 Li-Zhen Gao1,2
Li-Zhen Gao1,2 Song Lin
Song Lin- 1College of Computer Science and Information Engineering, Xiamen Institute of Technology, Xiamen, China
- 2Higher Educational Key Laboratory for Flexible Manufacturing Equipment Integration of Fujian Province, Xiamen Institute of Technology, Xiamen, China
- 3College of Computer and Cyber Security, Fujian Normal University, Fuzhou, China
- 4College of Mathematics and Statistics, Fujian Normal University, Fuzhou, China
- 5Digital Fujian Internet-of-Things Laboratory of Environmental Monitoring, Fujian Normal University, Fuzhou, China
Mahalanobis distance is a distance measure that takes into account the relationship between features. In this paper, we proposed a quantum KNN classification algorithm based on the Mahalanobis distance, which combines the classical KNN algorithm with quantum computing to solve supervised classification problem in machine learning. Firstly, a quantum sub-algorithm for searching the minimum of disordered data set is utilized to find out K nearest neighbors of the testing sample. Finally, its category can be obtained by counting the categories of K nearest neighbors. Moreover, it is shown that the proposed quantum algorithm has the effect of squared acceleration compared with the classical counterpart.
1 Introduction
With the development of era, the amount of global data is increasing exponentially every year. People often use machine learning to extract valid information from large amounts of data. However, with the increase of the amount of data, classical machine learning algorithms need a lot of time. How to design an efficient learning algorithm has become a major difficulty in the field of machine learning. At this point, the speed advantage of quantum computing over classical computing in solving certain specific problems has led more and more scholars to think about how to use quantum computing to solve the problem more efficiently and has given rise to a new field of research – quantum machine learning (QML). Quantum machine learning uses quantum superposition, quantum entanglement and other basic principles of quantum mechanics to realize computing tasks [1]. That is to say, QML is a quantum version of machine learning algorithms, which can achieve an exponential or squared quantum acceleration effect.
In recent years, researchers have studied quantum machine learning algorithms in depth and have achieved outstanding works in many branches of research, such as quantum K-nearest neighbor (QKNN) algorithm [2–4], quantum support vector machine (QSVM) [5, 6], quantum neural network (QNN) [7–9] and so on [10, 11]. These algorithms take full advantage of quantum superposition and entanglement properties, allowing them to achieve quantum acceleration compared to classical algorithms.
QKNN algorithms is a combination of quantum computing and classical algorithm. In 2013, Lloyd proposed a distance-based supervised learning quantum algorithm [12], which has exponential acceleration effect compared with classical algorithms. In 2014, Wiebe raised a QKNN algorithm based on inner product distance [2] with squared acceleration effect. In 2017, Ruan realized a QKNN algorithm based on Hamming distance [3], which has a time complexity of
In this paper, we propose an efficient quantum version of KNN algorithm based on Mahalanobis distance. The algorithm architecture is similar to the classical algorithm. Similarly, we also notice two key points in designing the KNN algorithm. One is to efficiently compute the distance between M training samples and test sample, and the other is to find the smallest K number of samples. However, compared with the existing algorithms, the proposed algorithm takes fully account of the sample correlations and uses Mahalanobis distance to eliminate the interference of correlations between variables. Finally, the test samples are successfully classified using the algorithm of searching for K-nearest neighbor samples and the calculated Mahalanobis distance. The algorithm achieves a quadratic speedup in terms of time complexity.
2 Preliminaries
In this section, we briefly review the main process of the classical KNN classification and the Mahalanobis distance.
2.1 K-nearest neighbors classification algorithm
KNN algorithm is a common supervised classification algorithm, which works as follows: given a test sample and a training sample set, where the training sample set contains M training samples. Then, we compute the distances between the test sample and the M training samples, and find the K nearest training samples by comparing these distances. If the majority of the K nearest neighbor training samples of the test sample belong to a class, then the class of the test sample is that class [13, 14]. In the KNN algorithm, the most complex step is to compute the distance between the test sample and all training samples. Moreover, the computational complexity increases with the number and dimensionality of the training samples. In order to classify the test samples with dimension N and perform the distance metric with M N-dimensional training samples, we need to perform
The general process of classical KNN classification can be summarized in the following points.
1) Choose an appropriate distance metric and calculate the distance between the test sample with M training samples.
2) Find the K training samples with closest distance to the test sample.
3) Count the class with the highest frequency among these K training samples, and that class is the class of the sample to be classified.
Although the K-nearest neighbor algorithm has better performance and accuracy, we should note that the choice of the distance metric is extremely important [15]. In general, we use the Euclidean distance as the metric. In fact, the Euclidean distance is just an integration of the two samples’ deviations on each variable by treating all variables equally, which has some limitations in terms of data relevance. Instead, we use a generalization of the Euclidean distance: the Mahalanobis distance, which calculates the distance between two points by covariance and is an effective method to calculate the similarity of two unknown samples. Unlike the Euclidean distance, it takes into account the correlation between various variables. The difference between Euclidean distance and Mahalanobis distance is shown in Figure 1.
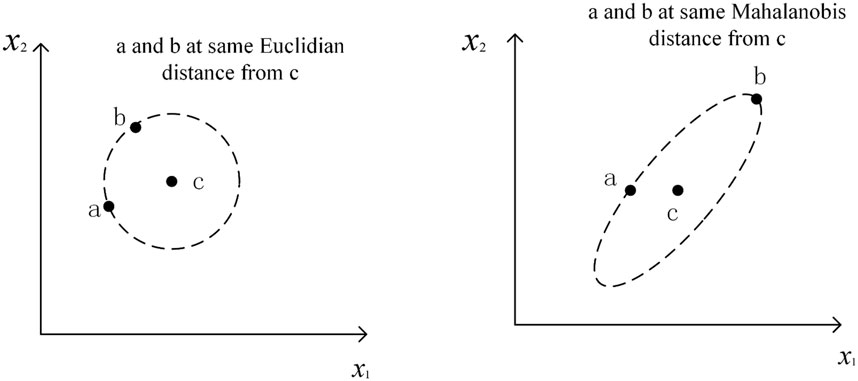
FIGURE 1. The difference between Euclidean distance and Mahalanobis distance.
As shown above, we can easily find that the Mahalanobis distance is better than the Euclidean distance. The Mahalanobis distance can be used to reasonably unify the data between different features, since its computation takes into account the fact that the scale units are different in different directions.
2.2 The Mahalanobis distance
Mahalanobis distance is an effective metric to calculate the distance between two samples, which considers the different feature attributes. It also has two advantages as follows. 1) It is independent of the magnitude and the distance between two points is independent of the measurement units of the original data. 2) The Mahalanobis distance can also eliminate the interference of correlation between variables.
In this paper, the training samples and the test sample are combined into a data set
where, the ij term in the covariance matrix (the ij term is a covariance) is
The Mahalanobis distance between data points x and y is
where Σ is the covariance matrix of x and y. By multiplying the inverse of the covariance matrix based on Euclidean distance, the effect of correlation between the data can be eliminated.
As description above all, it is not difficult to find approaches to calculate the Mahalanobis distances between M training samples and the test sample
Σ represents the covariance matrix of X and v. The covariance matrix is a semi-positive definite symmetric matrix that allows for eigenvalue decomposition.
While we need to get the K minimum distance of them, thus we just need to get
3 The proposed quantum K-nearest neighbor classification algorithm
In this section, we mainly describe the significant steps of the proposed quantum KNN classification algorithm.
3.1 Calculating the Mahalanobis distance
Computing similarity is an important subprogram in classification algorithms. For the classification of non-numerical data, Mahalanobis distance is one of the popular ways to calculate similarity. Here, we describe a quantum method to calculate Mahalanobis distance between xi and v in parallel.
A1: Prepare the superposition state
According to Eq. 6, we need to prepare the required quantum states
Here, we firstly introduce the preparation process of
At first, we prepare
However, our aim is to get the initial superposition qubits
FIGURE 2. Prepare the quantum state
With the help of two auxiliary particles
Then we measure the auxiliary particles to obtain the target state. When the result is
Finally, we access the classical data based on the quantum random access memory theory. It is assumed that there exists a quantum channel that can access the data stored in quantum random access memory, and the data xi − v is stored in the form of classical data in M storage units in QRAM. So, we can access xi − v efficiently through a black box Ox in
Next, we show how to get the covariance matrix. Since the covariance matrix Σ is semi-positive definite, we can implement it by Hamiltonian simulation [18]. Assuming that
Compared with the classical algorithm, the state eiΣt obtained by the quantum circuit has exponential acceleration effect. Its time complexity is
A2: Compute distances
In the following, we talk about how to compute the Mahalanobis distances between the test sample and the training samples, i.e., Eq. 6. Obviously, by performing the steps of A1, we have obtained the state
Step 2.1 Adding one register in the state |0⟩ to get the state
In phase estimation,
Step 2.2 Adding an auxiliary qubit
Suppose that θ ∈ R,
So, the following operation can be achieved by setting the relevant parameters.
Apparently, if
From the preceding information, we know that the Mahalanobis distance is
For applying the Mahalanobis distance calculated by the above process to the classification algorithm, we have to use the amplitude estimation (AE) algorithm to transfer the distance information to qubits [20]. Then, we get the state about distance information
3.2 Searching K minimum distances
In this section, we use the state
Step 1. The set
Step 2. By Grover’s algorithm, we get one point xi at a time from the quantum state
Step 3. In order to get the k points with the smallest distance, repeat Step 2 to make q smaller and smaller (q is the number of remaining points in the set Q) until q = 0. That is, we find the k points that are closest to the test sample.
To analyze the time complexity of the above process more easily, we introduce a set Q, which is a subset of X beyond of D and smaller than some points in set D from the test sample. q is the number of points in set Q. In the following, we will use the size of q to analyze the performance of the algorithm after each operation. Repeating Step 2 k times can decrease q to
4 Complexity analysis
Let us start with discussing the time complexity of the whole algorithm. As mentioned above, the algorithm contains three steps:
A1. Preparation of the initial state.
A2. Parallel computation of the martingale distance.
A3. Search for K nearest neighbor samples.
An overview of the time complexity of each step is shown in Table 1. A detailed analysis of each step of this algorithm is depicted as follows.

TABLE 1. The time complexity of the algorithm.
In step A1,
Therefore, the time complexity of the whole algorithm is
5 Conclusion
In this paper, we combine the ideology of quantum computation with classical KNN classification algorithm to propose a quantum KNN classification algorithm based on Mahalanobis distance. First, we quantified the similarity measure algorithm based on the Mahalanobis distance. Then, K nearest neighbor samples are filtered using the quantum minimum search algorithm. Compared with other quantum KNN classification algorithms based on Hamming distance or Euclidean distance, the Mahalanobis distance used in this paper overcomes the drawback that individual feature attributes with different degrees of variation play the same role in calculating the distance metric and excludes the interference of different degrees of correlation between variables. When the training sample is very large, the time complexity of the algorithm is
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
This work was supported by the National Natural Science Foundation of China (Grants Nos. 61,772,134, 61,976,053 and 62,171,131), the Higher Educational Key Laboratory for Flexible Manufacturing Equipment Integration of Fujian Province (Xiamen Institute of Technology), the research innovation team of Embedded Artificial Intelligence Computing and Application at Xiamen Institute of Technology (KYTD202003), and the research innovation team of Intelligent Image Processing and Application at Xiamen Institute of Technology (KYTD202101).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Nielsen MA, Chuang IL. Quantum computation and quantum information. Math Structures Comput Sci (2002) 17(6):1115.
2. Nathan W, Kapoor A, Svore K. Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning. Quan Inf Comput (2014) 15(3):316–56. doi:10.26421/qic15.3-4-7
3. Yue R, Xue X, Liu H, Tan J, Li X. Quantum algorithm for k-nearest neighbors classification based on the metric of hamming distance. Int J Theor Phys (Dordr) (2017) 56(11):3496–507. doi:10.1007/s10773-017-3514-4
4. Hai VT, Chuong PH, Bao PT. New approach of knn algorithm in quantum computing based on new design of quantum circuits. Informatica (2022) 46(5):2022. doi:10.31449/inf.v46i5.3608
5. Rebentrost P, Mohseni M, Lloyd S. Quantum support vector machine for big data classification. Phys Rev Lett (2014) 113(13):130503. doi:10.1103/physrevlett.113.130503
6. Zhang R, Wang J, Jiang N, Hong L, Wang Z. Quantum support vector machine based on regularized Newton method. Neural Networks (2022) 151:376–84. doi:10.1016/j.neunet.2022.03.043
7. Farhi E, Neven H. Classification with quantum neural networks on near term processors (2018). arXiv preprint arXiv:1802.06002.
8. Nathan K, Bromley TR, Arrazola JM, Schuld M, Quesada N, Lloyd S. Continuous-variable quantum neural networks. Phys Rev Res (2019) 1:033063. doi:10.1103/physrevresearch.1.033063
9. Cong I, Choi S, Lukin MD. Quantum convolutional neural networks. Nat Phys (2019) 15(12):1273–8. doi:10.1038/s41567-019-0648-8
10. Wu C, Huang F, Dai J, Zhou N. Quantum susan edge detection based on double chains quantum genetic algorithm. Physica A: Stat Mech its Appl (2022) 605:128017. doi:10.1016/j.physa.2022.128017
11. Zhou N, Xia S, Ma Y, Zhang Y. Quantum particle swarm optimization algorithm with the truncated mean stabilization strategy. Quan Inf Process (2022) 21(2):42–23. doi:10.1007/s11128-021-03380-x
12. Lloyd S, Mohseni M, Rebentrost P. Quantum algorithms for supervised and unsupervised machine learning (2013). arXiv preprint arXiv:1307.0411.
13. Dang Y, Jiang N, Hu H, Ji Z, Zhang W. Image classification based on quantum k-nearest-neighbor algorithm. Quan Inf Process (2018) 17(9):239–18. doi:10.1007/s11128-018-2004-9
14. Zhou N, Liu X, Chen Y, Du N. Quantum k-nearest-neighbor image classification algorithm based on k-l transform. Int J Theor Phys (Dordr) (2021) 60(3):1209–24. doi:10.1007/s10773-021-04747-7
15. Yu K, Guo G, Jing L, Lin S. Quantum algorithms for similarity measurement based on Euclidean distance. Int J Theor Phys (Dordr) (2020) 59(10):3134–44. doi:10.1007/s10773-020-04567-1
16. Giovannetti V, Lloyd S, Maccone L. Quantum random access memory. Phys Rev Lett (2008) 100(16):160501. doi:10.1103/physrevlett.100.160501
17. Wang D, Liu Z, Zhu W, Li S. Design of quantum comparator based on extended general toffoli gates with multiple targets. Comput Sci (2012) 39(9):302–6.
18. Rebentrost P, Steffens A, Marvian I, Lloyd S. Quantum singular-value decomposition of nonsparse low-rank matrices. Phys Rev A (Coll Park) (2018) 97(1):012327. doi:10.1103/physreva.97.012327
19. He X, Sun L, Lyu C, Wang X. Quantum locally linear embedding for nonlinear dimensionality reduction. Quan Inf Process (2020) 19(9):309–21. doi:10.1007/s11128-020-02818-y
20. Brassard G, Høyer P, Mosca M, Tapp A. Quantum amplitude amplification and estimation (2000). arXiv preprint arXiv:quant-ph/0005055.
21. Gavinsky D, Ito T. A quantum query algorithm for the graph collision problem (2012). arXiv preprint arXiv:1204.1527.
Keywords: quantum computing, quantum machine learning, k-nearest neighbor classification, Mahalanobis distance, quantum algorithm
Citation: Gao L-Z, Lu C-Y, Guo G-D, Zhang X and Lin S (2022) Quantum K-nearest neighbors classification algorithm based on Mahalanobis distance. Front. Phys. 10:1047466. doi: 10.3389/fphy.2022.1047466
Received: 18 September 2022; Accepted: 06 October 2022;
Published: 21 October 2022.
Edited by:
Xiubo Chen, Beijing University of Posts and Telecommunications, ChinaReviewed by:
Guang-Bao Xu, Shandong University of Science and Technology, ChinaLihua Gong, Nanchang University, China
Bin Liu, Chongqing University, China
Copyright © 2022 Gao, Lu, Guo, Zhang and Lin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chun-Yue Lu, bHVfY2h5dWU2NkAxNjMuY29t; Gong-De Guo, Z2dkQGZqbnUuZWR1LmNu; Song Lin, bGluczk1QGdtYWlsLmNvbQ==