
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Neurosci. , 13 June 2023
Sec. Brain Imaging Methods
Volume 17 - 2023 | https://doi.org/10.3389/fnins.2023.1203104
This article is part of the Research Topic Generative AI for Brain Imaging and Brain Network Construction View all 10 articles
 Changwei Gong1,2Changhong Jing1,2Xuhang Chen1,3Chi Man Pun3Guoli Huang1Ashirbani Saha4Martin Nieuwoudt5Han-Xiong Li6Yong Hu7*Shuqiang Wang1,2*
Changwei Gong1,2Changhong Jing1,2Xuhang Chen1,3Chi Man Pun3Guoli Huang1Ashirbani Saha4Martin Nieuwoudt5Han-Xiong Li6Yong Hu7*Shuqiang Wang1,2*Recent years have witnessed a significant advancement in brain imaging techniques that offer a non-invasive approach to mapping the structure and function of the brain. Concurrently, generative artificial intelligence (AI) has experienced substantial growth, involving using existing data to create new content with a similar underlying pattern to real-world data. The integration of these two domains, generative AI in neuroimaging, presents a promising avenue for exploring various fields of brain imaging and brain network computing, particularly in the areas of extracting spatiotemporal brain features and reconstructing the topological connectivity of brain networks. Therefore, this study reviewed the advanced models, tasks, challenges, and prospects of brain imaging and brain network computing techniques and intends to provide a comprehensive picture of current generative AI techniques in brain imaging. This review is focused on novel methodological approaches and applications of related new methods. It discussed fundamental theories and algorithms of four classic generative models and provided a systematic survey and categorization of tasks, including co-registration, super-resolution, enhancement, classification, segmentation, cross-modality, brain network analysis, and brain decoding. This paper also highlighted the challenges and future directions of the latest work with the expectation that future research can be beneficial.
Brain imaging, providing a way to non-invasively map the structure and function of the brain, has developed significantly in recent years (Gui et al., 2010). For instance, functional brain imaging, such as functional magnetic resonance imaging (fMRI), has the potential to revolutionize researchers' understanding of the physical basis of the brain and offers a powerful tool to understand how the brain adapts to various cognitive activities and tasks (Allen et al., 2014). Additionally, it offers a powerful tool that assists in understanding how the brain adapts to various cognitive activities and tasks. Generative artificial intelligence refers to new technologies that employ existing data including images, text, and audio files to create new content. This new content has a similar underlying pattern of real-world data and has great potential applications in many areas. Synthetic data from generative AI (Wang et al., 2017; Lei et al., 2020b) can train machine learning models (Liu Y. et al., 2021; Lei et al., 2022b) to be less biased and help robots to learn more abstract concepts both in the real and virtual world. The development of neuroimaging as a cross-discipline between imaging and neuroscience has enabled the qualitative and quantitative analysis of images in multiple dimensions. Neuroimaging is a powerful tool for studying brain science, revealing the anatomical structure and working mechanisms of the brain, as well as diagnosing and treating brain diseases. The synergistic developments between emerging analytic technologies and data-sharing initiatives have the potential to transform the role of neuroimaging in clinical applications. While basic neuroscience focuses on understanding how brain activity produces behavior, clinical applications aim to develop tools that are useful for clinical decision-making and treatment development.
Brain images reveal multiple modalities due to different imaging principles and techniques. As shown in Figure 1, multi-modality brain imaging contains many different types, such as diffusion tensor imaging (DTI), fluid-attenuated inversion recovery (FLAIR) MRI, Susceptibility weighted imaging (SWI) MRI, resting state functional MRI (rs-fMRI) and fluorodeoxyglucose positron emission tomography (FDG-PET), etc. Brain imaging can be divided into two broad categories such as functional and structural imaging. Functional neuroimaging, which has generated great optimism about its potential to both revolutionize researchers' understanding of the physical basis of the brain and to provide clinically useful tools (Yu et al., 2021b), has made significant progress in achieving the former goal. However, functional neuroimaging results and models have yet to be incorporated into clinical practice. For decades, numerous translational neuroimaging and radiological studies have identified the characteristics that predict health-related outcomes (Wang S.-Q. et al., 2015; Wang et al., 2020a), including current diagnostic categories and measures of symptoms (Lei et al., 2022a), cognitive and affective computing processes, and cognitive performance. Redefining diagnostic categories, identifying neuropathological features, and assessing healthy brain function outside of current clinical diagnostic categories are potential outcomes of such studies.

Figure 1. Multi-modality brain imaging includes DTI, sMRI, fMRI, PET, and other imaging types.
Further analysis of brain images can provide morphological information about brain regions, such as their volume, thickness, and surface area. Automated computer analysis has replaced expert anatomists' manual labeling of brain images. In voxel-based morphometry, voxels are segmented into one of three tissue categories (cerebrospinal fluid, white matter, or gray matter) based on their image intensity. After recording all scans in the study into a common anatomical space, the gray matter density of each voxel can be compared between the whole brain and the subject, using the average brain as a template. This process extracts graphical data information about brain-related patterns from brain imaging voxels with high-resolution structures. Lundervold and Lundervold (2019) demonstrated that the introduction of automated computer analysis of magnetic resonance imaging has facilitated the in vivo study of whole-brain coordinated patterns in thousands of individuals (Hu et al., 2020b).
Moreover, in the field of network neuroscience (Bassett and Sporns, 2017), the theory and applications of generative AI offer a powerful tool for brain imaging and brain network computing including but not limited to extraction of brain spatiotemporal features and the reconstruction of the topological connectivity of brain networks (Calhoun et al., 2014; Gong et al., 2022). Brain networks, which represent the global connectivity of the brain's structure and function, are crucial in understanding the neural basis of cognitive processes, neuroanatomy, functional brain imaging, and neurodevelopment. Brain network computing involves the construction, reconstruction, analysis, and optimization of brain networks. While brain imaging allows for the qualitative and quantitative analysis of the brain's anatomical and functional structure in two or three dimensions, brain network computing enables the study of brain topological features and covariant features (Isallari and Rekik, 2021). Various tools, such as PANDA (Cui et al., 2013) and GRETNA (Wang J. et al., 2015), can be used for constructing brain networks. However, the brain networks produced by these tools are subjective, time-consuming, and depend on the operator's experience. This review also surveys the development of AI-based algorithms that can automatically construct brain networks.
This paper provides a brief overview of research related to generative learning models in brain imaging from three different perspectives: AI-based generative models, tasks for brain imaging, and the prospects of generative AI for brain imaging. The paper reviews recent developments and advancements made in each of these areas.
The generative learning model refers to a class of machine learning (ML) models that can generate new data similar to the training data on which they were trained. Large-scale generative models are trained on massive datasets and require specialized hardware, such as GPUs, for efficient training. As shown in Figure 2, several types of generative models exist, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), Flow Models, and Denoising Diffusion Probabilistic Models (DDPMs). Introduced by Goodfellow et al. (2014), GANs are a type of neural network comprising two parts: a generator network that creates new data and a discriminator network that distinguishes between real and fake data. VAEs, proposed by Kingma and Welling (2013), generate new data by learning a compressed representation of the input data. Flow Models, proposed by Rezende and Mohamed (2015), model the probability distribution of the input data and invert it. DDPMs, a new type of generative model introduced by Ho et al. (2020), have gained popularity in recent years. They draw inspiration from the physical process of gas molecule diffusion, in which molecules diffuse from high-density to low-density areas. DDPMs learn to model the data distribution from input data incrementally.
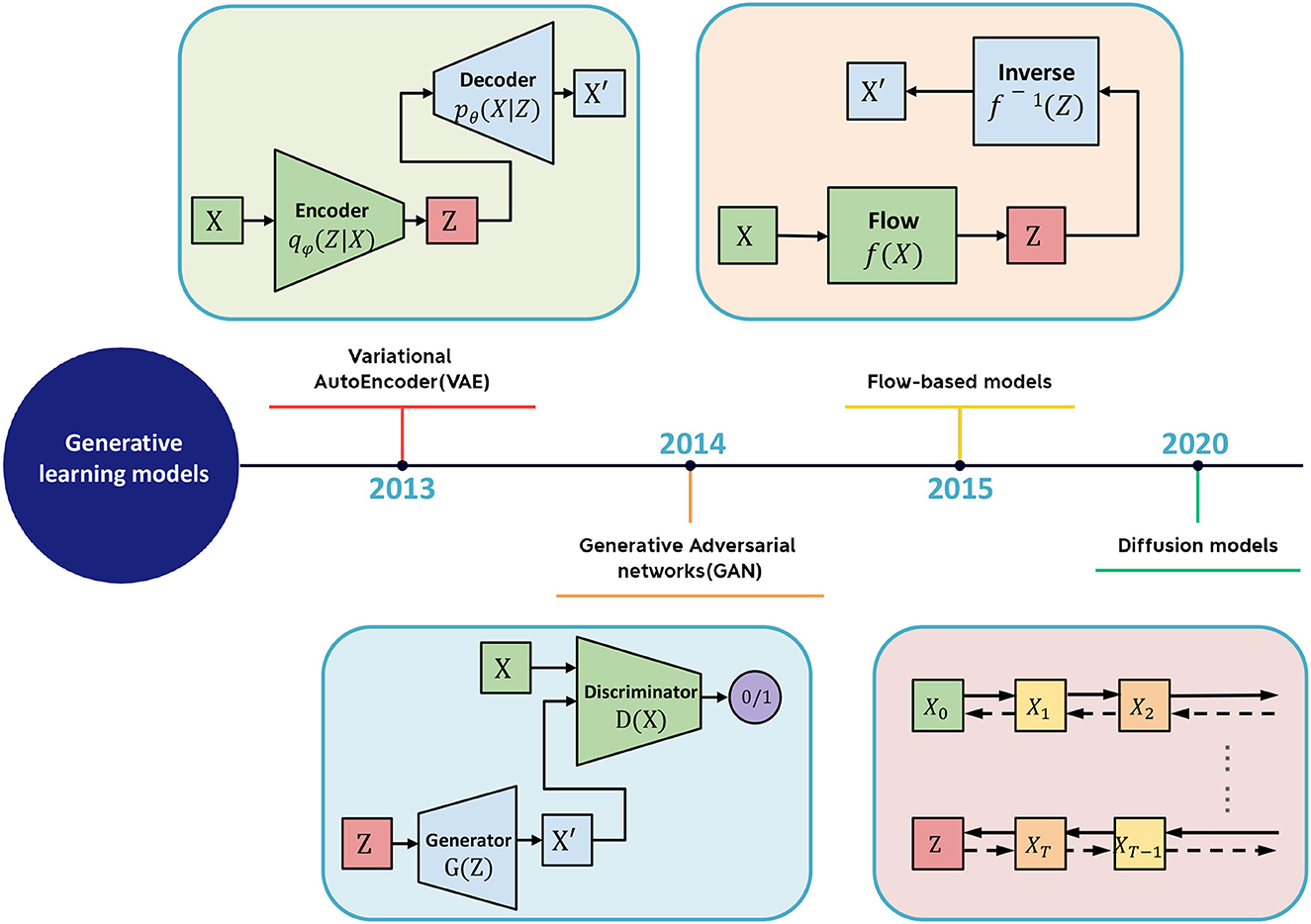
Figure 2. The schematic diagram of generative learning model includes VAE, GAN, flow-based model, and diffusion model.
Autoencoders are a type of neural network that encode the input X into a low-dimensional vector z, also known as the latent space, and then reconstruct the input X based on z. By minimizing the error between X and the generated output ˆX, autoencoders are trained to gradually reduce the reconstruction error, thereby achieving the goal of reconstruction. However, autoencoders suffer from the limitation of not being able to generate new content as they cannot produce latent vectors arbitrarily. This is because the latent vectors z are all encoded from the original images by the encoder.
In Equation (1), where a set of raw data samples X1, ..., Xn is available to describe the population, direct sampling from the probability distribution p(X) would be feasible if p(X) were known. However, in practice, the distribution of the raw data p(X) is typically unknown.
To address this issue, researchers have added constraints to the latent space Z (the space corresponding to the latent vectors) to impose a prior distribution on the latent vectors. This led to the development of the variational autoencoder (VAE) model, which adds a constraint to the encoder to force it to produce latent variables that follow a normal distribution in Equation (2). It is this constraint that distinguishes VAE from traditional autoencoders.
A key aspect of variational autoencoders (VAEs) is the addition of a constraint that enforces a normal distribution on the latent space Z. Determining this normal distribution is the primary objective of VAEs. To specify a normal distribution, two parameters must be determined: the mean μ and the standard deviation σ. To accomplish this, the encoder encodes input samples X into two latent dimension vectors, μ and σ, which represent the mean and variance of the latent space assumed to follow a normal distribution (Mo and Wang, 2009). To sample Z from this latent space, VAE assumes that the latent normal distribution can generate the input images. VAE first samples a random vector ϵ from the standard normal distribution N(0, I), and then computes:
Here ⊙ denotes element-wise multiplication. Z is a vector sampled from the latent space, and Z is used as input to the decoder to generate a reconstructed sample ˆX. The above steps constitute the forward propagation process of the entire network. To perform backpropagation, the loss function is evaluated from two aspects: the similarity between the generated output ˆX and the original input X and the similarity between the distribution of the latent space and the normal distribution. The similarity between X and ˆX is generally measured using reconstructions loss, while the similarity between two distributions is generally measured using the Kullback-Leibler divergence (Joyce, 2011).
In summary, VAEs have found useful applications in brain imaging. VAEs can effectively cluster similar patterns in brain activity data and detect subtle changes that may not be easily perceptible to the human eye (Tezcan et al., 2017; Cheng et al., 2021). Furthermore, the learned lower-dimensional representation by VAEs can also serve as a data compression method to minimize computational resources when analyzing complex brain network data (Qiao et al., 2021). The ability to model complex data and generate new data points that resemble the original ones makes VAEs a powerful tool in gaining insights into the underlying mechanisms of neurological disorders and diseases (Zhao et al., 2019).
A Generative Adversarial Network (GAN) is a type of machine learning framework designed by Goodfellow et al. (2014). GANs are composed of two neural networks that compete against each other in a zero-sum game, where one agent's gain is another agent's loss. The framework learns to generate new data with the same statistics as the training set, enabling the GAN to generate new data that resembles the original data.
GANs are based on game theory and can be viewed as a two-player minimax game, where the generator aims to minimize the difference between the distribution of the generated samples and the distribution of the real data, while the discriminator aims to maximize the difference between the two distributions. During training, the generator tries to produce samples that can mislead the discriminator into thinking they are real, while the discriminator tries to correctly distinguish between real and synthetic samples.
The generator usually consists of a series of deconvolutional layers that gradually upsample the random input vector into a sample that is intended to resemble the training data. The discriminator usually consists of a series of convolutional layers that downsample the input image or sample into a lower-dimensional feature representation, followed by a few fully connected layers that compute the final prediction. The loss function used in GANs is typically the binary cross-entropy loss, which measures the difference between the predicted probabilities of the discriminator and the true labels (0 for synthetic samples and 1 for real samples). Other loss functions such as Wasserstein distance or hinge loss have been proposed to address some of the limitations of the binary cross-entropy loss. However, the original GAN suffers from the issue of gradient vanishing, which can lead to unstable training and poor sample quality. One of the main challenges of training GANs is the mode collapse problem, where the generator produces a limited variety of samples that are similar to each other, rather than generating diverse samples that cover the entire range of the training data. Several techniques have been proposed to overcome this problem, such as adding noise to the input of the discriminator, using different types of regularization, or using multi-scale or multi-modal architectures. To overcome this limitation, methods such as WGAN were introduced, which use the Wasserstein distance to measure the distance between the real and generated distributions.
The Wasserstein GAN (WGAN), proposed by Arjovsky et al. (2017), aims to overcome the limitations of the original GAN model by using the Wasserstein distance to measure the distance between the real and generated distributions. The objective of WGAN is to minimize the optimal transport cost function, which represents the minimum cost of transforming the generated distribution q(x) into the real distribution ˜p(x) through a series of small steps. The cost of each step is measured by the cost function c(x, y), which represents the distance between the samples x and y. By using the Wasserstein distance instead of the Jensen-Shannon divergence used in the original GAN, WGAN is able to provide more stable training and generate higher quality samples.
WGAN, which uses the Wasserstein distance instead of the Jensen-Shannon divergence used in the original GAN, provides more stable training and generates higher quality samples. WGAN also has other advantages, such as improved convergence properties and the ability to measure the distance between distributions more accurately. Overall, WGAN represents a significant advancement in the field of generative modeling and has been successfully applied in various applications, such as image generation, data augmentation, and domain adaptation. Its success has led to the development of several variants, such as Wasserstein GAN with Gradient Penalty (WGAN-GP; Gulrajani et al., 2017), which further improves the stability and efficiency of training.
Another widely used GAN variant in the medical field is CycleGAN, a type of unsupervised learning technique proposed by Zhu et al. (2017), which can learn the mapping between two different domains without any paired data. CycleGAN has several advantages, such as its ability to learn the mapping between two domains without the need for paired data and its ability to handle multimodal and many-to-many mappings. It has been successfully applied in various applications, including medical image analysis, such as image-to-image translation, segmentation, and registration. CycleGAN has also inspired the development of several variants, such as DualGAN (Yi et al., 2017), DiscoGAN (Kim et al., 2017), and UNIT (Liu et al., 2017), which further improve the performance and versatility of the original CycleGAN. The main idea behind CycleGAN is to use two generators and two discriminators to learn the mapping between the domains. The formula for CycleGAN is as follows:
The two generators in CycleGAN are used to generate images from one domain and then transform them into images from the other domain. The two discriminators are used to distinguish between the generated images and the real images from the other domain. The CycleGAN objective function includes two GAN losses, which encourage the generators to generate realistic images, and a cycle-consistency loss, which encourages the generators to learn a mapping between the two domains.
Overall, GANs have found useful applications in brain imaging and network analysis. They can generate synthetic data samples that resemble real data (Dar et al., 2019), enabling researchers to explore brain activity patterns and identify underlying structures. GANs can also augment data by generating synthetic samples to balance imbalanced classes in the dataset, improving deep learning performance in tasks such as image segmentation and classification (Gao et al., 2021). Also, GANs (Lei et al., 2020a) can generate new brain activity patterns (Zuo et al., 2021) in brain network analysis, which can be used to simulate brain activity under various conditions and understand how the network responds to different stimuli. GANs (Wang et al., 2020b) can also help model the relationships between different brain regions and predict the functional connectivity patterns of the brain.
Flow-based generative models are a type of deep generative model that can learn to generate new samples similar to a given dataset. Flow-based models are based on the concept of normalizing flows, which are transformations that can map a simple distribution (e.g., Gaussian) to a more complex distribution (e.g., the distribution of the training data). Flow-based models have been applied to a wide range of applications, such as image generation, video generation, text generation, and even molecular design. Several variations of flow-based models have been proposed, such as conditional flow-based models, which can generate samples conditioned on a given input, and autoregressive flow-based models, which can generate samples by sequentially generating each dimension of the sample.
Flow-based models consist of a series of invertible transformations that map a simple distribution to the distribution of the training data. The inverse of each transformation is also computable, which allows for efficient computation of the likelihood of the data and generation of new samples. The transformations can be learned using maximum likelihood estimation or other methods.
During training, the flow-based model learns to maximize the likelihood of the training data, which is typically computed using the change of variables formula and the likelihood of the simple distribution. The model can be trained using stochastic gradient descent or other optimization methods. It has several advantages over other types of generative models, such as explicit likelihood computation, efficient sampling, and the ability to perform exact inference. However, they also have some limitations, such as the requirement of invertible transformations, which can restrict the expressiveness of the model.
In summary, Flow-Based Generative Models offer a promising approach for modeling complex data distributions and have potential applications in brain imaging and brain network research. These models can accurately cluster brain activity patterns, identify the structure of the data, and generate synthetic data that resemble the real samples (Dong et al., 2022). Additionally, Flow-Based Models can be used to learn a lower-dimensional representation of the functional connectivity patterns in the brain, enabling researchers to identify relevant features for predicting network changes. The direct modeling of likelihood and the ability to generate novel samples make these models a powerful tool in understanding the underlying mechanisms of complex systems.
Diffusion models belong to the category of latent variable models in machine learning that utilize Markov chains and variational inference to discern the underlying structure of a dataset. They offer a promising avenue for deep generative modeling owing to their straightforward training process, robust expressive capacity, and ability to generate data via ancestral sampling without the prerequisite of a posterior distribution.
The optimization of the diffusion model culminates in training a neural network to predict the original image from any time step of the noise image as input, with the optimization objective being to minimize the prediction error. Moreover, the optimization of the noise-matching term in equation 15 can be approximated by minimizing the expected prediction error at each time step using random sampling.
In contrast to other deep generative models such as VAE, GAN, and normalizing flow, diffusion models offer unique advantages while overcoming several limitations and challenges. The training of VAEs can be challenging due to the difficulty in selecting the variational posterior, while GANs require an additional discriminator network, and normalizing flow models have limited expressive power. In contrast, diffusion models utilize the diffusion process of data points through the latent space to derive a solution that involves training only a generator with a simple objective function, without the need for training other networks.
In computer vision, diffusion models train neural networks to denoise images blurred with Gaussian noise by learning to reverse the diffusion process. Three examples of generic diffusion modeling frameworks used in computer vision include denoising diffusion probabilistic models, noise-conditioned score networks, and stochastic differential equations. In brain imaging and brain network analysis, diffusion models serve as a valuable tool for estimating the underlying structure of brain function and structure (Chung and Ye, 2022), which is essential for understanding the mechanisms of neurological disorders and diseases (Myronenko, 2018). By modeling the diffusion of data points through the latent space, diffusion models are capable of effectively capturing changes in brain connectivity over time and identifying regions critical to brain structure (Wolleb et al., 2022). Additionally, diffusion models can simulate brain activity under different conditions and predict how the brain network will respond to various stimuli.
Overall, diffusion models provide a valuable approach to modeling latent spaces in various fields, including computer vision, brain imaging, and brain network analysis. By offering an efficient and effective means of estimating the underlying structure of datasets, diffusion models can be a powerful tool for gaining insights into the spatiotemporal dynamics of large and complex systems.
In this section, tasks in brain imaging and brain network construction are specifically categorized and investigated in eight categories, including co-registration and super-resolution (shown in Figure 3), enhancement and classification (shown in Figure 4), segmentation and cross-modality (shown in Figure 5), and brain network analysis and brain decode (shown in Figure 6).
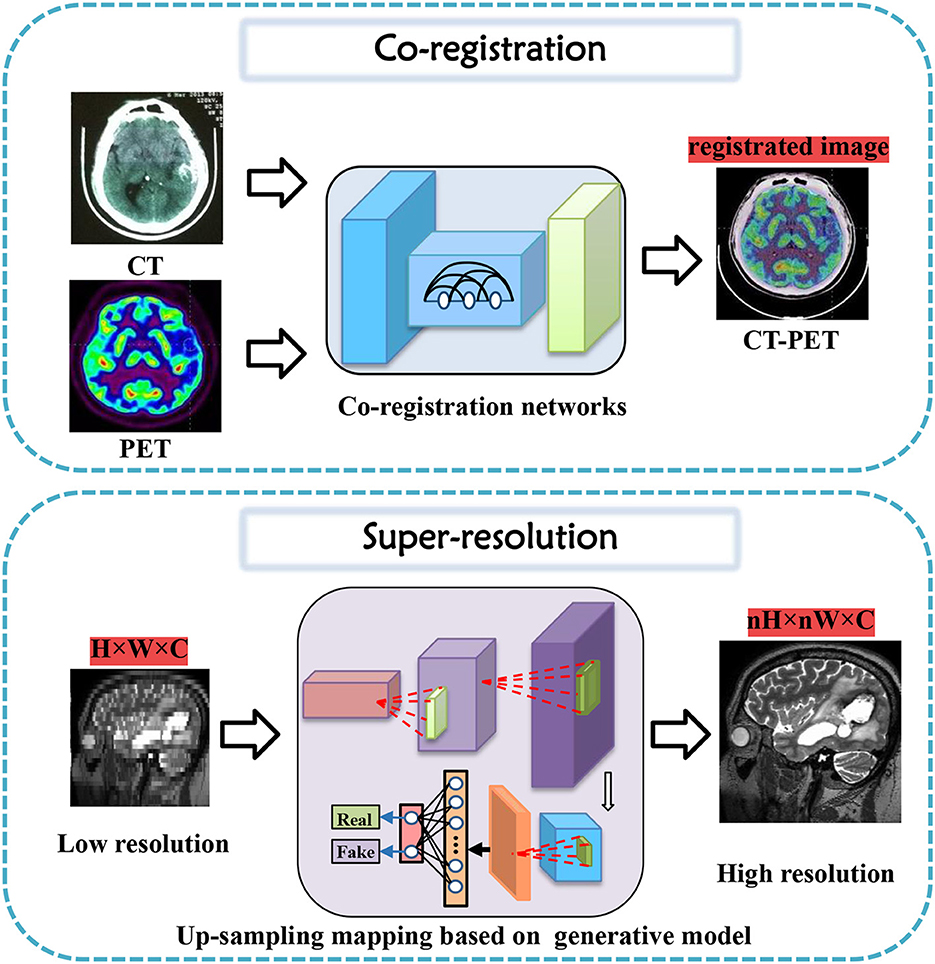
Figure 3. Co-registration and super-resolution task diagrams applying generative AI for brain imaging.
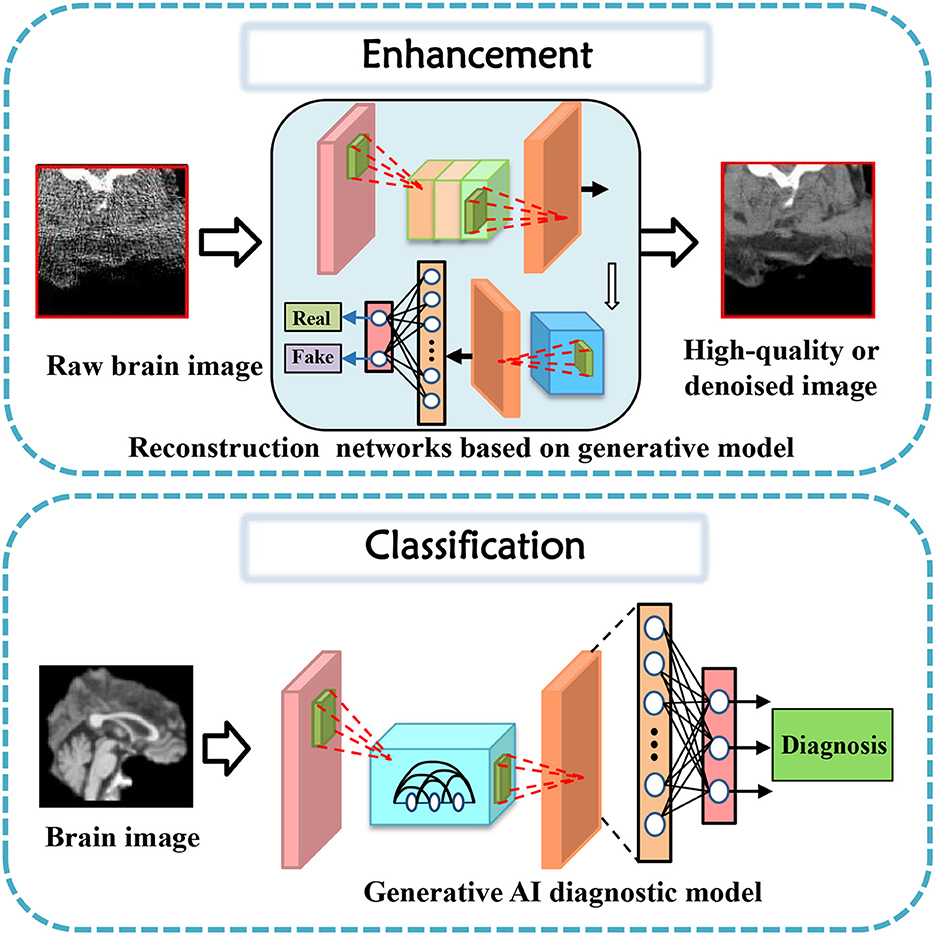
Figure 4. Enhancement and classification task diagrams applying generative AI for brain imaging.
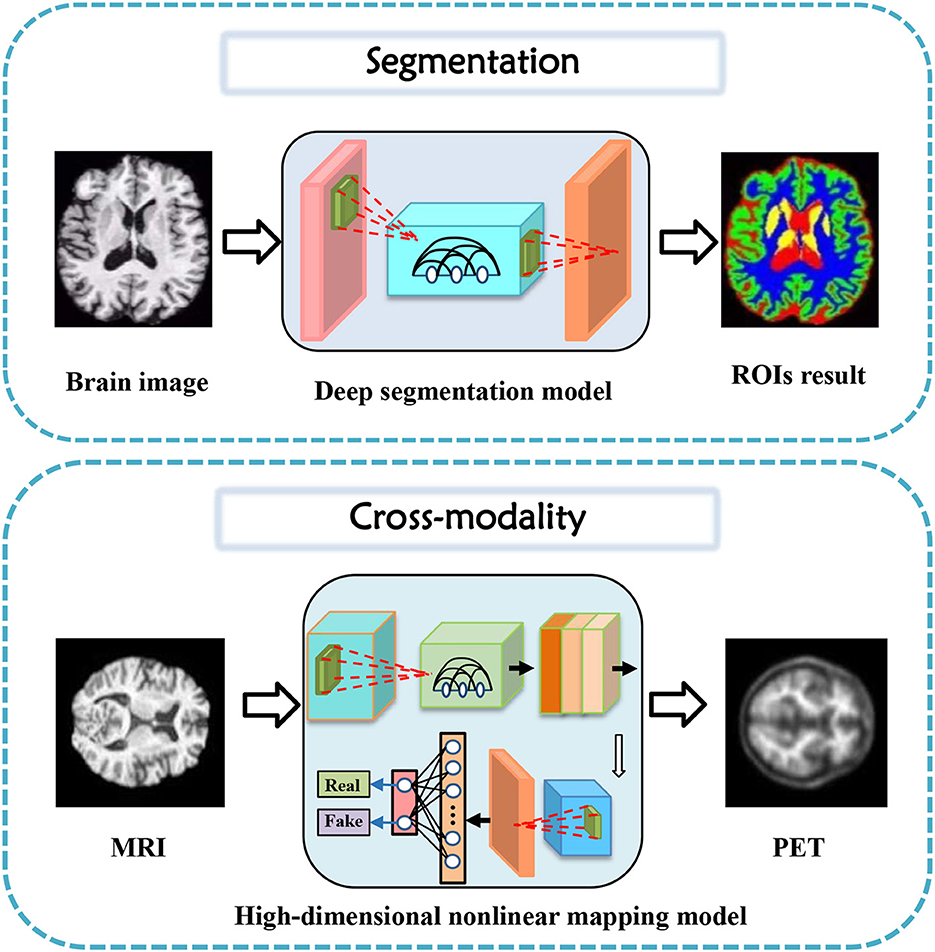
Figure 5. Segmentation and cross-modality task diagrams applying generative AI for brain imaging.

Figure 6. Brain network analysis and brain decode task diagrams applying generative AI for brain imaging.
Co-registration is a crucial step in medical image analysis to align images from different modalities or time points. However, it is a challenging task due to various factors, such as noise, artifacts, motion, and anatomical differences. Many innovative methods have been proposed to tackle these challenges and improve co-registration performance.
For instance, Sundar et al. (2021) proposed conditional GANs to address intra-frame motion problems in dynamic PET studies of the brain. Yang et al. (2020) proposed indirect multimodal image registration and completion by using synthetic CT images obtained from multi-contrast MRI. Kong et al. (2021) introduced RegGAN for image-to-image translation and registration which includes noise reduction. Furthermore, Wang B. et al. (2022) proposed invertible AC-flow for direct generation of attenuation-corrected PET images without CT or MR images. Apart from these deep learning-based methods, a diffusion-based image registration method called DiffuseMorph was introduced by Kim et al. (2022). This method overcomes the limitations of traditional and deep learning-based methods due to computational complexity and topological folding.
These proposed methods have shown promising results in improving co-registration performance in medical imaging. Future research can explore further advances to overcome the remaining challenges, such as reducing the time taken for co-registration while maintaining high accuracy and improving the robustness and generalization of existing solutions.
Research into high-resolution brain imaging has yielded promising results, with generative models proving to be a popular and effective approach (Sun et al., 2022). One such approach, as described in Song et al. (2020), involves using a GAN architecture with anatomical and spatial inputs for creating super-resolved brain PET images. According to the authors, the proposed GAN outperforms other deep learning models and penalized deconvolution techniques. Similarly, You et al. (2022) suggests using fine perceptive generative adversarial networks (FP-GANs) for high-resolution magnetic resonance imaging. This technique applies a sub-band generative adversarial network and sub-band attention for super-resolution in individual sub-bands.
These studies contribute to the growing body of literature on super-resolution tasks for brain imaging, with generative models emerging as promising solutions. The success of these models suggests that they could be applied to other high-resolution imaging tasks requiring greater detail and precision (Wicaksono et al., 2022). However, further research is needed to fully evaluate the performance and potential limitations of generative models for these tasks.
Data enhancement is a widely adopted approach in improving the performance of deep learning models for various medical image analysis tasks. Some studies cater to the task of data enhancement in medical tasks using generative AI. The first CycleGAN-based method for MR-to-CT synthesis proposed by Wolterink et al. (2017), shows that this technique can generate high-quality synthetic CT scans that are similar in appearance to real ones. Both the designed GAN model and novel loss function take enhancement tasks a step further in their performance (Dar et al., 2019).
Similarly, Yurt et al. (2021) proposed a multi-stream approach that integrates multiple source images to synthesize missing multi-contrast MRI images, outperforming other state-of-the-art methods. Zhan et al. (2021) proposed a Multi-scale Gate Mergence based GAN model that accurately diagnoses patients with corrupted image sequences by weighing different modalities across locations. Luo et al. (2021) proposed an edge-preserving MRI image synthesis GAN model, infusing an auxiliary edge image generation task to help preserve edge information and improve latent representation features, and an iterative multi-scale fusion module to further improve the quality of the synthesized target modality. Recently, Upadhyay et al. (2021) proposed a robust GAN-based framework that models an adaptive loss function to improve robustness to out-of-distribution (OOD)-noisy data and estimates per-voxel uncertainty in predictions for image-to-image translation across two real-world datasets in medical imaging applications. Luo et al. (2022) proposed an adaptive rectification-based GAN model with spectral constraint to synthesize high-quality standard-dose PET images from low-dose PET images, reducing radiation exposure while maintaining accurate diagnoses.
These studies demonstrate the promising potential of deep learning-based approaches and data enhancement in enhancing the quality and performance of medical image generation tasks.
Classification of brain diseases is a crucial task for early diagnosis and effective treatment. The advancements in deep learning techniques have led to the development of various generative models for the automatic classification of neuroimages. Recently, serval generative models were proposed to focus on brain disease classification tasks.
In 2019, Pan et al. (2019) propose a unified deep learning framework to jointly perform image synthesis and disease diagnosis using incomplete multi-modal neuroimaging data. The proposed method includes two networks: a Disease-Image Specific Neural Network (DSNN) to capture the spatial information of MRI/PET scans and a Feature-consistent Generative Adversarial Network (FGAN) to synthesize missing images by encouraging DSNN feature maps of synthetic images and their respective real images to be consistent. The method achieves state-of-the-art performance for Alzheimer's disease identification and mild cognitive impairment conversion prediction tasks. Besides, pattern expression offered complementary performance to biomarkers in predicting clinical progression, making these deep-learning-derived biomarkers promising tools for precision diagnostics and targeted clinical trial recruitment. Yang Z. et al. (2021) applied deep learning framework to longitudinal data and revealed two distinct progression pathways that were predictive of future neurodegeneration rates.
Indeed, there are several generative models that have been designed with a deeper consideration of prior settings for tasks such as biomarkers and clinical reports. Wang et al. (2020a) propose an ensemble of 3D convolutional neural networks (CNNs) with dense connections for automatic diagnosis of Alzheimer's disease (AD) and mild cognitive impairment (MCI). The proposed model was evaluated on the ADNI dataset using a probability-based fusion method that combines multiple architectures. Shin et al. (2020) propose a GAN-based approach for the diagnosis of Alzheimer's Disease (AD) using T1-weighted MRIs as input data. The authors incorporate AD diagnosis into the training objective to achieve better classification performance. This architecture shows state-of-the-art results for three- or four-class classification tasks involving MCI, normal cognition, or Alzheimer's disease. Kim et al. (2020) propose a GAN-based model for classifying Alzheimer's disease (AD) and normal cognitive condition (NC). The authors use slice-selective learning to reduce computational costs and extract unbiased features. The researchers trained the model using an 18F-fluorodeoxyglucose ([18F] FDG) PET/CT dataset obtained from the Alzheimer's Disease Neuroimaging Initiative database. The approach seems feasible when there are insufficient datasets available for training individual deep neural networks (Wang et al., 2018; Yu et al., 2020) with single-source training datasets.
Furthermore, like Baur et al. (2020) propose a practical method for unsupervised brain MRI anomaly detection in clinical scenarios using a CycleGAN-based style-transfer framework. The proposed approach involves mapping real healthy data to a distribution with lower entropy and suppressing anomalies by filtering high-frequency components during training. The experiments demonstrate that the proposed method outperforms existing methods on various metrics, such as F1 score, PRC AUC, and ROC AUC, thus demonstrating its potential for practical applications in clinical settings.
Therefore, generative models have demonstrated their potential in various classification tasks for brain diseases. These models can extract features that are not directly visible, thereby aiding in the early diagnosis and accurate classification of diseases.
Generative models have gained significant attention in the field of medical image segmentation for their capability of reducing the dependence on manually labeled data. This paper reviewed the recent advances in generative models for segmentation tasks, focusing on brain tumor segmentation (Myronenko, 2018). In 2019, Yuan et al. (2020) presented a 3D unified generative adversarial network, achieving any-to-any modality translation and multimodal segmentation through a single network based on the anatomical structure. Ding et al. (2021) proposed ToStaGAN, a two-stage generative adversarial neural network, for brain tumor segmentation, which incorporates coarse prediction maps with fine-grained extraction modules and dense skip connections. In 2022, Wang S. et al. (2022) introduced Consistent Perception Generative Adversarial Network (CPGAN), an alternative to deep learning algorithms with expensive labeled masks, demonstrating superior segmentation performance over other methods with less labeled data on Anatomical Tracings of Lesions After Stroke. Wu et al. (2021) presented an unsupervised brain tumor segmentation method called Symmetric-Driven Generative Adversarial Network (SD-GAN) in 2021, which utilizes inherent anatomical variations by learning a non-linear mapping between left and right brain images. SD-GAN outperforms state-of-the-art unsupervised methods, providing a promising solution to unsupervised segmentation tasks.
These studies demonstrate that generative models have become increasingly important for medical image segmentation owing to their ability to learn from unannotated data and promising performance in comparison to traditional supervised methods.
Cross-modality image synthesis has become an active research area in medical imaging, where the goal is to generate images in a target modality from the input in another modality. Several generative models have been proposed for this task, including variations of generative adversarial networks (GANs) and encoder-decoder models. In recent years, significant progress has been made in using generative models for cross-modality image synthesis in the brain.
One of the early works in this area introduced gEa-GAN and dEa-GAN by Yu et al. (2019), which integrated edge information to bridge the gap between different imaging modalities. The resulting synthesized images showed superior quality compared to several state-of-the-art methods, as demonstrated on various datasets. Another study (Hu et al., 2021) introduced Bidirectional GAN, which used a bidirectional mapping mechanism to embed diverse brain structural features into the high-dimensional latent space. The method achieved better quality in generating PET images than other models trained on the same dataset, while preserving diverse details of brain structures across different subjects. Other studies explored more challenging scenarios, such as Jiao et al. (2020) generating magnetic resonance (MR)-like images directly from clinical ultrasound (US) images of fetal brains and Sharma and Hamarneh (2019) synthesizing multiple modalities of neuroimaging data. The former study proposed an end-to-end trainable model that utilized shared latent features between US and MR data to generate realistic MR-like images, while the latter study introduced a multi-input, multi-output variant of GAN to synthesize sequences missing in brain MRI scans. The proposed models achieved promising results and demonstrate the feasibility of using generative models in clinical practice. Moreover, a bidirectional mapping mechanism is designed to embed the semantic information of PET images into the high-dimensional latent potential space for improving the visual quality of the cross-modal synthesized images (Hu et al., 2019, 2020a). The most attractive part is that the method can synthesize perceptually realistic PET images while preserving the different brain structures of different subjects.
Several other studies have also proposed novel generative models, including MouseGAN (Yu et al., 2021c) for segmenting mouse brain structures in MRI images and SC-GAN (Lan et al., 2021) for synthesizing multimodal 3D neuroimaging data. The former study achieved improved segmentation using modality-invariant information, while the latter used spectral normalization, feature matching, and self-attention modules to stabilize the training process and ensure optimization convergence. These studies have shown that generative models have the potential to improve existing neuroimaging analysis tasks and provide new tools for diagnosis and follow-up.
Finally, some studies have attempted to integrate generative models with disease diagnoses (Yang H. et al., 2021). Moreover, in neuroimaging data, One study (Pan et al., 2022) proposed a disease-image-specific deep learning framework that utilizes image-disease specificity to highlight different disease-relevant regions in the brain, with promising results on Alzheimer's Disease and mild cognitive impairment conversion prediction tasks. These studies highlight the potential of generative models to not only generate images of other modalities but also aid in downstream analysis and diagnoses using inter-modality information.
Brain network modeling is a critical research field in neuroscience that aims to understand the complex relationships among structural and functional connectivity patterns in the human brain. In recent years, deep learning has been increasingly used in brain network analysis as it shows promising results in predicting brain graphs, inferring effective connectivity, and diagnosing Alzheimer's disease using multimodal neuroimaging data. To this end, several deep learning frameworks have been proposed to generate reliable individual structural connectivity from functional connectivity, MultiGraphGAN, and MGCN-GAN proposed by Bessadok et al. (2020) and Zhang et al. (2020). These frameworks combine adversarial learning and topology preservation to generate high-quality brain graphs from limited data effectively. Some studies focused on inferring effective connectivity from functional MRI data, including EC-GAN and MGCN-GAN proposed by Liu et al. (2020), incorporate adversarial learning and graph convolutional networks to effectively infer brain structure-function relationships. Additionally, some studies aimed at diagnosing Alzheimer's disease using multimodal neuroimaging data, such as MRL-AHF and HGGAN proposed by Zuo et al. (2021) and Pan et al. (2021), which leverage adversarial learning and hypergraph representation to effectively integrate and represent multimodal data. Overall, deep learning frameworks have been shown to hold great potential in brain network modeling, rapidly advancing our understanding of brain structure-function relationships and improving the prediction accuracy of brain disorders, such as brain drug addiction (Gong et al., 2023). Future research in this area will likely continue to explore and develop new deep learning-based approaches to further enhance modeling accuracy and generalization performance.
Generative models have become a popular research focus in the field of brain decoding tasks, especially in the reconstruction of perceived images from fMRI signals. Baek et al. (2021) proposed a hierarchical deep neural network model of the ventral visual stream to explain the innate emergence of face-selectivity. VanRullen and Reddy (2019) applied a deep learning system to reconstruct face images from fMRI data, achieving accurate gender classification and decoding of visually similar inputs. Ren et al. (2021) proposed the Dual-Variational Autoencoder/Generative Adversarial Network framework, which outperforms state-of-the-art methods in terms of visual reconstruction accuracy. Chen et al. (2022) introduced the MinD-Vis framework, which uses a self-supervised representation of fMRI data and a latent diffusion model to reconstruct high-quality images with semantic details, outperforming state-of-the-art methods in semantic mapping and generation quality. Dado et al. (2022) presented a novel experimental paradigm, HYPER, for neural decoding of faces from brain recordings using generative adversarial networks, achieving the most accurate reconstructions of perception to date. These studies demonstrate the potential of generative models in brain decoding tasks, which can help advance our understanding of brain function and perception.
The application division of generative artificial intelligence methods in the field of brain image analysis is shown in Figure 7. The existing models mentioned above are divided according to tasks, and the names of the corresponding models are marked under the relevant tasks, which can be mainly divided into eight categories as shown in the figure. The most representative methods shown in the figure, the more research is optimized under this mainstream model. The four mainstream methods have different adaptation conditions for different tasks. In terms of coregistration, cross-modality, segmentation, classification, clustering, and super-scoring tasks, the optimization of the GAN model is significantly better than the other three mainstream models. The reason is that the GAN-based method can be well applied to brain image generation tasks. In brain network analysis and brain decoding tasks, the encoding and decoding structure of the VAE-based method will have more advantages. Flow-based models have relatively few applications and have a certain degree of application in super-resolution, brain decoding, and co-registration tasks. Diffusion models have high-quality generation effects and have been gradually used in various tasks of brain image analysis, and have achieved certain achievements.
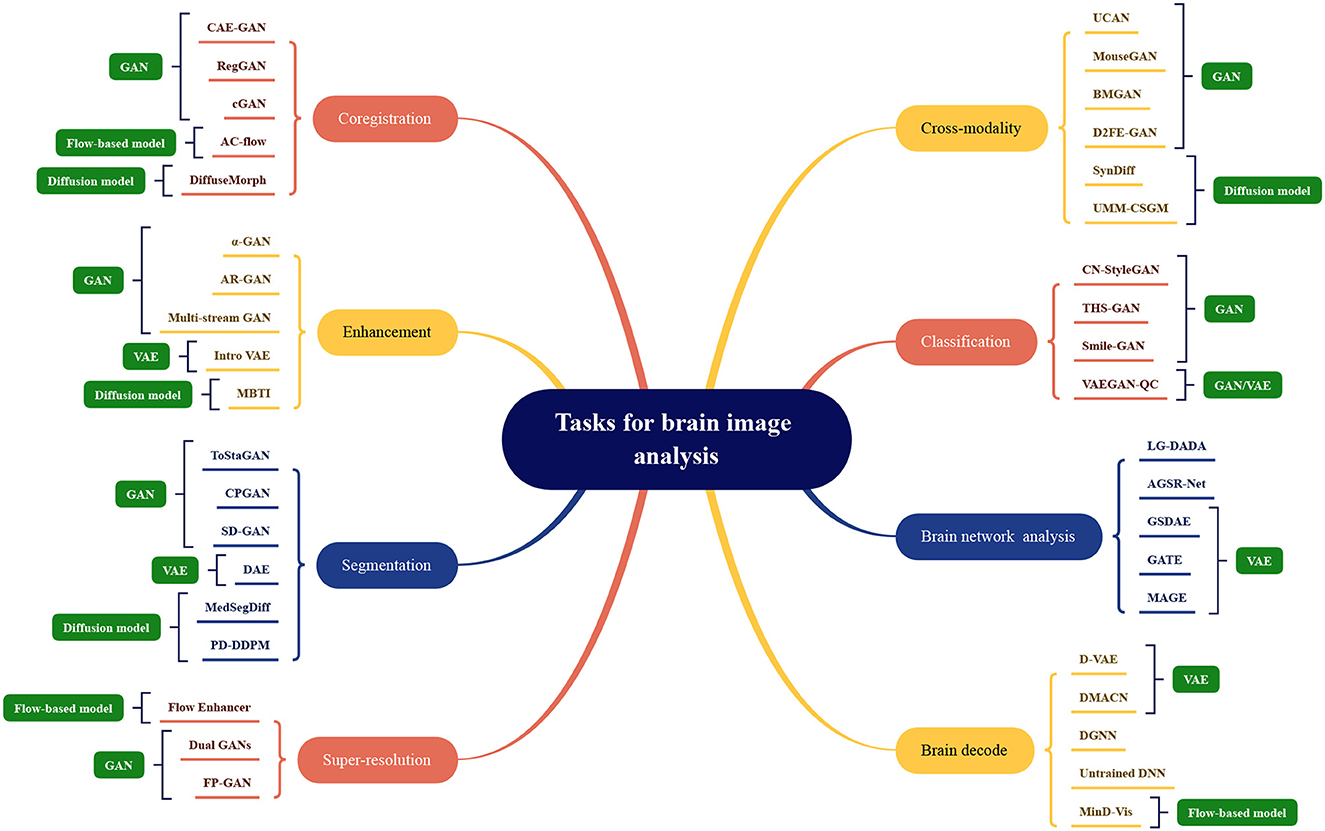
Figure 7. Model categorization map under different brain image analysis tasks. Coregistration: CAE-GAN (Yang et al., 2020), RegGAN (Kong et al., 2021), cGAN (Sundar et al., 2021), AC-flow (Wang B. et al., 2022), DiffuseMorph (Kim et al., 2022); Enhancement: α-GAN (Kwon et al., 2019), AR-GAN (Luo et al., 2022), Multi-stream GAN (Yurt et al., 2021), Intro VAE (Hirte et al., 2021), MBTI (Rouzrokh et al., 2022); Segmentation: ToStaGAN (Ding et al., 2021), CPGAN (Wang S. et al., 2022), SD-GAN (Wu et al., 2021), DAE (Bangalore Yogananda et al., 2022), MedSegDiff (Wu et al., 2022), PD-DDPM (Guo et al., 2022); Super-resolution: Flow Enhancer (Dong et al., 2022), Dual GANs (Song et al., 2020), FP-GAN (You et al., 2022); Cross-modality: UCAN (Zhou et al., 2021), MouseGAN (Yu et al., 2021c), BMGAN (Hu et al., 2021), D2FE-GAN (Zhan et al., 2022), SynDiff (Özbey et al., 2022), UMM-CSGM (Meng et al., 2022); Classification: CN-StyleGAN (Lee et al., 2022), THS-GAN (Yu et al., 2021a), Smile-GAN (Yang Z. et al., 2021), VAEGAN-QC (Mostapha et al., 2019); Brain network analysis: LG-DADA (Bessadok et al., 2021), AGSR-Net (Isallari and Rekik, 2021), GSDAE (Qiao et al., 2021), GATE (Liu M. et al., 2021), MAGE (Pervaiz et al., 2021); Brain decode: D-VAE (Ren et al., 2021), DMACN (Lu et al., 2021), DGNN (VanRullen and Reddy, 2019), Untrained DNN (Baek et al., 2021), MinD-Vis (Chen et al., 2022).
The domain of brain image analysis and brain network computing confronted many obstacles that have impeded the development of the field. In order to progress future research more effectively, this review delves into some significant challenges and expounds on them in the following:
Medical image datasets are generally much smaller than datasets in other fields, due to the challenging task of acquiring and annotating medical images. For example, for lung nodule detection tasks, due to the small number of lung nodules, the number of positive samples in the dataset is very small, and the size, shape, and position of lung nodules also vary greatly, making it difficult for algorithms to accurately detect lung nodules. Therefore, the small sample problem has become one of the major obstacles for machine learning algorithms in the field of medical imaging. In addition to methods such as meta-learning that can effectively solve the small sample problem, improvement can be done by using prompts to modify pre-trained models, utilizing prior knowledge, and model ensembles. For example, in lung nodule detection tasks, pre-trained models can be used to extract features and prompts can be used to guide the model on how to detect lung nodules. In addition, prior knowledge can be used to constrain the output of the model, such as constraining the size and shape of the output lung nodules. Finally, model ensembles can be used to improve algorithm robustness and generalization capabilities.
Medical scans or images are typically high-dimensional data types that contain large amounts of information. For example, in brain medical imaging, 3D MRI or fMRI is typically used to obtain brain structure and functional information. These data often contain millions of pixels or thousands of time points, so extracting meaningful, non-redundant, and non-overfitting features from such high-dimensional data is a new challenge for machine learning algorithms in the field of medical imaging. For the task of feature extraction from high-dimensional brain data, due to the complexity of brain structure and function, single modality feature extraction methods often have difficulty in extracting meaningful features. For example, in brain MRI images, tissue such as gray matter, white matter, and cerebrospinal fluid have different shapes and positions, so multi-modality feature analysis methods are required to extract meaningful features. In addition, as there are complex relationships between brain structure and function, multi-modality feature analysis methods are necessary to extract the relevant features between structure and function.
Generative models have been widely applied in the field of medical data generation. However, the generated modality data may suffer from the problems of unreliability or modality inconsistency. MRI and fMRI are common modalities in medical imaging. For MRI image generation, there may be problems such as insufficient reconstructed image resolution, lacking local details, and artifacts. In fMRI data generation, there may be signal suppression in local regions, interference from noise, and motion artifacts. In recent years, the generation of genetic data has also had a significant impact on the medical field. One major problem in generating genetic data is that the generated data may differ from real genetic data because real genetic data are produced by many genetic factors working together. Thus, when generating genetic data, multiple factors must be considered to improve the realism and consistency of generated data. While problems that could occur in extensively experimented image modalities may be easily identified and optimized, this realism problem can be hard to discern in complex or abstract modalities. Ultimately, such erroneously generated data may lead to incorrect diagnoses or treatments. To address this problem, researchers have proposed many methods, such as introducing special loss functions, such as cycle consistency in the model process in the image domain, and introducing strategies such as multi-modality joint and multi-task learning to improve the generative quality and realism of modal data.
The lack of universally accepted validation standards for evaluating the performance of machine learning models in the field of medical imaging makes it difficult to compare results from different studies or ensure the best performance of the models. As the structure of the human brain is complex and diverse, specific to the generation task of brain diseases, more requirements are raised, and large differences exist between different regions, thus how to evaluate the performance of generative models to produce meaningful generative models. For example, for the generation task of MRI images, evaluation metrics can use traditional image quality evaluation indicators such as PSNR, SSIM, FID, etc., but these indicators cannot fully reflect the performance of the model in medical applications, such as whether the model generates anatomy structure consistent with real data, and whether it can better display lesion areas. Therefore, researchers have proposed some specific evaluation indicators, such as similarity of structure with real images, neuron activation, diagnostic accuracy, etc., to more accurately evaluate the performance of generative models. However, the universality and comparability of these indicators still need more experimental verification and exploration in order to be better applied to different tasks and datasets.
The issue of model interpretability is another challenge that must be addressed in medical image generation models. The model needs to have a certain level of interpretability so that physicians and researchers can understand the model's predictions and generate results. In the task of generating brain disease, model interpretability is particularly critical. Doctors need to be able to understand the relationship between the abnormal structures in the generated images and the underlying diseases, in order to make accurate diagnoses and treatment decisions. During the generation of images, the model may introduce factors such as image noise and artifacts, which can seriously affect medical diagnosis. To address these issues, interpretability techniques can provide valuable assistance. For example, visualization techniques can help doctors and researchers better understand the generated results and identify abnormal factors by generating comparative images and visualizing the internal feature maps of the model. In addition, model interpretability can also be achieved by adding interpretation layers or using interpretable models. However, there are some limitations to the use of data in the scenario of generating brain diseases. For example, due to privacy issues involving patients, medical imaging data is often highly sensitive and therefore difficult to obtain large-scale datasets directly. In addition, the different brain structures of different patients pose a challenge to the generated results of the model. Therefore, when generating brain diseases, it is necessary to consider the balance between data usage scenarios and model interpretability in order to obtain more accurate and interpretable results.
There are still inescapable limitations to brain imaging computing using generative AI. Firstly, before the application of the synthetic brain image data set for training, if the differences between the synthetic data set and the real data set are not fully studied, the generated results will be biased. Secondly, most current generative brain image analysis methods may generate illogical “unnatural data" due to the lack of labels and causal features in the generating process. The robustness and reliability of the algorithm may be impacted. Thirdly, in the process of model training, it is possible to remember the distribution of original training samples. If the original training sample can be reversely inferred from the synthesized data, there will be “implicit privacy" leakage problem, and how to protect privacy more closely is still a question to be explored.
New generative methods in brain network research are likely to find applications in both basic and clinical research. In the coming years, generative learning and signal processing techniques will remain essential tools for furthering our understanding of the brain. This paper presents three perspectives on future approaches to brain network research:
The application of generative models in brain circuit research is gaining more attention. Through the utilization of generative models, researchers are able to extract significant information about neural circuits from brain data. In the field of neuroscience, neural circuits are key elements for understanding brain function and are crucial for regulating various cognitive and affective behaviors. Deep learning can assist in revealing the intricate structure, profound functionality, and impact of the brain. Generative models can support neural circuit research by learning data features in brain circuits. In particular, generative models can be employed to generate, transform, and improve neuroimaging data, consequently creating novel and high-quality data to facilitate a more profound comprehension of neural circuits. Furthermore, generative models can serve as a data augmentation technique to diversify the limited neural circuit data samples, which can boost both training and disease diagnosis efficiency. Moreover, this technique can simulate and generate experiments related to the connection and variation of neural circuits among patients, ultimately resulting in more experimental evidence and predictive capacity for neural circuit research, therefore yielding more information for disease diagnosis and treatment.
In the field of brain disorders, exploration of potential treatment options is a common practice. Generative models are capable of assisting in the comprehension of neural regulation and localization by producing intricate images that reflect the interconnectivity between different regions of the brain. Neural regulation denotes the procedure through which the brain controls behavior and emotions by moderating the excitatory and inhibitory activities of neurons. In neuroscience, generative models can simulate and forecast complex neural regulation processes. These models are instrumental in comprehending the mechanisms of neural regulation during brain development, deducing the reciprocal interaction between neurons and synapses, and predicting the patterns of connectivity between distinct neurons. Furthermore, synthetic neural imaging data is useful in providing researchers with a better appreciation of macroscopic neural regulation patterns. To pinpoint the location and function of particular brain areas, researchers can input significant image data into a generative model to learn the features of brain structures and more precisely localize brain regions. In functional connectivity analysis, generative models can generate hypothetical functional connectivity data and compare it with actual data to identify the links between various brain regions. The identification of possible targets for the treatment of brain-related disorders involves investigating the associations between the functions of neurons, synapses, and specific diseases. Generative models, as tools for data analysis and prediction, can effectively learn features and patterns automatically from vast amounts of neural data, and aid in target identification for the moderation or treatment of such diseases. Thus, generative models can enable the comprehension of neural regulation and brain localization, facilitate the search for targets and solutions to treat brain disorders, and ultimately improve patients' quality of life.
Neurodegenerative diseases, particularly Alzheimer's disease, are caused by damage to neurons and synapses in the brain, resulting in declines in cognitive and memory function and eventually leading to dementia. Studies have shown that generative models can forecast the speed of a patient's cognitive function decline, aiding physicians in early disease diagnosis. These models can also assimilate prior knowledge on diverse physiological, neural, cognitive, and behavioral processes, such as visual information processing, perception, language, and memory cognition. Generative models have helped in analyzing the onset mechanism of the disease and developing individualized treatment plans. Consequently, they are expected to become pivotal tools for exploring and comprehending brain mechanisms, with the potential to boost the precision of neurodegenerative disease diagnosis and treatment (Jing et al., 2022).
Population-based multi-scale brain research is a prominent focus in neuroscience (Betzel and Bassett, 2017). Its goal is to integrate information from multiple levels to understand the structure and function of the brain, establish connections between them, and gain insights into the working principles of the brain. Macro-level research investigates the overall structure and function of the brain, while micro-level research focuses on the cellular-level structure and function of neurons and synapses. Meso-scale research investigates small structures, such as cortical columns, connections, and neuronal clusters. Genomics studies the influence of genes on the brain's structure and function. Generative models integrate multiple data sources to reveal the complex mechanisms of the brain and explore the interactions between neurons and brain regions, providing a comprehensive view of the brain network. They can also predict gene expression data, diagnose and treat individual differences in diseases. Although the use of generative models in the study of the brain is still in its early stages, the accumulation of data and technological advances are expected to expand their usage.
These approaches will help build a comprehensive and accurate representation of the human brain and enable the discovery of new insights across neurological and psychiatric disorders.
This article provides a review of generative artificial intelligence for brain image computing and brain network computing. Generative AI can be divided into four main methods: variational autoencoder (VAE), generative adversarial network (GAN), flow-based model, and diffusion model. These models offer a promising solution for analyzing and interpreting large-scale brain imaging data. Generative AI has enabled researchers to gain a better understanding of the brain's physical basis and how it adapts to various cognitive activities in the field of brain imaging. In the context of brain network computing, generative AI can be used to reconstruct the topological connectivity of brain networks. However, there are limitations associated with using generative AI for analyzing brain imaging data. For instance, medical imaging data is often highly sensitive due to privacy issues involving patients, making it difficult to obtain large-scale datasets directly. Additionally, different brain structures of different patients pose a challenge to the generated results of the model. Therefore, when using generative AI techniques to generate brain diseases or analyze large-scale medical imaging datasets, it is necessary to balance data usage scenarios and model interpretability in order to obtain more accurate and interpretable results. In conclusion, generative AI has broad application prospects in brain imaging and brain network, which can help to better understand the internal function and structure of the brain, promote the diagnosis and treatment of brain diseases, and provide new opportunities and methods for neuroscience research.
SW and YH proposed the idea and co-managed the project. YH, SW, and CG co-designed the framework. CG, CJ, XC, CP, GH, SW, and YH co-wrote the manuscript. MN and AS supported the project and offered resources to accomplish this research. All authors read, contributed to revision, and approved the manuscript.
This work was supported by the National Natural Science Foundations of China under Grant 62172403, the Distinguished Young Scholars Fund of Guangdong under Grant 2021B1515020019, the Excellent Young Scholars of Shenzhen under Grant RCYX20200714114641211, and Shenzhen Key Basic Research Projects under Grant JCYJ20200109115641762.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Allen, E. A., Damaraju, E., Plis, S. M., Erhardt, E. B., Eichele, T., and Calhoun, V. D. (2014). Tracking whole-brain connectivity dynamics in the resting state. Cereb. Cortex 24, 663–676. doi: 10.1093/cercor/bhs352
Arjovsky, M., Chintala, S., and Bottou, L. (2017). “Wasserstein generative adversarial networks,” in International Conference on Machine Learning (Sydney: PMLR), 214–223.
Baek, S., Song, M., Jang, J., Kim, G., and Paik, S.-B. (2021). Face detection in untrained deep neural networks. Nat. Commun. 12, 1–15. doi: 10.1038/s41467-021-27606-9
Bangalore Yogananda, C. G., Das, Y., Wagner, B. C., Nalawade, S. S., Reddy, D., Holcomb, J., et al. (2022). “Disparity autoencoders for multi-class brain tumor segmentation,” in International MICCAI Brainlesion Workshop (Singapore: Springer), 116–124.
Bassett, D. S., and Sporns, O. (2017). Network neuroscience. Nat. Neurosci. 20, 353–364. doi: 10.1038/nn.4502
Baur, C., Graf, R., Wiestler, B., Albarqouni, S., and Navab, N. (2020). “Steganomaly: inhibiting cyclegan steganography for unsupervised anomaly detection in brain MRI,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Lima: Springer), 718–727. doi: 10.1007/978-3-030-59713-9_69
Bessadok, A., Mahjoub, M. A., and Rekik, I. (2020). “Topology-aware generative adversarial network for joint prediction of multiple brain graphs from a single brain graph,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Lima: Springer), 551–561.
Bessadok, A., Mahjoub, M. A., and Rekik, I. (2021). Brain graph synthesis by dual adversarial domain alignment and target graph prediction from a source graph. Med. Image Anal. 68, 101902. doi: 10.1016/j.media.2020.101902
Betzel, R. F., and Bassett, D. S. (2017). Multi-scale brain networks. Neuroimage 160, 73–83. doi: 10.1016/j.neuroimage.2016.11.006
Calhoun, V. D., Miller, R., Pearlson, G., and Adalı, T. (2014). The chronnectome: time-varying connectivity networks as the next frontier in fMRI data discovery. Neuron 84, 262–274. doi: 10.1016/j.neuron.2014.10.015
Chen, Z., Qing, J., Xiang, T., Yue, W. L., and Zhou, J. H. (2022). Seeing beyond the brain: conditional diffusion model with sparse masked modeling for vision decoding. arXiv.
Cheng, J., Gao, M., Liu, J., Yue, H., Kuang, H., Liu, J., et al. (2021). Multimodal disentangled variational autoencoder with game theoretic interpretability for glioma grading. IEEE J. Biomed. Health Informat. 26, 673–684. doi: 10.1109/JBHI.2021.3095476
Chung, H., and Ye, J.-C. (2022). Score-based diffusion models for accelerated MRI. Med. Image Anal. 80, 102479. doi: 10.1016/j.media.2022.102479
Cui, Z., Zhong, S., Xu, P., He, Y., and Gong, G. (2013). Panda: a pipeline toolbox for analyzing brain diffusion images. Front. Hum. Neurosci. 7, 42. doi: 10.3389/fnhum.2013.00042
Dado, T., Güçlütürk, Y., Ambrogioni, L., Ras, G., Bosch, S., van Gerven, M., et al. (2022). Hyperrealistic neural decoding for reconstructing faces from fMRI activations via the GAN latent space. Sci. Rep. 12, 1–9. doi: 10.1038/s41598-021-03938-w
Dar, S. U., Yurt, M., Karacan, L., Erdem, A., Erdem, E., and Çukur, T. (2019). Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Trans. Med. Imaging 38, 2375–2388. doi: 10.1109/TMI.2019.2901750
Ding, Y., Zhang, C., Cao, M., Wang, Y., Chen, D., Zhang, N., et al. (2021). Tostagan: an end-to-end two-stage generative adversarial network for brain tumor segmentation. Neurocomputing 462, 141–153. doi: 10.1016/j.neucom.2021.07.066
Dong, S., Hangel, G., Chen, E. Z., Sun, S., Bogner, W., Widhalm, G., et al. (2022). “Flow-based visual quality enhancer for super-resolution magnetic resonance spectroscopic imaging,” in MICCAI Workshop on Deep Generative Models (Springer), 3–13.
Gao, X., Shi, F., Shen, D., and Liu, M. (2021). Task-induced pyramid and attention GAN for multimodal brain image imputation and classification in Alzheimers disease. IEEE J. Biomed. Health Informat. 26, 36–43. doi: 10.1109/JBHI.2021.3097721
Gong, C., Chen, X., Mughal, B., and Wang, S. (2023). Addictive brain-network identification by spatial attention recurrent network with feature selection. Brain Informat. 10, 1–11. doi: 10.1186/s40708-022-00182-4
Gong, C., Xue, B., Jing, C., He, C.-H., Wu, G.-C., Lei, B., et al. (2022). Time-sequential graph adversarial learning for brain modularity community detection. Math. Biosci. Eng. 19, 13276–13293. doi: 10.3934/mbe.2022621
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). “Generative adversarial nets,” in Advances in Neural Information Processing Systems, eds Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Q. Weinberger (Montreal, QC: Curran Associates, Inc.), 2672–2680.
Gui, X., Chuansheng, C., Zhong-Lin, L., and Qi, D. (2010). Brain imaging techniques and their applications in decision-making research. Xin Li Xue Bao 42, 120. doi: 10.3724/SP.J.1041.2010.00120
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. C. (2017). Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 30, 5769–5779. doi: 10.5555/3295222.3295327
Guo, X., Yang, Y., Ye, C., Lu, S., Xiang, Y., and Ma, T. (2022). Accelerating diffusion models via pre-segmentation diffusion sampling for medical image segmentation. arXiv.
Hirte, A. U., Platscher, M., Joyce, T., Heit, J. J., Tranvinh, E., and Federau, C. (2021). Realistic generation of diffusion-weighted magnetic resonance brain images with deep generative models. Magn. Reson. Imaging 81, 60–66. doi: 10.1016/j.mri.2021.06.001
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 33, 6840–6851. doi: 10.5555/3495724.3496298
Hu, S., Lei, B., Wang, S., Wang, Y., Feng, Z., and Shen, Y. (2021). Bidirectional mapping generative adversarial networks for brain mr to pet synthesis. IEEE Trans. Med. Imaging 41, 145–157. doi: 10.1109/TMI.2021.3107013
Hu, S., Shen, Y., Wang, S., and Lei, B. (2020a). “Brain MR to pet synthesis via bidirectional generative adversarial network,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Cham: Springer), 698–707.
Hu, S., Yu, W., Chen, Z., and Wang, S. (2020b). “Medical image reconstruction using generative adversarial network for Alzheimer's disease assessment with class-imbalance problem,” in 2020 IEEE 6th International Conference on Computer and Communications (ICCC) (Chengdu: IEEE), 1323–1327.
Hu, S., Yuan, J., and Wang, S. (2019). “Cross-modality synthesis from MRI to pet using adversarial u-net with different normalization,” in 2019 International Conference on Medical Imaging Physics and Engineering (ICMIPE) (IEEE), 1–5.
Isallari, M., and Rekik, I. (2021). Brain graph super-resolution using adversarial graph neural network with application to functional brain connectivity. Med. Image Anal. 71, 102084. doi: 10.1016/j.media.2021.102084
Jiao, J., Namburete, A. I. L., Papageorghiou, A. T., and Noble, J. A. (2020). Self-supervised ultrasound to MRI fetal brain image synthesis. IEEE Trans. Med. Imaging 39, 4413–4424. doi: 10.1109/TMI.2020.3018560
Jing, C., Gong, C., Chen, Z., Lei, B., and Wang, S. (2022). TA-GAN: transformer-driven addiction-perception generative adversarial network. Neural Comp. Appl. 35, 1–13. doi: 10.1007/s00521-022-08187-0
Joyce, J. M. (2011). “Kullback-leibler divergence,” in International Encyclopedia of Statistical Science (Springer), 720–722.
Kim, B., Han, I., and Ye, J. C. (2022). “Diffusemorph: Unsupervised deformable image registration using diffusion model,” in European Conference on Computer Vision (Glasgow: Springer), 347–364.
Kim, H. W., Lee, H. E., Lee, S., Oh, K. T., Yun, M., and Yoo, S. K. (2020). Slice-selective learning for Alzheimer's disease classification using a generative adversarial network: a feasibility study of external validation. Eur. J. Nucl. Med. Mol. Imag. 47, 2197–2206. doi: 10.1007/s00259-019-04676-y
Kim, T., Cha, M., Kim, H., Lee, J. K., and Kim, J. (2017). “Learning to discover cross-domain relations with generative adversarial networks,” in International Conference on Machine Learning (Sydney, NSW: PMLR), 1857–1865.
Kong, L., Lian, C., Huang, D., Hu, Y., and Zhou, Q. (2021). Breaking the dilemma of medical image-to-image translation. Adv. Neural Inf. Process. Syst. 34, 1964–1978.
Kwon, G., Han, C., and Kim, D.-S. (2019). “Generation of 3D brain MRI using auto-encoding generative adversarial networks,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Shenzhen: Springer), 118–126.
Lan, H., Initiative, A. D. N., Toga, A. W., and Sepehrband, F. (2021). Three-dimensional self-attention conditional GAN with spectral normalization for multimodal neuroimaging synthesis. Magn. Resonan. Med. 86, 1718–1733. doi: 10.1002/mrm.28819
Lee, S., Jeong, B., Kim, M., Jang, R., Paik, W., Kang, J., et al. (2022). Emergency triage of brain computed tomography via anomaly detection with a deep generative model. Nat. Commun. 13, 1–11. doi: 10.1038/s41467-022-31808-0
Lei, B., Liang, E., Yang, M., Yang, P., Zhou, F., Tan, E.-L., et al. (2022a). Predicting clinical scores for Alzheimer's disease based on joint and deep learning. Expert Syst. Appl. 187, 115966. doi: 10.1016/j.eswa.2021.115966
Lei, B., Xia, Z., Jiang, F., Jiang, X., Ge, Z., Xu, Y., et al. (2020a). Skin lesion segmentation via generative adversarial networks with dual discriminators. Med. Image Anal. 64, 101716. doi: 10.1016/j.media.2020.101716
Lei, B., Yang, M., Yang, P., Zhou, F., Hou, W., Zou, W., et al. (2020b). Deep and joint learning of longitudinal data for Alzheimer's disease prediction. Pattern Recognit. 102, 107247. doi: 10.1016/j.patcog.2020.107247
Lei, B., Zhang, Y., Liu, D., Xu, Y., Yue, G., Cao, J., et al. (2022b). Longitudinal study of early mild cognitive impairment via similarity-constrained group learning and self-attention based SBI-LSTM. Knowledge-Based Systems 254:109466. doi: 10.1016/j.knosys.2022.109466
Liu, J., Ji, J., Xun, G., Yao, L., Huai, M., and Zhang, A. (2020). EC-GAN: inferring brain effective connectivity via generative adversarial networks. Proc. AAAI Conf. Artif. Intell. 34, 4852–4859. doi: 10.1609/aaai.v34i04.5921
Liu, M., Zhang, Z., and Dunson, D. B. (2021). Graph auto-encoding brain networks with applications to analyzing large-scale brain imaging datasets. Neuroimage 245, 118750–118750. doi: 10.1016/j.neuroimage.2021.118750
Liu, M.-Y., Breuel, T., and Kautz, J. (2017). Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 30, 700–708. doi: 10.1007/978-3-319-70139-4
Liu, Y., Liu, J., and Wang, S. (2021). “Effective distributed learning with random features: Improved bounds and algorithms,” in International Conference on Learning Representations (Vienna).
Lu, H., Liu, S., Wei, H., Chen, C., and Geng, X. (2021). Deep multi-kernel auto-encoder network for clustering brain functional connectivity data. Neural Netw. 135, 148–157. doi: 10.1016/j.neunet.2020.12.005
Lundervold, A. S., and Lundervold, A. (2019). An overview of deep learning in medical imaging focusing on MRI. Zeitschr. Med. Phys. 29, 102–127. doi: 10.1016/j.zemedi.2018.11.002
Luo, Y., Nie, D., Zhan, B., Li, Z., Wu, X., Zhou, J., et al. (2021). Edge-preserving MRI image synthesis via adversarial network with iterative multi-scale fusion. Neurocomputing 452, 63–77. doi: 10.1016/j.neucom.2021.04.060
Luo, Y., Zhou, L., Zhan, B., Fei, Y., Zhou, J., Wang, Y., et al. (2022). Adaptive rectification based adversarial network with spectrum constraint for high-quality pet image synthesis. Med. Image Anal. 77, 102335. doi: 10.1016/j.media.2021.102335
Meng, X., Gu, Y., Pan, Y., zhuan Wang, N., Xue, P., Lu, M., et al. (2022). A novel unified conditional score-based generative framework for multi-modal medical image completion. arXiv.
Mo, L., and Wang, S.-Q. (2009). A variational approach to nonlinear two-point boundary value problems. Nonlinear Anal. Theory Methods Appl. 71, 834–838. doi: 10.1016/j.na.2008.12.006
Mostapha, M., Prieto, J. C., Murphy, V., Girault, J. B., Foster, M., Rumple, A., et al. (2019). “Semi-supervised VAE-GAN for out-of-sample detection applied to MRI quality control,” in MICCAI (Shenzhen).
Myronenko, A. (2018). “3D MRI brain tumor segmentation using autoencoder regularization,” in International MICCAI Brainlesion Workshop (Granada: Springer), 311–320.
Özbey, M., Dalmaz, O., Dar, S. U., Bedel, H. A., Şaban Özturk, Güngör, A., and Çukur, T. (2022). Unsupervised medical image translation with adversarial diffusion models. arXiv.
Pan, J., Lei, B., Shen, Y., Liu, Y., Feng, Z., and Wang, S. (2021). “Characterization multimodal connectivity of brain network by hypergraph GAN for Alzheimer's disease analysis,” in PRCV2021, 467–478.
Pan, Y., Liu, M., Lian, C., Xia, Y., and Shen, D. (2019). “Disease-image specific generative adversarial network for brain disease diagnosis with incomplete multi-modal neuroimages,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Shenzhen: Springer), 137–145.
Pan, Y., Liu, M., Xia, Y., and Shen, D. (2022). Disease-image-specific learning for diagnosis-oriented neuroimage synthesis with incomplete multi-modality data. IEEE Trans. Pattern Anal. Mach. Intell. 44, 6839–6853. doi: 10.1109/TPAMI.2021.3091214
Pervaiz, U., Vidaurre, D., Gohil, C., Smith, S. M., and Woolrich, M. W. (2021). Multi-dynamic modelling reveals strongly time-varying resting fMRI correlations. Med. Image Anal. 77, 102366. doi: 10.1101/2021.06.23.449584
Qiao, C., Hu, X.-Y., Xiao, L., Calhoun, V. D., and Wang, Y.-P. (2021). A deep autoencoder with sparse and graph laplacian regularization for characterizing dynamic functional connectivity during brain development. Neurocomputing 456, 97–108. doi: 10.1016/j.neucom.2021.05.003
Ren, Z., Li, J., Xue, X., Li, X., Yang, F., Jiao, Z., et al. (2021). Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning. Neuroimage 228, 117602. doi: 10.1016/j.neuroimage.2020.117602
Rezende, D. J., and Mohamed, S. (2015). “Variational inference with normalizing flows,” in International Conference on Machine Learning (Lille: PMLR), 1530–1538.
Rouzrokh, P., Khosravi, B., Faghani, S., Moassefi, M., Vahdati, S., and Erickson, B. J. (2022). Multitask brain tumor inpainting with diffusion models: a methodological report. arXiv.
Sharma, A., and Hamarneh, G. (2019). Missing MRI pulse sequence synthesis using multi-modal generative adversarial network. IEEE Trans. Med. Imaging 39, 1170–1183. doi: 10.1109/TMI.2019.2945521
Shin, H.-C., Ihsani, A., Xu, Z., Mandava, S., Sreenivas, S. T., Forster, C., et al. (2020). “Gandalf: Generative adversarial networks with discriminator-adaptive loss fine-tuning for Alzheimer's disease diagnosis from MRI,” in Medical Image Computing and Computer Assisted Intervention-MICCAI 2020 (Cham. Springer International Publishing), 688–697.
Song, T.-A., Chowdhury, S. R., Yang, F., and Dutta, J. (2020). Pet image super-resolution using generative adversarial networks. Neural Netw. 125, 83–91. doi: 10.1016/j.neunet.2020.01.029
Sun, L., Chen, J., Xu, Y., Gong, M., Yu, K., and Batmanghelich, K. (2022). Hierarchical amortized GAN for 3D high resolution medical image synthesis. IEEE J. Biomed. Health Informat. 26, 3966–3975. doi: 10.1109/JBHI.2022.3172976
Sundar, L. K. S., Iommi, D., Muzik, O., Chalampalakis, Z., Klebermass, E.-M., Hienert, M., et al. (2021). Conditional generative adversarial networks aided motion correction of dynamic 18F-FDG pet brain studies. J. Nucl. Med. 62, 871–879. doi: 10.2967/jnumed.120.248856
Tezcan, K. C., Baumgartner, C. F., Luechinger, R., Pruessmann, K. P., and Konukoglu, E. (2017). MR image reconstruction using deep density priors. IEEE Trans. Med. Imag. 38, 1633–1642. doi: 10.1109/TMI.2018.2887072
Upadhyay, U., Sudarshan, V. P., and Awate, S. P. (2021). “Uncertainty-aware GAN with adaptive loss for robust MRI image enhancement,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (Montreal, QC), 3255–3264.
VanRullen, R., and Reddy, L. (2019). Reconstructing faces from fMRI patterns using deep generative neural networks. Commun. Biol. 2, 1–10. doi: 10.1038/s42003-019-0438-y
Wang, B., Lu, L., and Liu, H. (2022). “Invertible ac-flow: direct attenuation correction of pet images without ct or mr images,” in 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI) (Kolkata: IEEE), 1–4.
Wang, J., Wang, X., Xia, M., Liao, X., Evans, A., and He, Y. (2015). GRETNA: a graph theoretical network analysis toolbox for imaging connectomics. Front. Hum. Neurosci. 9, 386. doi: 10.3389/fnhum.2015.00386
Wang, S., Chen, Z., You, S., Wang, B., Shen, Y., and Lei, B. (2022). Brain stroke lesion segmentation using consistent perception generative adversarial network. Neural Comp. Appl. 34, 8657–8669. doi: 10.1007/s00521-021-06816-8
Wang, S., Shen, Y., Chen, W., Xiao, T., and Hu, J. (2017). “Automatic recognition of mild cognitive impairment from MRI images using expedited convolutional neural networks,” in Artificial Neural Networks and Machine Learning-ICANN 2017: 26th International Conference on Artificial Neural Networks, Proceedings, Part I 26 (Alghero: Springer), 373–380.
Wang, S., Shen, Y., Zeng, D., and Hu, Y. (2018). “Bone age assessment using convolutional neural networks,” in 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD) (Chengdu: IEEE), 175–178.
Wang, S., Wang, H., Cheung, A. C., Shen, Y., and Gan, M. (2020a). “Ensemble of 3D densely connected convolutional network for diagnosis of mild cognitive impairment and Alzheimer's disease,” in Deep Learning Applications (Singapore: Springer), 53–73.
Wang, S., Wang, X., Hu, Y., Shen, Y., Yang, Z., Gan, M., et al. (2020b). Diabetic retinopathy diagnosis using multichannel generative adversarial network with semisupervision. IEEE Transacti. Automat. Sci. Eng. 18, 574–585. doi: 10.1109/TASE.2020.2981637
Wang, S.-Q., Li, X., Cui, J.-L., Li, H.-X., Luk, K. D., and Hu, Y. (2015). Prediction of myelopathic level in cervical spondylotic myelopathy using diffusion tensor imaging. J. Magn. Reson. Imag. 41, 1682–1688. doi: 10.1002/jmri.24709
Wicaksono, K. P., Fujimoto, K., Fushimi, Y., Sakata, A., Okuchi, S., Hinoda, T., et al. (2022). Super-resolution application of generative adversarial network on brain time-of-flight mr angiography: image quality and diagnostic utility evaluation. Eur. Radiol. 33, 1–11. doi: 10.1007/s00330-022-09103-9
Wolleb, J., Bieder, F., Sandkühler, R., and Cattin, P. C. (2022). “Diffusion models for medical anomaly detection,” in MICCAI (Singapore).
Wolterink, J. M., Dinkla, A. M., Savenije, M., Seevinck, P. R., van den Berg, C., and Išgum, I. (2017). “MR-to-CT synthesis using cycle-consistent generative adversarial networks,” in Proc. Neural Inf. Process. Syst (Long Beach, CA: NIPS).
Wu, J., Fang, H., Zhang, Y., Yang, Y., and Xu, Y. (2022). Medsegdiff: Medical image segmentation with diffusion probabilistic model. arXiv.
Wu, X., Bi, L., Fulham, M., Feng, D. D., Zhou, L., and Kim, J. (2021). Unsupervised brain tumor segmentation using a symmetric-driven adversarial network. Neurocomputing 455, 242–254. doi: 10.1016/j.neucom.2021.05.073
Yang, H., Qian, P., and Fan, C. (2020). An indirect multimodal image registration and completion method guided by image synthesis. Comput. Math. Methods Med. 2020, 2684851. doi: 10.1155/2020/2684851
Yang, H., Sun, J., Yang, L., and Xu, Z. (2021). “A unified hyper-GAN model for unpaired multi-contrast mr image translation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Strasbourg: Springer), 127–137.
Yang, Z., Nasrallah, I. M., Shou, H., Wen, J., Doshi, J., Habes, M., et al. (2021). A deep learning framework identifies dimensional representations of Alzheimer's disease from brain structure. Nat. Commun. 12, 1–15. doi: 10.1038/s41467-021-26703-z
Yi, Z., Zhang, H., Tan, P., and Gong, M. (2017). “Dualgan: unsupervised dual learning for image-to-image translation,” in Proceedings of the IEEE International Conference on Computer Vision (Venice), 2849–2857.
You, S., Lei, B., Wang, S., Chui, C. K., Cheung, A. C., Liu, Y., et al. (2022). Fine perceptive gans for brain MR image super-resolution in wavelet domain. IEEE Transac. Neural Netw. Learn. Syst. 1–13. doi: 10.1109/TNNLS.2022.3153088
Yu, B., Zhou, L., Wang, L., Shi, Y., Fripp, J., and Bourgeat, P. (2019). EA-GANS: edge-aware generative adversarial networks for cross-modality MR image synthesis. IEEE Trans. Med. Imaging 38, 1750–1762. doi: 10.1109/TMI.2019.2895894
Yu, S., Wang, S., Xiao, X., Cao, J., Yue, G., Liu, D., et al. (2020). “Multi-scale enhanced graph convolutional network for early mild cognitive impairment detection,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Lima: Springer), 228–237.
Yu, W., Lei, B., Ng, M. K., Cheung, A. C., Shen, Y., and Wang, S. (2021a). “Tensorizing GAN with high-order pooling for Alzheimer's disease assessment,” in IEEE Transactions on Neural Networks and Learning Systems.
Yu, W., Lei, B., Shen, Y., Wang, S., Liu, Y., Feng, Z., et al. (2021b). “Morphological feature visualization of Alzheimer's disease via multidirectional perception GAN,” in IEEE Transactions on Neural Networks and Learning Systems.
Yu, Z., Zhai, Y., Han, X., Peng, T., and Zhang, X.-Y. (2021c). “Mousegan: GAN-based multiple MRI modalities synthesis and segmentation for mouse brain structures,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Strasbourg: Springer), 442–450.
Yuan, W., Wei, J., Wang, J., Ma, Q., and Tasdizen, T. (2020). Unified generative adversarial networks for multimodal segmentation from unpaired 3D medical images. Med. Image Anal. 64, 101731. doi: 10.1016/j.media.2020.101731
Yurt, M., Dar, S. U., Erdem, A., Erdem, E., Oguz, K. K., and Çukur, T. (2021). MUSTGAN: multi-stream generative adversarial networks for mr image synthesis. Med. Image Anal. 70, 101944. doi: 10.1016/j.media.2020.101944
Zhan, B., Li, D., Wu, X., Zhou, J., and Wang, Y. (2021). Multi-modal MRI image synthesis via GAN with multi-scale gate mergence. IEEE J. Biomed. Health Informat. 26, 17–26. doi: 10.1109/JBHI.2021.3088866
Zhan, B., Zhou, L., Li, Z., Wu, X., Pu, Y., Zhou, J., et al. (2022). D2FE-GAN: decoupled dual feature extraction based GAN for MRI image synthesis. Knowl. Based Syst. 252, 109362. doi: 10.1016/j.knosys.2022.109362
Zhang, L., Wang, L., and Zhu, D. (2020). “Recovering brain structural connectivity from functional connectivity via multi-gcn based generative adversarial network,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Lima: Springer), 53–61.
Zhao, Q., Adeli, E., Honnorat, N., Leng, T., and Pohl, K. M. (2019). “Variational autoencoder for regression: Application to brain aging analysis,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Shenzhen: Springer), 823–831.
Zhou, B., Wang, R., Chen, M.-K., Mecca, A. P., O'Dell, R. S., Dyck, C. H. V., et al. (2021). “Synthesizing multi-tracer pet images for Alzheimer's disease patients using a 3D unified anatomy-aware cyclic adversarial network,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Strasbourg: Springer), 34–43.
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. (2017). “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE International Conference on Computer Vision (Venice), 2223–2232.
Keywords: generative models, brain imaging, brain network, diffusion model, generative adversarial network, variational autoencoder
Citation: Gong C, Jing C, Chen X, Pun CM, Huang G, Saha A, Nieuwoudt M, Li H-X, Hu Y and Wang S (2023) Generative AI for brain image computing and brain network computing: a review. Front. Neurosci. 17:1203104. doi: 10.3389/fnins.2023.1203104
Received: 10 April 2023; Accepted: 22 May 2023;
Published: 13 June 2023.
Edited by:
Zhengwang Wu, University of North Carolina at Chapel Hill, United StatesReviewed by:
Hongjiang Wei, Shanghai Jiao Tong University, ChinaCopyright © 2023 Gong, Jing, Chen, Pun, Huang, Saha, Nieuwoudt, Li, Hu and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yong Hu, yhud@hku.hk; Shuqiang Wang, sq.wang@siat.ac.cn
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.