
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Pharmacol. , 29 October 2021
Sec. Pharmacogenetics and Pharmacogenomics
Volume 12 - 2021 | https://doi.org/10.3389/fphar.2021.749786
This article is part of the Research Topic The Potential of Machine-learning in Pharmacogenetics, Pharmacogenomics and Pharmacoepidemiology View all 5 articles
 Heidi E. Steiner1
Heidi E. Steiner1 Jason B. Giles1Hayley Knight Patterson1Jianglin Feng1Nihal El Rouby2Karla Claudio2,3Leiliane Rodrigues Marcatto4
Jason B. Giles1Hayley Knight Patterson1Jianglin Feng1Nihal El Rouby2Karla Claudio2,3Leiliane Rodrigues Marcatto4 Leticia Camargo Tavares4,5
Leticia Camargo Tavares4,5 Jubby Marcela Galvez6
Jubby Marcela Galvez6 Carlos-Alberto Calderon-Ospina6
Carlos-Alberto Calderon-Ospina6 Xiaoxiao Sun7
Xiaoxiao Sun7 Mara H. Hutz8
Mara H. Hutz8 Stuart A. Scott9
Stuart A. Scott9 Larisa H. Cavallari2
Larisa H. Cavallari2 Dora Janeth Fonseca-Mendoza6
Dora Janeth Fonseca-Mendoza6 Jorge Duconge3
Jorge Duconge3 Mariana Rodrigues Botton8,10
Mariana Rodrigues Botton8,10 Paulo Caleb Junior Lima Santos4,11
Paulo Caleb Junior Lima Santos4,11 Jason H. Karnes1,12*
Jason H. Karnes1,12*Populations used to create warfarin dose prediction algorithms largely lacked participants reporting Hispanic or Latino ethnicity. While previous research suggests nonlinear modeling improves warfarin dose prediction, this research has mainly focused on populations with primarily European ancestry. We compare the accuracy of stable warfarin dose prediction using linear and nonlinear machine learning models in a large cohort enriched for US Latinos and Latin Americans (ULLA). Each model was tested using the same variables as published by the International Warfarin Pharmacogenetics Consortium (IWPC) and using an expanded set of variables including ethnicity and warfarin indication. We utilized a multiple linear regression model and three nonlinear regression models: Bayesian Additive Regression Trees, Multivariate Adaptive Regression Splines, and Support Vector Regression. We compared each model’s ability to predict stable warfarin dose within 20% of actual stable dose, confirming trained models in a 30% testing dataset with 100 rounds of resampling. In all patients (n = 7,030), inclusion of additional predictor variables led to a small but significant improvement in prediction of dose relative to the IWPC algorithm (47.8 versus 46.7% in IWPC, p = 1.43 × 10−15). Nonlinear models using IWPC variables did not significantly improve prediction of dose over the linear IWPC algorithm. In ULLA patients alone (n = 1,734), IWPC performed similarly to all other linear and nonlinear pharmacogenetic algorithms. Our results reinforce the validity of IWPC in a large, ethnically diverse population and suggest that additional variables that capture warfarin dose variability may improve warfarin dose prediction algorithms.
Despite the availability of direct oral anticoagulants (DOACs), warfarin remains a commonly prescribed drug in the United States and Latin America. Although a highly effective anticoagulant, warfarin’s small therapeutic window and high inter-patient dose variability make it a leading cause of adverse drug events. While warfarin use may decline due to the requirement for regular clinical monitoring, a significant proportion of the population is likely to continue warfarin use preferentially over use of DOACs. Clinical concerns with DOACs continue to limit their use, including fewer indications than warfarin, concerns about bleeding risk and renal function, availability and cost of reversal agents, and contraindication in valvular heart disease (Nielsen et al., 2015; Verdecchia et al., 2016; Mendoza-Sanchez et al., 2018; Vinogradova et al., 2018; Zhu et al., 2018). This is especially true for medically underserved patients, including US Latino and Latin American (ULLA) patients, who may have access barriers to newer agents because of high costs and copays(Kirley et al., 2012; Shahin and Giacomini, 2020). Given the long track record of warfarin use in clinical practice, its affordable cost, and limited clinical utility of DOACs in special populations, warfarin is likely to continue to be preferentially used over DOACs in a substantial proportion of the population(Shahin et al., 2011; Barnes et al., 2015; Arwood et al., 2017).
In order to reduce warfarin-associated adverse drug events, warfarin stable dose prediction algorithms have been developed that incorporate clinical and genetic factors(Gage et al., 2008; Botton et al., 2011; Grossi et al., 2014; Alzubiedi and Saleh, 2016). Variables used in dose prediction algorithms account for approximately 50% of the variability in warfarin dose. However, these models, such as the International Warfarin Pharmacogenetics Consortium model (IWPC), were derived from populations with largely white participants and very small ULLA populations, including less than 1% ULLA in the IWPC cohort (International Warfarin Pharmacogenetics Consortium et al., 2009). Thus, it is possible that variability in warfarin stable dose requirements in ULLA patients may not be accurately modelled in commonly-used dose prediction algorithms, making these models potentially less effective for these patients(Kimmel et al., 2013; French et al., 2016; Johnson et al., 2017). This is particularly concerning since medically underserved patients, including disproportionately high ULLA patients, are at high risk for poor outcomes during warfarin treatment (White et al., 2006; Shen et al., 2007; Writing Group Members et al., 2016). Warfarin dosing in ULLA populations, which can have a mosaic-like ancestry that is admixed with the genomes of European, African, and Native American ancestors, (Wang et al., 2008) may be improved by developing algorithms trained with data from ULLA patients (Kaye et al., 2017). Recommended warfarin stable dose algorithms are based on multiple linear regression models(Johnson et al., 2017). Given that the relationship between warfarin dose and predictor variables is complex, nonlinear modeling strategies have been tested in warfarin dose prediction(Grossi et al., 2014; Liu et al., 2015; Roche-Lima et al., 2020). Non-parametric machine learning models are potentially powerful alternatives to linear parametric models in that they lack many of the assumptions of linear regression and they are flexible enough to fit virtually any curve in the data. However, the term machine learning technically applies to all models used in this analysis. The main aims of this study were to determine the validity of IWPC in ULLA patients and to apply machine learning to assess the accuracy of warfarin dose prediction with the published IWPC algorithm, a novel linear model, and three types of nonlinear models.
We analyzed publicly available data from IWPC combined with multiple cohorts of ULLA patients treated with stable doses of warfarin, creating a large ethnically diverse population. First, we obtained IWPC open access data from The Pharmacogenomics Knowledgebase (PharmGKB) website (https://www.pharmgkb.org/downloads, accessed December 2020), which contains data on 5,700 warfarin users recruited through 22 collaborative research groups from four continents (International Warfarin Pharmacogenetics Consortium et al., 2009). The IWPC cohort has been previously described in detail (International Warfarin Pharmacogenetics Consortium et al., 2009). The dataset contains detailed de-identified, curated data on demographics, clinical features, and genotypes for single nucleotide polymorphisms (SNPs) in CYP2C9 and VKORC1.
In this study, all ULLA patients self-reported Hispanic or Latino ethnicity or were recruited in a Latin American country. Herein, Hispanic ethnicity is used to refer to an individual with Spanish-speaking culture or origin and Latino ethnicity is used to refer to an individual with culture or origin from a Latin American country. Hispanic and Latino ethnicities are not mutually exclusive and are self-reported regardless of race. We chose the term ULLA to be inclusive of study participants who are not currently residing in Latin America (i.e., may not identify as Latin American), who are not Spanish speaking (i.e., do not identify as Hispanic), and who do not follow U.S. social constructs (i.e., may not identify as ethnically Hispanic/Latino). In addition to patients self-reporting as ULLA, patients also self-reported Black or White race. Given the incredible diversity within ULLA patients, statistical methods described below also included evaluation of the influence of self-reported race, as well as country of enrollment, within the ULLA cohort.
The cohort of ULLA patients comprised 1,757 warfarin-treated patients with Hispanic or Latino ethnicity recruited through research groups in North and South America. Each of the cohorts have been previously described (Perini et al., 2008; Lubitz et al., 2010; Botton et al., 2011; Bress et al., 2012; Santos et al., 2015; Duconge et al., 2016; Galvez et al., 2018; El Rouby et al., 2020). Data for a total of 411 self-reported Latinos were collected in North America, consisting of participant data from the University of Arizona (n = 76), University of Illinois at Chicago (n = 54), University of Puerto Rico (n = 260), and Icahn School of Medicine at Mount Sinai (n = 21). The South American cohorts were enrolled in Brazil from the University of São Paulo (n = 663) and Federal University of Rio Grande do Sul (n = 533) and in Colombia from the Hospital Universitario Mayor in Bogotá (n = 150). All participants were recruited while taking a stable dose of warfarin, defined as taking a consistent warfarin dose for two or more visits and achieving in target International Normalized Ratio (INR) range at both visits. DNA isolation and genotyping, which included VKORC1 c.-1639G>A (rs9923231), CYP2C9*2 (p.R144C, rs1799853), and CYP2C9*3 (p.I359L, rs1057910), were performed for each cohort individually as previously described (Galvez et al., 2018; El Rouby et al., 2020). Patients were ≥18 years of age and provided written informed consent for collection of their clinical data and either a venous blood or mouthwash sample for genetic analysis. The clinical studies associated with all sites for the ULLA cohort obtained Ethical and Human Subjects approvals from each organization’s Institutional Review Board. For ULLA data, please contact a2FybmVzQHBoYXJtYWN5LmFyaXpvbmEuZWR1.
Demographic characteristics were compared between IWPC and ULLA cohorts using the tableone R package version 0.12.0 (Yoshida and Bartel, 2020). Prior to analysis, we excluded participants: 1) who did not reach a stable dose, 2) with a weekly dose of over 175 mg or under 7 mg, 3) those with missing gender or age data, 4) with height above 200 cm or under 130 cm, and 5) with weight above 150 kg or under 35 kg, to account for biologically implausible or unlikely values. In the IWPC cohort, a target INR range of 2–3 was implemented. We derived and imputed variables with missing data for each of the datasets using packages and functions available in tidyverse in R version 1.3.0 (Wickham et al., 2019). Allele frequencies for the genetic locations were testing for Hardy-Weinberg Equilibrium using the HWChisq test in the HardyWeinberg package version 1.7.2 (Graffelman, 2015).
In order to address missing data, we imputed or derived missing values following the dataset curation steps described in the Supplementary Materials (Supplementary Methods and Supplementary Table S1). We curated two additional Merged datasets for sensitivity analyses to assess any impact of data curation/imputation on our results. First, we imputed missing values using Multivariate Imputation by Chained Equations with default parameters for diabetes status, statin use, smoking status and aspirin use implemented with the mice package version 3.13.0 (Mera-Gaona et al., 2021). MICE imputes missing values with plausible data values drawn from a distribution specifically designed for each missing datapoint. Second, we performed a complete-case analysis, including only participants with all required data and without imputation. Detailed descriptions of data curation and imputation are available in the Supplementary Materials.
Analyses presented in this study are based on the IWPC model, a novel multiple linear regression model termed the novel linear model (NLM), and three nonlinear regression models: Bayesian Additive Regression Trees (BART), Multivariate Adaptive Regression Splines (MARS), and Support Vector Regression (SVR). Model descriptions are available in Supplementary Methods. First, we reproduced the IWPC analysis with a multiple linear regression model using estimated coefficients derived from the published IWPC model (Figure 1). (International Warfarin Pharmacogenetics Consortium et al., 2009) Second, we predicted dose using the same variables included in the IWPC model but newly trained in the respective cohorts (IWPCV). Thus, the only difference between the IWPC and IWPCV models are the estimated coefficients. We then predicted dose with IWPC variables using the nonlinear methods described above with SVR (IWPC SVR), MARS (IWPC MARS), and BART (IWPC BART). This set of nonlinear models tested the improvement of warfarin dose prediction over IWPC by nonlinear modeling alone. All IWPC models included the variables age, height, weight, genotypes at CYP2C9 and VKORC1, race, amiodarone use, and enzyme inducer use. Next, we created the NLM, including additional predictor variables collected at all study sites (Supplementary Table S1). Finally, we fit another SVR, MARS, and BART using all available variables. The NLM and final three non-linear models (BART, MARS, SVR) included the IWPC variables and the additional variables gender, warfarin indication, statin use, aspirin use, smoking status, history of diabetes, and self-reported ethnicity. In analyses restricted to the ULLA cohort, country of enrollment was also included. All models were fit using the functions outlined below under default parameters using R version 4.0.2 (R Core Team, 2020). We used the lm function in the stats R package version 4.0.2 (R Core Team, 2020) to fit linear regression models and generate parameter estimates and standard errors, the bartMachine function in the bartMachine package version 1.2.5.1 (Kapelner and Bleich, 2016) for BART models, the train function in the caret package version 6.0-86 (Kuhn, 2020) using the “earth” method of the earth package version 5.2.0 (Hastie and wrapper, 2020) for MARS models, and the svm function in the e1071 package version 1.7-3 (Meyer et al., 2019) for SVR models. Finally, we estimated variable importance with partial R2 values of NLM variables with the rsq.partial function in the rsq package version 2.1(Zhang, 2020).
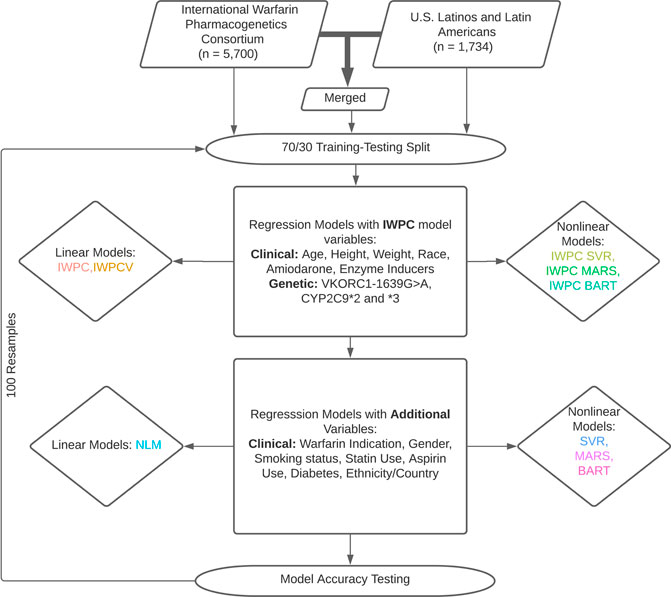
FIGURE 1. Dose Prediction Algorithm Creation and Testing. International Warfarin Pharmacogenetics Consortium (IWPC) data and data from US Latinos and Latin Americans (ULLA) were used for prediction independently and merged to test a combined sample. Linear and nonlinear models were fit with IWPC model variables and a set of extended variables in addition to IWPC predictors after a 70/30 training-testing split. All models were assessed for their ability to predict dose within 20% of actual. 100 replicates were performed from data splitting to model assessment.
We applied a square root transformation on weekly warfarin dose when fitting all the models. The primary outcome used to assess model performance was the proportion of patients whose predicted dose was within 20% of their actual stable dose, which represents a clinically relevant difference of 1 mg per day (International Warfarin Pharmacogenetics Consortium et al., 2009). Prior to fitting each replicate within each model, we assigned individuals in each cohort to training and testing datasets. We randomly selected, using a simple random sampling method, 70% among the patients as the training cohort to develop dose-prediction algorithms. The remaining 30% of the patients constituted the testing cohort. Models fit using the training dataset were used to predict values in the training and testing datasets. Estimates of mean absolute error (MAE) and the percentage of individuals predicted within 20% of their actual dose for each model were therefore based on both the training and the testing data. The MAE is the average of the absolute value of predicted dose minus the actual dose, and models with lower MAE tend to better predict the warfarin dose (Willmott and Matsuura, 2005). Uncertainty in model performance was derived from a total of 100 replicates including random resampling of training and testing datasets. Based on all 100 replicates analyzed within each of the models, we estimated the mean and corresponding 95% confidence intervals on MAE and the percentage within 20%. We fit a Friedman test to detect differences in median percentage within 20% across all models using the friedman_test function in the rstatix R package version 0.6.0 (Kassambara, 2020). Each linear model’s estimates and standard errors were surveyed from the 50th replicate to maintain consistency in the training/testing data. Finally, we used pairwise Wilcoxon signed-rank tests for paired data to examine whether pairs of models differ in their median proportions within 20% of actual and MAE. We implemented Wilcoxon signed-rank tests using the wilcox_test function again in the rstatix R package. All pairwise p-values were Bonferroni adjusted to correct for multiple comparisons. The R code associated with the project can be found at https://github.com/karneslab/warfarin-machinelearning.
We explored differences in model performance between subgroups based on actual-dose group, race, and country of enrollment for the ULLA cohort. First, we calculated MAE and percentage within 20% by actual-dose groups: high (>49 mg/week), intermediate, and low (≤21 mg/week). Next, we sought to investigate the validity of utilizing a clinical algorithm without pharmacogenetic variation as suggested by the Clinical Pharmacogenetics Implementation Consortium (CPIC) in patients with self-reported African ancestry who do not have genetic information available for CYP2C9*5,*6,*8, and *11 (Johnson et al., 2017). Thus, the IWPC clinical model, which does not include pharmacogenetic variation, was also used to predict dose in subgroup analyses by race and country of enrollment (International Warfarin Pharmacogenetics Consortium et al., 2009). Next, we evaluated percentage of participants predicted within 20% of actual by race groups. Patients self-reported Black or White race, or were imputed as “Mixed/Missing”. Finally, we examined differences in percentage within 20% and MAE by country/territory of enrollment (i.e. Brazil, Colombia, Puerto Rico, and continental United States) for each of the models.
Participants were removed from the PharmGKB IWPC dataset (n = 651) when they were outside the target INR range, not on a stable dose of warfarin, missing age and gender data, or were outside the range of inclusion for warfarin stable dose, weight, or height, leaving a total of 5,049 participants. In the ULLA cohort, we excluded 23 patients for a total of 1,734 study participants. To form the merged cohort we removed target INR restrictions and thus fewer (n = 404) patients were excluded from IWPC due to missing data or outlying dose, for a total of 7,030 warfarin users in the Merged cohort.
The characteristics of the IWPC and ULLA cohorts are outlined in Table 1. The median (interquartile range [IQR]) weekly warfarin dose (mg) was lower in the IWPC cohort (28.00 [95% Confidence Interval (95%CI) 19.25–38.50] mg/week) than the ULLA cohort (30.00 [95%CI 22.50–37.50] mg/week, p <0.001). A small minority (2.4%) of participants in IWPC were carriers of two variant CYP2C9 alleles. The majority (73.6%) of the participants had no variation in CYP2C9*2 or CYP2C9*3. In the ULLA cohort, 2.4% of the population carried two copies of variant CYP2C9 alleles, while 79.8% had no variation in CYP2C9*2 or CYP2C9*3. The VKORC1-1639G>A A allele frequency was 51.4% (AA: 32.5%, GA: 35.8%) in the IWPC cohort and 35.2% (AA: 12.5%, GA: 44.9%) in the ULLA. The IWPC cohort included less than 1% participants reporting Hispanic or Latino ancestry. Alternatively, the ULLA cohort by design was composed of 100% Hispanic or Latino reporting individuals. Demographic and genotype characteristics for the Merged cohort can be found in Supplementary Table S2.
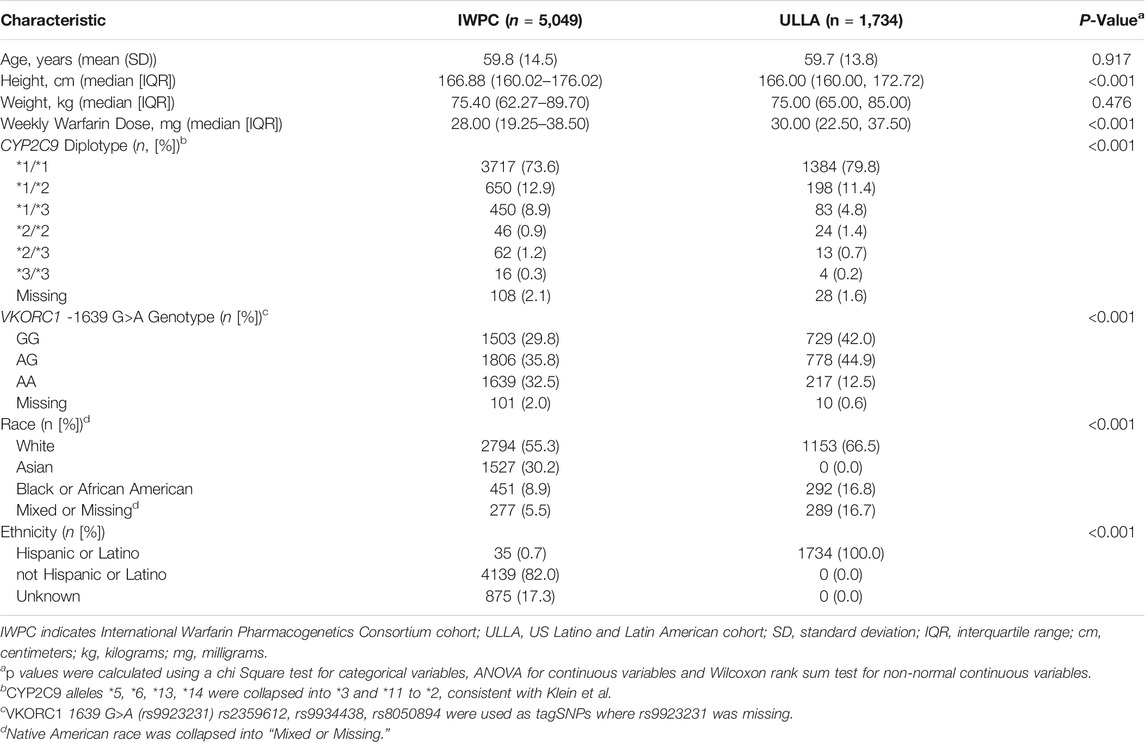
TABLE 1. Subject Characteristics in IWPC and ULLA cohorts.
In the IWPC cohort (n = 5,049), the most accurate model in terms of patients predicted within 20% of actual stable dose in the testing data was the novel NLM (47.4%) and the least accurate model was IWPC MARS (45.6%) (Table 2 and Supplementary Table S3, Supplementary Figure S1 in Supplementary Materials). All models with additional variables not contained in the IWPC model increased accurate dosing prediction by approximately one percent over the IWPC model (all p < 4.2 × 10−12; Supplementary Tables S3, S6). MAEs were similar for all nine models and ranged from 8.25 to 8.45 mg/week.
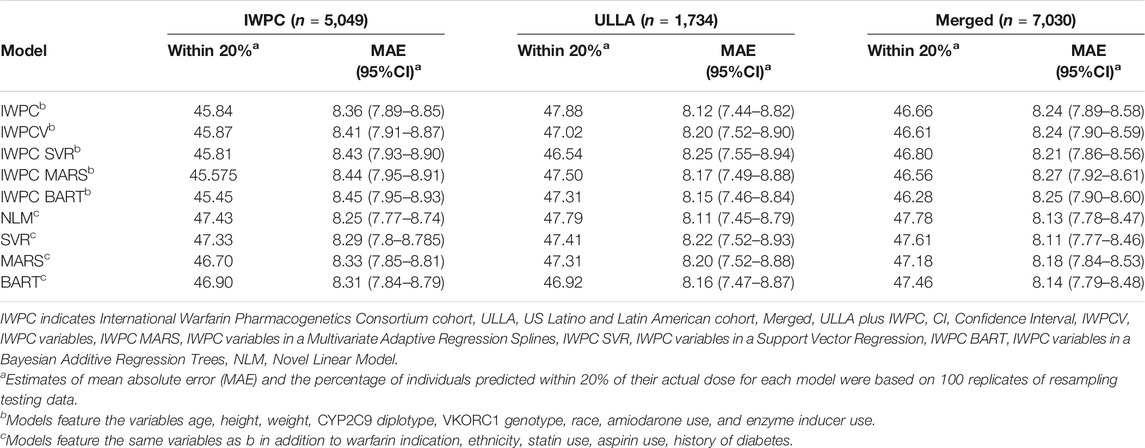
TABLE 2. Comparison of Warfarin Dose Prediction Algorithms by Median Percentage Predicted within 20% of Actual and Mean Absolute Error (MAE) in the IWPC, ULLA, and Merged cohorts.
In the ULLA cohort (n = 1,734), all models performed similarly (Figure 2A, Table 2 and Supplementary Table S4). IWPC predicted 47.9% of the population within 20% of actual dose compared to 47.0% for IWPCV (p < 4.28 × 10−6, Supplementary Tables S4, S6). While the NLM model had the lowest MAE 8.11 (7.45–8.79), all model MAEs were similar ranging from 8.11 to 8.25 mg/week. The median percentage of participants predicted within 20% in all models fit in the ULLA cohort differed by ∼1%.
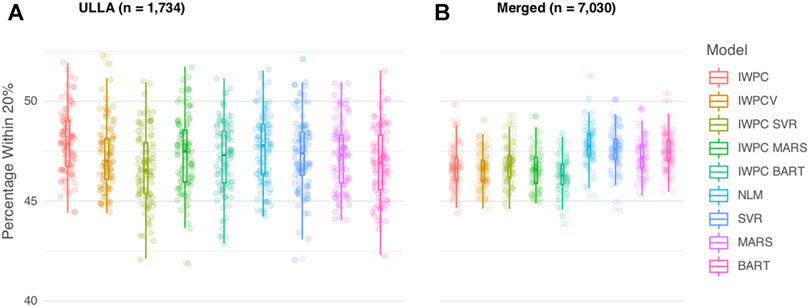
FIGURE 2. Comparison of Warfarin Dose Prediction Algorithms in the ULLA and Merged cohorts. Proportion of patients predicted within 20% of their actual dose is plotted in the (A) US Latinos and Latin Americans (ULLA) cohort and (B) Merged cohort containing both ULLA and IWPC cohorts. The boxplot visualizes five summary statistics (the median, 25 and 75% quartiles and two whiskers at 1.5* Interquartile Range). The points indicate the proportion of patients predicted within 20% at each of the 100 rounds of resampling. Models feature IWPC variables or IWPC variables in addition to new predictors. IWPC indicates International Warfarin Pharmacogenetics Consortium model, Merged, IWPC cohort plus ULLA cohort, IWPCV, IWPC variables, IWPC MARS, IWPC variables in a Multivariate Adaptive Regression Splines, IWPC SVR, IWPC variables in a Support Vector Regression, IWPC BART, IWPC variables in a Bayesian Additive Regression Trees, NLM, Novel Linear Model. From left to right, the first five models, IWPC, IWPCV, IWPC_SVR, IWPC_MARS, and IWPC_BART feature the clinical variables age, height, weight, race, enzyme inducer user, amiodarone use and the genetic variables CYP2C9 Diplotype and VKORC1-1639G>A Genotype, the next four models, NLM, SVR, MARS and BART feature the additional variables gender, ethnicity, statin use, aspirin use, history of diabetes, warfarin indication, the last model features only the clinical variables from the first set. IWPC indicates International Warfarin Pharmacogenetics Consortium model, IWPCV, IWPC variables, IWPC MARS, IWPC variables in a Multivariate Adaptive Regression Splines, IWPC SVR, IWPC variables in a Support Vector Regression, IWPC BART, IWPC variables in a Bayesian Additive Regression Trees, NLM, Novel Linear Model, Clinical, the IWPC Clinical model.
In the Merged cohort (n = 7,030), the NLM model was the most accurate in this population with 47.8% of the population predicted within 20% of actual dose. All models with additional variables not contained in the IWPC model increased accurate dosing prediction by ∼1% (all p < 2.2 × 10−10) in the testing data (Figure 2B, Table 2, Supplementary Tables S5, S6). MAEs were similar for all nine models and ranged from 8.11 to 8.27 mg/week. In sensitivity analyses, our results were robust to alternative imputation methods and complete case analysis (Supplementary Results and Supplementary Tables S7, S8).
We assessed performance in the ULLA cohort by actual-dose groups using the nine previously tested models. In the high dose group (weekly warfarin dose >49 mg), both BART models, BART and IWPC_BART, outperformed IWPC (p < 1.3 × 10−4, Figure 3A and Supplementary Tables S9, S10), while in the low dose group (≤21 mg/week), the IWPC model outperformed all other models (p < 1.5 × 10−15). In the intermediate group, all models perform similarly and systematically better than in other dose-groups.
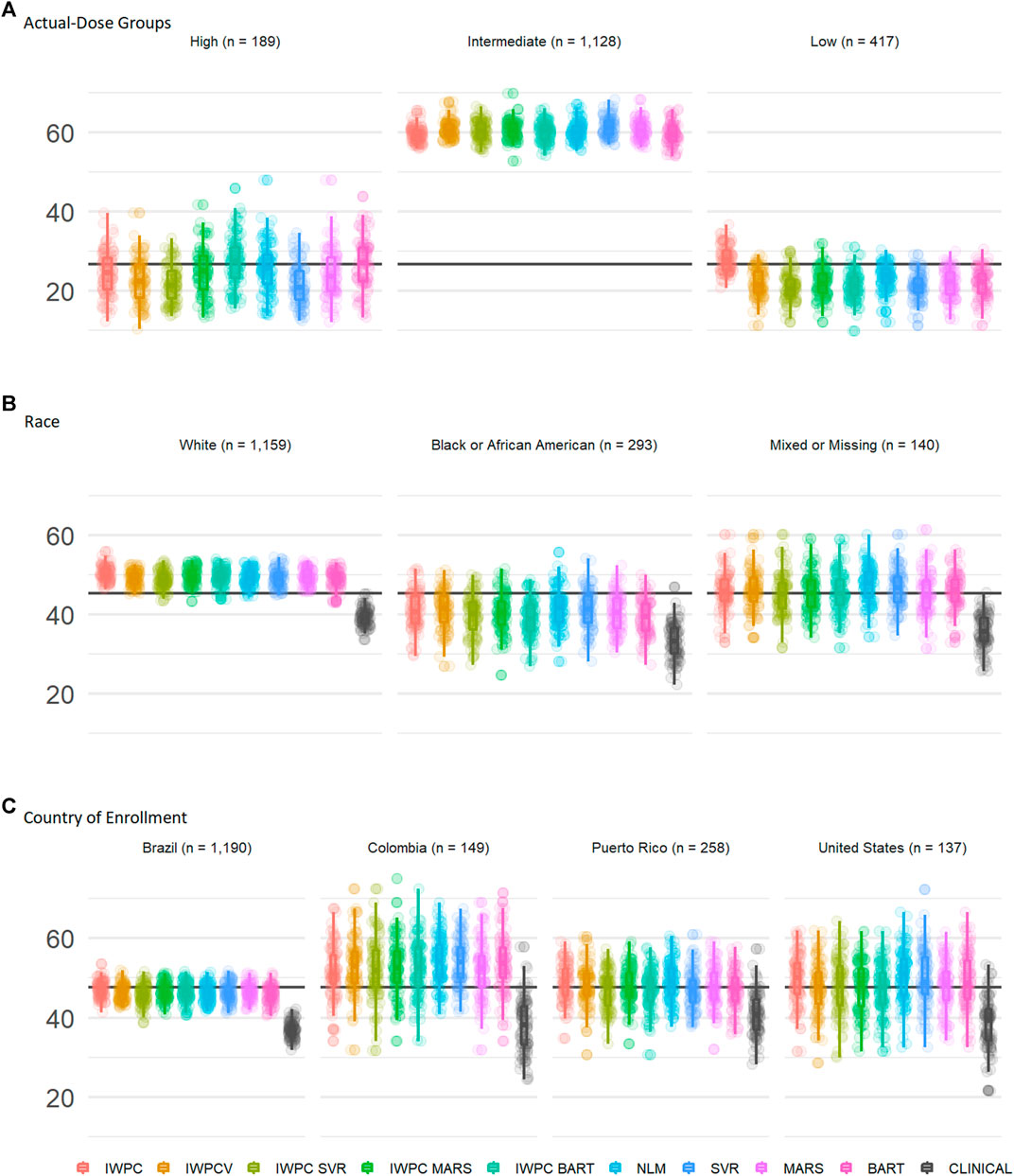
FIGURE 3. Subgroup Comparisons of Warfarin Dose Prediction Algorithms in the ULLA cohort. Proportion of patients predicted within 20% of their actual dose in the US Latinos and Latin Americans (ULLA) cohort by (A) actual-dose group, (B) race group, and (C) country of enrollment. The boxplot visualizes five summary statistics (the median, 25 and 75% quartiles and two whiskers at 1.5* Interquartile Range). The points indicate the proportion of patients predicted within 20% at each of the 100 rounds of resampling. The horizontal line indicates the median percentage predicted within 20% across all participants. From left to right, the first five models, IWPC, IWPCV, IWPC_SVR, IWPC_MARS, and IWPC_BART feature the clinical variables age, height, weight, race, enzyme inducer user, amiodarone use and the genetic variables CYP2C9 Diplotype and VKORC1-1639G>A Genotype, the next four models, NLM, SVR, MARS and BART feature the additional variables gender, ethnicity, statin use, aspirin use, history of diabetes, warfarin indication, the last model features only the clinical variables from the first set. IWPC indicates International Warfarin Pharmacogenetics Consortium model, IWPCV, IWPC variables, IWPC MARS, IWPC variables in a Multivariate Adaptive Regression Splines, IWPC SVR, IWPC variables in a Support Vector Regression, IWPC BART, IWPC variables in a Bayesian Additive Regression Trees, NLM, Novel Linear Model, Clinical, the IWPC Clinical model.
We assessed performance in the ULLA cohort by self-reported race group using the nine previously tested models alongside the IWPC clinical model, which excludes pharmacogenetic variants(International Warfarin Pharmacogenetics Consortium et al., 2009). In all three race groups, all models outperformed the clinical algorithm by at least 5% (all p < 0.001; Figure 3B, Table 3, and Supplementary Table S11). Apart from the clinical model, all models performed similarly in ULLA White and Black race groups. The NLM model outperformed IWPC in the Mixed or Missing race group (p = 3.64 × 10−4, Supplementary Table S11). The overall mean percentage of patients predicted within 20% of actual dose was highest in the White ULLA race group (49.1%) compared with the Mixed or Missing ULLA race group (45.4%) and the Black ULLA race group (40.0%).
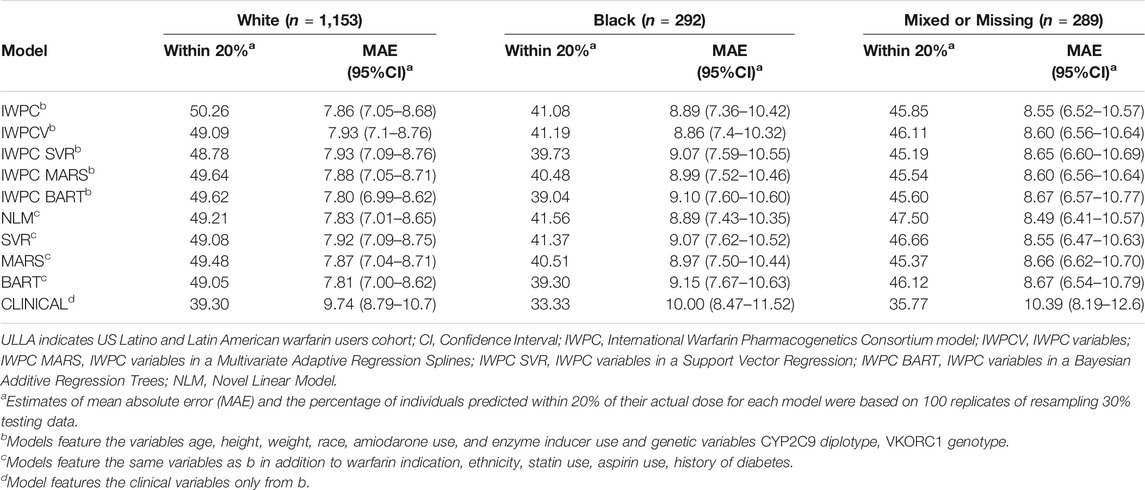
TABLE 3. Model comparisons by race data in the ULLA cohort (n = 1,734).
We assessed performance in the ULLA cohort by country/territory of enrollment using the nine previously tested models alongside the IWPC clinical model, which excludes pharmacogenetic variants (International Warfarin Pharmacogenetics Consortium et al., 2009). In all four national groups, all models outperformed the clinical algorithm by at least 5%, in some cases up to 15% (all p < 0.001; Figure 3C and Supplementary Tables S11, S12). The overall mean percentage predicted within 20% of actual dose was highest in the Colombian cohort (51.9%) compared with the continental United States (48.5%), Puerto Rico (47.4%), and Brazil (46.0%).
Parameter estimates, standard errors, and R2 values were similar across IWPC, IWPCV, and NLM models (Table 4). For the IWPCV and NLM models that included ULLA patients in their training datasets, we observed similar parameter estimates for pharmacogenetic variable effects relative to the IWPC model. For example, the estimates for the CYP2C9 *1/*2 diplotype ranged from −0.52 ± 0.04 in IWPC to −0.41 ± 0.04 (IWPCV) and to −0.42 ± 0.04 (NLM). In all instances, differences in betas were not outside the confidence intervals of each model. Among the additional variables not contained in the IWPC model, valve replacement indication (
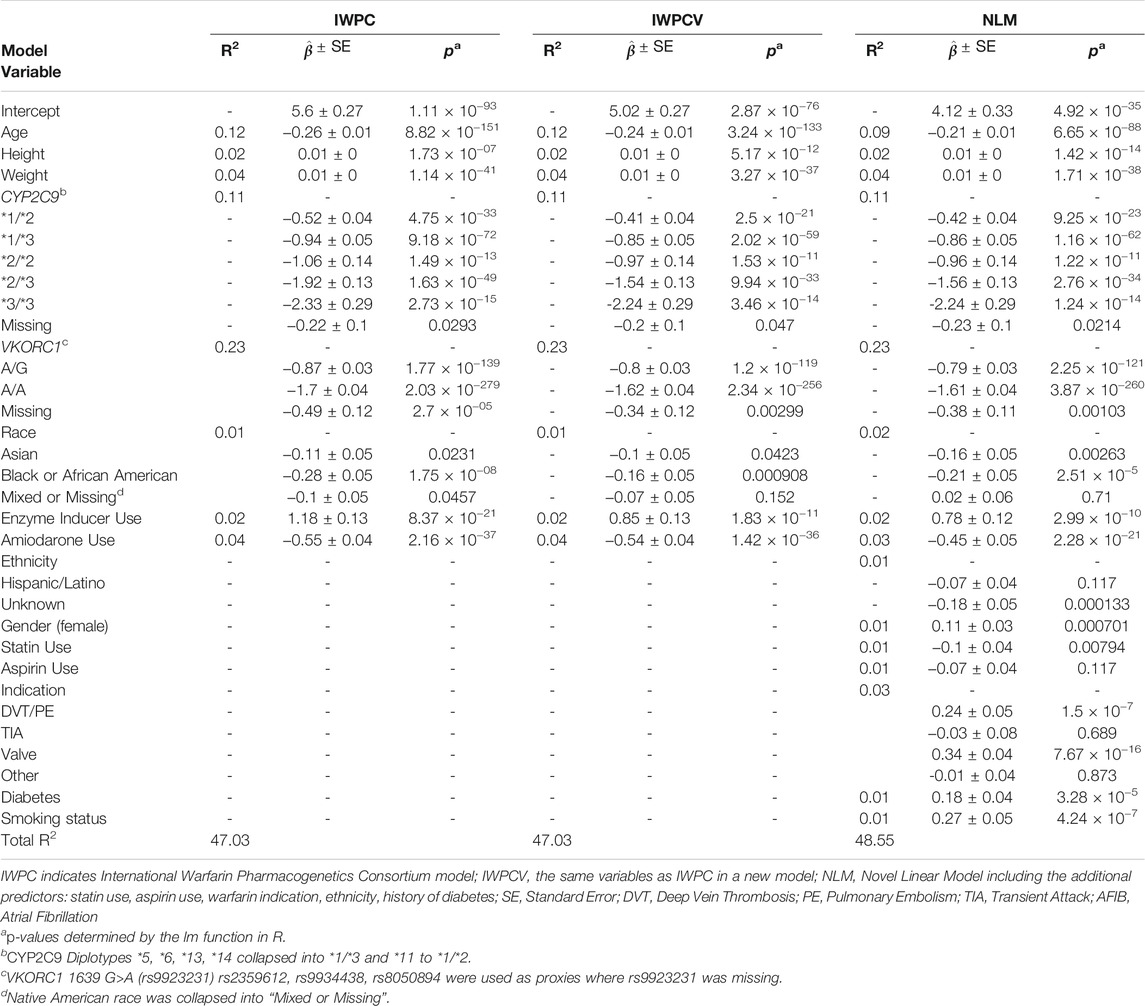
TABLE 4. Partial R2 values, parameter estimates with standard errors, and p-values of the 50th replicate of models trained in the Merged cohort (n = 7,030).
This study combined a large US Latino and Latin American cohort with IWPC data, constituting the largest available cohort for modelling stable warfarin dose in Hispanic and Latino patients. We found that IWPC models were accurate when applied to both our ULLA population and a combined cohort of ethnically diverse patients. We found limited evidence that nonlinear models significantly improve prediction of warfarin dose compared to linear models in any cohort in this analysis. Inclusion of additional predictor variables resulted in a small but significant improvement of prediction of warfarin dose relative to the published IWPC model. Specifically, the inclusion of warfarin indication, smoking status, diabetes, statin use, and gender informed warfarin dose prediction above that of the IWPC and IWPCV models. These results suggest that several important variables are not currently being captured by commonly used warfarin dose prediction algorithms. In care settings where warfarin dose algorithms are implemented, these data, which are routinely collected in electronic health record systems and in clinical assessments of warfarin users, should be accurate and readily available for improvement of algorithm accuracy.
In our study, nonlinear models did not out-perform linear regression models in our Latino/Latin American cohort, an observation that is inconsistent with some previous literature in other populations. One study used the IWPC cohort to model warfarin dose using nonlinear models, finding increased prediction accuracy with nonlinear models in under 400 Italian warfarin users (Liu et al., 2015). Another study investigated machine learning for predicting warfarin dose in a small Caribbean Hispanic population with similar results (Roche-Lima et al., 2020). However, neither study compared new models to the IWPC model. Another study observed improved warfarin dose prediction over IWPC with a nonlinear model using seven additional variables as used in our analysis, but no comparisons were made between linear and nonlinear models in the same cohort(Grossi et al., 2014). While some previous literature suggests nonlinear models may outperform multiple linear regression methods when used to predict warfarin dose, our observations suggest that linear models perform similarly to nonlinear models in diverse populations including a high number of ULLA participants.
Our results also demonstrate the robustness of the IWPC model in a diverse patient population and in ULLA populations. Overall, these results suggest the validity of utilizing IWPC algorithms in patients with Latino/Latin American ethnicity consistent with CPIC guideline recommendations (Johnson et al., 2017). Consistent with this observation, Latino/Latin American ethnicity was not associated with stable warfarin dose in our novel linear model. The median weekly dose was higher in the ULLA cohort, which may have been due to differential allele frequencies in important pharmacogenes (International Warfarin Pharmacogenetics Consortium et al., 2009). The VKORC1-1639 A allele frequency was 51.4% in the IWPC cohort and just 31.3% in the ULLA, and the percentage of patients carrying a CYP2C9*2 or *3 variant was lower in ULLA (20.4%) than IWPC (26.4%). These observations are consistent with previous literature reporting frequency of these variants in Hispanic and Latino populations (Kaye et al., 2017).
Subgroup analysis of actual-dose groups in our ULLA cohort showed a similar story as the overall results: IWPC performs as well as newly developed and trained models. In the low dose group, there was a stark decline in model accuracy as compared to the IWPC model. This result suggests that initial estimation of dose-groups may facilitate model choice for dose prediction. Latino individuals requiring low doses may benefit the most from dose prediction with the IWPC model.
In our ULLA cohort, the IWPC model performed as well numerous models trained in this cohort. This result may be due to a high rate of European admixture in our ULLA cohort, which we were not able to evaluate since sufficient genome-wide data was not available on all ULLA participants. In subgroup analysis of country/territory of enrollment, the Colombian cohort showed a marked advantage in prediction. This improved performance could be due to a larger proportion of European ancestry in this cohort relative to, for instance, our Brazilian cohort which had a higher proportion of self-reported Black participants (Wang et al., 2008; Salzano and Sans, 2014). It is also probable that more Latin American participants are included in the publicly available IWPC dataset than are indicated by the Hispanic/Latino ethnicity variable. Multiple data contributors in Latin America were listed in this effort, but only 1 percent of patients were considered Hispanic/Latino and this small number of participants were from multiple sites (International Warfarin Pharmacogenetics Consortium et al., 2009). Our observation that all models had lower accuracy in ULLA participants who self-reported Black or African American race reinforces previous work indicating that IWPC models perform poorly in individuals with African ancestry, in part due to the disregard for CYP2C9*5, *6, *8, and *11 alleles(Kimmel et al., 2013; Drozda et al., 2015).
Current CPIC guidelines for pharmacogenetic-guided warfarin dosing recommend different approaches for patients reporting African ancestry(Johnson et al., 2017). This is largely based on observations from the Clarification of Optimal Anticoagulation through Genetics (COAG) trial, which limited CYP2C9 genotyping to the *2 and *3 alleles and showed that Black patients spent less time in the therapeutic range in the pharmacogenetics-guided group than in the clinically-guided group(Kimmel et al., 2013; French et al., 2016). Subsequent analysis showed that not accounting for CYP2C9 variants common in people with African ancestry lead to significant over-dosing in Black patients. While our analyses suggest that increasing African ancestry leads to poor algorithm performance, our results also suggests that the IWPC clinical model underperforms for ULLA patients with self-reported black race. ULLA patients who report black race might be at risk of overdosing by disregarding genetic information in warfarin dosing, regardless of the presence of CYP variants of high predictive value in individuals of African ancestry. This observation may be due to a lower proportion of African ancestry in Black ULLA participants relative to African Americans from the COAG trial. Our observations in specific race and country/territory groups should be interpreted with caution as sample sizes are small after implementing a 70/30 training-testing split.
There are several limitations that are worthy of mention in this study. We were limited by the use of retrospective data to the variables that were included in the publicly available IWPC dataset. Since the publication of IWPC, a number of studies have reported additional warfarin dose predictor variables that might be included in future studies (Asiimwe et al., 2020; Roche-Lima et al., 2020). While we chose to focus on IWPC, other algorithms such as the Gage et al. algorithm might also have been tested. However, the dataset used to derive the Gage et al. algorithm was included in the IWPC dataset and both IWPC and Gage et al. algorithms have been shown to perform similarly across populations (Shin and Cao, 2011). Pharmacogenetic information used in this analysis was also limited to CYP2C9*2,*3 and VKORC1-1639G>A, which are variants identified in studies of primarily White populations. CYP2C9 *5,*6, *8, and *11 are important in the prediction of warfarin dose in Black or African patients and additional variants in CALU, the CYP2C cluster (e.g. rs12777823), and GGCX have been shown to affect warfarin dose (Wadelius et al., 2005; Voora et al., 2010). Furthermore, studies have identified the NQ O 1*2 (p. P187S; rs1800566) variant as a contributor to warfarin dose variation in Hispanic and Latino patients, and this genotype information was not available in the IWPC dataset (Bress et al., 2012; El Rouby et al., 2020). Data from a pharmacogenomic or genome-wide SNP platform would likely provide additional information useful in warfarin dose prediction, including additional CYP variants that are not biased by low MAFs in the discovery population and admixture proportions, both of which have been identified as important warfarin dose prediction variables(Hernandez et al., 2020). Apart from genetic variation, other potential sources of warfarin dose variability, including medication adherence data and environmental exposures such as vitamin K intake, were not available for this analysis.
In this systematic comparison of nine models, classic linear regression models remained advantageous compared to nonlinear models with respect to prediction accuracy of therapeutic warfarin dose in a large diverse cohort as well as a Hispanic/Latino cohort alone. Our results suggest that the inclusion of additional predictor variables, beyond those used in the IWPC model but often collected during warfarin treatment, may improve accuracy of warfarin stable dose algorithms. Our results also suggest that the IWPC model is accurate for stable dose prediction in populations with Hispanic/Latino ethnicity, with the possible exception of Afro-Latino warfarin users. This result warrants further exploration in additional Hispanic/Latino cohorts with careful consideration for race. Furthermore, our results indicate that the IWPC clinical model performs poorly relative to all other algorithms tested for US Latino and Latin American patients, regardless of whether they report African ancestry.
The datasets analyzed in this study are not publicly available due to privacy/ethical restrictions. Requests to access these datasets should be directed to karnes@pharmacy.arizona.edu.
The studies involving human participants were reviewed and approved by The University of Arizona Institutional Review Board found this study exempt from Human Subject’s approvals. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
HS, HP, JG, and JK wrote the manuscript; HS, JF, XS and JK designed the research; HS performed the research; HS analyzed the data; NE, KC, LT, MB, LM, JG, CC, MH, SS, LC, DF, JD and PS revised the manuscript and contributed data.
This work is supported by an institutional career development award from the University of Arizona Health Science Center (JK) and a Seed Grant to Promote Translational Research in Precision Medicine from the Flinn Foundation (JK). JK is supported by the National Heart, Lung, and Blood Institute (NHLBI, K01HL143137, R01 HL158686), JG is supported by the National Institute of Environmental Health Sciences (T32 ES007091), LC is supported by the National Center for Advancing Translational Sciences (UL1TR001427), and JD is supported by the NHLBI (SC1HL123911) and the National Institute of Minority Health Disparities (U54 MD007600). LM is supported by the São Paulo Research Foundation (FAPESP) (2016/23454-5). PCJLS is supported by FAPESP, the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior-Brazil (CAPES), Programa de Excelência Acadêmica (PROEX) and Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) (2013/09295-3; 2019/08338-7).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
We would like to thank Cristian Román Palacios, PhD for comments on early versions of the manuscript. We would also like to thank Andrea Peralta, BS, Juanita Gonzalez, RN, Echo Fallon, PharmD, Kevin Yee, PharmD, and Amy Kennedy, PharmD for their assistance with this project.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphar.2021.749786/full#supplementary-material
Alzubiedi, S., and Saleh, M. I. (2016). Pharmacogenetic-guided Warfarin Dosing Algorithm in African-Americans. J. Cardiovasc. Pharmacol. 67, 86–92. doi:10.1097/FJC.0000000000000317
Arwood, M. J., Deng, J., Drozda, K., Pugach, O., Nutescu, E. A., Schmidt, S., et al. (2017). Anticoagulation Endpoints with Clinical Implementation of Warfarin Pharmacogenetic Dosing in a Real-World Setting: A Proposal for a New Pharmacogenetic Dosing Approach. Clin. Pharmacol. Ther. 101, 675–683. doi:10.1002/cpt.558
Asiimwe, I. G., Zhang, E. J., Osanlou, R., Krause, A., Dillon, C., Suarez-Kurtz, G., et al. (2020). Genetic Factors Influencing Warfarin Dose in Black-African Patients: A Systematic Review and Meta-Analysis. Clin. Pharmacol. Ther. 107, 1420–1433. doi:10.1002/cpt.1755
Barnes, G. D., Lucas, E., Alexander, G. C., and Goldberger, Z. D. (2015). National Trends in Ambulatory Oral Anticoagulant Use. Am. J. Med. 128, 1300–5.e2. doi:10.1016/j.amjmed.2015.05.044
Botton, M. R., Bandinelli, E., Rohde, L. E., Amon, L. C., and Hutz, M. H. (2011). Influence of Genetic, Biological and Pharmacological Factors on Warfarin Dose in a Southern Brazilian Population of European Ancestry. Br. J. Clin. Pharmacol. 72, 442–450. doi:10.1111/j.1365-2125.2011.03942.x
Bress, A., Patel, S. R., Perera, M. A., Campbell, R. T., Kittles, R. A., and Cavallari, L. H. (2012). Effect of NQO1 and CYP4F2 Genotypes on Warfarin Dose Requirements in Hispanic-Americans and African-Americans. Pharmacogenomics 13, 1925–1935. doi:10.2217/pgs.12.164
Drozda, K., Wong, S., Patel, S. R., Bress, A. P., Nutescu, E. A., Kittles, R. A., et al. (2015). Poor Warfarin Dose Prediction with Pharmacogenetic Algorithms that Exclude Genotypes Important for African Americans. Pharmacogenet. Genomics 25, 73–81. doi:10.1097/FPC.0000000000000108
Duconge, J., Ramos, A. S., Claudio-Campos, K., Rivera-Miranda, G., Bermúdez-Bosch, L., Renta, J. Y., et al. (2016). A Novel Admixture-Based Pharmacogenetic Approach to Refine Warfarin Dosing in Caribbean Hispanics. PLoS One 11, e0145480. doi:10.1371/journal.pone.0145480
El Rouby, N., Rodrigues Marcatto, L., Claudio, K., Camargo Tavares, L., Steiner, H., Botton, M. R., et al. (2020). Multi‐site Investigation of Genetic Determinants of Warfarin Dose Variability in Latinos. Clin. Transl. Sci. 14, 268–276. doi:10.1111/cts.12854
French, B., Wang, L., Gage, B. F., Horenstein, R. B., Limdi, N. A., and Kimmel, S. E. (2016). A Systematic Analysis and Comparison of Warfarin Initiation Strategies. Pharmacogenet. Genomics 26, 445–452. doi:10.1097/FPC.0000000000000235
Gage, B. F., Eby, C., Johnson, J. A., Deych, E., Rieder, M. J., Ridker, P. M., et al. (2008). Use of Pharmacogenetic and Clinical Factors to Predict the Therapeutic Dose of Warfarin. Clin. Pharmacol. Ther. 84, 326–331. doi:10.1038/clpt.2008.10
Galvez, J. M., Restrepo, C. M., Contreras, N. C., Alvarado, C., Calderón-Ospina, C. A., Peña, N., et al. (2018). Creating and Validating a Warfarin Pharmacogenetic Dosing Algorithm for Colombian Patients. Pharmgenomics Pers Med. 11, 169–178. doi:10.2147/PGPM.S170515
Graffelman, J. (2015). Exploring Diallelic Genetic Markers: TheHardyWeinbergPackage. J. Stat. Soft. 64, 1–23. doi:10.18637/jss.v064.i03
Grossi, E., Podda, G. M., Pugliano, M., Gabba, S., Verri, A., Carpani, G., et al. (2014). Prediction of Optimal Warfarin Maintenance Dose Using Advanced Artificial Neural Networks. Pharmacogenomics 15, 29–37. doi:10.2217/pgs.13.212
Hastie, S. M. D., and wrapper, T. (2020). Earth: Multivariate Adaptive Regression Splines. Hastie, S.M.D. from mda:mars by T., wrapper, R.T.U.A.M.F. utilities with T.L. leaps, 2020.
Hernandez, W., Danahey, K., Pei, X., Yeo, K. J., Leung, E., Volchenboum, S. L., et al. (2020). Pharmacogenomic Genotypes Define Genetic Ancestry in Patients and Enable Population-specific Genomic Implementation. Pharmacogenomics J. 20, 126–135. doi:10.1038/s41397-019-0095-z
International Warfarin Pharmacogenetics Consortium, Klein, T. E., Klein, T. E., Altman, R. B., Eriksson, N., Gage, B. F., Kimmel, S. E., et al. (2009). Estimation of the Warfarin Dose with Clinical and Pharmacogenetic Data. N. Engl. J. Med. 360, 753–764. doi:10.1056/NEJMoa0809329
Johnson, J. A., Caudle, K. E., Gong, L., Whirl-Carrillo, M., Stein, C. M., Scott, S. A., et al. (2017). Clinical Pharmacogenetics Implementation Consortium (CPIC) Guideline for Pharmacogenetics-Guided Warfarin Dosing: 2017 Update. Clin. Pharmacol. Ther. 102, 397–404. doi:10.1002/cpt.668
Kapelner, A., and Bleich, J. (2016). bartMachine: Machine Learning with Bayesian Additive Regression Trees. J. Stat. Soft. 70, 1–40. doi:10.18637/jss.v070.i04
Kaye, J. B., Schultz, L. E., Steiner, H. E., Kittles, R. A., Cavallari, L. H., and Karnes, J. H. (2017). Warfarin Pharmacogenomics in Diverse Populations. Pharmacotherapy 37, 1150–1163. doi:10.1002/phar.1982
Kimmel, S. E., French, B., Kasner, S. E., Johnson, J. A., Anderson, J. L., Gage, B. F., et al. (2013). A Pharmacogenetic versus a Clinical Algorithm for Warfarin Dosing. N. Engl. J. Med. 369, 2283–2293. doi:10.1056/NEJMoa1310669
Kirley, K., Qato, D. M., Kornfield, R., Stafford, R. S., and Alexander, G. C. (2012). National Trends in Oral Anticoagulant Use in the United States, 2007 to 2011. Circ. Cardiovasc. Qual. Outcomes 5, 615–621. doi:10.1161/CIRCOUTCOMES.112.967299
Liu, R., Li, X., Zhang, W., and Zhou, H. H. (2015). Comparison of Nine Statistical Model Based Warfarin Pharmacogenetic Dosing Algorithms Using the Racially Diverse International Warfarin Pharmacogenetic Consortium Cohort Database. Plos One 10, e0135784. doi:10.1371/journal.pone.0135784
Lubitz, S. A., Scott, S. A., Rothlauf, E. B., Agarwal, A., Peter, I., Doheny, D., et al. (2010). Comparative Performance of Gene-Based Warfarin Dosing Algorithms in a Multiethnic Population. J. Thromb. Haemost. 8, 1018–1026. doi:10.1111/j.1538-7836.2010.03792.x
Mendoza-Sanchez, J., Silva, F., Rangel, L., Jaramillo, L., Mendoza, L., Garzon, J., et al. (2018). Benefit, Risk and Cost of New Oral Anticoagulants and Warfarin in Atrial Fibrillation; A Multicriteria Decision Analysis. PLoS One 13, e0196361. doi:10.1371/journal.pone.0196361
Mera-Gaona, M., Neumann, U., Vargas-Canas, R., and López, D. M. (2021). Evaluating the Impact of Multivariate Imputation by MICE in Feature Selection. PLoS ONE 16, e0254720. doi:10.1371/journal.pone.0254720
Meyer, D., Dimitriadou, E., Hornik, K., Weingessel, A., and Leisch, F. (2019). e1071: Misc Functions of the Department of StatisticsProbability Theory Group (Formerly: E1071). TU Wien.
Nielsen, P. B., Lane, D. A., Rasmussen, L. H., Lip, G. Y., and Larsen, T. B. (2015). Renal Function and Non-vitamin K Oral Anticoagulants in Comparison with Warfarin on Safety and Efficacy Outcomes in Atrial Fibrillation Patients: a Systemic Review and Meta-Regression Analysis. Clin. Res. Cardiol. 104, 418–429. doi:10.1007/s00392-014-0797-9
Perini, J. A., Struchiner, C. J., Silva-Assunção, E., Santana, I. S., Rangel, F., Ojopi, E. B., et al. (2008). Pharmacogenetics of Warfarin: Development of a Dosing Algorithm for Brazilian Patients. Clin. Pharmacol. Ther. 84, 722–728. doi:10.1038/clpt.2008.166
R Core Team (2020). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing.
Roche-Lima, A., Roman-Santiago, A., Feliu-Maldonado, R., Rodriguez-Maldonado, J., Nieves-Rodriguez, B. G., Carrasquillo-Carrion, K., et al. (2020). Machine Learning Algorithm for Predicting Warfarin Dose in Caribbean Hispanics Using Pharmacogenetic Data. Front. Pharmacol. 10, 1550. doi:10.3389/fphar.2019.01550
Salzano, F. M., and Sans, M. (2014). Interethnic Admixture and the Evolution of Latin American Populations. Genet. Mol. Biol. 37, 151–170. doi:10.1590/s1415-47572014000200003
Santos, P. C., Marcatto, L. R., Duarte, N. E., Gadi Soares, R. A., Cassaro Strunz, C. M., Scanavacca, M., et al. (2015). Development of a Pharmacogenetic-Based Warfarin Dosing Algorithm and its Performance in Brazilian Patients: Highlighting the Importance of Population-specific Calibration. Pharmacogenomics 16, 865–876. doi:10.2217/pgs.15.48
Shahin, M. H., and Giacomini, K. M. (2020). Oral Anticoagulants and Precision Medicine: Something Old, Something New. Clin. Pharmacol. Ther. 107, 1273–1277. doi:10.1002/cpt.1839
Shahin, M. H., Khalifa, S. I., Gong, Y., Hammad, L. N., Sallam, M. T., El Shafey, M., et al. (2011). Genetic and Nongenetic Factors Associated with Warfarin Dose Requirements in Egyptian Patients. Pharmacogenet. Genomics 21, 130–135. doi:10.1097/FPC.0b013e3283436b86
Shen, A. Y., Yao, J. F., Brar, S. S., Jorgensen, M. B., and Chen, W. (2007). Racial/ethnic Differences in the Risk of Intracranial Hemorrhage Among Patients with Atrial Fibrillation. J. Am. Coll. Cardiol. 50, 309–315. doi:10.1016/j.jacc.2007.01.098
Shin, J., and Cao, D. (2011). Comparison of Warfarin Pharmacogenetic Dosing Algorithms in a Racially Diverse Large Cohort. Pharmacogenomics 12, 125–134. doi:10.2217/pgs.10.168
Verdecchia, P., Angeli, F., Aita, A., Bartolini, C., and Reboldi, G. (2016). Why Switch from Warfarin to NOACs? Intern. Emerg. Med. 11, 289–293. doi:10.1007/s11739-016-1411-0
Vinogradova, Y., Coupland, C., Hill, T., and Hippisley-Cox, J. (2018). Risks and Benefits of Direct Oral Anticoagulants versus Warfarin in a Real World Setting: Cohort Study in Primary Care. BMJ 362, k2505. doi:10.1136/bmj.k2505
Voora, D., Koboldt, D. C., King, C. R., Lenzini, P. A., Eby, C. S., Porche-Sorbet, R., et al. (2010). A Polymorphism in the VKORC1 Regulator Calumenin Predicts Higher Warfarin Dose Requirements in African Americans. Clin. Pharmacol. Ther. 87, 445–451. doi:10.1038/clpt.2009.291
Wadelius, M., Chen, L. Y., Downes, K., Ghori, J., Hunt, S., Eriksson, N., et al. (2005). Common VKORC1 and GGCX Polymorphisms Associated with Warfarin Dose. Pharmacogenomics J. 5, 262–270. doi:10.1038/sj.tpj.6500313
Wang, S., Ray, N., Rojas, W., Parra, M. V., Bedoya, G., Gallo, C., et al. (2008). Geographic Patterns of Genome Admixture in Latin American Mestizos. PLOS Genet. 4, e1000037. doi:10.1371/journal.pgen.1000037
White, R. H., Dager, W. E., Zhou, H., and Murin, S. (2006). Racial and Gender Differences in the Incidence of Recurrent Venous Thromboembolism. Thromb. Haemost. 96, 267–273. doi:10.1160/TH06-07-0365
Wickham, H., Averick, M., Bryan, J., Chang, W., McGowan, L., François, R., et al. (2019). Welcome to the Tidyverse. Joss 4, 1686. doi:10.21105/joss.01686
Willmott, C., and Matsuura, K. (2005). Advantages of the Mean Absolute Error (MAE) over the Root Mean Square Error (RMSE) in Assessing Average Model Performance. Clim. Res. 30, 79–82. doi:10.3354/cr030079
Writing Group Members, Mozaffarian, D., Benjamin, E. J., Go, A. S., Arnett, D. K., Blaha, M. J., Cushman, M., et al. (2016). Heart Disease and Stroke Statistics-2016 UpdateHeart Disease and Stroke Statistics-2016 Update: A Report from the American Heart Association. Circulation 133, e38–360. doi:10.1161/CIR.0000000000000350
Yoshida, K., and Bartel, A. (2020). Tableone: Create “Table 1” to Describe Baseline Characteristics with or without Propensity Score Weights.
Keywords: pharmacogenetics, machine learning, anticoagulant, warfarin, Latino, Hispanic
Citation: Steiner HE, Giles JB, Patterson HK, Feng J, El Rouby N, Claudio K, Marcatto LR, Tavares LC, Galvez JM, Calderon-Ospina C-A, Sun X, Hutz MH, Scott SA, Cavallari LH, Fonseca-Mendoza DJ, Duconge J, Botton MR, Santos PCJL and Karnes JH (2021) Machine Learning for Prediction of Stable Warfarin Dose in US Latinos and Latin Americans. Front. Pharmacol. 12:749786. doi: 10.3389/fphar.2021.749786
Received: 29 July 2021; Accepted: 20 September 2021;
Published: 29 October 2021.
Edited by:
Elena García-Martín, University of Extremadura, SpainReviewed by:
Volker Martin Lauschke, Karolinska Institutet (KI), SwedenCopyright © 2021 Steiner, Giles, Patterson, Feng, El Rouby, Claudio, Marcatto, Tavares, Galvez, Calderon-Ospina, Sun, Hutz, Scott, Cavallari, Fonseca-Mendoza, Duconge, Botton, Santos and Karnes. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jason H. Karnes, a2FybmVzQHBoYXJtYWN5LmFyaXpvbmEuZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.