 Yihao Luo1
Yihao Luo1 Andong Wang
Andong Wang Qibin Zhao
Qibin Zhao- 1School of Automation, Guangdong University of Technology, Guangzhou, China
- 2RIKEN AIP, Tokyo, Japan
- 3Key Laboratory of Intelligent Detection and the Internet of Things in Manufacturing, Ministry of Education, Guangzhou, China
Benefiting from the superiority of tensor Singular Value Decomposition (t-SVD) in excavating low-rankness in the spectral domain over other tensor decompositions (like Tucker decomposition), t-SVD-based tensor learning has shown promising performance and become an emerging research topic in computer vision and machine learning very recently. However, focusing on modeling spectral low-rankness, the t-SVD-based models may be insufficient to exploit low-rankness in the original domain, leading to limited performance while learning from tensor data (like videos) that are low-rank in both original and spectral domains. To this point, we define a hybrid tensor norm dubbed the “Tubal + Tucker” Nuclear Norm (T2NN) as the sum of two tensor norms, respectively, induced by t-SVD and Tucker decomposition to simultaneously impose low-rankness in both spectral and original domains. We further utilize the new norm for tensor recovery from linear observations by formulating a penalized least squares estimator. The statistical performance of the proposed estimator is then analyzed by establishing upper bounds on the estimation error in both deterministic and non-asymptotic manners. We also develop an efficient algorithm within the framework of Alternating Direction Method of Multipliers (ADMM). Experimental results on both synthetic and real datasets show the effectiveness of the proposed model.
1 Introduction
Thanks to the rapid progress of computer technology, data in tensor format (i.e., multi-dimensional array) are emerging in computer vision, machine learning, remote sensing, quantum physics, and many other fields, triggering an increasing need for tensor-based learning theory and algorithms [1–6]. In this paper, we carry out both theoretic and algorithmic research studies on tensor recovery from linear observations, which is a typical problem in tensor learning aiming to learn an unknown tensor when only a limited number of its noisy linear observations are available [7]. Tensor recovery finds applications in many industrial circumstances where the sensed or collected tensor data are polluted by unpredictable factors such as sensor failures, communication losses, occlusion by objects, shortage of instruments, and electromagnetic interferences [7–9], and is thus of both theoretical and empirical significance.
In general, reconstructing an unknown tensor from only a small number of its linear observations is hopeless, unless some assumptions on the underlying tensor are made [9]. The most commonly used assumption is that the underlying tensor possesses some kind of low-rankness which can significantly limit its degree of freedom, such that the signal can be estimated from a small but sufficient number of observations [7]. However, as a higher-order extension of matrix low-rankness, the tensor low-rankness has many different characterizations due to the multiple definitions of tensor rank, e.g., the CANDECOMP/PARAFAC (CP) rank [10], Tucker rank [11], Tensor Train (TT) rank [12], and Tensor Ring (TR) rank [13]. As has been discussed in [7] from a signal processing standpoint, the above exampled rank functions are defined in the original domain of the tensor signal and may thus be insufficient to model low-rankness in the spectral domain. The recently proposed tensor low-tubal-rankness [14] within the algebraic framework of tensor Singular Value Decomposition (t-SVD) [15] gives a kind of complement to it by exploiting low-rankness in the spectral domain defined via Discrete Fourier Transform (DFT), and has witnessed significant performance improvements in comparison with the original domain-based low-rankness for tensor recovery [6, 16, 17].
Despite the popularity of low-tubal-rankness, the fact that it is defined solely in the spectral domain also naturally poses a potential limitation on its usability to some tensor data that are low-rank in both spectral and original domains. To address this issue, we propose a hybrid tensor norm to encourage low-rankness in both spectral and original domains at the same time for tensor recovery in this paper. Specifically, the contributions of this work are four-fold:
• To simultaneously exploit low-rankness in both spectral and original domains, we define a new norm named T2NN as the sum of two tensor nuclear norms induced, respectively, by the t-SVD for spectral low-rankness and Tucker decomposition for original domain low-rankness.
• Then, we apply the proposed norm to tensor recovery by formulating a new tensor least squares estimator penalized by T2NN.
• Statistically, the statistical performance of the proposed estimator is analyzed by establishing upper bounds on the estimation error in both deterministic and non-asymptotic manners.
• Algorithmically, we propose an algorithm based on ADMM to compute the estimator and evaluate its effectiveness on three different types of real data.
The rest of this paper proceeds as follows. First, the notations and preliminaries of low-tubal-rankness and low-Tucker-rankness are introduced in Section 2. Then, we define the new norm and apply it to tensor recovery in Section 3. To understand the statistical behavior of the estimator, we establish an upper bound on the estimation error in Section 4. To compute the proposed estimator, we design an ADMM-based algorithm in Section 5 with empirical performance reported in Section 6.
2 Notations and Preliminaries
Notations. We use lowercase boldface, uppercase boldface, and calligraphy letters to denote vectors (e.g., v), matrices (e.g., M), and tensors (e.g.,
Given a matrix
2.1 Spectral Rankness Modeled by t-SVD
The low-tubal-rankness defined within the algebraic framework of t-SVD is a typical example to characterize low-rankness in the spectral domain. We give some basic notions about t-SVD in this section.
Definition 1 (t-product [15]). Given
Definition 2 (tensor transpose [15]). Let
Definition 3 (identity tensor [15]). The identity tensor
Definition 4 (f-diagonal tensor [15]). A tensor is called f-diagonal if each frontal slice of the tensor is a diagonal matrix.
Definition 5 (Orthogonal tensor [15]). A tensor
Definition 6 (t-SVD, tubal rank [15]). Any tensor
where
where # counts the number of elements in a set.For convenience of analysis, the block diagonal matrix of 3-way tensors is also defined.
Definition 7 (block-diagonal matrix [15]). Let
Definition 8 (tubal nuclear norm, tensor spectral norm [17]). Given
whereas the tensor spectral norm ‖⋅‖ is the largest spectral norm of the frontal slices,
We can see from Definition 8 that TNN captures low-rankness in the spectral domain and is thus more suitable for tensors with spectral low-rankness. As visual data (like images and videos) often process strong spectral low-rankness, it has achieved superior performance over many original domain-based nuclear norms in visual data restoration [6, 17].
2.2 Original Domain Low-Rankness Modeled by Tucker Decomposition
The low-Tucker-rankness is a classical higher-order extension of matrix low-rankness in the original domain and has been widely applied in computer vision and machine learning [19–21]. Given any K-way tensor
where
Through relaxing the matrix rank in Eq. 4 to its convex envelope, i.e., the matrix nuclear norm, we get a convex relaxation of the Tucker rank, called Sum of Nuclear Norms (SNN) [20], which is defined as follows:
where αk’s are positive constants satisfying ∑kak = 1. As a typical tensor low-rankness penalty in the original domain, SNN has found many applications in tensor recovery [19, 20, 22].
3 A Hybrid Norm for Tensor Recovery
In this section, we first define a new norm to exploit low-rankness in both spectral and original domains and then use it to formulate a penalized tensor least squares estimator.
3.1 The Proposed Norm
Although TNN has shown superior performance in many tensor learning tasks, it may still be insufficient for tensors which are low-rank in both spectral and original domains due to its definition solely in the spectral domain. Moreover, it is also unsuitable for tensors which have less significant spectral low-rankness than the original domain low-rankness. Thus, it is necessary to extend the vanilla TNN such that the original domain low-rankness can also be exploited for sounder low-rank modeling.
Under the inspiration of SNN’s impressive low-rank modeling capability in the original domain, our idea is quite simple: to combine the advantages of both TNN and SNN through their weighted sum. In this line of thinking, we come up with the following hybrid tensor norm.
Definition 9 (T2NN). The hybrid norm called “Tubal + Tucker” Nuclear Norm (T2NN) of any 3-way tensor
where γ ∈ (0, 1) is a constant balancing the low-rank modeling in the spectral and original domains.As can be seen from its definition, T2NN approximates TNN when γ → 1, and it degenerates to SNN as γ → 0. Thus, it can be viewed as an interpolation between TNN and SNN, which provides with more flexibility in low-rank tensor modeling. We also define the dual norm of T2NN (named the dual T2NN norm) which are frequently used in analyzing the statistical performance of the T2NN-based tensor estimator.
Lemma 1. The dual norm of the proposed T2NN defined as
can be equivalently formulated as follows:
Proof of Lemma 1. Using the definition of T2NN, the supremum in Problem (7) can be equivalently converted to the opposite number of infimum as follows:
By introducing a multiplier λ ≥ 0, we obtain the Lagrangian function of Problem (9),
Since Slatter’s condition [23] is satisfied in Problem (9), strong duality holds, which means
Thus, we proceed by computing
where (i) is obtained by the trick of splitting
This completes the proof.Although an expression of the dual T2NN norm is given in Lemma 1, it is still an optimization problem whose optimal value cannot be straightforwardly computed from the variable tensor
Lemma 2. The dual T2NN norm can be upper bounded as follows:
Proof of Lemma 2. The proof is a direct application of the basic equality “harmonic mean ≤ arithmetic mean” with careful construction of auxiliary tensors
where the denominator M is given by
It is obvious that
Then, by using “harmonic mean ≤ arithmetic mean” on the right-hand side of Eq. 11, we obtain
which directly leads to Eq. 10.
3.2 T2NN-Based Tensor Recovery
3.2.1 The observation Model
We use
where
Let
Then, the observation model (13) can be rewritten in the following compact form:
3.2.2 Two Typical Settings
With different settings of the design tensors
• Tensor completion. In tensor completion, the design tensors
• Tensor compressive sensing. When
3.2.3 The Proposed Estimator
The goal of this paper is to recover the unknown low-rank tensor
Inspired by the capability of the newly defined T2NN in simultaneously modeling low-rankness in both spectral and original domains, we define the T2NN penalized least squares estimator
where the squared l2-norm is adopted as the fidelity term for Gaussian noises, the proposed T2NN is used to impose both spectral and original low-rankness in the solution, and λ is a penalization parameter which balances the residual fitting accuracy and the parameter complicity (characterized by low-rankness) of the model.
Given the estimator
4 Statistical Guarantee
In this section, we first come up with a deterministic upper bound of the estimation error and then establish non-asymptotic error bounds for the special cases of tensor compressive sensing with random Gaussian design and noisy tensor completion.
First, to describe the low-rankness of
• `Low-tubal-rank structure: Let
where
• Low-Tucker-rank structure: Let
where I denotes the identity matrix of appropriate dimensionality.
4.1 A Deterministic Bound on the Estimation Error
Before bounding the Frobenius-norm error
Proposition 1. By setting the regularization parameter
(I) rank inequality:
(II) sum of norms inequality:
(III) an upper bound on the “observed” error:
Proof of Proposition 1. The proof is given as follows:Proof of Part (I): According to the definition of
Due to the facts that
Also, according to the definition of
Due to the facts that
Proof of Part (II) and Part (III): The optimality of
By the definition of the error tensor
The definition that
where the last inequality holds due to the definition of the adjoint operator
According to the decomposibility of TNN (see the supplementray material of [25]) and the decomposibility of matrix nuclear norm [27], one has
and
Then, we obtain
Using the definition of T2NN and triangular inequality yields
Further using the setting
where by combing (i) and
Assumption 1 (RSC condition). The observation operator
for any
Then, a straightforward combination of Proposition 1 and Assumption 1 leads to an deterministic bound on the estimation error.
Theorem 1. By setting the regularization parameter
Note that we do not require information for distribution of the noise ξ in Theorem 1, which indicates that Theorem 1 provides a deterministic bound for general noise type. The bound on the right-hand side of Eq. 26 is in terms of the quantity,
which serves as a measure of structure complexity, reflecting the natural intuition that more complex structure causes larger error. The result is in consistent with the results for sum-of-norms-based estimators in [5, 22, 24, 28]. A more general analysis in [24, 28] indicates that the performance of sum-of-norms-based estimators are determined by all the structural complexities for a simultaneously structured signal, just as shown by the proposed bound (26).
4.2 Tensor Compressive Sensing
In this section, we consider tensor compressive sensing from random Gaussian design where
Lemma 3 (RSC of random Gaussian design). If
for any tensor
where
where random vector
where
Lemma 4 (bound on
Proof. Since ξm’s are i. i.d.
with high probability according to Proposition 8.1 in [29].For k = 1, 2, 3, let X∗(ξ) (k) be the mode-k unfolding of random tensor
with high probability. A similar argument of Lemma C.1 in [27] also yields
with high probability. Combining Eqs 30, 31, we can complete the proof.Then, the non-asymptotic error bound is obtained finally as follows.
Theorem 2 (non-asymptotic error bound). Under the random Gaussian design setup, there are universal constants c3, c4, and c5 such that for a sample size N greater than
and any solution to Problem (15) with regularization parameter
then we have
which holds with high probability.To understand the proposed bound, we consider the three-way cubical tensor
which means the estimation error is controlled by the tubal rank and Tucker rank of
for approximate tensor sensing.Another interesting result is that by setting the noise level σ = 0 in Eq. 33, the upper bound reaches 0, which means the proposed estimator can exactly recover the unknown truth
4.3 Noisy Tensor Completion
For noisy tensor completion, we consider a slightly modified estimator,
where
We consider noisy tensor completion under uniform sampling in this section.
Assumption 2 (uniform sampling scheme). The design tensors
Recall that Proposition 1 in Section 4.1 gives an upper bound on the “observed part” of the estimation error
when the error tensor Δ belongs to some set
where
Lemma 5 (RSC condition under uniform sampling). For any
where e is the base of the natural logarithm, and the entries ϵi of vector
and a quantity
which is the maximal absolute deviation of
Lemma 6 (concentration of ZT). There exists a constant c0 such that
Proof of Lemma 6. The proof is similar to that of Lemma 10 in [31]. The difference lies in the step of symmetrization arguments. Note that for any
which indicates
Then, Lemma 5 can be proved by using the peeling argument [30].Proof of Lemma 5. For any positive integer l, we define disjoint subsets of
with constants
and its sub-events for any
Note that Lemma 6 implies that
Thus, we have
Recall that
Proposition 2. With parameter
with probability at least
Since
Case 2: If
with probability at least
Combining Case 1 and Case 2, we obtain the result of Proposition 2. According to Proposition 2 and Lemma 5, it remains to bound
Suppose the sample complexity N in noisy tensor completion satisfies
Then, we have the following Lemma 7 and Lemma 8 to bound
Lemma 7. Under the sample complexity of noisy tensor completion in Eq. 44, it holds with probability at least
where Cϱ is a constant dependent on the ϱ that is defined in Eq. 43.Proof of Lemma 7. The proof can be straightforwardly obtained by adopting the upper bound of the dual T2NN norm in Lemma 2 and Lemma 5 in the supplementary material of [25], and Lemma 5 in [30] as follows:
• First, Lemma 5 in the supplementary material of [25] shows that letting N ≥ d1d3 ∨ d2d3 and
• For k = 1, 2, 3, let X∗(ξ) (k) be the mode-k unfolding of random tensor
Then, combining Eq. 46 and 47 and using union bound, Eq. 45 can be obtained.
Lemma 8. Under the sample complexity of noisy tensor completion in Eq. 44, it holds that
Proof of Lemma 8. Similar to the proof of Lemma 7, the proof can be straightforwardly obtained by adopting the upper bound of the dual T2NN norm in Lemma 2 and Lemma 6 in the supplementary material of [25], and Lemma 6 in [30].
• First, Lemma 6 in the supplementary material of [25] shows that letting N ≥ d1d3 ∨ d2d3 and N ≥ 2 (d1 ∧ d2) log2 (d1 ∧ d2) log (d1d3 + d2d3), then, the following inequality holds:
• For k = 1, 2, 3, let X∗(ϵ) (k) be the mode-k unfolding of random tensor
Then, Eq. 48 can be obtained by combining Eqs. 49 and 50.Further combining Lemma 7, Lemma 8, and Proposition 2, we arrive at an upper bound on the estimation error in the follow theorem.
Theorem 3. Suppose Assumption 2 is satisfied and
the estimation error of any estimator
with probability at least
which means the estimation error is controlled by the tubal rank and Tucker rank of
for approximate tensor completion.
5 Optimization Algorithm
The ADMM framework [33] is applied to solve the proposed model. Adding auxiliary variables
To solve Problem (55), an ADMM-based algorithm is proposed. First, the augmented Lagrangian is
where tensors
The primal variables
Update the first block
By taking derivative with respect to
Solving the above equation yields
where
Update the second block
where
Then,
where
Lemma 9 (proximal operator of TNN [34]). Let tensor
where
Lemma 10 (proximal operator of the matrix nuclear norm [35]). Let tensor
Update the dual variables
Termination Condition. Given a tolerance ϵ > 0, check the termination condition of primal variables
and convergence of constraints
The ADMM-based algorithm is described in Algorithm 1.
Algorithm 1. ADMM for Problem(55)

Computational complexity analysis: We analyze the computational complexity as follows.
• By precomputing
• Updating
• Updating
Overall, supposing the iteration number is T, the total computational complexity will be
which is very expensive for large tensors. In some special cases (like tensor completion) where
Convergence analysis: We then discuss the convergence of Algorithm 1 as follows.
Theorem 4 (convergence of Algorithm 1). For any positive constant ρ, if the unaugmented Lagrangian function
with u, v, w, and A defined as follows:
where vec (⋅) denotes the operation of tensor vectorization (see [18]).It can be verified that f (⋅) and g (⋅) are closed, proper convex functions. Then, Problem(55) can be re-written as follows:
According to the convergence analysis in [33], we have
where f ∗, g∗ are the optimal values of f(u), g(v), respectively. Variable w∗ is a dual optimal point defined as
where
6 Experimental Results
In this section, we first conduct experiments on synthetic datasets to validate the theory for tensor compressed sensing and then evaluate the effectiveness of the proposed T2NN on three types of real data for noisy tensor completion. MATLAB implementations of the algorithms are deployed on a PC running UOS system with an AMD 3 GHz CPU and a RAM of 40 GB.
6.1 Tensor Compressed Sensing
Our theoretical results on tensor compressed sensing are validated on synthetic data in this subsection. Motivated by [7], we consider a constrained T2NN minimization model that is equivalent to Model (15) for the ease of parameter selection. For performance evaluation, the proposed T2NN is also compared with TNN-based tensor compressed sensing [37]. First, the underlying tensor
• Step 1: Generate
• Step 2: Generate N compressed observations {yi}. Given a positive integer N ≪ D, we first generate N design tensors
For simplicity, we consider cubic tensors, i.e., d1 = d2 = d3 = d, and choose the parameter of T2NN by γ = 1/4, α1 = α2 = α3 = 1/3. Recall that the underlying tensor
(1) Phenomenon 1: In the noiseless setting, i.e., σ = 0, if the observation number N is larger than C0rd2 for a sufficiently large constant C0, then the estimation error
(2) Phenomenon 2: In the noisy case, the estimation error
To check whether Phenomenon 1 occurs, we conduct tensor compressed sensing by setting the noise variance σ2 = 0. We gradually increase the normalized observation number N/N0 from 0.25 to 5. For each different setting of d, r, and N/N0, we repeat the experiments 10 times and report the averaged estimation error
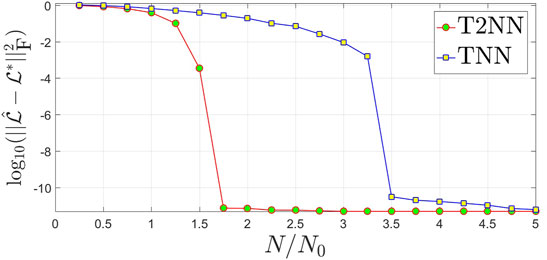
FIGURE 1. Estimation error in logarithm vs. the normalized observation number N/N0 for tensor compressed sensing of underlying tensors of size 16×16×16 and rank proxy r =2. The proposed T2NN is compared with TNN [37].
For the validation of Phenomenon 2, we consider the noisy settings with normalized sample complexity N/N0 = 3.5, which is nearly the phase transition point of TNN and much greater than that of T2NN. We gradually increase the noise level c = σ/σ0 from 0.025 to 0.25. For each different setting of d, r, and c, we repeat the experiments 10 times and report the averaged estimation error
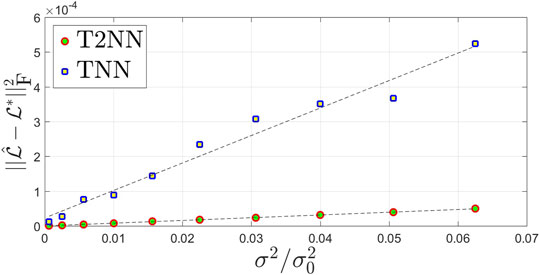
FIGURE 2. Estimation error vs. the (squared) noise level
6.2 Noisy Tensor Completion
This subsection evaluates effectiveness of the proposed T2NN through performance comparison with matrix nuclear norms (NN) [30], SNN [22], and TNN [25] by carrying out noisy tensor completion on three different types of visual data including video data, hyperspectral images, and seismic data.
6.2.1 Experimental Settings
Given the tensor data
6.2.2 Performance evaluation
The effectiveness of algorithms is measured by the Peak Signal Noise Ratio (PSNR) and structural similarity (SSIM) [38]. Specifically, the PSNR of an estimator
for the underlying tensor
where
6.2.3 Parameter Setting
For NN [30], we set the parameter
6.2.4 Experiments on Video Data
We first conduct noisy video completion on four widely used YUV videos: Akiyo, Carphone, Grandma, and Mother-daughter. Owing to computational limitation, we simply use the first 30 frames of the Y components of all the videos and obtain four tensors of size 144 × 17 × 30. We first report the averaged PSNR and SSIM values obtained by four norms for quantitative comparison in Table 1 and then give visual examples in Figure 3 when 95% of the tensor entries are missing for qualitative evaluation. A demo of the source code is available at https://github.com/pingzaiwang/T2NN-demo.
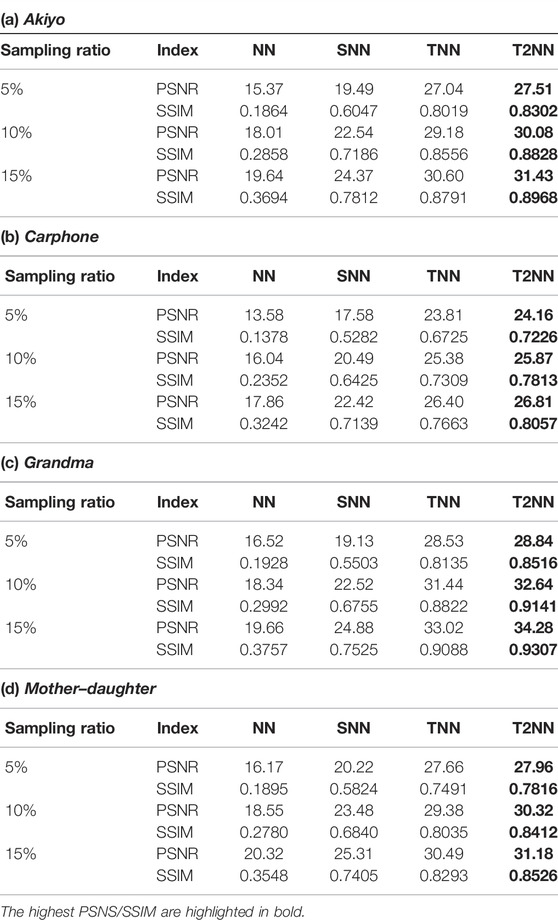
TABLE 1. PSNR and SSIM values obtained by four norms (NN [30], SNN [22], TNN [25], and our T2NN) for noisy tensor completion on the YUV videos.

FIGURE 3. Visual results obtained by four norms for noisy tensor completion with 95% missing entries on the YUV-video dataset. The first to fourth rows correspond to the video of Akiyo, Carphone, Grandman, and Mother-duaghter, respectively. The sub-plots from (A) to (F): (A) a frame of the original video, (B) the observed frame, (C) the frame recovered by NN [30], (D) the frame recovered by SNN [22], (E) the frame recovered by the vanilla TNN [25], and (F) the frame recovered by our T2NN.
6.2.5 Experiments on Hyperspectral Data
We then carry out noisy tensor completion on subsets of the two representative hyperspectral datasets described as follows:
• Indian Pines: The dataset was collected by AVIRIS sensor in 1992 over the Indian Pines test site in North-western Indiana and consists of 145 × 145 pixels and 224 spectral reflectance bands. We use the first 30 bands in the experiments due to the trade-off between the limitation of computing resources.
• Salinas A: The data were acquired by AVIRIS sensor over the Salinas Valley, California in 1998, and consists of 224 bands over a spectrum range of 400–2500 nm. This dataset has a spatial extent of 86 × 83 pixels with a resolution of 3.7 m. We use the first 30 bands in the experiments too.
The averaged PSNR and SSIM values are given in Table 2 for quantitative comparison. We also show visual examples in Figure 4 when 85% of the tensor entries are missing for qualitative evaluation.

TABLE 2. PSNR and SSIM values obtained by four norms (NN [30], SNN [22], TNN [25], and our T2NN) for noisy tensor completion on the hyperspectral datasets.
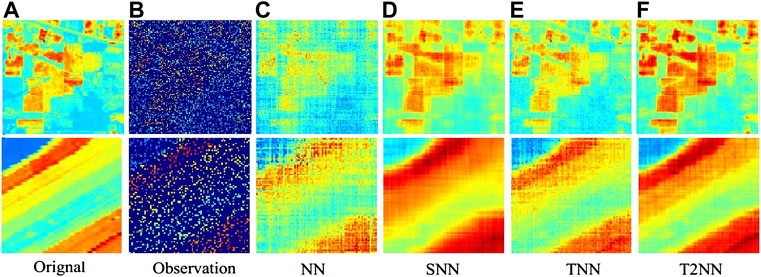
FIGURE 4. Visual results obtained by four norms for noisy tensor completion with 85% missing entries on the hyperspectral dataset (gray data shown with pseudo-color). The first and second rows correspond to Indian Pines and Salinas A, respectively. The sub-plots from (A) to (F): (A) a frame of the original data, (B) the observed frame, (C) the frame recovered by NN [30], (D) the frame recovered by SNN [22], (E) the frame recovered by the vanilla TNN [25], and (F) the frame recovered by our T2NN.
6.2.6 Experiments on Seismic Data
We use the seismic data tensor of size 512 × 512 × 3, which is abstracted from the test data “seismic.mat” of a toolbox for seismic data processing from Center of Geopyhsics, Harbin Institute of Technology, China. For quantitative comparison, we present the PSNR and SSIM values for two sampling schemes in Table 3.
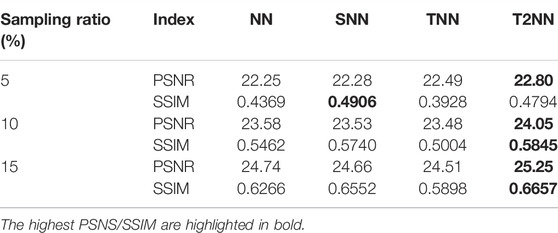
TABLE 3. PSNR and SSIM values obtained by four norms (NN [30], SNN [22], TNN [25], and our T2NN) for noisy tensor completion on the Seismic dataset.
6.2.7 Summary and Analysis of Experimental Results
According to the experimental results on three types of real tensor data shown in Table 1, Table 2, Table 3, and Figure 3, the summary and analysis are presented as follows:
1) In all the cases, tensor norms (SNN, TNN, and T2NN) perform better than the matrix norm (NN). It can be explained that tensor norms can honestly preserve the multi-way structure of tensor data such that the rich inter-modal and intra-modal correlations of the data can be exploited to impute the missing values, whereas the matrix norm can only handle two-way structure and thus fails to model the multi-way structural correlations of the tensor data.
2) In most cases, TNN outperforms SNN, which is in consistence with the results reported in [14, 17, 25]. One explanation is that the used video, hyperspectral images, and seismic data all possess stronger low-rankness in the spectral domain (than in the original domain), which can be successfully captured by TNN.
3) In most cases, the proposed T2NN performs best among the four norms. We owe the promising performance to the capability of T2NN in simultaneously exploiting low-rankness in both spectral and original domains.
7 Conclusion and Discussions
7.1 Conclusion
Due to its definition solely in the spectral domain, the popular TNN may be incapable to exploit low-rankness in the original domain. To remedy this weaknesses, a hybrid tensor norm named the “Tubal + Tucker” Nuclear Norm (T2NN) was first defined as the weighted sum of TNN and SNN to model both spectral and original domain low-rankness. It was further used to formulate a penalized least squares estimator for tensor recovery from noisy linear observations. Upper bounds on the estimation error were established in both deterministic and non-asymptotic senses to analyze the statistical performance of the proposed estimator. An ADMM-based algorithm was also developed to efficiently compute the estimator. The effectiveness of the proposed model was demonstrated through experimental results on both synthetic and real datasets.
7.2 Limitations of the Proposed Model and Possible Solutions
Generally speaking, the proposed estimator has the following two drawbacks due to the adoption of T2NN:
• Sample inefficiency: The analysis of [24, 28] indicates that for tensor recovery from a small number of observations, T2NN cannot provide essentially lower sample complexity than TNN.
• Computational inefficiency: Compared to TNN, T2NN is more time-consuming since it involves computing both TNN and SNN.
We list several directions that this work can be extended to overcome the above drawbacks.
• For sample inefficiency: First, inspired by the attempt of adopting the “best” norm (e.g., Eq. 8 in [28]), the following model can be considered:
for a certain noise level ϵ ≥ 0. Although Model (65) has a significantly higher accuracy and lower sample complexity according to the analysis in [28], it is impractical because it requires
where β > 0 is a regularization parameter.
• For computational inefficiency: To improve the efficiency of the proposed T2NN-based models, we can use more efficient solvers of Problem (15) by adopting the factorization strategy [40, 41] or sampling-based approaches [42].
7.3 Extensions to the Proposed Model
In this subsection, we discuss possible extensions of the proposed model to general K-order (K > 3) tensors, general spectral domains, robust tensor recovery, and multi-view learning, respectively.
• Extensions to K-order (K > 3) tensors: Currently, the proposed T2NN is defined solely for 3-order tensors, and it cannot be directly applied to tensors of more than 3 orders like color videos. For general K-order tensors, it is suggested to replace the tubal nuclear norm in the definition of T2NN with orientation invariant tubal nuclear norm [5], which is defined to exploit multi-orientational spectral low-rankness for general higher-order tensors.
• Extensions to general spectral and original domains: This paper considers the DFT-based tensor product for spectral low-rank modeling. Recently, the DFT based t-product has been generalized to the *L-product defined via any invertible linear transform [43], under which the tubal nuclear norm is also extended to *L-tubal nuclear norm [44] and *L-Spectral k-support norm [7]. It is natural to generalize the proposed T2NN by changing the tubal nuclear norm to *L-tubal nuclear norm or *L-Spectral k-support norm for further extensions. It is also interesting to consider other tensor decompositions for original domain low-rankness modeling such as CP, TT, and TR as future work.
• Extensions to robust tensor recovery: In many real applications, the tensor signal may also be corrupted by gross sparse outliers. Motivated by [5], the proposed T2NN can also be used in resisting sparse outliers for robust tensor recovery as follows:
where
• Extensions to multi-view learning: Due to its superiority in modeling multi-linear correlations of multi-modal data, TNN has been successfully applied to multi-view self-representations for clustering [45, 46]. Our proposed T2NN can also be utilized for clustering by straightforwardly replacing TNN in the formulation of multi-view learning models (e.g., Eq. 9 in [45]).
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here; https://sites.google.com/site/subudhibadri/fewhelpfuldownloads, https://engineering.purdue.edu/∼biehl/MultiSpec/hyperspectral.html, https://rslab.ut.ac.ir/documents/81960329/82035173/SalinasA_corrected.mat, https://github.com/sevenysw/MathGeo2018.
Author Contributions
Conceptualization and methodology—YL and AW; software—AW; formal analysis—YL, AW, GZ, and QZ; resources—YL, GZ, and QZ; writing: original draft preparation—YL, AW, GZ, and QZ; project administration and supervision—GZ, and QZ; and funding acquisition—AW, GZ, and QZ. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 61872188, 62073087, 62071132, 62103110, 61903095, U191140003, and 61973090, in part by the China Postdoctoral Science Foundation under Grant 2020M672536, and in part by the Natural Science Foundation of Guangdong Province under Grants 2020A1515010671, 2019B010154002, and 2019B010118001.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
AW is grateful to Prof. Zhong Jin in Nanjing University of Science and Technology for his long-time and generous support in both research and life. In addition, he would like to thank the Jin family in Zhuzhou for their kind understanding in finishing the project of tensor learning in these years.
Footnotes
1The Fourier version
References
1. Guo C, Modi K, Poletti D. Tensor-Network-Based Machine Learning of Non-Markovian Quantum Processes. Phys Rev A (2020) 102:062414.
2. Ma X, Zhang P, Zhang S, Duan N, Hou Y, Zhou M, et al. A Tensorized Transformer for Language Modeling. Adv Neural Inf Process Syst (2019) 32.
3. Meng Y-M, Zhang J, Zhang P, Gao C, Ran S-J. Residual Matrix Product State for Machine Learning. arXiv preprint arXiv:2012.11841 (2020).
4. Ran S-J, Sun Z-Z, Fei S-M, Su G, Lewenstein M. Tensor Network Compressed Sensing with Unsupervised Machine Learning. Phys Rev Res (2020) 2:033293. doi:10.1103/physrevresearch.2.033293
5. Wang A, Zhao Q, Jin Z, Li C, Zhou G. Robust Tensor Decomposition via Orientation Invariant Tubal Nuclear Norms. Sci China Technol Sci (2022) 34:6102. doi:10.1007/s11431-021-1976-2
6. Zhang X, Ng MK-P. Low Rank Tensor Completion with Poisson Observations. IEEE Trans Pattern Anal Machine Intelligence (2021). doi:10.1109/tpami.2021.3059299
7. Wang A, Zhou G, Jin Z, Zhao Q. Tensor Recovery via *L-Spectral k-Support Norm. IEEE J Sel Top Signal Process (2021) 15:522–34. doi:10.1109/jstsp.2021.3058763
8. Cui C, Zhang Z. High-Dimensional Uncertainty Quantification of Electronic and Photonic Ic with Non-Gaussian Correlated Process Variations. IEEE Trans Computer-Aided Des Integrated Circuits Syst (2019) 39:1649–61. doi:10.1109/TCAD.2019.2925340
9. Liu X-Y, Aeron S, Aggarwal V, Wang X. Low-Tubal-Rank Tensor Completion Using Alternating Minimization. IEEE Trans Inform Theor (2020) 66:1714–37. doi:10.1109/tit.2019.2959980
10. Carroll JD, Chang J-J. Analysis of Individual Differences in Multidimensional Scaling via an N-Way Generalization of “Eckart-Young” Decomposition. Psychometrika (1970) 35:283–319. doi:10.1007/bf02310791
11. Tucker LR. Some Mathematical Notes on Three-Mode Factor Analysis. Psychometrika (1966) 31:279–311. doi:10.1007/bf02289464
12. Oseledets IV. Tensor-Train Decomposition. SIAM J Sci Comput (2011) 33:2295–317. doi:10.1137/090752286
13. Zhao Q, Zhou G, Xie S, Zhang L, Cichocki A. Tensor Ring Decomposition. arXiv preprint arXiv:1606.05535 (2016).
14. Zhang Z, Ely G, Aeron S, Hao N, Kilmer M. Novel Methods for Multilinear Data Completion and De-Noising Based on Tensor-Svd. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014). p. 3842–9. doi:10.1109/cvpr.2014.485
15. Kilmer ME, Braman K, Hao N, Hoover RC. Third-Order Tensors as Operators on Matrices: A Theoretical and Computational Framework with Applications in Imaging. SIAM J Matrix Anal Appl (2013) 34:148–72. doi:10.1137/110837711
16. Hou J, Zhang F, Qiu H, Wang J, Wang Y, Meng D. Robust Low-Tubal-Rank Tensor Recovery from Binary Measurements. IEEE Trans Pattern Anal Machine Intelligence (2021). doi:10.1109/tpami.2021.3063527
17. Lu C, Feng J, Chen Y, Liu W, Lin Z, Yan S. Tensor Robust Principal Component Analysis with a New Tensor Nuclear Norm. IEEE Trans Pattern Anal Mach Intell (2020) 42:925–38. doi:10.1109/tpami.2019.2891760
18. Kolda TG, Bader BW. Tensor Decompositions and Applications. SIAM Rev (2009) 51:455–500. doi:10.1137/07070111x
19. Li X, Wang A, Lu J, Tang Z. Statistical Performance of Convex Low-Rank and Sparse Tensor Recovery. Pattern Recognition (2019) 93:193–203. doi:10.1016/j.patcog.2019.03.014
20. Liu J, Musialski P, Wonka P, Ye J. Tensor Completion for Estimating Missing Values in Visual Data. IEEE Trans Pattern Anal Mach Intell (2013) 35:208–20. doi:10.1109/tpami.2012.39
21. Qiu Y, Zhou G, Chen X, Zhang D, Zhao X, Zhao Q. Semi-Supervised Non-Negative Tucker Decomposition for Tensor Data Representation. Sci China Technol Sci (2021) 64:1881–92. doi:10.1007/s11431-020-1824-4
22. Tomioka R, Suzuki T, Hayashi K, Kashima H. Statistical Performance of Convex Tensor Decomposition. In: Proceedings of Annual Conference on Neural Information Processing Systems (2011). p. 972–80.
23. Boyd S, Boyd SP, Vandenberghe L. Convex Optimization. Cambridge: Cambridge University Press (2004).
24. Mu C, Huang B, Wright J, Goldfarb D. Square Deal: Lower Bounds and Improved Relaxations for Tensor Recovery. In: International Conference on Machine Learning (2014). p. 73–81.
25. Wang A, Lai Z, Jin Z. Noisy Low-Tubal-Rank Tensor Completion. Neurocomputing (2019) 330:267–79. doi:10.1016/j.neucom.2018.11.012
26. Zhou P, Lu C, Lin Z, Zhang C. Tensor Factorization for Low-Rank Tensor Completion. IEEE Trans Image Process (2018) 27:1152–63. doi:10.1109/tip.2017.2762595
27. Negahban S, Wainwright MJ. Estimation of (Near) Low-Rank Matrices with Noise and High-Dimensional Scaling. Ann Stat (2011) 2011:1069–97. doi:10.1214/10-aos850
28. Oymak S, Jalali A, Fazel M, Eldar YC, Hassibi B. Simultaneously Structured Models with Application to Sparse and Low-Rank Matrices. IEEE Trans Inform Theor (2015) 61:2886–908. doi:10.1109/tit.2015.2401574
29. Foucart S, Rauhut H. A Mathematical Introduction to Compressive Sensing, Vol. 1. Basel, Switzerland: Birkhäuser Basel (2013).
30. Klopp O. Noisy Low-Rank Matrix Completion with General Sampling Distribution. Bernoulli (2014) 20:282–303. doi:10.3150/12-bej486
31. Klopp O. Matrix Completion by Singular Value Thresholding: Sharp Bounds. Electron J Stat (2015) 9:2348–69. doi:10.1214/15-ejs1076
32. Vershynin R. High-Dimensional Probability: An Introduction with Applications in Data Science, Vol. 47. Cambridge: Cambridge University Press (2018).
33. Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations Trends® Machine Learn (2011) 3:1–122. doi:10.1561/2200000016
34. Wang A, Wei D, Wang B, Jin Z. Noisy Low-Tubal-Rank Tensor Completion Through Iterative Singular Tube Thresholding. IEEE Access (2018) 6:35112–28. doi:10.1109/access.2018.2850324
35. Cai J-F, Candès EJ, Shen Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J Optim (2010) 20:1956–82. doi:10.1137/080738970
36. He B, Yuan X. On the $O(1/n)$ Convergence Rate of the Douglas-Rachford Alternating Direction Method. SIAM J Numer Anal (2012) 50:700–9. doi:10.1137/110836936
37. Lu C, Feng J, Lin Z, Yan S. Exact Low Tubal Rank Tensor Recovery from Gaussian Measurements. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence (2018). p. 1948–54. doi:10.24963/ijcai.2018/347
38. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image Quality Assessment: from Error Visibility to Structural Similarity. IEEE Trans Image Process (2004) 13:600–12. doi:10.1109/tip.2003.819861
39. Zhang X, Zhou Z, Wang D, Ma Y. Hybrid Singular Value Thresholding for Tensor Completion. In: Twenty-Eighth AAAI Conference on Artificial Intelligence (2014). p. 1362–8.
40. Wang A-D, Jin Z, Yang J-Y. A Faster Tensor Robust Pca via Tensor Factorization. Int J Mach Learn Cyber (2020) 11:2771–91. doi:10.1007/s13042-020-01150-2
41. Liu G, Yan S. Active Subspace: Toward Scalable Low-Rank Learning. Neural Comput (2012) 24:3371–94. doi:10.1162/neco_a_00369
42. Wang L, Xie K, Semong T, Zhou H. Missing Data Recovery Based on Tensor-Cur Decomposition. IEEE Access (2017) PP:1.
43. Kernfeld E, Kilmer M, Aeron S. Tensor-Tensor Products with Invertible Linear Transforms. Linear Algebra its Appl (2015) 485:545–70. doi:10.1016/j.laa.2015.07.021
44. Lu C, Peng X, Wei Y. Low-Rank Tensor Completion with a New Tensor Nuclear Norm Induced by Invertible Linear Transforms. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019). p. 5996–6004. doi:10.1109/cvpr.2019.00615
45. Lu G-F, Zhao J. Latent Multi-View Self-Representations for Clustering via the Tensor Nuclear Norm. Appl Intelligence (2021) 2021:1–13. doi:10.1007/s10489-021-02710-x
Keywords: tensor decomposition, tensor low-rankness, tensor SVD, tubal nuclear norm, tensor completion
Citation: Luo Y, Wang A, Zhou G and Zhao Q (2022) A Hybrid Norm for Guaranteed Tensor Recovery. Front. Phys. 10:885402. doi: 10.3389/fphy.2022.885402
Received: 28 February 2022; Accepted: 27 April 2022;
Published: 13 July 2022.
Edited by:
Peng Zhang, Tianjin University, ChinaReviewed by:
Jingyao Hou, Southwest University, ChinaYong Peng, Hangzhou Dianzi University, China
Jing Lou, Changzhou Institute of Mechatronic Technology, China
Guifu Lu, Anhui Polytechnic University, China
Copyright © 2022 Luo, Wang, Zhou and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Andong Wang, dy5hLmRAb3V0bG9vay5jb20=