 Jianwen Tao
Jianwen Tao Yufang Dan
Yufang Dan Di Zhou
Di Zhou Songsong He
Songsong He- 1Institute of Artificial Intelligence Application, Ningbo Polytechnic, Ningbo, China
- 2Industrial Technological Institute of Intelligent Manufacturing, Sichuan University of Arts and Science, Dazhou, China
In practical encephalogram (EEG)-based machine learning, different subjects can be represented by many different EEG patterns, which would, in some extent, degrade the performance of extant subject-independent classifiers obtained from cross-subjects datasets. To this end, in this paper, we present a robust Latent Multi-source Adaptation (LMA) framework for cross-subject/dataset emotion recognition with EEG signals by uncovering multiple domain-invariant latent subspaces. Specifically, by jointly aligning the statistical and semantic distribution discrepancies between each source and target pair, multiple domain-invariant classifiers can be trained collaboratively in a unified framework. This framework can fully utilize the correlated knowledge among multiple sources with a novel low-rank regularization term. Comprehensive experiments on DEAP and SEED datasets demonstrate the superior or comparable performance of LMA with the state of the art in the EEG-based emotion recognition.
Introduction
Contemporarily, in the field of affective computing research, automated emotion recognition (AER) has attracted lots of attention from machine learning and computer vision (Kim et al., 2013). In traditional schema, one auto emotion recognition system driven by EEG signals usually includes two core components, i.e., feature extraction followed by emotion classification (Lan et al., 2018). Some representative EEG feature extraction methods (Jenke et al., 2014; Zhang et al., 2020b) can be viewed comprehensively in Jenke et al. (2014). This work mainly focuses on machine learning-based emotion classification methods.
In the past decade, a large scale of emotion recognition methods has been presented for effective emotion recognition using EEG features (Musha et al., 1997; Kim et al., 2013; Li et al., 2018b,c). Zheng (2017) proposed a novel emotion recognition method by exploiting the group sparse canonical correlation analysis, thus simultaneously implementing EEG channel selection and emotion recognition. Recently, Li et al. (2018c) also presented a sparse linear regression model with graph regularization for emotion recognition using EEG signals. In the past decade, due to their outperformed performance compared with traditional methods, deep emotion recognition methods using EEG signals have been widely explored in emotion feature extraction and recognition (Lotfi and Akbarzadeh-T, 2014), such as criminal psychological emotion recognition based on deep learning and EEG signals (Liu and Liu, 2021), EEG-based Deep Belief Network model (Zheng and Lu, 2015), multi-channel EEG-based recognition model (Song et al., 2018), and EEG-based neural network model (Li et al., 2018b).
It is worthy to note that the aforementioned works for emotion recognition perform well only in such scenario that both training and test samples follow the same distribution (Zhang et al., 2020a), in which the recognition models obtained from the source dataset(s) therefore can be easily utilized in the target dataset effectively (Zhang et al., 2019a). Unfortunately, these traditional methods may fail in addressing cross-subject/dataset emotion recognition due to the mismatch of feature distribution with EEG signals. To address this issue, many domain adaptation (DA) emotion recognition models for AER problem have been promoted (Chu et al., 2017; Li et al., 2018a; Li et al., 2020a,b; Bao et al., 2021; Wang et al., 2021). In a DA emotion recognition system, one usually focuses on exploring an effective recognition model on one target domain with few or even none of the labeled data, by borrowing some positive knowledge from other source domain(s) with slightly different distribution with that of the target domain (Bruzzone and Marconcini, 2010; Tao et al., 2012; Long et al., 2014; Zhang et al., 2019b).
A typical challenge in one EEG-based emotion recognition system is the cross-subject/dataset learning problem (Li et al., 2018a). In such scenario, DA techniques can be exploited to address this challenging issue where both training and test data follow slightly different distribution (Tao et al., 2012; Long et al., 2014; Li et al., 2021). To deal with the challenging cross-subject EEG emotion recognition problem, Pandey and Seeja (2019) proposed a subject-independent approach for EEG emotion recognition. Li et al. (2018a) proposed another method for cross-subject EEG emotion recognition. In the past decade, deep neural networks (DNNs) (Ganin et al., 2016; Li et al., 2018a) have also driven rapid progress in DA (Duan et al., 2012a; Ding et al., 2018a). The DA issues can be solved by the domain adversarial neural network (DANN) (Ganin et al., 2016). It remains unclear, however, whether the performance of deep DA methods is really contributed by their deep feature representation, the fine-tuned classifiers, or is rather an outcome of the adaptation regularization terms (Ghifary et al., 2017).
Although existing DA methods have obvious effectiveness and efficiency in the special use of emotion recognition (Chu et al., 2017), there is few work to use the joint feature selection method and then carry out the multi-source adaptive domain recognition of cross datasets by exploiting the correlation knowledge among domains and features. Besides, during DA, most of the multi-source domain adaptation (MDA) methods (Yang et al., 2007; Duan et al., 2012b,c; Tommasi et al., 2014; Tao et al., 2015, 2017; Ding et al., 2018b) generally cope with the sources independently without considering the correlation information among the source domains (Zhang et al., 2019c), which may destroy the discriminant structure (either intrinsic or extrinsic) of multi-source domains (Rosenstein et al., 2005). Last but not the least, for an MDA system, it is crucial for source weight determination during learning based on the correlation and quality of source domains. To the best of our knowledge, these characters are not feasible enough in extant MDA methods.
In order to solve the above problems in existing MDA, we explore to exploit the relevant knowledge among sources in the uncovered subspaces to learn a multi-source adaptive emotion recognition model. In other words, we mainly adopt the strategy of digging the relationship between multi-source domains and one target domain (including feature and distribution) for promoting multi-source adaptive emotion recognition with EEG signals. We aim to progress beyond existing works that have partially addressed those issues by exploring to solve all the above-mentioned issues in a unified framework. Specifically, we propose in this work a robust Latent Multiple-source Adaption (LMA) method for EEG-based emotion recognition by mining multiple shared latent subspaces, each for one source–target domain pair. The method employs the robust regression scheme to process high-dimensional, sparse outliers and non-i.i.d. (independently identical distribution) EEG features by jointly utilizing the l2,1-norm (Nie et al., 2010a) and trace norm. Under this framework, the row sparsity regularization is designed to obtain the solution of sparse feature selection (Zhang et al., 2020b). We match distributions between each domain pair (including both target and multi-source domains) by minimizing the nonparametric Maximum Mean Discrepancy (MMD) (Gretton et al., 2009; Pan et al., 2011) in each uncovered latent space shared by this source–target pair. The contributions of this paper are listed as follows:
(1) We propose a unified multi-source adaptive emotion recognition framework with EEG features by uncovering multiple latent subspaces.
(2) Our framework selects features in a collaborative way and considers the correlated knowledge among sources. In LMA, the importance of each feature does not need to be evaluated separately. In addition, in our unified framework, we can learn multiple loss functions with feature selection for all source adaptation subjects synchronously, so that our framework can use the correlated information of multiple sources as auxiliary information.
(3) In this framework, the original geometric structure is retained by using the graph Laplacian regularization, and the l2,1-norm minimization sparse regression approach is used to suppress the influence of noise or outliers in the domains, which shows the robustness of the framework.
(4) Through a large number of experiments on two EEG datasets, we prove the effectiveness and convergence of this framework.
The remainder of the paper is organized as follows: In section Related Work, we discussed the related works with feature selection and multi-source DA learning. In section Proposed Framework, our framework LMA will be designed, and section Algorithm arranges the corresponding optimal algorithm of LMA. The experimental results and analysis on two real EEG datasets are presented in section Experimental Evaluation. Finally, we conclude in Section Conclusion.
Related Work
In the past decades, affective computing community has paid increasing attention to the emotion recognition with brain–computer interfaces (BCI) (Mühl et al., 2014; Chu et al., 2017). A brain–computer interface system could capture certain emotion states and respectively make corresponding response to these states using spontaneous EEG signals even when explicit input from the subjects is unavailable (Zhang et al., 2019a), thus augmenting the user experience in the session of interactivity. Nowadays, a large number of methods (Zhang et al., 2016, 2017) have been proposed to recognize different emotion information from brain-wave signals. The latest works about affective BCI (aBCI) took account of machine learning algorithms on emotion recognition using a few discriminative features (Jenke et al., 2014; Mühl et al., 2014). In one representative BCI system, a certain feature extractor firstly extracts discriminative features from the raw EEG data, and then these features as well as labeled emotion states are sent into the classifier for real-time affection recognition. In the last decade, many aBCI-related works have presented sound and interesting emotion recognition performance (Mühl et al., 2014).
Although existing methods have obtained satisfied achievements on EEG-based emotion recognition, the expected performance could still be degraded by certain impacts in the case of cross-subject/dataset recognition due to the difference between subjects/datasets. Therefore, one needs to train a specific classifier for individual subject/dataset-of-interest. Even for the same subject, it is also indispensable to recalibrate the classifier frequently for maintaining a satisfied recognition accuracy since the EEG signals are unstable now and then. This would undoubtedly increase the costs of manual labor as well as time. Fortunately, the DA (a.k.a. domain transfer) technique can be leveraged to tackle these issues existing in EEG-based emotion recognition.
In the past decade, DA technique (Duan et al., 2012a,b,c; Tzeng et al., 2015; Tzeng et al., 2017; Ding et al., 2018a,b,c) has elicited an increasing attention in the community of machine learning. Up to now, domain-adaptation-based emotion recognition methods have nearly dominated the literature of aBCI Dolan, 2002; Mühl et al., 2014; Jayaram et al., 2016; Lan et al., 2018; Zhong et al., 2020; Zheng et al., 2015; Zheng and Lu, 2016; Chai et al., 2016; Chai et al., 2017; Shi et al., 2013; Koelstra et al., 2012; Zheng and Lu, 2015), which aim to address different issues in emotion classification by pursuing various DA skills using the EEG datasets such as SEED. In these preceding works, a commonly used strategy is to uncover a shared subspace from different domains by preserving certain discriminative properties, thus decreasing the differences among subjects or sessions extracted from the captured EEG signals (Tao and Dan, 2021). While extensive exploration on cross-subject/session has been conducted effectively in the prior works by leveraging various DA tricks, one obvious shortage in these works is that the evaluation dataset is just limited to one single database, e.g., SEED. In practical aBCI applications, the EEG datasets could also change since the EEG signals may be produced by different subjects, sessions, EEG devices, experimental schemes, and emotional stimuli. Henceforth, one of the yet unsolved issues in current research is the robustness and effectiveness of the proposed DA methods on cross-datasets/subjects.
Proposed Framework
Notation
In the context, the symbol definitions are listed in Table 1. We respectively denote by [A1, A2, …, Ak] and [A1; A2; …; Ak] the concatenation of k matrices according to the row (horizontally) and the column (vertically). In this work, we focus on the multi-source adaptation framework, which can be driven by S source domains of c-class. We denote by (a = 1, 2, …, S) the ath source dataset with na samples1. Its corresponding class label matrix can be denoted as with yil = 1 if the ith sample is labeled as the lth class and -1 others. Correspondingly, we denote by the target dataset of interest. Since the true classes of the samples in Xt are inaccessible in the training stage, the target labels (or pseudo labels) can be predicted by certain pre-trained classifiers trained on the source datasets with labeled data. Therefore, detecting the ground-truth label of each target sample is our ultimate goal.
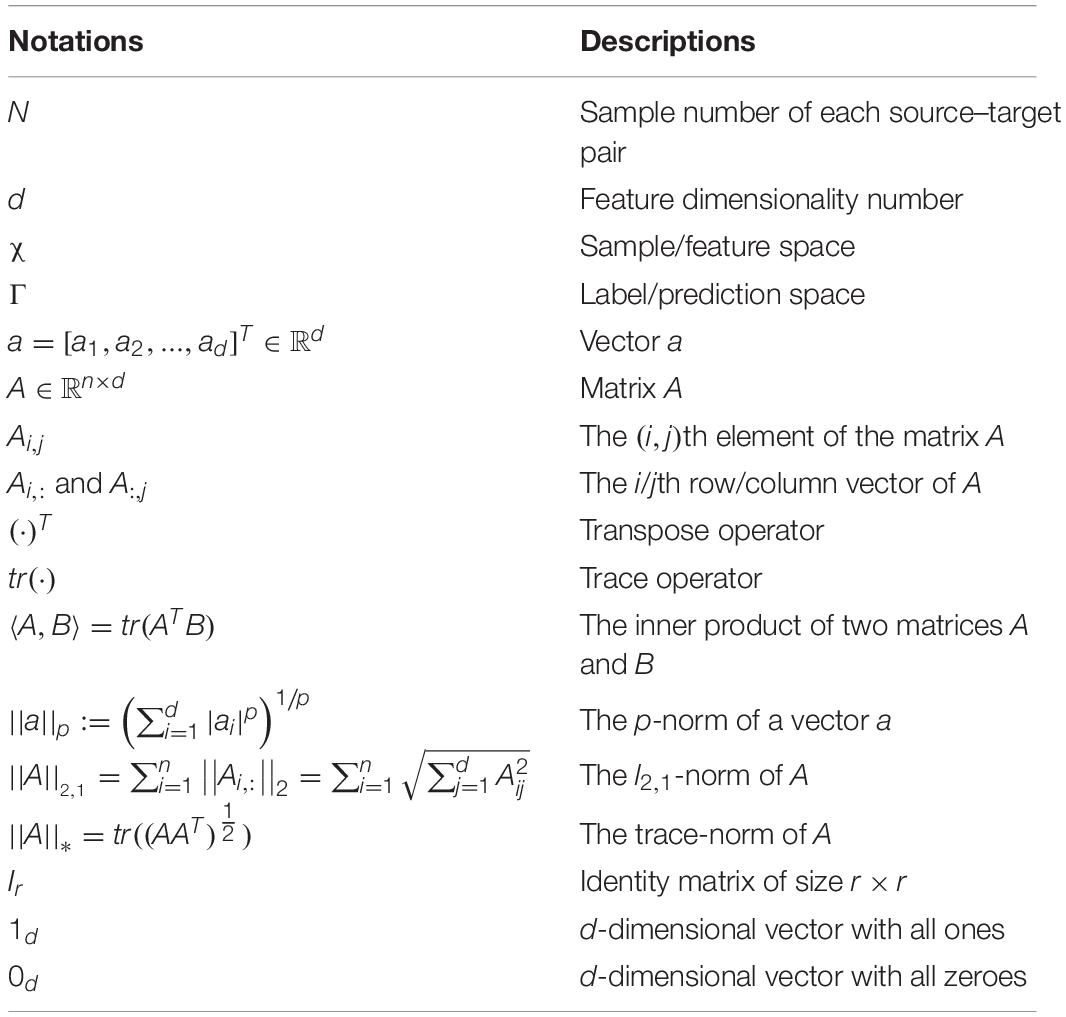
Table 1. Notations and descriptions.
We further denote Xa/Xt with the label as / (), and the ath source–target domain pair as Xa = [Xa, Xt] ∈ ℝd×N(N = nt + na) with label matrix Ya = [Ya, Yt] by packing the ath source and the target data.
Problem Statement
A commonly used strategy in the representative MDA is to acquire knowledge from multiple sources by leveraging certain common knowledge shared by them to promote the target learning of interest. We propose in this work a robust Latent Multiple-source Adaption (LMA) emotion recognition method based on EEG features. The method employs the robust regression scheme to process high-dimensional, sparse, outliers, and non-i.i.d. EEG features by jointly utilizing the l2,1-norm and trace norm (Yang et al., 2013). The designed method has three characteristics, which are integrated into a unified optimization formulation to find an effective emotion recognition model by aligning the feature distribution between each source–target domain pair. Specifically, it includes four technical aspects: (1) via employing the l2,1-norm minimization, a robust loss term is introduced into each source model learning by taking account of the influence of noise or outliers in EEG signal (Li et al., 2015), and a sparse regularization term is designed to eliminate over-fitting and a sparse features subset is selected; (2) based on the designed regression model and the semantic distribution matching between each pair of domains in each uncovered latent spaces (Tao et al., 2019), it not only provides robustness on loss function, but also retains the domain distribution (including local and global) structures (Nie et al., 2010b), and meanwhile maintains a high dependence on the (pseudo) label knowledge of the source domains and the target domain (Nie et al., 2010b; Ding et al., 2018c; Zhang et al., 2020a), so as to obtain preferable generalization performance; and (3) by exploiting the trace norm of matrix, we can make full use of the correlative information among multiple sources and transfer more discriminative knowledge to the target domain.
Specifically, we present the flow diagram of LWA in Figure 1 to illustrate our innovation: firstly, we can project each source EEG data into one domain-invariant subspace by minimizing the domain-wise distribution discrepancy; thus, S classifiers are being jointly learned by employing trace norm as well as l2,1-norm; we then obtain S target label matrices predicted from these source classifiers on the target domain; furthermore, in the original space, we also learn a target model using the squared regression scheme with the constraint of prediction consistency on the target data between those source models and the target model; and by uncovering multiple domain-invariant latent spaces, we finally formulate a joint learning framework of multi-source adaptation for EEG-based emotion recognition. To implement these properties, in the following part, we will detail the objective formulation of the proposed method.
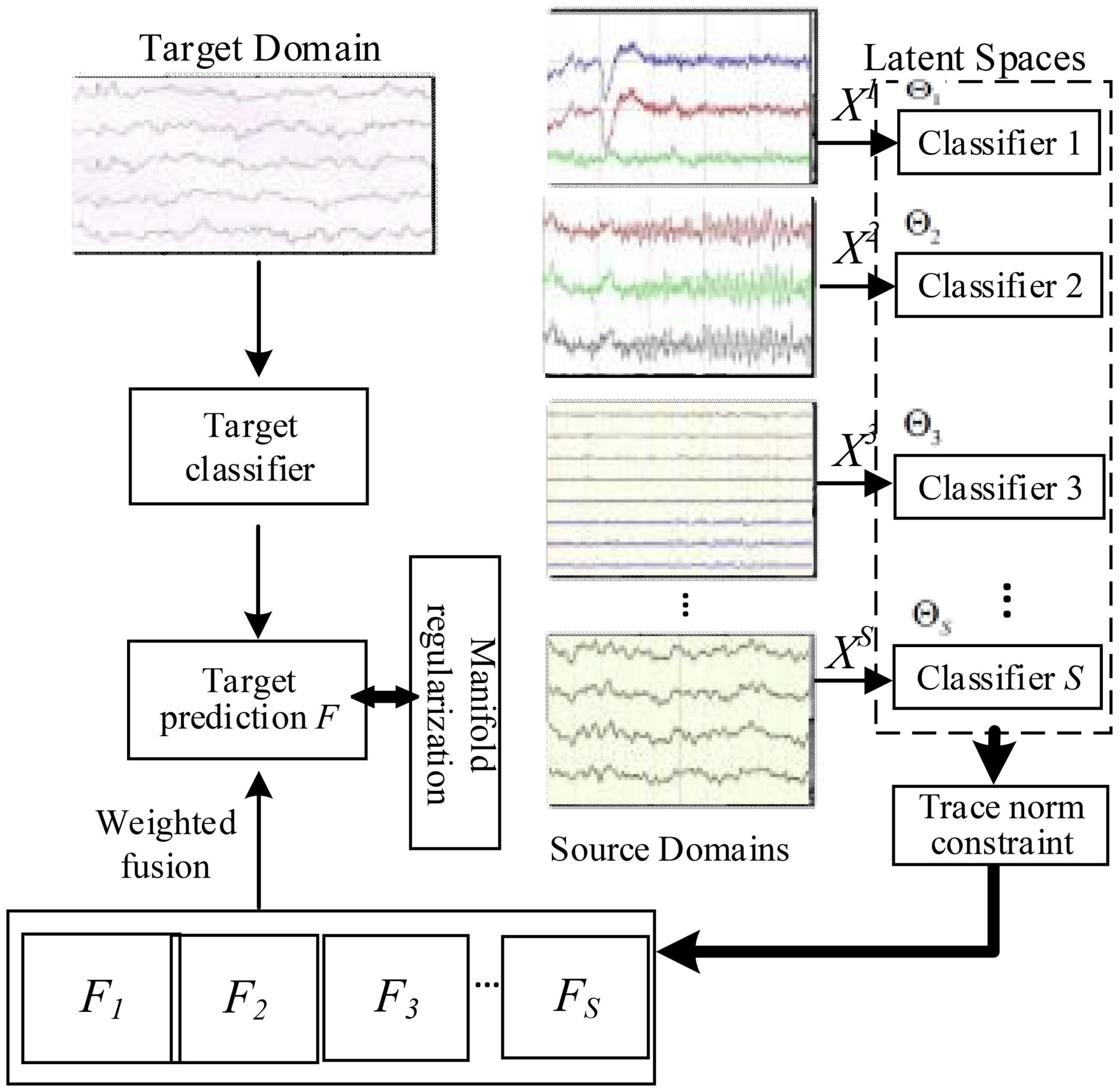
Figure 1. Flowchart of LMA on EEG-based emotion recognition.
General Formulation
In this section, we propose the general formulation of LMA framework underpinned by the robust regression principle and the regularization theory. We investigate the learning problem under multiclass setting, with the decision classifiers , where θ is the parameter of the hypothesis space of those decision functions. We propose a unified MDA framework by uncovering S discriminative latent subspaces Θa (a = 1, 2, …, S) (Tao and Xu, 2019) and to learn decision classifiers s of all sources simultaneously. In particular, the proposed method minimizes the distribution difference of each domain pair after the projection Pa into the subspace Θa, as well as the structural risk functional of the labeled data from the source domain Xa. We also let Θa be orthogonal on rows so that , where r(≪d) is the dimensionality of the shared latent space. We then endeavor to find S cross-domain models parameterized by via jointly utilizing correlated knowledge among sources in some latent spaces. We therefore propose the following general formulation of LMA:
where θa/t is the parameter set of the ath source/target model, enforces the discriminative consistency between the ath source and the target model on the target dataset, R(⋅,⋅) is the robust regression model, the regularization term controls the complexity of , distΘa(Xa, Xt) is for aligning the distributions of each domain pair in the latent space Θa, the regularizer controls the low rankness of all source models for mining the correlated knowledge. Hence, by solving the objective in (1), the subspace Θa and the decision functions s can be learned simultaneously. In the sequence, we will focus on designing these components in the general formulation one by one to construct a unified framework.
Design of Regression Model
In LMA, we learn a composite source classifier function trained on the EEG features, where Qa represents the source classifier model, and ° is the function combination operator. We therefore explore to find the best approximation Wt for ft by leverage Qa in Θa with the assumption that there exist some commonalities (e.g., discriminative structures) between different domains (Tao et al., 2019). Moreover, it should also maintain the discriminative structure in the original space. To capture the source correlation information, we respectively design the following classification functions for the ath source domain in the latent space:
where ϕ:χ→H2 is a known feature map projecting the ath source data from the input space χ into certain reproducing kernel Hilbert space (RKHS) (Nie et al., 2010b) H. The other component ψθ is a parameterized low-dimensional space that aims at encoding the shared structure between each source domain and the target domain. The weight vector Qa is defined in the projected subspace under the projection ψθ for the ath source, and Va is the weight matrix defined in the original feature space. With the parametric form in (2), the learned subspace ψθ can capture the intrinsic structure of source correlation in the MDA problem, which are shared by each source and the target domain. Correspondingly, we also can design the target recognition model: with the weight matrix Wt. We present the empirical kernel map as discussed in Gretton et al. (2009):
In the following, we will discuss both the linear classification function and the nonlinear (kernel) classification function and integrate them into a unified form.
• Linear classifier. We can consider a simple linear form of feature map, where θ = Θa is an r×d dimensional matrix and ψθ(x) = Θaψ(x), with a known d-dimensional vector function ψ(x). Furthermore, following (11), we can take a simple model ϕ(Xa) = ψ(Xa) = Xa into account. We can thereby write the linear classifier as
• Nonlinear classifier. If we take kernel learning into account and assume that the feature map ϕ(x) and ψ(x) belong to certain reproducing kernel Hilbert space (RKHS), Eq. (3) therefore can be kernelized. For ψ(x), we firstly denote the kernel matrix as Kψ = ⟨ψ(xi),ψ(xj)⟩. By using empirical kernel, we have kernel matrix Ka = ϕ(Xa) with , where . Finally, we can let ψθ = Θaψe, where Θa ∈ Rr×N is used to transform the empirical kernel vector to an r-dimensional space. Let denote the weight parameters in the embedded kernel subspace for the ath source. Hence, the kernelized decision functions become
where ωa is the weight coefficients in the original kernel space for the ath source.
In order to model the linear case in Eq. (3) and kernel case in Eq. (4) into a unified framework, we introduce
Moreover, in the following, we use two symbols, namely, Wa and Pa, where Wa denotes Va in the linear case and ωa in the kernel case, and Pa denotes Qa in the linear case and Ψa in the kernel case. Then, Eq. (5) becomes for both linear and kernel cases, and we can represent the data in linear space and nonlinear space as follows:
In the sequence, we also refer to Xa/t as if without special denotation for simplicity of expression. As a result, we can formulate the predictors, linear form as in Eq. (4) and nonlinear form as in Eq. (6), in a unified form as depicted in
We introduce the sparse regression scheme (Shi et al., 2015) by exploiting l2,1-norm minimization to enhance the robustness against the misclassification. We particularly construct a scaled pseudo label matrix for the target data, i.e., F = [f1, f2, …, fnt] = (Yt(Yt)T)−1/2Yt ∈ ℝnt×c, where the scaled pseudo label if is labeled, fi = 0 otherwise. Therefore, FFT = Int can be easily derived with additional constraint F≥0. We then respectively find the source classifiers trained on Xa (a = 1, 2, …, S) and the target classifier trained on Xt by minimizing the following loss functions.
where L denotes the graph Laplacian matrix induced from the target samples.
Moreover, it is intuitively reasonable that the outputs of fa s on the target domain are expected to be consistent with those of ft, which would gradually make Pa and Wt more accurate after lots of iterations. This prediction consistency can be minimized via the following residual:
In such a way, Pa and Wt would jointly enhance the target discriminations for the final emotion recognition.
Additionally, based on the parametric form of the decision function as in Eq. (7), we introduce the following regularizer:
which controls the complexity of each source classifier independently in the original and latent subspaces, respectively.
Uncovering Latent Spaces
In this subsection, we will present an effective strategy to capture multiple domain-invariant subspaces to mitigate the domain discrepancy as well as excavate some domain-invariant discriminative information. To this end, we give two main constraints or conditions on uncovering these latent spaces: (1) preserving the within-domain local structures and (2) aligning the inter-domain marginal distribution divergence as well as conditional distribution discrepancy. Following existing feature extraction methods (Tao et al., 2016), we further constrain Θa to be orthogonal on rows, i.e., , where r (typically far less than d) is the feature dimensionality in the latent space.
To fulfill the first condition, we construct a locality preserving regularizer to measure the smoothness along the intrinsic discriminative structure of the domain features (Nie et al., 2010b; Shi et al., 2015; Ding et al., 2018c). Specifically, one can construct an undirected graph with a weighted adjacency matrix ∏a = [(∏a)i, j]i, j = 1, 2, …, N, which is defined as (Yan et al., 2006):
where xi, xj ∈ Xa = [Xa, Xt], δk(x) denotes the k nearest neighbor set of x, and the hyper-parameter γ can be empirically computed as due to the impact of multi-class distribution, where is the squared root of the mean norm of Xa. Deriving a diagonal matrix Δa from ∏a with (Δa)i, i = ∑j(∏a)i, j, we then compute the graph Laplacian matrix as La = Δa−∏a. Thus, preserving the local geometrical structures of EEG features can be implemented by the following commonly used formulation in the manifold learning (Chen et al., 2013).
Benefiting from its simplicity and effectiveness, Maximum Mean Discrepancy (Gretton et al., 2009; Pan et al., 2011) has been commonly used to measure the distribution distance between two different domains. Consequently, to meet the second condition, we aim to minimize the MMD in certain optimized RKHS (Gretton et al., 2009). Specifically, the MMD between each domain pair is defined as follows:
The empirical counterpart of the MMD in Eq. (14) can be defined as:
which can recover an asymptotically unbiased estimation of the squared MMD in Eq. (14). Denote the gram matrix on dataset Xa as
where , , and (or ) are the Gram matrices respectively defined on the source domain, target domain, and cross domain data. Thus, the squared MMD in Eq. (15) can be formulated as
where
In the sequence, we will take into account the feature map ϕ in linear as well as kernel forms:
λ Linear kernel: if ϕ(x) = Θax, where Xa = [x1, x2, …, xN].
λ Nonlinear kernel: if ϕ(x) = Θaψe(x) = ΘaKa(⋅, x), where ψe(x) is the empirical kernel map defined in Eq. (4).
Recalling the definition of in Eq. (6), the domain discrepancy criterion defined in (17) can be reformulated:
where
Note that Eq. (19) could not preserve the local structures of the EEG data from the same class in the latent spaces due to the shortage of semantic alignment. This would significantly deteriorate the learning performance in some cases. To this end, we further address this issue by improving Eq. (19) with the following class distribution matching term:
where
, with Xa(l) and Xt(l) being the datasets of the lth class, respectively, from source and target domains, (respectively ) is the data size of the lth class from the ath source (respectively target) domain, and the elements of the matrix Da(l) = [Di, ja(l)] are defined as
Equation (21) explicitly forces EEG data from different domains but the same class to be mapped adjacently in the latent spaces. By unifying Eq. (19) and Eq. (21), we can obtain:
where and Da(0) = Da. We further denote . By combining Eq. (13) and Eq. (23), we can attempt to uncover a latent space by minimizing the following formulation:
Sharing Source Discriminative Structure
While each source model is learned in different latent space from each other, one still can presume that these source models might be correlated due to the correlation of source EEG signals in the model level (Tao et al., 2016). These correlated discriminative structures can be encoded by a low rank matrix of all source models, thus transferring the source knowledge from each other. For its simplicity of computation, the following trace norm of the matrix P = [P1, P2, …, PS], which is a surrogate of the rank minimization, can be adopted for correlating the source models.
Overall Formulation
Combining the above formulations respectively defined in Eqs (8) to (11) and Eqs (24) and (25) together, we have the following objective function:
where Ca = , ϑ = [ϑ1, …,ϑa]T is the weight vector to jointly combine all source regression loss, α, β, and λ are three regularization parameters, q1, q2 > 1 are two tunable parameters for avoiding trivial solution, and the tunable vector η = [η1,η2, …,ηS] denotes the adaptation degrees of different sources. The l2,1-norm regularization added on projection matrix Pa forces most of the rows in Pa (a = 1, …, S) to shrink to zero, thus performing feature selection on original data.
Emotion Recognition
After the best model parameters have been pursued, the source and target classifiers can be applied to recognize the emotion level of each probe EEG data. Specifically, we linearly fuse two recognition results on the probe data, i.e., obtained from source models, and ft(Xt) = (Xt)T Wt predicted from the target model, as the final prediction value. That is, the following combination function can be exploited for recognizing the emotion level of the given test data :
where δ is a trade-off parameter, tuned from [0,1]. In the experimental setting, we empirically set δ = 0.5 for initialization, followed by the evaluation of its impact on performance with different values of it.
Algorithm
In this section, an alternately iterative procedure is adopted to optimize the objective function in Eq. (26), which is followed by an overall algorithm.
Optimization
In terms of the definition in Nie et al. (2010a), we can derive , where Q is a diagonal matrix with the ith diagonal element . Hence, we can further transform Eq. (26) into Eq. (27):
where and .
By solving the derivative of Eq. (27) w.r.t. Wt and letting it equal to zero:
where , and is a diagonal matrix with the kth diagonal element being . Substituting Wt in Eq. (27) with Eq. (28), we have:
where . By solving the derivative of Eq. (29) w.r.t. Fa and letting it equal to zero, we have:
where . Plugging Fa in Eq. (30) into Eq. (29), we can get:
By solving the derivative of Eq. (31) w.r.t. F and letting it equal to 0, we obtain:
where
By replacing F and Fa in Eq. (29) with those in Eqs (30) and (32), respectively, and solving the derivative of Eq. (29) with reference to Ta and equaling to zero, we then get:
where:
Let and by replacing Ta in Eq. (29) with Eq. (34), and solving the derivative of Eq. (29) in reference to Pa and equaling to zero, we then get:
where
By substituting the optimal solution of the updated variables in Eqs (30), (32), (34), and (36) into Eq. (29) by mathematical calculation with the constraints , we then can get the following objective function in reference to Θa:
which is equivalent to the following objective:
where . According to Li et al. (2015), Θa can be relaxedly obtained by the Eigen-decomposition of Ra.
Lastly, we respectively optimize ϑa and ηa by fixing other variables. In this situation, the objective in Eq. (29) by preserving ϑa changes to the following problem:
Let , the Lagrange function of Eq. (39) is
Let the derivative of ℑ(ϑa,φ) with respect to ϑa be equivalent to 0 and we can obtain:
Substituting Eq. (41) into the constraint , we obtain
With the same deduction with that of ϑa, we also get the following optimal solution of ηa:
where .
Overall Algorithm
An overall optimization process of LMA can be outlined in the Algorithm 1. Following the same strategy in Zhang et al. (2019b), we employ a window-based breaking criterion to better achieve the convergence state of the algorithm. In terms of this strategy, we denote by ℏ = 6 the window size and compute ς = |MaxObjitr−MinObjitr|/MaxObjitr in itr−thiteration, where Objitr = {Objitr−ℏ + 1, …, Objitr} represents the set of historical target values in the window. While ς < ε = 10−5, our algorithm will stop the iteration.
| Algorithm 1: Multi-source adaptation learning. |
| Input: Source datasets , Laplacian matrices , target dataset Xt, and parameters α, β, and λ, the maximal iteration number ℓ. Output: Converged projection matrices , , and matrices and Wt. Initialization: Set itr = 0, and initialize Θa = Ir and randomly. Let ; 1: for a=1 to S do { 1) Compute matrix and , and and with empirical kernel mapping, thus computing , l = 1, …, c and Compute ; 2) Initialize Ta = ΘaPa and ; } 2: repeat { 3) Compute by Eq. (28) 4) Compute the matrix with ; 5) set a=1; repeat { 6) Compute the diagonal matrix , , and ; 7) Compute ; 8) Compute Θa according to Eq. (38) and then compute according to Eq. (43); 9) Compute by (30); 10) Compute Fitr by (32) after computing and by (33); 10) Compute by (34) with (35); 11) Compute by (36) after computing (36-1) and (36-2); 12) Compute according to Eq. (42); 13) Compute the matrix ; 14) a = a + 1; } until a > S 7) Update , thus s.t.a = 1,.., S; 8) Update according to (30) s.t.a = 1,.., S; 9) Update according to (42) s.t.a = 1,.., S; 10) Update according to (43) s.t.a = 1,.., S; 11) Update Fitr + 1 by (32), thus according to (28); 12) Let itr = itr + 1; }until itr > ℓ or ς < 10−5 3: return , , Wt, F and . |
In terms of the proof in Nie et al. (2010a), the convergence of the iterative procedures in Algorithm 1 can be guaranteed by the following theorem.
Theorem 1 (Tao and Dan, 2021). The objective value in Eq. (29) would steadily decline after several iterations by Algorithm 1, thus finally converging to the optimum.
Experimental Evaluation
In this part, we comprehensively compare the proposed method with several state of the arts on two widely used benchmark databases including SEED (Zheng and Lu, 2015) and DEAP (Koelstra et al., 2012) for EEG-based emotion recognition (Mansour et al., 2009).
Databases
According to Zhong et al. (2020) and Lan et al. (2018), there exist certain significant differences between SEED and DEAP since they can be generated by different subjects, sessions, EEG devices, experimental schemes, and emotional stimuli. Detailed information about these two datasets can be viewed in Lan et al. (2018). In the following experiments, we adopt the differential entropy (DE) (Lan et al., 2018; Zhong et al., 2020) as the data feature in emotion recognition, which has also been widely used in the preceding literatures (Shi et al., 2013; Zhang et al., 2015; Chai et al., 2016; Zheng and Lu, 2016; Chai et al., 2017; Lan et al., 2018; Zhong et al., 2020) for DA emotion recognition.
Baselines and Setting
We will systematically compare our method with such state of the arts as FSSL, an effective feature selection method without DA, FastDAM (Duan et al., 2012a), Multi-KT (Tommasi et al., 2014) with l2-norm constraint on p, A-SVM (Yang et al., 2007), and DSM (Duan et al., 2012a). Since existing deep DA frameworks have achieved many inspiring results on emotion recognition as well as visual recognition, we also additionally present comparisons with several deep (CNN-based) DA methods with deep features: DAN (Long et al., 2015), ReverseGrad (Ganin and Lempitsky, 2015), and MultiDIAL (Carlucci et al., 2020) based on AlexNet, SDDA (Ding et al., 2018a), and CCSA (Motiian et al., 2017), a unified framework of supervised DA and generalization with deep models.
In our multi-source adaptation settings, for the baselines FSSL and A-SVM, we just equally fuse all prediction values of the base classifiers respectively obtained from each source domain3.
In our method, LMA, there exist three vital parameters, i.e., λ, α, and β, that need to be tuned. In the community of machine learning, how to jointly search the best parameter values is still a yet unaddressed open issue. Consequently, we empirically choose these parameters using the grid search strategy also adopted in our previous work (Tao et al., 2019). Specifically, we fine-tune the values of λ, α, and β from the grid range {10−4,10−3, …,103,104} in a heuristic way. Additionally, we also empirically set q1 = q2 = 2 for preventing the trivial solution in terms of the conclusion reported in Hou et al. (2017). Finally, we search the nearest neighbor number k from the set {35,10,15,17}, which is also adopted in FSSL. In Algorithm 1, we pre-set the maximum iteration number τ = 100.
Through our experiments, we adopt the RBF kernel function, i.e., Ki, j = exp (−σ||xi−xj||2), for all nonlinear methods, where σ is equal to 1/d. In FastDAM, we operate the same practice in Duan et al. (2012a) and set (i = 1, …, S.), where δ = 100.
Cross-Subject Emotion Recognition
Note that different subjects even from the same dataset still have different EEG feature distributions due to the individual characteristics. We therefore practice the so-called leave-one-out cross-validation strategy conducted also in Lan et al. (2018) to evaluate the emotion recognition performance. That is, one subject remains to be the target domain, and others from the dataset are constructed as multiple sources. In this multi-source scenario, we follow the same setting as Tao and Dan (2021) to evaluate our method compared with other state of the arts on SEED and DEAP, respectively.
Performance Evaluation
We plot in Figure 2 the recognition performance of LMA compared with the baselines on two benchmark datasets. The final obtained upper bound of chance level (UBCL) with 95% confidence interval is also recorded in Figure 2. It is well known that the theoretical performance (or chance level) (about 33.33 %) of the random prediction could be achieved approximately by the real chance level if the size of training data approached infinity (Lan et al., 2018). When there are finite samples, we obtain the empirical chance level by repeating the trials with the samples in question equipped with randomized class labels (Lan et al., 2018).
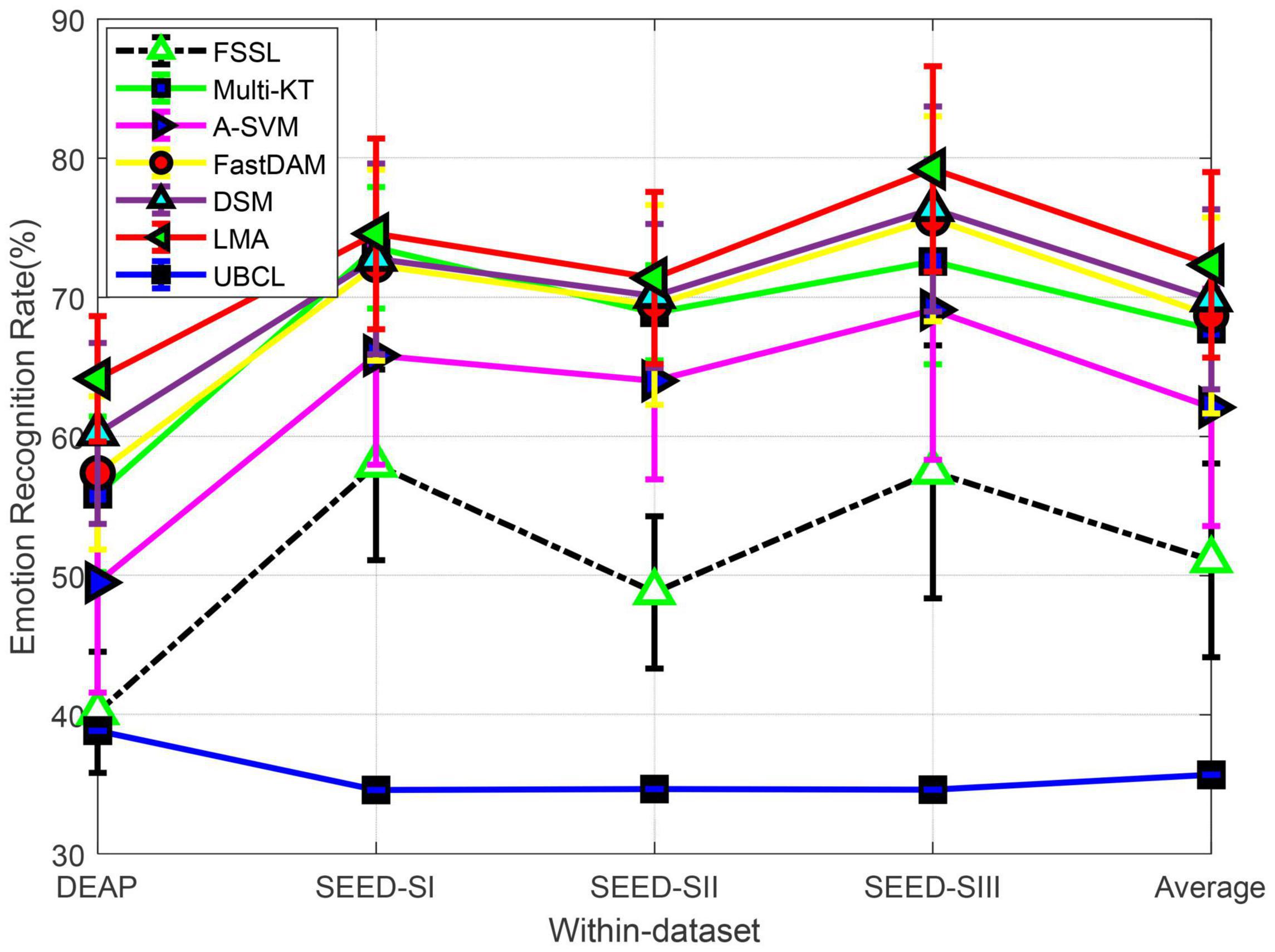
Figure 2. Domain adaptation emotion recognition on within-dataset (SI: Session I, SII: Session II, SIII: Session III).
From Figure 2, we can observe that the mean performance (40.16%) of FSSL on DEAP is very close to the random prediction. While it has significantly exceeded UBCL at a 5% significance level, the relatively worse performance of FSSL still indicates the imperative importance of DA in cross-subject emotion recognition due to the substantial distribution divergence between different subjects. This importance has been witnessed by almost all baseline adaptation methods, which have yielded better performance than FSSL in all cross-subject settings. Specifically, our method, LMA, undoubtedly obtains the best recognition accuracy (about 25.14% gains over FSSL), which is closely followed by DSM. While all DA as well as our method, LMA, achieved on DEAP obvious improvement over FSSL with respect to t-test with p-value > 0.05, the mean recognition performance of these methods is yet not satisfied so far due to the complexity and difference among all subjects.
The no-adaptation method FSSL touched on SEED an average accuracy of 53.78% on three sessions from SEED, which significantly outperformed UBCL. Those multi-source adaptation methods including our method, LMA, unsurprisingly achieved more accuracy gains than the no-adaptation method on SEED. We can still observe that our method, LMA, demonstrates the best performance on SEED by upgrading the average accuracy with 75.47% w.r.t. t-test with p-value > 0.05. An interesting observation is that all methods work better on SEED than DEAP, which has also been reported in Lan et al. (2018) and Tao and Dan. (2021). The reason for this phenomenon might be that the larger distribution discrepancy between different subjects from DEAP prevented boosting performance in these methods (Mansour et al., 2009; Lan et al., 2018).
Multiple Kernel Selection
As well known, the choice of kernel is a challenging issue in the kernel learning method. Recently, multiple kernel learning (MKL) has been effectively proposed for conquering this choice issue existing in single kernel learning methods. Consequently, we also evaluate the performance boost in our method by using MKL (called as MKLMA for short) for each source domain. To this end, the first step is to construct a new space spanned by multiple kernel mapping features. We firstly denote by an empirical kernel function set, which respectively projects Xa into ℧ different spaces. Then, an orthogonally integrated space can be constructed by concatenating these ℧ spaces. We denote the mapping features in this final space by , where xi ∈ Xa. Correspondingly, the kernel matrix in this final space can be easily deduced as , where is the ith kernel matrix from the ℧ feature spaces. Aiming to exploit the multiple kernel spaces, we therefore employ four kernel mapping functions including the above-used Gaussian kernel. The other additionally employed kernels are inverse square distance kernel function, Laplacian kernel function, and inverse distance kernel function, respectively, denoted as Kij = 1/(1 + σ||xi−xj||2), , and .
The observation from Figure 3, in which MKLMA significantly outperforms LMA, justifies that our LMA with MKL can further boost the recognition performance on DEAP and SEED. This also proves the importance of kernel choice in those kernel-based learning models.
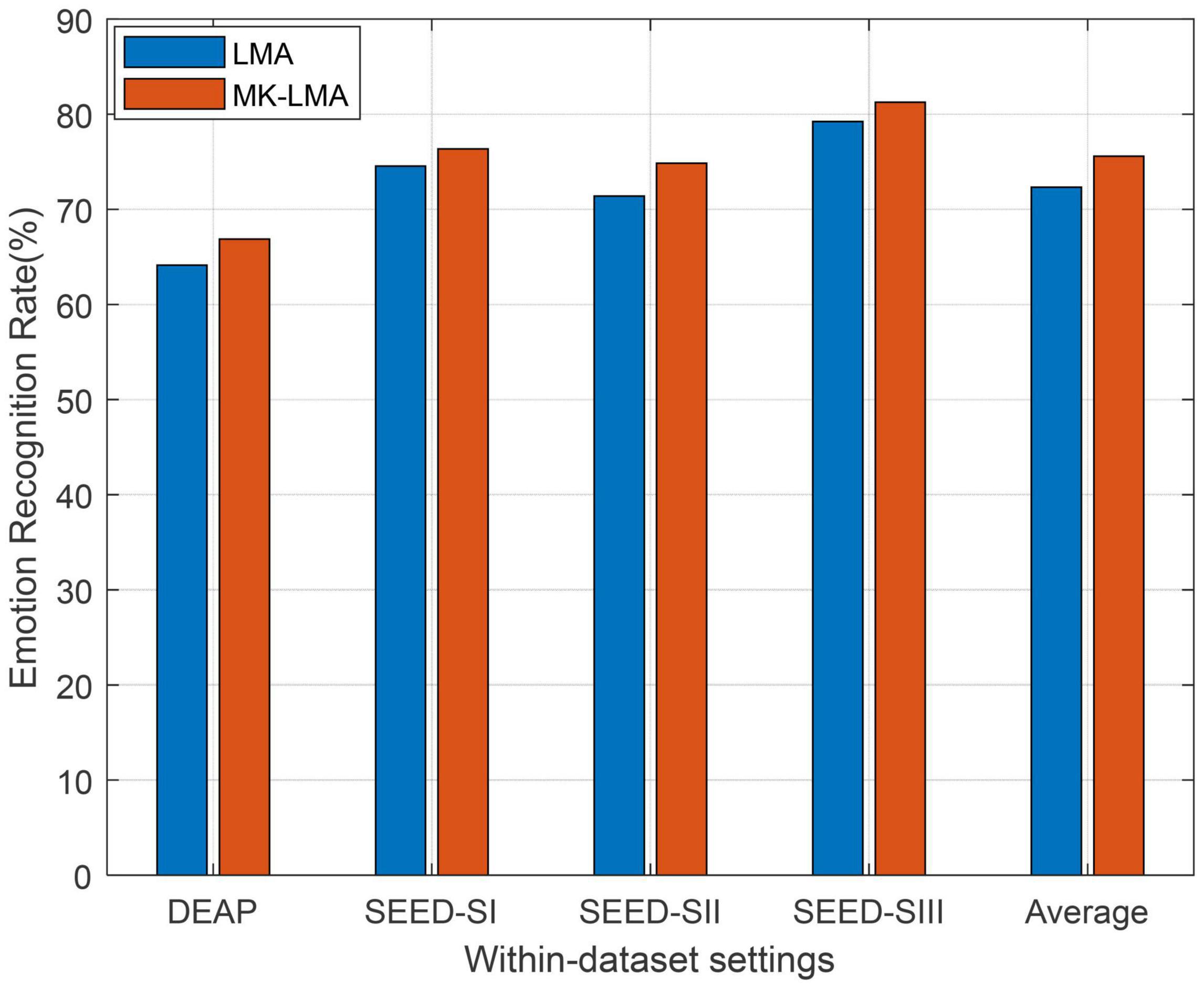
Figure 3. Domain adaptation emotion recognition on within-dataset with multi-kernel learning (SI: Session I, SII: Session II, SIII: Session III).
Cross-Dataset Emotion Recognition
Single-Source Adaptation
In this subsection, we will demonstrate the consistent robustness of LMA by evaluating its performance in several cross-dataset settings, which is more challenging than the cross-subject adaptation due to the intrinsic difference between datasets. For the scenario of cross-dataset adaptation, we specially design several different cross-dataset strategies by splitting the training set and test set, respectively, in terms of their EEG instruments and emotional stimuli sources, thus making up six cases, i.e., DEAP→SI, DEAP→SII, DEAP→SIII, SI→DEAP, SEED II→DEAP, and SIII→DEAP, where A→B denotes the adaptation from the dataset A to the dataset B, and SI, SII, and SIII are respectively denoted as the dataset of session I, session II, and session III from the database SEED.
A representative hypothesis used in DA is that the feature space of both source and target domains should be the same. Following this assumption, we employ in this part only 32 channels shared between SEED and DEAP to construct a common feature space with 160 dimensions for both domain datasets. In the first three trials, we sample 2,520 samples as the source from DEAP and 2,775 samples as the target from three different sessions (SI, SII, and SIII) in SEED. We evaluate each subject with respect to recognition accuracy in each session and then record the final mean results over 15 subjects from SEED. In the other trials, we resample 41,625 source samples from SEED and 180 target samples from DEAP. We also record the mean recognition accuracy of each subject in DEAP over 14 subjects. For the limitation of memory, 10% of the source data (4,162 samples) is randomly sampled as the actual training samples (Shi et al., 2013; Zheng and Lu, 2015, 2016; Chai et al., 2016, 2017; Lan et al., 2018; Zhong et al., 2020).
The mean recognition results on six cross-datasets are plotted in Figure 4. We can observe from these results that the performance of FSSL is almost near the random guess in that it is slightly inferior to UBCL with about 95% confidence interval. Besides, as observed from the results, the mean performance of each method is slightly worse on cross-dataset than within-dataset. This confirms the larger distribution gaps between two datasets than within-dataset. The advantage of DA would be reflected in this situation since DA could potentially relieve the distribution issue in the cross-dataset applications, which can also be justified by the observation from Figure 4, where all DA methods outperform the no-adaptation one. While Multi-KT and FastDAM occasionally obtain the best performance in some settings, our method, LMA, still contributes the best performance in most cases.
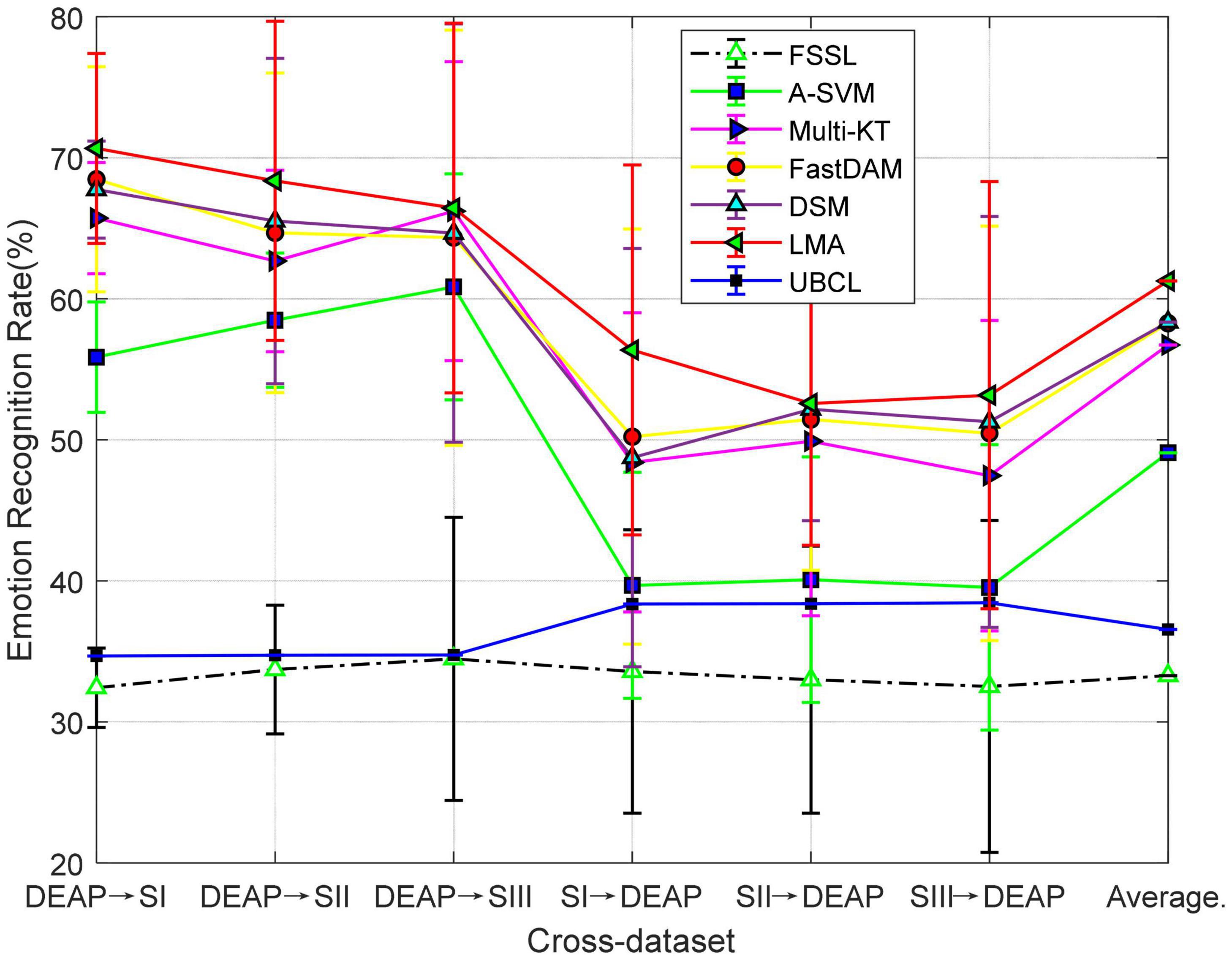
Figure 4. Domain adaptation emotion recognition on cross-dataset (SI: Session I, SII: Session II, SIII: Session III).
Multi-Source Adaptation
As reported in preceding works about DA learning, multiple source domains can improve the adaptation performance to some extent by integrating multiple prior knowledge. Nevertheless, in concrete applications, multi-source adaptation also incurs another challenge, i.e., source scalability issue, since multi-source learning could lead to the so-called “negative transfer” problem. In this scenario, how to discriminately exploit multiple sources becomes a challenge worthy to be addressed in the multi-source adaptation learning frameworks. To this end, we will explore in this part the different reliabilities of the prior sources in the emotion recognition task (Tao et al., 2019; Tao and Dan, 2021). We evaluate the performance of all baseline DA methods with multiple prior sources on the designed cross-dataset settings. The average accuracies of all methods are plotted in Figure 5, where A-SVM employs the average prior model.
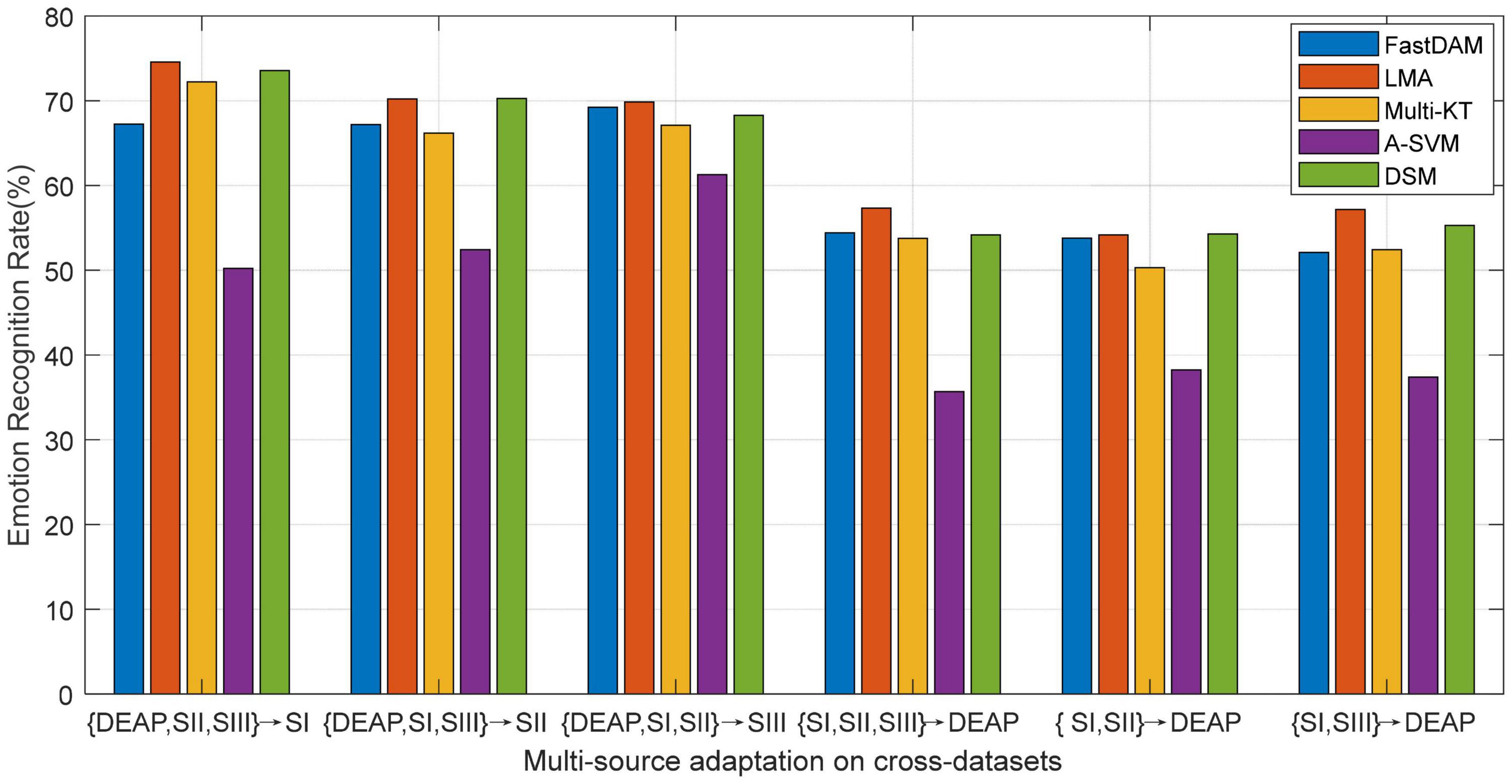
Figure 5. Multi-source adaptation emotion recognition accuracy (SI: Session I, SII: Session II, SIII: Session III).
When there exists very large distribution discrepancy between different domain datasets, it is hard for A-SVM to eliminate the inter-domain distribution bias. Therefore, the results in Figure 5 show that A-SVM is inferior to other multi-source adaptation methods in most settings. A-SVM even has a downgraded performance tendency with the increase of source domains in some scenarios, which indicates the existence of a “negative transfer” phenomenon in A-SVM. Another interesting observation from Figure 5 is that all DA methods except A-SVM achieve more improvement by leveraging multiple source knowledge than by bridging only one source (i.e., cross-subject settings) when the number of source domains increase. This proves that it is beneficial to leverage multiple sources for boosting the recognition performance. Moreover, LMA and DSM conquer others by touching on the top performance, due to their designed weights for discriminately screening the optimal sources. Our method, LMA, obtains more gains over DSM in some scenarios. A possible explanation is that the shared discriminative information among source models in LMA is advantageous to multi-source adaptation learning by utilizing the optimal weight vector.
Deep Feature Adaptation
In this subsection, we will particularly evaluate our method, LMA, with deeply extracted features by comparing it with several recently proposed deep adaptation models on cross-dataset emotion recognition using the multi-source settings.
In practical tasks, our method, LMA, can be trained on the deeply transformed features of all domains, which follows the same setup with that in Zhou et al. (2018) and Zhu et al. (2017). Concretely, some pretrained deep model (e.g., VGG16) is first fine-tuned using the source domain, then the deep features can be extracted from EEG signals in both source and target domains with this CNN model, and finally the recognition model would be trained on these extracted features. In the context of our experiments, we denote our methods with the VGG16 model as LMA+VGG16. As for DAN, SDDA, MultiDIAL, and ReverseGrad, we use their released source codes to fine-tune the pre-trained models by respectively using the pre-tuned parameters in their works (Ganin and Lempitsky, 2015; Long et al., 2015). Note that these deep adaptation methods typically aim to learn domain-invariant representations. Different from the deep adaptation frameworks, our proposed method explores to learn a domain-invariant recognition model with strong generalization ability from the source domain to the target domain. Consequently, we expect that our method can further upgrade the recognition performance with the co-learning strategy on the deeply extracted features from some deep model.
We plot the mean results of all methods in Figure 6, from which we can observe that our deep adaptation method LMA+VGG16 significantly outperforms LMA. This indicates the advantage of deep features, which can be attributed to its robust feature representation. Furthermore, LMA+VGG16 also obtains comparable recognition performance with respect to other deep adaptation methods. This may be attributed to the classification-level constraint in LMA, where most of the source discriminative structures are expected to be preserved by the guidance of target classification. In some cases, as shown in Figure 6, LMA+VGG16 even achieves the top performance compared with other deep adaptation frameworks. This phenomenon shows that the proposed LMA can become an effective surrogate to the deep adaptation model by just exploiting the deep features extracted from any one of the state-of-the-art deep models.
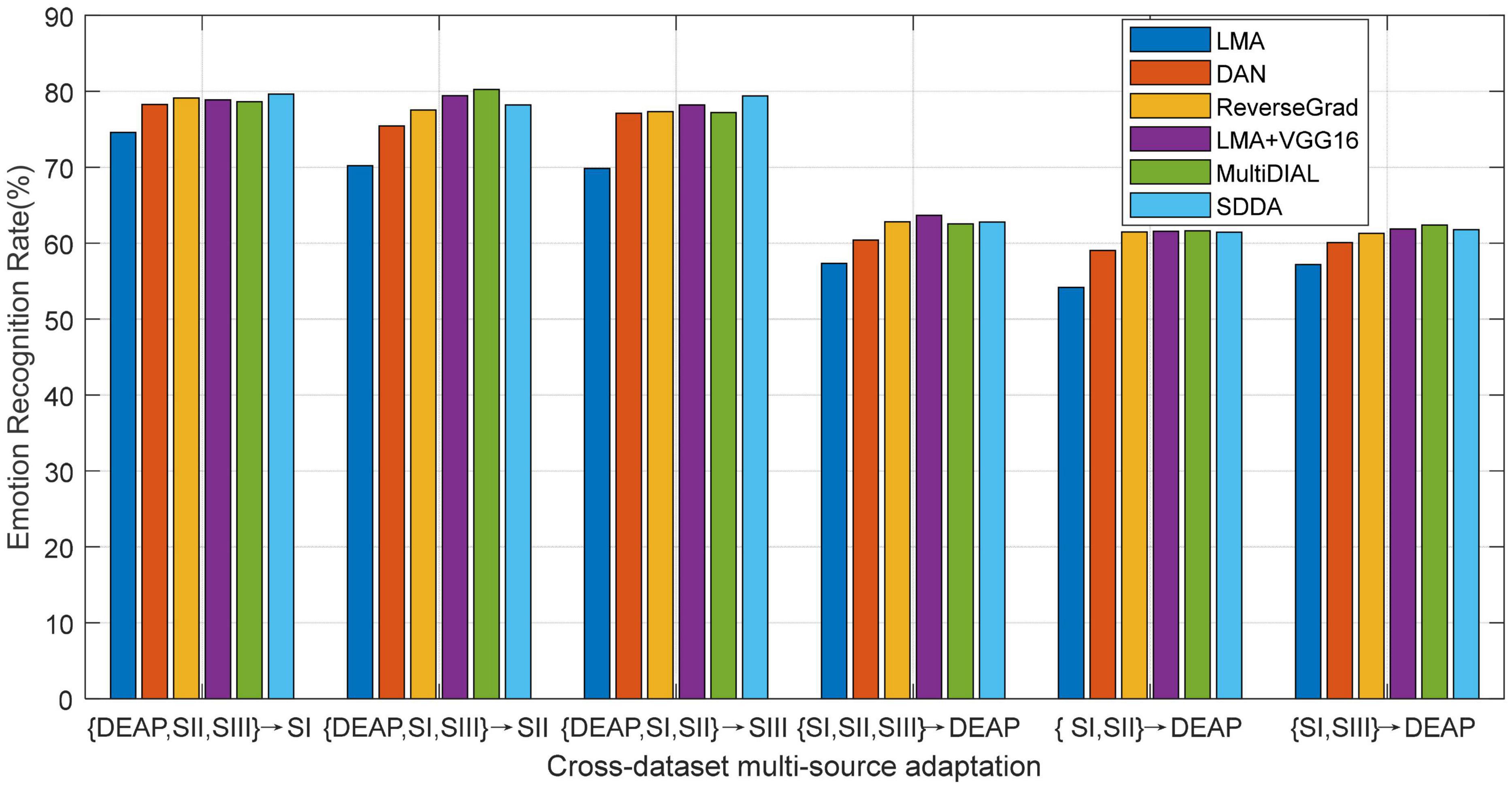
Figure 6. Emotion recognition accuracies of different methods using deeply extracted features (SI: Session I, SII: Session II, SIII: Session III).
Parameter Impact
In our method, LMA, there exist three hyper-parameters (i.e., λ, β, and α) that needed to be tuned. These hyper-parameters are mainly used to trade off different components of the LMA framework. We therefore respectively set these parameters into their extreme values to explore the importance of each component in LMA. To this end, we set β = 0 to denote LMA without target feature selection by LMA_NF, set α = ηa = 0 to denote by LMA_NL the case where LMA ignores latent space representations, and set λ = 0 to denote by LMA_NS the scenario where LMA fails to consider the shared discriminative structures among multiple sources. We evaluate these derived methods on cross-dataset recognition tasks.
The results in Table 2 clearly show that none of the three derived methods can achieve the best performance as that obtained by LMA. This further verifies the valuable contribution of each component to LMA. Specifically, LMA_NL has a significant downgraded manifestation compared with LMA, which, from the opposite side, proves that the utilization of shared latent spaces is very preferable to boosting the performance of LMA; the performance of LMA_NTF is slightly weaker than LMA, i.e., the performance of LMA would be slightly impacted by the target feature selection due to the intrinsic existence of some noise/outlier data in the target data; the inferior performance of LMA_NS proves the importance of the utilization of correlation knowledge among source models in cross-dataset emotion recognition.

Table 2. Multi-source adaptation emotion recognition accuracies of derived methods as well as LMA.
Note that in section Emotion Recognition, we use the following combination function to recognize the emotion level of the given test data :
where δ ∈ [0,1] is a trade-off parameter, which is empirically set as 0.5 in the preceding trials. In this part, we will further evaluate the impact on LMA with different values of δ in multi-source adaptation scenarios. We plot the recognition accuracy w.r.t. different values of δ in Figure 7. From the curves shown in Figure 7, we can observe the following several interesting results:
(1) Theoretically, δ controls the weight of source classifiers and larger values of δ will make the source classifiers more important in LMA. An extreme case is δ→ 1, where only source classifiers are guaranteed, but the target discriminative information for the test samples is discarded. In this case, all experimental results demonstrate a trend of slight downgrade. This shows the necessity of composite discrimination information by combining both source and target classifiers.
(2) Another extreme case is δ→ 0. In this case, LMA will recognize the emotion state of certain test data by only using the target discriminator, which cannot leverage the prior source information with discriminating power. From Figure 7, we can see that all curves show an obvious upgrade in performance around δ = 0, which shows the importance of multi-source discriminative models in our framework.
(3) We cannot obtain the best performance when δ values are relatively small or large, which shows the significance of exploiting the discriminative information from both source and target classifiers in our method.
(4) After δ > 0.5, we can see that most curves are relatively stable across δ values, which shows that our method is not significantly sensitive to δ > 0.5. Hence, we can empirically set δ = 0.5 in the experiments.
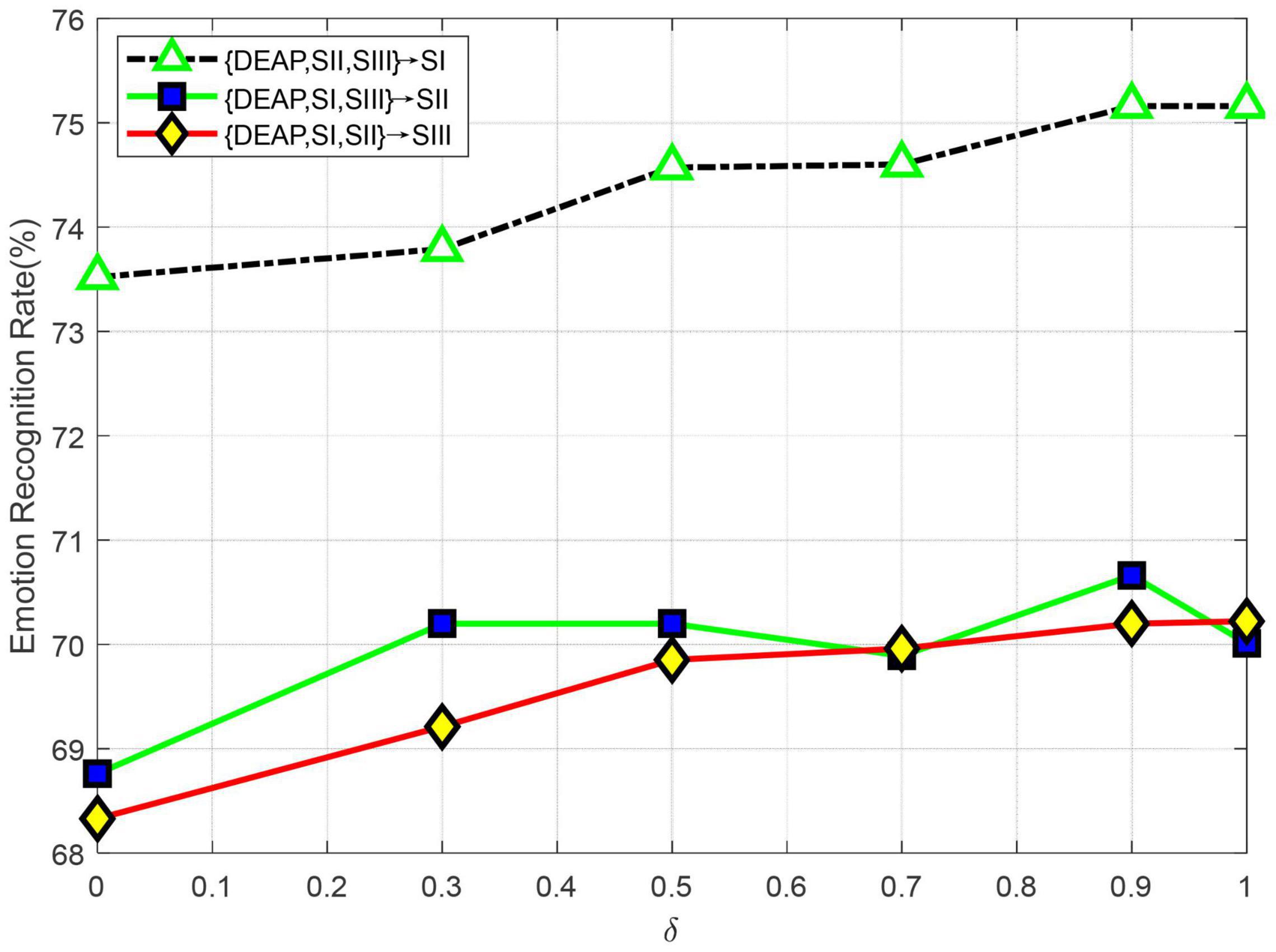
Figure 7. Emotion recognition accuracies with different values of δ (SI: Session I, SII: Session II, SIII: Session III).
Conclusion
To deal with the cross-subject/dataset EEG-based emotion recognition task, we proposed a robust LMA. In multiple domain-invariant latent spaces, LMA aims at transferring multi-source knowledge into target learning mainly by leveraging correlation knowledge among source models, which discriminatively screens unimportant prior evidences in sources. The comprehensive experiments performed on two public datasets verify the effectiveness of LMA in dealing with cross-subject/dataset emotion recognition. In most scenarios, our LMA (or LMA-VGG16) obtains the best results or comparable performance with respect to several representative baselines.
Since the implementation of LMA algorithm needs an iterative optimization procedure, how to improve the efficiency of LMA and seek a more efficient algorithm would be an issue worthy of further study in our future research. The unreliable and misleading pseudo labels strategy may be another potential problem in our LMA. Consequently, our successive work would explore how to seamlessly incorporate target label into the framework of LMA.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work, and approved it for publication.
Funding
This work was supported by the research institution special program of Ningbo Polytechnic under Grant No. NZ21JG006, and Zhejiang Provincial Natural Science Foundation of China under Grant No. Lgg20F020013.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
- ^ While we do not need to limit the number of instances in each source domain, which is identical with that assumed when shaped into the training matrix, for the sake of simplicity, we can extract the same number of training instances from each source domain.
- ^ It is important to note that the feature mapping function ϕ with respect to each source domain can be completely different from each other.
- ^ For each source domain, we train one SVM by using the corresponding labeled samples. Then, for each test instance x, the decision values from p SVM classifiers are converted into the probability values by using the sigmoid function (i.e., g(t) = 1/(1 + exp(−t)). Finally, we average the p probability values as the final pr.
References
Bao, G., Zhuang, N., Tong, L., Yan, B., Shu, J., Wang, L., et al. (2021). Two-level domain adaptation neural network for EEG-based emotion recognition. Front. Hum. Neurosci. 14:605246. doi: 10.3389/fnhum.2020.605246
Bruzzone, L., and Marconcini, M. (2010). Domain adaptation problems: A DASVM classification technique and a circular validation strategy. IEEE Trans. 32, 770–787. doi: 10.1109/TPAMI.2009.57
Carlucci, F. M., Porzi, L., Caputo, B., Ricci, E., and Buló, S. R. (2020). MultiDIAL: domain alignment layers for (Multisource) unsupervised domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 43, 4441–4452. doi: 10.1109/TPAMI.2020.3001338
Chai, X., Wang, Q., Zhao, Y., Li, Y., Liu, D., Liu, X., et al. (2017). A fast, efficient domain adaptation technique for cross-domain electroencephalography (EEG)-based emotion recognition. Sensors 17:1014. doi: 10.3390/s17051014
Chai, X., Wang, Q., Zhao, Y., Liu, X., Bai, O., and Li, Y. (2016). Unsupervised domain adaptation techniques based on auto-encoder for non-stationary EEG-based emotion recognition. Comput. Biol. Med. 79, 205–214. doi: 10.1016/j.compbiomed.2016.10.019
Chen, B., Lam, W., Tsang, I. W., and Wong, T. L. (2013). Discovering low-rank shared concept space for adapting text mining models. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1284–1297. doi: 10.1109/TPAMI.2012.243
Chu, W. S., De la Torre, F., and Cohn, J. F. (2017). Selective transfer machine for personalized facial action unit detection. IEEE Trans. Pattern Anal. Mach. Intell. 39, 529–545. doi: 10.1109/CVPR.2013.451
Ding, Z., Nasrabadi, N. M., and Fu, Y. (2018a). Semi-supervised deep domain adaptation via coupled neural networks. IEEE Trans. Image Process. 27, 5214–5224. doi: 10.1109/TIP.2018.2851067
Ding, Z., Nasrabadi, N. M., and Fu, Y. (2018b). Incomplete multisource transfer learning. IEEE Trans. Neural Networks Learn. Syst. 29, 310–323. doi: 10.1109/TNNLS.2016.2618765
Ding, Z., Sheng, L., Ming, S., and Fu, Y. (2018c). “Graph adaptive knowledge transfer for unsupervised domain adaptation,” in Proceedings of the 15th European Conference (ECCV2018) (Munich).
Duan, L., Tsang, I. W., and Xu, D. (2012a). Domain transfer multiple kernel learning. IEEE Trans. Pattern Anal. Mach. Intell. 34, 465–479. doi: 10.1109/TPAMI.2011.114
Duan, L., Xu, D., and Fu, C. S. (2012b). “Exploiting web images for event recognition in consumer videos: a multiple source domain adaptation approach,” in Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (Providence, RI), 1338–1345.
Duan, L., Xu, D., and Tsang, I. W. (2012c). Domain adaptation from multiple sources: a domain-dependent regularization approach. IEEE Trans. Neural Netw. Learn. Syst. 23, 504–518. doi: 10.1109/TNNLS.2011.2178556
Ganin, Y., and Lempitsky, V. (2015). “Unsupervised domain adaptation by back-propagation,” in Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICMR), Lille, 1180–1189.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., et al. (2016). Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17, 1–35. doi: 10.1109/TNNLS.2020.3025954
Ghifary, M., Balduzzi, D., Kleijn, W. B., and Zhang, M. (2017). Scatter component analysis: a unified framework for domain adaptation and domain generalization. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1414–1430. doi: 10.1109/TPAMI.2016.2599532
Gretton, A., Fukumizu, K., Harchaoui, Z., and Sriperumbudur, B. K. (2009). “A fast, consistent kernel two-sample test,” in Proceedings of the Conference on Neural Information Processing Systems 22, eds Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, and A. Culotta (Vancouver, BC: MIT Press), 673–681.
Hou, C., Nie, F., Tao, H., and Yi, D. (2017). Multi-view unsupervised feature selection with adaptive similarity and view weight. IEEE Trans. Knowl. Data Eng. 29, 1998–2011. doi: 10.1109/tkde.2017.2681670
Jayaram, V., Alamgir, M., Altun, Y., Scholkopf, B., and Grosse-Wentrup, M. (2016). Transfer learning in brain-computer interfaces. IEEE Comput. Intell. Magaz. 11, 20–31. doi: 10.1109/mci.2015.2501545
Jenke, R., Peer, A., and Buss, M. (2014). Feature extraction and selection for emotion recognition from EEG. IEEE Trans. Affect. Comput. 5, 327–339. doi: 10.1109/taffc.2014.2339834
Kim, M.-K., Kim, M., Oh, E., and Kim, S.-P. (2013). A review on the computational methods for emotional state estimation from the human EEG. Comput. Math. Methods Med. 2013:573734. doi: 10.1155/2013/573734
Koelstra, S., Mühl, C., Soleymani, M., Lee, J. S., Yazdani, A., Ebrahimi, T., et al. (2012). DEAP: a database for emotion analysis using physiological signals. IEEE Trans. Affect. Comput. 3, 18–31. doi: 10.1109/t-affc.2011.15
Lan, Z., Sourina, O., Wang, L., Scherer, R., and Müller-Putz, G. R. (2018). Domain adaptation techniques for EEG-based emotion recognition: a comparative study on two public datasets. IEEE Trans. Cogn. Dev. Syst. 11, 85–94. doi: 10.1109/tcds.2018.2826840
Li, H., Wan, R., Wang, S., and Kot, A. C. (2021). Unsupervised domain adaptation in the wild via disentangling representation learning. Int. J. Comput. Vis. 129, 267–283. doi: 10.1007/s11263-020-01364-5
Li, J., Qiu, S., Du, C., Wang, Y., and He, H. (2020a). Domain adaptation for EEG emotion recognition based on latent representation similarity. IEEE Trans. Cogn. Dev. Syst. 12, 344–353. doi: 10.1109/tcds.2019.2949306
Li, J., Qiu, S., Shen, Y.-Y., Liu, C.-L., and He, H. (2020b). Multisource transfer learning for cross-subject EEG emotion recognition. IEEE Trans. Cyber. 50, 3281–3293. doi: 10.1109/TCYB.2019.2904052
Li, X., Song, D., Zhang, P., Zhang, Y., Hou, Y., and Hu, B. (2018a). Exploring EEG features in cross-subject emotion recognition. Front. Neurosci. 12:162. doi: 10.3389/fnins.2018.00162
Li, Y., Zheng, W., Cui, Z., Zhang, T., and Zong, Y. (2018b). “A novel neural network model based on cerebral hemispheric asymmetry for EEG emotion recognition,” in Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI) (Palo Alto, CA).
Li, Y., Zheng, W., Cui, Z., Zong, Y., and Ge, S. (2018c). EEG emotion recognition based on graph regularized sparse linear regression. Neural Process. Lett. 49, 1–17. doi: 10.1109/taffc.2020.2994159
Li, Z., Liu, J., Tang, J., and Lu, H. (2015). Robust structured subspace learning for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 37, 2085–2098.
Liu, Q., and Liu, H. (2021). Criminal psychological emotion recognition based on deep learning and EEG signals. Neural Comput. Appl. 33, 433–447. doi: 10.1007/s00521-020-05024-0
Long, M., Cao, Y., Wang, J., and Jordan, M. (2015). “Learning transferable features with deep adaptation networks,” in Proceedings of the 32nd International Conference on Machine Learning (PMLR), Lille, 97–105.
Long, M., Wang, J., Ding, G., Pan, S. J., and Yu, P. S. (2014). Adaptation Regularization: A General Framework for Transfer Learning. IEEE Trans. Knowl. Data Eng. 26, 1076–1089. doi: 10.1109/tkde.2013.111
Lotfi, E., and Akbarzadeh-T, M.-R. (2014). Practical emotional neural networks. Neural Netw. 59, 61–72. doi: 10.1016/j.neunet.2014.06.012
Mansour, Y., Mohri, M., and Rostamizadeh, A. (2009). “Domain Adaptation with Multiple Sources,” in Proceedings of the Conference on Neural Information Processing Systems (Vancouver, BC: MIT Press), 1041–1048.
Motiian, S., Piccirilli, M., Adjeroh, D. A., and Doretto, G. (2017). “Unified deep supervised domain adaptation and generalization,” in Proceedings of the IEEEInternational Conference on Computer Vision ICCV (Venice).
Mühl, C., Allison, B., Nijholt, A., and Chanel, G. (2014). A survey of affective brain computer interfaces: principles, state-of-the-art, and challenges. Brain Comput. Interfaces 1, 66–84. doi: 10.1080/2326263x.2014.912881
Musha, T., Terasaki, Y., Haque, H. A., and Ivamitsky, G. A. (1997). Feature extraction from EEGs associated with emotions. Artif. Life Robot. 1, 15–19. doi: 10.1007/bf02471106
Nie, F., Huang, H., Cai, X., and Ding, C. (2010a). “Efficient and robust feature selection via Joint l2,1-norms minimization,” in Proceedings of the 22th Annual Conference Neural Information Processing Systems (Cambridge, MA: MIT Press), 1813–1821.
Nie, F., Xu, D., Tsang, I. W., and Zhang, C. (2010b). Flexible manifold embedding: a framework for semi-supervised and unsupervised dimension reduction. IEEE Trans. Image Process. 19, 1921–1932. doi: 10.1109/TIP.2010.2044958
Pan, S. J., Tsang, I. W., Kwok, J. T., and Yang, Q. (2011). Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 22, 199–210. doi: 10.1109/TNN.2010.2091281
Pandey, P., and Seeja, K. (2019). “Emotional state recognition with EEG signals using subject independent approach,” in Data Science and Big Data Analytics. Lecture Notes on Data Engineering and Communications Technologies, Vol. 16, eds D. Mishra, X. S. Yang, and A. Unal (Singapore: Springer), 117–124. doi: 10.1007/978-981-10-7641-1_10
Rosenstein, M. T., Marx, Z., and Kaelbling, L. P. (2005). “To transfer or not to transfer,” in Proceedings of the Conference on Neural Information Processing Systems, (Cambridge, MA: MIT Press).
Shi, L. C., Jiao, Y. Y., and Lu, B. L. (2013). “Differential entropy feature for EEG- based vigilance estimation. 2013,” in Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), (Osaka), 6627–6630.
Shi, X., Guo, Z., Lai, Z., and Yang, Z. Bao, and Zhang, D. (2015). A framework of joint graph embedding and sparse regression for dimensionality reduction. IEEE Trans. Image Process. 24, 1341–1355. doi: 10.1109/TIP.2015.2405474
Song, T., Zheng, W., Song, P., and Cui, Z. (2018). EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 11, 532–541. doi: 10.3389/fnbot.2022.834952
Tao, J., Chung, F. L., and Wang, S. (2012). On minimum distribution discrepancy support vector machine for domain adaptation. Pattern Recogn. 45, 3962–3984. doi: 10.1016/j.patcog.2012.04.014
Tao, J., and Dan, Y. (2021). Multi-source Co-adaptation for EEG-based emotion recognition by mining correlation information. Front. Neurosci. 15:677106. doi: 10.3389/fnins.2021.677106
Tao, J., Wen, S., and Hu, W. (2015). L1-norm locally linear representation regularization multi-source adaptation learning. Neural Netw. 69, 80–98. doi: 10.1016/j.neunet.2015.01.009
Tao, J., Wen, S., and Hu, W. (2016). Multi-source adaptation learning with global and local regularization by exploiting joint kernel sparse representation. Knowl. Based Syst. 98, 76–94. doi: 10.1016/j.knosys.2016.01.021
Tao, J., and Xu, H. (2019). Discovering domain-invariant subspace for depression recognition by jointly exploiting appearance and dynamics feature representations. IEEE Access 99, 186417–186436. doi: 10.1109/access.2019.2961741
Tao, J., Zhou, D., Liu, F., and Zhu, B. (2019). Latent multi-feature co-regression for visual recognition by discriminatively leveraging multi-source models. Pattern Recogn. 87, 296–316. doi: 10.1016/j.neunet.2019.02.007
Tao, J. W., Song, D., Wen, S., and Hu, W. (2017). Robust multi-source adaptation visual classification using supervised low-rank representation. Pattern Recogn. 61, 47–65. doi: 10.1016/j.patcog.2016.07.006
Tommasi, T., Orabona, F., and Caputo, B. (2014). Learning categories from few examples with multi-model knowledge transfer. IEEE Trans. Pattern Anal. Mach. Intell. 36, 928–941. doi: 10.1109/TPAMI.2013.197
Tzeng, E., Hoffman, J., Darrell, T., and Saenko, K. (2015). “Simultaneous deep transfer across domains and tasks,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, 4068–4076. doi: 10.1109/ICCV.2015.463
Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). “Adversarial Discriminative Domain Adaptation,” in Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Honolulu, HI), 2962–2971.
Wang, F., Zhang, W., Xu, Z., Ping, J., and Chu, H. (2021). A deep multi-source adaptation transfer network for cross-subject electroencephalogram emotion recognition. Neural Comput. Appl. 33, 9061–9073. doi: 10.1007/s00521-020-05670-4
Yan, S., Xu, D., Zhang, B., Zhang, H. J., Yang, Q., and Lin, S. (2006). Graph embedding and extensions: a general framework for dimensionality reduction. IEEE Trans. Pattern Anal. Mach. Intell. 29:40. doi: 10.1109/TPAMI.2007.12
Yang, J., Yan, R., and Hauptmann, A. G. (2007). “Cross-domain video concept detection using adaptive svms,” in Proceedings of the 15th ACM International Conference on Multimedia. ACM, (Augsburg), 188–197.
Yang, Y., Ma, Z., Hauptmann, A. G., and Sebe, N. (2013). Feature selection for multimedia analysis by sharing information among multiple tasks. IEEE Trans. Multimedia 15, 661–669. doi: 10.1109/tmm.2012.2237023
Zhang, K., Gong, M., and Schölkopf, B. (2015). “Multi-source domain adaptation: A causal view,” in Proceedings of the 29th AAAI Conference on Artificial Intelligence, (Menlo Park, CA), 3150–3157.
Zhang, Y., Chung, F., and Wang, S. (2020a). Clustering by transmission learning from data density to label manifold with statistical diffusion. Knowl. Based Syst. 193, 105330. doi: 10.1016/j.knosys.2019.105330
Zhang, Y., Chung, F. L., and Wang, S. (2019a). Takagi-sugeno-kang fuzzy systems with dynamic rule weights. J. Intell. Fuzzy Syst. 37, 8535–8550. doi: 10.1016/j.isatra.2017.10.012
Zhang, Y., Dong, J., Zhu, J., and Wu, C. (2019b). Common and special knowledge-driven TSK fuzzy system and its modeling and application for epileptic EEG signals recognition. IEEE Access 7, 127600–127614. doi: 10.1109/access.2019.2937657
Zhang, Y., Li, J., Zhou, X., Zhou, T., Zhang, M., Ren, J., et al. (2019c). A view-reduction based multi-view TSK fuzzy system and its application for textile color classification. J. Ambient Intell. Hum. Comput. 9, 1–11. doi: 10.1007/s12652-019-01495-9
Zhang, Y., Tian, F., Wu, H., Geng, X., Qian, D., Dong, J., et al. (2017). Brain MRI tissue classification based fuzzy clustering with competitive learning. J. Med. Imaging Health Inform. 7, 1654–1659. doi: 10.1006/cbmr.1996.0023
Zhang, Y., Wang, L., Wu, H., Geng, X., Yao, D., and Dong, J. (2016). A clustering method based on fast exemplar finding and its application on brain magnetic resonance images segmentation. J. Med. Imaging Health Inform. 6, 1337–1344. doi: 10.1166/jmihi.2016.1923
Zhang, Y., Wang, S., Xia, K., Jiang, Y., and Qian, P. (2020b). Alzheimer’s disease multiclass diagnosis via multimodal neuroimaging embedding feature selection and fusion. Inform. Fusion 66, 170–183. doi: 10.1016/j.inffus.2020.09.002
Zheng, W. (2017). Multichannel EEG-based emotion recognition via group sparse canonical correlation analysis. IEEE Trans. Cogn. Dev. Syst. 9, 281–290. doi: 10.1109/tcds.2016.2587290
Zheng, W. L., and Lu, B. L. (2015). Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Autonom. Ment. Dev. 7, 162–175. doi: 10.1109/tamd.2015.2431497
Zheng, W. L., and Lu, B. L. (2016). “Personalizing EEG-based affective models with transfer learning,” in Proceedings of the 25th International Joint Conference on Artificial Intelligence, (New York, NY), 2732–2738.
Zheng, W. L., Zhang, Y. Q., Zhu, J. Y., and Lu, B. L. (2015). “Transfer components between subjects for EEG-based emotion recognition,” in Proceedings of the2015 International Conference on Affective Computing and Intelligent Interaction (ACII), (Xi’an), 917–922.
Zhong, P., Wang, D., and Miao, C. (2020). EEG-based emotion recognition using regularized graph neural networks. IEEE Trans. Affect. Comput. 99:1.
Zhou, X., Jin, K., Shang, Y., and Guo, G. (2018). visually interpretable representation learning for depression recognition from facial images. IEEE Trans. Affect. Comput. 11, 542–552. doi: 10.1109/TAFFC.2018.2828819
Keywords: encephalogram, latent space, emotion recognition, co-adaptation, maximum mean discrepancy
Citation: Tao J, Dan Y, Zhou D and He S (2022) Robust Latent Multi-Source Adaptation for Encephalogram-Based Emotion Recognition. Front. Neurosci. 16:850906. doi: 10.3389/fnins.2022.850906
Received: 08 January 2022; Accepted: 11 February 2022;
Published: 27 April 2022.
Edited by:
Yuanpeng Zhang, Nantong University, ChinaReviewed by:
Jian Zhang, Wuhan University of Technology, ChinaFangfang Duan, Wuhan University of Technology, China
Copyright © 2022 Tao, Dan, Zhou and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Di Zhou, c2lvbjIwMDVAc2FzdS5lZHUuY24=
†These authors have contributed equally to this work