 Aftab Siddique
Aftab Siddique Samira Shirzaei
Samira Shirzaei Alice E. Smith
Alice E. Smith Jaroslav Valenta
Jaroslav Valenta Laura J. Garner
Laura J. Garner Amit Morey
Amit Morey- 1Department of Poultry Science, Auburn University, Auburn, AL, United States
- 2Department of Industrial and Systems Engineering and Department of Computer Science and Software Engineering, Auburn University, Auburn, AL, United States
- 3Department of Animal Science, Czech University of Life Sciences, Prague, Czechia
Breast meat from modern fast-growing big birds is affected with myopathies such as woody breast (WB), white striping, and spaghetti meat (SM). The detection and separation of the myopathy-affected meat can be carried out at processing plants using technologies such as bioelectrical impedance analysis (BIA). However, BIA raw data from myopathy-affected breast meat are extremely complicated, especially because of the overlap of these myopathies in individual breast fillets and the human error associated with the assignment of fillet categories. Previous research has shown that traditional statistical techniques such as ANOVA and regression, among others, are insufficient in categorising fillets affected with myopathies by BIA. Therefore, more complex data analysis tools can be used, such as support vector machines (SVMs) and backpropagation neural networks (BPNNs), to classify raw poultry breast myopathies using their BIA patterns, such that the technology can be beneficial for the poultry industry in detecting myopathies. Freshly deboned (3–3.5 h post slaughter) breast fillets (n = 100 × 3 flocks) were analysed by hand palpation for WB (0-normal; 1-mild; 2-moderate; 3-Severe) and SM (presence and absence) categorisation. BIA data (resistance and reactance) were collected on each breast fillet; the algorithm of the equipment calculated protein and fat index. The data were analysed by linear discriminant analysis (LDA), and with SVM and BPNN with 70::30: training::test data set. Compared with the LDA analysis, SVM separated WB with a higher accuracy of 71.04% for normal (data for normal and mild merged), 59.99% for moderate, and 81.48% for severe WB. Compared with SVM, the BPNN training model accurately (100%) separated normal WB fillets with and without SM, demonstrating the ability of BIA to detect SM. Supervised learning algorithms, such as SVM and BPNN, can be combined with BIA and successfully implemented in poultry processing to detect breast fillet myopathies.
Introduction
Globally, consumers are choosing meat and meat products for their higher nutritional value, especially protein (Heinz and Hautzinger, 2009). There has been a drastic increase in the consumption of these products worldwide in the last couple of decades. In developing countries, the per capita consumption of poultry has increased from 1.2 in the 1960s to 10.5 kg in the 2000s and will reach up to 14 kg by 2030 (FAO, 2003). In the United States, more than nine billion broilers were raised in 2018, with a total live weight of 27.1 billion kilogrammes; and in 2020, the per capita consumption of chicken was 44.23 kg (National Chicken Council, 2020). Chicken is a popular consumer choice because of various physicochemical and sensorial attributes such as texture, colour, and flavour (Petracci et al., 2013). To supply the increasing demand for breast meat, breeders have increased the growth rate of the birds through genetics, in turn increasing total carcass yield (Petracci and Cavani, 2012). Markets are continuously changing because of the preference and demands of consumers, which are presently driving the market toward cut-up chicken parts and further processed products. Fast-growing chickens with increased breast meat yield have developed breast muscle myopathies, leading to meat quality defects, such as woody breast (WB). In the past 10 years, WB has been more prominently found in heavier birds (Zampiga et al., 2020). Woody breast-affected fillets are characterised by an intricate and dull appearance (Sihvo et al., 2014; Kuttappan et al., 2017), and tough texture due to collagen deposition (Soglia et al., 2016). These breast myopathies also affect meat quality parameters such as pH, colour, water holding capacity (WHC), proximate composition, cook loss, and texture, which ultimately influence the quality of further processed products (Kuttappan et al., 2012). Because of lower meat quality, WB meat is sorted out in processing plants by manual hand-palpation (Figure 1) and different grading scales based on the level of severity (Table 1). However, this method is unreliable and subjective, leading to potential misclassification of the breast meat (Morey et al., 2020). By setting specific standards to accurately separate WB fillets, poultry processors will be able to reduce fillet misclassification and, ultimately, losses related to it.
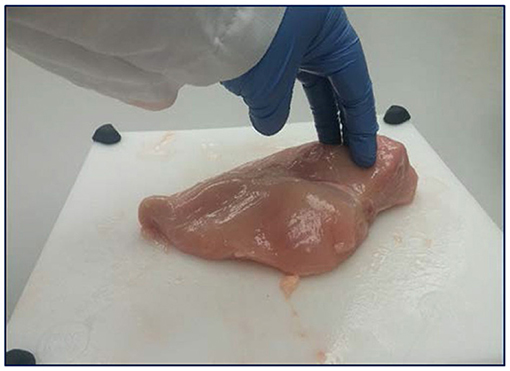
Figure 1. Hand-palpation method for identifying the severity of woody breast myopathy in breast fillets.
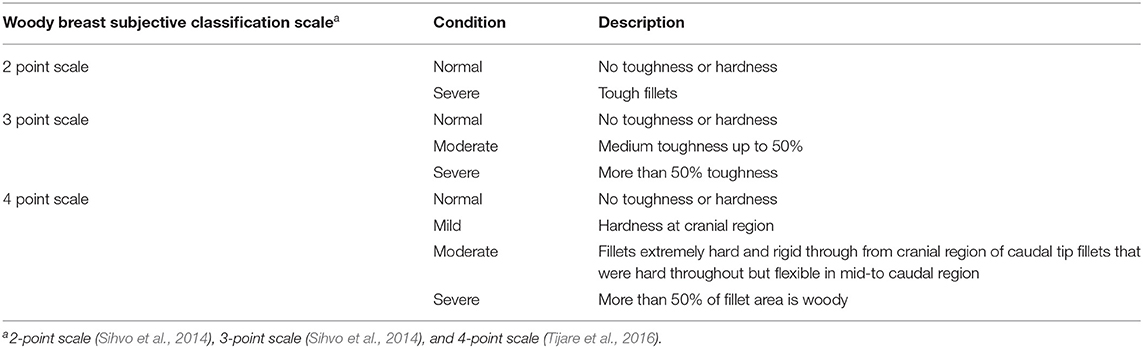
Table 1. Different subjective scales used for the classification of woody breast meat.
We investigated bioelectrical impedance analysis as a potential objective method to detect woody breast-affected fillets. Under ideal conditions, the resistance of a conducting material is directly proportional to its length (R α L) and inversely proportional to its cross-sectional area (R α 1/A) but can be affected by the shape, size, thickness, and composition of different matrixes (Kyle et al., 2004). The electrical conductivity of a conductor depends on cell physiological and biochemical composition (the amount of water with dissolved electrolytes, intracellular fluid, extra-cellular fluid, moisture, and protein content) and on the applied signal frequency (Bera, 2014). BIA technology has been used in many species to measure physical composition and properties such as body water content and fat content. Nyboer et al. (1950) and Hoffer et al. (1969) introduced the four-electrode, whole body, and bioelectrical impedance methods in clinical studies for the measurement of bodily fluid from hand to foot. Since its inception, the use of BIA has expanded beyond clinical studies. In the food sector, BIA parameters can be calibrated to specific species and have been used in fish for the rapid detection of proximate composition and the pre-harvest condition of fish (Cox et al., 2011). The ability of meat to conduct electricity can be potentially used to detect meat myopathies such as WB and SM. WB presents itself with increased proliferation of collagen (non-conducting material), affecting resistance, while changes in intra- and extra-cellular water (conducting material) in the meat matrix alter the reactance (Kyle et al., 2004; Sihvo et al., 2014; Velleman, 2015; Soglia et al., 2016; Morey et al., 2020). Morey et al. (2020) successfully demonstrated the ability of bioelectric impedance analysis to differentiate between varying levels of WB as well as SM. The researchers attributed the differences in the electrical properties to the accumulation of collagen and increase in extra-myofibrillar water (Kennedy-Smith et al., 2017; Tasoniero et al., 2017). Contrary to WB, Morey et al. (2020) reported that loose muscle fibres acted as insulators and increased resistance readings. Morey et al. (2020) have successfully demonstrated the ability of BIA to differentiate WB and SM at different severity levels as an alternative to hand palpation to reduce human error. However, various classification algorithms should be used to further increase the accuracy of the BIA technology.
Classification accuracies of bioelectrical impedance analysis data can be improved through the use of modern data analytics techniques such as machine learning (ML), which includes data mining, artificial neural networks (ANNs), deep learning (DL), and artificial intelligence (AI) (Tufféry, 2011). ML is a complex field with a wide range of frameworks, concepts, approaches, or a combination of these methods; it is commonly used in the manufacturing sector for process optimization, tracking, and management applications in production and predictive maintenance (Wiendahl and Scholtissek, 1994; Gardner and Bicker, 2000; Alpaydin, 2010). These techniques have been widely applied to enhance quality control in production processes (Apte et al., 1993), particularly in complex production processes where predicting causes of problems is challenging (Kusiak, 2006). Over the last few decades, automated product inspection systems incorporating ML have been used in a wide variety of food industries such as potato and apple (Tao et al., 1995), oil palm fruit (Abdullah et al., 2002), rice and grains (Carter et al., 2005), beef fat (Chen et al., 2010), and colour in bakery applications (Nashat et al., 2011).
The use of machine learning models has increased in recent years because of circumstances such as the availability of complex data with little accountability (Smola and Vishwanathan, 2008) and will become more critical in the future. Although several ML algorithms are available, such as ANNs, support vector machines (SVMs), and distributed hierarchical decision trees, their ability to deal with large data sets varies significantly (Monostori, 2003; Bar-Or et al., 2005; Do et al., 2010). In the production sector, only specific ML algorithms are capable of handling high-dimensional datasets, and having the ability to deal with high dimensionality is considered a benefit of using ML in the processing industry. One of the main benefits of ML algorithms is finding previously unknown (hidden) information and recognising its associations in large datasets. The available information criteria can depend mainly on the characteristics of an ML algorithm (supervised/unsupervised or reinforcement learning, RL). Nevertheless, the general process of the ML method for producing outcomes in a production environment has been proven conclusively (Filipič and Junkar, 2000; Guo et al., 2008; Alpaydin, 2010; Kala, 2012). The use of the BIA method in poultry processing provides complex data with high dimensionality, which can be used to train SVM algorithms for the classification of WB (based on severity) and SM fillets. Support vector machines (SVMs), with a kernel-based procedure, has emerged in machine learning as one strategy for sample classification (Pardo and Sberveglieri, 2005). The implication of SVMs in machine learning as a supervised learning technique provides good generalisation ability and more minor overfitting tendencies. Using kernel functions in SVMs makes original input values linearly separable in a higher dimensional space. Moreover, SVMs can simultaneously reduce estimation errors and model dimensions (Singh et al., 2011). The main objective of this research was to determine the accuracy of linear discriminant analysis (LDA), SVMs, and backpropagation neural networks (BPNNs) to classify WB and SM using multi-dimensional BIA data. The LDA, SVM, and BPNN methods are discussed in detail, their accuracies were compared, and reasons for the differences in the classification accuracies are discussed.
Poultry researchers and the industry collect enormous amounts of data on a regular basis but use simpler statistical methods to derive meaning from the data. Through the presented research, we envision to introduce the poultry research community to several data analytics techniques to analyze complex datasets.
Materials and Methods
Data Collection
Freshly deboned breast fillets from 56-day old broilers (Ross 708) were analysed in a federally inspected commercial poultry processing facility after deboning. The breast fillets (n = 300, 3 replications or flocks) were randomly selected from the processing line 3 to 3.5 h post slaughter. The deboned breast fillets were analysed for WB incidence through hand palpation by an experienced team member (Figure 1). The breast fillets were classified into normal, mild (for data analysis mild was grouped with normal), moderate, and severe WB fillets (Tijare et al., 2016), and SM presence was evaluated by observing the turgor in the cranial-ventral portion of the breast fillets, with a decrease in turgor indicating the presence of SM and increase in turgor representing the absence of SM. The collected chicken breast fillets from the processing line were subjected to BIA by utilising a hand-held CQ Reader (Figure 2; Seafood Analytics, Clinton Town, MI, United States) (Morey et al., 2020), equipped with four spring-loaded electrodes (RJL Systems, Detroit, MI, United States). All the four electrodes were placed to make contact with the ventral surface of the breast fillets. Once the electrodes were in contact with the breast fillets, the circuit was complete and linked. Then, the device measured the data for resistance, reactance, fat index, and protein index, and the stored data were downloaded for analysis later (Seafood Analytics Certified Quality Reader, Version 3.0.0.3; Seafood Analytics, MI, United States). Individual weights of the fillets were also determined using a weighing balance (Ohaus Corporation, Pine Brook, NJ, United States) for the analysis and used to train the SVM and BPNN models.

Figure 2. Hand-held bioelectrical impedance device to measure the severity level of fillets.
Linear Discriminant Analysis
Linear discriminant analysis is one of the conventional data mining algorithms used in supervised and unsupervised learning contemplated by Fisher (1936) for resolving the issue related to flower classification (Xanthopoulos et al., 2013). The LDA model is used to project an imaginary hyper-plane that minimises the interclass variance and maximises the distance between class means. Additionally, it produces a transformation in the data that is discriminative in some data cases (Fukunaga, 2013). LDA is more appropriate for data where unequal within-class frequencies are given, and its classification performances have been randomly examined on generated test data. This approach maximises the ratio of between-class variance to within-class variance with maximum separability. Data sets used in LDA analysis can be transformed, and related test vectors can be classified in the imaginary hyper-plane by class-dependent transformation and class independent transformation (Balakrishnama and Ganapathiraju, 1998). The class-dependent transformation approach maximises the ratio of between-class variance to within-class variance. This kind of class transformation helps in maximising class separability (Tharwat et al., 2017). The main objective for implementing LDA is to create a subspace of lower-dimensional data points compared with the sample data set, in which the original data points from the data set can be easily separable (Figure 3; Fisher, 1936). The use of LDA provides a solution that can be implemented in a generalised eigenvalue system, which provides huge and fast data optimization. The original LDA algorithm was used to solve binary classification taxonomic problems; however, Rao (1948) had also proposed multi-class generalisations. In this study, both class classification and multi-class case classification derivation were provided to better understand the concept from the simple two-class case (Xanthopoulos et al., 2013).
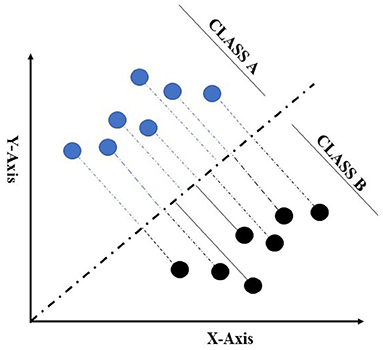
Figure 3. Representation of two-class data in dimensional space for linear discriminant analysis (LDA) to maximise the classifiable data on the hyper-plane. This Figure adapted from Fisher (1936).
Let “a1,., ap ∈ Rm” be a set of “q” data sets related to the two separate classes, A and B. For each class defined, sample means are
NA, NB is the total number of samples in data sets A and B. Scatter matrices for the data set by the equation
Each of the matrices mentioned above is used for the imaginary hyper-plane, which is defined by the vector (φ), and the variance for the calculation is minimal and can be explained by the equation
where S = SA + SB by definition and from equations 1.2, the scatter matrix for supposed two matrixes for the two classes are
LDA is based on Fisher's projection hyper-plane, i.e., maximizing the distance between the means and minimizing the variance of each considered class that can be mathematically described by Fisher's criterion equation as:
There could be several solutions for the optimization-related problem with the same function value. For a solution ϕ,* all the vectors c·φ* will give the same value, and considering no loss in generality, we select only one best possible solution by substituting the denominator with an equality constraint. Then, the problem becomes
The Lagrangian mechanism associated with this problem is
where λ is the LaGrange multiplier associated with the equation 1.6b. Since SAB is positive and the nature of the problem is convex, the global minimum will be at the point for which
The optimal φ obtained as the eigenvector that corresponds to the smallest value for the generalised eigensystem:
Multi-class LDA is only the extension of the two-class classification problem. Given x classes, the matrices will be redefined, and the intra-class matrix becomes
while the inter-class scatter matrix is annotated by
where the number of samples (pi) in the ith class, ai is the mean, and a is mean vector given in equation
The linear transformation φ can be achieved by solving the above equation:
to achieve a better classification by projection of the hyper-plane. Once the transformation ϕ is achieved, the class of a new point “y” is determined by
where an is the centroid of nth class. The calculation reflects that all the centroids of the classes were defined first and that the unknown points on the subspace were defined by φ and the closest class concerning D.
Support Vector Machines
Vapnik (2013) first contemplated the support vector machine method in 1995, and recently it has enticed an enormous level of endeavour in the machine learning applications community. Several studies have mentioned that the SVM method has immense performance in classification accuracy compared with other data classification algorithm methods (Maji et al., 2008; Shao and Lunetta, 2012; Vijayarani et al., 2015). SVM generates a line between two or more classes known as hyper-planes for data set classification. Input data Q that can fall on either side of the hyper-plane (QT•W–b) > 0 are labelled as +1, and those that fall on the other side, (QT•W–b) < 0, are labelled as −1 (Figure 4A; Lee and To, 2010); let {Qi, yi} ∈ Rn be training data set, yi∈{1, −1}, i = 1, 2,…,n.
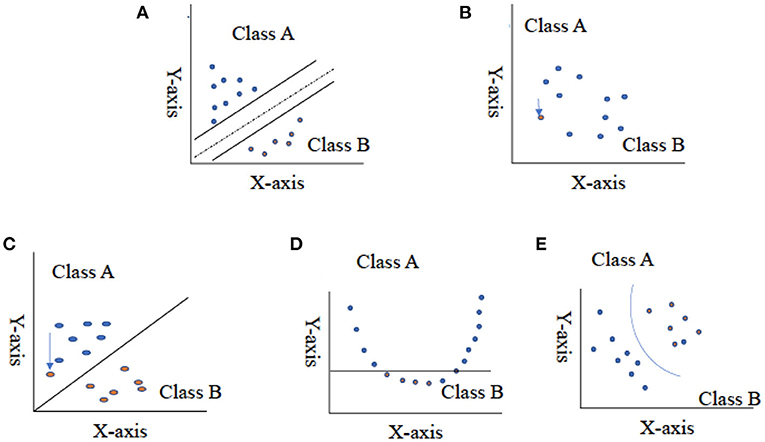
Figure 4. Representation of two-class data using hyper-plane for support vector machine. (A) Represents split data set in half, (B) represents the two-close value, (C) represents the outlier value as the solution for the figure (B), (D) represents non-linear data set, and (E) represents the use of kernel function and change in dimensionality of data. This Figure adapted from Noble (2006).
There exits hyper-plane,
The equation for the training data set can be written as
The above-mentioned equations can be written as
Another definition for the hyper-plane considering P− and P+, let {Qi, yi} ∈ Rn be training data set, y iÎ {1, −1}, i = 1,2,…,n,
The optimization mentioned above is a form non-convex optimization problem that relies on the absolute value of |W| and is difficult to solve than convex optimization problems. The equation for the absolute value W can be replaced using 1/ 2 | |W| |2 without having any change in the final solution; so, the representation of the SVM-related problem in quadratic programming (QP) form is as follows (Osuna et al., 1997):
After solving the SVM optimization problem using Lagrange multipliers (ai), the Wolfe dual of the optimization problem was achieved (Craven, 1989):
After solving for the value for W and b,
the solution in Equation (2.5) is the following condition:
putting the value of 2.6 into equation 2.4, we get the dual form of SVM,
The number of variables in the Equation derived is equivalent to the total number of data cases (n). The training set data with ai > 0 represents the position of support vectors for the classification, and Qi p+ or Qip–.
The equation for hyper-plane decision can be written as Pontil and Verri (1998)
where q is the unknown input data that need to be classified. The SVM method has been employed in a considerable range of real-world problems associated with different fields of automation, forensics, biotechnology, agriculture statistics, and is now being used in food sciences for the classification of bakery products, fresh produce, and meat product classifications (Liu et al., 2013; Chen and Zhang, 2014; Asmara et al., 2017; Chen et al., 2017; Arsalane et al., 2018). It has been proven that SVMs are persistently most appropriate for diverse supervised learning methods. Despite this, the performance of SVMs is very receptive to the cost parameter, and kernel frameworks are set. As a result, research industries want to conduct ample cross-validation to determine the most influential parameter setting (Durgesh and Lekha, 2010).
Backpropagation Neural Networking
According to Lippmann (1987), there were no practical algorithms available for interconnecting weight values to achieve an overall minimum training error in multilayer networks. Rumelhart et al. (1986) proposed a generalised rule for backpropagation neural networking, an iterative, gradient descent training procedure. The input data, in the form of vector, are a pattern to be learned, and the desired output is in the form of a vector produced by the network upon recall of the input training pattern (Paola and Schowengerdt, 1995). The main goal of the training is to minimise the overall error between the test set data and training set data outputs of the network (Paola and Schowengerdt, 1995). BPNN is also recognized as multilayer perceptrons, one of the multiple layers forward neural networks. A BPNN comprises one input layer, one or more hidden layers, and one output layer (Bharathi and Subashini, 2011; Liu et al., 2013). Consideration of distinct factors plays a fundamental role when developing a BPNN that consists of the structure of network, initialisation, and switch functions in each hidden and output layer, the training way and algorithm, the learning rate, the error-goal (ε), and preprocessed input data. BPNN has some advantages, such as easy architecture, ease of assembling the mannequin, and fast calculation speed. However, BPNNs have some issues, such as (i) possible to contain in local extremum, (ii) poor generalisation ability, (iii) lack of strict format packages with a theoretical foundation, and (iv) challenging to manage the learning and training method (Yao, 1999).
In spite of these problems, backpropagation neural networks have been successfully implemented in a range of fields. Users have applied their experiences and prior knowledge during the design of a BPNN to overcome these problems (Liu et al., 2013). A supervised BPNN learning algorithm consists of an input layer, one or more hidden layers, an output layer, and the nodes of the hidden layers primarily affect the classification efficiency of the neural network (Figure 5). Parameters that are required to be defined by the users are learning rate (0 < η < 1) and momentum (0 < η < 1).
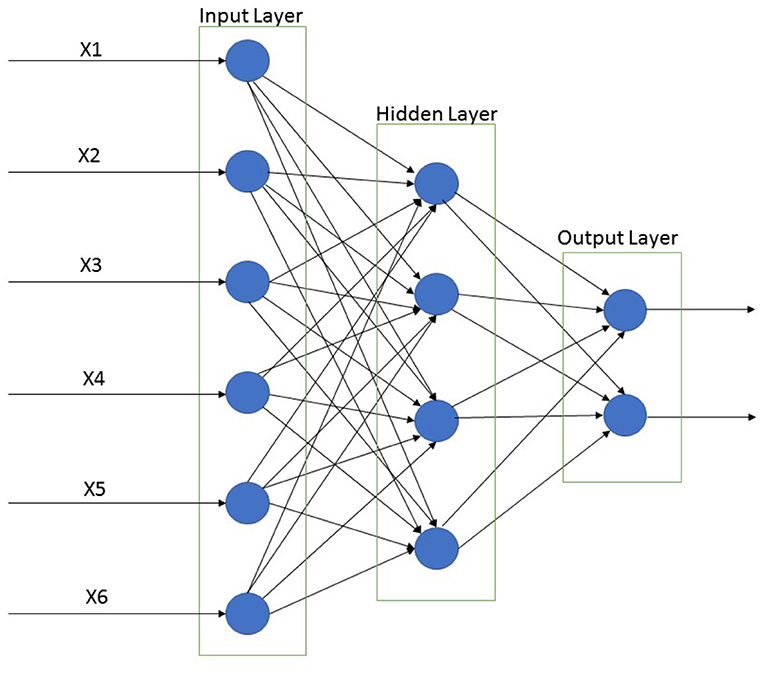
Figure 5. Back propagation neural network classification for input, hidden, and output layer. This Figure was adapted from Rumelhart et al. (1986).
BPNN program training procedure (Lee and To, 2010; Yang et al., 2011):
1. Design and input for network.
2. Normalise the initial input weights W and threshold values (θ).
3. Define the training and testing data set and input the training matrix X and output matrix Y.
4. Estimate the output vector of each neural synaptic unit.
(a). Evaluate the output vector (Z) for the hidden layer:
(b). The root of the mean square:
5. Estimate distance δ for the output layer and hidden layer from Equations (3.6, 3.7):
6. Evaluate modifications for initial weights (W) and distance (δ) (η is the learning rate, α is the momentum) for both output layer (Equations 3.8, 3.9) and hidden layer (Equations 3.10, 3.11):
7. Redefine initial weight (W) and the threshold value (θ), redefine W and θ of the output and hidden layer:
After modifying output and hidden layer, the steps will be renewed, and steps 3–7 will be repeated until converge.
BPNN program-testing process (Lee and To, 2010; Yang et al., 2011):
1. Input parameters related to the network.
2. Input the initial weights (W) and the threshold value (θ).
3. Unknown data entry for data matrix X.
4. Evaluate output vector (Z) for the output and hidden layer:
Statistical Analysis
All the parameters (resistance, reactance, fat index, protein index, and fillet weights) were analysed by one-way analysis of variance with Tukey's honestly significant difference (HSD) (p < 0.05) to determine significant differences among the levels of myopathy severity. The data were further analysed using three classification methods, linear discriminant analysis (LDA) (SAS, Version 9.4), support vector machines (SVMs), and backpropagation neural networking (BPNN). For each method, the data were analysed using three different scenarios: (1) all data (WB scores, fillet weight, resistance, reactance, protein index, and fat index); (2) without fillet weights (WB scores, resistance, reactance, protein index, and fat index); and (3) without fat and protein index (WB scores, fillet weight, resistance and reactance). For the SVM and BPNN analysis of collected data, R software (Version 4.0.0, Arbour Day) was used by using the caret package in the analysis to classify various chicken breast fillet myopathies. The data sets collected for the different conditions were divided into 70::30 training set and testing set. The caret package algorithm calculated the best-suited tuning parameter or value of cost (C) for both the training and testing data sets. A seed value was set for 3,000 for the SVM analysis. For BPNN the classification of fillets, the Neural net and BBmisc packages were used to classify the collected data sets (WB and SM), and the data sets were divided into 70::30 training and testing data sets. Low learning rate (0.01), the threshold value (0.01), number of maximum steps (10,000), and four hidden layers were used in the BPNN classification algorithm for the analysis.
Results
The differences in various parameters among the levels of woody breast and spaghetti meat severity are shown in Tables 2, 3, respectively. As shown in Table 2, there are significant differences (p < 0.05) in the resistance, reactance, and fillet weights among the WB categories. There were no significant differences (p > 0.05) in the fat and protein index between WB severity levels (Table 2). On the contrary, there are no significant differences in the parameters between breast fillets with and without SM (Table 3). Classification efficiencies of the fillets are greatly affected by the analysis of all the data, without fillet weights and without fat and protein index, indicating the significance of variables in classification accuracy (Table 2). The LDA, SVM, and BPNN analyses showed that when the fillet weights were removed from the dataset, classification accuracy (testing %) was reduced by as high as 20% (Table 2). The LDA analysis without fillet weight data set showed less classification efficiency in the testing data set (normal = 43.8%, moderate = 17.2%, and severe = 50.0%) compared with the training data set (normal= 62.1%, moderate = 32.2%, and severe = 64%), indicating that the training model was not efficient in classification at the testing stage. Similarly, the SVM analysis showed low classification efficiency for the testing set (normal = 56.52%, moderate = 49.77%, and severe = 64.63%). The removal of fat and protein index data from the analysis showed that the LDA analysis for normal (training::testing = 61.7::75.6) and moderate fillets (training::testing = 31.3::33.33) improved as compared with the analysis without the fillet weight data set and all the data sets (including resistance, reactance, protein index, fat index, and fillet weights). The lower efficiency may be due to the misclassification of fillets due to fat and protein index value overlapping. The SVM analysis showed a higher classification pattern for normal (training::testing = 65.75::73.28) and severe breast fillets (training::testing = 72.49::81.48), similar to the overall data set. For the classification of SM fillets from the normal fillets, the SVM analysis performed better in the classification of normal fillets (training::testing = 57.06::60.00) from spaghetti meat-conditioned fillets (training::testing = 45.5::22.2) (Table 2). On the other hand, the SVM analysis for the resistance, reactance, and weight data set showed slightly improved classification efficiency for fillets with SM condition (training::testing = 50.00::52.35). BPNN did not perform well in any of the given conditions for the classification of fillets based on WB severity and SM fillets conditions.

Table 2. Comparison of bioelectrical impedance parameters and fillet weights among woody breast fillets with varying myopathy severity levels.

Table 3. Comparison of bioelectrical impedance parameters and fillet weights among normal breast fillets with and without spaghetti meat conditions.
Discussion
Using only visual and hand palpation characteristics to identify woody breast and spaghetti meat muscle myopathies poses various challenges, such as misclassifications, processing inefficiencies, and increase in labour costs, when classification is performed on a processing line. WB is found primarily in the superficial area of breast fillets and, many times, includes the visual presence of surface haemorrhages, appearance of light-yellow surface, rigid bulged fillet, and by mechanical palpability of the muscle (Figure 6; Mazzoni et al., 2015; Mudalal et al., 2015). Additionally, normal breast fillets have smaller cross-sectional areas as compared with woody breast fillets (Huang and Ahn, 2018), with higher collagen content and elevated post processing pH (Petracci et al., 2015; Chatterjee et al., 2016; Clark and Velleman, 2016; Soglia et al., 2016). SM, on the other hand, is related to immature intramuscular connective tissues in the breast meat, and it has lower muscular cohesion than the breast meat from unaffected fillets (Figure 7; Bowker and Zhuang, 2016; Radaelli et al., 2017; Sihvo et al., 2017). The thickness of connective tissues in the breast fillets showing SM decreases gradually in the endomysium and perimysium, causing different muscle fibres to deteriorate or have a mushy texture (Baldi et al., 2018). Therefore, using an assortment of already available complex data, we were able to make improvements to the classification of fillets among the WB and SM myopathies.

Figure 6. Spaghetti meat condition in chicken breast fillets.

Figure 7. Severe woody breast fillet in the collected samples.
Significant differences were observed in the resistance and reactance among the normal, moderate, and severe woody breast fillets (Table 2), indicating changes in the muscle architecture and the intra- and extra-cellular water contents of the meat (Morey et al., 2020). It was expected to find significant differences in the fillet weights among the levels of WB severity, with severe WB fillets weighing significantly heavier than the normal fillets (p < 0.05). However, contrary to Morey et al. (2020), this research reports an inverse trend in resistance and reactance of normal and severe woody breast. Morey et al. (2020) reported that resistance and reactance were lower in normal meat (72.18 and 28.04 Ω, respectively), and higher in severe WB meat (78.27 and 37.54 Ω). In this study, resistance and reactance were higher in normal meat (71.89 and 36.93 Ω) and lower in severe WB meat (67.9 and 30.72 Ω). As for the normal meat with and without SM (Table 3), the observations were contrary to Morey et al. (2020). This study (Table 3) did not find significant differences in the resistance, reactance, fat index, protein index and weight of the normal fillets with and without SM.
In this study, the breast fillets were taken from water-chilled birds, which were immediately deboned on a deboning line and analysed in a plant, while in the study by Morey et al. (2020), the fillets were transported to a lab and analysed within 6 h of procurement. It would be of interest to investigate if the differences in bioelectrical properties are (1) water-retention in the normal breast fillets due to immersion chilling and (2) post deboning holding time. The findings emphasise the fact that the bioelectrical parameters were standardised by the processors prior to use.
The results obtained with training accuracy for linear discriminant analysis (70::30) classification were 72.31, 43.75, and 75% for the normal, moderate, and severe woody breast (Table 4) fillet classifications, respectively, using the bioelectrical impedance analysis and fillet weight data set (n = 300). The testing set was lower in accuracy than the training set, with only 52.63% normal classified, 29.41% moderate classified, and 59.09% severe WB classified (n = 300; Table 4). The testing data set was lower in accuracy compared with the training set data, possibly because of the low sample size and non-linearity of the data set. The non-linear data set is likely due to human error during the manual hand-palpation of the breast fillets; however, in future studies, larger data sets could be implemented to increase the accuracy of the BIA method combined with conventional algorithms. Morey et al. (2020) also performed LDA (60::40) with a BIA data set (n = 120) and reported 68.69–70.55% accuracy for the classification of normal fillets and 54.42–57.75% accuracy for severe WB fillets in the testing set. Wold et al. (2019) analysed a near infrared spectroscopy (NIR) data set (n = 102) using an LDA (50::50) classification algorithm with 100% accuracy for fillet classification in the training set and 96% accuracy in the testing set, for a rapid on-line detection method for WB myopathy in processing plants. LDA is a well-recognised technique for reducing the dimensionality of data in a dataset. However, LDA can only be used for single-label multi-class categorizations and cannot explicitly be extended to multi-label multi-class classification systems. The LDA technique is used to convert high-dimensional data into a low-dimensional data space, maximising the ratio of between-class variation to within-class variance, thereby ensuring optimal class separation (Pan et al., 2014). The LDA technique works by projecting the initial data matrix onto a lower-dimensional region. For the reduction of dimensionality, three steps are required: (i) the inter-class difference or between-class matrix is used to measure the separability across multiple categories (i.e., the distance between the means of different classes), (ii) the within-class variance, also known as the within-class matrix, is calculated as the difference between the mean and the class samples, and (iii) the creation of a lower-dimensional space that maximises between-class variance while minimising within-class variance (Mandal et al., 2009). In this research and that of Morey et al. (2020), the low performance of data collected and analysed by LDA compared with the data collected may have two key factors: small sample size and data linearity issues. Su et al. (2017) also found low performance in data sets with small sample size and non-linear data.
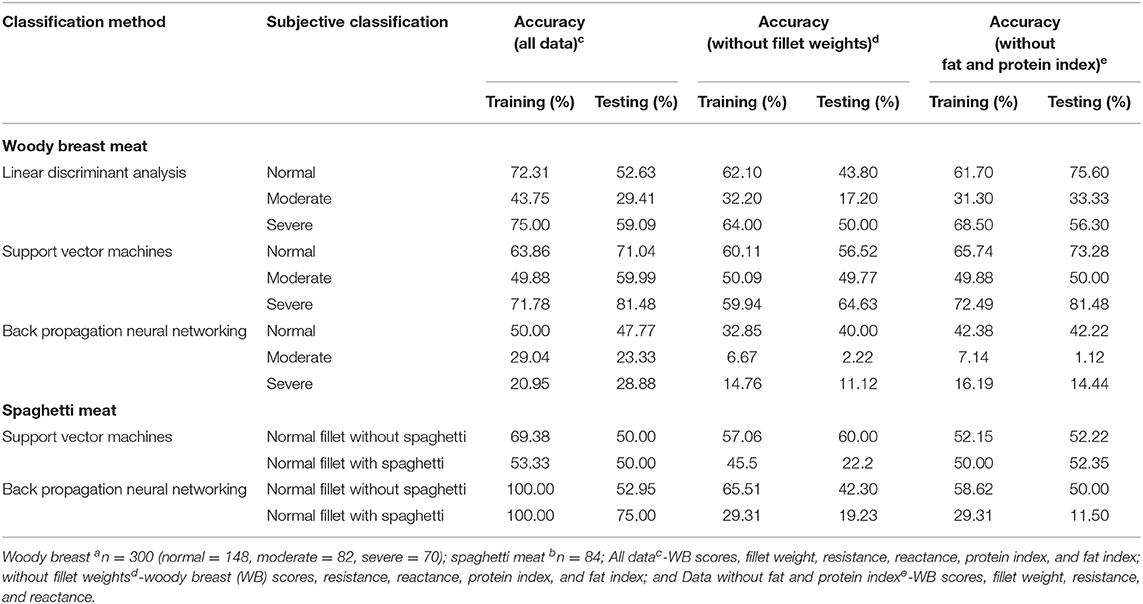
Table 4. Percentage classification efficiency for various supervised machine-learning algorithms (linear discriminant analysis, support vector machines, and back propagation neural networking) for breast fillets with woody breasta and spaghetti meatb in three different scenarios (all data, without fillet weights, and without fat and protein index value).
The linear discriminant analysis technique is used to find a linear transformation that discriminates between various groups. However, LDA cannot find a lower-dimensional space if the groups are non-linearly separable. In other words, where discriminatory knowledge is not in the means of classes, LDA fails to locate the LDA space. One of the significant issues with the LDA methodology is singularity, also known as small sample size or under-sampling. This issue arises because of high-dimensional trend classification problems or a low number of training samples available for each class compared with the dimensionality of the sample space (Huang et al., 2002; Lu et al., 2005; Zhuang and Dai, 2005; Su et al., 2017; Tharwat et al., 2017).
The machine learning theory lays the groundwork for support vector machine, and this algorithm has gained widespread attention because of its unique performance efficiency, and ability to accomplish pinpoint accuracy and manage high-dimensional, multi-variate data sources. Cortes and Vapnik (1995) implemented SVMs as a new ML technique for two-group classification problems. Researchers have reported that SVMs are an economical, sensitive, and easy to use classifier that can be implemented in organised evaluation assignments (Vapnik, 1995). The inspection of large collected data sets during production is a significant application of SVM (Burbidge et al., 2001; Chinnam, 2002). SVM is frequently used in various food production environments, including product monitoring systems, mechanical fault detection, and dimensional accuracy (Ribeiro, 2005; Salahshoor et al., 2011; Çaydaş and Ekici, 2012; Azadeh et al., 2013). SVMs are used in different processing areas, such as drug designing and discovery, surgery, and cancer treatment, in addition to the food product processing industry (Vapnik, 2013). Product quality control (Borin et al., 2006), polymer recognition, and other applications are also possible (Li et al., 2009) areas in which SVM can be incorporated. These examples from different industries demonstrate that SVM algorithms have a broad range of applicability and versatility (Kotsiantis et al., 2007). This research demonstrates the ability for the implementation of SVM and BPNN in combination with BIA and fillet weight data to classify WB and SM fillets.
Statistical learning theory (SLT) is a robust and appropriate supervised learning algorithm for production research problems. Under SLT, algorithmic learning allows it to use an achieving function, representing the relationship between different components without being directly connected (Evgeniou et al., 2000). The algorithm enquires about the problem concerning how well the selected method resolves the problem, and accuracy prediction performance for previously unknown inputs is the subject of SLT (Evgeniou et al., 2000). A few more realistic techniques, such as autoencoders, SVM, and Bayesian optimization, are based on the theories of SLT (Battiti et al., 2002). SVM is considered a mathematical expression in its most basic form, a method (or algorithm) for optimising alphanumeric equations, with a given set of data (Noble, 2006).
The fundamental idea of support vector machine algorithmic expression can be easily understood by four fundamental concepts: (i) the imaginary hyper-plane, (ii) the margin of hyper-plane, (iii) the soft margin, and (iv) the kernel function (Tharwat, 2019). A solid line splits the region in half in two dimensions (Figure 4A), but we require a hypothetical plane to split the area into three dimensions. A hyper-plane is a collective term for a straight line in a high-dimensional region, and the dividing hyper-plane is the line that separates the pieces of data (Kecman, 2001; Tharwat, 2019). SVM, on the other hand, differs from other hyper-plane-based classifiers based on how the hyper-plane is chosen. Consider the grouping shown in Figure 4. By implementing SLT, it is easier to find the best possible plane to create the hyper-plane that will be used in the classification of data (Vapnik, 1963). The capability of SVM to classify the correct data points between given classes can be improved by using an imaginary hyper-plane in the space. The SLT theorem implies that the data used to train SVM originates from the same dataset as the data used to test it. For example, if an SVM algorithm is trained on the sensory property of a product, it cannot be used to train the data collected for the subjective response of consumers. Furthermore, we cannot expect SVM to work well if training is conducted with an SM breast fillet data set, so a WB data set is used for testing. At the same time, the SLT principle does not assume that two data sets come from the same class of distributions. For example, an SVM algorithm does not assume that training data values follow a normal distribution.
For a better understanding of support vector machine and its function, we have concluded an imaginary data set for classes A and B, which can be divided using a straight line. When the values in a data set are closer together or intersected (Figure 4B), SVM will manage this overlapping of data by inserting a soft margin. In essence, this causes specific data points to pass across the margin of the dividing hyper-plane, without influencing the outcome. The use of the soft margin provides the solution to the problem of misclassification (shown in Figure 4B) by considering the data point as an outlier (shown in Figure 4C). Another essential function for SVM classification is the kernel function (shown in Figures 4D,E), a mathematical trick that allows SVM to perform a two-dimensional classification of a one-dimensional data set. In general, a kernel function projects data from a low-dimensional space to a space of higher dimension.
Support vector machine classification efficiency (Table 4) for the separation of high dimensionality data showed better classification efficiency for normal (training efficiency 63.86%, testing efficiency 71.04%), moderate (training efficiency 49.88%, testing efficiency 59.99%), and severe WB (training efficiency 71.78%, testing efficiency 81.48%) compared with the LDA algorithm used by Morey et al. (2020). The BIA and fillet weight data set used in training the SVM performed well because of the higher dimensionality of the data set. When data are highly dimensional and the sample sets are relatively small, SVM analysis is more accurate to classify data, and has been used by other authors to help classify multi-dimensional data. Barbon et al. (2018) used a relatively small data set (n = 158) of NIR results combined with SVM (75::25) to classify normal and pale meat, as it relates to pale, soft, and exudative poultry breast meat. They demonstrated the use of SVM as a classification tool for breast fillets with muscle myopathies where the classification accuracy for normal fillets was 53.4 and 72. % for pale fillets. Geronimo et al. (2019), using an NIR system equipped with an image acquisition system, found 91.83% classification efficiencies (fillet images) using SVM to analyze a WB fillet sample set (sample size is unclear) with a 70::30 model. These researchers also used multilayer perceptron (a feed-forward network differing from the backpropagation network in BPNN) to classify the data set, and classification accuracy was 90.67% for WB. Yang et al. (2021) analysed images derived from the expressible fluid of breast meat to classify WB using SVM (training and testing ratio is unreported) and DL (training to testing is 2 to 1). These researchers found fewer classification efficiencies for SVM algorithms in the testing set (38.25–63.89%), compared with the training set (40.41–81.94%) in three out of the four SVM classification methods used. In their DL classification (a type of ANN) to classify WB, they reported 100% accuracy in the training set and 93.3% accuracy in the testing set.
Connexions of random different nodes or units in a computing system to solve problems that are impossible to solve by conventional statistical methods are known as artificial neural networks and are based on the circuitry of the human brain. When applied to a processor framework, the subconscious network can execute unique functions (perception, speech synthesis, image recognition), which have proven to be useful in industrial applications (Alpaydin, 2010). Neural networks allow an automated artificial skill to operate unsupervised reinforcement and classification algorithm functions (neural networks) by simulating the decentralised “data analysis” capabilities of the central nervous platform through neural networks (Pham and Afify, 2005; Corne et al., 2012). Decentralisation employs many necessary interconnected neurons or nodes and the capacity to process data through the complex response of these endpoints and their links to exogenous variables (Akay, 2011). These algorithms are crucial in the modern machine learning development of today (Nilsson, 2005) and can be classified into two categories: interpretation and algorithm. Neural networks are used in a variety of industrial sectors for a range of problems (Wang et al., 2005) e.g., process control, emphasising their key benefit and overall predictive validity (Pham and Afify, 2005). However, ANN (similar to SVM) requires a large sample size to attain maximum precision (Kotsiantis et al., 2007). Overfitting, which is linked to high-variance implementations, is universally acknowledged as a disadvantage of the ANN algorithm (Kotsiantis et al., 2007). Other difficulties with using neural networks include the sophistication of generated models, aversion for missing values, and, often, lengthy dataset training method (Pham and Afify, 2005; Kotsiantis et al., 2007).
For backpropagation neural networks, the data were pre-processed and consisted of just two dimensions with a lower level of classification complexity (Panchal et al., 2011). Classification efficiencies for the WB fillets using BPNN (Table 4) show that the testing data set for the normal (47.77%) and moderate fillets (23.33%) did not perform well, compared with the classification efficiency for the severe WB fillets (28.88%). The BPNN classification algorithm for the WB fillets did not perform well-because of the complexity of the data after pre-processing, and overfitting of the learning model due to the uneven distribution of weight on the input neuron layer. The BPNN classification algorithm for the SM data set (Table 4) performed well for the training data set for normal (training 100%, testing 52.95%) and SM fillets (training 100%, testing 75%). However, due to the complexity of pre-processed data, overfitting of BPNN and small data set, the classification efficiency of the testing set was lower than that of the training set. These studies all use SVM and ANN algorithms to classify small sample data sets, where the results always show that the accuracy in the training set data was higher than that in the testing set data, indicating that the training of the model is not performing well. Collection of larger data set for the supervised learning methods of classification provides the chances for getting lower error rates and better learning ability for the machine learning algorithms.
In a backpropagation neural network, the input data vector represents the pattern to be trained, and the output data vector represents the optimal set of output values that the network can generate when the training pattern is recalled. The aim of BPNN training is to reduce the total error between the expected and real outputs of the network (Panchal et al., 2011). To generate a reduction in error, the residual differences in the weights at each iteration must be unmeasurable. A learning rate metric, which reflects the rate of the move taken toward minimal error, must be defined to accomplish a reasonable training period. Learning will take too much time if this amount is too small, and if it is too high, the loss function will degenerate and errors will rise (Ganatra et al., 2011). When using neural networks to analyze WB data, overlearning or overfitting happens when the algorithm takes too long to run, and the network is too complicated for the problem or the amount of data available, whereas, to classify SM in a group of fillets, BPNN was used, and data are processed differently.
Additional analysis of the data was conducted to determine if the parameters used in data classification would make a difference in classification accuracies using the three methods (linear discriminant analysis, support vector machine, and backpropagation neural network) for both woody breast and spaghetti meat. Irrespective of the methodologies used, removing fillet weight reduced the classification accuracies of WB classification by up to 20%, indicating the importance of using fillet weights (for classification), which were significantly different among the WB categories (p < 0.05; Table 2). Removing the fat and protein indexes, which were not significantly different among the WB categories (p > 0.05; Table 3) increased the classification accuracy (Testing %) of the LDA models, while it was similar for the SVM and BPNN models. The finding indicates the significance of using fillet weight in the models and that the SVM and BPNN models analyze the significance of each parameter in the classification models.
It was interesting to note that the bioelectrical impedance analysis parameters, such as weight, were not significantly different between normal meat with and without spaghetti meat (Table 3). However, those parameters could be used collectively to develop classification models using LDA, SVM and BPNN models. Most importantly, removing weights did make a difference in the classification accuracies, but retaining the fillet weights and removing the fat and protein indexes did not necessarily increase the accuracy of the model. In the case of SM, more data are needed to build more accurate and stronger models.
Conclusion
This project demonstrates the application of machine learning in poultry production processes to categorise chicken breast fillets into groups based on the severity of myopathy. The use of SVM and BPNN can be combined with BIA and fillet weight data to more accurately classify breast fillet myopathies, such as WB and SM, from normal breast fillets in real-time online, compared with the subjective hand palpation method. With the implementation of other meat quality parameters, such as water content, the classification accuracy of SVM and BPNN could be improved. To obtain a well-trained model for classification efficiency and to reduce overfitting and underfitting problems related to classification, future research should include larger data sets for breast fillet myopathies to avoid the overlapping of conditions caused by human error in the sorting of fillets. The innovative combination of these tools has the potential to improve poultry processing efficiencies and downgrades of breast fillets affected by undesirable myopathies while reducing customer complaints.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
Ethics approval was not required for this study in line with national/local guidelines.
Author Contributions
AM is the lead investigator who conceptualised the idea, secured funding, and conducted the research. AM, AS, and JV conducted the bioelectrical impedance analysis data collection. AS performed the SVM, BPNN analysis, and manuscript preparation. AES and SS have helped in the cross-validation of analysis results and review of the manuscript. AM and LG assisted in writing—review and editing. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abdullah, M. Z., Guan, L. C., Mohamed, A. M. D., and Noor, M. A. M. (2002). Color vision system for ripeness inspection of oil palm Elaeisguineensis. J. Food Process. Preserv. 26, 213–223. doi: 10.1111/j.1745-4549.2002.tb00481.x
Akay, D. (2011). Grey relational analysis based on instance-based learning approach for classification of risks of occupational low back disorders. Saf. Sci. 49, 1277–1282. doi: 10.1016/j.ssci.2011.04.018
Apte, C., Weiss, S., and Grout, G. (1993). “Predicting defects in disk drive manufacturing: A case study in high-dimensional classification. Artificial intelligence for applications,” in Proceedings of 9th IEEE Conference (Orlando, FL). doi: 10.1109/CAIA.1993.366608
Arsalane, A., El Barbri, N., Tabyaoui, A., Klilou, A., Rhofir, K., and Halimi, A. (2018). Anembedded system based on DSP platform and PCA-SVM algorithms for rapid beef meatfreshness prediction and identification. Comput. Electron. Agric. 152,385–392. doi: 10.1016/j.compag.2018.07.031
Asmara, R. A., Rahutomo, F., Hasanah, Q., and Rahmad, C. (2017). “Chicken meatfreshness identification using the histogram color feature,” in Sustainable Information Engineering and Technology (SIET) (Malang: IEEE). doi: 10.1109/SIET.2017.8304109
Azadeh, A., Saberi, M., Kazem, A., Ebrahimipour, V., Nourmohammadzadeh, A., and Saberi, Z. (2013). A flexible algorithm for fault diagnosis in a centrifugal pump with corrupted dataand noise based on ANN and support vector machine with hyper-parametersoptimization. Appl. Soft. Comput. 13, 1478–1485. doi: 10.1016/j.asoc.2012.06.020
Balakrishnama, S., and Ganapathiraju, A. (1998). “Linear discriminant analysis-a brief tutorial,” in Institute for Signal and Information Processing (Piscataway, NJ: IEEE), 1–8.
Baldi, G., Soglia, F., Mazzoni, M., Sirri, F., Canonico, L., Babini, E., et al. (2018). Implications of white striping and spaghetti meat abnormalities on meat quality and histological features in broilers. Animal 12, 164–173. doi: 10.1017/S1751731117001069
Barbon, S., Costa Barbon, A. P. A. D., Mantovani, R. G., and Barbin, D. F. (2018). Machinelearning applied to near-infrared spectra for chicken meat classification. J. Spectrosc. 2018:894971. doi: 10.1155/2018/8949741
Bar-Or, A., Schuster, A., Wolff, R., and Keren, D. (2005). “Decision tree induction in highdimensional, hierarchically distributed databases. Society for Industrial and Applied Mathematics,” in Proceedings SIAM International (Newport, CA). doi: 10.1137/1.9781611972757.42
Battiti, R., Brunato, M., and Villani, A. (2002). Statistical Learning Theory for Location Fingerprinting in Wireless LANs. Available online at: http://eprints.biblio.unitn.it/238/ (accessed April 15, 2021).
Bera, T. K. (2014). Bioelectrical impedance methods for noninvasive health monitoring: a review. J. Med. Eng. 2014, 1–28. doi: 10.1155/2014/381251
Bharathi, P. T., and Subashini, P. (2011). Optimization of image processing techniques usingneural networks: a review. WSEAS Trans. Inf. Sci. Appli. 8, 300–328.
Borin, A., Ferrao, M. F., Mello, C., Maretto, D. A., and Poppi, R. J. (2006). Least-squares supportvector machines and near infrared spectroscopy for quantification of common adulterantsin powdered milk. Anal. Chim. Acta 579, 25–32. doi: 10.1016/j.aca.2006.07.008
Bowker, B., and Zhuang, H. (2016). Impact of white striping on functionality attributes of broiler breast meat. Poult. Sci. 95, 1957–1965. doi: 10.3382/ps/pew115
Burbidge, R., Trotter, M., Buxton, B., and Holden, S. (2001). Drug design by machine learning: support vector machines for pharmaceutical data analysis. Comput. Chem. 26, 5–14. doi: 10.1016/S0097-8485(01)00094-8
Carter, R. M., Yan, Y., and Tomlins, K. (2005). Digital imaging-based classification andauthentication of granular food products. Meas. Sci. Technol. 17:235. doi: 10.1088/0957-0233/17/2/002
Çaydaş, U., and Ekici, S. (2012). Support vector machines models for surface roughness prediction in CNC turning of AISI 304 austenitic stainless steel. J. Intell. Manuf. 23, 639–650. doi: 10.1007/s10845-010-0415-2
Chatterjee, D., Zhuang, H., Bowker, B. C., Rincon, A. M., and Sanchez-Brambila, G. (2016). Instrumental texture characteristics of broiler Pectoralis major with the wooden breast condition. Poult. Sci. 95, 2449–2454. doi: 10.3382/ps/pew204
Chen, C. P., and Zhang, C. Y. (2014). Data-intensive applications, challenges, techniques andtechnologies: a survey on big data. Inf. Sci. 275, 314–347. doi: 10.1016/j.ins.2014.01.015
Chen, K., Sun, X., Qin, C., and Tang, X. (2010). Color grading of beef fat by using computervision and support vector machine. Comput. Electron. Agr. 70, 27–32. doi: 10.1016/j.compag.2009.08.006
Chen, Z., Cao, S., and Mao, Z. (2017). Remaining useful life estimation of aircraft engines using amodified similarity and supporting vector machine (SVM) approach. Energies 11, 1–14. doi: 10.3390/en11010028
Chinnam, R. B. (2002). Support vector machines for recognizing shifts in correlated and othermanufacturing processes. Int. J. Prod. Res. 40, 4449–4466. doi: 10.1080/00207540210152920
Clark, D. L., and Velleman, S. G. (2016). Spatial influence on breast muscle morphological structure, myofiber size, and gene expression associated with the wooden breast myopathy in broilers. Poult. Sci. 95, 2930–2945. doi: 10.3382/ps/pew243
Corne, D., Dhaenens, C., and Jourdan, L. (2012). Synergies between operations research and datamining: the emerging use of multi-objective approaches. Eur. J. Oper. Res. 221, 469–479. doi: 10.1016/j.ejor.2012.03.039
Cortes, C., and Vapnik, V. (1995). Support-vector networks. Mach. Learn. 20, 273–297. doi: 10.1007/BF00994018
Cox, M. K., Heintz, R., and Hartman, K. (2011). Measurements of resistance and reactance in fish with the use of bioelectrical impedance analysis: sources of error. Fishery Bull. 109, 34–47.
Craven, B. D. (1989). A modified Wolfe dual for weak vector minimization. Numer. Funct. Anal. Optim. 10, 899–907. doi: 10.1080/01630568908816337
Do, T. N., Lenca, P., Lallich, S., and Pham, N. K. (2010). “Classifying very-high-dimensional data with random forests of oblique decision trees,” in Advances in Knowledge Discovery and Management, eds F. Guillet, G. Ritschard, D. A. Zighed, and H. Briand (Berlin: Springer). doi: 10.1007/978-3-642-00580-0_3
Durgesh, K. S., and Lekha, B. (2010). Data classification using support vector machine. J. Theor. Appl. 12, 1–7.
Evgeniou, T., Pontil, M., and Poggio, T. (2000). Statistical learning theory: A primer. Int. J. Comput. Vis. 38, 9–13. doi: 10.1023/A:1008110632619
FAO (2003). Livestock Commodities. Available online at: http://www.fao.org/3/y4252e/y4252e00.htm#TopOfPage (accessed April 17, 2021).
Filipič, B., and Junkar, M. (2000). Using inductive machine learning to support decision making inmachining processes. Comput. Ind. 43, 31–41. doi: 10.1016/S0166-3615(00)00056-7
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Ann. Eugen. 7, 179–188. doi: 10.1111/j.1469-1809.1936.tb02137.x
Fukunaga, K. (2013). Introduction to Statistical Pattern Recognition. San Diego, CA: Academic Press, INC.
Ganatra, A., Kosta, Y. P., Panchal, G., and Gajjar, C. (2011). Initial classification through back propagation in a neural network following optimization through GA to evaluate the fitness of an algorithm. Int. J. Comput. Sci. Appl. 3, 98–116. doi: 10.5121/ijcsit.2011.3108
Gardner, R., and Bicker, J. (2000). Using machine learning to solve tough manufacturingproblems. Int. J. Ind. Eng. Theory Appl. Pract. 7, 359–364.
Geronimo, B. C., Mastelini, S. M., Carvalho, R. H., Júnior, S. B., Barbin, D. F., Shimokomaki, M., et al. (2019). Computer vision system and near-infrared spectroscopy foridentification and classification of chicken with wooden breast, and physicochemical andtechnological characterization. Infrared Phys. Technol. 96, 303–310. doi: 10.1016/j.infrared.2018.11.036
Guo, X., Sun, L., Li, G., and Wang, S. (2008). A hybrid wavelet analysis and support vectormachines in forecasting development of manufacturing. Expert Syst. Appl. 35, 415–422. doi: 10.1016/j.eswa.2007.07.052
Heinz, G., and Hautzinger, P. (2009). Meat Processing Technology for Small to Medium Scale Producers. FAO. Available online at: https://agris.fao.org/agris-search/search.do?recordID=XF2016077667 (accessed March 3, 2021).
Hoffer, E. C., Meador, C. K., and Simpson, D. C. (1969). Correlation of whole-body impedancewith total body water volume. J. Appl. Physiol. 27, 531–534. doi: 10.1152/jappl.1969.27.4.531
Huang, R., Liu, Q., Lu, H., and Ma, S. (2002). “Solving the small sample size problem of LDA,” in Object Recognition Supported by User Interaction for Service Robots (Quebec City, QC: IEEE), 29–32. doi: 10.1109/ICPR.2002.1047787
Huang, X., and Ahn, D. U. (2018). The incidence of muscle abnormalities in broiler breast meat–A review. Korean J. Food Sci. Anim. Resour. 38:835. doi: 10.5851/kosfa.2018.e2
Kala, R. (2012). Multi-robot path planning using co-evolutionary genetic programming. Expert Syst. Appl. 39, 3817–3831. doi: 10.1016/j.eswa.2011.09.090
Kecman, V. (2001). Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models. Cambridge, MA: MIT Press.
Kennedy-Smith, A., Johnson, M. L., Bauermeister, L. J., Cox, M. K., and Morey, A. (2017). Evaluating a novel bioelectric impedance analysis technology for the rapid detection of wooden breast myopathy in broiler breast filets. Int. Poultry Sci. 96:252.
Kotsiantis, S. B., Zaharakis, I., and Pintelas, P. (2007). “Supervised machine learning: a review of classification techniques” in Emerging Artificial Intelligence Applications in Computer Engineering (Amsterdam: IOS Press), 3–24. doi: 10.1007/s10462-007-9052-3
Kusiak, A. (2006). Data mining in manufacturing: a review. J. Manuf. Sci. Eng. 128, 969doi: 10.1115/1.2194554
Kuttappan, V., Lee, Y., Erf, G., Meullenet, J., McKee, S., and Owens, C. (2012). Consumer acceptance of visual appearance of broiler breast meat with varying degrees of white striping. Poul. Sci. J. 91, 1240–1247. doi: 10.3382/ps.2011-01947
Kuttappan, V. A., Owens, C. M., Coon, C., Hargis, B. M., and Vazquez-Anon, M. (2017). Incidence of broiler breast myopathies at 2 different ages and its impact on selected raw meat quality parameters. Poult. Sci. J. 96, 3005–3009. doi: 10.3382/ps/pex072
Kyle, U. G., Bosaeus, I., De Lorenzo, A. D., Deurenberg, P., Elia, M., Gómez, J. M., and Composition of the ESPEN Working Group. (2004). Bioelectrical impedance analysispart I: review of principles and methods. Clin. Nutr. 23, 1226–1243. doi: 10.1016/j.clnu.2004.06.004
Lee, M. C., and To, C. (2010). Comparison of support vector machine and back propagation neural network in evaluating the enterprise financial distress. IJAIA 1, 31–43. doi: 10.5121/ijaia.2010.1303
Li, H., Liang, Y., and Xu, Q. (2009). Support vector machines and its applications in chemistry. Chemom. Intell. Lab. Syst. 95, 188–198. doi: 10.1016/j.chemolab.2008.10.007
Lippmann, R. (1987). “An introduction to computing with neural nets” in IEEE Assp Magazine (New York, NY:IEEE), 4–22. doi: 10.1109/MASSP.1987.1165576
Liu, M., Wang, M., Wang, J., and Li, D. (2013). Comparison of random forest, support vector machine and back propagation neural network for electronic tongue data classification: Application to the recognition of orange beverage and Chinese vinegar. Sens. Actuat. B Chem. 177, 970–980. doi: 10.1016/j.snb.2012.11.071
Lu, J., Plataniotis, K. N., and Venetsanopoulos, A. N. (2005). Regularization studies of linear discriminant analysis in small sample size scenarios with application to face recognition. Patt. Recogn. Lett. 26, 181–191. doi: 10.1016/j.patrec.2004.09.014
Maji, S., Berg, A. C., and Malik, J. (2008). “Classification using intersection kernel support vector machines is efficient,” in Computer Vision and Pattern Recognition (Anchorage, AK: IEEE). doi: 10.1109/CVPR.2008.4587630
Mandal, T., Wu, Q. J., and Yuan, Y. (2009). Curvelet based face recognition via dimension reduction. Sig. Proc. 89, 2345–2353. doi: 10.1016/j.sigpro.2009.03.007
Mazzoni, M., Petracci, M., Meluzzi, A., Cavani, C., Clavenzani, P., and Sirri, F. (2015). Relationship between Pectoralis major muscle histology and quality traits of chicken meat. Poult. Sci. 94, 123–130. doi: 10.3382/ps/peu043
Monostori, L. (2003). AI and machine learning techniques for managing complexity, changes and uncertainties in manufacturing. Eng. Appl. Artif. Intell. 16, 277–291. doi: 10.1016/S0952-1976(03)00078-2
Morey, A., Smith, A. E., Garner, L. J., and Cox, M. K. (2020). Application of bioelectrical impedance analysis to detect broiler breast filets affected with woody breast myopathy. Front. Physiol. 11:808. doi: 10.3389/fphys.2020.00808
Mudalal, S., Lorenzi, M., Soglia, F., Cavani, C., and Petracci, M. (2015). Implications of white striping and wooden breast abnormalities on quality traits of raw and marinated chicken meat. Animals 9, 728–734. doi: 10.1017/S175173111400295X
Nashat, S., Abdullah, A., Aramvith, S., and Abdullah, M. Z. (2011). Support vector machineapproach to real-time inspection of biscuits on moving conveyor belt. Comput. Electron. Agr. 75, 147–158. doi: 10.1016/j.compag.2010.10.010
National Chicken Council (2020). Per Capita Consumption of Poultry and Livestock, 1965 to Estimated 2021. Available online at: https://www.nationalchickencouncil.org/about-the-industry/statistics/per-capita-consumption-of-poultry-and-livestock-1965-to-estimated-2021-in-pounds/ (accessed March 30, 2021).
Noble, W. S. (2006). What is a support vector machine? Nat. Biotechnol. 24, 1565–1567. doi: 10.1038/nbt1206-1565
Nyboer, J., Kreider, M. M., and Hannapel, L. (1950). Electrical impedance plethysmography: a physical and physiologic approach to peripheral vascular study. Circulation 2, 811–821. doi: 10.1161/01.CIR.2.6.811
Osuna, E., Freund, R., and Girosi, F. (1997). “An improved training algorithm for support vector machines”. in Neural Networks for Signal Processing VII (New York, NY:IEEE), 276–285. doi: 10.1109/NNSP.1997.622408
Pan, F., Song, G., Gan, X., and Gu, Q. (2014). Consistent feature selection and its application to face recognition. J. Intell. Inf. Syst. 43, 307–321. doi: 10.1007/s10844-014-0324-5
Panchal, G., Ganatra, A., Shah, P., and Panchal, D. (2011). Determination of over-learning and over-fitting problem in back propagation neural network. Int. J. Soft. Comput. 2, 40–51. doi: 10.5121/ijsc.2011.2204
Paola, J. D., and Schowengerdt, R. A. (1995). A review and analysis of backpropagation neuralnetworks for classification of remotely-sensed multi-spectral imagery. Int. J. Remote Sens. 16, 3033–3058. doi: 10.1080/01431169508954607
Pardo, M., and Sberveglieri, G. (2005). Classification of electronic nose data with support vectormachines. Sens. Actuat. B Chem. 107, 730–737. doi: 10.1016/j.snb.2004.12.005
Petracci, M., Bianchi, M., Mudalal, S., and Cavani, C. (2013). Functional ingredients for poultrymeat products. Trends Food Sci. Technol. 33, 27–39. doi: 10.1016/j.tifs.2013.06.004
Petracci, M., and Cavani, C. (2012). Muscle growth and poultry meat quality issues. Nutrients 4, 1–12. doi: 10.3390/nu4010001
Petracci, M., Mudalal, S., Soglia, F., and Cavani, C. (2015). Meat quality in fast-growing broiler chickens. Worlds Poult. Sci. J. 71, 363–374. doi: 10.1017/S0043933915000367
Pham, D. T., and Afify, A. A. (2005). Machine-learning techniques and their applications inmanufacturing. Proc. Inst. Mech. Eng. B J. Eng. Manuf. 219, 395–412. doi: 10.1243/095440505X32274
Pontil, M., and Verri, A. (1998). Properties of support vector machines. Neural Comput. 10, 955–974. doi: 10.1162/089976698300017575
Radaelli, G., Piccirillo, A., Birolo, M., Bertotto, D., Gratta, F., Ballarin, C., et al. (2017). Effect of age on the occurrence of muscle fiber degeneration associated with myopathies in broiler chickens submitted to feed restriction. Poult. Sci. 96, 309–319. doi: 10.3382/ps/pew270
Rao, C. R. (1948). The utilization of multiple measurements in problems of biological classification. J. R. Stat. Soc. Ser. B Stat. Methodol. 10, 159–193. doi: 10.1111/j.2517-6161.1948.tb00008.x
Ribeiro, B. (2005). Support vector machines for quality monitoring in a plastic injection moldingprocess. IEEE T. Syst. Man. Cyber. C 35, 401–410. doi: 10.1109/TSMCC.2004.843228
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). “Learning internal representations by error propagation” in Parallel Distributed Processing: Explorations in the Microstructures of Cognition (Cambridge, MA: MIT Press), 318–362. doi: 10.21236/ADA164453
Salahshoor, K., Khoshro, M. S., and Kordestani, M. (2011). Fault detection and diagnosis of anindustrial steam turbine using a distributed configuration of adaptive neuro-fuzzyinference systems. Simul. Model Pract. Theory 19, 1280–1293. doi: 10.1016/j.simpat.2011.01.005
Shao, Y., and Lunetta, R. S. (2012). Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRSJ. Photogramm. Remote Sens. 70, 78–87. doi: 10.1016/j.isprsjprs.2012.04.001
Sihvo, H., Immonen, K., and Puolanne, E. (2014). Myodegeneration with fibrosis and regeneration in thepectoralis major muscle of broilers. Vet. Pathol. 51, 619–623. doi: 10.1177/0300985813497488
Sihvo, H. K., Lindén, J., Airas, N., Immonen, K., Valaja, J., and Puolanne, E. (2017). Wooden breast myodegeneration of Pectoralis major muscle over the growth period in broilers. Vet. Pathol. 54, 119–128. doi: 10.1177/0300985816658099
Singh, K. P., Basant, N., and Gupta, S. (2011). Support vector machines in water qualitymanagement. Anal. Chim. Acta 703, 152–162. doi: 10.1016/j.aca.2011.07.027
Smola, A., and Vishwanathan, S. V. N. (2008). Introduction to Machine Learning. Cambridge: Cambridge University Press.
Soglia, F., Mudalal, S., Babini, E., Di Nunzio, M., Mazzoni, M., Sirri, F., and Petracci, M. (2016). Histology, composition, and quality traits of chicken Pectoralis major muscle affected bywooden breast abnormality. Poult. Sci. J. 95, 651–659. doi: 10.3382/ps/pev353
Su, B., Ding, X., Wang, H., and Wu, Y. (2017). Discriminative dimensionality reduction for multi-dimensional sequences. IEEE PAMI 40, 77–91. doi: 10.1109/TPAMI.2017.2665545
Tao, Y., Heinemann, P. H., Varghese, Z., Morrow, C. T., and Sommer, III. H. J. (1995). Machinevision for color inspection of potatoes and apples. Trans. ASAE 38, 1555–1561. doi: 10.13031/2013.27982
Tasoniero, G., Bertram, H. C., Young, J. F., Dalle Zotte, A., and Puolanne, E. (2017). Relationship between hardness and myowater properties in wooden breast affected chicken meat: a nuclear magnetic resonance study. LWT 86, 20–24. doi: 10.1016/j.lwt.2017.07.032
Tharwat, A. (2019). Parameter investigation of support vector machine classifier with kernel functions. Knowl. Inf. Syst. 61, 1269–1302. doi: 10.1007/s10115-019-01335-4
Tharwat, A., Gaber, T., Ibrahim, A., and Hassanien, A. E. (2017). Linear discriminant analysis: a detailed tutorial. AI Commun. 30, 169–190. doi: 10.3233/AIC-170729
Tijare, V. V., Yang, F. L., Kuttappan, V. A., Alvarado, C. Z., Coon, C. N., and Owens, C. M. (2016). Meat quality of broiler breast fillets with white striping and woody breast musclemyopathies. Poult. Sci. J. 95, 2167–2173. doi: 10.3382/ps/pew129
Tufféry, S. (2011). Data Mining and Statistics for Decision Making. Hoboken, NJ: John Wiley & Sons. doi: 10.1002/9780470979174
Vapnik, V. (1963). Pattern recognition using generalized portrait method. Autom. Remote Control 24, 774–780.
Vapnik, V. (1995). The Nature of Statistical Learning Theory. New York, NY: Springer-Verlag. doi: 10.1007/978-1-4757-2440-0
Vapnik, V. (2013). The Nature of Statistical Learning Theory. Berlin: Springer Science & Business Media.
Velleman, S. G. (2015). Relationship of skeletal muscle development and growth to breast muscle myopathies: a review. Avian Dis. 59, 525–531. doi: 10.1637/11223-063015-Review.1
Vijayarani, S., Dhayanand, S., and Phil, M. (2015). Kidney disease prediction using SVM and ANN algorithms. Int. J. Comput. Mark. Res. 6, 1–12.
Wang, K. J., Chen, J. C., and Lin, Y. S. (2005). A hybrid knowledge discovery model usingdecision tree and neural network for selecting dispatching rules of a semiconductor finaltesting factory. Prod. Plan. Control. 16, 665–680. doi: 10.1080/09537280500213757
Wiendahl, H. P., and Scholtissek, P. (1994). Management and control of complexity inmanufacturing. Cirp. Ann. Manuf. Techn. 43, 533–540. doi: 10.1016/S0007-8506(07)60499-5
Wold, J. P., Måge, I., Løvland, A., Sanden, K. W., and Ofstad, R. (2019). Near-infraredspectroscopy detects woody breast syndrome in chicken fillets by the markers proteincontent and degree of water binding. Poult. Sci. J. 98, 480–490. doi: 10.3382/ps/pey351
Xanthopoulos, P., Pardalos, P. M., and Trafalis, T. B. (2013). “Linear discriminant analysis”, in Robust Data Mining (New York, NY: Springer), 27–33. doi: 10.1007/978-1-4419-9878-1_4
Yang, Y., Wang, W., Zhuang, H., Yoon, S. C., Bowker, B., Jiang, H., et al. (2021). Evaluation of broiler breast fillets with the woody breast condition using expressible fluid measurement combined with deep learning algorithm. J. Food Eng. 288:110133. doi: 10.1016/j.jfoodeng.2020.110133
Yang, Y., Zhu, J., Zhao, C., Liu, S., and Tong, X. (2011). The spatial continuity study of NDVI based on kriging and BPNN algorithm. Math. Comput. Model 54, 1138–1144. doi: 10.1016/j.mcm.2010.11.046
Yao, X. (1999). Evolving artificial neural networks. Proc. IEEE 87, 1423–1447. doi: 10.1109/5.784219
Zampiga, M., Soglia, F., Baldi, G., Petracci, M., Strasburg, G. M., and Sirri, F. (2020). Muscle abnormalities and meat quality consequences in modern turkey hybrids. Front. Physiol. 11:554. doi: 10.3389/fphys.2020.00554
Keywords: support vector machines, backpropagation neural networking, woody breast, meat myopathies, spaghetti meat, bioelectrical impedance analysis, machine learning, artificial intelligence
Citation: Siddique A, Shirzaei S, Smith AE, Valenta J, Garner LJ and Morey A (2021) Acceptability of Artificial Intelligence in Poultry Processing and Classification Efficiencies of Different Classification Models in the Categorisation of Breast Fillet Myopathies. Front. Physiol. 12:712649. doi: 10.3389/fphys.2021.712649
Received: 20 May 2021; Accepted: 16 August 2021;
Published: 22 September 2021.
Edited by:
Sandra G. Velleman, The Ohio State University, United StatesReviewed by:
Hong Zhuang, US National Poultry Research Centre (USDA-ARS), United StatesGuillermo Tellez, University of Arkansas, United States
Copyright © 2021 Siddique, Shirzaei, Smith, Valenta, Garner and Morey. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Amit Morey, YXptMDAxMUBhdWJ1cm4uZWR1