Kersey, P. J. (2019). Plant genome sequences: past, present, future. Curr. Opin. Plant Biol. 48, 1–8. doi: 10.1016/j.pbi.2018.11.001
Khalid, M. N., Amjad, I., Nyain, M. V., Saleem, M. S., Asif, M., Ammar, A., et al. (2021). A review: tilling technique strategy for cereal crop development. Int. J. Appl. Chem. Biol. Sci. 2, 8–15.
Khan, S. U., Saeed, S., Khan, M. H. U., Fan, C., Ahmar, S., Arriagada, O., et al. (2021). Advances and challenges for QTL analysis and GWAS in the plant-breeding of high-yielding: a focus on rapeseed. Biomolecules 11:1516. doi: 10.3390/biom11101516
Khanna, A., Sharma, V., Ellur, R. K., Shikari, A. B., Gopala Krishnan, S., Singh, U., et al. (2015). Development and evaluation of near-isogenic lines for major blast resistance gene (s) in Basmati rice. Theor. Appl. Genet. 128, 1243–1259. doi: 10.1007/s00122-015-2502-4
Kilian, B., Martin, W., and Salamini, F. (2010). “Genetic diversity, evolution and domestication of wheat and barley in the Fertile Crescent” in Evolution in Action ed. M. Glaubrecht (Berlin:Springer), 137–166. doi: 10.1007/978-3-642-12425-9_8
Kim, D., Alptekin, B., and Budak, H. (2018). Crispr/Cas9 genome editing in wheat. Funct. Integr. Genomics 18, 31–41. doi: 10.1007/s10142-017-0572-x
Kole, C., Muthamilarasan, M., Henry, R., Edwards, D., Sharma, R., Abberton, M., et al. (2015). Application of genomics-assisted breeding for generation of climate resilient crops: progress and prospects. Front. Plant Sci. 6:563 doi: 10.3389/fpls.2015.00563
Kuraparthy, V., Sood, S., See, D. R., and Gill, B. S. (2009). Development of a Pcr assay and marker-assisted transfer of leaf rust and stripe rust resistance genes Lr57 and Yr40 into hard red winter wheats. Crop Sci. 49, 120–126. doi: 10.2135/cropsci2008.03.0143
Lai, K., Lorenc, M. T., Lee, H. C., Berkman, P. J., Bayer, P. E., Visendi, P., et al. (2015). Identification and characterization of more than 4 million intervarietal Snp s across the group 7 chromosomes of bread wheat. Plant Biotechnol. J. 13, 97–104. doi: 10.1111/pbi.12240
Li, H., Rasheed, A., Hickey, L. T., and He, Z. (2018). Fast-forwarding genetic gain. Trends Plant Sci. 23, 184–186. doi: 10.1016/j.tplants.2018.01.007
Li, Y. H., Zhou, G., Ma, J., Jiang, W., Jin, L. G., Zhang, Z., et al. (2014). De novo assembly of soybean wild relatives for pan-genome analysis of diversity and agronomic traits. Nat. Biotechnol. 32, 1045–1052. doi: 10.1038/nbt.2979
Liakos, K. G., Busato, P., Moshou, D., Pearson, S., and Bochtis, D. (2018). Machine learning in agriculture: a review. Sensors 18:2674. doi: 10.3390/s18082674
Libbrecht, M. W., and Noble, W. S. (2015). Machine learning applications in genetics and genomics. Nat. Rev. Genet. 16, 321–332. doi: 10.1038/nrg3920
Lin, F., Fan, J., and Rhee, S. Y. (2019). Qtg-Finder: a machine-learning based algorithm to prioritize causal genes of quantitative trait loci in Arabidopsis and rice. G3 9, 3129–3138. doi: 10.1534/g3.119.400319
Lin, K., Zhang, N., Severing, E. I., Nijveen, H., Cheng, F., Visser, R. G., et al. (2014). Beyond genomic variation–comparison and functional annotation of three Brassica rapa genomes: a turnip, a rapid cycling and a Chinese cabbage. BMC Genomics 15:250. doi: 10.1186/1471-2164-15-250
Liu, J., Li, J., Wang, H., and Yan, J. (2020). Application of deep learning in genomics. Sci. China Life Sci. 63, 1860–1878. doi: 10.1007/s11427-020-1804-5
Liu, S., Liu, Y., Zhao, J., Cai, S., Qian, H., Zuo, K., et al. (2017). A computational interactome for prioritizing genes associated with complex agronomic traits in rice (Oryza sativa). Plant J. 90, 177–188. doi: 10.1111/tpj.13475
Liu, S., Wang, X., Wang, H., Xin, H., Yang, X., Yan, J., et al. (2013). Genome-wide analysis of Zmdreb genes and their association with natural variation in drought tolerance at seedling stage of Zea mays L. PLoS Genet. 9:e1003790. doi: 10.1371/journal.pgen.1003790
Lu, F., Romay, M. C., Glaubitz, J. C., Bradbury, P. J., Elshire, R. J., Wang, T., et al. (2015). High-resolution genetic mapping of maize pan-genome sequence anchors. Nat. Commun. 6:6914. doi: 10.1038/ncomms7914
Lu, Y., Yi, S., Zeng, N., Liu, Y., and Zhang, Y. (2017). Identification of rice diseases using deep convolutional neural networks. Neurocomputing 267, 378–384. doi: 10.1016/j.neucom.2017.06.023
Ma, C., Xin, M., Feldmann, K. A., and Wang, X. (2014). Machine learning–based differential network analysis: a study of stress-responsive transcriptomes in Arabidopsis. Plant Cell 26, 520–537. doi: 10.1105/tpc.113.121913
Mahood, E. H., Kruse, L. H., and Moghe, G. D. (2020). Machine learning: a powerful tool for gene function prediction in plants. Appl. Plant Sci. 8:e11376. doi: 10.1002/aps3.11376
Malhi, G. S., Kaur, M., and Kaushik, P. (2021). Impact of climate change on agriculture and its mitigation strategies: a review. Sustainability 13:1318. doi: 10.3390/su13031318
Mayer, K., Waugh, R., Langridge, P., Close, T., Wise, R., Graner, A., et al. (2012). A physical, genetic and functional sequence assembly of the barley genome. Nature 491, 711–716. doi: 10.1038/nature11543
Mayer, K. F., Rogers, J., DoleŽel, J., Pozniak, C., Eversole, K., Feuillet, C., et al. (2014). A chromosome-based draft sequence of the hexaploid bread wheat (Triticum aestivum) genome. Science 345:1251788.
McClintock, B. (1956). Controlling Elements and the Gene. Cold Spring Harbor Symposia on Quantitative Biology. Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press, 197–216. doi: 10.1101/SQB.1956.021.01.017
McNally, K. L., Childs, K. L., Bohnert, R., Davidson, R. M., Zhao, K., Ulat, V. J., et al. (2009). Genomewide Snp variation reveals relationships among landraces and modern varieties of rice. Proc. Natl. Acad. Sci. 106, 12273–12278. doi: 10.1073/pnas.0900992106
Mejía-Guerra, M. K., and Buckler, E. S. (2019). A k-mer grammar analysis to uncover maize regulatory architecture. BMC Plant Biol. 19:103. doi: 10.1186/s12870-019-1693-2
Mendel, G. (1865). Experiments in plant hybridization. Verhandlungen des Naturforschenden Vereins Brünn IV, 3–47.
Miglani, G. S. (2017). Genome editing in crop improvement: present scenario and future prospects. J. Crop Improve. 31, 453–559. doi: 10.1080/15427528.2017.1333192
Mitrofanova, O., and Khakimova, A. (2017). New genetic resources in wheat breeding for increased grain protein content. Russ. J. Genet. 7, 477–487. doi: 10.1134/S2079059717040062
Montenegro, J. D., Golicz, A. A., Bayer, P. E., Hurgobin, B., Lee, H., Chan, C. K., et al. (2017). The pangenome of hexaploid bread wheat. Plant J. 90, 1007–1013. doi: 10.1111/tpj.13515
Moore, G. (2015). Strategic pre-breeding for wheat improvement. Nat. Plants 1, 1–3. doi: 10.1038/nplants.2015.18
Mosa, K. A., Ismail, A., and Helmy, M. (2017). “Omics and system biology approaches in plant stress research,” in Plant Stress Tolerance, ed. R. Sunkar (Cham: Springer). doi: 10.1007/978-3-319-59379-1
Murovec, J., Pirc, Ž, and Yang, B. (2017). New variants of CRISPR RNA-guided genome editing enzymes. Plant Biotechnol. J. 15, 917–926. doi: 10.1111/pbi.12736
Muth, J., Hartje, S., Twyman, R. M., Hofferbert, H. R., Tacke, E., and Prüfer, D. (2008). Precision breeding for novel starch variants in potato. Plant Biotechnol. J. 6, 576–584. doi: 10.1111/j.1467-7652.2008.00340.x
Muthamilarasan, M., Theriappan, P., and Prasad, M. (2013). Recent advances in crop genomics for ensuring food security. Curr. Sci. 104, 155–158.
Muthamilarasan, M., Venkata Suresh, B., Pandey, G., Kumari, K., Parida, S. K., and Prasad, M. (2014). Development of 5123 intron-length polymorphic markers for large-scale genotyping applications in foxtail millet. DNA Res. 21, 41–52. doi: 10.1093/dnares/dst039
Oladosu, Y., Rafii, M. Y., Samuel, C., Fatai, A., Magaji, U., Kareem, I., et al. (2019). Drought resistance in rice from conventional to molecular breeding: a review. Int. J. Mol. Sci. 20:3519. doi: 10.3390/ijms20143519
Parvin, S., Uddin, S., Tausz-Posch, S., Armstrong, R., Fitzgerald, G., and Tausz, M. (2019). Grain mineral quality of dryland legumes as affected by elevated Co2 and drought: a Face study on lentil (Lens culinaris) and faba bean (Vicia faba). Crop Past. Sci. 70, 244–253. doi: 10.1071/CP18421
Paterson, A. H., Bowers, J. E., Bruggmann, R., Dubchak, I., Grimwood, J., Gundlach, H., et al. (2009). The Sorghum bicolor genome and the diversification of grasses. Nature 457, 551–556. doi: 10.1038/nature07723
Pickar-Oliver, A., and Gersbach, C. A. (2019). The next generation of Crispr-Cas technologies and applications. Nat. Rev. Mol. Cell Biol. 20, 490–507. doi: 10.1038/s41580-019-0131-5
Polder, G., Blok, P. M., De Villiers, H. A., Van Der Wolf, J. M., and Kamp, J. (2019). Potato virus Y detection in seed potatoes using deep learning on hyperspectral images. Front. Plant Sci. 10:209. doi: 10.3389/fpls.2019.00209
Prabhakar, M., Purushothaman, R., and Awasthi, D. P. (2020). Deep learning based assessment of disease severity for early blight in tomato crop. Multimedia Tools Appl. 79, 28773–28784. doi: 10.1007/s11042-020-09461-w
Prasanna, B. M., Cairns, J., and Xu, Y. (2013). “Genomic tools and strategies for breeding climate resilient cereals,” in Genomics and Breeding for Climate-Resilient Crops: Concepts and Strategies, Vol. 1, ed. C. Kole (Berlin: Springer Berlin Heidelberg). doi: 10.1007/978-3-642-37045-8_5
Purugganan, M., and Fuller, D. (2009). The nature of selection during plant domestication. Nature 457, 843–848. doi: 10.1038/nature07895
Rai, K., Hash, C., Singh, A. K., and Velu, G. (2008). Adaptation and quality traits of a germplasm-derived commercial seed parent of pearl millet. Plant Genetic Resour. Newslett. 154, 20–24.
Ramcharan, A., Mccloskey, P., Baranowski, K., Mbilinyi, N., Mrisho, L., Ndalahwa, M., et al. (2019). A mobile-based deep learning model for cassava disease diagnosis. Front. Plant Sci. 10:272. doi: 10.3389/fpls.2019.00272
Ratna Madhavi, K., Rambabu, R., Abhilash Kumar, V., Vijay Kumar, S., Aruna, J., Ramesh, S., et al. (2016). Marker assisted introgression of blast (Pi-2 and Pi-54) genes in to the genetic background of elite, bacterial blight resistant indica rice variety, Improved Samba Mahsuri. Euphytica 212, 331–342. doi: 10.1007/s10681-016-1784-1
Ray, D. K., Mueller, N. D., West, P. C., and Foley, J. A. (2013). Yield trends are insufficient to double global crop production by 2050. PLoS One 8:e66428. doi: 10.1371/journal.pone.0066428
Raza, A., Tabassum, J., Kudapa, H., and Varshney, R. K. (2021). Can omics deliver temperature resilient ready-to-grow crops? Crit. Rev. Biotechnol. 41, 1209–1232. doi: 10.1080/07388551.2021.1898332
Razzaq, A., Saleem, F., Kanwal, M., Mustafa, G., Yousaf, S., Imran Arshad, H. M., et al. (2019). Modern trends in plant genome editing: an inclusive review of the CRISPR/Cas9 Toolbox. Int. J. Mol. Sci. 20:4045. doi: 10.3390/ijms20164045
Redon, R., Ishikawa, S., Fitch, K. R., Feuk, L., Perry, G. H., Andrews, T. D., et al. (2006). Global variation in copy number in the human genome. Nature 444, 444–454. doi: 10.1038/nature05329
Samantaray, S., Ali, J., Nicolas, K. L., Katara, J. L., Verma, R. L., Parameswaran, C., et al. (2021). “Doubled haploids in rice improvement: approaches, applications, and future prospects,” in Rice Improvement, eds J. Ali and S. H. Wani (Cham: Springer). doi: 10.1007/978-3-030-66530-2_12
Schatz, M. C., Maron, L. G., Stein, J. C., Hernandez Wences, A., Gurtowski, J., Biggers, E., et al. (2014). Whole genome de novo assemblies of three divergent strains of rice, Oryza sativa, document novel gene space of aus and indica. Genome Biol. 15:506. doi: 10.1186/PREACCEPT-2784872521277375
Scheben, A., and Edwards, D. (2017). Genome editors take on crops. Science 355, 1122–1123. doi: 10.1126/science.aal4680
Scheben, A., and Edwards, D. (2018). Bottlenecks for genome-edited crops on the road from lab to farm. Genome Biol. 19:178. doi: 10.1186/s13059-018-1555-5
Scheben, A., Wolter, F., Batley, J., Puchta, H., and Edwards, D. (2017). Towards CRISPR/Cas crops - bringing together genomics and genome editing. New Phytol. 216, 682–698. doi: 10.1111/nph.14702
Scheben, A., Yuan, Y., and Edwards, D. (2016). Advances in genomics for adapting crops to climate change. Curr. Plant Biol. 6, 2–10. doi: 10.1016/j.cpb.2016.09.001
Schmid, K. J., Ramos-Onsins, S., Ringys-Beckstein, H., Weisshaar, B., and Mitchell-Olds, T. (2005). A multilocus sequence survey in Arabidopsis thaliana reveals a genome-wide departure from a neutral model of DNA sequence polymorphism. Genetics 169, 1601–1615. doi: 10.1534/genetics.104.033795
Schmutz, J., Cannon, S. B., Schlueter, J., Ma, J., Mitros, T., Nelson, W., et al. (2010). Genome sequence of the palaeopolyploid soybean. Nature 463, 178–183. doi: 10.1038/nature08670
Segerman, B. (2012). The genetic integrity of bacterial species: the core genome and the accessory genome, two different stories. Front. Cell Infect. Microbiol. 2:116. doi: 10.3389/fcimb.2012.00116
Sharma, S., Sharma, R., Govindaraj, M., Mahala, R. S., Satyavathi, C. T., Srivastava, R. K., et al. (2021). Harnessing wild relatives of pearl millet for germplasm enhancement: challenges and opportunities. Crop Sci. 61, 177–200. doi: 10.1002/csc2.20343
Shi, J., Gao, H., Wang, H., Lafitte, H. R., Archibald, R. L., Yang, M., et al. (2017). Argos8 variants generated by CRISPR-Cas9 improve maize grain yield under field drought stress conditions. Plant Biotechnol. J. 15, 207–216. doi: 10.1111/pbi.12603
Singh, A., Ganapathysubramanian, B., Singh, A. K., and Sarkar, S. (2016). Machine learning for high-throughput stress phenotyping in plants. Trends Plant Sci. 21, 110–124. doi: 10.1016/j.tplants.2015.10.015
Singh, R., Govindan, V., and Andersson, M. S. (2017). Zinc-Biofortified Wheat: Harnessing Genetic Diversity for Improved Nutritional Quality. Bonn: The Global Crop Diversity Trust.
Springer, N. M., Ying, K., Fu, Y., Ji, T., Yeh, C.-T., Jia, Y., et al. (2009). Maize inbreds exhibit high levels of copy number variation (CNV) and presence/absence variation (PAV) in genome content. PLoS Genet. 5:e1000734. doi: 10.1371/journal.pgen.1000734
Sserumaga, J. P., Beyene, Y., Pillay, K., Kullaya, A., Oikeh, S. O., Mugo, S., et al. (2018). Grain-yield stability among tropical maize hybrids derived from doubled-haploid inbred lines under random drought stress and optimum moisture conditions. Crop Past. Sci. 69, 691–702. doi: 10.1071/CP17348
Stadler, L. J. (1928). Genetic effects of X-rays in maize. Proc. Natl. Acad. Sci. 14, 69–75. doi: 10.1073/pnas.14.1.69
Stetter, M. G., Zeitler, L., Steinhaus, A., Kroener, K., Biljecki, M., and Schmid, K. J. (2016). Crossing methods and cultivation conditions for rapid production of segregating populations in three grain amaranth species. Front. Plant Sci. 7:816. doi: 10.3389/fpls.2016.00816
Sundaram, R. M., Vishnupriya, M. R., Biradar, S. K., Laha, G. S., Reddy, G. A., Rani, N. S., et al. (2008). Marker assisted introgression of bacterial blight resistance in Samba Mahsuri, an elite indica rice variety. Euphytica 160, 411–422. doi: 10.1007/s10681-007-9564-6
Tao, Y., Zhao, X., Mace, E., Henry, R., and Jordan, D. (2019). Exploring and exploiting pan-genomics for crop improvement. Mol. Plant 12, 156–169. doi: 10.1016/j.molp.2018.12.016
Tehseen, M., Tonk, F., Tosun, M., Randhawa, H., Kurtulus, E., Ozseven, I., et al. (2022). Qtl mapping of adult plant resistance to stripe rust in a doubled haploid wheat population. Front. Genet. 13:900558. doi: 10.3389/fgene.2022.900558
Tettelin, H., Masignani, V., Cieslewicz, M. J., Donati, C., Medini, D., Ward, N. L., et al. (2005). Genome analysis of multiple pathogenic isolates of Streptococcus agalactiae: implications for the microbial “pan-genome”. Proc. Natl. Acad. Sci. U. S. A. 102, 13950–13955. doi: 10.1073/pnas.0506758102
Thormann, I., Endresen, D., Rubio-Teso, M., Iriondo, M., Maxted, N., and Parra-Quijano, M. (2014). Predictive Characterization of Crop Wild Relatives and Landraces: Technical Guidelines Version 1. Roma: Bioversity International.
Tiwari, J. K., Buckseth, T., Zinta, R., Bhatia, N., Dalamu, D., Naik, S., et al. (2022b). Germplasm, breeding, and genomics in potato improvement of biotic and abiotic stresses tolerance. Front. Plant Sci. 13:805671. doi: 10.3389/fpls.2022.805671
Tiwari, J. K., Buckseth, T., Challam, C., Zinta, R., Bhatia, N., Dalamu, D., et al. (2022a). CRISPR/Cas genome editing in potato: current status and future perspectives. Front. Genetics 13:827808. doi: 10.3389/fgene.2022.827808
Tiwari, J. K., Tuteja, N., and Khurana, S. (2022c). Genome editing (Crispr-Cas)-mediated virus resistance in potato (Solanum tuberosum L.). Mol. Biol. Rep. [Online ahead of print]. doi: 10.1007/s11033-022-07704-7
Tiwari, J. K., Buckseth, T., Singh, R. K., Kumar, M., and Kant, S. (2020a). Prospects of improving nitrogen use efficiency in potato: lessons from transgenics to genome editing strategies in plants. Front. Plant Sci. 11:597481. doi: 10.3389/fpls.2020.597481
Tiwari, J. K., Buckseth, T., Zinta, R., Saraswati, A., Singh, R. K., Rawat, S., et al. (2020b). Genome-wide identification and characterization of micrornas by small RNA sequencing for low nitrogen stress in potato. PLoS One 15:e0233076. doi: 10.1371/journal.pone.0233076
Tiwari, J. K., Buckseth, T., Zinta, R., Saraswati, A., Singh, R. K., Rawat, S., et al. (2020c). Transcriptome analysis of potato shoots, roots and stolons under nitrogen stress. Sci. Rep. 10, 1–18. doi: 10.1038/s41598-020-58167-4
Tong, H., and Nikoloski, Z. (2021). Machine learning approaches for crop improvement: leveraging phenotypic and genotypic big data. J. Plant Physiol. 257:153354. doi: 10.1016/j.jplph.2020.153354
Tran, T.-T., Choi, J.-W., Le, T.-T. H., and Kim, J.-W. (2019). A comparative study of deep CNN in forecasting and classifying the macronutrient deficiencies on development of tomato plant. Appl. Sci. 9:1601. doi: 10.3390/app9081601
Tyack, N., Dempewolf, H., and Khoury, C. K. (2020). The potential of payment for ecosystem services for crop wild relative conservation. Plants 9:1305. doi: 10.3390/plants9101305
Van Bueren, E. L., Jones, S. S., Tamm, L., Murphy, K. M., Myers, J. R., Leifert, C., et al. (2011). The need to breed crop varieties suitable for organic farming, using wheat, tomato and broccoli as examples: a review. Njas Wageningen J. Life Sci. 58, 193–205. doi: 10.1016/j.njas.2010.04.001
van Dijk, A. D. J., Kootstra, G., Kruijer, W., and De Ridder, D. (2021). Machine learning in plant science and plant breeding. Iscience 24:101890. doi: 10.1016/j.isci.2020.101890
Varshney, R. K., Bohra, A., Yu, J., Graner, A., Zhang, Q., and Sorrells, M. E. (2021). Designing future crops: genomics-assisted breeding comes of age. Trends Plant Sci. 26, 631–649. doi: 10.1016/j.tplants.2021.03.010
Varshney, R. K., Graner, A., and Sorrells, M. E. (2005). Genomics-assisted breeding for crop improvement. Trends Plant Sci. 10, 621–630. doi: 10.1016/j.tplants.2005.10.004
Varshney, R. K., Terauchi, R., and Mccouch, S. R. (2014). Harvesting the promising fruits of genomics: applying genome sequencing technologies to crop breeding. PLoS Biol. 12:e1001883. doi: 10.1371/journal.pbio.1001883
Vogel, B. (2014). “Marker assisted selection: a biotechnology for plant breeding without genetic engineering,” in Smart breeding: The next generation, Vol. 8, Ed. J. Cotter (Amsterdam: Greenpeace International), 59.
Voss-Fels, K. P., Stahl, A., and Hickey, L. T. (2019). Q&A: modern crop breeding for future food security. BMC Biol. 17:18. doi: 10.1186/s12915-019-0638-4
Waltz, E. (2016b). Gene-edited CRISPR mushroom escapes US regulation. Nature 532:293. doi: 10.1038/nature.2016.19754
Waltz, E. (2016a). CRISPR-edited crops free to enter market, skip regulation. Nat. Biotechnol. 34:582. doi: 10.1038/nbt0616-582
Waltz, E. (2018). With a free pass, CRISPR-edited plants reach market in record time. Nat. Biotechnol. 36, 6–7. doi: 10.1038/nbt0118-6b
Wang, C., Hu, S., Gardner, C., and Lübberstedt, T. (2017). Emerging avenues for utilization of exotic germplasm. Trends Plant Sci. 22, 624–637. doi: 10.1016/j.tplants.2017.04.002
Wang, H., Cimen, E., Singh, N., and Buckler, E. (2020). Deep learning for plant genomics and crop improvement. Curr. Opin. Plant Biol. 54, 34–41. doi: 10.1016/j.pbi.2019.12.010
Wang, S., Zhang, Y., Ju, W., Chen, J. M., Ciais, P., Cescatti, A., et al. (2020). Recent global decline of Co2 fertilization effects on vegetation photosynthesis. Science 370, 1295–1300. doi: 10.1126/science.abb7772
Wang, J.-K., and Pfeiffer, W. (2007). Simulation modeling in plant breeding: principles and applications. Agric. Sci. China 6, 908–921. doi: 10.1016/S1671-2927(07)60129-1
Wang, W., Mauleon, R., Hu, Z., Chebotarov, D., Tai, S., Wu, Z., et al. (2018). Genomic variation in 3,010 diverse accessions of Asian cultivated rice. Nature 557, 43–49. doi: 10.1038/s41586-018-0063-9
Wang, Z., and Huang, B. (2004). Physiological recovery of Kentucky bluegrass from simultaneous drought and heat stress. Crop Sci. 44, 1729–1736. doi: 10.2135/cropsci2004.1729
Warschefsky, E., Penmetsa, R. V., Cook, D. R., and Von Wettberg, E. J. (2014). Back to the wilds: tapping evolutionary adaptations for resilient crops through systematic hybridization with crop wild relatives. Am. J. Bot. 101, 1791–1800. doi: 10.3732/ajb.1400116
Washburn, J. D., Mejia-Guerra, M. K., Ramstein, G., Kremling, K. A., Valluru, R., Buckler, E. S., et al. (2019). Evolutionarily informed deep learning methods for predicting relative transcript abundance from DNA sequence. Proc. Natl. Acad. Sci. 116, 5542–5549. doi: 10.1073/pnas.1814551116
Watson, A., Ghosh, S., Williams, M. J., Cuddy, W. S., Simmonds, J., Rey, M.-D., et al. (2018). Speed breeding is a powerful tool to accelerate crop research and breeding. Nat. Plants 4, 23–29. doi: 10.1038/s41477-017-0083-8
Welsh, J., and McClelland, M. (1990). Fingerprinting enomes using Pcr with arbitrary primers. Nucleic Acids Res. 18, 7213–7218. doi: 10.1093/nar/18.24.7213
Wiśniewska, H., Majka, M., Kwiatek, M., Gawłowska, M., Surma, M., Adamski, T., et al. (2019). Production of wheat-doubled haploids resistant to eyespot supported by marker-assisted selection. Electron. J. Biotechnol. 37, 11–17. doi: 10.1016/j.ejbt.2018.10.003
Wójcik-Jagła, M., Rapacz, M., Dubas, E., Krzewska, M., Kopeć, P., Nowicka, A., et al. (2020). Candidate genes for freezing and drought tolerance selected on the basis of proteome analysis in doubled haploid lines of barley. Int. J. Mol. Sci. 21:2062. doi: 10.3390/ijms21062062
Wright, W. D., Shah, S. S., and Heyer, W. D. (2018). Homologous recombination and the repair of DNA double-strand breaks. J. Biol. Chem. 293, 10524–10535. doi: 10.1074/jbc.TM118.000372
Xu, C., and Jackson, S. A. (2019). Machine Learning and Complex Biological Data. Berlin: Springer. doi: 10.1186/s13059-019-1689-0
Xu, R., Yang, Y., Qin, R., Li, H., Qiu, C., Li, L., et al. (2016). Rapid improvement of grain weight via highly efficient CRISPR/Cas9-mediated multiplex genome editing in rice. J. Genet. Genomics 43, 529–532. doi: 10.1016/j.jgg.2016.07.003
Xu, X., Cheng, S., Zhang, B., Mu, D., Ni, P., Zhang, G., et al. (2011). Genome sequence and analysis of the tuber crop potato. Nature 475, 189–195. doi: 10.1038/nature10158
Yu, J., Tehrim, S., Zhang, F., Tong, C., Huang, J., Cheng, X., et al. (2014). Genome-wide comparative analysis of NBS-encoding genes between Brassica species and Arabidopsis thaliana. BMC Genomics 15:292. doi: 10.1186/s12864-017-3682-x
Zamir, D. (2001). Improving plant breeding with exotic genetic libraries. Nat. Rev. Genet. 2, 983–989. doi: 10.1038/35103590
Zhang, D. X., and Hewitt, G. M. (2003). Nuclear DNA analyses in genetic studies of populations: practice, problems and prospects. Mol. Ecol. 12, 563–584. doi: 10.1046/j.1365-294X.2003.01773.x
Zhang, X., Han, L., Dong, Y., Shi, Y., Huang, W., Han, L., et al. (2019). A deep learning-based approach for automated yellow rust disease detection from high-resolution hyperspectral Uav images. Remote Sensing 11:1554. doi: 10.3390/rs11131554
Zhao, Q., Feng, Q., Lu, H., Li, Y., Wang, A., Tian, Q., et al. (2018). Pan-genome analysis highlights the extent of genomic variation in cultivated and wild rice. Nat. Genet. 50, 278–284. doi: 10.1038/s41588-018-0041-z
Zhou, Y., Zhang, Z., Bao, Z., Li, H., Lyu, Y., Zan, Y., et al. (2022). Graph pangenome captures missing heritability and empowers tomato breeding. Nature 606, 527–534. doi: 10.1038/s41586-022-04808-9
Zuckerkandl, E., and Pauling, L. (1965). “Evolutionary divergence and convergence in proteins,” in Evolving Genes and Proteins, eds V. Bryson and H. J. Voge (Amsterdam: Elsevier). doi: 10.1016/B978-1-4832-2734-4.50017-6
Keywords: climate change, agriculture, genomics, breeding, food crops
Citation: Naqvi RZ, Siddiqui HA, Mahmood MA, Najeebullah S, Ehsan A, Azhar M, Farooq M, Amin I, Asad S, Mukhtar Z, Mansoor S and Asif M (2022) Smart breeding approaches in post-genomics era for developing climate-resilient food crops. Front. Plant Sci. 13:972164. doi: 10.3389/fpls.2022.972164
Received: 17 June 2022; Accepted: 15 August 2022;
Published: 16 September 2022.
Edited by:
Ting Peng, Henan Agricultural University, ChinaReviewed by:
Prashant Vikram, Shriram Bioseed Genetics, IndiaCopyright © 2022 Naqvi, Siddiqui, Mahmood, Najeebullah, Ehsan, Azhar, Farooq, Amin, Asad, Mukhtar, Mansoor and Asif. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Muhammad Asif, YXNpZi5iaW9zYWZldHlAZ21haWwuY29t
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.