 Zhe Sun
Zhe Sun Junping Wan1
Junping Wan1 Zhiqiang Cao
Zhiqiang Cao- 1Cyberspace Institute of Advanced Technology, Guangzhou University, Guangzhou, China
- 2College of Electrical Engineering, Zhejiang University, Hangzhou, China
- 3School of Cyber Science and Engineering, Huazhong University of Science and Technology, Wuhan, China
Data-driven deep learning has accelerated the spread of social computing applications. To develop a reliable social application, service providers need massive data on human behavior and interactions. As the data is highly relevant to users’ privacy, researchers have conducted extensive research on how to securely build a collaborative training model. Cryptography methods are an essential component of collaborative training which is used to protect privacy information in gradients. However, the encrypted gradient is semantically invisible, so it is difficult to detect malicious participants forwarding other’s gradient to profit unfairly. In this paper, we propose a data ownership verification mechanism based on Σ-protocol and Pedersen commitment, which can help prevent gradient stealing behavior. We deploy the Paillier algorithm on the encoded gradient to protect privacy information in collaborative training. In addition, we design a united commitment scheme to complete the verification process of commitments in batches, and reduce verification consumption for aggregators in large-scale social computing. The evaluation of the experiments demonstrates the effectiveness and efficiency of our proposed mechanism.
Introduction
Social computing, a field highly relevant to human behavior, has made considerable progress in recent years. With the proliferation of cell phones and IoT devices, information about humans, behaviors, and interactions is being recorded in unprecedented detail. Combined with deep learning models, the application of social computing can profoundly solve various industry challenges such as epidemic prediction [1, 2], social network service [3], and hot topic recommendations [4]. For example, data-driven epidemic propagation can help governments and hospitals prepare resources in advance [1]. Moreover, some well-designed pre-diagnosis models of COVID-19 may alleviate physician shortages [2].
As a data-driven technology, deep learning has a natural desire for data to be more accurate and higher-quality. Since user data in social computing is closely tied to privacy, providing the data directly would cause extremely serious privacy damage. Google [5] proposed the concept of federated learning in 2016, which is an innovation in collaborative training. Without directly obtaining local data from multiple parties, it can take full advantage of the value of the data by sharing gradients. However, transmitted gradients are subject to model inversion attacks, attribute inference attacks, membership inference attacks, etc. Thus, the privacy of users requires further protection.
To resolve the problem of privacy leakage in transmitted gradients, researchers have proposed a wide range of solutions that can be roughly divided into two categories: differential privacy [6] and cryptographic algorithms [7]. Differential privacy is a method of adding noise so that the attacker cannot determine the user’s exact gradient. However, the differential privacy-based method modifies the original data, resulting in a loss of model accuracy. Unlike differential privacy methods, cryptographic algorithms such as homomorphic encryption do not alter the value of the gradient. But instead, they prevent third parties and model aggregators from obtaining a single participant’s model parameters by encryption or concealment. Most cryptography-based parameter protection methods have a higher arithmetic overhead and many researchers are committed to optimizing their overhead.
Apart from performance issues, cryptography-based privacy-preserving methods will also introduce a derivative problem. Because of the semantic invisibility of encrypted data, data aggregators cannot judge whether a problem exists. The most obvious problem associated with data invisibility is that data tampering is difficult to detect, and some work has been done to try to resolve this. Li et al. [8] proposed to store verification tags on the blockchain and generate a Merkle tree as proof. The transaction information must be uploaded to the blockchain, which prevents malicious users from tampering during the training process. Weng et al. [9] proposed a blockchain-based auditing model called Deepchain that considers the malicious behavior of model aggregators.
However, another problem of semantic invisibility in encrypted data was left behind. Cryptography methods blur the user’s ownership of the real information corresponding to the ciphertext data during the transaction. Malicious users can steal historically encrypted gradients from publicly audited information or previous transactions, and upload them elsewhere to gain benefits, in what we call an encrypted forwarding attack. The attack will destroy the fairness of the entire system, and make fewer users willing to participate in collaborative training. Recently, researchers have proposed extracting user data features through the first few layers of deep neural networks, making them adaptable to multiple uncertain deep learning tasks [10, 11]. This will lead to a change in traditional collaborative training from focusing on a single defined task to completing multiple uncertain tasks, further expanding the reach of encrypted forwarding attacks.
In this paper, we aim to resolve the problem of encrypted forwarding attacks in collaborative training. To prevent users from submitting others’ encrypted gradients maliciously, users need to use Pedersen commitment to commit on the uploaded gradient. The model aggregator can verify the ownership of the encrypted gradient by determining whether the user has plaintext. Our main contributions are as follows:
• We propose a data ownership verification mechanism to counter encrypted forwarding attacks caused by cryptography-based privacy-preserving methods. We use an interactive Σ-protocol and Pedersen commitment algorithm to prove that the user has the plaintext corresponding to the encrypted gradients.
• We design a united commitment scheme to complete the verification process of commitments in batches, thereby reducing verification consumption for the aggregator.
• We verify the effectiveness of the model on a social face dataset CelebA and a digital recognition dataset MNIST, then provide a safety analysis. The experimental results demonstrate that the commitment scheme does not impose an additional burden on secure aggregation of social applications.
The rest of this paper is organized as follows. In Related Work, we introduce the existing work of cryptography-based privacy-preserving methods and derivative audits approaches of encrypted data. Preliminaries introduces the relevant background knowledge of the Σ-protocol, Pedersen commitment, and attack models. System Design elaborates the details of the ownership verification mechanism. In Security Analysis, we analyze the correctness and safety of our mechanism. Experimental Results evaluates and analyses the performance of Paillier algorithm and Pedersen commitment in our mechanism. Finally, we conclude our paper in Conclusion.
Related Work
Cryptography-Based Privacy-Preserving Methods in Collaborative Training
Privacy concern is one of the main problems in collaborative training. Although some collaborative training allows collaborative participants to only share model updates rather than raw training data, such as federated learning. There are still some privacy problems that are not completely solved [12–14]. Attackers may infer whether a sample exists in the training dataset or contain certain privacy attributes from the user gradient, called member inference attacks [15] and attribute inference attacks [16].
Secure aggregation [17] is a cryptography-based privacy-preserving method that prevents aggregators from gaining direct access to individual participants’ gradients and committing privacy attacks. Homomorphic encryption is a common security aggregation algorithm that allows users to operate on ciphertext and decrypt the results of operations, where the decryption result is the same as for operating on plaintext. Participants can first encrypt the gradient via homomorphic encryption. The parameter aggregator then aggregates all encrypted gradients and decrypts the aggregated result, thereby indirectly obtaining a global model update contributed by the participants. The existing homomorphic encryption methods are mainly based on full-homomorphic encryption [18] and semi-homomorphic encryption [19].
Fully homomorphic encryption is mainly based on ideal lattices theory [20]. It relies on a large number of polynomial-based power operations and modulo operations, which greatly increases the consumption of implementation. It is still difficult to apply directly in the existing work.
Paillier encryption [19] is a representative work of semi-homomorphism that is widely used because of its simple structure. Phong et al. [21] proposed the method combining asynchronous stochastic gradient descent and Paillier homomorphic encryption. They proved that the system could prevent the aggregator from learning the data privacy of the participants, and ensure the availability of the model training with the acceptable system overhead. Zhou et al. [22] applied a homomorphic encryption scheme to fog computing. They proposed a scheme that combines Paillier encryption and blindness technology, which can resist collusion attacks by multiple malicious entities.
In order to improve the efficiency of the homomorphic encryption system, Zhang et al. [23] proposed a federated learning model called BatchCrypt. They encoded batches of gradients and perform homomorphic encryption with less time, which greatly reduces the overhead of the whole system. LWE has more extensive applicability because of its full-homomorphism. Hao et al. [24] utilized and improved the BGV algorithm based on LWE, which achieves the secure aggregation of gradients to prevent privacy disclosure. It makes the scheme based on homomorphic encryption practical.
The above works complete the data privacy protection for the participants and make the system feasible, but another potential problem has appeared: it is difficult for the aggregator to determine whether a problem exists due to the semantic invisibility of the encrypted data.
Verification of Secure Aggregation
Semantic invisibility of encrypted data presents numerous challenges, including transmission errors, malicious tampering by intermediaries, and the exclusion of some user-generated gradients by dishonest aggregators.
The correctness audit of the transmission gradient becomes very difficult in the encrypted state. Weng et al. [9] provided an audit mechanism based on ∑-protocol [25] which generates proofs of correctness for each gradient. Guo et al. [26] proposed a Paillier-based zero-knowledge proof algorithm. The server and users can jointly calculate the statement of encrypted gradients to prove the correctness of gradients.
To ensure that the gradients provided by each participant are indeed aggregated correctly, Xu et al. [27] use a homomorphic hash technique combined with pseudorandom function to help users verify the correctness of aggregation. To extend the applicability of the algorithm, Guo et al. [28] proposed a commitment scheme based on linearly homomorphic hash to verify the integrity of aggregation. Before sending gradient to the server, the users need to generate and exchange the hash value of their gradient. The users can verify whether the gradient is tampered with by checking hash values.
Despite the foregoing, there is a serious problem that has not been addressed. Encrypted data may be accessed by multiple users as public data. Malicious users can forward them to other collaborative tasks with the same purpose for improper profit. There are even cases where multiple users claim ownership of ciphertext in the same task. This will undermine the willingness of honest users to engage in collaborative training and thus lead to a shortage of training data for social applications. In this paper, we propose an ownership verification mechanism based on the Patterson commitment that can prove that the user owns the plaintext of the data without providing the plaintext.
Preliminaries
In this section, we briefly recall the definition of Σ-protocol and Pedersen commitment, and introduce the attack models.
Σ-protocol
Σ-protocol [25] is a two-party interaction protocol in zero-knowledge proof field. It is used to prove that someone knows a secret without disclosing it. There are many classic examples such as Schnorr’s protocol [29], which is used for authentication.
Consider a binary relation
Suppose that there are two parties, one of which is prover, and the other is verifier. Without exposing

FIGURE 1. The general process of Σ-protocols.
Step 1: Prover computes a commitment
Step 2: Verifier returns a random value
Step 3: Prover sends a response
Step 4: Verifier uses instance
Since the challenge
Pedersen Commitment
Pedersen commitment [30] is a homomorphic commitment scheme, in which one computes a commitment bound to a chosen value. Pedersen commitment scheme can be used to prove that a committed value is not tampered with. According to its homomorphism, it is usually used to prove that the secret committed data satisfies certain binding relationships. The scheme consists of a commitment phase and a verification phase. In the beginning, A trusted third party selects a multiplicative group
Commitment: To commit to secret value
Verification: Committer sends
Pedersen commitment scheme is designed that the sum of two commitments can also be seen as a commitment. It can be represented by
Pedersen commitment scheme has the following properties: 1) Perfectly hiding: the
Different from Σ-protocol, the committed value in Pedersen commitment scheme needs to be revealed in the verification phase. It cannot be directly used to prove that the single encrypted gradient is not tampered with. In our scheme, we use the homomorphism of Pedersen commitment scheme to check whether the aggregated commitment is correctly corresponding to the aggregated gradient, further confirming the binding relationship between the commitment and encrypted gradient.
Threat Models
As we attempt to solve the problem of data silos in social computing through cooperative training, privacy protection and data ownership have become unavoidable difficulties. Cryptography-based secure aggregation methods can be a good solution to keep private information from being accessed by unauthorized users, but they also make it more difficult to verify data ownership. Two main roles are included in the current collaborative training:
Model Aggregator is a service provider that publishes the request for data training. It asks multiple users to provide trained gradients to conduct social computing.
Data Owners are users who have datasets and are willing to participate in collaborative training. They submit the trained models or gradients to the model aggregator for model updating.
Once we use a cryptography-based secure aggregation algorithm that prevents model aggregators from obtaining plaintext data from a single data owner. It is difficult to distinguish whether the user who submits encrypted data is its real owner or not. As shown in Figure 2, attackers can download encrypted data from elsewhere or historically, and then participate in the current cooperative training for improper profit, which we call encrypted forwarding attacks. In addition, we present several threat scenarios for encrypted forwarding attacks.
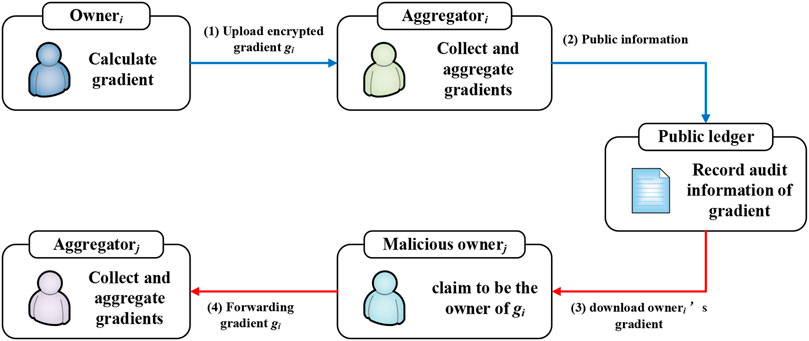
FIGURE 2. Encrypted forwarding attacks in cooperative training.
Threat 1. Attackers can only obtain encrypted data and claim ownership of the encrypted data. Malicious users access encrypted data through public channels, such as the available audit information or publicly accessible blocks on the blockchain. The encrypted data is being downloaded by attackers and forwarded to similar tasks for unfair gain.
Threat 2. Attackers can obtain encrypted data as well as its verification information. As an intermediate forwarder, a malicious user receives not only the encrypted data but also the previous verification information. By masquerading as a data owner and participating in social computing, traditional mechanisms of ownership verification may be bypassed.
Security Goal: To prevent encrypted forwarding attacks by malicious attackers, we need an ownership verification mechanism for encrypted data. For privacy reasons, it can conclusively confirm ownership of data without directly obtaining the plaintext of user’s data. In addition, verification information must be real-time to prevent falsification by forwarding historical verification information.
System Design
In this section, we present the specific construction of our data ownership verification mechanism. Our mechanism prevents the leakage of user information to curious aggregators while resisting encrypted forwarding attacks by malicious users, as detailed in the threat model.
System Overview
We suppose that there exist many users who possess private training data in a community. They all agree on the structure and configuration of a common task model. When a user wants to update its model, it claims to be a model aggregator and requests collaborative training from other users. Other data owners will respond to the model aggregator. We denote the model aggregator as
The aggregator
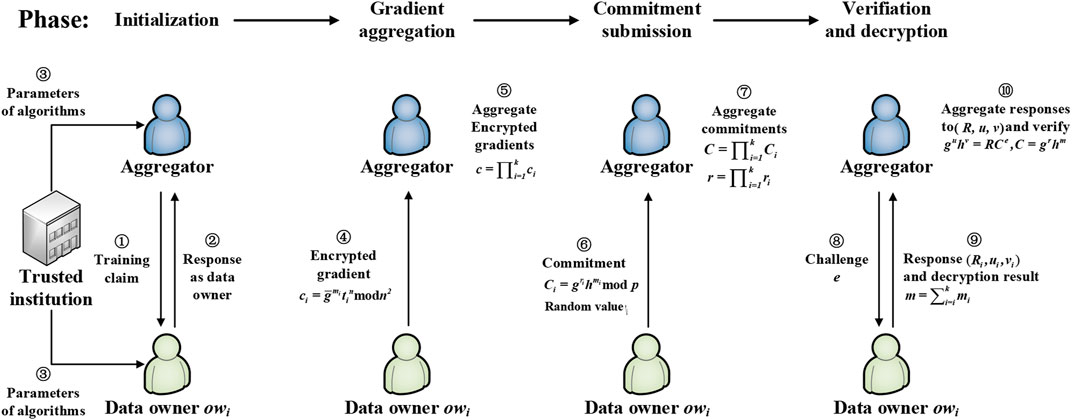
FIGURE 3. The workflow of our system.
Phase 1. Initialization
A user claims to be an aggregator to all other users in the community. Others will respond to the claim and form a group with the aggregator by some means [31]. After that, a trusted institution executes the initialization of threshold Paillier algorithm and Pedersen commitment scheme for the group.
Phase 2. Gradient Aggregation
After each data owner
Phase 3. Commitment Submission
Each data owner
Phase 4. Verification and Decryption
The aggregator
After the aggregator
Gradient Aggregation Based on Paillier Algorithm
Initialization: After the aggregator and data owners form a group together, a trusted institution will execute the initialization process. Concretely, it confirms the scale of the group and initializes the

The trusted institution publishes the public key
Ownership Verification
In the collaborative training based on homomorphic encryption such as Paillier encryption, the aggregator is set to obtain only the decrypted aggregation result but not any gradient from individual data owner. Only in this way, the privacy in gradients will not be directly obtained by the aggregator. If a malicious user obtains an encrypted gradient, he may forward the encrypted gradient to another aggregator to profit. To solve the forwarding problem, the aggregator is required to verify the ownership of each received encrypted gradient.
The verification mechanism is based on Σ-protocol and Pedersen commitment scheme. As for Pedersen commitment scheme, a trusted institution is required to select two prime elements
Commitment submission: After data owner
Commitment verification: The aggregator

Ownership verification: To verify the committed value is the correct gradient, the aggregator
Security Analysis
The Protection of Gradient
In order to maintain the correctness of gradient and prevent it from being obtained directly by others, we use the addictive threshold Paillier homomorphic encryption algorithm. Firstly, we discuss the feasibility of the threshold Paillier encryption algorithm for gradient protection in our scheme.
Lemma 1:
Lemma 2: A number
Lemma 3: Only when the generated random values
The Validity of Commitment
Lemma 4: Two commitments for two different messages are different, otherwise the relationship between
Experimental Results
In this section, we introduce the experiments in our scheme, including the performance evaluation of Paillier algorithm and Pedersen commitment scheme. We deploy an aggregator and multiple data owners to simulate the process of collaborative training.
We build the deep learning model with Python(version3.83), Numpy(version 1.18.5), Pytorch(1.6.0) on GPUs. We use CelebFaces Attributes Dataset (CelebA) to conduct smile recognition. The dataset includes 202,599 face images with 40 binary attributes. We randomly select 60,000 images and averagely assign them to the data owners. We also use the famous MNIST dataset to conduct handwritten digit recognition. We set the epoch of training as 3. The structure of the network is shown in Table 1.

TABLE 1. The structure of model.
After each iteration of the training, we output the gradient and evaluate the performance of Paillier algorithm. We compress the gradient by setting the precision of each gradient at 3–5, and use the gradient to update the model. Concretely, the data owners train their local model and output the gradient in given precision. Then we aggregate these gradients o update the model. With the change of given precision, the accuracy of the model is shown in Figure 4.
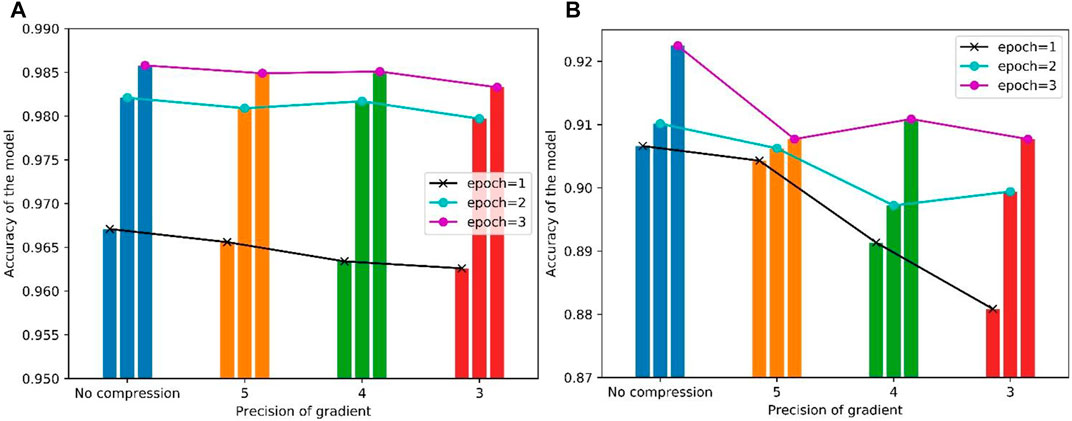
FIGURE 4. The accuracy with different precision of gradient. (A); On MNIST dataset (B) On CelebA dataset;
If we do not compress the gradient, the accuracy on CelebA dataset in each epoch is 90.66, 91.01, and 92.24%, respectively. The accuracy on MNIST dataset in each epoch is 96.71, 98.21, and 98.58%, respectively. When we control the precision of gradient at 5, 4, 3, the accuracy on CelebA dataset in the third epoch changes to 90.77, 91.08, and 90.41%, which is approximately 1.5% lower compared to the accuracy with no gradient compression. With gradient compression, the accuracy decline is not obvious on MNIST dataset, where the accuracy in the third epoch is 98.49, 98.51, and 98.33%. decreasing within 0.2%. The change of gradient precision has a more significant impact on large-scale training. When the precision decreases, the accuracy in different epochs is lower, which makes the training more difficult to converge. To ensure the quality and stability of training, we choose to set the precision at five in our subsequent experiment.
As for gradient encryption, we use the Paillier algorithm implemented in Python based on CPU. We use the Charm-crypto.1 library to perform the encryption and decryption process of Paillier algorithm. Charm-crypto is a Python library for fast encryption on large numbers. We encode the gradient as a vector of integers that can be encrypted by Paillier algorithm. By controlling the precision of gradients, we get multiple vectors of the gradient in various lengths. Because the precision changes, the total number of parameters varies. We choose to evaluate the Paillier algorithm on a message with a length of
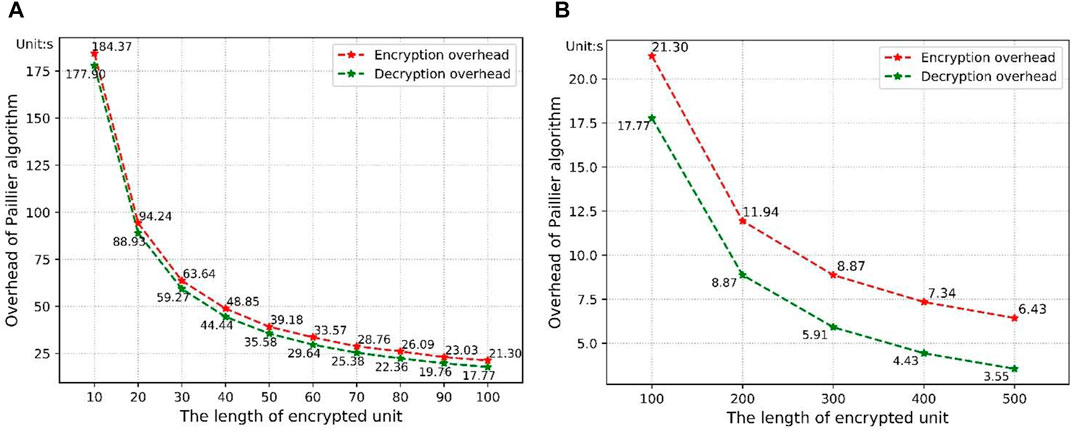
FIGURE 5. The overhead of Paillier algorithm. (A) encrypted unit
To maintain the correctness of decryption results after cipher aggregation, the length of the encrypted unit is limited by the number of ciphers and security parameters of the Paillier algorithm. On the premise that we maintain the correctness of decryption, we divide the message into multiple units to encrypt. When the length of an encrypted unit ranges from 10 to 100, as the length is doubled, the time consumption is almost halved. The length of the unit does not have a significant impact on unit encryption time. When the length ranges from 100 to 500, the unit encryption time obviously increases as the length increases, however, the total time consumption still decreases. It is better to choose a larger encryption unit if possible. Since training overhead is much higher than the gradient encryption in cooperative training, the overhead of Paillier algorithm above is acceptable.
As for the Pedersen commitment scheme, we use cryptographic algorithms based on discrete logarithm to deploy it. We divide the message with a length of
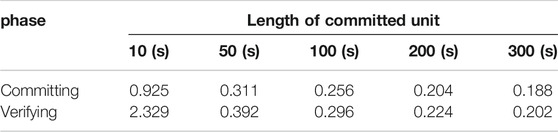
TABLE 2. Overhead of Pedersen commitment scheme with one data owner.
The time consumption of committing is much less than the time consumption of encryption and decryption. When the unit is larger, the total overhead of the commitment scheme is at a lower level. To evaluate the impact of the number of data owners on the commitment scheme, we set the number of data owners from 1 to 10, respectively. Each data owner needs to commit to a message with a length of
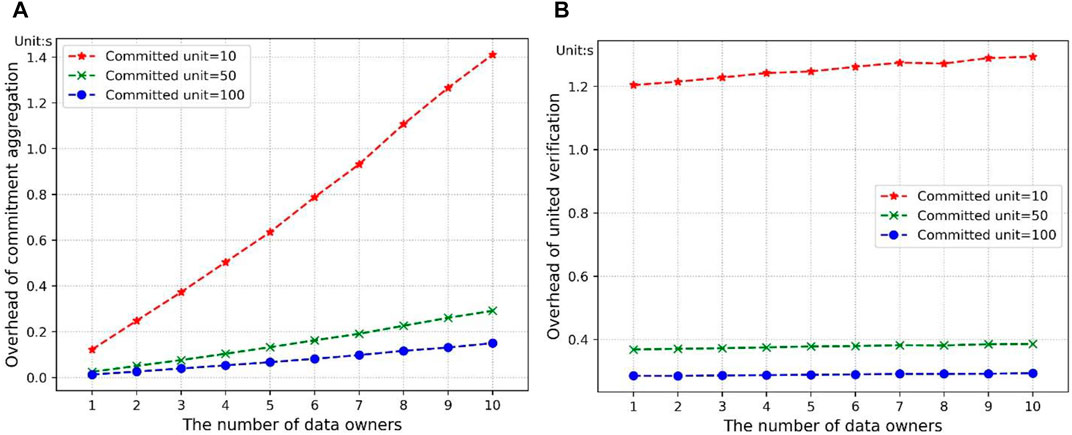
FIGURE 6. The overhead of Pedersen commitment scheme. (A) commitment aggregation; (B) commitment verification.
To better show the practicality of this commitment scheme in large-scale cooperative learning, we set the committed unit at 100, 200, respectively, and expand the number of devices to 50 and 100. The evaluation result can be seen in Tables 3, 4. The total time consumption is still much lower than the encryption and decryption. It means that the increase in data owners will not impose a clear burden on the commitment scheme. Our experimental results indicate that our commitment scheme is feasible in the cooperative training.
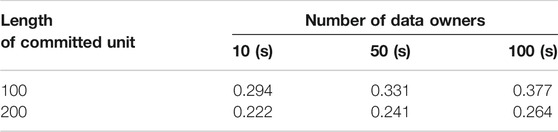
TABLE 3. Overhead of large-scale commitment aggregation.
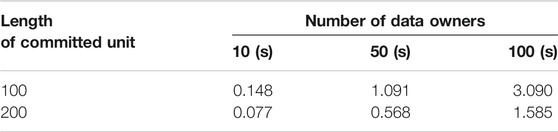
TABLE 4. The Overhead of large-scale commitment verification.
Conclusion
In this paper, we propose an ownership verification mechanism against encrypted forwarding attacks in data-driven social computing. It can defend against the malicious gradient stealing and forwarding behavior in cryptography-based privacy-preserving methods. Based on the premise of maintaining gradient privacy, we present a protocol based on Σ-protocol and Pedersen commitment to achieve our security goal. Specifically, we design a united commitment algorithm to make participants cooperate to submit gradients and provide proof of data ownership. If any user submits other’s gradient, it will fail to provide correct proof to pass the verification process. The experiment results validate the security of our proposed mechanism and demonstrate the practicality of our solution.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: the Large-scale CelebFaces Attributes (CelebA) Dataset, http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html, and THE MNIST DATABASE of handwritten digits, http://yann.lecun.com/exdb/mnist/.
Author Contributions
ZS: Conceptualization and methodology, writing—original draft preparation; JW: formal analysis, validation, writing —original draft preparation; ZC: visualization; BW: project administration, supervision, and writing—review and editing; RL and YH: writing—review and editing.
Funding
This work was supported in part by the National Key R&D Program of China (No. 2018YFB2100400), in part by the National Natural Science Foundation of China (No. 62002077, 61872100), in part by the China Postdoctoral Science Foundation (No. 2020M682657), in part by Guangdong Basic and Applied Basic Research Foundation (No. 2020A1515110385), in part by Zhejiang Lab (No. 2020NF0AB01), in part by Guangzhou Science and Technology Plan Project (202102010440).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank reviewers for their critical reading and improvement of the manuscript.
Footnotes
1The encryption library called Charm-crypto can be download in https://github.com/JHUISI/charm.
References
1. Zeroual A, Harrou F, Dairi A, Sun Y. Deep Learning Methods for Forecasting COVID-19 Time-Series Data: A Comparative Study. Chaos, Solitons & Fractals (2020) 140:110121. doi:10.1016/j.chaos.2020.110121
2. Liang W, Yao J, Chen A, Lv Q, Zanin M, Liu J, et al. Early Triage of Critically Ill COVID-19 Patients Using Deep Learning. Nat Commun (2020) 11:3543–7. doi:10.1016/j.physrep.2007.04.00410.1038/s41467-020-17280-8
3. Li F, Sun Z, Li A, Niu B, Li H, Cao G. Hideme: Privacy-Preserving Photo Sharing on Social Networks. In: IEEE INFOCOM 2019-IEEE Conference on Computer Communications; 2019, April 29-May 2; Paris, France (2019). doi:10.1109/INFOCOM.2019.8737466
4. Han W, Tian Z, Huang Z, Li S, Jia Y. Topic Representation Model Based on Microblogging Behavior Analysis. World Wide Web (2020) 23:3083–97. doi:10.1007/s11280-020-00822-x
5. Konečný J, McMahan HB, Ramage D, Richtárik P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. (2016) arXiv preprint arXiv:1610.02527.
6. Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, Zhang L. Deep Learning with Differential Privacy. In: Proceedings of the 2016 ACM SIGSAC conference on computer and communications security (2016). doi:10.1145/2976749.2978318
7. Li T, Sahu AK, Talwalkar A, Smith V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process Mag (2020) 37:50–60. doi:10.1109/MSP.2020.2975749
8. Li J, Wu J, Jiang G, Srikanthan T. Blockchain-based Public Auditing for Big Data in Cloud Storage. Inf Process Manage (2020) 57:102382. doi:10.1016/j.ipm.2020.102382
9. Weng J, Weng J, Zhang J, Li M, Zhang Y, Luo W. Deepchain: Auditable and Privacy-Preserving Deep Learning with Blockchain-Based Incentive. IEEE Trans Dependable Secure Comput (2019) 1. doi:10.1109/TDSC.2019.2952332
10. Li A, Duan Y, Yang H, Chen Y, Yang J. TIPRDC: Task-independent Privacy-Respecting Data Crowdsourcing Framework for Deep Learning with Anonymized Intermediate Representations. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; 2020, July 6-10; Virtual Event, CA, USA (2020). doi:10.1145/3394486.3403125
11. Sun Z, Yin L, Li C, Zhang W, Li A, Tian Z. The QoS and Privacy Trade-Off of Adversarial Deep Learning: An Evolutionary Game Approach. Comput Security (2020) 96:101876. doi:10.1016/j.cose.2020.101876
12. Aghasian E, Garg S, Gao L, Yu S, Montgomery J. Scoring Users' Privacy Disclosure across Multiple Online Social Networks. IEEE access (2017) 5:13118–30. doi:10.1109/ACCESS.2017.2720187
13. Li S, Zhao D, Wu X, Tian Z, Li A, Wang Z. Functional Immunization of Networks Based on Message Passing. Appl Maths Comput (2020) 366:124728. doi:10.1016/j.amc.2019.124728
14. Du J, Jiang C, Chen K-C, Ren Y, Poor HV. Community-structured Evolutionary Game for Privacy protection in Social Networks. IEEE Trans.Inform.Forensic Secur. (2018) 13:574–89. doi:10.1109/TIFS.2017.2758756
15. Shokri R, Stronati M, Song C, Shmatikov V. Membership Inference Attacks against Machine Learning Models. In: IEEE Symposium on Security and Privacy; 2017, May 22-26; San Jose, CA, USA (2017). doi:10.1109/SP.2017.41
16. Melis L, Song C, De Cristofaro E, Shmatikov V. Exploiting Unintended Feature Leakage in Collaborative Learning. In: IEEE Symposium on Security and Privacy. (2017); 2019, May 19-23; San Jose, CA, USA (2019). doi:10.1109/SP.2019.00029
17. Yin L, Feng J, Lin S, Cao Z, Sun Z. A Blockchain-Based Collaborative Training Method for Multi-Party Data Sharing. Comput Commun (2021) 173:70–8. doi:10.1016/j.comcom.2021.03.027
18. Brakerski Z, Vaikuntanathan V. Efficient Fully Homomorphic Encryption from (Standard) $\Mathsf{LWE}$. SIAM J Comput (2014) 43:831–71. doi:10.1137/120868669
19. Paillier P. Public-key Cryptosystems Based on Composite Degree Residuosity Classes. In: International Conference on the Theory and Applications of Cryptographic Techniques; 1999, May 2-6; Prague, Czech Republic (1999). p. 223–38. doi:10.1007/3-540-48910-X_16
20. Gentry C. Fully Homomorphic Encryption Using Ideal Lattices. In: Proceedings of the forty-first annual ACM symposium on Theory of computing; 2009, May 31-June 2; Bethesda, MD, USA (2009). doi:10.1145/1536414.1536440
21. Phong LT, Aono Y, Hayashi T, Wang L, Moriai S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans.Inform.Forensic Secur. (2018) 13:1333–45. doi:10.1109/TIFS.2017.2787987
22. Zhou C, Fu A, Yu S, Yang W, Wang H, Zhang Y. Privacy-preserving Federated Learning in Fog Computing. IEEE Internet Things J (2020) 7:10782–93. doi:10.1109/JIOT.2020.2987958
23. Zhang CL, Li SY, Xia JZ, Wang W. Batchcrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning. In: USENIX Annual Technical Conference. (2020); 2020, July 15-17; Boston, MA, USA (2020).
24. Hao M, Li H, Luo X, Xu G, Yang H, Liu S. Efficient and Privacy-Enhanced Federated Learning for Industrial Artificial Intelligence. IEEE Trans Ind Inf (2020) 16:6532–42. doi:10.1109/TII.2019.2945367
25. Damgård I. On Σ-protocols. Lecture Notes. University of Aarhus, Department for Computer Science (2002).
26. Guo JL, Liu ZY, Lam KY, Zhao J, Chen YQ, Xing CP. Secure Weighted Aggregation for Federated Learning. (2020) arXiv preprint arXiv:2010.08730.
27. Xu G, Li H, Liu S, Yang K, Lin X. Verifynet: Secure and Verifiable Federated Learning. IEEE Trans.Inform.Forensic Secur. (2020) 15:911–26. doi:10.1109/TIFS.2019.2929409
28. Guo X, Liu Z, Li J, Gao J, Hou B, Dong C, et al. VeriFL: Communication-Efficient and Fast Verifiable Aggregation for Federated Learning. IEEE Trans.Inform.Forensic Secur. (2021) 16:1736–51. doi:10.1109/TIFS.2020.3043139
29. Schnorr CP. Efficient Signature Generation by Smart Cards. J Cryptology (1991) 4:161–74. doi:10.1007/BF00196725
30. Pedersen TP. Non-interactive and Information-Theoretic Secure Verifiable Secret Sharing. In: Annual international cryptology conference; 1991, July 11-15; Santa Barbara, CA, USA (1991). p. 129–40. doi:10.1007/3-540-46766-1_9
31. Li S, Jiang L, Wu X, Han W, Zhao D, Wang Z. A Weighted Network Community Detection Algorithm Based on Deep Learning. Appl Maths Comput (2021) 401:126012. doi:10.1016/j.amc.2021.126012
32. Schoenmakers B, Veeningen M. Universally Verifiable Multiparty Computation from Threshold Homomorphic Cryptosystems. In: International Conference on Applied Cryptography and Network Security; 2015, June 2-5; New York, USA (2015). p. 3–22. doi:10.1007/978-3-319-28166-7_1
Keywords: ownership verification, cryptography-based privacy-preserving, pedersen commitment, Σ-protocol, social computing
Citation: Sun Z, Wan J, Wang B, Cao Z, Li R and He Y (2021) An Ownership Verification Mechanism Against Encrypted Forwarding Attacks in Data-Driven Social Computing. Front. Phys. 9:739259. doi: 10.3389/fphy.2021.739259
Received: 10 July 2021; Accepted: 05 August 2021;
Published: 07 September 2021.
Edited by:
Peican Zhu, Northwestern Polytechnical University, ChinaReviewed by:
Wei Du, University of Arkansas, United StatesCheng Huang, University of Waterloo, Canada
Copyright © 2021 Sun, Wan, Wang, Cao, Li and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bin Wang, YmluX3dhbmdAemp1LmVkdS5jbg==