 Sai Kalyan Ranga Singanamalla
Sai Kalyan Ranga Singanamalla Chin-Teng Lin
Chin-Teng Lin
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Neurosci. , 04 April 2022
Sec. Neuroprosthetics
Volume 16 - 2022 | https://doi.org/10.3389/fnins.2022.792318
This article is part of the Research Topic The Intersection of Artificial Intelligence and Brain for High-performance Neuroprosthesis and Cyborg Systems View all 7 articles
Brain-computer interfaces (BCI) relying on electroencephalography (EEG) based neuroimaging mode has shown prospects for real-world usage due to its portability and optional selectivity of fewer channels for compactness. However, noise and artifacts often limit the capacity of BCI systems especially for event-related potentials such as P300 and error-related negativity (ERN), whose biomarkers are present in short time segments at the time-series level. Contrary to EEG, invasive recording is less prone to noise but requires a tedious surgical procedure. But EEG signal is the result of aggregation of neuronal spiking information underneath the scalp surface and transforming the relevant BCI task's EEG signal to spike representation could potentially help improve the BCI performance. In this study, we designed an approach using a spiking neural network (SNN) which is trained using surrogate-gradient descent to generate task-related multi-channel EEG template signals of all classes. The trained model is in turn leveraged to obtain the latent spike representation for each EEG sample. Comparing the classification performance of EEG signal and its spike-representation, the proposed approach enhanced the performance of ERN dataset from 79.22 to 82.27% with naive bayes and for P300 dataset, the accuracy was improved from 67.73 to 69.87% using xGboost. In addition, principal component analysis and correlation metrics were evaluated on both EEG signals and their spike-representation to identify the reason for such improvement.
Using the brain signals to communicate with external devices without the intervention of explicit human motor actions, called Brain-Computer Interfaces (BCI), provides a new dimension to interactive technology (Allison et al., 2007; Rashid et al., 2020). Notable examples of BCI application include controlling of wheelchair (Zhang et al., 2015), exoskeleton (Wang et al., 2018), speller (Rezeika et al., 2018), gaming (Ahn et al., 2014), etc. Apart from commercial prospects, BCIs have also been proved to be efficient in various clinical applications, for example, by-passing information from the brain to hand muscle through external stimulation due to the damage of motor nerves (Pohlmeyer et al., 2009), restoration of lost functionality with BCI training (Grosse-Wentrup et al., 2011), etc. As such, BCI has shown tremendous possibility toward its integration into daily life activities and clinical rehabilitation. The most common mode of neuroimaging method utilized for brain signal assessment is Electroencephalography (EEG) due to its high temporal resolution and ease of usage (Min et al., 2010; Zhang et al., 2010). Rapid developments in EEG acquisition devices enabled it to be user-friendly, portable and transit data wirelessly. Depending on the application, different number of EEG channels and modalities such as Motor imagery (MI) (Padfield et al., 2019), Steady-state Visually Evoked Potentials (SSVEP) (Bin et al., 2009) and Event-related potentials (ERP) (Kaufmann et al., 2011; Mayaud et al., 2013). In parallel, advances have been made toward bridging the gap between laboratory settings and real-world usage by enhancing EEG-based BCI systems performance. To this end, studies have focused on the development of novel machine learning methods and feature extraction techniques to improve the BCI system performance. In particular, Deep learning studies have shown promising results in this regard (Manor and Geva, 2015; Lawhern et al., 2018). For example, Lawhern et al. (2018) introduced EEGNet based on convolution neural network and has shown improved performance on various BCI modalities. However, few shortcomings need to be accounted for to yield complete advantage of such a deep learning model such as the availability of a large sample of training data, more EEG channels, fine-tuning model parameters, etc. For example, Lawhern et al. (2018) used approximately 2,000 samples for P300 classification, more than 6,000 samples by Manor and Geva (2015) for RSVP classification, and more than 10,000 samples by Ma et al. (2021). In practice, EEG data collections require a tedious experimental setup and are often time-consuming for a user to record huge datasets. Alternatively, classical techniques though can execute with fewer data samples but lack efficient feature representation. However, EEG signals recorded over the scalp surface are the collective information of multiple neuronal action potentials underneath the surface. We hypothesize that extracting spiking information from EEG signals could potentially help advance the BCI performance.
A model that naturally accommodates spiking information is Spiking Neural Network (SNN) and it is the third generation of neural networks. Contrary to artificial neural networks, they communicate via spikes mimicking the properties of the biological neural circuit, and as such SNNs have been gaining traction in the field of machine learning (Bellec et al., 2018; Woźniak et al., 2020). For example, Bellec et al. (2018) has leveraged adaptive properties of spiking neurons to obtain Long-Short-Term-Memory (LSTM) equivalent performance. Similarly, few studies have shown the efficiency of SNN toward speech recognition (Wu et al., 2020), objection detection (Kim et al., 2020), and language modeling (Woźniak et al., 2020). Also, SNN was examined in its ability to classify non-stationary EEG signals. For example, Antelis et al. (2020) encoded Motor Imagery (MI)-based EEG to spiking data for assessing the classification performance by SNN. Apart from BCI application, few studies have shown that SNN can also be adopted as classifiers for emotion recognition (Luo et al., 2020), seizure detection (Ghosh-Dastidar and Adeli, 2009), understand functional connectivity changes due to mind-fullness training (Doborjeh et al., 2019), and depression (Shah et al., 2019). These mentioned studies assume SNN to be a classifier as a standard notion similar to artificial neural networks, where the input (such as EEG) is provided to the network and it outputs a class label.
Recently, besides classification, our previous study has shown that SNN can be adopted as a generator model to efficiently generate artificial EEG signals to tackle the data augmentation problem of MI-based BCI systems and improve the performance (Singanamalla and Lin, 2021). In continuation of our previous work, we believe that reverse engineering SNN to extract spiking information from EEG signals could also improve BCI system performance. Similar to our previous work, the SNN is trained to produce task-relevant multi-channel EEG template signals. However, a major difference in this study is that, instead of using a trained model to create artificial samples, the model is used to extract spike-representation of EEG sample and this spike-representation is evaluated against baseline EEG classification performance. Major bottleneck issues for the practical outdoor usage of the BCI system are the noise/artifacts, fewer channels (for compactness), and fewer samples (less training time). Therefore for this study, two different BCI modalities, P300 and Error-Related Negativity (ERN) were primarily focused as they contain their biomarker in the time-series and as such more sensitive to noise. In addition, considering the above bottleneck issues, datasets with limited channels and fewer samples were considered to evaluate the proposed approach. Based on the result, we have observed that the proposed approach could potentially improve the BCI performance. This study further explored the reasoning as to why there is a performance enhancement due to the spike representation.
Each node in an SNN adheres to the dynamics of a spiking neuron and computes on a time-scale contrary to an artificial neuron which acts as a non-linear function. A family of spiking neuron models offering different levels of detailed simulation & complexity exists such as Hodgkin Huxley (HH) model (Hodgkin and Huxley, 1952), Izhikevich model (Izhikevich, 2003), Spike-Response model (SRM) (Jolivet et al., 2003), Leaky-Integrate and Fire (LIF) model (Neftci et al., 2019), Spiking Neural Unit (SNU) (Woźniak et al., 2020) etc. LIF model is the widely adopted model for building SNN due to its computational simplicity and efficiency. The membrane potential dynamics of a LIF neuron is described according to Equation (1).
where ui(t) describes the membrane potential of the neuron indexed by i and it's input current is presented by Ii(t) at a given time point t. The constant parameters of this model include, baseline resting membrane potential urest, membrane time constant τm , resistance R, and the synaptic time constant τs. The input current dynamics is described by Equation (2).
Si(t) is the spike train (sum of a dirac delta function, δ) of a neuron and is the kth firing time of the corresponding neuron. The membrane potential increases with input current, and after reaching a threshold ϑ, the neuron emits a spike and resets its potential to urest. By incorporating this reset property the updated membrane dynamics is presented by Equation (4):
For ease of use, the membrane dynamics can be further simplified, as suggested in Neftci et al. (2019), where an approximated version of the LIF membrane potential and input current for a small simulation time step Δt > 0, as shown in Equations (5, 6), by incorporating the numerical value of R, urest, and ϑ from Table 1.
where , .

Table 1. List of spiking neuron and Adam optimizer properties.
In addition to LIF, we have also tested SNU (whose dynamics are represented by Equation 7) based SNN model. The advantage of SNU is that it can act as both artificial and spiking neuron depending on the choices of activation function. To compare with LIF, here we choose activation functions g = relu and h = heaviside to implement spiking functionality.
where, xt, ut, st represent the input, membrane potential and spike output, respectively at time step t. A detailed list of all the parameter of LIF and SNU are presented in Table 1.
A recurrent based SNN model (RSNN) in which each node is based on a simplified LIF or SNU model and computes following Equation (5) for producing EEG signals. Similar to Singanamalla and Lin (2021), since the source spiking information that generates desired EEG signal is often not available, the input layers generate spike-trains adhering to Poisson distribution with a firing rate of 10 Hz. This spike train is then processed via the RSNN population. Since EEG signal is continuous contrary to spike-trains (discrete-time series), a double exponential synaptic filter (see Section 2.2.2) is applied to the neural activity of RSNN to smoothen the spike-trains, denoted as a latent layer. The filtered spike-trains are then weighted averaged to produce a multi-channel EEG signal. An overview of the proposed architecture is depicted in Figure 1. The proposed architecture comprises a different number of nodes(or neurons) in each layer as follows: 50 for the input layer, 100 for RSNN, 100 for the latent layer, and 2 for the output layer. The model was built using pytorch, a popular python-based deep learning library, and the weight connections between the all layers and recurrent weights within RSNN are trained using surrogate-gradient descent (see Section 2.2.1) with Adam optimizer.
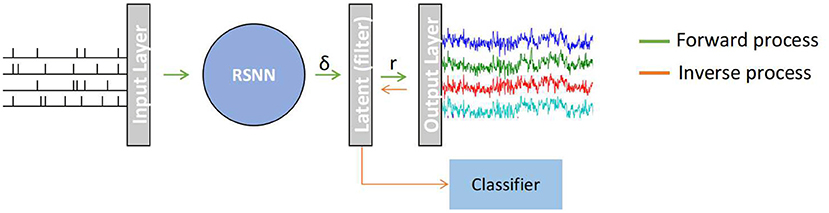
Figure 1. A recurrent spiking neural network (RSNN) model that maps a random input spike-train from Input Layer to a multi-channel EEG signal in the Output Layer. The spike trains (δ) from RSNN are processed in the latent layer to continuous signal r using a double exponential synaptic filer before converting to an EEG signal. This model works in two stages: (1) Forward process in which SNN generates template EEG signal, (2) Inverse process in which the non-template signal are transformed to spike-representation for classification.
In a given EEG dataset, no two samples are the same for a defined stimulus. So, training the model for each EEG sample independently to obtain latent information (i.e., the spike-representation of EEG sample) is computationally demanding. Therefore, a representative EEG signal, called template EEG, was initially obtained from a given dataset for the training process. As suggested in Singanamalla and Lin (2021), a classifier was trained and tested with a dataset and the sample with the highest probability of being categorized correctly into its respective class will be considered as the EEG template.
The model is implemented in a two-stage process namely, Forward process and Inverse process. In the Forward process, the model was trained using surrogate gradient descent to reproduce multi-channel EEG templates of a given dataset. Following this, the Inverse process transforms each of the non-template signals (i.e., samples other than template in a given dataset) to its spike-representation by Equation (8) in which the pseudo-inverse of trained weights (connecting latent-layer to output layer) is multiplied by EEG samples.
where Wf is the trained weight matrix from latent layer to EEG signal output.
Gradient descent optimization is the most widely adopted optimization technique in an artificial neural network. Gradient estimation requires the function to be continuous such that it is differentiable. However, for a spiking neuron's spike emission process mimics the step activation function, i.e., when the voltage exceeded its threshold a spike is produced and resets immediately. As such, the resulting discontinuous function limits the usage of the standard gradient descent algorithm. To this end, Neftci et al. (2019) developed an approach called surrogate-gradient descent, in which the step activation applied to membrane voltage at a time step t, Si[t]∝Θ(ui[t]−ϑ), during forward propagation is replaced with Sigmoid activation function during backpropagation as follows: σ(ui[t]−ϑ), where σ(x) = 1/(1+exp(−x)). This flexibility of using pseudo-derivatives during backward propagation enables the use of gradient descent optimization variants. It is important to note that, the sigmoid replacement happens only during backpropagation while the step function remains fixed during forward propagation.
A spike train is a discontinuous time series with a value of 1 (spike) or 0 (no-spike) at each time step. Therefore, as suggested in Nicola and Clopath (2017), a double exponential synaptic filter is applied (latent layer) to the spike trains of RSNN in the Forward process to obtain a continuous signal. This filtered signal is later transformed into a multi-channel (2 channels in this study) EEG signal. For a spike train from one node, the synaptic filter is estimated according to Equation (9).
where, τr represents synaptic rise time, τd is the synaptic decay time, and δ is the spike train of RSNN layer (see Figure 1). The spike is first filtered with one intermediary exponential filter hj and followed by another exponential filter rj. The activity of rj is the output of latent layer.
Two types of ERP signal, Error-Related negativity (ERN) and P300, are considered for this study. The datasets are publicly available from Van Veen et al. (2019) and Kappenman et al. (2021), respectively. A standard EEG processing pipeline containing bandpass filtering between 0.5 and 45 Hz, epoch extraction, and channel selection were applied to each of the datasets. For both ERN and P300 datasets, 20 subject data were considered. A template EEG signal was extracted (as mentioned in Section 2.2) for each subject dataset independently and smoothed using a moving average window. This template was later utilized for training the SNN model. For SNU-based model, the signal is also normalized from −1 to 1 for better fitting.
For ERN and P300 signals, the EEG time series data are considered as features for classification. The most predominantly used classifiers for both ERN and P300 include Support Vector Machine's (SVM), Gaussian classifiers, and tree-based algorithms (Ventouras et al., 2011; Chavarriaga et al., 2014; Sarraf et al., 2021). Therefore, this study had adopted these classifiers for assessing the baseline EEG classification accuracy. For a fair comparison, the spike-representation (with both LIF and SNU-based SNN) of EEG signals was classified with the same classifiers. A 5 × 10-fold cross-validation (CV) was applied for each subject data and the overall performance of given subject data is the average of all the folds. To test the significance in performance improvement with spike-representation, a two-sided wilcoxon signed-rank test was performed on the classification accuracies obtained from each classifier independently. Refer to Section 3.2 on the outcomes of classification and significance test results.
Based on the classification results (see Section 3.2), we observed that the performance be enhanced above baseline by transforming the EEG signals to spike-representation. Debugging the reasoning behind such accuracy increment could better help understand the neural origins of EEG signals and to why EEG signal is often ineffective compared to invasive electrode recordings. Principal component analysis (PCA) was applied to the EEG data and its corresponding spike-representation to estimate the variance explanation ratio. This assisted in exploring if the proposed approach was able to extract novel features (or more independent variables). In addition, we have compared the confusion matrix analysis and correlation properties to explore the attributes of spike-transformed data.
For each subject dataset, a new instance of the model (LIF or SNU-based SNN) was trained to generate a set of EEG template signal. In the case of ERN and P300 datasets, this set comprises of two template signals (one from each class denoted as target and non-target). Accordingly, two Poisson spike trains (at 10 Hz rate) were initialized to acts as input signal to the SNN model. For some subjects as shown in Figures 2A, 3A, the model was able to reproduce these template EEG signals for both P300 and ERN signals, respectively. Also, it can be observed that RSNN activity was rearranged during the training process for both ERN (see Figure 2B) and P300 EEG signal (see Figure 3B). Since the objective of the model is to reproduce a time series signal (i.e., EEG template), a Mean Square Error (MSE) loss function was adopted as a cost function. From Figures 2C, 3C, it can be observed this loss converged quickly for both P300 and ERN EEG signal generation. A detailed list of neuron and optimizer parameter are provided in Table 1.
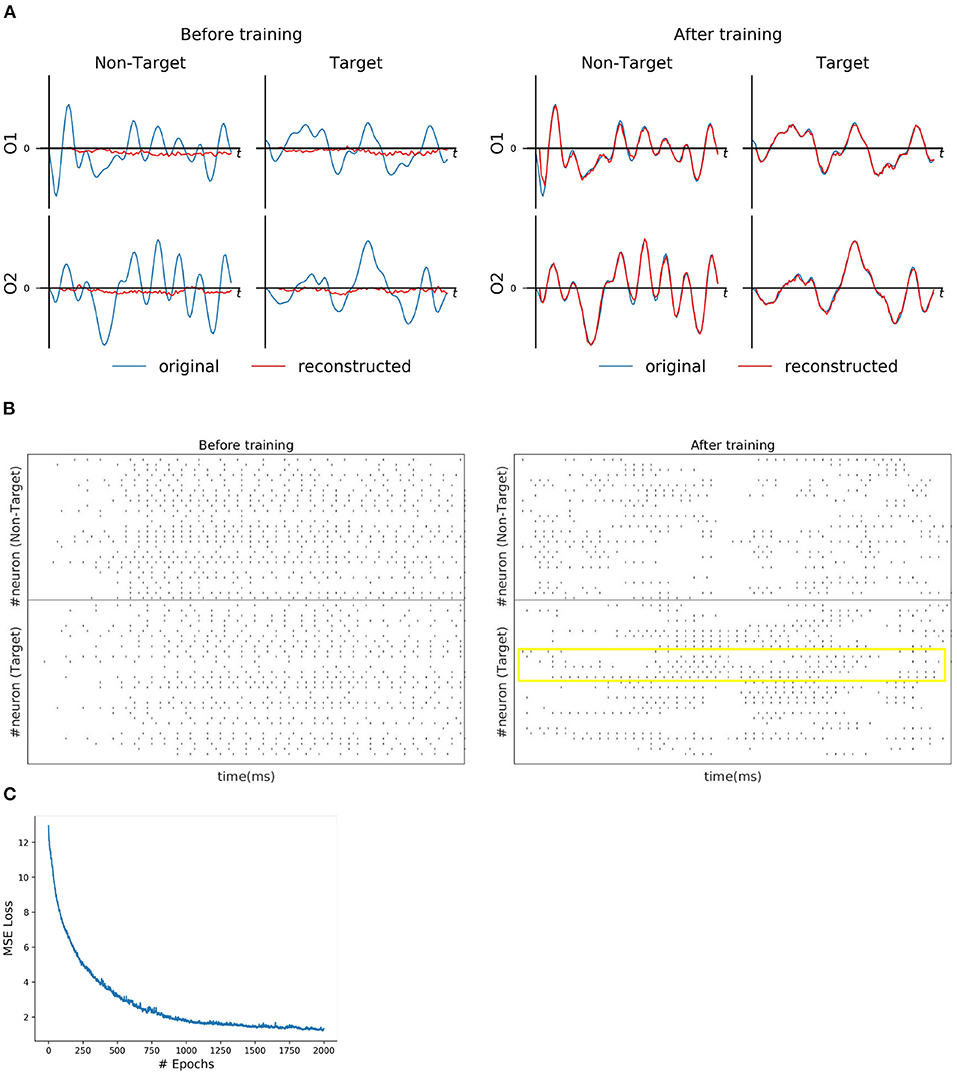
Figure 2. P300 signal reconstruction outcomes. (A) Illustration of original (blue line) and reconstructed (red line) for O1 and O2 EEG signals for both Target and Non-Target classes before and after training. (B) Spike trains of RSNN activity before and after the training process from 30 randomly selected neurons. The yellow box indicates the effectiveness of the training process in reorganizing the spike trains across layers. (C) The convergence of MSE loss value across epochs during the training process.
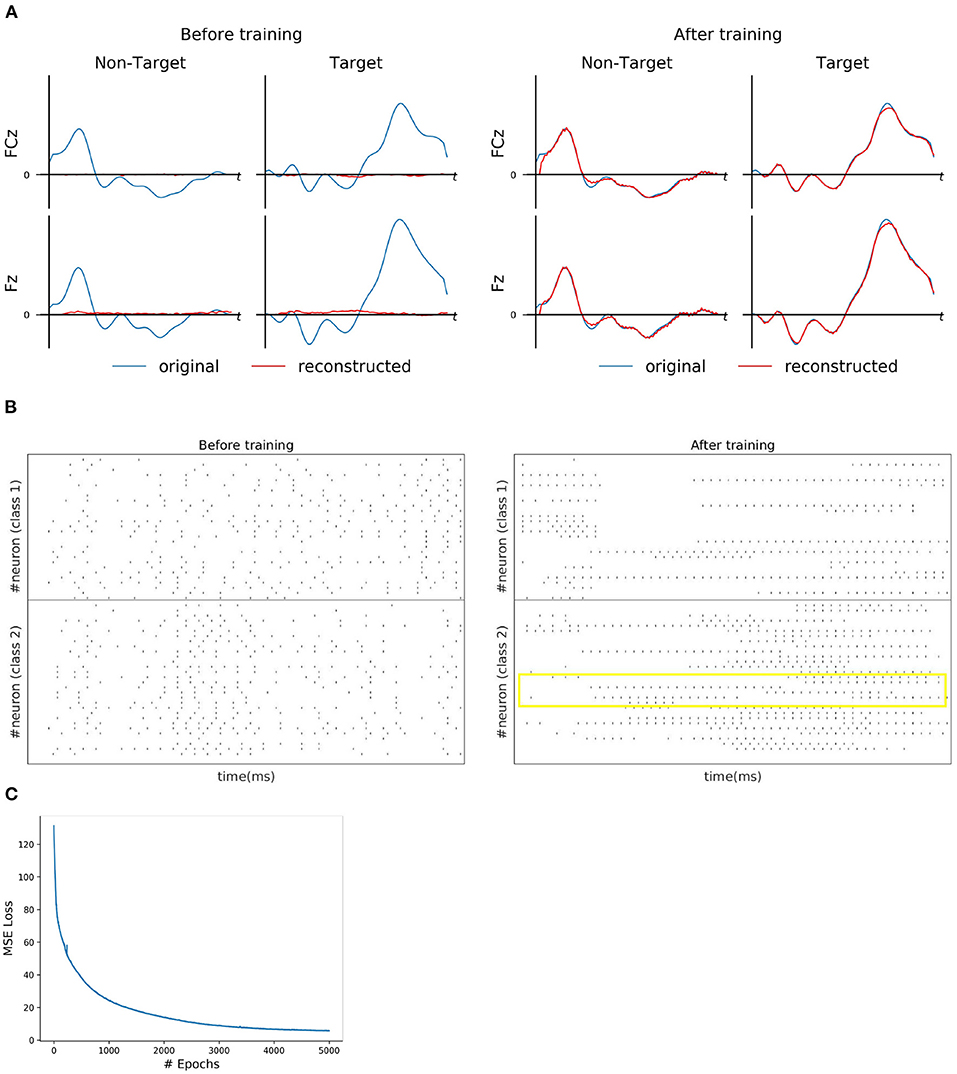
Figure 3. ERN signal reconstruction outcomes. (A) Illustration of original (blue line) and reconstructed (red line) for FCz and Fz EEG signals for both Target and Non-Target classes before and after training. (B) Spike trains of RSNN activity before and after the training process from 30 randomly selected neurons. The yellow box indicates the effectiveness of the training process in reorganizing the spike trains across layers. (C) The convergence of MSE loss value across epochs during the training process.
In the P300 analysis, 20 subjects' data from open source (Van Veen et al., 2019) was considered for this study. The datasets were pre-processed according to the pipeline mentioned in Section 2.3. As previously mentioned the limits of practicality, only two channels that contribute to P300 bio-maker, FCz & Fz were considered toward the further process. To extract the template signal from a given subject dataset, all the samples in the dataset are used for both training and testing with the SVM classifier. The sample that obtained the highest probability of being correctly categorized into its class is considered as the template. Since P300 is a binary class (Target and Non-target) system, we obtained two EEG templates, one for each class. After training the model to generate this EEG template, each of the remaining samples in the data (i.e., non-template) were converted to its spike representation through Equation (8). Then, different classifiers such as SVM, Naive Bayes (NVB), and xGboost were used for comparing the performance of EEG signals (baseline performance) and their respective spike-representation signals. For each subject, classification accuracy represents the average of a 5 × 10-fold CV (i.e., 5 times 10-fold), in which each fold was executed with 90%of the randomly selected samples as training set and remaining for the testing set. As shown in Table 2, using xGboost, spike-representation of EEG signals has obtained an average accuracy of 69.87% (with SNU-based SNN), 69.56% (with LIF-based SNN), and exceeded the baseline performance (EEG signal classification accuracy) of 67.73%. In addition, few subjects (such as S13 and S19) showcased significant improvement from baseline performance by up to 5–7%. A one-sided wilcoxon-signed rank test was applied between accuracies obtained from EEG and their spike-representation (either from LIF or SNU) from each classifier separately. This statistical significance analysis resulted in a p < 0.05 for all the classifiers.
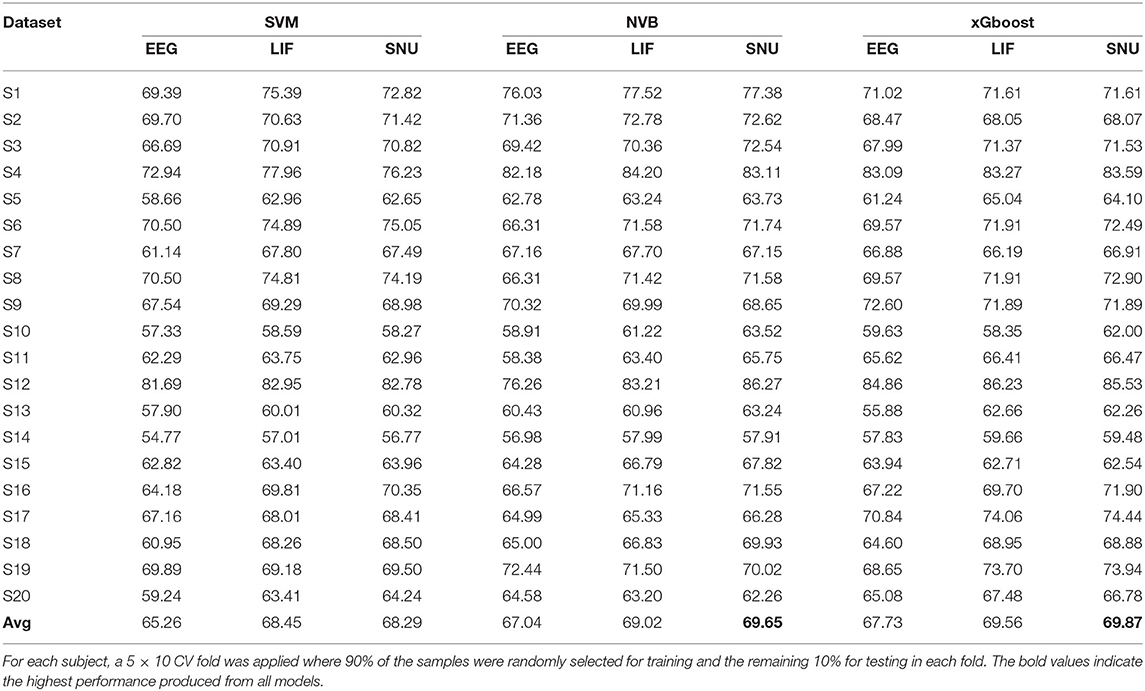
Table 2. Comparison of classification performance of P300 based EEG signal and its spike-representation by LIF-based and SNU-based SNN using SVM, NVB, and xGboost classifiers.
The SNN model training process for ERN was similar to P300 except that the channels selected for this dataset are Pz & Oz. In total 20 subject datasets were considered for assessing the spike-representation competency for this BCI mode. Similar to the P300 assessment in Section 3.2.1, the template signal for each subject was extracted based on the probability (obtained by SVM) of each sample to be categorized into its respective class. The classification performance of the ERN signal and its spike representation was evaluated using SVM, NVB, and xGboost classifiers. As shown in Table 3, with NVB, spike-representation of EEG signals has obtained an accuracy of 82.27% (with LIF-based SNN), 81.66% (with SNU-based SNN) and exceeded the baseline (EEG) performance of 79.22%. In addition, few subjects (such as S15) have shown a significant increase (up to 7%) with spike-representation. Similar to P300, the statistical significance analysis for ERN using one-sided wilcoxon signed-rank test has also resulted in a p < 0.05 for all the classifiers with LIF and for SNU p-values are 0.082 (for SVM), 0.018 (for SVB), and 0.095 (for xGboost).
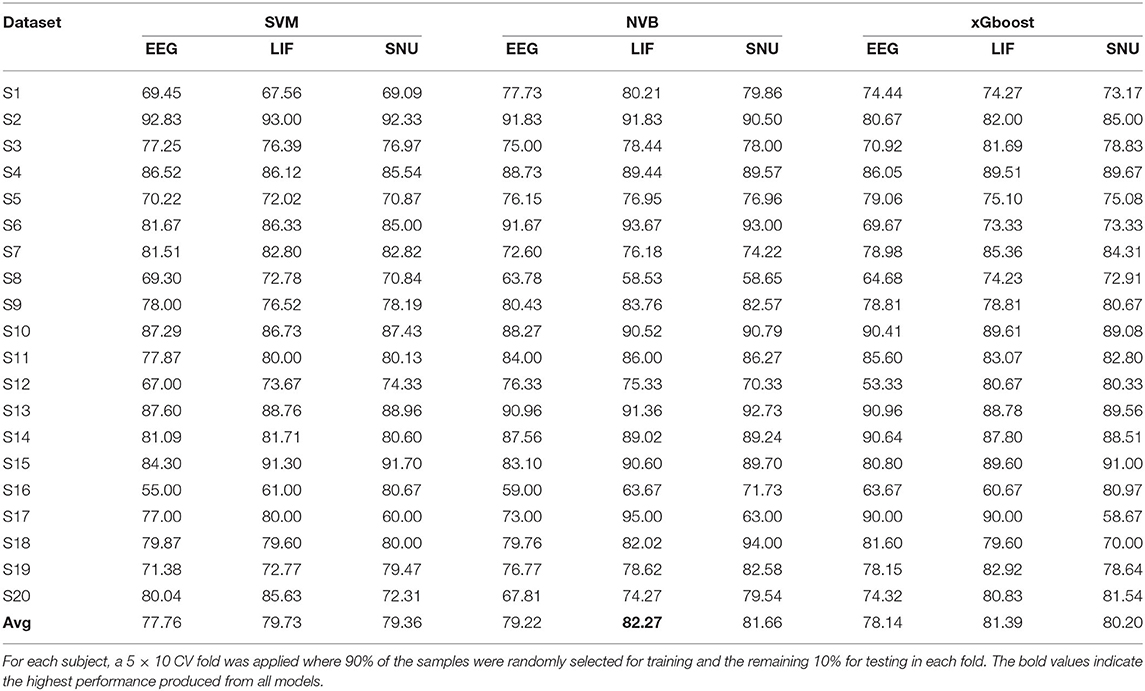
Table 3. Comparison of the classification performance of ERN's EEG signal and its spike-representation by LIF-based and SNU-based SNN using SVM, NVB, and xGboost classifiers.
To further assess the impact of SNN on performance improvement, we have transformed the ERN signal to a high-dimension signal (in Equation 8) in two ways as a control study: (1) using a random weight matrix (of normal distribution equivalent to initialized SNN weights) and (2) Liquid State Machines (LSM; based on LIF) in which all RSNN related weight matrices (feedforward & recurrent) are fixed except for the output layer weights that convert filtered signal r to EEG signal during the model training process. The performance of the transformed signal with these two approaches is estimated using NVB as it has obtained the best performance previously. As shown in Table 4, the average performances with random weight is 80.70% (p = 0.287 with one-sided wilcoxon test) and LSM is 81.83% with p = 0.74. The effect of SNN's trained weights on performance is not significantly higher than these control methods, but provided an additional edge in the average performance.
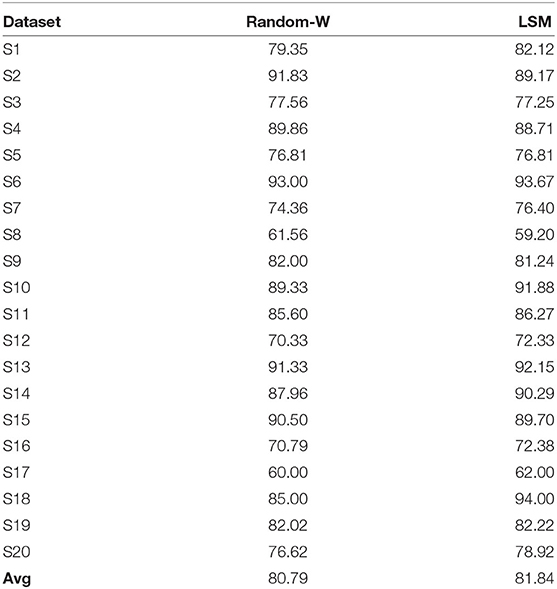
Table 4. Comparison of classification performance of ERN dataset via NVB for transformed signal with random weight and LSM.
From Tables 2, 3, it can be observed that spike-representation can improve the classification performance. However, the classification metric alone does not provide enough details on the model performance. Therefore, confusion matrix analysis with xGboost classifier was performed on a select subject, from both ERN and P300 datasets, that had significant improvement over baseline performance. Based on Figure 4, we found that for ERN, the proposed approach increased both true positive and false negative. This indicates that the spike representation was able to account for patterns of both target and non-target samples and improve their detection rate. Similar behavior was identified for the P300 dataset as well (see Supplementary Figure 1).
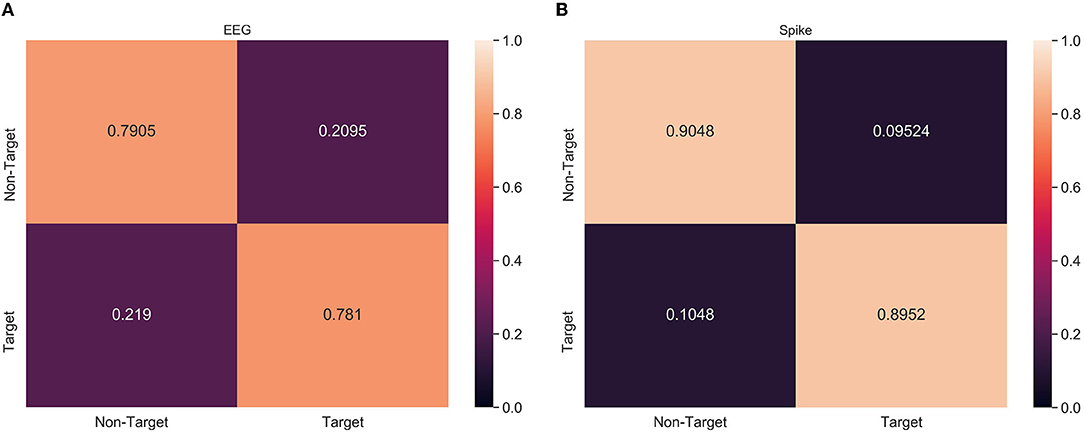
Figure 4. Confusion matrix analysis of (A) EEG and (B) Spike-representation (from LIF) of ERN dataset. Recognition of both Target and Non-Target categories improved for spike-representation compared to EEG signal.
Though EEG signal and its spike-representation are directly analogous, spike-representation of the data was able to provide better performance. Exploring the reason behind the performance increment could better help in further enhancing the credibility of BCI systems. To this end, PCA and correlation measures were applied to both EEG signal and its spike-representation data to assess the internal factor that leads to performance enhancement.
It is common that not all variables in a data is useful to provide meaningful information. Explained variance analysis is often used to measure the ratio of information represented by principal components. In other words, it helps to identify the fraction of data variability contributed by a given set independent variable (features). In this study, we indent to explore if spike-representation of EEG signals provide additional information for improving the accuracy. Using PCA, we analyzed this metric on EEG signal & its spike-representation. As shown in Figure 5, it can be observed that for a given dataset from ERN, the spike-representation (red line) required more components than EEG signal (blue line) to explain 75% (black line) of variability in the data. This could imply that the proposed method was able to extract more unique independent features from the spike-representation of data and this could in turn enabled the classifier for better classification. Supplementary Figure 2 showcases a similar observation for P300 datasets.
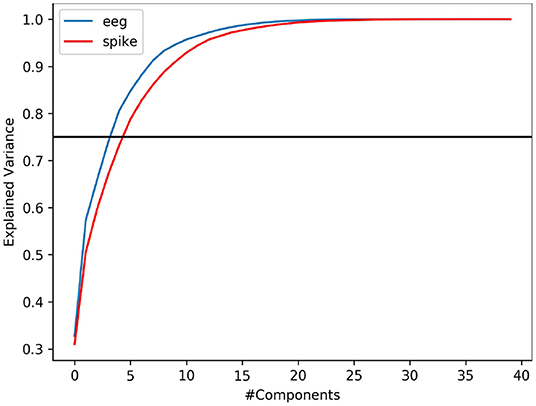
Figure 5. PCA-based variance explanation of EEG signal (blue line) and its corresponding spike representation (from LIF; red line) for ERN dataset. Blackline represents the 75% variance. Spike-representation (from LIF) was able to extract a more independent eigenvector from EEG signal to account for a given fraction of variance in the dataset.
To further understand the reason for performance enhancement, we analyzed the similarity among EEG samples and among their respective spike-representation. To this end, the correlation between all the samples of a given ERN dataset was estimated using Pearson's correlation technique. Figure 6, showcases the correlation matrix for all EEG samples, all spike-representation sample, and the difference of these two matrices (Spike-EEG plot). Each pixel represents the correlation between any two samples. It can be deduced from Spike-EEG plot that correlation among the spike-representation samples is slightly higher than of its EEG samples. This could imply that the proposed approach tends to enhance the similarity among the samples of given class (i.e., target and non-target classes) and this in-turn increased the performance. A similar increase in correlation for the P300 dataset is shown in Supplementary Figure 3.
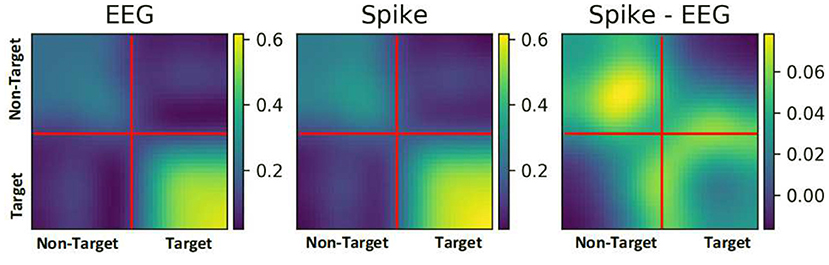
Figure 6. Pearson correlation among all the samples in an ERN dataset for both EEG signal and its spike-representation (from LIF). Spike representation forged a higher correlation among the samples of a given class.
For both ERN and P300, their prominent bio-maker (feature) can be found directly through their time-series signal. However, each subject's EEG template is unique and it is possible for the template to even contain noise and information irrelevant to the biomarker. Therefore, the number of nodes in RSNN required to generate an EEG template may vary depending on the complexity (i.e., variance) of the signal. As a result, we hypothesize that not all nodes in RSNN may contain reliable information, and considering only a few nodes' activities (referred to as node prioritization) could further improve the classification performance. The nodes with weights (from latent layer and output layer) that fall outside μ±1.5*σ range are assumed to be major contributors of EEG signals and as such only these nodes' activity is considered from spike-representation of EEG data. Here, μ and σ represent the mean and standard deviation of the weight distribution obtained after training the model. Also, it could be possible that such prioritization may not be ideal for all subjects. For this reason, we have compared to different modes: (a) node-prioritization and (b) threshold-based node prioritization. For the threshold-based approach, we have estimated the variance of the EEG template signal from each subject and considered the median value (from all variances) as a threshold for determining whether to apply node prioritization for a given subject dataset. In other words, node prioritization was applied to the subject data whose template signals have higher variance. As shown in Table 5, for ERN, the two mentioned prioritization modes improved the performance by a minor fraction compared to the performance compared to the original spike-representation performance. A similar observation was seen for P300 datasets as well (see Supplementary Table 1).
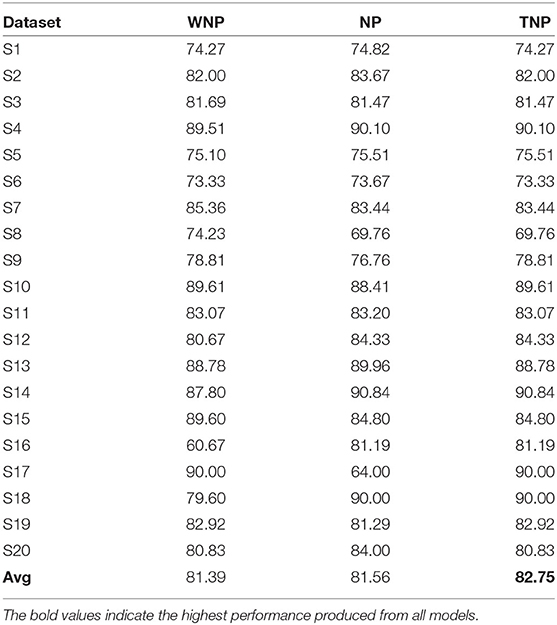
Table 5. Comparison of classification performance of spike-representation (from LIF) of ERN datasets with xGboost under different prioritization conditions such as: without node prioritization (WNP), node prioritization (NP), and threshold-based node prioritization (TNP).
EEG measurements had been a longstanding preferred mode of neuroimaging technique for BCI applications development due to its compactness, portability, and ease of use. However, EEG signals are often noisy and affect the performance of BCI systems. In addition, ERP-based BCI modalities such as ERN and P300 explicitly rely on the time-series segment of the signal for identifying the biomarkers. As such, they are often susceptible to noise and artifacts. Broadly, an EEG signal is the result of an accumulation of neural spiking information beneath the scalp surface. Theoretically, though the invasive recording is less prone to noise and contains robust information compared to EEG, it requires complex surgical effort. Extracting such predecessor spiking information responsible for an ERP could potentially help to understand the internal processes of BCI relevant activity and in turn, improve the BCI performance. Therefore, this study designed an approach based on SNN to generate relevant EEG signals (such as ERN and P300) and in turn extract its spike representation from the latent layer. This spike-representation is assessed toward BCI performance enhancements.
As shown in Section 3.2, the proposed approach was able to re-organize its spiking activity (see Figure 2B) and generate both ERN & P300 template signals. By evaluating using 5 × 10-fold CV metric with different standardized classifiers such as SVM, NVB, and xGboost, the spike-representation obtained from the LIF-based model has shown enhanced average BCI performance compared to baseline performance and further significantly for certain datasets. Also, besides LIF, the classification enhancement was observed with another spiking neuron, SNU. Besides ERN and P300, the model was also tested with non-ERP signals such as MI and we observed similar performance increment with spike-representation compared to (see Supplementary Table 2). In addition to classification, inferring the reason behind such performance improvement using PCA and correlation analysis has showcased that the proposed approach was able to extract more independent eigenvector (features) and increased within-class correlation and it facilitated the classifiers to better categorize the samples. To further validate the impact of SNN's trained weights, we have also compared the performance of transformed signal obtained with random weight, LSM and has shown that SNN's weights provided additional edge in performance enhancement. A current limitation of this study is that the threshold estimation requires information many datasets for node-prioritization. However, this technique offers advantages in terms of faster inference in edge devices as the prioritization enables node reduction profoundly. As a proof-of-concept, this also suggests that novel techniques such as pruning (Li et al., 2019) and deep-rewiring (Bellec et al., 2017) could be a desired approach for the future direction.
The template signal extraction was based on the assumption that a given stimulus should ideally produce similar neural activity over repeated trials (Mainen and Sejnowski, 1995). However, it could be plausible for a template containing irrelevant information to influence the spike representation too. Therefore, the future direction of this work includes the derivation of a clean template signal such that the representation of its in spike format can be more robust. Recent advances in deep learning have shown that Representation learning methods have enabled for better organization of data and in turn enhance the performance (Bengio et al., 2013; Le-Khac et al., 2020). For example, Khosla et al. (2020) introduced supervised contrastive learning where a loss function accounts for similarity and dissimilarity among samples for learning better representations. Adopting such techniques in the future direction could further enrich the spike representations.
The datasets used in this study are publicly available from https://osf.io/thsqg/, and https://zenodo.org/record/2649069/# (YPy2NDoRUUF).
SS and C-TL conceptualized the concept and methodology and wrote the manuscript. SS wrote the code and performed the simulations. All authors contributed to the article and approved the submitted version.
This work was supported in part by the Australian Research Council (ARC) under discovery grant DP220100803 and DP210101093. Research was also sponsored in part by the Australia Defence Innovation Hub under Contract No. P18-650825, US Office of Naval Research Global under Cooperative Agreement Number ONRG - NICOP - N62909-19-1-2058, and AFOSR – DST Australian Autonomy Initiative.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2022.792318/full#supplementary-material
Ahn, M., Lee, M., Choi, J., and Jun, S. C. (2014). A review of brain-computer interface games and an opinion survey from researchers, developers and users. Sensors 14, 14601–14633. doi: 10.3390/s140814601
Allison, B. Z., Wolpaw, E. W., and Wolpaw, J. R. (2007). Brain–computer interface systems: progress and prospects. Expert Rev. Med. Devices 4, 463–474. doi: 10.1586/17434440.4.4.463
Antelis, J. M.Falcón, L. E., et al. (2020). Spiking neural networks applied to the classification of motor tasks in EEG signals. Neural Netw. 122, 130–143. doi: 10.1016/j.neunet.2019.09.037
Bellec, G., Kappel, D., Maass, W., and Legenstein, R. (2017). Deep rewiring: training very sparse deep networks. arXiv preprint arXiv:1711.05136. doi: 10.48550/arXiv.1711.05136
Bellec, G., Salaj, D., Subramoney, A., Legenstein, R., and Maass, W. (2018). Long short-term memory and learning-to-learn in networks of spiking neurons. arXiv preprint arXiv:1803.09574. doi: 10.48550/arXiv.1803.09574
Bengio, Y., Courville, A., and Vincent, P. (2013). Representation learning: a review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1798–1828. doi: 10.1109/TPAMI.2013.50
Bin, G., Gao, X., Yan, Z., Hong, B., and Gao, S. (2009). An online multi-channel SSVEP-based brain–computer interface using a canonical correlation analysis method. J. Neural Eng. 6, 046002. doi: 10.1088/1741-2560/6/4/046002
Chavarriaga, R., Sobolewski, A., and Millán, J. D. R. (2014). Errare machinale est: the use of error-related potentials in brain-machine interfaces. Front. Neurosci. 8, 208. doi: 10.3389/fnins.2014.00208
Doborjeh, Z., Doborjeh, M., Taylor, T., Kasabov, N., Wang, G. Y., Siegert, R., et al. (2019). Spiking neural network modelling approach reveals how mindfulness training rewires the brain. Sci. Rep. 9, 1–15. doi: 10.1038/s41598-019-42863-x
Ghosh-Dastidar, S., and Adeli, H. (2009). A new supervised learning algorithm for multiple spiking neural networks with application in epilepsy and seizure detection. Neural Netw. 22, 1419–1431. doi: 10.1016/j.neunet.2009.04.003
Grosse-Wentrup, M., Mattia, D., and Oweiss, K. (2011). Using brain–computer interfaces to induce neural plasticity and restore function. J. Neural Eng. 8, 025004. doi: 10.1088/1741-2560/8/2/025004
Hodgkin, A. L., and Huxley, A. F. (1952). A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 117, 500–544.
Izhikevich, E. M.. (2003). Simple model of spiking neurons. IEEE Trans. Neural Netw. 14, 1569–1572. doi: 10.1109/TNN.2003.820440
Jolivet, R., Timothy, J., and Gerstner, W. (2003). “The spike response model: a framework to predict neuronal spike trains,” in Artificial Neural Networks and Neural Information Processing–ICANN/ICONIP 2003 (Berlin: Springer), 846–853.
Kappenman, E. S., Farrens, J. L., Zhang, W., Stewart, A. X., and Luck, S. J. (2021). ERP core: an open resource for human event-related potential research. NeuroImage 225, 117465. doi: 10.1016/j.neuroimage.2020.117465
Kaufmann, T., Schulz, S. M., Grünzinger, C., and Kübler, A. (2011). Flashing characters with famous faces improves ERP-based brain–computer interface performance. J. Neural Eng. 8, 056016. doi: 10.1088/1741-2560/8/5/056016
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., et al. (2020). Supervised contrastive learning. arXiv preprint arXiv:2004.11362. doi: 10.48550/arXiv.2004.11362
Kim, S., Park, S., Na, B., and Yoon, S. (2020). “Spiking-yolo: spiking neural network for energy-efficient object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence (California), 11270–11277.
Lawhern, V. J., Solon, A. J., Waytowich, N. R., Gordon, S. M., Hung, C. P., and Lance, B. J. (2018). EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 15, 056013. doi: 10.1088/1741-2552/aace8c
Le-Khac, P. H., Healy, G., and Smeaton, A. F. (2020). Contrastive representation learning: a framework and review. IEEE Access. 8, 193907–193934. doi: 10.1109/ACCESS.2020.3031549
Li, L., Zhu, J., and Sun, M.-T. (2019). “Deep learning based method for pruning deep neural networks,” in 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW) (New Jersey, NJ: IEEE), 312–317.
Luo, Y., Fu, Q., Xie, J., Qin, Y., Wu, G., Liu, J., et al. (2020). EEG-based emotion classification using spiking neural networks. IEEE Access 8, 46007–46016. doi: 10.1109/ACCESS.2020.2978163
Ma, R., Yu, T., Zhong, X., Yu, Z. L., Li, Y., and Gu, Z. (2021). Capsule network for ERP detection in brain-computer interface. IEEE Trans. Neural Syst. Rehabil. Eng. 29, 718–730. doi: 10.1109/TNSRE.2021.3070327
Mainen, Z. F., and Sejnowski, T. J. (1995). Reliability of spike timing in neocortical neurons. Science 268, 1503–1506.
Manor, R., and Geva, A. B. (2015). Convolutional neural network for multi-category rapid serial visual presentation BCI. Front. Comput. Neurosci. 9, 146. doi: 10.3389/fncom.2015.00146
Mayaud, L., Congedo, M., Van Laghenhove, A., Orlikowski, D., Figère, M., Azabou, E., et al. (2013). A comparison of recording modalities of p300 event-related potentials (ERP) for brain-computer interface (BCI) paradigm. Clin. Neurophysiol. 43, 217–227. doi: 10.1016/j.neucli.2013.06.002
Min, B.-K., Marzelli, M. J., and Yoo, S.-S. (2010). Neuroimaging-based approaches in the brain–computer interface. Trends Biotechnol. 28, 552–560. doi: 10.1016/j.tibtech.2010.08.002
Neftci, E. O., Mostafa, H., and Zenke, F. (2019). Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 36, 51–63. doi: 10.1109/MSP.2019.2931595
Nicola, W., and Clopath, C. (2017). Supervised learning in spiking neural networks with force training. Nat. Commun. 8, 1–15. doi: 10.1038/s41467-017-01827-3
Padfield, N., Zabalza, J., Zhao, H., Masero, V., and Ren, J. (2019). EEG-based brain-computer interfaces using motor-imagery: techniques and challenges. Sensors 19, 1423. doi: 10.3390/s19061423
Pohlmeyer, E. A., Oby, E. R., Perreault, E. J., Solla, S. A., Kilgore, K. L., Kirsch, R. F., et al. (2009). Toward the restoration of hand use to a paralyzed monkey: brain-controlled functional electrical stimulation of forearm muscles. PLoS ONE 4, e5924. doi: 10.1371/journal.pone.0005924
Rashid, M., Sulaiman, N., Abdul Majeed, P. P. A., Musa, R. M., Bari, B. S., Khatun, S., et al. (2020). Current status, challenges, and possible solutions of EEG-based brain-computer interface: a comprehensive review. Front. Neurorobot. 14, 25. doi: 10.3389/fnbot.2020.00025
Rezeika, A., Benda, M., Stawicki, P., Gembler, F., Saboor, A., and Volosyak, I. (2018). Brain–computer interface spellers: a review. Brain Sci. 8, 57. doi: 10.3390/brainsci8040057
Sarraf, J., and Vaibhaw Pattnaik, P. (2021). A study of classification techniques on p300 speller dataset. Mater. Tdy Proc. doi: 10.1016/j.matpr.2021.06.110
Shah, D., Wang, G. Y., Doborjeh, M., Doborjeh, Z., and Kasabov, N. (2019). “Deep learning of EEG data in the neucube brain-inspired spiking neural network architecture for a better understanding of depression,” in International Conference on Neural Information Processing (Berlin: Springer), 195–206.
Singanamalla, S. K. R., and Lin, C.-T. (2021). Spiking neural network for augmenting electroencephalographic data for brain computer interfaces. Front. Neurosci. 15, 651762. doi: 10.3389/fnins.2021.651762
Van Veen, G. F. P., Barachant, A., Andreev, A., Cattan, G., Coelho, R. P. L., and Congedo, M. (2019). Building brain invaders: EEG data of an experimental validation. Zenedo. doi: 10.5281/zenodo.2649069
Ventouras, E. M., Asvestas, P., Karanasiou, I., and Matsopoulos, G. K. (2011). Classification of error-related negativity (ERN) and positivity (PE) potentials using KNN and support vector machines. Comput. Biol. Med. 41, 98–109. doi: 10.1016/j.compbiomed.2010.12.004
Wang, C., Wu, X., Wang, Z., and Ma, Y. (2018). Implementation of a brain-computer interface on a lower-limb exoskeleton. IEEE Access 6, 38524–38534. doi: 10.1109/ACCESS.2018.2853628
Woźniak, S., Pantazi, A., Bohnstingl, T., and Eleftheriou, E. (2020). Deep learning incorporating biologically inspired neural dynamics and in-memory computing. Nat. Mach. Intell. 2, 325–336. doi: 10.1038/s42256-020-0187-0
Wu, J., Yılmaz, E., Zhang, M., Li, H., and Tan, K. C. (2020). Deep spiking neural networks for large vocabulary automatic speech recognition. Front. Neurosci. 14, 199. doi: 10.3389/fnins.2020.00199
Zhang, B., Wang, J., and Fuhlbrigge, T. (2010). “A review of the commercial brain-computer interface technology from perspective of industrial robotics,” in 2010 IEEE International Conference on Automation and Logistics (New Jersey, NJ: IEEE), 379–384.
Keywords: spiking neural network, brain-computer interface, electroencephalography, P300, error-related negativity, classification
Citation: Singanamalla SKR and Lin C-T (2022) Spike-Representation of EEG Signals for Performance Enhancement of Brain-Computer Interfaces. Front. Neurosci. 16:792318. doi: 10.3389/fnins.2022.792318
Received: 10 October 2021; Accepted: 12 January 2022;
Published: 04 April 2022.
Edited by:
Qian Zheng, Nanyang Technological University, SingaporeReviewed by:
Qi Li, Changchun University of Science and Technology, ChinaCopyright © 2022 Singanamalla and Lin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chin-Teng Lin, Y2hpbi10ZW5nLmxpbkB1dHMuZWR1LmF1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.