
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Oncol., 17 June 2022
Sec. Cancer Imaging and Image-directed Interventions
Volume 12 - 2022 | https://doi.org/10.3389/fonc.2022.886739
This article is part of the Research TopicDeep Learning Approaches in Image-guided Diagnosis for TumorsView all 14 articles
 Kadiyala Ramana1
Kadiyala Ramana1 Madapuri Rudra Kumar2K. Sreenivasulu2
Madapuri Rudra Kumar2K. Sreenivasulu2 Thippa Reddy Gadekallu3
Thippa Reddy Gadekallu3 Surbhi Bhatia4
Surbhi Bhatia4 Parul Agarwal5
Parul Agarwal5 Sheikh Mohammad Idrees6*
Sheikh Mohammad Idrees6*Lung cancer is the cellular fission of abnormal cells inside the lungs that leads to 72% of total deaths worldwide. Lung cancer are also recognized to be one of the leading causes of mortality, with a chance of survival of only 19%. Tumors can be diagnosed using a variety of procedures, including X-rays, CT scans, biopsies, and PET-CT scans. From the above techniques, Computer Tomography (CT) scan technique is considered to be one of the most powerful tools for an early diagnosis of lung cancers. Recently, machine and deep learning algorithms have picked up peak energy, and this aids in building a strong diagnosis and prediction system using CT scan images. But achieving the best performances in diagnosis still remains on the darker side of the research. To solve this problem, this paper proposes novel saliency-based capsule networks for better segmentation and employs the optimized pre-trained transfer learning for the better prediction of lung cancers from the input CT images. The integration of capsule-based saliency segmentation leads to the reduction and eventually reduces the risk of computational complexity and overfitting problem. Additionally, hyperparameters of pretrained networks are tuned by the whale optimization algorithm to improve the prediction accuracy by sacrificing the complexity. The extensive experimentation carried out using the LUNA-16 and LIDC Lung Image datasets and various performance metrics such as accuracy, precision, recall, specificity, and F1-score are evaluated and analyzed. Experimental results demonstrate that the proposed framework has achieved the peak performance of 98.5% accuracy, 99.0% precision, 98.8% recall, and 99.1% F1-score and outperformed the DenseNet, AlexNet, Resnets-50, Resnets-100, VGG-16, and Inception models.
Lung tumor (LT) is the most lethal cancer on the planet. As a result, numerous countries are working on early detection measures for lung disease. The NLST experiment (1) found that screening high-risk participants three times a year with low-dose computed tomography (CT) reduces death rates significantly (2). As a result of these procedures, a radiologist will have to examine a large number of CT scan images. Because lesions are difficult to identify, even for qualified clinicians, the strain on radiologists grows exponentially as the quantity of CT scans to review grows.
Lung cancer is the second most prevalent cause of cancer death in people. Cancers of the bladder, breast, colon, cervix and, prostate have 5-year survival rates of over 80%. Thus, early identification of lung cancer is critical to reducing mortality or facilitating full care. Due to their thin cell layers (0.2-1mm) and lack of symptoms, early lung malignancies and precancers such as dysplasia and carcinoma in situ (CIS) are difficult to identify visually using traditional diagnostic procedures such as medical imaging. In clinical practice, roughly 80% of cases are advanced when initially diagnosed and verified, losing the best chance for surgical therapy. Clearly, early detection of lung cancer is clinically significant.
With the predicted rise in the number of preventive/early-detection measures, scientists are developing automated solutions to assist doctors in decreasing their workload, improving diagnostic precision by minimizing subjectivity, speeding up analysis, and lowering medical costs. Specific traits must be detected and assessed to identify the cancerous cells in the lung region. Cancer risk can be determined by the observed features and their combination. Even for an experienced medical expert, this work is challenging because nodule existence and a positive cancer diagnosis are not easily linked. Volume, shape, subtlety, firmness, spiculation, sphericity, and other previously described properties are used in common computer-assisted diagnostic (CAD) techniques.
Machine learning (ML) techniques like Support Vector Machine (SVM) are utilized to identify the nodules as benign or cancerous. Despite the fact that numerous works employ comparable machine learning frameworks (3–10), the limitation of this technique is that in order for the system to function properly, different variables must be customized, making it difficult to repeat results. Furthermore, the lack of uniformity among CT scans and screening parameters makes these systems vulnerable. The development of deep training in CAD systems might do end-to-end identification by acquiring the most essential factors during training. The network is resistant to variations since it gathers tumor features in multiple CT scans with repeated modes. By adopting a training set that is rich in variability, the system may be able to learn invariant properties from malignant nodules intrinsically and enable higher performances (11, 12). Since no characteristics are generated, the system may be able to understand the relationship between traits and disease using the data provided on its own. Once trained, the network should be able to generalize its training and recognize cancerous lesions (or malignancy at the clinical bedside) on cases reported that have never been observed before (13, 14). Figure 1 shows the normal and abnormal CT lung images. Early classification and classification of lung cancers play a critical role in designing an intelligent and accurate diagnosis system (15). With the advent of machine and deep learning algorithms, the design of early diagnosis systems has reached new heights. Machine learning algorithms such as artificial neural networks (ANN), Support Vector Machines (SVM), Naïve Bayes Classifiers (NB), and Ensemble classifiers (EC) are primarily used for an early diagnosis of lung cancers (16). Also, deep learning is considered to be the most promising field which can enhance the performance of various medical imaging and diagnosis systems (17).
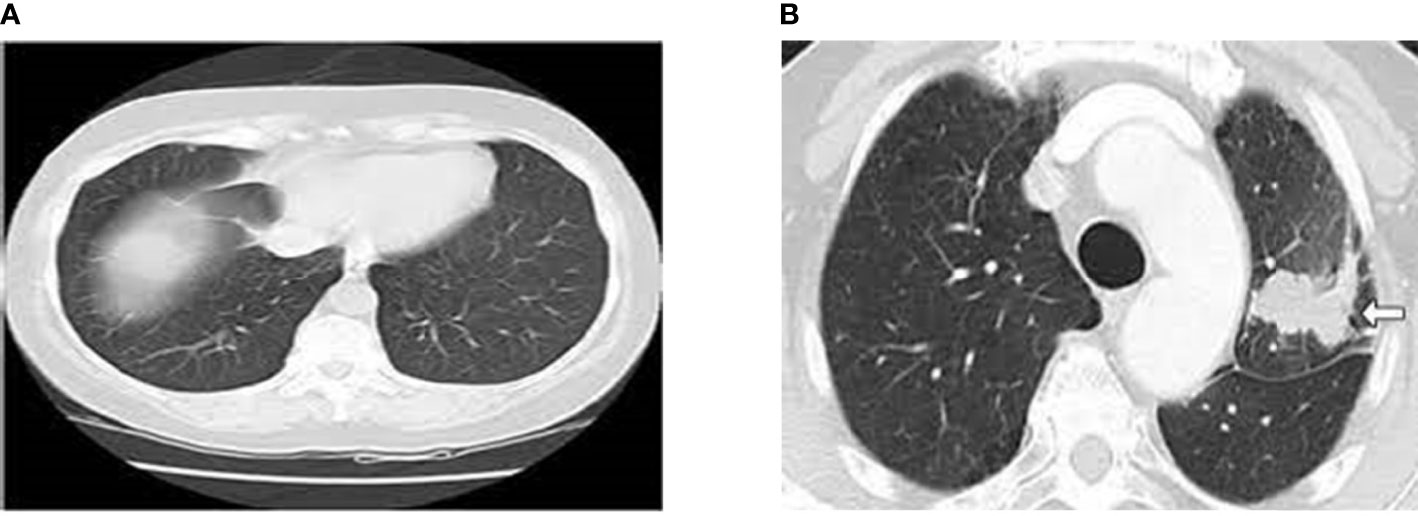
Figure 1 (A) Normal CT Lung Image (B) Abnormal CT Lung Image (Cancer Image).
However, handling the images with different imaging protocols remains a real challenge to train the learning modes for greater performance. To compensate for the above drawback of learning models, this paper proposes the novel hybrid intelligent diagnosis framework Deep Fused Features Based Reliable Optimized Networks (DFF-RON), which fuses the saliency maps and convolutional layers for better segmentation and feature extraction that are used to train the ant-lion optimized single feedforward networks. To the best of our knowledge, this is the first work that has integrated the fused features and optimized learning networks to design an efficient and high-performance CT-based lung cancer diagnosis system.
1. A novel hybrid deep learning based model is proposed for the early detection of lung cancer using CT scan images. The proposed architecture has been trained with LIDC datasets and performance metrics have been calculated and compared with other existing models.
2. The proposed architecture introduces the capsule network’s better segmentation and transfer learning for feature extraction. Also, the proposed fusion algorithm can increase the high diagnosis rate.
3. The whale optimization algorithm is proposed for training the features obtained from the hybrid fusion of saliency maps and capsule networks. The feed-forward layers are designed based on the principle of Extreme Learning Machines (ELM).
The rest of the paper is organized as follows: Section-II presents the related works proposed by more than one author. The working mechanism of the saliency maps, CNN layers, ant lion optimization, and feedforward networks are presented in Section-III. The dataset descriptions, experimentations, results, findings, and analysis are presented in Section-IV. Finally, the paper is concluded in Section-V with future enhancements.
In De Bruijne (18), the presented framework looked at the most up-to-date lung cancer detection and diagnosis methods. Using standardized databases LIDC-IDRI, LUNA 16, and Super Bowl Dataset 2016, the newest lesion detection, identification, and detectors are acquainted with labeled models. According to the author Jindal et al. (19), these are the most common and typical threshold CT data considered for diagnosing. The authors in Nalepa and Kawulok (20) developed the modified-CNN in order to recognize the tumor cells in the lung regions with the segmented images. The ACM method has been used for segregating the tumor region initially and identifying cancer or normal cells.
The label-free techniques do not injure cells or cause effects on cell structure or intrinsic features. To enhance cell identification using recorded optical profiles, this study combined advancements in optical coherence tomography with Prony methods. In Ganesan et al. (21), the framework finds signature genes by improving Tobacco Exposure Pattern (TEP) Prediction model and revealing their interaction connections at many biological levels. TTZ Kasinathan et al. (22) is a new way to extract core features and use them as an input variable in the TEP classification model. With two distinct LUAD datasets used to train and evaluate the TEP classification model, 34 genes were identified as nicotine-associated mutation signature genes, with an accuracy of 94.65% for training data and 91.85% for validation data.
The researcher examined tissue samples and devised a categorization method to discriminate between five types of pulmonary and colorectal tissues (two benign and three malignant). According to the observations, the suggested approach can detect tumor cells up to 96.33% of the time (23). The framework presented in Suzuki (24) described how to use computer-assisted diagnostics to assess EGFR mutation status, including gathering, evaluating, and merging multi-type interdependence characteristics. This research uses a new hybrid network model based on CNN-RNN architecture. CNN is used to extract image quantitative properties, and the link between different types of features is modeled. Their study indicate that multi-type dependency-based feature representations beat single-type feature representations (accuracy = 75%, AUC = 0.78) when compared to conventional features extracted.
The 3D_Alex Net unsupervised learning model (25) was introduced for lung cancer detection. The 3D CNN is a highly predictive architecture with an improved steepest descent input signal that increases the appearance of tumor tissues. The LUNA database is used to assess the proposed Alex Net detection technique to an existing 2D CNN training classifier. Due to a lack of testing data, the proposed model is unsuccessful, with just 10% of the training database being utilized.
Tajbakhsh and Suzuki (26) examined the performance of CNNs and MTANNs for detecting and classifying lung nodules. Achieving 100% sensitivity and 2.7 false positives per patient, MTANN exceeds the top performing CNN (AlexNet) in their testing. The MTANNs achieved an accuracy of 0.88 in classifying nodules as benign or malignant.
Gu et al. (27) suggested a unique 3D-CNN CAD system for lung nodule detection. They used a multiscale technique to improve the system’s detection of nodules of varying sizes. The suggested CAD system considers preprocessing, which is common in standalone CAD systems. It uses volume segmentation to create ROI cubes for 3D-CNN classification. After categorization, DBSCAN was used to blend adjacent regions that could be from the same nodule. Larger scale cubes have lesser sensitivity (88%) but an average of one false positive per patient, according to the LUNA16 dataset.
The multi-section CNN model suggested by Sahu et al. (28) uses multiple view sampling to classify nodules and estimate malignancy. Their proposed model is faster than the widely utilized 3D-CNNs. To develop their system, they employed pre-trained MobileNet networks and sample slices extracted in various directions. On the LUNA2016 dataset, the suggested model had a sensitivity of 96% and an AUC of 98%. They estimate the class likelihood of malignancy using a logistic regression model. It estimated malignancy with 93.79% accuracy. Because it is so light, it can be used on smaller devices like phones and tablets.
Deep3DSCan was proposed by Bansal et al. (29). To do so, they applied a deep 3D segmentation technique on CTs. The ResNet-based model was trained using a combination of deep fine-tuned residual network and morphological features. The LUNA16 dataset was utilized for training and testing. The proposed architecture achieved an F1 score of 0.88 in segmentation and classification tasks.
In Jothi et al. (30), the framework designed a controlled CNN classifier for patients with lung cancer to detect potential adenocarcinoma (ADC) and squamous cell carcinoma (SCC). CNN has already been verified using authentic Non-SCLC patient information from preliminary phase afflicted subjects collected at Massachusetts General Hospital (31). In the record, there are 311 data phases that have been collected. The created CNN, which is a VGG system training predictor, only had a 71% AUC predictive performance, which was insufficient. The VGG CNN model’s flaw is that it hasn’t been preprocessed for background subtraction or image reconstruction fragmentation, which increases the predictive accuracy. In Kasinathan and Jayakumar (32), the new cloud-based tumor recognition model was developed. The author analyzed various standard dataset “CT-scans and PET-scans” for segmenting the ROC and for recognizing the tumor. In Jakimovski and Davcev (33), the framework proposes a novel deep learning method based on binary particle swarm optimization with a decision tree (BPSO-DT) and CNN to identify the malignant or normal cells in the lung region using the genetic features (34).
Figure 2 shows the complete architecture for the proposed framework. The working mechanism of the proposed deep learning-based diagnosis and classification system is subdivided into three important phases. Image preprocessing and augmentation process, capsule based saliency segmentation, accurate feature extraction using the pretrained transfer learning, and finally trained by the whale optimized extreme learning networks.
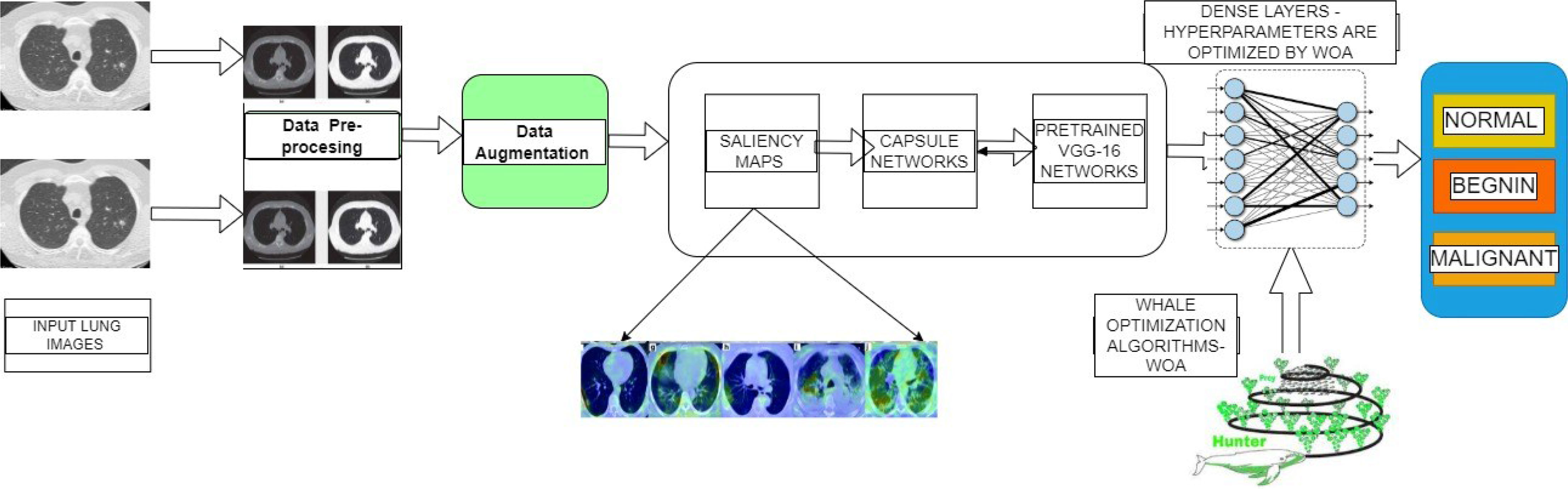
Figure 2 Overall Working Flow Diagram for the Proposed Architectures.
As the first step, CT scans are differentiated by using the Histogram Equalization (HOE) process. This pre-processing step is applied for adjusting the image intensities and contrast. The mathematical expression of HOE applied for image preprocessing is given by
Where T*N – Number of Pixels in N levels where N=0, 1, 2, 3………………255
P - Total Number of Pixels.
After preprocessing, an adaptive median filter (AMF) is applied over the images for effective denoising. AMF is a category of bilateral images which renders “clean, crisp, and artifact-free edges,” and improves the overall appearance.
In the second stage, the image augmentation process is used in the suggested architecture. Deep Neural Network (DNN) (35, 36) leads to overfitting problems where a limited quantity of labeled data is available. The most proficient and efficient method to tackle this problem is data augmentation. During the data augmentation phase, each image undergoes a series of transformations, producing a huge amount of newly corrected training image samples. As discussed in Pei and Hsiao (37), an affine transformation is employed for efficient data augmentation. The offline transformation techniques, such as conversion, ascending, and spins are used. Inputs are correlated with the augmentation step which is extracted before the training phase and the correlated values are utilized to avoid the over-fitting issue. Figure 3 shows the different lung images obtained after applying the offline transformations.
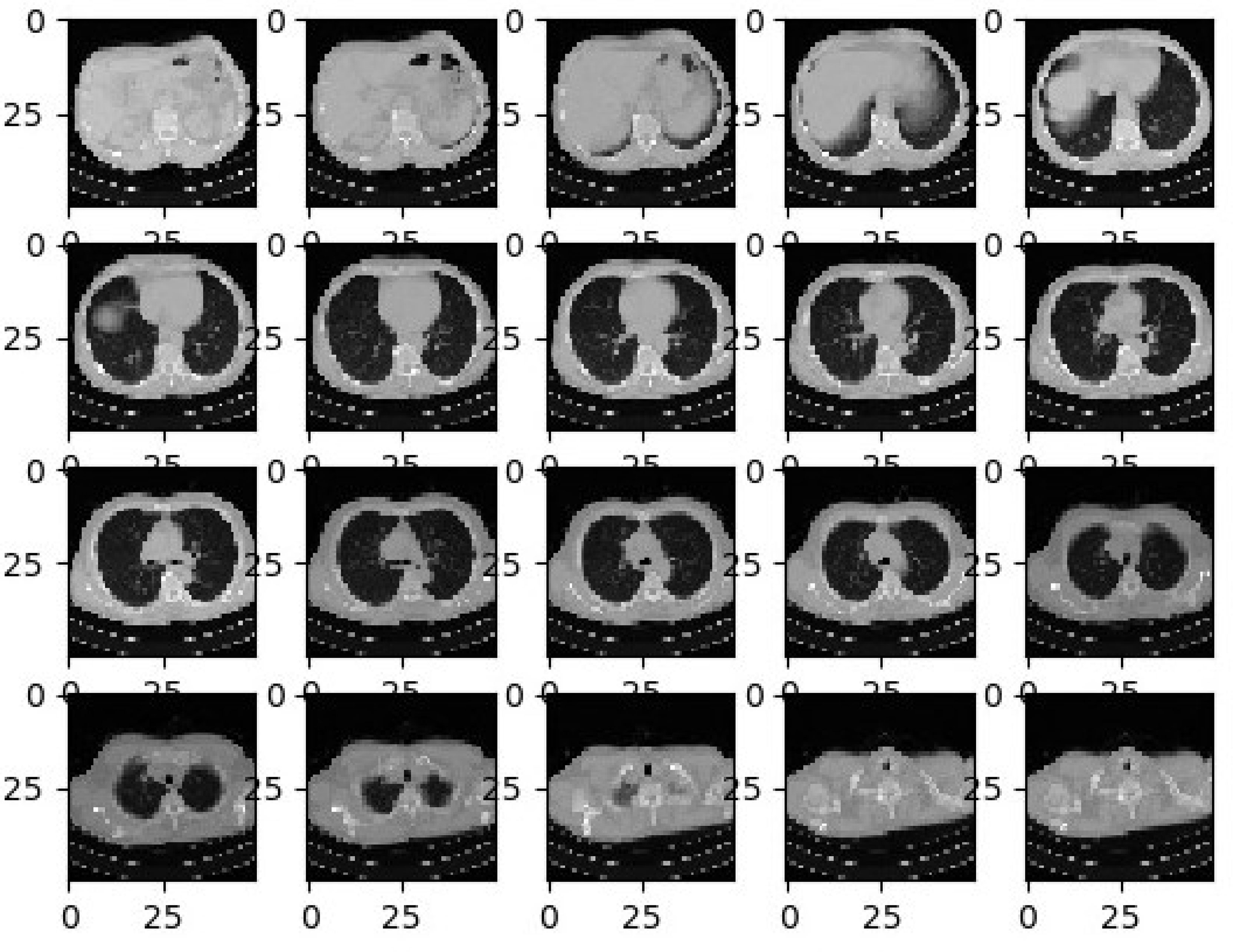
Figure 3 Sample CT-Lung Images after Augmentation Process.
Segmentation is a technique of partitioning the images with different magnitudes of patterns and pixels. For segregating the images, various techniques have been established. Capsule saliency maps are a structured technique that has been presented here. It subdivides the images into compacted and diverse parts. There will be a reduction in the number of unnecessary elements in the images.
To build the saliency models (38), color difference and spatial difference is applied in a pixel-based processing in which each pixel is represented as a block. To achieve this, pixels ‘X’ of images and then disintegrated into non-overlapping blocks with size nxn where n=8 and 16, respectively. Hence the saliency maps S(k) are calculated by using the mathematical expressions given by
Since the location, dimensions, and shape of cancer cells are the same in their adjacent slices, the finishing saliency maps are calculated as the biased sum of the authentic (S(m), preceding (S(m1) and next blocks(S(m2)) color and spatial saliency as mentioned in Banerjee et al. (38)
After calculating the saliency maps, post-processing techniques need to be adopted for refinement of segmentation images. Active contour methods [28] are used for the recognition of cancer cells in the most consecutive twin blocks. Also, accurate separation of cancer cells from the other parts of CT scan images is badly needed to give a precise output. Moreover, active contours are based on image intensity, which probably fails in differentiating the cancer cells. Additionally, these contour methods require higher computation time, which is considered to be a serious problem in handling larger datasets.
Motivated by this drawback, this paper introduces capsule networks with pretrained optimized models to obtain high performance and accurate detection of CT lung cancer images. Its main disadvantage seems to be that, in order to get such high standard findings, these techniques necessitate substantial fine-tuning and optimization that is clearly not feasible with massive datasets and has an impact on the recognition rates. But in this proposed system, training effort take reduced time and increase the efficiency and performance of the system.
Capsule network (39) is the new and upcoming network that is replacing the prevailing models. The capsule network contains four layers: 1) convolutional layer, 2) hidden layer, 3) PrimaryCaps layer, and 4) DigitCaps layer. Figure 4 shows the entire working structure for the given training model. The capsule networks provide more advantages in categorizing the distinct saliency maps in the images. The input preprocessed visual image is given as the input to the proposed capsule networks. Capsules are groupings of cells that encrypt the location data as well as the likelihood of an object being present in an image. In capsules networking, there is a shell for every object in an image that gives:
1. Probability of existence in entities
2. Entities’ instantiation parameters
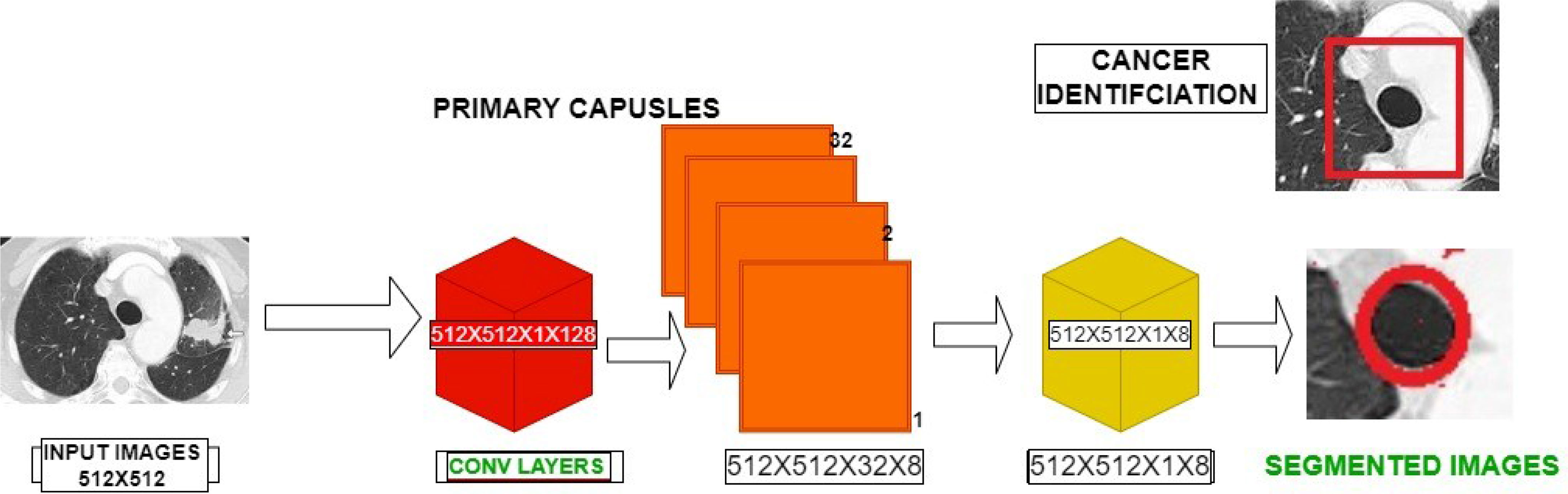
Figure 4 Capsule Architecture for the Saliency Based Segmentation.
The combination of the matrices of the input variables with the weight matrix is computed to represent the essential spatial correlation between poor and large-scale features within the image.
Equation (5) estimates the total weight which is calculated to determine the updating of the current capsule values and the same id feedforward into the next level of capsule determination.
At last, the squash task is used to apply non-linearity. The squashing utility translates a vector to an extreme length of one and the least length of zero while keeping its orientation.
Figure 4 shows the capsule architecture employed for the saliency segmentation. The preprocessed images are encoded using the equation (2) which involves the convolutional layers and capsule layers. The convolutional operations are first performed over the preprocessed images from conv layers to the capsules of the first capsule layers often followed by the higher capsule layers. The data transformations between the one capsule to other capsule layers are formulated by mathematical equations (3) and (4). Finally, the last layer produces the saliency segmented information which are used toward the categorization.
In this process, the transfer learning technique is adopted for better feature extraction and classification. Transfer learning approaches are considered as the pretrained convolutional neural networks that can be repurposed to solve different image classification problems. In this research, the Inception V3 module has been implemented due to its high accuracy and high flexibility. The custom Inception-V3 weights are pre-trained using ImageNet and it considers the reshaped size of 150×150×3 for all images.
After the segmentation process, features extracted are then fed for training the networks. In the proposed architecture, traditional training networks are replaced with feedforward networks that are based on the principle of ELM. ELM is a category of neural network proposed by G.B. Huang (40). This kind of neural network utilizes the single hidden layers in which the hidden layers don’t require the tuning mandatorily. Compared with the other learning algorithms such as “support vector machine (SVM) and Random Forest (RF), ELM exhibits the better performance,” high speed, and less computational overhead.
The working procedure of single-layer network is illustrated with the mathematical formulation which is given below. Generally, the ML classifiers or predictors follow the feature extraction, weights formulation, and identifying the final score for the given problem. The algorithm itself generates the weights and bias factors for identifying the best final score without any backpropagation or stochastic gradient approach which minimizes the computation complexity. This is a major benefit of ELM compared to other networks (41). Due to this, ELM reduces the training error that achieves better results. Most of the categorization problem utilizes this single-layer network and many applications adopt this network for low-level data availability.
In the below statistical estimation, the extracted features are represented as “p” points with their objective function (i.e., sigmoid) where the final score is denoted as a linear graph. The concealed layer may include N-number of nodes which is not tuned mandatorily. The concealed layer’s weights are assigned at random (counting the biàs loads). Nodes are not irrelevant; however, they do not need to be calibrated, and the concealed synapse characteristics might be created arbitrarily even in advance. That is, before dealing with the data from the training set. The system yield for a single-hidden layer ELM is given by equation (7)
where, p→ input
“L” denotes the output weight vector and it is denoted as
The minimal non-linear least square method is used to denote the basic calculation of ELM that is represented by the below equation.
Where ab* → inverse of “ab”: Moore-Penrose generalized inverse.
Hence the output function can be found by using the above equation
Though extreme learning principle-based feedforward networks produce the best performance, non-optimal tuning of hyperparameters such as input weights, hidden neurons, and learning rate affects the accuracy of classification. Hence, optimization is required for tuning the hyperparameters for achieving the best performance. The next section discusses the proposed algorithm used for optimization of the extreme learning networks.
This section discusses whale optimization algorithm (WOA) and proposed optimized extreme classification layers.
WOA, first proposed in Mukherjee et al. (42), has sparked renewed interest in recent years. This stochastic search technique is computed by the following simulation of humpback whale behavior and movements in their search for food and supplies. WOA was inspired by the bubble-net attacking method, in which whales target fish by forming tailspin bubbles surrounding them down to 12 meters below the surface, subsequently swimming back up to trap and grab their prey, as shown in Figure 5. The search phase in this method is characterized by a randomized hunt for food based on the spatial location of whales, which can be statistically interpreted by automatically updating responses rather than picking the appropriate ones by selecting random solutions.

Figure 5 WOA Basic Structure.
In addition to this intriguing behavior, WOA differs from other optimization algorithms in that it only requires the adjustment of two parameters. These variables allow for a smooth transition between the exploitation and exploration phases.
Encircling prey: The search process initiated from starting point and circles the food around the nearby region in order to update their process to the best target. The working process is detailed with statistical formulations.
If (c < 0.5 and mod(k) < 1)
where c=0.1 (constant), “V(q+1)” represent the best solution and other attributes are estimated as per the below formulations.
Where k denotes the arbitrary value within the range of {0 - 2}
Prey Searching: In the food searching process, the input “V” is denoted with “Vrandom” which is estimated using the below equation.
During the search phase of the WOA approach, the target was encircled and spiral upgrade was performed. Equation (19) represents the quantitative phrase for updating a new position.
“R” denotes the distance among the initial and updated position after each iteration and “s1” denotes the constant 0-1
As discussed, the WOA model is utilized to enhance the weights of ELM networks. In this case, the whale’s criteria for searching and fixing the prey are used as the main term to optimize the weights of ELM networks. Typically, the ELM channels are fed a randomized weight matrix and biased. The performance index is defined as the highest precision. The numerical simulations (14), (15), and (16) are used to determine input bias and weights for each repetition. These parameters are then fed into the ELM system, which generates the exponential function utilizing equations (9). If the output function equals the fitness value, the repetition will either come to a halt or continue. Whale adaptation has a slower convergence time than other meta-heuristic methods, but it takes less time to refine and improve response time. The whale optimized ELM is now used as the classification of lung cancer images. Table 1 presents the optimized parameters used for training the network.
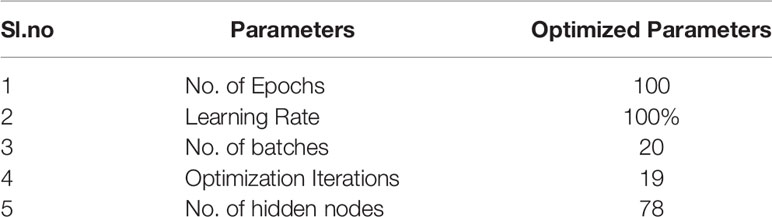
Table 1 Optimized Parameters for Whale Optimized Extreme Learning Networks.
The experiments are carried out using lung CT images which are obtained from the cancer imaging archives (https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI). The collection contains 1018 lung CT scans from the National Cancer Institute, which were connected with proteomics and genetic experimental data. All trained radiographs are sorted into normal and cancerous tumors in this article. A benign lesion with a grade of less than 3 is called a normal nodule, while a malignancy lesion with a score of more than 3 is known as a malignant lesion. To eliminate ambiguity in lesion specimens, bronchial lesions with a value of 3 in malignancy are deleted. Separate software NBIA retriever is used for the conversion of tcia format data to DICOM image data which can be used for further processing. The detailed description of the datasets used for testing is presented in the tcia website (43).
The whole experiment is carried out in the Intel I7CPU with 2GB NVIDIA GeForce K+10 GPU, 16GB RAM, 3.0 GHZ with 2TB HDD. The proposed architecture is implemented using Tensorflow 1.8 with Keras API. All the programs are implemented in the anaconda environment with python 3.8 programming.
The proposed architecture implements the six CNN layers for the better classification of cancer cells in lung images. Table 2 depicts the partitioned datasets used for preparation and analysis the network.

Table 2 Total Number of Datasets (After Augmentation).
Various metrics such as accuracy, sensitivity, specificity, recall, and f1-score are calculated. The following are the mathematical expressions for calculating the metrics used for evaluating the proposed architecture.
This section highlights the validation results obtained through proposed tumor predictor along with other depth networks. The validation testing data have been segregated into four distinct folds (i) confusion matrix and (ii) ROC for the first iteration. In the next fold, the projected design is compared with the other prevailing transfer learning models such as convolutional neural network (CNN), Resnets-100, Resnets-150, InceptionV3, Google-Net, Mobile-Net, and Densenet-169 by computing the diverse performance metrics as mentioned in Table 4. The proposed algorithm is tested with the random 900Lung CT (50% benign, 50% normal, and 50% malignant) scan images in order to overcome the imbalance problems.
The ROC curve (Figure 6) and the confusion matrix (Figure 7) of the proposed framework in detecting the categories of CT scan lung Images. Tables 3–5 highlight the performance obtained through presented framework that is associated with other prevailing algorithms. From Table 3, it is found that the suggested algorithm has shown the accuracy of 98.95% with 98.85% sensitivity, 98.76% precision, and high f1score of 98.85% in detecting the normal, benign, and malignant CT images. A similar performance is found in Table 4 in detecting images of malignancy. Tables 3–5 show that fusion of saliency with capsule and optimized transfer learning optimized has shown the better detection ratio using the presented network than the traditional methods. Figures 8–10 represent the performance analysis in predicting the normal, benign, and malignant cancer in lung CT images.
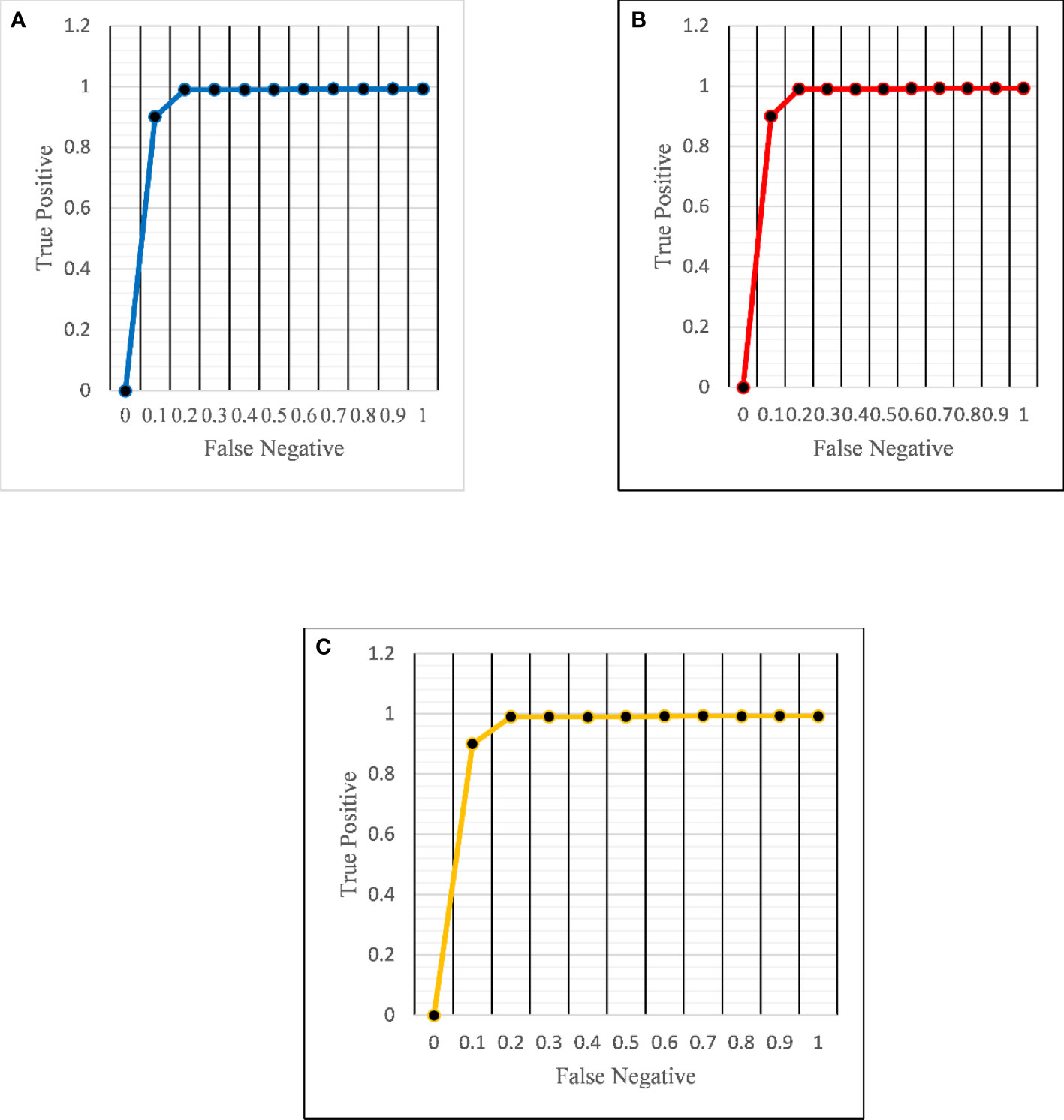
Figure 6 ROC curves for the proposed architecture in detecting (A) normal (B) benign and (C) malignant images.
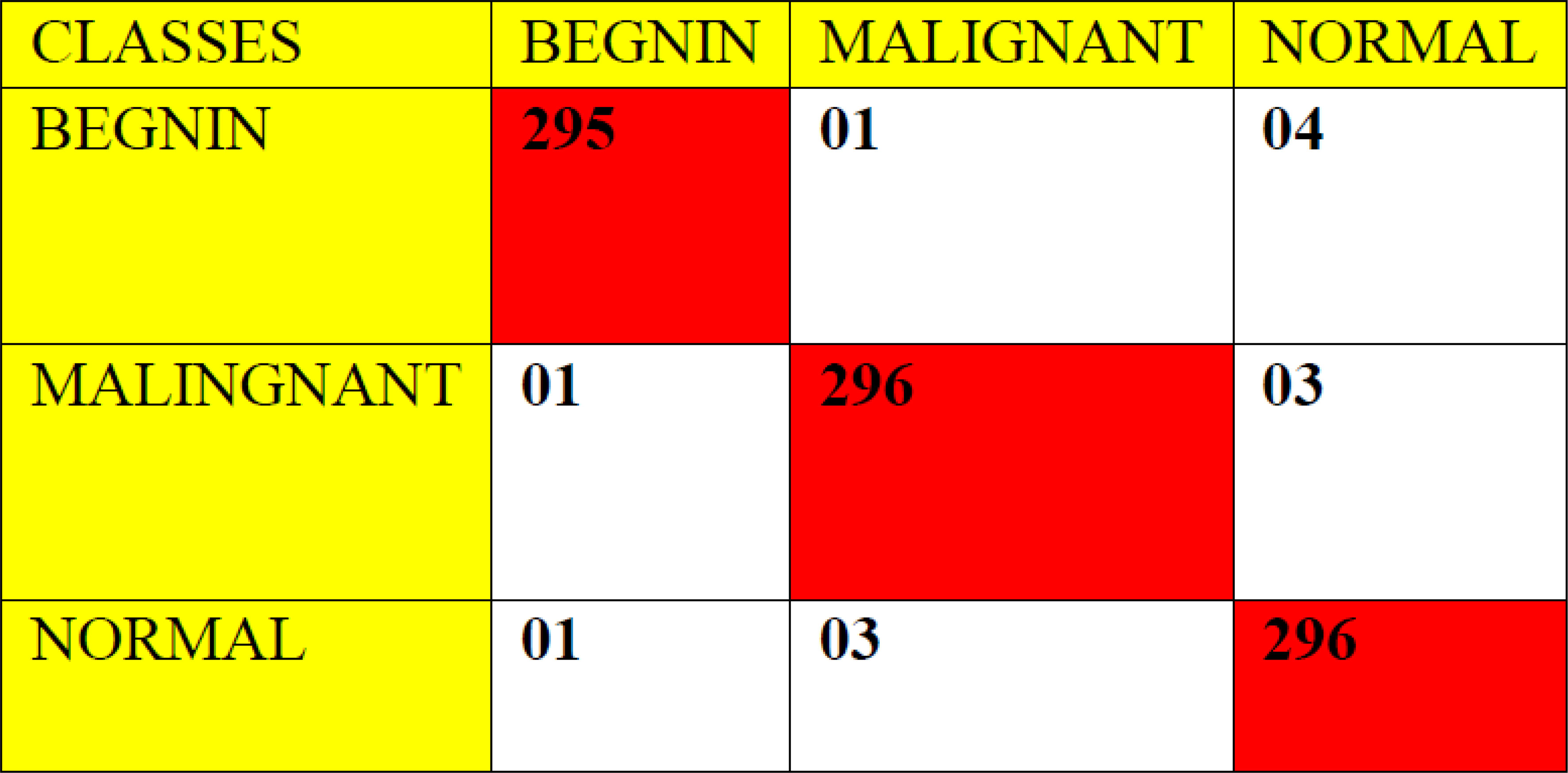
Figure 7 Confusion matrix for the proposed architecture using 900 random tested images.
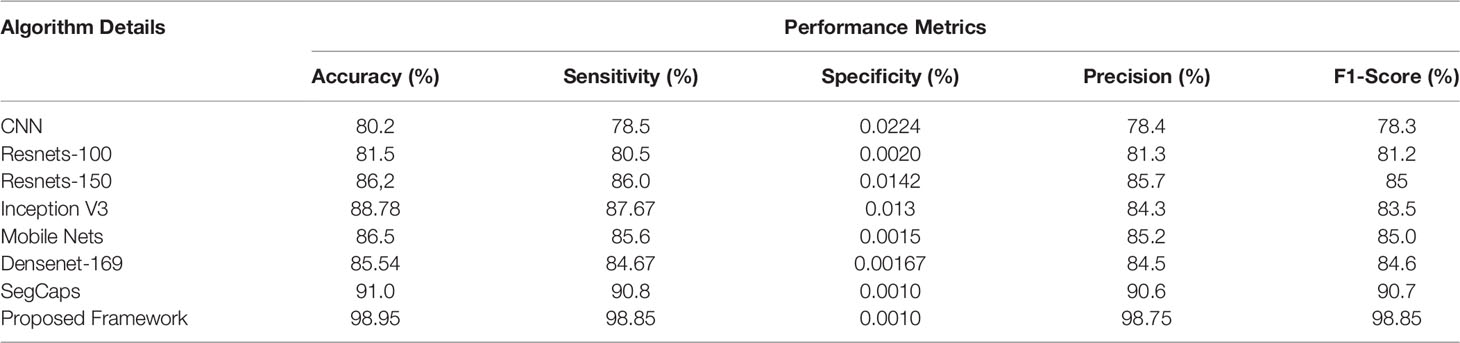
Table 3 Different deep learning architectures’ performance such as accuracy, sensitivity, specificity, precision, and recall in predicting normal tissue in lung CT images.
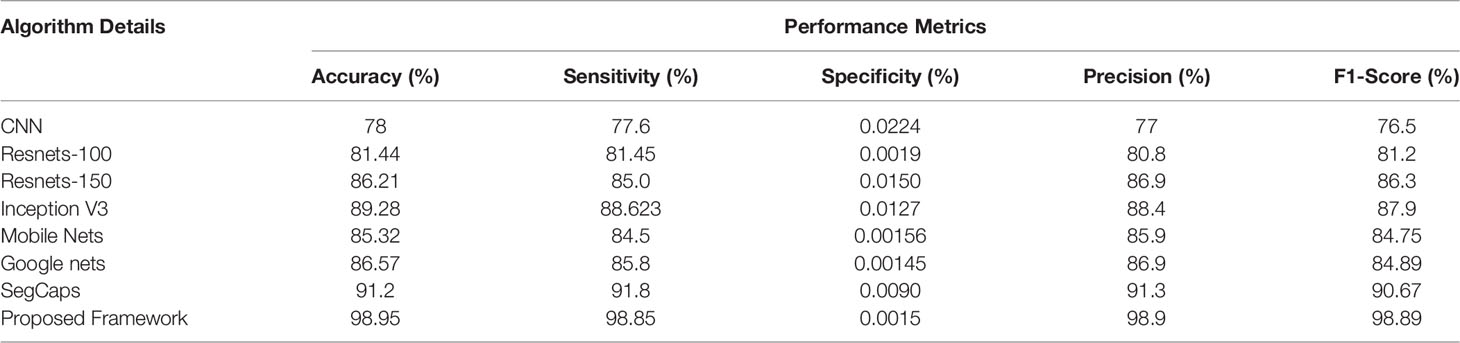
Table 4 Different deep learning architectures’ performance such as accuracy, sensitivity, specificity, precision, and recall in predicting benign tissue in lung CT images.
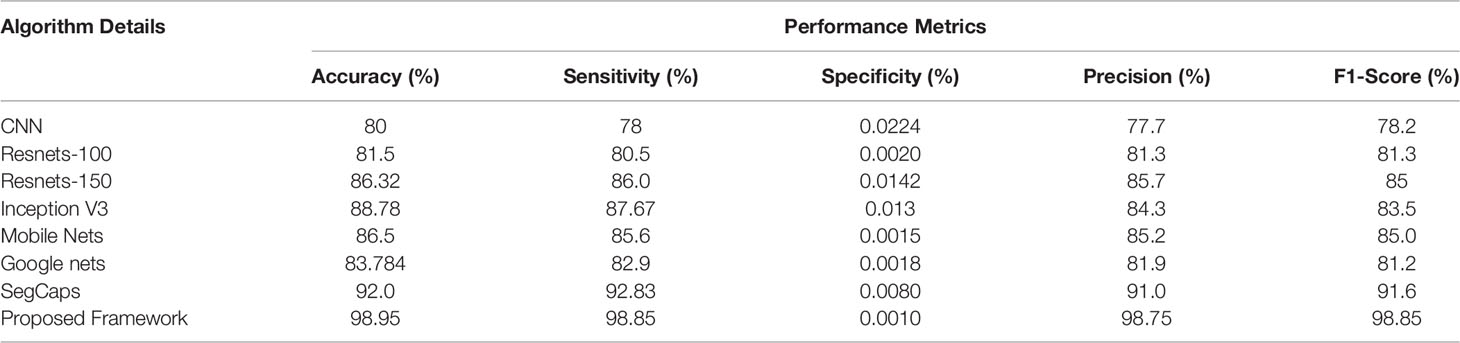
Table 5 Different deep learning architectures’ performance such as accuracy, sensitivity, specificity, precision, and recall in predicting malignant cancer in lung CT images.
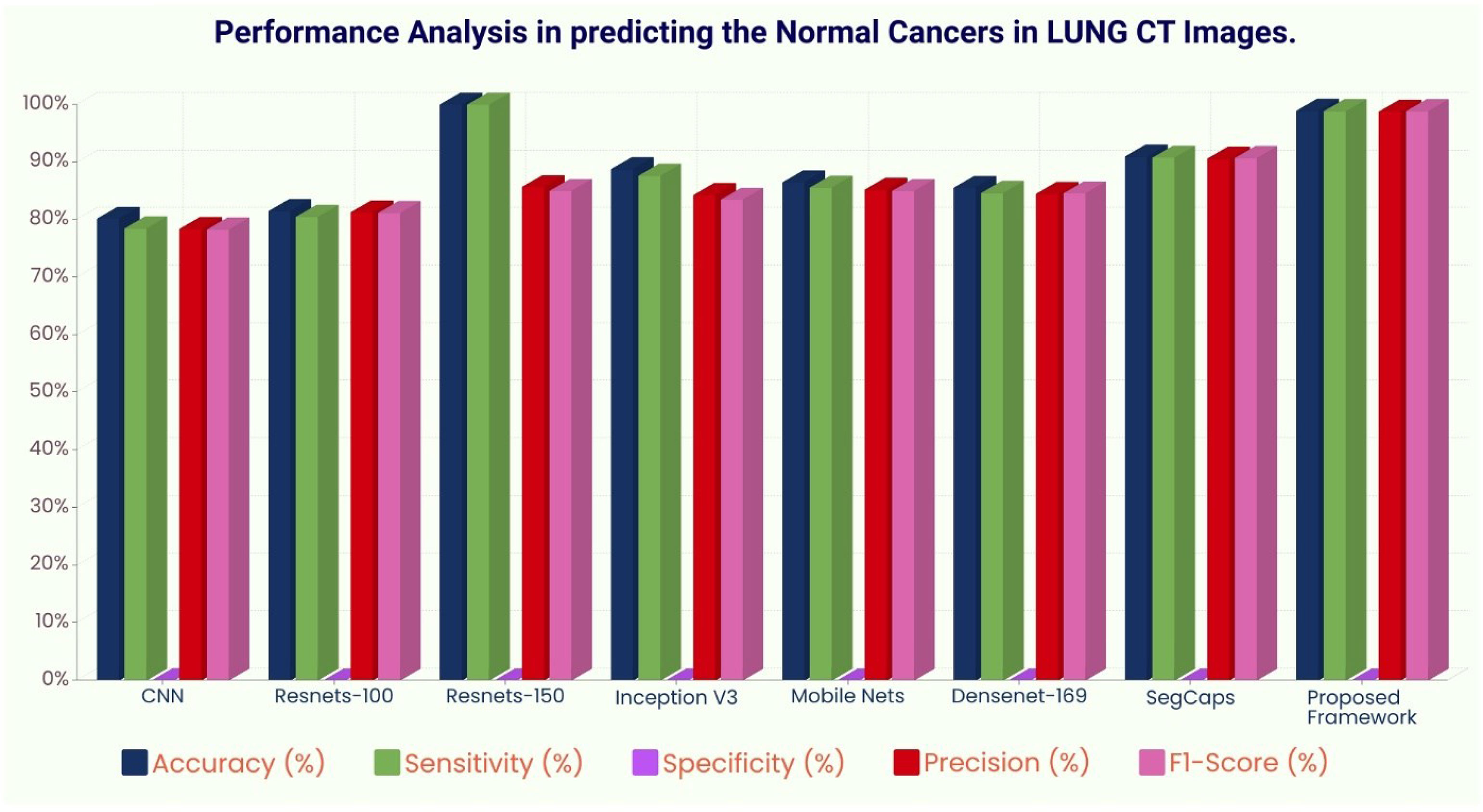
Figure 8 Performance analysis in predicting normal tissue in lung CT images.
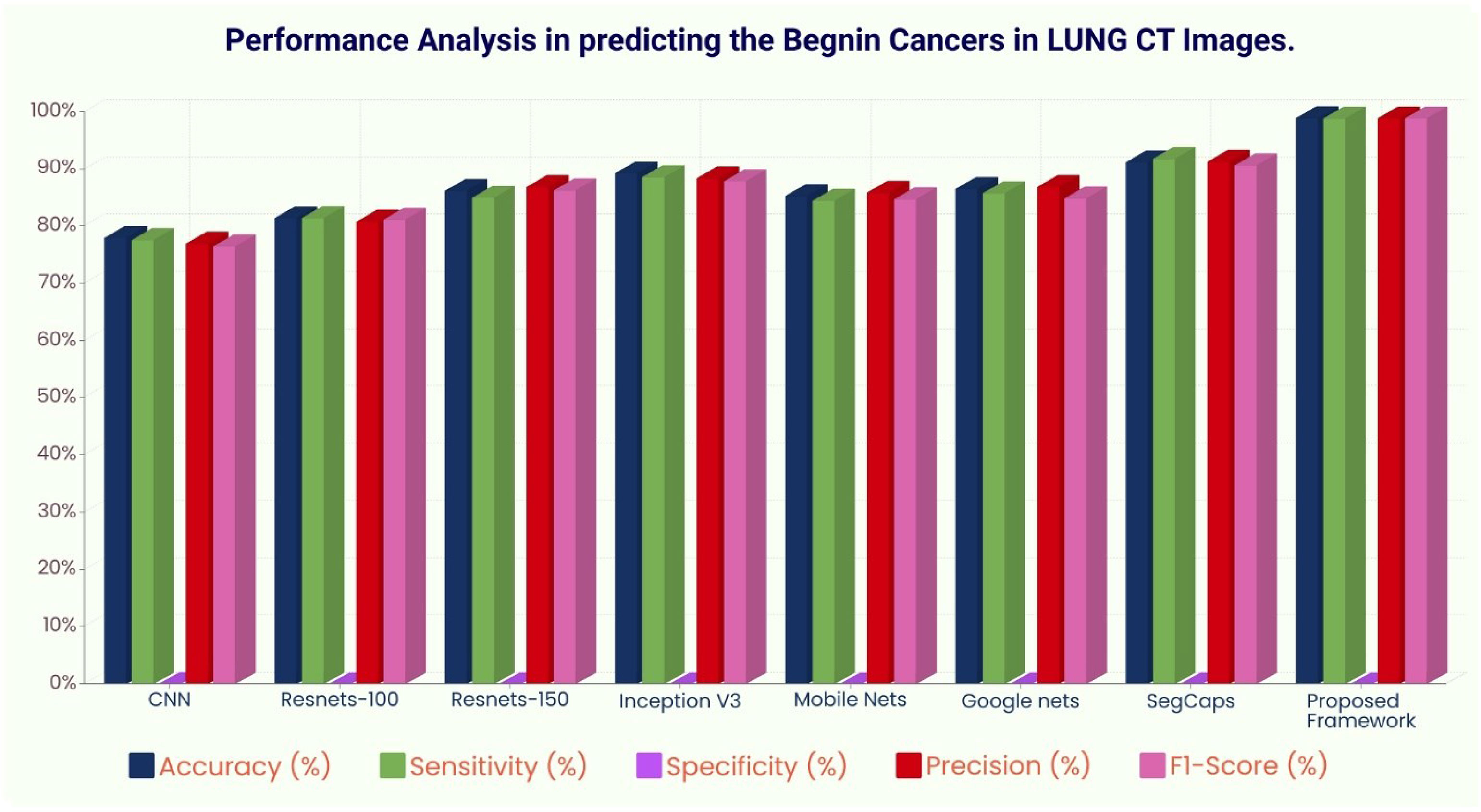
Figure 9 Performance analysis in predicting benign tissue in lung CT images.
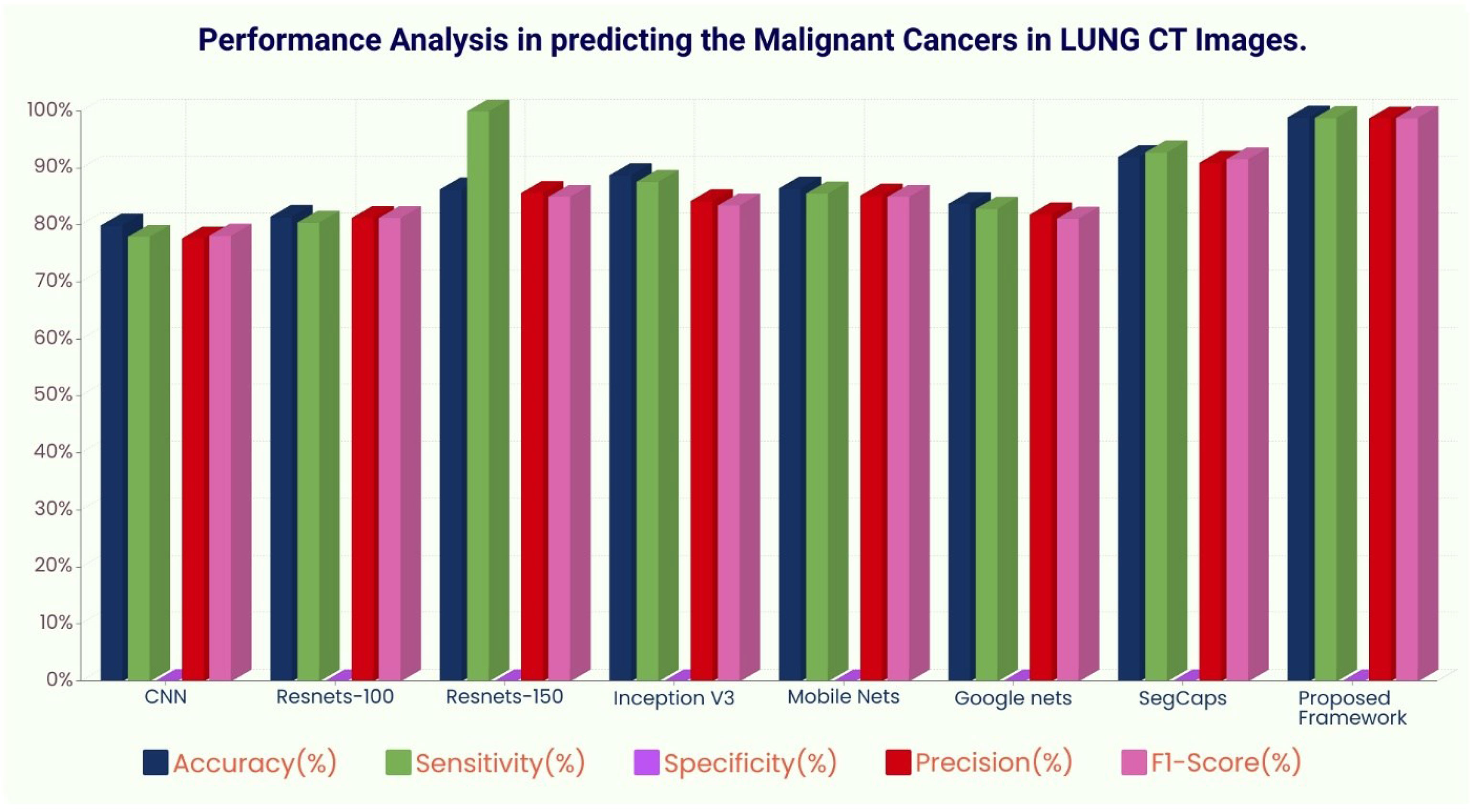
Figure 10 Performance analysis in predicting malignant cancer in lung CT images.
This research goal is to detect and classify malignant and benign cancer cells using CT scan lung images. To detect the location of cancer cells, this work uses the capsule-based saliency segmentation and transfer learning-based feature extraction. Furthermore, the proposed architecture employs the whale-based classification layers to achieve better accuracy. Tensorflow 1.8 tool with Keras API has been used to evaluate the presented tumor detection approach, and various performance metrics such as accuracy, precision, recall, specificity, and f1-score are calculated and analyzed. The experimental results show that the proposed architecture has achieved the best results associated with other standard architectures and obtained the best peak results. In the future, more vigorous testing is required using larger real-time clinical datasets. Additionally, the proposed algorithm needs improvisation in terms of computational complexity which will play a significant role in the analysis and identification of tumor cells as per radiologists’ perspective more accurately in future.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
All authors listed have made a substantial, direct, and intellectual contribution to the work, and approved it for publication.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2022.886739/full#supplementary-material
1. Bharati S, Podder P, Mondal R, Mahmood A, Raihan-Al-Masud M. Comparative Performance Analysis of Different Classification Algorithm for the Purpose of Prediction of Lung Cancer. In: International Conference on Intelligent Systems Design and Applications. Vellore, India: Springer (2018). p. 447–57.
2. Coudray N, Ocampo PS, Sakellaropoulos T, Narula N, Snuderl M, Fenyö D, et al. Classification and Mutation Prediction From non–Small Cell Lung Cancer Histopathology Images Using Deep Learning. Nat Med (2018) 24:1559–67. doi: 10.1038/s41591-018-0177-5
3. Nie L, Wang M, Zhang L, Yan S, Zhang B, Chua TS. Disease Inference From Health-Related Questions via Sparse Deep Learning. In: IEEE Transactions on Knowledge and Data Engineering (2015). p. 2107–19.
4. Nie L, Zhang L, Yang Y, Wang M, Hong R, Chua TS. Beyond Doctors: Future Health Prediction From Multimedia and Multimodal Observations. In: Proceedings of the 23rd ACM International Conference on Multimedia. Brisbane, Australia: ACM (2015). p. 591–600.
5. Sun W, Zheng B, Qian W. Computer Aided Lung Cancer Diagnosis With Deep Learning Algorithms. Med Imaging 2016: Computer-aided Diag (SPIE) (2016) 9785:241–8. doi: 10.1117/12.2216307
6. Zhou ZH, Jiang Y, Yang YB, Chen SF. Lung Cancer Cell Identification Based on Artificial Neural Network Ensembles. Artif Intell Med (2002) 24(1):25–36. doi: 10.1016/S0933-3657(01)00094-X
7. Dhaware BU, Pise AC. Lung Cancer Detection Using Bayasein Classifier and Fcm Segmentation. In: International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT). Pune, India: IEEE (2016). p. 170–4.
8. da Silva GLF, Carvalho FA, AC S, Paiva A, Gattass M. Taxonomic Indexes for Differentiating Malignancy of Lung Nodules on Ct Images. Res Biomed Eng (2016) 32(3):263–72. doi: 10.1590/2446-4740.04615
9. Revathi A, Kaladevi R, Ramana K, Jhaveri RH, Rudra Kumar M, Sankara Prasanna Kumar M. Early Detection of Cognitive Decline Using Machine Learning Algorithm and Cognitive Ability Test. Secur Communicat Networks (2022) 2021:1–13. doi: 10.1155/2022/4190023
10. Reddy GT, Khare N. An Efficient System for Heart Disease Prediction Using Hybrid Ofbat With Rule-Based Fuzzy Logic Model. J Circuit Syst Comput (2017) 26(4):1750061. doi: 10.1142/S021812661750061X
11. Obulesu O, Kallam S, Dhiman G, Patan R, Kadiyala R, Raparthi Y, et al. Adaptive Diagnosis of Lung Cancer by Deep Learning Classification Using Wilcoxon Gain and Generator. J Healthcare Eng (2021) 2021:1–13. doi: 10.1155/2021/5912051
12. Deepa N, Prabadevi B, Maddikunta PK, Gadekallu TR, Baker T, Khan MA, et al. An Ai-Based Intelligent System for Healthcare Analysis Using Ridge-Adaline Stochastic Gradient Descent Classifier. J Supercomputing (2021) 27:1998–2017. doi: 10.1007/s11227-020-03347-2
13. Shitharth S, Mohammad GB, Ramana K, Bhaskar V. Prediction of Covid-19 Wide Spread in India Using Time Series Forecasting Techniques. (2021). doi: 10.21203/rs.3.rs-354432/v1
14. Mubashar A, Asghar K, Javed AR, Rizwan M, Srivastava G, Gadekallu TR, et al. Storage and Proximity Management for Centralized Personal Health Records Using an Ipfs-Based Optimization Algorithm. J Circuit Syst Comput (2022) 31(1):2250010. doi: 10.1142/S0218126622500104
15. Park SC, Tan J, Wang X, Lederman D, Leader JK, Kim SH, et al. Computer-Aided Detection of Early Interstitial Lung Diseases Using Low-Dose Ct Images. Phys Med Biol (2011) 56(4):1139. doi: 10.1088/0031-9155/56/4/016
16. Song Q, Zhao L, Luo X, Dou X. Using Deep Learning for Classification of Lung Nodules on Computed Tomography Images. J Healthcare Eng (2017) 2017:1–7. doi: 10.1155/2017/8314740
17. Ignatious S, Joseph R. Computer Aided Lung Cancer Detection System. In: Global Conference on Communication Technologies (GCCT). Thuckalay, India: IEEE (2015). p. 555–8.
18. De Bruijne M. Machine Learning Approaches in Medical Image Analysis: From Detection to Diagnosis. Med Image Anal (2016) 33:94–7. doi: 10.1016/j.media.2016.06.032
19. Jindal A, Aujla GS, Kumar N, Chaudhary R, Obaidat MS, You I. Sedative: Sdn-Enabled Deep Learning Architecture for Network Traffic Control in Vehicular Cyber-Physical Systems. In: IEEE network (2018). p. 66–73.
20. Nalepa J, Kawulok M. Selecting Training Sets for Support Vector Machines: A Review. Artif Intell Rev (2019) 52:857–900. doi: 10.1007/s10462-017-9611-1
21. Ganesan N, Venkatesh K, Rama M, Palani AM. Application of Neural Networks in Diagnosing Cancer Disease Using Demographic Data. Int J Comput Appl (2010) 1(26):76–85. doi: 10.5120/476-783
22. Kasinathan G, Jayakumar S, Gandomi AH, Ramachandran M, Fong SJ, Patan R. Automated 3-D Lung Tumor Detection and Classification by an Active Contour Model and Cnn Classifier. Expert Syst Appl (2019) 134:112–9. doi: 10.1016/j.eswa.2019.05.041
23. Shen D, Wu G, Suk HI. Deep Learning in Medical Image Analysis. Annu Rev Biomed Eng (2017) 19:221–48. doi: 10.1146/annurev-bioeng-071516-044442
24. Suzuki K. Overview of Deep Learning in Medical Imaging. Radiol Phys Technol (2017) 10(3):257–73. doi: 10.1007/s12194-017-0406-5
25. Bharati S, Podder P, Mondal MRH. Hybrid Deep Learning for Detecting Lung Diseases From X-Ray Images. Inf Med Unlocked (2020) 20:100391. doi: 10.1016/j.imu.2020.100391
26. Tajbakhsh N, Suzuki K. Comparing Two Classes of End-to-End Machine-Learning Models in Lung Nodule Detection and Classification: Mtanns vs. Cnns. Pattern Recognit (2017) 63:476–86. doi: 10.1016/j.patcog.2016.09.029
27. Gu Y, Lu X, Yang L, Zhang B, Yu D, Zhao Y, et al. Automatic Lung Nodule Detection Using a 3d Deep Convolutional Neural Network Combined With a Multi-Scale Prediction Strategy in Chest Cts. Comput Biol Med (2018) 103:220–31. doi: 10.1016/j.compbiomed.2018.10.011
28. Sahu P, Yu D, Dasari M, Hou F, Qin H. A Lightweight Multi-Section Cnn for Lung Nodule Classification and Malignancy Estimation. IEEE J Biomed Health Inf (2018) 23(3):960–8. doi: 10.1109/JBHI.2018.2879834
29. Bansal G, Chamola V, Narang P, Kumar S, Raman S. Deep3dscan: Deep Residual Network and Morphological Descriptor Based Framework for Lung Cancer Classification and 3d Segmentation. IET Imag Process (2020) 14(7):1240–7. doi: 10.1049/iet-ipr.2019.1164
30. Jothi G, Inbarani HH. Soft Set Based Feature Selection Approach for Lung Cancer Images. ArXiv Preprint ArXiv (2012) 1212.5391.
31. Anthimopoulos M, Christodoulidis S, Ebner L, Christe A, Mougiakakou S. Lung Pattern Classification for Interstitial Lung Diseases Using a Deep Convolutional Neural Network. IEEE Trans Med Imaging (2016) 35(5):1207–16. doi: 10.1109/TMI.2016.2535865
32. Kasinathan G, Jayakumar S. Cloud-Based Lung Tumor Detection and Stage Classification Using Deep Learning Techniques. BioMed Res Int (2022) 2022:1–17. doi: 10.1155/2022/4185835
33. Jakimovski G, Davcev D. Using Double Convolution Neural Network for Lung Cancer Stage Detection. Appl Sci (2019) 9(3):427. doi: 10.3390/app9030427
34. Yu H, Zhou Z, Wang Q. Deep Learning Assisted Predict of Lung Cancer on Computed Tomography Images Using the Adaptive Hierarchical Heuristic Mathematical Model. In: . IEEE Access (2020). p. 86400–10.
35. Chauhan D, Jaiswal V. An Efficient Data Mining Classification Approach for Detecting Lung Cancer Disease. In: International Conference on Communication and Electronics Systems (ICCES). Coimbatore, India: IEEE (2016). p. 1–8.
36. Shakeel PM, Burhanuddin M, Desa MI. Automatic Lung Cancer Detection From Ct Image Using Improved Deep Neural Network and Ensemble Classifier. Neural Comput Appl (2020) 34:1–14. doi: 10.1007/s00521-020-04842-6
37. Pei SC, Hsiao YZ. Spatial Affine Transformations of Images by Using Fractional Shift Fourier Transform. IEEE Int Symposium Circuit Syst (ISCAS) (IEEE) (2015) 1586–9. doi: 10.1109/ISCAS.2015.7168951
38. Banerjee S, Mitra S, Shankar BU, Hayashi Y. A Novel Gbm Saliency Detection Model Using Multi-Channel Mri. PLoS One (2016) 11(1):e0146388. doi: 10.1371/journal.pone.0146388
39. Takács P, Manno-Kovacs A. Mri Brain Tumor Segmentation Combining Saliency and Convolutional Network Features. In: International Conference on Content-Based Multimedia Indexing (CBMI). La Rochelle, France: IEEE (2018). p. 1–6.
40. Huang GB, Zhu QY, Siew CK. Extreme Learning Machine: Theory and Applications. Neurocomputing (2006) 70(1–3):489–501. doi: 10.1016/j.neucom.2005.12.126
41. Wang B, Huang S, Qiu J, Liu Y, Wang G. Parallel Online Sequential Extreme Learning Machine Based on Mapreduce. Neurocomputing (2015) 149:224–32. doi: 10.1016/j.neucom.2014.03.076
42. Mukherjee A, Chakraborty N, Das BK. Whale Optimization Algorithm: An Implementation to Design Low-Pass Fir Filter. In: Innovations in Power and Advanced Computing Technologies (I-PACT). Vellore, India: IEEE (2017). p. 1–5.
43. Dataset. Lidc-Idri - the Cancer Imaging Archive (Tcia) Public Access - Cancer Imaging Archive Wiki (2021). Available at: https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI (Accessed on 02/12/2021).
Keywords: computer tomography (CT) scan images, saliency segmentation, pre-trained models, whale optimization, DenseNet, VGG-16, inception models
Citation: Ramana K, Kumar MR, Sreenivasulu K, Gadekallu TR, Bhatia S, Agarwal P and Idrees SM (2022) Early Prediction of Lung Cancers Using Deep Saliency Capsule and Pre-Trained Deep Learning Frameworks. Front. Oncol. 12:886739. doi: 10.3389/fonc.2022.886739
Received: 28 February 2022; Accepted: 13 May 2022;
Published: 17 June 2022.
Edited by:
Shahid Mumtaz, Instituto de Telecomunicações, PortugalReviewed by:
Delphin Raj, Kookmin University, South KoreaCopyright © 2022 Ramana, Kumar, Sreenivasulu, Gadekallu, Bhatia, Agarwal and Idrees. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sheikh Mohammad Idrees, c2hlaWtoLm0uaWRyZWVzQG50bnUubm8=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.