 Xiaolong Li1
Xiaolong Li1 Fei Liu
Fei Liu- 1College of Biosystems Engineering and Food Science, Zhejiang University, Hangzhou, China
- 2Huanan Industrial Technology Research Institute of Zhejiang University, Guangzhou, China
Soybean seed purity is a critical factor in agricultural products, standardization of seed quality, and food processing. In this study, laser-induced breakdown spectroscopy (LIBS) as an effective technology was successfully used to identify ten varieties of soybean seeds. We improved the traditional sample preparation scheme for LIBS. Instead of grinding and squashing, we propose a time-efficient method by pressing soybean seeds into rubber sand filled with culture plates through a ruler to ensure a relatively uniform surface height. In our experimental scheme, three LIBS spectra were finally collected for each soybean seed. A majority vote based on three spectra was applied as the final decision judging the attribution of a single soybean seed. The results showed that the support vector machine (SVM) obtained the optimal identification accuracy of 90% in the prediction set. In addition, PCA-ResNet (propagation coefficient adaptive ResNet) and PCSA-ResNet (propagation coefficient synchronous adaptive ResNet) were designed based on typical ResNet structure by changing the way of self-adaption of propagation coefficients. Combined with a new form of input data called spectral matrix, PCSA-ResNet obtained the optimal performance with the discriminate accuracy of 91.75% in the prediction set. T-distributed stochastic neighbor embedding (t-SNE) was used to visualize the clustering process of the extracted features by PCSA-ResNet. For the interpretation of the good performance of PCSA-ResNet coupled with the spectral matrix, saliency maps were further applied to visually show the pixel positions of the spectral matrix that had a significant influence on the discrimination results, indicating that the content and proportion of elements in soybean seeds could reflect the variety differences.
Introduction
Soybean is one of the most important agricultural products, which has abundant vegetable protein and oil. The yield and quality of soybeans are directly related to their variety with different genetic purity, physical purity, germination ability, and vigor (John et al., 2016; Mccarville et al., 2017; Zhu et al., 2019a). Mixed and adulterated soybean seeds cause substantial problems for farmers and lead to seed market complexities (Liu et al., 2016). With the increasing requirements for food quality, it is necessary to process different products according to different seed varieties. For instance, the soymilk and tofu made from high-protein soybeans are more delicious (Sato et al., 2014; Yu et al., 2014). Therefore, rapid identification of soybean seed varieties plays an essential role in agricultural products, standardization of seed quality, and food processing. It becomes more and more crucial to build a general discriminant model for distinguishing different soybean seed varieties with large amounts but little difference (Luo et al., 2019).
DNA analysis and protein-based technologies are regarded as powerful tools for specific and precise identification of soybean seed varieties, such as polymerase chain reaction (PCR) (Grohmann et al., 2017), high-performance liquid chromatography (HPLC) (Cho et al., 2013; Kim et al., 2013) and simple sequence repeat (SSR) analysis (Zhang et al., 2014). These genetic methods often require environmentally unfriendly chemical agents to show results. By comparison, the spectroscopy technique does not need any chemical agent and causes minor damage to samples. Therefore, the spectroscopy technique can be an alternative as a non-genetic method to achieve fast genotype discrimination.
Laser-induced breakdown spectroscopy (LIBS) is an atomic emission spectroscopy technique which is characteristically fast, micro-damaging, and with simple sample pretreatment (Erler et al., 2020). In a typical LIBS system, a high-energy pulsed laser is transmitted nearly to the surface of the sample. After that, the plasma is created with the vaporization and excitation of the sample (Li et al., 2019). The emitted spectra from the plasma are collected for multi-element analysis (Liu et al., 2019; Wang et al., 2020). So far, LIBS technology has been widely used in qualitative and quantitative analysis in agricultural products such as rice (Luo et al., 2020), psoralea corylifolia seeds (Dhar et al., 2013), cucurbit seeds (Singh et al., 2017), coffee beans (Song et al., 2017), soybean seeds (Gamela et al., 2020; Larios et al., 2020), and grape seeds (He et al., 2020). However, the samples above were grounded and pressed into tablets before collecting LIBS spectra for better signals, which greatly reduced the detection efficiency. This study proposed an innovative method of pressing soybean seeds into a culture plate filled with rubber sand, with a ruler used to ensure a relatively uniform surface in height. Then the soybean seeds could be directly shot by laser beam without any specific pretreatments, markedly reducing the time cost. The LIBS spectra of 2,000 soybeans contributed to establishing a discriminant model with improved generalization due to extensive data.
Much attention has been paid to the traditional machine learning algorithms for modeling LIBS data but little to deep learning and its interpretation (Zhao et al., 2019). For example, support vector machine (SVM) is a commonly used algorithm in machine learning (Liakos et al., 2018). SVM is intrinsically a binary classifier that constructs a linear separating hyperplane to classify data instances (Vapnik and Chapelle, 2000). On account of kernel trick and structural risk minimization principles, SVM usually presents a better performance in classification and regression (Hesami et al., 2020). It has been applied in various fields in agriculture (Ang and Seng, 2021), such as plant breeding (Yoosefzadeh-Najafabadi et al., 2021), pest detection (Ebrahimi et al., 2017), and soil condition prediction (Morellos et al., 2016). However, SVM usually takes a long time to search for optimal parameters. What is more, for multiclass classification, SVM may have a lower classification accuracy than artificial neural network (ANN) (Xia et al., 2018). Therefore, it is necessary to use advanced methods like deep learning. Convolutional neural network (CNN) is one kind of deep learning, which is often used for image and speech recognition. CNN can also be used for spectral data processing (Yan et al., 2021). Compared to ANN, CNN is more likely to reduce the risk of overfitting by sharing the same convolution parameters. Moreover, CNN can identify important spectra regions by applying the same convolutional kernel in a spectrum (Acquarelli et al., 2017). A saliency map is a powerful tool to show the important regions visually (Peruzzi et al., 2021). As we all know, CNN is particularly suitable for image data processing relying on the two-dimensional and self-adaptive characteristics of the convolution kernel. Therefore, we proposed a new form of input data by connecting three spectra of a soybean seed into a spectral matrix. Because of the self-adaptive characteristic of convolution kernel, we expect CNN to learn the important features of the spectral matrix and further improve the modeling effect. At the same time, we can use t-distributed stochastic neighbor embedding (t-SNE) (van der Maaten and Hinton, 2008) to display the learning effect for different layers in CNN. Thus, the main objectives of this study are: (1) to compare identification accuracy between machine learning and deep learning; (2) to use spectral matrix as the input of CNN; (3) to use t-SNE to visually observe the learning process of CNN; (4) to use saliency maps to find the more influential positions in the spectral matrix on the discriminant results.
Materials and Methods
Sample Preparation
The soybean seeds from a single batch were purchased from a seed company in Shuyang Pengyuan horticulture farm, Suqian, Jiangsu, including Guandou 1, Zhoudou 23, Hedou 13, Jiadou 23, Hedou 33, Lvbaoshi, Hedou 25, Qihuang 34, Zhonghuang 13, and Wandou 15, which were correspondingly numbered from variety 1 to variety 10 for convenient description. Two hundred seeds free from damage and disease spots for each variety were selected. Then, without any other pretreatment, every four soybean seeds were pressed into rubber sand in a culture plate using a ruler to ensure a relatively uniform surface height (Figure 1) for the LIBS experiment.
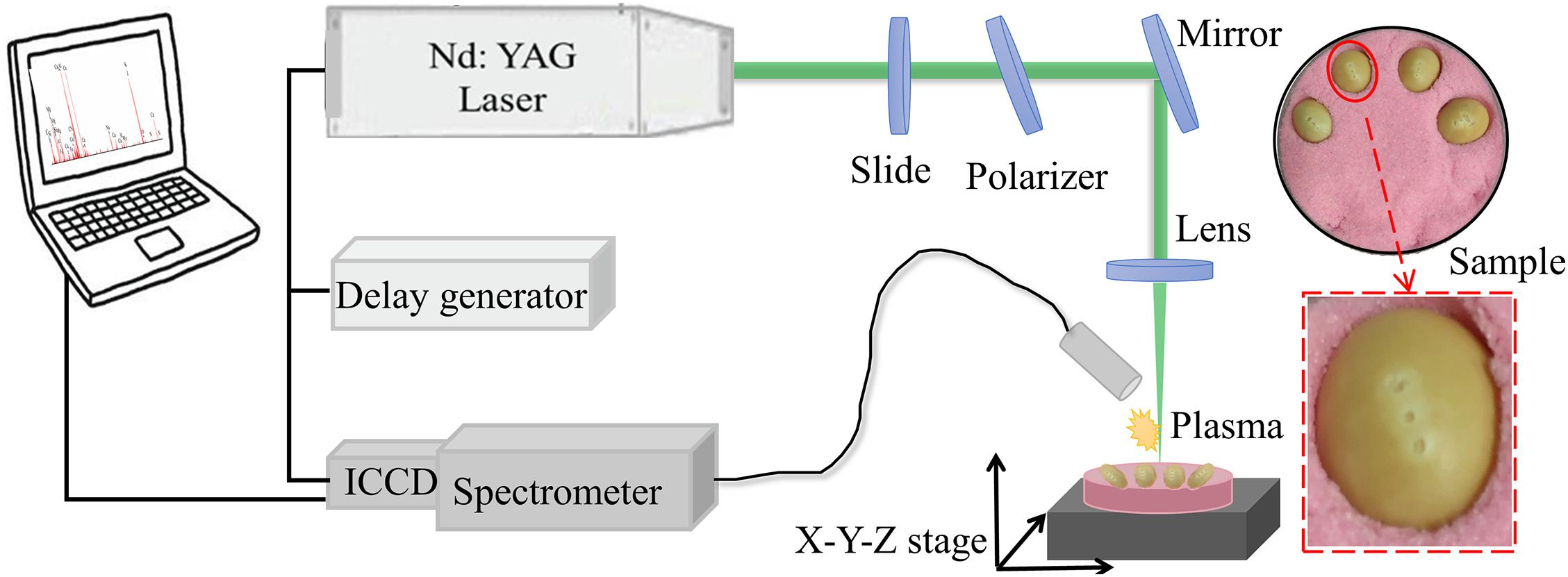
Figure 1. The schematic diagram of the laser-induced breakdown spectroscopy (LIBS) experiment.
Experimental Setup
The experiment was completed using the LIBS system as shown in Figure 1. A Q-switched Nd:YAG pulse laser (Vlite-200, Beamtech Optronics, Beijing, China) was used to generate a pulse laser at 532 nm with a pulse duration of 8 ns, beam diameter of 7 mm, and maximum energy of 200 mJ. Then, the pulse laser was guided to the sample by an optical system, in which a glass slide and a polarizer was combined to control laser energy and a plano-convex lens (f = 100 mm) was fixed to focus the laser beam 2 mm below the surface of the sample. To avoid repeat ablations, an X-Y-Z motorized stage was applied to move the sample every ten accumulation shots. The LIBS spectra were separated by the high-resolution Echelle spectrometer (ME5000, Andor Information Technology Ltd., Belfast, United Kingdom) in the range of 230–904 nm with 0.01 nm resolution and then collected by an intensified charge coupled device (ICCD) camera (DH334, Andor Information Technology Ltd., Belfast, United Kingdom). The delay generator (DG645, Stanford Research Systems Inc., Sunnyvale, CA, United States) was applied to adjust the delay time between the action of the laser ablation and the camera working.
The pulse energy, delay, and integration time were the three important parameters for LIBS, which were optimized as 60 mJ, 2 μs, and 10 μs, respectively, improving the data quality. In the air environment, three different points on a soybean seed were used to be ablated as shown in Figure 1. The horizontal distance between two adjacent points is one millimeter and the middle point is the highest. At each point, the spectra with 10 times accumulation were collected to gather information from the surface to the inside of the soybean seed. The average spectra were taken as the final spectrum. Thus, one soybean seed produced three spectra and a total of 6,000 spectra were produced in this experiment. It only took 30 s to complete the spectral acquisition for one soybean seed.
Data Preprocess
LIBS spectra within soybean seeds contained obvious random noise in the head and end of the spectra. Thus, the wavelengths in the range of 242–882 nm were studied. To reduce fluctuations from point to point, area normalization method was used for each LIBS spectrum following the equation below:
where xi is the ith variable relative intensity measured by LIBS system, n is the total number of LIBS spectral variables, Xi is the relative intensity by area normalization. Then variables with near-zero standard deviation were removed to reduce the dimension of LIBS spectra (Boucher et al., 2015). All soybean seeds were randomly divided into the calibration set, validation set, and prediction set according to the ratio of 3:1:1. The number of the LIBS spectra in the three data sets was 3,600, 1,200, and 1,200, respectively.
Principal Component Analysis
Principal component analysis (PCA) is a commonly used method to generate an easy visualization of the distribution of samples (Velioglu et al., 2018; Zhu et al., 2019b). The principle of PCA is to find the unit vector to maximize the variance after the original spectral data is projected on the vector, so that the information of the original spectral data can be retained to the greatest extent. The variance can be calculated by the following equation:
Where xi is a LIBS spectrum, v is unit vector and C is covariance matrix of all pixel spectra. So, v = argmax(vT Cv), subjected to vTv−1 = 0. We can use the lagrange multiplier method to solve v. The process is as below:
Where, λ is the lagrangian multiplier.
Therefore, λ is the eigenvalue of C and v is eigenvector of C. Through PCA, we can get different unit vectors vs with different λs. The larger is, the greater the contribution rate of v is. In this study, the first three vs were used to generate three principal components (PCs). PC1 = Xv1,PC2 = Xv2,PC3 = Xv3. We can intuitively see the clustering of samples by scoring 3-D scatter plots of PC1, PC2, and PC3.
Discriminant Analysis Method
Machine Learning
K-nearest neighbor (KNN) is the simplest classification algorithm in machine learning. The distances between samples are calculated first. Then, k nearest samples are considered to be in the same category. In this study, k is determined by the discriminant accuracy of the validation set and selected in the range of 3–20.
SVM is a stable supervised classification model, which is also suitable for small and high-dimensional data (Vapnik and Chapelle, 2000; Scholkopf et al., 2001). In the process of SVM modeling, the optimal hyperplane is searched to separate the samples by exploring support vector points. At the same time, the structural risks should be minimized. Due to the simplicity of radial basis function (RBF) and its ability to solve complex nonlinear problems, RBF was selected as the kernel function in this study. Kernel function parameter g determines the linearity of the hyperplane and the regularization parameter c determines the capacity of fault tolerance (Yu et al., 2016). In order to guarantee the better performance of SVM, the optimal parameters c and g were selected through grid-search procedure from 10–8 to 108 and determined by classification accuracy of five-fold cross validation.
Deep Learning
Deep learning has become the hottest topic in the field of artificial intelligence. CNN is one of the well-known deep learning structures for classification (Kamilaris and Prenafeta-Boldu, 2018; Ren et al., 2020). In this study, three kinds of common network structures called LeNet (Lecun et al., 1998), DenseNet (Huang et al., 2017) and ResNet (He et al., 2016) were compared firstly. Then according to the discriminant results, two kinds of self-proposed network structures based on ResNet were further studied. The detailed structures based on LeNet and DenseNet are shown in Supplementary Figures 1, 2.
For three kinds of ResNets, basic network architecture is shown in Figure 2. Residual block (RES. Block) is the main characteristic that distinguishes this network structure from others. RES. Block is composed of two convolution layers (Convs), each of which is followed by a batch normalization process and rectified linear unit (Relu) activation function. The two Convs have the same parameters in kernel size, padding, and strides with values of 3, 1, and 1. For four RES. Blocks, the channel number of Convs was 64, 64, 128, and 128, respectively. It is worth noting that the input data can be propagated forward directly to the data before passing through the last layer. For common ResNet, the value of the propagation coefficient W is 1. We proposed the self-adaption of W including propagation coefficient adaptive ResNet (PCA-ResNet) and propagation coefficient synchronous adaptive ResNet (PCSA-ResNet). For PCA-ResNet, there is no limit between the four W and they are updated separately during the back-propagation process. For PCSA-ResNet, the four W are updated synchronously during the back propagation following the equation below:
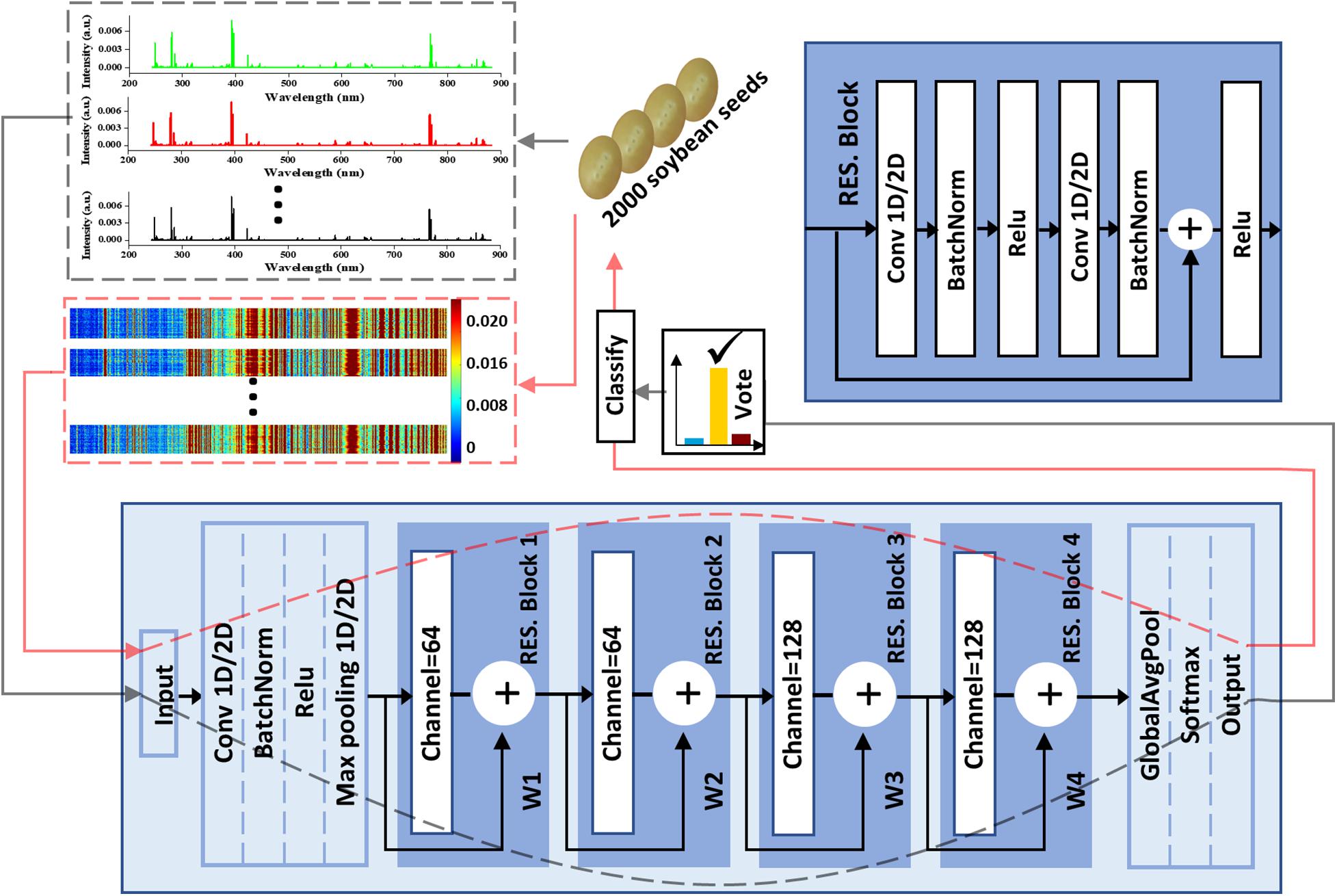
Figure 2. The soybean seeds classification flowchart including data input, ResNet-based classifier, and a majority vote strategy.
Between the input layer and the RES. Block 1, there was a pretreatment process as shown in Figure 2. In the process, the channel number, kernel_size, padding, and strides of Conv were 64, 7, 3, and 2, respectively, to deal with more information at once. A soybean seed could produce three spectra which could be treated separately or concatenated together into a spectral matrix. Therefore, all the Convs in 1D-CNN had two states including one dimension (1D) or two dimensions (2D) corresponding to different data forms. Additionally, a majority vote was employed to make the final decision for classification when the data form was the first one and the corresponding data transmission flow was marked using gray dotted lines. Another data transmission flow for the spectral matrix was marked using red dotted lines.
VGG is another common network structure for image processing (Simonyan and Zisserman, 2014). The model based on VGG was built as a comparison. The detailed structure is shown in Supplementary Figure 3. In order to compare the modeling effects of different 2D-CNNs, the same pretreatment process as shown in Figure 2 (between the input layer and the RES. Block 1) was added to 2D-LeNet, 2D-DenseNet, and 2D-VGG.
Deep learning models were trained using stochastic gradient descent (SGD) with different learning rates. At the beginning of model training, the learning rate was high and gradually decreased to approximate the optimal accuracy. For each learning rate, there was a threshold for the accuracy of the validation set, which gradually increased with the decrease of the learning rate. When the accuracy of the validation set reached the threshold, the training of the model was stopped. If the accuracy of the validation set could not reach the threshold, the model training would be stopped after 100 iterations. The learning rates and thresholds were set together at different stages of the training process of the model. Taking PCSA-ResNet based on spectral matrix as an example, the learning rates were set as 0.25, 0.124, 0.05, and 0.01, respectively, and the corresponding thresholds were set as 0.84, 0.86, 0.88, and 0.887. The accuracy of the validation set finally converged to 0.887.
Model Evaluation and Visualization
Discriminant accuracy was used to evaluate each model in this study, defined as the ratio of the number of correctly discriminated soybean seed to the total number. To further evaluate model performance, four common evaluation indicators including precision, recall, F-measure, and Matthews correlation coefficient (MCC) were calculated. The corresponding formula refers to the article by Yoosefzadeh-Najafabadi et al. (2021). In this article, the average value of the four indicators was used for a more convenient evaluation.
A confusion matrix was applied to analyze the detailed effects of classification further. The difference between the prediction results and actual results for each soybean seed could be visually observed. The confusion matrix consists of a square matrix whose vertical axis represents the true category and horizontal axis represents the predicted category. Therefore, the number on the diagonal indicated the number of soybean seeds correctly classified.
T-SNE was used to visualize the clustering process of the extracted features from the deep learning model. It could realize the nonlinear dimension reduction of high-dimensional spectra data (Husnain et al., 2019). In t-SNE, the Gaussian distribution’s perplexity was defined as 30, and the initial dimensions of PCA were defined as 12 for layers of Max pooling and RES Block4. For Dense layer, since the length of the feature vector was 10, the dimensions of PCA were set as 6, which should be smaller than 10. The spectral matrix (similar to image data format) was first reshaped into tensor in three dimensions including channel and image, and then each image data of channels was averaged (Zhang et al., 2020).
The deep learning model could calculate the weight of each pixel on the input image (spectral matrix) through the back-propagation algorithm. The graph composed of the weight value of each pixel was called the saliency map. Through the saliency map, we could visually see the pixel positions that had a higher influence on the discrimination results. The calculation formula of the weight of each pixel was as follows:
Where, I is spectral matrix, Dense is the output vector (ten probability values) of Dense 10, Correct is a vector of 0 and 1 that corresponds to the Dense. For example, if the spectral matrix comes from variety 3, the third position is set as 1 and the others are set as 0.Grad is the gradient of the spectral matrix.
Software and Hardware
The machine learning algorithms were run on Matlab R2014b (The MathWorks, Natick, MA, United States). The software was installed on a Windows7 Desktop with Intel Xeon E5-2620 and 64 GB RAM. CNN was deployed on the framework of Apache MXNet1.4.0 in another computer of Ubuntu Desktop with GTX1080Ti (NVIDIA, California, United States) and 48 GB RAM.
Results and Discussion
Average Spectral Analysis
The average spectra of soybean seeds from 10 varieties are shown in Figure 3. The ten LIBS spectra showed a high degree of similarity in the position of excitation peak, as they all came from the same agricultural product called soybean. Based on the National Institute of Standards and Technology (NIST), the elements corresponding to the excitation wavelength were marked in the average spectra from variety 1 (Guandou 1). The marked molecular bands CN 0–0 (around 388 nm) are usually associated with organic compounds (Fernandez-Bravo et al., 2013). It is well known that soybeans are rich in calcium, leading to many excitation lines representing calcium that could be observed at 317.93 nm, 393.37 nm, 396.8 nm, 422.67 nm, 430.25 nm, 445.48 and 854.21 nm. In addition, some microelements such as C (247.86 nm), Si (251.61 nm), Mg (279.55 nm, 280.27 nm), H (656.28 nm), K (766.49 nm, 769.90 nm), O (777.54 nm), and N (746.83 nm, 821.63 nm, and 868.03) and microelements like Fe (844.80 nm) and Na (589.59 nm) could also be easily recognized. Although the signal intensity varied among different varieties, it was difficult to distinguish them just by LIBS spectra intuitively. Thus, it was necessary to adopt mathematical data analysis to identify soybean seed varieties.
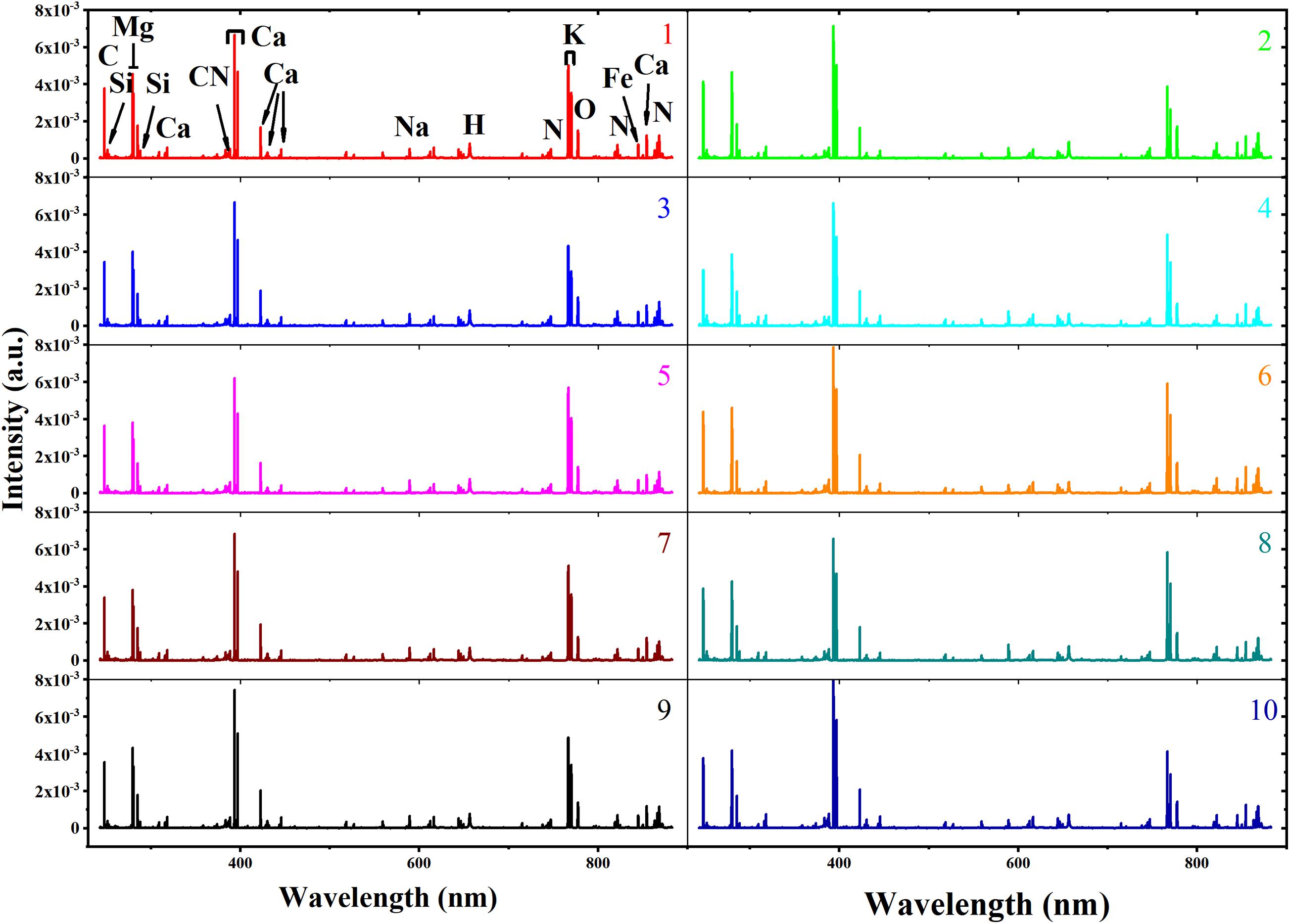
Figure 3. The average spectra of soybean seed samples including different varieties numbered 1–10.
Principal Component Analysis
To test the feasibility of an unsupervised classification, a qualitative analysis of PCA was applied to explore the differences among ten different varieties of soybean seeds. The 3D score scatter plot (X-axis: PC1, Y-axis: PC2, and Z-axis: PC3) is presented in Figure 4. The first three PCs had explained 77.4% of the variation with PC1 of 33.0, PC2 of 25.9, and PC3 of 18.5%. Each variety of soybean seeds was marked with different color or shape for better visualization. We could see a slight distinction among different varieties. But spectra from the same variety could not be completely clustered together. For variety 10 (Wandou 15) marked with a blue circle, two clusters appeared, which indicated that PCA could not explore the variety differences very well. Therefore, supervised data processing was needed to explore the differences among the ten varieties of soybean seeds.
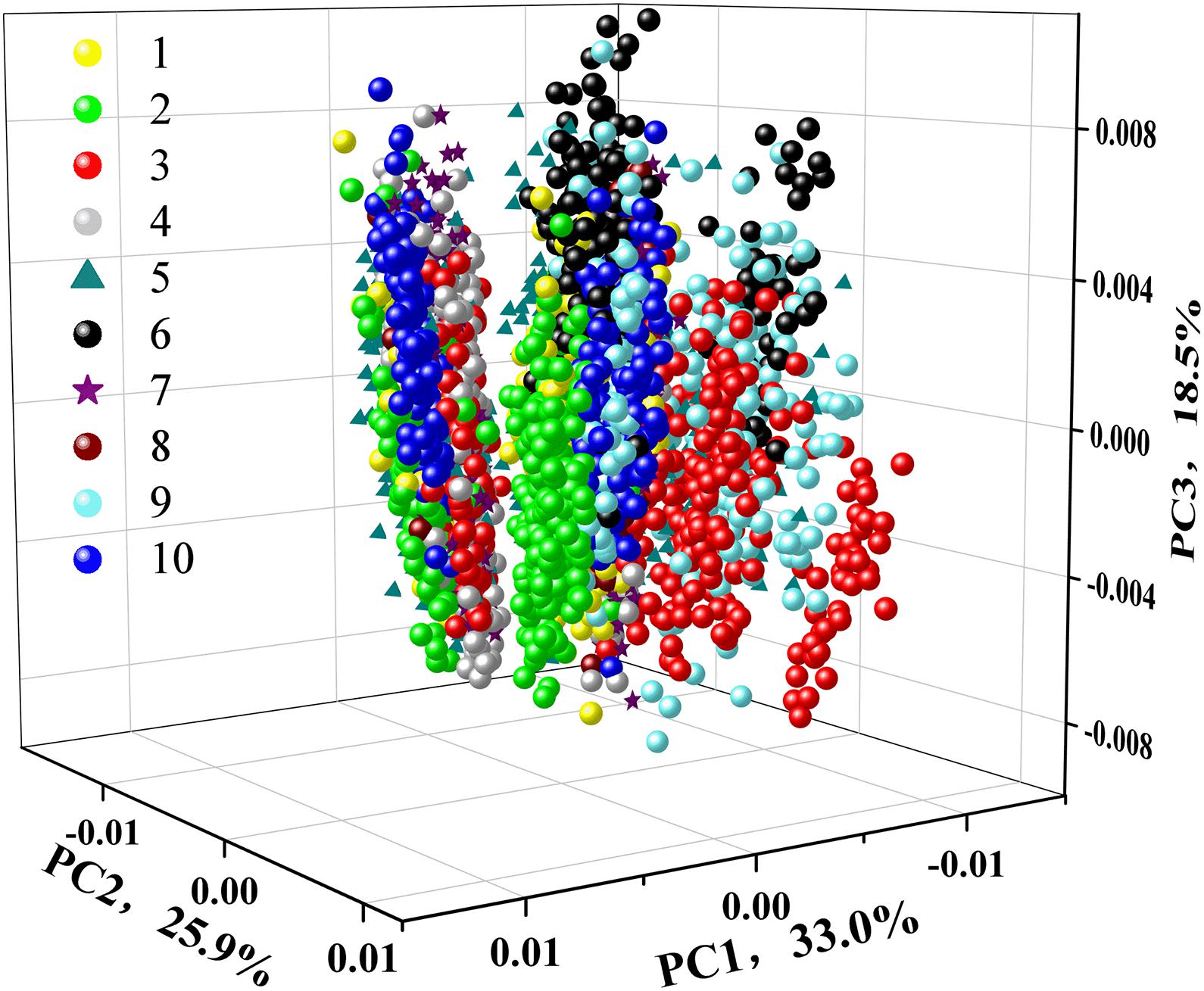
Figure 4. 3D scatter plot of 10 different varieties of soybeans based on the first three principal components (PCs).
Machine Learning and 1D-Convolutional Neural Network
Both 1D-LeNet and 1D-DenseNet had poor performances after trying different model parameters. The accuracy in the prediction set is about 10% for them. For machine learning and ResNets, Table 1 shows the results based on a single spectrum and a majority vote. Based on a single spectrum, KNN had the worst performance with the accuracy of 64.33% in the prediction set. SVM had a higher accuracy of 84.67%. Three different kinds of 1D-ResNets were superior to machine learning. The accuracy in the prediction set was 86.42, 86.00, and 86.83%, respectively, for 1D-ResNet, 1D-PCA-ResNet, and 1D-PCSA-ResNet. For 1D-PCA-ResNet, four different propagation coefficients of W1,W2,W3,andW4 had the value of –0.15, –1.06, 0.04, and 3.13, respectively. For 1D-PSCA-ResNet, the shared W∗ had the value of 1.52. Based on a majority vote, the discriminant accuracy of the validation set and prediction set were both improved. For machine learning, SVM obtained the highest accuracy of 90% in the prediction set. For deep learning, 1D-PCA-ResNet obtained the highest accuracy of 89.50% in the prediction set.
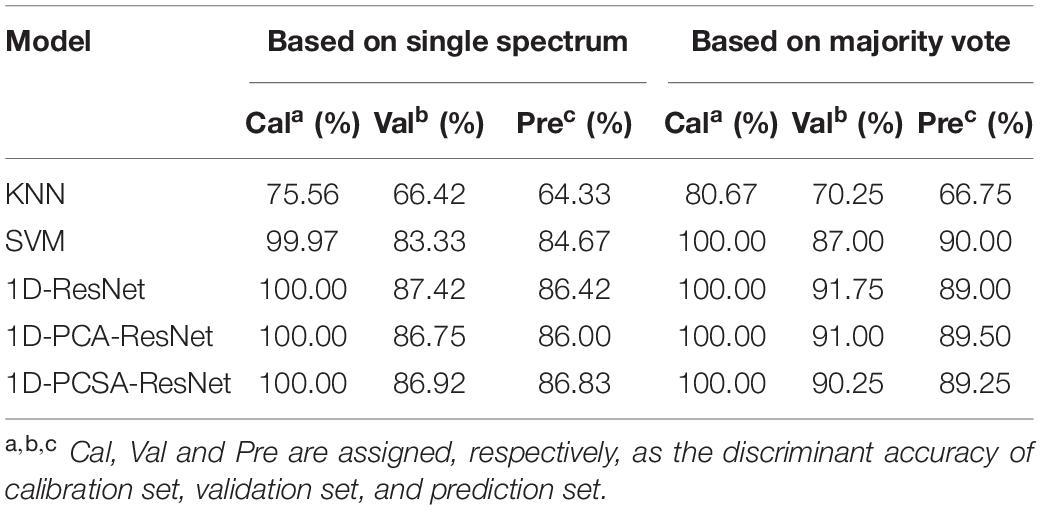
Table 1. The results of discriminant models based on single spectrum and a majority vote.
Based on a single spectrum, the discriminant effects from deep learning were superior to machine learning, revealing the advantages and effectiveness of deep learning in spectral analysis. This is because CNN has different principles in data processing from SVM. The output of each convolutional layer of CNN is directly related to small regions of the input spectrum. Thus, CNN can identify important regions of the input spectrum (Acquarelli et al., 2017). The existing research in spectral application showed that CNN might have better performance than machine learning (Brugger et al., 2021; Chen et al., 2021). The network structure based on ResNet had higher accuracy than that based on LeNet and Densenet. Therefore, residual block played a vital role in the soybean genotype discrimination coupled with LIBS spectra. The main feature of the residual block is that the data can be propagated forward more quickly through a cross-layer data path (Moussa and Owais, 2021). However, the propagation coefficient of common ResNet was set directly as 1. We believe that propagation coefficient can also be automatically learned like convolution parameters to achieve better results. The results showed that 1D-PCSA-ResNet obtained higher accuracy for a single spectrum, which aligns with our ideas. In order to determine the variety of soybean seeds, the voting strategy was proposed. The classification accuracy for both validation and prediction sets was further improved. The results illustrated the stability and effectiveness of the voting strategy. However, the optimal classification accuracy was obtained by SVM rather than 1D-PCSA-ResNet. The reason might be that SVM was characterized by minimal structural risk (Yoosefzadeh-Najafabadi et al., 2021). In the three spectra from a soybean seed, one may be misclassified. Through majority vote, the classification accuracy could be improved.
2D-Convolutional Neural Network
2D-DenseNet had the same poor performances as 1D-DenseNet. The accuracy in the prediction set was about 10%. For other 2D-CNNs, Table 2 shows the results. The accuracy in the prediction set of 2D-LeNet and 2D-VGG were 85.25 and 85.75%, respectively. The model based on residual block outperformed them. 2D-ResNet had an accuracy of 89.75%. 2D-PCA-ResNet had a lower accuracy of 89.00%. The four different propagation coefficients had values of –0.15, –0.92, 0.04, and 2.43, respectively. Whereas 2D-PCSA-ResNet obtained the highest accuracy in the prediction set with the value of 91.75%. The four same propagation coefficients had the value of 1.30. For 2D-ResNet and 2D-PCSA-ResNet, the average value of four indicators including precision, recall, F-measure and MCC was calculated. For 2D-ResNet, they were 0.90, 0.90, 0.90, and 0.89, respectively. For 2D-PCSA-ResNet, they were 0.92, 0.92, 0.92, and 0.91, respectively.

Table 2. The results of 2D-CNNs based on a spectral matrix.
The highest accuracy was 91.75% from 2D-PCSA-ResNet, whose result was still 1.75 higher than SVM by voting strategy, demonstrating that taking spectral matrix as the input of CNN could improve the classification accuracy. One spectrum could only contain the information of one point on the soybean seed while the spectral matrix could involve more sufficient information. Moreover, the 2D convolution kernel could automatically learn the joint useful information (Zhang et al., 2020). These might be the reason for a higher accuracy. Also, all four indicators of 2D-PCSA-ResNet had higher values than that of 2D-ResNet, indicating that 2D-PCSA-ResNet performed better, consistent with our idea in 3.3 again.
Training and Testing Curves of 2D-Propagation Coefficient Synchronous Adaptive-ResNet
Figure 5 shows the training and testing curves of 2D-PCSA-ResNet. As the number of iterations increased, the loss value decreases gradually and the accuracy of the modeling set increased gradually. The accuracy of the validation set fluctuated but finally converged just like the calibration set. The accuracy of the modeling set, validation set, and prediction set was 100, 88.75, and 91.75%, respectively. There was no fitting phenomenon in the 2D-PCSA-ResNet model.
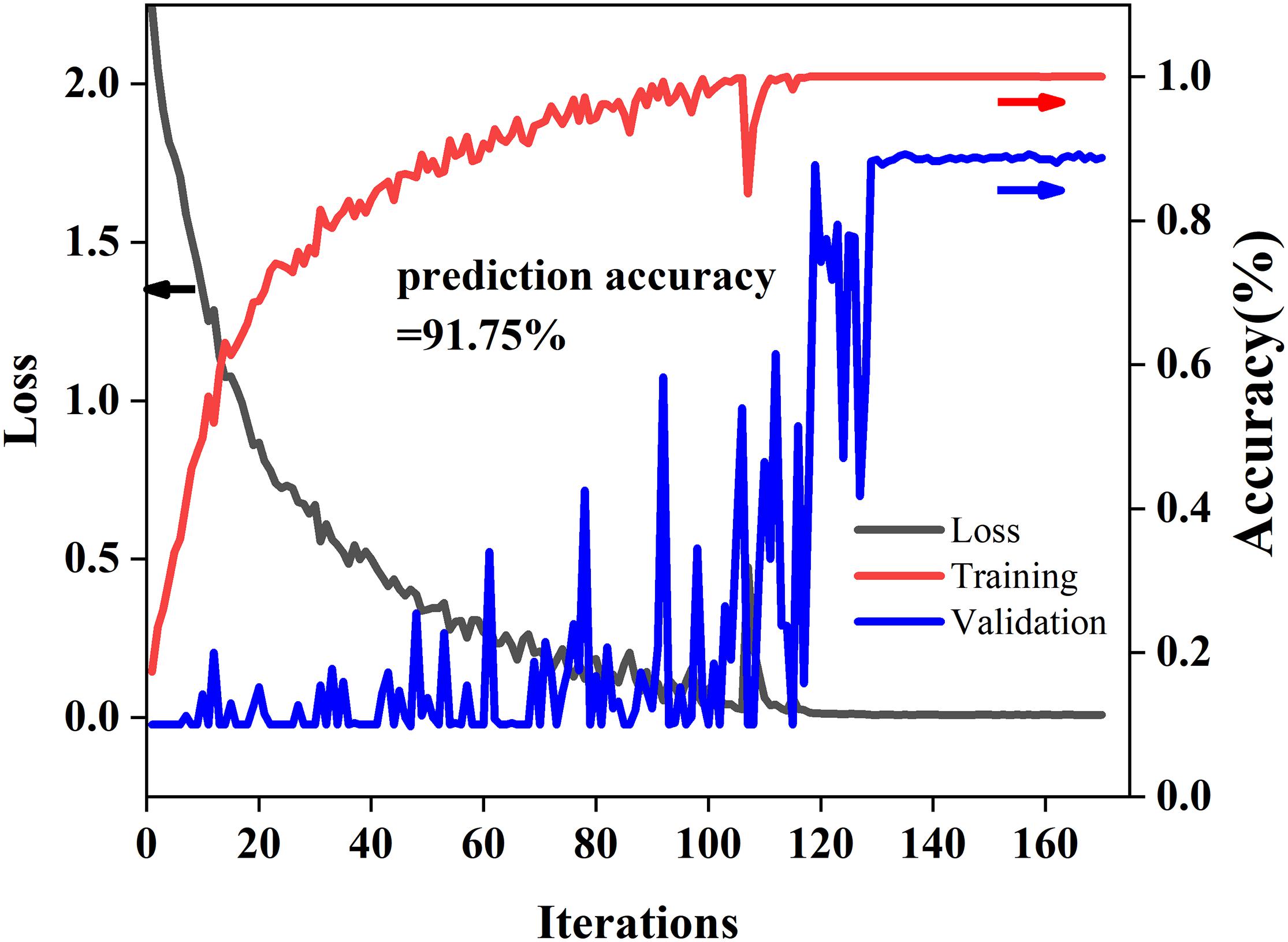
Figure 5. Training and testing curves of 2D-PCSA-ResNet.
Feature Clustering Process in 2D-Propagation Coefficient Synchronous Adaptive-ResNet
The clustering effects of features extracted from Max pooling, RES. Block4 and Dense 10 in 2D-PCSA-ResNet are visualized in Figure 6. As the layers went from shallow to deep, the feature clustering phenomenon became more apparent, indicating that the features learned by the deep learning model were more and more representative with the deepening of layers. As shown in Figure 6C, the layer close to the output had successfully learned the soybean seed varieties’ characteristics. Although a small number of data points were misclassified, the classification results were generally satisfactory.
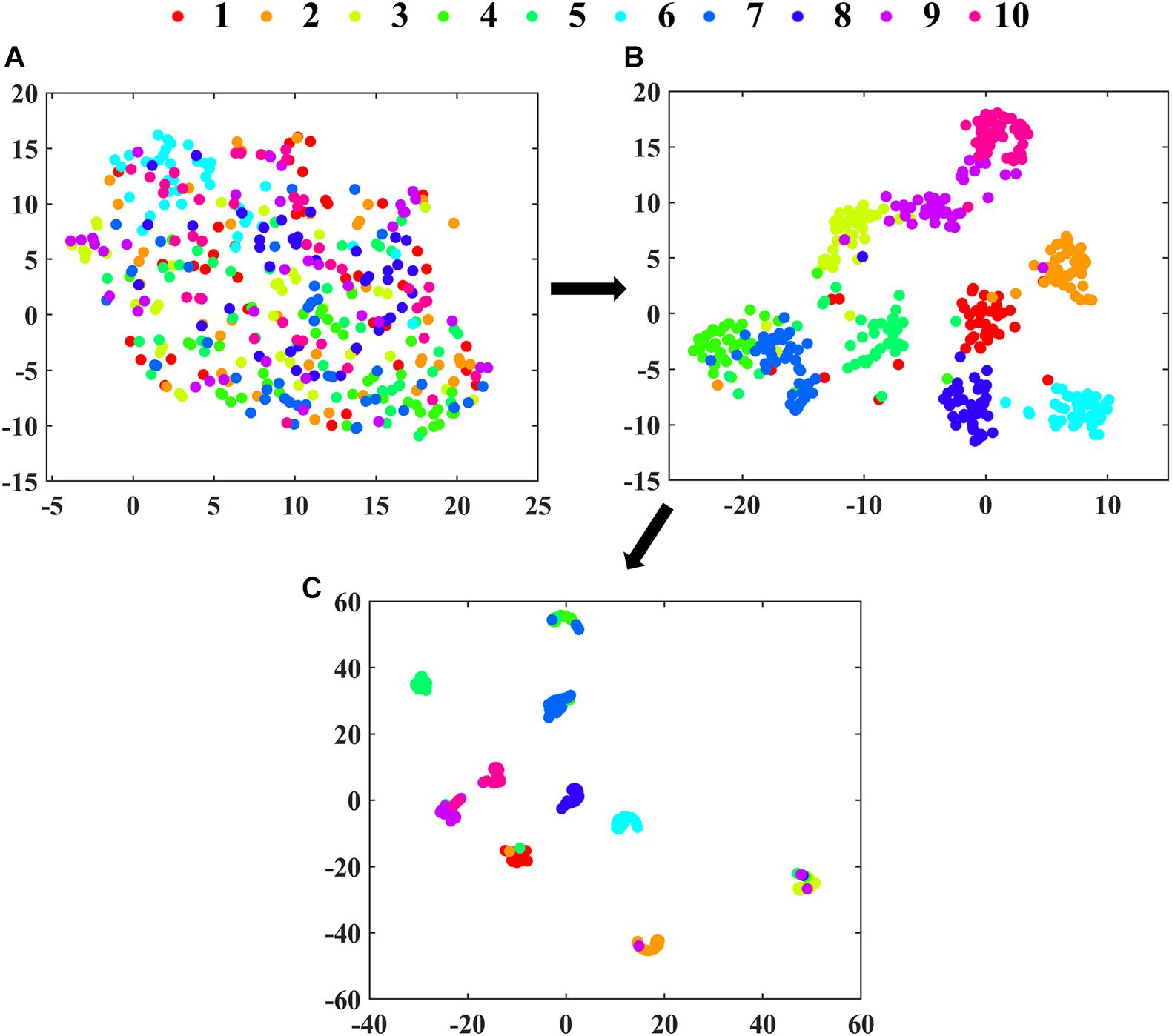
Figure 6. The visualization of clustering effects in layers of (A) Max pooling, (B) RES. Block4 and (C) Dense 10 in 2D-PCSA ResNet by t-SNE.
Saliency Map of the Input Spectral Matrices
Connected saliency maps of spectral matrices of soybean seeds in the prediction set from ten varieties based on 2D-PCSA-ResNet are shown in Figure 7. The darker the color was, the greater the influence of the corresponding pixels on the discrimination results. (1) It could be seen that the saliency pixels for each variety were distributed in strips. This was because the essence of the input image was spectral matrices. The wavelength and the corresponding intensity of the spectrum could reflect the differences of different samples (Liu et al., 2017). (2) For each variety, there were slight differences in color at the same wavelength. The reason might be that the three spectra that made up the spectral matrix came from three different points on the surface of a soybean seed. And the deep learning model could automatically identify the valuable information for the discrimination (Acquarelli et al., 2017). (3) The saliency maps from different soybean varieties were different. For example, saliency maps from variety 4 had significantly more red spots in the number range of 250–1,000 than that of varieties 3 and 2. These differences were the fundamental reason why the 2D-PCSA-ResNet could distinguish different soybean seed varieties. Moreover, these differences had a certain corresponding relationship with the excitation peak of LIBS spectra, indicating that the content and proportion of elements (C, Si, Mg, Ca, Na, H, K, O, N) in soybean seeds played an important role in variety differences.

Figure 7. Connected saliency maps for spectral matrix of soybean seeds in prediction set from ten varieties based on 2D-PCSA-ResNet. The two spectra at the bottom are same and are the average spectra from prediction set.
Confusion Matrix Analysis
Figure 8 shows the confusion matrices of validation and prediction for 2D-PCSA-ResNet. The details of misclassification of each variety of soybean seeds could be observed clearly.
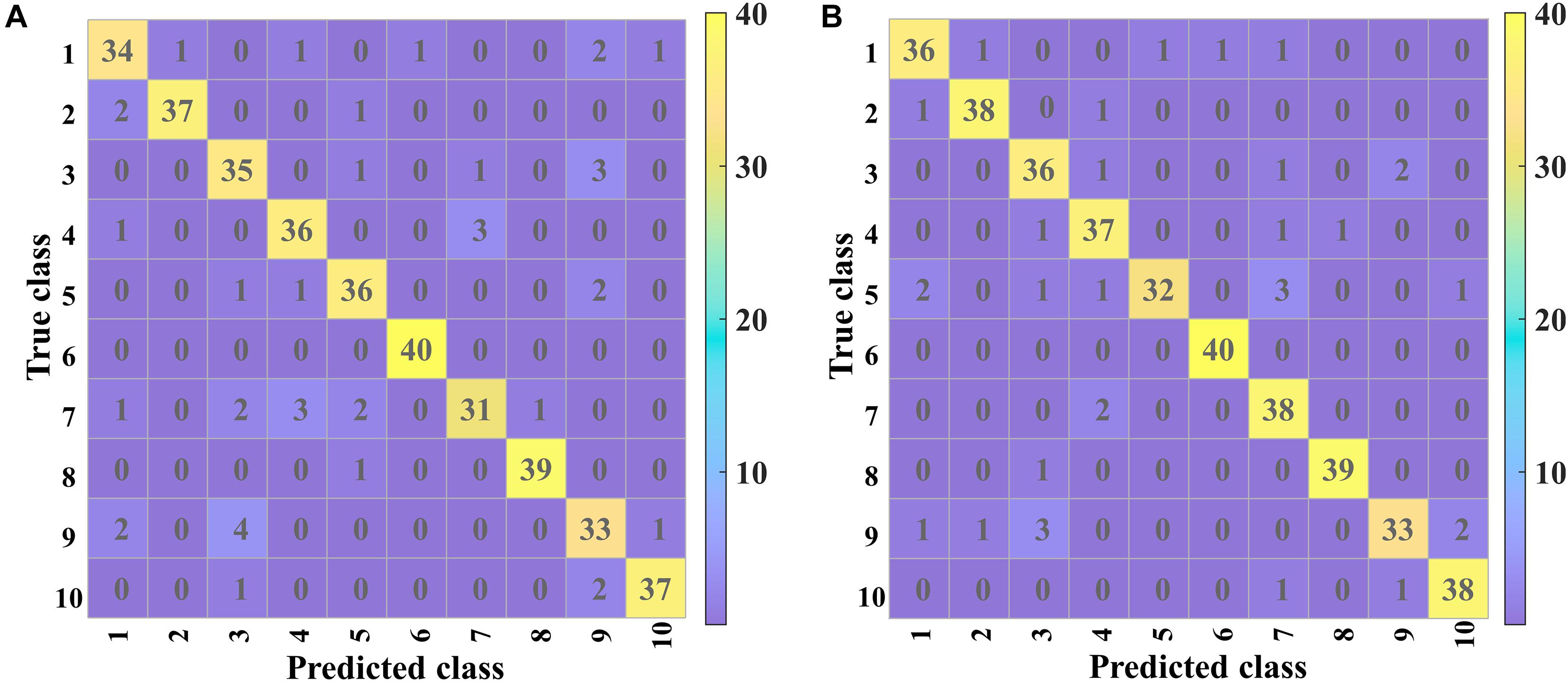
Figure 8. The confusion matrix for the (A) validation and (B) prediction based on 2D-PCSA-ResNet.
Good classification performances could be found for Variety 6 (Lvbaoshi) and Variety 8 (Qihuang 34), for which few samples were misclassified. For the validation set, the classification results of Variety 7 (Hedou 25) and Variety 9 (Zhonghuang 13) were poor, more likely to be misclassified as Variety 4 (Jiadou 23) and Variety 3 (Hedou 13), respectively. For the prediction set, Variety 9 (Zhonghuang 13) had similar poor classification results to those in the validation set and Variety 5 (Hedou 33) was more likely to be misclassified as Variety 7 (Hedou 25).
All the samples from Variety 6 (Lvbaoshi) could be correctly classified, which might be attributed to the fact that Lvbaoshi have a distinct color (green) compared to other varieties (yellow), causing the different element distribution from other varieties. Variety 5 (Hedou 33) and Variety 7 (Hedou 25) are easy to be misclassified as each other. This was probably because they were both a type of Hedou with similar genotypes. Variety 9 (Zhonghuang 13) and Variety 3 (Hedou 13) are easy to be misclassified as each other. The reason might be that the saliency maps of Variety 9 and Variety 3 were similar, which was related to the internal structure of the discriminant model. As for variety 9 with the lowest accuracy of 82.5%, special attention should be paid to actual application. Generally, most soybean seeds could be accurately classified, which indicated that LIBS coupled with CNN could be used as a rapid and small-invasive detection method to identify soybean seed varieties.
Conclusion
Laser-induced breakdown spectroscopy combined with deep learning was successfully applied to the fast identification of soybean seed varieties. It only took 30 s to complete the spectral collection for one soybean seed. Considering the two-dimensional and self-adaptive features of the convolution kernel of CNN, the three spectra of a soybean seed were connected into a spectral matrix as the input. Coupled with spectral matrix, 2D-PSCA-ResNet obtained the highest accuracy in the prediction set with an accuracy of 91.75%. In the future, it can be considered to combine with portable LIBS instruments to realize rapid and on-site identification of soybean seed variety. Meanwhile, more ablation schemes (different laser wavelengths, ablation times, more suitable ablation locations, etc.) can be studied to enhance the detection effects further.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
XL conceived, designed the experiments and wrote the whole manuscript. XL, ZH, and RC performed the experiments. XL and FL contributed to data analysis, contributed reagents, materials, and analysis tools. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This research was funded by the Key Projects of International Scientific and Technological Innovation Cooperation among Governments under National Key R&D Plan (Grant No. 2019YFE0103800).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2021.714557/full#supplementary-material
References
Acquarelli, J., Van Laarhoven, T., Gerretzen, J., Tran, T. N., Buydens, L. M. C., and Marchiori, E. (2017). Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 954, 22–31. doi: 10.1016/j.aca.2016.12.010
Ang, K. L.-M., and Seng, J. K. P. (2021). Big data and machine learning with hyperspectral information in agriculture. IEEE Access 9, 36699–36718. doi: 10.1109/ACCESS.2021.3051196
Boucher, T. F., Ozanne, M. V., Carmosino, M. L., Dyar, M. D., Mahadevan, S., Breves, E. A., et al. (2015). A study of machine learning regression methods for major elemental analysis of rocks using laser-induced breakdown spectroscopy. Spectrochim. Acta Part B Atom. Spectros. 107, 1–10. doi: 10.1016/j.sab.2015.02.003
Brugger, A., Schramowski, P., Paulus, S., Steiner, U., Kersting, K., and Mahlein, A.-K. (2021). Spectral signatures in the UV range can be combined with secondary plant metabolites by deep learning to characterize barley-powdery mildew interaction. Plant Pathol. 70, 1572–1582. doi: 10.1111/ppa.13411
Chen, C., Yang, B., Si, R., Chen, C., Chen, F., Gao, R., et al. (2021). Fast detection of cumin and fennel using NIR spectroscopy combined with deep learning algorithms. Optik 242:167080. doi: 10.1016/j.ijleo.2021.167080
Cho, K. M., Ha, T. J., Lee, Y. B., Seo, W. D., Kim, J. Y., Ryu, H. W., et al. (2013). Soluble phenolics and antioxidant properties of soybean (Glycine max L.) cultivars with varying seed coat colours. J. Funct. Foods 5, 1065–1076. doi: 10.1016/j.jff.2013.03.002
Dhar, P., Gembitsky, I., Rai, P. K., Rai, N. K., Rai, A. K., and Watal, G. (2013). A possible connection between antidiabetic & antilipemic properties of Psoralea corylifolia seeds and the trace elements present: a LIBS based study. Food Biophys. 8, 95–103. doi: 10.1007/s11483-012-9280-1
Ebrahimi, M. A., Khoshtaghaz, M. H., Minaei, S., and Jamshidi, B. (2017). Vision-based pest detection based on SVM classification method. Comput. Electron. Agric. 137, 52–58. doi: 10.1016/j.compag.2017.03.016
Erler, A., Riebe, D., Beitz, T., Loehmannsroeben, H.-G., and Gebbers, R. (2020). Soil nutrient detection for precision agriculture using handheld laser-induced breakdown spectroscopy (LIBS) and multivariate regression methods (PLSR, Lasso and GPR). Sensors 20, 418–435. doi: 10.3390/s20020418
Fernandez-Bravo, A., Delgado, T., Lucena, P., and Javier Laserna, J. (2013). Vibrational emission analysis of the CN molecules in laser-induced breakdown spectroscopy of organic compounds. Spectrochim. Acta Part B Atomic Spectros. 89, 77–83. doi: 10.1016/j.sab.2013.08.004
Gamela, R. R., Costa, V. C., Speranca, M. A., and Pereira-Filho, E. R. (2020). Laser-induced breakdown spectroscopy (LIBS) and wavelength dispersive X-ray fluorescence (WDXRF) data fusion to predict the concentration of K, Mg and P in bean seed samples. Food Res. Int. 132, 109037–109045. doi: 10.1016/j.foodres.2020.109037
Grohmann, L., Belter, A., Speck, B., Goerlich, O., Guertler, P., Angers-Loustau, A., et al. (2017). Screening for six genetically modified soybean lines by an event-specific multiplex PCR method: collaborative trial validation of a novel approach for GMO detection. J. Consum. Prot. Food Saf. 12, 23–36. doi: 10.1007/s00003-016-1056-y
He, K. M., Zhang, X. Y., Ren, S. Q., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, (New York, NY: IEEE), 770–778.
He, Y., Zhao, Y., Zhang, C., Li, Y., Bao, Y., and Liu, F. (2020). Discrimination of grape seeds using laser-induced breakdown spectroscopy in combination with region selection and supervised classification methods. Foods 9, 199–213. doi: 10.3390/foods9020199
Hesami, M., Naderi, R., Tohidfar, M., and Yoosefzadeh-Najafabadi, M. (2020). Development of support vector machine-based model and comparative analysis with artificial neural network for modeling the plant tissue culture procedures: effect of plant growth regulators on somatic embryogenesis of chrysanthemum, as a case study. Plant Methods 16:15. doi: 10.1186/s13007-020-00655-9
Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger, K. Q. (2017). “densely connected convolutional networks,” in Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, (New York, NY: IEEE), 2261–2269.
Husnain, M., Missen, M. M. S., Mumtaz, S., Luqman, M. M., Coustaty, M., and Ogier, J.-M. (2019). Visualization of high-dimensional data by pairwise fusion matrices using t-SNE. Symmetry-Basel 11, 107–123. doi: 10.3390/sym11010107
John, K. M. M., Natarajan, S., and Luthria, D. L. (2016). Metabolite changes in nine different soybean varieties grown under field and greenhouse conditions. Food Chem. 211, 347–355. doi: 10.1016/j.foodchem.2016.05.055
Kamilaris, A., and Prenafeta-Boldu, F. X. (2018). Deep learning in agriculture: a survey. Comput. Electron. Agric. 147, 70–90. doi: 10.1016/j.compag.2018.02.016
Kim, S.-L., Lee, J.-E., Kwon, Y.-U., Kim, W.-H., Jung, G.-H., Kim, D.-W., et al. (2013). Introduction and nutritional evaluation of germinated soy germ. Food Chem. 136, 491–500. doi: 10.1016/j.foodchem.2012.08.022
Larios, G. S., Nicolodelli, G., Senesi, G. S., Ribeiro, M. C. S., Xavier, A. P., Milori, D. M. B. P., et al. (2020). Laser-induced breakdown spectroscopy as a powerful tool for distinguishing high- and low-vigor soybean seed lots. Food Anal. Methods 13, 1691–1698. doi: 10.1007/s12161-020-01790-8
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324. doi: 10.1109/5.726791
Li, T., Hou, Z., Fu, Y., Yu, J., Gu, W., and Wang, Z. (2019). Correction of self-absorption effect in calibration-free laser-induced breakdown spectroscopy (CF-LIBS) with blackbody radiation reference. Anal. Chim. Acta 1058, 39–47. doi: 10.1016/j.aca.2019.01.016
Liakos, K. G., Busato, P., Moshou, D., Pearson, S., and Bochtis, D. (2018). Machine learning in agriculture: a review. Sensors 18:2674. doi: 10.3390/s18082674
Liu, F., Wang, W., Shen, T., Peng, J., and Kong, W. (2019). Rapid identification of kudzu powder of different origins using laser-induced breakdown spectroscopy. Sensors 19, 1453–1464. doi: 10.3390/s19061453
Liu, Y., Xie, H., Chen, Y., Tan, K., Wang, L., and Xie, W. (2016). Neighborhood mutual information and its application on hyperspectral band selection for classification. Chemometr. Intell. Lab. Syst. 157, 140–151. doi: 10.1016/j.chemolab.2016.07.009
Liu, Y. W., Pu, H. B., and Sun, D. W. (2017). Hyperspectral imaging technique for evaluating food quality and safety during various processes: a review of recent applications. Trends Food Sci. Technol. 69, 25–35. doi: 10.1016/j.tifs.2017.08.013
Luo, H., Zhu, J., Xu, W., and Cui, M. (2019). Identification of soybean varieties by terahertz spectroscopy and integrated learning method. Optik 184, 177–184. doi: 10.1016/j.ijleo.2019.02.148
Luo, Z., Rao, H., Huang, L., Liu, M., Chen, T., Yao, M., et al. (2020). Effect of Cu stress on minerals in rice by analyzing husk based on laser-induced breakdown spectroscopy. Appl. Phys. B-Lasers Opt 126:8. doi: 10.1007/s00340-019-7359-9
Mccarville, M. T., Marett, C. C., Mullaney, M. P., Gebhart, G. D., and Tylka, G. L. (2017). Increase in soybean cyst nematode virulence and reproduction on resistant soybean varieties in Iowa from 2001 to 2015 and the effects on soybean yields. Plant Health. Prog. 18, 146–155. doi: 10.1094/php-rs-16-0062
Morellos, A., Pantazi, X. E., Moshou, D., Alexandridis, T., Whetton, R., Tziotzios, G., et al. (2016). Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 152, 104–116. doi: 10.1016/j.biosystemseng.2016.04.018
Moussa, G. S., and Owais, M. (2021). Modeling hot-mix asphalt dynamic modulus using deep residual neural networks: parametric and sensitivity analysis study. Constr. Build. Mater. 294:18. doi: 10.1016/j.conbuildmat.2021.123589
Peruzzi, T., Pasquato, M., Ciroi, S., Berton, M., Marziani, P., and Nardini, E. (2021). Interpreting automatic AGN classifiers with saliency maps. Astron. Astrophys. 652:13. doi: 10.1051/0004-6361/202038911
Ren, C., Kim, D.-K., and Jeong, D. (2020). A survey of deep learning in agriculture: techniques and their applications. J. Inf. Process. Syst. 16, 1015–1033. doi: 10.3745/jips.04.0187
Sato, T., Van Schoote, M., Wagentristl, H., and Vollmann, J. (2014). Effects of divergent selection for seed protein content in high-protein vs. food-grade populations of early maturity soybean. Plant Breed. 133, 74–79. doi: 10.1111/pbr.12138
Scholkopf, B., Platt, J. C., Shawe-Taylor, J., Smola, A. J., and Williamson, R. C. (2001). Estimating the support of a high-dimensional distribution. Neural Comput. 13, 1443–1471. doi: 10.1162/089976601750264965
Simonyan, K., and Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online at: https://arxiv.org/abs/1409.1556 (accessed April 10, 2015).
Singh, J., Kumar, R., Awasthi, S., Singh, V., and Rai, A. K. (2017). Laser induced breakdown spectroscopy: a rapid tool for the identification and quantification of minerals in cucurbit seeds. Food Chem. 221, 1778–1783. doi: 10.1016/j.foodchem.2016.10.104
Song, K.-L., Zhang, C., Peng, J.-Y., Ye, L.-H., Liu, F., and He, Y. (2017). Determination of caffeine content in coffee beans based on laser induced breakdown spectroscopy. Spectrosc. Spectral Anal. 37, 2199–2204. doi: 10.3964/j.issn.1000-0593201707-2199-06
van der Maaten, L., and Hinton, G. (2008). Visualizing data using t-SNE. J. Mach. Learn Res. 9, 2579–2605.
Vapnik, V., and Chapelle, O. (2000). Bounds on error expectation for support vector machines. Neural Comput. 12, 2013–2036. doi: 10.1162/089976600300015042
Velioglu, H. M., Sezer, B., Bilge, G., Baytur, S. E., and Boyaci, I. H. (2018). Identification of offal adulteration in beef by laser induced breakdown spectroscopy (LIBS). Meat Sci. 138, 28–33. doi: 10.1016/j.meatsci.2017.12.003
Wang, W., Kong, W., Shen, T., Man, Z., Zhu, W., He, Y., et al. (2020). Application of laser-induced breakdown spectroscopy in detection of cadmium content in rice stems. Front. Plant Sci. 11:599616. doi: 10.3389/fpls.2020.599616
Xia, J. A., Yang, Y., Cao, H., Zhang, W., Xu, L., Wan, Q., et al. (2018). Hyperspectral identification and classification of oilseed rape waterlogging stress levels using parallel computing. IEEE Access 6, 57663–57675. doi: 10.1109/access.2018.2873689
Yan, T. Y., Xu, W., Lin, J., Duan, L., Gao, P., Zhang, C., et al. (2021). Combining multi-dimensional convolutional neural network (CNN) with visualization method for detection of Aphis gossypii glover infection in cotton leaves using hyperspectral imaging. Front. Plant Sci. 12:15. doi: 10.3389/fpls.2021.604510
Yoosefzadeh-Najafabadi, M., Earl, H. J., Tulpan, D., Sulik, J., and Eskandari, M. (2021). Application of machine learning algorithms in plant breeding: predicting yield from hyperspectral reflectance in soybean. Front. Plant Sci. 11:14. doi: 10.3389/fpls.2020.624273
Yu, K., Woodrow, L., and Poysa, V. (2014). AAC stern soybean. Can. J. Plant. Sci. 94, 457–459. doi: 10.4141/cjps2013-306
Yu, K.-Q., Zhao, Y.-R., Liu, F., and He, Y. (2016). Laser-induced breakdown spectroscopy coupled with multivariate chemometrics for variety discrimination of soil. Sci. Rep. 6, 27574–27584. doi: 10.1038/srep27574
Zhang, C. B., Peng, B., Zhang, W. L., Wang, S. M., Sun, H., Dong, Y. S., et al. (2014). Application of SSR markers for purity testing of commercial hybrid soybean (Glycine max L.). J. Agric. Sci. Technol. 16, 1389–1396.
Zhang, J., Yang, Y., Feng, X., Xu, H., Chen, J., and He, Y. (2020). Identification of bacterial blight resistant rice seeds using terahertz imaging and hyperspectral imaging combined with convolutional neural network. Front. Plant Sci. 11:821. doi: 10.3389/fpls.2020.00821
Zhao, Y., Guindo, M. L., Xu, X., Sun, M., Peng, J., Liu, F., et al. (2019). Deep learning associated with laser-induced breakdown spectroscopy (LIBS) for the prediction of lead in soil. Appl. Spectrosc. 73, 565–573. doi: 10.1177/0003702819826283
Zhu, S., Chao, M., Zhang, J., Xu, X., Song, P., Zhang, J., et al. (2019a). Identification of soybean seed varieties based on hyperspectral imaging technology. Sensors 19, 5225–5239. doi: 10.3390/s19235225
Keywords: soybean seed, variety identification, laser-induced breakdown spectroscopy, convolutional neural network, voting strategy
Citation: Li X, He Z, Liu F and Chen R (2021) Fast Identification of Soybean Seed Varieties Using Laser-Induced Breakdown Spectroscopy Combined With Convolutional Neural Network. Front. Plant Sci. 12:714557. doi: 10.3389/fpls.2021.714557
Received: 25 May 2021; Accepted: 09 September 2021;
Published: 06 October 2021.
Edited by:
Alexis Joly, Research Centre Inria Sophia Antipolis Méditerranée, FranceReviewed by:
Mohsen Yoosefzadeh Najafabadi, University of Guelph, CanadaMichael Gomez Selvaraj, Consultative Group on International Agricultural Research (CGIAR), United States
Copyright © 2021 Li, He, Liu and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fei Liu, ZmxpdUB6anUuZWR1LmNu