 Gloria Wu
Gloria Wu David A. Lee2
David A. Lee2 Weichen Zhao
Weichen Zhao Sahej Sidhu
Sahej Sidhu
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Ophthalmol., 16 November 2023
Sec. Glaucoma
Volume 3 - 2023 | https://doi.org/10.3389/fopht.2023.1260415
This article is part of the Research TopicTranslational Opportunities for AI in GlaucomaView all 10 articles
Purpose: Our study investigates ChatGPT and its ability to communicate with glaucoma patients.
Methods: We inputted eight glaucoma-related questions/topics found on the American Academy of Ophthalmology (AAO)’s website into ChatGPT. We used the Flesch–Kincaid test, Gunning Fog Index, SMOG Index, and Dale–Chall readability formula to evaluate the comprehensibility of its responses for patients. ChatGPT’s answers were compared with those found on the AAO’s website.
Results: ChatGPT’s responses required reading comprehension of a higher grade level (average = grade 12.5 ± 1.6) than that of the text on the AAO’s website (average = 9.4 grade ± 3.5), (0.0384). For the eight responses, the key ophthalmic terms appeared 34 out of 86 times in the ChatGPT responses vs. 86 out of 86 times in the text on the AAO’s website. The term “eye doctor” appeared once in the ChatGPT text, but the formal term “ophthalmologist” did not appear. The term “ophthalmologist” appears 26 times on the AAO’s website. The word counts of the answers produced by ChatGPT and those on the AAO’s website were similar (p = 0.571), with phrases of a homogenous length.
Conclusion: ChatGPT trains on the texts, phrases, and algorithms inputted by software engineers. As ophthalmologists, through our websites and journals, we should consider encoding the phrase “see an ophthalmologist”. Our medical assistants should sit with patients during their appointments to ensure that the text is accurate and that they fully comprehend its meaning. ChatGPT is effective for providing general information such as definitions or potential treatment options for glaucoma. However, ChatGPT has a tendency toward repetitive answers and, due to their elevated readability scores, these could be too difficult for a patient to read.
ChatGPT (OpenAI, San Francisco, CA, USA) is a free, large language model AI chatbot. It was launched on 30 November 2022 and by April 2023 it was visited an average of over 60 million times per day. ChatGPT has natural language processing capabilities that enable it to be trained in the auto-completion of sentences and ideas. Given the word “glaucoma,” these models may predict the next word to be “open angle” or “angle closure” based on the statistical parameters learned from prior training data sets. ChatGPT has gained traction due to its unprecedented ability to generate human-like language and respond to a massive range of inputs (1).
Approximately 130 million Americans lack proficiency in literacy, with a reading level below the sixth grade (2). The average American reads material of a level between the seventh and eighth grades (2, 3). Health literacy is a recognized problem for most Americans (2–4). For patients using ChatGPT, health literacy may be a problem (1, 5, 6). ChatGPT generates text in fully formed paragraphs which may be difficult for the average patient, who has a sixth- to eighth-grade reading level.
Glaucoma is the leading cause of blindness in America (7). Its associated visual loss is painless, progressive, and can remain undetected for years. The medication regimen may involve multiple instillations of eye drops at different times of the day, leading to non-compliance (8–10).
Glaucoma is a chronic disease that requires medication adherence and an understanding of the risks and benefits of treatment. Glaucoma patients with poor education and a low socioeconomic status have worse outcomes than those with better education and a higher socioeconomic status who can better appreciate the glaucoma treatment paradigms (10–12).
Poor patient compliance has led to poor visual field outcomes and the eventual deterioration of vision (9, 10). We sought to discover if ChatGPT could be a source of patient education for our glaucoma patients, and if it is accurate and understandable (13). We used the American Academy of Ophthalmology’s website, AAO.org, an education interface for the public that was created by board-certified ophthalmologists in America, as a reference point for the questions/topics inputted into ChatGPT (14).
In our study, we delve into the connection between ChatGPT and the necessary reading levels for glaucoma literacy. Owing to the absence of patient subjects or data, Institutional Review Board approval was not required.
In the section of the AAO’s website named “Public & Patients,” which leads to the “What is Glaucoma” page (13), we found a series of eight questions/topics to input into ChatGPT. The bot’s responses were compared with the video responses on the AAO’s website, which were then transcribed into text. We chose to use version 3.5 of ChatGPT because it is free to use.
Eight questions/topics taken from the AAO’s “Guide to Glaucoma” (13) were used: (1) “What is glaucoma?”; (2) “What causes glaucoma?”; (3) “Types of glaucoma”; (4) “What is angle-closure glaucoma?”; (5) “What are common glaucoma symptoms?”; (6) “Who is at risk for glaucoma?”; (7) “Glaucoma diagnosis”; and (8) “Glaucoma treatment”.
The AAO's website shows the following keywords as bolded and underlined:
● Question/topic 1: aqueous humor, trabecular meshwork, drainage angle, over age 60;
● Question/topic 2: aqueous humor, IOP (pressure in the eye), drainage angle, optic nerve;
● Question/topic 3: open-angle glaucoma, closed-angle/narrow-angle glaucoma, iris, acute attack, “suddenly blurry” halos around lights, severe eye pain, headache, nausea/vomiting, red eye, rainbow halos around lights, ophthalmologist;
● Question/topic 4: narrow/shallow angle, pressure increase;
● Question/topic 5: regular eye exams, ophthalmologist, angle-closure glaucoma, decreased/blurred vision, severe pain in eye/forehead, redness of the eye, seeing rainbows or halos, headache, nausea, vomiting, normal-tension glaucoma, eye pressure, ocular hypertension, pigment dispersion syndrome (PDS);
● Question/topic 6: over age 40, family history, race/African American/Asian/Hispanic, high eye pressure, farsighted, nearsighted, eye injury, long-term steroid use, thin corneas in the center, thinning of the optic nerve, diabetes, migraines, high blood pressure, poor blood circulation, other health problems affecting the whole body, ophthalmologist;
● Question/topic 7: complete eye exam, measure eye pressure, inspect eye drainage angle, examine optic nerve for damage, test peripheral/side vision, picture or computer measurement of optic nerve, measure thickness of cornea, no symptoms in its early stages, silent thief of sight, ophthalmologist;
● Question/topic 8: eye drop, glaucoma medication, stinging or itching sensation, red eyes or red skin around eyes, changes in pulse or heartbeat, changes in energy level, changes in breathing (asthma), dry mouth, blurred vision, eyelash growth, changes in eye color and skin around eyes/eyelid appearance, laser surgery, trabeculoplasty, iridotomy, operating room surgery, trabeculectomy, sclera, conjunctiva, glaucoma drainage devices, glaucoma drainage implant, cataract surgery, eye’s natural lens, narrow angles, ophthalmologist.
For the determination of reading level, we used the following readability formulas (14):
1) Gunning Fog Index
2) SMOG Index
3) Dale–Chall readability formula
These formulas evaluate the reading level of a text according to its word count and comprehension difficulty. Their internal algorithm defines a “difficult word” as any word outside of a predetermined list of 3,000 words (15). To use the Dale–Chall readability formula, we were directed to a different website called readabilityformulas.com, which then computed the Dale–Chall Score (DCS).
First, we calculated the raw score using the following equation:
If the percentage of “difficult” words exceeded 5%, a Dale–Chall adjusted score was then calculated, and we used this score in our research paper
To score the reading level, we used the Flesch–Kincaid readability test, originally used by the US Navy and Pennsylvania Insurance Department and Florida Office of Insurance Regulation for contracts (14–16), but which is now widely used (15, 16). These test scores are based on two factors, that is, the average sentence length and the average number of syllables per word: (14)
The resulting score indicated the reading grade level needed to understand the written sentences. The transcribed English language responses were pasted into WebFx.com (14) to obtain the reading levels.
To determine the word count, we employed Google Document tools. The keywords from the answers on the AAO’s website were compared with those in the responses produced by ChatGPT (Table 1). In addition, important clinical concepts were selected by two ophthalmologists (GW and DAL) (Table 1). A total of 86 terms were compiled for the eight questions/topics taken from the AAO’s website.
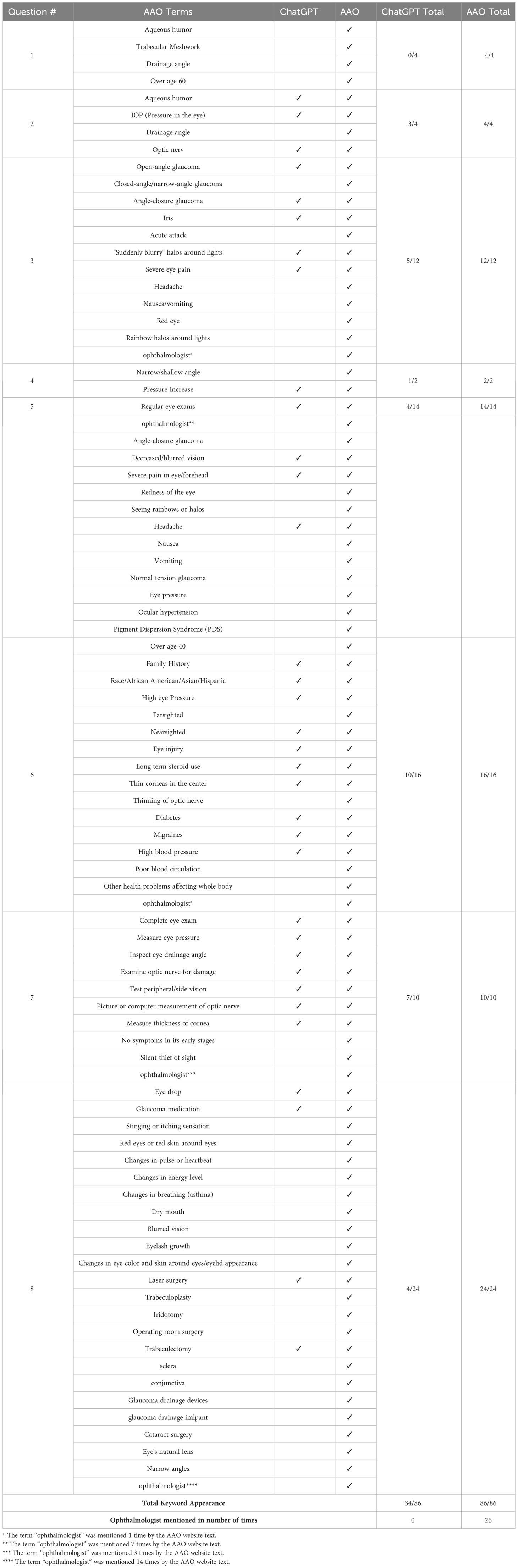
Table 1 Selected Keywords: ChatGPT responses vs AAO website text.
The average reading grade levels of the answers on the AAO’s website and the responses produced by ChatGPT, determined using the Flesch–Kincaid test, were grade 9.4 ± 3.5 and grade 12.5 ± 1.80, respectively (p ≤ 0.0384) (Table 2). For all the reading metrics, the average reading grade level of the ChatGPT responses was higher than that of the answers on the AAO’s website. The p-values, all of which were less than 0.05, are listed in Table 2. Notably, for question 6 (risk factors for glaucoma), the answer on the AAO’s website had a higher reading grade level according to the four reading metrics. This answer contained words such as “farsighted,” “nearsighted,” “steroid medications,” “corneas,” “optic nerve,” diabetes”, and “blood circulation,” which are medical terms and not part of the vocabulary of the lay public. The term “eye doctor” appears once in the ChatGPT response to question 7. On the AAO’s website, the term “ophthalmologist” is mentioned 26 times in total in the answers to questions 3, 4, 5, 6, 7, and 8: 23 times in the text and 3 times in the videos (Table 1). For the results obtained using the Flesch–Kincaid test, a larger number correlates with a higher reading grade level (Table 2).
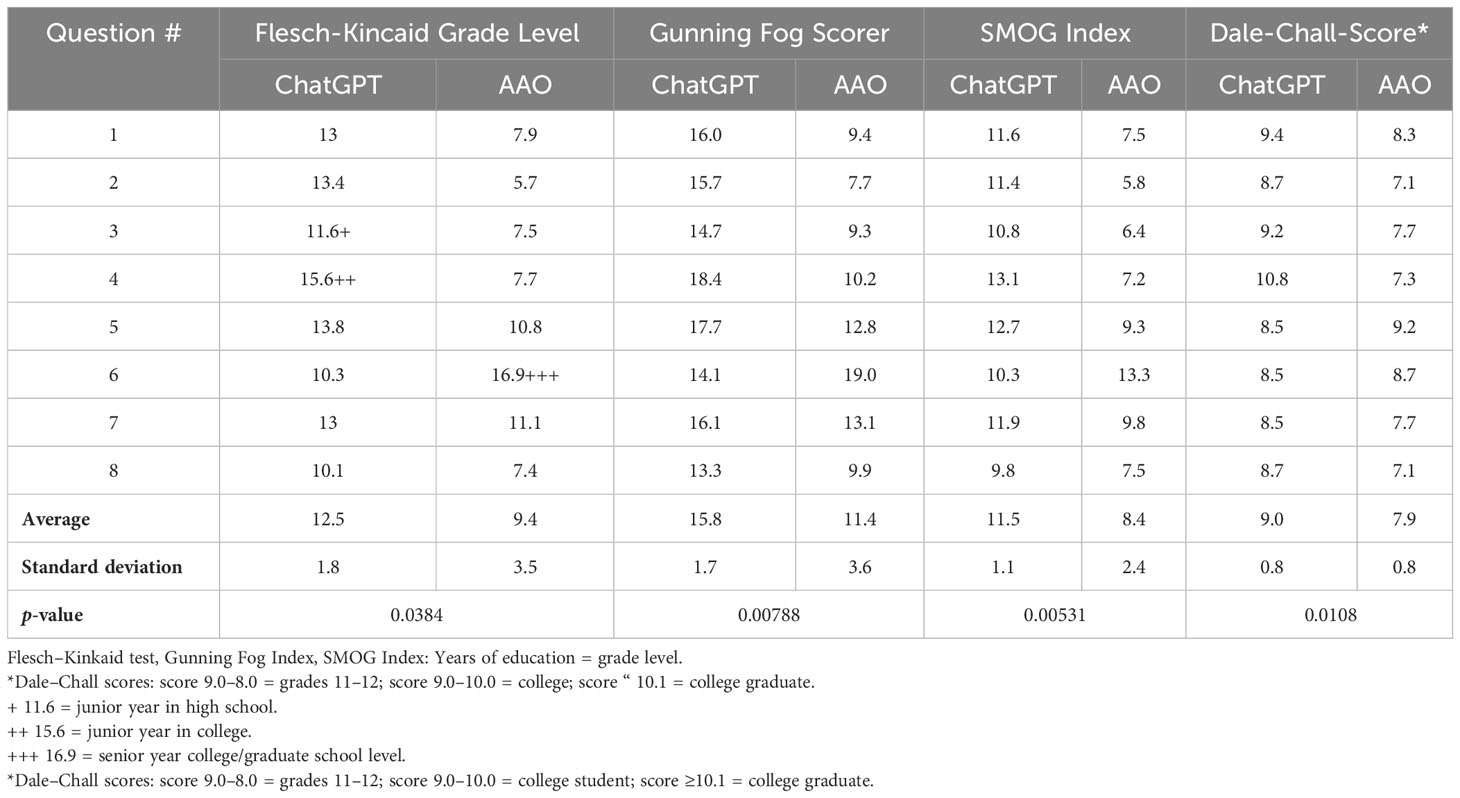
Table 2 Grade levels of the text produced in response to Questions (Qn)/topics 1–8 determined using the Flesch–Kincaid test, Gunning Fog Index, SMOG Index, and Dale–Chall readability formula.
Each ChatGPT (CG) response and the text on the AAO’s website were scored for the correlation of keywords. For the ChatGPT responses, the final score was 34 out of 86, compared with 86 out of 86 for the text on the AAO’s website. In terms of word counts, the responses on the AAO’s website and those produced by ChatGPT had similar word counts when averaged over the eight questions/topics. For five out of eight questions/topics, the responses produced by ChatGPT had a greater word count than the answers on the AAO’s website (Table 3)
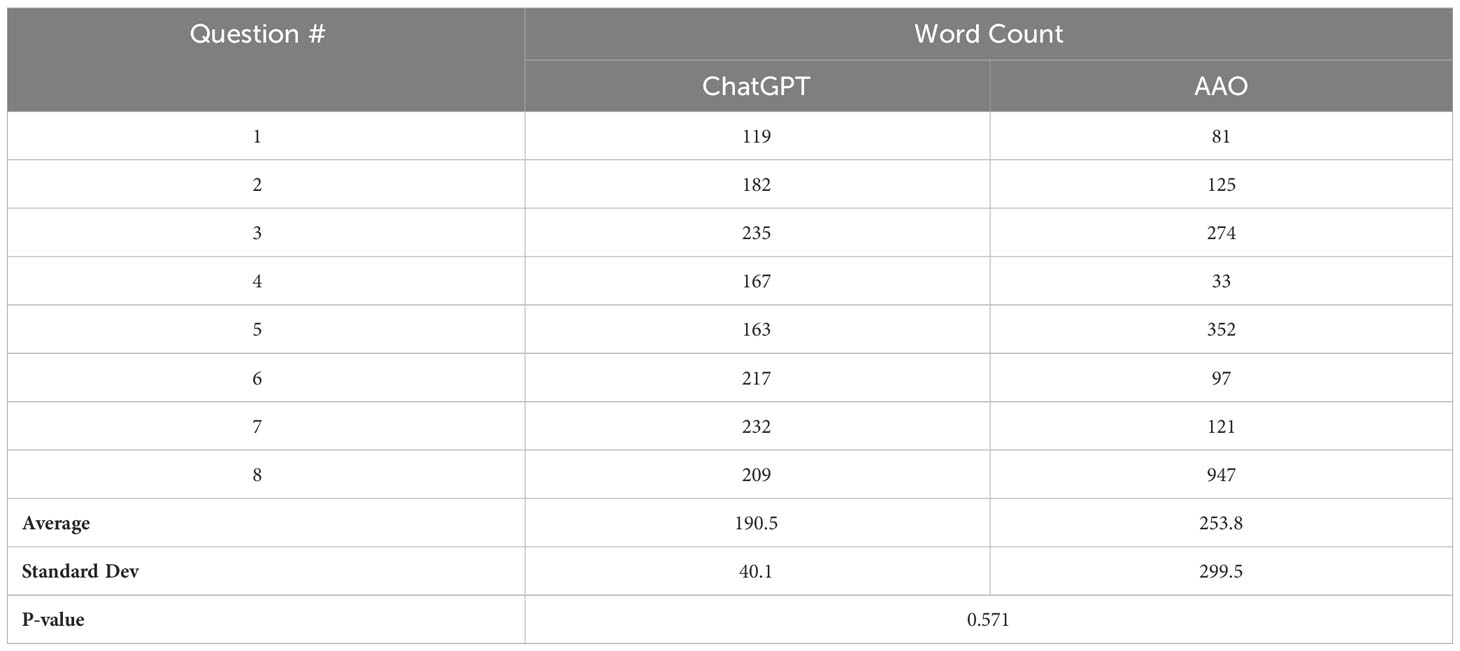
Table 3 Word count for ChatGPT responses and the AAO website text.
The same eight questions/topics were inputted into ChatGPT on 4 January 2023 and again on 5 May 2023, and the responses remained the same.
During the COVID-19 pandemic, many patients resorted to self-isolation or were hesitant to visit their eye doctors. Consequently, their family members turned to the internet for patient information; however, the information found on the internet can be incorrect (17–21). The introduction of ChatGPT on 30 November 2022 fulfilled an unmet need, drawing users from all parts of the world (17–19).
Our study was focused on exploring ChatGPT’s ability to engage with glaucoma patients. It is estimated that 4 million Americans have this disease, with an additional 2.4 million undiagnosed cases (17).
ChatGPT has been trained using internet data from approximately 2021, and its popularity lies in its ease of use. In the space of one week in 2021, it gained millions of users. The literature has discussed the need for patient education for individuals with chronic conditions such as diabetes, for which certified diabetes educators play a crucial role (9). Although there are no certified ophthalmic educators, certified ophthalmic technicians could help with the education of our glaucoma patients. These ophthalmic technicians are paid employees, whereas ChatGPT is free. The use of ChatGPT would achieve cost savings for our office budgets, but the responses provided by it are not accurate enough to function as standalone solutions that address the gaps in glaucoma patients’ education (22, 23).
Although ChatGPT has great potential to contribute to patient education, its responses seldom contain the terms “eye doctor” or “ophthalmologist”. There is a distinction between the training and surgical knowledge and expertise of an eye doctor (i.e., an optician or optometrist) and that of a board-certified physician ophthalmologist. When prompted with the term “glaucoma,” ChatGPT’s predictions were based on statistical parameters learned from prior training data sets and internet data from 2021, meaning that its responses are potentially missing newer information related to innovative medications and techniques for glaucoma treatment. In addition, the reliability of the training data sets used for chatbots such as ChatGPT remains unclear, particularly if data sets rely heavily on sources such as Wikipedia and social media platforms that may not explicitly mention “ophthalmology” or “ophthalmologist” in the context of glaucoma (5, 18, 19, 22).
Search engine optimization of the AAO’s website may depend on the user’s location and search history, potentially affecting the visibility of the website when searching for glaucoma. Furthermore, the AAO’s website may not have utilized specific coding practices to associate “ophthalmology” with “glaucoma,” thus limiting chatbots and other search engines from recognizing the connection between these terms.
Although ChatGPT is trained in medical literature, articles written by ophthalmologists for ophthalmologists do not commonly include phrases such as “see an ophthalmologist” in the context of glaucoma. As a consequence, chatbots will not generate such phrases with the word “ophthalmologist.”
Although reading-level assessment tools are not perfect, we used those commonly used by the military and state insurance bureaus. ChatGPT’s text responses require reading comprehension at an 11th-to-12th-grade reading level, whereas the average American reads at a 7th-to-8th-grade level (2, 3). This discrepancy poses a challenge for patients with lower health literacy and may affect their understanding of treatment relevance and vision loss prevention. Improved adherence to glaucoma eye drops is closely associated with higher health literacy, socioeconomic status, and education level (10–12). In order to elicit a simpler explanation of glaucoma, one could preface their instruction to ChatGPT with the phrase "Tell me like I am in fifth grade." However, for the purpose of the study, we consciously used the exact questions found on the AAO's website when preparing our data.
In comparing the responses produced by ChatGPT with the answers on the AAO’s website, we found that the latter were at a lower reading grade than high school level, although they still exceeded the comprehension level of seventh- or eighth-graders. The inclusion of videos on the AAO’s website enhances its accessibility and clarity. Conversely, ChatGPT’s responses may contain errors of omission, potentially leading patients to disregard their glaucoma symptoms or underestimate the urgency of seeking specialized care (Table 1). The chatbot’s responses do not emphasize that angle closure can rapidly cause irreversible vision loss or the urgency of consulting an eye care specialist, ophthalmologist, or emergency room physician (Table 1). This is consistent with ChatGPT’s programming, which is to provide descriptions but not “make decisions” (17). Repeated questioning of ChatGPT led to similar answers, with minimal changes in the content. However, if the subsequent queries were different each time, the answers would be more variable. For the purposes of this study, we used the same wording as in the AAO glaucoma questions for the queries inputted into ChatGPT.
The availability of large language models such as ChatGPT has ushered in a new era in which physicians can leverage AI for clinical decision-making and limited patient education (13, 17, 19). Other large language models, such as BARD and PaLM2, also exist (20, 21). Both of these were created by Google’s team of AI developers. BARD was released to a select audience in March 2023 and April 2023 but opened to the general public in mid-August 2023 in the USA, with a multilingual capability of 40 languages (24–27). The original version of BARD launched in February 2023 contained bugs, which led to the closure of the app 24 hours later. PaLM2 is another Google product with 140 languages in its algorithms and a greater ability for “deductive reasoning.” There are plans for PaLM2 to intersect with technical fields, such as medicine, health, and programming languages (21). The PaLM2 family of algorithms also feeds into BARD (20, 21). For now, the free version 3.5 of ChatGPT continues to be updated. The field of AI is quickly changing, and its major players will continue to make their chatbots more responsive to the public’s needs.
In the near future, ophthalmology residency and fellowship programs may utilize chatbots to enhance trainees’ clinical reasoning skills through generative case reports, similar to oral board examination questions. As physicians, we must be aware of the capabilities and limitations of AI-mediated chatbots, as they may generate inaccurate or biased results (17–21). It is crucial for physicians to recognize the influence of their written “phrases” and “word associations,” as these are used in the training of chatbots by their software programmers. In addition, the frequent inclusion of the phrase “see an ophthalmologist” in the software codes of ophthalmic websites and web journals may be needed to ensure the inclusion of the word “ophthalmologists” in the training algorithms of AI-mediated chatbots.
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
GW: Conceptualization, Data curation, Investigation, Methodology, Writing – original draft, Writing – review & editing, Formal Analysis, Validation, Visualization. DL: Conceptualization, Data curation, Investigation, Methodology, Writing – original draft, Writing – review & editing, Validation, Visualization, Formal Analysis. WZ: Conceptualization, Data curation, Investigation, Methodology, Writing – original draft, Writing – review & editing, Validation, Formal Analysis, Visualization. AW: Conceptualization, Data curation, Investigation, Methodology, Writing – original draft, Writing – review & editing, Validation, Visualization, Formal Analysis. SS: Conceptualization, Data curation, Investigation, Methodology, Writing – review & editing, Validation, Visualization, Formal Analysis.
This study was supported by the Susan And Richard Anderson Distinguished Chair in Ophthalmology endowment, McGovern Medical School, UTHealth Houston.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Eysenbach G. The role of chatGPT, generative language models, and artificial intelligence in medical education: A conversation with chatGPT and a call for papers. JMIR Med Educ (2023) 9:e46885. doi: 10.2196/46885
2. Kutner M, Greenberg E, Jin Y, et al. Literacy in Everyday Life: Results from the 2003 National Assessment of Adult Literacy [U.S. Department of Education web site] (2007). Available at: https://nces.ed.gov/Pubs2007/2007480_1.pdf (Accessed April 20, 2023).
3. Camille LR, Bauman K. Educational Attainment in the United States: 2015. [U.S. Census Bureau web site] (2016). Available at: https://www.census.gov/library/publications/2016/demo/p20-578.html (Accessed April 21, 2023).
4. An L, Bacon E, Hawley S, Yang P, Russell D, Huffman S, et al. Relationship Between Coronavirus-Related eHealth Literacy and COVID-19 Knowledge, Attitudes, and Practices among US Adults: Web-Based Survey Study. J Med Internet Res (2021) 23(3):e25042. doi: 10.2196/25042
5. Hirosawa T, Harada Y, Yokose M, Sakamoto T, Kawamura R, Shimizu T. Diagnostic accuracy of differential-diagnosis lists generated by generative pretrained transformer 3 chatbot for clinical vignettes with common chief complaints: A pilot study. Int J Environ Res Public Health (2023) 20(4):3378. doi: 10.3390/ijerph20043378
6. Bader M, Zheng L, Rao D, Shiyanbola O, Myers L, Davis T, et al. Towards a more patient-centered clinical trial process: A systematic review of interventions incorporating health literacy best practices. Contemp Clin Trials. (2022) 116:106733. doi: 10.1016/j.cct.2022.106733
7. Tham YC, Li X, Wong TY, Quigley HA, Aung T, Cheng CY. Global prevalence of glaucoma and projections of glaucoma burden through 2040: a systematic review and meta-analysis. Ophthalmology (2014) 121:2081–90. doi: 10.1016/j.ophtha.2014.05.013
8. Kass MA, Meltzer DW, Gordon M, Cooper D, Goldberg J. Compliance with topical pilocarpine treatment. Am J Ophthalmol (1986) 101:515–23. doi: 10.1016/0002-9394(86)90939-6
9. Sleath B, Blalock S, Covert D, Stone JL, Skinner AC, Muir K, et al. The relationship between glaucoma medication adherence, eye drop technique, and visual field defect severity. Ophthalmology (2011) 118:2398–402. doi: 10.1016/j.ophtha.2011.05.013
10. Hahn SR, Friedman DS, Quigley HA, Kotak S, Kim E, Onofrey M, et al. Effect of patient -centered communication training on discussion and detection of nonadherence in glaucoma. Ophthalmology (2010) 117:1339–47. doi: 10.1016/j.ophtha.2009.11.026
11. Cheng BT, Kim AB, Tanna AP. Readability of online patient education. Materials for glaucoma. J Glaucoma (2022) 31(6):438–42. doi: 10.1097/IJG.0000000000002012
12. Hark LA, Radakrishnan A, Madhava M, Anderson-Quiñones C, Fudemberg S, Robinson D, et al. Awareness of ocular diagnosis, transportation means, and barriers to ophthalmology follow-up in the Philadelphia Telemedicine Glaucoma Detection and Follow-up Study. Soc Work Health Care (2019) 58:651–64. doi: 10.1080/00981389.2019.1614711
13. Boyd K. What is Glaucoma? Symptoms, Causes, Diagnosis, Treatment. [AAO website] (2022). Available at: https://www.aao.org/eye-health/diseases/what-is-glaucoma (Accessed April 30, 2023).
14. Readability Test. Available at: https://www.webfx.com/tools/read-able/ (Accessed April 20, 2023).
15. Pennsylvania Department of Insurance. How to Measure Readability. Pennsylvania Code and Bulletin (2023). Available at: https://www.pacodeandbulletin.gov/Display/pacode?file=/secure/pacode/data/031/chapter64/s64.14.html&d=reduce (Accessed August 25, 2023). Title 31, ch 64, Sec 64.14.
16. Williamson JML, Martin AG. Analysis of patient information leaflets provided by a district general hospital by the Flesch and Flesch–Kincaid method. Int J Clin Pract (2010) 64(13):1824–31. doi: 10.1111/j.1742-1241.2010.02408.x
17. Metz C. What Google Bard Can Do (and What It Can’t Do), in: The New York Times. Available at: https://www.nytimes.com/2023/03/21/technology/google-bard-guide-test.html (Accessed August 24, 2023).
18. Ayers JW, Poliak A, Dredze M, Leas EC, Zhu Z, Kelley JB, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med (2023) 183(6):589–96. doi: 10.1001/jamainternmed.2023.1838
19. Li R, Kumar A, Chen JH. How chatbots and large language model artificial intelligence systems will reshape modern medicine: fountain of creativity or pandora’s box? Intern Med (2023) 183(6):596–7. doi: 10.1001/jamainternmed.2023.1835
20. Anil R, Dai AM, Firat O, Johnson M, Lepikhin D, Passos A, et al. PaLM2 Technical Report. ArXit./abs.10403. Available at: https://arxiv.org/abs/2305.10403 (Accessed August 24, 2023).
21. BARD. Available at: www.google.comhttps://bard.google.com/updates (Accessed August 24, 2023).
22. Crigger E, Reinbold K, Hanson C, Kao A, Blake K, Irons M. Trustworthy augmented intelligence in health care. J Med Syst (2022) 46(2):12. doi: 10.1007/s10916-021-01790-z
23. Budenz DL. A clinician’s guide to the assessment and management of nonadherence in glaucoma. Ophthalmology (2009) 116(11 Suppl):S43–7. doi: 10.1016/j.ophtha.2009.06.022
24. Erdem E, Kuyu M, Yagcioglu S, Frank A, L, Plank Parcalabescu B, et al. Neural Language Generation: A Survey on Multilinguality, multimodality, controllability, and Learning. J Artif Intell Res (2022) 73:1131–207. doi: 10.1613/jair.1.12918
25. Brender TD. Medicine in the era of artificial intelligence: hey chatbot, write me an H&P. JAMA Intern Med (2023) 183(6):507–8. doi: 10.1001/jamainternmed.2023.1832
26. Shaikh Y, Yu F, Coleman AL. Burden of undetected and untreated glaucoma in the United States. Am J Ophthalmol (2014) 158:1121–1129.e1. doi: 10.1016/j.ajo.2014.08.023
Keywords: glaucoma, ophthalmology, ChatGPT, artificial intelligence, patient education
Citation: Wu G, Lee DA, Zhao W, Wong A and Sidhu S (2023) ChatGPT: is it good for our glaucoma patients? Front. Ophthalmol. 3:1260415. doi: 10.3389/fopht.2023.1260415
Received: 17 July 2023; Accepted: 01 September 2023;
Published: 16 November 2023.
Edited by:
Rebecca M. Sappington, Wake Forest University, United StatesReviewed by:
Parul Ichhpujani, Government Medical College and Hospital, IndiaCopyright © 2023 Wu, Lee, Zhao, Wong and Sidhu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gloria Wu, Z3d1MjU1MEBnbWFpbC5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.