 Juliette Ryan-Lortie
Juliette Ryan-Lortie Gabriel Pelletier1*
Gabriel Pelletier1* Matthew Pilgrim
Matthew Pilgrim Lesley K. Fellows
Lesley K. Fellows- 1Department of Neurology and Neurosurgery, Montreal Neurological Institute, McGill University, Montreal, QC, Canada
- 2Department of Psychology, University of Southern California, Los Angeles, CA, United States
Introduction: While many everyday choices are between multi-attribute options, how attribute values are integrated to allow such choices remains unclear. Recent findings suggest a distinction between elemental (attribute-by-attribute) and configural (holistic) evaluation of multi-attribute options, with different neural substrates. Here, we asked if there are behavioral or gaze pattern differences between these putatively distinct modes of multi-attribute decision-making.
Methods: Thirty-nine healthy men and women learned the monetary values of novel multi-attribute pseudo-objects (fribbles) and then made choices between pairs of these objects while eye movements were tracked. Value was associated with individual attributes in the elemental condition, and with unique combinations of attributes in the configural condition. Choice, reaction time, gaze fixation time on options and individual attributes, and within- and between-option gaze transitions were recorded.
Results: There were systematic behavioral differences between elemental and configural conditions. Elemental trials had longer reaction times and more between-option transitions, while configural trials had more within-option transitions. The effect of last fixation on choice was more pronounced in the configural condition.
Discussion: We observed differences in gaze patterns and the influence of last fixation location on choice in multi-attribute value-based choices depending on how value is associated with those attributes. This adds support for the claim that multi-attribute option values may emerge either elementally or holistically, reminiscent of similar distinctions in multi-attribute object recognition. This may be important to consider in neuroeconomics research that involve visually-presented complex objects.
1. Introduction
Whether choosing your major in college or what to eat for breakfast, decisions are often between complex options with multiple value-predictive attributes. At breakfast, for example, options might be evaluated on their healthiness, taste, and visual appeal. How are these multiple attributes considered during decision-making? In principle, multi-attribute options might be evaluated “elementally” by aggregating the subjective motivational value of individual attributes, or “configurally” by assigning a value to the whole option based on its unique combination of attributes.
Research on multi-attribute decision-making has generally studied elemental evaluation strategies, often using process tracing methods (Ford et al., 1989). Attributes are typically explicitly presented in tables (a.k.a. information boards), usually as text, and the pattern of information acquisition as participants view each piece of information is used to shed light on the underlying evaluation processes (Payne, 1976; Payne et al., 1992; Bettman et al., 1998). Other research on value-based decision making has used visually presented multi-attribute objects such as foods, trinkets, or artwork either without addressing how overall values emerge from these attributes (Busemeyer et al., 2019), or by assuming that individual elements are valued and then combined to estimate the overall value or influence choice (Lim et al., 2013; Suzuki et al., 2017; Vaidya et al., 2018).
An alternative perspective on multi-attribute evaluation is offered by neuroscience research on complex object recognition. This work has established that there are distinct neural substrates for representations of lower-level visual features and for multi-feature configurations that allow whole object recognition (Riesenhuber and Poggio, 1999; McTighe et al., 2010). For example, perirhinal cortex damage impairs object recognition based on unique configurations of features while sparing ‘elemental’ recognition based on individual features (Bussey et al., 2005). There are also behavioral differences suggesting that information is acquired differently in these two forms of object recognition: for example, gaze patterns differ during configural compared to elemental recognition of faces (Bombari et al., 2009, 2013; Boutet et al., 2017).
Similar elemental and configural distinctions recently have been proposed for the evaluation of multi-attribute objects. Damage to ventromedial frontal lobe (VMF), a region implicated in tracking option value, was associated with impaired choices between novel multi-attribute pseudo-objects (fribbles) only when value was related to attribute configuration; choices based on summing the individual values of attributes remained intact (Pelletier and Fellows, 2019). A follow-up eye-tracking and fMRI experiment that asked healthy people to estimate the value of fribbles presented one at a time found that gaze patterns, as well as activity in VMF and perirhinal cortex, differed in configural and elemental value conditions (Pelletier et al., 2021).
The decision neuroscience literature has argued that gaze, as a proxy of attention, can provide additional insights into choice processes beyond what may be inferred from reaction time and choice behavior (Krajbich et al., 2010). Binary value-based choice experiments have shown that longer fixation of an option increases the likelihood of choosing that option, that the option that is fixated last has a higher probability of being chosen, and that the option fixated more over the course of a trial is more likely to be chosen (Krajbich, 2019), in line with models proposing sequential sampling of information to reach a decision. Of note, such tasks have typically involved visual images of complex multi-attribute objects such as snack foods or trinkets.
Here, we asked if these behavioral and eye-tracking outcomes differ across configural and elemental multi-attribute evaluation conditions in healthy young men and women. Participants made binary value-based choices between fribble stimuli in two conditions, with value either associated with individual attributes or the configural relationship between attributes. Because fribble attributes are spatially distinct, eye-tracking could be used to infer information acquisition strategies at both the attribute and the whole option level. We hypothesized that gaze transition patterns would systematically differ across conditions, with the elemental condition prompting an attribute-based strategy with more between-object transitions and the configural condition promoting option-based information acquisition with more within-object transitions. We also tested whether the relationships between gaze patterns and choice considered to be hallmarks of sequential sampling differed across conditions.
2. Materials and methods
Forty-one adults were recruited from the local community through online advertising. Participants had normal uncorrected vision, no history of neurological or psychiatric conditions, and had no prior experience with the fribble stimuli. In addition to compensation of 15$ per hour, participants received a monetary bonus based on task performance. Two participants did not complete the full experiment due to time constraints. The final sample of 39 participants had a mean age of 22y, SD 2.7, mean education 16y, SD 2.1, and was comprised of 25 women and 14 men. Participants gave written informed consent in accordance with the Declaration of Helsinki. The study was approved by the McGill University Health Centre Research Ethics Board.
All participants were tested in-lab on a desktop computer equipped with a 19-inch monitor. Experiments were programmed in Matlab (version 2019b, The Mathworks, Inc.), using the Psychtoolbox extension (Brainard, 1997). Eye movements were recorded from the left eye with a desk-mounted eye tracker (EyeLink 1,000 Plus, SR Research) with a sampling frequency of 1,000 Hz. Fixation information was extracted from the EyeLink algorithm (position, duration). To separate attributes of fribbles into distinct regions of interest (ROI), we partitioned the fribbles in two using a Voronoi tessellation. A fixation within an ROI of a fribble followed by a fixation in the other ROI of the same fribble was coded as a within-object transition, and a fixation within an ROI of a fribble followed by a fixation in an ROI of the other fribble was coded as a between-object transition.
The experimental paradigm was adapted from Pelletier and Fellows (2019). Stimuli were renderings of three-dimensional pseudo-objects called fribbles, originally developed for object processing research (Williams and Simons, 2000; Barry et al., 2014). Fribbles are composed of one main ‘body’ and several appendages, which we refer to as attributes. Each set of fribbles had three possible forms for the upper attribute (A, B or C) and the lower attribute (x, y or z). Participants were told that these fribbles were collectors’ items, and that they would learn their market values by observing online ‘auctions’. In the learning phase of the task, they were trained on the approximate monetary values of each fribble by watching such auctions until they reached a learning criterion. This was followed by a choice phase, where participants chose between pairs of fribbles while eye-tracking data were acquired. Chosen fribbles were added to the participant’s own inventory. Participants were told they would sell their inventory back to the experimenter at the end of the experiment, and receive a monetary amount proportional to the proceeds of the sale as part of their compensation for participation, thus incentivizing them to choose the highest value fribbles throughout the choice phase.
The task had two conditions: in the configural condition, the value of each fribble was predicted by the object as a whole through the configural relationship of two attributes (i.e., unique attribute combinations, denoted here Ax, By, Cz, Cx, Bz, Ay). This meant that an individual attribute did not predict a unique value; instead, its value could only be inferred in the presence of the second attribute, i.e., the value was related to the whole object. In the elemental condition, each individual attribute (denoted here A, B, C and x, y, z) was associated with a unique value, i.e., the value of one attribute did not depend on the other attributes that made up the fribble. Thus, the overall fribble value could be derived by summing individual attribute-values (see Figure 1). Different sets of fribbles were used for each condition, counterbalanced across participants. In the elemental condition, all possible combination of attributes were shown, resulting in 9 fribbles. Six unique fribbles were used in the configural condition.
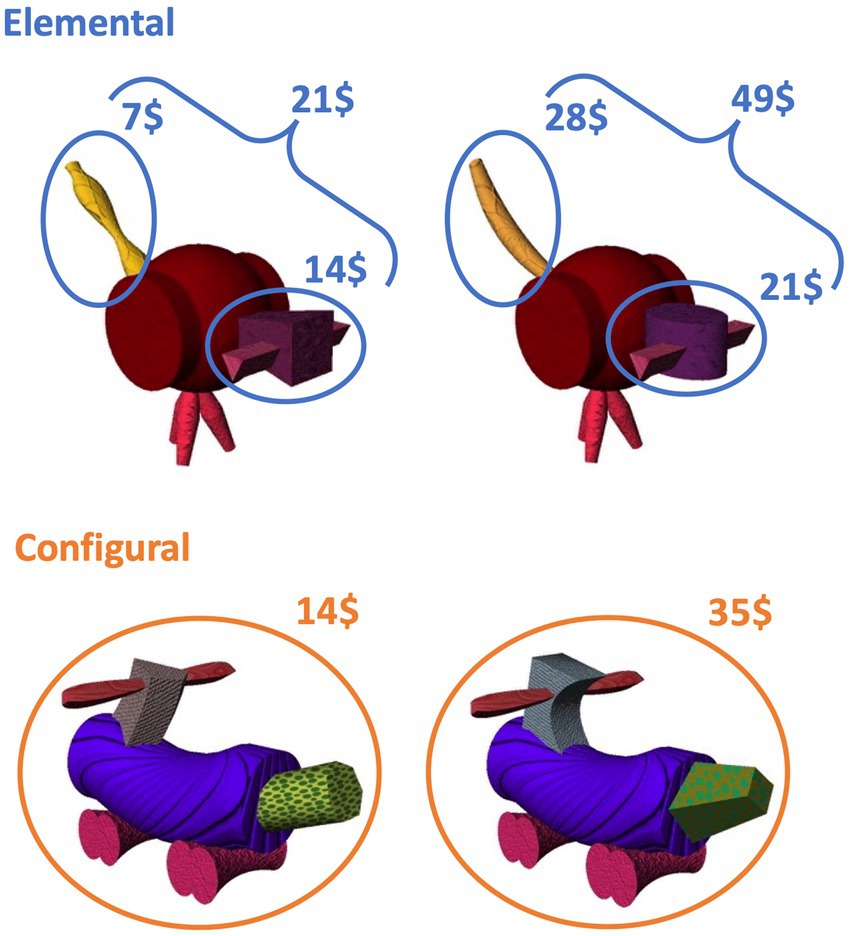
Figure 1. Stimuli. Example of pairs from two families of fribbles, used for each condition. In the elemental condition, each attribute has a value, and a fribble’s value is the sum of its two attributes’ values. In the configural condition, no value is assigned to attributes individually, rather each attribute combination has a value.
The structure of the experiment is depicted in Figure 2A. In the elemental condition, participants were trained on the value associated with individual attributes. To simplify the training, in each learning set only 4 out of the 6 possible attributes were used (e.g., A, B, x, y). On each training trial, one fribble was shown, and the selling price then appeared in the upper right corner of the screen (Figure 2B). Monetary values were drawn at random from a distribution around the following mean values: A = 7$, B = 28$, C = 42$%; x = 14$, y = 21$, z = 35$. Learning trials were self-paced. Participants were instructed that the selling price was related to a single attribute of the fribble. This instruction was further emphasized by highlighting the informative attribute, i.e., by masking the body and irrelevant attributes of the fribble with a semitransparent mask. Each fribble was shown 8 times, for a total of 32 learning trials in a block, followed by a learning probe. The learning probe trials showed two fribbles on the screen, varying on the same 4 attributes as during training, with the relevant attribute highlighted as during training, and participants were instructed to select the fribble whose “highlighted” attribute had the higher value, using left and right arrow keys (Figure 2C). In the learning probe, the 6 possible pairs were shown 8 times, for a total of 48 learning probe trials. The learning probe was stopped if the participant made the same mistake (chose the lower-value attribute) more than once. In this case, the learning block was repeated. The next learning set used another subset of 4 attributes out of the possible 6 (ex: B, C, y and z), as did the third learning set (ex: C, A, z and x), following the same training.
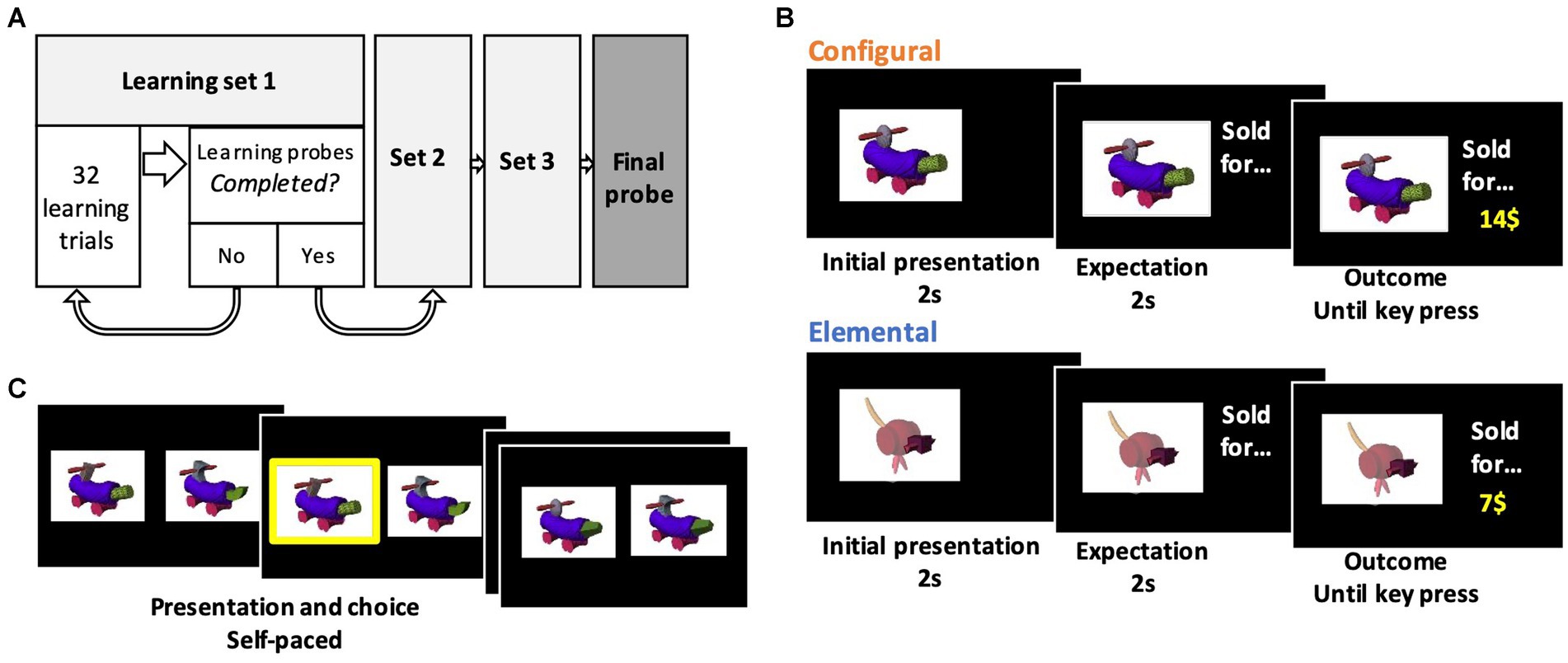
Figure 2. Experiment paradigm. (A) Structure of the experiment. Participants went through 3 cycles of learning trials and probes with a subset of stimuli to learn the values of either attributes (in the elemental condition) or configurations of attributes (in the configural condition). (B) Learning trials. These trials included presentation of a fribble (with a mask highlighting a specific attribute in the elemental condition), followed by an associated monetary amount. (C) Probe trials. These trials had two fribbles presented and participants were instructed to pick the higher-value fribble using arrows on the keyboard in a self-paced fashion. In the elemental learning probes, specific attributes were highlighted like in the elemental learning trials depicted in panel B.
After completing the three learning sets, participants then moved to the final probe, involving all 6 attributes presented in all possible pairs (9 fribbles). Each of the 36 possible choice combinations were presented 5 times for a total of 180 choice trials. On these trials, participants were told to consider the values of both attributes of each fribble when making their choice. No mask was used on these trials, so all attributes were equally visually salient. These trials were self-paced. Participants’ gaze was tracked during these final probe trials.
Training in the configural condition followed the same format as the elemental condition except that no mask was used during learning and there were only 6 fribbles. Participants were instructed that selling price was related to the unique combination of attributes that made up the fribble as a whole, and were trained on a subset of 4 fribbles at time until they met the learning criterion. The selling values were drawn at random from a distribution around the following mean values: Ax = 7$, By = 14$, Cz = 21$, Cx = 28, Bz = 35, Ay = 42. This was followed by a final probe in which each of the 15 possible combinations of attributes was shown 6 times for a total of 90 trials.
The primary analysis included all 90 configural trials and a subset (N = 77) of the elemental trials that were matched to the configural trials for decision difficulty in terms of relative value and the requirement to consider both attributes of each fribble. This meant that choices in which the value difference between fribble pairs was greater than the range of value differences in the configural set (maximum difference $35), or where fribbles only differed by a single attribute, or where a single attribute was of such high value that on its own it was greater than the sum of the values of the attributes of the other fribble, were excluded.
Linear mixed effect (LME) and generalized linear mixed effect (GLME) models were implemented in R (lme4 package, Bates et al., 2015). LME models were used when the dependent variable was continuous. GLME models were used when the dependent variable was either a count or a binomial, and were fitted with either a Poisson or a binomial distribution, respectively. All models included subject as a random factor, and other predictors are specified for each model in the Results section. Model outputs of LMEs are estimates and are interpretable directly. GLME models for count data provide incidence rate ratios (IRR). Here, these are interpretable as the occurrence ratio of the dependent variable in the configural condition compared to the elemental condition. Since the elemental condition was the reference condition, an IRR > 1 indicates a higher rate of occurrence in the configural condition, and an IRR < 1 indicates a higher rate of occurrence in the elemental condition. GLME models for binomial data output odds ratios. These ratios indicate, as a proportion, the relative occurrence of the dependent variable for the configural condition compared to the elemental condition. The elemental condition was the reference condition, so an odds ratio > 1 indicates a higher occurrence in the configural condition while an odds ratio < 1 indicates a lower occurrence in the configural condition. For GLME models with 2-way interactions, odds were calculated according to the following formula:
Payne Index values were calculated from the eye-tracking data for each trial with the following formula:
3. Results
3.1. Learning
The number of learning blocks required to meet criterion is shown in Table 1. Participants required more training to meet criterion in the configural than the elemental condition. In the configural condition, 67% of learning sets were learned after one training block and 21% required two training blocks, compared to the elemental condition where 91% of sets were learned after one training block and 8.6% required two blocks. A chi-square test of independence showed that there was a significant association between condition and learning (X2 (3, N = 234) = 25.31, p < 0.001, φ = 0.33).
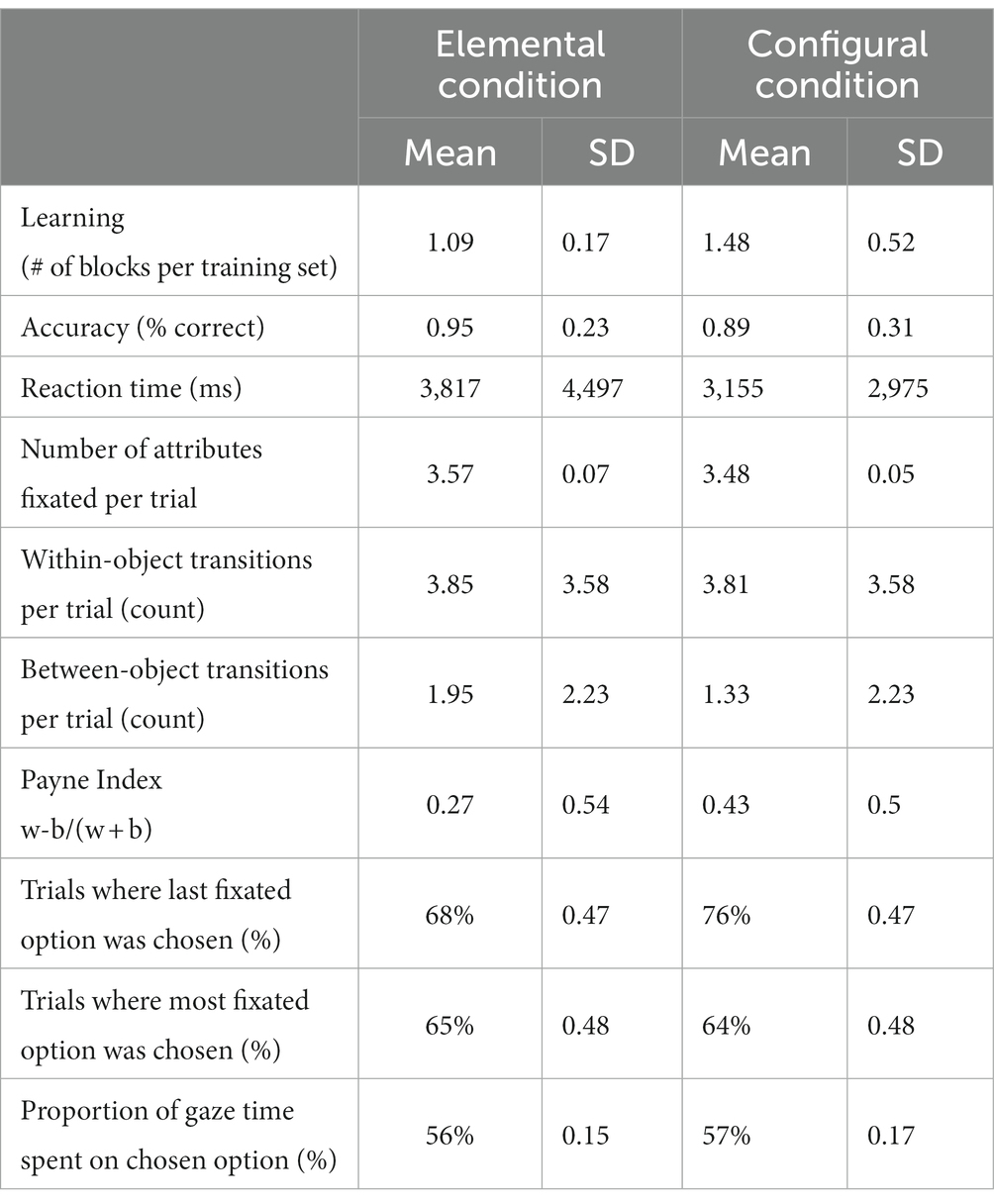
Table 1. Behavioral outcomes by condition: the first row shows performance during the training phase; all other outcomes are from the final probe phase of the experiment.
3.2. Reaction time and accuracy
We first verified that elemental trials where a single attribute was sufficient to make the correct choice (where fribbles only differed on a single attribute or where there was a ‘dominant’ attribute that alone was of higher value than any combination of attributes) were behaviorally distinct from the two-attribute elemental trials of interest. The reaction times were indeed much shorter for the elemental trials involving fribbles that differed on a single attribute (M 2697 ms, SD 2101) compared to the elemental trials where both attributes differed (M 3817 ms, SD 4497; t (5380) = −11.2, p < 0.001, d = 0.86) and to configural trials (M 3155 ms, SD 2975; t(5887) = −6.51, p < 0.001, d = 0.37). All remaining analyses focused on the elemental trials that required consideration of two attributes for each fribble, as this was most comparable to the information processing requirements of the configural condition.
An optimal response was defined as the choice of the objectively higher value fribble. Although the difficulty of the decisions based on the subjective value difference between options was similar across conditions, and participants were trained to the same criterion in both conditions, choices were slower and more accurate in the elemental condition (Table 1). GLME models with condition as a predictor confirmed a significant effect of condition on proportion of optimal choices, and on and reaction time (Table 2).
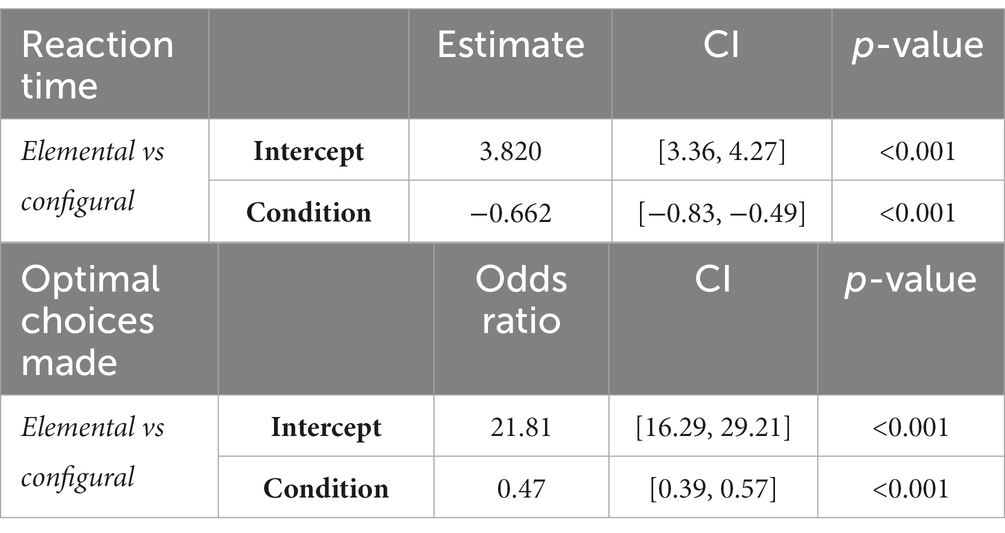
Table 2. Reaction time and proportion of optimal choices.
3.3. Eye-tracking indicators of information acquisition
Eye-tracking data indicated that all four informative attributes were fixated on most trials in both conditions, with a mean of 3.57 attributes fixated per trial in the elemental condition and 3.48 in the configural condition (Table 1). A GLME model analysis with condition as a predictor revealed a marginal effect of condition (p = 0.069), with participants tending to fixate more attributes in the elemental than in the configural condition.
We next compared gaze transition metrics, taking an approach inspired by process tracking in decision psychology “information board” experiments. Raw counts of gaze transitions within objects and between objects were compared across conditions (Table 1). A GLME model fitted with a Poisson distribution with condition as a predictor revealed no significant effect of condition on the raw count of within-object transitions (p = 0.351; Table 3). The same model on the raw count of between-object transitions yielded a significant effect of condition with more between-object transitions in the elemental (M = 1.95) than in the configural condition (M = 1.33). The IRR indicates that the model predicts more between-object transitions in the elemental condition than the configural condition with a ratio of 1 to 0.68 (p < 0.001; Table 3). This difference in between-object transitions persisted even after accounting for the observation that trials were longer in the elemental condition, by adding RT at the trial level as an offset variable predictor. Accounting for RT also revealed a significant effect of condition on within-object transitions (Table 3; Figure 3).
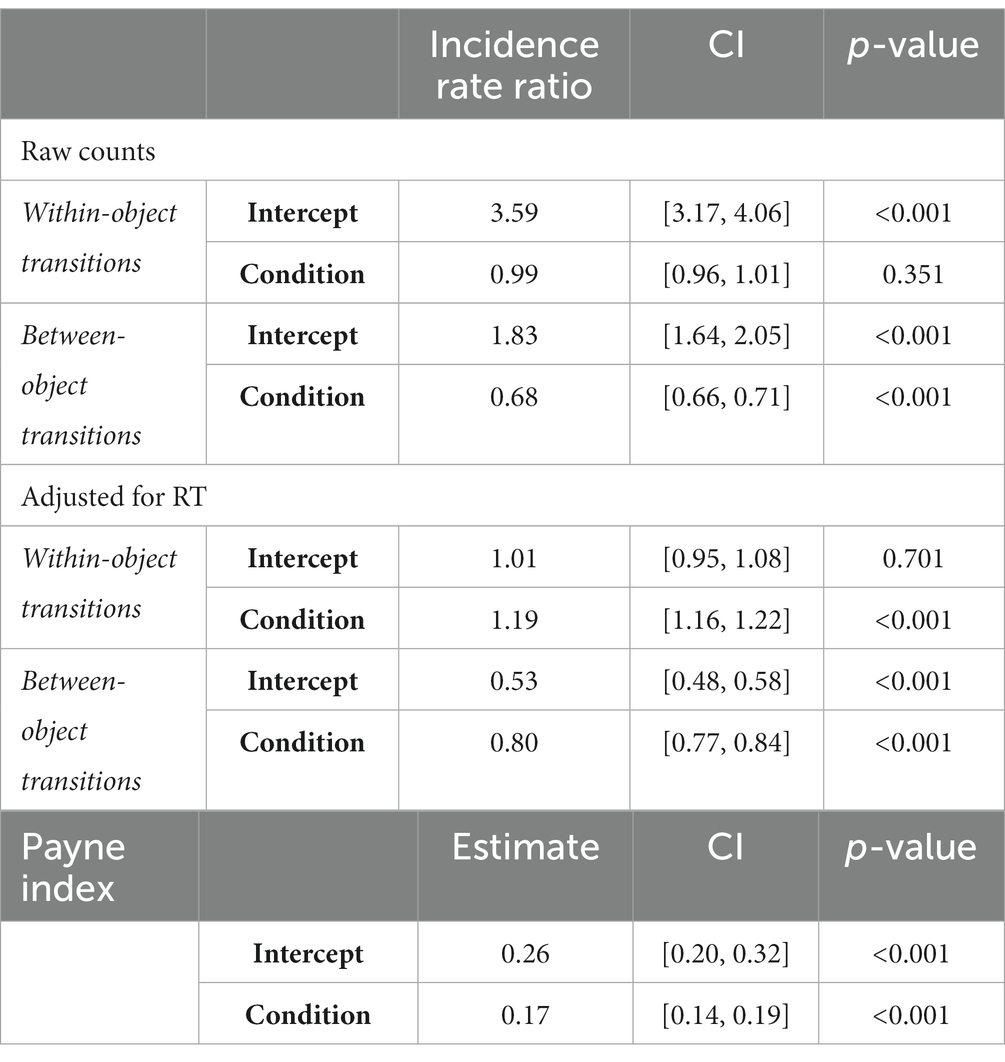
Table 3. Model output for effects of condition on within-object and between-object gaze transitions.
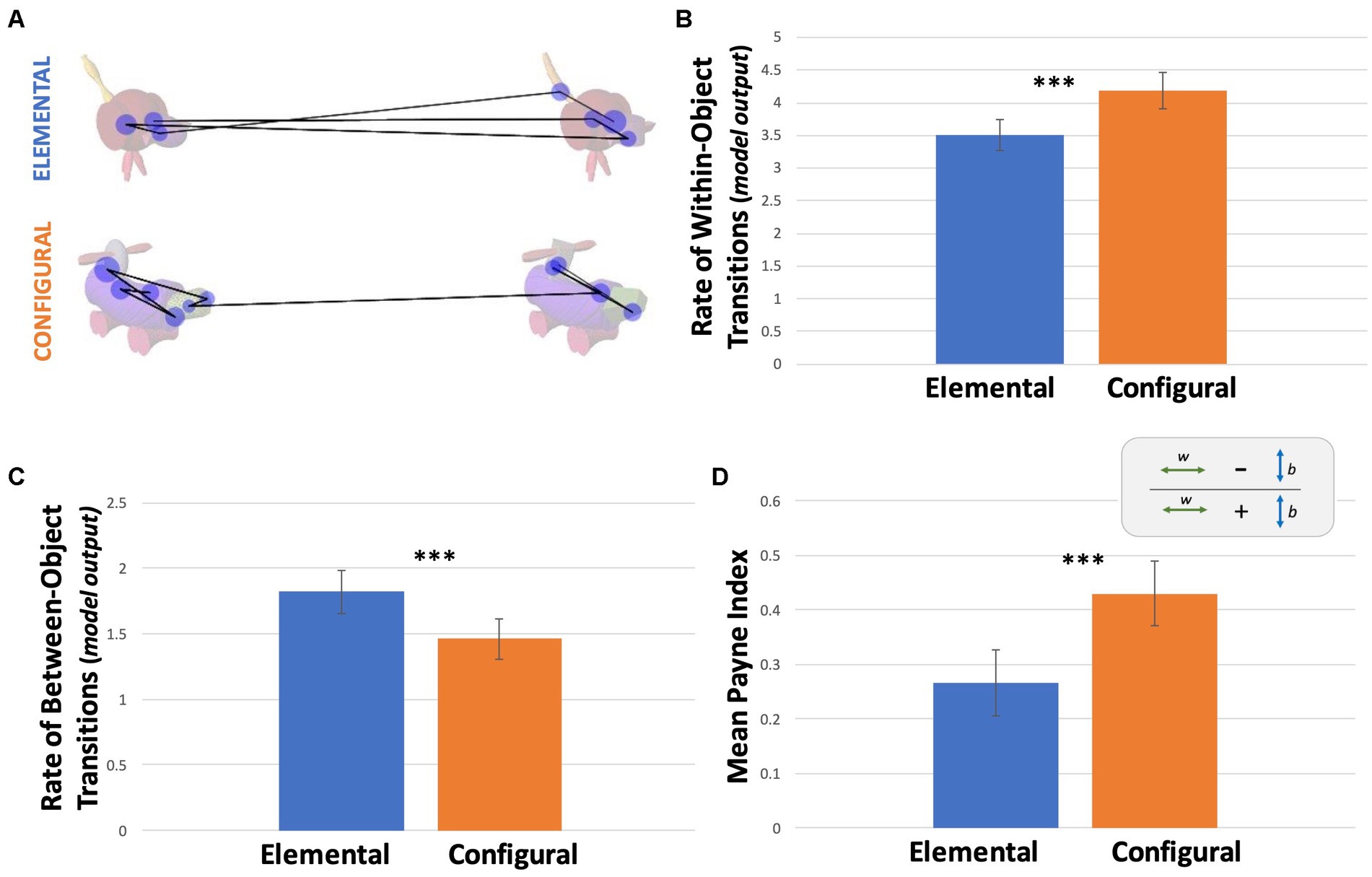
Figure 3. Information Acquisition Patterns. (A) Examples of scan paths for both conditions from Subject 216. Lines represent transitions and blue circles represent fixations. (B) Estimated rates from the model for within-object transitions across conditions (model output). (C) Estimates rates from the model for between-object transitions across conditions (model output). Estimated rates in B and C account for trial duration differences between conditions. (D) Average Payne Index for both conditions calculated from raw number of within (w) and between (b) transitions, P = (w-b)/(w + b). Error bars represent 95% confidence intervals.
To allow comparison with the decision psychology literature, we also calculated the Payne Index for each trial across the two conditions to assess the relative occurrence of within-object and between- object transitions. The average Payne Index in the configural condition was 0.43 and 0.27 in the elemental condition (Figure 3D; Table 1). An LME model with condition as a predictor revealed a significant effect of condition (Table 3). Thus, while both conditions tended towards within-object processing (Payne Index >1), this tendency was more evident in the configural condition. Adjusting for reaction time was not necessary, as the difference between the two types of transitions was divided by the total number of transitions for each trial.
3.4. Effect of last fixation location on choice
We next examined gaze effects on choice predicted by evidence accumulation models. A one-sample t-test revealed that for all conditions together, the mean proportion of trials where the last fixated option was chosen (72% of trials, SD 0.45) was significantly different than 50% (t (6512) = 40.22, p < 0.001, d = 0.45). A GLME model with condition as a predictor revealed a significant effect of condition (p < 0.001), with more trials where the last fixated option was chosen in the configural condition than in the elemental condition (Figure 4A; Table 1). The Odds Ratio indicates that in the configural condition there were 50% more trials in which the last-fixated option was chosen (Table 4).
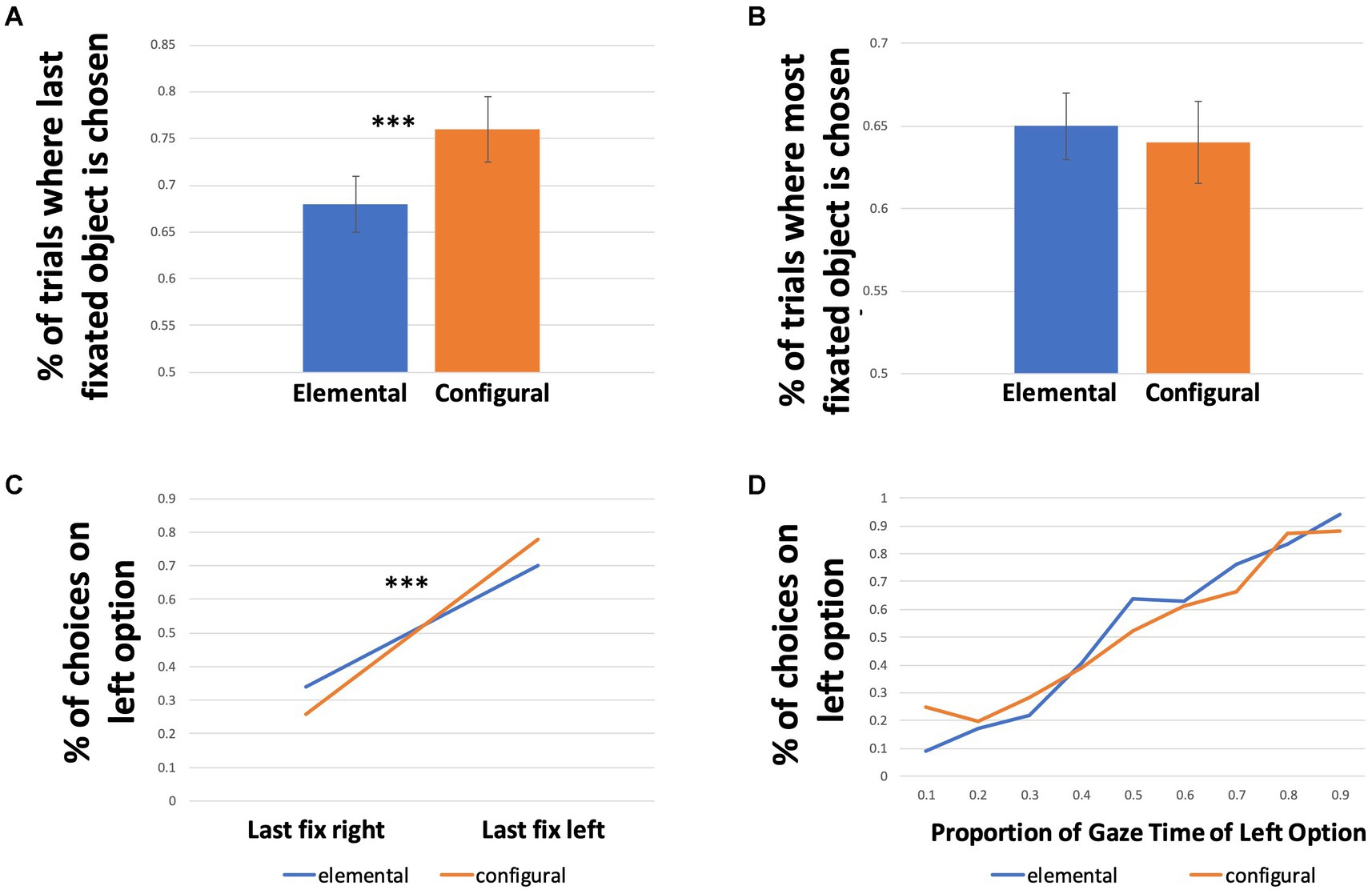
Figure 4. Effects of last fixation and gaze time on choice. (A) Proportion of trials where the option that was fixated last was chosen, for both conditions. Error bars represent 95% confidence intervals. (B) Proportion of trials where the option with the higher gaze time was chosen, for both conditions. Error bars represent 95% confidence intervals. (C) Proportion of trials where the left option was chosen as a function of location of the last fixation, across conditions. (D) Proportion of trials where the left option was chosen as a function of gaze time proportion on the left option, across conditions.
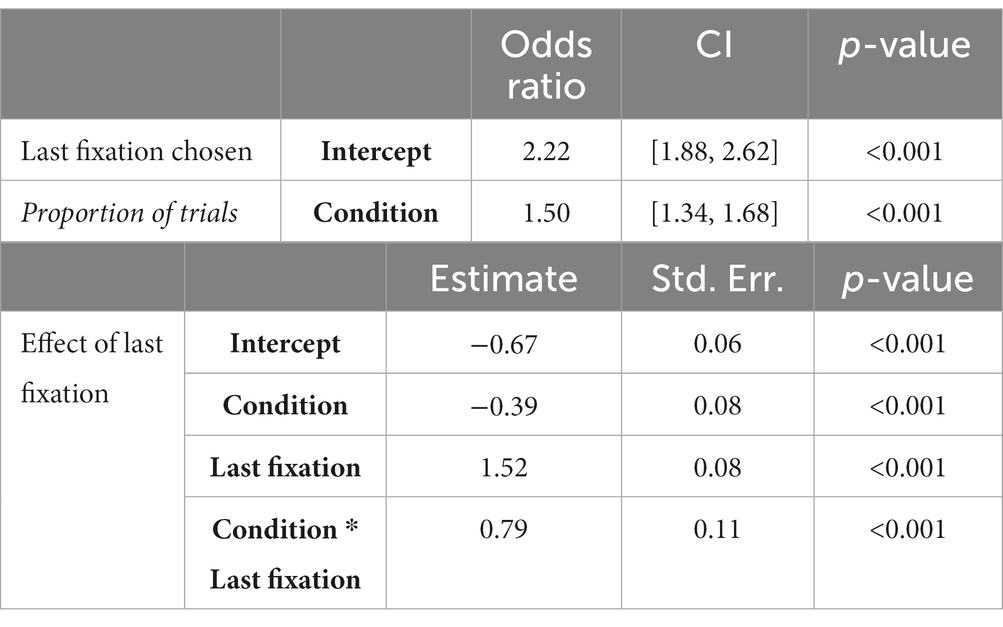
Table 4. Model output for effect of last fixation on choice.
Given the apparent difference in effects between conditions, we examined the interaction between last fixation location and condition. The proportion of choices of the left option as a function of whether the left option was fixated last are presented in Figure 4B. In the configural condition, the left option was chosen in 26% (SD 0.44) of the trials where the last fixation was on the right option compared to 78% (SD 0.42) of trials where the last fixation was on the left option. In the elemental condition, the left option was chosen in 34% (SD 0.47) of the trials where the last fixation was on the right option compared to 70% (SD 0.46) of trials where the last fixation was on the left option. A GLME model fit with a binomial distribution with the interaction of condition and last fixation location as a predictor revealed a significant interaction of condition and last fixation location on choice, suggesting that the effect of last fixation location on choice was greater in the configural condition than the elemental condition (Table 4). To estimate the effect size of this difference, we calculated the expected values of the dependent variable, i.e., the proportion of choices, from the regression table output of the model, and exponentiated them to get the odds for each fixed factor level (Table 5). The odds ratio was calculated by dividing the odds of the configural condition by the odds of the elemental condition for each level of last fixation location. For example, the odds ratio of 1.49 for trials where the left option was fixated last indicates that the estimated likelihood of choosing the left option was 49% higher in the configural condition than in the elemental condition.

Table 5. Odds and odds ratios for effect of last fixation location.
3.5. Effect of gaze time on choice
We asked whether spending a larger proportion of time fixating one option in a trial led to a higher probability of choosing that option. We first assessed whether this effect was present in the data overall, and then whether this differed across conditions. A one-sample t-test revealed that, collapsed across conditions, the mean proportion of trials where the most fixated option was chosen (64% of trials, SD 0.48) was significantly different from 50% (t(6512) = 23.70, p < 0.001, d = 0.29), suggesting an overall effect of gaze time advantage on choice. Comparing conditions, we observed that the most fixated object was chosen in 64% of trials in the configural condition compared to 65% of trials in the elemental condition (Figure 4C; Table 1). A one-way GLME model fit with a binomial distribution with condition as a predictor revealed no significant difference between the conditions for the effect of gaze time on choice (Table 6). Figure 4D depicts the proportion of left choices as a function of gaze time on the left option for both conditions.
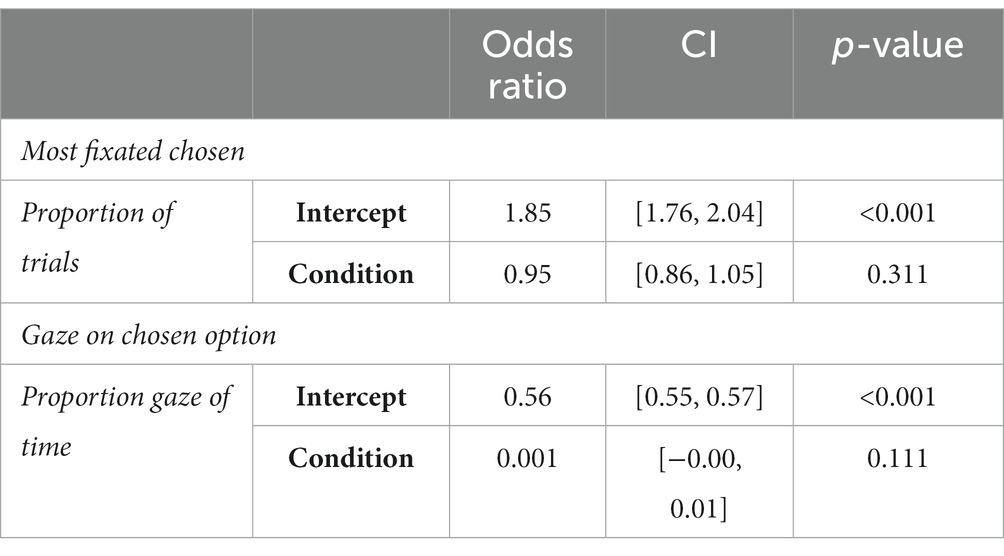
Table 6. Model output for effect of gaze time on choice.
We also considered the average proportion of gaze time spent on the chosen object. A one-sample t-test revealed that the overall group mean (56% of gaze, SD 0.16) was significantly different from 50% (t (6512) = 31.23, p < 0.001, d = 0.39). A one-way LME with condition as a predictor model found no significant difference between gaze time on the chosen object across conditions (Table 1 for means, Table 6 for model output).
4. Discussion
This study sought evidence of behavioral differences between configural and elemental multi-attribute option evaluation in a value-based binary choice task between complex visual objects with spatially distinct attributes. There were several behavioral differences identified, largely in line with our hypotheses. Configural evaluation was faster, less accurate, involved more within-option gaze transitions, and there was a greater influence of last fixation on choice. There were also interesting commonalities across conditions. Participants fixated between 3 and 4 value-informative attributes in both conditions and, despite the differences in gaze fixation transitions, the chosen option was overall fixated more than the non-chosen option to a similar degree across conditions.
Process tracing research has used eye movements as indicators of information acquisition during value-based decision-making in multi-attribute choice, but in contexts where option attributes (elements) are described with text, generally arrayed in a table (Russo and Rosen, 1975; Payne, 1976; Raaij, 1977; Payne et al., 1993; Russo and Leclerc, 1994; Russo and Dosher, 1983). The complex object stimuli used here had spatially distinct attributes, allowing both option- and attribute-level fixations to be studied. Our findings show that the process-tracing analysis framework can be applied to complex visual objects. While option-based information acquisition patterns predominated in both conditions (i.e., the Payne Index was on average, positive), this option-based pattern was more marked in the configural condition. The effects observed are in line with our conceptualization of configural evaluation as more option-based, and, elemental evaluation relying on attribute-by-attribute comparisons between options. The spatial proximity of attributes of the same fribble might explain the overall bias towards within-option information acquisition (Russo and Rosen, 1975; Ballard et al., 1995); future work could test this speculation by adapting the fribble stimuli to more widely space the value-informative attributes within-object.
Our findings suggest that the extent to which attributes interact in predicting value is an important factor influencing information acquisition in the service of choice “strategies” (which, here, may or may not be explicit, top-down strategies), revealed by gaze patterns. A study from our lab using a similar paradigm also found systematic gaze pattern differences between elemental and configural conditions when fribbles were evaluated one at a time (Pelletier et al., 2020).
This application of eye-tracking to distinguish configural and elemental evaluation complements perceptual studies where this method has been applied to compare configural and elemental face recognition processes (Bombari et al., 2009, 2013; Boutet et al., 2017). Bombari et al. (2009) found more transitions (and therefore, more fixations) within face stimuli under configural conditions. The authors suggested that different recognition strategies were at play, with the configural condition involving a more pronounced analysis of spatial relations between attributes.
As reviewed in Pelletier and Fellows (2021), there is evidence that value emerges as part of the recognition process rather than through a separate evaluation step that follows recognition (Mogami and Tanaka, 2006; Serences, 2008; Arsenault et al., 2013; Persichetti et al., 2015; Kaskan et al., 2017). Multi-attribute value construction may be organized hierarchically in the brain, from evaluation of basic features and attributes to the evaluation of complex conjunctions and objects, in line with the processing stages underlying object perception. Lesion and neuroimaging studies from our lab using a similar paradigm show differences in the brain regions engaged by, and critical for, configural and elemental evaluation (Pelletier and Fellows, 2019; Pelletier et al., 2021).
We speculate that the familiar complex objects (e.g., snack food packages) used in many binary choice studies in decision neuroscience are likely to promote configural evaluation. We wondered if key behavioral effects that have been taken as support for sequential sampling evidence accumulation models might be unique to, or at least especially prominent in, configural evaluation. Such models typically do not address what information is being sampled during evaluation, although, as with the earlier process-tracking literature, there is often an assumption that value-predictive attributes are being sampled (Lim et al., 2011, 2013; Krajbich et al., 2012). Most recent extensions of sequential sampling models applied to value-based decision-making predict that the last-fixated option is most likely to be chosen (Krajbich et al., 2010; Krajbich and Rangel, 2011; Morii and Sakagami, 2015; Smith and Krajbich, 2019; Liu et al., 2020). Our finding that the effect of last fixation on choice was more striking in the configural condition suggests that sequential-sampling models may be more applicable when option value is assessed holistically. The corollary of this observation is that different models may be needed for decisions where individual elements predict value. Recent efforts to extend attentional drift diffusion models to multi-attribute contexts where attribute values are explicitly considered (Yang and Krajbich, 2022) are promising, as they offer a way to account for potentially distinct mechanisms of multi-attribute evaluation. Further research in this direction is needed, to develop models that allow for either configural or elemental evaluation, and to acquire experimental data to test the predictions of such models.
Evidence accumulation models also predict that longer time spent gazing at an option allows more evidence to be accumulated (Armel et al., 2008; Orquin and Loose, 2013), bringing that option closer to the decision threshold and therefore more likely to be chosen. Here, we replicated this effect. In contrast to the effect of last fixation on choice, overall gaze time advantage for the chosen option was of similar magnitude across conditions, despite the differences in how value was related to the stimuli.
This work has limitations. Although we aimed to match the two conditions for difficulty by training to a common criterion across conditions and matching trials on option value difference, differences in learning and accuracy were observed, with the higher value fribble chosen less often and more learning blocks required to learn the values in the configural trials. The range of absolute values for fribbles also differed between conditions. However, the relative value of fribbles within choices, the most important factor in binary choice behavior, Kim and Beck (2020) was similar across conditions. While participants were instructed to ‘add up’ the learned values of individual attributes in the elemental trials, they could have adopted other attribute-based strategies including shortcuts such as a ‘take the best’ single attribute strategy, which could have yielded high accuracy without considering all attribute-values individually in some trials. However, elemental trial reaction times were longer, and fixation number was similar in both conditions, arguing that participants likely gathered all available value information. Finally, by design, the salience of individual attributes was emphasized during the elemental training phase, through both the value association and partial masking of task-irrelevant portions of the fribble. While no masking was used in the final probe phase, it is possible that the masking during training may have enhanced the effect of the attribute-value association alone.
Gaze is known to be an imperfect indicator of attention and thus of information acquisition. Studies have found that subjects are capable of maintaining fixation on one feature while detecting probes in the close periphery (Fluharty et al., 2016), and that attention can be deployed to multiple non-contiguous areas of the visual field without changing the gaze fixation location (Kramer, 1998). A recent study found poor correspondence between instructed strategy use (based on computer simulation of optimal strategies) and actual information acquisition patterns, but this was in a decision task where the best strategy was cognitively very demanding (Takemura et al., 2023). Given the size of the ROIs used here and their spatial proximity, fixation on one attribute could be enough to recognize the whole fribble. However, we observed fixations to, on average, 3.5/4 informative attributes in both conditions, arguing that gaze was a reasonable proxy for attention, and therefore of the underlying choice strategy, in this self-paced, low time pressure, relatively simple task.
While we observed differences between conditions in several behavioral metrics, these behavioral phenomena alone are unlikely to reliably distinguish elemental and configural evaluation in more naturalistic paradigms where other factors might influence gaze and where attributes may not be spatially distinct. At the least, careful experimental control would be needed for the various additional factors known to influence eye movement patterns, such as spatial arrangement of stimuli (Reutskaja et al., 2011) and social context (Peshkovskaya and Myagkov, 2020). Moreover, when values are not experimentally assigned, as they were here, the evaluation processes and strategies engaged can differ across individuals, as well as within individuals as decision difficulty varies (Lee and Cummins, 2004; Day et al., 2009).
Nonetheless, the behavioral effects we observed may be useful in distinguishing between these evaluation modes in future work. Without expressly considering the elemental-configural distinction we studied here, process-tracing experiments often assume some form of elemental attribute integration. Sequential sampling models are generally agnostic as to how the value-predictive attributes of complex objects are combined during choice. We found that some of the behavioral predictions of such models are more strongly supported under configural evaluation conditions. Different models may be more appropriate for decisions where individual elements predict value.
This study adds to a growing literature that aims to more tightly define the processes involved in assessing the value of complex decision options, with the intent to relate these to their underlying neural substrates. A better understanding of the behavioral and brain mechanisms that underlie how humans make complex choices also may help us present multi-attribute information in ways that the human brain is best prepared to consider.
Data availability statement
The datasets presented in this article are not readily available because Informed consent was not obtained for open data sharing; at the time the data were collected this was not a routine aspect of the ethics process. Requests to access the datasets should be directed to anVsaWV0dGUucnlhbi1sb3J0aWVAbWFpbC5tY2dpbGwuY2E=.
Ethics statement
The studies involving humans were approved by McGill University Health Center Research Ethics Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
GP and LF designed the study. MP collected the data. JR-L, GP, and LF conceived of the research questions. JR-L and LF analyzed the data and wrote the first draft and carried out the final revisions of the paper. GP advised on the analysis of the data. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the Canadian Institutes of Health Research (Grant MOP-11920) and the Natural Sciences and Engineering Research Council of Canada (RGPIN 2016–06066).
Acknowledgments
The authors would like to thank all volunteers for their participation in the study, as well as Dr. Ross Otto and Dr. Ian Krajbich for helpful comments on this work.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Armel, K. C., Beaumel, A., and Rangel, A. (2008). Biasing simple choices by manipulating relative visual attention. Judgm. Decis. Mak. 3, 396–403. doi: 10.1017/S1930297500000413
Arsenault, J. T., Nelissen, K., Jarraya, B., and Vanduffel, W. (2013). Dopaminergic reward signals selectively decrease fMRI activity in primate visual cortex. Neuron 77, 1174–1186. doi: 10.1016/j.neuron.2013.01.008
Ballard, D. H., Hayhoe, M. M., and Pelz, J. B. (1995). Memory representations in natural tasks. J. Cogn. Neurosci. 7, 66–80. doi: 10.1162/jocn.1995.7.1.66
Barry, T. J., Griffith, J. W., De Rossi, S., and Hermans, D. (2014). Meet the Fribbles: novel stimuli for use within behavioural research. Front. Psychol., 5, 103. doi: 10.3389/fpsyg.2014.00103
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bettman, J. R., Luce, M. F., and Payne, J. W. (1998). Constructive consumer choice processes. J. Consum. Res. 25, 187–217. doi: 10.1086/209535
Bombari, D., Mast, F. W., and Lobmaier, J. S. (2009). Featural, configural, and holistic face-processing strategies evoke different scan patterns. Perception 38, 1508–1521. doi: 10.1068/p6117
Bombari, D., Schmid, P. C., Schmid Mast, M., Birri, S., Mast, F. W., and Lobmaier, J. S. (2013). Emotion recognition: the role of Featural and Configural face information. Q. J. Exp. Psychol. 66, 2426–2442. doi: 10.1080/17470218.2013.789065
Boutet, I., Lemieux, C. L., Goulet, M.-A., and Collin, C. A. (2017). Faces elicit different scanning patterns depending on task demands. Atten. Percept. Psychophys. 79, 1050–1063. doi: 10.3758/s13414-017-1284-y
Brainard, D. H. (1997). The psychophysics toolbox. Spat. Vis., 10, 433–436. doi: 10.1163/156856897X00357
Busemeyer, J. R., Gluth, S., Rieskamp, J., and Turner, B. M. (2019). Cognitive and neural bases of multi-attribute, multi-alternative, value-based decisions. Trends Cogn. Sci. 23, 251–263. doi: 10.1016/j.tics.2018.12.003
Bussey, T. J., Saksida, L. M., and Murray, E. A. (2005). The perceptual-mnemonic/feature conjunction model of perirhinal cortex function. Q. J. Exp. Psychol. B. 58, 269–282. doi: 10.1080/02724990544000004
Day, R.-F., Lin, C.-H., Huang, W.-H., and Chuang, S.-H. (2009). Effects of music tempo and task difficulty on multi-attribute decision-making: an eye-tracking approach. Comput. Hum. Behav. 25, 130–143. doi: 10.1016/j.chb.2008.08.001
Fluharty, M., Jentzsch, I., Spitschan, M., and Vishwanath, D. (2016). Eye fixation during multiple object attention is based on a representation of discrete spatial foci. Sci. Rep. 6:31832. doi: 10.1038/srep31832
Ford, J. K., Schmitt, N., Schechtman, S. L., Hults, B. M., and Doherty, M. L. (1989). Process tracing methods: contributions, problems, and neglected research questions. Organ. Behav. Hum. Decis. Process. 43, 75–117. doi: 10.1016/0749-5978(89)90059-9
Kaskan, P. M., Costa, V. D., Eaton, H. P., Zemskova, J. A., Mitz, A. R., Leopold, D. A., et al. (2017). Learned value shapes responses to objects in frontal and ventral stream networks in macaque monkeys. Cereb. Cortex 27, 2739–2757. doi: 10.1093/cercor/bhw113
Kim, S., and Beck, M. R. (2020). Impact of relative and absolute values on selective attention. Psychon. Bull. Rev. 27, 735–741. doi: 10.3758/s13423-020-01729-4
Krajbich, I. (2019). Accounting for attention in sequential sampling models of decision making. Curr. Opin. Psychol. 29, 6–11. doi: 10.1016/j.copsyc.2018.10.008
Krajbich, I., Armel, C., and Rangel, A. (2010). Visual fixations and the computation and comparison of value in simple choice. Nat. Neurosci. 13, 1292–1298. doi: 10.1038/nn.2635
Krajbich, I., Lu, D., Camerer, C., and Rangel, A. (2012). The attentional drift-diffusion model extends to simple purchasing decisions. Front. Psychol. 3:193. doi: 10.3389/fpsyg.2012.00193
Krajbich, I., and Rangel, A. (2011). Multialternative drift-diffusion model predicts the relationship between visual fixations and choice in value-based decisions. Proc. Natl. Acad. Sci. 108, 13852–13857. doi: 10.1073/pnas.1101328108
Kramer, S. H. A. F. (1998). Further evidence for the division of attention among non-contiguous locations. Vis. Cogn. 5, 217–256. doi: 10.1080/713756781
Lee, M. D., and Cummins, T. D. R. (2004). Evidence accumulation in decision making: unifying the “take the best” and the “rational” models. Psychon. Bull. Rev. 11, 343–352. doi: 10.3758/BF03196581
Lim, S.-L., O’Doherty, J. P., and Rangel, A. (2011). The decision value computations in the vmPFC and striatum use a relative value code that is guided by visual attention. J. Neurosci. 31, 13214–13223. doi: 10.1523/JNEUROSCI.1246-11.2011
Lim, S.-L., O’Doherty, J. P., and Rangel, A. (2013). Stimulus value signals in ventromedial PFC reflect the integration of attribute value signals computed in fusiform gyrus and posterior superior temporal gyrus. J. Neurosci. Off. J. Soc. Neurosci. 33, 8729–8741. doi: 10.1523/JNEUROSCI.4809-12.2013
Liu, H.-Z., Zhou, Y.-B., Wei, Z.-H., and Jiang, C.-M. (2020). The power of last fixation: biasing simple choices by gaze-contingent manipulation. Acta Psychol. 208:103106. doi: 10.1016/j.actpsy.2020.103106
McTighe, S. M., Cowell, R. A., Winters, B. D., Bussey, T. J., and Saksida, L. M. (2010). Paradoxical false memory for objects after brain damage. Science 330, 1408–1410. doi: 10.1126/science.1194780
Mogami, T., and Tanaka, K. (2006). Reward association affects neuronal responses to visual stimuli in macaque te and perirhinal cortices. J. Neurosci. Off. J. Soc. Neurosci. 26, 6761–6770. doi: 10.1523/JNEUROSCI.4924-05.2006
Morii, M., and Sakagami, T. (2015). The effect of gaze-contingent stimulus elimination on preference judgments. Front. Psychol. 6:1351. doi: 10.3389/fpsyg.2015.01351
Orquin, J. L., and Loose, S. M. (2013). Attention and choice: a review on eye movements in decision making. Acta Psychol. 144, 190–206. doi: 10.1016/j.actpsy.2013.06.003
Payne, J. W. (1976). Heuristic search processes in decision making ACR North American Advances, NA-03 Available at: https://www.acrwebsite.org/volumes/9285/volumes/v03/NA-03/full.
Payne, J. W., Bettman, J. R., Coupey, E., and Johnson, E. J. (1992). A constructive process view of decision making: multiple strategies in judgment and choice. Acta Psychol. 80, 107–141. doi: 10.1016/0001-6918(92)90043-D
Payne, J. W., Bettman, J. R., and Johnson, E. J. (1993). The adaptive decision maker. Cambridge: Cambridge University Press.
Pelletier, G., Aridan, N., Fellows, L. K., and Schonberg, T. (2020). The value of the whole or the sum of the parts: the role of ventromedial prefrontal cortex in multi-attribute object evaluation. BioRxiv, [Epub ahead of preprint] doi: 10.1101/2020.09.29.319293
Pelletier, G., Aridan, N., Fellows, L. K., and Schonberg, T. (2021). A preferential role for ventromedial prefrontal cortex in assessing “the value of the whole” in multiattribute object evaluation. J. Neurosci. 41, 5056–5068. doi: 10.1523/JNEUROSCI.0241-21.2021
Pelletier, G., and Fellows, L. K. (2019). A critical role for human ventromedial frontal lobe in value comparison of complex objects based on attribute configuration. J. Neurosci. 39, 4124–4132. doi: 10.1523/JNEUROSCI.2969-18.2019
Pelletier, G., and Fellows, L. K. (2021). Viewing orbitofrontal cortex contributions to decision-making through the lens of object recognition. Behav. Neurosci. 135, 182–191. doi: 10.1037/bne0000447
Persichetti, A. S., Aguirre, G. K., and Thompson-Schill, S. L. (2015). Value is in the eye of the beholder: early visual cortex codes monetary value of objects during a diverted attention task. J. Cogn. Neurosci. 27, 893–901. doi: 10.1162/jocn_a_00760
Peshkovskaya, A., and Myagkov, M. (2020). Eye gaze patterns of decision process in prosocial behavior. Front. Behav. Neurosci. 14:525087. doi: 10.3389/fnbeh.2020.525087
Raaij, W. V. (1977), “Consumer information processing for different information structures and formats,” in NA - Advances in Consumer Research Volume 04 eds. Perreault, William D. Jr, Atlanta, GA: Association for Consumer Research, 176–184. doi: 10.1086/209397
Reutskaja, E., Nagel, R., Camerer, C. F., and Rangel, A. (2011). Search dynamics in consumer choice under time pressure: an eye-tracking study. Am. Econ. Rev. 101, 900–926. doi: 10.1257/aer.101.2.900
Riesenhuber, M., and Poggio, T. (1999). Hierarchical models of object recognition in cortex. Nat. Neurosci. 2, 1019–1025. doi: 10.1038/14819
Russo, J. E., and Rosen, L. D. (1975). An eye fixation analysis of multialternative choice. Mem. Cogn. 3, 267–276. doi: 10.3758/BF03212910
Russo, J. E., and Dosher, B. A. (1983). Strategies for Multiattribute Binary Choice. J. Exp. Psychol. Learning, Memory, and Cognition 9:676–96. doi: 10.1037//0278-7393.9.4.676
Russo, J. E., and Leclerc, F. (1994). An eye-fixation analysis of choice processes for consumer nondurables. J. Consum. Res. 21, 274–290.
Serences, J. T. (2008). Value-based modulations in human visual cortex. Neuron 60, 1169–1181. doi: 10.1016/j.neuron.2008.10.051
Smith, S. M., and Krajbich, I. (2019). Gaze amplifies value in decision making. Psychol. Sci. 30, 116–128. doi: 10.1177/0956797618810521
Suzuki, S., Cross, L., and O’Doherty, J. P. (2017). Elucidating the underlying components of food valuation in the human orbitofrontal cortex. Nat. Neurosci. 20, 1780–1786. doi: 10.1038/s41593-017-0008-x
Takemura, K., Tamari, Y., and Ideno, T. (2023). Avoiding the worst decisions: a simulation and experiment. Mathematics 11:1165. doi: 10.3390/math11051165
Vaidya, A. R., Sefranek, M., and Fellows, L. K. (2018). Ventromedial frontal lobe damage alters how specific attributes are weighed in subjective valuation. Cereb. Cortex 28, 3857–3867. doi: 10.1093/cercor/bhx246
Yang, X., and Krajbich, I. (2022). A dynamic computational model of gaze and choice in multi-attribute decisions. Psychol Rev 130, 52–70. doi: 10.1037/rev0000350
Keywords: neuroeconomics, sequential sampling models, attention, eye-tracking, value
Citation: Ryan-Lortie J, Pelletier G, Pilgrim M and Fellows LK (2023) Gaze differences in configural and elemental evaluation during multi-attribute decision-making. Front. Neurosci. 17:1167095. doi: 10.3389/fnins.2023.1167095
Edited by:
Igor Kagan, Deutsches Primatenzentrum, GermanyReviewed by:
Ali Ghazizadeh, Sharif University of Technology, IranKazuhisa Takemura, Waseda University, Japan
Copyright © 2023 Ryan-Lortie, Pelletier, Pilgrim and Fellows. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Juliette Ryan-Lortie, SnVsaWV0dGUucnlhbi1sb3J0aWVAbWFpbC5tY2dpbGwuY2E=; Gabriel Pelletier, Z2FicmllbC5mZWxsb3dzQG1jZ2lsbC5jYQ==