 Saad Arif
Saad Arif Saba Munawar
Saba Munawar Hashim Ali
Hashim Ali
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Physiol. , 30 March 2023
Sec. Computational Physiology and Medicine
Volume 14 - 2023 | https://doi.org/10.3389/fphys.2023.1153268
This article is part of the Research Topic Artificial Intelligence in Bioimaging and Signal Processing View all 8 articles
Introduction: Drowsy driving is a significant factor causing dire road crashes and casualties around the world. Detecting it earlier and more effectively can significantly reduce the lethal aftereffects and increase road safety. As physiological conditions originate from the human brain, so neurophysiological signatures in drowsy and alert states may be investigated for this purpose. In this preface, A passive brain-computer interface (pBCI) scheme using multichannel electroencephalography (EEG) brain signals is developed for spatially localized and accurate detection of human drowsiness during driving tasks.
Methods: This pBCI modality acquired electrophysiological patterns of 12 healthy subjects from the prefrontal (PFC), frontal (FC), and occipital cortices (OC) of the brain. Neurological states are recorded using six EEG channels spread over the right and left hemispheres in the PFC, FC, and OC of the sleep-deprived subjects during simulated driving tasks. In post-hoc analysis, spectral signatures of the δ, θ, α, and β rhythms are extracted in terms of spectral band powers and their ratios with a temporal correlation over the complete span of the experiment. Minimum redundancy maximum relevance, Chi-square, and ReliefF feature selection methods are used and aggregated with a Z-score based approach for global feature ranking. The extracted drowsiness attributes are classified using decision trees, discriminant analysis, logistic regression, naïve Bayes, support vector machines, k-nearest neighbors, and ensemble classifiers. The binary classification results are reported with confusion matrix-based performance assessment metrics.
Results: In inter-classifier comparison, the optimized ensemble model achieved the best results of drowsiness classification with 85.6% accuracy and precision, 89.7% recall, 87.6% F1-score, 80% specificity, 70.3% Matthews correlation coefficient, 70.2% Cohen’s kappa score, and 91% area under the receiver operating characteristic curve with 76-ms execution time. In inter-channel comparison, the best results were obtained at the F8 electrode position in the right FC of the brain. The significance of all the results was validated with a p-value of less than 0.05 using statistical hypothesis testing methods.
Conclusions: The proposed scheme has achieved better results for driving drowsiness detection with the accomplishment of multiple objectives. The predictor importance approach has reduced the feature extraction cost and computational complexity is minimized with the use of conventional machine learning classifiers resulting in low-cost hardware and software requirements. The channel selection approach has spatially localized the most promising brain region for drowsiness detection with only a single EEG channel (F8) which reduces the physical intrusiveness in normal driving operation. This pBCI scheme has a good potential for practical applications requiring earlier, more accurate, and less disruptive drowsiness detection using the spectral information of EEG biosignals.
Sleep deprivation and persistent tiredness due to environmental noise and excessive traffic could be the leading cause of driving fatigue. Mental exhaustion and fatigue may cause driving drowsiness onset. Vehicle drivers are more likely to nod off at the steering wheel during long stretches of uninterrupted driving on smooth highways and straight road patches. All these reasons contribute to drowsy driving, which is a leading cause of car accidents (Ahn et al., 2016). These accidents can have devastating personal, societal, and monetary consequences, along with fatalities. So, vehicular safety and driving drowsiness detection methods to avoid dire losses are always motivational aspects for researchers.
There are several subjective and objective methods to detect drowsiness in drivers. Subjective methods include self-assessment report-based test questionnaires to measure the level of drowsiness. Karolinska Sleepiness Scale (KSS), Stanford Sleepiness Scale (SSS), Epworth Sleepiness Scale (ESS), visual analog scale (VAS), and observer-rated sleepiness (ORS) are some self-assessment approaches (Poursadeghiyan et al., 2017; Baiardi et al., 2018). These reports ask individuals to rate their tiredness by answering questions, but most subjects overestimate their drowsiness. Objective methods for driver drowsiness detection rely on measurements of the driver’s physiological and behavioral characteristics or on-road vehicle response to detect signs of drowsiness (Hu, 2017b). These methods do not rely on the driver’s self-assessment report and are considered more reliable than subjective methods. Behavioral methods incorporate computer vision algorithms that use onboard cameras to detect changes in the driver’s behavior (Akrout and Mahdi, 2021). Drowsiness is characterized by facial recognition, frequent yawning, delayed eye closures, rapid blink rates, lowered head posture, microsleep, or dozing-off behaviors (Rundo et al., 2021). However, identifying tiredness with behavioral cues, such as eye blinks, lip movement, yawn frequency, and facial features, may cause false detections. These methods are accurate for online drowsiness detection but require excessive computational power and expensive equipment to run computer vision algorithms on live video feeds (Bamidele et al., 2019). Background variation and poor ambient light might cause erroneous detections. Vehicular methods measure the drowsiness with the driving performance, which is assessed through vehicle response measured with onboard sensors. Parameters such as vehicle speed, driver’s reaction time, continuous lane deviation, missed traffic signs, and steering jerking are used to detect signs of drowsiness (Collet and Musicant, 2019). Tesla, Mercedes Benz, and others use behavioral driver assistance technologies to avoid accidents. Samsung and Eyesight collaborated to track driver attentiveness using facial patterns and features (Jabbar et al., 2020). They introduced assisted steering, automatic braking, lane departure warnings, and variable cruise control. Vehicular methods are not suitable for earlier detection as they ascertain the driver’s drowsiness when an accident is more likely. On the other hand, physiological methods measure various physiological parameters, such as eye movement with electrooculography (EOG), heart rate variability (HRV) with electrocardiography (ECG), and neurophysiological measures with electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS). These methods can detect fatigue and drowsiness using bodily organs such as the heart, muscles, eyes, and brain (Kartsch et al., 2018). Some studies additionally examine the link between drowsiness and alertness using respiratory rate, skin electrochemistry, body temperature, etc. (Adão Martins et al., 2021). These methods are disruptive to the normal driving task and potentially cause the driver discomfort but have shown promising results in detection accuracy (Arif et al., 2021b). As each method has its pros and cons, deciding between vehicular, behavioral, and physiological measures is a challenging task. Drivers require detection systems to be less intrusive as well as more accurate with earlier detection; it is a trade-off between these two aspects. However, all the bodily states primarily originated from the human brain, so it could be a potentially useful location for earlier drowsiness detection if the intrusiveness of the physiological measurement system could be reduced.
Brain activities are classified into three categories: active (intentional tasks like mental arithmetic, computation, and body motion), reactive (response to some external stimulus such as pain, audio, or video), and passive (unintentional activities like drowsiness, intelligence, possessiveness, stress, and fatigue) (Naseer et al., 2016; Qureshi et al., 2017; Nazeer et al., 2020a). Passive brain states are more difficult to detect than active and reactive brain states (Alimardani and Hiraki, 2020; Belo et al., 2021). Detection of sleep or drowsy passive states during attention-seeking tasks like driving is most crucial due to the life risks involved. Non-invasive brain–computer interfaces (BCIs) record the hemodynamic response of the brain, like changes in blood oxygen level, blood flow, and volume with fNIRS or electrophysiological signals and electrical neuronal activity with EEG. Due to low cost and effective utility, EEG and fNIRS-based BCIs are more widely used to detect activities of the brain (Arif et al., 2021b). EEG has comparatively better temporal resolution with less complex hardware, while fNIRS has good spatial resolution and more stable signals (Khan et al., 2018). Some studies are based on hybrid solutions to merge the benefits of both techniques and the application of these methods on real-life subjects (Khan et al., 2021). EEG-based passive BCI (pBCI) for drowsiness detection is a widely used method for measuring and analyzing brain activities during alertness or drowsiness (Min et al., 2017; LaRocco et al., 2020) due to its good temporal resolution. Various methods can be used to analyze the EEG signals and determine the level of drowsiness, such as frequency analysis, correlation analysis, and time domain analysis with machine learning (ML) and deep learning (DL) techniques (Aboalayon et al., 2016). DL techniques may achieve more accuracy; however, they have several potential drawbacks, including data requirements, intensive computations, black box problems, overfitting, and biases. ML algorithms are more promising and effective in avoiding such drawbacks (Khan et al., 2021).
The performance of the activity classification algorithm in the pBCI scheme mainly depends upon the number of features and their extraction complexity. Feature extraction is the process of extracting relevant and informative characteristics from the raw EEG signal to represent the drowsiness level of a driver. These characteristics, also known as features or attributes, are used as input to the classifier. There are several common feature extraction methods used in driving drowsiness detection, including temporal features extracted from the raw EEG signals in the time domain, and they include statistical measures, such as mean, standard deviation, skewness, and kurtosis (Nazeer et al., 2020b; Arif et al., 2021b; Khan et al., 2021). Frequency domain features are extracted from the EEG signals after transforming them into the frequency domain using methods such as Fourier transform, wavelet transform, or short-time Fourier transform. Examples of frequency domain or spectral features include power spectral density (PSD), alpha and beta band powers, and the ratio of different EEG frequency bands (Huang et al., 2014; Hong et al., 2018; Sasaki et al., 2019). Non-linear features are extracted using non-linear methods, such as fractal dimension, approximate entropy, and sample entropy (Li et al., 2018; Zhou and Li, 2020). These methods are used to capture the complex and non-linear dynamics of the EEG signals. However, studies have shown better classification results using spectral features with temporal correlation (Awais et al., 2017).
The channel selection approach to reduce the number of measurement electrodes is effective in reducing the intrusiveness of pBCI. EEG channel selection is the process of selecting specific electrodes on the scalp to measure brain activity from spatially localized regions. It is an important step in EEG-based drowsiness detection systems as it can affect the accuracy and reliability of the detection results. There are multiple methods for EEG channel selection, including statistical methods which use statistical significance tests to select the most informative EEG channels, such as mutual information, entropy, or variance (Alotaiby et al., 2015; Min et al., 2017). Feature-based methods use features extracted from the EEG signal, such as PSD, to select the most relevant channels with maximum information gain (Arif et al., 2021a). ML-based methods use ML algorithms to learn the relationship between the EEG signals and the drowsiness state to select the most relevant channels based on the model performance (Hu, 2017a). The commonly selected channels used in drowsiness detection include the electrodes located over the prefrontal cortex (PFC) (Fp1, Fp2), the central region of the scalp (C3, C4), frontal cortex (FC) (F7, F8), occipital cortex (OC) (O1, O2), and parietal region of the scalp (P3, P4) (Quercia et al., 2018; Kim et al., 2022). These regions are known to be associated with sleep and wakefulness and are commonly used in drowsiness detection studies (Hong and Khan, 2017; Tanveer et al., 2019).
In the preview of the aforestated introduction, this study aimed to develop an EEG-based pBCI scheme that is capable of effective drowsiness detection with less intrusion for drivers and is computationally inexpensive. For this purpose, the primary focus is on feature selection to reduce the feature extraction cost and channel selection to reduce the number of required EEG channels while obtaining higher classification results with ML-based classifiers. In this research work, raw EEG data are collected from drowsy drivers during simulated driving tasks. In a post-hoc analysis of neurophysiological signals, spectral features are extracted from multi-channel EEG data. Then, various feature selection approaches are applied to find the optimal features that are best representative of drowsy and alert brain states. After feature selection, extensive classification is carried out to find the single EEG channel of interest (COI), which is the significant contribution of this study. The experimental setup and adopted methodology are explained in Section 2, with detailed results presented in Section 3 and discussion in Section 4. Section 5 concludes the study with the main findings of the work.
This experimental study was conducted on the EEG dataset collected from 12 right-handed male subjects. The average age of the recruited healthy subjects was 30 ± 2 years. All the participants had developed driving skills with experience of more than 2 years. The subjects were briefed about the study and experimental procedures before the data collection and enquired about their mental and physical fitness. None of the participants had any neurological, psychological, or mental disorders, and all had normal vision. The subjects willingly consented to participate in this study and gave written informed consent. All experiments were conducted according to the latest version of the Declaration of Helsinki. The study was reviewed and approved by the research ethics committee of HITEC University Taxila, Pakistan.
The experimental setup includes a driving simulator with a vehicle-like hardware controller to get a more realistic driving environment and subject responses. All the neurophysiological data acquisition experiments were conducted around 3 AM when sleep-deprived subjects felt most drowsy (Chaput et al., 2020). For all the subjects, data were recorded in multiple sessions on different days with similar environmental conditions to minimize the environmental effects on driving drowsiness. Figure 1 shows the flow diagram of the drowsiness detection scheme and details of the experiment. The subjects were required to experience and familiarize the whole experimental procedure with initial trials of 15 min at least until they got completely accustomed to the controls and environment. The later period of initial trials was used for baseline adjustment and thresholding of EEG signals subject-wise. The experiment was initiated after 5 min of rest. Subjects were assigned the lane-keeping task during simulated driving for at least 45 min, during which synchronous EEG signal recordings were performed for 30 ± 2 min. The pedestrian and traffic densities were kept at minimum in the driving environment. User display and room lighting were kept fairly dim along with quietness in the experiment room to further enhance the drowsiness-inducing conditions for the subjects. The room was vacant so that the subjects could focus on the experiment and their attention would not be diverted. The complete experiment was synchronously recorded for post-hoc data labeling and validation of drowsy/alert biomarkers. The subjects’ faces and physical responses were recorded with multiple cameras from different view angles and with screen recordings of driving performance. The state biomarkers were recorded for significant changes in facial expressions, eye closures, head nodding, lane deviations, abrupt physical responses, etc. The subjects were instructed to minimize unnecessary head and body motions to avoid artifacts in the neurophysiological signals.
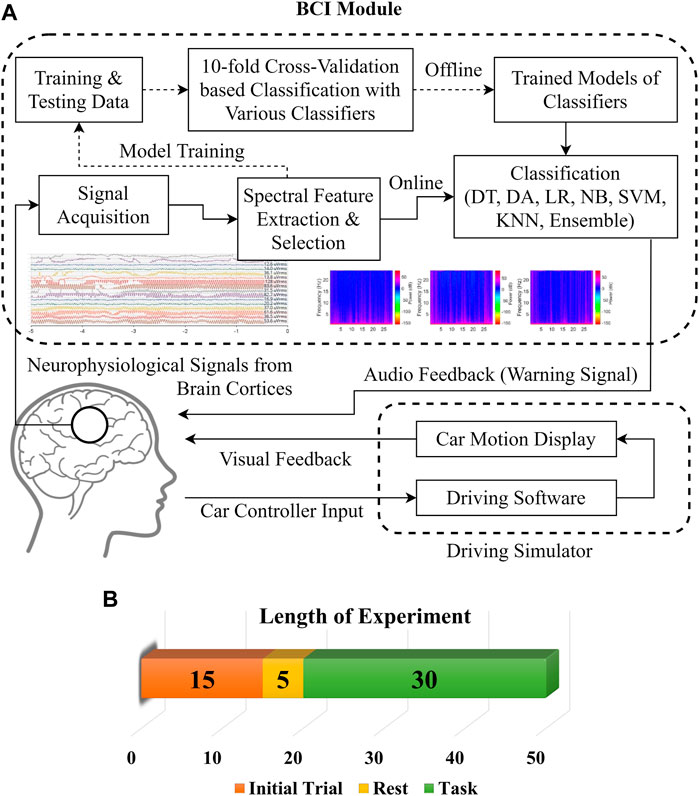
FIGURE 1. (A) Process flow diagram for BCI module. (B) Experiment details.
An OpenBCI Ultracortex Mark-IV EEG headset in a 16-channel configuration is used to acquire neuronal activity from anterior and posterior brain regions, as shown in Figure 2A. The raw EEG signals are recorded at a 125 Hz sampling rate. Figure 2B shows the locations of 16 dry EEG electrodes placed according to the international 10–20 system. This referential montage acquires time-series data from both the right and left hemispheres of the brain in the PFC, FC, OC, temporal, central, and parietal cortices, with references set at the ear lobes. Out of these 16, only six promising channels are selected for detailed analysis based on results from previous studies. Two channels per cortex and one in each hemisphere are selected from the PFC (Fp1, Fp2), FC (F7, F8), and OC (O1, O2) for experimental dataset preparation. One of the main objectives of this study is to find the most promising brain region for drowsiness detection. A single COI is to be determined out of these six selected channels. Such localization of a single COI effectively reduces the sensory hardware, computational cost, and intrusiveness in the normal driving operation. Designed methodology and detailed analysis are performed for this localization task with promising results of drowsiness classification metrics.
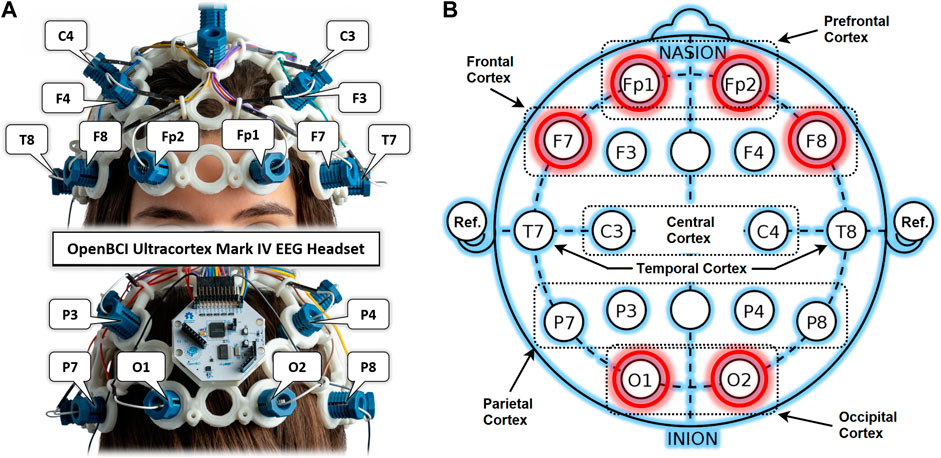
FIGURE 2. (A) OpenBCI Ultracortex Mark-IV EEG headset in a 16-channel configuration. (B) EEG referential montage according to the 10–20 system of electrode placement with selected channels highlighted in red.
Signal processing with Gaussian filters was performed to remove the artifacts within certain frequency ranges and at specific frequencies. Notch reject filters were used to remove 50 Hz and 60 Hz frequencies, which are caused due to electrical interference from equipment circuits, amplifiers, and sensing boards. Artifacts due to Mayer waves and breathing were removed using band reject filters in frequency ranges of <0.01 Hz and 0.3–0.4 Hz, respectively. Higher frequency artifacts >40 Hz were removed from the data using a third-order Butterworth low-pass filter to retain the EEG frequency bands between 0.5–40 Hz. All the subjects are healthy, and none have any myogenic disorders, such as Parkinson’s disease or tremors, which indicates the absence of electromyographic artifacts in the brain signals.
The filtered frequency range of 0.5–40 Hz is further subdivided into five EEG frequency bands which are indicative of the specific physiological conditions of the human body. These are the delta (
The PSD estimates with Welch’s method for all the selected channels are computed to find the channel ranking in terms of promising representation of significant band powers over the entire band range under consideration (0.5–25 Hz). It computes the modified periodograms of overlapping segments with averaging estimation to subdue the overall spectral noise distribution and to avoid spectral information leakage. A hamming window with a 50% overlap between segments is used to calculate power distribution among frequency bins. The non-parametric spectral estimation with Welch’s PSD is computed with the following equations:
where
Another important spectral signature is the spectral band power synchronized with the occurrence time information. It is computed using the spectrograms which represent the time-series signals in frequency and time-frequency domains. Spectrograms computed the individual EEG band dominance in terms of spectral band power for the complete length of the experiment. They are beneficial for observing the band rhythm variations and transitions in discrete time windows synced with the driver’s state labels (Ruffini et al., 2019; Arif et al., 2021a). The spectrograms are computed using the short-time Fourier transform for all the selected channels according to the following relationship:
where
A total of eight spectral features are extracted from the spectral data according to the promising spectral signatures of EEG bands obtained from the spectrograms. The frequency band powers of
where
The other four spectral features are the band power ratio (BPR) indices between the four EEG bands, which are used for drowsiness detection in many studies (Ahn et al., 2016; Diaz et al., 2016). These BPR indicators are computed to capture the inter-band variations during physiological state transitions. The mostly used ratios are given as follows, which are regarded as promising predictors to classify the drowsy and alert shifts with the help of relative band power changes in each windowed segment of the experiment.
These BPR indices are computed for each observation in the dataset of spectral band powers to complete the feature set. Hence, this feature set is collected for the complete length of the experiment for all the selected channels individually.
Feature rescaling/normalization is performed when feature extraction is complete. It is performed to support the data regularization in minimizing the loss function and to achieve faster convergence during classifier model training. All the eight spectral features in the dataset are rescaled using the min-max normalization as follows:
where
The feature space for this BCI scheme comprises all the possible two- to five-dimensional feature combinations of all the spectral features. The combination of all eight features is also included in the feature space. The complete feature space is used for extensive experimentation to find the optimal combination of features, resulting in the best accuracy of drowsiness detection. Figure 3 shows the scatter plots for promising 2D feature pairs of spectral band powers and BPR indices in selected channels. From top to bottom, each row shows the plots for Fp1, Fp2, O1, O2, F7, and F8 channels, respectively. Figure 4 shows the 3D scatter plots for all the possible ternary combinations of five selected features which resulted from the global feature selection approach, as described in the next section. The red and blue data samples from drowsy and alert classes, respectively, are plotted against the respective band power magnitudes on the axes in these feature space plots. The feature values are displayed over a logarithmic scale for better visualization of class dispersion. These plots are analyzed to visually observe the data dispersion and assess the degree of non-linearity involved in class separation boundaries between drowsy and alert states.
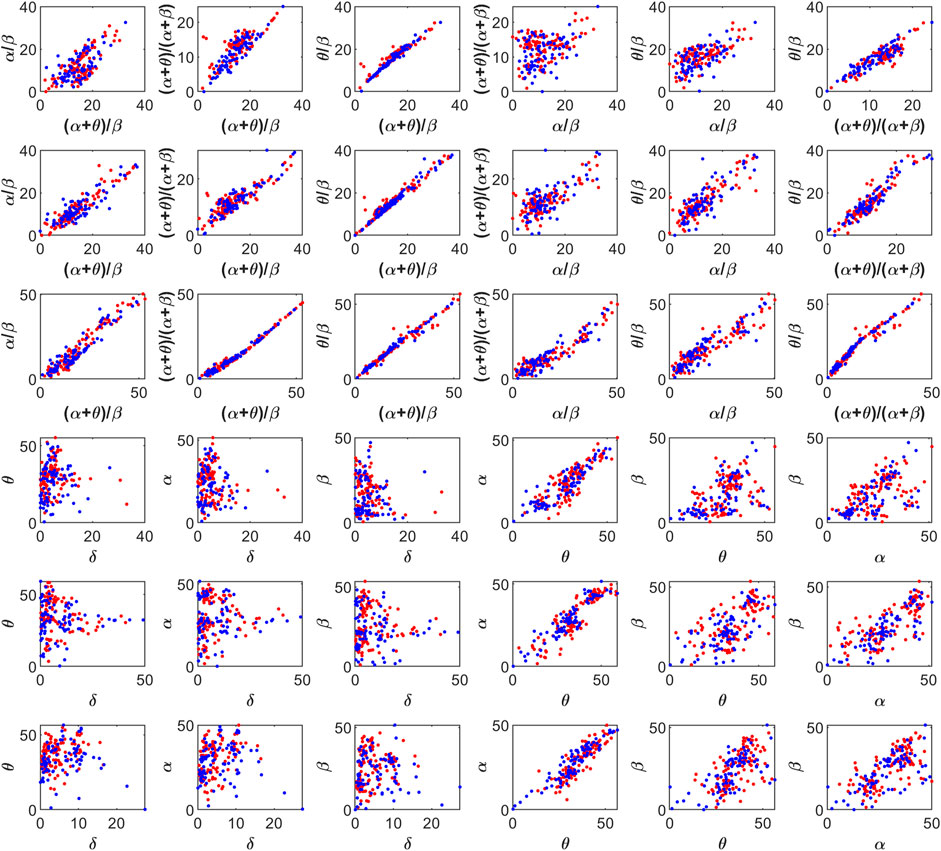
FIGURE 3. 2D scatter plots on a log scale for feature pairs between band power ratios (top three rows), and spectral band powers (bottom three rows). Fp1, Fp2, O1, O2, F7, and F8 channels in each row from top to bottom, respectively. Red and blue data points represent drowsy and alert states, respectively.
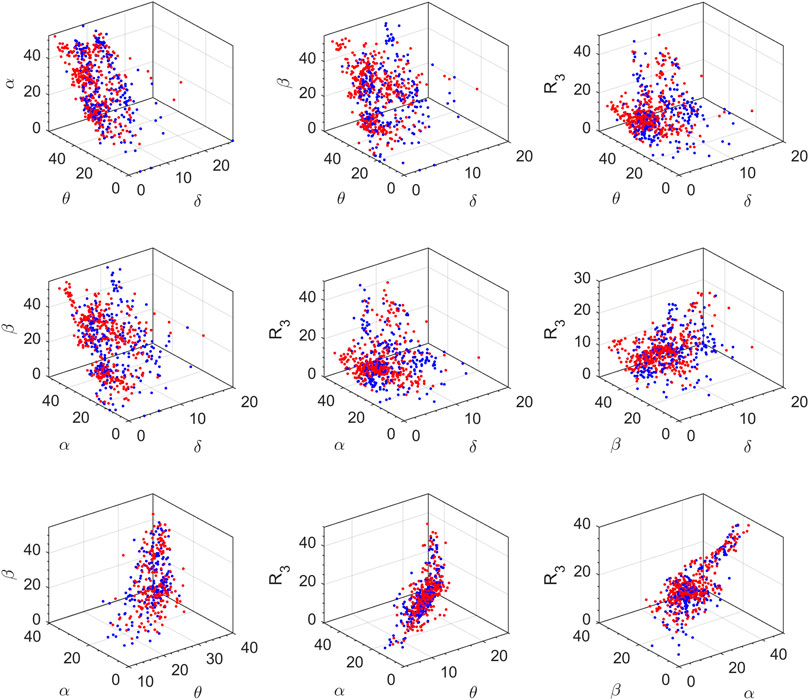
FIGURE 4. 3D scatter plots on a log scale for all the ternary combinations of five top-ranked features. Red and blue data points represent drowsy and alert states, respectively (channel F8, all subjects).
Multiple feature selection methods are used in this study to find the most representative and optimum number of features which give the best prediction results. Feature selection approaches are used to aid the reduction in data dimensionality and computational costs. The classifier training process becomes faster, and convergence is achieved earlier with the optimum number of features used. Primarily, three filter-type feature ranking approaches are applied to this spectral EEG feature set. The embedded-type feature selection approach is also used by training multiple classifiers with developed feature space. The primary feature ranking approaches are discussed in the following section.
The minimum redundancy maximum relevance (MRMR) feature selection method ranks all the features in the feature set in order of maximum inter-feature dissimilarity to subdue the redundant features. Meanwhile, it also checks the maximum relevance of ranked features with the target variable. It ranks the features with a balanced ratio of both these aspects to end up with an optimized feature set ordered by descending predictor importance score (Fathima and Kore, 2021; Pudjihartono et al., 2022). For this purpose, this algorithm performs the redundancy check on all the possible 2D feature pairs of the feature space. The entropy-based mutual information index
Furthermore, the algorithm also performs the relevance check between all the features and responses in the dataset. The obtained optimal feature set
The final predictor importance score is computed by maximizing the mutual information balance for each feature which is the ratio of feature relevance to the feature redundancy. The MRMR method-based predictor importance scores are computed using the fscmrmr built-in function of MATLAB 9.12.
The
where
This filter-type feature selection method measures the quality of features in terms of their ability to effectively differentiate the neighboring samples when they belong to different classes. Unlike other feature selection approaches which measure the dependence of features and the response variable, this method determines the feature importance by examining the number of observations. This algorithm increases or decreases the weight of each feature based on the comparative variance in its value for the same and different class neighboring samples (Fathima and Kore, 2021; Pudjihartono et al., 2022). All feature weights are initialized with zero and updated after each iteration of the algorithm. In each iteration, the algorithm selects a random observation and finds the k number of nearest neighboring observations from each class of the response variable using the Manhattan distance metric or L1 norm. After neighbor selection, the feature vectors of all the observations are compared feature-wise, and the cumulative magnitude of difference in each predictor’s value is computed. If a feature shows less variance for observations in the same class as compared to those from different classes, then its weight is updated with an increase. The weight update of the feature is penalized with a decrease if its value shows comparatively higher variance for the neighboring observations of the same class. Similarly, the weights of all the features get updated at each iteration of the algorithm. The following relationships represent the feature weight updating criteria of the algorithm:
where
The ReliefF algorithm performs such iterations for all the observations to increase its reliability with the highest probability estimates, particularly for smaller datasets having a lesser number of observations. This exhaustive computation is well suited for smaller datasets but incurs computational penalties with larger datasets (Pudjihartono et al., 2022). In that case, the choice of random sampling for observations is best with the significant number of iterations by keeping in view the computational cost admissibility. Generally, the number of algorithm iterations is dependent upon the probability estimates of the required reliability level. Finally, the features are ranked according to their weights after complete iterations of the algorithm. The predictor importance score is calculated with this algorithm using the relieff built-in function of MATLAB 9.12.
The global predictor importance (GPI) is calculated to find the global feature ranking influenced by each of the aforementioned feature selection methods. As all three approaches give predictor importance scores in different ranges with different means and variances, they cannot be averaged out to get their cumulative effect. Normalizing the importance scores in the same range with typical normalization methods and calculating their mean is not a viable solution either because this approach results in altering the skewness and kurtosis of the original shape distribution (Nazeer et al., 2020b; Singh and Singh, 2020). The considerable drop in the feature importance score of adjacent ranked features is a considerable factor in feature selection as it shows the decrease in response predictive power of low-ranked features. Skewness and kurtosis of the original distribution must be retained when getting the cumulative effect. For this purpose, the GPI is calculated as follows, using the
where
Multiple supervised learning-based classification methods are used to perform binary classification of drowsiness and alert neurophysiological states of driving subjects. Seven classifiers are used in this study: decision trees (DT), discriminant analysis (DA), logistic regression (LR), naïve Bayes (NB), support vector machines (SVM), k-nearest neighbor (
The classification DT algorithm expands the flowchart-like tree structure with features at branches, feature split tests at nodes, and classification decisions at leaf nodes. The tree data structure expands to include features with minimum entropy and maximum information gain, leading to zero entropy leaf nodes which are class labels. This classifier is implemented using the fitctree built-in function of MATLAB with three sets of hyperparameters. The tuned hyperparameter is the maximum number of splits which is the tree depth controlling factor, while the other hyperparameter is the split criterion which is fixed to Gini’s diversity index. The tree depth controlling factor is a significant parameter that should be increased to increase the classification accuracy at the expense of increased training time. The increase in the predictive power of the DT also increases its complexity level. Highly blended data dispersion of distinct classes requires a greater number of tree splits to draw fine class-distinction boundaries. The increase in non-linearity of class separation boundaries requires a greater number of splits to achieve better classification accuracy. Three presets of DT are tested here with 100, 20, and 4 splits at maximum and are known as fine, medium, and coarse trees, respectively.
The DA classifier tends to establish a linear or quadratic combination of features to make simpler decision boundaries between different class data. Generally, it has a linear and a quadratic variant, known as linear discriminant analysis (LDA) and quadratic discriminant analysis (QDA), respectively, along with diagonal linear and diagonal quadratic variants. LDA draws linear class separation boundaries with the assumption of Gaussian distribution of the classes, while QDA draws non-linear class separation boundaries of parabolic, hyperbolic, or elliptical trends for blended data dispersion. These methods use the full covariance structure of the data and converge rapidly. They have good classification accuracy for distinctive data scatters. Both variants are implemented using the fitcdisc function of MATLAB.
The LR classifier uses the logistic or sigmoid function to classify the class probabilities for binary classification problems. The binomial LR classifier is implemented here using the generalized linear regression model fitglm function of MATLAB. Like DA methods, LR is also faster to train, but classification accuracy may degrade when data scatter plots do not have distinctive class separation boundaries. The binomial logistic regression function is represented by the following equation:
where
The NB classifier performs probabilistic classification based on Bayes’ theorem with an assumption of inter-feature independence. It works on prior and posterior probabilities of features with probability density estimation functions. The two presets for numeric predictors are the Gaussian NB and kernel NB which are applied here using the fitcnb function of MATLAB. The Gaussian NB works on the assumption of normal distribution of the data among response classes. The kernel NB applies the kernel distribution function on numeric predictors with Gaussian-type kernel smoother. The NB classifiers are generally faster in training convergence but achieve good classification accuracy with the categorical predictors as compared to numeric features.
The SVM classifier establishes the hyperplanes for class separation boundaries using the polynomial kernel function and radial basis function (RBF) kernels. The objective of the algorithm is to find the hyperplane with the maximum margin. The linear, quadratic, and cubic polynomial kernel functions are used to generate respective hyperplanes, but they are computationally expensive for higher dimensional data and take a significant amount of training time without a significant increase in accuracy (Qureshi et al., 2016). On the other hand, the RBF kernel-based Gaussian SVM achieves better classification accuracies with less training time for higher dimensional data as well. They are also effective for classifying the non-linear boundaries of mixed-class data dispersions. The SVM is applied using the fitcsvm function of MATLAB for this binary classification problem. Three Gaussian SVM presets are used here, namely, fine, medium, and coarse Gaussian SVM, which differ by Gaussian kernel scale of values
The
The ensemble classifier aggregates the cumulative performance of various weak learners to achieve higher accuracy. It is implemented using the fitcensemble function of MATLAB with various hyperparameters like the ensemble method, the maximum number of splits for DT learners, the number of weak learners, and the learning rate. The number of learners is set to 30 to avoid delayed convergence and yet achieve higher detection accuracy. The adaptive boosting (AdaBoost) and random under-sampling boost (RUSBoost) ensemble methods with a learning rate of 0.1 and 20 maximum splits are the boosted trees and RUSBoosted trees, respectively. The bootstrap aggregating (bagging) ensemble method with random forest DT and 3002 number of splits is bagged trees. The subspace discriminant (DA learner) and subspace
The confusion matrix-based classification performance evaluation metrics are used to show the results of this study. In this driving drowsiness detection scheme, the drowsy brain state is a positive class (
Classification accuracy gives the measure of the correct prediction power of the classifier with the ratio of correct prediction of both the brain states to the total population of the dataset. It is calculated as
Precision or positive predictive value (
Recall, sensitivity, or true-positive rate (
F1-score gives the harmonic mean of the sensitivity and precision of the classifier to find a balanced measure of correct identification of drowsiness out of all the positive predictions and all actual positive states in the dataset.
Specificity, selectivity, or true-negative rate (
Matthews correlation coefficient (MCC) represents the relationship between the actual and predicted responses in the presence of a class imbalance in the dataset (Akhtar et al., 2022). It overcomes the bias effect in the predictions caused by the probability shift due to class imbalance and gives a reliable and balanced measure of the classifier’s prediction capability.
Cohen’s kappa coefficient (
Fall-out or false-positive rate (
In addition to the aforementioned metrics, the overall performance of the trained classifiers is shown by the receiver operating characteristics (ROC) curve and area under the curve (AUC), which is plotted between the recall and fall-out. The well-trained models have higher
In the initial testing of the data, Welch’s PSD estimates were analyzed to observe the spectral information gain among selected EEG channels. Figure 5 shows the PSD distribution over the complete frequency range of
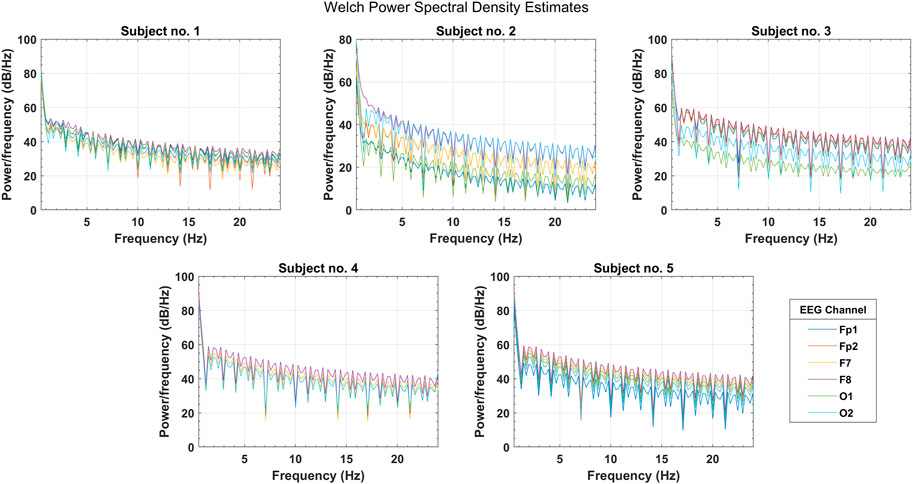
FIGURE 5. Welch’s power spectral density estimates for selected PFC, FC, and OC channels over the spectral range of four EEG bands (subjects 1–5).
After the PSD estimates, the spectrograms were visually analyzed to access the effectiveness of the selected channels in representing the frequency distribution among the EEG bands. Figure 6 represents the spectrograms computed for each selected channel over the complete length of the experiment showing the spectral band power distribution. The vertical orange spikes rising above 20 Hz are the time instances of alert states when subjects were engaged in mental computation during the driving task. In such scenarios, band powers are higher among all the bands, especially in the
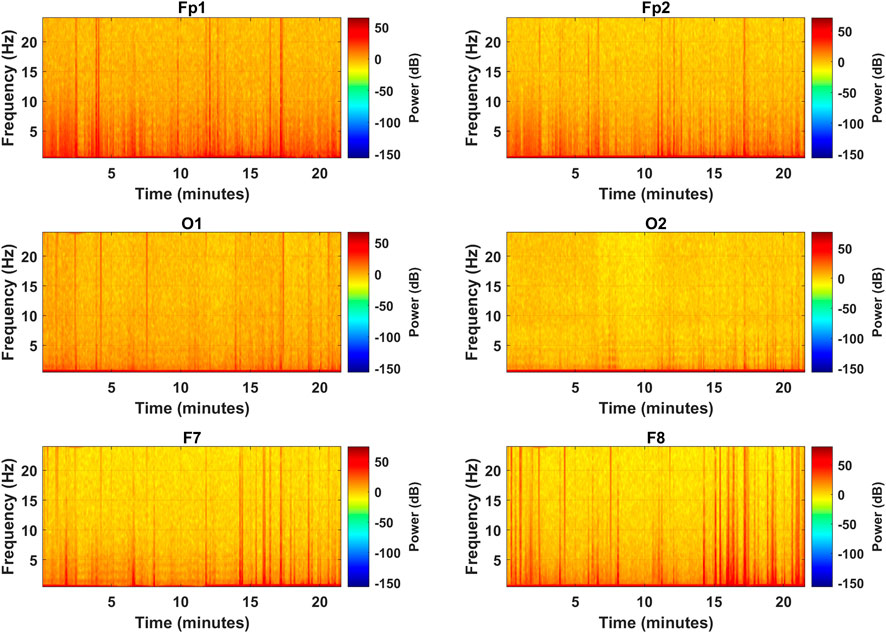
FIGURE 6. Spectrograms for the complete experiment over the frequency range of all EEG bands for the selected channels (subject 2).
The F8 channel was further investigated band-wise to ascertain the individual band powers as representative features for brain state classification. The subject was alert at the start and end of the experiment, with intermittent alert states at the 16th, 17th, and 19th minutes, as shown in Figure 7. During these instances, the higher band power spikes in all the bands can be observed with up to 35 dB, 40 dB, 45 dB, and 50 dB magnitudes in
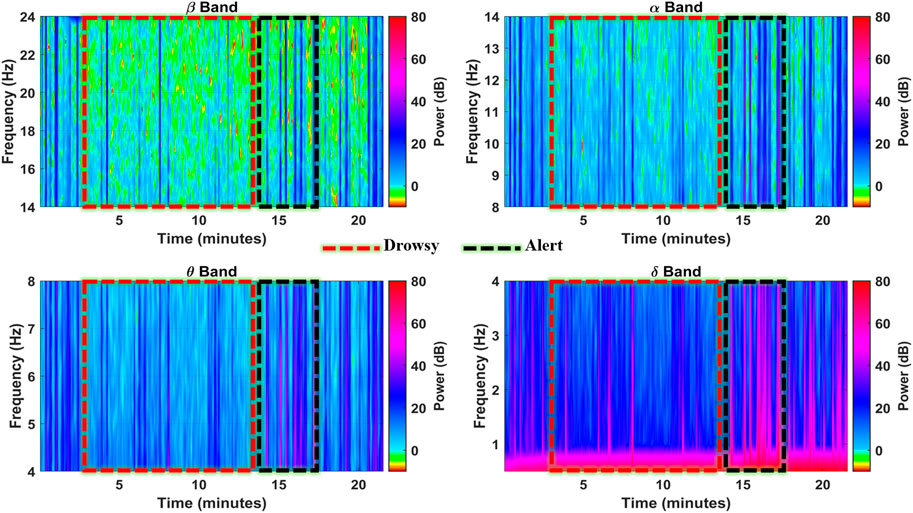
FIGURE 7. Spectrograms showing spectral band powers in individual EEG frequency bands in the F8 channel (subject 4).
The results of the three feature selection approaches and their cumulative effect on global feature ranking are shown in Figure 8. According to the MRMR algorithm, only the
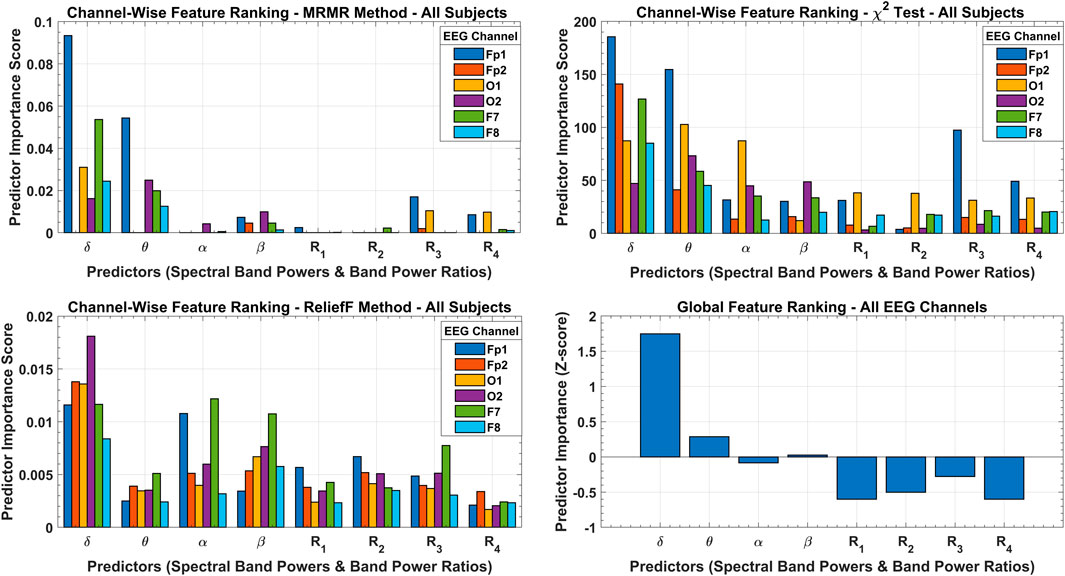
FIGURE 8. Channel-wise feature ranking with MRMR, chi-square, and ReliefF methods with predictor importance scores over all subjects’ data. The cumulative effect of all feature selection methods is shown with a global feature ranking scheme with predictor importance in terms of Z-score.
To ensure the results of global feature ranking, the exhaustive embedded-type feature selection is performed based on the maximum relevance of the feature set to the response variable and is evaluated with the help of detection accuracy. Figure 9A shows the ensemble classification accuracy for all 2D feature pairs and higher-order combinations. All combinations of
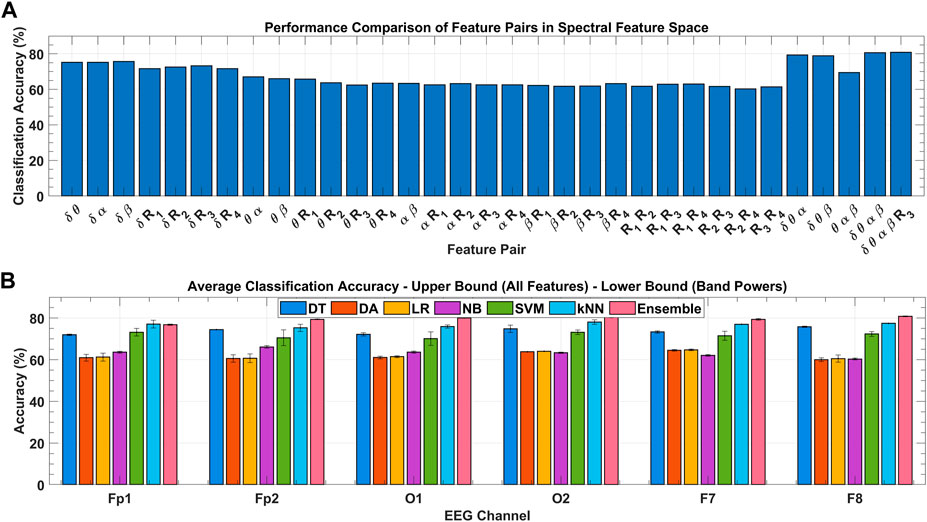
FIGURE 9. (A) Classification performance comparison among feature combinations of spectral feature space for the F8 channel with ensemble classifier over all subject’s data. (B) Classification performance comparison among various classifiers for the F8 channel over all subject’s data with variance bounds obtained with varying feature combinations.
Figure 9B shows the channel-wise average classification accuracies obtained using the seven classifiers under consideration over all subjects’ data. Error bars in each classifier were obtained with the use of different feature sets. Upper and lower bounds mark the accuracy obtained with the classification using; all eight spectral features, and the four band powers, respectively. In inter-classifier comparison, ensemble,
A similar classification process is also performed for all the subjects individually. Table 1 tabulates the subject-wise average classification accuracies obtained using all spectral features in all the selected channels. The best-performing variant of each classifier is also mentioned. The maximum accuracy achieved by a classifier with its preset is highlighted with bold values. Results are shown here for five subjects only, and statistical significance test results are discussed to conclude the entire population. All the classifiers achieved the highest accuracies in the F8 channel most of the time, with few exceptions of very insignificant differences, whereas the ensembles of bagged and boosted trees achieved the highest accuracies among all the classifiers in each EEG channel. There is a minor difference in the performance of ensemble,
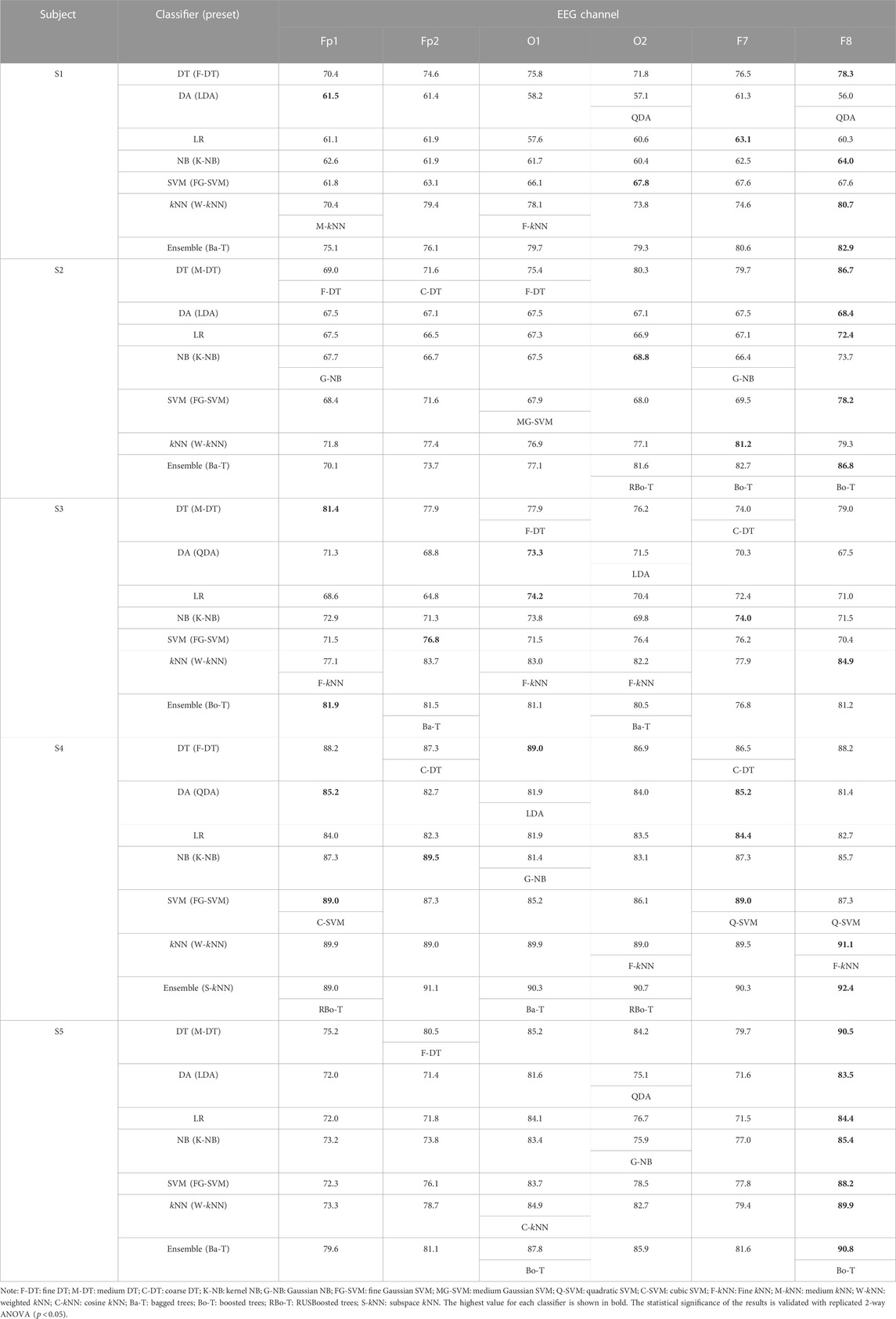
TABLE 1. Average classification accuracies (%) obtained with all spectral features, for all channels, and all the classifiers with best-performing presets (subjects 1–5).
Figure 10A presents the heat map chart showing the best classification accuracies obtained for all the classifiers using the four most important spectral features (EEG band powers). These accuracies were obtained over five classification trials of each method in each channel. In addition, 10-fold cross-validation was used in each trial. All the classifiers achieved 60% and above classification accuracy, which is the minimum confidence threshold for BCI applications. Overall, the ensemble method achieved the best classification results among all the classifiers in all channels, with 85.6% highest accuracy obtained in the F8 channel of the right FC. The Fp2 is ranked second, followed by OC, and the left hemisphere is the last in this channel ranking. Figure 10B shows the execution time in milliseconds (ms) for all the classifiers. The LR classifier has the minimum execution time but achieved the minimum accuracies among all. In the best-performing classifiers, the ensemble model took the least execution time of 76 ms. The statistical significance of these results is validated with 2-way ANOVA tests. The inter-classifier comparison shows the statistically significant performance of the ensemble classifier (
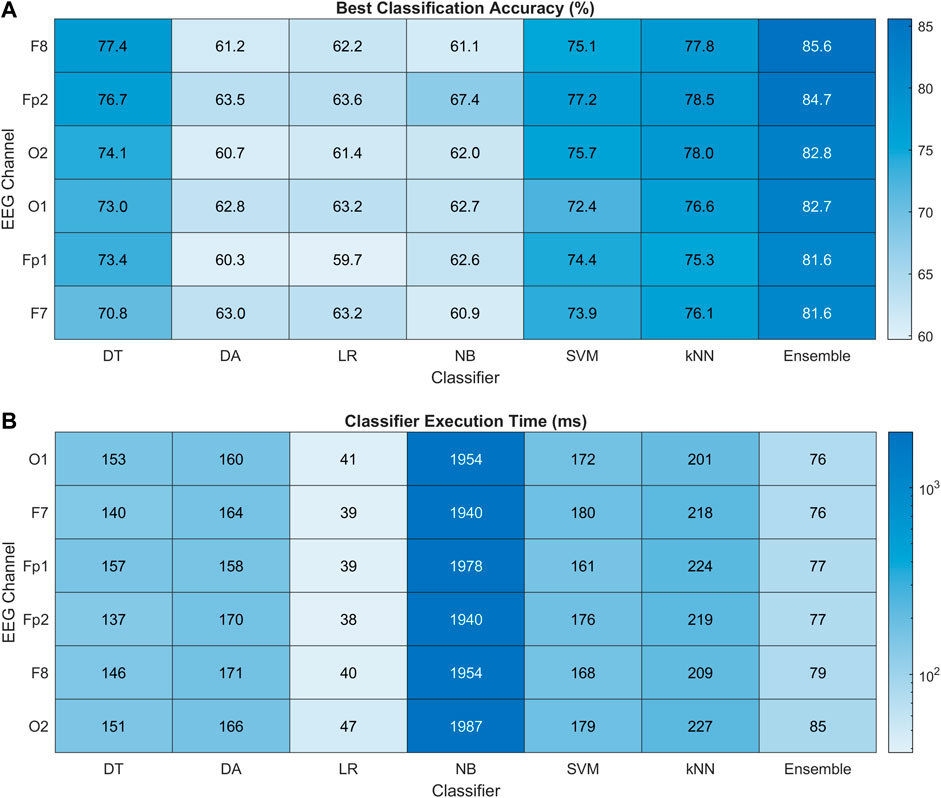
FIGURE 10. (A) Heat map chart for performance comparison with percentage accuracy of all the classification methods using
The corresponding confusion matrices and ROC curves for binary classification in each channel with the optimized ensemble are shown in Figure 11. Class labels “1” and “0” are assigned to drowsy and alert brain states, respectively. In Figure 11A, the diagonal and off-diagonal entries represent the correct and false classification percentages, respectively, with the normalized sample distribution in each class. The overall false detection rate is less in the range of 14%–18% against the higher accuracies. In Figure 11B, the ROC curves between sensitivity and fall-out represent the well-trained classifiers with 0.90 AUC, 88% sensitivity, and 23% fall-out on average for the drowsy class. The complete performance of the trained models is assessed with the help of other metrics too.
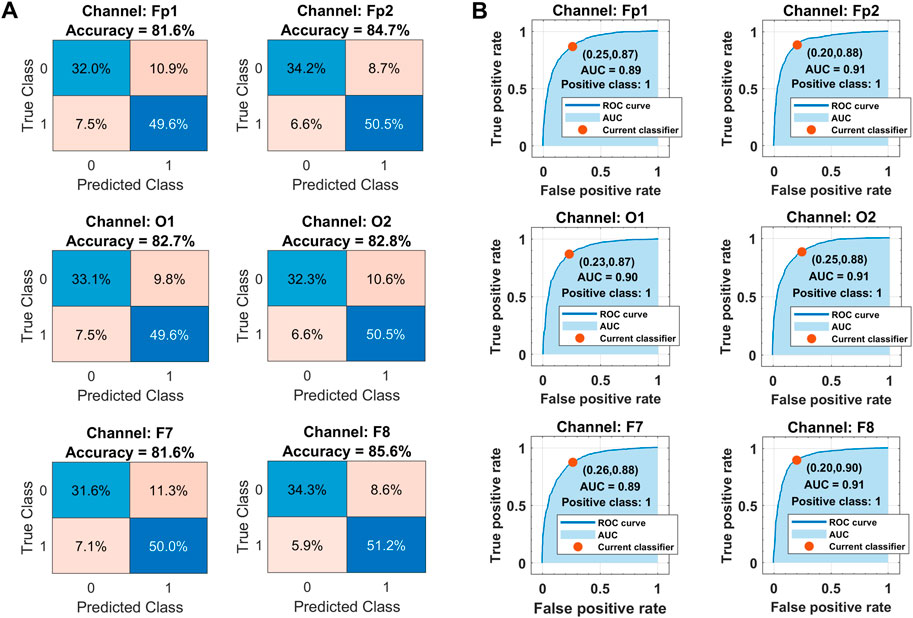
FIGURE 11. (A) Classification results in terms of confusion matrices. (B) Receiver operating characteristics curves over all subjects’ data in each selected channel with Bayesian optimization-based ensemble classifier. Class labels: 1 = drowsy, 0 = alert.
Table 2 shows the channel-wise results of confusion matrix-based performance assessment metrics obtained with the optimized ensemble classifier. Mainly, the optimized ensemble method is selected along with other hyperparameters’ tuning using Bayesian optimization. Multiple optimization sessions supported the confidence in using bagged trees to obtain the best classification results. All these reported results are obtained with bagged tree-based ensemble classifier and GPI ranked features, for all subjects’ data. The best results of all the metrics are obtained in the F8 channel, with 85.6% accuracy and precision, 89.7% sensitivity, 87.6% F1-score, 80% selectivity, 70.3% MCC, 70.2% kappa score, and 91% AUC. The single COI selection is validated with multiple paired Student’s
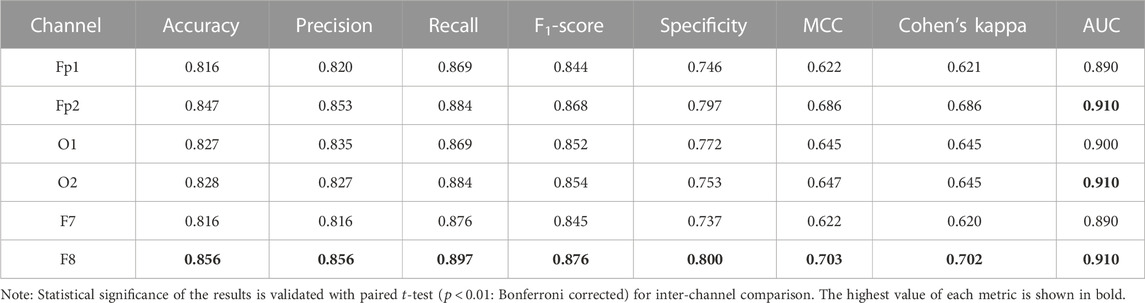
TABLE 2. Confusion matrix-based performance evaluation metrics over all subjects’ data with globally ranked features and Bayesian optimization-based ensemble classifier.
This EEG-based neurophysiology study is focused on achieving multiple objectives like feature selection to minimize the feature extraction cost at runtime, achieving higher drowsiness detection accuracy, and EEG channel selection to spatially localize the promising brain location for drowsiness detection. Reducing the number of electrodes up to one is achieved with channel selection. The single COI makes the pBCI hardware ergonomic by minimizing intrusion into normal driving tasks with accurate detection of passive brain activity. Various studies have investigated EEG-based drowsiness detection, but very few studies have worked upon all these objectives together to the best of the authors’ knowledge. The proposed pBCI scheme is compared with a few existing studies on various aspects, and the comparison results are summarized in Table 3. These works are similar and comparable as they have presented the offline driver drowsiness detection scheme based on physiological data collected during the lane-keeping task in a simulated driving environment.
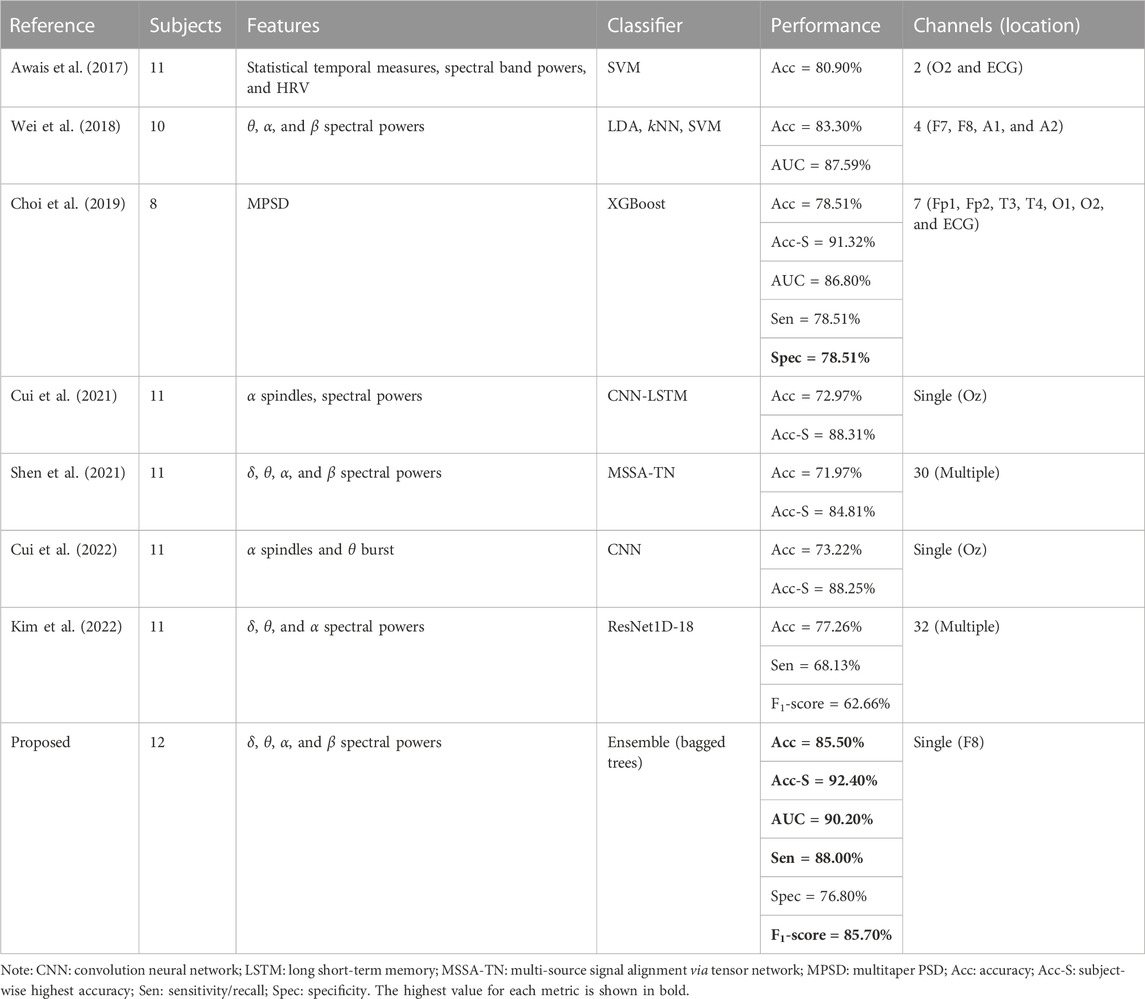
TABLE 3. Detailed comparison of proposed drowsiness detection scheme with existing studies.
The feature extraction process significantly increases the processing time and computational cost during real-time classification tasks when a large number of features are involved. Predictor importance-based feature selection methods greatly optimize the feature extraction process by selecting only the promising and important features which are best representative of the response variable. Cui et al. (2021), Shen et al. (2021), Cui et al. (2022), and Kim et al. (2022) used DL models for feature extraction and classification, which incur higher computational costs, but they used spectral features, which are more effective and representative of physiological brain states. On the other hand, Awais et al. (2017), Wei et al. (2018), and Choi et al. (2019) used self-extracted spectral features and conventional ML classifiers for drowsiness detection, similar to this study. It is to be noted that the mentioned ML-based studies achieved higher classification accuracies and other metrics as compared to DL-based works. A possible reason for this difference is the use of hybrid physiological measures as Awais et al. (2017) and Choi et al. (2019) used ECG in addition to EEG measurements; Awais et al. (2017) also used statistical temporal features in their work. Both these studies used
The experimental procedure, collected dataset, used feature set, and time of drowsiness detection window have posed a few limitations in this study. As the dataset is collected during a simulated driving environment with offline data processing of the experiment, real driving experience may pose different issues for the proposed work. The participants belong to a certain age group with less frequent driving experience, so the proposed scheme should be adaptive for different classes of subjects. This study is focused on EEG spectral signatures only, so limited feature domains may have performance limitations. This work is effective for drowsiness detection in a 10-s time window, which should be reduced for earlier detection. In our ongoing research, neurophysiological data in controlled real driving experiments are being collected from comparatively aged subjects with higher commute frequencies as they are more likely to experience driving drowsiness. Furthermore, a new pBCI scheme is being developed with a significantly shorter time window for earlier drowsiness detection. The time domain characteristics of EEG, hybrid physiological measures, and DL-based classifiers are also being explored for further performance enhancement.
This study is aimed at designing a passive brain–computer interface (pBCI) scheme for driving drowsiness detection with minimum disruption to the driving task. As all the physiological states originate from the human brain, it is a promising location for earlier drowsiness detection in objective methods than that of behavioral and vehicular measures. The objective is to develop such a pBCI system that must be ergonomically less intrusive and easy to wear or place at the driver’s brain. It is possible if the pBCI scheme uses a fewer number of electrodes. To find out the single channel of interest is the main objective of this work.
The computational cost and algorithm execution time are minimized by introducing the feature ranking scheme in the feature extraction process. Multiple filter-type feature selection methods are ensembled with
The presented single COI-based EEG neurophysiology scheme has a minimal ergonomic design which is easy to wear and less disruptive to normal driving tasks and practically detects the drowsiness correctly at an earlier stage to avoid life loss in vehicular driving scenarios. Improving the detection results with statistical temporal and spatiotemporal features in a smaller detection window or deep learning-based automatic feature extraction methods is the future direction of this study.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by the research ethics committee of HITEC University Taxila, Pakistan. The patients/participants provided their written informed consent to participate in this study.
SA conceived the study and was involved in the design of experiments, data curation, methodology, and writing of the manuscript. SM was involved in the literature review, data collection and processing, formal analysis, visualization, and writing of the manuscript. HA proposed the project and was involved in checking and validation of results, manuscript editing, funding acquisition, and project supervision. All authors have read and agreed to the published version of the manuscript.
This research was supported by Nazarbayev University, Kazakhstan, through Social Policy Research Grant Program (SPRG) grant.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abidi, A., Ben Khalifa, K., Ben Cheikh, R., Valderrama Sakuyama, C. A., and Bedoui, M. H. (2022). Automatic detection of drowsiness in EEG records based on machine learning approaches. Neural Process. Lett. 54, 5225–5249. doi:10.1007/s11063-022-10858-x
Aboalayon, K. a. I., Faezipour, M., Almuhammadi, W. S., and Moslehpour, S. (2016). Sleep stage classification using EEG signal analysis: A comprehensive survey and new investigation. Entropy 18, 272. doi:10.3390/e18090272
Adão Martins, N. R., Annaheim, S., Spengler, C. M., and Rossi, R. M. (2021). Fatigue monitoring through wearables: A state-of-the-art review. Front. physiology 12, 790292. doi:10.3389/fphys.2021.790292
Ahn, S., Nguyen, T., Jang, H., Kim, J. G., and Jun, S. C. (2016). Exploring neuro-physiological correlates of drivers' mental fatigue caused by sleep deprivation using simultaneous EEG, ECG, and fNIRS data. Front. Hum. Neurosci. 10, 219. doi:10.3389/fnhum.2016.00219
Akhtar, T., Arif, S., Mushtaq, Z., Gilani, S. O., Jamil, M., Ayaz, Y., et al. (2022). “Ensemble-based effective diagnosis of thyroid disorder with various feature selection techniques,” in 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 09-11 May 2022 (IEEE), 14–19.
Akhtar, T., Gilani, S. O., Mushtaq, Z., Arif, S., Jamil, M., Ayaz, Y., et al. (2021). Effective voting ensemble of homogenous ensembling with multiple attribute-selection approaches for improved identification of thyroid disorder. Electronics 10, 3026. doi:10.3390/electronics10233026
Akrout, B., and Mahdi, W. (2021). A novel approach for driver fatigue detection based on visual characteristics analysis. J. Ambient Intell. Humaniz. Comput. 14, 527–552. doi:10.1007/s12652-021-03311-9
Ali, I., Mushtaq, Z., Arif, S., Algarni, A. D., Soliman, N. F., and El-Shafai, W. (2023). Hyperspectral images-based crop classification scheme for agricultural remote sensing. Comput. Syst. Sci. Eng. 46, 303–319. doi:10.32604/csse.2023.034374
Alimardani, M., and Hiraki, K. (2020). Passive brain-computer interfaces for enhanced human-robot interaction. Front. Robotics AI 7, 125. doi:10.3389/frobt.2020.00125
Alotaiby, T., El-Samie, F. E. A., Alshebeili, S. A., and Ahmad, I. (2015). A review of channel selection algorithms for EEG signal processing. EURASIP J. Adv. Signal Process. 2015, 66–21. doi:10.1186/s13634-015-0251-9
Arif, S., Arif, M., Munawar, S., Ayaz, Y., Khan, M. J., and Naseer, N. (2021a). “EEG spectral comparison between occipital and prefrontal cortices for early detection of driver drowsiness,” in International Conference on Artificial Intelligence and Mechatronics Systems (AIMS), Bandung, Indonesia, 28-30 April 2021 (IEEE), 1–6.
Arif, S., Khan, M. J., Naseer, N., Hong, K. S., Sajid, H., and Ayaz, Y. (2021b). Vector phase analysis approach for sleep stage classification: A functional near-infrared spectroscopy-based passive brain–computer interface. Front. Hum. Neurosci. 15, 658444. doi:10.3389/fnhum.2021.658444
Awais, M., Badruddin, N., and Drieberg, M. (2017). A hybrid approach to detect driver drowsiness utilizing physiological signals to improve system performance and wearability. Sensors 17, 1991. doi:10.3390/s17091991
Baiardi, S., La Morgia, C., Sciamanna, L., Gerosa, A., Cirignotta, F., and Mondini, S. (2018). Is the Epworth Sleepiness Scale a useful tool for screening excessive daytime sleepiness in commercial drivers? Accid. Analysis Prev. 110, 187–189. doi:10.1016/j.aap.2017.10.008
Bamidele, A. A., Kamardin, K., Abd Aziz, N. S. N., Sam, S. M., Ahmed, I. S., Azizan, A., et al. (2019). Non-intrusive driver drowsiness detection based on face and eye tracking. Int. J. Adv. Comput. Sci. Appl. 10, 775. doi:10.14569/ijacsa.2019.0100775
Belo, J., Clerc, M., and Schön, D. (2021). EEG-based auditory attention detection and its possible future applications for passive BCI. Front. Comput. Sci. 3, 661178. doi:10.3389/fcomp.2021.661178
Chaput, J. P., Dutil, C., Featherstone, R., Ross, R., Giangregorio, L., Saunders, T. J., et al. (2020). Sleep timing, sleep consistency, and health in adults: A systematic review. Appl. Physiology, Nutr. Metabolism 45, S232–S247. doi:10.1139/apnm-2020-0032
Choi, H. S., Min, S., Kim, S., Bae, H., Yoon, J. E., Hwang, I., et al. (2019). Learning-based instantaneous drowsiness detection using wired and wireless electroencephalography. IEEE Access 7, 146390–146402. doi:10.1109/access.2019.2946053
Collet, C., and Musicant, O. (2019). Associating vehicles automation with drivers functional state assessment systems: A challenge for road safety in the future. Front. Hum. Neurosci. 13, 131. doi:10.3389/fnhum.2019.00131
Croce, P., Quercia, A., Costa, S., and Zappasodi, F. (2018). Circadian rhythms in fractal features of EEG signals. Front. physiology 9, 1567. doi:10.3389/fphys.2018.01567
Cui, J., Lan, Z., Liu, Y., Li, R., Li, F., Sourina, O., et al. (2022). A compact and interpretable convolutional neural network for cross-subject driver drowsiness detection from single-channel EEG. Methods 202, 173–184. doi:10.1016/j.ymeth.2021.04.017
Cui, J., Lan, Z., Zheng, T., Liu, Y., Sourina, O., Wang, L., et al. (2021). “Subject-independent drowsiness recognition from single-channel EEG with an interpretable CNN-LSTM model,” in International Conference on Cyberworlds (CW), Caen, France, 28-30 September 2021 (IEEE), 201–208.
Diaz, B. A., Hardstone, R., Mansvelder, H. D., Van Someren, E. J., and Linkenkaer-Hansen, K. (2016). Resting-state subjective experience and EEG biomarkers are associated with sleep-onset latency. Front. Psychol. 7, 492. doi:10.3389/fpsyg.2016.00492
Fathima, S., and Kore, S. K. (2021). Formulation of the challenges in brain-computer interfaces as optimization problems—A review. Front. Neurosci. 14, 546656. doi:10.3389/fnins.2020.546656
Hong, K. S., Khan, M. J., and Hong, M. J. (2018). Feature extraction and classification methods for hybrid fNIRS-EEG brain-computer interfaces. Front. Hum. Neurosci. 12, 246. doi:10.3389/fnhum.2018.00246
Hong, K. S., and Khan, M. J. (2017). Hybrid brain–computer interface techniques for improved classification accuracy and increased number of commands: A review. Front. neurorobotics 35, 35. doi:10.3389/fnbot.2017.00035
Hu, J. (2017a). Automated detection of driver fatigue based on AdaBoost classifier with EEG signals. Front. Comput. Neurosci. 11, 72. doi:10.3389/fncom.2017.00072
Hu, J. (2017b). Comparison of different features and classifiers for driver fatigue detection based on a single EEG channel. Comput. Math. methods Med. 2017, 5109530. doi:10.1155/2017/5109530
Huang, C. S., Lin, C. L., Ko, L. W., Liu, S. Y., Su, T. P., and Lin, C. T. (2014). Knowledge-based identification of sleep stages based on two forehead electroencephalogram channels. Front. Neurosci. 8, 263. doi:10.3389/fnins.2014.00263
Jabbar, R., Shinoy, M., Kharbeche, M., Al-Khalifa, K., Krichen, M., and Barkaoui, K. (2020). “Driver drowsiness detection model using convolutional neural networks techniques for android application,” in IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 02-05 February 2020 (IEEE), 237–242.
Kartsch, V. J., Benatti, S., Schiavone, P. D., Rossi, D., and Benini, L. (2018). A sensor fusion approach for drowsiness detection in wearable ultra-low-power systems. Inf. Fusion 43, 66–76. doi:10.1016/j.inffus.2017.11.005
Khan, H., Naseer, N., Yazidi, A., Eide, P. K., Hassan, H. W., and Mirtaheri, P. (2021). Analysis of human gait using hybrid EEG-fNIRS-based BCI system: A review. Front. Hum. Neurosci. 14, 613254. doi:10.3389/fnhum.2020.613254
Khan, R. A., Naseer, N., Qureshi, N. K., Noori, F. M., Nazeer, H., and Khan, M. U. (2018). fNIRS-based Neurorobotic Interface for gait rehabilitation. J. neuroengineering rehabilitation 15, 7–17. doi:10.1186/s12984-018-0346-2
Khan, R. A., Naseer, N., Saleem, S., Qureshi, N. K., Noori, F. M., and Khan, M. J. (2020). Cortical tasks-based optimal filter selection: An fNIRS study. J. Healthc. Eng. 2020, 1–15. doi:10.1155/2020/9152369
Kim, D. Y., Han, D. K., Jeong, J. H., and Lee, S. W. (2022). "EEG-Based driver drowsiness classification via calibration-free framework with domain generalization,” in IEEE International Conference on Systems, Man, and Cybernetics (SMC), Prague, Czech Republic, 09-12 October 2022 (IEEE), 2293–2298.
Larocco, J., Le, M. D., and Paeng, D. G. (2020). A systemic review of available low-cost EEG headsets used for drowsiness detection. Front. neuroinformatics 42, 553352. doi:10.3389/fninf.2020.553352
Li, G., and Chung, W. Y. (2022). Electroencephalogram-based approaches for driver drowsiness detection and management: A review. Sensors 22, 1100. doi:10.3390/s22031100
Li, X., Song, D., Zhang, P., Zhang, Y., Hou, Y., and Hu, B. (2018). Exploring EEG features in cross-subject emotion recognition. Front. Neurosci. 12, 162. doi:10.3389/fnins.2018.00162
Liu, S., Shen, J., Li, Y., Wang, J., Wang, J., Xu, J., et al. (2021). EEG power spectral analysis of abnormal cortical activations during REM/NREM sleep in obstructive sleep apnea. Front. Neurology 12, 643855. doi:10.3389/fneur.2021.643855
Min, J., Wang, P., and Hu, J. (2017). Driver fatigue detection through multiple entropy fusion analysis in an EEG-based system. PLoS one 12, e0188756. doi:10.1371/journal.pone.0188756
Naseer, N., Noori, F. M., Qureshi, N. K., and Hong, K. S. (2016). Determining optimal feature-combination for LDA classification of functional near-infrared spectroscopy signals in brain-computer interface application. Front. Hum. Neurosci. 10, 237. doi:10.3389/fnhum.2016.00237
Nazeer, H., Naseer, N., Khan, R. A., Noori, F. M., Qureshi, N. K., Khan, U. S., et al. (2020a). Enhancing classification accuracy of fNIRS-BCI using features acquired from vector-based phase analysis. J. Neural Eng. 17, 056025. doi:10.1088/1741-2552/abb417
Nazeer, H., Naseer, N., Mehboob, A., Khan, M. J., Khan, R. A., Khan, U. S., et al. (2020b). Enhancing classification performance of fNIRS-BCI by identifying cortically active channels using the z-score method. Sensors 20, 6995. doi:10.3390/s20236995
Poursadeghiyan, M., Mazloumi, A., Saraji, G. N., Niknezhad, A., Akbarzadeh, A., and Ebrahimi, M. H. (2017). Determination the levels of subjective and observer rating of drowsiness and their associations with facial dynamic changes. Iran. J. public health 46, 93–102.
Pudjihartono, N., Fadason, T., Kempa-Liehr, A. W., and O'sullivan, J. M. (2022). A review of feature selection methods for machine learning-based disease risk prediction. Front. Bioinforma. 2, 927312. doi:10.3389/fbinf.2022.927312
Quercia, A., Zappasodi, F., Committeri, G., and Ferrara, M. (2018). Local use-dependent sleep in wakefulness links performance errors to learning. Front. Hum. Neurosci. 12, 122. doi:10.3389/fnhum.2018.00122
Qureshi, N. K., Naseer, N., Noori, F. M., Nazeer, H., Khan, R. A., and Saleem, S. (2017). Enhancing classification performance of functional near-infrared spectroscopy-brain–computer interface using adaptive estimation of general linear model coefficients. Front. neurorobotics 33, 33. doi:10.3389/fnbot.2017.00033
Qureshi, N. K., Noori, F. M., Abdullah, A., and Naseer, N. (2016). “Comparison of classification performance for fNIRS-BCI system,” in 2nd International Conference on Robotics and Artificial Intelligence (ICRAI), Rawalpindi, Pakistan, 01-02 November 2016 (IEEE), 54–57.
Radüntz, T. (2017). Dual frequency head maps: A new method for indexing mental workload continuously during execution of cognitive tasks. Front. physiology 8, 1019. doi:10.3389/fphys.2017.01019
Ruffini, G., Ibañez, D., Castellano, M., Dubreuil-Vall, L., Soria-Frisch, A., Postuma, R., et al. (2019). Deep learning with EEG spectrograms in rapid eye movement behavior disorder. Front. neurology 10, 806. doi:10.3389/fneur.2019.00806
Rundo, F., Conoci, S., Spampinato, C., Leotta, R., Trenta, F., and Battiato, S. (2021). Deep neuro-vision embedded architecture for safety assessment in perceptive advanced driver assistance systems: The pedestrian tracking system use-case. Front. neuroinformatics 15, 667008. doi:10.3389/fninf.2021.667008
Sasaki, M., Iversen, J., and Callan, D. E. (2019). Music improvisation is characterized by increase EEG spectral power in prefrontal and perceptual motor cortical sources and can be reliably classified from non-improvisatory performance. Front. Hum. Neurosci. 13, 435. doi:10.3389/fnhum.2019.00435
Shen, M., Zou, B., Li, X., Zheng, Y., Li, L., and Zhang, L. (2021). Multi-source signal alignment and efficient multi-dimensional feature classification in the application of EEG-based subject-independent drowsiness detection. Biomed. Signal Process. Control 70, 103023. doi:10.1016/j.bspc.2021.103023
Singh, D., and Singh, B. (2020). Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 97, 105524. doi:10.1016/j.asoc.2019.105524
Tanveer, M. A., Khan, M. J., Qureshi, M. J., Naseer, N., and Hong, K. S. (2019). Enhanced drowsiness detection using deep learning: An fNIRS study. IEEE access 7, 137920–137929. doi:10.1109/access.2019.2942838
Wei, C. S., Wang, Y. T., Lin, C. T., and Jung, T. P. (2018). Toward drowsiness detection using non-hair-bearing EEG-based brain-computer interfaces. IEEE Trans. neural Syst. rehabilitation Eng. 26, 400–406. doi:10.1109/TNSRE.2018.2790359
Keywords: electroencephalography, brain–computer interface, spectral features, drowsiness detection, feature selection, supervised learning, neurophysiology, channel selection
Citation: Arif S, Munawar S and Ali H (2023) Driving drowsiness detection using spectral signatures of EEG-based neurophysiology. Front. Physiol. 14:1153268. doi: 10.3389/fphys.2023.1153268
Received: 29 January 2023; Accepted: 09 March 2023;
Published: 30 March 2023.
Edited by:
Shujaat Khan, Siemens Healthineers, United StatesReviewed by:
Nauman Khalid Qureshi, ETH Zürich, SwitzerlandCopyright © 2023 Arif, Munawar and Ali. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hashim Ali, aGFzaGltLmFsaUBudS5lZHUua3o=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.