
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Phys. , 26 June 2023
Sec. Complex Physical Systems
Volume 11 - 2023 | https://doi.org/10.3389/fphy.2023.1046077
 Jiahui Song1
Jiahui Song1 Gaoxia Wang1,2*
Gaoxia Wang1,2*Identifying influential nodes in complex networks is one of the most important and challenging problems to help optimize the network structure, control the spread of the epidemic and accelerate the spread of information. In a complex network, the node with the strongest propagation capacity is known as the most influential node from the perspective of propagation. In recent years, identifying the key nodes in complex networks has received increasing attention. However, it is still a challenge to design a metric that has low computational complexity but can accurately identify important network nodes. Currently, many centrality metrics used to evaluate the influence capability of nodes cannot balance between high accuracy and low time complexity. Local centrality suffers from accuracy problems, while global metrics require higher time complexity, which is inefficient for large scale networks. In contrast, semi-local metrics are with higher accuracy and lower time cost. In this paper, we propose a new semi-local centrality measure for identifying influential nodes under complex contagion mechanisms. It uses the higher-order structure within the first and second-order neighborhoods of nodes to define the importance of nodes with near linear time complexity, which can be applied to large-scale networks. To verify the accuracy of the proposed metric, we simulated the disease propagation process in four real and two artificial networks using the SI model under complex propagation. The simulation results show that the proposed method can identify the nodes with the strongest propagation ability more effectively and accurately than other current node importance metrics.
We are surrounded by a variety of complex systems and most of the complex systems we come across can be abstracted into a complex network model with a certain topology, these networks contain a large number of nodes, which are interconnected by some strong or weak relationship. Complex network models are widely used in the research of various fields. The identification and ranking of influential nodes has always been one of the most fundamental problems in modern network science, it may facilitate our understanding of the structure, function and characteristic of networks [1, 2]. In recent years, efforts have been made to identify influential nodes in complex networks. So far, researchers have proposed a variety of metrics, including traditional measures such as degree centrality [3], betweenness centrality [4], Closeness centrality [5] and K-core centrality [6]. Depending on the node location and topology under consideration, The current node importance metrics are divided into three main categories: local measure, semi-local measure and global measure [7]. Local measures are relatively straightforward and have low time complexity because they only consider the number of nodes in the first-order neighborhood. Instead, global measures have higher accuracy and time complexity, using the overall information of the network to determine the importance of a node. Considering the low accuracy of local measures and the high time complexity of global measures, semi-local centrality measures are proposed, which use the information in the second-order neighborhood of the nodes to improve the accuracy of the measure while maintaining a relatively low time complexity. In terms of local measure, Xu et al. [8] proposed a local clustering h-index (LCH) centrality measure for identifying and ranking influential nodes in complex networks. It takes into account both topological connections between neighboring nodes, the number and quality of neighboring nodes. Nodes can be distinguished more effectively and ranked more accurately Salavati et al. [9] proposed a novel local node sorting algorithm that utilizes local structure to improve closeness centrality aiming to reduce computational complexity. The method is able to find the best set of seed nodes with high propagation capacity and low time complexity is suitable for large-scale networks Ruan et al. [10] considered the links of a node and the connectivity within the neighborhood of that node and proposed an efficient method based on semi-local features to identify key nodes that play an important role in maintaining network connectivity Zhao et al. [11] proposed NL metrics based on the importance of neighborhoods and links, considered the influence of second-order neighborhoods on the nodes, used the connectivity and irreplaceability of links to distinguish the topological positions of nodes Hu et al. [12] proposed a new ranking method using structural holes to identify influential nodes (E-Burt), which takes fully into account the total connection strength of nodes within their local area and the number of connected links Zhu et al. [13] proposed a local h-index centrality method to identify and rank influential nodes in the network. The LH-index method considers both the h-index values of the node itself and its neighbors. In terms of global measure, Enduri et al. [14] used the relative change in the local network on the average shortest path when nodes are removed to define node importance. The method identifies the initial seed nodes and effectively measures the spread of information within the network. From an information theory point of view Yang et al. [15] proposed the EnRenew algorithm aimed to identify a set of influential nodes via information entropy. Firstly, the information entropy of each node is calculated as initial spreading ability. Then, select the node with the largest information entropy and renovate its l-length reachable nodes’ spreading ability by an attenuation factor, repeat this process until specific number of influential nodes are selected. The impressive results on the SIR simulation model Wen et al. [16] proposed a method for identifying influencers in complex networks via the local information dimensionality. The proposed method considers the local structural properties around the central node. A node is more influential when its local information dimensionality is higher. Compared with the other four importance measures in six real networks, the simulation results show the superiority of this measure. From the perspective of artificial intelligence, Fan et al. [17] proposed a deep reinforcement learning framework to find the most important group of spreaders in the network. The proposed framework opens up a new direction for using deep learning techniques to understand how complex networks are organized, which allows us to design more powerful networks to enhance or inhibit propagation. Considering the loop structure in the network, Fan et al. [18] defined two loop-based node characteristics, namely, loop number and loop ratio, which can be used to measure the importance of nodes (in terms of network connectivity). It was verified that nodes with higher cycle ratios are more important for network connectivity and the number of cycles better quantifies the impact of diffusion based on the cycle structure than the general clustering-based node centrality Lin et al. [19] defined the cycle number matrix, a matrix containing cycle information in the network and a metric to quantify the importance of nodes, i.e., the cycle ratio Zhang et al. [20] introduced the node cycle ratio to determine how close the network is to a tree-like network [18–20]. Innovatively introduce the loop structure, which has been previously neglected in the analysis and modeling of networks into the importance measure of nodes, opening another new perspective for identifying nodes with high propagation capacity. It has been proven that loops as a mesoscopic structure in the network, play an important role in the structure and function of the network. In terms of the transmission dynamics of the network, Chen et al. [21] proposed a new method for dynamic ordering of nodes using a probabilistic model to measure the ordering of nodes. This simple and effective method opens new ideas for the identification of important nodes in network propagation dynamics. In terms of semi-local measure, A new semi-local centrality measure was proposed by Kamal et al. [22]. It uses the positive effect of the secondary neighborhood clustering coefficient and the negative effect of the node clustering coefficient to define the importance of a node. That is, a node with a high clustering coefficient may be a “hub” node or a “bridge” node. If the sum of the clustering coefficients of a node’s secondary neighbors is high, then the node’s secondary neighbors are located in the dense part of the network. If a node has low clustering, high and dense secondary neighbors, it is identified as a structural hole Lei et al. [23] introduced a centrality metric (HIC) to identify influential nodes in complex networks. It combines node neighborhood, location and topology features to identify influential nodes. In terms of identifying multiple influential nodes, Mishra et al. [24] identify a set of influential nodes in undirected and unweighted networks, using only the local topology of the network in the absence of global information about the network. In this paper, we propose a centrality measure based on the higher-order structure within the second-order neighborhood of a node. Taking into account the fully connected quadrilateral and diagonal quadrilateral in the first-order neighborhood and the loop and diagonal quadrilateral in the second-order neighborhood, the higher-order structures considered are more diverse and more varied. We extend the traditional clustering coefficient to a higher-order form. This metric is also used as a measure to compare with the current representative measure of node propagation ability in terms of node circulation rate (CR) [19], Measurement of positive and negative clustering coefficient based on node neighborhood (FI) [22] and measurement based on structural hole features (SHF) [10]. We used the SI model to simulate the virus propagation process on six networks under the condition of complex contagion. The numerical simulation results show that the proposed node importance metric can identify the nodes with the strongest propagation ability more quickly and accurately.
The structure of this paper is as follows. In the first part, a brief introduction to the three metrics used for comparison and the basic concepts related to this paper is given first, focusing on the higher-order structure of networks and defining the concept of high-order node degree, it also illustrates how the higher-order structure affects the propagation dynamics on the network. In the second part, a new measure for evaluating the importance of nodes is introduced, extending the traditional clustering coefficients based on nodes to the form of higher-order within the second-order neighborhood of nodes and a optimal algorithm for finding the higher-order structure within the second-order neighborhood of nodes is also proposed in the Supplementary Materials. In the third part, the models and data sets used are described. In the fourth part, simulations are done in six networks using the SI model under complex propagation mechanism and the superiority of the proposed metric is derived. Finally, we conclude with a summary of the work done and some prospects for future research.
A complex network can be represented by graph G = (V, E), where G is an undirected connected graph, with n nodes, m edges,
Because there are more existing indicators of the importance of nodes. Therefore, only three of the most representative indicators of the propagation ability of nodes are selected for comparative illustration.
Loops are another widely observed structure that plays an important role in both structural organization and functional implementation. A loop can be simply defined as a closed path with the same start and end nodes. The size of a loop is equal to the number of links it contains. The loop containing node i with the smallest size is defined as the shortest loop associated with node i and the corresponding size is called the perimeter of node i. Define the loop rate of a node, i.e.,
Where
This metric was proposed by Kamal and it is a semi-local centrality metric used to identify influential propagators in complex networks. A node is an important “connector” between dense parts of the network (modules) if it has low clustering, high degree and a large sum of clustering coefficients of the nodes in its second-order neighborhood, i.e., a structural hole (influential propagator). The formula is defined as,
Where
A node is more important to the network when it is characterized by more structural holes. Based on this Ruan et al. proposed a node importance ranking algorithm (SHF) that incorporates structural hole features to identify the network nodes that play an important role in maintaining network connectivity. The formula is defined as,
where
Networks are inherently limited to describing pairwise interactions, whereas real-world systems are often characterized by higher-order interactions involving three or more units. Therefore, higher-order structures, such as hypergraphs and simplicial complex are better tools for depicting the real structure of many social, biological and man-made systems [25]. A triangle is the smallest higher-order structure, which is a third-order (number of nodes is 3) connected subgraph formed by three nodes connected to each other. It is the basic unit of association and the basic topology of the network. The size of the higher-order structure is between a single node and a large dense community. It is a fully or partially connected subgraph consisting of a few nodes connected in a guaranteed closed-loop situation, which occurs more frequently in real networks than in their corresponding random networks and increases with the increase of network size and connection density between nodes. As shown in Figure 1.
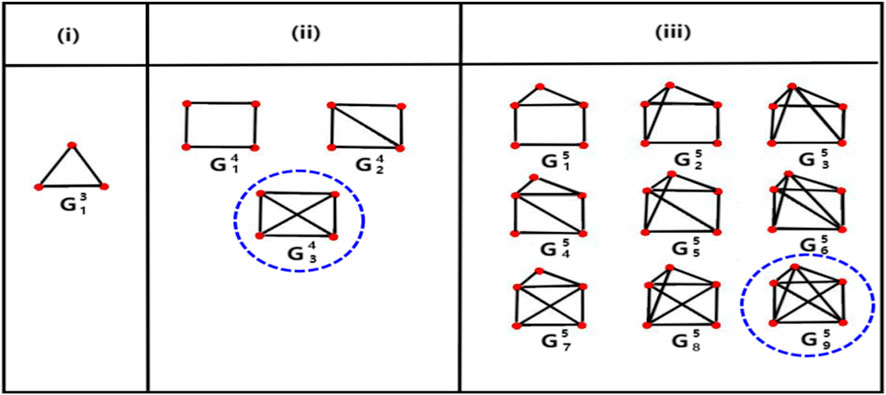
FIGURE 1. From (i–iii), they are third-order, fourth-order and five-order, respectively. Where
The traditional node clustering coefficient measures how many triangles with the node as the vertex in the first-order neighborhood, i.e., how sparsely the neighboring nodes are connected to each other in the first-order neighborhood. The formula is:
Where,
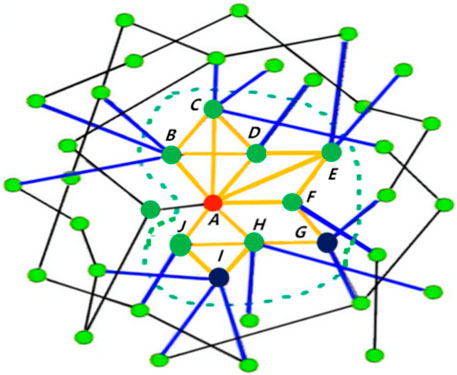
FIGURE 2. A toy networks. In the first-order neighborhood of node A (red), the nodes located on the same higher-order structure with node A are B、C、D、E、F、H、J (green). The second-order neighbor nodes located on the same higher-order structure as node A are G and I (black). The triangle in the first-order neighborhood of node A are ABC、ABD、ACD、ADE、AEF、AHJ, the diagonal quadrilateral is ADEF, a fully connected quadrilateral is ABCD. The diagonal quadrilateral in the second-order neighborhood of node A is AHIJ, the empty quadrilateral (loop) is AFGH. In addition, the yellow link represents the internal link of the small community formed by the four types of high-order structures in the first and second-order neighborhood of node A, the blue links represent the small community’s links to external contacts.
Several studies have shown that the presence of higher-order interactions may severely affect the dynamics of network systems, from diffusion [26, 27] and synchronization [28, 29] to social [30–33] and evolutionary processes [34], possibly leading to the emergence of abrupt (explosive) transitions between states. Under different mechanisms of simple and complex contagion, the presence of higher-order structures can make the propagation process on the network significantly different [35–38]. Diffusion is often described as either “simple contagion” or “complex contagion”, where simple contagion is a process in which a node is easily infected through a single contact with an infected neighbor. Complex infection is a collaborative merged infection process in which nodes are usually exposed to multiple infected neighbors multiple times before changing state. Under a simple transmission mechanism, infected nodes transmit the virus through their links at a fixed infection rate per unit time. Predisposing nodes change states and become infected, whose rate is related linearly to the number of infected neighbors. In the complex contagion definition of disease interactions, a susceptible node is co-infected by more than one neighboring infected node. In fact, there exists a threshold of co-infection beyond which the threshold is exceeded. As the infection rate increases, the clustered network structure will enhance the propagation of the co-combination infection. This is the reinforcement mechanism from the higher order structure. As shown in Figure 3, the different infection pathways of susceptible node i are shown. Under the simple infection mechanism, node i contacts with one (A, C) or more (B, D) infected nodes through the links and is infected at each time step at the rate
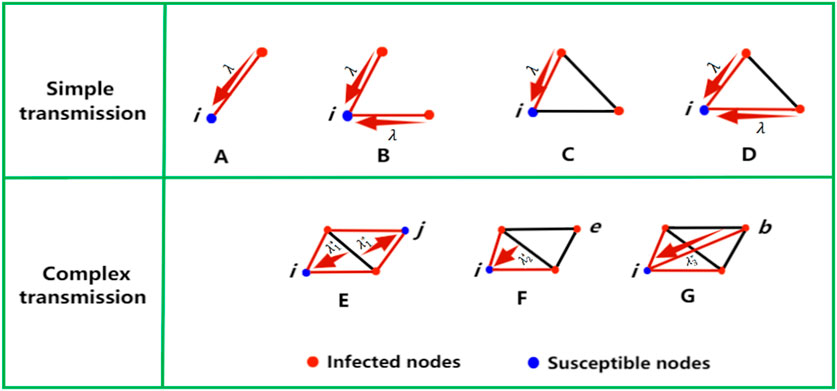
FIGURE 3. There are simple contagion and complex contagion. (A–D) for simple contagion. In the case of complex contagion we have (E–G). Because of the higher-order interaction, the rate of infection varies with different modes of contagion.
The node importance metric proposed in this paper is a generalization of the traditional clustering coefficients of nodes. The scope is extended from the first-order neighborhood of nodes to the second-order neighborhood, the types of higher-order structures are extended from a single triangle to loops and quadrilaterals. In terms of the topology of the network, the influence of the loop structure on the propagation is also taken into account. In terms of propagation mechanism, the influence of fully connected quadrilateral and diagonal quadrilateral on the propagation of viruses with mutual superposition is considered. The equation of the metric is expressed as follows:
Where
According to the proposed node importance measure, we take node A in Figure 2 as an example to calculate its CK value.
In order to test the effectiveness of the proposed method, we apply it to real-world networks and artificial networks. Real world networks include (i) electricity: the network of power grids; (ii) network science: the coauthor network in network science consists of 1,589 nodes. We chose the largest dense community of 400 nodes in this network. (iii) Email: the email network of the University Rovirai Virgili. (iv) Yeast: the protein-protein interaction network. The two artificial networks are Watts-Strogatz (WS) small world network [39] and Barabasi-Alber (BA) scale-free network [40]. First, a small world network (WS) is constructed, in which nodes

TABLE 1. Some statistical properties of six networks. Its topological features include: number nodes (
To compare the accuracy of the proposed metric in identifying node propagation capabilities, the susceptible infection (SI) model is used to simulate propagation and evolution in real networks. The SI model contains only two types of nodes, susceptible (S) and infected (I). Once a node is infected, it will never be able to recover. Assume that the total network scale of disease transmission is N, S(t) represents the number of susceptible nodes at time t, I(t) represents the number of infected nodes at time t (S(t) + I(t) = N). At t = 0, all nodes are susceptible, that is S (0) = N and I(t) = 0. At t = 1, we selected a node in the network as the initial source of infection. It is assumed that each node has
In this paper, we use SI model under complex propagation mechanism. This is different from the SI model in the simple transmission mechanism because we consider the strengthening mechanism of the higher-order structure in the transmission process and define that the diseases can be superimposed and co-infected. In our model, as soon as the initial infected node infects the node on the same link as it, the complex propagation mechanism will be triggered and the complex propagation process will begin in the form of a link. At the same time, the propagation rate does not remain constant, but increases gradually with the participation of more and more higher-order structures. In this case, the transmission rate is
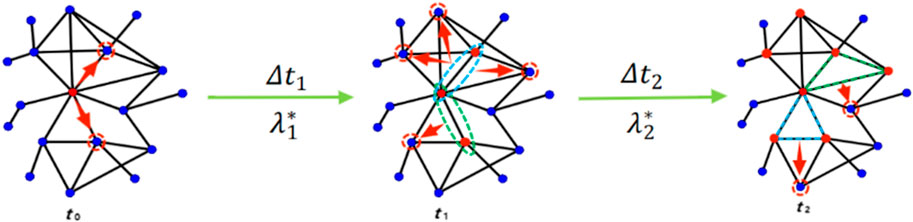
FIGURE 4. An evolutionary diagram of a complex propagation process. The red nodes are infected nodes and the blue nodes are susceptible nodes.
From the perspective of propagation dynamics, the greater the influence of a node, the stronger the diffusion ability of the node. That is, the number of nodes in the network that are ultimately infected is more. We use the number of final infected nodes
Where, M is the total number of experimental repetitions,
Kendall’s tau correlation coefficient is selected to determine the consistency between the ranking list obtained by the specific measurement method and ranking list obtained by SI model based on standard Monte Carlo simulation. Give two ranking lists X and Y,
In this paper, X represents the ranking result of nodes obtained from a centrality measure, and Y represents the ranking result of the number of infected nodes obtained from the SI model based on standard Monte Carlo simulation. If
In order to distinguish the propagation ability of all nodes, each node should assign a unique indicator through centrality measurement. The proportion of repeating elements in a sequence is called the monotonicity of the sequence. In order to quantify the monotonicity of different sorting methods, we use [8] and define it as:
Where
Pearson coefficient (R) is used to explain the correlation between different sorting methods. The formula of R is as follows [22]:
Where,
In the experiments, the proposed node importance metric was compared with three other metrics, including CR, FI, and SHF. We use different methods to analyze the performance of the proposed centrality metric in terms of propagation ability, correlation and monotonicity.
At time step t = 1, the nodes with the largest values of SHF, FI, CR, and CK are selected as the initial infection sources. Set the initial transmission rate of the disease to be slightly greater than the propagation threshold of the network. The final proportion of infected nodes in the six networks was observed after 100 time steps. The experimental results are shown in Figure 5, it can be seen from Figures 5A-E that the proposed metric CK results in the largest proportion of final infected nodes after 100 time steps. This is followed by FI, SHF, and CR. In fact, under the complex contagion mechanism, nodes with larger FI metric values have dense second-order neighbors and their second-order neighbors are part of the dense part of the network, the disease triggers the complex contagion mechanism once it spreads to the second-order neighbors of the node, which facilitates the global spread of the disease. However, the clustering coefficients of the nodes are small, which makes it harder for the initial spread of the disease to trigger complex contagion on a large scale, so the FI is ultimately secondary to the CK. For SHF, this metric only considers the degree of node and the number of common neighbors in the first-order neighborhood. Therefore, the initial spread of the disease is carried out under complex transmission with triangles and subsequently spreads to second-order neighborhoods. This inhibits the spread of the disease to some extent due to the lack of information related to the second-order neighborhood, so the SHF is ultimately subordinate to the FI. It is difficult to trigger complex propagation with an infection source on a loop (except for triangles), this is mainly because all nodes on the loop except the nodes at both ends of the link cannot achieve direct interaction, i.e., the loop lacks higher-order structures that trigger complex contagion, so it can be seen that the CR metric has the lowest number of final infected nodes. In Figure 5F, it can be seen that the only difference is that the propagation rate of FI is slightly greater than CK after t = 35. This is mainly because BA is a network of many small communities connected by the large-degree nodes and FI happens to identify the large degree nodes in the BA network. The tight clustering maximizes the complex propagation mechanism when the virus propagates to the second-order neighborhoods of the nodes identified by the FI. In addition, we looked at disease transmission rates over 100 time steps. Here we set the initial transmission of the disease is slightly greater than that of each network propagation threshold value, which in turn were 0.26, 0.14, 0.06, 0.065, 0.16, and 0.10. The results are shown in Figure 6. It can be seen that when the node identified by metric index CK is taken as the initial transmission source, the transmission rate of the disease in the 6 networks is always the largest in 100 time steps. This also shows from the side that there are the most high-order structures involved in the whole propagation process and further explains the accuracy of CK in identifying the most important nodes under the complex propagation mechanism. In Eqs 1, 4–6, the effect of measurement index FI is better than that of SHF. In Eq. 2, the effect of FI and SHF is roughly equivalent. In Eq. 3, SHF is superior to FI. However, the effect of CR is always the worst in the six networks. Secondly, the measurement index FI in Eq. 6 also has a good effect. To sum up, under the complex transmission mechanism based on SI model, when the node identified by the metric index CK is the initial infection source, the number of nodes infected and disease transmission rates in the network will be the largest after 100 time steps.
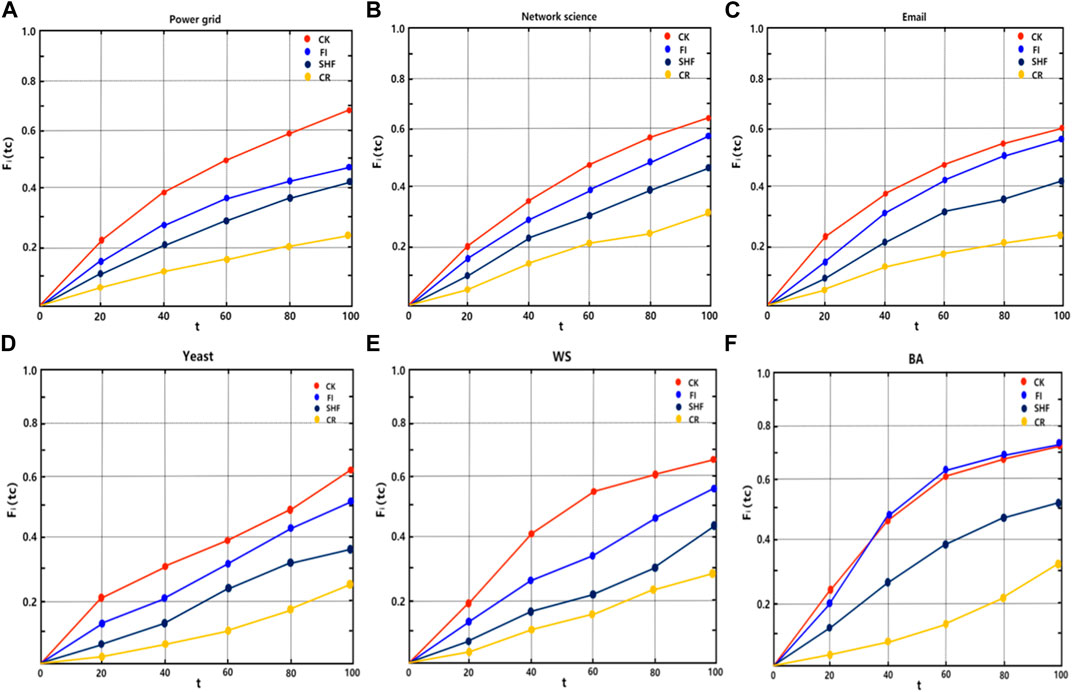
FIGURE 5. The number of final infected nodes caused by four different centrality measures on six networks in (A-F). The horizontal axis corresponds to the infection time and the vertical axis represents the diffusion capacity
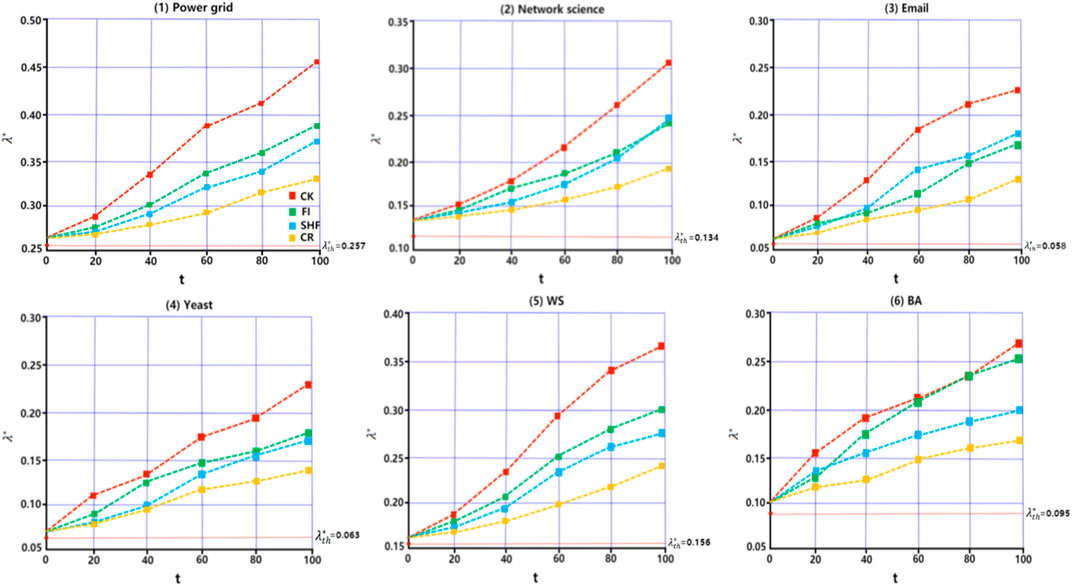
FIGURE 6. Network propagation rate
In order to test the accuracy of the proposed centrality measure, it is compared with three different centrality measures on six networks under the complex SI model. The closer to 1 is
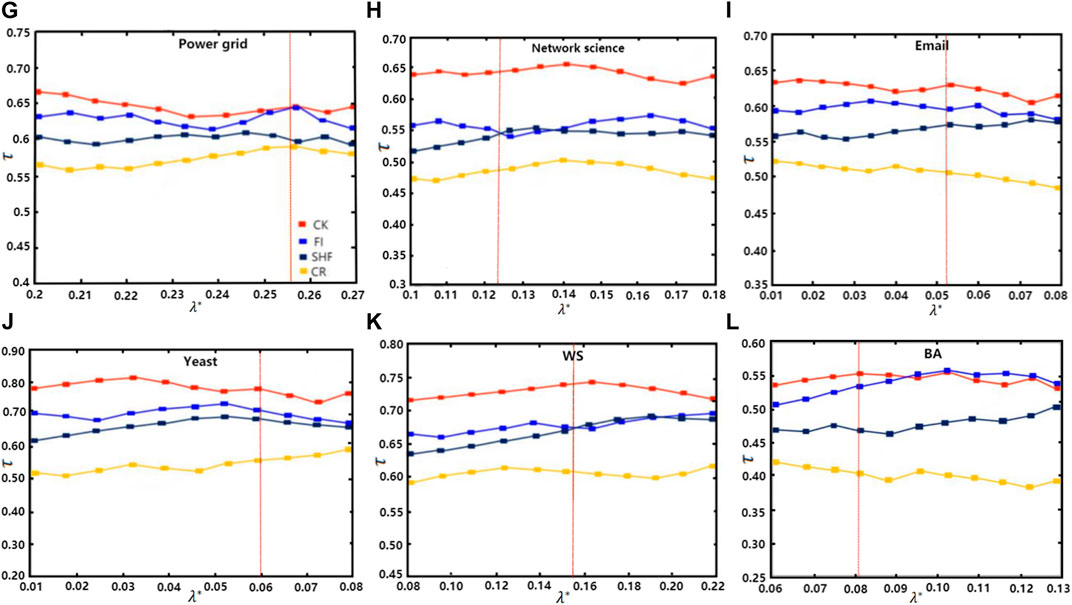
FIGURE 7. The Kendall’s tau correlation coefficient (
A good centrality measure should be able to distinguish between nodes with different propagation capabilities. Table 2 shows the monotonicity of the four centrality measures in six different networks. The closer M is to 1 the better the performance of the centrality measure is. It can be seen that among the four centrality measures, the monotonicity value of CK (black bold) is always close to 1 in all networks. In summary, CK can better distinguish nodes with different propagation capabilities. We conclude that under the complex propagation mechanism based on SI model, the metric index CK can well distinguish nodes with different propagation capabilities in the network.
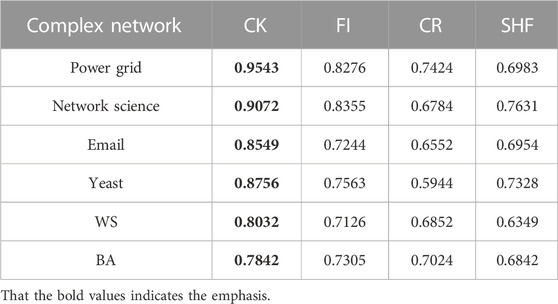
TABLE 2. Monotonicity of four centrality measures in six networks.
Figure 8 shows the correlation matrix between CK and the other three centrality metrics. Each of these elements represents the average of the correlation coefficient r between the two metrics over the six networks, the results are accurate to two decimal places. It can be seen that CK, FI has the strongest correlation, followed by CK SHF、CK CR. This is because FI considers triangles in the first-order neighborhood of a node, diagonal quadrilateral and loops in the second-order neighborhood. SHF considers only triangles in the first-order neighborhood of a node. CR only considers the loops in the second-order neighborhood of the node. The proposed metric CK based on the higher-order vertex degree of the node not only considers the loop in the second-order neighborhood but also the diagonal quadrilateral, the fully connected quadrilateral in the first-order neighborhood and the diagonal quadrilateral, which is an extension of the other three metrics considering a more diverse higher-order structure. The same result is obtained from Figure 9. Each point denotes one node in the network, the color of the node indicates the nodal spreading ability simulated by the complex SI model, denoted by
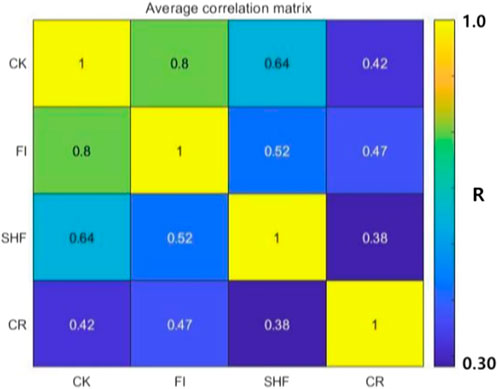
FIGURE 8. The average correlation matrix for the four indices of node importance over six networks. Each element is the averaged value of the correlation R between the two indices corresponding to its position over the six networks, and the value is visualized by the color. The correlation increases gradually from blue to yellow.
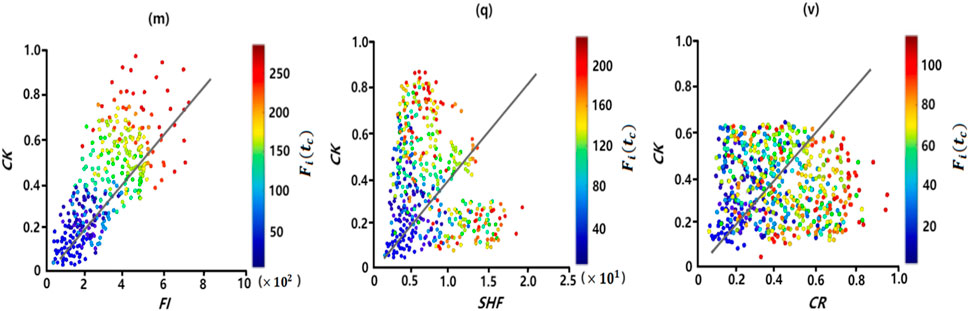
FIGURE 9. Average correlation between the proposed CK centrality and the other three measures of centrality in the six networks in (m), (q) and (v). Each point represents a node, and its color denotes the
In this paper, a new node importance metric is proposed for identifying nodes with the strongest propagation capacity under complex contagion mechanisms. The metric innovatively considers diagonal quadrilateral, loop (empty quadrilateral) and fully connected quadrilateral in the first and second-order neighborhood of a node. The impact of these structures on the complex propagation dynamics on the network is considered. Meanwhile, the high-order node degree are defined and a complex propagation model which has been neglected in the past is introduced. The superiority of the proposed metric is obtained by analyzing the simulation results on real and synthetic networks. In addition, only some of the higher-order forms in the first and second-order neighborhoods of the nodes are considered in this paper, in fact their higher-order structures are much richer than we can imagine. Moreover, as the analysis range (the neighborhood of nodes) extends outward, its computational complexity is exponentially increasing, and we will face more difficult problems. This work will be explored in the next step. Our future work will mainly focus on finding the optimal combination of higher-order structures in the node’s neighborhood that can most efficiently facilitate the information dissemination. At the same time, we will also propose some targeted protection strategies for the higher-order organization of the network.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
JS proposed the advice and conducted the numerical experiments. GW checked the paper in the later stage. All authors contributed to the article and approved the submitted version.
We would like to thank all the anonymous reviewers for their helpful suggestions to improve the quality of our manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphy.2023.1046077/full#supplementary-material
1. Domenico MD, Solé-Ribalta A, Omodei E. Ranking in interconnected multilayer networks reveals versatile nodes. Nat Commun (2017) 6:6868. doi:10.1038/ncomms7868
2. Li M, Liu RR, Lü L, Hu MB, Xu S, Zhang YC. Percolation on complex networks: Theory and application. Phys Rep (2021) 907:1–68. doi:10.1016/j.physrep.2020.12.003
3. Freeman LC. Centrality in social networks conceptual clarification. Social Networks (1978) 79:215–39. doi:10.1016/0378-8733(78)90021-7
4. Latora V, Marchiori M. A measure of centrality based on the network efficiency. open-access J Phys (2004) 402:345–51. doi:10.1103/85.066127
5. Arruda GD, Petri G, Rodrigues FA. Impact of the distribution of recovery rates on disease spreading in complex networks. Phys Rev Res (2018) 5:1012. doi:10.1103/PhysRevResearch.2.013046
6. Kitsak M, Gallos LK, Havlin S, Liljeros F, Muchnik L, Stanley HE, et al. Identification of influential spreaders in complex networks. Nat Phys (2010) 6:888–93. doi:10.1038/nphys1746
7. Chen DB, Gao H, Linyuan L, Zhou T. Identifying influential nodes in large-scale directed networks: The role of clustering. PLoS ONE (2013) 8:e77455. doi:10.1371/journal.pone.0077455
8. Xu GQ, Meng L, Tu DQ, Yang PL. Lch: A local clustering H-index centrality measure for identifying and ranking influential nodes in complex networks*. Chin Phys B (2021) 30:088901. doi:10.1088/1674-1056/abea86
9. Salavati C, Abdollahpouri A, Manbari Z. Ranking nodes in complex networks based on local structure and improving closeness centrality. Neurocomputing (2019) 336:36–45. doi:10.1016/j.neucom.2018.04.086
10. Ruan Y, Tang J, Wang H, Guo J, Qin W. Method for measuring node importance in complex networks based on local characteristics. Int J Mod Phys B (2021) 18:174–86. doi:10.1142/S0217979221502313
11. Shao Z, Liu S, Zhao Y, Liu Y. Correction to: Identifying influential nodes in complex networks based on Neighbours and edges. Peer-to-Peer Networking Appl (2018) 12:1538–7. doi:10.1007/s12083-018-0686-5
12. Hu P, Mei T. Ranking influential nodes in complex networks with structural holes. Physica A (2018) 490:624–31. doi:10.1016/j.physa.2017.08.049
13. Qiang L, Zhu Y, Yan J. Leveraging local h-index to identify and rank influential spreaders in networks. Physica A (2017) 512:379–91. doi:10.1016/j.physa.2018.08.053
14. Hajarathaiah K, Enduri MK, Anamalamudi S. Efficient algorithm for finding the influential nodes using local relative change of average shortest path. Physica A (2022) 591:126708. doi:10.1016/j.physa.2021.126708
15. Guo C, Yang L, Chen X, Chen D, Gao H, Ma J. Influential nodes identification in complex networks via information entropy. Entropy (2020) 22(2):242. doi:10.3390/e22020242
16. Wen T, Deng Y. Identification of influencers in complex networks by local information dimensionality. Inf Sci (2020) 512:549–62. doi:10.1016/j.ins.2019.10.003
17. Fan C, Zeng L, Sun Y, Liu YY. Finding key players in complex networks through deep reinforcement learning. Nat Machine Intelligence (2020) 2:317–24. doi:10.1038/s42256-020-0177-2
18. Fan T, Lü L, Shi D. Towards the cycle structures in complex network: A new perspective. Phys Soc (2019) 3:1–22. doi:10.48550/arXiv.1903.01397
19. Fan T, Lü L, Shi D, Zhou T. Characterizing cycle structure in complex networks. Nat Commun (2020) 4:272. doi:10.1038/s42005-021-00781-3
20. Zhang WJ, Li W, Deng WB. The characteristics of cycle-nodes-ratio and its application to network classification. Commun Nonlinear Sci Numer Simulation (2021) 1007:105804. doi:10.1016/j.cnsns.2021.105804
21. Chen DB, Sun HL, Tang Q, Tian SZ, Xie M. Identifying influential spreaders in complex networks by propagation probability dynamics. Chaos (2019) 29:033120. doi:10.1063/1.5055069
22. Kamal B, Asgarali B, Samadi N. A new centrality measure based on the negative and positive effects of clustering coefficient for identifying influential spreaders in complex networks. Chaos Solitons & Fractals (2018) 110:41–54. doi:10.1016/j.chaos.2018.03.014
23. Lei W, Xu G, Yang P, Tu D. A novel potential edge weight method for identifying influential nodes in complex networks based on neighborhood and position. J Comput Sci (2022) 60:101591. doi:10.1016/j.jocs.2022.101591
24. Gupta M, Mishra R. Spreading the information in complex networks: Identifying a set of top- N influential nodes using network structure. Decis Support Syst (2021) 149:113608. doi:10.1016/j.dss.2021.113608
25. Burt RS. Structural holes: The social structure of competition[J]. Econ J (1994) 40(2). doi:10.2307/2234645
26. Battiston F, Amico E, Barrat A, Bianconi G, Ferraz de Arruda G, Franceschiello B, et al. The physics of higher-order interactions in complex systems. Nat Phys (2021) 17:1093–8. doi:10.1038/s41567-021-01371-4
27. Schaub MT, Benson AR, Horn P, Lippner G, Jadbabaie A. Random walks on simplicial complexes and the normalized hodge 1-laplacian. SIAM Rev (2018) 62:353–91. doi:10.1137/18M1201019
28. Mulas R, Kuehn C, Bhle T, Jost J. Random walks and Laplacians on hypergraphs: When do they match? Discrete Appl Math (2021) 317:26–41. doi:10.1016/j.dam.2022.04.009
29. Millán AP, Torres JJ, Bianconi G. Synchronization in network geometries with finite spectral dimension. Phys Rev E (2019) 99:022307. doi:10.1103/PhysRevE.99.022307
30. Skardal PS, Arenas A. Abrupt desynchronization and extensive multistability in globally coupled oscillator simplices. Phys Rev Lett (2019) 122(24):248301.1–248301.6. doi:10.48550/arXiv.1903.12131
31. Iacopini I, Petri G, Barrat A, Latora V. Simplicial models of social contagion. Nat Commun (2018) 10:2485. doi:10.1038/s41467-019-10431-6
32. Guilherme F, Petri G, Rodriguez PM. Multistability, intermittency and hybrid transitions in social contagion models on hypergraphs (2021). Available at: https://arxiv.org/abs/2112.04273 (Accessed December 8, 2021).
33. Neuhuser L, Mellor A, Lambiotte R. Multibody interactions and nonlinear consensus dynamics on networked systems. Phys Rev E (2022) 101:032310. doi:10.1103/PhysRevE.101.032310
34. Alvarez-Rodriguez U, Battiston F, De Arruda GF, Moreno Y, Perc M, Latora V. Evolutionary dynamics of higher-order interactions in social networks. Nat Hum Behav (2020) 5:586–95. doi:10.1038/s41562-020-01024-1
35. O'Sullivan DJP, O'Keeffe GJ, Fennell PG. Mathematical modeling of complex contagion on clustered networks. Front Phys (2015) 3:71. doi:10.3389/fphy.2015.00071
36. Nematzadeh A, Ferrara E, Flammini A, Ahn YY. Optimal network modularity for information diffusion. Phys Rev Lett (2014) 113(8):088701. doi:10.1103/PhysRevLett.113.088701
37. Davis JT, Perra N, Zhang Q, Moreno Y, Vespignani A. Phase transitions in information spreading on structured populations. Nat Phys (2022) 16:590–6. doi:10.1038/s41567-020-0810-3
38. Laurent HD, Althouse BM. Complex dynamics of synergistic coinfections on realistically clustered networks. Proc Natl Acad Sci (2015) 112:10551–6. doi:10.1073/pnas.1507820112
39. Barabasi A-L, Albert R. Emergence of scaling in random networks. Science (1999) 286:509–12. doi:10.1126/science.286.5439.509
Keywords: complex network, high-order structure, higher-order clustering coefficient, node importance, complex propagation
Citation: Song J and Wang G (2023) Identifying influential nodes in complex contagion mechanism. Front. Phys. 11:1046077. doi: 10.3389/fphy.2023.1046077
Received: 16 September 2022; Accepted: 09 June 2023;
Published: 26 June 2023.
Edited by:
Ferenc Kun, University of Debrecen, HungaryCopyright © 2023 Song and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gaoxia Wang, Z2FveGlhd2FuZ0AxNjMuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.