 Debashis Ghosh
Debashis Ghosh Emily Mastej
Emily Mastej Rajan Jain3
Rajan Jain3
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Neurosci. , 20 June 2022
Sec. Brain Imaging Methods
Volume 16 - 2022 | https://doi.org/10.3389/fnins.2022.884708
This article is part of the Research Topic Modern Statistical Learning Strategies in Imaging Genetics View all 8 articles
The widespread use of machine learning algorithms in radiomics has led to a proliferation of flexible prognostic models for clinical outcomes. However, a limitation of these techniques is their black-box nature, which prevents the ability for increased mechanistic phenomenological understanding. In this article, we develop an inferential framework for estimating causal effects with radiomics data. A new challenge is that the exposure of interest is latent so that new estimation procedures are needed. We leverage a multivariate version of partial least squares for causal effect estimation. The methodology is illustrated with applications to two radiomics datasets, one in osteosarcoma and one in glioblastoma.
Radiomics explores relationships between image-derived characteristics of a tumor and other parameters, including clinical outcomes and genomic profiles, including gene expression, somatic mutations, and DNA methylation (Mazurowski, 2015). In particular, several groups have built classifiers to predict tumor molecular phenotypes using radiomic inputs (e.g., Kickingereder et al., 2016; Rios Velazquez et al., 2017; Yip et al., 2017; Xi et al., 2018). More recently, there has been tremendous interest in using modern machine learning and in particular deep learning tools in order to build state-of-the-art classifiers for predictions (Lao et al., 2017; Li et al., 2017; Parnian et al., 2020).
In spite of their state-of-the-art performance, use of these complex models comes at a cost. Because many of these classifiers are “black-box” in nature, clinicians consequently have a difficult time understanding the predictions. More generally, most work in radiomics has focused on pattern-based associations in the data with a machine learning viewpoint in one of two ways. First, these analyses could take the form of clustering algorithms, such as t-SNE or UMAP, in which interesting clusterings lead to followup discoveries. Second, a classification or supervised learning framework could be adopted in which the radiomics features could be used to predict a class label or phenotype of interest. For this approach, a typical evaluation is classification accuracy of the ROC curve or F1 values where higher values are better. While there has been tremendous successes in radiomics with these machine learning techniques, it still remains elusive from the end goal of developing mechanistic insights into tumorigenesis.
In this article, we seek to introduce causal modeling concepts into radiomics. While there has been much work on using these ideas in genomics (e.g., Huang and Pan, 2016; Aung et al., 2020) and brain imaging (e.g., Chén et al., 2018), their application to radiomics has not occurred. We argue that adopting this viewpoint in radiomics has the following advantages:
1. It allows one to view radiomics as measurements of properties of the tumor and its characteristics.
2. Developing a causal model allows one to link tumorigenic mechanisms to observed data.
3. The causal inferential pathway is compatible with the trend toward systems biology (Alon, 2019) while not being as purely reductionist as approaches such as those based on mathematical models or ordinary differential equations.
However, a challenge that this approach introduces is that we must view the tumor as a latent construct, and causal inference with latent structures is much more challenging. There has been much recent interest in the use of latent class modeling of treatment effects on outcomes (Collins and Lanza, 2009). Bandeen-Roche et al. (1997) proposed a latent class modeling approach in which pseudodraws from the inferred latent class distribution are then used to fit regression models on the outcome. Multiple pseudodraws are generated, and the multiple regression results are combined using Rubin's imputation rules (Little and Rubin, 2019). A simpler approach is to use a classify/analyze approach (Clogg, 1995) in which each individual is assigned to a latent class, and then the group assignment is used as a covariate for which standard propensity score methods can be applied. In a recent study, Schuler et al. (2014) compared these approaches, along with a joint modeling approach developed by Kang and Schafer from an unpublished technical report at the Methodology Center of Penn State University. The approaches can be broadly grouped as being 1-step vs. 3-step approaches (Asparouhov and Muthén, 2014). The former methods fit a joint model describing both the latent classes as well as the latent classes' effect on the outcome. The latter go through a series of three steps: (a) fit a model to describe the joint classes; (b) assign membership of the individuals to these classes; (c) fit a regression model of the outcome on the inferred latent class. Schuler et al. (2014) provide a nice discussion of the strengths and weaknesses of each approach. In their conclusions, they suggest that 1-step methods offer many advantages but that one barrier to their implementation is computational. To be precise, estimation based on a joint likelihood for both the latent class and causal effect modeling might have issues with numerical convergence.
Our new contributions to the literature in the current paper are the following:
1. Extension and formalization of the classical potential outcomes framework (Rubin, 1974; Holland, 1986) to accomommodate latent treatment effects. This entails developing the necessary assumptions for definition and identification of an appropriate causal estimate with observed data. This leads to a new quantity, the local latent average causal effect.
2. Development of a new estimation procedure for the local causal effect with latent variables. This leverages techniques from sufficient dimension reduction and partial least squares (Naik and Tsai, 2000).
To our knowledge, the use of latent causal inferential techniques has not been developed for effect estimation in radiomics or genomics. The most related technique comes from genetics, where principal components-type approaches are used to adjust for population stratification, which is a type of confounding (Patterson et al., 2006; Epstein et al., 2007). However, in that setup, latent variables are used to model confounders, not the main effect of interest, which is the focus of the current article. As a proof of concept, we apply our approach to two radiomics datasets in the literature, one from glioblastoma, the other a public available data from osteosarcoma (Zhang et al., 2019).
In this article, we will use two datasets to illustrate the methodology as a proof of concept. We use these because the distribution of the outcome is different. For the study described in Section 2.1, the outcome is continuous, while for that in Section 2.2, the outcome is binary.
Glioma is the most common type of brain cancer; it develops in the glial cells (Ohgaki, 2009). Among these, glioblastoma multiforme (GBM) is the most frequent and malignant histologic type. Patients with GBM have on average 3% 5-year survival after diagnosis (Ohgaki, 2009). The dataset we work with comes from the Cancer Genome Atlas, consisting of data on 226 subjects with GBM. For these subjects, imaging was done using three protocols: T1, T2 and FLAIR. In this paper, we only focus on the first two. T1 and T2 refer to protocols that utilize two different properties of fMRI. With fMRI, the magnetic current induces a magnetic field, and T1 refers to the speed at which the electron spins in the blood realign with the recovery of the longitudinal orientation. T2 refers to the loss of magnetization as a result of the loss in phase coherence of the electrons. The T1 and T2 images were represented in DICOM format, which was then converted to NIfTI format and processed for standardization with 1mm isovoxel resolution as follows:
1. Postcontrast T1-weighted images (T1C) were resampled to 1mm isovoxel resolution.
2. T2 images were registered to T1C images after skull stripping, using the FMRIB software library (http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FSL).
3. Image signal intensity was normalized using the WhiteStripe R package.
The tumor areas, defined as areas of T2 hyper-intense tumor and edema on FLAIR images, were segmented by using semi-automatic methods, including signal intensity thresholding, region growing, and edge detection, with an open source software (Medical Image Processing, Analysis and Visualization, https://mipav.cit.nih.gov/). Radiomic features were extracted from all isotropic voxel image segmented regions of interest (ROIs) using pyRadiomics (Van Griethuysen et al., 2017). Extraction settings were configured to features from original images, as well as Wavelet filtered and Laplacian of Gaussian (LoG) filtered images and were calculated considering adjacent voxel in 3 dimensions. In total, 1046 radiomic features were extracted per image.
Osteosarcoma is a cancer that usually develops in the cells that form bone, the osteoclasts. It happens most often in children, adolescents, and young adults. In a recent study, Zhang et al. (2021) conducted a study of 102 subjects with osteosarcoma who underwent neoadjuvant chemotherapy. Prior to having treatment, they received a dynamic contrast-enhanced MRI (DCE-MRI) scan. The Response Evaluation Criteria in Solid Tumors were used to evaluate the neoadjuvant chemotherapy response as effective (complete remission and/or partial remission) or ineffective (stable and progressive disease).
Using the Radcloud software platform, Zhang et al. (2021) extracted a total of 1,409 quantitative imaging features. They can be divided into four groups: (a) Group 1 represent typical summaries for the distribution of voxel intensities within the MR image; (b) Group 2 are three-dimensional features that reflect the shape and size of the region; (c) Group 3 are second-order texture features that quantify region heterogeneity differences, calculated from gray-level run length and gray-level co-occurrence texture matrices; (d) Group 4 contains 1,302 first-order statistics and texture features after applying Laplacian, logarithmic, exponential, and wavelet filters on the image. The goal is to see whether or not radiomics can predict treatment response.
We first review the potential outcomes framework of Rubin (1974) and Holland (1986) and begin by assuming that the treatment is observed. For the sake of exposition, we will assume that it is continuous, similar to Imai and Van Dyk (2004). Let Z denote the treatment, with possible values z∈Ƶ. Define {Yi(z):z∈Ƶ} to the set of potential outcomes for subject i, i = 1, …, n; Yi(z) represents the potential outcome for subject i with the treatment equals z. In addition, we assume the existence of a set of confounders X. For proper causal inference within the potential outcomes framework, one needs the assumption based on strong ignorability of the treatment:
which in words states that treatment assignment is conditionally independent of the set of potential outcomes given covariates. In the case of binary treatment, Rosenbaum and Rubin (1983) refer to (1) as the strongly ignorable treatment assumption. Heuristically, what (1) implies is that the potential outcomes can be viewed as predefined random variables. The randomness in the populations occurs due to the non-ignorable missing data mechanism, in the sense of Little and Rubin (2019), that makes only one of the potential outcomes observable for each subject. In addition, we make the assumption of consistency so that the observed outcome for a subject coincides with the corresponding potential outcome.
Based on the potential outcomes, we can define the following local causal effect parameter
for i = 1, …, n. We also note the dependence of (2) on the treatment. If we assume that the effect is constant over levels of Z, then it would be possible to pool effects to result in a statistically more efficient estimator of the local causal effect.
Two more assumptions that are commonly invoked in the causal inference literature are the positivity assumption and the common support condition. The former states that E(Z|X)≠0 for all possible values of X. In other words, there exist no regions of the confounder distribution that preclude observe any possible value of the treatment. The common support condition states that there is sufficient overlap in X across all values of Z.
If we were to average the local causal effects (2) over all subjects (i = 1, …, n), then this would correspond to a local average causal effect. In the case where the treatment is binary, this effect reduces to the average causal effect that has been considered in the literature.
Analogous to the propensity score of Rosenbaum and Rubin (1983) in the case of binary treatment, we can consider a quantity representing the conditional mean of treatment given confounders, E(Z|X). This is a special case of the generalized propensity score of Imai and Van Dyk (2004) and has several desirable properties. The first is that it reduces the modeling of confounders to modeling a conditional mean of treatment, which reduces the dimension. Second, provided E(Z|X) is correctly modeled, then it functions as a balancing score in that if (1) holds, then {Y(z):z∈Ƶ}||Z|E(Z|X). The properties of E(Z|X) lead to a natural strategy for performing causal inference:
1. Fit a model for E(Z|X).
2. Given the predicted conditional mean in (1), perform a regression of Y on Z in which an adjustment is made using E(Z|X).
There is a variety of approaches to perform adjustment in the second step of this algorithm. These include inverse weighting methods, regression adjustment, matching, subclassification, or a combination thereof. Please see Lunceford and Davidian, 2004 for more discussion on these methods.
We now relax the assumption that the treatment Z be observed. Instead, we now have available several observations U≡(U1, …, UK) that capture the latent treatment variable Z. A commonly used assumption here is the so-called local independence assumption (Henning, 1989), which states that conditional on Z, U1, …, UK are conditionally independent. We can then factorize the joint distribution of the potential outcomes (denoted here as Y(·)) Z, X and U as
where we have the assumption (1) to simplify the conditional distribution going from the first line to the second. If we further assumption that the joint density fX, U are ancillary for the causal parameters of interest, then we can base our approach to inference by specifying likelihoods corresponding to fY(·)|U, X and fZ|X, U, respectively. Recapping, here are the assumptions we need for valid causal effect estimation of the LCE in the latent case:
1. Z||{Y(z):z∈Ƶ}.
2. The components of U are conditionally independent given Z.
3. The components of U are conditionally independent of any variable S given Z.
4. E(Z|X) exists for all X.
We note that Assumptions 2 and 3 look similar but are conceptually different. The former deals with the radiomics features providing conditionally independent information given the tumor and is referred to as local independence. By contrast, the latter has to do with measurement invariance (Meredith, 1993), namely that the radiomics measurements are capturing the same concept independent of other variables. In fact, it is assumption 3 that is a very important one if one wishes to have any chance of the radiomics data analyses reflecting potentially generalizable findings.
Figure 1 depicts our conceptual model. We could then convert Figure 1 into a causal diagram (Greenland et al., 1999) which leverages the graphical model for causation (Pearl, 2009). We can use the traditional rules about directed acyclic graphs to model conditional independence. In particular, the observed radiomics data will be conditionally independent given the latent variable. In addition, the latent variable d-separates (Pearl, 2009) the confounders from U. The causal effect we focus on in Figure 1 is that from the latent variable to the clinical outcome. This separation of the scientific estimants (i.e., causal effects) from the data represent one of the appealing features of Figure 1.
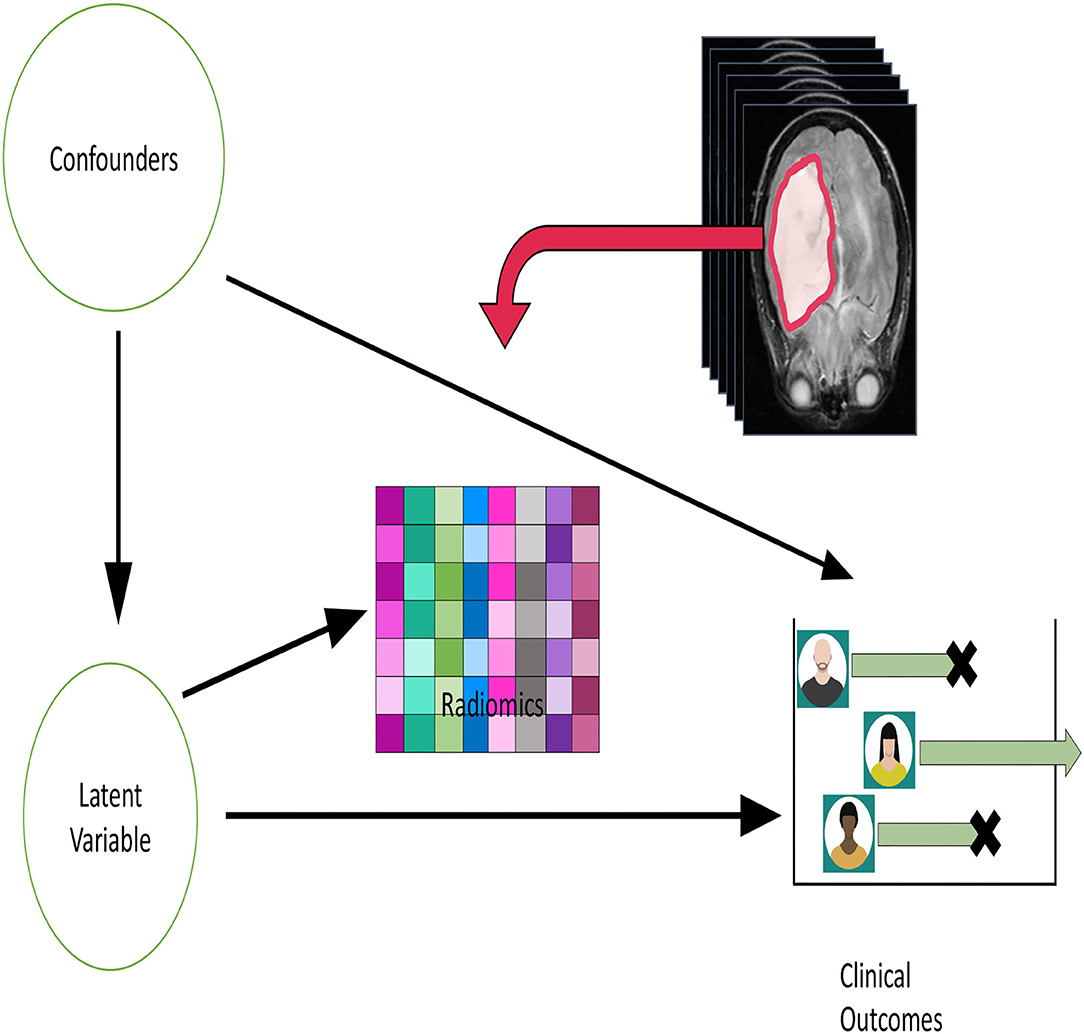
Figure 1. A conceptual model diagram relating confounders, radiomics and outcome variables in medical studies. The goal is to estimate the causal effect corresponding from the arrow from the “Latent variable” circle to the clinical outcome.
We note that the structure of Figure 1 is related to diagrams used by practitioners of structural equations modeling (SEM, Bollen and Pearl, 2013). In that literature, relationships between latent variables are referred to as the structural model, while those relating latent to measured are called measurement models. SEM combines the two types of models in order to induce a joint distribution for the observed data which is then used for estimation and inference. As described by Bollen and Pearl (2013), the structural model is consistent with the potential outcomes framework that we outlined in Section 3.1.
Thinking of the radiomics data as the main effect in a causal analysis is consistent with a tumor progression model in which the cancer's behavior at clinical diagnosis matters, and any biological preceding events can only play the role of confounders. Biologically, this means that confounders increase the propensity for tumorigenesis to occur.
Based on the assumptions and conditional independence statements we have laid out in the previous sections, we have following proposition.
Proposition 1. The random variable Z d-separates both U and X and Y and X.
While proposition 1 is quite simple in nature, it in fact reveals a powerful result and leads to a new approach to causal effect estimation. In particular, we can estimate Z as a latent variable in two simultaneous regression models: (1) U on X; (2) Y on X. This simultaneous estimation has potential benefits largely due to the absence of direct arrows from U to Y in Figure 1. We have thus converted a causal effect estimation problem into a multi-task learning problem with a latent variable.
Our algorithms for causal effect estimation will be based on partial least squares (PLS) (Helland, 1988, 1990). PLS presumes that Ui and Xi (i = 1, …, n) are both linear functions of a set of common latent factors. An alternative characterization for PLS was given by Stone and Brooks (1990). Suppose that we are fitting the following model:
Then, Stone and Brooks (1990) consider the following class of objective functions:
where Var and Cov and short-hand notation for variance and covariance, and α is a number between 0 and 1. In this framework, values of α = 0, α = 1/2 and α = 1 correspond to the objective functions maximized by ordinary least squares (OLS), partial least squares (PLS) and principal components regression (PCR), respectively. Using this framework, we find that the PLS algorithm acts as some hybrid between the usual least squares estimator and the principal components regression approach of Massy (1965).
The algorithm for multivariate PLS that we will use is the kernel algorithm proposed by Dayal and MacGregor (1997). We assume that the columns of U and X are centered and scaled. Recall again that the PLS model formulation is given by
where T and V are n × l matrices, and P and Q are the so-called locaing matrices corresponding to X and U, respectively. The dimension of P is p × l, while for Q, it is m × l. The matrices E and F are the error terms with entries being independent and identically distributed normal random variables with mean zero and variance σ2.
The kernel algorithm proceeds as follows:
1. Compute the matrices X′X and X′U.
2. Let b = 1. Compute q1 as the eigenvector corresponding to the largest eigenvalue of U′X′XU. Then set and rescale the entries of wb to have unit norm. For b = 1, ; for b > 1, its definition will be given in (5).
3. Compute rb. For b = 1, r1 = w1, while for b > 1,
4. Compute tb = Xrb, and .
5. Compute
1. Repeat steps (2)-(5).
At the end, the regression coefficients are given by the outer product of the matrix consisting of rb and that consisting of qb. This kernel algorithm has been implemented in the kernelpls.fit function that is available in the pls package (Wehrens and Mevik, 2007).
Partial least squares methods were given a justification for the single-index model by Naik and Tsai (2000). This was done by incorporating ideas from the field of sufficient dimension reduction (Li, 2018). This is a branch of statistics in which the goal is to develop “model-free” procedures in order to summarize data while preserving regression relationships. The field started with the observation by Brillinger (2012) in which ordinary least squares methods provide estimates that were consistent up to a sign for regression parameters in more general single-index models. A recent overview of the field can be found in Li (2018).
We now develop a multivariate extension of the results of Naik and Tsai (2000). To do this, we consider a multivariate response for each subject that can be summarized as a an K−dimensional vector U along with a p−dimensional vector of covariates X.
We then formulate the following multivariate regression model:
where gj (j = 1, …, K) are monotonic functions in both arguments and ϵ1, …, ϵK are random vectors representing the error distributions for the models. In (6), the p−dimensional parameter vectors β1, …, βK specify the directions of interest. In the case where K = 1, model (6) reduces to a generalized single-index model. We make the following assumptions.
Assumption 1. X has a multivariate normal distribution. Assumption 2. The covariance matrices n−1X′X and n−1X′U converge in probability to limits Σxx and Σxu, respectively. Assumption 3. Taken as an operator, the range of Σxx coincides with the range of Σxu.
Based on these three assumptions, we have the following result.
Theorem: Under Assumptions 1–3, the multivariate PLS estimator converges in probability to a constant times (β1, …, βm).
Proof: The multivariate PLS estimator can be expressed as , where is the matrix derived from the Kryvlov sequence of matrices of n−1X′X and n−1X′U. By assumption 2, this will converge to . By assumption 3, β* will the in the space spanned by R so that will be in the space spanned by . The statement of the theorem then follows.
One of the major assumptions in traditional sufficient dimension reduction procedures has been the linearity assumption, which is satisfied by multivariate normal distributions and more generally, elliptically symmetric distributions. This gets violated in situations with discrete predictors. Recently, Ghosh (2022) has developed an interpretation of sufficient dimension reduction methods from an information-theoretic point of view. In this interpretation, the partial least squares algorithm can be viewed as an information-maximization operation under less restrictive distributional assumptions than those required in Theorem 1 of the paper.
In examining Figure 1, we propose the following strategy for causal effect estimation.
1. Run a multivariate PLS regression of the radiomics data on the confounders.
2. Using the scores as the inferred latent treatment from the output of the PLS regression, perform causal inference of the treatment on outcome.
We have lots of choices on how to perform step 2. above. Our approach is to use regression adjustment as a means of inferring causal effects. For the standard error, we will use the non-parametric bootstrap (Efron, 1981).
We note that the outcome of the multivariate PLS can be fairly general. These include variables that are continuous, binary or unordered categorical. For right-censored failure time variables, we use the suggestion of Keleş and Segal (2002) and compute a first-stage martingale residual from a null model (i.e., one with no covariates). We then treat the residual as a continuous variable to be input into the partial least squares algorithm.
The confounders available in this analysis are gender, grade, and IDH mutation status. Mutations of the isocitrate dehydrogenase (IDH1) gene has been shown to be a marker of oncogenesis and is one of the most specific biomarkers in the diagnostic classification of secondary GBM (Dang et al., 2010) Gliomas with mutated IDH have improved prognosis compared to gliomas with wild-type IDH and are detected by immunohistochemistry and magnetic resonance (MR) spectroscopy (Cohen et al., 2013). We first characterize survival in the population and by grade, IDH mutation status and gender. These are presented in Figure 2.
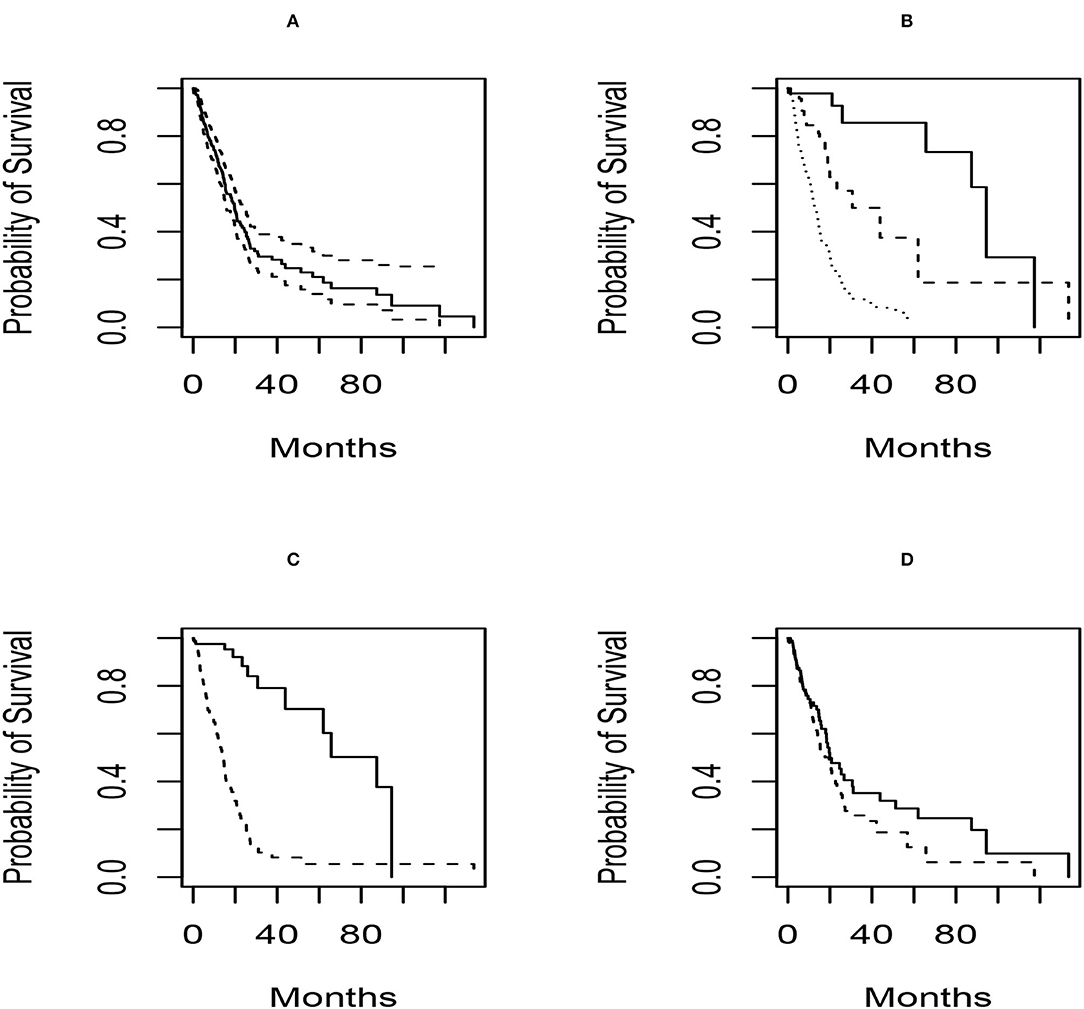
Figure 2. Survival distribution plots for the subjects in the glioblastoma radiomics study. For all plots, the x axis represents the time in weeks and the y-axis is the survival probability. Panel (A) shows the Kaplan–Meier plot for the entire population, along with associated 95% pointwise confidence intervals. Panel (B) shows the Kaplan–Meier estimates by grade (solid = grade 2; dashed = grade 3; dotted = grade 4). In Panel (C), the survival distributions by IDH mutation status (solid = mutant; dashed = wild-type) are presented. Finally, the gender-specific survival distributions (solid = female; dashed = male) are given in (D).
Based on the plots, we see that there are differences in survival based on grade and IDH mutation status and not for gender. We also note that 22 subjects are missing IDH mutation, while 1 is missing grade and gender.
We next applied the latent causal effect approach in the paper with two sets of confounders: (gender, grade) and (gender, grade, IDH mutation statu). We note that the former analysis will have 225 subjects, while the latter will have 203. The results are shown in Table 1.
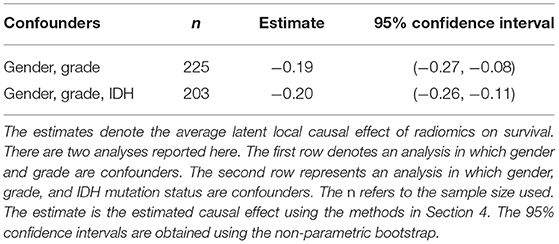
Table 1. Latent causal effects and associated confidence intervals in glioblastoma study.
The model that is being fit is for the adjusted survival time as a function of the latent variable. Based on the analysis, we see that there is a highly significant effect of the treatment on outcome. Both analyses that higher values of the latent construct are associated with lower adjusted times to death.
In this dataset, there is only one confounder, the stage of cancer (stage IIB vs. not). Of the 102 subjects, 75 were stage IIB. The effect of radiomics on treatment response was analyzed here. The multivariate PLS algorithm yields an average causal effect of 0.099, with an associated 95% confidence interval of (−0.13, 0.20). As an alternative, we computed the first principal components using the radiomics data and fit a regression model of treatment response Y on the principal component and stage. Based on the fitted model, we obtained the following equation:
with associated standard errors of 0.01 and 0.11 for the principal component and stage. While both variables are statistically significant at a 0.05 level of significance (p-values of 0.05 and 0.03 for PC score and stage, respectively), we note that the direction of the effect is reverse that from the multivariate PLS approach.
In this article, we have introduced an approach to causal modeling with radiomics data. The assumptions needed for identification of the causal effects from observed data along with an estimation procedure for causal effects. We have demonstrated the application of the methodology to two radiomics datasets in cancer. Further evaluations are need to demonstrate validation of the methodology. To help readers, we have made code available to do the analysis with the osteosarcoma data at the following location: http://github.com/GhoshLab/CausalRadiomics.
An alternative approach to radiomics data is to treat it as a mediation variable in a causal effects analysis. There, it would be an intermediate variable, and genetic data would serve as the main exposure. Viewing the radiomics as mediation variable makes explicit the role of initiating events. In Figure 3, we suggest a DNA mutation as the beginning event, but other choices could be entertained.
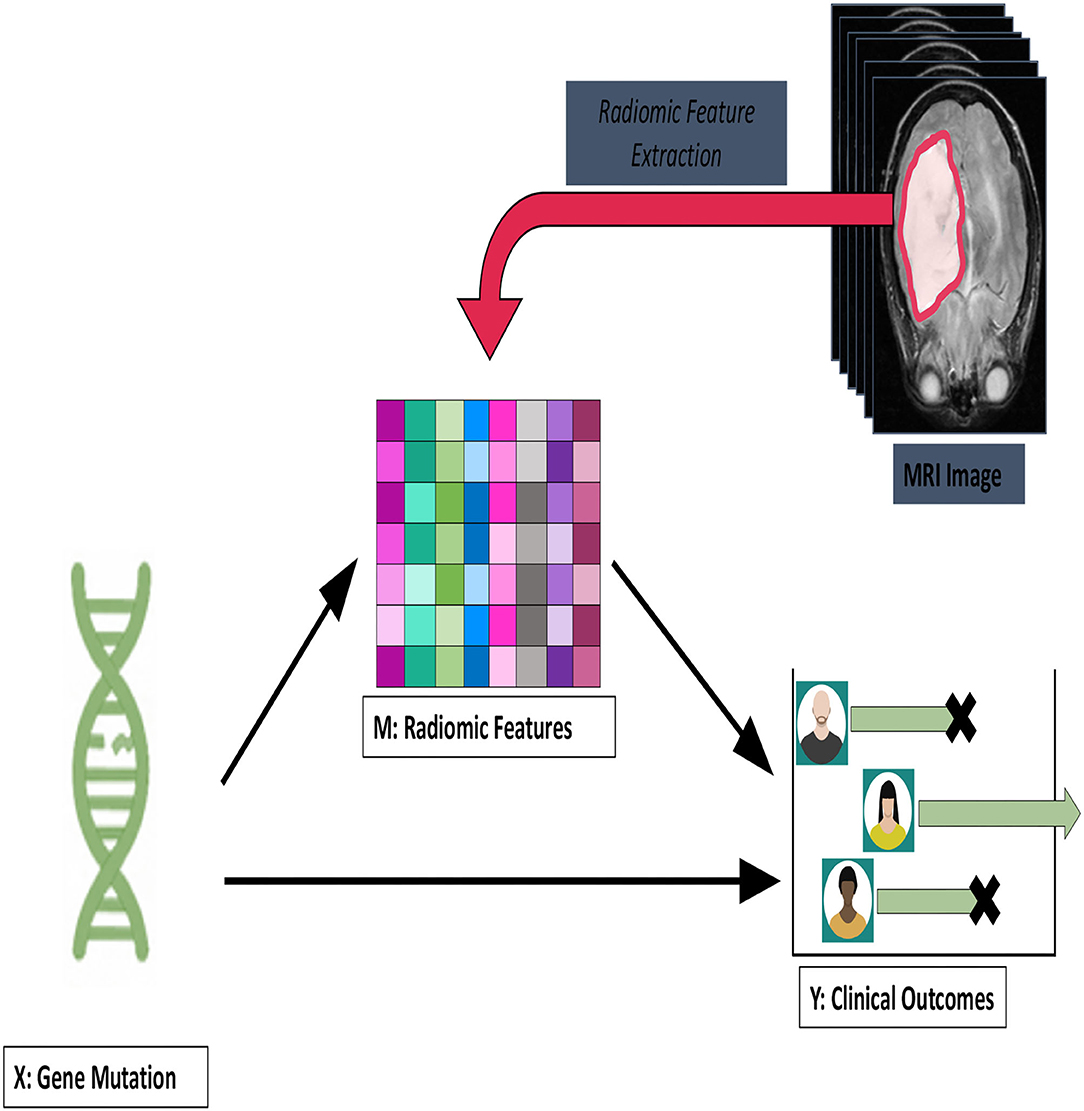
Figure 3. A framework for viewing the radiomics measurements as mediation variables. The exposure here is a DNA mutation which leads to tumorigenesis that is captured by the imaging and radiomics feature and which leads to a clinical outcome.
In this setup, the radiomics is viewed as a downstream event, and the mutation will have effects on survival as mediated through the radiomics and effects outside the pathway. In Huang and Pan (2016), the authors used microRNA as the exposure and gene expression from several pathways as the mediators. For this setup, they develop tests of mediation and associated testing procedures. More recently, in Aung et al. (2020), a Bayesian approach to mediation analysis as developed, in which methylation profiles were the high-dimensional mediators of a univariate exposure. Their algorithm was based on a variable selection procedure with shrinkage priors to select for mediators. Finally, we note the principal mediation directions approach of Chén et al. (2018). For their application, subject-level functional magnetic resonance imaging profiles were the mediator, and the goal was to understand the areas of the brain that mediated pain-invoked stimuli. In Chén et al. (2018), the authors used a supervised principal components approach similar to what is presented here. We will explore extensions of our latent causal inference procedures to the mediation problem in future work.
The data are available from YSC upon reasonable request. Requests to access these datasets should be directed to eW9vbnNlb25nLmNob2kwN0BnbWFpbC5jb20=.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
DG led the conceptualization of the project, methodological development, analysis, and writing of the first draft of the manuscript. All authors participated in the writing process and approved the final manuscript.
EM was supported by T15 LM009451.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
DG would like to acknowledge support from NIH R01 CA129102 and NSF DMS 1914937.
Alon, U. (2019). An Introduction to Systems Biology: Design Principles of Biological Circuits. New York, NY: CRC Press. doi: 10.1201/9780429283321
Asparouhov, T., and Muthén, B. (2014). Auxiliary variables in mixture modeling: three-step approaches using m plus. Struct. Equat. Model. 21, 329–341. doi: 10.1080/10705511.2014.915181
Aung, M. T., Song, Y., Ferguson, K. K., Cantonwine, D. E., Zeng, L., McElrath, T. F., et al. (2020). Application of an analytical framework for multivariate mediation analysis of environmental data. Nat. Commun. 11, 1–13. doi: 10.1038/s41467-020-19335-2
Bandeen-Roche, K., Miglioretti, D. L., Zeger, S. L., and Rathouz, P. J. (1997). Latent variable regression for multiple discrete outcomes. J. Am. Stat. Assoc. 92, 1375–1386. doi: 10.1080/01621459.1997.10473658
Bollen, K. A., and Pearl, J. (2013). “Eight myths about causality and structural equation models,” in Handbook of Causal Analysis for Social Research, ed S. Morgan (Springer), 301–328. doi: 10.1007/978-94-007-6094-3_15
Brillinger, D. R. (2012). “A generalized linear model with “Gaussian” regressor variables,” in Selected Works of David Brillinger, eds P. Guttorp and D. Brillinger (Springer), 589–606. doi: 10.1007/978-1-4614-1344-8_34
Chén, O. Y., Crainiceanu, C., Ogburn, E. L., Caffo, B. S., Wager, T. D., and Lindquist, M. A. (2018). High-dimensional multivariate mediation with application to neuroimaging data. Biostatistics 19, 121–136. doi: 10.1093/biostatistics/kxx027
Clogg, C. C. (1995). “Latent class models,” in Handbook of Statistical Modeling for the Social and Behavioral Sciences, eds G. Arminger, C. C. Clogg, and M. E. Sobel (Springer), 311–359. doi: 10.1007/978-1-4899-1292-3_6
Cohen, A. L., Holmen, S. L., and Colman, H. (2013). IDH1 and IDH2 mutations in gliomas. Curr. Neurol. Neurosci. Rep. 13, 345. doi: 10.1007/s11910-013-0345-4
Collins, L. M., and Lanza, S. T. (2009). Latent Class and Latent Transition Analysis: With Applications in the Social, Behavioral, and Health Sciences, Vol. 718. New York, NY: John Wiley & Sons.
Dang, L., Jin, S., and Su, S. M. (2010). IDH mutations in glioma and acute myeloid leukemia. Trends Mol. Med. 16, 387–397. doi: 10.1016/j.molmed.2010.07.002
Dayal, B. S., and MacGregor, J. F. (1997). Improved PLS algorithms. J. Chemometr. 11, 73–85. doi: 10.1002/(SICI)1099-128X(199701)11:1<73::AID-CEM435>3.0.CO;2-#
Efron, B. (1981). Nonparametric estimates of standard error: the jackknife, the bootstrap and other methods. Biometrika 68, 589–599. doi: 10.1093/biomet/68.3.589
Epstein, M. P., Allen, A. S., and Satten, G. A. (2007). A simple and improved correction for population stratification in case-control studies. Am. J. Hum. Genet. 80, 921–930. doi: 10.1086/516842
Ghosh, D. (2022). Sufficient dimension reduction: an information-theoretic viewpoint. Entropy 24, 167. doi: 10.3390/e24020167
Greenland, S., Pearl, J., and Robins, J. M. (1999). Causal diagrams for epidemiologic research. Epidemiology 10, 37–48. doi: 10.1097/00001648-199901000-00008
Helland, I. S. (1988). On the structure of partial least squares regression. Commun. Stat. Simul. Comput. 17, 581–607. doi: 10.1080/03610918808812681
Helland, I. S. (1990). Partial least squares regression and statistical models. Scand. J. Stat. 17, 97–114.
Henning, G. (1989). Meanings and implications of the principle of local independence. Lang. Test. 6, 95–108. doi: 10.1177/026553228900600108
Holland, P. W. (1986). Statistics and causal inference. J. Am. Stat. Assoc. 81, 945–960. doi: 10.1080/01621459.1986.10478354
Huang, Y.-T., and Pan, W.-C. (2016). Hypothesis test of mediation effect in causal mediation model with high-dimensional continuous mediators. Biometrics 72, 402–413. doi: 10.1111/biom.12421
Imai, K., and Van Dyk, D. A. (2004). Causal inference with general treatment regimes: generalizing the propensity score. J. Am. Stat. Assoc. 99, 854–866. doi: 10.1198/016214504000001187
Keleş, S., and Segal, M. R. (2002). Residual-based tree-structured survival analysis. Stat. Med. 21, 313–326. doi: 10.1002/sim.981
Kickingereder, P., Gutz, M., Muschelli, J., Wick, A., Neuberger, U., Shinohara, R. T., et al. (2016). Large-scale radiomic profiling of recurrent glioblastoma identifies an imaging predictor for stratifying anti-angiogenic treatment response. Clin. Cancer Res. 22, 5765–5771. doi: 10.1158/1078-0432.CCR-16-0702
Lao, J., Chen, Y., Li, Z.-C., Li, Q., Zhang, J., Liu, J., et al. (2017). A deep learning-based radiomics model for prediction of survival in glioblastoma multiforme. Sci. Rep. 7, 1–8. doi: 10.1038/s41598-017-10649-8
Li, B. (2018). Sufficient Dimension Reduction: Methods and Applications with R. New York, NY: CRC Press. doi: 10.1201/9781315119427
Li, Z., Wang, Y., Yu, J., Guo, Y., and Cao, W. (2017). Deep learning based radiomics (dlr) and its usage in noninvasive idh1 prediction for low grade glioma. Sci. Rep. 7, 1–11. doi: 10.1038/s41598-017-05848-2
Little, R. J., and Rubin, D. B. (2019). Statistical Analysis With Missing Data, Vol. 793. New York, NY: John Wiley & Sons. doi: 10.1002/9781119482260
Lunceford, J. K., and Davidian, M. (2004). Stratification and weighting via the propensity score in estimation of causal treatment effects: a comparative study. Stat. Med. 23, 2937–2960. doi: 10.1002/sim.1903
Massy, W. F. (1965). Principal components regression in exploratory statistical research. J. Am. Stat. Assoc. 60, 234–256. doi: 10.1080/01621459.1965.10480787
Mazurowski, M. A. (2015). Radiogenomics: what it is and why it is important. J. Am. Coll. Radiol. 12, 862–866. doi: 10.1016/j.jacr.2015.04.019
Meredith, W. (1993). Measurement invariance, factor analysis and factorial invariance. Psychometrika 58, 525–543. doi: 10.1007/BF02294825
Naik, P., and Tsai, C.-L. (2000). Partial least squares estimator for single-index models. J. R. Stat. Soc. Ser. B 62, 763–771. doi: 10.1111/1467-9868.00262
Ohgaki, H. (2009). Epidemiology of brain tumors. Cancer Epidemiol. 472, 323–342. doi: 10.1007/978-1-60327-492-0_14
Parnian, A., Arash, M., Tyrrell, P. N., Cheung, P., Ahmed, S., Plataniotis, K. N., et al. (2020). DRTOP: deep learning-based radiomics for the time-to-event outcome prediction in lung cancer. Sci. Rep. 9, 19518. doi: 10.1038/s41598-020-69106-8
Patterson, N., Price, A. L., and Reich, D. (2006). Population structure and eigenanalysis. PLoS Genet. 2, e190. doi: 10.1371/journal.pgen.0020190
Rios Velazquez, E., Parmar, C., Liu, Y., Coroller, T. P., Cruz, G., Stringfield, O., et al. (2017). Somatic mutations drive distinct imaging phenotypes in lung cancer. Cancer Res. 77, 3922–3930. doi: 10.1158/0008-5472.CAN-17-0122
Rosenbaum, P. R., and Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika 70, 41–55. doi: 10.1093/biomet/70.1.41
Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. J. Educ. Psychol. 66, 688. doi: 10.1037/h0037350
Schuler, M. S., Leoutsakos, J.-M. S., and Stuart, E. A. (2014). Addressing confounding when estimating the effects of latent classes on a distal outcome. Health Serv. Outcomes Res. Methodol. 14, 232–254. doi: 10.1007/s10742-014-0122-0
Stone, M., and Brooks, R. J. (1990). Continuum regression: cross-validated sequentially constructed prediction embracing ordinary least squares, partial least squares and principal components regression. J. R. Stat. Soc. Ser. B 52, 237–258. doi: 10.1111/j.2517-6161.1990.tb01786.x
Van Griethuysen, J. J., Fedorov, A., Parmar, C., Hosny, A., Aucoin, N., Narayan, V., et al. (2017). Computational radiomics system to decode the radiographic phenotype. Cancer Res. 77, e104–e107. doi: 10.1158/0008-5472.CAN-17-0339
Wehrens, R., and Mevik, B.-H. (2007). The PLS Package: Principal Component and Partial Least Squares Regression in R.
Xi, Y. B., Guo, F., Xu, Z. L., Li, C., Wei, W., Tian, P., et al. (2018). Radiomics signature: a potential biomarker for the prediction of MGMT promoter methylation in glioblastoma. J. Magn. Reson. Imaging 47, 1380–1387. doi: 10.1002/jmri.25860
Yip, S. S., Kim, J., Coroller, T. P., Parmar, C., Velazquez, E. R., Huynh, E., et al. (2017). Associations between somatic mutations and metabolic imaging phenotypes in non-small cell lung cancer. J. Nuclear Med. 58, 569–576. doi: 10.2967/jnumed.116.181826
Zhang, L., Ge, Y., Gao, Q., Zhao, F., Cheng, T., Li, H., et al. (2021). Machine learning-based radiomics nomogram with dynamic contrast-enhanced MRI of the osteosarcoma for evaluation of efficacy of neoadjuvant chemotherapy. Front. Oncol. 11, 758921. doi: 10.3389/fonc.2021.758921
Keywords: latent causal effect, link-free inference, medical imaging, personalized medicine, sufficient dimension reduction
Citation: Ghosh D, Mastej E, Jain R and Choi YS (2022) Causal Inference in Radiomics: Framework, Mechanisms, and Algorithms. Front. Neurosci. 16:884708. doi: 10.3389/fnins.2022.884708
Received: 26 February 2022; Accepted: 20 May 2022;
Published: 20 June 2022.
Edited by:
Chao Huang, Florida State University, United StatesReviewed by:
Bingxin Zhao, Purdue University, United StatesCopyright © 2022 Ghosh, Mastej, Jain and Choi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Debashis Ghosh, ZGViYXNoaXMuZ2hvc2hAY3VhbnNjaHV0ei5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.