
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Oncol. , 07 July 2022
Sec. Cancer Imaging and Image-directed Interventions
Volume 12 - 2022 | https://doi.org/10.3389/fonc.2022.878061
 Yafang Zhang1†
Yafang Zhang1† Qingyue Wei2†Yini Huang1Zhao Yao2Cuiju Yan1Xuebin Zou1Jing Han1Qing Li1Rushuang Mao1Ying Liao1Lan Cao1Min Lin1Xiaoshuang Zhou1
Qingyue Wei2†Yini Huang1Zhao Yao2Cuiju Yan1Xuebin Zou1Jing Han1Qing Li1Rushuang Mao1Ying Liao1Lan Cao1Min Lin1Xiaoshuang Zhou1 Xiaofeng Tang1Yixin Hu1Lingling Li1Yuanyuan Wang2
Xiaofeng Tang1Yixin Hu1Lingling Li1Yuanyuan Wang2 Jinhua Yu2*
Jinhua Yu2* Jianhua Zhou1*
Jianhua Zhou1*Background and Aims: Microvascular invasion (MVI) is a well-known risk factor for poor prognosis in hepatocellular carcinoma (HCC). This study aimed to develop a deep convolutional neural network (DCNN) model based on contrast-enhanced ultrasound (CEUS) to predict MVI, and thus to predict prognosis in patients with HCC.
Methods: A total of 436 patients with surgically resected HCC who underwent preoperative CEUS were retrospectively enrolled. Patients were divided into training (n = 301), validation (n = 102), and test (n = 33) sets. A clinical model (Clinical model), a CEUS video-based DCNN model (CEUS-DCNN model), and a fusion model based on CEUS video and clinical variables (CECL-DCNN model) were built to predict MVI. Survival analysis was used to evaluate the clinical performance of the predicted MVI.
Results: Compared with the Clinical model, the CEUS-DCNN model exhibited similar sensitivity, but higher specificity (71.4% vs. 38.1%, p = 0.03) in the test group. The CECL-DCNN model showed significantly higher specificity (81.0% vs. 38.1%, p = 0.005) and accuracy (78.8% vs. 51.5%, p = 0.009) than the Clinical model, with an AUC of 0.865. The Clinical predicted MVI could not significantly distinguish OS or RFS (both p > 0.05), while the CEUS-DCNN predicted MVI could only predict the earlier recurrence (hazard ratio [HR] with 95% confidence interval [CI 2.92 [1.1–7.75], p = 0.024). However, the CECL-DCNN predicted MVI was a significant prognostic factor for both OS (HR with 95% CI: 6.03 [1.7–21.39], p = 0.009) and RFS (HR with 95% CI: 3.3 [1.23–8.91], p = 0.011) in the test group.
Conclusions: The proposed CECL-DCNN model based on preoperative CEUS video can serve as a noninvasive tool to predict MVI status in HCC, thereby predicting poor prognosis.
Hepatocellular carcinoma (HCC) is the sixth most common malignancy worldwide and the second leading cause of cancer-related death in China (1). For small tumors less than 5 cm, surgical resection is considered the first-line treatment. However, approximately 50% of patients suffer early recurrence within 2 years after curative hepatectomy (2).
Microvascular invasion (MVI) is a well-known risk factor for early recurrence and poor survival (3). Several studies reported that accurate preoperative prediction of MVI status may help determine surgical resection margins to improve prognosis (4, 5). Patients with MVI-positive HCC can benefit from adjuvant trans-arterial chemoembolization (TACE) (6, 7). Therefore, preoperative prediction of MVI is of great importance for effective treatment and subsequent improvement of prognosis.
However, preoperative prediction of MVI is still challenging because it can only be obtained through histopathologic examinations of the surgical resected specimens. Several studies developed clinical models based on some clinical risk factors including tumor number, size, and alpha-fetoprotein (AFP) to predict MVI status (AUC not exceeding 0.81) (8–10). Recent studies found that predictive models performed better when incorporating some radiomic features on computed tomography (CT) or magnetic resonance (MR) (11–13). However, CT or MR is performed according to a predetermined timing regime and gets a static image, which might miss typical diagnostic enhancing patterns in early or late arterial phase due to the mistiming of the arterial phase image acquisition (14).
Compared with enhanced CT and MR, contrast-enhanced ultrasound (CEUS), which allows real-time monitoring of blood perfusion of liver lesions, provides higher specificity for diagnosing HCC (15, 16). Additionally, CEUS is a favorable technique that can visualize small vascular beds during the arterial phase (17), which can be recorded as a continuous video. Hence, CEUS video may contain information regarding tumor biological behavior. However, CEUS is a video that dynamically changes with contrast injection and has a high spatial and temporal complexity. Therefore, the quantitative assessment of CEUS is difficult.
Recently, deep learning has demonstrated superior performance in dynamic video recognition and classification (18), and they provide a promising solution to quantitative assessment of CEUS video. In this study, we proposed a deep learning model based on CEUS video to predict MVI and evaluated the prognostic value of the predicted MVI.
The institutional ethics review board approved this single-center retrospective study and waived the requirement for written informed consent. An institutional database was searched for all patients with pathologically proven HCC who underwent preoperative CEUS during two periods, January 2012 to December 2015 and August 2016 to December 2016, and found 614 patients. The final cohort was made up of 436 patients who met the following inclusion criteria (Figure 1): (a) nodules visible on the grayscale; (b) no previous liver cancer treatment; (c) MVI status is available in pathologic reports or sections; (d) CEUS quality appropriate to analyze; and (e) CEUS arterial phase video available. The cohort was divided into a training group (n = 301) and a validation group (n = 102) from January 2012 to December 2015 according to a ratio of 3:1, and a time-independent test group (n = 33) from August 2016 to December 2016.
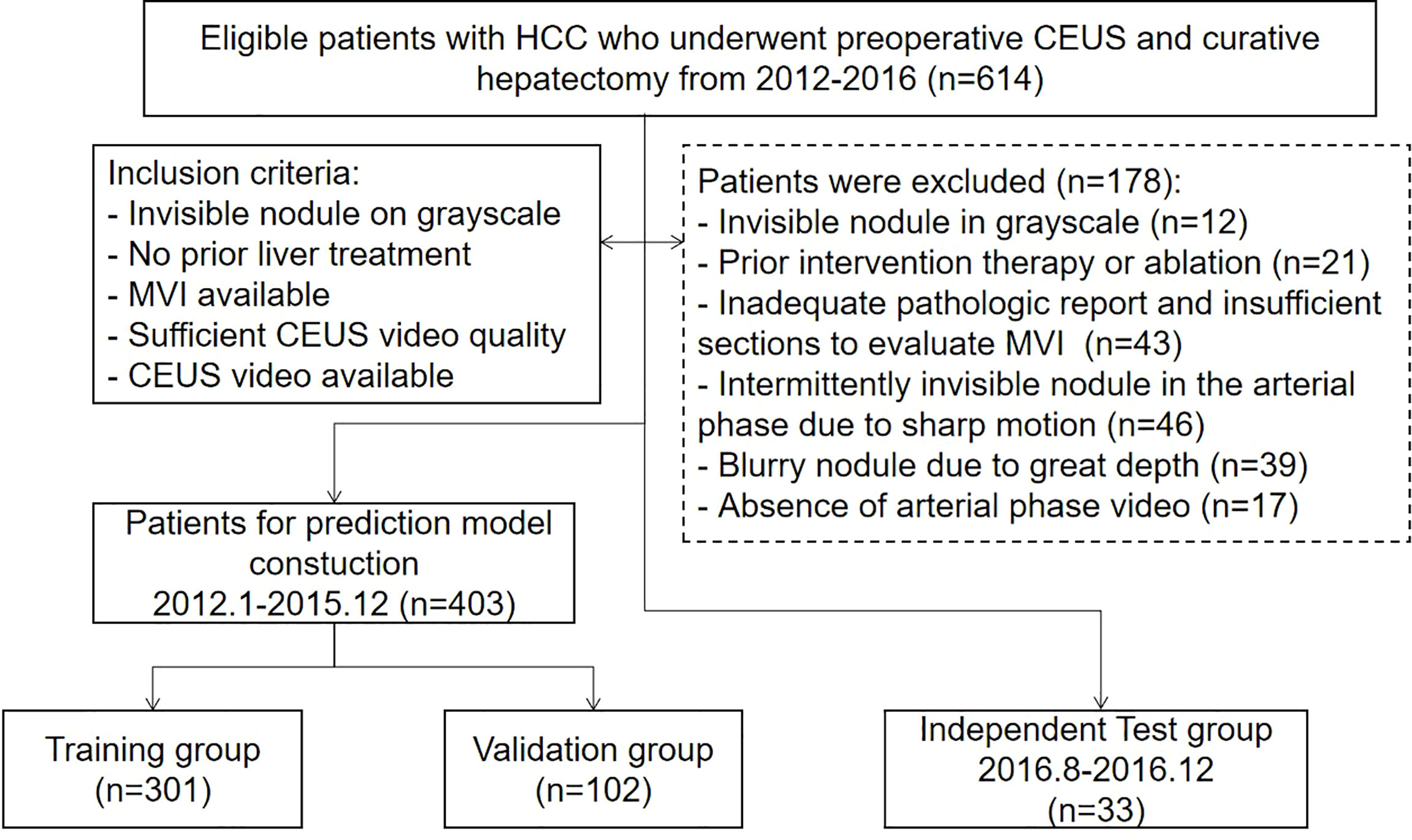
Figure 1 The flowchart of study group enrollment.
The presence of MVI was mainly determined from pathologic reports and re-checked by one senior pathologist with 10-year experience. MVI was defined as the presence of tumor emboli within the vessels adjacent to HCC. Tumor maximum diameter, AFP level, and the number of nodules were recorded. The tumor maximum diameter was categorized as ≤33 mm, 33–40 mm, 40–50 mm, 50–60 mm, and >60 mm. AFP level was divided into ≤20 ng/ml, 20–400 ng/ml, and >400 ng/ml. The number of nodules was categorized as single and multiple.
Patients were followed up regularly after surgery at intervals of 3 to 6 months, based on AFP and imaging studies. If patients were unable to visit the clinic, they were consistently kept in touch through the telephone.
CEUS examination was performed on an Acuson Sequoia 512 (Siemens Medical Solutions, Mountain View, CA) US system with a 4C1 convex array probe. After identifying the target lesion on the grayscale, the contrast pulse sequencing imaging mode (mechanical index, 0.19) was transferred. At the start of the CEUS mode, a volume of 2.0 ml of SonoVue (Bracco Imaging, Milan, Italy) was injected into the antecubital vein followed by a volume of 5.0 ml of saline flush. The target lesion was continuously scanned for at least 1 min immediately after the administration of the contrast agent to collect the continuous dynamic images of the arterial phase and partial portal phase. Then, the transducer ran over the entire liver and returned to the target lesion at an interval of 20–30 s until 5 min to capture the delay phase. Contrast clips were stored as video sequences or still images in Dicom format.
Tumor segmentation was performed with ITK-SNAP (http://www.itksnap.org/) by a radiologist with 2 years of experience in CEUS, and then revised by a senior radiologist with over 20 years of CEUS experience. The tumor boundary was drawn manually on the 1-min CEUS video, and 2- and 3-min still images. Since each CEUS video consists of 430–520 frames, the workload would be tremendous for the radiologist to annotate each frame. Thus, annotations were given discontinuously and about 50–70 frames in each video have segmentations, covering all tumor moving trajectory due to patient’s breath during the CEUS examination. According to the union of given annotations in 1-min CEUS, a bounding box was extracted and extended outward by 1/4 length of each side in every video as the region of interest (ROI), as shown in Supplementary Figure 1.
Age, sex, AFP level, tumor maximum diameter, and the number of nodules were potential clinical parameters to predict the MVI status (8–10). Univariate and multivariate logistic regression analyses were performed in the combination of the training and validation group. The parameters significant with p < 0.05 in the univariate analysis were taken in the multivariate analysis. The independent significant parameters made up the clinical parameter-based model (Clinical model) and participated in the later clinical parameter combining CEUS video deep learning model (CECL-DCNN model). The predictive performance of the Clinical model was evaluated in the test group.
A CEUS-based DCNN model (CEUS-DCNN model) was constructed to predict the MVI status. We developed a deep learning model that considered both temporal and spatial features. The whole network was divided into two parts, a Gated Recurrent Unit (GRU)-based module for extracting temporal features of contrast perfusion and a Convolution neural network (CNN)-based module for extracting spatial distribution features of contrast agents. The overall structure of the proposed model is shown in Figure 2A.
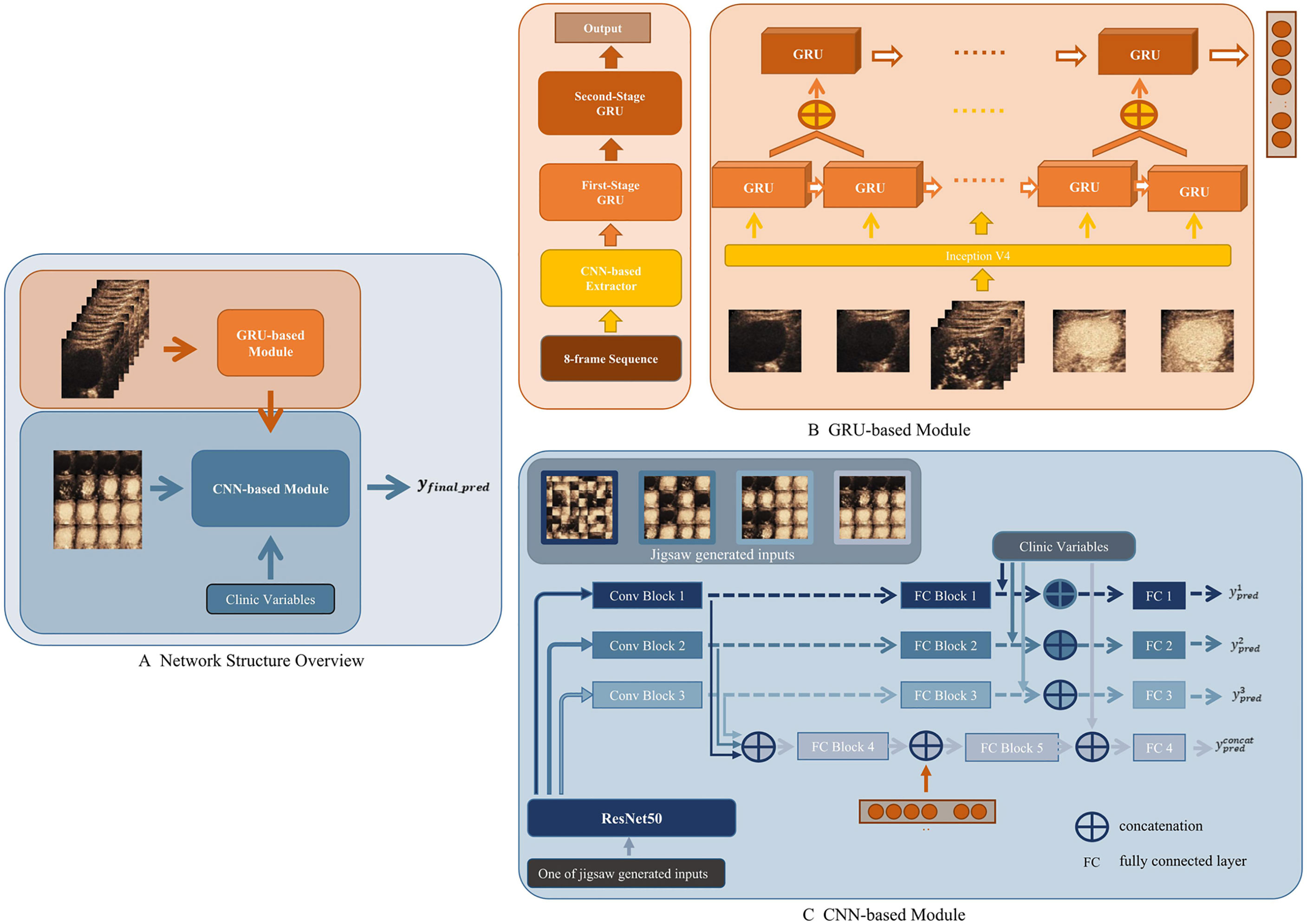
Figure 2 Workflow of deep convolution neural network (DCNN) analysis. (A) Network Structure Overview. Eight-frame sequence was the input of the Gated Recurrent Unit (GRU)-based module. Sixteen-frame spliced image, output of the GRU-based module, and the clinic variables were the inputs of the convolution neural network (CNN)-based module. (B) GRU-based module. The feature extracted by the CNN-based Extractor was fed into a two-stage cascade GRU to get a one-dimension output. (C) CNN-based module. In the training stage, a jigsaw puzzle generator was applied to randomly generate three different patch sizes of image inputs based on the 16-frame spliced image. Three generated image inputs and the original image were then fed into pipelines composed by Conv Blocks and fully connected (FC) Blocks, respectively.
The GRU-based module was seamlessly composed by Inception V4 as the backbone and two-stage cascade Bidirectional GRU (19). The input of the GRU-based module was the 8-frame sequence uniformly extracted from a 1-min CEUS video. Each ROI was shrunk or enlarged to the same size, in order to be spliced into the input. An ImageNet pre-trained Inception V4 was used to extract the most significant feature of each frame—brightness. Then, the results were delivered to the first-stage GRU. As shown in Figure 2B, the second-stage GRU took the concatenation of adjacent outputs from the first stage as the input. The two-stage GRU extracted information about the changes in contrast brightness at different time intervals. When all frames were passed through the network, the temporal features of the whole CEUS video were obtained.
The CNN-based module was developed based on ResNet50 (20). The input of the CNN-based module was the 16-frame spliced image uniformly extracted from the 1-min CEUS video. As a backbone feature extractor, ResNet50 could produce intermediate features with a different number of channels, widths, and lengths of the feature map. In the proposed module, we used three different scales of extracted feature maps from ResNet50. As shown in Figure 2C, these selected feature maps on three different scales would then be fed into a similar pipeline separately to get a prediction based on its input. Specifically, there were three pipelines in the presented module. In each pipeline, features were first fed into Conv Blocks and then delivered to fully connected (FC) Blocks. The output of an FC Block would become the prediction of each pipeline. A saliency map was used to help visually explain the feature extractions (21).
As a network with fusion of temporal and spatial features, this deep learning model reasonably fused a GRU-based module and a CNN-based module, and solved the training problem of the fusion network by a progressive training strategy, which was inspired by the Progressive Multi-Granularity (PMG) training framework (22). The specific approach was to input the temporal features extracted by the GRU-based module into the FC Block of the CNN-based module (Figure 2C).
Incorporating significant clinical parameters, we proposed the CECL-DCNN model based on the CEUS-DCNN model. Clinical parameters were concatenated with the output of the FC Blocks or the two-stage fully connected layers (Figure 2C). Another fully connected layer was added in each stage. The fused feature was fed into such a layer to obtain the prediction for each stage. Clinical parameters, the GRU-based module, and prediction of the stage using features obtained in the three pipelines made up the final prediction of the combined model. The detailed calculation method and training strategy are described in Supplementary Materials—Network Architecture.
Analysis of variance (ANOVA, for continuous variables) and the Mann–Whitney rank-sum test (for categorical variables) were used to compare the basic characteristics among the training, validation, and test groups. The area under the receiver operating characteristic curve (AUC) was used to quantify the discriminative efficacy for MVI prediction. The DeLong test was performed to compare the AUCs of different models. Comparisons of the sensitivity, specificity, and accuracy were performed using the chi-square test. Recurrence-free survival (RFS) and overall survival (OS) were defined as the interval between diagnosis and radiographic detection of recurrence, last follow-up, or death. Survival curves were generated with the Kaplan–Meier method and compared by a two-sided log-rank test according to the predicted MVI.
CEUS-DCNN and CECL-DCNN model building and evaluation were conducted using Python (version 2.7, https://www.python.org/). Statistical analyses were performed using a statistical software package (SPSS version 26, SPSS, Inc., Chicago, IL). Differences of p < 0.05 were considered statistically significant.
The clinical characteristics of the patients in the training, validation, and test groups are listed in Table 1. There was no significant difference in characteristics among the three cohorts. A total of 103 patients (34.2%) in the training cohort, 35 patients (34.3%) in the validation cohort, and 12 patients (36.4%) in the test cohort were pathologically identified with MVI.
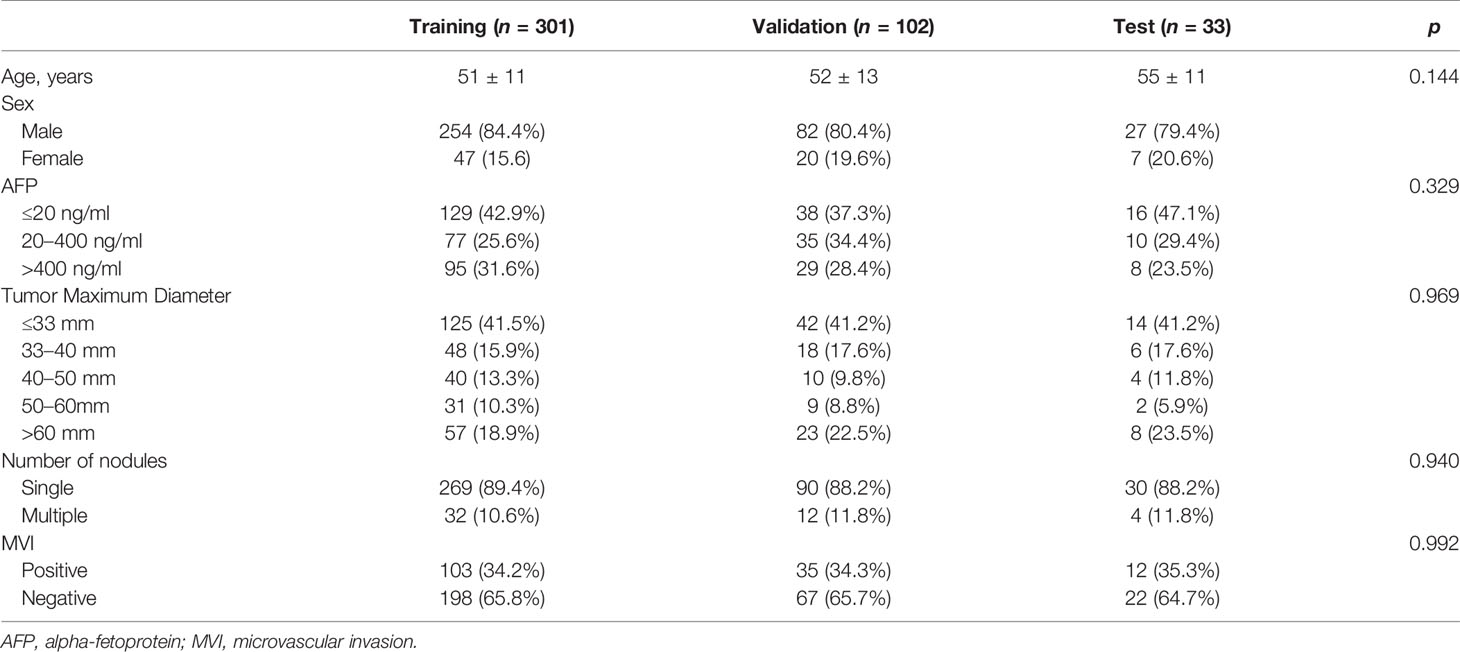
Table 1 The clinical characteristics of training, validation, and test groups.
All clinical variables were obtained preoperatively. In the combination of training and validation groups, AFP level, tumor maximum diameter, and the number of nodules were significantly associated with MVI. These three important clinical variables made up the Clinical model. The detailed results of univariate and multivariate logistic analysis are presented in Table 2. The performance of the Clinical model was evaluated in the test group.
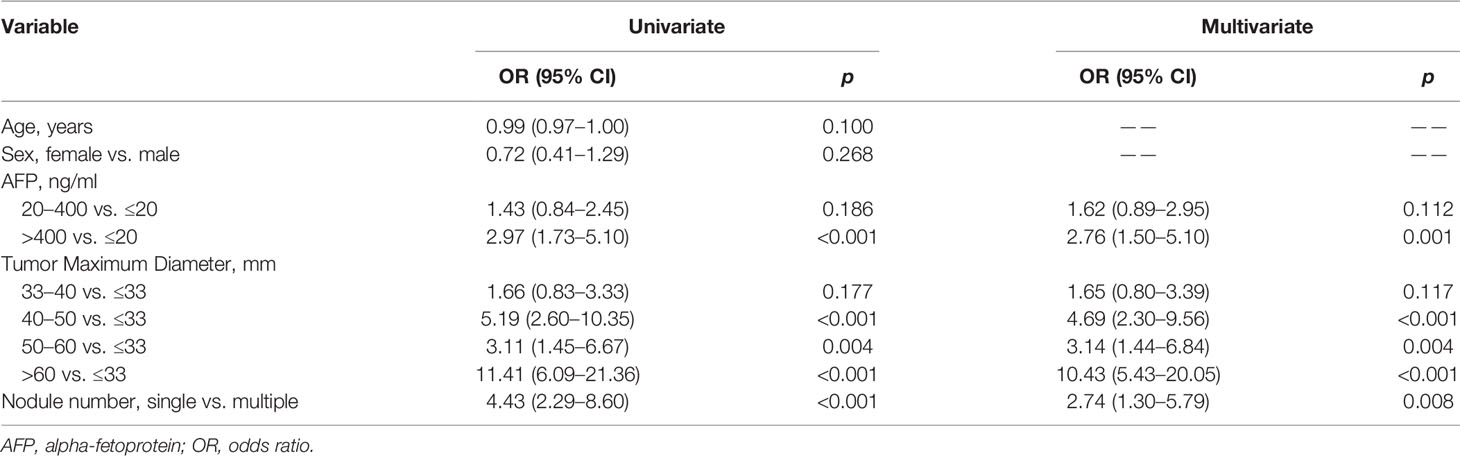
Table 2 Univariate and multivariate logistic analysis of MVI based on clinical variable.
The visual explanation of the spatial–temporal features extracted by the DCNN model is shown in Figure 3. The areas that the CNN module paid most attention to were the periphery and neighboring of the tumor, conforming to the regions where MVI probably existed (Figures 3A, B). Generally, the early arterial phase of contrast agent perfusion into the liver is the most sensitive period for visualization of the vascular bed. The first two bars in Figure 3C, representing the pre-arterial phase and the beginning of the arterial phase, were the tallest of all, which means they made the most contributions to the prediction of MVI status. The contributions of the frames declined afterwards, but got high at the sixth frame when the arterial phase alternated with the portal vein phase, which is important for diagnosis. These changes in the frames’ contributions produced by the GRU-based module were consistent with the clinical experience.
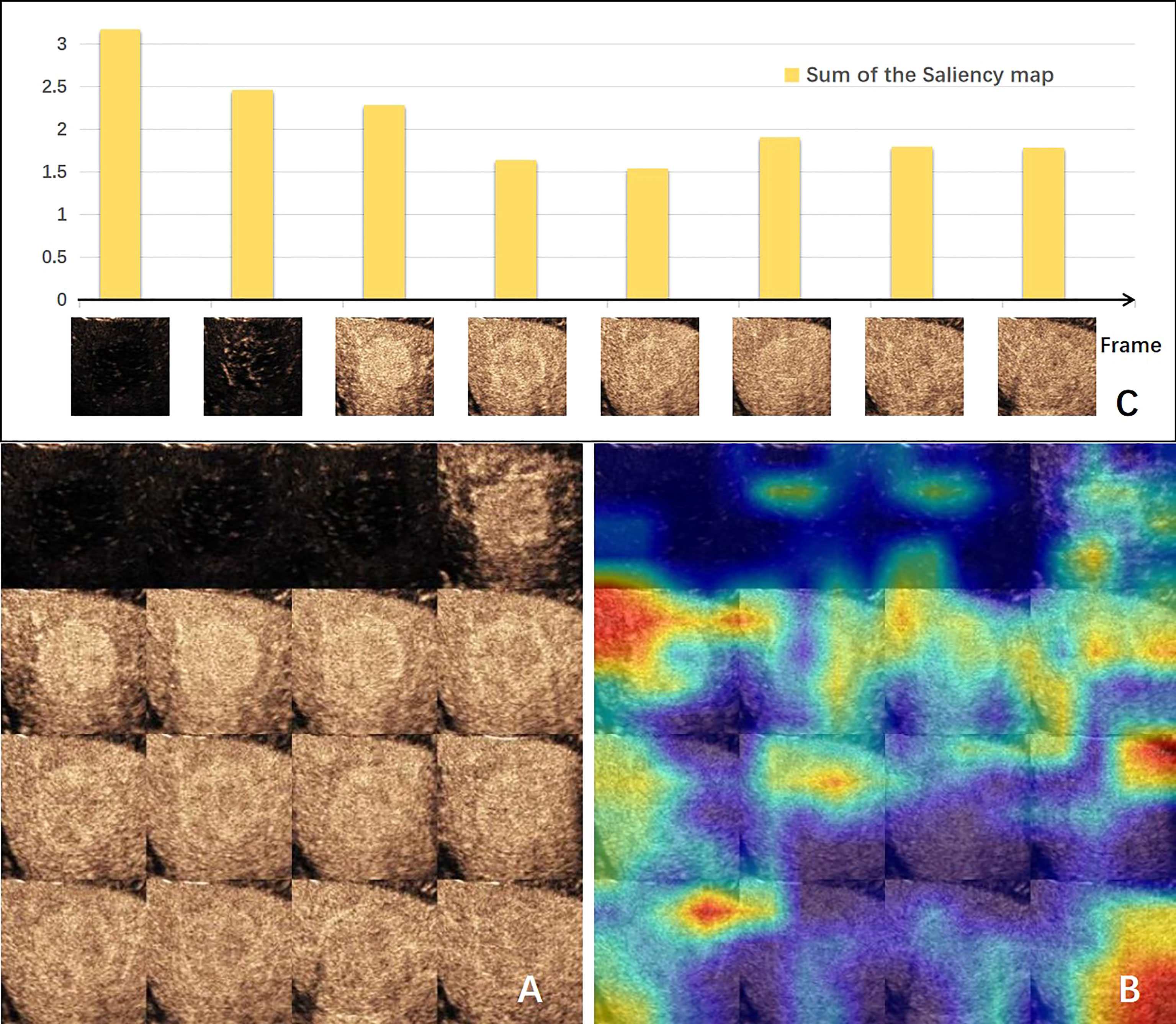
Figure 3 Visual explanation of the deep convolution neural network (DCNN) model. (A) Input of CNN-based module made by 16-frame sliced images extracted from the 1-min video. (B) Corresponding gradient-weighted class activation map. Highlighted areas were the network paid attention for MVI prediction. (C) Bar chart of the sum of the saliency maps of each input frame for the GRU-based module. The value indicates the degree of the importance for this frame predicting MVI. CNN, convolution neural network; MVI, microvascular invasion.
Table 3 summarizes the predictive performances of the three models. Compared with the Clinical model, the CEUS-DCNN model exhibited similar sensitivity, but higher specificity (76.1% vs. 63.4%, p = 0.05 in the validation group; 71.4% vs. 38.1%, p = 0.03 in the test group). The CECL-DCNN model, which incorporated CEUS video and clinical parameters, achieved not only higher specificity (86.6% vs. 63.4%, p < 0.001 in the validation group; 81.0% vs. 38.1%, p = 0.005 in the test group) but also higher accuracy than the Clinical model (81.4% vs. 68.0%, p = 0.008 in the validation group; 78.8% vs. 51.5%, p = 0.009 in the test group). Additionally, the CECL-DCNN model had a promising diagnostic performance (AUC = 0.879 in the validation group and AUC = 0.865 in the test group).

Table 3 Predictive efficacy of the clinical, CEUS-DCNN, and CECL-DCNN models.
The study was censored on September 30, 2020. The median follow-up was 63.6 months (interquartile range, 46.2–77.5) in all 436 patients. The mean RFS was 37.2 months (95% confidence interval [CI]: 30.6–43.9) for those with histologic MVI and 63.5 months (95% CI: 58.6–68.5) for those without histologic MVI (p < 0.001). The mean OS was 62.3 months (95% CI: 22.9–68.7) for those with histologic MVI and 88.9 months (95% CI: 85.5–92.4) for those without histologic MVI (p < 0.001). Histologic MVI was confirmed to be an important prognostic factor for poor prognosis.
The predicted MVI of the three models could significantly distinguish the patients with poor outcomes in the validation group (p < 0.05, seen in Supplementary Figure 2), but in the test group, the prognostic results of the three models were different (Figure 4). The prognostic effects of the Clinical model predicted MVI on survival and recurrence did not reach any statistical significance (both p > 0.05), while in the same group, the CEUS-DCNN predicted MVI was a significant prognostic factor only for RFS (hazard ratio [HR] with 95% CI: 2.92 [1.1–7.75], p = 0.024). Nevertheless, the CECL-DCNN predicted MVI could significantly distinguish the patients with shorter survival (mean OS = 37.3 vs. 59.7 months, HR with 95% CI: 6.03 [1.7–21.39], p = 0.009) and earlier recurrence (mean RFS = 23.5 vs. 45.3 months, HR with 95% CI: 3.3 [1.23–8.91], p = 0.011). The survival curves of the CECL-DCNN predicted MVI were the most similar to that of the histologic MVI (Figure 4). The patients with positive MVI had shorter survival (mean OS = 32.9 vs. 60.5 months, HR with 95% CI: 8.45 [2.24–31.86], p = 0.001) and earlier recurrence (mean RFS = 20.8 vs. 44.6 months, HR with 95% CI: 3.87 [1.32–11.31], p = 0.002).
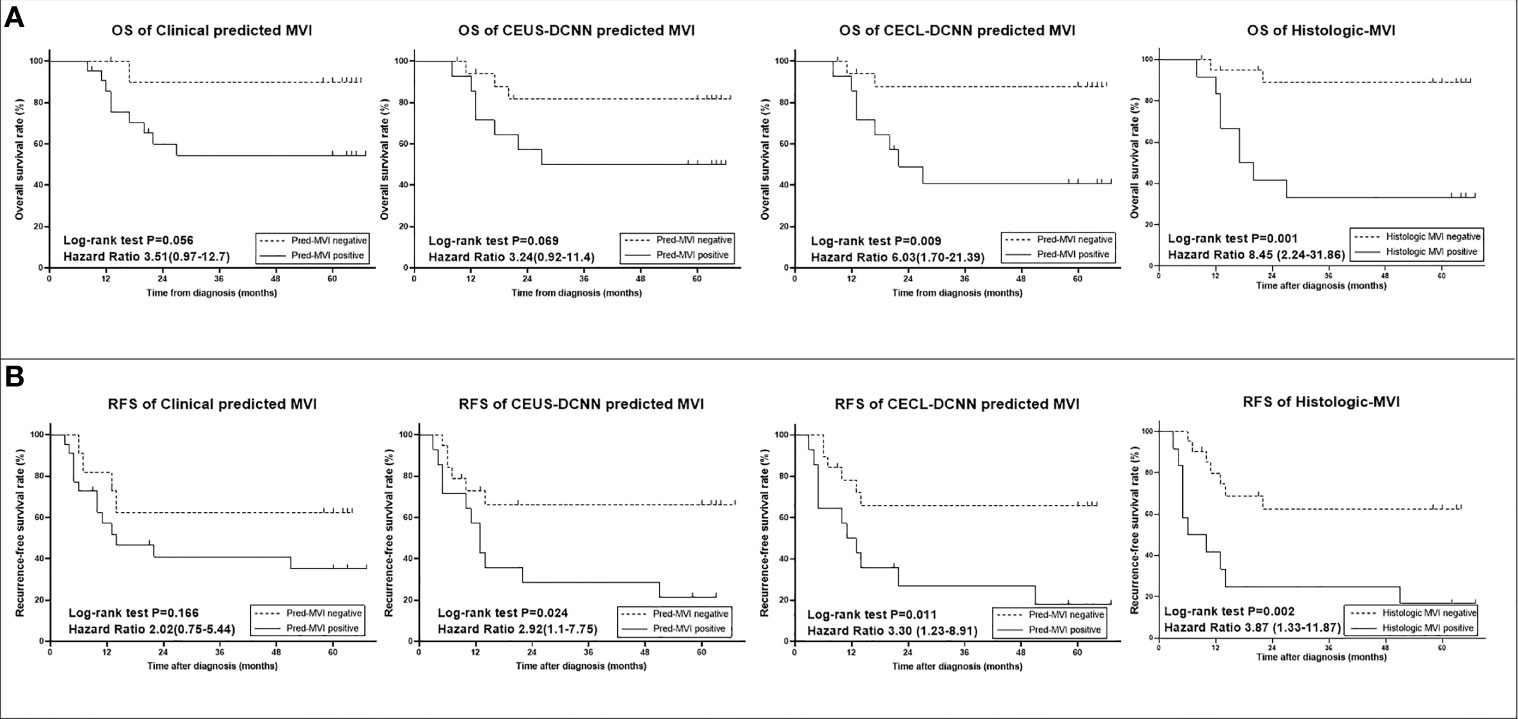
Figure 4 Survival curves of histologic microvascular invasion (MVI) and predicted MVI of the three models in the test group (n = 33). (A) Overall survival (OS) curves. (B) Recurrence-free survival (RFS) curves. Comparisons between curves were performed with the log-rank test. CEUS-DCNN: CEUS video-based deep convolution neural network model. CECL-DCNN: clinical parameter combining CEUS-based deep convolution neural network model.
In the present study, we proposed a CECL-DCNN model, which integrated clinical information and temporal–spatial information from the CEUS video, to predict histologic MVI in patients with HCC. The CECL-DCNN model showed significantly higher specificity and accuracy than the Clinical model in validation and test groups, achieving a satisfying diagnostic performance (AUC = 0.879 and 0.865 in two groups, respectively). Additionally, the CECL-DCNN predicted MVI was a prognostic factor to poor long-term outcomes, indicating its impact on clinical decisions before surgery.
Compared to CT and MR, US has the advantages of being readily accessible, radiation-free, and easy to operate and having economic benefits. Furthermore, CEUS allows real-time evaluation of the enhancement of a nodule, providing more sensitive detection of arterial phase enhancement (APHE) than CT or MR, which may fail to demonstrate APHE due to the arterial phase mistiming (23). Previously, Zhang et al. found that the CEUS radiomics nomogram could predict MVI with an AUC of 0.788 in the validation dataset, but the specificity was only 70.83% (24). Zhou et al. found that CEUS LR-M combining clinical features could predict MVI with an AUC of 0.84, but the specificity was slightly lower than the clinical model (78.6% vs. 85.7%, p = 0.06) (25). In this study, the CEUS-DCNN model, which only used CEUS information, could predict MVI with a significantly higher specificity than the Clinical model. As regards clinical information, the CECL-DCNN model could achieve better specificity (86.6% in the validation group and 81.0% in the test group) and accuracy (81.4% in the validation group and 78.8% in the test group). The specificity of our study was much higher than the results of the above two CEUS studies. Xu et al. (12) reported that radiomics of enhanced CT predicted MVI with an AUC of 0.889 and a specificity of 79.2%, and Yang et al. (26) found that enhanced MR could predict MVI with an AUC of 0.861 and a specificity of 81.4%. Our result was as good as theirs. Furthermore, many studies lacked survival analysis to validate the model’s validity. In this study, the CECL-DCNN predicted MVI demonstrated the most similarity to true histologic MVI of the three models in the comparison of survival curves, indicating the reliability of this model. Accordingly, our study provided another straightforward, noninvasive, and robust approach for predicting MVI before surgery.
Deep learning is a state-of-the-art machine learning approach. Early studies of deep learning applied to MVI prediction based on enhanced CT or MR have reported superior performances (27, 28), but they did not evaluate the model in an independent group. Liu et al. (29) found that deep learning of enhanced CT could predict MVI with an AUC of 0.777, and Wei et al. (30) reported that deep learning of enhanced MR and enhanced CT could predict MVI with an AUC of 0.812 and 0.736, respectively, in the external test group. Our study established an independent test group in addition to the training and validation groups, and the deep learning model based on CEUS and clinical variables made excellent diagnostic performances with an AUC of 0.865 in the test groups.
At present, there are no studies about deep learning of CEUS to predict MVI. This is probably because CEUS was a dynamic video with a high spatial and temporal complexity, and quantitative analysis of CEUS is difficult. Previously, Xie and Tian’s team found that a deep learning radiomics-based CEUS model could accurately predict the response to TACE for HCC patients (31) and could predict prognosis literally after surgery and radiofrequency ablation to help patients with treatment decision-making (32), which inspired us to use deep learning to analyze CEUS video. Compared to the traditional radiomics method, our DCNN model did not pre-define features in terms of feature selection and extraction. Moreover, DCNN algorithms have great advantages at learning features in a data-driven mode and thus make predictions more practical (33). In this study, we developed a DCNN model made up of the GRU-based module and the CNN-based module, focusing on temporal information and texture information, respectively. Considering the computing cost and redundant information in CEUS video, frames were uniformly sampled from videos, and short-time and long-time intervals were used separately when forming the inputs of the CNN-based and GRU-based modules. Inputs of the CNN- and GRU-based modules included frames in both the arterial phase and the portal phase, and thus, our model could thoroughly use the information in the video.
It should be noted that this study has some limitations. On the one hand, this was a single-center retrospective study. Therefore, results from our center should be supplemented with further prospective validation by larger cohorts from other centers. On the other hand, although manually segmenting the tumor is relatively precise, it is tedious and laborious. Next, we will develop an algorithm for automatic video object segmentation.
The proposed CECL-DCNN model, based on preoperative CEUS video and clinical parameters, can serve as a noninvasive tool to predict MVI status in HCC, thereby predicting poor long-term outcomes, indicating its impact on clinical decisions before the surgery.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by The ethics committee of Sun Yat-Sen University Cancer Center. The ethics committee waived the requirement of written informed consent for participation.
Conception and design: JZ and JY. Development of methodology: QW and YZ. Acquisition of data (acquired and managed patients and prognosis, and acquired CEUS): YZ, CY, YH, and XZ. Data analysis and interpretation (ROI segmentation, computational analysis, and statistical analysis): YZ and QW. Writing, review, and/or revision of the manuscript: YZ, QW, JZ, and JW. Administrative, technical, technical, or material support: YZ and QW. Study supervision and guarantors: JZ and JY. All authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2022.878061/full#supplementary-material
Supplementary Figure 1 | The region of interest (ROI) segmentation in CEUS. (A)An example of annotations manually made in each frame of one CEUS cine (Red line). (B) A mask was formed from the union of annotations based on each frames’ annotations projection in time dimension. (C) Annotation manually drawn (Red line). A bounding box according to the union of annotations (Green line). Extension of the bounding box (Blue line).
Supplementary Figure 2 | Survival curves of histologic microvascular invasion (MVI) and predicted MVI of the three models in validation group (n=102). (A) Overall survival (OS) curves. (B) Recurrence-free survival (RFS) curves. Comparisons between curves were performed with the log-rank test. CEUS-DCNN: CEUS video- based deep convolution neural network model. CECL-DCNN: clinical parameter combining CEUS-based deep convolution neural network model.
1. Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, Jemal A. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA: Cancer J Clin (2018) 68(6):394–424. doi: 10.3322/caac.21492
2. Tabrizian P, Jibara G, Shrager B, Schwartz M, Roayaie S. Recurrence of Hepatocellular Cancer After Resection: Patterns, Treatments, and Prognosis. Ann Surg (2015) 261:947–55. doi: 10.1097/SLA.0000000000000710
3. Erstad DJ, Tanabe KK. Prognostic and Therapeutic Implications of Microvascular Invasion in Hepatocellular Carcinoma. Ann Surg Oncol (2019) 26:1474–93. doi: 10.1245/s10434-019-07227-9
4. Han J, Li Z-L, Xing H, Wu H, Zhu P, Lau WY, et al. The Impact of Resection Margin and Microvascular Invasion on Long-Term Prognosis After Curative Resection of Hepatocellular Carcinoma: A Multi-Institutional Study. HPB (Oxford) (2019) 21:962–71. doi: 10.1016/j.hpb.2018.11.005
5. Shindoh J, Hasegawa K, Inoue Y, Ishizawa T, Nagata R, Aoki T, et al. Risk Factors of Post-Operative Recurrence and Adequate Surgical Approach to Improve Long-Term Outcomes of Hepatocellular Carcinoma. HPB (Oxford) (2013) 15(1):31–9. doi: 10.1111/j.1477-2574.2012.00552.x
6. Peng Z, Chen S, Xiao H, Wang Y, Li J, Mei J, et al. Microvascular Invasion as a Predictor of Response to Treatment With Sorafenib and Transarterial Chemoembolization for Recurrent Intermediate-Stage Hepatocellular Carcinoma. Radiology (2019) 292(1):237–47. doi: 10.1148/radiol.2019181818
7. Wei W, Jian P-E, Li S-H, Guo Z-X, Zhang Y-F, Ling Y-H, et al. Adjuvant Transcatheter Arterial Chemoembolization After Curative Resection for Hepatocellular Carcinoma Patients With Solitary Tumor and Microvascular Invasion: A Randomized Clinical Trial of Efficacy and Safety. Cancer Commun (Lond) (2018) 38(1):61. doi: 10.1186/s40880-018-0331-y
8. Lei Z, Li J, Wu D, Xia Y, Wang Q, Si A, et al. Nomogram for Preoperative Estimation of Microvascular Invasion Risk in Hepatitis B Virus-Related Hepatocellular Carcinoma Within the Milan Criteria. JAMA Surg (2016) 151(4):356–63. doi: 10.1001/jamasurg.2015.4257
9. Wang L, Jin Y-X, Ji Y-Z, Mu Y, Zhang S-C, Pan S-Y. Development and Validation of a Prediction Model for Microvascular Invasion in Hepatocellular Carcinoma. World J Gastroenterol (2020) 26(14):1647–59. doi: 10.3748/wjg.v26.i14.1647
10. Nitta H, Allard M-A, Sebagh M, Ciacio O, Pittau G, Vibert E, et al. Prognostic Value and Prediction of Extratumoral Microvascular Invasion for Hepatocellular Carcinoma. Ann Surg Oncol (2019) 26(8):2568–76. doi: 10.1245/s10434-019-07365-0
11. Huang J, Tian W, Zhang L, Huang Q, Lin S, Ding Y, et al. Preoperative Prediction Power of Imaging Methods for Microvascular Invasion in Hepatocellular Carcinoma: A Systemic Review and Meta-Analysis. Front Oncol (2020) 10:887. doi: 10.3389/fonc.2020.00887
12. Xu X, Zhang H-L, Liu Q-P, Sun S-W, Zhang J, Zhu F-P, et al. Radiomic Analysis of Contrast-Enhanced CT Predicts Microvascular Invasion and Outcome in Hepatocellular Carcinoma. J Hepatol (2019) 70(6):1133–44. doi: 10.1016/j.jhep.2019.02.023
13. Feng S-T, Jia Y, Liao B, Huang B, Zhou Q, Li X, et al. Preoperative Prediction of Microvascular Invasion in Hepatocellular Cancer: A Radiomics Model Using Gd-EOB-DTPA-Enhanced MRI. Eur Radiol (2019) 29(9):4648–59. doi: 10.1007/s00330-018-5935-8
14. Wilson SR, Lyshchik A, Piscaglia F, Cosgrove D, Jang HJ, Sirlin C, et al. CEUS LI-RADS: Algorithm, Implementation, and Key Differences From CT/MRI. Abdom Radiol (NY) (2018) 43(1):127–42. doi: 10.1007/s00261-017-1250-0
15. Manini MA, Sangiovanni A, Fornari F, Piscaglia F, Biolato M, Fanigliulo L, et al. Clinical and Economical Impact of 2010 AASLD Guidelines for the Diagnosis of Hepatocellular Carcinoma. J Hepatol (2014) 60(5):995–1001. doi: 10.1016/j.jhep.2014.01.006
16. Aub C, Oberti F, Lonjon J, Pageaux G, Seror O, N'Kontchou G, et al. EASL and AASLD Recommendations for the Diagnosis of HCC to the Test of Daily Practice. Liver Int (2017) 37(10):1515–25. doi: 10.1111/liv.13429
17. Schaible J, Stroszczynski C, Beyer LP, et al. Quantitative Perfusion Analysis of Hepatocellular Carcinoma Using Dynamic Contrast Enhanced Ultrasound (CEUS) to Determine Tumor Microvascularization. Clin Hemorheol Microcirc (2019) 73(1):95–104. doi: 10.3233/CH-199221
18. Pan F, Huang Q, Li X. (2019). Classification of Liver Tumors With CEUS Based on 3D-CNN, in: 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), 845–49. doi: 10.1109/ICARM.2019.8834190
19. Gulcehre C, Cho K, Pascanu R, Bengio Y. (2014). Learned-Norm Pooling for Deep Feedforward and Recurrent Neural Networks, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 2014 Berlin, Heidelberg: Springer Berlin Heidelberg, 530–46. doi: 10.1007/978-3-662-44848-9_34
20. He K, Zhang X, Ren S, Sun J. (2016). Deep Residual Learning for Image Recognition, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA. 770–8. doi: 10.1109/CVPR.2016.90
21. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D, et al. (2017). Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization, in: 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy: IEEE. 618–26. doi: 10.1109/ICCV.2017.74
22. Du R, Chang D, Bhunia AK, Xie J, Ma Z, Song Y-Z, et al. Fine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches. Comput Vision Pattern Recognit Vedaldi A, Bischof H, Brox T, Frahm J-M. Eds. (2020) 153–68. doi: 10.1007/978-3-030-58565-5_10
23. Kim TK, Noh SY, Wilson SR, Kono Y, Piscaglia F, Jang H-J, et al. Contrast-Enhanced Ultrasound (CEUS) Liver Imaging Reporting and Data System (LI-RADS) 2017 - a Review of Important Differences Compared to the CT/MRI System. Clin Mol Hepatol (2017) 23(4):280–9. doi: 10.3350/cmh.2017.0037
24. Zhang D, Wei Q, Wu GG, Zhang XY, Lu WW, Lv WZ, et al. Preoperative Prediction of Microvascular Invasion in Patients With Hepatocellular Carcinoma Based on Radiomics Nomogram Using Contrast-Enhanced Ultrasound. Front Oncol (2021) 11:709339. doi: 10.3389/fonc.2021.709339
25. Zhou H, Sun J, Jiang T, Wu J, Li Q, Zhang C, et al. A Nomogram Based on Combining Clinical Features and Contrast Enhanced Ultrasound LI-RADS Improves Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Front Oncol (2021) 11:699290. doi: 10.3389/fonc.2021.699290
26. Yang L, Gu D, Wei J, Yang C, Rao S, Wang W, et al. A Radiomics Nomogram for Preoperative Prediction of Microvascular Invasion in Hepatocellular Carcinoma. Liver Cancer (2019) 8(5):373–86. doi: 10.1159/000494099
27. Song D, Wang Y, Wang W, Wang Y, Cai J, Zhu K, et al. Using Deep Learning to Predict Microvascular Invasion in Hepatocellular Carcinoma Based on Dynamic Contrast-Enhanced MRI Combined With Clinical Parameters. J Cancer Res Clin Oncol (2021) 147(12):3757–67. doi: 10.1007/s00432-021-03617-3
28. Zhang Y, Lv X, Qiu J, Zhang B, Zhang L, Fang J, et al. Deep Learning With 3d Convolutional Neural Network for Noninvasive Prediction of Microvascular Invasion in Hepatocellular Carcinoma. J Magn Reson Imaging (2021) 54(1):134–43. doi: 10.1002/jmri.27538
29. Liu SC, Lai J, Huang JY, Cho CF, Lee PH, Lu MH, et al. Predicting Microvascular Invasion in Hepatocellular Carcinoma: A Deep Learning Model Validated Across Hospitals. Cancer Imaging (2021) 21(1):56. doi: 10.1186/s40644-021-00425-3
30. Wei J, Jiang H, Zeng M, Wang M, Niu M, Gu D, et al. Prediction of Microvascular Invasion in Hepatocellular Carcinoma via Deep Learning: A Multi-Center and Prospective Validation Study. Cancers (Basel) (2021) 13(10):2368. doi: 10.3390/cancers13102368
31. Liu D, Liu F, Xie X, Su L, Liu M, Xie X, et al. Accurate Prediction of Responses to Transarterial Chemoembolization for Patients With Hepatocellular Carcinoma by Using Artificial Intelligence in Contrast-Enhanced Ultrasound. Eur Radiol (2020) 30(4):2365–76. doi: 10.1007/s00330-019-06553-6
32. Liu F, Liu D, Wang K, Xie X, Su L, Kuang M, et al. Deep Learning Radiomics Based on Contrast-Enhanced Ultrasound Might Optimize Curative Treatments for Very-Early or Early-Stage Hepatocellular Carcinoma Patients. Liver Cancer (2020) 9(4):397–413. doi: 10.1159/000505694
Keywords: deep learning, contrast-enhanced ultrasound, microvascular invasion, hepatocellular carcinoma, prognosis
Citation: Zhang Y, Wei Q, Huang Y, Yao Z, Yan C, Zou X, Han J, Li Q, Mao R, Liao Y, Cao L, Lin M, Zhou X, Tang X, Hu Y, Li L, Wang Y, Yu J and Zhou J (2022) Deep Learning of Liver Contrast-Enhanced Ultrasound to Predict Microvascular Invasion and Prognosis in Hepatocellular Carcinoma. Front. Oncol. 12:878061. doi: 10.3389/fonc.2022.878061
Received: 23 February 2022; Accepted: 14 June 2022;
Published: 07 July 2022.
Edited by:
Wenli Cai, Massachusetts General Hospital and Harvard Medical School, United StatesReviewed by:
Lian-Ming Wu, Shanghai Jiao Tong University, ChinaCopyright © 2022 Zhang, Wei, Huang, Yao, Yan, Zou, Han, Li, Mao, Liao, Cao, Lin, Zhou, Tang, Hu, Li, Wang, Yu and Zhou. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jinhua Yu, amh5dUBmdWRhbi5lZHUuY24=; Jianhua Zhou, emhvdWpoQHN5c3VjYy5vcmcuY24=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.