 Guanghua Zhang
Guanghua Zhang Bin Sun
Bin Sun Zhaoxia Zhang3†
Zhaoxia Zhang3† Weihua Yang
Weihua Yang Yunfang Liu
Yunfang Liu- 1Department of Intelligence and Automation, Taiyuan University, Taiyuan, China
- 2Graphics and Imaging Laboratory, University of Girona, Girona, Spain
- 3Shanxi Eye Hospital, Taiyuan, China
- 4Department of Materials and Chemical Engineering, Taiyuan University, Taiyuan, China
- 5Affiliated Eye Hospital, Nanjing Medical University, Nanjing, China
- 6The First Affiliated Hospital of Huzhou University, Huzhou, China
Diabetic retinopathy (DR) is one of the most threatening complications in diabetic patients, leading to permanent blindness without timely treatment. However, DR screening is not only a time-consuming task that requires experienced ophthalmologists but also easy to produce misdiagnosis. In recent years, deep learning techniques based on convolutional neural networks have attracted increasing research attention in medical image analysis, especially for DR diagnosis. However, dataset labeling is expensive work and it is necessary for existing deep-learning-based DR detection models. For this study, a novel domain adaptation method (multi-model domain adaptation) is developed for unsupervised DR classification in unlabeled retinal images. At the same time, it only exploits discriminative information from multiple source models without access to any data. In detail, we integrate a weight mechanism into the multi-model-based domain adaptation by measuring the importance of each source domain in a novel way, and a weighted pseudo-labeling strategy is attached to the source feature extractors for training the target DR classification model. Extensive experiments are performed on four source datasets (DDR, IDRiD, Messidor, and Messidor-2) to a target domain APTOS 2019, showing that MMDA produces competitive performance for present state-of-the-art methods for DR classification. As a novel DR detection approach, this article presents a new domain adaptation solution for medical image analysis when the source data is unavailable.
1 Introduction
Diabetic retinopathy (DR) is a complication of diabetic patients and a significant cause of blindness globally among the working population (Antonetti et al., 2021). There are 451 million suffering from DR in the world, and this is projected to increase to 639 million in 2045 (Cho et al., 2018). In diabetics, blood is provided to all retina layers through micro blood vessels that are sensitive to unrestricted blood sugar levels. DR may cause no symptoms or only mild vision problems at first, but it can cause blindness eventually. When substantial glucose or fructose is collected in the blood, blood vessels begin to collapse due to insufficient oxygen supply to the cells. Occlusion in these blood vessels can cause serious eye damage. As a result, metabolic rate decreases, and abnormal blood vessels accumulate in DR (Dai et al., 2021). Microaneurysms (MAs) are the early signs of DR, which cause changes in the size (swelling) of the blood vessels. Moreover, hemorrhages (HMs), exudates (EXs), and abnormal blood vessel growth are the symptoms of DR. The International Clinical Diabetic Retinopathy (ICDR) scale is one of the most commonly used clinical scales and is composed of five levels of DR: normal, mild, moderate, severe and proliferative (Bodapati et al., 2021). Generally, diabetic retinopathy is divided into referable diabetic retinopathy (RDR) and non-referable diabetic retinopathy (NRDR).
Blindness can be completely avoided by early diagnosis. Annual regular clinical examination for diabetics is strongly recommended, especially for middle-aged and older adults (Mohamed et al., 2007; Ferris, 1993). Nevertheless, researchers find that a considerable number of people with diabetes failed to have annual eye examinations due to very mild symptoms, long examination time, and a shortage of ophthalmologists (Owsley et al., 2006; MacLennan et al., 2014; Chou et al., 2014). Therefore, it is necessary to adopt automatic DR diagnosis methods to lighten the workload on eye specialists and shorten the detection time, making patients understand the condition and get treatment in time.
Artificial intelligence (AI) is a popular technique for computer-aided automatic DR diagnosis to overcome these obstacles and deep learning has achieved progress in biomedical image analysis (Meng et al., 2021b; Preston et al., 2021; Meng et al., 2021a). Yoo and Park (2013) utilized ridge, elastic net, and LASSO to perform validation on 1052 DR patients. Roychowdhury et al. (2013) proposed a novel two-step approach for DR detection, where non-lesions or normal images are rejected in the first step, and bright and red lesions are classified as hard exudates and hemorrhages, respectively in the second step. In addition to the machine learning methods, the deep learning method becomes very popular in DR screening in recent years. For instance, Vo and Verma (2016) used a deep neural network improved upon GoogLeNet and VGGNet for DR recognition, aiming to learn fine-grained features of retinal images. Moreover, He et al. (2020) combined two attention blocks with a backbone network to solve the imbalanced DR data distribution problem and capture more detailed lesion information, respectively. Ai et al. (2021) proposed an algorithm adopting deep ensemble learning and attention mechanism to detect DR. However, both traditional machine learning methods (Yoo and Park, 2013; Roychowdhury et al., 2013) and supervised deep learning methods (Vo and Verma, 2016; He et al., 2020; Mohamed et al., 2021; Ai et al., 2021) require a large amount of labeled retinal images to train their models, which fail to new data from other domains. As an effective solution, domain adaptation always requires source data, which is usually difficult to access in practical applications because of the strict privacy rules in medical image management agencies.
To tackle this critical problem in supervised deep learning methods, this article attempts to develop a multi-model domain adaptation (MMDA) to conduct transfer learning for DR classification without access to source data. As shown in Figure 1, the proposed method can sufficiently utilize the knowledge of source models and unlabeled target images to improve the DR detection performance.
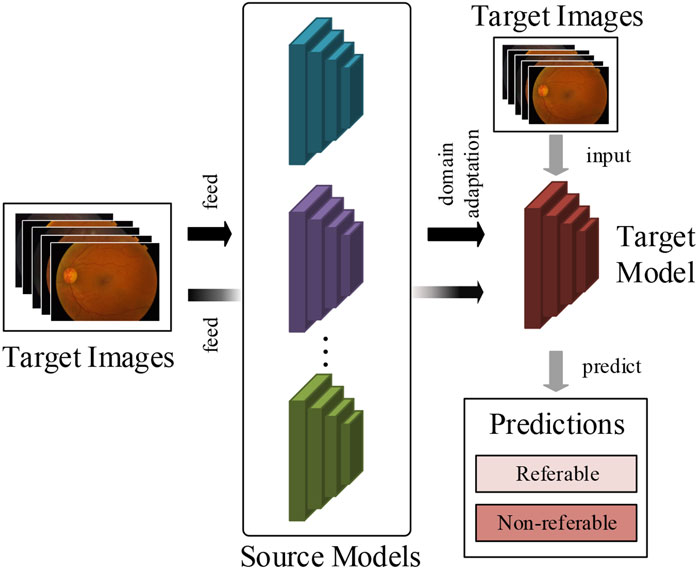
FIGURE 1. The work flow of our method. We train the target prediction model to simply use pre-trained multiple source models and unlabeled target retinal images.
In the MMDA framework, the target model is initially parameterized, and the trained source models are provided. We propose a model weight determination module to estimate the importance of each source model by measuring the average distance between two retinal feature groups extracted from the source models and target model. This module is optimized by a weight determination loss to output realistic model weights in target feature learning. By using the weights of source models, the pseudo label of the target images is obtained in a feature-level clustering-based way. Finally, we optimize the target model by cross-entropy loss and information maximization loss to guarantee the performance of diabetic retinopathy detection.
To evaluate the performance of MMDA, we conduct extensive experiments on five publicly available retinal image datasets: DDR, IDRiD, Messidor, Messidor-2, and APTOS 2019, obtaining excellent performance without access to source data. The results demonstrate that our proposed method can effectively complete the DR diagnosis task with only unlabeled target data.
2 Materials and Methods
2.1 Data Acquisition
In order to validate our method for diabetic retinopathy diagnosis, we trained four source models from publicly available datasets (DDR, IDRiD, Messidor, and Messidor-2) and employed APTOS 2019 as the target domain.
DDR dataset (Diabetic retinopathy detection, 2015) involves 12,522 fundus images from a 45° field of view. In detail, it has 6,266 normal fundus images and 6,256 abnormal samples. Moreover, the class distribution of the dataset is imbalanced in that the normal images are more than the abnormal data.
The IDRiD dataset (Porwal et al, 2018) contains 516 fundus images which were captured by an ophthalmologist from an Indian eye clinic. It provides adequate quality and clinically relevant fundus images with ground truths.
The Messidor dataset (Decencière et al., 2014) is a publicly available diabetic retinopathy dataset provided by the Messidor program partners, which consists of 1,200 retinal images, and for each image, two grades, retinopathy grade, and risk of macular edema, are provided.
The Messidor-2 dataset (Decencière et al., 2014) has been globally used by researchers for DR detection algorithm analysis, which is an extension of Messidor. It contains 1,748 retinal images of 874 examinations. Although there are no official annotations for this dataset, the third-party grades for 1,744 out of the 1,748 images adjudicated by a panel of three retina specialists are available for researchers (Messidor-2 dr grades, 2018).
The APTOS 2019 dataset (Khalifa et al., 2019) is the most recent publicly available Kaggle dataset from the APTOS Blindness Detection competition on Kaggle for DR detection. It contains 3,662 labeled fundus photography images.
The above datasets are graded into five stages from 0 to 4 for no DR, mild DR, moderate DR, severe DR, and proliferative DR, respectively, according to the ICDR severity scale. The label distribution of the datasets and the division of the referable and non-referable DR are shown in Table 1. Moreover, the APTOS 2019 dataset is regarded as the target domain, and the other four datasets are used as source datasets to train source models.
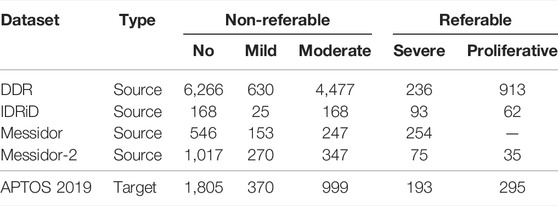
TABLE 1. Label distributions of DDR, IDRiD, Messidor, Messidor-2, and APTOS 2019 datasets.
2.2 Data Preprocessing
When collecting retinal images, the differences in lighting conditions and camera types may cause a large data inconsistency (Graham, 2015). Data preprocessing mitigates noise and enhances image details, reducing inconsistency and playing a significant role in improving performance.
In order to eliminate these negative effects and make data consistent, we perform data preprocessing in the following two steps (Figure 2):
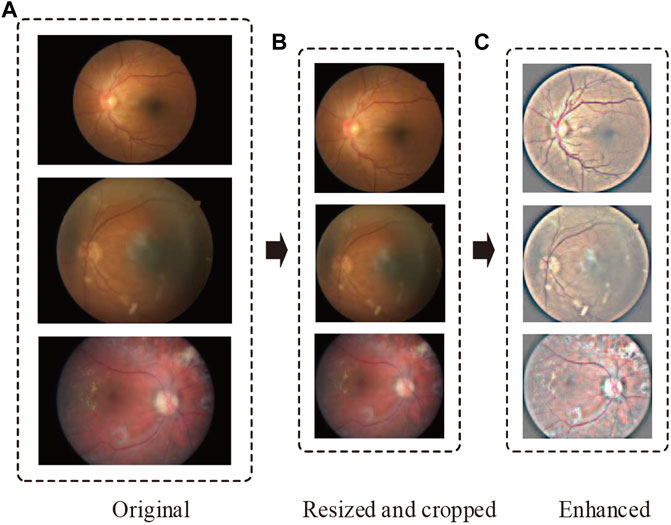
FIGURE 2. Representative retinal images adopting our preprocessing techniques. From top to bottom, the representative images are sampled from no DR, moderate DR, and proliferative DR, respectively. The parts (A–C) denote the original, resized and cropped, and enhanced retinal images.
Step 1: Resize and crop.
Considering various resolutions of retinal images in different datasets, we resize all images to 1,024 pixels if their width or height is bigger than that size. Then, we crop as much of the black space by identifying the center and radius of the circle in the retinal images.
Step 2: Image enhancement.
In DR detection, the observation of hard exudates, hemorrhages, and cotton wools is significant for eye specialists to diagnose. However, the variations of brightness and resolution not only make ophthalmologists produce misdiagnoses but also make it difficult for a model to compose robust features. To address this problem, we perform image enhancement after resizing and cropping by the following formula:
where I (x, y) denotes the input retinal image, G (x, y; σ) is a Gaussian filter with standard deviation σ, “∗” represents the convolution operator. λ, ω and δ are manually adjusted variables. In our study, λ, ω and δ are set to 4, -4 and 128, respectively. By improving image contrast with Eq. 1, the lesion area is easier to distinguish.
2.3 Multi-Model Domain Adaptation Architecture
This subsection elaborates on our proposed MMDA method, which aims to address the central problem that the labeled image data cannot always be obtained in automatic DR detection.
2.3.1 Overview
Domain adaptation is one of the branches of transfer learning in computer science. For a vanilla multi-source unsupervised domain adaptation task, we have n source domains with fundus images, and
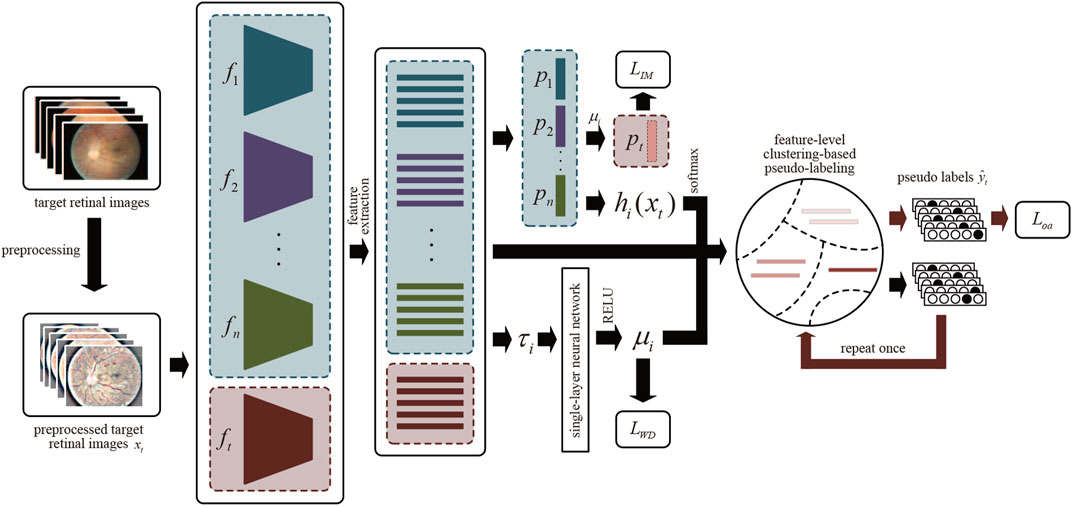
FIGURE 3. The overview of MMDA architecture. After preprocessing, we obtain the features of target retinal images by source models
Suppose that we have multiple trained source models for DR classification and an ImageNet pre-trained target model. Each model contains two modules: the feature encoding module
2.3.2 Source Model Generation
We consider producing several source backbone pre-trained source models, i.e., hi = pi◦fi (i = 1, 2, ⋯n), by optimizing them using the following cross-entropy loss:
where
where qk,ls = (1 − α)qk + α/K represents the smoothed label and α is the smoothing factor which is set to 0.1 experientially.
2.3.3 Information Maximization Loss for Target Model
Due to the source classifier modules encoding the distribution information of unseen source data, our framework is proposed to learn the domain-specific feature encoding module while the source classifier modules are fixed. Specifically, MMDA employs the weighted source classifier modules during the target model learning process:
where μi is the weight for the ith source model, which will be explained in detail in the following subsection.
In essence, our goal is to obtain an optimal target feature extractor
where ht(x) = pt ( ft(x)) is the K-dimensional output logits of each retinal images, 1K is an all-ones vector with K elements, and
2.3.4 Model Weight Determination
In the MMDA framework, a robust target feature encoder is learned by bridging the domain gap between each source domain and the target domain. However, the feature discrepancies between each source domain and target domain are different. To measure the feature discrepancies, we propose a Model Weight Mechanism (MWM). Precisely, we first calculate the average Euclidean Distance between the ith source domain and the target domain:
The closer the τi is, the more important the source model, i.e., the greater the weight is. To this end, we integrate a single-layer neural network, which is parameterized by a weight vector
where ReLU(⋅) = max (0, ⋅) is an activation function, which guarantees the nonnegativity of μi. The role of the above softmax operation is to guarantee the model weight satisfy the following property:
We optimize the weight vector of the single-layer neural network w by minimizing the following loss function:
That is, a larger distance
2.3.5 Feature-Level Clustering-Based Pseudo-Labeling
The role of IM loss in Eq. 5 is to enforce the similarity of one-hot encoding output. Therefore, an accurate prediction network is crucial to reduce this impact. For this purpose, a pseudo-labeling strategy at the feature level is applied for better supervision during the adaptation process.
First, the weighted features centroid of target retinal images for each class is obtained, similar to weighted k-means clustering.
These centroids can robustly and more reliably characterize the distribution of different categories within the target domain. Then, the pseudo labels can be attained via the nearest centroid classifier:
where
Based on generated
We refer to
To sum up, given n source models hi = pi◦fi (i = 1, 2, ⋯n) and the final pseudo labels
where γ > 0 is a balancing hyper-parameter. The whole implementation of MMDA model is shown in
Algorithm 1. Pseudo-code of MMDA training process.

2.4 Implementation Details
In the experiments we first train the source models by corresponding source retinal datasets, and each model is designed following ResNet-50 (He et al., 2016). As for the target model, it also employs ResNet-50, initialized by pre-trained parameters from ImageNet (Deng et al., 2009). We perform data argumentation by applying random horizontal flips, vertical flips, and random rotation to prevent overfitting. The input size of the MMDA is 224 × 224. We trained 40 epochs for all the source models using the Stochastic Gradient Descent (SGD) optimization algorithm (Kingma and Ba, 2014) with a learning rate decay factor of 1e−4. The learning rates for DDR, IDRiD, Messidor, and Messidor-2 datasets are 5 × 10–3 equally. For the target training, we adopt a mini-batch SGD with momentum 0.9, weight decay 1e−4, and learning rate ζ = 1e−2. The balance factor for IM loss β and the overall loss γ are set to 0.3 and 0.3, respectively. In addition, a batch size of 64 is set for the entire experimental process. MMDA is implemented on two NVIDIA RTX 2080Ti GPUs with 2 × 11 GB RAM using the PyTorch framework.
To validate the effectiveness of MWM (Section 2.3.4), we adjust μi in Eqs 4, 10, 12. Moreover, hyper-parameters β in LIM and γ are fine-tuned to analyze their influence on DR detection performance. Details are described in Section 3.3 and Section 3.4. Note that we do not integrate model weight mechanism and pseudo-labeling into the target model until training the target model several epochs with IM loss. That means we attach the model weight and pseudo-labeling modules when the target model has a certain diagnosing capability.
3 Results
3.1 Evaluation Metrics
To measure the performance of the MMDA model, we employ accuracy and sensitivity as the measurements. The accuracy can be defined as the percentage of correctly classified images. Sensitivity measures the ability of a test to correctly identify samples with referable DR, which is an effective metric to measure the DR diagnosis.
This metric is calculated as follows. First, we compute the accuracy by
3.2 Performance Compared With Supervised Learning Methods
We first compare MMDA with the existing supervised learning methods on the APTOS2019 dataset. Specifically, Xie et al. (2017) present a simple, highly modularized network architecture for image classification, which is often employed in DR detection; Vives-Boix and Ruiz-Fernández (2021) conducted automated detection of DR by directly interfering in both learning and memory by reinforcing less common occurrences during the learning process; Narayanan et al. (2020) proposed a hybrid machine learning architecture to detect and grade the level of diabetic retinopathy; Farag et al. (2022) proposed an automatic deep-learning-based model for severity detection by utilizing a single color fundus photograph. From Table 2, it is observed that MMDA achieves approving results with 90.6% accuracy and 98.5% sensitivity. Our method performs a relatively excellent accuracy compared with the compared methods, which only remains a distance of 2.2%, and it presents the second-best sensitivity of 98.5%, only weaker than Narayanan et al. (2020). Although the results of MMDA are lower than these supervised learning methods, huge amounts of labeled data are essentially required in their training process. In contrast, we train MMDA simply to utilize unlabeled retinal images and obtain satisfactory performance, showing the superiority of our framework for DR diagnosis.
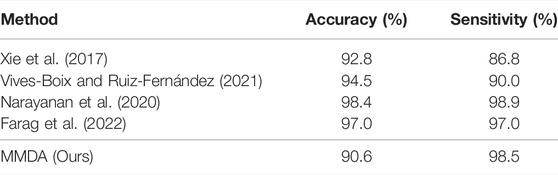
TABLE 2. Accuracy and sensitivity of MMDA for diabetic retinopathy diagnosis compared with state-of-the-art supervised learning approaches on the APTOS 2019 dataset.
3.3 Performance Analysis on Model Weight Mechanism
We design a novel model weight mechanism (MWM) to assign a learnable weight to each model. To verify the effect of the MWM, we perform ablation studies to analyze the MWM for the source classifier modules and the pseudo-labeling process using different backbones.
MWM for source classifier modules: We fix the source classifier modules, so we can fully utilize the source distribution information in the modules when the source data is not available. Meanwhile, the discrepancy between each source domain and the target domain cannot be ignored. Specifically, we integrate the weight mechanism into the classifiers by Eq. 4. To verify the effect of MWM in utilizing the source distribution information, we conduct a study using Average-weighted Classifier Multi-model Domain Adaptation (ACDA), which is the MMDA model with
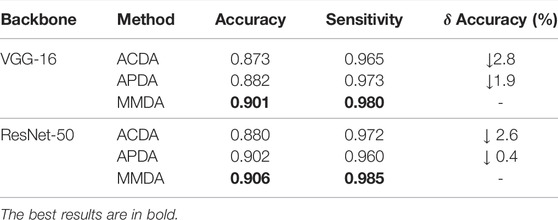
TABLE 3. The DR classification results of MMDA with different backbones on the APTOS 2019 dataset.
MWM for pseudo-labeling: To evaluate the contribution of MWM in features centroid determination, we carry out an experiment named APDA, which is a modified MMDA with
3.4 Performance Analysis on Hyper-Parameters
To further validate the effectiveness of each component in MMDA, we explore the influence of hyper-parameters on the performance of our model.
The choice of β in LIM: β is a balancing factor that adjusts the contribution of fair diversity-promoting objective Ldiv. The DR classification performance of MMDA with β from 0.1 to 0.5 is shown in Table 4. As reported, both accuracy and sensitivity is improved with the increase of β, and MMDA achieves the best performance when β is set to 0.3. However, when we further increase the value of β, the results start to decrease. We consider that the high β value weakens the effect of Lce, which leads the decision boundary to go through the high-density region.
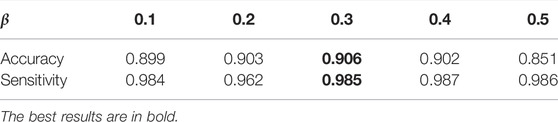
TABLE 4. DR classification results using different β on the APTOS 2019 dataset.
The choice of γ: γ is a balancing factor of the information maximization loss LIM and the cross-entropy loss in the overall loss Loa. In this section, we investigate the effectiveness of this hyper-parameter. The results shown in Table 5 demonstrate that MMDA achieves the highest effectiveness when γ is set to 0.3. The cross-entropy loss in the overall loss Loa acts as a guide of the target model. If γ is too small, the effect of the pseudo labels is reduced. If γ is too large, the generalization of the target model will be limited. In order to learn more discriminative features in the target domain and enhance the DR diagnosis performance of the model, it is necessary to adjust the best value of γ.
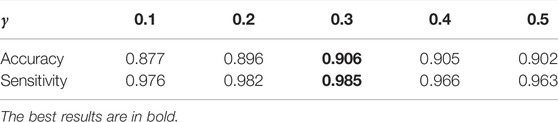
TABLE 5. DR classification results using different γ on the APTOS 2019 dataset.
3.5 Visual Analysis of Model Performance
Furthermore, in order to prove the superiority of the MMDA framework for practical applications, the ROC curve, and t-SNE plot are adopted to visualize our model.
ROC curve: The receiver operating characteristic curve is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied. The ROC curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. In the ROC curve, the closer the apex of the curve toward the upper left corner, the greater the discriminatory ability of the test. The ROC curve of MMDA for diabetic retinopathy classification is drawn in Figure 4, which obtains the area under the ROC curve of 0.94 and is above the diagonal and close to the point in the upper left corner, demonstrating that MMDA has a satisfying prediction performance.
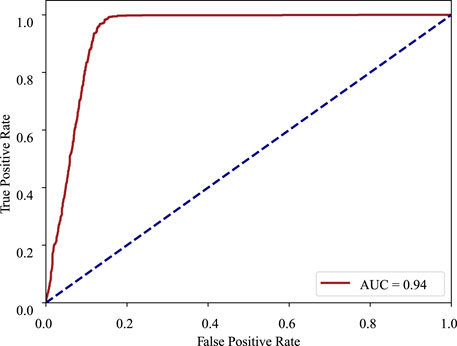
FIGURE 4. ROC curve of DR diagnosis on the APTOS 2019 dataset.
t-SNE plot: t-Distributed Stochastic Neighbor Embedding (t-SNE) is a technique for dimensionality reduction that is particularly well suited for the visualization of high-dimensional data. It maps high-dimensional data to two or more dimensions suitable for human observation. In order to validate the effectiveness of MMDA, we perform a t-SNE plot using the target image features extracted by the trained target feature encoding module (ft). As shown in Figure 5, retinal images of non-referable DR and referable DR are well separated, because MMDA can learn discriminative features to detect referable diabetic retinopathy. The relatively clear boundaries in Figure 5 suggest that it is practical to train a robust prediction model using MMDA in the absence of labeled target data.
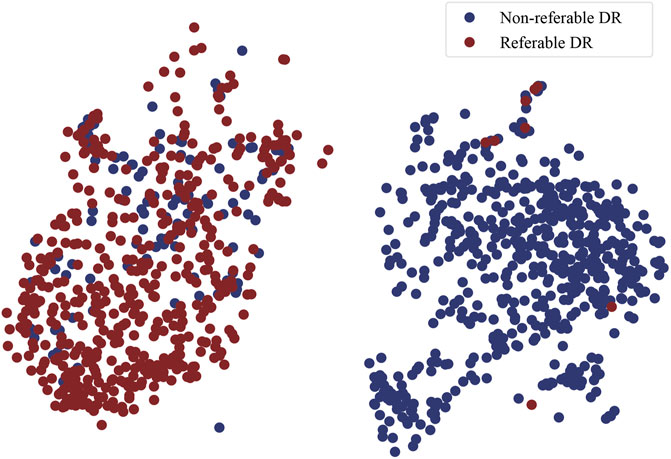
FIGURE 5. The t-SNE plot of DR classification on the APTOS 2019 dataset.
4 Discussion
Retinal images are usually used to build an automatic diabetic retinopathy diagnosis system (Gardner et al., 1996; Acharya et al., 2009; Ram et al., 2010; Gulshan et al., 2016; Lam et al., 2018; Jiang et al., 2019; Preston et al., 2021). However, whether using traditional machine learning methods (Gardner et al., 1996; Acharya et al., 2009; Ram et al., 2010) or deep supervised learning methods (Gulshan et al., 2016; Lam et al., 2018; Jiang et al., 2019; Preston et al., 2021), they all need a large amount of labeled data during training. In the biomedical image analysis field, labeling work is expensive and the privacy issue is highly sensitive. To tackle this challenge, we consider developing an unsupervised method that the DR diagnosis performance is excellent but labeled retinal images are unnecessary.
In this article, we present a novel MMDA that incorporates model weight mechanism into the MMDA technique. MMDA can be trained in an end-to-end manner with merely unlabeled target retinal images for DR classification. To the best of our knowledge, MMDA is the first attempt to automatically diagnose diabetic retinopathy by adopting an unsupervised domain adaptation technique with multiple source models. The main advantage of this article is that the MMDA can learn helpful knowledge only from source models without any source data, which can relieve the limitation of data privacy from different medical agencies.
Our proposed MMDA method aims to exploit the source knowledge and relationship between the source models and the target model, instead of learning from labeled retinal images directly, thus helping protect the patients’ privacy and no need to label images.
In order to fully explore the discrepancy between each source domain and target domain, we propose a model weight mechanism. By incorporating the mechanism into the source classifiers and feature-level clustering-based pseudo-labeling process, the diagnosis performance of the target model is improved.
Extensive experiments and ablation studies on the APTOS2019 dataset demonstrate that MMDA achieves competitive DR diagnosis performance in comparison with state-of-the-art supervised learning methods. However, the DR classification performance still has a distance from the advanced supervised methods due to the discrepancy between source and target models, especially for the invalid access to source data.
Model visualizations (Figures 4, 5) suggest that non-referable (grade 0, 1) and referable cases (from grade 2 to 4) can be diagnosed well. We will focus on the fine-grained classification of the DR grading task (Zheng et al., 2017) in the future.
5 Conclusion
When incorporating deep learning techniques in the automatic DR diagnosis system, time-consuming labeling work and privacy issues are critical problems. The present study is designed to exploit existing models and unlabeled retinal images for DR diagnosis to resolve these issues. Ablation studies show the effectiveness of our proposed modules, and the comparison with state-of-the-art supervised learning approaches demonstrates the superiority of our method. Moreover, model visualization indicates that our method can effectively diagnose non-referable and referable cases, with excellent diagnosing results.
Data Availability Statement
The original contributions presented in the study are included in the article material, further inquiries can be directed to the corresponding authors.
Author Contributions
GZ, BS, and ZZ contributed to conception and design of the study. JP organized the database and performed the statistical analysis. GZ and BS wrote the first draft of the manuscript. ZZ wrote the revised manuscript. WY and YL wrote sections of the manuscript, and supervised this work. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This work was supported by the Research Funds of Shanxi Transformation and Comprehensive Reform Demonstration Zone (Grant No. 2018KJCX04), the Fund for Shanxi “1331 Project,” and the Key Research and Development Program of Shanxi Province (Grant No. 201903D311009). The work was also partially sponsored by the Research Foundation of the Education Bureau of Shanxi Province (Grant No. HLW-20132), the Scientific Innovation Plan of Universities in Shanxi Province (Grant No. 2021L575), the Shanxi Scholarship Council of China (Grant No. 2020-149), the Innovation and entrepreneurship training program for College Students (NO.202111242006X), the Medical Science and Technology Development Project Fund of Nanjing (Grant No. YKK21262), and the Nanjing Enterprise Expert Team Project. This work was also supported by the Medical Big Data Clinical Research Project of Nanjing Medical University, Medical and Health Research Project of Zhejiang Province (2018PY066).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Acharya U. R., Lim C. M., Ng E. Y. K., Chee C., Tamura T. (2009). Computer-based Detection of Diabetes Retinopathy Stages Using Digital Fundus Images. Proc. Inst. Mech. Eng. H. 223, 545–553. doi:10.1243/09544119JEIM486
Ai Z., Huang X., Fan Y., Feng J., Zeng F., Lu Y. (2021). DR-IIXRN : Detection Algorithm of Diabetic Retinopathy Based on Deep Ensemble Learning and Attention Mechanism. Front. Neuroinform 15, 778552. doi:10.3389/fninf.2021.778552
Antonetti D. A., Silva P. S., Stitt A. W. (2021). Current Understanding of the Molecular and Cellular Pathology of Diabetic Retinopathy. Nat. Rev. Endocrinol. 17, 195–206. doi:10.1038/s41574-020-00451-4
Bodapati J. D., Shaik N. S., Naralasetti V. (2021). Deep Convolution Feature Aggregation: an Application to Diabetic Retinopathy Severity Level Prediction. SIViP 15, 923–930. doi:10.1007/s11760-020-01816-y
Cho N. H., Shaw J. E., Karuranga S., Huang Y., da Rocha Fernandes J. D., Ohlrogge A. W. (2018). Idf Diabetes Atlas: Global Estimates of Diabetes Prevalence for 2017 and Projections for 2045. Diabetes Res. Clin. Pract. 138, 271–281. doi:10.1016/j.diabres.2018.02.023
Chou C.-F., Sherrod C. E., Zhang X., Barker L. E., Bullard K. M., Crews J. E., et al. (2014). Barriers to Eye Care Among People Aged 40 Years and Older with Diagnosed Diabetes, 2006–2010. Diabetes care 37, 180–188. doi:10.2337/dc13-1507
Dai L., Wu L., Li H., Cai C., Wu Q., Kong H., et al. (2021). A Deep Learning System for Detecting Diabetic Retinopathy across the Disease Spectrum. Nat. Commun. 12, 1–11. doi:10.1155/2021/9943067
Decencière E., Zhang X., Cazuguel G., Lay B., Cochener B., Trone C., et al. (2014). Feedback on a Publicly Distributed Image Database: the Messidor Database. Image Analysis Stereology 33, 231–234. doi:10.5566/ias.1155
Deng J., Dong W., Socher R., Li L.-J., Li K., Fei-Fei L. (2009). “Imagenet: A Large-Scale Hierarchical Image Database,” in 2009 IEEE conference on computer vision and pattern recognition (IEEE), 248–255. doi:10.1109/cvpr.2009.5206848
Farag M. M., Fouad M., Abdel-Hamid A. T. (2022). Automatic Severity Classification of Diabetic Retinopathy Based on Densenet and Convolutional Block Attention Module. IEEE Access. doi:10.1109/access.2022.3165193
Ferris F. L. (1993). How Effective Are Treatments for Diabetic Retinopathy? Jama 269, 1290–1291. doi:10.1001/jama.269.10.1290
Gardner G. G., Keating D., Williamson T. H., Elliott A. T. (1996). Automatic Detection of Diabetic Retinopathy Using an Artificial Neural Network: a Screening Tool. Br. J. Ophthalmol. 80, 940–944. doi:10.1136/bjo.80.11.940
Graham B. (2015). Kaggle Diabetic Retinopathy Detection Competition Report. Coventry: University of Warwick.
Gulshan V., Peng L., Coram M., Stumpe M. C., Wu D., Narayanaswamy A., et al. (2016). Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. Jama 316, 2402–2410. doi:10.1001/jama.2016.17216
He A., Li T., Li N., Wang K., Fu H. (2020). Cabnet: Category Attention Block for Imbalanced Diabetic Retinopathy Grading. IEEE Trans. Med. Imaging. 40, 143–153. doi:10.1109/TMI.2020.3023463
He K., Zhang X., Ren S., Sun J. (2016). “Deep Residual Learning for Image Recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778. doi:10.1109/cvpr.2016.90
Hu W., Miyato T., Tokui S., Matsumoto E., Sugiyama M. (2017). Learning Discrete Representations via Information Maximizing Self-Augmented TrainingInt. Conf. Mach. Learn., 1558–1567.
Jiang H., Yang K., Gao M., Zhang D., Ma H., Qian W. (2019). “An Interpretable Ensemble Deep Learning Model for Diabetic Retinopathy Disease Classification,” in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (IEEE), 2045–2048. doi:10.1109/embc.2019.8857160
Khalifa N. E. M., Loey M., Taha M. H. N., Mohamed H. N. E. T. (2019). Deep Transfer Learning Models for Medical Diabetic Retinopathy Detection. Acta Inform. Medica 27, 327. doi:10.5455/aim.2019.27.327-332
Kingma D. P., Ba J. (2014). Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980
Lam C., Yi D., Guo M., Lindsey T. (20182018). Automated Detection of Diabetic Retinopathy Using Deep Learning. AMIA summits Transl. Sci. Proc., 147.
Müller R., Kornblith S., Hinton G. (2019). When Does Label Smoothing Help? arXiv preprint arXiv:1906.02629
MacLennan P. A., McGwin G., Searcey K., Owsley C. (2014). A Survey of alabama Eye Care Providers in 2010–2011. BMC Ophthalmol. 14, 1–10. doi:10.1186/1471-2415-14-44
Meng Y., Zhang H., Gao D., Zhao Y., Yang X., Qian X., et al. (2021a). “Bi-gcn: Boundary-Aware Input-dependent Graph Convolution Network for Biomedical Image Segmentation,” in The British Machine Vision Conference. doi:10.48550/arXiv.2110.14775
Meng Y., Zhang H., Zhao Y., Yang X., Qiao Y., MacCormick I. J., et al. (2021b). Graph-based Region and Boundary Aggregation for Biomedical Image Segmentation. IEEE Trans. Med. Imaging 41, 690–701. doi:10.1109/TMI.2021.3123567
Mohamed E., Abd Elmohsen M., Basha T. (2021). “Improved Automatic Grading of Diabetic Retinopathy Using Deep Learning and Principal Component Analysis,” in 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) (IEEE), 3898–3901. doi:10.1109/embc46164.2021.9630919
Mohamed Q., Gillies M. C., Wong T. Y. (2007). Management of Diabetic Retinopathy: a Systematic Review. Jama 298, 902–916. doi:10.1001/jama.298.8.902
Narayanan B. N., Hardie R. C., De Silva M. S., Kueterman N. K. (2020). Hybrid Machine Learning Architecture for Automated Detection and Grading of Retinal Images for Diabetic Retinopathy. J. Med. Imaging 7, 034501. doi:10.1117/1.JMI.7.3.034501
Owsley C., McGwin G., Scilley K., Girkin C. A., Phillips J. M., Searcey K. (2006). Perceived Barriers to Care and Attitudes about Vision and Eye Care: Focus Groups with Older African Americans and Eye Care Providers. Investigative Ophthalmol. Vis. Sci. 47, 2797–2802. doi:10.1167/iovs.06-0107
Porwal P., Kokare R., Pachade S. (2018). Indian Diabetic Retinopathy Image Dataset (Idrid). Data 18, 25. doi:10.3390/data3030025
Preston F. G., Meng Y., Burgess J., Ferdousi M., Azmi S., Petropoulos I. N., et al. (2021). Artificial Intelligence Utilising Corneal Confocal Microscopy for the Diagnosis of Peripheral Neuropathy in Diabetes Mellitus and Prediabetes. Diabetologia, 1–10. doi:10.1007/s00125-021-05617-x
Ram K., Joshi G. D., Sivaswamy J. (2010). A Successive Clutter-Rejection-Based Approach for Early Detection of Diabetic Retinopathy. IEEE Trans. Biomed. Eng. 58, 664–673. doi:10.1109/TBME.2010.2096223
Roychowdhury S., Koozekanani D. D., Parhi K. K. (2013). Dream: Diabetic Retinopathy Analysis Using Machine Learning. IEEE J. Biomed. health Inf. 18, 1717–1728. doi:10.1109/JBHI.2013.2294635
Vives-Boix V., Ruiz-Fernández D. (2021). Diabetic Retinopathy Detection through Convolutional Neural Networks with Synaptic Metaplasticity. Comput. Methods Programs Biomed. 206, 106094. doi:10.1016/j.cmpb.2021.106094
Vo H. H., Verma A. (2016). “New Deep Neural Nets for Fine-Grained Diabetic Retinopathy Recognition on Hybrid Color Space,” in 2016 IEEE International Symposium on Multimedia (ISM) (IEEE), 209–215. doi:10.1109/ism.2016.0049
Xie S., Girshick R., Dollár P., Tu Z., He K. (2017). “Aggregated Residual Transformations for Deep Neural Networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 1492–1500. doi:10.1109/cvpr.2017.634
Yoo T. K., Park E.-C. (2013). Diabetic Retinopathy Risk Prediction for Fundus Examination Using Sparse Learning: a Cross-Sectional Study. BMC Med. Inf. Decis. Mak. 13, 1–14.
Keywords: diabetic retinopathy classification, multi-model, domain adaptation, convolutional neural network, deep learning
Citation: Zhang G, Sun B, Zhang Z, Pan J, Yang W and Liu Y (2022) Multi-Model Domain Adaptation for Diabetic Retinopathy Classification. Front. Physiol. 13:918929. doi: 10.3389/fphys.2022.918929
Received: 12 April 2022; Accepted: 12 May 2022;
Published: 01 July 2022.
Edited by:
Wei Wang, Huzhou Maternity and Child Health Care Hospital, ChinaReviewed by:
Xuefei Song, Shanghai Ninth People’s Hospital, ChinaSomayah Abdullah Albaradei, King Abdullah University of Science and Technology, Saudi Arabia
Copyright © 2022 Zhang, Sun, Zhang, Pan, Yang and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yunfang Liu, cGFubGVsZTA3MDFAMTM5LmNvbQ==; Weihua Yang, YmVuYmVuMDYwNkAxMzkuY29t
†These authors have contributed equally to this work