 Song Qian
Song Qian Yan Xue
Yan Xue
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Phys., 28 February 2025
Sec. Optics and Photonics
Volume 13 - 2025 | https://doi.org/10.3389/fphy.2025.1498335
Stereo vision systems are increasingly utilized in various applications, however, the presence of noise significantly hampers the quality of the captured images. Traditional denoising methods often fail to address the complex noise patterns in such scenarios, which can adversely affect feature encoding and subsequent processing tasks. This paper introduces a novel stereo denoising approach that leverages cross-view information to enhance the robustness of noise reduction. A Cross-Channel and Spatial Context Information Mining Module is employed to encode long-range spatial dependencies and to bolster inter-channel feature interaction. This module utilizes large convolutional kernels, channel attention mechanisms, and a simple gating structure to enhance feature representation. Our approach relies on an encoder-decoder architecture, which facilitates cross-view and cross-scale feature interactions. The network is trained with a composite loss function that includes both spatial and perceptual domain constraints, ensuring a comprehensive optimization of the denoising process. Extensive experiments conducted on our proposed NoisyST dataset demonstrate the superior performance of our method in terms of noise removal and detail preservation. Notably, the method outperforms existing State-Of-The-Art techniques, as evidenced by its effectiveness in various evaluation metrics.
In recent years, computer vision tasks have received extensive attention and ushered in rapid development, such as image classification [1, 2], target detection [3], and instance segmentation tasks [4, 5]. These advancements have been significantly propelled by the advent of deep learning, which has revolutionized the way we process and understand visual data. Techniques such as convolutional neural networks (CNNs) have become fundamental in extracting features and making accurate predictions on complex visual tasks. Moreover, the growth of large-scale datasets and the increased computational power have further accelerated the progress in this field. As a result, we are witnessing a transformative era where computer vision systems not only replicate but also, in some cases, surpass human-level performance in various tasks, opening up new possibilities for applications in autonomous driving, medical imaging, and beyond. At the same time, with the wide application of binocular cameras, stereo vision has also ushered in rapid progress. However, binocular cameras are very sensitive to noise [6], and there is a lack of measures to deal with it. The rapid evolution of deep learning has led to the widespread application of convolutional neural networks (CNNs) in a multitude of single image processing tasks. These include single image deblurring [7], dehazing [8], deraining [9], and enhancement of images under low-light conditions [3]. In parallel, an increasing array of methods leveraging CNNs has been employed in the realm of stereo image processing, further expanding the horizons of what is achievable in the field.
Stereo vision technology has become a cornerstone in various high-precision applications such as robotics, autonomous vehicles, and augmented reality, providing a rich and nuanced understanding of the three-dimensional world. The ability to perceive depth and spatial relationships is paramount for these systems to operate effectively. However, the presence of noise in stereo imagery, often an unavoidable byproduct of real-world imaging conditions, poses a significant challenge to the accuracy and reliability of depth perception. Noise in stereo images not only obscures fine details but also introduces discrepancies between the paired images, which can lead to erroneous depth calculations and subsequent misinterpretations. The traditional noise model is represented as
Our method is designed with the unique characteristics of stereo imagery in mind, focusing on the harmonization of noise reduction and detail preservation across both images of a stereo pair. We demonstrate the efficacy of our approach through rigorous experimentation on a dataset that simulates real-world noise conditions in stereo images. The results indicate that our stereo image denoising technique not only achieves superior noise reduction performance but also maintains the critical details necessary for accurate depth estimation. This work contributes to the literature by offering a robust solution that enhances the resilience of stereo vision systems to noisy conditions, thereby bolstering their applicability in practical scenarios.
In this paper, we propose a robust stereo image enhancement paradigm tailored to address the degradation induced by noise attachment. Furthermore, this paper introduce a strategy aimed at the efficient extraction of interactive interocular information. In summary, the primary contributions of this paper can be categorized into three main aspects:
• NoisyST Dataset for benchmarking deep learning methods in Stereo Image Denoising task. To the best of our knowledge, we are the first to propose a stereo image denoising dataset named NoisyST which contains pairs of clear and noisy stereo images for training and testing neural networks.
• Omni-channel Information Mining Block(OIMB). This paper design a novel module named OIMB for intra-view intra-scale information mining and feature fusion. OIMB can not only realize long-distance modeling, but also effectively capture the information of channel dimension for efficient feature fusion. Firstly, this paper use a Channel-extended Information Mining Module (CIMM) to mine the information flow of the wide-area channel dimension. Secondly, unlike ViT, inspired by NAFNet, this paper propose a mechanism using large convolution kernels to capture long-range dependencies, Large-kernel Long-range Dependency Capture (LLDC).
• Decoupled Infromation Fusion Module(DIFM). This paper design a novel module named DIFM for cross-view cross-scale information mining and feature fusion. DIFM decouples the information fusion into two components, cross-view interactions and cross-scale interactions which focus on view-interaction feature fusion and scale-interaction information minin, respectively.
• CCDDNet: Learning a Cross-Scale Cross-View Decoupled Denoising Network by Mining Omni-channel Information. We propose a network equiped with Omni-channel Information Mining Blocks called CCDDNet. Experiments on NoisyST datasets demonstrate that our proposed framework can recover the details by removing noise in stereo images and obtain SOTA performance.
We briefly review recent progress in single image noise removal and stereo image restoration.
Zhang et al. [10] introduced a deep convolutional neural network (DnCNN) for image denoising that excels in blind Gaussian denoising and extends effectively to tasks like super-resolution and JPEG deblocking, demonstrating high efficiency and performance through residual learning and batch normalization. The work of Zhang et al. [12] presents a significant step forward in the field of image restoration, showcasing the effectiveness of deep learning-based denoising within a flexible Plug-and-Play approach. Zhang et al. [11] have demonstrated the efficacy of integrating fast and powerful CNN denoisers into model-based optimization methods to solve inverse problems in image restoration, showcasing improved performance and flexibility. Thakur and Maji [13] introduced a novel blind denoising approach employing multi-scale pixel attention and feature extraction in a dual-path neural network, demonstrating superior performance with lightweight architecture.
The iPASSR [14] method utilizes cross-view information and symmetry cues within stereo image pairs, offering a novel and effective solution for the challenge of stereo image super-resolution. In the domain of stereo image super-resolution, NAFSSR [15] stands out for its winning performance at the NTIRE 2022 challenge, showcasing the potential of integrating NAFNet’s robust feature extraction with cross-view feature fusion. Zheng et al. [6] introduced DCI-Net, a novel approach for low-light stereo image enhancement that leverages decoupled cross-scale cross-view interaction, demonstrating superior performance in illumination adjustment and detail recovery. Zhao et al. [16]introduced a novel approach for low-light stereo image enhancement that simultaneously addresses brightness adjustment and denoising by leveraging a low-frequency information enhanced image space and cross-channel spatial context mining.
In this section, this paper introduce the proposed CCDDNet in detail. We first illustrate the overall architecture of CCDDNet. Then, we describe the individual components of the designed modules, including the Omni-channel Information Mining Block (OIMB) and the Decoupled Information Fusion Module (DIFM). Finally, the used loss functions are discussed.
The overall structure of our proposed CCDDNet is shown in Figure 1. The proposed model, CCDDNet, is adept at processing a duo of stereo images laden with noise. It adeptly enhances the luminance of each view and subsequently delivers a pair of refined, noise-free stereo images. The methodology unfolds in a three-tiered approach: initial feature extraction from the shallow layers, profound feature extraction from the deeper layers, and ultimately, the reconstruction of the stereo images. Specifically, the model employs a pair of convolutional layers at the onset and terminus of the pipeline. The initial layer is tasked with the extraction of superficial features, whereas the final layer is responsible for the reconstruction of the enhanced, normal-illuminated stereo images. Mathematically, the process for a given set of noisy stereo images can be encapsulated by the following Equation 1:
where
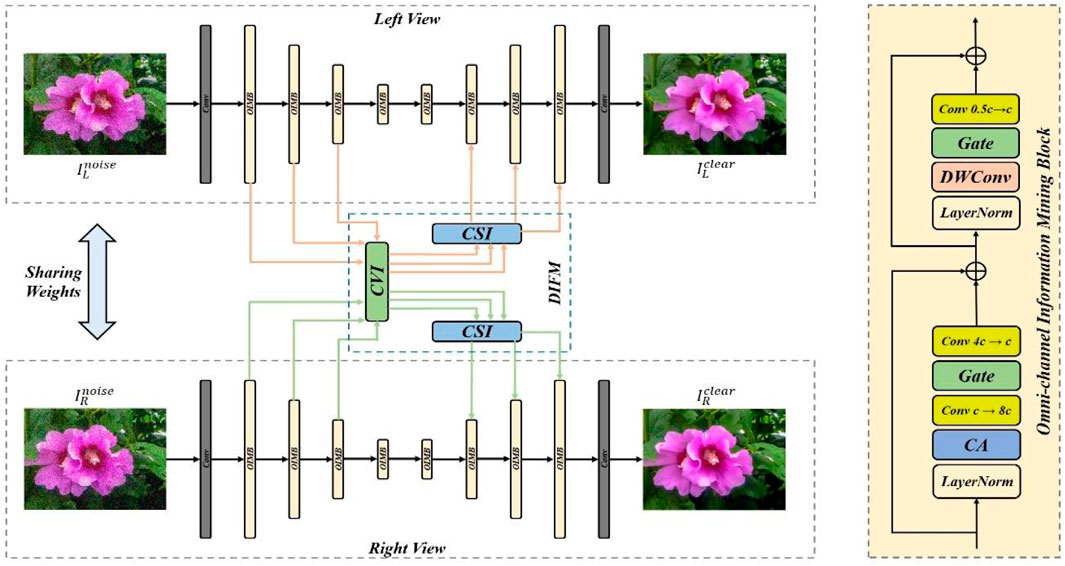
Figure 1. The overall framework of our proposed CCDDNet for Stereo Image Denoising. CVI and CSI means cross-view interaction and cross-scale interaction.
In reviewing previous methods for single image denoising and stereo image enhancement, the neural network backbones employed often maintain the channel count within blocks unchanged, followed by the use of residual connections to align inputs with outputs. Such an approach can inadvertently overlook the additional useful auxiliary information encapsulated within the neural network channels. To address this issue, this paper propose a framework called the Channel-wise Information Extraction Module (CIEM), which amplifies the channel count within the network to capture valuable information. Furthermore, Vision Transformers (ViTs) are frequently utilized to capture long-range dependencies and have been demonstrated to effectively enhance accuracy. However, the computational cost associated with ViTs is prohibitively high. Currently, the success of ViTs may be attributed more to the overall architecture rather than self-attention mechanisms [17]. Inspired by this, this paper introduce a Large-kernel Long-range Dependency Capture module (LLDC) designed to seize information on long-range dependencies using large kernel convolutional layer, a technique that has been proven effective [18].
The channel dimension within convolutional neural networks (CNNs) contains a wealth of crucial information that is often underutilized. In the context of stereo image processing, many neural networks maintain a constant channel count in the backbone, which is not conducive to extracting the hidden information in the channel dimension. To address this issue, this paper propose a channel dimension information extraction mechanism. This mechanism employs an exceptionally large channel dimension to expand the original channel eight times and combines attention weights to fully mine the hidden information in the channel dimension of the convolutional neural network. Specifically, the input features first pass through a layer normalization layer to stabilize the distribution, followed by a channel attention layer to empower the features with attention. Then, a
where
Divergent from the Channel Information Extraction Module (CIEM) introduced in the initial phase of the OIMB, which focuses on channel dimension information, the Large-kernel Long-range Dependency Capture (LLDC) stage primarily delves into the extraction of spatial dimension information. Echoing the foundational premise of the visual Transformer, our objective in the LLDC stage is to seize long-distance dependencies within the data. Concurrently, to mitigate computational overhead, this paper opt for a large convolution kernel to fulfill this objective efficiently. In the LLDC stage, we employ a large kernel size to cover a broader spatial context and capture the intricate patterns that span across wider regions of the image. This approach allows us to tap into the rich, long-range spatial correlations that are often crucial for understanding the global structure of scenes within visual tasks. By doing so, we enhance the model’s ability to recognize coherent objects and shapes, which is particularly beneficial for tasks like image segmentation and object detection where holistic scene understanding is required. Moreover, the use of a single, large kernel also helps to reduce the number of parameters and computations compared to a stack of smaller convolutions, thus striking a balance between the model’s complexity and its performance. This strategic design choice ensures that our model remains lightweight and efficient, making it suitable for real-time applications and devices with limited computational resources. As depicted in Figure 1, the LLDC process is succinctly encapsulated in the following Equation 3:
where
Stereo image processing is different from monocular image processing. One of its key points is to explore the correlation between the two views in order to better extract features, which is particularly evident in the task of stereo image denoising. Therefore, since most monocular image denoising methods only consider one view [10, 11], they are not effective in enhancing stereoscopic images. Although some existing algorithms for stereo image processing have mastered the information interaction between cross-views [14, 15], they lack the understanding of the importance of cross-scale information interaction. However, the importance of cross-scale information interaction is important in stereo image processing [6]. In order to solve the above problems, this paper propose a Decoupled Information Fusion Module (DIFM), which decouples cross-scale information and cross-view information, and studies the importance of the two to promote further feature fusion and interaction.
The integration of cross-scale information is crucial for enhancing the performance of Stereo image denoising tasks. Despite its significance, many existing Stereo image processing techniques overlook this aspect. To address this oversight, this paper have developed a solution that adeptly and efficiently merges cross-scale data, thereby enhancing the quality of feature fusion. The architecture of this cross-scale interaction is depicted in Figure 2. As the left view features
where
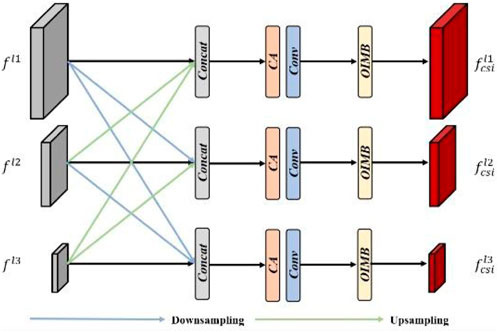
Figure 2. The detailed structure of our proposed cross-scale interaction in DIFM. Only the process of left view is shown for simplicity.
Incorporating the aforementioned cross-scale information fusion, this paper address the prevalent issue of insufficient cross-scale integration in most stereo-view interaction methodologies by proposing a multi-scale stereo-view fusion approach. This innovative multi-scale stereo-view fusion approach systematically integrates information across different scales to enhance the interaction between stereo views. By leveraging a pyramid structure, we enable the model to capture both local details and global context effectively. At each scale, the stereo views are first processed independently to extract features, and then fused using our cross-scale information fusion strategy. This fusion operation allows the model to leverage the complementary strengths of both views, such as depth cues and texture information, which are critical for tasks like depth estimation and scene understanding in stereo images. The multi-scale nature of our approach also ensures robustness against various levels of noise and occlusions, which are common challenges in real-world stereo vision applications. The intricate structure of this method is illustrated in Figure 3. The input is a stereo feature map. Our Cross-View Interaction (CVI) mechanism computes an interaction weight matrix, which is then utilized to refine the synthesis of features across different views. This sophisticated process is succinctly articulated by the subsequent Equation 5:
where
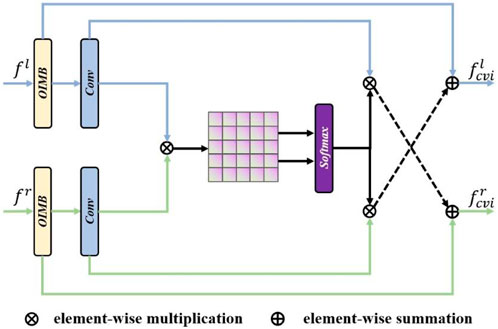
Figure 3. The detailed structure of our proposed cross-view interaction in DIFM. Only the process of single scale is shown for simplicity. CVI integrates the information of two perspectives, thus further realizing the complementarity of stereo dimensions and improving the effect of stereo image denoising.
The total loss function
where
where
where
This paper propose the first binocular image denoising dataset NoisyST for training neural networks. Following the previous works [6, 14], this paper also select data from the existing stereo image dataset to synthesize. Specifically, for the training dataset, we utilize 800 stereo image pairs from Flickr1024 [22] dataset and 60 stereo image pairs from Middlebury [23] dataset; for the testing set, this paper select 112 stereo image pairs from Flickr1024 [22], 20 stereo image pairs from KITTI2012 [24], 5 stereo image pairs from Middlebury [23] and 20 stereo image pairs from KITTI2015 dataset [25]. For the synthesis of noisy images, this paper use the method of randomly adding noise during the training process. For the evaluation method, this paper use the widely used PSNR and SSIM. The higher the two indicators are, the better the image quality is.
All experiments are conducted by using Pytorh with NVIDIA RTX3080GPUs. Following [6], we crop images into
Firstly, we introduce the experimental setting in this paper. Then, we show the experimental results and analysis of our proposed method.
To enhance clarity and visual appeal, this paper present the denoised stereo images alongside their noisy counterparts in Figures 4, 6, showcasing various components of our NoisyST dataset, including ZeroDCE [29], iPASSR [14], NAFSSR [15], DVENet [27], DCINet [6], LFENet [16].

Figure 4. Visual results of SOTA methods on Flickr1024 dataset.
Figure 4 illustrates the superior noise reduction capabilities of our method on the Flickr2014 stereo image dataset, resulting in the highest quality image restoration. Figures 5, 6 further demonstrate the effectiveness of our method in the context of autonomous driving, highlighting the impact of denoising on the KITTI2012 and KITTI2015 datasets. It is evident that our approach not only recovers the clearest stereo images but also detects the most noise, significantly enhancing autonomous driving perception and subsequent processes.

Figure 5. Visual results of SOTA methods on Kitti2012 dataset.

Figure 6. Visual results of SOTA methods on Kitti2015 dataset.
For our proposed CCDDNet, this paper evaluate its performance on our proposed NoisyST dataset at three different noise levels. Tables 1–3 shows the numerical results of left view and right view of denoising images at different noise levels, e.g., 15, 25 and 50. Tables 1–3 clearly demonstrates that our proposed method excels in recovering images with superior visual quality and detecting noise more effectively than other methods. It is evident that methods dedicated to single image denoising, such as DnCNN [10], DRUNet [12], IRCNN [11], NGDCNet [26], NIFBGDNet [13], are limited by their lack of robust mechanisms for information interaction, which hinders their ability to effectively integrate the left and right perspectives in stereo images. Moreover, stereo image processing methods, including DVENet [27], NAFSSR [15], and iPASSR [14], are found to be deficient in cross-view multi-scale information interaction. The cross-view interaction techniques they employ are also suboptimal. Lastly, methods that utilize cross-view and cross-scale information interaction, such as LFENet [16] and DCINet [6], require refinement of their information interaction techniques. Concurrently, the foundational backbone networks they employ are lacking in their capacity to model channel dimension information and capture long-range dependencies.
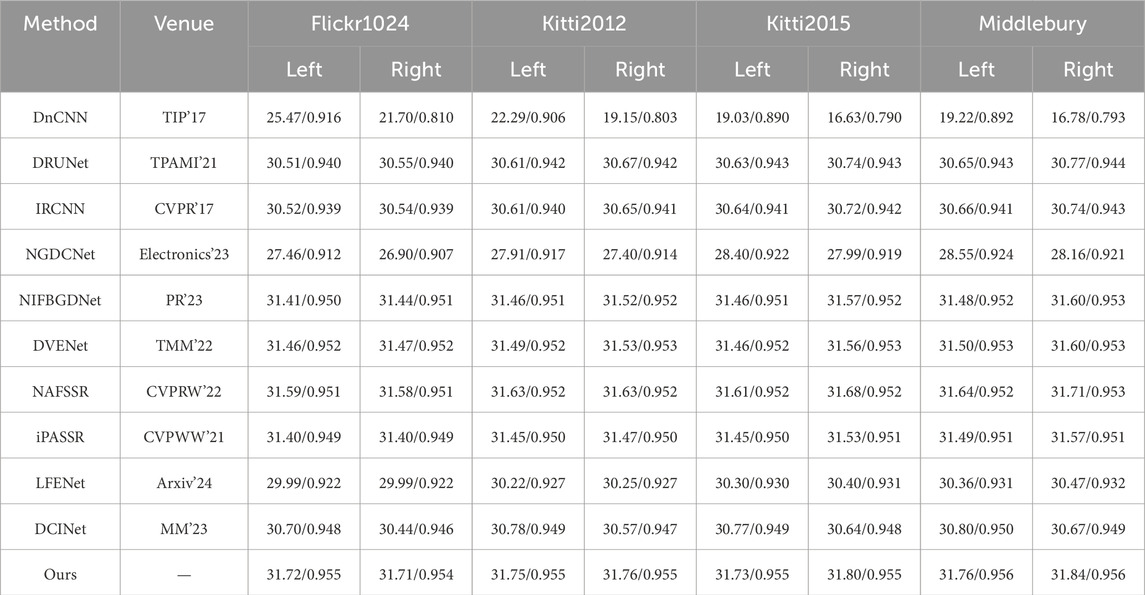
Table 1. Comparative results on synthetic stereo noisy images and the noise level is 15.
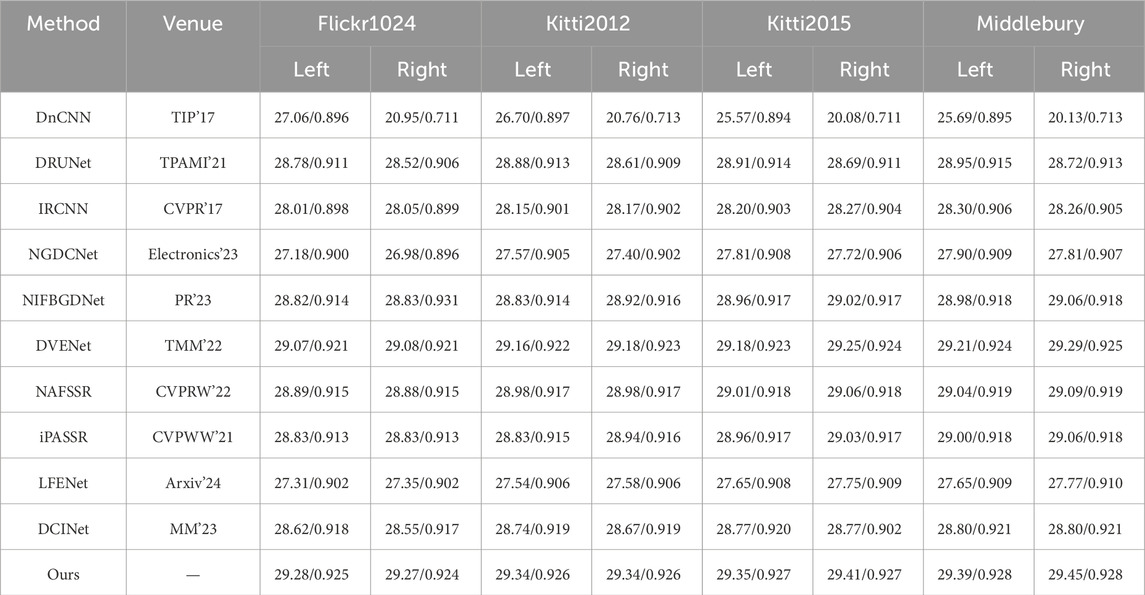
Table 2. Comparative results on synthetic stereo noisy images and the noise level is 25.
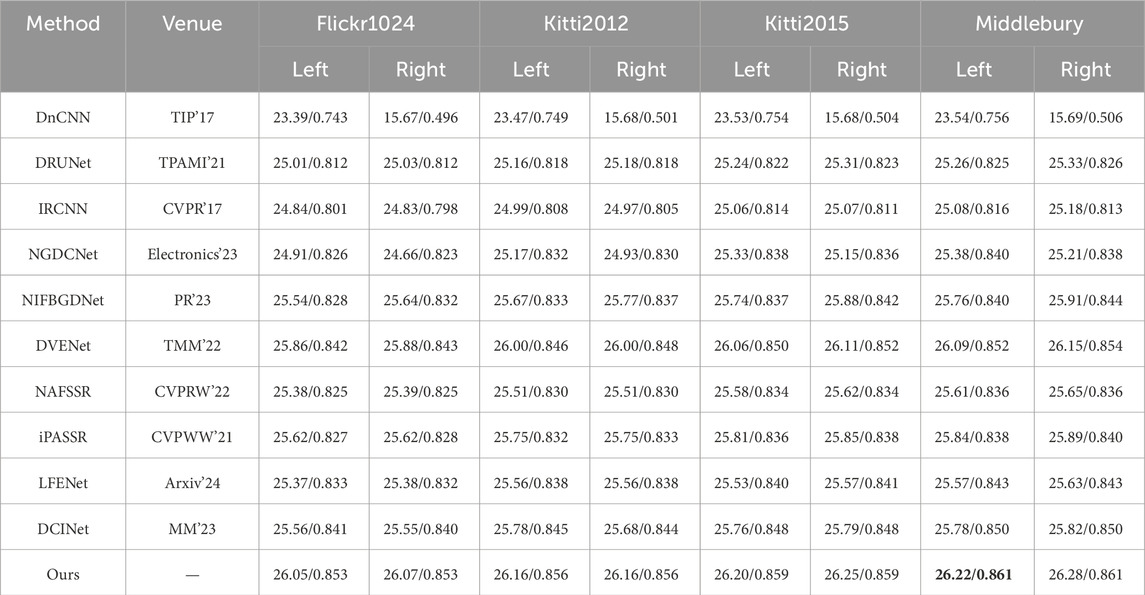
Table 3. Comparative results on synthetic stereo noisy images and the noise level is 50.
This paper show the ablation studies to demonstrate the rationality of independent components of our proposed CCDDNet, including designed modules, losses and backbones. The ablation experiments are performed on the Flickr1024 part of our proposed NoisyST dataset. The numerical results are shown in Table 4.
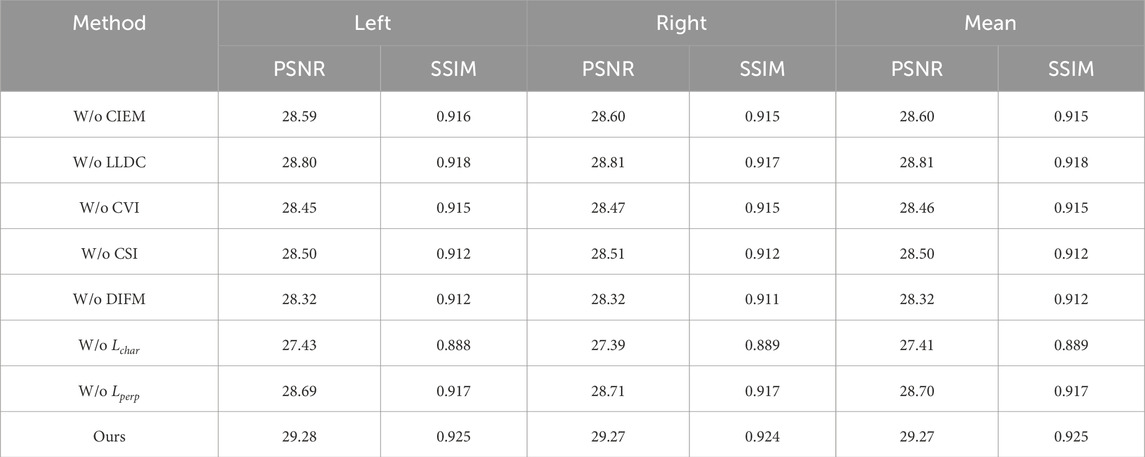
Table 4. Ablation studies on the effects of designed backbones, losses, and modules of our proposed method. The noise level is 15.
To demonstrate the effectiveness of our proposed OIMB, this paper use two modules as shown in Table 4. Specifically, W/o CIEM and W/o LLDC denote removing CIEM and LLDC from OIMB respectively. From Table 4, it clearly illustrates that the capabilities of CIEM and LLDC to independently extract channel dimension information and capture long-distance dependencies, respectively, are crucial for optimal performance. It is evident that the removal of either component leads to a significant decline in performance, underscoring the indispensable nature of both mechanisms in maintaining the module’s effectiveness.
This paper subsequently confirm the contribution of DIFM by dropping CVI, CSI and DIFM in our proposed CCDDNet, which are denoted as W/o CVI, W/o CSI and W/o DIFM in Table 4. It can be seen from the table that the removal of CVI and CSI alone will cause a serious reduction in performance. Further, when the entire DIFM is removed, it will cause the most serious reduction in performance, which indicates the rationality of using DIFM and the excellent performance of DIFM.
We proceed to confirm the role of the loss functions in this paper. As shown in Table 4, W/o
This paper explore a new vision task, stereo image denoising, and we propose a new benchmark called NoisyST dataset which can be used for training and testing neural networks. In general, this paper propose a novel model for stereo image denoising, called CCDDNet. Specifically, addressing the deficiency in effective cross-view information interaction and cross-scale information fusion within stereo vision image processing tasks, this paper delve into the development of robust solutions tailored for stereo image denoising, thereby enhancing the overall performance of stereo image denoising techniques. Further, aiming at the lack of feature extraction ability of channel dimension and the ability of long-distance dependence capture in stereo image denoising, this paper propose a backbone network module called OIMB, including channel dimension information mining module CIEM and long-distance dependence capture module LLDC. These two modules are responsible for mining channel dimension information and capturing long-distance dependencies in the network learning process. The comparative experiments conducted on our NoisyST dataset demonstrate not only its suitability as a benchmark for training neural networks but also the exceptional performance of our proposed CCDDNet. Our method stands out in restoring images with the highest visual quality and achieving the most outstanding results. Additionally, the ablation study of CCDDNet’s components further validates the soundness of our approach. In the future, we are committed to exploring even more efficient methods for stereo image denoising.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
SQ: Conceptualization, Funding acquisition, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. YX: Data curation, Supervision, Validation, Writing–review and editing. YC: Conceptualization, Methodology, Software, Supervision, Validation, Visualization, Writing–original draft, Writing–review and editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was Sponsored by Xinjiang Uygur Autonomous Region Tianshan Talent Programme Project (No.2023TCLJ02).
We thank all the editors and reviewers in advance for their valuable comments that will improve the presentation of this paper.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Iqbal I, Odesanmi GA, Wang J, Liu L. Comparative investigation of learning algorithms for image classification with small dataset. Appl Artif Intelligence (2021) 35(10):697–716. doi:10.1080/08839514.2021.1922841
2. He K, Zhang X, Ren S. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer 345 vision and pattern recognition (2016). p. 770–8.
3. Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: IEEE transactions on pattern analysis and machine intelligence (2016) 39(6), 1137–1149. doi:10.1109/TPAMI.2016.2577031
4. Iqbal I, Shahzad G, Rafiq N, Mustafa G, Ma J. Deep learning-based automated detection of human knee joint's synovial fluid from magnetic resonance images with transfer learning. IET Image Process (2020) 14(10):1990–8. doi:10.1049/iet-ipr.2019.1646
5. Badrinarayanan V, Kendall A, Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans pattern Anal machine intelligence (2017) 39(12):2481–95. doi:10.1109/tpami.2016.2644615
6. Zheng H, Zhang Z, Fan J. Decoupled cross-scale cross-view interaction for stereo image enhancement in the dark. In: Proceedings of the 31st ACM international conference on multimedia (2023). p. 1475–84.
7. Nah S, Hyun Kim T, Mu Lee K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2017). p. 3883–91.
8. Qin X, Wang Z, Bai Y, Xie X, Jia H. FFA-Net: feature fusion attention network for single image dehazing. In: Proceedings of the AAAI conference on artificial intelligence (2020) 34(07):11908–15. doi:10.1609/aaai.v34i07.6865
9. Jiang K, Wang Z, Yi P. Multi-scale progressive fusion network for single image deraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2020). p. 8346–55.
10. Zhang K, Zuo W, Chen Y, Meng D, Zhang L. Beyond a Gaussian denoiser: residual learning of deep cnn for image denoising. IEEE Trans image Process (2017) 26(7):3142–55. doi:10.1109/tip.2017.2662206
11. Zhang K, Zuo W, Gu S, Zhang L. Learning deep CNN denoiser prior for image restoration. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2017). p. 3929–38.
12. Zhang K, Li Y, Zuo W, Zhang L, Van Gool L, Timofte R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans Pattern Anal Machine Intelligence (2021) 44(10):6360–76. doi:10.1109/tpami.2021.3088914
13. Thakur RK, Maji SK. Multi scale pixel attention and feature extraction based neural network for image denoising. Pattern Recognition (2023) 141:109603. doi:10.1016/j.patcog.2023.109603
14. Wang Y, Ying X, Wang L. Symmetric parallax attention for stereo image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2021). p. 766–75.
15. Chu X, Chen L, Yu W. Nafssr: stereo image super-resolution using nafnet. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022). p. 1239–48.
16. Zhao M, Qin X, Du S, Bai X, Lyu J, Liu Y. Low-light stereo image enhancement and de-noising in the low-frequency information enhanced image space. Expert Systems with Applications (2025). 265, 125803. doi:10.1016/j.eswa.2024.125803
17. Yu W, Luo M, Zhou P. Metaformer is actually what you need for vision. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022). p. 10819–29.
18. Ding X, Zhang X, Han J. Scaling up your kernels to 31x31: revisiting large kernel design in cnns. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022). p. 11963–75.
19. Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution. In: Proceedings, Part II 14 Computer Vision–ECCV 2016: 14th European Conference; October 11-14, 2016; Amsterdam, The Netherlands. Springer International Publishing (2016). p. 694–711.
20. Lai WS, Huang JB, Ahuja N, Yang MH. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans pattern Anal machine intelligence (2018) 41(11):2599–613. doi:10.1109/tpami.2018.2865304
22. Wang L, Wang Y, Liang Z. Learning parallax attention for stereo image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2019). p. 12250–9.
23. Scharstein D, Hirschmüller H, Kitajima Y. High-resolution stereo datasets with subpixel-accurate ground truth. In: Proceedings 36 Pattern Recognition: 36th German conference, GCPR 2014, Münster, Germany. September 2-5, 2014: Springer Interna 383 tional Publishing (2014). p. 31–42.
24. Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving the kitti vision benchmark suite. In: 2012 IEEE conference on computer vision and pattern recognition. IEEE (2012). p. 3354–61.
25. Menze M, Geiger A. Object scene flow for autonomous vehicles. In: Proceedings of the IEEE conference on computer vision and pattern recognition (2015). p. 3061–70.
26. Zhu M, Li Z. NGDCNet: noise gating dynamic convolutional network for image denoising. Electronics (2023) 12(24):5019. doi:10.3390/electronics12245019
27. Huang J, Fu X, Xiao Z, Zhao F, Xiong Z. Low-light stereo image enhancement. IEEE Trans Multimedia (2022) 25:2978–92. doi:10.1109/tmm.2022.3154152
28. Xu X, Wang R, Fu CW. SNR-aware low-light image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022). p. 17714–24.
Keywords: stereo image processing, noise removal, cross-view feature interaction, attentive cross-scale fusion, deeplearning
Citation: Qian S, Xue Y and Chang Y (2025) Learning a cross-scale cross-view decoupled denoising network by mining Omni-channel information. Front. Phys. 13:1498335. doi: 10.3389/fphy.2025.1498335
Received: 18 September 2024; Accepted: 10 February 2025;
Published: 28 February 2025.
Edited by:
Xin Hu, East Carolina University, United StatesReviewed by:
Satyendra Kumar Mishra, Centre Tecnologic De Telecomunicacions De Catalunya, SpainCopyright © 2025 Qian, Xue and Chang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Youbao Chang, MTM3NzM1ODM4MjNAMTYzLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.