
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Pharmacol., 20 June 2022
Sec. Experimental Pharmacology and Drug Discovery
Volume 13 - 2022 | https://doi.org/10.3389/fphar.2022.852143
 Natasha Salame1†
Natasha Salame1† Katharine Fooks2,3†
Katharine Fooks2,3† Nehme El-Hachem4†Jean-Pierre Bikorimana5François E. Mercier2,3*
Nehme El-Hachem4†Jean-Pierre Bikorimana5François E. Mercier2,3* Moutih Rafei4,5,6*
Moutih Rafei4,5,6*Multi-omic approaches offer an unprecedented overview of the development, plasticity, and resistance of cancer. However, the translation from anti-cancer compounds identified in vitro to clinically active drugs have a notoriously low success rate. Here, we review how technical advances in cell culture, robotics, computational biology, and development of reporter systems have transformed drug discovery, enabling screening approaches tailored to clinically relevant functional readouts (e.g., bypassing drug resistance). Illustrating with selected examples of “success stories,” we describe the process of phenotype-based high-throughput drug screening to target malignant cells or the immune system. Second, we describe computational approaches that link transcriptomic profiling of cancers with existing pharmaceutical compounds to accelerate drug repurposing. Finally, we review how CRISPR-based screening can be applied for the discovery of mechanisms of drug resistance and sensitization. Overall, we explore how the complementary strengths of each of these approaches allow them to transform the paradigm of pre-clinical drug development.
The systematic analysis of cancer genomes has led to the identification of recurrently mutated drivers and, on a fundamental level, to a greater understanding of the diverse mechanisms of oncogenesis (Bailey et al., 2018). Clinically, this genetic characterization has further refined the classification of tumors, led to personalized treatment strategies, and guided pharmacological innovation (Liu et al., 2018). Successful examples include the development of inhibitors targeting the tyrosine kinases BCR-ABL in chronic myeloid leukemia (Druker, 2008) and ALK in a subset of lung cancers (Gristina et al., 2020).
Unfortunately, several challenges persist in the clinical translation of cancer genetic information. Importantly, several cancer alleles lead to loss of function that cannot be directly rescued by pharmacological means. In addition, the net phenotypic result of complex genetic interactions may be difficult to predict. Further, targeted inhibition of single biological pathways in malignant cells often leads to resistance that operates at several levels: outgrowth of genetically distinct subclones (Ding et al., 2012), epigenetic rewiring (Rathert et al., 2015), transcriptional heterogeneity (van Galen et al., 2019), metabolic adaptations (Stevens et al., 2020), and post-translational feedback mechanisms (Bertacchini et al., 2014). Finally, tumor extrinsic factors, such as microenvironmental cues and the immune response (Dao et al., 2021), lead to heterogeneous behavior of genetically similar cancers among patients. The identification of the functional adaptations of tumors driving resistance to therapy has led to a crucial need for potent and specific pharmacological inhibitors.
Transcending the mutational profile of cancer, screening approaches that focus on functional surrogates of biological activity, such as changes in cellular phenotype, gene, or protein expression, directly assess the link between perturbagen and desired clinical effect. Such screening strategies do not require prior understanding of the molecular target of the disease, nor of the mechanism of action of the compound. Instead, the process of phenotypic screening directly converges on biological effect. phenotypic screens can accelerate the identification of compounds targeting these adaptations, thus facilitating the bi-directional feedback between drug design and clinical observations. Complementing this approach, novel bioinformatic strategies can discover relationships between chemical compounds, molecular targets, and biological pathways, and genetic perturbation screens can identify drivers of resistance. In this review, we describe how these technological advances operate and how they have transformed cancer drug development.
HTS assays offer the potential to accelerate the discovery and development of new pharmacological compounds for various types of medical indications (Abbott, 2003). In fact, many anti-cancer, anti-glycemic or cardiovascular drugs found on the market nowadays were initially identified via this strategy (Macarron et al., 2011). In addition, technological advancements have largely facilitated the way that HTS is conducted. For instance, large libraries can be easily and rapidly screened due to customizable robotic installations, enhanced read-out technologies as well as the ability to miniaturize assays (Liu et al., 2004).
Biochemical assays aim to detect, quantify, or study the activity of a biological molecule in a given pathway. These would include for example, activity assays such as the colorimetric mitochondrial metabolic activity test (Mosmann, 1983), fluorescent-based assays (Titus et al., 2012; Fouda et al., 2017), receptor-binding assays (Takenaka, 2001) or disease-related assays (Ramaekers and Bosman, 2004; Zock, 2009). As the name implies, biochemical or target-based assays require prior knowledge of the desired target. Once several hits are identified using such HTS screens, the drugs’ mechanism of action are already known as they interfere with the reaction consisting of two major players (A+ B → C). This is the main strength of this type of screening and can simplify or accelerate the ability to design analogs and/or pre-clinical drug development. For example, in a sophisticated study, Z. Chen et al. (2012). designed a luminescence-based assay to screen for potential inhibitors of Giardia lamblia carbamate kinase, a crucial enzyme for the metabolism of this parasite. In fact, carbamate kinase converts carbamoyl phosphate into several products including ATP. The resulting ATP is then used by the luciferase luminescent enzyme to generate light. Therefore, a greater light production correlates with higher carbamate kinase’s activity. Screening almost 4,100 compounds, this assay identified enzyme inhibitors that could potentially serve as drugs against the targeted pathogen. Although biochemical screens succeed in identifying target-specific compounds, many complex biological processes induced by the drugs screened will be omitted, such as unexpected activities, toxicities or responses (Zheng et al., 2013). For instance, if the objective consists of developing an agonist molecule capable of binding a specific receptor, then an assay based on ligand-receptor binding may not be suitable as it cannot differentiate between agonist and antagonist ligands during the screening process since the effect of the ligand on signaling is not directly assessed (Zheng et al., 2013).
Despite the importance of target-based assays in drug development, phenotypic screening or ‘‘forward pharmacology’’ has contributed to the discovery of most FDA-approved drugs between 1999 and 2008, emphasizing its major role in drug discovery (Swinney and Anthony, 2011). Phenotypic screens are designed according to a disease’s characteristic, after which compounds are screened for their ability to improve the illness’s phenotype. Furthermore, prior knowledge of the drug’s mode of action is not required, while still testing its activity and efficacy. Nonetheless, the identification of the drug’s target later becomes challenging. This would also limit one’s ability to optimize the compound’s properties or develop series of analogs prior to understanding the drug’s exact mode of action. (Swinney and Anthony, 2011). Going back to the previously described example, Z. Chen et al. (2011). have also conducted a phenotypic viability assay to screen for several compounds in a HTS. The cells were treated with the compounds or control, after which the ATP levels were measured using a commercially available kit based on the luciferase activity. A greater light signal is associated with more viable cells and therefore, a less efficient drug (Chen et al., 2011). Interestingly, 28 hits in the target-based assay were inactive in the viability screen, probably because of: 1) difficulty crossing the cell membrane, or 2) the compounds were converted by the parasite’s metabolism into inactive products. This elegant example demonstrates that phenotypic screens can detect physiologically active compounds, while being more sensitive to the drugs’ pharmacokinetic properties and without knowledge of the compounds’ targets (Chen et al., 2011).
To sum up, both assays intend to provide different data related to drug discovery. As biochemical assays identify compounds hitting a specific target under study, phenotypic screens can pick-out small molecules inducing a desired change in the phenotype of the cell.
While earlier versions of phenotypic HTS identified chemotherapeutic compounds through direct cytotoxic or growth-arresting effect on cancer cell lines, several of these compounds have dose-limiting toxicities on normal tissues intrinsically linked to their mechanism (such as DNA damage or inhibition of cell division). A better characterization of molecular pathways in cancer (Hanahan and Weinberg, 2000) has inspired the search for less toxic compounds specifically targeting these.
For example, in an elegant study, Sykes et al. (2016). conducted a fluorescence-based differentiation screen in acute myeloid leukemia (AML). The homeobox factor HOXA9, normally downregulated in myeloid cells, is expressed in the majority of AML, resulting in differentiation arrest (Kroon et al., 1998). An estrogen receptor-HoxA9 fusion protein was used to immortalize cultures of murine bone marrow from a reporter mouse with GFP-knocked into the lysozyme locus. Since lysozyme is a granule protein expressed in differentiated cells, the GFP expression allowed to screen for molecules capable of triggering myeloid differentiation (Faust et al., 2000). In this system, they screened 330,000 small molecules within the NIH library and identified inhibition of dihydroorotate dehydrogenase (DHODH) as a potent pro-differentiation agent. This study has sparked an interest in testing DHODH inhibitors in AML and other cancers.
Similarly, knowledge of molecular pathways that are dysregulated in cancer can inform the development of reporter cell lines in which the activity of the pathway is coupled with expression of a reporter (fluorescence or bioluminescence) amenable to HTS, a concept previously termed “mechanism-informed phenotypic drug discovery” (MIPDD) (Moffat et al., 2014). Wnt signaling is one of the key regulatory pathways of cell development and stemness and its dysregulation has been highly associated with cancer growth, particularly in colorectal cancer, but also in many more tumor entities (Zhan et al., 2017). Wnt ligands activate a β–catenin/T-cell factor (TCF)-dependent transcription program. Ewan et al. ran a cell-based assay to identify compounds that could inhibit Wnt-dependent transcription (Ewan et al., 2010). The screen used a HEK293-based reporter cell line, coding for luciferase and GFP under the control of a TCF-binding promoter. The HEK293 cells could inducibly activate Wnt through a Disheveled-estrogen receptor fusion (Dvl2-ER). As estradiol levels triggered Dvl2 activity and increased the amount of intracellular β–catenin, clones displaying TCF-dependent transcription were selected by FACS sorting for the screen. Out of the 63,040 compounds screened, 9 of those who operated at the TCF-dependent pathway were selected for further studies. While an exhaustive list of all anti-cancer drugs discovered through phenotypic screens is beyond the scope of this article, other notable examples include the use of luciferase reporters of androgen receptor or sonic hedgehog signaling to identify the inhibitor enzalutamide (Tran et al., 2009)and vismodegib (Moffat et al., 2014), respectively. An excellent review by Moffat and colleagues (Moffat et al., 2014)demonstrates that 17 of the 48 FDA cancer drugs approved between 1999 and 2013 were identified with the help of phenotypic screens.
We recently described a fluorescence-based lymphocyte assay designed as a tool to screen for immunomodulatory compounds (Liu and Wang, 2012). This assay required a commercially available mouse model containing a bacterial artificial chromosome in which the Nur77 promoter is cloned upstream of the green fluorescent protein (GFP) (Fouda et al., 2017). As a result, engagement of the T-cell receptor (TCR) or the B-cell receptor (BCR) triggers the Nur77 immediate early response gene (within 3 h), which would turn on GFP expression in parallel (Ashouri and Weiss, 2017). We thus exploited this system to design a phenotypic screen centered on inhibiting T-cell activation using GFP as a surrogate marker (Figure 1) (Fouda et al., 2017). The system was then tested using a representative library containing 4,398 small molecules (chemotypes selected based on a common core structures). The primary screen led to the discovery of 160 potential hits exhibiting immunomodulatory activity. After validation, two compounds with anti-cancer properties were identified: InhiTinib and TACIMA-218. Although InhiTinib exhibited powerful suppressive activity on activated CD8 T cells, this sulfonyl-containing compound could also induce the production of reactive oxygen species (ROS) in several murine and human cancer cell lines consequently resulting in their cell death by apoptosis. Furthermore, administration of InhiTinib to mice with large, pre-established tumors significantly prolonged their survival (El-Kadiry et al., 2020). Despite differences in its molecular structure, TACIMA-218 triggered similar effects on various cancer cell lines irrespective of their p53 status, with the exception that it mainly targeted mitochondrial activity (Abusarah et al., 2021).
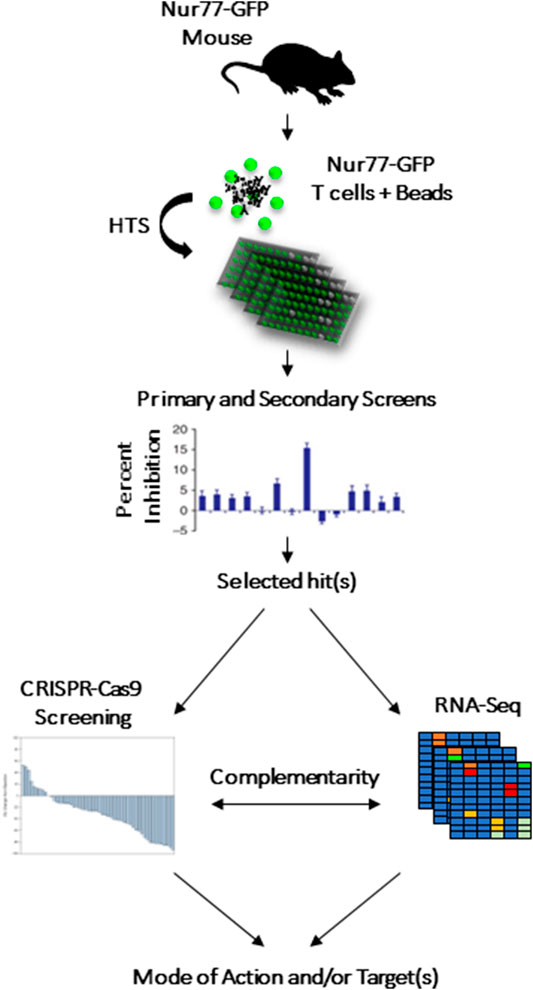
FIGURE 1. CRISPR-Cas9 and RNA-seq to complement HTS screening as means to highlight the drug’s potential target or biological pathway.
In 2015, Vincent et al. formulated a “rule of 3” for phenotypic screening with three criteria to assess the relevance of phenotypic assays: 1) “System” to assess how representative of the disease is the cellular assay; 2) “Stimulus” to assess how well can the experimental conditions reproduce the cellular response to study (e.g., inflammation). 3) “Readout” to assess the relationship between the assay readout and the clinical end point. From a technical standpoint, to properly identify inhibitors or activators for a given molecular target or cellular function, the quality of the assay should be first established to ensure reproducibility and the ease in quantifying its triggered signal (luminescence, fluorescence, or radioactivity). (Vincent et al., 2015).
Although phenotypic screens enabled the discovery of several first-in-class cancer drugs, they do not allow to elucidate the exact mode of action and/or molecular targets. Therefore, the use of other complementary strategies such as biochemical screening, RNA-seq and CRISPR-Cas9 screening can complement HTS findings, as they may easily narrow down the list of plausible targets.
Additionally, significant efforts are being made to account for the genetic heterogeneity found within human cancers and identify pharmaceutical compounds whose efficacy is tied to a specific genotype. In the case of RAS-mutant cancer, several comparative HTS screens could identify bioactive compounds tied to this genotype (Moffat et al., 2014). In addition, recent advances in the ability to propagate, ex vivo, cancer stem cells derived from patients with glioma or AML, allow to correlate genotype with drug susceptibility. The Leucegene project is an example of phenopytic HTS performed on arrays of patient-derived samples in acute myeloid leukemia (Baccelli et al., 2019).
As traditional HTS relies on the use of in vitro models, its efficacy in identifying drugs modulating interactions between cancer cells and their microenvironment remains limited. In fact, the tumor’s microenvironment interacts with the tumor itself, altering its response to treatments (Whiteside, 2008). Three dimensional models, or organoids, mimic better the tumor’s complexity in vivo. In a study by Hou et al. (2018), bioprinting-based 3D models were developed for HTS screening. This assay led to the discovery of potent anti-pancreatic cancer compounds against solid tumors, such as bortezomib, a proteasome inhibitor. Most of the drugs tested showed lower activity on the 3D models, compared to the 2D models. Yet, some showed preference in hitting the 3D model, such as disulfiram. Future HTS systems in vitro will likely incorporate microenvironmental interactions and multiparametric measurements of cellular response.
A crucial strategy in drug development requires the identification of a cellular target that is functionally involved in the molecular pathogenesis of a disease (Zheng et al., 2006). Although traditional approaches are aimed to tune drugs against a single-target (enzyme, receptor, etc.) or better known as the “on-target” effect, it is now accepted that several complex pathways dictate the mechanism of action of a given drug, suggesting that “off-targets” with different biological interpretations could explain the high attrition rates when it comes to clinical trials (Waring et al., 2015). Failures due to lack of efficacy or toxicity concerns highlighted the importance of shifting towards a “one-size-does-not-fit-all” paradigm in patients’ cohorts, and consequently a routine profiling for genetic alterations is finding its way into clinical trials.
In the past decade, substantial technical advances in high throughput molecular technologies, at the DNA, RNA and protein levels illuminated on the complexity of human biology and created unprecedented levels of datasets (Chen and Butte, 2016). This in turn has revolutionized another parallel discipline that combines computational methods and machine learning techniques with molecular information from multiple biological and chemical databases, to better understand the drug’s mechanism of action and link to molecular mechanisms underlying complex diseases and clinicopathological effects (Vamathevan et al., 2019).
Among the multiomics-driven molecular profiles (genomics, transcriptomics, and proteomics), genomics has enabled the first attempts to discover new druggable targets in the human genome through the analysis of genome wide association studies (GWAS), opening a new era for human genetics to inform new therapies (Visscher et al., 2017). A popular example is the “human knockout” of PCSK9 gene (proprotein convertase subtilisin/kexin type 9). Individuals with inactivating mutations in this gene are protected against coronary diseases and show very low levels of LDL cholesterol, which led to the development of PCSK9 inhibitors for the treatment of patients with genetic forms of hypercholesterolemia (Khera and Ridker, 2017). GWAS studies have been very useful in the context of cancer and have identified novel cancer-susceptibility loci. Earlier studies have focused on high penetrance genes (BRCA1/BRCA2) which warrant surveillance at the population level. A first meta-analysis of 9 GWAS studies associated 27 commonly inherited loci in 10,052 breast cancer cases to an increased risk of developing breast cancer (Michailidou et al., 2013). A recent study identified subtype-specific susceptibility loci in 133,384 breast cancer cases which informs that predisposition alleles have likely differential impact across breast cancer-subtypes and suggested novel drug targets with genetic evidence (Zhang et al., 2020).
GWAS from the United Kingdom Biobank (48,961 cancer cases) and the Kaiser Permanente Genetic Epidemiology Research on Adult Health and Aging cohorts (16,001 cancer cases) also provided insights from pan cancer studies and have detected 21 genome-wide significant associations that could identify deregulated targets and carcinogenesis mechanisms across tissue-types (Rashkin et al., 2020). United Kingdom Biobank present a unique opportunity to identify novel pharmacogenes and putative drug-targets for several complex diseases (Bycroft et al., 2018).
One of the prominent applications of GWAS is pharmacogenomics (Giacomini et al., 2012). The latter studies the relationship between genetic variations observed in thousands of individuals and corresponding drug response or metabolism. Identified genetic variations/loci (aka pharmacogenomic biomarkers) can serve as putative drug targets or risk loci when assessing drug efficacy and safety (Abbott, 2003; Karczewski et al., 2012). Bioinformatic approaches have changed the landscape of pharmacogenomic research, especially in cancer drug development (Iorio et al., 2016).
Initially, much of the pharmacogenomic (PGx) discovery was carried out in the laboratory setting through cell line resources such as the Cancer Cell Line Encyclopedia (CCLE) and the Genomics of Drug Sensitivity in Cancer (GDSC) (Barretina et al., 2012; Yang et al., 2013). PGx findings are aggregated by PharmGKB, a public interactive tool for researchers investigating how genetic variation affects drug response (Barretina et al., 2012). As described previously, genetic association studies and DNA sequencing capture the variation across the human genome and propose loss or gain-of-function hypotheses. Yet, they cannot elucidate the downstream or upstream effects underlying complex pathways. In contrast to DNA driven approaches, genome-wide transcriptional profiling (transcriptomics) can be seen as a proxy source of information for the understanding of the cellular changes under different treatments (drug vs. DMSO) or conditions (cancer vs. healthy).
Systems biology approaches using transcriptomic data from mRNA-sequencing and microarrays have been extensively used to understand perturbations caused by drug or chemical treatments to infer novel drug-targets, mechanism of action and repurposing avenues for old and existing drugs (Barretina et al., 2012). Public transcriptome databases can be leveraged to inform target selection and validation. Functional hypotheses can be interrogated from high throughput experiments such as mRNA expression in normal tissues (GTEX), cancer patients from The Cancer Genome Atlas (TCGA), or databases spanning a wide range of diseases, model organisms and multiple tissue types, such as the Gene Expression Omnibus (GEO) repository and the ArrayExpress Archive of Functional Genomics Data (Barrett et al., 2013; Cancer Genome Atlas Research Network et al., 2013; GTEx Consortium, 2015). More recently, machine learning and deep learning algorithms have used CRISPR-Cas9 genetic perturbation and transcriptomic data from thousands of cancer cell lines to predict biomarkers of drug response and cancer dependencies.
The following section will discuss the use of transcriptomics to connect or cluster similar drugs, infer novel drug-target predictions and identify novel drugs that could reverse molecular states (aka drug repositioning) as a cost-effective alternative to the classical drug discovery pipeline.
In 2006, the connectivity map (CMap) pioneered the concept that commonalities in drug mechanism of action can be inferred from similar transcriptional responses upon treating cancer cells with 1,309 bioactive compounds (Lamb et al., 2006). It was superseded by the LINCS dataset expanding to over 1 million gene expression profiles spanning ∼20,000 chemical perturbations. The idea can be summarized as follows: 1) Identifying a new chemical/drug of interest with unknown property or MoA; 2) Experimental design consisting of drug-treated cells vs. untreated or vehicle controls (can be in vitro and in vivo); 3) Extraction of mRNA and capturing global molecular perturbations via RNA-seq or microarray assays; 4) Applying bioinformatic methods (e.g, differential gene expression analysis) to extract a robust drug induced gene expression signature that discriminate treated groups at different dose levels and time points; 5) Applying statistical algorithms (e.g, connectivity mapping) to score up and down-regulated genes with respect to similar expression patterns induced by reference compounds in the connectivity map.
This “guilt by association” concept generates new hypotheses for uncharacterized compounds. This approach has been applied successfully to understand the MoA of celastrol, a natural herbal compound (Engerström, 1990). Celastrol’s gene expression mimicked HSP90 inhibitors and its activity on reducing the androgen receptor-HSP90 interaction has been experimentally validated in the LNCaP prostate cancer cell line (Hieronymus et al., 2006). Although celastrol shared a low chemical similarity with these HSP90 inhibitors, it was intriguing how similarity in transcriptional profiles can be independent of chemical structure (Chen et al., 2015).
Given that structural and molecular layers are complementary, several recent studies have used integrative computational approaches to elucidate drug MoA and propose new repurposing avenues. A versatile method known as Drug Network Fusion (DNF), has fused drug-centric networks relying only on basic drug characteristics such as structural information from pubchem and NCI60, and drug-induced perturbation profiles from LINCS and CMap (Shoemaker, 2006; Subramanian et al., 2017; Kim et al., 2019). DNF taxonomy identified most of the known drug communities, was able to capture on and off-target effects and demonstrated the scalability of unsupervised network methods in the context of drug repurposing (Koleti et al., 2018).
The LINCS database contains both gene expression profiles of ∼20,000 chemical treatments and ∼13,000 shRNAs targeting 3,800 genes across 9 cell lines (El-Hachem et al., 2017a; Subramanian et al., 2017; Koleti et al., 2018) . This setting can be used to infer novel drug-target interactions by correlating expression profiles from a specific gene knock down (KD) with drug-induced expression profiles. Pabon et al. (2018). have trained a random forest classifier (RF) on a set of 29 FDA drugs and found that this machine learning algorithm correctly identified the target in the top 100 for 16 out of 29 FDA approved drugs (55%). They also found that for some compounds such as proteasome inhibitors, chemical-induced perturbations correlated well with the corresponding gene KD (e.g, PSMA1). From a target-centric perspective, and using the RF predictive algorithm, they identified phloretin and RS-39604 as potential inhibitors of HRAS/KRAS respectively and validated their activity at μM concentrations. They further showed that wortmannin, a PI3K inhibitor, binds PDK1. This has been validated by a model of wortmannin bound to the PDK1 catalytic domain and assessed with a PDK1-PIP3 interaction-displacement assay which resulted in a decreased PIP3 interaction with increasing concentrations of wortmannin. In contrast to other classical methods that rely on chemical similarity, methods based on drug-induced molecular perturbations provide an unprecedented opportunity for polypharmacological therapies and repurposing by identifying key pathological pathways shared by multiple disease modules and prioritizing drug targets that can lead to novel therapeutic alternatives (El-Hachem et al., 2017b; Peyvandipour et al., 2018; Chan et al., 2019).
Since the creation of the earlier version of the connectivity map (CMap), drugs that induce an anticorrelated expression profile with respect to a given disease expression signature could be considered as therapeutic agents. Using this algorithmic technique, it was hypothesized that in a given “disease state,” a set of perturbed gene sets or biological pathways can return to a baseline or “normal state” following an effective drug treatment. Sirota et al. (2011), showed that the antiulcer drug cimetidine reduced tumor formation in lung adenocarcinoma using mouse xenograft models. Chen et al. (2017a). identified anthelmintic drugs as potential therapeutic candidates in hepatocellular carcinoma (HCC). The disease signature was built by contrasting gene expression profiles from cancer patients and normal liver tissue from TCGA (Cancer Genome Atlas Research Network et al., 2013). Among the tested FDA-approved drugs, niclosamide showed strong reversal of the gene expression signature in HCC and its efficacy was confirmed in vitro, in patient derived xenografts and in genetic engineered models of HCC. Interestingly, the measured reversal of expression by a compound correlates with its efficacy in the tested cell lines. This systems pharmacology approach is gaining popularity for precision medicine applications (Chen et al., 2017b).
Gene expression (microarray and RNA-sequencing) has been widely harnessed to understand drug-induced transcriptional perturbations and how it implicates drug repurposing, target and biomarker identification. Still, CRISPR/Cas9 functional genomic assays are now powerful tools to identify context dependent drug-targets; its combination with transcriptomics could offer a path forward in drug discovery and development.
The most common approaches to study the causal link between genes and cellular responses involve perturbing normal gene expression using techniques that either: 1) alter the DNA sequence of a gene to inactivate it (e.g., Cas9 or Cas12); 2) alter levels of expression (inactive Cas9 fused with transcriptional activators or repressors, or 3) repress a gene by targeting mRNA transcripts for degradation (shRNAs). The advantages of both CRISPR and shRNA screening technologies are their scalability and flexibility. Using simple rules for the design of gene targeting sequences, most protein-coding genes in the genome can be efficiently perturbed. Thousands of shRNA and CRISPR screens have been reported at the scale of the genome in various contexts, ranging from identifying genes that are essential in malignant cells, to those that mediate resistance to chemotherapy or promote immune responses in vivo (Zuber et al., 2011; Tzelepis et al., 2016; Manguso et al., 2017; Wang et al., 2017; Dong et al., 2019).
In their simplest form, genetic perturbation screens can be performed to identify genes that are essential for cellular growth (Aguirre et al., 2016; Munoz et al., 2016; Tsherniak et al., 2017). The Cancer Dependency Map (https://depmap.org/portal/) is a collaboration between the Broad Institute and the Wellcome Sanger institute (Aguirre et al., 2016; Munoz et al., 2016), which screened the genome of more than a thousand cancer cell lines. The screening of many cancer cell lines from different tissues has enabled the identification of genes that are specifically essential depending on the tissue of origin or mutated oncogenic driver. For example, comparisons of screening results between RAS-mutated and RAS-wild-type leukemic cells identified essential partners of oncogenic RAS(75).
Since pharmaceutical compounds elicit a cellular response characterized by coordinated gene expression programs, genetic perturbation screens performed in the presence of compounds can identify which genes are essential to such responses (Colic and Hart, 2019).
CRISPR-based pharmacogenomic screens are widely used to help identify drug targets and characterize mechanisms of therapeutic resistance or sensitivity. In recent years, genome-wide CRISPR-Cas9 screens have successfully been used to identify candidate targets across diverse cell types. In 2017, a screen by Hou et al. found that loss of the genes SPRY3 and GSK3 drives resistance to FLT3-inhibition in acute myeloid leukemia (AML) (Hou et al., 2017). FLT3-inhibitors are currently in clinical trials as a monotherapy and in combination with chemotherapy for the treatment of AML. However, many patients ultimately develop resistance. Hou et al. (2017). further demonstrated that SPRY3 and GSK3 expression correlates with clinical resistance to the FLT3-inhibitor Quizartinib in primary human AML samples, and inhibition of their downstream pathways re-sensitizes AML cells to Quizartinib in vitro. In addition to providing a novel resistance mechanism to FLT3-inhibition in AML, these hits offered a strategy for targeting of new pathways to lessen resistance.
Dr. Daniel Durocher’s group in Toronto have similarly used genome wide CRISPR screening to study genes driving sensitivity to PARP inhibition in human cancer cell lines. In 2018, Zimmermann et al. (2018). published a series of CRISPR screens demonstrating that loss of the genes coding for RNase H2, an enzyme complex not previously linked to response to PARP-inhibition, is synergistically lethal with PARP-inhibitors (Zimmermann et al., 2018). The authors performed an initial set of CRISPR screens to identify the RNASEH2 genes as powerful sensitizers to PARP-inhibition, followed by a second set of screens in RNase H2-KO cell lines to examine the mechanisms underlying this result. This work demonstrated that deficient RNase H2 activity impairs ribonucleotide excision repair, producing PARP-trapping lesions and causing genomic damage.
Figure 2 demonstrates a typical workflow for CRISPR pharmacogenomic screening. Pooled genetic screens involve transducing cells with a pool of diverse shRNA or sgRNA sequences, targeting a group of genes simultaneously, then measuring their relative abundances over time using next-generation sequencing. When shRNA or sgRNA sequences are delivered within the cells using lentiviruses, the sequences integrate in the genome and are propagated to daughter cells. By counting the abundance of these sequences over time in the population, it is possible to infer their biological effect in various conditions, based on a fixed stoichiometry between shRNA or CRISPR sequences and dividing cells due to lentiviral integration. The optimal experimental design of a pooled genetic perturbation screen aims to minimize stochastic changes in sgRNA abundance due to cell culture or passaging, while maximizing the statistical power to detect biologically meaningful effects. Some important experimental concepts are defined in Table 1.
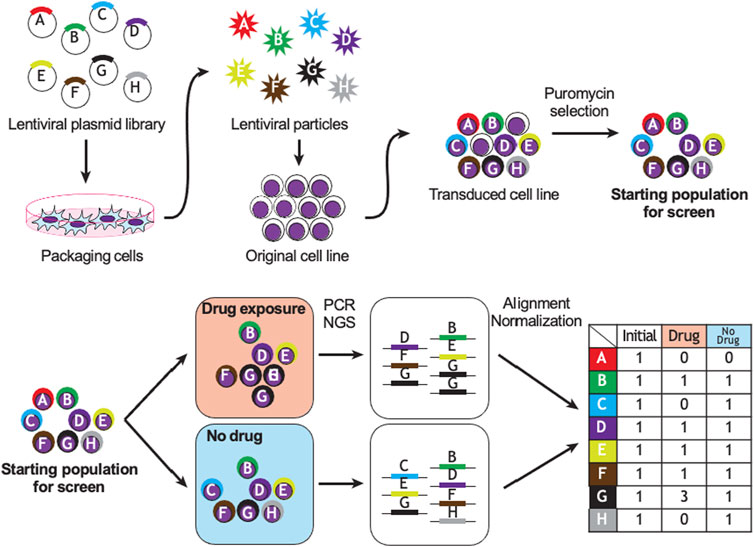
FIGURE 2. Example of CRISPR or shRNA pharmacogenomic screen. Sequence A targets a gene essential to cell survival; B, D, E, F are biologically neutral; G promotes drug resistance and C and H promote drug sensitivity. PCR: polymerase chain reaction, NGS: next-generation sequencing.
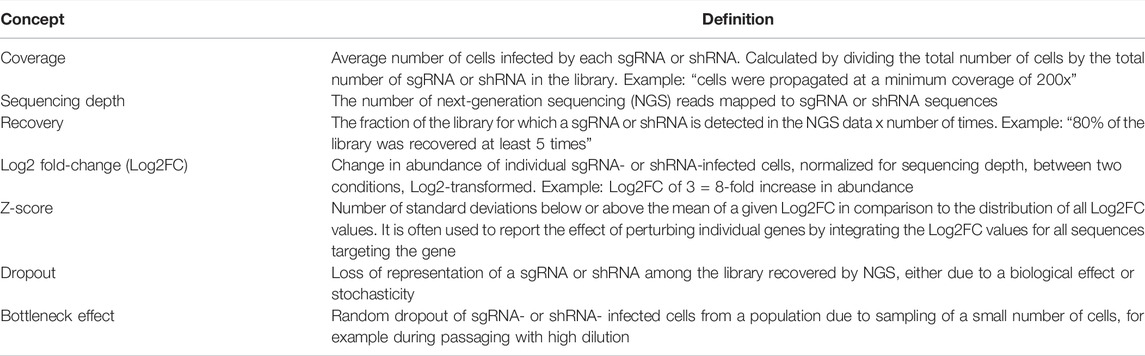
TABLE 1. Frequently used concepts in CRISPR screening.
Methods for CRISPR genetic screening have rapidly improved and new tools and applications are continuously published. Using data from previous genome-wide CRISPR screens, linear regression models and deep learning algorithms have been produced to improve the design of sgRNAs and reduce the potential for off-target effects (Wang D. et al., 2019). Online tools with these models are now available to help predict the on-target activity of the user’s sgRNAs and select sgRNAs for Cas9 enzymes binding a variety of PAM sequences. The selection of sgRNAs with fewer off-target effects considerably improves the coverage of sgRNA libraries and reduces the potential of false positive results. Several validated human genome-wide libraries, such as the GeCKO v2 (Sanjana et al., 2014), Toronto KnockOut (Hart et al., 2017), and Broad Brunello libraries (Doench et al., 2016), have been made publicly available to increase the accessibility of CRISPR screening.
From the standpoint of genetic perturbation screening, it is important to consider the different effects of CRISPR and shRNA on gene expression. CRISPR often leads to bi-allelic gene knockout through the introduction of small insertions or deletion. Consequently, if a given gene, involved in the response of a cell to a pharmaceutical compound, is also essential to survival of the cell, it will likely not be identifiable in a pharmacogenomic CRISPR screen. In contrast, shRNAs have a partial and varied effect on mRNA transcript abundance, so they might be better suited for the study of the subset of genes that are essential to survival of the cell. However, a significant drawback for shRNA screening is the greater occurrence of “off-target” effects with shRNA: the targeting sequence of shRNAs may affect other non-intended mRNA transcripts, thus affecting the interpretation of some experimental results. To circumvent this issue, the CRISPR system can be repurposed to transiently enhance or repress gene expression instead of producing a gene knockout (Maeder et al., 2013; Qi et al., 2013). The CRISPR activation (CRISPRa) system involves the fusion of deactivated Cas9 to a transcriptional activator domain. The deactivated Cas9 no longer cleaves the DNA; instead, the activator domain recruits the transcriptional machinery to enhance expression of the target gene (Maeder et al., 2013). Similarly, CRISPR interference (CRISPRi) is comprised of inactive Cas9 fused to a repressor domain which acts to temporarily reduce gene expression (Qi et al., 2013). In some cases, CRISPRi may be preferable to the traditional CRISPR system which can generate multiple DNA breaks and induce a DNA damage response (Haapaniemi et al., 2018).
A variety of publicly available resources exist for the analysis of CRISPR screening data. The complete analysis of CRISPR-Cas9 screens requires multiple steps after NGS, including data normalization, quality control, and identification of positively or negatively selected genes and relevant biological pathways (Li et al., 2014). Some of the most commonly used computational tools for CRISPR data analysis are the MAGeCK, BAGEL, CERES, and drugZ algorithms. These methods are based on different statistical approaches and are each suited to specific experimental designs.
The MAGeCK (Model-based Analysis of Genome-wide CRISPR-Cas9 Knockout) algorithm was published in 2014 and is one of the most popular comprehensive methods for analyzing CRISPR data. MAGeCK uses a negative binomial model to test whether sgRNAs differ significantly between conditions and produces a list of FDR-adjusted hits (Li et al., 2014). Two updated versions of MAGeCK, MAGeCK-VISPR and MAGeCK-Flute, were released in 2015 and 2019 by the same group (Li et al., 2015; Wang B. et al., 2019). The MAGeCK-Flute package adopts the MAGeCK version suitable for the selected experimental design and offers pathway enrichment analysis and data visualization functions (Wang B. et al., 2019).
The BAGEL (Bayesian Analysis of Gene EssentiaLity) pipeline was developed to leverage data from previous CRISPR screens. BAGEL uses essential and non-essential reference gene sets to identify novel essential genes in a screen and provides a Bayes factor for each gene (Hart and Moffat, 2016). Although the BAGEL algorithm is highly sensitive, the reference gene list requirement limits its use.
Many cancer cell lines show high copy number variation (CNVs). In CRISPR-cas9 screening, this presents an issue as sgRNA targets within high CNV regions may cause multiple DNA double-stranded breaks and cell death independent of gene essentiality (Meyers et al., 2017). CERES was designed to compensate for this phenomenon by normalizing changes specific to a cancer cell line. This reduces the number of false positives; however, the algorithm requires CNV profiles from multiple cell lines which may not be available for all screens (Meyers et al., 2017).
The drugZ algorithm was developed specifically for the analysis of pharmacogenomic CRISPR screens. DrugZ calculates gene-level normalized Z-scores and FDR values, and can be applied to identify genes involved in conferring drug resistance and sensitivity (Colic et al., 2019).
Though widely used, a shortcoming of the described packages is the required programming knowledge. More recently tools such as Cas-analyzer and PinAPL-Py have been published to provide complete web-based CRISPR analysis pipelines for researchers with less computational experience (Park et al., 2017; Spahn et al., 2017).
Although the majority of CRISPR-Cas9 screens are performed in vitro, the technology has also been adapted for in vivo use (Chow and Chen, 2018). In vivo screening provides a better disease model in contrast to in vitro cultures and more accurately recapitulates the microenvironment of the chosen cell type. Advanced forms of in vivo screening involve the use of Cas9 transgenic animals. In these screens, the sgRNAs are intravenously injected or directly administered to the target site within the animal and act directly within the chosen tissue (Chow and Chen, 2018). In immunocompetent animals, this system also mimics the immune involvement of the target site. However, this method has the significant challenge of achieving the desired number of transfected cells, sgRNA coverage and MOI within the chosen tissue which may be poorly accessible (Chow and Chen, 2018). Another method of in vivo screening is the use of indirect or transplant screens, which are performed by transplanting knockout cells generated in vitro. Transplant screens similarly involve the target site microenvironment; however, the engraftment rates of the transplanted cells are highly variable, and some models may require large numbers of cells to be successful. Indirect screens also often require immune deficient hosts which less faithfully reflects the tissue microenvironment and disease pathogenesis (Chow and Chen, 2018).
The accumulated knowledge gained on disease pathophysiology combined to the urgent need for new small molecules with outstanding therapeutic potential highlight the importance and potential of HTS. Although biochemical-based HTS allow the discovery of chemotypes with known mode of action or target, phenotypic screening provides a list of compounds displaying a desired biological effect in the absence of target(s) knowledge. Besides, the identification of genes or phenotypes through pharmacogenomic or phenotypic screens do not always provide information concerning the pharmacological properties of the identified/lead compound. Thus, phenotypic screening requires almost always complementary biochemical approaches to fully characterize the molecular target binding and MoA of the compound of interest. A possible combinatory strategy or alternative would consist of designing a library of competitive antagonists or negative allosteric modulators prior to their screening in a phenotypic assay. The latter approach is particularly interesting as negative allosteric modulators are usually known for their higher target selectivity compared to competitive antagonists. This would then result in better selectivity and less side effects while exhibiting the desired biological effect (Ni et al., 2019; Slosky et al., 2021). Simultaneously, advancements in the field of systems biology have led to the development of various strategies capable of linking chemotypes with modulated target(s), whereas CRISPR and shRNA pharmacogenomic screens can identify genes essential to the pharmacological property of the compound. CRISPR and shRNA screens performed in the context of drug exposure are especially useful to identify biological pathways in cellulo that modulate sensitivity or resistance, which can inform predictive models of patient response (when gene expression data is available) or the development of pharmacological synergies (when “druggable” targets are identified).These powerful and synergistic approaches have led to the approval of several new drugs and herald a bright future for cancer drug development (Moffat et al., 2014).
NS and J-PB wrote the HTS section. NE-H wrote the section related to transcriptomics. KF and FM contributed to the section regarding the CRISPR screens. MR supervised the writing process.
The work summarized in this review was supported by the Merck Frosst Start-up funds provided by Université de Montréal to MR. FM holds a Junior I Award from the Fonds de la Recherche en Santé du Québec and is recipient of a transition grant from the Cole Foundation.
FM received consultancy fees from Sanofi-Genzyme.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors thank W. Saad and F. Mardani for critical reading of the review.
Abbott, A. (2003). With Your Genes? Take One of These, Three Times a Day. Nature 425 (6960), 760–762. doi:10.1038/425760a
Abusarah, J., Cui, Y., El-Hachem, N., El-Kadiry, A. E., Hammond-Martel, I., Wurtele, H., et al. (2021). TACIMA-218: A Novel Pro-Oxidant Agent Exhibiting Selective Antitumoral Activity. Mol. Cancer Ther. 20 (1), 37–49. doi:10.1158/1535-7163.MCT-20-0333
Aguirre, A. J., Meyers, R. M., Weir, B. A., Vazquez, F., Zhang, C. Z., Ben-David, U., et al. (2016). Genomic Copy Number Dictates a Gene-Independent Cell Response to CRISPR/Cas9 Targeting. Cancer Discov. 6 (8), 914–929. doi:10.1158/2159-8290.CD-16-0154
Ashouri, J. F., and Weiss, A. (2017). Endogenous Nur77 Is a Specific Indicator of Antigen Receptor Signaling in Human T and B Cells. J. Immunol. 198 (2), 657–668. doi:10.4049/jimmunol.1601301
Baccelli, I., Gareau, Y., Lehnertz, B., Gingras, S., Spinella, J. F., Corneau, S., et al. (2019). Mubritinib Targets the Electron Transport Chain Complex I and Reveals the Landscape of OXPHOS Dependency in Acute Myeloid Leukemia. Cancer Cell 36 (1), 84–e8. doi:10.1016/j.ccell.2019.06.003
Bailey, M. H., Tokheim, C., Porta-Pardo, E., Sengupta, S., Bertrand, D., Weerasinghe, A., et al. (2018). Comprehensive Characterization of Cancer Driver Genes and Mutations. Cell 174 (2), 1034–1035. doi:10.1016/j.cell.2018.07.034
Barretina, J., Caponigro, G., Stransky, N., Venkatesan, K., Margolin, A. A., Kim, S., et al. (2012). The Cancer Cell Line Encyclopedia Enables Predictive Modelling of Anticancer Drug Sensitivity. Nature 483 (7391), 603–607. doi:10.1038/nature11003
Barrett, T., Wilhite, S. E., Ledoux, P., Evangelista, C., Kim, I. F., Tomashevsky, M., et al. (2013). NCBI GEO: Archive for Functional Genomics Data Sets-Uupdate. Nucleic Acids Res. 41 (Database issue), D991–D995. doi:10.1093/nar/gks1193
Bertacchini, J., Guida, M., Accordi, B., Mediani, L., Martelli, A. M., Barozzi, P., et al. (2014). Feedbacks and Adaptive Capabilities of the PI3K/Akt/mTOR axis in Acute Myeloid Leukemia Revealed by Pathway Selective Inhibition and Phosphoproteome Analysis. Leukemia 28 (11), 2197–2205. doi:10.1038/leu.2014.123
Bycroft, C., Freeman, C., Petkova, D., Band, G., Elliott, L. T., Sharp, K., et al. (2018). The UK Biobank Resource with Deep Phenotyping and Genomic Data. Nature 562 (7726), 203–209. doi:10.1038/s41586-018-0579-z
Cancer Genome Atlas Research Network Weinstein, J. N., Weinstein, J. N., Collisson, E. A., Mills, G. B., Shaw, K. R., Ozenberger, B. A., et al. (2013). The Cancer Genome Atlas Pan-Cancer analysis project. Nat. Genet. 45 (10), 1113–1120. doi:10.1038/ng.2764
Chan, J., Wang, X., Turner, J. A., Baldwin, N. E., and Gu, J. (2019). Breaking the Paradigm: Dr Insight Empowers Signature-free, Enhanced Drug Repurposing. Bioinformatics 35 (16), 2818–2826. doi:10.1093/bioinformatics/btz006
Chen, B., and Butte, A. J. (2016). Leveraging Big Data to Transform Target Selection and Drug Discovery. Clin. Pharmacol. Ther. 99 (3), 285–297. doi:10.1002/cpt.318
Chen, C. Z., Kulakova, L., Southall, N., Marugan, J. J., Galkin, A., Austin, C. P., et al. (2011). High-throughput Giardia Lamblia Viability Assay Using Bioluminescent ATP Content Measurements. Antimicrob. Agents Chemother. 55 (2), 667–675. doi:10.1128/AAC.00618-10
Chen, C. Z., Southall, N., Galkin, A., Lim, K., Marugan, J. J., Kulakova, L., et al. (2012). A Homogenous Luminescence Assay Reveals Novel Inhibitors for Giardia Lamblia Carbamate Kinase. Curr. Chem. Genomics 6, 93–102. doi:10.2174/1875397301206010093
Chen, B., Greenside, P., Paik, H., Sirota, M., Hadley, D., and Butte, A. J. (2015). Relating Chemical Structure to Cellular Response: An Integrative Analysis of Gene Expression, Bioactivity, and Structural Data Across 11,000 Compounds. CPT Pharmacometrics Syst. Pharmacol. 4 (10), 576–584. doi:10.1002/psp4.12009
Chen, B., Wei, W., Ma, L., Yang, B., Gill, R. M., Chua, M. S., et al. (2017a). Computational Discovery of Niclosamide Ethanolamine, a Repurposed Drug Candidate that Reduces Growth of Hepatocellular Carcinoma Cells In Vitro and in Mice by Inhibiting Cell Division Cycle 37 Signaling. Gastroenterology 152 (8), 2022–2036. doi:10.1053/j.gastro.2017.02.039
Chen, B., Ma, L., Paik, H., Sirota, M., Wei, W., Chua, M. S., et al. (2017b). Reversal of Cancer Gene Expression Correlates with Drug Efficacy and Reveals Therapeutic Targets. Nat. Commun. 8, 16022. doi:10.1038/ncomms16022
Chow, R. D., and Chen, S. (2018). Cancer CRISPR Screens In Vivo. Trends Cancer 4 (5), 349–358. doi:10.1016/j.trecan.2018.03.002
Colic, M., and Hart, T. (2019). Chemogenetic Interactions in Human Cancer Cells. Comput. Struct. Biotechnol. J. 17, 1318–1325. doi:10.1016/j.csbj.2019.09.006
Colic, M., Wang, G., Zimmermann, M., Mascall, K., McLaughlin, M., Bertolet, L., et al. (2019). Identifying Chemogenetic Interactions from CRISPR Screens with drugZ. Genome Med. 11 (1), 52. doi:10.1186/s13073-019-0665-3
Dao, F. T., Wang, J., Yang, L., and Qin, Y. Z. (2021). Development of a Poor-Prognostic-Mutations Derived Immune Prognostic Model for Acute Myeloid Leukemia. Sci. Rep. 11 (1), 4856. doi:10.1038/s41598-021-84190-0
Ding, L., Ley, T. J., Larson, D. E., Miller, C. A., Koboldt, D. C., Welch, J. S., et al. (2012). Clonal Evolution in Relapsed Acute Myeloid Leukaemia Revealed by Whole-Genome Sequencing. Nature 481 (7382), 506–510. doi:10.1038/nature10738
Doench, J. G., Fusi, N., Sullender, M., Hegde, M., Vaimberg, E. W., Donovan, K. F., et al. (2016). Optimized sgRNA Design to Maximize Activity and Minimize Off-Target Effects of CRISPR-Cas9. Nat. Biotechnol. 34 (2), 184–191. doi:10.1038/nbt.3437
Dong, M. B., Wang, G., Chow, R. D., Ye, L., Zhu, L., Dai, X., et al. (2019). Systematic Immunotherapy Target Discovery Using Genome-Scale In Vivo CRISPR Screens in CD8 T Cells. Cell 178 (5), 1189–1204.e23. doi:10.1016/j.cell.2019.07.044
Druker, B. J. (2008). Translation of the Philadelphia Chromosome into Therapy for CML. Blood 112 (13), 4808–4817. doi:10.1182/blood-2008-07-077958
El-Hachem, N., Gendoo, D. M. A., Ghoraie, L. S., Safikhani, Z., Smirnov, P., Chung, C., et al. (2017). Integrative Cancer Pharmacogenomics to Infer Large-Scale Drug Taxonomy. Cancer Res. 77 (11), 3057–3069. doi:10.1158/0008-5472.CAN-17-0096
El-Hachem, N., Ba-Alawi, W., Smith, I., Mer, A. S., and Haibe-Kains, B. (2017). Integrative Cancer Pharmacogenomics to Establish Drug Mechanism of Action: Drug Repurposing. Pharmacogenomics 18 (16), 1469–1472. doi:10.2217/pgs-2017-0132
El-Kadiry, A. E., Abusarah, J., Cui, Y. E., El-Hachem, N., Hammond-Martel, I., Wurtele, H., et al. (2020). A Novel Sulfonyl-Based Small Molecule Exhibiting Anti-cancer Properties. Front. Pharmacol. 11, 237. doi:10.3389/fphar.2020.00237
Engerström, I. W. (1990). Rett Syndrome in Sweden. Neurodevelopment--Disability--Pathophysiology. Acta Paediatr. Scand. Suppl. 369, 1–60.
Ewan, K., Pajak, B., Stubbs, M., Todd, H., Barbeau, O., Quevedo, C., et al. (2010). A Useful Approach to Identify Novel Small-Molecule Inhibitors of Wnt-Dependent Transcription. Cancer Res. 70 (14), 5963–5973. doi:10.1158/0008-5472.CAN-10-1028
Faust, N., Varas, F., Kelly, L. M., Heck, S., and Graf, T. (2000). Insertion of Enhanced Green Fluorescent Protein Into the Lysozyme Gene Creates Mice with Green Fluorescent Granulocytes and Macrophages. Blood 96 (2), 719–726. doi:10.1182/blood.v96.2.719
Fouda, A., Tahsini, M., Khodayarian, F., Al-Nafisah, F., and Rafei, M. (2017). A Fluorescence-Based Lymphocyte Assay Suitable for High-throughput Screening of Small Molecules. J. Vis. Exp. 121, 55199. doi:10.3791/55199
Giacomini, K. M., Yee, S. W., Ratain, M. J., Weinshilboum, R. M., Kamatani, N., and Nakamura, Y. (2012). Pharmacogenomics and Patient Care: One Size Does Not Fit All. Sci. Transl. Med. 4 (153), 153ps18. doi:10.1126/scitranslmed.3003471
Gristina, V., La Mantia, M., Iacono, F., Galvano, A., Russo, A., and Bazan, V. (2020). The Emerging Therapeutic Landscape of ALK Inhibitors in Non-Small Cell Lung Cancer. Pharm. (Basel) 13 (12), 474. doi:10.3390/ph13120474
GTEx Consortium (2015). Human Genomics. The Genotype-Tissue Expression (GTEx) Pilot Analysis: Multitissue Gene Regulation in Humans. Science 348 (6235), 648–660. doi:10.1126/science.1262110
Haapaniemi, E., Botla, S., Persson, J., Schmierer, B., and Taipale, J. (2018). CRISPR-Cas9 Genome Editing Induces a p53-Mediated DNA Damage Response. Nat. Med. 24 (7), 927–930. doi:10.1038/s41591-018-0049-z
Hanahan, D., and Weinberg, R. A. (2000). The Hallmarks of Cancer. Cell 100 (1), 57–70. doi:10.1016/s0092-8674(00)81683-9
Hart, T., and Moffat, J. (2016). BAGEL: a Computational Framework for Identifying Essential Genes from Pooled Library Screens. BMC Bioinforma. 17, 164. doi:10.1186/s12859-016-1015-8
Hart, T., Tong, A. H. Y., Chan, K., Van Leeuwen, J., Seetharaman, A., Aregger, M., et al. (2017). Evaluation and Design of Genome-Wide CRISPR/SpCas9 Knockout Screens. G3 (Bethesda) 7 (8), 2719–2727. doi:10.1534/g3.117.041277
Hieronymus, H., Lamb, J., Ross, K. N., Peng, X. P., Clement, C., Rodina, A., et al. (2006). Gene Expression Signature-Based Chemical Genomic Prediction Identifies a Novel Class of HSP90 Pathway Modulators. Cancer Cell 10 (4), 321–330. doi:10.1016/j.ccr.2006.09.005
Hou, P., Wu, C., Wang, Y., Qi, R., Bhavanasi, D., Zuo, Z., et al. (2017). A Genome-Wide CRISPR Screen Identifies Genes Critical for Resistance to FLT3 Inhibitor AC220. Cancer Res. 77 (16), 4402–4413. doi:10.1158/0008-5472.CAN-16-1627
Hou, S., Tiriac, H., Sridharan, B. P., Scampavia, L., Madoux, F., Seldin, J., et al. (2018). Advanced Development of Primary Pancreatic Organoid Tumor Models for High-Throughput Phenotypic Drug Screening. SLAS Discov. 23 (6), 574–584. doi:10.1177/2472555218766842
Iorio, F., Knijnenburg, T. A., Vis, D. J., Bignell, G. R., Menden, M. P., Schubert, M., et al. (2016). A Landscape of Pharmacogenomic Interactions in Cancer. Cell 166 (3), 740–754. doi:10.1016/j.cell.2016.06.017
Karczewski, K. J., Daneshjou, R., and Altman, R. B. (2012). Chapter 7: Pharmacogenomics. PLoS Comput. Biol. 8 (12), e1002817. doi:10.1371/journal.pcbi.1002817
Khera, A. V., and Ridker, P. M. (2017). Demystifying HDL Cholesterol-A "Human Knockout" to the Rescue? Clin. Chem. 63 (1), 33–36. doi:10.1373/clinchem.2016.258244
Kim, S., Chen, J., Cheng, T., Gindulyte, A., He, J., He, S., et al. (2019). PubChem 2019 Update: Improved Access to Chemical Data. Nucleic Acids Res. 47 (D1), D1102–D9. doi:10.1093/nar/gky1033
Koleti, A., Terryn, R., Stathias, V., Chung, C., Cooper, D. J., Turner, J. P., et al. (2018). Data Portal for the Library of Integrated Network-Based Cellular Signatures (LINCS) Program: Integrated Access to Diverse Large-Scale Cellular Perturbation Response Data. Nucleic Acids Res. 46 (D1), D558–D66. doi:10.1093/nar/gkx1063
Kroon, E., Krosl, J., Thorsteinsdottir, U., Baban, S., Buchberg, A. M., and Sauvageau, G. (1998). Hoxa9 Transforms Primary Bone Marrow Cells Through Specific Collaboration with Meis1a but Not Pbx1b. EMBO J. 17 (13), 3714–3725. doi:10.1093/emboj/17.13.3714
Lamb, J., Crawford, E. D., Peck, D., Modell, J. W., Blat, I. C., Wrobel, M. J., et al. (2006). The Connectivity Map: Using Gene-Expression Signatures to Connect Small Molecules, Genes, and Disease. Science 313 (5795), 1929–1935. doi:10.1126/science.1132939
Li, W., Xu, H., Xiao, T., Cong, L., Love, M. I., Zhang, F., et al. (2014). MAGeCK Enables Robust Identification of Essential Genes From Genome-Scale CRISPR/Cas9 Knockout Screens. Genome Biol. 15 (12), 554. doi:10.1186/s13059-014-0554-4
Li, W., Köster, J., Xu, H., Chen, C. H., Xiao, T., Liu, J. S., et al. (2015). Quality Control, Modeling, and Visualization of CRISPR Screens with MAGeCK-VISPR. Genome Biol. 16, 281. doi:10.1186/s13059-015-0843-6
Liu, Q., and Wang, H. G. (2012). Anti-Cancer Drug Discovery and Development: Bcl-2 Family Small Molecule Inhibitors. Commun. Integr. Biol. 5 (6), 557–565. doi:10.4161/cib.21554
Liu, B., Li, S., and Hu, J. (2004). Technological Advances in High-Throughput Screening. Am. J. Pharmacogenomics 4 (4), 263–276. doi:10.2165/00129785-200404040-00006
Liu, J., Lichtenberg, T., Hoadley, K. A., Poisson, L. M., Lazar, A. J., Cherniack, A. D., et al. (2018). An Integrated TCGA Pan-Cancer Clinical Data Resource to Drive High-Quality Survival Outcome Analytics. Cell 173 (2), 400–416.e11. doi:10.1016/j.cell.2018.02.052
Macarron, R., Banks, M. N., Bojanic, D., Burns, D. J., Cirovic, D. A., Garyantes, T., et al. (2011). Impact of High-throughput Screening in Biomedical Research. Nat. Rev. Drug Discov. 10 (3), 188–195. doi:10.1038/nrd3368
Maeder, M. L., Linder, S. J., Cascio, V. M., Fu, Y., Ho, Q. H., and Joung, J. K. (2013). CRISPR RNA-Guided Activation of Endogenous Human Genes. Nat. Methods 10 (10), 977–979. doi:10.1038/nmeth.2598
Manguso, R. T., Pope, H. W., Zimmer, M. D., Brown, F. D., Yates, K. B., Miller, B. C., et al. (2017). In Vivo CRISPR Screening Identifies Ptpn2 as a Cancer Immunotherapy Target. Nature 547 (7664), 413–418. doi:10.1038/nature23270
Meyers, R. M., Bryan, J. G., McFarland, J. M., Weir, B. A., Sizemore, A. E., Xu, H., et al. (2017). Computational Correction of Copy Number Effect Improves Specificity of CRISPR-Cas9 Essentiality Screens in Cancer Cells. Nat. Genet. 49 (12), 1779–1784. doi:10.1038/ng.3984
Michailidou, K., Hall, P., Gonzalez-Neira, A., Ghoussaini, M., Dennis, J., Milne, R. L., et al. (2013). Large-Scale Genotyping Identifies 41 New Loci Associated With Breast Cancer Risk. Nat. Genet. 45 (4), 35361e1–612. doi:10.1038/ng.2563
Moffat, J. G., Rudolph, J., and Bailey, D. (2014). Phenotypic Screening in Cancer Drug Discovery - Past, Present and Future. Nat. Rev. Drug Discov. 13 (8), 588–602. doi:10.1038/nrd4366
Mosmann, T. (1983). Rapid Colorimetric Assay for Cellular Growth and Survival: Application to Proliferation and Cytotoxicity Assays. J. Immunol. Methods 65 (1-2), 55–63. doi:10.1016/0022-1759(83)90303-4
Munoz, D. M., Cassiani, P. J., Li, L., Billy, E., Korn, J. M., Jones, M. D., et al. (2016). CRISPR Screens Provide a Comprehensive Assessment of Cancer Vulnerabilities but Generate False-Positive Hits for Highly Amplified Genomic Regions. Cancer Discov. 6 (8), 900–913. doi:10.1158/2159-8290.CD-16-0178
Ni, D., Liu, N., and Sheng, C. (2019). Allosteric Modulators of Protein-Protein Interactions (PPIs). Adv. Exp. Med. Biol. 1163, 313–334. doi:10.1007/978-981-13-8719-7_13
Pabon, N. A., Xia, Y., Estabrooks, S. K., Ye, Z., Herbrand, A. K., Süß, E., et al. (2018). Predicting Protein Targets for Drug-Like Compounds Using Transcriptomics. PLoS Comput. Biol. 14 (12), e1006651. doi:10.1371/journal.pcbi.1006651
Park, J., Lim, K., Kim, J. S., and Bae, S. (2017). Cas-Analyzer: an Online Tool for Assessing Genome Editing Results Using NGS Data. Bioinformatics 33 (2), 286–288. doi:10.1093/bioinformatics/btw561
Peyvandipour, A., Saberian, N., Shafi, A., Donato, M., and Draghici, S. (2018). A Novel Computational Approach for Drug Repurposing Using Systems Biology. Bioinformatics 34 (16), 2817–2825. doi:10.1093/bioinformatics/bty133
Qi, L. S., Larson, M. H., Gilbert, L. A., Doudna, J. A., Weissman, J. S., Arkin, A. P., et al. (2013). Repurposing CRISPR as an RNA-Guided Platform for Sequence-Specific Control of Gene Expression. Cell 152 (5), 1173–1183. doi:10.1016/j.cell.2013.02.022
Ramaekers, F. C., and Bosman, F. T. (2004). The Cytoskeleton and Disease. J. Pathol. 204 (4), 351–354. doi:10.1002/path.1665
Rashkin, S. R., Graff, R. E., Kachuri, L., Thai, K. K., Alexeeff, S. E., Blatchins, M. A., et al. (2020). Pan-Cancer Study Detects Genetic Risk Variants and Shared Genetic Basis in Two Large Cohorts. Nat. Commun. 11 (1), 4423. doi:10.1038/s41467-020-18246-6
Rathert, P., Roth, M., Neumann, T., Muerdter, F., Roe, J. S., Muhar, M., et al. (2015). Transcriptional Plasticity Promotes Primary and Acquired Resistance to BET Inhibition. Nature 525 (7570), 543–547. doi:10.1038/nature14898
Sanjana, N. E., Shalem, O., and Zhang, F. (2014). Improved Vectors and Genome-Wide Libraries for CRISPR Screening. Nat. Methods 11 (8), 783–784. doi:10.1038/nmeth.3047
Shoemaker, R. H. (2006). The NCI60 Human Tumour Cell Line Anticancer Drug Screen. Nat. Rev. Cancer 6 (10), 813–823. doi:10.1038/nrc1951
Sirota, M., Dudley, J. T., Kim, J., Chiang, A. P., Morgan, A. A., Sweet-Cordero, A., et al. (2011). Discovery and Preclinical Validation of Drug Indications Using Compendia of Public Gene Expression Data. Sci. Transl. Med. 3 (96), 96ra77. doi:10.1126/scitranslmed.3001318
Slosky, L. M., Caron, M. G., and Barak, L. S. (2021). Biased Allosteric Modulators: New Frontiers in GPCR Drug Discovery. Trends Pharmacol. Sci. 42 (4), 283–299. doi:10.1016/j.tips.2020.12.005
Spahn, P. N., Bath, T., Weiss, R. J., Kim, J., Esko, J. D., Lewis, N. E., et al. (2017). PinAPL-Py: A Comprehensive Web-Application for the Analysis of CRISPR/Cas9 Screens. Sci. Rep. 7 (1), 15854. doi:10.1038/s41598-017-16193-9
Stevens, B. M., Jones, C. L., Pollyea, D. A., Culp-Hill, R., D'Alessandro, A., Winters, A., et al. (2020). Fatty Acid Metabolism Underlies Venetoclax Resistance in Acute Myeloid Leukemia Stem Cells. Nat. Cancer 1 (12), 1176–1187. doi:10.1038/s43018-020-00126-z
Subramanian, A., Narayan, R., Corsello, S. M., Peck, D. D., Natoli, T. E., Lu, X., et al. (2017). A Next Generation Connectivity Map: L1000 Platform and the First 1,000,000 Profiles. Cell 171 (6), 1437–e17. doi:10.1016/j.cell.2017.10.049
Swinney, D. C., and Anthony, J. (2011). How Were New Medicines Discovered? Nat. Rev. Drug Discov. 10 (7), 507–519. doi:10.1038/nrd3480
Sykes, D. B., Kfoury, Y. S., Mercier, F. E., Wawer, M. J., Law, J. M., Haynes, M. K., et al. (2016). Inhibition of Dihydroorotate Dehydrogenase Overcomes Differentiation Blockade in Acute Myeloid Leukemia. Cell 167 (1), 171–e15. doi:10.1016/j.cell.2016.08.057
Takenaka, T. (2001). Classical vs Reverse Pharmacology in Drug Discovery. BJU Int. 88 Suppl 2, 7–10. discussion 49-50. doi:10.1111/j.1464-410x.2001.00112.x
Titus, S. A., Southall, N., Marugan, J., Austin, C. P., and Zheng, W. (2012). High-Throughput Multiplexed Quantitation of Protein Aggregation and Cytotoxicity in a Huntington's Disease Model. Curr. Chem. Genomics 6, 79–86. doi:10.2174/1875397301206010079
Tran, C., Ouk, S., Clegg, N. J., Chen, Y., Watson, P. A., Arora, V., et al. (2009). Development of a Second-Generation Antiandrogen for Treatment of Advanced Prostate Cancer. Science 324 (5928), 787–790. doi:10.1126/science.1168175
Tsherniak, A., Vazquez, F., Montgomery, P. G., Weir, B. A., Kryukov, G., Cowley, G. S., et al. (2017). Defining a Cancer Dependency Map. Cell 170 (3), 564–576.e16. doi:10.1016/j.cell.2017.06.010
Tzelepis, K., Koike-Yusa, H., De Braekeleer, E., Li, Y., Metzakopian, E., Dovey, O. M., et al. (2016). A CRISPR Dropout Screen Identifies Genetic Vulnerabilities and Therapeutic Targets in Acute Myeloid Leukemia. Cell Rep. 17 (4), 1193–1205. doi:10.1016/j.celrep.2016.09.079
Vamathevan, J., Clark, D., Czodrowski, P., Dunham, I., Ferran, E., Lee, G., et al. (2019). Applications of Machine Learning in Drug Discovery and Development. Nat. Rev. Drug Discov. 18 (6), 463–477. doi:10.1038/s41573-019-0024-5
van Galen, P., Hovestadt, V., Wadsworth Ii, M. H., Hughes, T. K., Griffin, G. K., Battaglia, S., et al. (2019). Single-Cell RNA-Seq Reveals AML Hierarchies Relevant to Disease Progression and Immunity. Cell 176 (6), 1265–e24. doi:10.1016/j.cell.2019.01.031
Vincent, F., Loria, P., Pregel, M., Stanton, R., Kitching, L., Nocka, K., et al. (2015). Developing Predictive Assays: The Phenotypic Screening "Rule of 3". Sci. Transl. Med. 7 (293), 293ps15. doi:10.1126/scitranslmed.aab1201
Visscher, P. M., Wray, N. R., Zhang, Q., Sklar, P., McCarthy, M. I., Brown, M. A., et al. (2017). 10 Years of GWAS Discovery: Biology, Function, and Translation. Am. J. Hum. Genet. 101 (1), 5–22. doi:10.1016/j.ajhg.2017.06.005
Wang, B., Wang, M., Zhang, W., Xiao, T., Chen, C. H., Wu, A., et al. (2019). Integrative Analysis of Pooled CRISPR Genetic Screens Using MAGeCKFlute. Nat. Protoc. 14 (3), 756–780. doi:10.1038/s41596-018-0113-7
Wang, D., Zhang, C., Wang, B., Li, B., Wang, Q., Liu, D., et al. (2019). Optimized CRISPR Guide RNA Design for Two High-Fidelity Cas9 Variants by Deep Learning. Nat. Commun. 10 (1), 4284. doi:10.1038/s41467-019-12281-8
Wang, T., Yu, H., Hughes, N. W., Liu, B., Kendirli, A., Klein, K., et al. (2017). Gene Essentiality Profiling Reveals Gene Networks and Synthetic Lethal Interactions with Oncogenic Ras. Cell 168 (5), 890–e15. doi:10.1016/j.cell.2017.01.013
Waring, M. J., Arrowsmith, J., Leach, A. R., Leeson, P. D., Mandrell, S., Owen, R. M., et al. (2015). An Analysis of the Attrition of Drug Candidates from Four Major Pharmaceutical Companies. Nat. Rev. Drug Discov. 14 (7), 475–486. doi:10.1038/nrd4609
Whiteside, T. L. (2008). The Tumor Microenvironment and its Role in Promoting Tumor Growth. Oncogene 27 (45), 5904–5912. doi:10.1038/onc.2008.271
Yang, W., Soares, J., Greninger, P., Edelman, E. J., Lightfoot, H., Forbes, S., et al. (2013). Genomics of Drug Sensitivity in Cancer (GDSC): a resource for therapeutic biomarker discovery in cancer cells. Nucleic Acids Res. 41 (Database issue), D955–D961. doi:10.1093/nar/gks1111
Zhan, T., Rindtorff, N., and Boutros, M. (2017). Wnt Signaling in Cancer. Oncogene 36 (11), 1461–1473. doi:10.1038/onc.2016.304
Zhang, H., Ahearn, T. U., Lecarpentier, J., Barnes, D., Beesley, J., Qi, G., et al. (2020). Genome-Wide Association Study Identifies 32 Novel Breast Cancer Susceptibility Loci from Overall and Subtype-Specific Analyses. Nat. Genet. 52 (6), 572–581. doi:10.1038/s41588-020-0609-2
Zheng, C. J., Han, L. Y., Yap, C. W., Ji, Z. L., Cao, Z. W., and Chen, Y. Z. (2006). Therapeutic Targets: Progress of their Exploration and Investigation of their Characteristics. Pharmacol. Rev. 58 (2), 259–279. doi:10.1124/pr.58.2.4
Zheng, W., Thorne, N., and McKew, J. C. (2013). Phenotypic Screens as a Renewed Approach for Drug Discovery. Drug Discov. Today 18 (21-22), 1067–1073. doi:10.1016/j.drudis.2013.07.001
Zimmermann, M., Murina, O., Reijns, M. A. M., Agathanggelou, A., Challis, R., Tarnauskaitė, Ž., et al. (2018). CRISPR Screens Identify Genomic Ribonucleotides as a Source of PARP-Trapping Lesions. Nature 559 (7713), 285–289. doi:10.1038/s41586-018-0291-z
Zock, J. M. (2009). Applications of High Content Screening in Life Science Research. Comb. Chem. High. Throughput Screen 12 (9), 870–876. doi:10.2174/138620709789383277
Zuber, J., Rappaport, A. R., Luo, W., Wang, E., Chen, C., Vaseva, A. V., et al. (2011). An Integrated Approach to Dissecting Oncogene Addiction Implicates A Myb-Coordinated Self-Renewal Program as Essential for Leukemia Maintenance. Genes. Dev. 25 (15), 1628–1640. doi:10.1101/gad.17269211
AML acute myeloid leukemia
BAGEL bayesian analysis of gene essentiality
BCR B-cell receptor
CCLE cancer cell encyclopedia
CMap connectivity map
CNV copy number variation
CRISPR clustered regularly interspaced short palindromic repeats
CRISPRa CRISPR activation
CRISPRi CRISPR interference
DNF drug network fusion
GDSC genomics of drug sensitivity in cancer
GEO gene expression omnibus
GFP green fluorescent protein
GWAS genome wide association studies
HCC hepatocellular carcinoma
HTS high-throughput screening
KD knock down
LDL low-density lipoproteins
MAGeCK model-based analysis of genome-wide CRISPR-Cas9
MIPDD mechanism-informed phenotypic drug discovery
MOI multiplicity of infection
NGS next generation sequencing
PAM protospacer adjacent motif
PCR polymerase chain reaction
PCSK9 proprotein convertase subtilisin/kexin type 9
PGx pharmacogenomics
RF random forest classifier
ROS reactive oxygen species
sgRNA single guide RNA
TCF β–catenin/T-cell factor
TCGA the cancer genome atlas
TCR T-cell receptor
UKB United Kingdom biobank
Keywords: HTS screening, fluorescence-based assay, immunomodulatory compounds, anti-cancer therapeutics, transcriptomics, CRISPR-Cas9
Citation: Salame N, Fooks K, El-Hachem N, Bikorimana J-P, Mercier FE and Rafei M (2022) Recent Advances in Cancer Drug Discovery Through the Use of Phenotypic Reporter Systems, Connectivity Mapping, and Pooled CRISPR Screening. Front. Pharmacol. 13:852143. doi: 10.3389/fphar.2022.852143
Received: 10 January 2022; Accepted: 31 May 2022;
Published: 20 June 2022.
Edited by:
Wei Chen, Gan and Lee Pharmaceuticals, ChinaReviewed by:
Raghu Sinha, The Pennsylvania State University, United StatesCopyright © 2022 Salame, Fooks, El-Hachem, Bikorimana, Mercier and Rafei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: François E. Mercier, ZnJhbmNvaXMubWVyY2llckBtY2dpbGwuY2E=; Moutih Rafei, bW91dGloLnJhZmVpLjFAdW1vbnRyZWFsLmNh
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.