 Shuqin Wang
Shuqin Wang Yongyong Chen
Yongyong Chen Fangying Zheng
Fangying Zheng- 1Institute of Information Science, Beijing Jiaotong University, Beijing, China
- 2School of Computer Science and Technology, Harbin Institute of Technology, Shenzhen, China
- 3Department of Mathematical Sciences, Zhejiang Sci-Tech University, Hangzhou, China
Multi-view clustering has been deeply explored since the compatible and complementary information among views can be well captured. Recently, the low-rank tensor representation-based methods have effectively improved the clustering performance by exploring high-order correlations between multiple views. However, most of them often express the low-rank structure of the self-representative tensor by the sum of unfolded matrix nuclear norms, which may cause the loss of information in the tensor structure. In addition, the amount of effective information in all views is not consistent, and it is unreasonable to treat their contribution to clustering equally. To address the above issues, we propose a novel weighted low-rank tensor representation (WLRTR) method for multi-view subspace clustering, which encodes the low-rank structure of the representation tensor through Tucker decomposition and weights the core tensor to retain the main information of the views. Under the augmented Lagrangian method framework, an iterative algorithm is designed to solve the WLRTR method. Numerical studies on four real databases have proved that WLRTR is superior to eight state-of-the-art clustering methods.
Introduction
The advance of information technology has unleashed a multi-view feature deluge, which allows data to be described by multiple views. For example, an article can be expressed in multiple languages; an image can be characterized by colors, edges, and textures. Multi-view features not only contain compatible information, but also provide complementary information, which boost the performance of data analysis. Recently, [1] applied multi-view binary learning to obtain the supplementary information from multiple views. [2] proposed a kernelized multi-view subspace analysis method via self-weighted learning. Due to the lack of label, clustering using multiple views has become a popular research direction [3].
A large number of clustering methods have been developed in the past several decades. The most classic clustering method is the k-means method [4–6]. However, it cannot guarantee the accuracy of clustering since it is based on the distance of the original features and them are easily affected by outliers and noises. Many researchers have pointed out that the subspace clustering method can effectively overcome the above problem. As a promising technique, subspace clustering aims to find clusters within different subspaces by the assumption that each data point can be represented as a linear combination of the other samples [7]. The subspace clustering-basaed methods can be roughly divided into three types: matrix factorization methods [8–11], statistical methods [12] and spectral clustering methods [7,13,14]. The matrix factorization-based subspace clustering methods perform low-rank matrix factorization on the data matrix to achieve clustering, but they are only suitable for noise-free data matrices and thus loss of generalization. Although the statistical-based subspace clustering methods can clearly deal with the influence of outliers or noise, their clustering performance is also affected by the number of subspaces, which hinders their practical applications. At present, the spectral clustering-based subspace clustering methods are widely used because they can well deal with high-dimensional data with noise and outliers. Among them, two representative examples includes sparse subspace clustering (SSC) [13] and low-rank representation (LRR) [7] by obtaining a sparse or low-rank linear representation of datasets, respectively. When encountering multi-view features, SSC and LRR can not well discover the high correlation among them. To overcome this limitation, Xia et al. [15] applied LRR for multi-view clustering to learn a low-rank transition probability matrix as the input of the standard Markov chain clustering method. Taking the different types of noise in samples into account, Najafi et al. [16] combined the low-rank approximation with error learning to eliminate noise and outliers. The work in [17] used low-rank and sparse constraints for multi-view clustering simultaneously. One common limitation of them is that the above methods only capture the pairwise correlation between different views. Considering the possible high-order correlation of multiple views, Zhang et al. [3] proposed a low-rank tensor constraint-regularied multi-view subspace clustering method. The study in [18] was inspired by [3] to introduce Hyper-Laplacian constraint to preserve the geometric structure of the data. Compared with most matrix-based methods [15,17], the tensor-based multi-view clustering methods have achieved satisfactory results, which demonstrates that the high-order correlation of the data is indispensable. The above methods impose the low-rank constraint on the constructed self-representative tensor through the unfolding matrix nuclear norm. Unfortunately, this rank-sum tensor norm lacks a clear physical meaning for general tensor [19].
In this paper, we proposed the weighted low-rank tensor representation (WLRTR) method for multi-view subspace clustering. Similar to the above tensor-based methods [3,18], WLRTR still stacks the self-representation matrices of all views into a representation tensor, and then applies low-rank constraint on it to obtain the high-order correlation among multiple views. Different from them, we exploits the classic Tucker decomposition to encode the low-rank property, which decomposes the representation tensor into one core tensor and three factor matrices. Considering that the information contained in different views may be partially different, and the complementary information between views contributes differently to clustering, the proposed WLRTR treats the singular values differently to improve the capability. The main contributions of this paper are summarized as follows:
(1) We propose a weighted low-rank tensor representation (WLRTR) method for multi-view subspace clustering, in which all representation matrices are stored as a representation tensor with two spatial and one view modes.
(2) Tucker decomposition is used to calculate the core tensor for the representation tensor and the low-rank constraints are applied to capture high-order correlation among multiple views and remove redundant information. WLRTR assigns different weights on the singular values in the core tensor to differently treat singular values.
(3) Based on the augmented Lagrangian multiplier method, we design an iterative algorithm to solve the proposed WLRTR model, and conduct experiments on four challenging databases to verify the superiority of WLRTR method over eight state-of-the-art single-view and multi-view clustering methods.
The remainder of this paper is organized as follows. Section 2 summarizes the notations, basic definitions and related content of subspace clustering involved in this paper. In Section 3, we introduce the proposed WLRTR model, and design an iterative algorithm to solve it. Extensive experiments and model analysis are reported in Section 4. The conclusion of this paper is summarized in Section 5.
Related Works
In this section, we aim to introduce the notations, basic definitions through this paper and the framework of subspace clustering methods.
Notations
For a third-order tensor, we represent it using bold calligraphy letter (e.g.,
Subspace Clustering
Subspace clustering is an effective method for processing high-dimensional data clustering. It divides the original feature space into several subspaces and then imposes constraints on each subspace to construct the similarity matrix. Suppose
where
The LRR-based multi-view method not only improves the accuracy of clustering, but also detects outliers from multiple angles [20]. However, with the increase of feature views, the above models will inevitably suffer from information loss when fusing high-dimensional data views. It is urgent to explore efficient clustering methods.
Weighted Low-Rank Tensor Representation Model
In this section, we first introduce an existing tensor-based multi-view clustering method, and then propose a novel weighted low-rank tensor representation (WLRTR) method. Finally, the WLRTR is solved by the augmented Lagrangian multiplier (ALM) method.
Model Formulation
In order to make full use of the compatible and complementary information among multiple views, Zhang et al. [3] used LRR to perform tensor-based multi-view clustering. The main process is to stack the self-representation matrix of each view as a frontal slice of the third-order representation tensor which is imposed low-rank constraint. The whole model is formulated as follows
where the tensor nuclear norm is directly extended from the matrix nuclear norm:
where
Optimization of WLRTR
In this section, we aim to use the ALM to solve the proposed WLRTR model in Eq. 4. Since the variable
Correspondingly, the augmented Lagrangian function of constrained model in Eq. 5 is obtained by
where
Update self-representation tensor
By setting the derivative of Eq. 7 with respect to
Update auxiliary variable
The closed-form of
Update core tensor
According to [21], the Eq.(11) can be rewritten as
where
Update error matrixE: Similar to the subproblems
where F represents the matrix that vertically concatenates the matrix
Update Lagrangian multipliers
where
Algorithm 1: WLRTR for multi-view subspace clustering
Input: multi-view features
Initialize:
1: while not converged do
2: Update
3: Update
4: Update
5: Update
6: Update
7: Check the convergence condition:
8:
9: end while
Output:
Experimental Results
In this section, we conduct experiments on four real databases and compare with eight state-of-the-art methods to verify the effectiveness of the proposed WLRTR. In addition, we reported a detailed analysis of the parameter selection and convergence performance of the proposed WLRTR method.
Experimental settings
(1) Datasets: We evaluate the performance of WLRTR on three categories of databases: news stories (BBC4view, BBCSport), face images (ORL), handwritten digits (UCI-3views). BBC4view contains 685 documents and BBCSport consists of 544 documents, which belong to 5 clusters. We use 4 and 2 features to construct multi-view data, respectively. ORL includes 400 face images with 40 clusters. We use 3 features for clustering on ORL database, i.e.,
(2) Compared methods: We compared WLRTR with eight state-of-the-art methods, including three single-view clustering methods and five multi-view clustering methods. Single-view clustering methods: SSC [13], LRR [7] and LSR [23], which use nuclear norm,
(3) Evaluation metrics: We exploit six popular clustering metrics, including, accuracy (ACC), normalized mutual information (NMI), adjusted rank index (AR), F-score, Precision and Recall to comprehensively evaluate the clustering performance. The closer the values of all evaluation metrics are to 1, the better the clustering results are. We run 10 trials for each experiment and report its average performance.

FIGURE 1. Samples of (A) ORL and (B) UCI-3views databases.

TABLE 1. Information of four real multi-view databases.
Experimental Results
Tables 2–5 report the clustering performance of all comparison methods on the four databases. The best results are highlighted in bold and the second best results are underlined. From four tables, we can draw the following conclusions: Overall, the proposed WLRTR method has achieved better or comparable clustering results on all databases over all competing methods. Especially on the BBC4view database, WLRTR method outperforms all competing methods on six metrics. As for the ACC metric, the proposed WLRTR is higher than all methods on all datasets. In particular, WLRTR method shows better results than single-view clustering methods: SSC, LRR, LSR in most cases. This is because the multi-view clustering methods fully capture the complementary information among multiple views. The above conclusions have verified the effectiveness of the proposed WLRTR method.
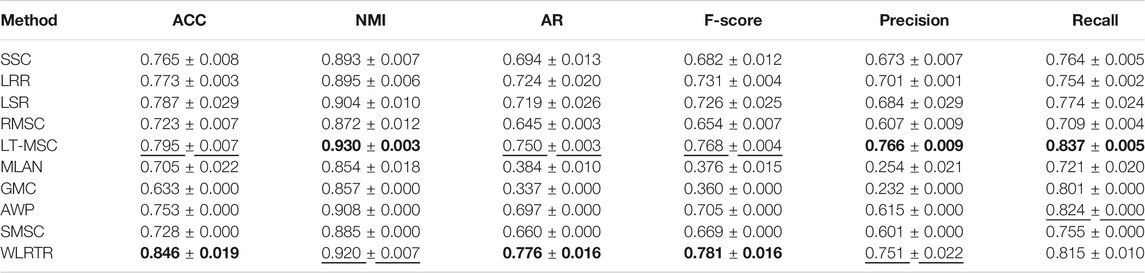
TABLE 2. Clustering results on ORL database.
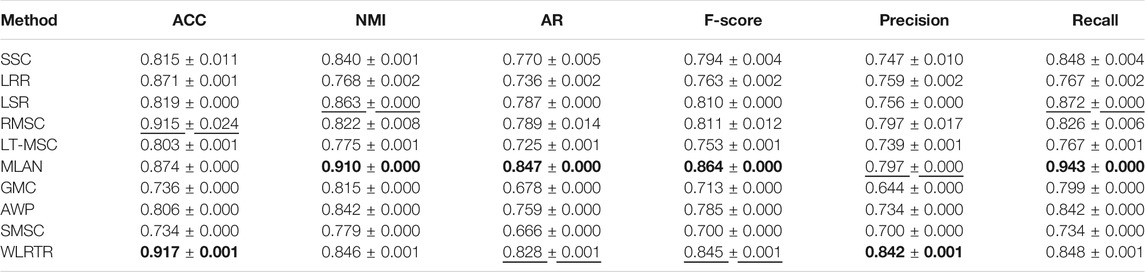
TABLE 3. Clustering results on UCI-3views database.
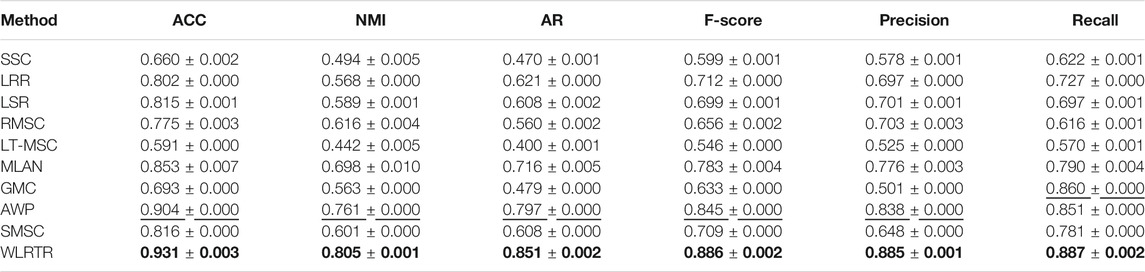
TABLE 4. Clustering results on BBC4view database.
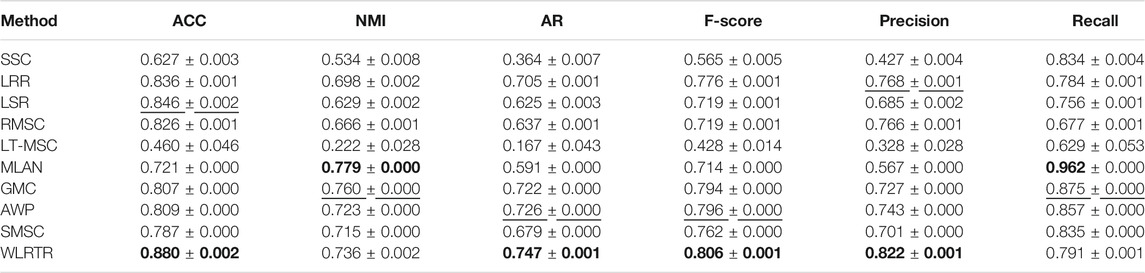
TABLE 5. Clustering results on BBCSport database.
On the ORL database, the proposed WLRTR and LT-MSC methods have the best clustering effect among all the comparison methods. This shows that the tensor-based clustering methods can well explore the high-order correlation of multi-view features. Compared with LT-MSC method, WLRTR has improved ACC, AR and F-score metrics by
On UCI-3views and BBCSport databases, although MLAN is better than WLRTR in some metrics, the clustering results of MLAN on different databases are unstable, and even lower than all single-view clustering methods on ORL database. In addition, we can find that the results of the recently proposed GMC method on the four databases cannot achieve satisfactory performance. The reason may be the graph-based clustering methods: MLAN and GMC usually use the original features to construct the affinity matrix, however, the original features usually are destroyed by noise and outliers.
Model Analysis
In this section, we conduct the parameter selection and convergence analysis of the proposed WLRTR method.
Parameter Selection
We perform experiments on ORL and BBCSport databases to investigate the influence of three parameters, i.e., α, β and c for the proposed WLRTR method, where parameters α and β are empirically selected from
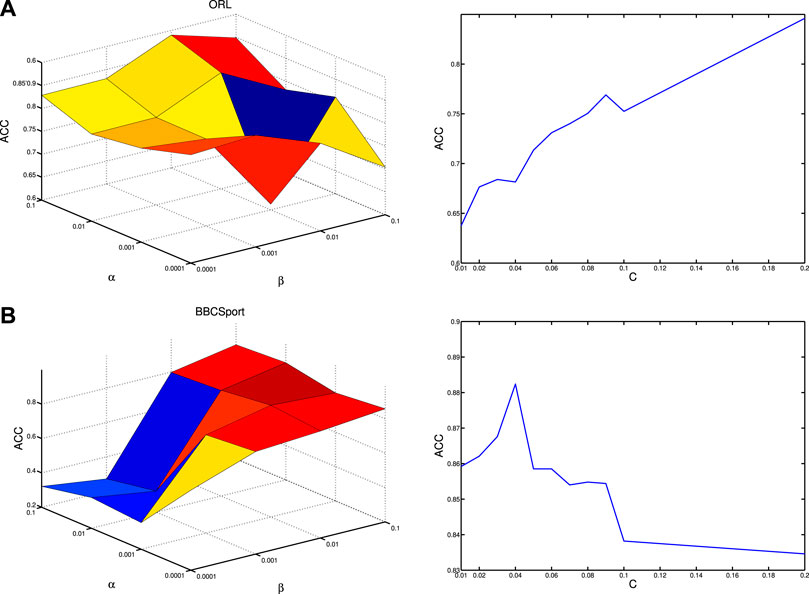
FIGURE 2. ACC versus different values of parameters α and β(left), and parameter c(right) on (A) ORL and (B) BBCSport.
Numerical Convergence
This subsection investigates the numerical convergence of the proposed WLRTR method. Figure 3 shows the iterative error curves on the ORL and BBCSport databases. The iterative error is calculated by
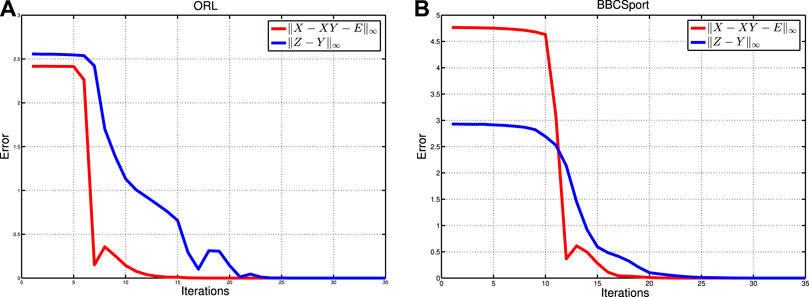
FIGURE 3. Errors versus iterations on (A) ORL and (B) BBCSport databases.
Conclusion and Future Work
In this paper, we developed a novel clustering method called weighted low-rank tensor representation (WLRTR) for multi-view subspace clustering. The main advantage of WLRTR is to encode the low-rank structure of the tensor through Tucker decomposition and
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
SW conducted extensive experiments and wrote this paper. YC proposed the basic idea and revised this paper. FZ contributed to multi-view clustering experiments and funding support.
Funding
This work was supported by Natural Science Foundation of Zhejiang Province, China (Grant No. LY19A010025).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Jiang G, Wang H, Peng J, Chen D, Fu X (2019). Graph-based multi-view binary learning for image clustering. Available at: https://arxiv.org/abs/1912.05159
2. Wang H, Wang Y, Zhang Z, Fu X, Li Z, Xu M, et al. Kernelized multiview subspace analysis by self-weighted learning. IEEE Trans Multimedia (2020) 32. doi:10.1109/TMM.2020.3032023
3. Zhang C, Fu H, Liu S, Liu G, Cao X. Low-rank tensor constrained multiview subspace clustering. in: 2015 IEEE International Conference on Computer Vision (ICCV); Santiago, Chile; December 7–13, 2015 (IEEE), 1582–1590. (2015). doi:10.1109/ICCV.2015.185
4. Bickel S, Scheffer T. Multi-view clustering. in: Fourth IEEE International Conference on Data Mining (ICDM'04); Brighton, UK; November 1–4, 2004 (IEEE), 19–26. (2004). doi:10.1109/ICDM.2004.10095
5. Macqueen JB. Some methods for classification and analysis of multivariate observations. in: Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, (University of California Press), 281–297. (1967).
6. Wu X, Kumar V, Quinlan JR, Ghosh J, Yang Q, Motoda H, et al. Top 10 algorithms in data mining. Know Inf Syst (2008) 14:1–37. doi:10.1007/s10115-007-0114-2
7. Liu G, Lin Z, Yan S, Sun J, Yu Y, Ma Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans Pattern Anal Mach Intell (2013) 35:171–184. doi:10.1109/TPAMI.2012.88
8. Gao J, Han J, Liu J. Multi-view clustering via joint nonnegative matrix factorization. in: Proceedings of the 2013 SIAM International Conference on Data Mining; Austin, TX; May 2–4, 2013, 252–60. (2013). doi:10.1137/1.9781611972832.28
9. Shao W, He L, Yu P. Multiple incomplete views clustering via weighted nonnegative matrix factorization with l2,1 regularization. Proc Joint Eur Conf Mach Learn Knowl Disc Data (2015) 9284:318–34. doi:10.1007/978-3-319-23528-8_20
10. Zong L, Zhang X, Zhao L, Yu H, Zhao Q. Multi-view clustering via multi-manifold regularized non-negative matrix factorization. Neural Networks (2017) 88:74–89. doi:10.1016/j.neunet.2017.02.003
11. Huang S, Kang Z, Xu Z. Auto-weighted multiview clustering via deep matrix decomposition. (2020) Pattern Recognit 97:107015. doi:10.1016/j.patcog.2019.107015
12. Rao SR, Tron R, Vidal R., Ma Y. Motion segmentation via robust subspace separation in the presence of outlying, incomplete, or corrupted trajectories. in: 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, June 23–28, 2008, 1–8. (2008). doi:10.1109/CVPR.2008.4587437
13. Elhamifar E, Vidal R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans Pattern Anal Mach Intell (2013) 35, 2765–2781. doi:10.1109/TPAMI.2013.57
14. Chen Y, Xiao X, Zhou Y. Jointly learning kernel representation tensor and affinity matrix for multi-view clustering. IEEE Trans on Multimedia (2020) 22, 1985–1997. doi:10.1109/TMM.2019.2952984
15. Xia R, Pan Y, Du L, Yin J. Robust multi-view spectral clustering via low-rank and sparse decomposition. Proc AAAI Conf Artif Intell (2014) 28, 2149–2155.
16. Najafi M, He L, Yu PS. Error-robust multi-view clustering. Proc Int Conf on big data (2017) 736–745. doi:10.1109/BigData.2017.8257989
17. Brbic M, Kopriva I. Multi-view low-rank sparse subspace clustering. Pattern Recognit (2018) 73, 247–258. doi:10.1016/j.patcog.2017.08.024
18. Lu G, Yu Q, Wang Y, Tang G. Hyper-laplacian regularized multi-view subspace clustering with low-rank tensor constraint. Neural Networks (2020) 125:214–223. doi:10.1016/j.neunet.2020.02.014
19. Xie Y, Tao D, Zhang W, Liu Y, Zhang L, Qu Y. On unifying multi-view self-representations for clustering by tensor multi-rank minimization. Int J Comput Vis (2018) 126:1157–1179. doi:10.1007/s11263-018-1086-2
20. Li S, Shao M, Fu Y. Multi-view low-rank analysis with applications to outlier detection. ACM Trans Knowl Discov Data (2018) 12:1–22. doi:10.1145/3168363
21. Chang Y, Yan L, Fang H, Zhong S, Zhang Z. Weighted low-rank tensor recovery for hyperspectral image restoration. Comput Vis Pattern Recognit (2017) 50:4558–4572. doi:10.1109/TCYB.2020.2983102
22. Chen Y, Guo Y, Wang Y, Wang D, Peng C, He G. Denoising of hyperspectral images using nonconvex low rank matrix approximation. IEEE Transactions on Geoscience Remote Sensing (2017) 55:5366–5380. doi:10.1109/TGRS.2017.2706326
23. Lu C-Y, Min H, Zhao Z-Q, Zhu L, Huang D-S, Yan S. Robust and efficient subspace segmentation via least squares regression. Proc Eur Conf Comput Vis (2012) 7578:347–360. doi:10.1007/978-3-642-33786-4_26
24. Nie F, Cai G, Li J, Li X. Auto-weighted multi-view learning for image clustering and semi-supervised classification. IEEE Trans Image Process (2018a) 27:1501–1511. doi:10.1109/TIP.2017.2754939
25. Wang H, Yang Y, Liu B. GMC: Graph-based multi-view clustering. IEEE Trans Knowl Data Eng (2019) 32:1116–1129. doi:10.1109/TKDE.2019.2903810
26. Nie F, Tian L, Li X. Multiview clustering via adaptively weighted procrustes. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge, July 2018, 2022–2030. (2018b). doi:10.1145/3219819.3220049
Keywords: clustering, low-rank tensor representation, subspace clustering, tucker decomposition, multi-view clustering
Citation: Wang S, Chen Y and Zheng F (2021) Weighted Low-Rank Tensor Representation for Multi-View Subspace Clustering. Front. Phys. 8:618224. doi: 10.3389/fphy.2020.618224
Received: 16 October 2020; Accepted: 07 December 2020;
Published: 21 January 2021.
Edited by:
Gang Zhang, Nanjing Normal University, ChinaReviewed by:
Guangqi Jiang, Dalian Maritime University, ChinaWei Yan, Guangdong University of Technology, China
Copyright © 2021 Chen, Wang and Zheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yongyong Chen, WW9uZ3lvbmdDaGVuLmNuQGdtYWlsLmNvbQ==