 Musatafa Abbas Abbood Albadr
Musatafa Abbas Abbood Albadr Masri Ayob
Masri Ayob Sabrina Tiun1
Sabrina Tiun1- 1Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science and Technology, Universiti Kebangsaan Malaysia, Bangi, Selangor, Malaysia
- 2Department of Communication Engineering, School of Electrical Engineering, Universiti Teknologi Malaysia, (UTM), Johor Bahru, Johor, Malaysia
- 3Department of Computer Science, Birzeit University, Birzeit, Palestine
- 4Department of Communication Technology Engineering, College of Information Technology, Imam Ja’afer Al-Sadiq University, Baghdad, Iraq
The use of machine learning (ML) and data mining algorithms in the diagnosis of breast cancer (BC) has recently received a lot of attention. The majority of these efforts, however, still require improvement since either they were not statistically evaluated or they were evaluated using insufficient assessment metrics, or both. One of the most recent and effective ML algorithms, fast learning network (FLN), may be seen as a reputable and efficient approach for classifying data; however, it has not been applied to the problem of BC diagnosis. Therefore, this study proposes the FLN algorithm in order to improve the accuracy of the BC diagnosis. The FLN algorithm has the capability to a) eliminate overfitting, b) solve the issues of both binary and multiclass classification, and c) perform like a kernel-based support vector machine with a structure of the neural network. In this study, two BC databases (Wisconsin Breast Cancer Database (WBCD) and Wisconsin Diagnostic Breast Cancer (WDBC)) were used to assess the performance of the FLN algorithm. The results of the experiment demonstrated the great performance of the suggested FLN method, which achieved an average of accuracy 98.37%, precision 95.94%, recall 99.40%, F-measure 97.64%, G-mean 97.65%, MCC 96.44%, and specificity 97.85% using the WBCD, as well as achieved an average of accuracy 96.88%, precision 94.84%, recall 96.81%, F-measure 95.80%, G-mean 95.81%, MCC 93.35%, and specificity 96.96% using the WDBC database. This suggests that the FLN algorithm is a reliable classifier for diagnosing BC and may be useful for resolving other application-related problems in the healthcare sector.
1 Introduction
Uncontrolled cell growth within an organ leads to tumors, which can be cancer (1). Malignant and benign tumors are two different types of tumors. A cancerous or malignant tumor spreads and has an impact on human health and life. Although it is not spreading and does not pose a threat to life, the benign or non-cancerous tumor is not normal (2, 3). Figure 1 illustrates digital representations of the FNA (fine needle aspirate) for both benign and malignant breast tumors. Malignant breast cancer is the expected result when growing cells are found in the breast tissue. One of the main causes of cancer death in women between the ages of 40 and 55 is breast cancer (BC) (5). In addition, BC is the second most common malignancy in the world after lung cancer (6). Early detection of BC will increase the chance of survival (7).
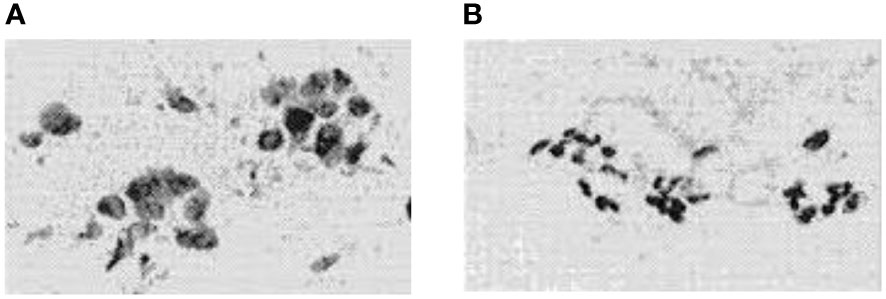
Figure 1 FNA’s digitized photos were: (A) is malignant and (B) is benign (4).
In recent decades, numerous fields, including emotion speech recognition (8), COVID-19 detection (9, 10), language identification (11–13), speaker gender identification (14), diabetic retinopathy detection (15), and voice pathology detection (16–18), have shown the effectiveness of data mining (DM) and machine learning (ML) techniques. As a result, significant attempts have recently been made to use DM and ML algorithms to diagnose BC (19, 20). These works, however, have a number of flaws, including the fact that the accuracy rates of the majority of the earlier works are still unsatisfactory and need improvement, that they have only been reviewed using one database, and that their performance has only been assessed using a limited number of assessment metrics without statistical analysis (21, 22).
The fast learning network (FLN) has recently become one of the best known ML algorithms (23). It is a double-parallel forward neural network (DPFNN), which is a parallel connection of a multilayer feedforward neural network (FNN) and a single-layer feedforward neural network (SLFN) (24, 25). The DPFNN’s output layer neurons also receive the external information directly through the input layer neurons, rather than just through the hidden layer neurons such as in the extreme learning machine and the standard neural network, which only receive external information after it has been modified (26). The input weights and hidden layer biases of the FLN are produced stochastically. Additionally, the values of the weights connecting the input layer with the output layer and the hidden layer with the output layer are analytically computed using least-square methods (27). In most situations, the FLN algorithm, which has fewer hidden neurons than other algorithms, can achieve good generalization performance with stability at a high speed (28).
Recently, the researchers prefer the FLN algorithm because it outperforms the conventional SVM (support vector machine) and BPNN (backpropagation neural network) (29, 30) particularly via the following: a) it eliminates overfitting, b) it has the ability to be implemented in both multi and binary classification tasks, and c) it has a similar capability to kernel-based SVM and works with a neural network structure. These components boost the FLN’s ability to produce exceptional learning outcomes. Nevertheless, as far as we are aware, no studies have used the FLN algorithm to detect BC. Furthermore, no studies have employed a variety of evaluation metrics and statistical analysis to assess the effectiveness based on the two separate databases Wisconsin Diagnostic Breast Cancer (WDBC) and Wisconsin Breast Cancer Database (WBCD). Consequently, the objectives of this work are as follows:
● To propose a new BC diagnosing classifier based on the FLN algorithm using two different databases WBCD and WDBC.
● To assess the proposed BC diagnosing classifier performance based on numerous assessment measurements such as G-mean, accuracy, specificity, F-measure, MCC (Matthews Correlation Coefficient), recall, ROC (receiver operating characteristic), precision, and execution time.
● To statistically assess the proposed BC diagnosing classifier performance based on mean, root mean square error (RMSE), and standard deviation (STD) in order to prove that the achieved results were not by chance.
● To evaluate the suggested BC classifier’s precision in contrast to the most recent works that utilized the same databases.
The rest of the paper is structured as follows: the related works are presented in Section 2. The materials and proposed technique are covered in Section 3. The findings of the experiments are explained in Section 4. Lastly, Section 5 provides the conclusion of the current study.
2 Related work
The research in (31) has proposed the ELM-ANN (extreme learning machine-artificial neural networks) approach for diagnosing the BC. The proposed ELM-ANN approach has been assessed based on the WBCD. The experimental results have shown that the proposed ELM-ANN approach outperformed its comparatives and achieved an accuracy that reached up to 96.40%.
Additionally, by utilizing the K-mean technique, the authors of (32) have presented a system for diagnosing the BC. Based on the BCWD, the suggested system’s evaluation was carried out. The results showed that the suggested method performed better than its counterparts and had an accuracy of 92.00%.
Further, the study in (33) has proposed six different classifiers LR (logistic regression), SVM, KNN (K-nearest neighbors), DT (decision tree), NB (naive Bayes), and RF (random forest) for BC diagnosing. These six different classifiers were assessed based on the WDBC database. The experiment results have revealed that the RF and SVM classifiers have achieved the highest performance with an accuracy that reached up to 96.50%.
In addition, the work in (34) has proposed a BC diagnosing classifier by using Kernel Neutrosophic c-Means Clustering as a feature weighting and random decision forest with Bayesian optimization as a classifier. The proposed system has been evaluated based on the WDBC database. The experimental outcomes have shown the superiority of the proposed system over its comparatives with an accuracy that reached up to 80.00%.
Furthermore, the research in (35) has tested five different ML algorithms, which are RF, SVM, KNN, DT, and LR in the diagnosis of the BC. The proposed five different ML algorithms have been assessed based on the WDBC database. The results have revealed that the SVM outperformed the other algorithms with an accuracy that reached up to 97.20%.
Additionally, the authors in (36) have proposed a hybrid BC diagnosing model by combining the genetic algorithm (GA) with the SVM for feature weighting and optimization of parameters. The proposed hybrid model was assessed based on the BCWD. The outcomes have demonstrated that the performance of the proposed model outperformed its comparatives with an achieved accuracy of 97.28%.
Also, the study in (37) has tested six different ML algorithms MLP (multilayer perceptron), GRU-SVM, NN (nearest neighbor), linear regression, SVM, and Softmax Regression (SR) in diagnosing the BC. The evaluation of the six different ML algorithms was conducted using the WDBC database. The experimental outcomes have revealed that among the six different ML algorithms, the MLP has achieved the highest performance with an accuracy rate that reached up to 99.04%.
Also, the work in (38) has proposed four different ML algorithms NB, SVM, DT, and KNN for BC diagnosing. The three different ML algorithms were assessed using the WBCD. The experimental results have shown that the SVM algorithm achieved the highest performance with an accuracy of 97.13%.
The research in (39) has proposed three different ML classifiers LR, SVM, and KNN for diagnosing the BC. The assessment of the three different classifiers was conducted based on the WBCD. The experiments outcomes have demonstrated that the KNN classifier has achieved the highest performance with an accuracy of 99.28%.
Moreover, the authors in (40) have proposed the averaged-perceptron machine-learning classifier for detecting the breast cancer. The proposed averaged-perceptron machine-learning classifier was evaluated based on the WBCD. The experiment outcomes have shown that the highest achieved accuracy of the proposed averaged-perceptron machine-learning classifier reached up to 98.40%.
In addition, the study in (41) has proposed a new breast cancer detection system by using the genetic programming with machine learning algorithms. The proposed system (i.e., genetic programming with machine learning algorithms) has been assessed based on the WDBC database. The experimental results have revealed that the highest performance of the proposed system (i.e., genetic programming with machine learning algorithms) was achieved with an accuracy of 98.24%.
The work in (42) has proposed numerous machine learning techniques such as SVM, RF, K-NN, DT, NB, LR, AdaBoost (AB), gradient boosting (GB), MLP, nearest cluster classifier (NCC), and voting classifier (LR+SVM) for diagnosing the breast cancer. All the proposed machine learning techniques were evaluated based on the WDBC database. The experiment results have demonstrated that the voting classifier (LR+SVM) achieved the highest performance with an accuracy reaching up to 98.77%.
The researchers in (43) have built an ensemble learning technique based on the Bayesian network and radial basis function (BN+RBF) for detecting the breast cancer. The assessment of the proposed ensemble learning technique (BN+RBF) was conducted using the WBCD. The experimental outcomes have shown that the highest performance of the proposed ensemble learning technique (BN+RBF) was accomplished with an accuracy of 97.42%. Table 1 presents a summary of the prior works of the BC diagnosis using various ML and DM algorithms.
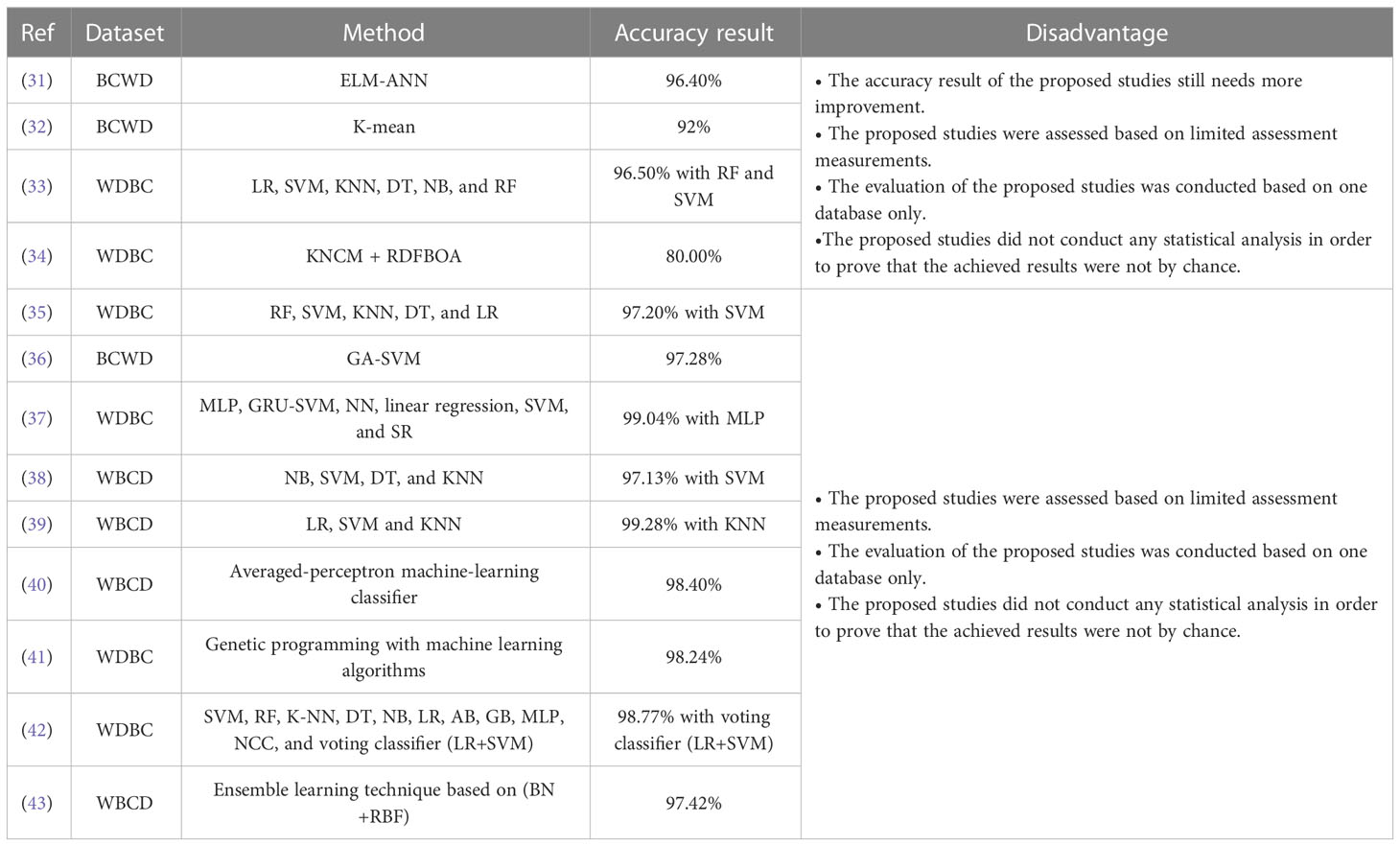
Table 1 Summary of the previous works.
Based on all the abovementioned prior studies in diagnosing the BC, we can conclude the following:
● Most of the previous works such as (31–43) have been evaluated based on one database only.
● The accuracy results of most prior works, such as (31–34), are still not encouraging and need more enhancement.
● The performance of most former works, such as (31–43), were assessed utilizing a limited set of evaluation metrics (i.e., recall, accuracy, precision, specificity, and F-measure).
● The performance assessment of most previous works such as (31–43) have not conducted any statistical analysis in order to prove that the achieved results were not by chance.
3 Proposed method
This work proposes a breast cancer diagnosis classifier based on the utilization of the FLN algorithm. Two different standard databases (i.e., WBCD with nine extracted features and WDBC with 30 extracted features) were used as input to evaluate the performance of the proposed FLN algorithm in diagnosing the breast cancer. The FLN algorithm in the classification stage is used to diagnose whether the input’s sample is benign or malignant. Figure 2 depicts the proposed breast cancer diagnosis classifier diagram.
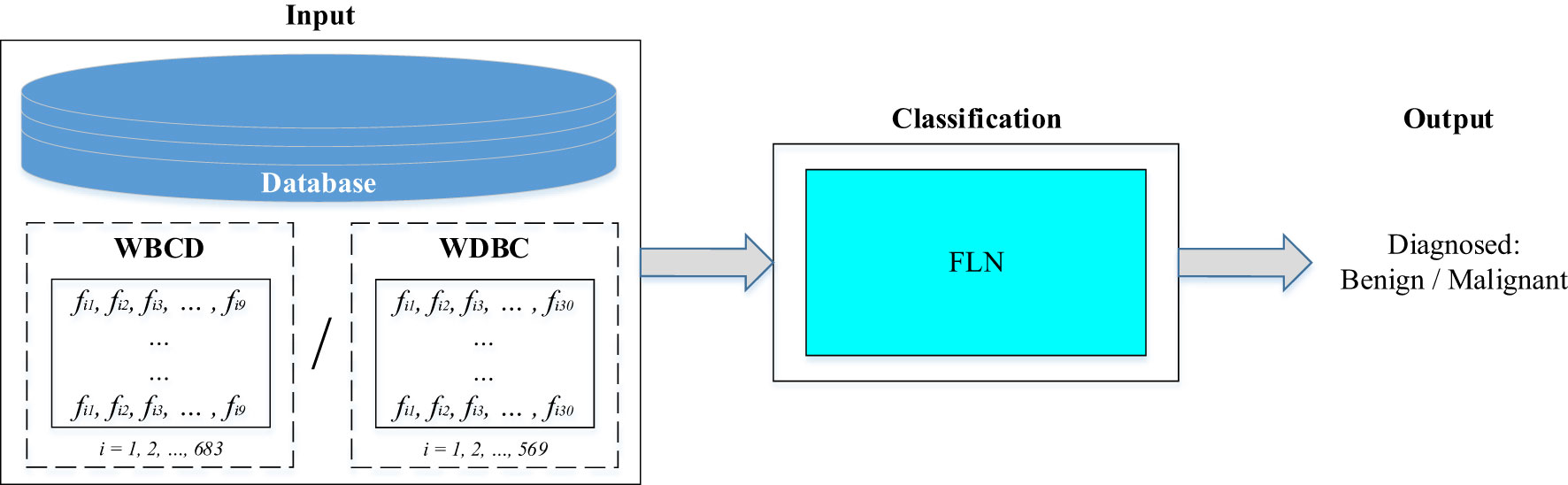
Figure 2 Diagram of the proposed breast cancer diagnosis classifier.
3.1 Database
In this work, two different standard databases (i.e., WBCD and WDBC) were used to evaluate the performance of the proposed FLN algorithm in diagnosing the breast cancer. The two different databases (i.e., WBCD and WDBC) have been provided in form of features. Deep descriptions and details of both databases and their extracted features are provided in the following:
• WBCD: The WBCD was obtained from the University of Wisconsin Hospital (44). There are 699 samples altogether in the WBCD. However, 16 samples in the WBCD had missing values. In this study, all 16 samples with missing values were eliminated, and only 683 samples were taken into consideration (i.e., 458 samples for the benign category and 241 samples for the malignant category). A deep description and explanation of the WBCD are provided in (45). All the experiments of the current work are applied based on dividing the database into 30% for testing purposes and 70% for training purposes. Table 2 presents the WBCD which has been utilized in this work.
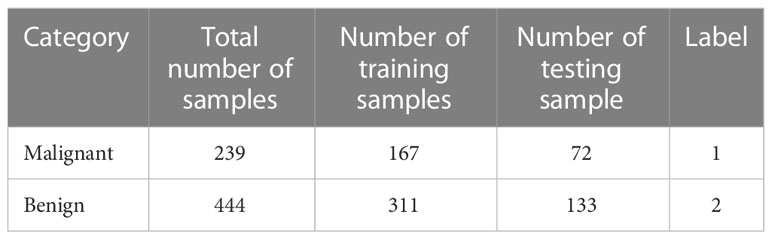
Table 2 Description of the WBCD which has been utilized in this work.
The WBCD was provided in a form of features where it contains nine features along with the label of the class (i.e., benign category or malignant category) and the ID number of the subject. These nine features are clump thickness, uniformity of cell size, uniformity of cell shape, marginal adhesion, single epithelial cell size, bare nuclei, bland chromatin, normal nucleoli, and mitoses. The values of these features are integers in the range of (1–10) where the 10 value refers to the critical state. Table 3 illustrates the nine features of the WBCD. More details on the WBCD features are provided in (45).
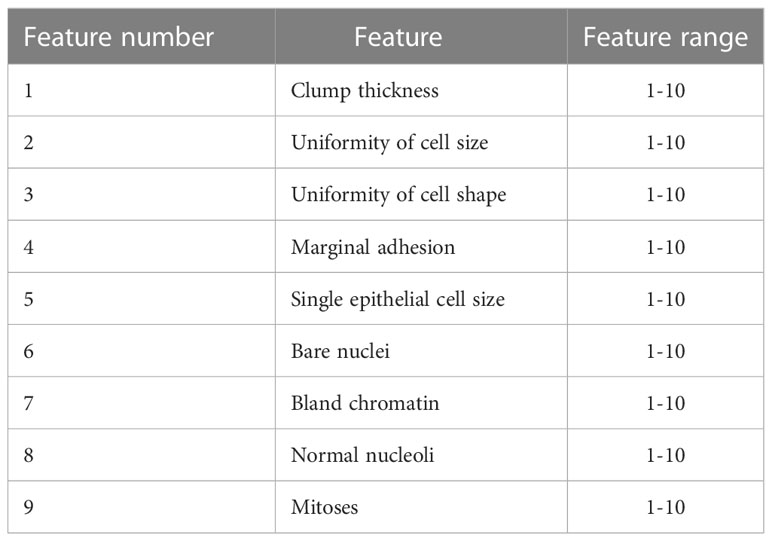
Table 3 Illustration of the WBCD features (45).
• WDBC database: The WDBC database has been downloaded from the UCI website, which is a machine-learning repository (46). The WDBC database consists of tumor features that are computed from a digital image of the FNA of the breast mass. The total number of samples in the WDBC database is 569 samples (i.e., 357 samples for the benign category and 212 samples for the malignant category). A deep description and explanation of the WDBC database are provided in (45). All the experiments of the present work are implemented based on dividing the database into 30% for testing purposes and 70% for training purposes. Table 4 depicts the WDBC database which has been used in this work.
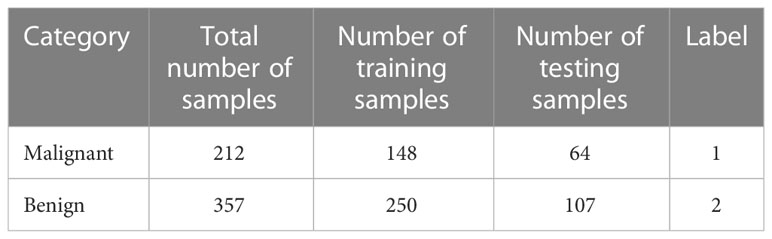
Table 4 Depiction of the WDBC database which has been used in this work.
The WDBC database was provided in a form of 32 tumor features that have been calculated from a digital image of the breast mass FNA. These 32 tumor features represent i) the ID number of the subject, ii) the label of the class, which refers to whether the subject belongs to a benign category or malignant category, and iii) 30 actual tumor features. For each subject, 10 characteristics of the cell nuclei (visual in the digital image of the breast FNA) are obtained: these are texture, radius, area, perimeter, compactness, smoothness, symmetry, concavity, fractal dimension, and concave points.
where
Radius: mean of distances from the center to points on the perimeter;
Texture: standard deviation of gray-scale values;
Perimeter: size of the core tumor;
Area;
Smoothness: local variation in radius lengths;
Compactness: perimeter2/area—1.0;
Concavity: severity of concave portions of the contour;
Concave points: number of concave portions of the contour;
Symmetry; and
Fractal dimension: coastline approximation—1.
Then, different measurements such as standard error, mean, and maximum of these 10 characteristics are computed, which results in 30 features. Table 5 depicts these measurements, which represents the tumor features in the WDBC database. More details on these features of the WDBC database are provided in (45).
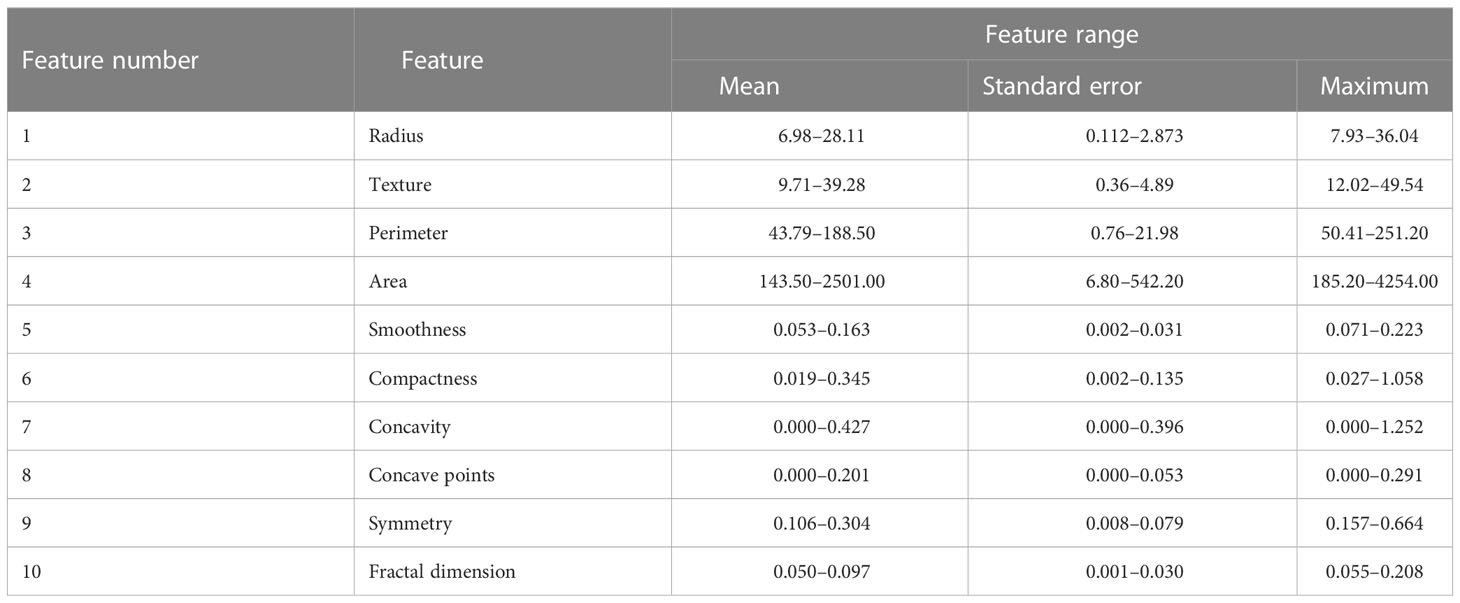
Table 5 Description of the WDBC database features (45).
3.2 FLN algorithm
FLN is a double-parallel forward artificial neural network proposed by (47). The FLN algorithm is based on the least-square techniques. Figure 3 presents the general FLN algorithm diagram, and it is followed by a deep explanation of the FLN algorithm.
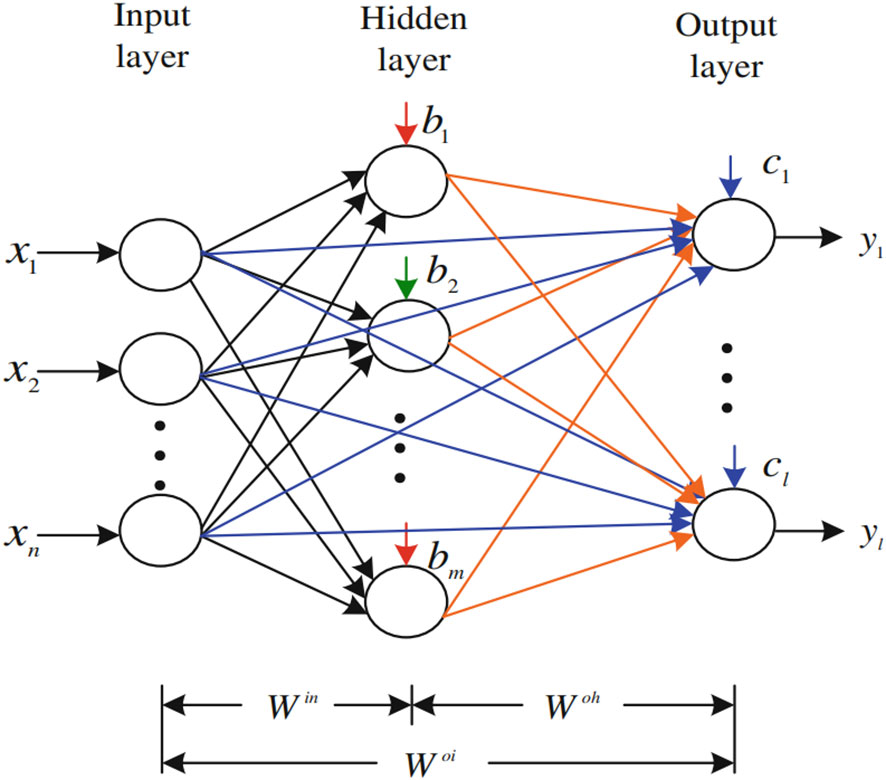
Figure 3 The FLN algorithm diagram.
Assume that N refers to arbitrary distinct samples {xi, yi}, where xi = [xi1, xi2… xin]T Rn is a vector of the ith training sample with n dimension, and yi = [yi1, yi2 … yil]T Rl is a vector of the ith target with the l dimension.
According to Figure 3, the FLN has m nodes in the hidden layer. Win refers to the matrix of the input weights with (m × n) dimension that links the input-layer nodes and hidden-layer nodes, while b = [b1, b2 … bm] T represents the matrix of the hidden-layer node biases. In addition, Woh denotes the weights’ matrix with (l × m) dimension that links the hidden-layer nodes with the output-layer nodes. Woi refers to the weights’ matrix with (l × n) dimension that links the input-layer nodes with the output-layer nodes. c = [c1, c2 … cl] T represents the matrix of the output-layer node biases. The active functions of the output-layer nodes and hidden-layer nodes are and , respectively. When the output-layer nodes’ biases c = [c1, c2 … cl] T are set equivalent to zeros, it will be ignored in the active function of the output-layer nodes. Consequently, the FLN algorithm mathematical model is depicted as follows:
Moreover, it could be represented as follows (see Equation 2):
where:
refers to the weight vector that is linking the rth input-layer node with the output-layer nodes. represents the weight vector that is linking the kth hidden-layer node with the output-layer nodes. Also, denotes the weights vector that is linking the kth hidden-layer node and the input-layer nodes. The hidden-layer nodes’ output (G) are computed as the following equation:
The output weights’ matrix could be determined by the inverse of Moore–Penrose generalization (see Equation 4).
are computed as follows (see Equation 5):
where is the number of the output nodes (i.e., number of classes); is the number of the input nodes (i.e., number of features); and is the number of the hidden nodes.
Suppose that N is the given training set {xi, yi}, where xi = [xi1, xi2… xin]T Rn and yi = [yi1, yi2 … yil]T Rl, activation function , and m is the hidden-layer nodes’ number, where
xi = the input, which is the extracted features (nine extracted features for the WBCD and 30 extracted features for the WDBC database).
yi = the true value (expected output).
Subsequently, the FLN algorithm learning procedure would be summarized as the following steps:
INPUT: training-set N
Step 1: Generate the Win and b (i.e., the input weights and biases) matrices randomly in the range of (–1, 1) for the input weights and [0, 1] for the biases.
Step 2: Compute the hidden-layer output matrix by using Equation (3).
Step 3: Calculate the combination matrix () by using Equation (4).
Step 4: Calculate the FLN algorithm parameter model by using Equation (5).
OUTPUT: the random generated Win and b (i.e., the input weights and biases) and the analytically computed Woi and Woh (i.e., weight values that connect the input layer with the output layer and the hidden layer with the output layer) by using the least-square method.
Once the learning process of the FLN algorithm is done, the obtained FLN model is tested on the testing data and its performance evaluated based on several evaluation measurements.
4 Experiments setup, results, and discussions
In this study, several experiments were implemented to assess the proposed FLN algorithm’s performance in diagnosing the BC using two databases WBCD and WDBC. These experiments were performed based on varying the hidden neuron number in the range of [25–200] with 25 increment steps. In order to statistically assess the effectiveness of the suggested FLN algorithm, a total of eight experiments were conducted, with each experiment being run 50 times. As in the literature (48, 49), the eight experiments were run based on dividing the database into 30% for testing purposes and 70% for training purposes. Additionally, all experiments were carried out using the MATLAB R2022a programming language on a computer that has Windows 10 Pro, 12 GB of RAM, and an Intel Core i7 running at 3.60 GHz. The outcomes of each run were assessed based on numerous evaluation measurements such as accuracy, precision, recall, F-measure, G-mean, MCC, and specificity. The mathematical calculation of these assessment measurements is depicted in Equations 6–12 (50, 51).
(8)
where TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
The 50 runs’ results of each experiment were used to calculate the mean, RMSE, and STD in order to statistically assess the proposed FLN algorithm’s performance in diagnosing the BC. These three assessments are considered the most common statistical evaluation measures (52, 53). The mean measures how close the overall performance of the classifier is during several runs to the optimal solution, while the RMSE measures how concentrated the results of several runs are around the optimal solution. The STD measures how far the results of several runs are from the mean. Thus, in the current study, if the mean value is high and close to 100.00%, this means the classifier performance was good during the several runs, while a low value for RMSE and STD indicates that the classifier performed rather well during the many runs and frequently produced results similar to or almost equal to 100.00%. Tables 6 and 7 present the statistical results for all experiments of the proposed FLN algorithm using WBCD and the WDBC database, respectively. In Tables 6 and 7, the best statistical results are presented in bold font. Equations 13–15 (54) are used to calculate the mean, RMSE, and STD.
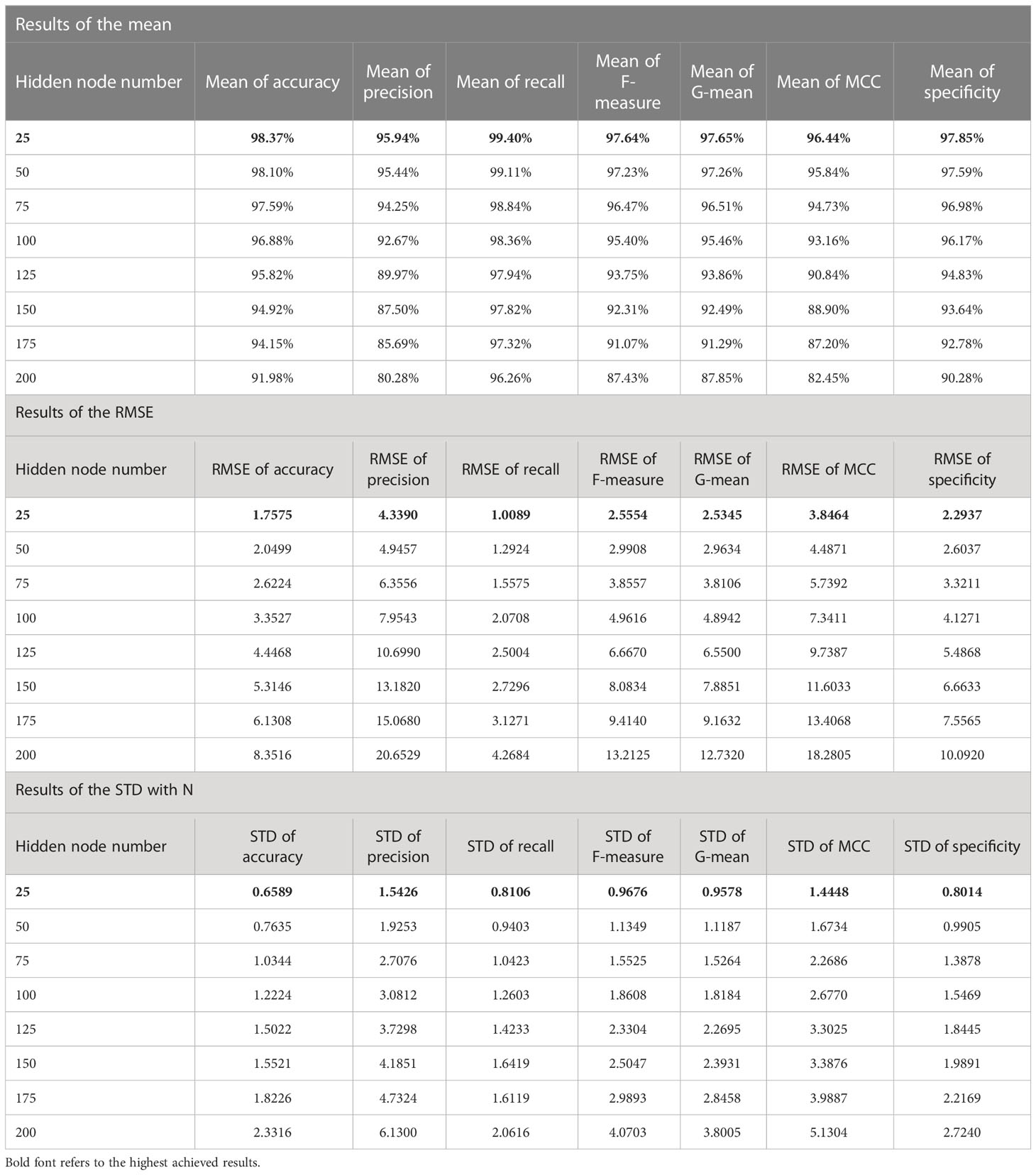
Table 6 The statistical results for all experiments of the proposed FLN algorithm using the WBCD.
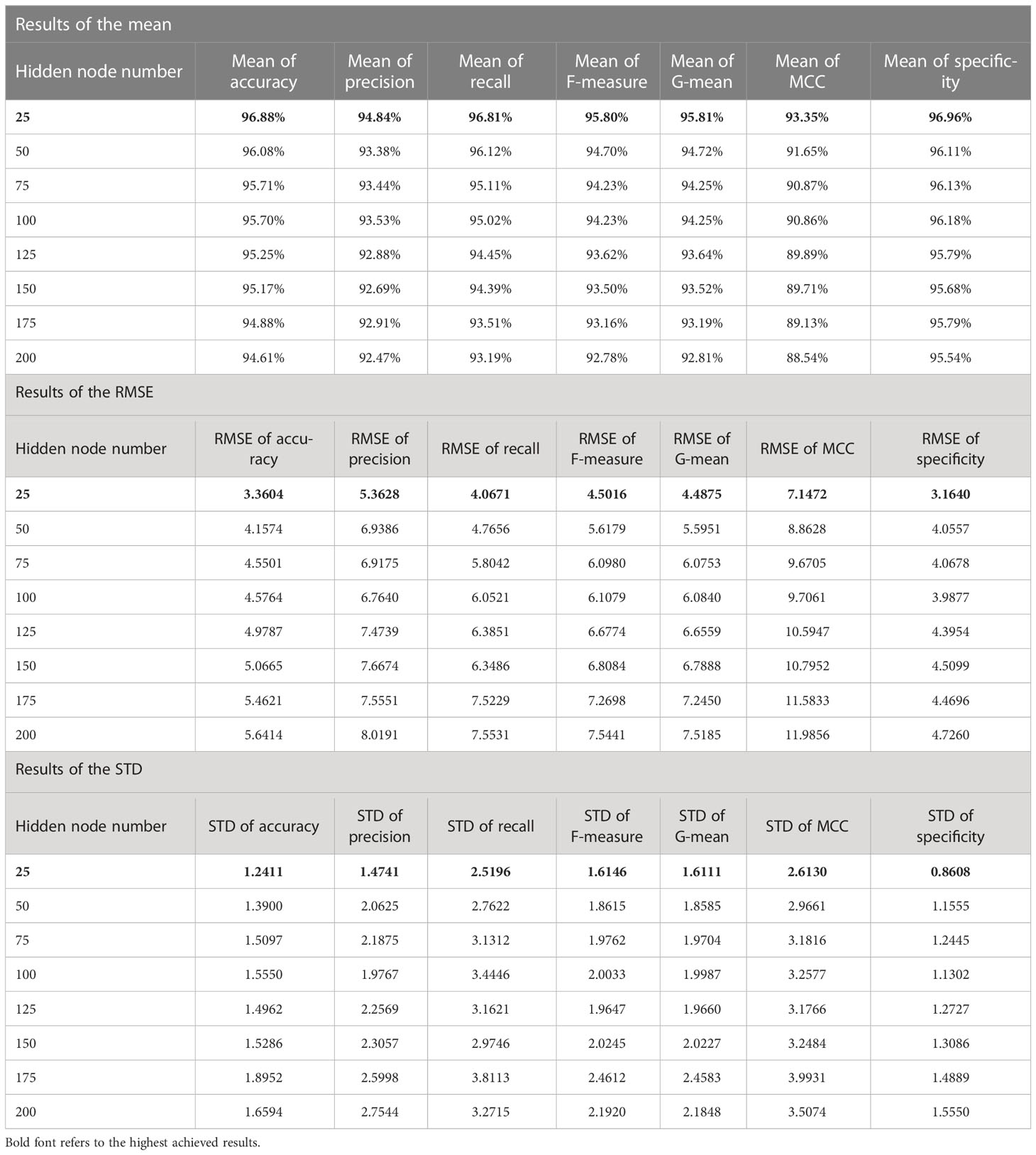
Table 7 The statistical results for all experiments of the proposed FLN algorithm using the WDBC database.
where refers to the mean of the population, Xi represents each value of the population, N denotes the number of values in the population, and o refers to the observed/optimal value (i.e., 100.00%).
According to the results in Tables 6 and 7, the mean values of all measurements are close to 100.00%; that means the achieved accuracy, precision, recall, F-measure, G-mean, MCC, and specificity by the FLN algorithm were quite close to 100.00% most of the time during the 50 runs. While the values of both RMSE and STD are low (i.e., close to zero), which proves the effectiveness of the FLN algorithm in terms of achieving a high classification performance during the 50 runs. The proposed FLN algorithm has achieved the best statistical results when the number of the hidden neurons was 25 using both WBCD and the WDBC database.
For the WBCD (see Table 6):
a. The mean value of the accuracy was 98.37%, precision was 95.94%, recall was 99.40%, F-measure was 97.64%, G-mean was 97.65%, MCC was 96.44%, and specificity was 97.85%.
b. The RMSE values were accuracy 1.7575, precision 4.3390, recall 1.0089, F-measure 2.5554, G-mean 2.5345, MCC 3.8464, and specificity 2.2937.
c. The STD values were accuracy 0.6589, precision 1.5426, recall 0.8106, F-measure 0.9676, G-mean 0.9578, MCC 1.4448, and specificity 0.8014.
For the WDBC database (see Table 7):
a) The mean values of the accuracy, precision, recall, F-measure, G-mean, MCC, and specificity were 96.88%, 94.84%, 96.81%, 95.80%, 95.81%, 93.35%, and 96.96%, respectively.
b) The RMSE value for the accuracy was 3.3604, precision 5.3628, recall 4.0671, F-measure 4.5016, G-mean 4.4875, MCC 7.1472, and specificity 3.1640.
c) The STD values for the accuracy was 1.2411, precision 1.4741, recall 2.5196, F-measure 1.6146, G-mean 1.6111, MCC 2.6130, and specificity 0.8608.
Moreover, Figures 4 and 5 show the boxplot of all evaluation measurements’ results during the 50 runs for the eight experiments using the WBCD and WDBC database.
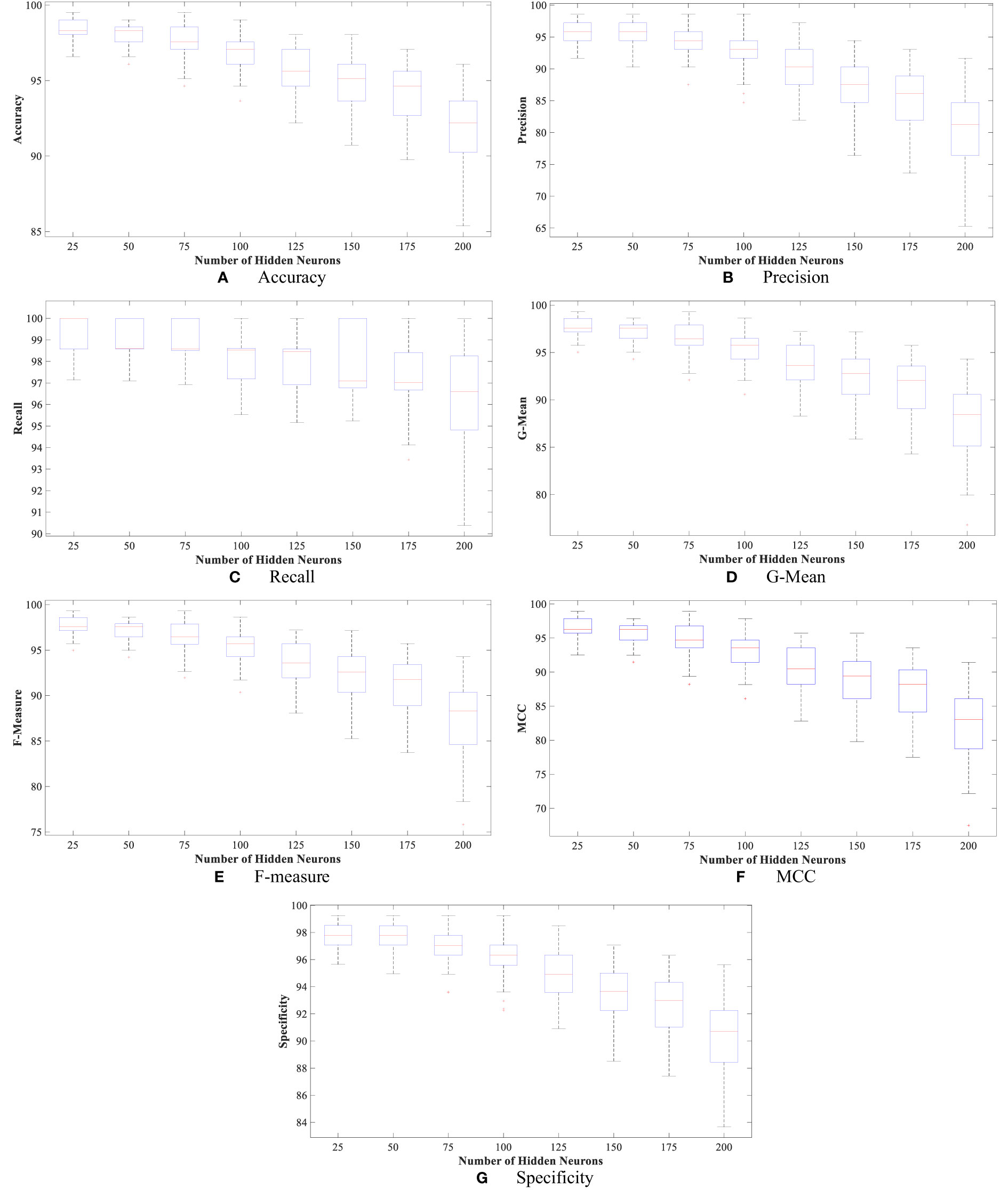
Figure 4 The proposed FLN algorithm’s results for the 50 runs in all experiments using WDBC database: (A) FLN algorithm accuracy results for the 50 runs in all experiments, (B) FLN algorithm precision results for the 50 runs in all experiments, (C) FLN algorithm recall results for the 50 runs in all experiments, (D) FLN algorithm G-mean results for the 50 runs in all experiments, (E) FLN algorithm F-measure results for the 50 runs in all experiments, (F) FLN algorithm MCC results for the 50 runs in all experiments, and (G) FLN algorithm specificity results for the 50 runs in all experiments.
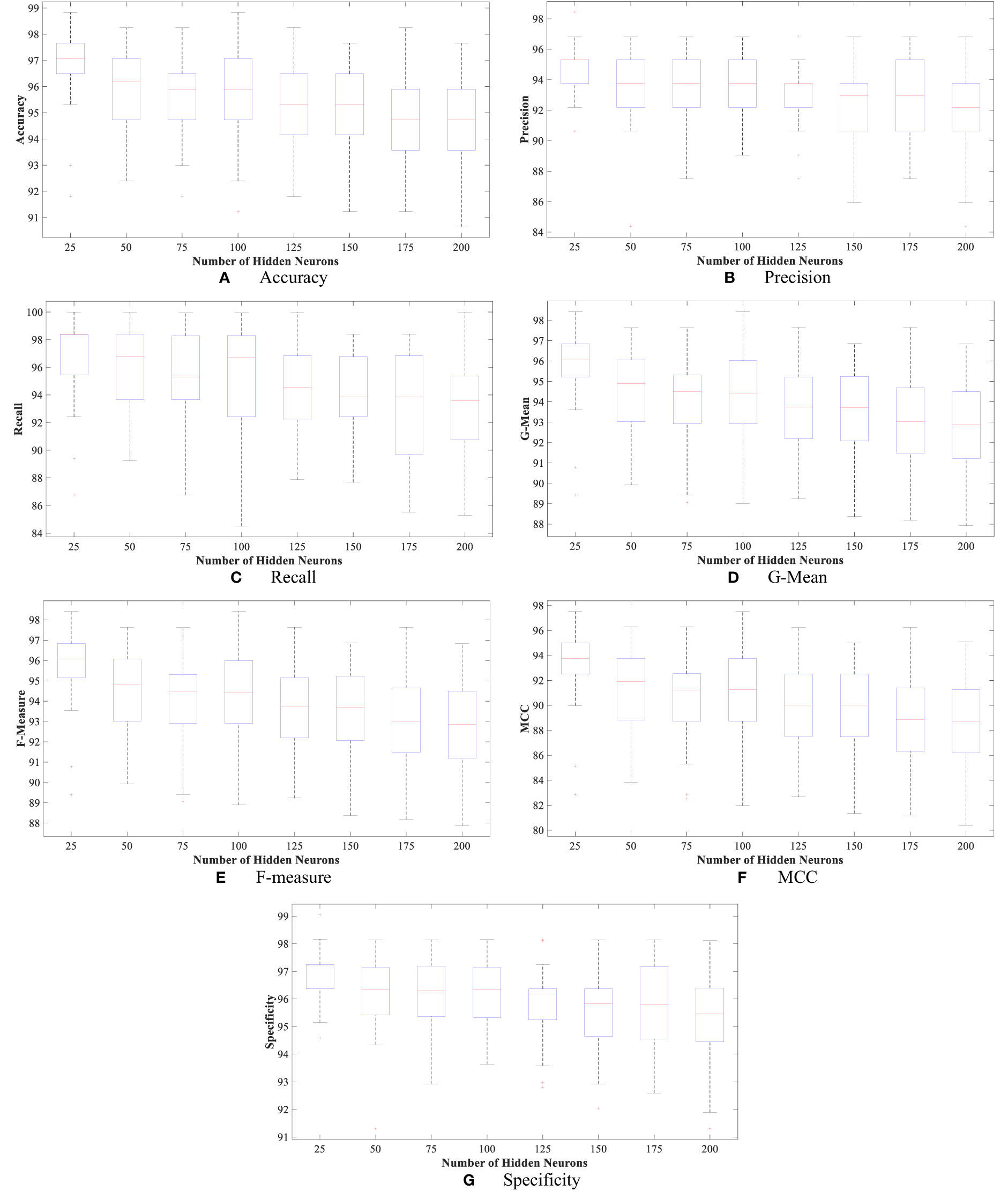
Figure 5 The proposed FLN algorithm’s results for the 50 runs in all experiments using the WBCD. (A) FLN algorithm accuracy results for the 50 runs in all experiments, (B) FLN algorithm precision results for the 50 runs in all experiments, (C) FLN algorithm recall results for the 50 runs in all experiments, (D) FLN algorithm G-mean results for the 50 runs in all experiments, (E) FLN algorithm F-measure results for the 50 runs in all experiments, (F) FLN algorithm MCC results for the 50 runs in all experiments, and (G) FLN algorithm specificity results for the 50 runs in all experiments.
Figures 4 and 5 show the results, which clearly show that the proposed FLN algorithm has done well across 50 runs in all trials utilizing the WBCD and WDBC database. For both the WBCD and WDBC datasets, the best 50 runs’ results of the proposed FLN algorithm were obtained using 25 hidden neurons (see Figures 4, 5). For the WBCD, the range of accuracy is 96.59%–99.51%, precision 91.67%–98.61%, recall 97.14%–100.00%, F-measure 94.96%–99.30%, G-mean 95.03%–99.30%, MCC 92.52%–98.93%, and specificity 95.65%–99.25%, while for the WBCD, the respective ranges of accuracy, precision, recall, F-measure, G-mean, MCC, and specificity are 91.81%–98.83%, 90.63%–98.44%, 86.77%–100.00%, 89.39%–98.41%, 89.44%–98.43%, 82.84%–97.52%, and 94.60%–99%. The FLN algorithm’s best outcomes using the WBCD and WDBC database are shown in Table 8. Additionally, utilizing the WBCD and WDBC database, Figures 6 and 7 display the confusion matrix for the FLN algorithm’s best outcomes, which is a clear indication that the proposed FLN algorithm on the WBCD was able to accurately classify 71 out of 72 malignant samples while successfully classifying all 33 testing samples of benign tissue (see Figure 6). For the WDBC database, it demonstrates that the suggested FLN method was capable of correctly classifying all of the testing samples, with the exception of two samples from the malignant category (64 malignant and 107 benign) (see Figure 7). The remarkable FLN performance is due to output layer neurons of the FLN that are also receiving external information directly through the input layer neurons, rather than just through the hidden layer neurons, which only receive the external information after it is modified.
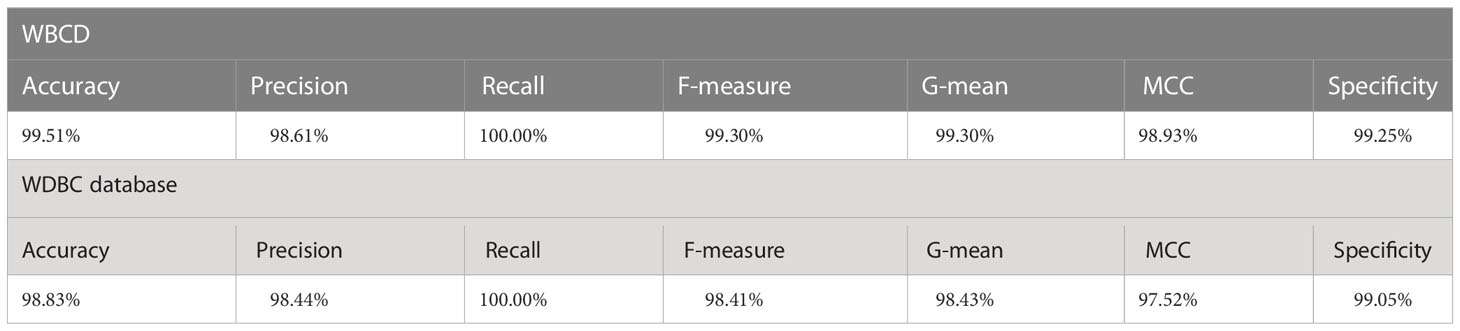
Table 8 The highest achieved results of the FLN algorithm using the WBCD and WDBC database.
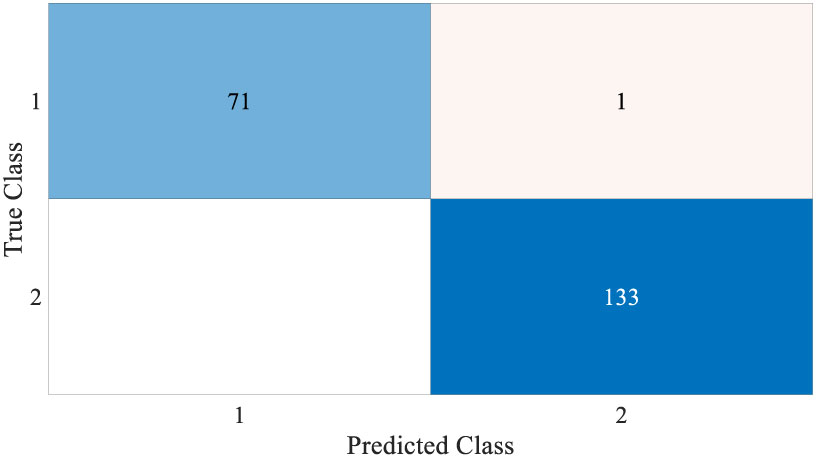
Figure 6 Confusion matrix for the best achieved results by the FLN algorithm using the WBCD.

Figure 7 Confusion matrix for the best achieved results by the FLN algorithm using the WDBC database.
Additionally, the proposed FLN algorithm has been evaluated in terms of execution time and ROC. Table 9 provides the execution time of the FLN algorithm based on the WBCD and WDBC database, where the results of the execution time in Table 9 proves that the performance of the proposed FLN algorithm is quite fast and needs only a few milliseconds for the classification process, while Figures 8 and 9 display the ROC of the best achieved results by the FLN algorithm using the WBCD and WDBC database. Based on the results in Figures 8 and 9, the proposed FLN algorithm achieved 0.99306 AROC using the WBCD and 0. 98438 AROC using the WDBC database. This obviously shows and proves that the proposed FLN algorithm correctly classified almost all the malignant and benign category points.

Table 9 The total run time for the 50 runs in all experiments of the proposed FLN algorithm using the WBCD and WDBC database.
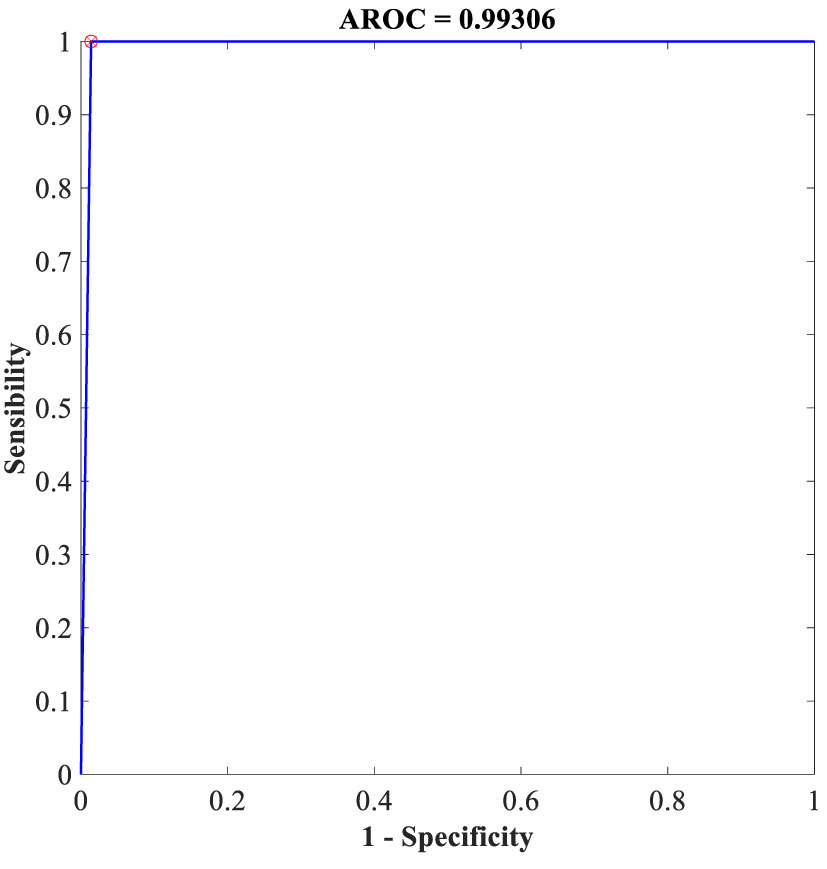
Figure 8 ROC for the best achieved results by the FLN algorithm using the WBCD.
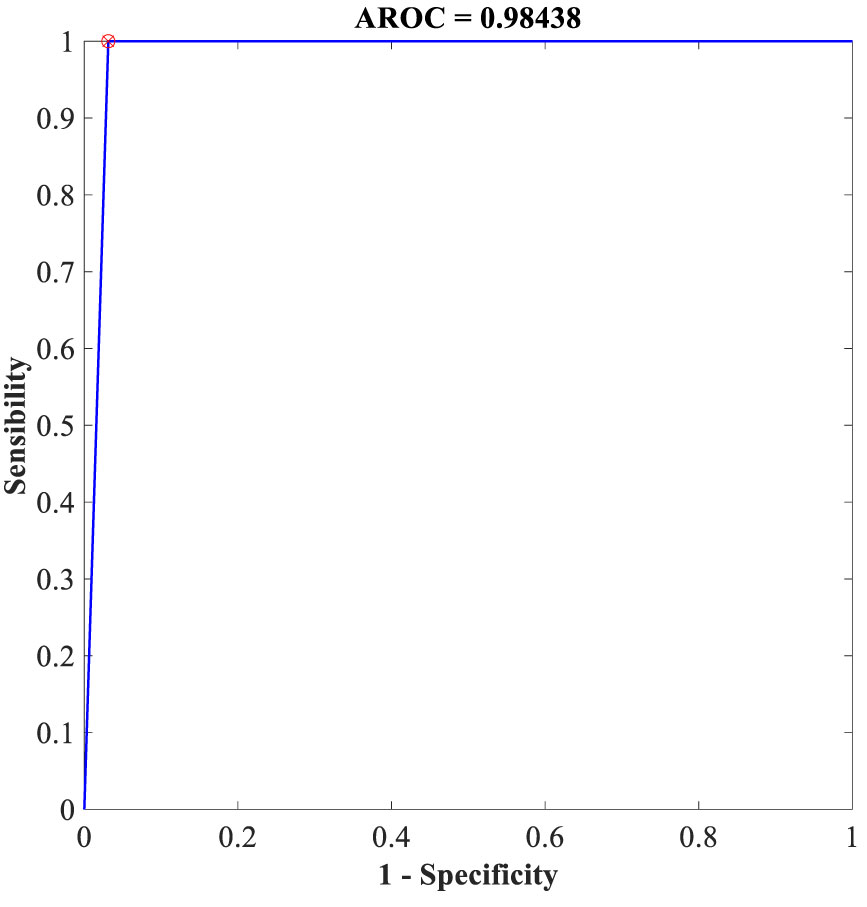
Figure 9 ROC for the best achieved results by the FLN algorithm using the WDBC database.
Additionally, the proposed FLN algorithm’s accuracy performance was compared with several recent studies (55–72) that made use of the same WBCD and WDBC datasets. Various ML and DM techniques have been reported in these publications for diagnosing the BC (i.e., diagnose whether the tumor is benign or malignant). Table 10 provides a comparison of these studies’ rates of classification accuracy in BC diagnosis.
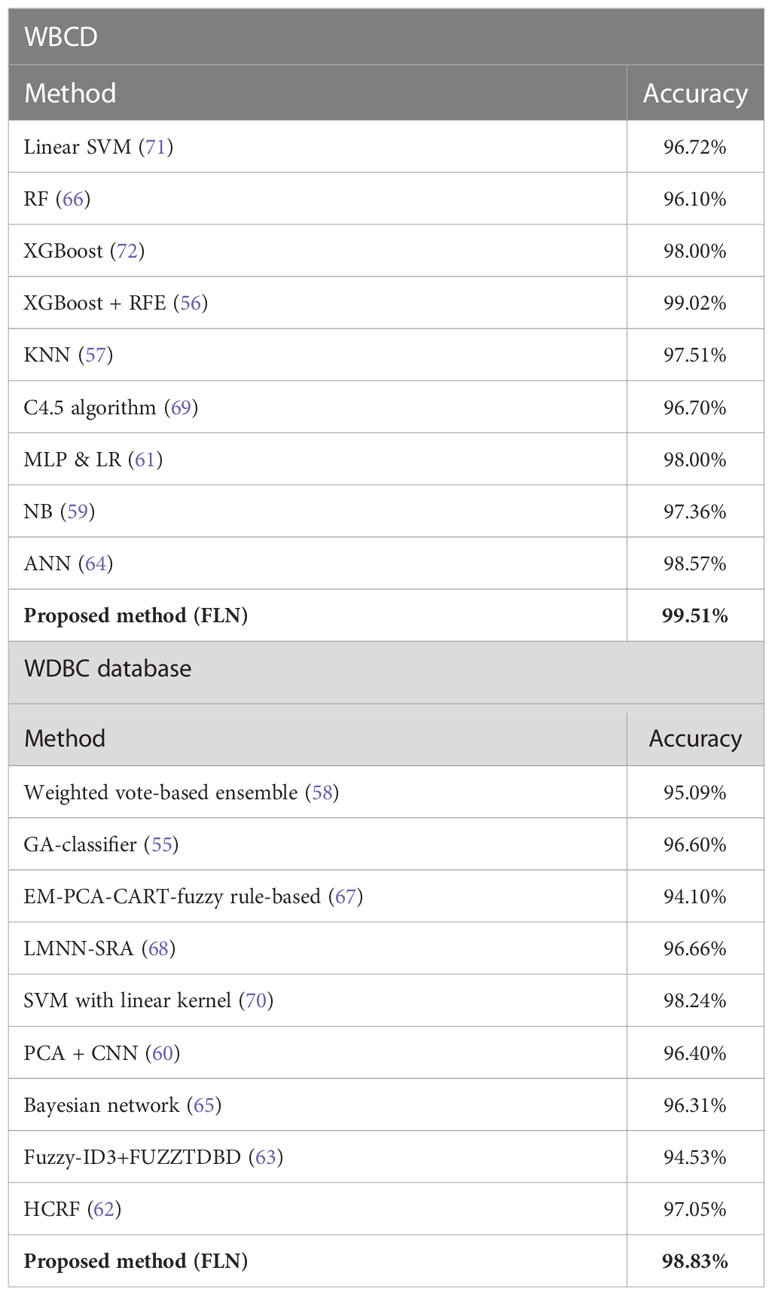
Table 10 The comparison of the accuracy rate (the best result) among the methods in diagnosing the BC based on the WBCD and WDBC database.
The results in Table 10 demonstrate that the proposed FLN algorithm has outperformed all of its peers in terms of classification accuracy rate. However, there are still some challenges with the current work, which are as follows:
● The current work has considered the off-line classification task only while an online classification task is required.
● The present work has taken into account the task of breast cancer detection only and ignored the task of breast cancer stage classification.
● The fact that the FLN algorithm needs to be optimized in terms of the random generated input weights and biases has been ignored, where the random input weights and biases of the hidden layer are not the best parameters, which cannot always meet the training goals of the FLN to achieve the global minimum. In other words, based on given training data, there is no way to assure that the trained FLN is the most appropriate in performing the classification.
5 Conclusion
In this study, we have proposed a BC diagnosing classifier based on the FLN algorithm. The FLN algorithm was applied on two different BC databases WBCD and WDBC. Several experiments were implemented to assess the proposed FLN algorithm performance in diagnosing the BC by varying the hidden neuron number. The outcomes of each run were assessed based on accuracy, precision, recall, F-measure, G-mean, MCC, and specificity. The 50 runs’ results of each experiment were used to calculate the mean, RMSE, and STD in order to statistically assess the proposed FLN algorithm performance in diagnosing the BC. The statistical analysis proved the effectiveness of the proposed FLN algorithm in diagnosing the BC, and it confirms that the achieved results were not by accident. The performance of the FLN algorithm was impressive with an accuracy average reaching up to 98.37% using the WBCD and 96.88% using the WDBC database. The outstanding FLN performance is a result of the fact that external information is also directly received by FLN output layer neurons via input layer neurons, as opposed to merely through hidden layer neurons, which only receive external information after it has been transformed. Nevertheless, despite the fact that an online classification task was required, the current study only considered the offline classification problem. In addition, the present work has taken into account the task of breast cancer detection only and ignored the task of breast cancer stage classification. In addition, the need to optimize the FLN algorithm with respect to the input weights and biases generated at random has been omitted. The random input weights and biases of the hidden layer are not the best parameters, which cannot always meet the training goals of the FLN to achieve the global minimum. In other words, based on given training data, there is no way to assure that the trained FLN is the most appropriate in performing the classification. Therefore, in order to produce more appropriate biases and input weights for the FLN algorithm and reduce classification mistakes, the study’s future work should employ an optimization technique. Moreover, the proposed work was used to address the problems of the breast cancer stages classification as well as other healthcare applications.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: WBCD: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Original%29; WDBC: https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic).
Author contributions
MAAA: conceptualization, methodology, writing of the original draft, software, writing of the review, and editing. MA: supervision, funding acquisition, and project administration. ST: supervision. FA-D: writing of the review and editing. AA: investigation. SK: investigation. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the Kementerian Pengajian Tinggi Malaysia and Universiti Kebangsaan Malaysia under research grants TRGS/1/2019/UKM/01/4/1 and PP-FTSM-2022.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Khan F, Khan MA, Abbas S, Athar A, Siddiqui SY, Khan AH, et al. Cloud-based breast cancer prediction empowered with soft computing approaches. J healthcare Eng (2020) 2020:1–16. doi: 10.1155/2020/8017496
3. Sathyapriya T, Ramaprabha T. Deep learning algorithems for breast cancer image classification. Int J Eng Res Technol (2020) 8(3):1–4.
4. Zafiropoulos E, Maglogiannis I, Anagnostopoulos I. (2006). A support vector machine approach to breast cancer diagnosis and prognosis, in: IFIP international conference on artificial intelligence applications and innovations. Athens, Greece: Springer, pp. 500–7.
5. DeSantis CE, Ma J, Gaudet MM, Newman LA, Miller KD, Sauer Goding A, et al. Breast cancer statistics, 2019. CA: Cancer J Clin (2019) 69(6):438–51. doi: 10.3322/caac.21583
6. Briguglio G, Costa C, Pollicino M, Giambo F, Catania S, Fenga C. Polyphenols in cancer prevention: new insights. Int J Funct Nutr (2020) 1(2):1–1. doi: 10.3892/ijfn.2020.9
7. Dubey AK, Gupta U, Jain S. (2015). A survey on breast cancer scenario and prediction strategy, in: Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA) 2014, . pp. 367–75. Springer.
8. Albadr MAA, Tiun S., Ayob M., AL-Dhief FT., Omar K., Maen MK. Speech emotion recognition using optimized genetic algorithm-extreme learning machine. Multimedia Tools Appl (2022) p:1–27. doi: 10.1007/s11042-022-12747-w
9. Albadr MAA, Tiun S, Ayob M, Al-Dhief FT, Omar K, Hamzah FA. Optimised genetic algorithm-extreme learning machine approach for automatic COVID-19 detection. PloS One (2020) 15(12):e0242899. doi: 10.1371/journal.pone.0242899
10. Albadr MAA, Tiun S, Ayob M, Al-Dhief FT. Particle swarm optimization-based extreme learning machine for COVID-19 detection. Cogn Comput (2022) p:1–16. doi: 10.1007/s12559-022-10063-x
11. Albadr MAA, Tiun S, Ayob M, Al-Dhief FT, Abdali T-AN, Abbas AF. (2021). Extreme learning machine for automatic language identification utilizing emotion speech data, in: 2021 International Conference on Electrical, Communication, and Computer Engineering (ICECCE). (Kuala Lumpur, Malaysia: IEEE).
12. Albadr MAA, Tiun S. Spoken language identification based on particle swarm optimisation–extreme learning machine approach. Circuits Systems Signal Process (2020) 39(9):4596–622. doi: 10.1007/s00034-020-01388-9
13. Albadr MAA, Tiun S, Al-Dhief FT, Sammour MA. Spoken language identification based on the enhanced self-adjusting extreme learning machine approach. PloS One (2018) 13(4):e0194770. doi: 10.1371/journal.pone.0194770
14. ALIPOOR G, SAMADI E. Robust speaker gender identification using empirical mode decomposition-based cepstral features. Asia-Pacific Journal of Information Technology and Multimedia (2018) 7:71–81.
15. Albadr MAA, Ayob M, Tiun S, Al-Dhief FT, Hasan MK. Gray Wolf optimization-extreme learning machine approach for diabetic retinopathy detection. Front Public Health (2022) 10:925901–1. doi: 10.3389/fpubh.2022.925901
16. Al-Dhief FT, Latiff NMaA, Malik NNNA, Salim NS, Baki MM, Albadr MAA, et al. A survey of voice pathology surveillance systems based on internet of things and machine learning algorithms. IEEE Access (2020) 8:64514–33. doi: 10.1109/ACCESS.2020.2984925
17. AL-Dhief FT, Latiff NMaA, Malik NNNA, Sabri N, Baki MM, Albadr MAA, et al. Voice pathology detection using machine learning technique. In: 2020 IEEE 5th international symposium on telecommunication technologies (ISTT). Shah Alam, Malaysia: IEEE (2020).
18. AL-Dhief FT, Latiff NMAA, Baki MM, Malik NNNA, Sabri N, Albadr MAA. (2021). Voice Pathology Detection Using Support Vector Machine Based on Different Number of Voice Signals, in: 2021 26th IEEE Asia-Pacific Conference on Communications (APCC). (Kuala Lumpur, Malaysia: IEEE).
19. Fatima N, Liu L, Hong S, Ahmed H. Prediction of breast cancer, comparative review of machine learning techniques, and their analysis. IEEE Access (2020) 8:150360–76. doi: 10.1109/ACCESS.2020.3016715
20. Thomas T, Pradhan N, Dhaka VS. (2020). Comparative analysis to predict breast cancer using machine learning algorithms: a survey, in: 2020 International Conference on Inventive Computation Technologies (ICICT). (Coimbatore, India: IEEE).
21. Gardezi SJS, Elazab A, Lei B, Wang T. Breast cancer detection and diagnosis using mammographic data: systematic review. J Med Internet Res (2019) 21(7):e14464. doi: 10.2196/14464
22. Yue W, Wang Z, Chen H, Payne A, Liu X. Machine learning with applications in breast cancer diagnosis and prognosis. Designs (2018) 2(2):13. doi: 10.3390/designs2020013
23. Ali MH, Jaber MM. Comparison between extreme learning machine and fast learning network based on intrusion detection system. (2021). EasyChair. No. 5103.
24. Albadra MAA, Tiuna S. Extreme learning machine: a review. Int J Appl Eng Res (2017) 12(14):4610–23.
25. Niu P, Ma Y, Li M, Yan S, Li G. A kind of parameters self-adjusting extreme learning machine. Neural Process Lett (2016) 44(3):813–30. doi: 10.1007/s11063-016-9496-z
26. Niu P, Chen K, Ma Y, Li X, Liu A, Li G. Model turbine heat rate by fast learning network with tuning based on ameliorated krill herd algorithm. Knowledge-Based Syst (2017) 118:80–92. doi: 10.1016/j.knosys.2016.11.011
27. Ali MH, Al-Jawaheri K, Adnan MM, Aasi A, Radie AH. (2020). Improved intrusion detection accuracy based on optimization fast learning network model, in: 2020 3rd International Conference on Engineering Technology and its Applications (IICETA). Najaf, Iraq: IEEE.
28. Ayoub B, Nora T. An optimized parkinson's disorder identification through evolutionary fast learning network. Int J Intelligent Computing Cybernetics (2021). doi: 10.1108/IJICC-07-2021-0138
29. Ali MH, Al Mohammed BAD, Ismail A, Zolkipli MF. A new intrusion detection system based on fast learning network and particle swarm optimization. IEEE Access (2018) 6:20255–61. doi: 10.1109/ACCESS.2018.2820092
30. Ali MH, Moorthy K, Morad M, Mohammed M. Propose a new machine learning algorithm based on cancer diagnosis. Jour of Adv Research in Dynamical & Control Systems (2018) 10:2668–72.
31. Utomo CP, Kardiana A, Yuliwulandari R. Breast cancer diagnosis using artificial neural networks with extreme learning techniques. Int J Adv Res Artif Intel (2014) 3(7):10–14.
32. Dubey AK, Gupta U, Jain S. Analysis of k-means clustering approach on the breast cancer Wisconsin dataset. Int J Comput assisted Radiol Surg (2016) 11(11):2033–47. doi: 10.1007/s11548-016-1437-9
33. Ara S, Das A, Dey A. (2021). Malignant and benign breast cancer classification using machine learning algorithms, in: 2021 International Conference on Artificial Intelligence (ICAI). (Islamabad, Pakistan: IEEE).
34. Kumar P, Nair GG. An efficient classification framework for breast cancer using hyper parameter tuned random decision forest classifier and Bayesian optimization. Biomed Signal Process Control (2021) 68:102682. doi: 10.1016/j.bspc.2021.102682
35. Naji MA, El Filali S, Aarika K, Benlahmar EH, Abdelouhahid RA, Debauche O. Machine learning algorithms for breast cancer prediction and diagnosis. Proc Comput Sci (2021) 191:487–92. doi: 10.1016/j.procs.2021.07.062
36. Phan AV, Nguyen ML, Bui LT. Feature weighting and SVM parameters optimization based on genetic algorithms for classification problems. Appl Intell (2017) 46(2):455–69. doi: 10.1007/s10489-016-0843-6
37. Agarap AFM. (2018). On breast cancer detection: an application of machine learning algorithms on the wisconsin diagnostic dataset, in: Proceedings of the 2nd international conference on machine learning and soft computing, Phu Quoc Island Vietnam.
38. Asri H, Mousannif H, Al Moatassime H, Noel T. Using machine learning algorithms for breast cancer risk prediction and diagnosis. Proc Comput Sci (2016) 83:1064–9. doi: 10.1016/j.procs.2016.04.224
39. Kumari M, Singh V. Breast cancer prediction system. Proc Comput Sci (2018) 132:371–6. doi: 10.1016/j.procs.2018.05.197
40. Birchha V, Nigam B. Performance analysis of averaged perceptron machine learning classifier for breast cancer detection. Proc Comput Sci (2023) 218:2181–90. doi: 10.1016/j.procs.2023.01.194
41. Dhahri H, Al Maghayreh E, Mahmood A, Elkilani W, Nagi Faisal M. Automated breast cancer diagnosis based on machine learning algorithms. J healthcare Eng (2019) 2019:1–11. doi: 10.1155/2019/4253641
42. Uddin KMM, Biswas N, Rikta ST, Dey SK. Machine learning-based diagnosis of breast cancer utilizing feature optimization technique. Comput Methods Programs Biomedicine Update (2023) p:100098. doi: 10.1016/j.cmpbup.2023.100098
43. Jabbar MA. Breast cancer data classification using ensemble machine learning. Eng Appl Sci Res (2021) 48(1):65–72. doi: 10.1109/ICAI52203.2021.9445249
44. Wolberg WH. Breast cancer Wisconsin (Original) data set. UCI Machine Learning Repository (1992). https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Original%29.
45. Dora L, Agrawal S, Panda R, Abraham A. Optimal breast cancer classification using gauss–newton representation based algorithm. Expert Syst Appl (2017) 85:134–45. doi: 10.1016/j.eswa.2017.05.035
46. Dr. William H, Wolberg GSD. Wisconsin Diagnosis breast cancer (WDBC). UCI Machine Learning Repository (1995). https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic).
47. Li G, Niu P, Duan X, Zhang X. Fast learning network: a novel artificial neural network with a fast learning speed. Neural Computing Appl (2014) 24(7):1683–95. doi: 10.1007/s00521-013-1398-7
48. Shaila S, VijayaLaxmi I, Rajesh T, Anusha H, Pranami C, Shahwar A, et al. Analysis and prediction of breast cancer using multi-model classification approach. In: Data engineering and intelligent computing. Springer (2022). p. 109–18.
49. ZEID MA-E, EL-BAHNASY K, ABU-YOUSSEF S. AN EFFICIENT OPTIMIZED FRAMEWORK FOR ANALYZING THE PERFORMANCE OF BREAST CANCER USING MACHINE LEARNING ALGORITHMS. J Theor Appl Inf Technol (2022) 100(14):5165–78.
50. Al-Dhief FT, Baki MM, Latiff N.MAA, Malik NNNA, Salim NS, Albader MAA, et al. Voice pathology detection and classification by adopting online sequential extreme learning machine. IEEE Access (2021) 9:77293–306. doi: 10.1109/ACCESS.2021.3082565
51. Albadr MAA, Tiun S, Ayob M, Mohammed M, AL-Dhief FT. Mel-Frequency cepstral coefficient features based on standard deviation and principal component analysis for language identification systems. Cogn Comput (2021) 13(5):1136–53. doi: 10.1007/s12559-021-09914-w
52. Albadr MA, Tiun S, Ayob M, Al-Dhief F. Genetic algorithm based on natural selection theory for optimization problems. Symmetry (2020) 12(11):1758. doi: 10.3390/sym12111758
53. Albadr MAA, Tiun S, Ayob M, AL-Dhief FT. Spoken language identification based on optimised genetic algorithm–extreme learning machine approach. Int J Speech Technol (2019) 22(3):711–27. doi: 10.1007/s10772-019-09621-w
54. Zhou Q, Chen D, Hu Z, Chen X. Decompositions of Taylor diagram and DISO performance criteria. Int J Climatology (2021) 41(12):5726–32. doi: 10.1002/joc.7149
55. Aalaei S, Shahraki H, Rowhanimanesh A, Eslami S. Feature selection using genetic algorithm for breast cancer diagnosis: experiment on three different datasets. Iranian J basic Med Sci (2016) 19(5):476.
56. Abdulkareem SA, Abdulkareem ZO. An evaluation of the Wisconsin breast cancer dataset using ensemble classifiers and RFE feature selection. Int J Sci. Basic Appl Res (2021) 55(2):67–80.
57. Amrane M, Oukid S, Gagaoua I, Ensari T. Breast cancer classification using machine learning. In: 2018 electric electronics, computer science, biomedical engineerings' meeting (EBBT). Istanbul, Turkey: IEEE (2018).
58. Bashir S, Qamar U, Khan FH. Heterogeneous classifiers fusion for dynamic breast cancer diagnosis using weighted vote based ensemble. Qual Quantity (2015) 49(5):2061–76. doi: 10.1007/s11135-014-0090-z
59. Chaurasia V, Pal S, Tiwari B. Prediction of benign and malignant breast cancer using data mining techniques. J Algorithms Comput Technol (2018) 12(2):119–26. doi: 10.1177/1748301818756225
60. Hasan MM, Haque MR, Kabir MMJ. (2019). Breast cancer diagnosis models using PCA and different neural network architectures, in: 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), .
61. HOUFANI D, Slatnia S, Kazar O, Zerhouni N, Saouli H, Remadna I. Breast cancer classification using machine learning techniques: a comparative study. Med Technol J (2020) 4(2):535–44. doi: 10.26415/2572-004X-vol4iss2p535-544
62. Huang Z, Chen D. A breast cancer diagnosis method based on VIM feature selection and hierarchical clustering random forest algorithm. IEEE Access (2021) 10:3284–93. doi: 10.1109/ACCESS.2021.3139595
63. Idris NF, Ismail MA. Breast cancer disease classification using fuzzy-ID3 algorithm with FUZZYDBD method: automatic fuzzy database definition. PeerJ Comput Sci (2021) 7:e427. doi: 10.7717/peerj-cs.427
64. Islam M, Haque M, Iqbal H, Hasan M, Hasan M, Kabir MN. Breast cancer prediction: a comparative study using machine learning techniques. SN Comput Sci (2020) 1(5):1–14. doi: 10.1007/s42979-020-00305-w
65. Krishnakumar N, Abdou T. Detection and diagnosis of breast cancer using a Bayesian approach. In: Canadian Conference on artificial intelligence. Ottawa, Canada: Springer (2020).
66. Li Y, Chen Z. Performance evaluation of machine learning methods for breast cancer prediction. Appl Comput Math (2018) 7(4):212–6. doi: 10.11648/j.acm.20180704.15
67. Nilashi M, Ibrahim O, Ahmadi H, Shahmoradi L. A knowledge-based system for breast cancer classification using fuzzy logic method. Telematics Inf (2017) 34(4):133–44. doi: 10.1016/j.tele.2017.01.007
68. Sánchez A, Soguero-Ruíz C, Mora-Jiménez I, Rivas-Flores FJ, Lehmann DJ, Rubio-Sánchez M. Scaled radial axes for interactive visual feature selection: a case study for analyzing chronic conditions. Expert Syst Appl (2018) 100:182–96. doi: 10.1016/j.eswa.2018.01.054
69. Sarkar SK, Nag A. Identifying patients at risk of breast cancer through decision trees. Int J Advanced Res Comput Sci (2017) 8(8):88–91. doi: 10.26483/ijarcs.v8i8.4602
70. SAYGILI A. Classification and diagnostic prediction of breast cancers via different classifiers. Int Sci Vocational Stud J (2018) 2(2):48–56.
71. Showrov MIH, Islam MT, Hossain MD, Ahmed MS. Performance comparison of three classifiers for the classification of breast cancer dataset. In: 2019 4th international conference on electrical information and communication technology (EICT). Khulna, Bangladesh: IEEE (2019).
Keywords: breast cancer, machine learning algorithms, data mining algorithms, fast learning network, Wisconsin breast cancer database, Wisconsin Diagnostic Breast Cancer
Citation: Albadr MAA, Ayob M, Tiun S, AL-Dhief FT, Arram A and Khalaf S (2023) Breast cancer diagnosis using the fast learning network algorithm. Front. Oncol. 13:1150840. doi: 10.3389/fonc.2023.1150840
Received: 02 February 2023; Accepted: 10 April 2023;
Published: 27 April 2023.
Edited by:
San-Gang Wu, First Affiliated Hospital of Xiamen University, ChinaReviewed by:
Saurabh Pal, Veer Bahadur Singh Purvanchal University, IndiaLaboni Akter, Khulna University of Engineering and Technology, Bangladesh
Copyright © 2023 Albadr, Ayob, Tiun, AL-Dhief, Arram and Khalaf. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Musatafa Abbas Abbood Albadr, bXVzdGFmYV9hYmJhczE5ODhAeWFob28uY29t