 Prabhu Ramamoorthy
Prabhu Ramamoorthy Buchi Reddy Ramakantha Reddy2
Buchi Reddy Ramakantha Reddy2 Mohamed Abouhawwash
Mohamed Abouhawwash- 1Department of Electronics and Communication Engineering, Gnanamani College of Technology, Namakkal, India
- 2Department of Computer Science and Engineering, Sri Venkateswara College of Engineering, Tirupathi, India
- 3Department of Statistics and Operations Research, College of Science, King Saud University, Riyadh, Saudi Arabia
- 4Department of Mathematics, Faculty of Science, Mansoura University, Mansoura, Egypt
Breast cancer (BC) is the leading cause of female cancer mortality and is a type of cancer that is a major threat to women's health. Deep learning methods have been used extensively in many medical domains recently, especially in detection and classification applications. Studying histological images for the automatic diagnosis of BC is important for patients and their prognosis. Owing to the complication and variety of histology images, manual examination can be difficult and susceptible to errors and thus needs the services of experienced pathologists. Therefore, publicly accessible datasets called BreakHis and invasive ductal carcinoma (IDC) are used in this study to analyze histopathological images of BC. Next, using super-resolution generative adversarial networks (SRGANs), which create high-resolution images from low-quality images, the gathered images from BreakHis and IDC are pre-processed to provide useful results in the prediction stage. The components of conventional generative adversarial network (GAN) loss functions and effective sub-pixel nets were combined to create the concept of SRGAN. Next, the high-quality images are sent to the data augmentation stage, where new data points are created by making small adjustments to the dataset using rotation, random cropping, mirroring, and color-shifting. Next, patch-based feature extraction using Inception V3 and Resnet-50 (PFE-INC-RES) is employed to extract the features from the augmentation. After the features have been extracted, the next step involves processing them and applying transductive long short-term memory (TLSTM) to improve classification accuracy by decreasing the number of false positives. The results of suggested PFE-INC-RES is evaluated using existing methods on the BreakHis dataset, with respect to accuracy (99.84%), specificity (99.71%), sensitivity (99.78%), and F1-score (99.80%), while the suggested PFE-INC-RES performed better in the IDC dataset based on F1-score (99.08%), accuracy (99.79%), specificity (98.97%), and sensitivity (99.17%).
1 Introduction
Breast cancer (BC) is the primary cause of death from cancer for women globally. For BC, classification, histopathology, imaging [ultrasound, magnetic resonance imaging (MRI), and computed tomography (CT)], and clinical findings are employed (1). By generating histological tissue for microscopy, pathologists use histology to evaluate the development of cancer. The tissues surrounding cells and structures are represented in histopathological specimens in a variety of ways (2). Hematoxylin and eosin (H&E) is a commonly used histological dye. Cell nuclei are stained blue, and the cytoplasm is stained pink. When stained with H&E, cancer cells commonly have an abnormal appearance, and the pathologist can identify them from normal cells by examining the structure of cells (3, 4). Cancer cells multiply at a rapid pace, and if not correctly identified, they become a serious threat to the patient (5). Early and accurate diagnoses are considered to be significant in improving cancer survival chances (6). Early BC has a persistence rate of approximately 80%, while late-stage illness has a rate of under 20% (7). Among the several diagnostic screening methods for predicting early BC, mammography has become the most expensive and most medically acceptable method (8).
Invasive ductal carcinoma (IDC) and ductal carcinoma in situ (DCIS) are two kinds of BC. Only 2% of patients with BC have DCIS, which is a relatively low rate. Additionally, IDC is harmful because it contains whole breast cells. Eighty percent of patients with BC have IDC, with a mortality rate of 10% (9). Histopathological evaluation of breast tissue biopsy images plays a substantial part in the detection of BC (10). Pathological images not only include pathological characteristics of growth, tumor form, and distribution but also provide radiomics benefits such as low cost, high speed, and non-invasiveness (11). Larger size patches that are sampled from a histology image have enough data to be assigned to the patches using the image label (12). However, it is possible that cell-level patches are taken from high-resolution histology images that do not have enough diagnostic information (13, 14). A deep learning approach based on CNN and a clustering model are used to automatically screen more discriminative patches (15). The primary goal is to provide a thorough and efficient method for the multi-classification of histology BC images to enhance diagnostic capabilities, taking into account the aforementioned two factors.
The main contributions are specified as follows:
● Primarily, this research analysis is performed on histopathological images (HIs) of BC using BreakHis and IDC datasets. Previously, the collected datasets are pre-processed by means of super-resolution generative adversarial networks (SRGANs), which belong to advanced deep neural network (DNN) processes and are proficient in producing high-resolution images. SRGANs upsample a low-resolution image into a higher-resolution one with negligible data error.
● Afterwards, high-quality images are processed using data augmentation techniques such as rotation, random cropping, mirroring, and color-shifting to enhance the downstream performance. Data augmentation is vital for many applications, as accuracy increases with the amount of training data. In fact, research studies have found that augmentation significantly enhances the accuracy on image tasks, for example, classification.
● Then, feature extraction is performed by patch-based feature extraction using Inception V3 and Resnet-50 (PFE-INC-RES) to regularize the network's output and diminish the percentage of errors.
● Once the feature extraction is done, a transductive long short-term memory (TLSTM)-based classifier is introduced that efficiently classifies the BC as malignant and benign, which results in higher classification accuracy.
The structure of this manuscript is prepared as follows: Section 2 describes the existing works and Section 3 describes the proposed methodology of this study. Section 4 demonstrates the results and comparison. Section 5 delivers the discussion part. The conclusion is described in Section 6.
2 Literature review
Saini and Susan (16) implemented a deep transfer network, VGGIN-NET, to discuss the class imbalance problem in BC. The appropriate layers from the VGG16 were combined with the naïve inception module, dense layer, batch normalization, and flattening to construct the VGGIN-NET architecture. Regularization was employed in the form of data augmentation and dropout to enhance the performance of the VGGIN-NET. Both the majority and minority classes of the VGGIN-NET were effectively classified. Furthermore, the suggested VGGIN-Net is designed to deal with the imbalanced BC dataset and helps to improve the robustness and generalizability of the approach. Whenever the number of layers in VGGIN-Net increases, the convolutional kernel reduces the number of parameters in the convolutional layer, which was equivalent to increasing the regularization. Still, other deep network architectures require the multi-class unbalanced biological dataset for the classification of BC.
Joseph et al. (17) presented a handcrafted feature extraction method and DNN for the multi-classification of BC employing histopathology images on BreakHis. The features were utilized to train DNN classifiers by SoftMax and four dense layers. The presented model avoids overfitting issues by employing the data augmentation method. However, the extraction of several handcrafted features leads to high-dimensional feature vectors, which enhance computing complexity and contain unnecessary or redundant data.
Hamza et al. (18) introduced an improved bald eagle search optimization with synergic deep learning for BC detection employing histopathological images (IBESSDL-BCHI). The introduced method's purpose was to detect and classify BC utilizing HIs. The IBES enables the accurate classification of HIs into two categories: malignant and benign. The IBESSDL-BCHI achieves an improved general efficacy score for the classification of BC. However, to ensure robustness and scalability, the IBESSDL-BCHI method needs to be validated on large-scale real-time datasets.
Khan et al. (19) implemented a MultiNet framework that relies on transfer learning to categorize binary and multiclass BC using the datasets of BreakHis and ICIAR-2018. In the MultiNet framework, three well-known pre-trained models, VGG16, DenseNet-201, and NasNetMobile, were used to extract features from the images of the microscope. A robust hybrid model was created by transferring the extracted features into the concatenate layer. In BreakHis and ICIAR-2018, the MultiNet framework effectively classifies all images as benign. However, establishing a learning rate in the MultiNet framework was difficult since high learning rates lead to unwanted behavior.
Guleria et al. (20) presented a variational autoencoder (VAE) based on a convolutional neural network (CNN) for reconstructing the images to enhance the detection of BC. Images processed from histopathology were presented to detect brain cancer. Various CNN configurations with autoencoder variants were used to produce the prediction outcomes of the VAE. The presented method minimizes the amount of time pathologists use to manually examine the report. However, the computational cost for the architecture of training deep VAEs based on CNN was high.
Liu et al. (21) introduced a novel framework AlexNet-BC model for the classification of BC pathology. The suggested method was trained on ImageNet and fine-tuned by the augmentation. An enhanced cross-entropy loss function was used to penalize and generate forecasts appropriate for uniform distributions. AlexNet-BC has high robustness and generalization characteristics that produce benefits for histopathological clinical systems of computer-aided diagnosis. However, the classifier of SoftMax has a significant threat of overfitting when combined with the loss function of cross-entropy.
The implementation of multiscale voting classifiers (MVCs) for BC histology images was presented by Jakub Nalepa et al. (22). The suggested MVC used clinically interpretable features that are taken from histopathology images of BC. Afterwards, the method was utilized to classify a four-class real-world H&E set using the BACH challenge framework. Finally, the statistical tests supported the trials and showed that the provided classifiers offer high-quality classification, are fast to train, and can draw conclusions quickly. This method helps to reduce the number of false negatives; the number of false positives for these classes partially increases, but it was significantly more cost-effective for medical applications.
Kumari and Ghosh (23) offered a transfer learning method based on the deep convolutional neural network (DCNN) to classify BC from the histological images. The transfer learning method has employed three different DCNN architectures as base models: Densenet-201, Xception, and VGG-16. Each test image has been categorized as malignant or benign after the features from each test image was extracted using three pre-trained base models. The presented method has the potential because of the method's high classification accuracy, which helps doctors accurately diagnose BC in patients. However, the presented method was ineffective in classifying breast histopathology images into various stages of BC.
A deep CNN method has been introduced by Bhausaheb and Kashyap (24) to identify and categorize BC. The deep CNN, which depends on optimization, was utilized for classification, while the V-net design was used for segmentation. The weighted variables are effectively and very steadily trained using the optimization method in conjunction with a deep CNN classifier. However, only histopathologic images have been utilized for verifying the recommended approach.
A data exploratory technique (DET) through predictive algorithms has been developed by Rasool et al. (25) to improve the accuracy of BC diagnosis. The distribution and correlation of features, the removal of recursive features, and the optimization of hyper-parameters are the four layers that make up the DET. Four models' preliminary information were acquired, and predictive algorithms like SVM, LR, KNN, and the ensemble model were used to classify the data. The four algorithms' best performances were taken into account, improving classification accuracy, whereas if tested using the WDBCD dataset, the SVM generates an ineffective outcome.
In order to classify BC, Egwom et al. (26) established a machine learning model called linear discriminant analysis–support vector machine (LDA-SVM), which was used to classify BC, and LDA was used to extract features based on the pre-processed images. To improve accuracy, the information was trained using the cross-validation method. However, the lack of a feature selection procedure made classification a little more difficult.
For the categorization of histopathology images, Fan et al. (27) used transfer learning methods (AlexNet) of the SVM classifier and the traditional softmax classifier. To increase accuracy, the fully connected layer was used in conjunction with SVM. Cross-validation on a fourfold scale is used by the softmax-SVM classifier to increase the effectiveness. In order to identify BC in histopathology images, Ahmed et al. (28) employed PMNet, and the classification procedure makes use of a scaled matrix. Applying the dryad test database, the PMNet system for classification has been assessed. However, it is a laborious and difficult task that is dependent on the knowledge of pathologists.
This work offers a thorough analysis of the advancements in the field of pathological imaging research related to BC and offers dependable suggestions for the design of deep models for various applications. The number of BC diagnoses has significantly increased over time, and this increase has been associated with genetic and environmental problems. There are two groups of BC-related lesions: benign (not cancerous) and malignant (cancerous). Subsequently, because it is dependent on temperature and skin lesions, digital infrared imaging is not the ideal tool for diagnosing early BC. To accelerate the cancer detection process, detection methods have been produced based on the histopathology dataset for BC. Still, conventional feature extraction techniques extract a few low-level characteristics from images, and in order to choose meaningful features, previous information is required, which can be substantially influenced by people. Furthermore, there are few sampled cell-level patches that do not have adequate data to balance the image tag. In order to surpass the problems associated with unsuitable classification, this study presented an advanced classification by means of deep learning algorithm.
3 Proposed method
The proposed method included several steps, for example, pre-processing, augmentation, extraction, and classification, where the input data are obtained from BreakHis and IDC. Then, the images gathered from BreakHis and IDC are pre-processed using SRGAN to produce high-resolution images. The pre-processed image then proceeds to the data augmentation stage, where rotation, random cropping, mirroring, and color-shifting are used to either generate new data points or make minor adjustments to the dataset. Next, utilizing PFE-INC-RES, the features from the augmentation are extracted. TLSTM is introduced during the classification stage, where the extracted features are processed, to decrease the frequency of wrong diagnoses and boost classification accuracy. Figure 1 shows the overall procedure involved in BC classification.
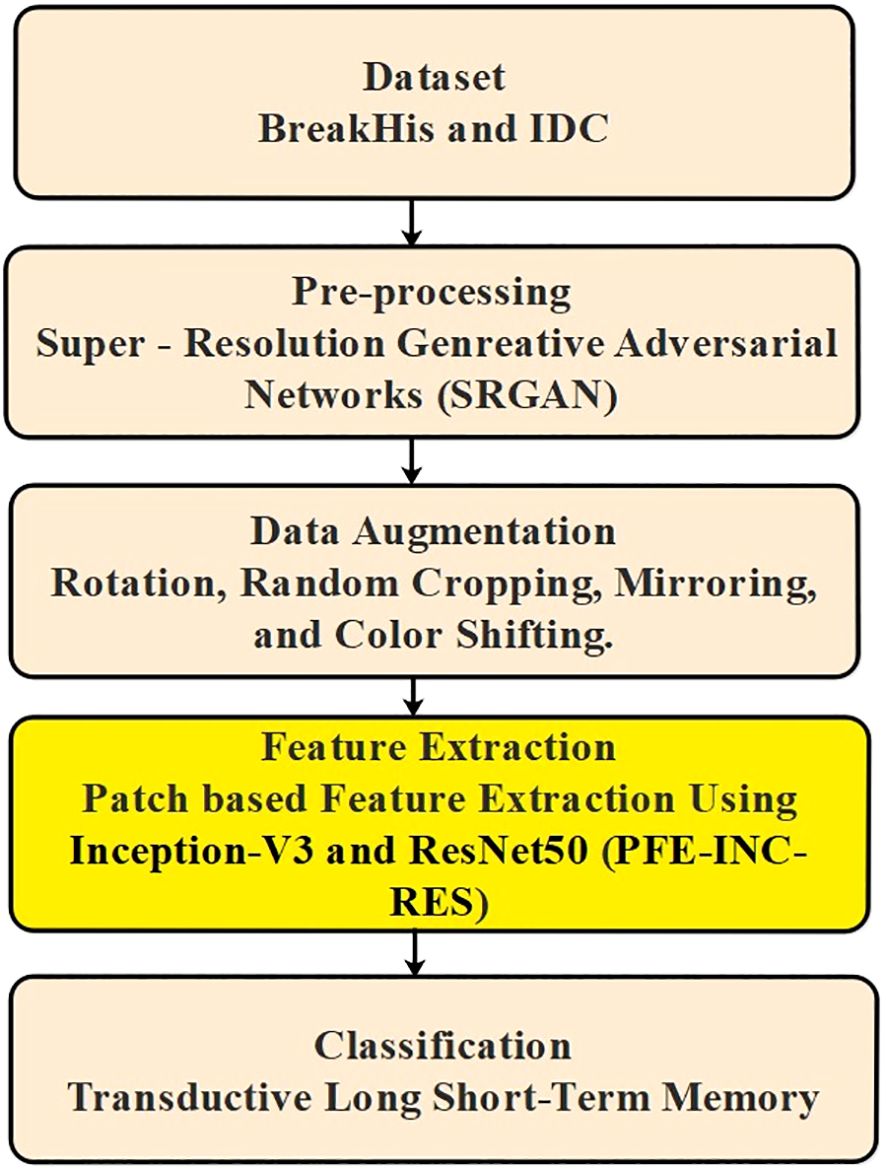
Figure 1 Overall block diagram of the proposed system.
3.1 Dataset description
3.1.1 BreakHis dataset
Here, in this dataset, 9,109 microscopic images of breast tumor material obtained from 82 patients with dissimilar magnification factors (40×, 100×, 200×, and 400×) make up BC Histopathological Image Classification (BreakHis). It now has 5,429 malignant samples and 2,480 benign samples. Together with the P&D Laboratory of Pathological Anatomy and Cytopathology in Brazil, the record was originally created (http://www.prevencaoediagnose.com.br). Additionally, researchers might find this dataset to be beneficial because it enables benchmarking and assessment in the future (29). To digitize the images from the breast tissue slides, a Samsung digital color camera SCC-131AN is connected to an Olympus BX-50 system microscope equipped with a relay lens that has a magnification of The 1/3" Sony SuperHADTM (Hole-Accumulation Diode) IT (Interline Transfer) CCD (charge-coupled device) used in this camera has a total pixel count of 752×582 with a pixel size of 6.5 µm × 6.25 µm. Magnification factors of are used to gather images in three-channel RGB (red–green–blue) TrueColor (24-bit color depth, 8 bits per color channel) color space. The following is how images are acquired at various magnifications: The pathologist initially determines the tumor's identity and establishes a region of interest (ROI). Several images are taken at the lowest magnification to cover the whole ROI. Almost all the time, the pathologist chooses images with only one form of tumor; however, occasionally, images consist of transitional tissue.
The latest version's examples were obtained using the surgical open biopsy (SOB), similarly recognized as the partial mastectomy technique. Relative to other needle biopsy techniques, this type of operation extracts a greater quantity of tissue, and it is performed under general anesthesia in a hospital. Depending on how the tumoral cells appear through a microscope, benign and malignant breast tumors can be divided into many kinds. Every image's file name contains information regarding the image itself, including the biopsy technique, the type of tumor, the patient’s identity, and the magnification level. Figures 2, 3 display the BreakHis dataset's sample benign and malignant images with a magnification factor. The proposed method is introduced for classifying BC images with a magnification of in benign and malignant tumors. The detected areas have been magnified to for enabling the pathologist to compute cell shape and achieve a higher accuracy.

Figure 2 Four types of benign sample images with a magnification of . (A) Adenosis, (B) Fibroadenoma, (C) Phyllodes tumor, (D) Tubular adenona.

Figure 3 Four types of malignant sample images with a magnification of . (A) Ductal carcinoma, (B) Lobular carcinoma, (C) Mucinous carcinoma, (D) Papillary carcinoma.
3.1.2 IDC dataset
In the Hospital of the University of Pennsylvania (HUP) as well as the Cancer Institute of New Jersey (CINJ), 162 women’s WSIs for diagnosed IDCs have undergone initial digitization. The least prevalent form of BC is IDC. Diagnosticians generally concentrate on zones that contain IDC once the severity of the complete mounted sample is determined (https://www.kaggle.com/datasets/paultimothymooney/breast-histopathology-images). As a result, the common pre-processing stage for automatic aggressiveness grading is to define the precise sections of IDC inside of a whole mount slide. A total of 162 complete mounted slide images of BC samples that had been scanned at 40× made up the original dataset. A total of 277,524 patches of size 50 × 50 were retrieved from it, of which 78,786 were IDC-positive patches and 128,738 were IDC-negative patches. The file name for every patch follows a specific format (30). The image patches were shuffle-selected and categorized into three groups. The training and testing sets have been split as 80:20 from the total dataset. Figure 4 displays the IDC dataset’s sample images.
Figure 4 The sample images of the IDC dataset. (A) IDC (-), (B) IDC (+).
After the data collection, the super-resolution reconstruction technique is used to convert the images from low-resolution (LR) to high-resolution (HR) domains, which improves image resolution while restoring the image data. To convert LR images into HR images, traditional image super-resolution algorithms must first pair HR and LR images, then figure out their maps. Since true HR and LR image pairs are hard to come by, the present approach for creating HR-LR image datasets mostly consists of establishing a degradation model, from which the corresponding LR image is derived from the HR image. At the moment, the accuracy of the degradation model has a significant impact on how well super-resolution techniques work with nonideal datasets. To solve the above stated issue, this research suggested a super-resolution GAN model for the collected datasets to enhance the image resolution quality, which is clearly described below.
3.2 Preprocessing using super-resolution generative adversarial networks
The components of conventional GAN loss functions and effective sub-pixel nets were combined to motivate the concept of SRGAN. In order to create image details and achieve a better visual impression, SRGAN uses a convolutional neural network as the generation network. This allows the network to be improved by discriminating against training and generating a network. The perceptual loss function is the most notable component of SRGANs. As the generator and discriminator are trained using the GAN design, SRGANs rely on an additional loss function to reach their destination.
In SRGANs, both of the networks are deep convolution neural networks and contain convolution layers and upsampling layers. Each convolution layer is followed by a batch normalization operation and an activation layer. Therefore, in this phase, SRGANs are suggested, which learn the extracted LR images through the multi-scale properties of the two subnetworks, followed by employing high-frequency data across multiple scales to produce HR images. Super resolution (SR) takes the benefits of GAN’s ability to reconstruct an image’s appearance and make an image with high-frequency features (31).
The aim is to generate an SR image from LR using HR’s bicubic procedure. The LR and HR images will be denoted by d accordingly. The end-to-end mapping function among d are solved through the subsequent Equation 1:
refers to the network parameter set that needs to be enhanced; refers to the loss function for lessening the variance among and The training sample’s number is referred to as GAN is a generative framework that contains a generator (G) and a discriminator (D) as demonstrated in Figure 5. Although the discriminator valuates if the input data are generated by to be false or real, receives the data using the initially provided noisy data. Once is capable of assessing the legitimacy of data and roduces enough strength to distort judgment, and plays towards one another frequently through this procedure, which continues to return data while enhancing their network features accordingly.
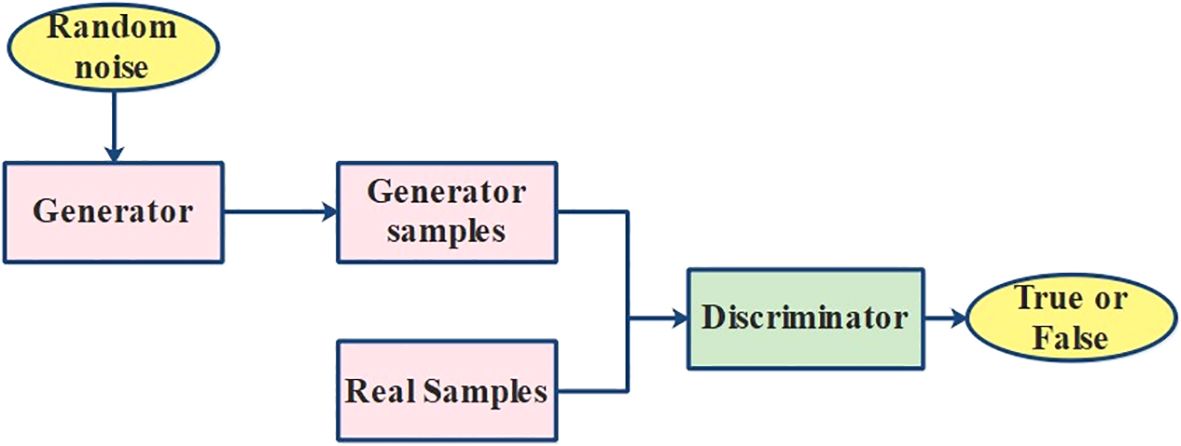
Figure 5 Process of the GAN model.
As a result, in order to address the adversarial min–max problem, additionally design a discriminator network and optimize it alternately with which is defined in Equation 2,
and signify true sample and generator distribution. Subsequently, the total loss function demarcated as the weighted sum of individual loss functions, which is defined in Equation 3,
Here, the weighting parameters are referred to as signifies the content loss that is exploited as optimization target for SR image; signifies the adversarial loss of GAN; refers to the downsampling factor; represent the image size (32).
3.3 Data augmentation
The process of including slightly altered copies of current data without effectively gathering new data from previous training data is known as data augmentation. Additionally, the photographs show variation in elements like magnification, perspective, region of interest, and light, which complicates the classification work. Because of this unpredictability, the classifier may possibly overfit or underfit, which would result in subpar accuracy. The classifier will therefore not generalize very well. The training dataset size can be intentionally increased via data warping or oversampling, which additionally helps the model avoid overfitting by preventing it from the source of the issue. We added to our data using several augmentation settings, including rotation, random cropping, mirroring, and color-shifting (33), to address this overfitting.
3.3.1 Rotation
The key benefit of rotation over flipping is that, when used to some degree, including in the range [−45, +45], it does not completely alter the meaning of the data. The additional benefit when performing rotation at random throughout training is that the algorithm never encounters the same image repeatedly.
3.3.2 Random cropping
Random cropping is a process that involves randomly selecting a portion of the image to crop, which improves durability over partial occlusions. It is carried out to reduce overfitting and introduce regularization throughout training. It is frequently used during training, which prevents the model from seeing the same image repeatedly.
3.3.3 Mirroring
Mirroring across the vertical axis is perhaps the most straightforward data augmentation technique. By flipping an image, a new image is produced. Mirroring continues to maintain the same class of picture for the majority of computer vision applications. This approach is useful in areas like face recognition and object identification datasets where object orientation is not essential. By rotating or mirroring the image, the model could be learned to recognize an object in any direction.
3.3.4 Color shifting
Color shifting is an additional type of data augmentation that is frequently employed to strengthen the learning algorithm’s resistance to changes in the colors of the relevant images. These data augmentation techniques add new instances to the training set while simultaneously expanding the range of inputs the model encounters and absorbs. The model is encouraged to learn broader patterns as a result of both of these factors, which make it harder for the model to merely memorize mappings. These augmented images are specified as input to the extraction phase, where patch-based automatic feature extraction using pretrained architectures is introduced and explained in detail.
3.4 Patch-based feature extraction using pretrained architectures
The framework for the multi-class categorization of BC histology images provides a concise summary of the key processes: To maintain important details and to contain features at the cell and tissue levels, firstly extract two distinct kinds of patches from BC histological images using the PFE-INC-RES method.
3.4.1 Sampling patches
The objective is to divide the histology image into the subsequent two categories: malignant and benign. The data gathered from the images have a significant impact on categorization performance. Subsequently, to depict each complete image, employ breast cell-related characteristics and global tissue features. In order to decide if cells are cancerous, cell-level characteristics, including nuclei data form and fluctuation, and cell organization features, consisting of volume and anatomy, are used. The histology images in the dataset have pixels that are 0.42 mm by 0.42 mm in size, and the cell radius is roughly between 3 and 11 pixels. Therefore, to obtain cell-level characteristics, we extract tiny patches of pixels. In addition, the sick tissue may have an unusual shape. The starting tissue division is not the only place where invasive cancer can spread (34). To distinguish among in situ and invasive carcinomas, knowledge of tissue architecture is crucial. It is impractical for CNNs to acquire characteristics from a large-sized histological image. Then, extract patches of pixels to store data on the global tissue patterns based on image size in the provided dataset. Then, from BC histological pictures, extract patches using a sliding window method. Also extract continuous, non-overlapping patches from histology pictures since the pixel patches are modest and concentrate on cell-related properties. Additionally, we take overlapping patches of pixels by 50% overlap to obtain data regarding constant tissue shape as well as architecture. The label for each extracted patch matches the associated histological image.
3.4.2 Feature extractor
Two pre-trained models are used for patch-based feature extraction, namely, Inception-V3 and ResNet-50, also known as PFE-INC-RES. The cell shape, texture, tissue architecture, and other aspects of the histopathology images vary. For classification, the representation of complicated features is important. The feature extraction method is labor-intensive, and extracting discriminatory features using it is challenging since it requires extensive expert subject knowledge. CNNs have achieved impressive achievements in a variety of disciplines and can directly extract representative characteristics from histopathology images.
3.4.2.1 Inception-V3
Inception-V3 is selected as a preliminary feature extraction method since it has the capability to extract high-level features with a variety of filter modifications (277), as well as an efficient grouping of several forms of convolution process (35). In this technique, a gain of 28% can be achieved utilizing two () convolutions. The total number of parameters discovered for the () convolution layer is nine. In contrast, a sequence of two () convolution layers followed by a third () layer, which results in a total of six constraints, represents a 33% reduction overall. The suggested architecture uses a reduction method to overcome issues with conventional pre-trained models.
The images with the dimensions () are originally supplied to the suggested model for the extraction task without the secondary module, which produces texture features from the final concatenate layer and utilizes a flattened layer that produced an output of as shown in Equations 4, 5, where texture feature is converted into a 1D vector.
3.4.2.2 ResNet-50
To obtain high-level feature extraction, ResNet-50 is utilized to concentrate on low-level features and employ remaining connections in the architecture (36). After becoming saturated during convergence, the Inception-V3 efficiency somewhat declines. In order to overcome these challenges, this dissertation offers ResNet-50 for the FE procedure. ResNet-50 design has 50 layers in five blocks. The residual function, F, for each of these blocks has three convolution layers with the dimensions (), (), and respectively. The output () is derived through averaging its input and residual function as shown in Equation 6. The weight matrix of three consecutive layers is updated by on The input image which has the shape (), was used to extract features that are provided to ResNet-50, and the output of , is employed for final classification. previously converted by means of a flattened layer to produce the 1D vector output of that is demarcated in Equations 7 and 8 correspondingly.
The DNN classifier’s functional design uses the extracted feature to predict a class. The concatenation of the two features is done after taking the features from separate models. As a result, the concatenation layer creates a single 1D hybrid vector called which includes features based on texture and form, i.e., expressed in Equation 9.
3.4.3 Screening patches
This section’s goal is to introduce the PFE-INC-RES-based method for screening discriminative 128 by 128 pixel patches. The PFE-INC-RES is trained using highly discriminative data and extract features with patches that are then retrained using the patches. The PFE-INC-RES features that were extracted are used as input for the TLSTM-based classification stage. In this phase, the patient’s BC is separated into benign and malignant varieties based on its nature, which is briefly detailed in the following subsection.
3.5 Classification using transductive long short-term memory
An LSTM is a specific kind of recurrent neural network (RNN) that records interunit relationships across extended distances. The LSTM architecture was chosen because it has integrated nonlinear hidden layers among input and output layers. These layers allow the learning of complicated functions and features for better prediction by underpinning the functional relationships from the incoming data (37). This part (38) covers transductive LSTM (T-LSTM), a limited-edition LSTM model. Additionally, all training data point’s influence on T-LSTM’s recommended factors depends on how similar it is to the test data point of length As a result, the goal is to enhance performance close to the test point, and the effectiveness of the model in forecasting training samples close to the test point is given more attention (39). This makes it conceivable to claim that the test point is a necessity for all linear models.
● Consider as a hidden state, the state space model of T-LSTM is mentioned in Equation 10,
It should be noted that the model shown in Equation 14 differs from the previous one in that the model variables in T-LSTM depend on the test point’s feature space, whereas the parameter estimations in LSTM are independent of the test point. The T-LSTM model’s structure is depicted in Figure 6.
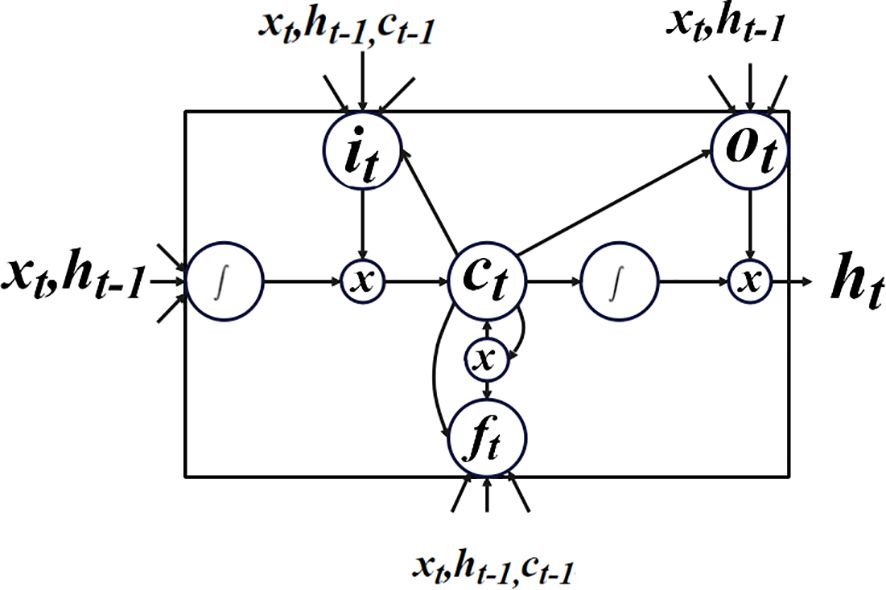
Figure 6 Structure of the T-LSTM process.
● Use the subscript to demonstrate that the linear models depend on the newly supplied data point . Note that the test label is considered to be invisible, and that the test point’s function during the training stage is to change the significance of data points, which is close to their feature vectors.
The prediction is expressed as Equation 11 by utilizing the dense layer,
● Here, and are referred to as weights and bias terms.
● To determine the needs of the fresh hidden point, consider as the resemblance among and by signifying every constraint in () and () correspondingly. The objective function is expressed in Equation 12,
where .
referred to as a tuning parameter in Equation 12. Moreover, the transductive method’s tuning parameter is the number of neurons displayed in LSTM. Additionally, the model in this instance is unable to employ training data from the majority of similar datasets. As a result, there should not be a significant change in the original series pattern, and our study is predicated on that assumption. In feature space, there is not much of a distance between two consecutive data points. Since samples from the final training phase were collected before the test point, they are located in feature space close to the test point. The validation group is chosen to consist of these samples.
● The parameters are dependent on Z(η). Therefore, every unseen subsample has been rehabilitated. It shows every constraint ω(η) and b(η) is diverse for every test point.
Depending on the particulars of the problem, one can question if this approach is suitable for modeling due to the high processing cost of T-LSTM. In contrast to the transductive technique, which trains a different model for each test point, the qualitative methodology’s components are chosen without regard to the test point. When the relationship between components in distinct sections of the input space vary, T-LSTM is also relevant.
● For Z(η) the updated hidden state is described as Equation 13,
● Here, η…, η+T−1. Later, the final prediction is attained as Equation 14,
is referred to as input. Still, the updated hidden state and prediction in T-LSTM based on the new point feature vector, where model constraints are adjusted between training points and is designated as the subscript in and in Equations 13, 14.
4 Results
In this research, two datasets called the BreakHis dataset and IDC are used to evaluate the proposed PFE-INC-RES model. The suggested method is implemented into testing with MATLAB 2021b version 9.11, which has the following system requirements: Windows 11 OS, an Intel Core i7 processor, and 16 GB of RAM. The system performance was estimated by the suggested BC detection approach by means of several metrics. The statistical analysis of accuracy, specificity, precision, sensitivity, F1-score, and its mathematical expression is described in Equations 15–19:
where TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
4.1 Performance analysis on the BreakHis dataset
The proposed PFE-INC-RES is evaluated on a 40× magnitude factor (MF) in the BreakHis dataset using a variety of extraction methods, which is revealed in Table 1; Figure 7. This section validates the suggested PFE-INC-RES executed with a training and testing split ratio of 80:20 on 40× using AlexNet, GoogLeNet, ResNet-50, and Inception-V3.
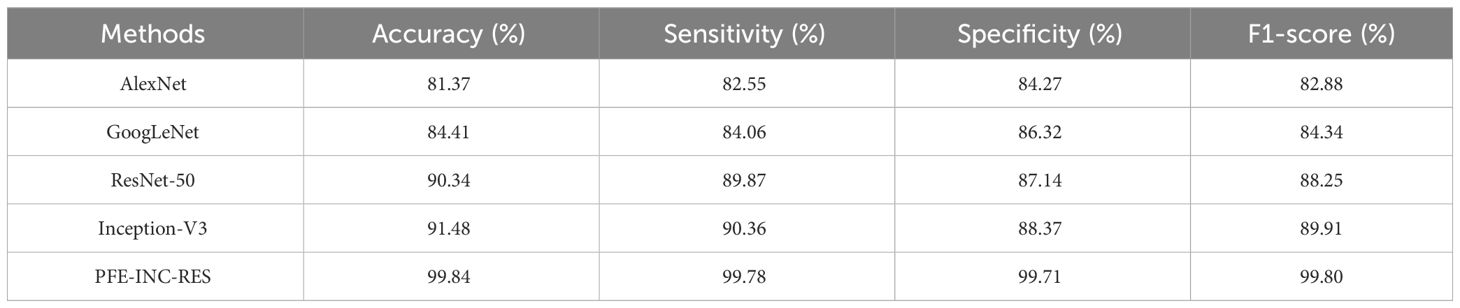
Table 1 Analysis of feature extraction methods at 40× MF.
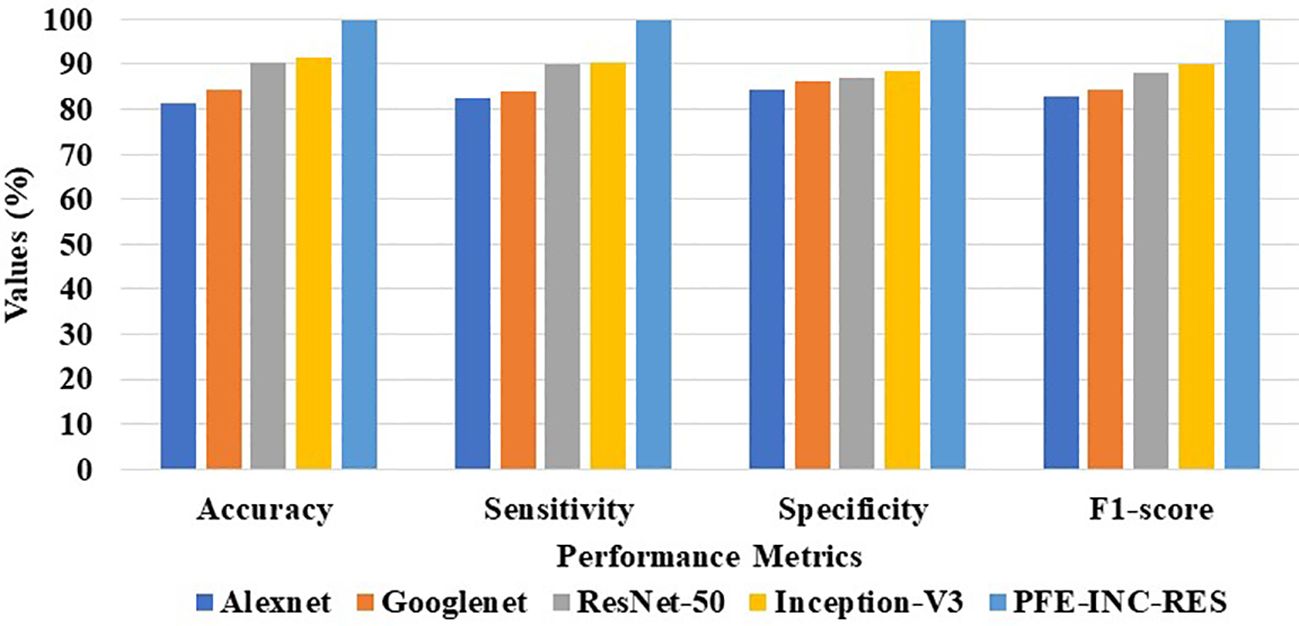
Figure 7 Graphical illustration of feature extraction methods at 40× MF.
According to Table 1, the proposed PFE-INC-RES clearly exceeds the current classifiers in terms of accuracy (99.84%), sensitivity (99.78%), specificity (99.71%), and F1-score (99.80%). Once the features have been extracted, the TLSTM for the BC classifier on the BreakHis dataset is applied using the PFE-INC-RES technique. Then, using a 40× MF, the TLSTM approach is tested with a variety of classifiers, including MVC, CNN, RNN, deep belief networks (DBNs), and LSTM.
Table 2 clearly demonstrates that the existing LSTM classifier performs classification in terms of accuracy (89.94%), sensitivity (87.49%), specificity (88.65%), and F1-score (88.14%), which are less than those of the TLSTM model. The proposed PFE-INC-RES is then verified using a variety of feature extraction techniques (AlexNet, GoogLeNet, ResNet-50, and Inception-V3), as revealed in Table 3; Figure 8.
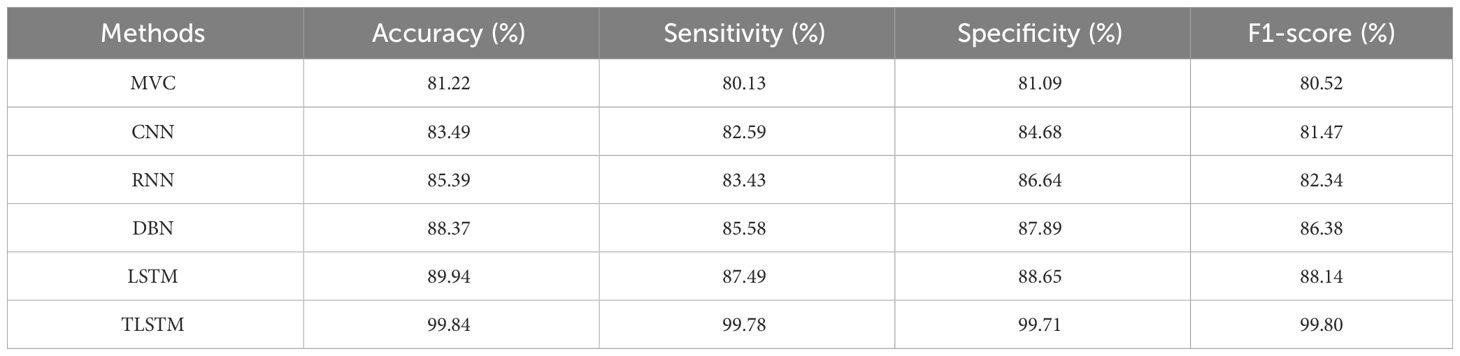
Table 2 Analysis of deep learning classifiers on 40× MF.

Table 3 Analysis of feature extraction methods at 100× MF.
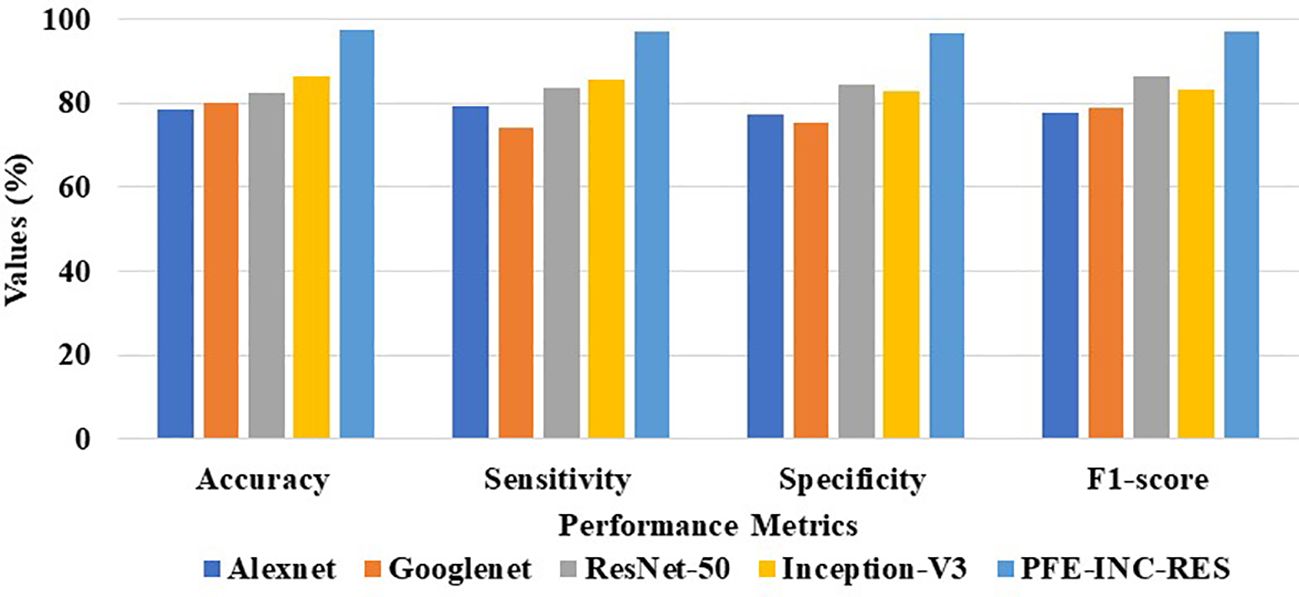
Figure 8 Graphical illustration of feature extraction methods at 100× MF.
According to Table 3, the suggested PFE-INC-RES performs better than the currently used feature extraction methods in terms of accuracy (97.36%), sensitivity (97.01%), specificity (96.48%), and F1-score (97.14%) on a scale of 100× MF. Once the characteristics from the PFE-INC-RES technique are extracted, TLSTM is used to classify BC. The TLSTM approach is then tested using a variety of classifiers, including MVC, CNN, RNN, DBN, and LSTM, on a 100× MF, as revealed in Table 4.
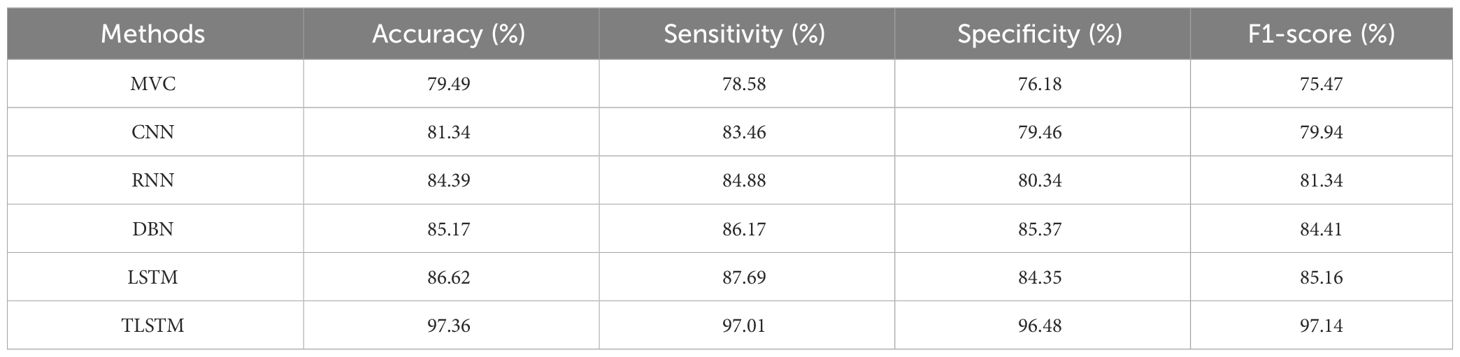
Table 4 Analysis of deep learning classifiers on 100× MF.
Table 4 clearly proves that the LSTM classifier performs classification in terms of accuracy (86.62%), sensitivity (87.69%), specificity (84.35%), and F1-score (85.16%), which are less than those of the TLSTM model. After that, the proposed PFE-INC-RES is then verified on a 200× MF using a variety of feature extraction techniques, as shown in Table 5; Figure 9.
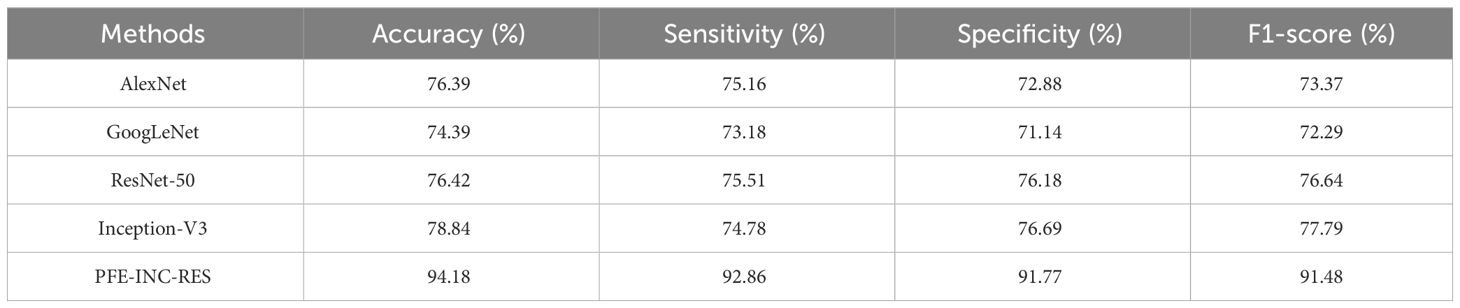
Table 5 Analysis of feature extraction methods on 200× MF.
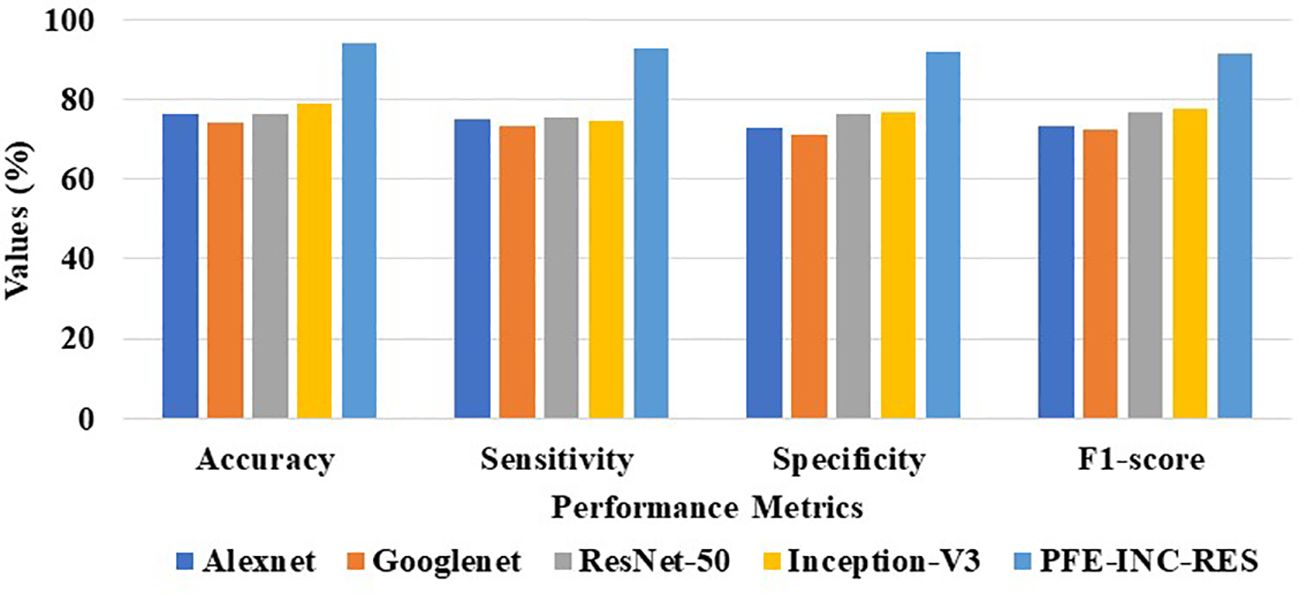
Figure 9 Graphical illustration of feature extraction methods at 200× MF.
According to Table 5, the suggested PFE-INC-RES performs better than the current feature extraction methods in terms of accuracy (94.18%), sensitivity (92.86%), specificity (91.77%), and F1-score (91.48%) by a factor of 200× MF. Once the characteristics from the PFE-INC-RES technique are extracted, TLSTM is used to classify BC. The TLSTM approach is then assessed using a variety of classifiers, including MVC, CNN, RNN, DBN, and LSTM, on a 200× MF, as revealed in Table 6.
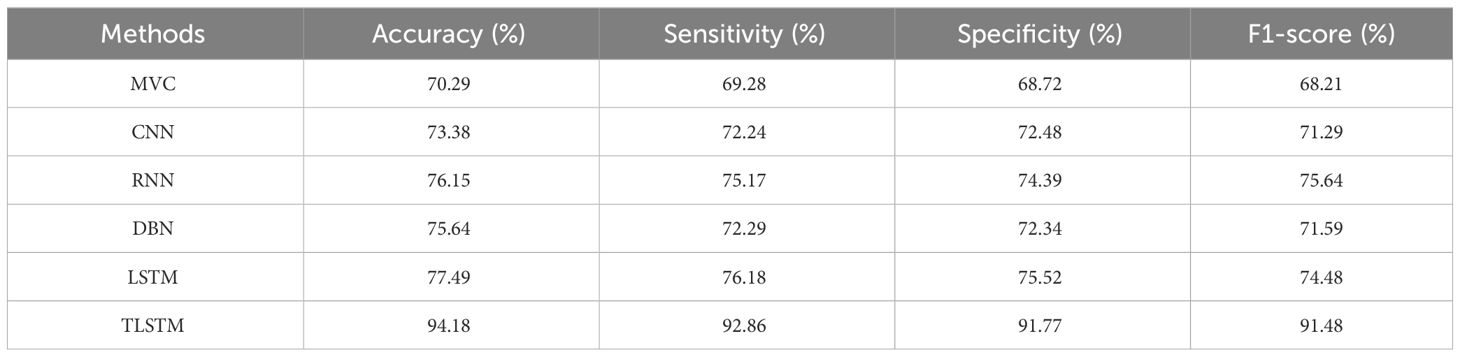
Table 6 Analysis of deep learning classifiers on 200× MF.
Table 6 clearly demonstrates that the LSTM classifier performs BC classification in terms of accuracy (77.49%), sensitivity (76.18%), specificity (75.52%), and F1-score (74.48%), which are less than those of TLSTM. Next, the proposed PFE-INC-RES is then tested on 400× MF using a variety of extraction methods, as revealed in Table 7; Figure 10.
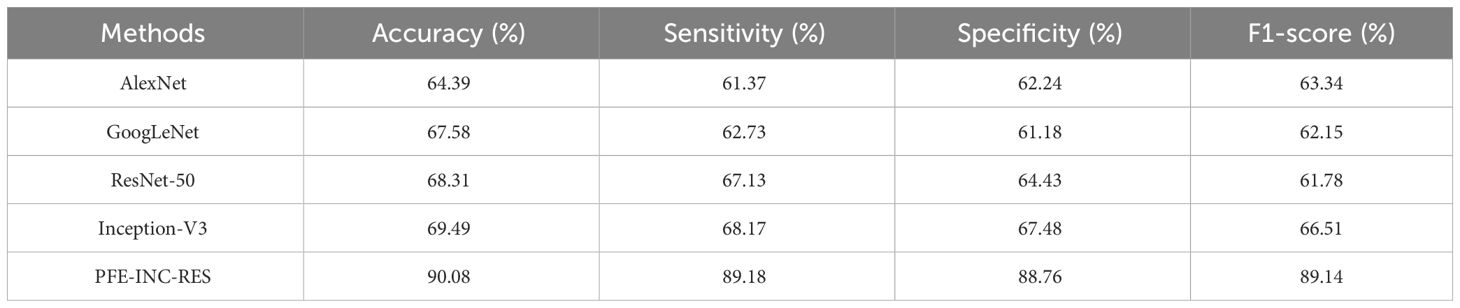
Table 7 Analysis of feature extraction methods on 400× MF.
Figure 10 Graphical illustration of feature extraction methods at 400× MF.
Table 7 shows that the suggested PFE-INC-RES performs better than the current feature extraction approaches in terms of accuracy (90.08%), sensitivity (89.18%), specificity (88.76%), and F1-score (89.14%) by a factor of 400×. Once the characteristics from the PFE-INC-RES technique are extracted, TLSTM is used to classify BC. The TLSTM approach is then assessed using a variety of classifiers including MVC, CNN, RNN, DBN, and LSTM, on a 400× MF, as shown in Table 8.
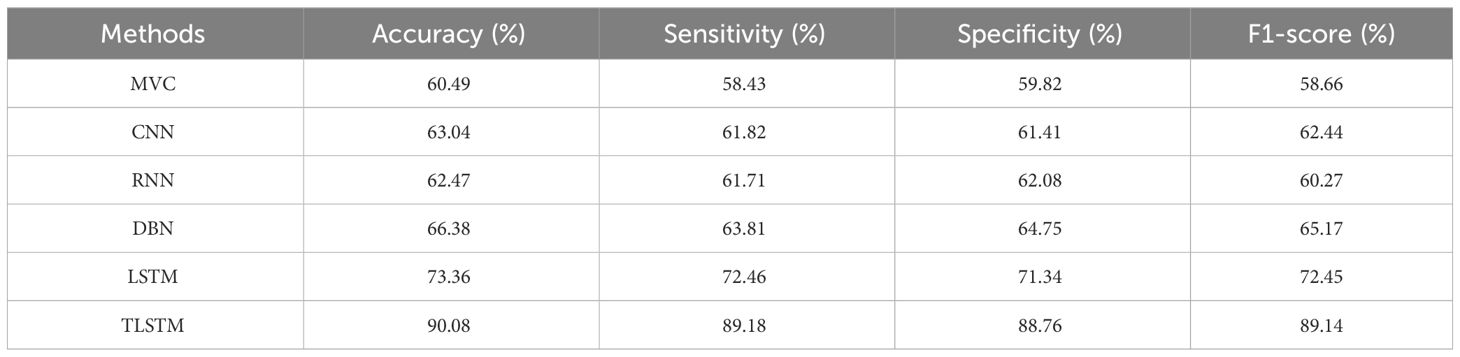
Table 8 Analysis of deep learning classifiers on 400× MF.
Table 8 clearly demonstrates that the LSTM classifier performs classification in terms of accuracy (73.36%), sensitivity (72.46%), specificity (71.34%), and F1-score (72.45%), which are less than those of the TLSTM model. In terms of BC classification, the suggested technique is more effective than conventional classifiers.
To evaluate the efficacy of the suggested approach, statistical tests such as the Friedman, Wilcoxon, Quade, and Friedman aligned tests have been conducted. In this research, the performances that were utilized to contrast the classification algorithms are investigated using the Friedman test (statistical analysis). The Friedman test is also known as a nonparametric statistical test that is employed in this study. This test assesses the null hypothesis that makes all column effects equal by using the ranks of the data rather than the actual data. In particular, every classifier model was employed in this study to extract features. The chance of reaching the observed sample outcome (p-value) in the scalar value within the range [0, 1] is the result of this test. Smaller p values generally prevent the null hypothesis from becoming true.
4.2 Performance analysis of the IDC dataset
On the IDC dataset for BC classification, the proposed PFE-INC-RES method is evaluated and contrasted with industry-standard feature extraction techniques (AlexNet, GoogLeNet, ResNet-50, and Inception-V3). The TLSTM is then evaluated for BC classification in comparison to common classifiers (MVC, CNN, RNN, DBN, and LSTM). The proposed PFE-INC-RES is evaluated in the IDC dataset using a variety of feature extraction techniques, as shown in Table 9. This section validates the suggested PFE-INC-RES on 40× using AlexNet, GoogLeNet, ResNet-50, and Inception-V3.
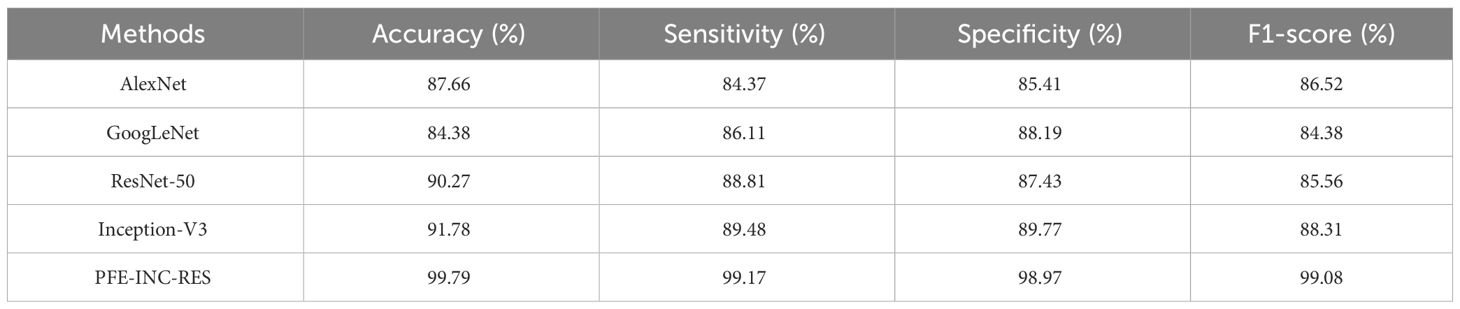
Table 9 Analysis of feature extraction on the IDC dataset.
Table 9 clearly demonstrates that the proposed PFE-INC-RES operates better than the current extraction methods on the IDC in terms of accuracy (99.79%), sensitivity (99.17%), specificity (98.97%), and F1-score (99.08%), while the existing Inception-V3 has obtained the following values: accuracy (91.78), sensitivity (89.48%), specificity (89.77%), and F1-score (88.31%), which are less than those of the proposed PFE-INC-RES. Figure 11 shows a graphic representation of feature extraction techniques. Once the characteristics from the PFE-INC-RES technique are extracted, TLSTM is used to classify BC. The TLSTM approach is then tested on the IDC dataset, which is shown in Table 10, using a variety of classifiers, including MVC, CNN, RNN, DBN, and LSTM.
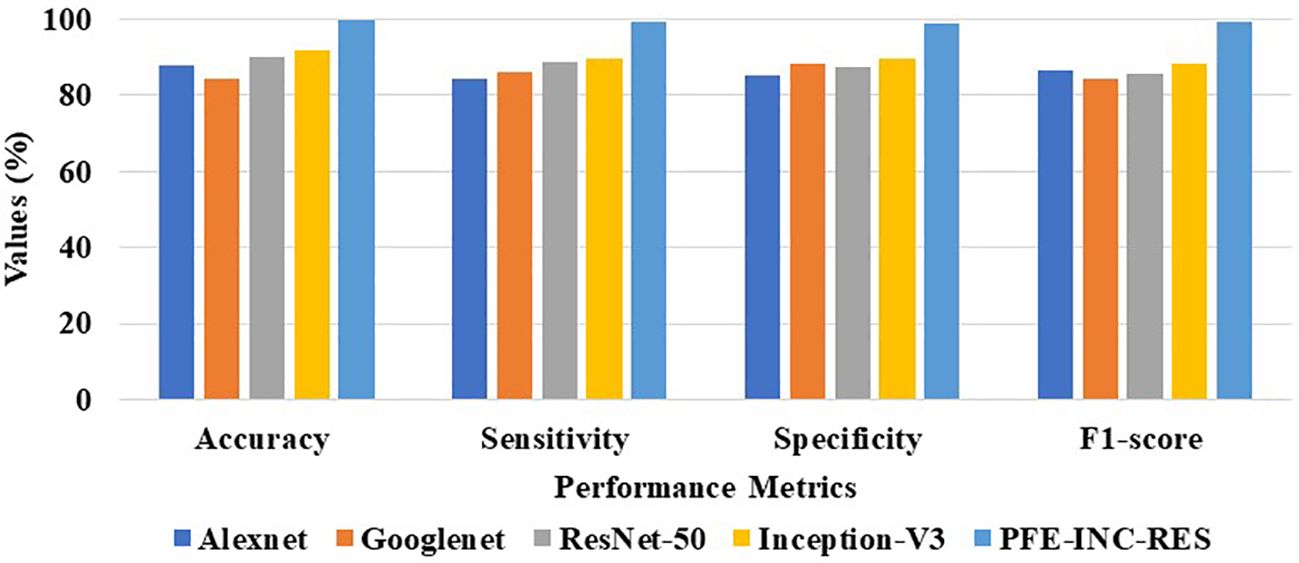
Figure 11 Graphical illustration of feature extraction methods on the IDC dataset.
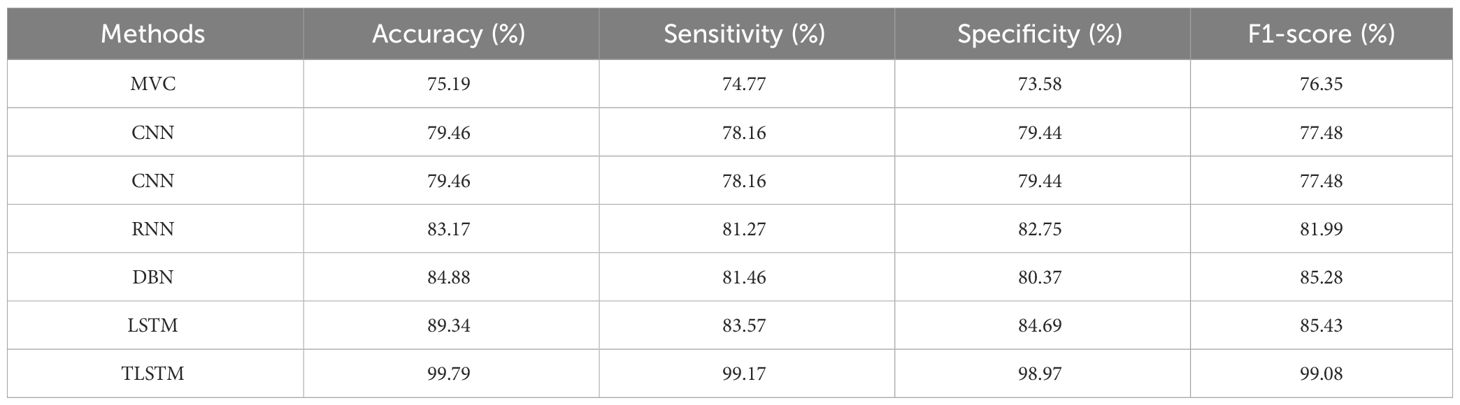
Table 10 Analysis of existing classifiers on the IDC dataset.
Table 10 clearly demonstrates that the TLSTM classifier performs better than the current classifiers in all performance metrics, while the existing LSTM has obtained the following values: accuracy (89.34%), sensitivity (83.57%), specificity (84.69%), and F1-score (85.43%), which are less than those of the TLSTM classifier. In terms of BC classification, the suggested technique is more effective than conventional classifiers. Figure 12 shows a graphical representation of classifiers on the IDC dataset.
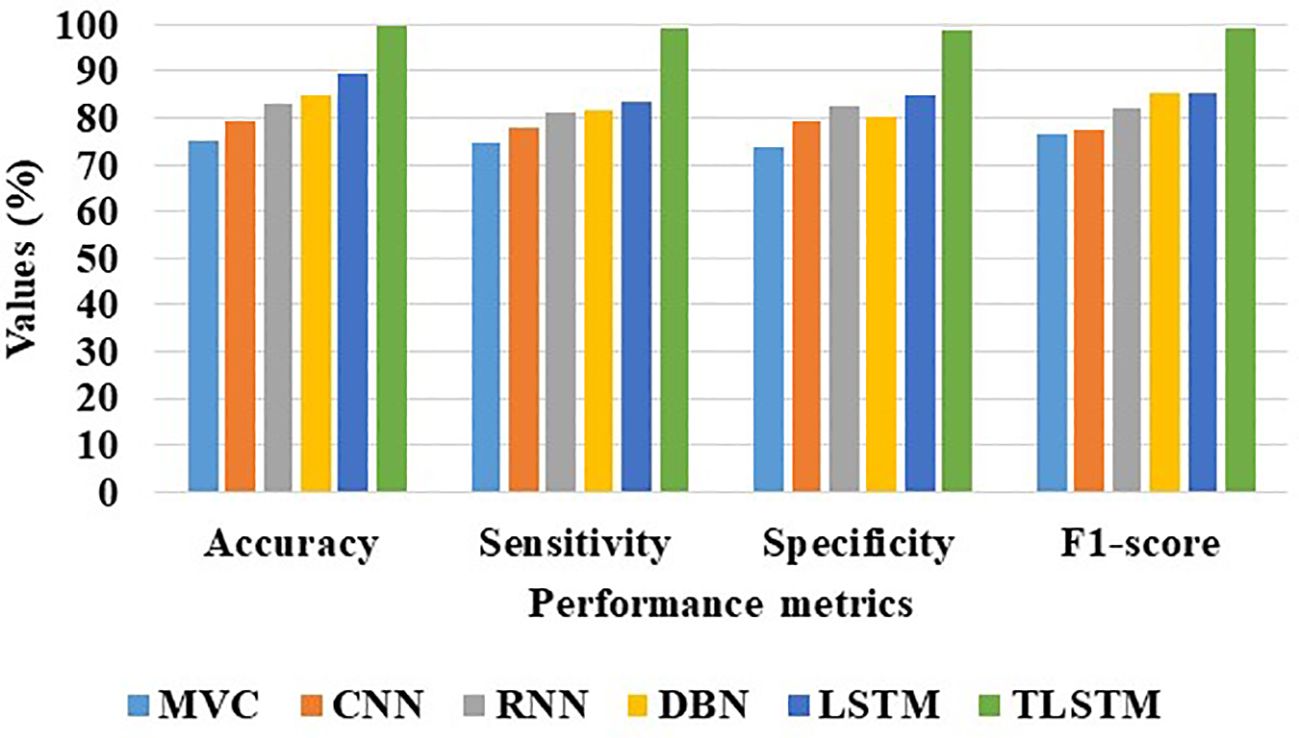
Figure 12 Graphical illustration of various classifiers on the IDC dataset.
4.3 Comparative analysis
This section provides information about the comparison of the PFE-INC-RES approach to previous studies on BC classification. On the BreakHis dataset, the PFE-INC-RES approach is compared to existing models such as VGGIN-NET (16), DNN (17), IBESSDL-BCHI (18), MultiNet (19), AlexNet-BC (21), and DCNN (23), which is shown in Figure 13 and Table 11. Because of increased exploration and exploitation, which helps in overcoming weak convergence and local optimum conditions, the PFE-INC-RES model performs more efficiently in terms of classification. The PFE-INC-RES model extracts the best characteristics to lessen the issue of overfitting.
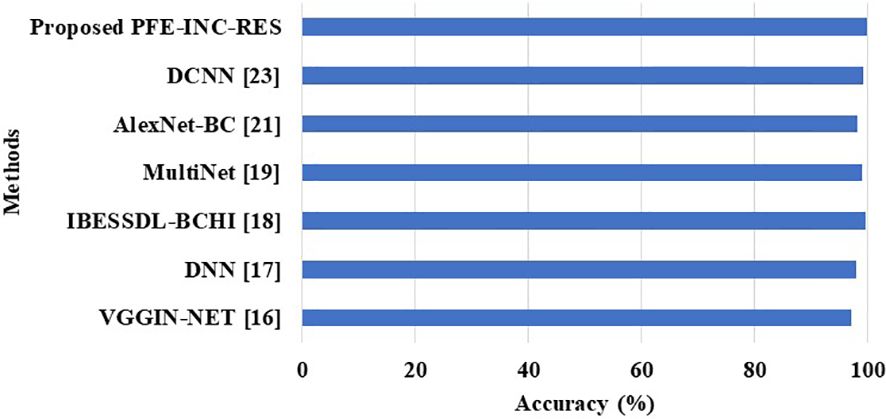
Figure 13 Comparison performances on the BreakHis dataset.
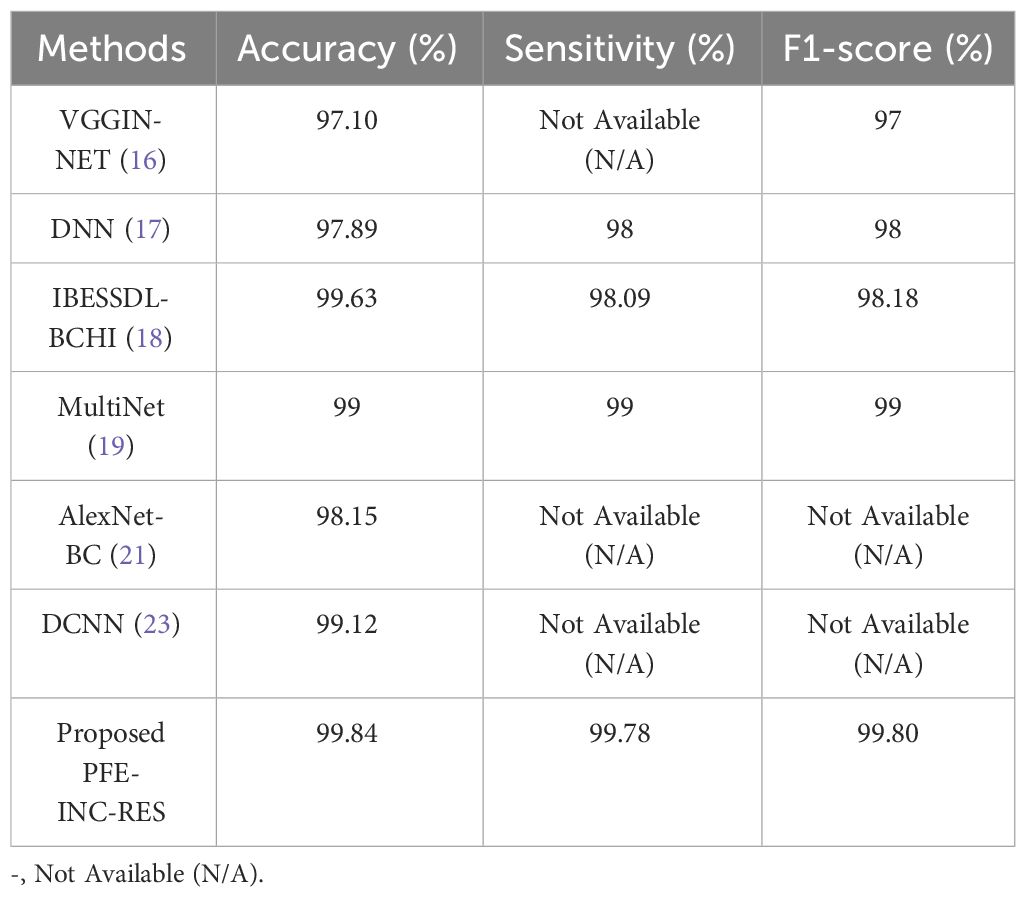
Table 11 Comparison of the BreakHis dataset.
Table 11 clearly shows that the existing models such as VGGIN-NET (16), DNN (17), IBESSDL-BCHI (18), MultiNet (19), AlexNet-BC (21), and DCNN (23) have achieved an accuracy of 97.10%, 97.89%, 99.63%, 99%, 98.15%, and 99.12%, respectively, on the BreakHis dataset, while the proposed PFE-INC-RES has obtained a higher accuracy of 99.84%, a sensitivity of 99.78%, and a specificity of 99.80%, which are better than those of the existing models. Table 12 and Figure 14 show the evaluation study for BC classification on the IDC dataset.
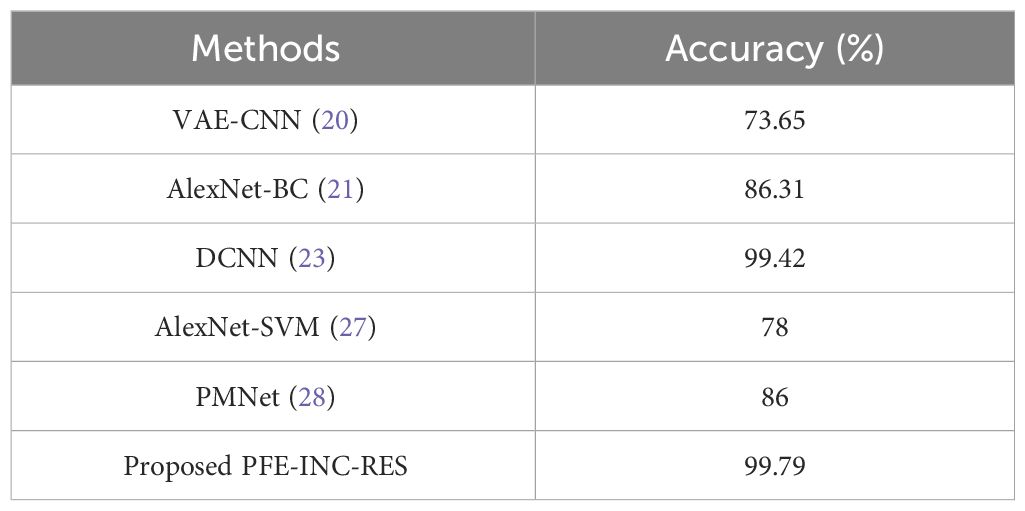
Table 12 Comparison of the IDC dataset.
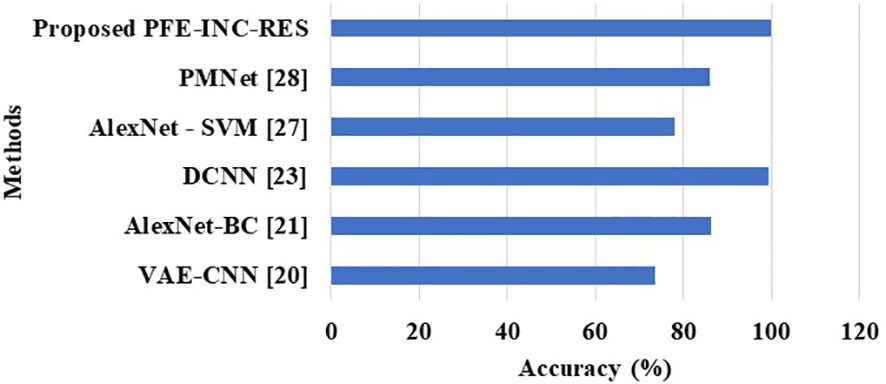
Figure 14 Comparison performance on the IDC dataset.
Table 12 clearly shows that the PFE-INC-RES model shows a higher performance accuracy of 99.79%, which is better than the existing models, whereas the existing VAE-CNN (20), AlexNet-BC (21), DCNN (23), AlexNet-SVM (27), and PMNet (28) have accomplished an accuracy of 73.65%, 86.31%, 99.42%, 78%, and 86%, respectively, on the IDC dataset. From the overall analysis, the proposed PFE-INC-RES surpasses the conventional models on the basis of all the performance metrics in both BreakHis and IDC datasets.
5 Discussion
From the analysis, traditional feature extraction methods only extract a few low-level characteristics from images; prior knowledge is needed to select optimal features. Moreover, a portion of the sampled cell-level patches lack sufficient data to balance the image tag. This work presented a deep learning algorithm-based advanced classification technique to address the problems associated with inappropriate detection and classification. Appropriate data representation is necessary for this research project to succeed. A significant portion of the work is focused on feature engineering, a labor-intensive procedure that utilizes plenty of in-depth domain knowledge to extract valuable features. Additionally, the classification of histology images of BC into benign and malignant categories was the main focus of this study. The overall results from a comparative study show that the suggested PFE-INC-RES achieved better results when associated with existing classifiers. For the BreakHis dataset, the proposed PFE-INC-RES is compared with the existing VGGIN-NET (16), DNN (17), IBESSDL-BCHI (18), MultiNet (19), AlexNet-BC (21), and DCNN (23) classifiers, which achieved an accuracy of 97.10%, 97.89%, 99.63%, 99%, 98.15%, and 99.12%, respectively, on the BreakHis dataset. Similarly, on the IDC dataset, the PFE-INC-RES model shows a higher performance accuracy of 99.79%, which is better than that of the existing models, whereas the existing VAE-CNN (20), AlexNet-BC (21), DCNN (23), AlexNet-SVM (27), and PMNet (28) have accomplished an accuracy of 73.65%, 86.31%, 99.42%, 78%, and 86%, respectively. The suggested PFE-INC-RES performance is evaluated separately for accuracy (99.84%), specificity (99.71%), sensitivity (99.78%), and F1-score (99.80%) based on the overall analysis conducted on the BreakHis dataset. The suggested PFE-INC-RES outperformed the previous models in the IDC dataset in terms of accuracy (99.79%), specificity (98.97%), sensitivity (99.17%), and F1-score (99.08%). The suggested system can be modified for a variety of tasks related to the classification of histological images that are relevant to clinical settings.
6 Conclusion
BC is a type of cancer that is associated with a high cancer mortality rate in women. It can take a lot of time to diagnose diseases using HIs when numerous images with varying magnification levels need to be examined. Nowadays, deep learning methods are widely applied in many medical fields, especially those involving classification. However, the learning methods that were in place at the time were consistently producing low classification accuracy. Consequently, deep learning models are employed to analyze histological images of BC using publicly accessible datasets named BreakHis and IDC. The images obtained from BreakHis and IDC are then pre-processed using SRGAN, which creates realistic textures throughout single-image super-resolution. After the image has been pre-processed, it progresses on to the data augmentation stage, where new data points are generated for the dataset by using rotation, random cropping, mirroring, and color-shifting. The features are then extracted from augmentation using PFE-INC-RES. Using feature extractors, the extracted features are chosen from both larger and smaller patches, and the final feature is computed to train a classifier. The TLSTM classifier is included after the extracted features have been analyzed during the classification stage to minimize the count of false diagnoses and increase classification accuracy. The accuracy (99.84%), specificity (99.71%), sensitivity (99.78%), and F1-score (99.80%) of the suggested PFE-INC-RES performances were assessed for the BreakHis dataset, while in the IDC dataset, the proposed PFE-INC-RES achieved better results in terms of accuracy (99.79%), specificity (98.97%), sensitivity (99.17%), and F1-score (99.08%). This analysis clearly states that the proposed PFE-INC-RES significantly outperforms the conventional methods. In the future, an enhanced feature extraction method will be introduced and will be performed using an optimization approach to improve the classification accuracy.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
Author contributions
PR: Conceptualization, Data curation, Formal Analysis, Methodology, Resources, Visualization, Writing – original draft. BR: Formal Analysis, Investigation, Methodology, Resources, Software, Validation, Writing – original draft. SA: Formal Analysis, Funding acquisition, Methodology, Resources, Software, Validation, Writing – review & editing. MA: Conceptualization, Data curation, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This project is funded by King Saud University, Riyadh, Saudi Arabia. Researchers Supporting Project number (RSP2024R167), King Saud University, Riyadh, Saudi Arabia.
Acknowledgments
We acknowledge Researchers Supporting Project number (RSP2024R167), King Saud University, Riyadh, Saudi Arabia.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Mondol RK, Millar EKA, Graham PH, Browne L, Sowmya A, Meijering E. Hist2RNA: An efficient deep learning architecture to predict gene expression from BC histopathology images. Cancers. (2023) 15:2569. doi: 10.3390/cancers15092569
2. Aldhyani THH, Nair R, Alzain E, Alkahtani H, Koundal D. Deep learning model for the detection of real time BC images using improved dilation-based method. Diagnostics. (2022) 12:2505. doi: 10.3390/diagnostics12102505
3. Ashtaiwi A. Optimal histopathological magnification factors for deep learning-based BC prediction. Appl System Innovation. (2022) 5:87. doi: 10.3390/asi5050087
4. Zhou Y, Zhang C, Gao S. BC classification from histopathological images using resolution adaptive network. IEEE Access. (2022) 10:35977–91. doi: 10.1109/ACCESS.2022.3163822
5. Ahmad N, Asghar S, Gillani SA. Transfer learning-assisted multi-resolution BC histopathological images classification. Visual Comput. (2022) 38:2751–70. doi: 10.1007/s00371-021-02153-y
6. Obayya M, Maashi MS, Nemri N, Mohsen H, Motwakel A, Osman AE, et al. Hyperparameter optimizer with deep learning-based decision-support systems for histopathological BC diagnosis. Cancers. (2023) 15:885. doi: 10.3390/cancers15030885
7. Rahman A, Alqahtani A, Aldhafferi N, Nasir MU, Khan MF, Khan MA, et al. Histopathologic oral cancer prediction using oral squamous cell carcinoma biopsy empowered with transfer learning. Sensors. (2022) 22:3833. doi: 10.3390/s22103833
8. Humayun M, Khalil MI, Almuayqil SN, Jhanjhi NZ. Framework for detecting BC risk presence using deep learning. Electronics. (2023) 12:403. doi: 10.3390/electronics12020403
9. Wang X, Ahmad I, Javeed D, Zaidi SA, Alotaibi FM, Ghoneim ME, et al. Intelligent hybrid deep learning model for BC detection. Electronics. (2022) 11:2767. doi: 10.3390/electronics11172767
10. Ahmed AA, Abouzid M, Kaczmarek E. Deep learning approaches in histopathology. Cancers. (2022) 14:5264. doi: 10.3390/cancers14215264
11. Yang J, Ju J, Guo L, Ji B, Shi S, Yang Z, et al. Prediction of HER2-positive BC recurrence and metastasis risk from histopathological images and clinical information via multimodal deep learning. Comput Struct Biotechnol J. (2022) 20:333–42. doi: 10.1016/j.csbj.2021.12.028
12. Yosofvand M, Khan SY, Dhakal R, Nejat A, Moustaid-Moussa N, Rahman RL, et al. Automated detection and scoring of tumor-infiltrating lymphocytes in BC histopathology slides. Cancers. (2023) 15:3635. doi: 10.3390/cancers15143635
13. Aljuaid H, Alturki N, Alsubaie N, Cavallaro L, Liotta A. Computer-aided diagnosis for BC classification using deep neural networks and transfer learning. Comput Methods Programs Biomedicine. (2022) 223:106951. doi: 10.1016/j.cmpb.2022.106951
14. Alshehri A, AlSaeed D. BC detection in thermography using convolutional neural networks (CNNs) with deep attention mechanisms. Appl Sci. (2022) 12:12922. doi: 10.3390/app122412922
15. Li L, Xie N, Yuan S. A federated learning framework for BC histopathological image classification. Electronics. (2022) 11:3767. doi: 10.3390/electronics11223767
16. Saini M, Susan S. Vggin-net: Deep transfer network for imbalanced BC dataset. IEEE/ACM Trans Comput Biol Bioinf. (2023) 20:752–62. doi: 10.1109/TCBB.2022.3163277
17. Joseph AA, Abdullahi M, Junaidu SB, Ibrahim HH, Chiroma H. Improved multi-classification of BC histopathological images using handcrafted features and deep neural network (dense layer). Intelligent Syst Appl. (2022) 14:200066. doi: 10.1016/j.iswa.2022.200066
18. Hamza MA, Mengash HA, Nour MK, Alasmari N, Aziz ASA, Mohammed GP, et al. Improved bald eagle search optimization with synergic deep learning-based classification on BC imaging. Cancers. (2022) 14:6159. doi: 10.3390/cancers14246159
19. Khan SI, Shahrior A, Karim R, Hasan M, Rahman A. MultiNet: A deep neural network approach for detecting BC through multi-scale feature fusion. J King Saud University-Computer Inf Sci. (2022) 34:6217–28. doi: 10.1016/j.jksuci.2021.08.004
20. Guleria HV, Luqmani AM, Kothari HD, Phukan P, Patil S, Pareek P, et al. Enhancing the breast histopathology image analysis for cancer detection using variational autoencoder. Int J Environ Res Public Health. (2023) 20:4244. doi: 10.3390/ijerph20054244
21. Liu M, Hu L, Tang Y, Wang C, He Y, Zeng C, et al. A deep learning method for BC classification in the pathology images. IEEE J Biomed Health Inf. (2022) 26:5025–32. doi: 10.1109/JBHI.2022.3187765
22. Nalepa J, Piechaczek S, Myller M, Hrynczenko K. (2019). Multi-scale voting classifiers for breast-cancer histology images, in: InAdvances in Intelligent Networking and Collaborative Systems: The 10th International Conference on Intelligent Networking and Collaborative Systems (INCoS-2018), . pp. 526–34. Springer International Publishing.
23. Kumari V, Ghosh R. A magnification-independent method for BC classification using transfer learning. Healthcare Anal. (2023) 3:100207. doi: 10.1016/j.health.2023.100207X
24. Bhausaheb DP, Kashyap KL. Detection and classification of breast cancer availing deep canid optimization based deep CNN. Multimedia Tools Appl. (2023) 82:18019–37. doi: 10.1007/s11042-022-14268-y
25. Khan MM, Tazin T, Hussain MZ, Mostakim M, Rehman T, Singh S, et al. Breast tumor detection using robust and efficient machine learning and convolutional neural network approaches. Comput Intell Neurosci. (2022) 2022:6333573. doi: 10.1155/2022/6333573
26. Egwom OJ, Hassan M, Jesse JT, Hamada M, Ogar OM. An LDA-SVM machine learning model for breast cancer classification. BioMedInformatics. (2022) 2:345–58. doi: 10.3390/biomedinformatics2030022
27. Fan J, Lee J, Lee Y. A transfer learning architecture based on a support vector machine for histopathology image classification. Appl Sci. (2021) 11:6380. doi: 10.3390/app11146380
28. Ahmed S, Tariq M, Naveed H. Pmnet: A probability map based scaled network for BC diagnosis. Comput Intell Neurosci. (2021) 89:101863. doi: 10.1016/j.compmedimag.2021.101863
29. Singh S, Kumar R. BC detection from histopathology images with deep inception and residual blocks. Multimedia Tools Appl. (2022) 81:5849–65. doi: 10.1007/s11042-021-11775-2
30. Gupta I, Nayak SR, Gupta S, Singh S, Verma KD, Gupta A, et al. A deep learning-based approach to detect IDC in histopathology images. Multimedia Tools Appl. (2022) 81:36309–30. doi: 10.1007/s11042-021-11853-5
31. Jiang M, Zhi M, Wei L, Yang X, Zhang J, Li Y, et al. FA-GAN: Fused attentive generative adversarial networks for MRI image super-resolution. Computerized Med Imaging Graphics. (2021) 92:101969. doi: 10.1016/j.compmedimag.2021.101969
32. Xu Y, Luo W, Hu A, Xie Z, Xie X, Tao L. TE-SAGAN: an improved generative adversarial network for remote sensing super-resolution images. Remote Sens. (2022) 14:2425. doi: 10.3390/rs14102425
33. Zhang C, Bao N, Sun H, Li H, Li J, Qian W, et al. A deep learning image data augmentation method for single tumor segmentation. Front Oncol. (2022) 12:782988. doi: 10.3389/fonc.2022.782988
34. Liu X, Yuan P, Li R, Zhang D, An J, Ju J, et al. Predicting BC recurrence and metastasis risk by integrating color and texture features of histopathological images and machine learning technologies. Comput Biol Med. (2022) 146:105569. doi: 10.1016/j.compbiomed.2022.105569
35. Poola RG, Pl L, Sankar SY. COVID-19 diagnosis: A comprehensive review of pre-trained deep learning models based on feature extraction algorithm. Results Eng. (2023) 16:101020. doi: 10.1016/j.rineng.2023.101020
36. Mohapatra S, Muduly S, Mohanty S, Ravindra JVR, Mohanty SN. Evaluation of deep learning models for detecting breast cancer using histopathological mammograms Images. Sustain Operat Comput. (2022) 3:296–302. doi: 10.1016/j.susoc.2022.06.001
37. Li Q, Zhang L, Xu L, Zou Q, Wu J, Li Q. Identification and classification of promoters using the attention mechanism based on long short-term memory. Front Comput Sci. (2022) 16:164348. doi: 10.1007/s11704-021-0548-9
38. Venkatachalam K, Trojovský P, Pamucar D, Bacanin N, Simic V. DWFH: An improved data-driven deep weather forecasting hybrid model using Transductive Long Short-Term Memory (T-LSTM). Expert Syst Appl. (2023) 213:119270. doi: 10.1016/j.eswa.2022.119270
Keywords: breast cancer, histopathology, Inception V3, Resnet-50, super-resolution generative adversarial networks, transductive long short-term memory
Citation: Ramamoorthy P, Ramakantha Reddy BR, Askar SS and Abouhawwash M (2024) Histopathology-based breast cancer prediction using deep learning methods for healthcare applications. Front. Oncol. 14:1300997. doi: 10.3389/fonc.2024.1300997
Received: 01 October 2023; Accepted: 12 April 2024;
Published: 04 June 2024.
Edited by:
Natalie Julie Serkova, University of Colorado Anschutz Medical Campus, United StatesReviewed by:
Summrina Kanwal, Independent researcher, Helsinborg, SwedenJakub Nalepa, Silesian University of Technology, Poland
Copyright © 2024 Ramamoorthy, Ramakantha Reddy, Askar and Abouhawwash. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohamed Abouhawwash, YWJvdWhhd3dAbXN1LmVkdQ==