 Xihe Qiu
Xihe Qiu Chenghao Wang1
Chenghao Wang1 Huijie Tong
Huijie Tong
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurosci., 10 May 2024
Sec. Sleep and Circadian Rhythms
Volume 18 - 2024 | https://doi.org/10.3389/fnins.2024.1336307
Introduction: Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a common sleep-related breathing disorder that significantly impacts the daily lives of patients. Currently, the diagnosis of OSAHS relies on various physiological signal monitoring devices, requiring a comprehensive Polysomnography (PSG). However, this invasive diagnostic method faces challenges such as data fluctuation and high costs. To address these challenges, we propose a novel data-driven Audio-Semantic Multi-Modal model for OSAHS severity classification (i.e., ASMM-OSA) based on patient snoring sound characteristics.
Methods: In light of the correlation between the acoustic attributes of a patient's snoring patterns and their episodes of breathing disorders, we utilize the patient's sleep audio recordings as an initial screening modality. We analyze the audio features of snoring sounds during the night for subjects suspected of having OSAHS. Audio features were augmented via PubMedBERT to enrich their diversity and detail and subsequently classified for OSAHS severity using XGBoost based on the number of sleep apnea events.
Results: Experimental results using the OSAHS dataset from a collaborative university hospital demonstrate that our ASMM-OSA audio-semantic multimodal model achieves a diagnostic level in automatically identifying sleep apnea events and classifying the four-class severity (normal, mild, moderate, and severe) of OSAHS.
Discussion: Our proposed model promises new perspectives for non-invasive OSAHS diagnosis, potentially reducing costs and enhancing patient quality of life.
Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a prevalent sleep-breathing disorder worldwide, significantly impacting patients' health and quality of life. However, the gold standard of OSAHS diagnosis typically involves complex and time-consuming processes, relying on resource-intensive methods of Polysomnography (PSG). This invasive method limits its applicability in large-scale screening and may potentially result in delays in patient intervention and treatment, thereby exacerbating health risks. Considering that OSAHS patients experience recurrent partial or complete upper airway blockages during sleep, leading to breathing pauses or reduced airflow, these sleep apnea events can result in a range of clinical consequences, including daytime sleepiness, fatigue, hypertension, diabetes, lipid abnormalities, cognitive impairments, cardiovascular events, and even mortality (Franklin and Lindberg, 2015). Therefore, developing a simple, precise, and cost-efficient approach to automatically diagnose the severity of OSAHS is crucial. In recent years, snoring has garnered significant attention as an early symptom of OSAHS. Snoring, which results from the vibration of upper airway structures, is observed in nearly 80% of OSAHS patients. Analyzing snoring audio collected from OSAHS patients can provide essential information about sleep apnea events.
Current OSAHS screening approaches rely on physiological signals extracted from PSG, such as electroencephalography (EEG) and electrooculography (EOG), to classify the severity of OSAHS in patients. However, obtaining these signals requires patients to connect multiple signal recorders, which complicates the extraction process, increases costs, and fails to precisely differentiate between different degrees of OSAHS patients (Emoto et al., 2007; Azarbarzin and Moussavi, 2010; Franklin and Lindberg, 2015; Qian et al., 2016, 2019). In addition to employing invasive PSG, some researchers (Chatburn and Mireles-Cabodevila, 2011; Ma et al., 2015, 2024; Albornoz et al., 2017; Likitha et al., 2017; Winursito et al., 2018) utilize the conspicuous correlation between patients' snoring audio and the severity of OSAHS. Hou et al. (2021) proposed an innovative approach for estimating the Sleep Apnea Hypopnea Index (AHI) by analyzing snore sounds using the Equivalent Rectangular Bandwidth (ERB) correlation dimension, demonstrating a potential non-invasive method for assessing the risk of sleep apnea. These studies have achieved a certain degree of success in classifying OSAHS by analyzing patients' sleep audio features. However, challenges persist in accurately categorizing patients into distinct classifications, such as normal, mild, moderate, and severe.
To address these challenges, we have introduced a multi-feature analysis-based audio-semantic multimodal model for assessing the severity of OSAHS in patients. We concentrate on analyzing sleep audio recordings from subjects suspected of having OSAHS, with the goal of both streamlining the screening process and diagnosing the severity of OSAHS. As shown in Figure 1, we automatically segment patients' audio data and extract Mel-frequency Cepstral Coefficients (MFCC) as audio features. Concurrently, we employ the PubMedBERT language model (Tinn et al., 2023) to transform these audio features into text features, capturing correlations among MFCC dimensions and thereby enhancing feature discriminability. Subsequently, we concatenate the audio features and text features to form the final sleep audio features for suspected patients. We utilize an XGBoost (Chen and Guestrin, 2016) to calculate the total number of sleep apnea events and compute the AHI score (Malhotra et al., 2021), which is used to classify the severity of OSAHS in patients. In conclusion, we concatenate the audio and text features through multimodal data fusion, leveraging both audio and text features, improving XGBoost's robustness for the automatic classification of OSAHS severity. This approach offers insights into early OSAHS diagnosis and treatment. Specifically, the main contributions of our work are as follows:
• We present ASMM-OSA, a data-driven multimodal model for analyzing sleep audio data in individuals susceptible to OSAHS. Our objective is to automatically detect sleep apnea events and assess their severity. Through the fusion of audio and text features via feature concatenation, we successfully integrate these modalities. Employing XGBoost for preliminary classification, our model effectively distinguishes various sleep apnea event types within audio segments. This approach enhances audio feature diversity, thereby improving OSAHS classification reliability. Additionally, our model enhances feature representation and achieves superior classification accuracy.
• By leveraging a pre-trained language model PubMedBERT, we incorporate patient-specific semantic information, including vital signs, pertinent medical history, and other relevant data, to aid in overnight snoring audio diagnosis. Our results demonstrate superior performance, demonstrating the effects of integrating semantic prior knowledge in enhancing classification accuracy.
• We extensively evaluate our ASMM-OSA using a clinical dataset from a collaborative university hospital. Our model outperforms baseline methods, achieving a state-of-the-art diagnosis accuracy of 77.6% in identifying sleep apnea events, offering a rapid and effective automatic tool for early diagnosis.
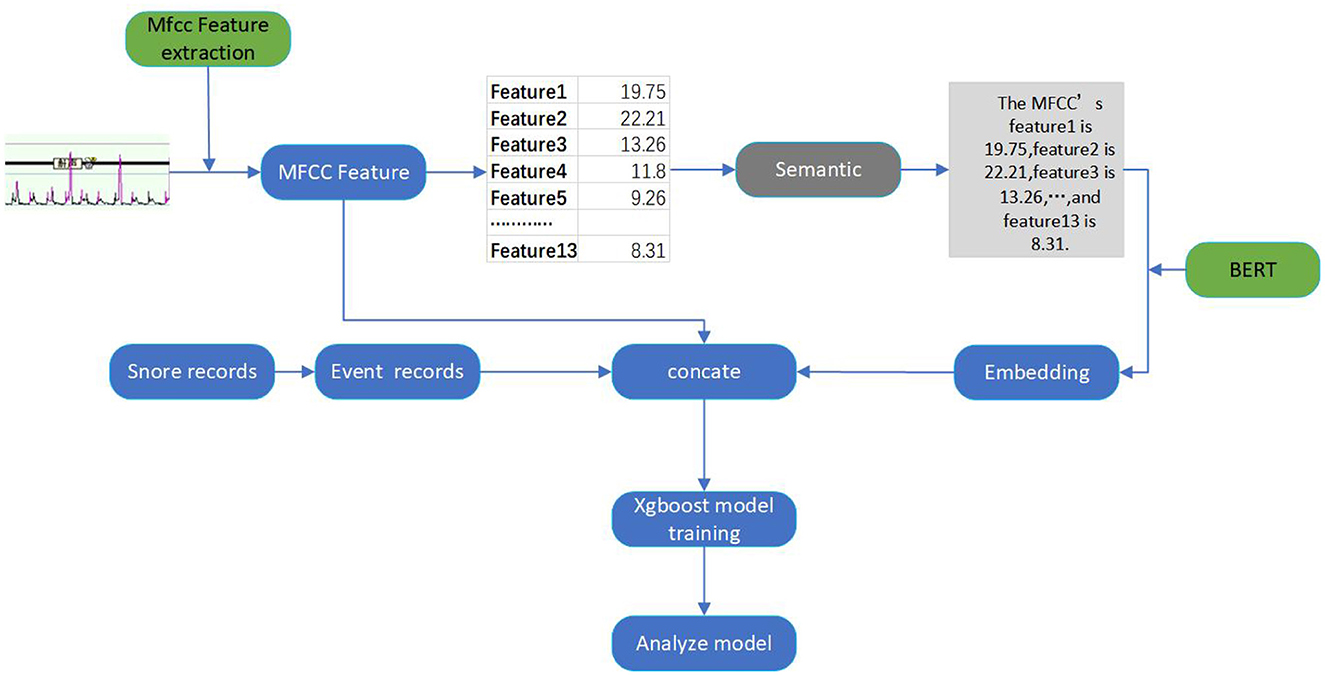
Figure 1. The overall framework of our proposed audio-semantic multimodal model ASMM-OSA.
The rest of the paper is organized as follows. Section 2 reviews related work on snoring features and semantic information extraction. Section 3 introduces the proposed framework, and Section 4 describes detailed experimental results and ablation studies. Section 5 concludes the paper.
Due to the strong correlation between snoring and OSAHS, prior research typically concentrates on analyzing patients' snoring and subsequently determining whether they have OSAHS. Emoto et al. (2007) utilized second-order autoregressive models to characterize snoring sounds and analyze the severity of OSAHS. Azarbarzin and Moussavi (2010) proposed an automatic unsupervised snoring detection algorithm that used two microphones, one on the trachea and one in the surrounding environment, to capture respiratory sound signals from patients. The vertical box (V-Box) algorithm was then employed to identify sound segments as either snoring or non-snoring. Qian et al. (2019) used machine listening techniques to identify the obstruction and vibration positions in the upper airway of subjects, analyzing their snoring data and employing a naive Bayes model as a classifier. Similarly, Qian et al. (2016) introduced a novel feature set based on wavelet transform and a support vector machine classifier to differentiate Velum, Oropharynx lateral wall, Tongue base, and Epiglottis (VOTE) snoring data detected by in-sleep endoscopy, distinguishing between OSAHS patients and primary snorers. However, these studies are confined to focusing on the analysis of snoring features to ascertain whether patients snore or have OSAHS. Despite their success, they still face difficulty accurately categorizing OSAHS severity into multiple classes (normal, mild, moderate, and severe cases), limiting its potential usage in assisting medical diagnoses.
The analysis of snoring characteristics is fundamentally a part of audio analysis. Currently, Chatburn and Mireles-Cabodevila (2011) and Likitha et al. (2017) have successfully utilized acoustic features to analyze speakers' emotions, achieving excellent performance. Building on this foundation, in recent years, researchers have employed MFCC for acoustic feature analysis to classify different types of snoring. Albornoz et al. (2017) utilized MFCC to extract snoring features and employed a support vector machine (SVM) for snoring type classification. Ma et al. (2015) detected snoring candidates using V-Box and then extracted MFCC features from each candidate to classify snoring or non-snoring using the K-Harmonic Mean clustering algorithm. Sun et al. (2020) used MFCC to obtain snoring features and applied support vector machines for snoring localization. However, most of these methods either do not classify the types of snoring accurately or do not focus on OSAHS severity assessment, which is crucial for effective patient treatment.
Pre-trained language models have been widely demonstrated as extremely effective. These language models are typically pre-trained on large text datasets and can be fine-tuned in different domains to extract distinctive features, exhibiting exceptional performance across various tasks.
In the medication domain, Shin et al. (2020) proposed BioMegatron, an improvement on BERT, to understand biomedical language and context. Fang and Wang (2022), Chen et al. (2021), and Tian and Zhang (2021) used PubMedBERT for COVID-19 literature classification and annotation. Almeida et al. (2022) utilized PubMedBERT's contextual embeddings to enhance document retrieval and question-answering tasks. Bevan and Hodgskiss (2021) employed BERT to learn feature representations of chemical entities. Portelli et al. (2021) evaluated and selected SpanBERT and PubMedBERT for medical text recognition. Liu et al. (2022) introduced MetBERT for predicting metastatic cancer from clinical records. Lin et al. (2021) proposed EntityBERT, a BERT-based model, to explore the clinical domain using a masked strategy. Miao et al. (2021) and collaborators utilized PubMedBERT for CID entity relation classification through Text-CNN fine-tuning. Danilov et al. (2021) applied PubMedBERT to classify short scientific texts and demonstrated better performance compared to other models. Zhang et al. (2021) used models like BioBERT and PubMedBERT for generating answers in QA tasks, with PubMedBERT showing good performance but not matching the BioBERT-MNLI-SQuAD model fine-tuned on external datasets, potentially due to differences in pre-training corpora. Rao (2022) tested the capabilities of BERT models in microbiology text mining and compared their applicability. Gupta et al. (2023) proposed an automated report generation method combining a visual transformer and PubMedBERT. Shen et al. (2022) and Mullin et al. (2023) employed various BERT models to analyze electronic health records of Alzheimer's disease patients and study the impact of lifestyle on the disease. Wang et al. (2021) introduced Cross-contrast BERT for obtaining semantic information in biomedical tasks. In the medical field, pre-trained language models have been widely used to extract text features from medical records, including patient medical histories and symptom descriptions. This text information aids doctors in disease diagnosis, prediction, and treatment decisions. Although previous research has utilized BERT models (Devlin et al., 2018; Qi et al., 2023) and extensions such as PubMedBERT and BioBERT, these models have not been applied to extracting text information from patients' snoring data, which has primarily focused on electronic health records.
Figure 1 demonstrates the overall framework of our proposed method, comprising audio feature extraction, semantic feature conversion, feature concatenation, and classification.
For each patient's sleep audio, we utilize the Mel Frequency Cepstral Coefficients (MFCC) to extract audio features. MFCC, a widely used method in audio signal processing, excels at capturing spectral sound characteristics. This process involves multiple steps, including preprocessing, Fast Fourier transform (FFT), Mel filter banks, logarithmic operations, Discrete Cosine Transform (DCT), as well as dynamic feature extraction. The specific steps of this process are as follows.
After performing data framing and windowing preprocessing steps, we apply the Fast Fourier Transform (FFT) to map the obtained time-domain signal into the frequency domain. This transformation is then converted into a power spectrum, which facilitates the subsequent transformation to the Mel scale.
Where x(n) represents the input audio signal, N is the frame size, and k is the frequency index.
The Mel filter bank is employed to transform the linear spectrum into the Mel spectrum.
Where X(k) represents the spectral values of the audio frame,where k ranges from 1 to K(often K is half the number of FFT points), representing different frequency components. while Hm(k) corresponds to the response of the m-th Mel filter.
After obtaining the energy values for each Mel filter as described above, a logarithm is taken to prepare for cepstral analysis.
The obtained Mel energy values for each filter are then subjected to Discrete Cosine Transform (DCT) to obtain the final Mel-Frequency Cepstral Coefficients (MFCCs).
Following these steps, we obtain MFCC feature vectors for each minute, including 13-dimensional static coefficients that reflect the energy distribution and spectral characteristics of snoring sounds. These MFCC feature vectors can then be utilized for subsequent data processing.
We employ a pre-trained PubMedBERT model to transform the MFCC features. We encode the MFCC features for each minute into a sentence-like format and input them into the PubMedBERT model to obtain semantic information. PubMedBERT is a model trained on a large-scale collection of medical literature data, endowed with robust semantic representation capabilities, enabling it to effectively capture specific features and knowledge within the medical domain.
We utilize the notation C1, C2, …, Ct to denote the MFCC feature vector for each minute, where Ct represents the MFCC features at the t minute. These MFCC features are structured into a sentence-like format:
Where Sinput is the obtained sentence, the encoding format is shown in Figure 1. We then input this sentence into the PubMedBERT model to get semantic information:
Soutput represents the semantic feature obtained by PubMedBERT.
We extracted snoring event records for each minute from the text files corresponding to the audio data. This yielded a 480-dimensional event record dataset, where each entry indicated the presence or absence of a snoring event for a specific minute. We further converted these records into binary labels: 1 represented the sleep apnea event lasting 30 s or more within the minute, while 0 denoted the normal sleep event. This transformation facilitated the integration of snoring event information into subsequent analyses.
Where eT represents the event records for each minute, with 1 indicating the sleep apnea event and 0 indicating the normal sleep event. These records form a 480-dimensional dataset.
We then concatenate the obtained semantic feature with the sleep apnea event records. The audio data is 480-dimensional, and the semantic feature we obtained after transformation is also 480-dimensional, aligning with the dimensionality of the event records. By concatenating the MFCC features, semantic features, and event records along their respective dimensions, we built a comprehensive feature. The feature serves as the input for the classification model, which is used for training and prediction purposes.
Where st represents the semantic feature of the t minute, et represents the event record of the t minute, Ct is a 480-dimensional vector, and Ft represents the comprehensive feature of the t minute. This comprehensive feature includes semantic features, event records, and audio features.
XGBoost (Chen and Guestrin, 2016), based on gradient boosting trees, incrementally integrates multiple decision tree models to enhance predictive performance. This iterative approach allows XGBoost to extract knowledge from multiple relatively weak learners, gradually approaching the true complexity of the problem. In the diagnosis of OSAHS, a multitude of features are at play, and the capabilities of XGBoost empower us to more effectively capture these complex relationships, consequently enhancing diagnostic accuracy.
The loss function of XGBoost consists of two parts: the regularization term and the data fitting term. Specifically, the loss function of XGBoost can be expressed as:
Where,n is the training sample size,yi is the ground-truth label,ŷi is the predicted label,K is the number of trees,fk represents the k-th tree, ℓ(yi, ŷi) is the data fitting term, and Ω(fk) is the regularization term.
We adopt the XGBoost to construct a classification model aimed at determining the presence of sleep apnea events on a per-minute basis. The model takes as input the comprehensive feature data obtained through prior steps. By training the model, we are able to predict sleep apnea events for each minute, consequently enabling the computation of the total count of such events throughout the entire night. This predictive capacity of the XGBoost model plays a pivotal role in diagnosing the severity of obstructive sleep apnea, offering insights into the patient's sleep-related respiratory patterns.
Based on the total count of overnight sleep apnea events, we can assess the severity of a patient's sleep apnea syndrome. We calculate the Apnea-Hypopnea Index (AHI) for each individual, computed as the count of events with occurrences during the entire night's sleep divided by the duration of the sleep.
Where N denotes the count of sleep apnea events during a patient's night of sleep, and t signifies the duration of that night's sleep in hours. Subsequently, the patient's severity of OSAHS is categorized into four levels using the AHI index, including simple snoring (AHI < 5), mild (5 ≤ AHI < 15), moderate (15 ≤ AHI < 30), and severe (AHI≥30) (Marti-Soler et al., 2016).
Additionally, we employ metrics such as Mean Squared Error(MSE), Mean Absolute Error(MAE), precision, recall, F1 score, and Area Under the ROC Curve (AUC) to assess the model's performance, ensuring its accuracy and reliability. The AUC measures the area under the ROC curve, with a range from 0 to 1. The larger the AUC value, the better the performance of the classifier.
The definitions of these six metrics are as follows:
where: yi denotes the ground-truth label, ŷi denotes the prediction and ȳ denotes the mean value.
The dataset was collected from the Eye & Ent Hospital of Fudan University consisting of 250 patients. The dataset includes patients' audios and corresponding OSAHS severity and event labels, labeled by three clinical experts. The data acquisition and processing followed these steps: first, we recorded 8 h of sleep audio for each patient at a sampling rate of 8 kHz. Subsequently, the sleep recordings were divided into hourly segments, generating eight-hour audio clips, each containing sleep state and snoring information for its corresponding hour. For each hourly audio clip, a 13-dimensional MFCC feature extraction was applied, which effectively captures audio spectral features. Then, the MFCC features are standardized to have a mean of 0 and a variance of 1, enhancing the stability and effectiveness of the model. The dataset is split into 80% for training and 20% for testing. Table 1 is a depiction of our dataset, including the number of patients in the training and test sets, the number of patients with different types of snoring, the number of males and females, and the age distribution.

Table 1. Description of the dataset.
To obtain event labels, the sleep apnea events and their durations were annotated in the respective text based on the patient's overnight sleep pattern. Event determination relied on whether the event duration exceeded 30 s, thus deciding the presence of a sleep apnea event per minute. Combining each patient's MFCC values with their corresponding event labels resulted in a 480-dimensional dataset. This dataset was further combined with the previously acquired semantic information, creating a comprehensive dataset containing semantic information, MFCC features, and event labels for training and testing experiments.
During training, the model's hyperparameters (such as learning rate, number of trees, maximum depth, etc.) are adjusted to optimize the model's performance. Table 2 shows our hyperparameter settings. We utilized cross-validation to choose the best combination of hyperparameters and avoid overfitting.
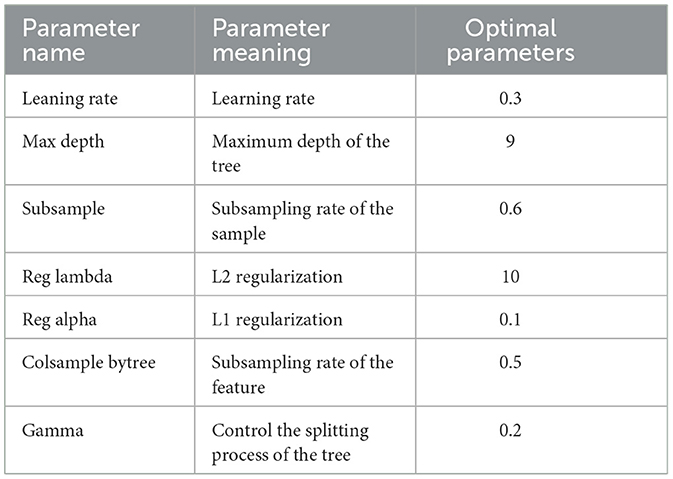
Table 2. Optimal parameters for the classification model.
We selected 50 patients as the test set and divided them into 10 groups, with each group containing five patients, conducting a total of 10 experiments. Through training the dataset with the XGBoost model, using MFCC values as features, we predicted the occurrence and type of sleep apnea events per minute and compared them with the ground-truth sleep apnea events, thus assessing the predictive performance of the model. The results presented in Table 3 showed that our model achieved superior performance in identifying sleep apnea events, with an average accuracy of 77.6%, and an average AUC of 0.709.
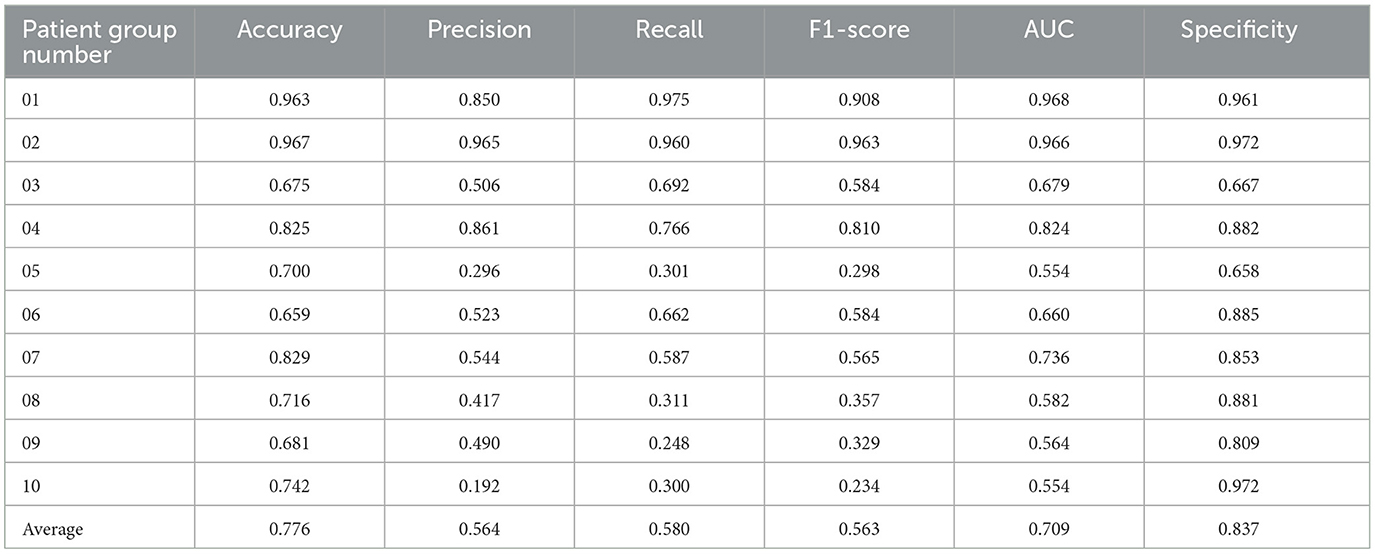
Table 3. Sleep apnea event classification results for 10 groups of patients.
In addition, we have further evaluated our proposed model using a confusion matrix (Figure 2). A confusion matrix is a fundamental tool for assessing the performance of a binary classification model. TP represents the cases where our model correctly identified positive instances, meaning it accurately detected the condition we were interested in, such as a medical condition or an event. TN stands for the cases where the model correctly recognized negative instances, indicating that it correctly ruled out the presence of the condition or event. In our study, we analyzed 23,370 samples, These samples originate from audio snippets of participants' entire night's sleep, each audio sample representing whether an apnea event occurred. Following the preprocessing of these audios, the total number of samples amounted to 23,370. The essential characteristic of these samples is the MFCC per minute. Label 0 represents a normal sleep event, while 1 indicates the occurrence of an apnea event. And the confusion matrix revealed 12,869 TP cases and 4,643 TN cases. These results demonstrate the model's efficacy in accurately discerning the presence of sleep apnea events. The abundance of TP cases underscores its accuracy in identifying positive instances, while the significant TN count signifies its proficiency in correctly excluding negative instances.
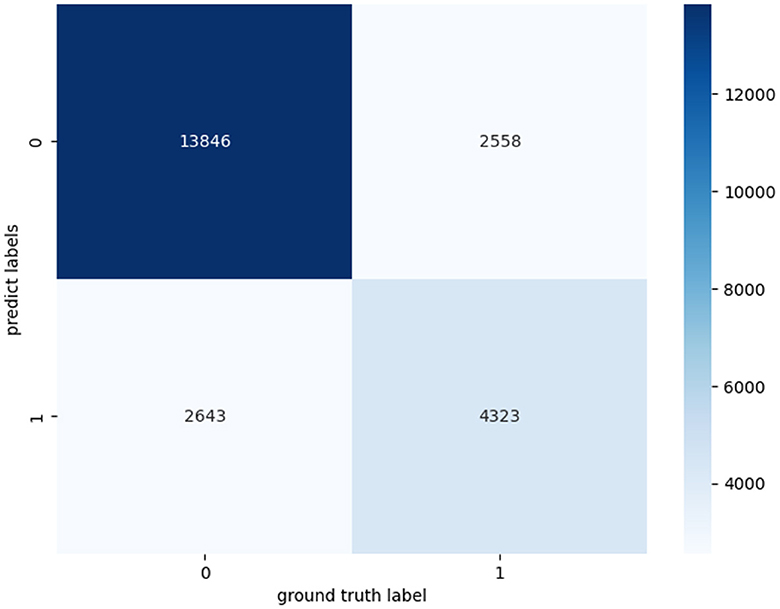
Figure 2. Confusion matrices for apnea event classification.
As presented in Figure 3, we also employed The Receiver Operating Characteristic (ROC) curves for model evaluation. The ROC curve is a graphical tool that visually assesses a model's binary classification performance. It plots the True Positive Rate (TPR), also known as Sensitivity, against the False Positive Rate (FPR), reflecting the model's accuracy in classifying positive instances while minimizing negative. A higher AUC value close to 1 indicates the model's superior capacity to differentiate between positive and negative instances. In our study, an AUC of 0.8 indicates a strong discriminative ability in distinguishing sleep apnea events.
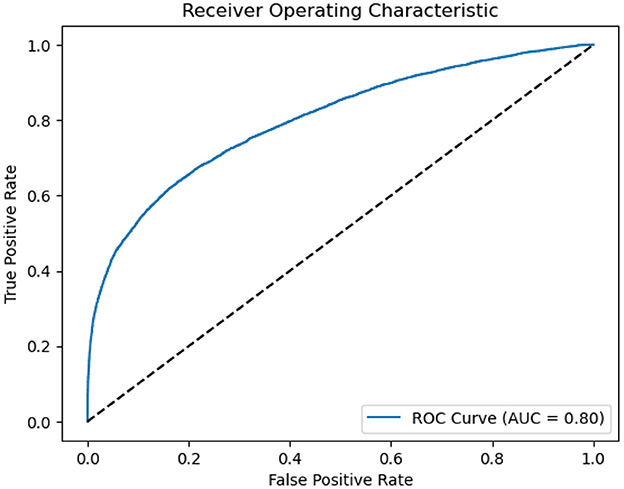
Figure 3. ROC of ASMM-OSA. The horizontal axis quantifies the proportion of healthy cases incorrectly identified as diseased, while the vertical axis quantifies the proportion of diseased cases correctly identified.
In this paper, we use the SHAP model to perform an interpretive analysis of the XGBoost model's output. The importance ranking of the features of the SHAP is shown in Figure 4, where the most important feature in the AHI predict process is average SPO2, In addition to average SPO2, Lowest SPO2, and Longest Apnea Duration are also an important indicator for AHI predict.
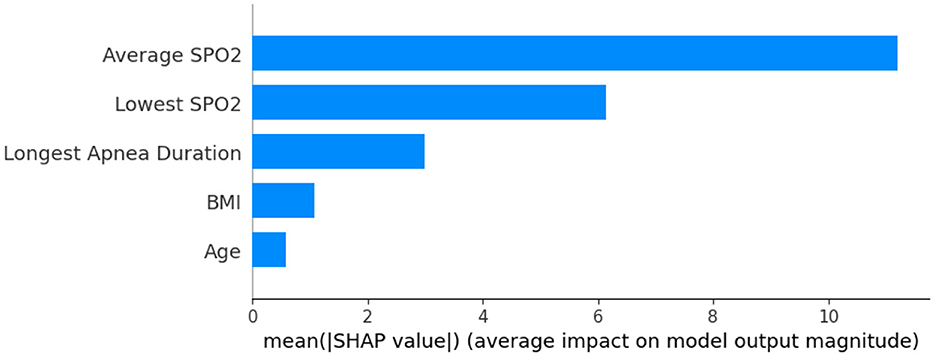
Figure 4. Feature importance ranking.
Figure 5 shows the feature dependence plots of “Longest Apnea Duration”. The scatter plot reveals the contributions of “Longest Apnea Duration” and “BMI” to the model prediction. The gray histogram represents the sample distribution of “Longest Apnea Duration”, while points of different colors depict the distribution of SHAP values for sample features with various BMI. The larger the SHAP value, the greater the positive contribution of the corresponding feature value in the model. The color represents the numerical values of BMI, with the color bar displaying the BMI value ranges corresponding to different colors. The figure indicates a positive correlation between “Longest Apnea Duration” and SHAP values, implying that as the duration of apnea prolongs, the corresponding SHAP values increase, suggesting a higher dependence on this feature. Meanwhile, the distribution of BMI appears more scattered, which indicates the influence of BMI on “Longest Apnea Duration” is relatively independent rather than linearly correlated, underscoring the complexity of the model's prediction.
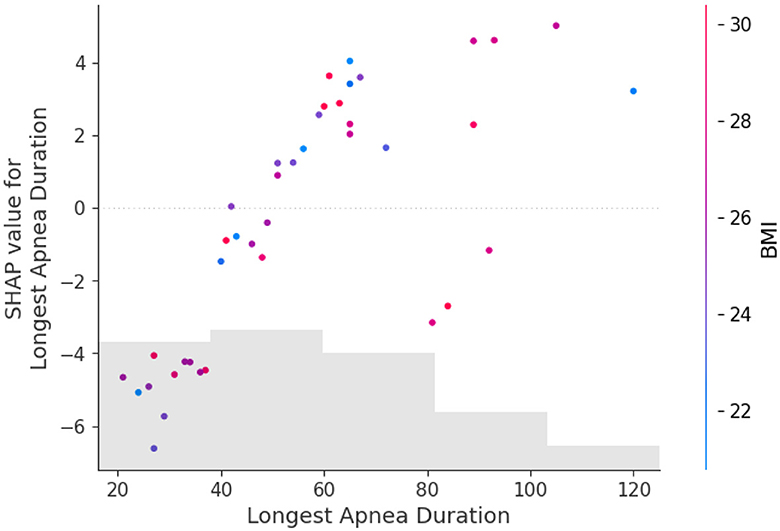
Figure 5. The dependence between longest apnea duration and BMI. The gray histogram represents the sample distribution of the Longest Apnea Duration, while points of different colors depict the BMI of different samples.
In our experiments, we compared our model with other models from related studies, and the results are shown in Table 4, which indicates that our metrics outperform other snoring classification prediction models in several assessment metrics. The chosen baselines are as follows, implemented according to the details specified within each baseline:
• Limin et al. (2019) extracted MFCC and used the Gaussian mixture model to model and classify snoring sound all night, and then estimated the AHI index of the subjects.
• Zhao et al. (2021) extracted the formants of snoring sound and compared them with the personalized threshold to describe the difference between OSAHS patients and simple snorers, and estimated the simulated AHI of subjects.
• Shen et al. (2020) applied the Long Short Term Memory (LSTM) to explore deeply representative features from MFCC, LPC, and the integration of LPCC and MFCC.
• Ding et al. (2023) detected apnea hypopnea-related snoring sound based on analysis of the Mel-spectrogram.
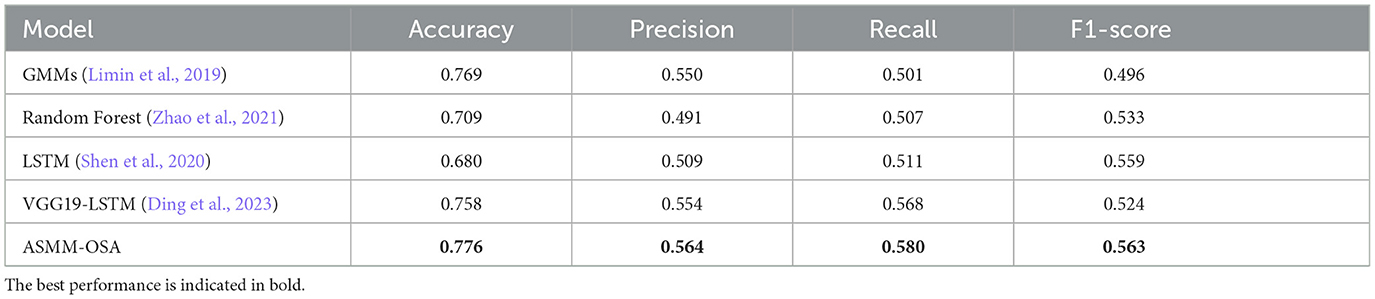
Table 4. Experimental results for the differentiation of sleep apnea events using the baseline classification approach.
We utilize a test set consisting of 50 patients, calculating the AHI score for each patient and determining their corresponding severity level. These results are then compared to the severity levels derived from the ground truth derived from PSG. We label 0, 1, 2, and 3 to represent the different degrees of OSAHS severity: 0 denotes normal, 1 signifies mild, 2 indicates moderate, and 3 represents severe.
Table 5 presents the label distribution of patients with different severity level labels and the predictive accuracy of the four-class classification. The overall predictive accuracy of the four classes is 58%. It is noted that our model exhibits superior performance in categorizing patients with moderate and severe conditions. In practical situations, prioritizing the classification of moderate and severe cases is crucial, given their potential need for urgent hospital treatment. Consequently, the diagnostic outcomes facilitate swift and precise identification of moderate and severe patients, enabling expedited and effective interventions by healthcare professionals.
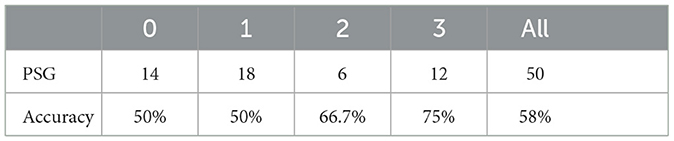
Table 5. The number of people with each symptom in PSG and test results.
Table 6 shows our model accurately estimates the actual Apnea-Hypopnea Index (AHI) for most subjects, especially for patients 1–7 and 9. The prediction discrepancies observed in patients 8 and 10 can be attributed to patient diversity and the first-night effect, which refers to variations in sleep patterns during an individual's first exposure to a sleep study environment. Additionally, the size of the dataset may have impacted the model's generalizability. Despite the challenges of data variability and size, Table 4 demonstrates that our approach outperforms the baseline on the same dataset, highlighting the effectiveness of our proposed model.
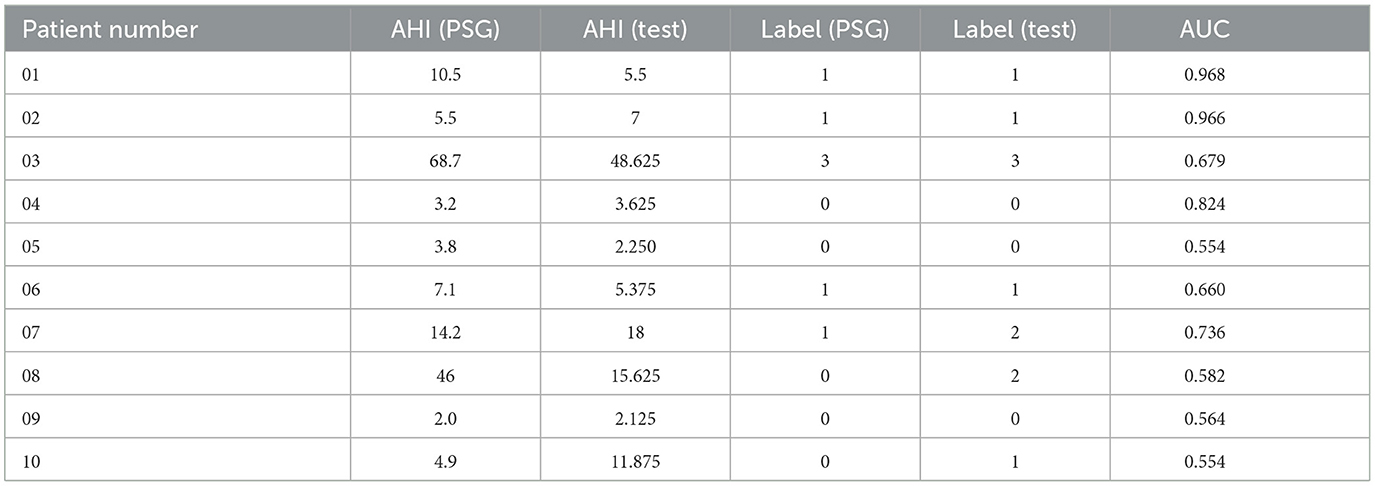
Table 6. The comparison of OSAHS degree of our method compared with the gold standard PSG results in 10 random patients.
We further conducted ablations concentrating on evaluating the impact of semantic information features on the classification performance of the ASMM-OSA. We designed two components, with one utilizing MFCC as the feature and the other concatenating semantic features as the final feature representation. The results are presented in Table 7. From the experimental results, it can be observed that after incorporating PubMedBERT, the average accuracy increased to 0.776, compared to 0.746 without utilizing PubMedBERT. Furthermore, there was a discernible improvement in precision and ASMM-OSA demonstrated superior precision in classifying positive samples when PubMedBERT was employed.
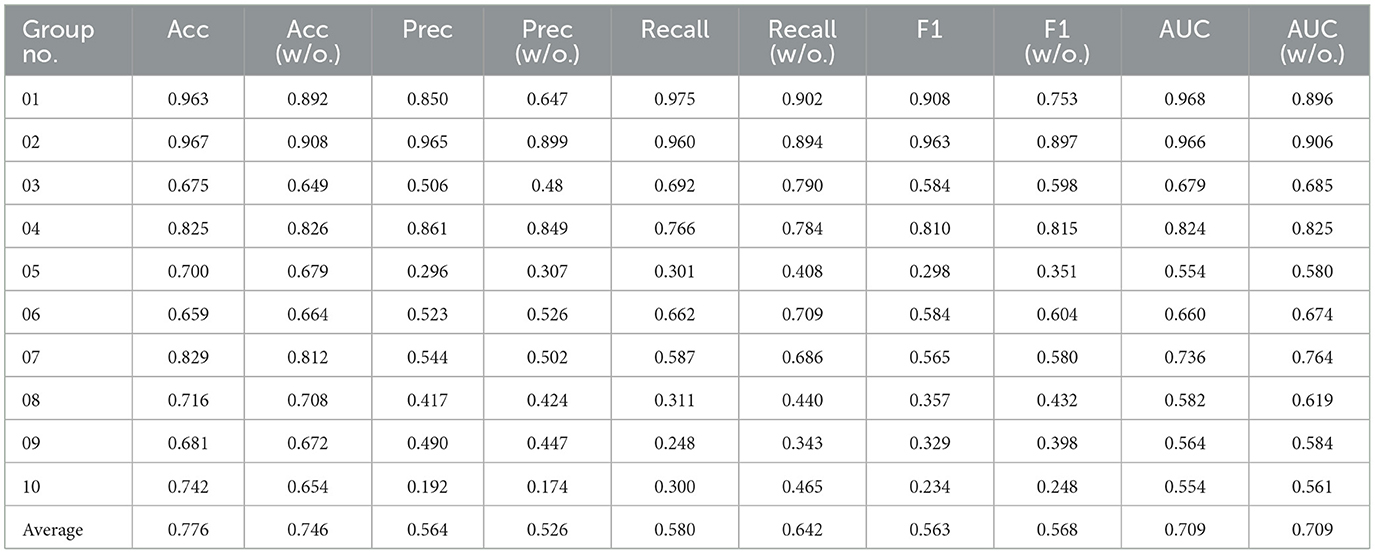
Table 7. The results of the ablation experiment sleep apnea event classification in 10 groups of patients.
Due to PubMedBERT being pre-trained on a large-scale biomedical literature dataset, ASMM-OSA has acquired enhanced semantic feature-capturing capabilities, particularly excelling in capturing medical domain-specific features. Comparatively, incorporating PubMedBERT significantly improves the performance of ASMM-OSA in classifying the severity of OSAHS patients when contrasted with not introducing this language model.
In this paper, we introduce an audio-semantic multimodal model for the classification of OSAHS severity (i.e., ASMM-OSA). We integrate patients' sleep audio features with semantic features and employ XGBoost to classify sleep apnea events, thereby calculating the patient's AHI score to assess the severity of OSAHS. Experimental results demonstrate the enhancement in classification performance achieved by incorporating semantic information, highlighting the superior performance of ASMM-OSA in classifying sleep apnea events. This approach provides a robust tool for precisely diagnosing sleep-related disorders. In the future, we will conduct a thorough analysis of performance variations among different patient groups. We will investigate aspects such as feature selection, model fine-tuning, and other enhancements to further improve model performance and its generalization capabilities.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by the Ethics Committee of the Eye & ENT Hospital of Fudan University. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
XQ: Methodology, Supervision, Writing—original draft. CW: Software, Writing—original draft. BL: Validation, Writing—review & editing. HT: Writing—review & editing. XT: Writing—review & editing. LY: Writing—review & editing. JT: Data curation, Writing—review & editing. JH: Data curation, Resources, Supervision, Writing—review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Shanghai Municipal Natural Science Foundation (23ZR1425400), Eye & ENT Hospital's double priority project A (YGJC026 to Dr. Wei and JH).
We would like to thank the colleagues for helping acquire data from Eye & ENT Hospital of Fudan University, Shanghai.
XT was employed by INF Technology (Shanghai) Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Albornoz, E. M., Bugnon, L. A., and Martínez, C. E. (2017). “Snore recognition using a reduced set of spectral features,” in 2017 XVII Workshop on Information Processing and Control (RPIC) (Mar del Plata: IEEE), 1–5.
Almeida, T., Pinho, A., Pereira, R., and Matos, S. (2022). Deep Learning Solutions Based on Fixed Contextualized Embeddings From PubMedBERT on BioASQ 10b and Traditional IR in Synergy. RWTH Aachen University: CEUR-WS.org.
Azarbarzin, A., and Moussavi, Z. M. (2010). Automatic and unsupervised snore sound extraction from respiratory sound signals. IEEE Transact. Biomed. Eng. 58, 1156–1162. doi: 10.1109/TBME.2010.2061846
Bevan, R., and Hodgskiss, M. (2021). “Fine-tuning transformers for automatic chemical entity identification in pubmed articles,” in Proceedings of the Seventh BioCreative Challenge Evaluation Workshop (Virtual Conference).
Chatburn, R. L., and Mireles-Cabodevila, E. (2011). Closed-loop control of mechanical ventilation: description and classification of targeting schemes. Respir. Care 56, 85–102. doi: 10.4187/respcare.00967
Chen, Q., Allot, A., and Lu, Z. (2021). Litcovid: an open database of covid-19 literature. Nucleic Acids Res. 49, D1534–D1540. doi: 10.1093/nar/gkaa952
Chen, T., and Guestrin, C. (2016). “Xgboost: a scalable tree boosting system,” in Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining (San Francisco, CA), 785–794.
Danilov, G., Ishankulov, T., Kotik, K., Orlov, Y., Shifrin, M., and Potapov, A. (2021). The classification of short scientific texts using pretrained bert model. Public Health Informat. 281:83–87. doi: 10.3233/SHTI210125
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). Bert: pre-training of deep bidirectional transformers for language understanding. arXiv [preprint]. arXiv:1810.04805.
Ding, L., Peng, J., Song, L., and Zhang, X. (2023). Automatically detecting apnea-hypopnea snoring signal based on vgg19+ lstm. Biomed. Signal Process. Control 80:104351. doi: 10.1016/j.bspc.2022.104351
Emoto, T., Abeyratne, U., Akutagawa, M., Nagashino, H., and Kinouchi, Y. (2007). “Feature extraction for snore sound via neural network processing,” in 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (Lyon: IEEE), 5477–5480.
Fang, L., and Wang, K. (2022). Multi-label topic classification for covid-19 literature with bioformer. arXiv:2204.06758v1. doi: 10.48550/arXiv.2204.06758
Franklin, K. A., and Lindberg, E. (2015). Obstructive sleep apnea is a common disorder in the population—a review on the epidemiology of sleep apnea. J. Thorac. Dis. 7:1311. doi: 10.3978/j.issn.2072-1439.2015.06.11
Gupta, S., Jiang, Y., and Imran, A. A. Z. (2023). “Transforming radiology workflows: pretraining for automated chest x-ray report generation,” in Medical Imaging with Deep Learning, Short Paper Track (Nashville, TN).
Hou, L., Pan, Q., Yi, H., Shi, D., Shi, X., and Yin, S. (2021). Estimating a sleep apnea hypopnea index based on the erb correlation dimension of snore sounds. Front. Digit. Health 2:613725. doi: 10.3389/fdgth.2020.613725
Likitha, M., Gupta, S. R. R., Hasitha, K., and Raju, A. U. (2017). “Speech based human emotion recognition using MFCC,” in 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET) (Chennai: IEEE), 2257–2260.
Limin, H., Zhang, W., Shi, D., and Huancheng, L. (2019). Estimation of apnea hypopnea index based on acoustic features of snoring. Sch. Commun. Inf. Eng. 25, 435–444. doi: 10.12066/j.issn.1007-2861.1942
Lin, C., Bethard, S., Savova, G., Miller, T., and Dligach, D. (2021). Entitybert: Bert-Based Models Pretrained on Mimic-III With or Without Entity-Centric Masking Strategy for the Clinical Domain. virtual.
Liu, K., Kulkarni, O., Witteveen-Lane, M., Chen, B., and Chesla, D. (2022). “Metbert: a generalizable and pre-trained deep learning model for the prediction of metastatic cancer from clinical notes,” in AMIA Annual Symposium Proceedings, Vol. 2022 (San Francisco, CA: American Medical Informatics Association), 331.
Ma, G., Xue, B., Hong, H., Zhu, X., and Wang, Z. (2015). “Unsupervised snore detection from respiratory sound signals,” in 2015 IEEE International Conference on Digital Signal Processing (DSP) (Singapore: IEEE), 417–421.
Ma, J., Qiu, X., Sun, L., Cong, N., Wei, Y., Wei, C., et al. (2024). Utility of the psychomotor vigilance task in screening for obstructive sleep apnoea. Eur. Arch. Otorhinolaryngol. 281, 3115–3123. doi: 10.1007/s00405-023-08373-3
Malhotra, A., Ayappa, I., Ayas, N., Collop, N., Kirsch, D., Mcardle, N., et al. (2021). Metrics of sleep apnea severity: beyond the apnea-hypopnea index. Sleep 44:zsab030. doi: 10.1093/sleep/zsab030
Marti-Soler, H., Hirotsu, C., Marques-Vidal, P., Vollenweider, P., Waeber, G., Preisig, M., et al. (2016). The nosas score for screening of sleep-disordered breathing: a derivation and validation study. Lancet Respir. Med. 4, 742–748. doi: 10.1016/S2213-2600(16)30075-3
Miao, D., Zhongqi, S., Xiaobei, Z., Xue, L., Zhigang, C., and Lei, C. (2021). Improving pubmedbert for cid-entity-relation classification using text-cnn. Data Anal. Knowl. Discov. 5, 145–152. doi: 10.11925/infotech.2096-3467.2021.0671
Mullin, S., McDougal, R., Cheung, K.-H., Kilicoglu, H., Beck, A., and Zeiss, C. J. (2023). Chemical entity normalization for successful translational development of Alzheimer's disease and dementia therapeutics. Res. Sq. doi: 10.21203/rs.3.rs-2547912/v1
Portelli, B., Lenzi, E., Chersoni, E., Serra, G., and Santus, E. (2021). “Bert prescriptions to avoid unwanted headaches: a comparison of transformer architectures for adverse drug event detection,” in Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 1740–1747.
Qi, Z., Tan, X., Qu, C., Xu, Y., and Qi, Y. (2023). “Safer: a robust and efficient framework for fine-tuning bert-based classifier with noisy labels,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track) (Toronto, ON), 390–403.
Qian, K., Janott, C., Zhang, Z., Heiser, C., and Schuller, B. (2016). “Wavelet features for classification of vote snore sounds,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Shanghai: IEEE), 221–225.
Qian, K., Schmitt, M., Janott, C., Zhang, Z., Heiser, C., Hohenhorst, W., et al. (2019). A bag of wavelet features for snore sound classification. Ann. Biomed. Eng. 47, 1000–1011. doi: 10.1007/s10439-019-02217-0
Rao, B. K. (2022). Microbial Named Entity Recognition Using BERT Models (PhD thesis) Urbana-Champaign, IL: University of Illinois.
Shen, F., Cheng, S., Li, Z., Yue, K., Li, W., Dai, L., et al. (2020). Detection of snore from osahs patients based on deep learning. J. Healthc. Eng. 2020:8864863. doi: 10.1155/2020/8864863
Shen, Z., Schutte, D., Yi, Y., Bompelli, A., Yu, F., Wang, Y., et al. (2022). Classifying the lifestyle status for Alzheimer's disease from clinical notes using deep learning with weak supervision. BMC Med. Inform. Decis. Mak. 22, 1–11. doi: 10.1186/s12911-022-01819-4
Shin, H.-C., Zhang, Y., Bakhturina, E., Puri, R., Patwary, M., Shoeybi, M., et al. (2020). Biomegatron: Larger biomedical domain language model. arXiv [preprint]. doi: 10.18653/v1/2020.emnlp-main.379
Sun, J., Hu, X., Chen, C., Peng, S., and Ma, Y. (2020). Amplitude spectrum trend-based feature for excitation location classification from snore sounds. Physiol. Meas. 41:085006. doi: 10.1088/1361-6579/abaa34
Tian, S., and Zhang, J. (2021). “Team fsu2021 at biocreative VII litcovid track: Bert-based models using different strategies for topic annotation of covid-19 literature,” in Proceedings of the Seventh BioCreative Challenge Evaluation Workshop (Virtual Conference).
Tinn, R., Cheng, H., Gu, Y., Usuyama, N., Liu, X., Naumann, T., et al. (2023). Fine-tuning large neural language models for biomedical natural language processing. Patterns 4:100729. doi: 10.1016/j.patter.2023.100729
Wang, X., Xiong, Y., Niu, H., Zhang, Y., and Zhu, Y. (2021). “C2bert: cross-contrast bert for chinese biomedical sentence representation,” in 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (Houston, TX: IEEE), 1569–1574.
Winursito, A., Hidayat, R., and Bejo, A. (2018). “Improvement of mfcc feature extraction accuracy using pca in indonesian speech recognition,” in 2018 International Conference on Information and Communications Technology (ICOIACT) (Yogyakarta: IEEE), 379–383.
Zhang, Y., Han, J.-C., and Tsai, R. T.-H. (2021). “Ncu-iisr/as-gis: results of various pre-trained biomedical language models and linear regression model in bioasq task 9b phase b,” in CLEF (Working Notes) (Bucharest), 360–368.
Keywords: obstructive sleep Apnea-Hypopnea Syndrome, snoring sounds, semantic information, PubMedBERT, multimodal model
Citation: Qiu X, Wang C, Li B, Tong H, Tan X, Yang L, Tao J and Huang J (2024) An audio-semantic multimodal model for automatic obstructive sleep Apnea-Hypopnea Syndrome classification via multi-feature analysis of snoring sounds. Front. Neurosci. 18:1336307. doi: 10.3389/fnins.2024.1336307
Received: 14 December 2023; Accepted: 29 April 2024;
Published: 10 May 2024.
Edited by:
Bin Chen, University of Shanghai for Science and Technology, ChinaReviewed by:
Xiaodong Huang, South China University of Technology, ChinaCopyright © 2024 Qiu, Wang, Li, Tong, Tan, Yang, Tao and Huang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jingjing Huang, Z2VubmllX3h1YW5AMTYzLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.