
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Pharmacol., 08 August 2022
Sec. Experimental Pharmacology and Drug Discovery
Volume 13 - 2022 | https://doi.org/10.3389/fphar.2022.948283
This article is part of the Research TopicComputational Intelligence in Personalized MedicineView all 11 articles
 Jianbin Guo1*
Jianbin Guo1* Pei-Wei Tsai2
Pei-Wei Tsai2 Xingsi Xue3Dong Wu4
Xingsi Xue3Dong Wu4 Qui Tran Van2
Qui Tran Van2 Chanaka Nimantha Kaluarachchi2
Chanaka Nimantha Kaluarachchi2 Hong Thi Dang2
Hong Thi Dang2 Nikhitha Chintha2
Nikhitha Chintha2Identifying the right accessories for installing the dental implant is a vital element that impacts the sustainability and the reliability of the dental prosthesis when the medical case of a patient is not comprehensive. Dentists need to identify the implant manufacturer from the x-ray image to determine further treatment procedures. Identifying the manufacturer is a high-pressure task under the scaling volume of patients pending in the queue for treatment. To reduce the burden on the doctors, a dental implant identification system is built based on a new proposed thinner VGG model with an on-demand client-server structure. We propose a thinner version of VGG16 called TVGG by reducing the number of neurons in the dense layers to improve the system’s performance and gain advantages from the limited texture and patterns in the dental radiography images. The outcome of the proposed system is compared with the original pre-trained VGG16 to verify the usability of the proposed system.
Oral radiography images are widely used in assisting dentists in making judgements on a patient’s case, evaluating the conditions, and deciding on further treatment or operations that work the best for the patient. One of the essential steps in observing the oral radiography image is that the dentist needs to identify which manufacturer is the one who manufactured the particular implant that has been placed in the patient’s mouth. Identifying the correct implant manufacturer is vital because different implant manufacturers have different operating procedures and corresponding accessories for their products. Using the right supplements and operating procedures ensures the dental prosthesis’s sustainability and reliability. Thus, identifying the dental implant manufacturer from either the intraoral or the extraoral x-ray image is the key to ensuring the quality of the work.
An intraoral x-ray image is obtained by having a film positioned in the buccal cavity. Unlike the intraoral x-ray image, an extraoral x-ray image is obtained by positioning the patient between the x-ray source and the radiographic film. The intraoral technique produces images focusing on a local region of the mouth, but the extraoral approach provides panoramic x-ray images of the mouth. Either way, the dentist needs to identify the manufacturer by observing the implant’s characteristics (Saghiri et al., 2020), shapes (Guarnieri et al., 2019), and patterns (Makary et al., 2019) from the x-ray image and judge from which manufacturer the implant should be. This can be a high-pressure task when a large volume of patients are pending in the queue for proper treatments. The chance of humans making mistakes under a high-pressure scenario is much greater than average. Having a support system assisting the dentists in identifying the implant’s manufacturer is ideal for lifting the burden on the dentists as a solution for this. Hence, many machine learning-based support systems for identifying the dental implant’s manufacturer and related usability studies have been proposed in recent years.
The remaining of this article is organised as follows: the related works are discussed in Section 2, the proposed system model is revealed in Section 3, the experiments and results are summarized and discussed in Section 4 and is followed by the conclusion in Section 5.
Training a deep neural network from scratch is heavily resource consuming. To avoid getting the model with the hard way, using transfer learning to adjust the model based on a pre-trained model is a popular solution. For example, Kim et al. test a set of transfer learning-based systems for identifying the dental implant in 2020 (Kim et al., 2020). They conclude that the tested convolutional neural network (CNN) models can properly classify four dental implants from manufactors of “Brånemark Mk TiUnite,” “Dentium Implantium,” “Straumann Bone Level,” and “Straumann Tissue Level” with high accuracy. Some data augmentation techniques are applied to their collected data set for preventing overfitting. Their experimental results are produced by SquuezeNet (Iandola et al., 2016), GoogLeNet (Szegedy et al., 2015), ResNet (He et al., 2015), and MobileNet-v2 (Sandler et al., 2018). All models used in their work are pre-trained by ImageNet. However, image sources collected in ImageNet are natural images. The pattern and details contained in those images are very different from and much more complex than those in medical radiography images. Using a thinner network structure may already be sufficient for the dental implant identification task. The terminology “thinner” refers to a network layer with less neurons and thus the width of a layer is narrower. A thinner network structure can save much more resources and computational cost in training and model deployment.
Sukegawa et al. compare the dental implant classification results obtained by the basic CNN with three convolution layers, the VGG16 and the VGG19 models (Sukegawa et al., 2020). According to their findings, the classification accuracy before fine-tuning the VGG models is already higher than the basic CNN model. The accuracy is lifted to above 90% after the fine-tuning for both VGG16 and VGG19. This result shows the advantage of using VGG model over the conventional CNN. In 2015, Simonyan and Zisserman conclude that having up to 19 weight layers of the CNN structure is sufficient for the classification accuracy on the ImageNet challenge dataset (Simonyan and Zisserman, 2015). Nevertheless, fine-tuning a deep learning model is highly resource consuming. Lighten the model to accommodate the radiography images may be a more efficient solution.
In 2020, Almubarak et al. propose a two-stage mask R-CNN model for decomposing the object identification task into the object cropping task and the object classification task in a sequence (Almubarak et al., 2020). Their approach utilizes the bounding box and the semantic segmentation output from the mask R-CNN (He et al., 2020) to locate the target for cropping in the first stage. The cropped target is sent to the second stage as the input for classification. The drawback of this method is that it requires the annotation mask to indicate the ground truth for training. The annotation is highly labor demanded and thus is less preferred in many applications. Besides, the quality of the annotation is vital to the model accuracy. Keeping the annotation in the same quality level is also challenging.
Vuola et al. utilize the ensemble learning technique to aggregate the output from a mask R-CNN and a U-Net (Ronneberger et al., 2015) in the nuclei segmentation application (Vvola et al., 2019). Their finding indicate that the mask R-CNN and the U-Net models make mistakes in different parts of the input image. Thus, using ensemble learning to integrate their output provides a better result in the nuclei segmentation task. Although their experiment is carried out with the fluorescence and histology images, similar experience is potential to be taken in use in the dental implant application as well.
In 2022, Liu et al. use R-CNN to detect marginal bone loss around dental implants (Liu et al., 2022). They find that their model output performs similarly to the resident dentist but is less accurate than the experienced dentist. The reason could be that the model is yet fine-tuned. With proper fine-tuning and optimization, the model is expected to be improved. Moreover, R-CNN model has been improved from the original version to the fast R-CNN, the faster R-CNN, and the current state-of-the-art: the mask R-CNN. By using the more advanced model, the result should be lifted to the next level.
Summarizing the lesson learned from the related works, we notice that the radiography image has more minor features and patterns than the natural image. This implies that a thinner network structure may already be sufficient to complete the task. The observed knowledge inspired us to simplify the complexity of the VGG structure for our system.
Our goal in this work is to create a support system for the dentist to quickly identify the dental implant manufacturers from the x-ray image automatically. With the output from the support system, the dentist only needs to verify whether the result is correct rather than identifying the manufacturer with no reference information. Furthermore, considering the x-ray image is relatively monotone than the natural image, we expect a thinner network structure can accommodate the given task. Thus, we build a thinner VGG16 network called TVGG16 with a reduced number of neurons in the dense layers to reduce the computational cost. Figure 1 shows the diagram of the proposed dentist supporting system.
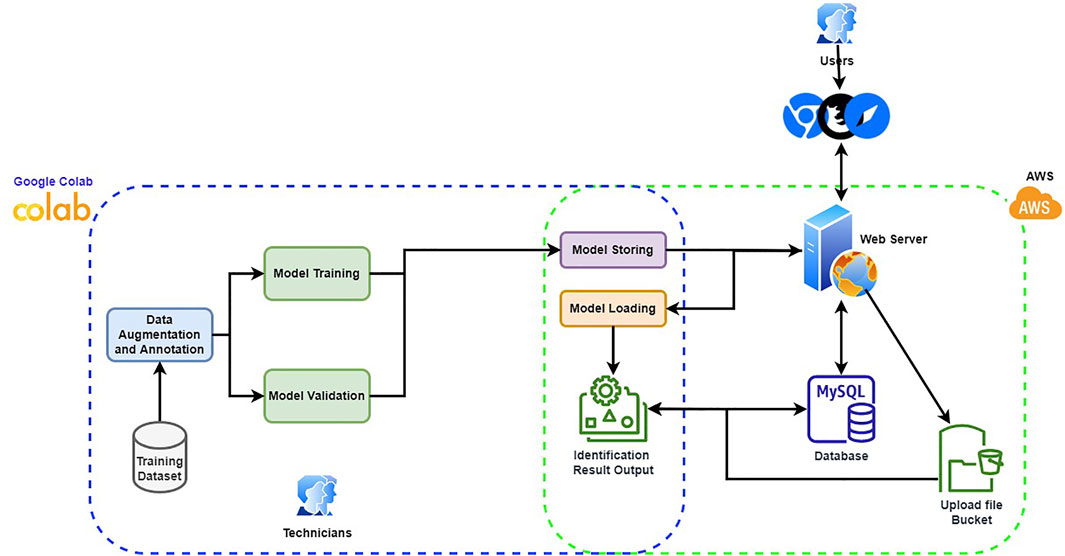
FIGURE 1. Proposed supporting system diagram.
To make the system user friendly, the system is equipped with a graphical user interface (GUI), which is built by JavaScript with React plus the Flask API with Python. The model training is completed offline. The trained model is stored and loaded on the server. When the user inputs a dental x-ray image, the GUI offers cropping boxes for users to pinpoint the region of interest (RoI). The copped image is further resized to fit the model’s input and is uploaded from the client to the server for manufacturer identification. The identification results are collected from the enabled models, stacked up as the final result, and returned to the user with probabilities corresponding to different manufacturers. The back-end, including model building, training and test, are processed via Python with Google Colab as the IDE. Amazon Web Services (AWS) is used to host the server and the database. The database stores the information about the RoIs and the information will be used if a user latches a ticket for correcting the identification result. The server is used to store the trained models and to process the user-input test image. Users can hook up to the system via any web browser and connect to the web server to pass the submitted test image to the back-end process. The GUI guides the user through the process of choosing the test images and the RoIs. The identification result will then be returned and displayed in the browser. Since the built-in models are treated as on-demand modules to be loaded depending on whether the user chooses to include them in the identification process, the designed system can be easily scaled up by integrating new models in the back-end. More details of the components in the proposed system are given in the following subsections.
Considering the potential users of the proposed support system are not from the computer science background, a user-friendly interface is essential to lift the system’s usability. Hence, the system is designed with a GUI instead of a command line-based interface. Figure 2A demonstrates the GUI of the system for users to upload the x-ray image, and select the size of the bounding box. Figure 2B shows the GUI for users to indicate the RoI and select models. Two standard sizes, e.g. 224 × 224 and 256 × 256 of the RoI are built into the system to match the input image size of the pre-trained models. After uploading the x-ray image, users can drag on the interface to draw the user-defined RoIs. Once the RoIs are drawn, the cropping function is triggered automatically and resizes the RoIs to fit in the model input size. Users can then tick the boxes to select which models are employed in the identification process. Users can delete the RoIs or the uploaded image anytime before submitting them to the system by clicking the bin icon.
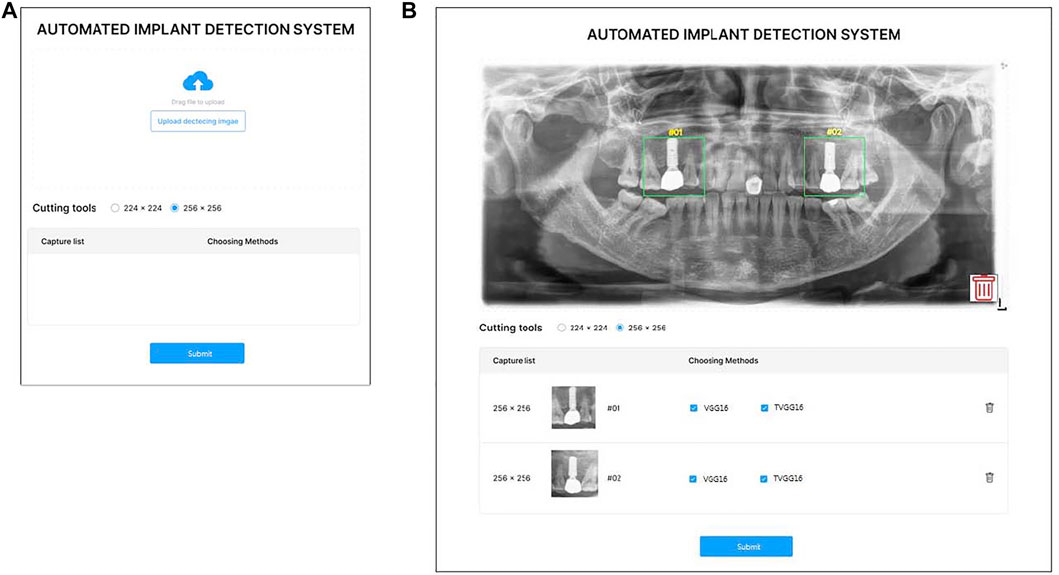
FIGURE 2. GUI of the proposed system (A) is the entry GUI (B) is the model selection and RoI specification GUI.
After the user clicks on the submission button, the RoIs are fed into the selected models on the server. After all models complete their prediction, the probabilities output from the selected models are returned for displaying on the system interface (see Figure 3). If the user clicks on the home button, the system returns to the entry page and stand-by to receive other dental x-ray images.
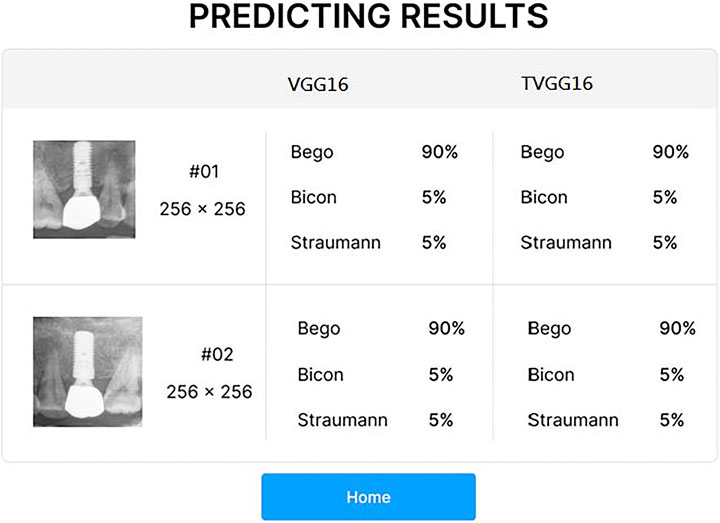
FIGURE 3. Result presentation GUI.
We choose VGG to be our base model for implementation because the existing study shows that VGG has more advantages in terms of energy consumption than other models (Canziani et al., 2017). As mentioned in Section 2, the monotone texture and patterns in the dental x-ray image caught our attention, and we assume that a simplified network structure is sufficient to cope with the implant manufacturer identification task. Nevertheless, adopting pre-trained models also has a strong point in reducing the training cost. If we remove layers in the model, we will need to start the training from scratch, which is much more resources and power-hungry than adopting the pre-trained model and performing fine-tuning. Aside from fine-tuning, we use the well-known dropout technique (Srivastava et al., 2014) as the tool to thinner the width of the dense layers. Dropout was originally proposed to prevent the network goes into overfitting. We adopt this technique but use its concept in removing neurons in the dense layers. Thus, this results in the dense layer in the modified VGG, e.g. the TVGG has much fewer neurons in the last few layers.
Figure 4A shows the conventional VGG16 layout (Simonyan and Zisserman, 2015), Figure 4B reveals our proposed TVGG layout, and Figure 4C presents the legend. Since the pre-trained VGG16 model is adopted as the base model, weights on the first-five convolution blocks are frozen in the training process. Only the weights on the full-connection layers are updated. Moreover, we replaced the original full connection layers from the flatten layer followed by three dense layers to the compact structure composed of the global average pooling and two dense layers. The dense layer size is also reduced by dropping out more than three-fourths of neurons.
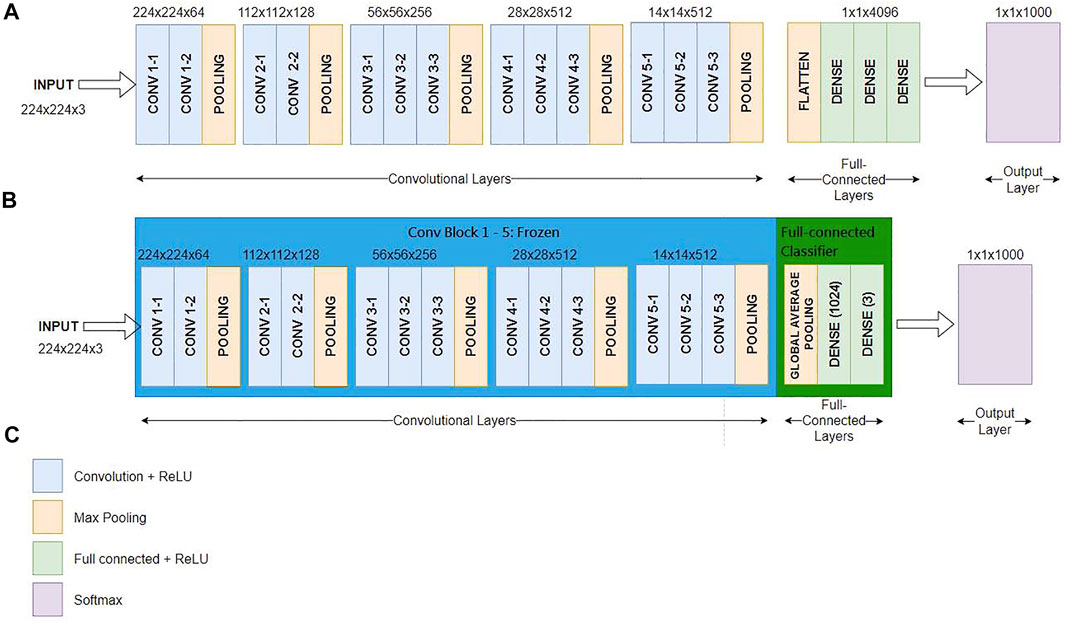
FIGURE 4. Network layout comparison (A) is the network layout of the conventional VGG16 (B) is the network layout of the TVGG (C) is the legend.
The experiments are conducted in Python with Google Colab. The training environment contains two virtual CPUs, 24GB RAM, 150 GB storage space, and GPUs of K80, P100, and T4. Python libraries used in constructing the models include Tensorflow and Keras. Details of the experiment contents are described below.
The dental x-ray images are collected at Fujian Medical University - Fujian Stomatological Hospital in P.R. China. It contains three classes of the dental implant manufacturer, namely, the Bego, the Bicon, and the Straumann, with 850, 892, and 527 x-ray images for the corresponding groups, respectively. This dataset is a hybrid of intraoral and extraoral x-ray images. Each of the classes contains both types of images. All collected x-ray images are containing implants from a single manufacturer. Mixture cases are not included in the collection.
To ensure we have a balanced dataset across images from all manufacturers, data augmentation methods are used to expand the volume of the dataset to ensure all classes have the same quantity of data. Moreover, having data augmentation involved in the process helps avoid the overfitting issue. The methods used in the data augmentation process include a random rotation between
The structure of the conventional VGG16 and our proposed TVGG is described in Section 3.2. We add another VGG16 model for comparison but replace the flatten layer with the global-average-pooling to have more models for comparison. The Adam optimization is used in all models in the training phase.
The common evaluation criteria in classification, including precision, recall, f1-score, and accuracy, are used to quantify the experimental results. Let TP, FP, TN, and FN represent the true positive, false positive, true negative, and false negative, respectively; these matrices can be calculated by Eqs 1–4.
We use VGG16, VGG16-GAP, and TVGG15 to indicate the conventional VGG16 model, the conventional VGG16 but replacing the flatten layer with global-average-pooling, and the thinner VGG, respectively. Figure 5 shows the confusion matrices from all models.
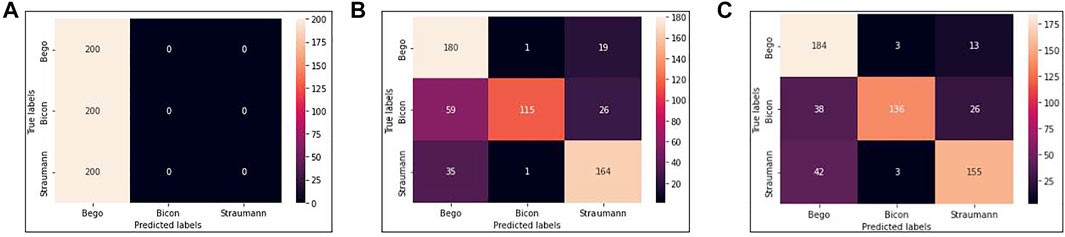
FIGURE 5. Confusion matrices (A) is obtained by VGG16 (B) is obtained by VGG16-GAP (C) is obtained by TVGG15.
Our dataset size is relatively small compared to other studies. Figure 5A shows that using a small dataset to fine-tune the pre-trained VGG16 is not feasible because the training data volume is insufficient to support the tuning on a large scale of weights. Thus, we create the VGG16-GAP model to give the network a boost. From Figure 5B, the improvement is observable by the eye, and the correct classification results start to go across all classes. On the other hand, in the TVGG15 model, the correctly classified results (see Figure 5C) are getting higher than in the VGG16-GAP model.
Table 1 reveals the values from the evaluation matrices obtained by different implant manufacturers, namely, Bego, Bicon, and Straumann, respectively. The bold font marks the model performing the best in the column. It is observable that TVGG15 owns the most counts of achieving the best. The average performance across all classes is summarized in Table 2.

TABLE 1. Evaluation matrices of all class.

TABLE 2. Model training information.
Figure 6 shows the accuracy calculated from the test results. TVGG15 presents the highest accuracy while VGG16-GAP achieves the second.
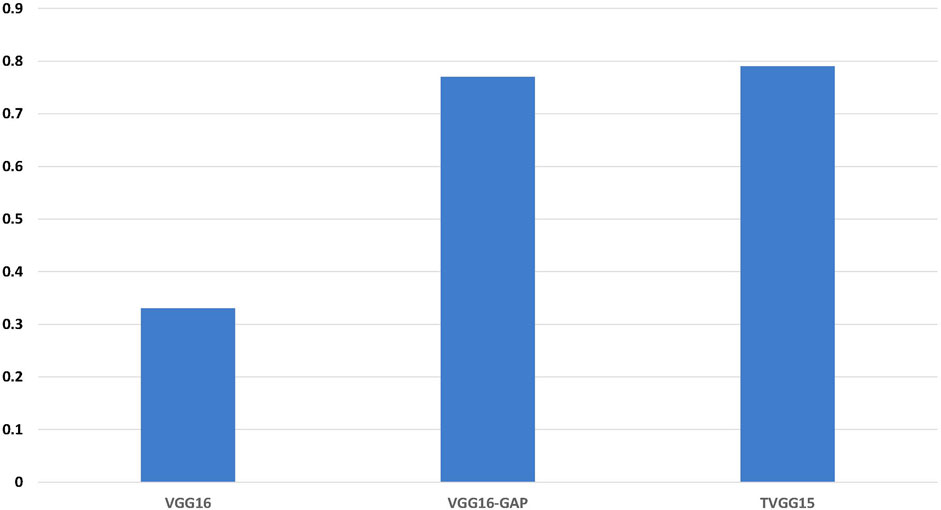
FIGURE 6. Identification accuracy across all models.
Table 3 shows the resource occupation, the training cost, and the training outcomes recorded by executing 200 epochs for each model. We can see that the TVGG15 model size is 2, 215 times less than VGG16 and 4.37 times less than VGG16-GAP. This compact characteristic gives TVGG15 an advantage in deploying the client-server internet environment. Moreover, by using the same resources for training the model, the training time of TVGG15 is reduced 4.3% than VGG16. The TVGG15 model also achieved the highest best training and validation accuracy.
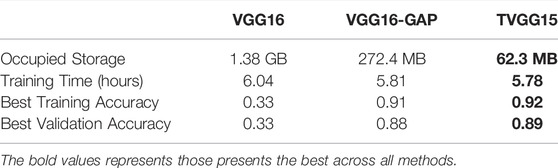
TABLE 3. Model training information.
In this work, we create a dentist supporting system for automatic dental implant manufacturer identification from the dental x-ray images. The proposed system uses the TVGG15 model, which is an improved version from the VGG16 model pre-trained by ImageNet. The experiment results indicate that the pre-trained VGG16 is too large to be fine-tuned with the available quantity of data in our study. However, the proposed TVGG15 presents a satisfactory result in the case that the available training data is limited. Moreover, the proposed model occupies 2, 215 times less storage resource for preserving the model parameters given that the structure is not only more compact but also much thinner than the conventional VGG16 model. To gain the advantage of using a pre-trained model, the modification is only applied to the full connection layers in the CNN structure.
The dataset used in the experiment contains dental implants from a single manufacturer in each x-ray image, and thus no mixture case is included. However, our proposed system crops images into multiple RoIs. Even if there is an x-ray image containing a mixture of dental implants from numerous manufacturers, the proposed system should also present its performance as stable on the same level as in the current experiments.
In terms of building an application system, we see the potential to adopt the ensemble learning structure into the system back-end to increase the number of available candidate models in the future work. Heterogeneous models are more preferred because they can discover different characteristics of the input data. Moreover, we plan to remove the option for selecting the RoI cropping size in the GUI and only keep the one to a greater extent. Although different pre-trained models may require other input image sizes, the smaller RoI can be obtained by applying proper down-sampling techniques in the back-end and automatically satisfying this need. Furthermore, we plan to use some intelligent optimization methods to extend the modifiable parameters from the dense layers to the convolutional layers. This is a potential way to further imporve the performance of the models without retrain the whole models.
The datasets presented in this article are not readily available because the patients' data is not publicly accessible. Further inquiries can be directed to the corresponding author JG, amlhbmJpbkBmam11LmVkdS5jbg==.
The studies involving human participants were reviewed and approved by Hospital of Stomatology, Fujian Medical University. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Data collection and ground truth establishment by JG and DW; System and framework design by JG, P-WT, XX; experiment data validation and check by JG and DW; GUI design by HD and NC; system implementation by QTV and CNK; experiment result validation by P-WT and XX; article writing by JG, P-WT, XX and DW.
This work is supported by Fujian Provincial Natural Science Foundation (No. 2020J01646), Joint Funds for the Innovation of Science and Technology Fujian Province (No. 2020Y9031), Science and Technology Planning Project of Fujian Provincial Health Commission (No. 2021CXA035) and Fuzhou Science and Technology Planning Project (No. 2021-ZD-286).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Almubarak, H., Bazi, Y., and Alajlan, N. (2020). Two-Stage Mask-Rcnn Approach for Detecting and Segmenting the Optic Nerve Head, Optic Disc, and Optic Cup in Fundus Images. Appl. Sci. 10, 3833–3848. doi:10.3390/app10113833
Canziani, A., Culurciello, E., and Paszker, A. (2017). An Analysis of Deep Neural Network Models for Practical Applications. arXiv. 1–12. doi:10.48550/arXiv.1605.07678
Guarnieri, R., Di Nardo, D., Di Giorgio, G., Miccoli, G., and Testarelli, L. (2019). Clinical and Radiographics Results at 3 Years of Rct with Split-Mouth Design of Submerged vs. Nonsubmerged Single Laser-Microgrooved Implants in Posterior Areas. Int. J. Implant Dent. 5, 44–10. doi:10.1186/s40729-019-0196-0
He, K., Gkioxari, G., Dollar, P., and Girshick, R. (2020). Mask R-Cnn. IEEE Trans. Pattern Anal. Mach. Intell. 42, 386–397. doi:10.1109/TPAMI.2018.2844175
He, K., Zhang, X., Ren, S., and Sum, J. (2015). Deep Residual Learning for Image Recognition. arXiv 1–12. doi:10.48550/arXiv.1512.03385
Iandola, F. N., Han, S., Moskewicz, M. W., Ashraf, K., Dally, W. J., and Keutzer, K. (2016). Squeezenet: Alexnet-Level Accuracy with 50x Fewer Parameters and
Kim, J. E., Nam, N. E., Shim, J. S., Jung, Y. H., Cho, B. H., and Hwang, J. J. (2020). Transfer Learning via Deep Neural Networks for Implant Fixture System Classification Using Periapical Radiographs. J. Clin. Med. 9, 1–11. doi:10.3390/jcm9041117
Liu, M., Wang, S., Chen, H., and Liu, Y. (2022). A Pilot Study of a Deep Learning Approach to Detect Marginal Bone Loss Around Implants. BMC Oral Health 22, 1–8. doi:10.1186/s12903-021-02035-8
Makary, C., Menhall, A., Zammarie, C., Lombardi, T., Lee, S. Y., and Stacchi, C. (2019). Primary Stability Optimization by Using Fixtures with Different Thread Depth According to Bone Density: A Clinical Prospective Study on Early Loaded Implants. Mater. (Basel) 12, 1–15. doi:10.3390/ma12152398
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-Net: Convolutional Networks for Biomedical Image Segmentation,” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. Editors N. Navab, J. Hornegger, W. M. Wells, and A. F (Frangi (Germany: SpringerLink), 234–241. doi:10.1007/978-3-319-24574-4_28
Saghiri, M. A., Asatourian, A., Kazerani, H., Gutmann, J. L., and Morgano, S. M. (2020). Effect of Thermocycling on the Surface Texture and Release of Titanium Particles from Titanium Alloy (Ti6al4v) Plates and Dental Implants: An In Vitro Study. J. Prosthet. Dent. 124, 801–807. doi:10.1016/j.prosdent.2019.11.013
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. (2018). “Mobilenetv2: Inverted Residuals and Linear Bottlenecks,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition (IEEE), 4510–4520. doi:10.1109/cvpr.2018.00474
Simonyan, K., and Zisserman, A. (2015). “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in The 3rd International Conference on Learning Representations (IEEE), 1–14.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 15, 1–30.
Sukegawa, S., Yoshii, K., Hara, T., Yamashita, K., Nakano, K., Yamamoto, N., et al. (2020). Deep Neural Networks for Dental Implant System Classification. Biomolecules 10, 1–13. doi:10.3390/biom10070984
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going Deeper with Convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition. Editors K. Grauman, E. Learned-Miller, A. Torralba, and A. Zisserman (IEEE), 1–9. doi:10.1109/cvpr.2015.7298594
Keywords: VGG, CNN, dental implant, radiography image, implant identification
Citation: Guo J, Tsai P-W, Xue X, Wu D, Van QT, Kaluarachchi CN, Dang HT and Chintha N (2022) TVGG Dental Implant Identification System. Front. Pharmacol. 13:948283. doi: 10.3389/fphar.2022.948283
Received: 19 May 2022; Accepted: 09 June 2022;
Published: 08 August 2022.
Edited by:
Khin Wee Lai, University of Malaya, MalaysiaReviewed by:
Wen Zhang, Fuzhou University, ChinaCopyright © 2022 Guo, Tsai, Xue, Wu, Van, Kaluarachchi, Dang and Chintha. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jianbin Guo, amlhbmJpbkBmam11LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.